modelo de aprendizaje cooperativo basado en arquitectura ... · 3 modelo de aprendizaje cooperativo...
TRANSCRIPT

Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros Industriales
Departamento de Automática, Ingeniería Electrónica e Informática Industrial
Máster Universitario en Electrónica Industrial
Modelo de aprendizaje cooperativo basado en arquitectura multiagente
para sistemas con inteligencia embebida
Autora: Mónica Villaverde San José
Tutor: Félix Moreno González
Marzo de 2014
Trabajo Fin de Máster


3
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Agradecimientos
De nuevo aquí, ante un nuevo libro, un nuevo trabajo –el tercero- y con ganas de seguir recorriendo el camino. Durante estos años en la universidad he conocido a mucha gente y muchos han sido los que me han demostrado su apoyo y me han proporcionado su ayuda haciendo posible que hoy esté aquí, alcanzando esta nueva meta. Por ello, no quiero dejar pasar la oportunidad de dedicarles unas líneas para agradecer todo lo que me han ofrecido durante todo este tiempo.
En primer lugar quiero agradecer al Centro de Electrónica Industrial y a los
profesores que forman parte de él por permitirme compaginar perfectamente el desarrollo del máster con la elaboración de este proyecto, dándome la oportunidad de trabajar “en sus filas”. En especial a mi tutor Félix Moreno por las facilidades que me ha ofrecido siempre a la hora de trabajar con él, por todos los conocimientos que me ha aportado y por todo el tiempo que ha dedicado a mi seguimiento y formación. También a Noemí por su compañía y porque siempre ha estado dispuesta a ofrecerme su ayuda cuidando de nuestra “Tecalum”. Gracias a todos.
Quiero también mostrar mi agradecimiento a mis compañeros y amigos, de aquí
y de allí, porque sin su apoyo todo esto hubiese sido menos llevadero. En especial a “mis gemelas”, “los IAEIs” y a todos los que rodean y forman parte del grupo: Mati, María y Ángel. Todos me habéis ayudado muchísimo y habéis conseguido hacer divertido lo que parecía aburrido y fácil lo que parecía difícil. Gracias chic@s porque siempre he sentido vuestra preocupación por cómo me van las cosas confiando en mis capacidades para llevarlas a cabo.
Mención especial se merece mi familia. Sobre todo mis padres, Ana y Luciano, y
mi hermana Sandra; por su apoyo incondicional ante cualquier circunstancia y porque siempre habéis sido capaces de comprenderme: os quiero. Muchas gracias también a Pilar y Antonio, los padres de David, que han estado atentos en todo momento ofreciéndome su ayuda. Muchísimas gracias a todos, por vuestro apoyo y por lo que hacéis y decís para que siga adelante con todo lo que me proponga.
Por último y no menos importante te lo quiero agradece a ti, David, que eres el
que está a mi lado en cada momento y que sabes lo que necesito sin que diga una palabra. Gracias por todo… porque sin ti este camino no habría sido lo mismo .
¡GRACIAS!


Índice 5
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Índice
Presentación ............................................................................................... 11
Introducción ............................................................................................... 13
I. Resumen y Estado del Proyecto ................................................................................. 14
II. Motivación del Trabajo Fin de Máster ...................................................................... 20
III. Referencias ..................................................................................................................... 21
Objetivos ..................................................................................................... 23
Estado del arte ............................................................................................ 25
I. Aprendizaje cooperativo versus aprendizaje colaborativo ..................................... 25
II. Inteligencia artificial ...................................................................................................... 26
II.1 Agentes inteligentes .......................................................................................... 28 II.2 Sistemas multiagentes ....................................................................................... 30 II.3 Inteligencia de enjambre (Swarm Intelligence) ............................................ 33 II.4 Redes neuronales .............................................................................................. 35 II.5 Algoritmos evolutivos ...................................................................................... 36 II.6 Métodos multiclasificadores: Bagging y Boosting ....................................... 37
III. Comunicaciones inalámbricas ..................................................................................... 38
III.1 Antenas ............................................................................................................... 41 III.2 Tecnologías inalámbricas ................................................................................. 43
IV. Líneas de investigación actuales ................................................................................. 45
V. Referencias ..................................................................................................................... 47
Desarrollo y experimentación .................................................................... 49
I. Desarrollo previo .......................................................................................................... 49
I.1 Primera etapa. Resultados teóricos ................................................................ 50 I.2 Segunda etapa. Resultados prácticos I ........................................................... 51 I.3 Tercera etapa. Resultados prácticos II ........................................................... 53 I.4 Cuarta etapa. Resultados prácticos III ........................................................... 53 I.5 Comparativa de los resultados previos .......................................................... 54
II. Origen y planteamiento del nuevo trabajo ............................................................... 55
III. Implementación de la red de comunicaciones ......................................................... 58

6 Índice
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
IV. Implementación del sistema cooperativo ................................................................. 65
IV.1 Algoritmo 1: Decisión por consenso mayoritario ....................................... 72 IV.2 Algoritmo 2: Decisión mediante pesos globales .......................................... 73 IV.3 Algoritmo 3: Decisión mediante pesos condicionados............................... 75
V. Referencias ..................................................................................................................... 80
Resultados ................................................................................................... 81
I. Caso 1: Influencia de la calidad individual de los nodos sobre los aciertos, fallos y empates producidos en el sistema cooperativo. ................................................. 81
I.1 Experimento 1. Nodos con probabilidades de acierto bajas ..................... 82 I.2 Experimento 2. Nodos con probabilidades de acierto altas ...................... 83 I.3 Experimento 3. Nodos con probabilidades de acierto dispares entre sí .. 84
II. Caso 2: Evolución del aprendizaje para distintos tipos de redes .......................... 86
II.1 Experimento 4. Nodos con probabilidades de acierto bajas ..................... 87 II.2 Experimento 5. Nodos con probabilidades de acierto altas ...................... 89 II.3 Experimento 6. Nodos con probabilidades de acierto dispares entre sí .. 90
III. Caso 3: Influencia de la tasa de aprendizaje para distintos tipos de redes ........... 92
III.1 Experimento 7. Sistema cooperativo formado por 3 nodos (40-60%) .... 93 III.2 Experimento 8. Sistema cooperativo formado por 8 nodos (40-60%) .... 94 III.3 Experimento 9. Sistema cooperativo formado por 3 nodos (40-90%) .... 95 III.4 Experimento 10. Sistema cooperativo formado por 8 nodos (40-90%) .. 96
Conclusiones .............................................................................................. 97
I. Conclusiones Caso 1: Influencia de la calidad individual de los nodos sobre los aciertos, fallos y empates producidos en el sistema cooperativo ....................... 97
I.1 Conclusiones del experimento 1..................................................................... 97 I.2 Conclusiones del experimento 2..................................................................... 98 I.3 Conclusiones del experimento 3..................................................................... 99
II. Conclusiones Caso 2: Evolución del aprendizaje para distintos tipos de redes100
II.1 Conclusiones del experimento 4.................................................................. 101 II.2 Conclusiones del experimento 5.................................................................. 105 II.3 Conclusiones del experimento 6.................................................................. 106
III. Conclusiones Caso 3: Influencia de la tasa de aprendizaje para distintos tipos de redes .......................................................................................................................... 108
III.1 Conclusiones del experimento 7.................................................................. 108 III.2 Conclusiones del experimento 8.................................................................. 109 III.3 Conclusiones de los experimentos 9 y 10 .................................................. 110

Índice 7
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
IV. Conclusiones generales ............................................................................................. 110
Trabajos futuros ........................................................................................ 113
Índice de Figuras y Tablas
FIGURAS
Figura 1. Sistema de iluminación inteligente de Luix S.L. ..................................................... 14
Figura 2. Señal acondicionada del radar. .................................................................................. 15
Figura 3. Resultados de la comparación del patrón coche con señal que representa un coche. .................................................................................................................................... 16
Figura 4. Explicación del fenómeno de acierto efectivo. ...................................................... 17
Figura 5. Árbol de decisión genérico. ....................................................................................... 18
Figura 6. Gráfico comparativo acierto real: Correlación vs. Sistema Experto. ................. 19
Figura 7. Gráfico comparativo acierto efectivo: Correlación vs. Sistema Experto. .......... 20
Figura 8. Nuevos conceptos para incrementar la tasa de acierto del sistema. ................... 21
Figura 9. Enfoques de la inteligencia artificial según Rusell y Norvig. ............................... 27
Figura 10. Colaboración entre agentes. Opciones propuestas por D. D. Corkill [16]. .... 31
Figura 11. Distribución espacial: colaboración concurrente e iterativa. Según D. D. Corkill. .................................................................................................................................. 32
Figura 12. Modelo de neurona propuesto por McCulloch y Pitts. ...................................... 36
Figura 13. Funcionamiento básico de un algoritmo evolutivo. ............................................ 37
Figura 14. Diagrama de radiación tridimensional y bidimensional. ..................................... 41
Figura 15. Transmisión de señal en un entorno con obstáculos. ......................................... 43
Figura 16. Plataforma hardware desarrollada (Plataforma TECALUM V2)...................... 49
Figura 17. Ubicación del radar en la primera etapa del desarrollo. ...................................... 50
Figura 18. Aspecto de la aplicación de verificación del funcionamiento del sistema. ...... 51
Figura 19. Ubicación del radar en la segunda etapa de desarrollo. ...................................... 52
Figura 20. Influencia de la altura en la recepción del eco. .................................................... 53

8 Índice
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 21. Comparativa completa de las etapas de desarrollo previo. ................................ 54
Figura 22. Comparativa en términos de tasa de acierto efectiva. ......................................... 55
Figura 23. Estructura de unión de varios sistemas de detección e identificación. ............ 56
Figura 24. Estructura del sistema cooperativo. ....................................................................... 57
Figura 25. Proceso de identificación del sistema cooperativo. ............................................. 57
Figura 26. Módulo ZigBee. ........................................................................................................ 58
Figura 27. Variación de la potencia recibida en función de la distancia. ............................ 61
Figura 28. Estructura del sistema cooperativo considerando las comunicaciones. .......... 62
Figura 29. Flujogramas que explican el funcionamiento general de los nodos de la red. 63
Figura 30. Interacción entre el nodo coordinador y el resto de nodos generales. ............ 65
Figura 31. Esquema de funcionamiento del sistema cooperativo. ...................................... 66
Figura 32. Esquema de funcionamiento del sistema cooperativo. Decisión mayoritaria.67
Figura 33. Esquema de funcionamiento del sistema cooperativo. Decisión ponderada. 68
Figura 34. Flujograma del algoritmo cooperativo por consenso mayoritario. ................... 72
Figura 35. Flujograma del algoritmo cooperativo usando pesos globales. ......................... 74
Figura 36. Flujograma de actualización de pesos para el algoritmo de pesos globales. ... 75
Figura 37. Flujograma del algoritmo cooperativo usando pesos condicionados. ............. 77
Figura 38. Ej. de actualización de pesos para el algoritmo de pesos condicionados. ....... 78
Figura 39. Flujograma de actualización de pesos para el algoritmo de pesos condicionados. .................................................................................................................... 79
Figura 40. Resultados exp. 1. Nodos con probabilidades de acierto bajas (40-60%). ...... 82
Figura 41. Resultados exp. 2. Nodos con probabilidades de acierto altas (80-90%). ....... 84
Figura 42. Resultados exp. 3: Prueba 1. Nodos con probabilidades acierto 40-90%. ...... 85
Figura 43. Resultados exp.3: Prueba 2. Nodos con probabilidades acierto 40-90%. ....... 86
Figura 44. Resultados exp. 4: Prueba 1. Nodos con prob. de acierto bajas (40-60%). .... 88
Figura 45. Resultados exp. 4: Prueba 2. Nodos con prob. de acierto bajas (40-60%). .... 89
Figura 46. Resultados exp. 5. Nodos con probabilidades de acierto altas (80-90%). ....... 90
Figura 47. Resultados exp. 6: Prueba 1. Nodos con prob. de acierto 40-90%. ................. 91
Figura 48. Resultados exp. 6: Prueba 2. Nodos con prob. de acierto 40-90%. ................. 92

Índice 9
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 49. Resultados exp. 7. Red de 3 nodos con probabilidades de acierto 40-60%. ... 93
Figura 50. Resultados exp. 8. Red de 8 nodos con probabilidades de acierto 40-60%. ... 94
Figura 51. Resultados exp. 9. Red de 3 nodos con probabilidades de acierto 40-90%. ... 95
Figura 52. Resultados exp. 10. Red de 8 nodos con probabilidades acierto 40-90%. ...... 96
Figura 53. Comparativa del algoritmo3. Exp. 1 vs. Prueba 1 del exp. 3. ......................... 100
TABLAS
Tabla 1. Detalles del Proyecto. Subprograna INNPACTO. ................................................ 14
Tabla 2. Resultados de los análisis obtenidos mediante la función de correlación. .......... 17
Tabla 3. Resultados de los análisis obtenidos mediante la función de correlación. .......... 19
Tabla 4. Resultados de los análisis obtenidos mediante la función de correlación. .......... 34
Tabla 5. Ventajas e inconvenientes de las redes inalámbricas respecto a las redes cableadas. ............................................................................................................................. 39
Tabla 6. Nivel de penetración para diferentes materiales. .................................................... 41
Tabla 7. Comparativa de las algunas tecnologías inalámbricas. ........................................... 45
Tabla 8. Valores aplicados para la estimación de la potencia recibida. ............................... 60
Tabla 9. Alternativas planteadas para el análisis del resultado de la cooperación. ............ 69
Tabla 10. Comparativa experimento 3: Probabilidades ≥ 90 %. ......................................... 99
Tabla 11. Análisis de pendientes y promedios para la prueba 1 del experimento 4. ..... 101
Tabla 12. Análisis de pendientes y promedios para la prueba 2 del experimento 4. ..... 103
Tabla 13. Análisis de pendientes y promedios para el experimento 5. ............................ 105
Tabla 14. Análisis de pendientes y promedios para la prueba 1 del experimento 6. ..... 106
Tabla 15. Análisis de pendientes y promedios para la prueba 2 del experimento 6. ..... 107


Presentación 11
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Presentación
En este Trabajo Fin de Máster se propone un modelo de aprendizaje cooperativo basado en arquitectura multiagente para la implementación de un sistema de identificación de objetos con inteligencia embebida. Se parte de un radar de bajo coste y de un sistema hardware con dsPIC que incorpora un algoritmo de detección e identificación de objetos. Este algoritmo implementa un árbol de decisión por lo que sus resultados, basados en cálculos probabilísticos y de entropías, equivalen en cualquier caso una de las categorías definidas en su fuente de conocimiento.
La realización de este trabajo pretende mejorar la arquitectura del sistema inicial
para que los resultados entregados por el mismo proporcionen tasas de acierto más fiables. Para ello se trabaja con un modelo multiagente sobre el que encaja a la perfección el concepto de cooperación para conseguir que varias de estas plataformas cooperen conjuntamente formando un nuevo sistema global. Este nuevo sistema permite incluso la implementación de algún tipo de aprendizaje con el fin de que los resultados mejoren a medida que el sistema evoluciona. La cooperación se llevará a cabo mediante la inclusión de una red inalámbrica que permita la transferencia de información. Por su parte, el aprendizaje estará basado en algoritmos cuyas bases se sustentan en las ideas generales de la inteligencia de enjambre y los métodos multiclasificadores que hacen uso de la idea de recompensa o penalización a través de la asignación de pesos.
En los siete capítulos principales en los que se divide este documento queda
reflejado todo el trabajo realizado. Los capítulos son los siguientes: Introducción, Objetivos, Estado del arte, Desarrollo y experimentación, Resultados, Conclusiones y Trabajos futuros.
En la primera parte de este trabajo se realiza una introducción al proyecto que da
origen a la aplicación gestionada con este sistema, así como la motivación que conlleva a la realización de este Trabajo Fin de Máster. A continuación se exponen los objetivos que se persiguen con la realización de este trabajo, especificando cuál es el objetivo principal del mismo.
En el capítulo titulado estado del arte se realiza una visión general de algunas de
las alternativas existentes para incorporar inteligencia a un sistema. Además, como uno de los objetivos es formar una red cooperativa, en este apartado también se exponen diferentes opciones que permitan crear una red de dispositivos así como los aspectos teóricos a tener en cuenta cuando se realizan estimaciones a la hora de implementar una red inalámbrica.

12 Presentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Posteriormente se desarrolla un capítulo dedicado al desarrollo y la experimentación. En este capítulo se exponen los desarrollos previos a este trabajo para definir el punto de partida, a la vez que se explica cómo se llevará a cabo la cooperación. También se especifica el análisis de diversas alternativas para la implementación del modelo de aprendizaje cooperativo basado en arquitectura multiagente.
El capítulo de resultados pone de manifiesto los resultados obtenidos tras la
realización de varios experimentos simulados con el objetivo de determinar qué alternativa presenta mejores resultados y cómo influyen determinadas variables en el resultado del sistema cooperativo para cada una de estas alternativas. Todos los comentarios sobre los resultados y las conclusiones extraídas de los distintos análisis se ponen de manifiesto en el apartado de conclusiones.
Por último, se realiza un capítulo dedicado exclusivamente a los trabajos futuros.
En este apartado se exponen diferentes alternativas que pueden desarrollarse a partir de la elaboración de este trabajo y que podrían contribuir de forma muy positiva a mejorar los resultados para la identificación de objetos en el campo bajo análisis.

Introducción 13
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Introducción
Este Trabajo Fin de Máster (TFM) ha surgido como consecuencia del proyecto “TECALUM: Sistema de Iluminación Inteligente” que se ha desarrollado, y aún sigue desarrollándose, en el Centro de Electrónica Industrial (CEI) de la Universidad Politécnica de Madrid y que se engloba dentro del subprograma INNPACTO del Ministerio de Ciencia e Innovación.
La convocatoria de ayudas INNPACTO forma parte del Plan de INNOVACIÓN
del Ministerio de Ciencia e Innovación. Este Plan está formado por un conjunto de acciones para la promoción y financiación de la innovación mediante la colaboración público-privada. El objetivo principal del subprograma INNPACTO es “propiciar la creación de proyectos de cooperación entre organismos de investigación y empresas para la realización conjunta de proyectos de I+D+i que ayuden a potenciar la actividad innovadora, movilicen la inversión privada, generen empleo y mejoren la balanza tecnológica del país” [1]. Las características principales del subprograma INNPACTO son las siguientes:
Duración del proyecto de al menos 24 meses con una fecha límite del 31 de diciembre de 2014.
Financiación de proyectos con un presupuesto mínimo de 700.000 €. Obligatoriedad de participación en el consorcio de un organismo de
investigación público o privado. La participación de cada entidad en el presupuesto del proyecto será mayor
del 8% y menor del 70% para empresas o 40% para organismos de investigación.
Las empresas asumirán una aportación al presupuesto del 60-80% y los centros de investigación del 20-40%.
La financiación a las empresas consiste en un préstamo de hasta el 95% del presupuesto al 0% de interés, 11 años de amortización y 3 de carencia.
La financiación para organismos de investigación es de subvención más préstamo.
En la presente convocatoria se han añadido dos dotaciones presupuestarias destinadas a proyectos estratégicos en el ámbito de la salud y la energía.
Los datos del proyecto se muestran en la Tabla 1.

14 Introducción
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Tabla 1. Detalles del Proyecto. Subprograna INNPACTO.
Título del proyecto TECALUM: Sistema de Iluminación Inteligente
Referencia Ministerial IPT-2011-1977-920000
Coordinador Iluminación Inteligente Luix S.L.
Centro UPM E.T.S.I. Industriales
Departamento Automática, Ingeniería Electrónica e Informática Industrial.
Este proyecto está siendo desarrollado dentro del marco de la convocatoria INNPACTO-2011, habiendo sido financiado por el Ministerio de Economía y Competitividad (antiguo Ministerio de Ciencia e Innovación, dentro del Plan Nacional de Investigación Científica, Desarrollo e Innovación Tecnológica, 2008-2011).
I. Resumen y Estado del Proyecto
La finalidad del Proyecto TECALUM es controlar la iluminación del alumbrado público en función de las necesidades de la vía dependiendo de la presencia que se detecte en la zona a iluminar. Esta idea surgió en el seno del Centro de Investigación Tecnológica TECNALIA y dio origen al nacimiento de Luix Iluminación Inteligente S.L., cuyo objetivo es incrementar la eficiencia energética gestionando el alumbrado público garantizando el mismo nivel de confort, seguridad y utilidad.
Figura 1. Sistema de iluminación inteligente de Luix S.L.

Introducción 15
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
La gestión del alumbrado implica un mejor aprovechamiento de la energía así como una reducción de la contaminación lumínica debido a que la iluminación sólo se aplica cuando se detecta la presencia de personas o vehículos en la zona a iluminar. Teniendo en cuenta que existen varios estudios que demuestran que más del 70% del alumbrado se desaprovecha en iluminar espacios vacíos, este sistema de gestión permitiría alcanzar ahorros de hasta un 85%.
A través de la convocatoria INNPACTO 2011, la Universidad Politécnica de
Madrid (UPM) colabora con la empresa Luix Iluminación Inteligente S.L. en el desarrollo de un sistema de detección e identificación para la gestión del alumbrado público mediante el uso de un radar de bajo coste. Hasta el momento se dispone de una plataforma hardware basada en un DSP de Microchip que es capaz de detectar e identificar con una cierta probabilidad la presencia de personas y vehículos analizando la señal proporcionada por un radar de bajo coste. La Figura 2 muestra la señal acondicionada del radar cuando no se produce ninguna detección y cuando se detecta un objeto en movimiento dentro del campo de actuación del radar.
Figura 2. Señal acondicionada del radar.
Todo el trabajo de detección e identificación y su análisis previo se ha llevado a
cabo como consecuencia de la elaboración de dos Proyecto Fin de Carrera [2] y[3]. Ambos proyectos buscan el mismo objetivo y se sustentan sobre la misma plataforma y el mismo mecanismo de detección, sin embargo atacan el problema de la identificación de objetos desde dos puntos de vista diferentes aplicando distintos métodos de análisis.
Por un lado en [3] se realiza un estudio basado en el análisis de la similitud de
señales utilizando la función de correlación (1).
Detección de un objeto
16 Introducción
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
𝐶𝑜𝑟𝑟𝑒𝑙𝑎𝑐𝑖ó𝑛[𝑚] = 𝑥[𝑛] ∘ 𝑦[𝑛] = ∑𝑥[𝑛] ⋅ 𝑦[𝑚 + 𝑛] (1)
𝑛
No obstante, para obtener buenos resultados con este procedimiento es indispensable realizar un minucioso análisis de las señales proporcionadas por el radar con el fin de crear una serie de patrones que representen a cada una de las categorías que se desean identificar.
Una vez obtenidos los patrones se aplica la función de correlación entre cada
uno de estos patrones y la señal que proporciona el radar, de forma que se pueda diferenciar con mayor o menor exactitud la categoría a la que pertenece el objeto detectado.
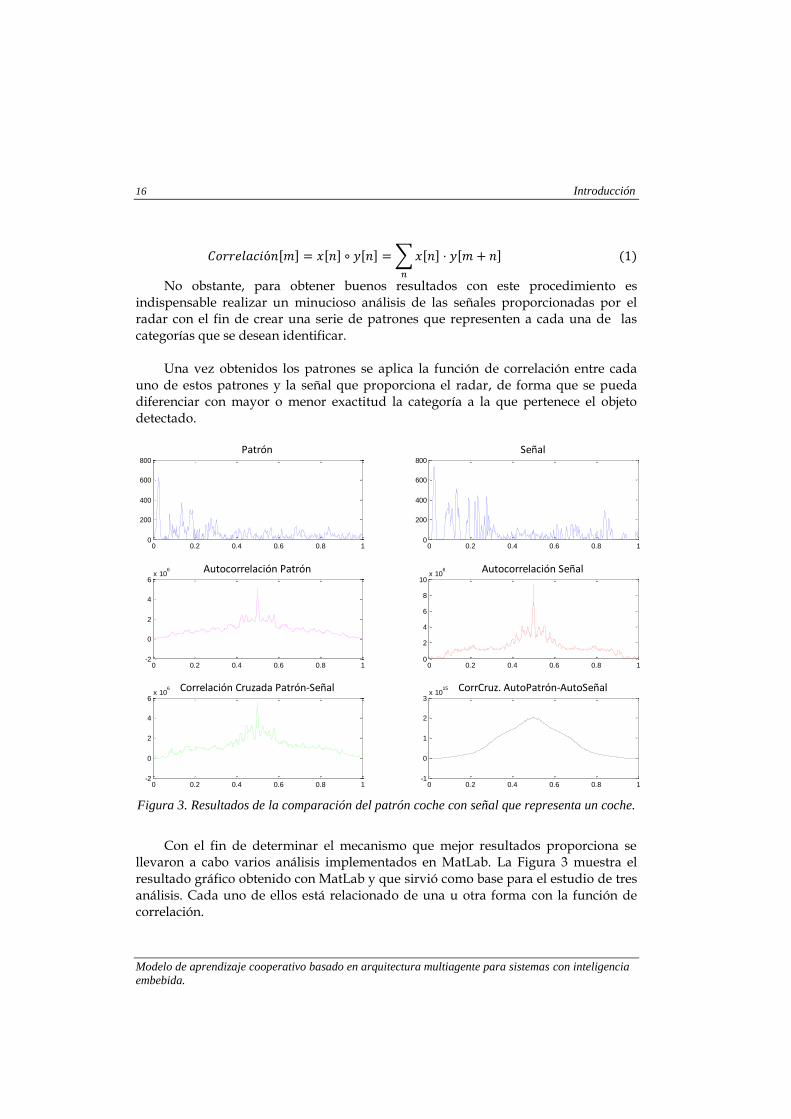
Figura 3. Resultados de la comparación del patrón coche con señal que representa un coche.
Con el fin de determinar el mecanismo que mejor resultados proporciona se
llevaron a cabo varios análisis implementados en MatLab. La Figura 3 muestra el resultado gráfico obtenido con MatLab y que sirvió como base para el estudio de tres análisis. Cada uno de ellos está relacionado de una u otra forma con la función de correlación.
0 0.2 0.4 0.6 0.8 10
200
400
600
800
Patrón
0 0.2 0.4 0.6 0.8 10
200
400
600
800
Señal
0 0.2 0.4 0.6 0.8 1-2
0
2
4
6x 10
6 Autocorrelación Patrón
0 0.2 0.4 0.6 0.8 10
2
4
6
8
10x 10
6 Autocorrelación Señal
0 0.2 0.4 0.6 0.8 1-2
0
2
4
6x 10
6 Correlación Cruzada Patrón-Señal
0 0.2 0.4 0.6 0.8 1-1
0
1
2
3x 10
15 CorrCruz. AutoPatrón-AutoSeñal

Introducción 17
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Análisis 1. Estudio de la amplitud del pico de la correlación cruzada entre el patrón y la señal.
Análisis 2. Estudio de la desviación de la amplitud del pico de la correlación cruzada respecto a la amplitud de pico de al autocorrelación del patrón.
Análisis 3. Estudio de la amplitud de pico de la correlación cruzada de autocorrelaciones.
La Tabla 2 muestra los resultados en términos probabilísticos de cada uno de los
análisis anteriormente mencionados.
Tabla 2. Resultados de los análisis obtenidos mediante la función de correlación.
Análisis 1 Análisis 2 Análisis 3
% Acierto real
% Acierto efectivo
% Acierto real
% Acierto efectivo
% Acierto real
% Acierto efectivo
Coche 92,31% 92,31% 88,46% 92,31% 0,00% 0,00% Persona 63,64% 81,82% 9,09% 63,64% 0,00% 0,00% Entorno 50,00% 50,00% 50,00% 50,00% 100,00% 100,00%
Nótese que únicamente se definen tres categorías de objetos (coche, persona y
entorno) y que se hace una distinción entre la tasa de acierto real y la tasa de acierto efectiva. La tasa de acierto real representa la probabilidad de clasificar correctamente cada detección clasificándola dentro de su categoría correspondiente. Por otro lado, la tasa de acierto efectiva se debe interpretar como la probabilidad de que el sistema funcione correctamente a pesar de que la identificación haya resultado errónea, es decir, que se considerará acierto cuando el sistema responda aumentando la intensidad lumínica aunque el objeto real sea un coche y el identificado sea una persona o viceversa. La Figura 4 representa el concepto de probabilidad efectiva.
Figura 4. Explicación del fenómeno de acierto efectivo.

18 Introducción
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Por otro lado, el proyecto [2] aborda la identificación desde otro punto de vista, puesto que utiliza un sistema experto basado en árboles de decisión como pilar fundamental para determinar la categoría a la que pertenece el objeto detectado. Para alcanzar la identificación mediante este procedimiento es indispensable realizar un análisis detallado de las señales y extraer sus características más significativas que permitan su clasificación.
El procedimiento basado en árboles de decisión consiste en la captura de
ejemplos denominados instancias. Cada instancia está compuesta por la categoría a la que pertenece el objeto más una serie de atributos o características que la definen. Cuanto mayor sea el número de instancias, más fiable será el análisis. Con toda esta información y con la ayuda de diferentes métodos probabilísticos es posible construir un árbol de clasificación estableciendo unos umbrales para los diferentes atributos, de forma que cada nodo del árbol analiza un atributo, cada rama establece la división en función de los umbrales y cada hoja determina la categoría a la que pertenece (Figura 5).
Figura 5. Árbol de decisión genérico.
Dado que existen diferentes métodos probabilísticos, en el proyecto mencionado
se realizan diferentes estudios para comprobar cómo responde el sistema ante diferentes árboles de decisión utilizando dos software externos para análisis estadístico y generación de árboles: SPSS y Weka. Con estas herramientas se analizan tres tipos de árboles basados en diferentes algoritmos: C4.5, CHAID y CRT. Los resultados obtenidos se muestran, en términos probabilísticos, en la Tabla 3. Nótese que, para realizar una comparativa entre los árboles de decisión y la función de
Atributo 3
Clase AAtributo 1
Atributo 2Clase B
Atributo n
Clase AClase C
Clase C
≥ W< W
< X ≥ X
< Y ≥ Y
= Z != Z
Nodos
Hojas
Ramas

Introducción 19
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
correlación, en este caso también se ha trabajado con las mismas categorías y con el mismo concepto de tasa de acierto real y efectiva.
Tabla 3. Resultados de los análisis obtenidos mediante la función de correlación.
Algoritmo C4.5 Algoritmo CHAID Algoritmo CRT
% Acierto real
% Acierto efectivo
% Acierto real
% Acierto efectivo
% Acierto real
% Acierto efectivo
Coche 65,38% 73,08% 69,23% 84,62% 88,46% 96,15% Persona 90,91% 90,91% 100,00% 100,00% 90,91% 90,91% Entorno 75,00% 75,00% 50,00% 50,00% 50,00% 50,00%
A la vista de los resultados de ambos proyectos se observa que los análisis que
aportan mejores resultados en cada uno de los proyectos son, respectivamente, el análisis 1 y el algoritmo CRT. En la Figura 6 y Figura 7 se muestran las comparativas de ambos análisis en términos de probabilidad de acierto real y efectiva.
Figura 6. Gráfico comparativo acierto real: Correlación vs. Sistema Experto.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Coche Persona Entorno
Comparación métodos de identificación(Porcentaje de acierto real)
Función de correlación
(Análisis 1)
Sistema experto
(Algoritmo CRT)

20 Introducción
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 7. Gráfico comparativo acierto efectivo: Correlación vs. Sistema Experto.
II. Motivación del Trabajo Fin de Máster
Dado que la mayor complejidad del sistema reside en realizar una buena identificación de objetos parece lógico encaminar las siguientes etapas de desarrollo hacia nuevas alternativas que permitan obtener mayores éxitos a la vez que se dota de mayor capacidad al sistema completo.
A la vista de la comparativa mostrada en las gráficas anteriores, el sistema
experto basado en árboles de decisión ofrece mejores resultados que la función de correlación para el tipo de señales con las que se trabaja. Por este motivo se descarta la función de correlación como mecanismo aislado para realizar las identificaciones. Sin embargo, podría resultar interesante analizar, aunque sea brevemente, cómo varía el comportamiento del árbol si el resultado de la correlación se incluye como un nuevo atributo a tener en cuenta.
Por otro lado el sistema podría mejorar su tasa de acierto si se incorporan
nuevos mecanismos destinados a proporcionar una ayuda adicional para que la elección de la categoría se realice de forma más fiable. Entre estos mecanismos cabe destacar la posibilidad de dotar al sistema con una fase de aprendizaje supervisado de manera que su inteligencia se vea favorecida y enriquecida con los resultados obtenidos del aprendizaje. De esta forma se podría modificar el árbol de decisión en
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Coche Persona Entorno
Comparación métodos de identificación(Porcentaje de acierto efectivo)
Función de correlación
(Análisis 1)
Sistema experto
(Algoritmo CRT)

Introducción 21
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
función de los resultados que se obtienen con el sistema en funcionamiento a la vez que se le pueden incorporar nuevas categorías para que la identificación sea más exhaustiva. El criterio que se persigue en este caso es que cuanta mayor adaptación del sistema al entorno mayor fiabilidad se puede alcanzar. Esta alternativa se lleva a cabo en el Trabajo Fin de Máster titulado “Sistema de inteligencia embebida con autoaprendizaje basado en una arquitectura de árbol de decisión dinámico y adaptativo”[4] que se realiza de forma paralela a este trabajo.
Otro de los mecanismos que pueden ayudar a que el sistema sea más fiable es el
que se plantea en este Trabajo Fin de Máster. La idea básicamente consiste en que la decisión de la categoría en la fase de identificación no dependa de un único dispositivo, sino que el criterio de decisión esté consensuado. En este caso, el lema que se persigue es que a mayor número de opiniones mayor será la fiabilidad del sistema. Del mismo modo que un sistema redundante es más fiable porque es difícil que más de un elemento falle, este sistema podría reducir su probabilidad de fallo si la decisión final no depende de una única identificación. Para poder realizar este procedimiento se ha pensado en que uno o varios dispositivos puedan comunicarse con otros para consultar así las decisiones que éstos han determinado de forma que la decisión final se lleve a cabo de un modo cooperativo.
Figura 8. Nuevos conceptos para incrementar la tasa de acierto del sistema.
III. Referencias
[1] Ministerio de Ciencia e Innovación, «Orden CIN/699/2011, de 23 de marzo, por la que
se aprueba la convocatoria del año 2011, para la concesión de ayudas correspondientes al
subprograma INNPACTO, dentro de la línea instrumental de articulación e
internacionalización del Sistema.,» Boletín Oficial del Estado, 2011.
[2] D. Pérez Daza, Detección e identificación de objetos mediante procesamiento de señal

22 Introducción
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
de radar. Sistema experto. Madrid: PFC. ETSII., 2012.
[3] M. Villaverde San José, Detección e identificación de objetos mediante procesamiento
de señal radar. Función de correlación. Madrid: PFC. ETSII., 2012.
[4] D. Pérez Daza, Sistema de inteligencia embebida con autoaprendizaje basado en una
arquitectura de árbol de decisión dinámico y adaptativo, Madrid: TFM-UPM, 2014.

Objetivos 23
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Objetivos
La idea general de este trabajo fin de máster consiste en analizar una vía alternativa para incrementar la fiabilidad del sistema de identificación desarrollado en [2] y[3]. Hasta el momento el sistema existente es capaz de proporcionar una tasa de acierto que, en el mejor de los casos, está próxima al 90%. Además éste es extremadamente dependiente de su localización puesto que, si la ubicación final del equipo difiere en gran medida de la ubicación en la que se realizan las pruebas de test, es muy probable que el sistema proporcione peores resultados, es decir, su tasa de acierto se verá reducida considerablemente.
El nuevo planteamiento desarrollado en este trabajo ofrece la posibilidad de
tener en cuenta diferentes hipótesis para alcanzar un único resultado. Se propone una nueva arquitectura que permita la cooperación de varios de estos sistemas de forma que, mediante la comunicación entre dispositivos, se pueda alcanzar una solución que proporcione mayores tasas de acierto.
A la vista de lo expuesto anteriormente, el objetivo principal de este trabajo
consiste en implementar una arquitectura cooperativa que gestione de forma inteligente las hipótesis proporcionadas por cada uno de los sistemas que componen dicha arquitectura con el objetivo de proporcionar un resultado más fiable.
Para alcanzar el objetivo principal del proyecto es necesario implementar una
serie de objetivos secundarios sin los cuales sería imposible conseguir el primero. Entre los objetivos secundarios que se deben alcanzar destacan los siguientes:
Estudio y análisis de diferentes estrategias inteligentes para la gestión de la información proporcionada por cada uno de los sistemas individuales.
Análisis de las diferentes alternativas para la creación de la red -que servirá de soporte al sistema cooperativo- analizando el tipo de tecnología a emplear para su implementación.
Desarrollo de una red que sirva como soporte para el intercambio de información.
Análisis de la distribución de la red y estudio de la cobertura en caso de utilizar tecnología inalámbrica.
Implementar diferentes algoritmos cooperativos para la gestión inteligente de la información con el objetivo de analizar cuál de ellos proporciona los mejores resultados.


Estado del arte 25
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Estado del arte
En este capítulo se realiza un repaso de los conceptos básicos en los que se fundamenta este trabajo así como de diferentes alternativas existentes para llevarlo a cabo. Se debe tener en cuenta que no se pretende realizar un estudio en profundidad de cada uno de los puntos que se presentan sino más bien definir únicamente los conceptos generales.
En primer lugar se lleva a cabo un estudio de los conceptos de aprendizaje
cooperativo y colaborativo, para resaltar los pequeños matices que los diferencian de forma que sea más sencillo interpretar cómo será la relación entre los distintos elementos que forman el conjunto del sistema. Seguidamente se introduce el concepto de inteligencia artificial y se explican algunos de las metodologías aplicables dentro de este campo. A continuación se realiza una breve exposición acerca de las comunicaciones inalámbricas y sus tecnologías así como unas pinceladas acerca de la propagación de señales y el uso de las antenas. Para terminar se exponen algunas de las líneas de investigación que se están siguiendo en la actualidad dentro del entorno que engloba este proyecto.
I. Aprendizaje cooperativo versus aprendizaje colaborativo
En muchas ocasiones los conceptos de aprendizaje cooperativo y aprendizaje colaborativo se utilizan indistintamente, ya que la barrera que los delimita es muy difusa. Sin embargo existen pequeños matices que los diferencian aunque dependiendo del autor estos matices pueden ser unos u otros, por lo que en este apartado se exponen algunas de esas opiniones. Así mismo, es importante destacar que prácticamente toda la información destinada a explicar la diferencia entre ambos tipos de aprendizaje está enfocada a la relación “alumnos-profesor”. Si bien es posible extrapolar estas explicaciones y referirlas al funcionamiento del sistema que aborda este trabajo por lo que se realiza un breve análisis de ambos conceptos; aunque el enfoque de la referencias bibliográficas esté orientado a otro campo de aplicación.
Ciertos autores, entre los que destaca Theodore Panitz, recalcan la existencia de
pequeñas diferencias entre el aprendizaje cooperativo y el colaborativo enfocadas hacia la libertad de decisión de cada uno de los miembros [5]. Para comprender mejor la distinción entre ambos tipos de aprendizaje este autor presenta unas definiciones para los términos colaboración y cooperación que matizan el hecho de que ambos conceptos no son exactamente sinónimos. Por un lado, se puede entender

26 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
la colaboración como una filosofía de interacción donde los individuos son responsables de sus acciones, incluyendo el aprendizaje y el respeto por las aportaciones y las capacidades de sus compañeros. Por otro lado, la cooperación puede entenderse como una estructura de interacción diseñada para facilitar el logro de un objetivo final específico mediante el trabajo en grupos. Teniendo en cuenta estas definiciones Panitz concluye que las diferencias entre el aprendizaje cooperativo y el aprendizaje colaborativo están íntimamente relacionadas con el grado de libertad que se les otorga a los elementos que aprenden -en su caso se entiende que dichos elementos son los alumnos-. De forma que, el aprendizaje colaborativo implica mayor grado de libertad, pues es el propio grupo el que asume la responsabilidad de la respuesta mientras que el aprendizaje cooperativo está mucho más dirigido por el profesor. Esto supone que en la colaboración sitúa al estudiante como foco principal frente al modelo cooperativo que requiere un ente que organice y estructure el trabajo. Aunque bien es cierto que en ambos procedimientos todo el equipo trabaja conjuntamente para alcanzar un objetivo común, la metodología seguida para alcanzarlo difiere ligeramente en función del tipo de aprendizaje que se aplique.
Otros autores como Dillenbourg, Baker, Blaye y O’Malley expresan que la
diferencia entre el aprendizaje cooperativo y el colaborativo se centra principalmente en el modo en el que trabajan los integrantes del equipo y la repartición que se hace del trabajo conjunto [6]. Así para ellos, trabajar en colaboración significa trabajar de forma conjunta sobre un mismo problema, mientras que trabajar de forma cooperativa implica dividir el trabajo en sub-tareas que se resuelven de forma individual para posteriormente combinar los resultados parciales en un único resultado global.
II. Inteligencia artificial
A pesar de que el concepto de máquinas inteligentes y sus ideas fundamentales se remontan a la época de la antigua Grecia, no fue hasta el siglo XX cuando se empezaron a producir avances significativos relacionados con esta temática[7].
Las aportaciones más significativas se produjeron a partir de los años 40 aunque
la evolución de la inteligencia artificial ha sido intermitente y no tan alentadora como
muchos esperaban. En 1943 Warren McCulloch y Walter Pitts crearon el primer modelo constituido por neuronas artificiales. Siguiendo este concepto, Donald Hebb consiguió, en 1949, demostrar una regla que servía para actualizar los enlaces entre neuronas (a día de hoy esa regla aún sigue vigente bajo el término aprendizaje hebbiano), pero el gran punto de inflexión en este campo se produjo en 1950 cuando Alan Turing publicó su artículo titulado Computing Machinery and Intelligence en el

Estado del arte 27
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
que expuso su famoso Test de Turing para demostrar la existencia de inteligencia en una máquina [8]. Sin embargo, el término inteligencia artificial se adoptó hace menos de 60 años [9]. Fue en el verano de 1956 en el Dartmouth College (New Hampshire, Estados Unidos) donde un grupo de expertos, liderados por John McCarthy, se reunieron durante dos meses en un taller formativo para conjeturar sobre la posible creación de máquinas que simulasen aspectos del aprendizaje o cualquier otra característica de la inteligencia [10]. Los resultados de ese taller no supusieron notables avances pero sí puso en contacto a las personalidades más importantes de ese campo.
Los primeros años de la inteligencia artificial como rama científica de entidad
propia fueron notablemente significativos, se produjeron numerosas aportaciones que en la actualidad siguen siendo conceptos claves dentro de ese ámbito. Especialmente significativo fue el desarrollo de los primeros algoritmos genéticos basados en simples mutaciones. Éstos aparecieron en torno a 1958 y eran conocidos con el término evolución automática. Dos o tres años después, empezaron a desarrollarse los primeros sistemas expertos de la mano de Edward Feigenbaum, pero hasta 1982 no se presentó el primer sistema experto comercial. Por otro lado, la minería de datos y el concepto de agentes son dos áreas que se desarrollaron casi en los años 90.
A tenor de lo mencionado anteriormente, los avances desarrollados en el área
de la inteligencia artificial han sido muchos y de muy diversa índole. Con la intención de organizar los conceptos, Rusell y Norvig [7] determinan que se pueden diferenciar cuatro enfoques dentro de la inteligencia artificial (Figura 9) y que relacionan entre sí cuatro conceptos: pensar, actuar, modelos más próximos a lo humano o más próximos a la máquina.
Figura 9. Enfoques de la inteligencia artificial según Rusell y Norvig.

28 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
II.1 Agentes inteligentes
El concepto de agente no es especialmente reciente pues ya a finales de los 80 se hablaba de este concepto y desde entonces se ha elaborado multitud de documentación que trata esta temática. Sin embargo, a pesar de los años transcurridos, aún hoy en día no se dispone de una definición formal de agente inteligente. Stan Franklin y Art Graesser exponen varias definiciones en su artículo “Is it an Agent, or Just a Program?: A Taxonomy for Autonomous Agents” [11] en el que se recogen diversas definiciones de diferentes agentes proporcionadas por otros autores de la materia. Algunas de estas definiciones se muestran a continuación:
Un agente es cualquier cosa capaz de percibir el entorno a través de sensores y actuar sobre él por medio de actuadores [7].
Los agentes autónomos son sistemas computacionales que sobreviven en algún entorno complejo y dinámico, midiendo algunas de sus variables y actuando autónomamente en este entorno para alcanzar los objetivos para los cuales han sido diseñados [12].
Los agentes inteligentes son entidades de software que llevan a cabo, con cierta autonomía e independencia, un conjunto de operaciones en nombre de un usuario u otro programa empleando algún conocimiento de los deseos del usuario. [Definición de IBM en “IBM's Intelligent Agent Strategy White Paper”].
Los agentes inteligentes realizan tres funciones de forma continuada: perciben las condiciones dinámicas del medio ambiente, actúan sobre éste para cambiar dichas condiciones, y razonan para interpretar percepciones, resolver problemas, hacer inferencias y determinar las próximas acciones [13].
Los agentes software son programas que participan en diálogos, negocian y gestionan la transferencia de información [14].
Cada una de las definiciones anteriormente mencionadas especifica diferentes cualidades de los agentes, sin embargo no hay que perder de vista el enfoque en el que se centra cada una de ellas. No es lo mismo definir un agente que un agente inteligente o que un agente software, porque estos pequeños matices incluyen ciertas características que hacen que una misma definición no sea aplicable a todos los casos. Además, el agente es una entidad que depende significativamente de la aplicación sobre la que se esté aplicando, por lo que es la propia aplicación la que determina cuál es la definición que mejor se ajusta en cada caso. A pesar de todo esto, se podría determinar en un ámbito más o menos generalista que un agente necesita de información externa para poder actuar en consecuencia y alcanzar el objetivo para el que ha sido diseñado añadiendo además que, en algunos casos, dicho objetivo podrá ser alcanzado por medio del razonamiento, con mayor o menor autonomía e incluso mediante la trasferencia de información.

Estado del arte 29
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Una vez que el concepto de agente ha sido introducido es posible hablar sobre
cómo se comportan éstos internamente y es en ese punto donde entra en juego la inteligencia artificial ya que ésta debe especificar cómo se tiene que implementar la función del agente. Stuart y Norvig [7] especifican cuatro categorías relacionadas con el comportamiento interno del agente cuyos conceptos básicos se explican a continuación sin entrar en demasiados detalles:
Agente reactivo simple. Este tipo de agentes condicionan su actuación a los estímulos recibidos en el instante actual, ignorando la evolución histórica de los estímulos que recibió con anterioridad. Esto les convierte en agentes muy sencillos pero con una inteligencia muy limitada.
Agente reactivo basado en modelo. Estos agentes, a diferencia de los anteriores, además de verificar cómo está el entorno en el instante actual disponen también de un estado interno que depende de la evolución histórica de los estímulos anteriores. Necesitan disponer de información sobre cómo evoluciona el mundo sin tener en cuenta al propio agente y sobre cómo afectan las decisiones del agente al entorno en el que trabaja. A este conocimiento del mundo se le conoce como modelo.
Agente basado en objetivos. En este caso, los agentes además de disponer información del entorno en el instante actual también se ven afectados por la meta que quieren alcanzar, de forma que su decisión estará condicionada por el objetivo que quieran ver cumplido. En ocasiones el agente basado en objetivos puede disponer además de un estado interno que funciona igual que en el caso anterior.
Agente basado en utilidad. Estos agentes también deben evaluar como maximizar la utilidad de su decisión para conseguir alcanzar un estado de mayor “felicidad” o confortabilidad. Entendiéndose como utilidad el mecanismo para ponderar la probabilidad de éxito en función de la importancia de los objetivos. Esto significa que los agentes deben analizar si la decisión que van a tomar les llevará a un estado de mayor satisfacción.
Cada uno de los agentes anteriormente descritos puede disponer además de la capacidad de aprendizaje. Un agente que aprende puede operar en diferentes entornos y además podría ser más competente ya que su base de conocimiento se ve actualizada. Según esto, el aprendizaje en el caso de agentes puede definirse como el mecanismo de modificación de una o varias de sus componentes de forma que éste pueda actuar más en consonancia con la información que recibe del entorno, pudiendo así mejorar su nivel de actuación.
A pesar de que la clasificación de agentes mostrada anteriormente está muy
extendida, existen otros análisis que asocian otra serie de calificativos a los agentes.

30 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Wooldridge [15] por ejemplo define al agente inteligente como un sistema de computación que puede actuar de forma autónoma y flexible en un entorno, entendiendo como flexible la capacidad para ser reactivo (que responda a cambios), pro-activo (que cumpla sus propios objetivos) y social (que se comunique con otros agentes).
II.2 Sistemas multiagentes
Cuando varios agentes trabajan conjuntamente para alcanzar un objetivo se dice que estamos ante un sistema multiagente. Los sistemas multiagente se caracterizan por presentar, en mayor o menor medida, las siguientes características [16]:
Distribución. No existe un repositorio central de información, cada agente dispone de sus propios medios para alcanzar el objetivo para el que ha sido concebido.
Autonomía. El sistema es autónomo y está gestionado por medio de un control local.
Interacción. Los sistemas multiagente necesitan que la información fluya entre sus entidades, de forma que se requiere comunicación entre los distintos agentes.
Coordinación. Las decisiones tomadas por el sistema deben tener coherencia y ser apropiadas con las soluciones entregadas por los agentes.
Organización. El sistema debe conocer cómo está formado para poder comportarse acorde a su organización.
Son estas características las que diferencian un sistema multiagente de un sistema basado en “blackboard”.
Un sistema de “blackboard” está formado fundamentalmente por tres
componentes básicos: las fuentes de conocimiento (knowledge sources), el control y la propia “blackboard”. Daniel D. Corkill explica con un cierto grado de detalle cada uno de estos tres componentes en su artículo [16]. Sin embargo en este trabajo, se explica brevemente cada uno de estos conceptos extrayendo la idea fundamental que el autor expone en su artículo. De esta forma y por resumir y compactar conceptos, se puede decir que las fuentes de conocimientos son entidades independientes entre sí y que están especializadas en resolver un problema determinado. Por su parte, el elemento “blackboard” es un repositorio global que contiene, entre otros datos, los datos de entrada y las soluciones parciales. Y finalmente, el componente de control es el elemento que toma las decisiones acerca del proceso que debe seguirse para alcanzar la solución, a la vez que gestiona el acceso al “blackboard”.

Estado del arte 31
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
A pesar de las diferencias que existen entre los sistemas multiagente y los sistemas de “blackboard”, en muchas ocasiones ambos conceptos se utilizan conjuntamente dando lugar a sistemas híbridos en los que la colaboración o cooperación entre agentes es la característica común (Figura 10).
Figura 10. Colaboración entre agentes. Opciones propuestas por D. D. Corkill [16].
Teniendo en cuenta los conceptos explicados por Daniel D. Corkill, es posible
ubicar estas soluciones dentro de un entorno dependiente de tres variables: concurrencia, distribución y vida útil de los agentes. De forma que define la existencia de un abanico de posibilidades situado entre la colaboración iterativa y la colaboración concurrente (Figura 11).
Agente A
Agente C
Agente B
Agente D
Agente A
Agente C
Agente B
Agente D
Agente Blackboard
Agente A
Agente C
Agente B
Agente D
Agente Blackboard
+Control
Agente A
KSsBB
Agente B
KSsBB
Agente C
KSsBB
Agente D
KSsBB
Interacción Directa
Con un agente gestor y “Blackboard” Cada agente es un sistema “Blackboard”
Con un agente “Blackboard”

32 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 11. Distribución espacial: colaboración concurrente e iterativa. Según D. D. Corkill.
Los sistemas multiagente también pueden aprender y uno de los mecanismos
que pueden ser de gran utilidad para lograrlo es la colaboración o cooperación entre agentes. Aunque en muchas ocasiones el hecho de trabajar de forma conjunta no es suficiente para que el sistema pueda adaptarse al entorno y mejorar así sus propios resultados. Por este motivo, en ocasiones, puede resultar de gran utilidad el hecho de dotar al sistema con un cierto grado de inteligencia. Para conseguir implementar inteligencia es necesario definir un método de aprendizaje, seleccionando aquel que mejor se adapte al funcionamiento o a la estructura y organización del propio sistema [17].
Aprendizaje supervisado en el que el sistema tiene noción de cómo lo está haciendo, de cómo está aprendiendo.
Aprendizaje no supervisado en el que el sistema no tiene ningún tipo de realimentación sobre cómo de buenos son sus resultados.
Aprendizaje por recompensa en el que a cada elemento se le asigna una “recompensa” tras evaluar la calidad de la salida que ha proporcionado distinguiéndose a su vez dos subcategorías: el aprendizaje por refuerzo que consiste en penalizar o recompensar generalmente mediante pesos y el aprendizaje evolutivo que se basa en modelos darwinianos de forma que se consigue mejorar las poblaciones creando nuevos individuos mediante la combinación o mutación de los padres.
Sistemas “blackboard”
Sistemas multiagentes
Vida útil del agente
Distribución
Concurrencia
Colaboración concurrente
Colaboración iterativa

Estado del arte 33
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
En [17], Panait y Luke también exponen las diferentes alternativas aplicables al aprendizaje cooperativo en sistemas multiagentes definiendo dos categorías relacionadas con el comportamiento del propio sistema: aprendizaje en equipo y aprendizaje concurrente.
En el aprendizaje en equipo sólo está involucrado un aprendiz que es el que se
encarga de analizar el comportamiento del equipo completo y modificar su algoritmo en función de dicho comportamiento. Este tipo de aprendizaje facilita la gestión del sistema pues sólo hay un elemento que toma las decisiones de forma iterativa. Por otro lado, en el aprendizaje concurrente existen varios aprendices de manera que se llevan a cabo distintos algoritmos de aprendizaje en un mismo instante de tiempo (concurrentemente). El uso de uno u otro tipo de aprendizaje depende en gran medida de la aplicación en cuestión pues cada uno de estos tipos tiene sus ventajas y sus inconvenientes, de forma que la elección de la metodología más adecuada está supeditada a los recursos y al funcionamiento del sistema.
II.3 Inteligencia de enjambre (Swarm Intelligence)
La inteligencia de enjambre está basada en el análisis del comportamiento de las colonias de insectos. Eso significa que implica la interacción directa o indirecta de varios individuos para alcanzar un objetivo común mediante la cooperación o colaboración, consiguiendo así que el sistema global se comporte como un sistema complejo e inteligente formado por subsistemas de menor complejidad. Este tipo de inteligencia encaja muy bien dentro del modelo basado en agentes. De hecho cada uno de los individuos que forman parte del enjambre es representado al menos por un agente, así pues se puede afirmar que existe una analogía directa entre los términos individuo y agente.
El intercambio de información entre los distintos individuos es un aspecto clave
que condiciona el comportamiento de todo el conjunto. En [18] se especifica cómo puede manifestarse el intercambio de información realizando una clasificación en torno a dos dimensiones: Topología del conjunto y flujo de información (Tabla 4).

34 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Tabla 4. Resultados de los análisis obtenidos mediante la función de correlación.
Topología del conjunto
Centralizado (Existe un agente de control)
Distribuido (Todos los agentes son iguales)
Flu
jo d
e in
form
aci
ón
Directo (intercambio de mensajes entre agentes)
Órdenes/Restricciones Conversación
Indirecto (No hay comunicación mediante mensajes)
Limitaciones en el entorno
“Estigmergia” o “estimergia” 1 (cambios en el entorno)
La topología centralizada implica la existencia de un individuo que gestione el tráfico de información mediante órdenes o restricciones en el caso de que la interacción sea directa o bien que produzca cambios en el entorno visibles por el resto de individuos en el caso de que la interacción sea indirecta.
Por otro lado, la topología distribuida supone una estructura “de iguales”, es
decir, ningún individuo soporta una carga especial o adicional sino que todos y cada uno de los individuos que intervienen tienen la misma importancia. En este sentido, una interacción directa implica una conversación entre los miembros teniendo todos las mismas oportunidades de participar en la misma, mientras que la interacción indirecta supone la aparición de un mecanismo de coordinación entre individuos a través de un medio físico -“estigmergia”-.
Uno de los ejemplos más usados cuando se habla de la interacción indirecta
mediante “estigmergia” son las colonias de hormigas. Estos insectos forman perfectas hileras a la hora de buscar alimento siguiendo las rutas óptimas para encontrarlo. La búsqueda de la ruta óptima es el aspecto que se encuentra bajo estudio dentro de la temática de la inteligencia de enjambre y se produce a través de una comunicación indirecta entre los miembros de una misma comunidad: “estigmergia”. En este ejemplo, cada individuo contribuye a alcanzar el objetivo común -que es encontrar
1 El término "estigmergia" o “estimergia” (stimergy) fue introducido por el biólogo francés Pierre-Paul Grassé en 1959 para referirse al comportamiento de las termitas. Lo definió como: "La estimulación de los trabajadores por el desempeño que han logrado". Su origen etimológico se deriva de las palabras griegas “estigma” (στίγμα) "marca, señal" y “ergon” (ἔργον) "el trabajo, la acción", y recoge la idea de que las acciones de un agente dejan señales en el ambiente para que él mismo y otros agentes puedan realizar sus acciones posteriores acorde a esas señales.

Estado del arte 35
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
alimento para toda la comunidad- y para ello va dejando a su paso un rastro de feromonas que servirá para que el resto de individuos pueda seguir el camino seguido por el primero. Mediante este mecanismo es posible encontrar la ruta óptima que te lleva hasta el alimento. La ruta óptima acabará siendo la más concurrida y la que mayor cantidad de feromonas presenta ya que la evaporación esta sustancia implica que las rutas menos favorables tiendan a contener menos cantidad de feromonas y acaben, por tanto, siendo las rutas menos concurridas. La aparición y evaporación de feromonas en las rutas seguidas por los individuos es lo que produce el cambio en el entorno, es decir, es el mecanismo de “estigmergia” utilizado.
En definitiva, la inteligencia de enjambre comprende un conjunto de estrategias
basadas en la cooperación o colaboración de varios individuos que buscan alcanzar un fin común y que requieren algún tipo de comunicación directa o indirecta para poder adaptarse al entorno analizando el comportamiento del resto del conjunto.
De forma generalizada, la aplicación de este tipo de técnicas resulta muy
interesante para la implementación de sistemas basados en agentes dada la predisposición que presentan estos sistemas hacia las arquitecturas cooperativas. En [19] se propone una metodología para trabajar con agentes fundamentados en la inteligencia de enjambre que, a pesar de los problemas de rendimiento relacionados con las comunicaciones, presenta ventajas significativas en términos de robustez, escalabilidad, y simplicidad de los individuos.
II.4 Redes neuronales
Las redes neuronales tratan de simular el comportamiento del cerebro humano basándose en la estructura y organización de éste. Al igual que el cerebro, las redes neuronales están formadas por neuronas interconectadas entre sí. Estas neuronas son los principales elementos de procesamiento.
Los primeros modelos de redes neuronales datan de 1943 cuando McCulloch y
Pitts publicaron su artículo [20] en el cual se presentaba el modelo matemático de una neurona. En dicho modelo (Figura 12) cada neurona genera una única salida a partir de un conjunto de entradas en las que cada una de las entradas se ve afectada por un peso determinado. Al final, la salida se obtiene como resultado de la suma ponderada de las entradas por su peso (activación) a la que se la aplica una función específica denominada función de transferencia. En este primer modelo básico se utiliza la función escalón como función de transferencia sin embargo hay distintos tipos de función que pueden ser aplicados, entre los que destacan la función lineal, sigmoidea, tangente hiperbólica y gaussiana.

36 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 12. Modelo de neurona propuesto por McCulloch y Pitts.
Todo modelo de red neuronal requiere una fase previa de aprendizaje o
entrenamiento consistente en ajustar los pesos que se deben aplicar a cada entrada con el objetivo de que la salida sea lo más próxima a la salida deseada. Por este motivo, las redes neuronales una vez entrenadas son muy dependientes del tipo de aplicación y su uso está muy acotado a conseguir unos objetivos muy concretos. De forma que, si se utilizan para alcanzar unos objetivos para los que no fueron entrenadas, los resultados se verán notablemente afectados y su efectividad se verá significativamente disminuida.
II.5 Algoritmos evolutivos
La computación evolutiva trata de crear modelos computacionales basados en la evolución natural de los seres vivos a través de la implementación de algoritmos evolutivos. Este concepto se basa en la evolución de una población inicial, en la que cada individuo modifica sus características para que en la siguiente generación se creen nuevos individuos mejorados dando lugar al progreso evolutivo. Dicho progreso está fundamentado en dos pilares básicos. Por un lado, la selección natural que implica que sólo los más fuertes pueden sobrevivir, lo cual lleva implícito un cierto carácter competitivo y por otro lado, la transferencia genética mediante la cual es posible que los individuos de las siguientes generaciones mejoren sus características respecto a los de las generaciones anteriores.
Por su parte, los algoritmos evolutivos son mecanismos para implementar
modelos evolutivos que deben ser aplicados sobre una población inicial. Hay que tener presente además que son algoritmos probabilísticos, es decir, que un mismo algoritmo probado sobre los mismos datos puede dar lugar a comportamientos diferentes, y que también son heurísticos pues encuentran soluciones en un tiempo razonable a través de la evaluación del progreso entre una generación y la siguiente.
Salida
Umbral o sesgo
S f
Entrada1
Entrada2
Entrada3
Entradan
Peso1
Peso2
Peso3
Peson
.
.
.

Estado del arte 37
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
La evolución de los individuos puede llevarse a cabo mediante procesos de recombinación y/o de mutación y la evaluación del proceso se analiza mediante la aplicación de una función de fitness o de evaluación. En la Figura 13 se muestra el funcionamiento básico de un algoritmo evolutivo.
Figura 13. Funcionamiento básico de un algoritmo evolutivo.
II.6 Métodos multiclasificadores: Bagging y Boosting
Los métodos multiclasificadores tienen como objetivo mejorar la precisión, en términos de fiabilidad, de determinados algoritmos de aprendizaje. A partir de un conjunto de hipótesis se realizan predicciones sobre el conjunto (generalmente por votación) de forma que la fiabilidad del conjunto obtenida por la combinación de hipótesis individuales supera generalmente la tasa de acierto que aporta cada componente individual del conjunto.
Los dos métodos más conocidos para la combinación de modelos son el Bagging
y el Boosing. Ambos métodos consisten en obtener una solución basada en el análisis y valoración de las soluciones individuales (votación). Sin embargo, cada método lleva a cabo la votación de manera diferente. El Bagging (Bootstrap Aggregating) se efectúa mediante una votación mayoritaria, es decir, el resultado obtenido es aquel que presenta un mayor número de votos. Por otro lado, el Boosting se realiza

38 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
mediante la asignación de pesos a cada uno de los resultados individuales de forma que no todas las soluciones influyen de la misma forma sobre la solución final.
Dos aspectos claves a tener en cuenta cuando se trabaja con este tipo de
métodos son la precisión y la diversidad de los elementos que va a proporcionar el conjunto de hipótesis. Por un lado, la precisión está íntimamente relacionada con el grado de fiabilidad con el que se alcanza una determinada hipótesis, es decir, cómo de probable es que la hipótesis propuesta sea acertada. Por otro lado, la diversidad está relacionada con el grado de similitud de los componentes de forma que, si todos los componentes son muy similares entre sí y se realiza una votación equitativa, el hecho de que uno proporcione una hipótesis incorrecta supondrá que el resto también proporcionen hipótesis incorrectas (y viceversa). Para minimizar este efecto, el método de Bagging requiere generalmente que cada modelo individual aprenda de un subconjunto diferente de datos (conjuntos de entrenamiento diferentes) aumentando así la diversidad entre los diferentes modelos. Los subconjuntos de entrenamiento son creados mediante el mecanismo denominado Bootstrap Aggregation que consiste en generar subconjuntos de manera aleatoria permitiendo la repetición de ejemplos en los distintos subconjuntos. Por su lado, el Boosting, mediante la asignación de pesos, intenta minimizar el número de errores cometidos realizando un reajuste en los pesos para crear nuevos modelos en cada iteración del algoritmo. Para ello, incrementa el peso de los ejemplos errados y decrementa el de los ejemplos acertados con el objetivo de generar un nuevo modelo en la próxima iteración que otorgue más relevancia a los ejemplos que en los modelos anteriores se habían clasificado de manera incorrecta. De esta forma se consigue crear un clasificador “fuerte” a partir de varios clasificadores “débiles”.
A pesar de que estos métodos de clasificación surgieron en los años 90, en la
actualidad siguen teniendo gran aceptación en multitud de aplicaciones, ya sea mediante la aplicación de los algoritmos clásicos de Boosting o Bagging o bien aplicando alguna de sus variantes. El algoritmo de AdaBoost es la versión más popular derivada del clásico Boosting [21], no obstante existen otras variantes que se pueden aplicar en función del tipo de aplicación. Por ejemplo, en [22] aplican un algoritmo de Boosting para entrenar conjuntos de redes neuronales.
III. Comunicaciones inalámbricas
Las comunicaciones inalámbricas, a diferencia de las cableadas, se basan en la idea de la conectividad total pues no requieren un medio dedicado para unir físicamente los extremos de la comunicación sino que utilizan el aire. Esto significa que no disponen de un enlace físico que une directamente el transmisor con el receptor, sin embargo no implica que las ondas radioeléctricas puedan rondar

Estado del arte 39
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
libremente por todo el espacio, ya que existen restricciones para asegurar la inexistencia de interferencias entre distintas comunicaciones inalámbricas.
A pesar de las ventajas que pueden presentar las redes frente a sus homólogas
cableadas, también hay que tener en cuenta una serie de inconvenientes de notable importancia. En la Tabla 5 se especifican las ventajas y los inconvenientes más destacables asociados a las redes inalámbricas frente a las redes cableadas.
Tabla 5. Ventajas e inconvenientes de las redes inalámbricas respecto a las redes cableadas.
Ventajas Inconvenientes Menor coste de mantenimiento. Al hacer uso del aire y no requerir una infraestructura física que conecte todos los elementos, se pueden conseguir ahorros de mantenimiento importantes que se hacen aún más significativos a medida que la red aumenta su tamaño.
Calidad del servicio. Las interferencias afectan de manera más significativa a los enlaces inalámbricos. Esto hace que, en determinados entornos industriales, sea indispensable el despliegue de una red cableada que ofrece más inmunidad a los campos electromagnéticos.
Flexibilidad. Los enlaces inalámbricos otorgan más libertad de movimiento de cara a reposicionar los elementos en la red.
Seguridad. Al utilizar el aire como medio de comunicación, las redes inalámbricas son más susceptibles de sufrir ataques externos.
Comodidad en el despliegue. Dado el carácter inalámbrico, no se requiere una planificación tan exhaustiva de la red. La distribución de los elementos no tiene tanta influencia, sólo hay que tener en cuenta que ninguno de ellos quede aislado del resto, es decir, hay que asegurar que todos quedan dentro de la cobertura de la red.
Influencia del entorno. La presencia de objetos o muros en el recorrido del enlace inalámbrico ocasiona la pérdida o atenuación de la señal, lo que obliga a realizar un análisis previo de las condiciones del entorno para poder especificar las distancias máximas de transmisión.
Robustez. El hecho de no requerir una infraestructura cableada hace que las redes inalámbricas sean más robustas ante accidentes involuntarios. Se evitan las roturas o desperfectos en los cables.
Velocidad de transmisión. Los enlaces inalámbricos proporcionan menor ancho de banda que los enlaces cableados, por lo que la velocidad de transmisión de los primeros es menor.
Escalabilidad. Los elementos de la red no están ligados físicamente los unos con los otros por lo que es más sencilla la inclusión de nuevos dispositivos.
Mayor inversión inicial. De términos generales, el coste de los equipos de una red inalámbrica suele ser superior al de los equipos de una red cableada.

40 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
A la vista de los resultados anteriores, las redes inalámbricas son una buena alternativa para muchas aplicaciones, sobre todo para aquellas en las que los elementos no están muy definidos desde la fase inicial de diseño de la red. Sin embargo, hay un concepto que siempre debe tenerse muy presente a la hora de crear una red inalámbrica: la cobertura. En las conexiones inalámbricas la información a transmitir es tratada adecuadamente para convertirse en una señal eléctrica, la cual es radiada por una antena en el transmisor y captada por otra antena en el receptor. Por este motivo, y para conseguir conectividad entre todos los elementos de la red es imprescindible determinar las distancias máximas de alcance realizando un estudio de la propagación de la señal teniendo en cuenta las condiciones del entorno y las potencias de transmisión y recepción.
No obstante, y a pesar de la importancia que tiene, determinar con precisión el
alcance del enlace radio es una tarea muy complicada y generalmente el establecimiento del área de cobertura está basado en estimaciones y aproximaciones ya que las condiciones del canal de radio varían dinámicamente con el tiempo. Con el objetivo de simplificar esta tarea, se definen una serie de parámetros a tener en cuenta cuando se analiza la cobertura de la red. Estos parámetros son la potencia transmitida, la sensibilidad, la atenuación y la relación señal-ruido (SNR).
La potencia transmitida es un concepto relacionado con la antena emisora e
indica la cantidad de energía que puede transmitirse por unidad de tiempo. Por su parte, la sensibilidad está ligada a la antena receptora y representa el nivel mínimo de señal que puede ser reconocido por ésta. Hay que tener en cuenta que a mayor nivel de potencia transmitida, mayor será el alcance de la señal, mayor nivel será captado por el receptor ante las mismas condiciones de entorno y por lo tanto existirá mayor facilidad para distinguir la señal útil del ruido ya que la diferencia entre la señal y el ruido será mayor (aumenta la relación señal-ruido); sin embargo, como contrapartida se necesitará más energía para poder transmitir con mayor potencia. Por otro lado, la atenuación define la reducción del nivel de señal ocasionado por los obstáculos que ésta se encuentra a su paso, así como la ocasionada por la propia propagación de la señal. Esto implica que la señal puede verse atenuada a causa de la distancia que debe recorrer para alcanzar al receptor pero también como consecuencia de la presencia de obstáculos en su recorrido ya que éstos provocan la dispersión de la señal y la absorción o penetración de parte de la misma.
El fenómeno de dispersión o scattering ocasiona la pérdida de parte de la señal
como consecuencia de las reflexiones que se producen cuando la señal encuentra un obstáculo en su camino ya que la señal reflejada se dispersa en todas las direcciones. Por otro lado, las ondas electromagnéticas pueden atravesar ciertos materiales, pero esa penetración depende de factores como la naturaleza y el espesor del material y la

Estado del arte 41
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
frecuencia y la potencia de la señal. En la Tabla 6 se muestra de forma aproximada y cualitativa el nivel de penetración para distintos materiales [23].
Tabla 6. Nivel de penetración para diferentes materiales.
Material Nivel de penetración
Baja frecuencia Frecuencia media Alta frecuencia
Vacío Bueno Bueno Bueno
Aire Bueno (dispersión) Bueno Bueno (atenuación
por lluvia)
Agua Aceptable Malo Muy malo
Tierra Malo Malo Malo
III.1 Antenas
Una antena es un dispositivo capaz de enviar y recibir ondas electromagnéticas de una frecuencia determinada y está caracterizada por su diagrama de radiación. El diagrama de radiación es una representación gráfica que indica cómo se distribuye la potencia transmitida en las diferentes direcciones del espacio. En la Figura 14 se muestra la representación de forma tridimensional y bidimensional de un diagrama de radiación.
Figura 14. Diagrama de radiación tridimensional y bidimensional.
La representación bidimensional de un diagrama de radiación se produce al
cortar mediante un plano la representación tridimensional. A tenor de esto, es necesario proporcionar dos representaciones para que el diagrama quede completamente definido, lo cual implica realizar dos cortes mediante dos planos

42 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
sobre la representación tridimensional: plano azimutal (horizontal) y plano de elevación (vertical).
Por otro lado, la direccionalidad de una antena indica la concentración de
potencia radiada en una dirección particular. Acorde a este atributo, las antenas pueden clasificarse en dos tipos: antenas omnidireccionales (que radian por igual en cualquier dirección), antenas direccionales (que entregan más potencia en una/s dirección/es determinada/s).
Otra característica muy importante asociada a las antenas es su ganancia. La
ganancia de una antena es la relación entre la potencia que entra en una antena y la potencia que sale de ésta en una dirección determinada. Cuando la ganancia viene definida en dBi implica que se refiere a la comparación de la energía que sale de la antena en relación con la que saldría de una antena isotrópica, entendiéndose como antena isotrópica a aquella que cuenta con un patrón de radiación esférico perfecto y una ganancia lineal unitaria.
Una vez definidos varios conceptos importantes a tener en cuenta a la hora de
seleccionar una antena y los factores que influyen en la propagación de la señal, se puede estimar la potencia recibida por el elemento receptor a partir de la potencia transmitida por el elemento transmisor. La relación entre la de la potencia recibida y la potencia transmitida se lleva a cabo mediante la aplicación de la fórmula de Friis, representada en la ecuación (2).
)2(4
2
OBSRTRT
T
R LLLGGDP
P
De la expresión anterior se puede estimar la potencia recibida por la antena
receptora. Para ello se debe conocer la potencia que transmite la antena emisora (PT), las ganancias proporcionadas por sendas antenas (GT y GR) así como la distancia que las separa (D), las pérdidas ocasionadas entre las antenas y los equipos emisor y receptor (LT y LR) y las pérdidas que se ocasionan en los obstáculos a consecuencia de la penetración (LOBS). Además, otra cuestión importante es que sólo hay que considerar aquellos obstáculos cuyas dimensiones sean comparables con la longitud
de onda () de la señal. En la Figura 15 se ilustran estos conceptos.

Estado del arte 43
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 15. Transmisión de señal en un entorno con obstáculos.
III.2 Tecnologías inalámbricas
Existen varias alternativas para implementar una red inalámbrica, sin embargo, se debe seleccionar el protocolo que mejor se ajuste a las características de la aplicación. Por este motivo en este trabajo se realiza una comparativa entre los protocolos de Bluetooth, ZigBee, UWB (Ultra WideBand) y Wi-Fi (Wireless Fidelity) con el objetivo de conocer las ventajas y los puntos débiles de cada uno de ellos. Esta comparativa está basada fundamentalmente en el análisis realizado por Jin-Shyan Lee et al. en 2007 [24].
Cada uno de los protocolos nombrados anteriormente está avalado por un
estándar del IEEE. En general, todos ellos están diseñados para comunicaciones inalámbricas de corto y medio alcance, sin embargo las aplicaciones para las que fueron diseñados inicialmente son muy distintas y son las que han marcado claramente las diferencias existentes entre ellos. Por un lado, Bluetooth se definió originariamente como un protocolo orientado a las comunicaciones entre los periféricos inalámbricos (ratón, teclado, auriculares, etc.) y el ordenador. Por su parte, UWB está más orientado a los enlaces multimedia que requieren un gran ancho de banda. Por otro lado, ZigBee se definió como un protocolo fiable para la implementación de redes de control y supervisión. Y por último, Wi-Fi está pensado para la comunicación entre ordenadores o equipos. No obstante, a pesar de la orientación de cada uno de estos protocolos, éstos pueden usarse en otras aplicaciones siempre que las ventajas que presenten se ajusten a la aplicación en cuestión.

44 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Bluetooth se corresponde con el estándar IEEE 802.15.1 y en general está
diseñado para redes de corto alcance por lo que generalmente se aplica en redes WPAN (Wireless Personal Area Network). La red básica compuesta por dispositivos Bluetooth se denomina piconet. Una piconet es una red WPAN dirigida por un dispositivo que ejerce de maestro y que contiene además un número variable de dispositivos que ejercen de esclavos. Los esclavos únicamente pueden comunicarse con el maestro por lo que trabajan con conexiones punto a punto. Por su parte, el maestro puede establecer conexión multipunto ya que puede comunicarse con varios esclavos. Cuando se tiene más de una piconet trabajando conjuntamente la topología de la red recibe el nombre de scatternet.
El estándar IEEE 802.15.3 se corresponde con el protocolo UWB. Este tipo de
tecnología está orientada a comunicaciones inalámbricas de corto alcance (WPAN) pero de alta velocidad. Esta tecnología está regulada por la FCC (Federal Communications Commision) que especifica que el rango de frecuencias de funcionamiento esté comprendido entre los 3.1 GHz y los 10.6 GHz y que la potencia máxima de transmisión se limite en -41 dBm/MHz. Debido a que utiliza un gran ancho de banda, la tecnología UWB presenta una gran inmunidad frente a interferencias además como emite con poca densidad espectral de potencia ofrece a su vez mayor seguridad en las comunicaciones. Con velocidades que llegan a superar los 110Mbps, esta alternativa se presenta como la mejor opción para las aplicaciones multimedia [25].
ZigBee por su parte se asocia con el estándar IEEE 802.15.4 y su uso está
especialmente destinado a redes WPAN con baja tasa de datos, es decir, no es una tecnología pensada para la transmisión de grandes cantidades de información. Entre sus principales características destacan su bajo consumo y la posibilidad para crear redes con topología de malla (mesh). Acorde al papel que juegan en la red se definen tres tipos de dispositivos ZigBee: coordinador, router y dispositivo final; sin embargo acorde a su funcionalidad se realiza una clasificación en dos tipos de dispositivos: dispositivo de funcionalidad completa (FFD) y dispositivo de funcionalidad reducida (RFD). De forma general se considera que los coordinadores y los routers son dispositivos FFD, mientras que los dispositivos finales son considerados RFD. Es importante destacar también que cualquiera de estos dispositivos tienen la opción de pasar a un estado de reposo con el fin de reducir el consumo de potencia de la red ZigBee, permitiendo alcanzar los niveles óptimos en temas de energía que tanto caracterizan a este tipo de tecnología.
Por último, el estándar IEEE 802.11a/b/c/n se corresponde con Wi-Fi. La
característica principal que distancia esta tecnología de las anteriores es que permite alcanzar mayores distancias de conexión inalámbrica lo cual la convierte en una

Estado del arte 45
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
buena opción para utilizar en redes WLAN (Wireless Local Area Network). De forma habitual las redes Wi-Fi se identifican con redes ad-hoc ya que suelen crearse sin planificación previa y los dispositivos que la forman hacen uso de la misma de forma automática durante periodos determinados (conexiones y desconexiones sin previo aviso).
Una comparativa más resumida y esquemática de las características de cada una
de estas alternativas se muestra en la Tabla 7.
Tabla 7. Comparativa de las algunas tecnologías inalámbricas.
Característica Bluetooth UWB ZigBee Wi-Fi
Estándar 802.15.1 802.15.3a 802.15.4 802.11a/b/c/n
Frecuencias 2.4 GHz 3.1-10.6 GHz 868/915 MHz 2.4 GHz
2.4 GHz 5 GHz
Velocidad 1 Mb/s 110 Mb/s 250 Kb/s 150 Mb/s (300 Mb/s)
Rango/alcance 10 metros 10 metros 10-100 metros 100 metros
Potencia de TX 0-10 dBm -41.3 dBm/MHz (-25)-0 dBm 15-20 dBm
A parte de los datos mencionados anteriormente, se puede añadir que el
protocolo Bluetooth es el protocolo más complejo de los cuatro analizados, ya que es con diferencia el que presenta mayor número de primitivas y eventos. En el extremo opuesto se encuentra ZigBee que es el protocolo más simple teniendo en cuenta el mismo criterio de evaluación. Según el criterio de consumo de potencia, el protocolo ZigBee es el más adecuado para dispositivos portátiles con baja transferencia de información. Sin embargo, si se requiere transmitir grandes cantidades de datos es posible que UWB o Wi-Fi sean más aconsejables pues, en términos de mJ/Mb estos dos protocolos presentan mejor eficiencia.
IV. Líneas de investigación actuales
Como ya se ha visto a lo largo de este capítulo, el campo de la inteligencia artificial engloba multitud de métodos, técnicas y algoritmos que son aplicables a diversos tipos de aplicaciones. En la actualidad se sigue trabajando en la creación de sistemas capaces de tomar decisiones de forma inteligente y actuar de forma autónoma. Por su parte las redes inalámbricas están siendo utilizadas en un gran número de aplicaciones de diversa índole. En este apartado se mencionan algunos de los trabajos que se están llevando a cabo en la actualidad relacionados con esta temática.

46 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Por su parte, los sistemas multiagente permiten la interacción de varios agentes autónomos que negocian e interactúan con el entorno. Esto les convierte en herramientas muy versátiles que pueden adaptarse a multitud de aplicaciones. Por ejemplo en [26], Bobtsov et al. presentan un sistema multiagente de vehículos aéreos para el monitoreo ecológico en zonas de difícil acceso. Cada agente está compuesto por un conjunto de sensores y cámaras y poseen memoria local para el almacenamiento de datos a la vez que disponen de un sistema que permite la trasmisión de los datos a la estación base en tiempo real. Por el hecho de ser agentes que trabajan en colaboración, es posible mantener la formación del sistema completo durante toda la inspección lo cual permite una amplia movilidad a velocidades más que razonables. También es posible asociar conceptos de los algoritmos evolutivos con los sistemas multiagentes. Por ejemplo en [27], Lichocki et al. proponen una metodología evolutiva para la formación de equipos de agentes permitiendo el intercambio y reusabilidad de los agentes en los distintos equipos. Otra aplicación diferente basada en un sistema multiagente queda reflejada en el trabajo [28] realizado por Oviedo et al. En este trabajo los autores presentan una red neuronal que controla el posicionamiento de los paneles solares para un aprovechamiento óptimo de la energía, para lo cual implementan un sistema multiagente en el que los agentes con capaces de cooperar y coordinarse para dotar al sistema de mecanismos que le permitan la adaptación a las diversas condiciones del entorno.
Por otro lado, la inteligencia de enjambre resulta de gran utilidad ante
problemas de enrutamiento de la información en diversos tipos de redes. Por ejemplo, en [29] se presenta un algoritmo basado en inteligencia de enjambre que permite reducir el número de saltos para la transferencia de información en una red inalámbrica de sensores con el objetivo de alargar el tiempo de vida de la red reduciendo los grandes consumos que se producen durante los envíos. Otro ejemplo del uso de la inteligencia de enjambre, se presenta en el trabajo realizado por Yong y Yaodong en [30] donde se expone una solución para el rutado de redes de comunicación que contribuye positivamente a mejorar la calidad del servicio (QoS) y la tolerancia a fallos. No obstante la inteligencia de enjambre también está presente en otros campos de aplicación como por ejemplo en [31], donde Fortier et al. desarrollan un algoritmo para el entrenamiento de redes neuronales mediante la asignación local de créditos. La ventaja del algoritmo que proponen es que es el proceso de aprendizaje está completamente distribuido sin necesidad de implementar una red global compartida por todas las neuronas para la evaluación del fitness. En relación al uso de redes inalámbricas en sistemas inteligentes de enjambre, el trabajo expuesto en [32] propone un algoritmo en el que un conjunto de dispositivos robóticos trabajan de forma conjunta en la búsqueda de determinados objetivos móviles. Cada robot dispone de sensores de ultrasonidos para evitar obstáculos, sensores térmicos para la detección de blancos y módulos ZigBee para la comunicación local.

Estado del arte 47
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
V. Referencias
[5] T. Panitz, «Collaborative versus cooperative learning. A comparison of the two concepts
which will help us understand the underlying nature of interactive learning,» 1999. [En
línea]. Available: http://files.eric.ed.gov/fulltext/ED448443.pdf. [Último acceso: Octubre
2013].
[6] P. Dillenbourg, M. Baker, A. Blaye y C. O'Malley, «The evolution of research on
collaborative learning,» de Learning in Humans and Machines: Towards an
Interdisciplinary Learning Science , Oxford, UK., P. Reimann, & H. Spada (Eds.).
Elsevier, 1996, pp. 189-211.
[7] S. J. Russell y P. Norvig, Inteligencia artificial: Un enfoque moderno. Segunda Edición,
Madrid: Pearson Education. Prentice Hall, 2004.
[8] A. Turing, «Computing Machinery and Intelligence,» Mind, vol. 59, nº 236, pp. 433-460,
1950.
[9] AAAI: Association for the Advancement of Artificial Intelligence, «AITopics,» 2005.
[En línea]. Available: http://aitopics.org/misc/brief-history. [Último acceso: Octubre
2013].
[10] J. McCarthy, M. L. Minsky, N. Rochester y C. E. Shannon, «A proposal for the
Dartmouth summer research project on artificial intelligence,» Hanover (New
Hampshire, Estados Unidos), 1955.
[11] S. Franklin y A. Graesser, «Is it an Agent, or just a Program?: A Taxonomy for
Autonomous Agents,» Proceedings of the Third International Workshop on Agent
Theories, Architectures, and Languages. Springer-Verlag, pp. 21-35, 1996.
[12] P. Maes, «Artificial Life Meets Entertainment: Life like Autonomous Agents,»
Communications of the ACM, vol. 38, nº 11, pp. 108-114, 1995.
[13] B. Hayes-Roth, «An Architecture for Adaptive Intelligent Systems,» Artificial
Intelligence. Elsevier, vol. 72, pp. 329-365, 1995.
[14] M. L. Coen, «SodaBot: A Software Agent Environment and Construction System,»
Tesis. Massachusetts Institute of Tecnology (MIT), Massachusetts, 1994.
[15] M. Wooldridge y N. R. Jennings, «Intelligent Agents: Theory and Practice,» Knowledge
Engineering Review, vol. 10, nº 2, 1995.
[16] D. D. Corkill, «Colaborating Software. Blackboard and Multi-Agent Systems & the
Future,» de Proceedings of the International Lisp Conference, New York, 2003.
[17] L. Panait y S. Luke, «Cooperative Multi-Agent Learning: The State of the Art,»
Autonomous Agents and Multi-Agent Systems. Springer, vol. 11, nº 3, pp. 387-434, 2005.
[18] H. Van Dyke Parunak y S. A. Brueckner, «Engineering Swarming Systems,» de
Methodologies and Software Engineering for Agent Systems. The Agent-Oriented
Software Engineering Handbook, Vols. %1 de %211 (Multiagent Systems, Artificial
Societies, and Simulated Organizations). Springer, Boston, Kluwer Academic
Publishers, 2004, pp. 341-376.
[19] Y. Meng, O. Kazeem y J. C. Muller, «A Swarm Intelligence Based Coordination
Algorithm for Distributed Multi-Agent Systems,» de International Conference on

48 Estado del arte
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Integration of Knowledge Intensive Multi-Agent Systems. KIMAS 2007, Waltham,
Massachusetts, 2007.
[20] W. S. McCulloch y W. Pitts, «A logical calculus of the ideas immanent in nervous
activity,» Bulletin of Mathematical Biophysics, vol. 5, 1943.
[21] Y. Freund y R. E. Schapire, «A Decision-Theoretic Generalization of On-Line Learning
and an Application to Boosting,» Journal of Computer and System Sciences, vol. 55, p.
119–139, 1997.
[22] K. Alam y M. Islam, «Combining Boosting with Negative Correlation Learning for
Training Neural Network Ensembles,» de International Conference on Information and
Communication Technology. ICICT '07, 2007.
[23] D. Roldán, Comunicaciones inalámbricas, Madrid: RA-MA, 2004.
[24] J.-S. Lee, Y.-W. Su y C.-C. Shen, «A Comparative Study of Wireless Protocols:
Bluetooth, UWB, ZigBee and Wi-Fi,» de The 33rd Annual conference of the IEEE
Industrial Electronics society (IECON), Taipei. Taiwan, 2007. Noviembre.
[25] J. Ahmad y R. M. Rahman Pir, «UWB - The Technology for Short-Range High-
Bandwidth Communications,,» International Journal of Research and Reviews in
Computer Science (IJRRCS), vol. 2, nº 1, 2011.
[26] A. A. Bobtsov y A. S. Borgul, «Multiagent Aerial Vehicles System for Ecological
Monitoring,» The 7th IEEE International Conference on Intelligent Data Acquisition
and Advanced Computing Systems: Technology and Application, vol. Berlín, pp. 807 -
809, 12-14 Septiembre 2013.
[27] P. Lichocki, S. Wischmann, L. Keller y D. Floreano, «Evolving Team Compositions by
Agent Swapping,» IEEE Transactions on Evolutionary Computation, vol. 17, nº 2, pp.
282 - 298 , Abril 2013.
[28] D. Oviedo, M. Romero-Ternero, A. Carrasco, F. Sivianes, M. Hernandez y J. Escudero,
«Multiagent system powered by neural network for positioning control of solar panels,»
39th Annual Conference of the IEEE Industrial Electronics Society, IECON 2013, vol.
Viena, pp. 3615 - 3620 , 13-10 Noviembre 2013.
[29] L. D. Samper Escalante, «Swarm intelligence based energy saving greedy routing
algorithm for wireless sensor networks,» 2013 International Conference on Electronics,
Communications and Computing (CONIELECOMP), vol. Cholula, pp. 36-39, 11-13
Marzo 2013.
[30] L. Yong y Z. Yaodong, «Routing Algorithm based on Swarm Intelligence,» 2012 10th
World Congress on Intelligent Control and Automation (WCICA), vol. Beijing , pp. 47-
50, 6-8 Julio 2012.
[31] N. Fortier, J. W. Sheppard y K. G. Pillai, «DOSI: Training artificial neural networks
using overlapping swarm intelligence with local credit assignment,» 2012 Joint 6th
International Conference on Soft Computing and Intelligent Systems (SCIS) and 13th
International Symposium on Advanced Intelligent Systems (ISIS), vol. Kobe, pp. 1420-
1425 , 20-24 Noviembre 2012.
[32] A. Jevtic, G. Peymon, D. Andina y M. Jamshidi, «Building a swarm of robotic bees,»
2010 World Automation Congress (WAC), vol. Kobe, pp. 1-6, 19-23 Septiembre 2010.

Desarrollo y experimentación 49
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Desarrollo y experimentación
I. Desarrollo previo
Este trabajo se desarrolla como consecuencia de la evolución de dos Proyectos Fin de Carrera[2][3] y la finalidad del mismo es mejorar el sistema ya desarrollado. Como resultado de la realización de los dos proyectos se dispone de una plataforma hardware (Figura 16) basada en un dsPIC de la familia 33F de Microchip [33]. Esta plataforma es capaz de realizar el procesamiento de una señal de radar con el objetivo de identificar los objetos detectados por el radar MDU4200 [34] de Microwave Solutions.
Figura 16. Plataforma hardware desarrollada (Plataforma TECALUM V2).
El sistema es capaz de detectar el movimiento de un objeto y clasificarlo en
función del tipo para actuar en consecuencia ya que, sólo en caso de que se detecte un vehículo o una persona, el sistema debe encender la luminaria. La consecución del encendido se lleva a cabo en dos fases. En primer lugar el sistema debe ser capaz de determinar la existencia de un objeto en movimiento para que el segundo lugar, se pueda llevar a cabo la identificación de dicho objeto.
La fase de detección es relativamente sencilla pues, debido al procesamiento
hardware, la señal que recibe el dsPIC no es una señal muy ruidosa. Esto implica que, distinguir la presencia de variaciones en la misma no es una tarea de alta complejidad. Además, es posible configurar una serie de parámetros de forma que la detección pueda ajustarse a distintas condiciones de entorno. Por ejemplo, entre los

50 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
parámetros que se pueden modificar destaca el valor mínimo (umbral) que debe alcanzar la señal para considerar que se ha producido una detección.
La fase de identificación requiere mayores esfuerzos puesto que su realización
no es trivial. De hecho, inicialmente se analizaron dos posibles vías para realizar la clasificación e identificación de los objetos detectados. En [2] se estudió la aplicación de un sistema experto basado en árboles de clasificación mientras que, de forma paralela, en [3] se analizó el uso de la función de correlación sobre las mismas señales capturadas para analizar el mismo problema. Sin embargo, no todo el problema finalizó tras la realización de ambos proyectos sino que la implementación del sistema completo y la tarea de incrementar la tasa de acierto del sistema pasó por diferentes etapas. Los resultados de cada una de estas etapas se muestran de forma conjunta en una gráfica resumen al final de este apartado (Apartado I.5: Figura 21).
I.1 Primera etapa. Resultados teóricos
Se entiende por resultados teóricos a aquellos resultados obtenidos a partir de señales reales que se analizaron sobre un software externo a la plataforma hardware desarrollada. Esto significa que para la obtención de estos resultados fue necesario poner en marcha el sistema sobre la plataforma hardware para poder así almacenar las señales capturas por el radar cuando se producía la detección de algún objeto. Para ello, se montó el sistema en una vía pública tal y como se observa en la Figura 17 y se tomaron diferentes capturas de objetos en movimiento colocando el radar a nivel de calle. De todas esas capturas se seleccionaron algunas de ellas formando la base de datos para la generación del árbol de decisión y la creación de los patrones necesarios en el análisis basado en la función de correlación.
Figura 17. Ubicación del radar en la primera etapa del desarrollo.
Las señales capturadas eran señales reales y se analizaron mediante distintos
programas estadísticos (MatLab y SPSS ejecutándose sobre un ordenador) para

Desarrollo y experimentación 51
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
realizar la clasificación y establecer la identificación de cada uno de esos objetos detectados. De esta forma se obtuvieron las probabilidades de acierto que se han mostrado en la Figura 6 del apartado I de este trabajo y que se proporcionaron como resultados de los proyectos [2] y [3].
I.2 Segunda etapa. Resultados prácticos I
Una vez comprobado que los algoritmos basados en la función de correlación y el sistema experto proporcionan resultados que pueden considerarse aceptables y estando en disposición de la base de datos generada con varias de las señales capturadas en la etapa anterior, da comienzo la segunda etapa de desarrollo. Esta segunda etapa tiene como objetivo la inclusión de los algoritmos de clasificación en el dsPIC para que el sistema posea la autonomía suficiente para poder realizar la tarea de identificación sin depender de ningún software externo y su puesta en marcha en una ubicación más próxima a la ubicación real.
La programación de los algoritmos de identificación implica que el sistema debe
proporcionar el resultado de cada identificación como salida del mismo para poder verificar el grado de fiabilidad de cada algoritmo. Como tarea adicional y, para facilitar la verificación de los resultados de los diferentes algoritmos programados, se desarrolló una aplicación de test en LabView que permite visualizar el objeto que provoca la detección así como el resultado proporcionado por el dsPIC tras la aplicación de los distintos algoritmos. La Figura 18 muestra el aspecto que tiene la aplicación de LabView desarrollada.
Figura 18. Aspecto de la aplicación de verificación del funcionamiento del sistema.

52 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Una vez programado el dsPIC y desarrollada la aplicación de test, el sistema se probó en una ubicación práctica más próxima a la real. Se situó el radar a una altura de 4 o 5 metros sobre el nivel de calle. La Figura 19 muestra una imagen real tomada desde la vía pública sobre la que se puede apreciar la localización del sistema para la realización de esta segunda etapa.
Figura 19. Ubicación del radar en la segunda etapa de desarrollo.
El sistema se puso en marcha en la nueva posición y mediante el uso de la aplicación de test se obtuvieron unos nuevos resultados. Dichos resultados distaban bastante de los resultados teóricos obtenidos en la etapa anterior ya que el sistema presentaba una tasa de acierto menor de la esperada debido a que su ubicación física influye notablemente en la forma de la señal captada por el sistema, por lo que los patrones tomados en la etapa anterior y el árbol de decisión programado en base a dichas señales no eran válidos para la nueva posición. Un cambio de la posición del radar en altura hace que la velocidad radial de la señal recibida por el sistema también se vea modificada siendo éste el motivo principal de las diferencias que aparecen ante el cambio de ubicación. La Figura 20 muestra la implicación que tiene el hecho de posicionar el sistema a diferente altura.

Desarrollo y experimentación 53
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 20. Influencia de la altura en la recepción del eco.
Cabe destacar además que los resultados que se obtuvieron en esta segunda
etapa también reflejaban que las variaciones que sufría la señal, por el simple hecho de estar localizada en otra ubicación, eran muy influyentes sobre los resultados proporcionados por el empleo de la función de correlación. Por este motivo se descartó el uso de la correlación como método para realizar la identificación, de forma que los análisis posteriores sólo están basados en la creación y aplicación de árboles de decisión que gestionan de forma más adecuada las variaciones ocasionadas por el posicionamiento del sistema.
I.3 Tercera etapa. Resultados prácticos II
Para comprobar si el sistema completo, con la incorporación de los algoritmos de identificación programados en el propio dsPIC, era capaz de aproximarse en mayor grado a los resultados teóricos obtenidos en la primera etapa, se decidió realizar una nueva captura de señales con el sistema situado a 4 o 5 metros de altura para generar un nuevo árbol de decisión.
La implementación de los nuevos árboles generados a partir de las señales
capturadas en la nueva posición consiguió que los resultados fuesen más homogéneos. Las tasas de acierto, en general, superaban el 80% llegando casi a alcanzar el 90% en algunos casos.
I.4 Cuarta etapa. Resultados prácticos III
Tanto en la segunda etapa de desarrollo previo como en la tercera sólo se tuvieron en cuenta señales que representaban coches y personas debido a la dificultad existente para capturar señales de entorno en la nueva ubicación ante condiciones ambientales normales.

54 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
La novedad en esta cuarta etapa es que se incluyeron nuevos algoritmos de identificación generados teniendo en cuenta nuevas señales capturadas ante condiciones meteorológicas adversas. De esta forma se lograba probar el comportamiento del sistema cuando las condiciones de entorno no son tan favorables y a la vez se disponía de un nuevo conjunto de señales originadas por la caída de gotas de agua sobre la propia envolvente del radar.
Los resultados obtenidos en esta cuarta etapa no sólo se mantienen próximos a
las tasas de acierto obtenidas en la etapa anterior para la detección de personas y coches, sino que además el sistema es capaz de clasificar e identificar adecuadamente las gotas que caen frente al radar, logrando así identificar esa situación con un goteo y no con la aparición de un objeto moviéndose en la vía pública.
I.5 Comparativa de los resultados previos
La Figura 21 muestra un gráfico general en el que se pueden apreciar los resultados obtenidos en cada una de las cuatro etapas mencionadas anteriormente.
Figura 21. Comparativa completa de las etapas de desarrollo previo.
Los resultados obtenidos y que se muestran en la figura anterior representan la
tasa de acierto real para cada una de las fases de desarrollo. No obstante, en términos de probabilidad efectiva (concepto explicado gráficamente en la Figura 4), esos porcentajes de acierto aumentan de forma considerable. En la Figura 22 se muestra,

Desarrollo y experimentación 55
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
en términos de tasa de acierto efectiva, el gráfico comparativo para los algoritmos que han presentado mejores resultados en términos generales: Algoritmo 5 (Alg.5) y Algoritmo 6 (Alg.6).
Figura 22. Comparativa en términos de tasa de acierto efectiva.
A la vista de los resultados que se reflejan en las dos últimas figuras (Figura 21 y
Figura 22) se puede afirmar que el trabajo realizado hasta ahora ha permitido obtener, para determinadas situaciones, tasas de acierto que rondan e incluso superan el 90% y que, en el peor de los casos y ante condiciones meteorológicas adversas, la probabilidad de identificar correctamente un coche disminuye hasta el 60%. No obstante, las tasas de acierto efectivas demuestran que, de forma general, el sistema responde adecuadamente actuando correctamente sobre las luminarias de la vía pública a pesar de no realizar una clasificación exhaustiva en cada caso.
II. Origen y planteamiento del nuevo trabajo
A pesar de que los resultados demuestran que el sistema parece comportarse de manera adecuada, es muy probable que futuras pruebas en distintas localizaciones no produzcan resultados tan alentadores. Por este motivo parece interesante dedicar nuevos esfuerzos para mejorar la fiabilidad del sistema mejorando, si cabe aún más, las tasas de acierto. Por este motivo en este trabajo se plantea la creación de un modelo de agentes basado en una arquitectura colaborativa.
La arquitectura propuesta está formada por varios sistemas de detección e
identificación que, en principio, son independientes entre sí. Varios radares, conectados a su propia plataforma hardware TECALUM, se encargan de vigilar y supervisar una misma zona de la vía pública con el objetivo de disponer de distintos

56 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
puntos de vista sobre un mismo objeto detectado (Figura 23). Cada sistema puede considerarse como un agente -agente de identificación- cuya finalidad es proporcionar una salida que indique el resultado de su identificación de forma que la cooperación se consigue mediante el conocimiento de la hipótesis que plantea cada agente.
Figura 23. Estructura de unión de varios sistemas de detección e identificación.
En principio la estructura propuesta es una estructura centralizada en la que un
elemento de control gestiona la información del resto permitiendo así la cooperación a través del paso de información lo cual implica la existencia de agentes de red. Dicho elemento de control posee un triple rol, por un lado se comporta como un agente de identificación normal, puesto que lleva a cabo su propia identificación, pero a su vez también actúa como agente de gestión de red encargado de gestionar la red y como agente evaluador puesto que también debe evaluar la información que recibe del resto de agentes. La Figura 24 refleja la estructura del sistema cooperativo global.
+ +
+
Sistema 1Radar + TECALUM
Sistema 2Radar + TECALUM
Sistema 3Radar + TECALUM

Desarrollo y experimentación 57
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 24. Estructura del sistema cooperativo.
Los agentes de identificación se encargan de clasificar el objeto que han detectado.
Para lograrlo todos ellos se basan en la implementación de un mismo árbol de
decisión pero cada uno parte de la señal detectada por su radar correspondiente de esta manera cada sistema puede determinar la categoría a la que pertenece el objeto detectado proporcionando su propio resultado o hipótesis. El conjunto de hipótesis o resultados individuales es analizado por el agente evaluador que recibe toda la información para generar una única solución como respuesta del sistema cooperativo mediante la aplicación de un algoritmo de decisión (Figura 25).
Figura 25. Proceso de identificación del sistema cooperativo.

58 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
III. Implementación de la red de comunicaciones
El hecho de requerir una comunicación entre agentes que están implementados en distintos sistemas implica la necesidad de crear un enlace que permita la transferencia de información entre ellos. Toda esta transferencia de información y todo lo relacionado con la implementación de la red de comunicaciones es gestionado a través del agente de gestión y tratado con los agentes de red.
En este trabajo se ha optado por la creación de una red inalámbrica para
establecer la comunicación debido a que ofrece mayor flexibilidad y escalabilidad que una red cableada y mayor simplicidad de montaje, sobre todo teniendo en cuenta que no se conoce a priori el número de sistemas que estarán conectados a dicha red. Por otro lado, la tecnología empleada es ZigBee porque ofrece un alto grado de versatilidad a la hora de crear la topología de la red, tiene un consumo muy reducido y además ofrece un ancho de banda más que suficiente para la cantidad de datos que se van a transmitir. Para establecer los enlaces inalámbricos mediante el protocolo ZigBee se ha seleccionado el módulo ETRX2HR-PA de Telegesis [35]. Este módulo pertenece a la familia ETRX2 cuya estructura se basa fundamentalmente en tres bloques:
El chip EM250 de Ember que está compuesto por un transceptor que trabaja con señales radio en la banda de los 2,4 GHz (Banda ISM) y un microprocesador de 16 bits.
Un cristal que genera la señal de referencia a 24 MHz. Circuitería adicional para optimizar la señal de radiofrecuencia.
En concreto, el modelo seleccionado (ETRX2HR-PA) incorpora un amplificador de potencia en la línea de transmisión y un conector U.FL macho del fabricante japonés Hirose para la conexión de una antena externa que aporte mayor ganancia. Con estos dos elementos adicionales se consigue aumentar el alcance inalámbrico del dispositivo alcanzando mayores distancias entre ellos (Figura 26).
Figura 26. Módulo ZigBee.
ETRX2 HR - PAIncorpora conector
U.FL de Hirose
Incorpora un
amplificador de potencia

Desarrollo y experimentación 59
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Además, el módulo ETRX2HR-PA tiene implementada la pila del protocolo ZigBee y, con el firmware proporcionado por defecto, es posible realizar el control de dicho módulo a través de una interfaz de “comandos AT”. El uso de estos comandos permite la abstración de las capas inferiores del protocolo facilitando así la tarea de implementación y gestión de la red.
Algunas de las características más significativas del módulo ETRX2HR-PA se
especifican a continuación:
Tensión de alimentación típica de 3.3 V por lo que el uso de este módulo está orientado a aplicaciones cuyos dispositivos se alimentan con baterías.
Potencia de transmisión típica por defecto de 3 dBm. Alta sensibilidad (hasta -97 dBm). Bajo consumo de corriente en modo “sleep” (inferior a 1µA). Interfaz UART. Es posible configurar una interfaz I2C o SPI bajo petición
aplicando una versión personalizada del firmware.
Por otro lado, la antena seleccionada es el modelo ANT-24G-WHJ-SMA del fabricante RF Solutions que trabaja entre 2.4 y 2.5 GHz. Tiene un patrón de radiación omnidireccional y su ganancia viene determinada por la frecuencia de funcionamiento. La información proporcionada por el fabricante revela que la antena aporta una ganancia de 1.733 cuando trabaja a 2.4 GHz. A la vista de estos datos se puede afirmar que la ganancia que proporciona no es demasiado elevada ya que es una antena de bajo coste, sin embargo sirve de ejemplo para analizar la influencia que ésta tiene sobre el sistema completo.
Cabe destacar que la antena seleccionada dispone de un conector de tipo SMA
por lo que se requiere un elemento adicional que permita la conexión entre la propia antena (conector SMA) y el módulo ETRX2HR-PA (conector U.FL). Para realizar esta conexión se ha seleccionado un cable específico para esta labor de 7.5 cm de largo del fabricante Hirose que presenta una atenuación de 3.1 dB/m, lo cual implica que este elemento atenúa 0.2325 dB.
A partir de toda la información obtenida de los datasheets de los dispositivos se
ha realizado un estudio simplificado y aproximado del alcance de los módulos ZigBee con la idea de determinar de forma aproximada las distancias máximas admisibles entre módulos para cuatro casos diferentes:
Caso 1: Situación ideal. No se consideran pérdidas y tampoco se tiene en cuenta ninguna ganancia, es decir, se dispone únicamente de los módulos ZigBee sin antenas y en el espacio libre.

60 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Caso 2: Situación real sin antena. En este caso, aunque tampoco se dispone de ninguna antena que aporte ganancia, la comunicación no se realiza en el espacio libre sino que, a diferencia del caso 1, se tienen en cuenta pérdidas por obstáculos.
Caso 3: Situación semi-real. Se considera una situación semi-real puesto que, a pesar de que se tienen en cuenta la ganancia de la antena (en transmisión y recepción) y las pérdidas ocasionadas por los obstáculos, no se considera la atenuación causada por el efecto del cable que sirve de conexión entre la antena y el módulo (interfaz SMA-U.FL).
Caso 4: Situación real. En este caso se tienen en cuenta las atenuaciones por obstáculos y las causadas por los cables de conexión (tanto en transmisión como en recepción) así como la ganancia de la antena (en transmisión y en recepción).
La estimación de la potencia recibida en función de la distancia existente entre módulos se realiza mediante la aplicación de la fórmula de Friis. En la Tabla 8 se muestran los parámetros que se han tenido en cuenta a la hora de realizar este análisis para los distintos casos anteriormente mencionados.
Tabla 8. Valores aplicados para la estimación de la potencia recibida.
Aplicación de la fórmula de Friis Parámetro Valor Valor (ud. naturales)
Frecuencia (f) - 2.4 GHz
Longitud de onda () - 0.125 m
Potencia transmitida (PT) 3 dBm ≡ - 27 dB 1.995 mW
Ganancia de antena (GT y GR) 32.39 dBm ≡ 2.3880 dB 1.7330
Pérdidas por obstáculos (LOBS) 0 dBm ≡ - 30 dB 0.001
Pérdidas por cable (LT y LR) 29.77 dBm ≡ - 0.2325 dB 0.9479
Sensibilidad - 97 dBm ≡ - 127 dB 0.1995 pW
Cabe mencionar que el valor que representa las pérdidas por obstáculos es una
estimación al considerar que se trabaja en un espacio multiobjeto, es decir, que se producen múltiples pérdidas provocadas por la presencia de un alto número de obstáculos. Esta estimación se ha realizado teniendo en cuenta los cálculos presentados por Hernando Rábanos en el capítulo 3 de su libro titulado Transmisión por Radio [36] que siguen las recomendaciones de la UIT (Unión Internacional de Telecomunicaciones, o en inglés ITU: International Telecomunication Union). La UIT [37] es el organismo de las Naciones Unidas especializado en las tecnologías de la información y la comunicación (TICs). Las Recomendaciones UIT-R constituyen una serie de normas técnicas de nivel internacional, desarrolladas por el Sector de Radiocomunicaciones de la propia UIT y, aunque su aplicación no es obligatoria, su
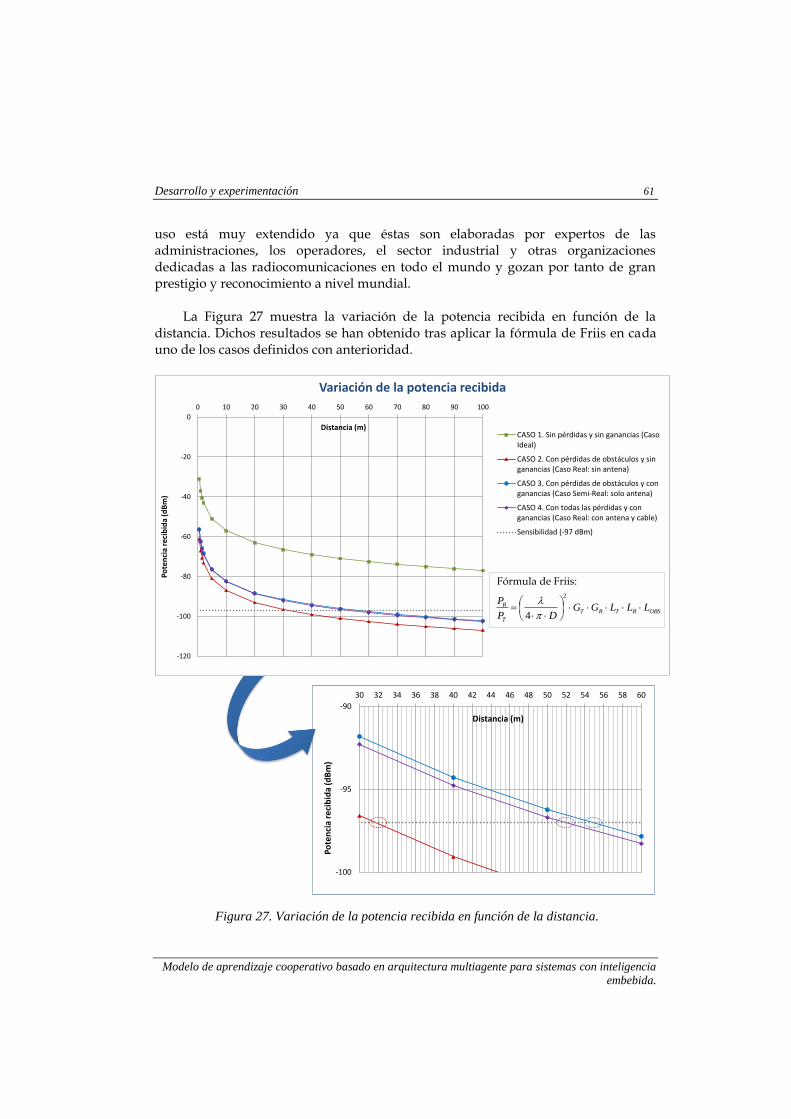
Desarrollo y experimentación 61
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
uso está muy extendido ya que éstas son elaboradas por expertos de las administraciones, los operadores, el sector industrial y otras organizaciones dedicadas a las radiocomunicaciones en todo el mundo y gozan por tanto de gran prestigio y reconocimiento a nivel mundial.
La Figura 27 muestra la variación de la potencia recibida en función de la
distancia. Dichos resultados se han obtenido tras aplicar la fórmula de Friis en cada uno de los casos definidos con anterioridad.
Figura 27. Variación de la potencia recibida en función de la distancia.
-100
-95
-90
30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60
Po
ten
cia
reci
bid
a (d
Bm
)
Distancia (m)
-120
-100
-80
-60
-40
-20
0
0 10 20 30 40 50 60 70 80 90 100
Po
ten
cia
reci
bid
a (d
Bm
)
Distancia (m)
Variación de la potencia recibida
CASO 1. Sin pérdidas y sin ganancias (CasoIdeal)
CASO 2. Con pérdidas de obstáculos y singanancias (Caso Real: sin antena)
CASO 3. Con pérdidas de obstáculos y conganancias (Caso Semi-Real: solo antena)
CASO 4. Con todas las pérdidas y conganancias (Caso Real: con antena y cable)
Sensibilidad (-97 dBm)
)2(
4
2
OBSRTRT
T
R LLLGGDP
P
Fórmula de Friis:

62 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
A la vista de los resultados se puede afirmar que las pérdidas ocasionadas por el cable que une la antena al módulo son prácticamente despreciables puesto que los valores obtenidos para el caso 3 son prácticamente los mismos que los obtenidos para el caso 4. Además se comprueba también que las máximas distancias alcanzables son 31.5, 54.5 y 52 metros aproximadamente para los casos 2, 3 y 4 respectivamente. Sin embargo, no es aconsejable que las potencias recibidas se aproximen al valor indicado como sensibilidad del receptor, se debe dejar un margen para asegurar que el receptor será capaz de recibir la señal enviada por el transmisor. Es importante destacar también que cuanto mayor sea la potencia recibida más sencillo será interpretar la señal del emisor, ya que ésta se verá menos influenciada por el ruido y las interferencias. Por todos estos motivos, se intentará trabajar con distancias que no superen los 30 metros.
Una vez determinada la máxima distancia de separación admisible entre
módulos es posible proceder con la creación de la red. Para ello se debe crear un programa que integre toda la funcionalidad de la plataforma para poder así alcanzar el resultado de la identificación del sistema cooperativo. Sin embargo, antes de seguir adelante con la lectura de este trabajo es importante especificar qué elementos forman el sistema cooperativo y cuál es su estructura. La Figura 28 muestra un esquema similar al de la Figura 24, pero en este caso se otorga mayor nivel de detalle en la especificación del sistema ya que se incluyen los aspectos relacionados con la implementación de la red inalámbrica.
Figura 28. Estructura del sistema cooperativo considerando las comunicaciones.

Desarrollo y experimentación 63
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Como muestra la figura anterior, un nodo es un sistema compuesto por el radar, la plataforma hardware Tecalum y el módulo ZigBee con su antena. Se considera además que se debe hacer una distinción entre el nodo coordinador y el resto de nodos de ámbito general puesto que el primero lleva asociado la implementación de tres agentes: agente de gestión para la gestión de red, agente evaluador para determinar el resultado final y agente de identificación; mientras que los nodos generales únicamente implementan la funcionalidad del agente de identificación y del agente de red. La Figura 29 muestra los flujogramas básicos de los dos tipos de nodos.
Figura 29. Flujogramas que explican el funcionamiento general de los nodos de la red.
Crear la red
Escanear red
Fin espera nodos?
SÍ
NO
Fin espera respuesta?
SÍ
NO
Detección?
SÍ
NO
Identificar objeto
Solicitar el resultado de la identificación a
todos los nodos
Nodo coordinador
Obtener su MAC
SÍ
NO
Nodo general
Unirse a red
Detección?
Identificar objeto
Resultado solicitado?
Enviar resultado de la identificación
SÍ
NO
Calcular el resultado de la identificación
del sist. cooperativo
Ag
en
te d
e g
estió
n d
e r
ed
Ag
en
te d
e
ge
stió
n d
e r
ed
Ag
en
te d
e id
en
tifica
ció
nA
ge
nte
eva
lua
do
r
Ag
en
te d
e id
en
tifica
ció
nA
ge
nte
de
re
d

64 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Básicamente, el comportamiento del nodo general se basa en cuatro acciones. En primer lugar debe averiguar la dirección del módulo ZigBee al que está conectado para poder identificarse cada vez que se establezca una comunicación con el nodo coordinador. En segundo lugar debe ser capaz de unirse a la red que ha creado el coordinador. Además, debe realizar la identificación del objeto que ha detectado, especificando la categoría a la que pertenece dicho objeto tras analizar la señal de eco recibida y aplicar el árbol de decisión que tiene programado. Como cuarta tarea tiene que ser capaz de enviar el resultado de la identificación del objeto que ha detectado desde su posición, para lo cual debe reconocer el comando que le envía el nodo coordinador para interpretarlo como una orden de envío de resultado, mientras que no se reciba ese comando específico el nodo no tiene que enviar el resultado de la identificación.
Sin embargo, la labor del nodo coordinador es algo más compleja y puede
resumirse en cinco tareas. En primer lugar el coordinador debe crear la red y esperar un tiempo para que el resto de nodos se conecten. A continuación, debe escanear
dicha red para comprobar cuántos nodos se han unido, poder almacenar sus direcciones y conocer así en todo momento el estado de los nodos y toda la información asociada a cada uno. Al igual que el resto de nodos, el coordinador debe realizar su propia identificación del objeto detectado siguiendo el mismo procedimiento que los demás nodos. Una vez detectado e identificado el objeto, el coordinador solicita al resto de nodos los resultados individuales que cada uno de ellos ha obtenido para que, en último lugar, pueda determinar el resultado
cooperativo aplicando distintos métodos que gestionen esos datos. Para llevar a cabo la interacción entre los módulos ZigBee ETRX2HR-PA y las
distintas plataformas hardware Tecalum encargadas de realizar la identificación de objetos desde distintos puntos de vista, se hace uso de los comandos AT. El uso de estos comandos simplifica la gestión de información, facilitando así la tarea de comunicación entre módulos, y su envío y recepción se realiza a través de la UART, de forma que es el microprocesador el encargado de enviar cada comando, carácter a carácter, y recibir del mismo modo la respuesta entregada por su módulo ZigBee. Los datos recibidos pueden haber sido generados por el propio módulo ZigBee o bien puede que sean parte de un mensaje enviado por otro nodo de la red. Por este motivo, la interrupción de recepción de la UART juega un papel muy importante ya que debe analizar si el carácter recibido se corresponde con algún carácter de control utilizado por las distintas plataformas Tecalum para comunicarse entre ellas o bien se corresponde con la transferencia de información entre los distintos nodos -como por ejemplo las direcciones que identifican a cada nodo de la red o los resultados de las identificaciones de objetos parciales-. En la Figura 30 se observa un diagrama de estados que representa la interacción entre el nodo coordinador y el resto de nodos generales y que define el comportamiento de la interrupción de la UART. Como

Desarrollo y experimentación 65
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
puede apreciarse a simple vista, en dicha figura se definen dos tipos de estado diferentes marcados en rojo o en azul. Por un lado, en rojo se representan los estados cuyo comportamiento se basa en la recepción de caracteres propios del módulo ZigBee como consecuencia del envío de comandos AT y que por tanto no requieren contestación expresa de otro módulo; como por ejemplo AT+SN. Por otro lado, en azul se marcan aquellos estados que requieren la intervención directa de otro módulo ya que parte de la información que se transmite en este caso viene definida por el comportamiento de otro nodo; por lo que en estos casos siempre se requiere la intervención de un comando del tipo AT+UCAST (mensaje unicast mandado desde un nodo a otro nodo concreto) o AT+BCAST (mensaje broadcast mandado por el coordinador al resto de nodos).
Figura 30. Interacción entre el nodo coordinador y el resto de nodos generales.
IV. Implementación del sistema cooperativo
Se dice que en este trabajo se implementa un sistema cooperativo porque la decisión final del mismo depende de las decisiones individuales de varios subsistemas. En este caso, los subsistemas se encargan de realizar la detección e
INICIO
Obtener mi
dirección
(ATS04?)
Escanear red
(AT+SN)
Esperar
identificación
de objeto
Almacenar
resultado de
identificación
Mandar resultado
de identificación
(AT+UCAST)
Tipo nodo = GENERALTipo nodo = COORDINADOR
No “timeout” ni
máx_num_nodos almacenados
Almacenando dirección“timeout” o máx_num_nodos
almacenados
Fin almacenamiento
dirección
Tipo nodo = COORDINADOR y
solicitud_resultado (mediante AT+UCAST)
Almacenando
resultado
Fin almacenamiento
resultado
No solicitud_resultado
Tipo nodo = GENERAL y
solicitud_resultado (mediante AT+BCAST)
Enviando
Fin_envío

66 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
identificación de los objetos presentes en la vía pública analizando la señal precedente de un radar. Sin embargo, el hecho de que la señal de radar sea tan dependiente del entorno, posición, velocidad, trayectoria y tipo de movimiento del objeto hace que dicha identificación sea altamente variable impidiendo que, en algunos casos, no se alcance una tasa de acierto tan elevada como la que se espera a priori. La implementación de un sistema cooperativo podría ser una alternativa para mejorar la tasa de acierto del sistema de detección e identificación básico ya que en ese caso se colocarían varios de estos sistemas en distintas localizaciones físicas de forma que pudiesen “ver” al objeto desde distintos puntos de vista.
A tenor de lo mencionado se puede afirmar que la cooperación hace su
aparición en el momento en el que varios de estos sistemas tienen que contribuir de forma conjunta para alcanzar una única solución final. Es importante destacar que no se realiza una repartición del trabajo en distintas tareas sino que se lleva a cabo una contribución conjunta al resultado definitivo. En este sentido y siguiendo esta línea de desarrollo, la idea general consiste en recopilar información parcial para finalmente obtener una solución global dependiente de las anteriores de forma que el sistema pueda ser capaz de desatender las identificaciones erróneas aumentando así la tasa de acierto del sistema. Este procedimiento requiere la existencia de un mecanismo de decisión y de un elemento que ejerza el rol de gestor de información. En este trabajo el gestor de información es el nodo coordinador ya que éste es el encargado de recopilar la información procedente del resto de nodos y de decidir el resultado final del sistema. Por su parte, el mecanismo de decisión puede llevarse a cabo mediante distintos procedimientos, sin embargo en este trabajo únicamente se estudian dos alternativas posibles lo cual no implica que no puedan existir otras soluciones.
Figura 31. Esquema de funcionamiento del sistema cooperativo.
Nodo 1 Nodo 2 Nodo 3 Nodo 4
Nodo 5
(coordinador)
Conjunto
de
soluciones
Solución
coordinador
Solución
Cooperativa

Desarrollo y experimentación 67
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
En primer lugar, la alternativa cooperativa más sencilla sería el consenso por
mayoría. Al igual que la redundancia, el consenso por mayoría se basa en que la probabilidad de acierto de un individuo es, en general, menor que la de un grupo de individuos. De esta forma, se asume que si se dispone de información redundante o repetida la solución obtenida estará más validada, lo que supone que será más probable que sea cierta (Figura 32).
Figura 32. Esquema de funcionamiento del sistema cooperativo. Decisión mayoritaria.
La alternativa por mayoría estima la solución final en “tiempo real”, es decir,
después de cada detección se estima la identificación a través de la información proporcionada por cada agente de identificación, esto implica que no existe ningún tipo de aprendizaje ya que cada nueva identificación se realiza sin valorar el comportamiento previo del agente de identificación propio de cada nodo. Para tener en cuenta este aspecto se define la segunda alternativa cooperativa. Esta segunda opción presenta la oportunidad de combinar conceptos extraídos del campo de la inteligencia de enjambre con algún método de clasificación, con el objetivo de que el sistema global pueda aprender para intentar así que sus resultados presenten mejoras con el paso del tiempo.
Como ha quedado expuesto en el apartado II.3 de este trabajo, la inteligencia de
enjambre implica la interacción directa o indirecta de un grupo de individuos que trabajan de forma cooperativa mediante el intercambio de información para alcanzar un objetivo común. En este caso particular que trata de resolver el encendido y apagado de las farolas, cada nodo es tratado como un individuo de la comunidad quedando representado por al menos un agente dentro del modelo de agentes, y la información considerada para alcanzar el aprendizaje viene determinada por el comportamiento general de los nodos. Cada agente de identificación captura
Nodo 1 Nodo 2 Nodo 3 Nodo 4
Nodo 5
(coordinador)
Conjunto
de
soluciones
Solución
coordinador
Solución
Cooperativa
MAYORIA

68 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
información del entorno para procesarla y proporcionar una solución. Dicha solución es transmitida a través del agente de red al agente evaluador para que determine la solución final. Hasta este punto, no hay nada que difiera en gran medida respecto a la primera alternativa, sin embargo se debe considerar que esta segunda opción trabaja con una tabla de pesos que permite dotar al sistema de un cierto nivel de aprendizaje (Figura 33).
Figura 33. Esquema de funcionamiento del sistema cooperativo. Decisión ponderada.
El concepto de la asignación de pesos está relacionado con la aplicación del
método de Boosting cuyo objetivo se basa fundamentalmente en conseguir que no todas las aportaciones tengan la misma influencia sobre el resultado final sino que dicha influencia sea variable en función de las circunstancias. La evaluación de la influencia es lo que está directamente relacionado con la línea seguida por la inteligencia de enjambre. En este caso los pesos se reajustarán teniendo en cuenta la precisión de los resultados previos de cada agente de identificación simulando así el comportamiento de las hormigas al seguir el rastro de feromonas dejado en las rutas por sus antecesoras. No obstante, existen diversas formas de valorar la precisión de los resultados previos siendo algunas de ellas más triviales y de menor coste computacional que otras.
En este trabajo se proponen dos alternativas diferentes para la gestión de los
pesos en función del nivel de detalle que se desee valorar. La primera de las alternativas propuestas es más simple de implementar que la segunda debido a que requiere un menor conocimiento del entorno y del comportamiento real de los nodos que cooperan. Esta opción consiste en considerar a cada nodo como un buen clasificador o un mal clasificador, es decir, entiende el comportamiento del nodo desde un punto de vista general –da buenos resultados o no da buenos resultados-
Nodo 1 Nodo 2 Nodo 3 Nodo 4
Nodo 5
(coordinador)
Conjunto
de
soluciones
Solución
coordinador
Solución
Cooperativa
PESOS
1
1.5
1.80.5
0.3

Desarrollo y experimentación 69
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
sin entrar en detalles de su comportamiento ante distintos tipos de objetos detectados. Por el contrario la segunda alternativa pretende ir más allá considerando que los nodos pueden responder correctamente ante determinados tipos de objetos e incorrectamente ante la presencia de otros tipos de objetos. Esta segunda opción implica que cada nodo se vea influenciado por el tipo de objeto que intenta clasificar, admitiendo así la posibilidad de que un nodo pueda ser bueno identificando objetos de tipo A pero no lo sea identificando objetos de tipo B. De cara a diferenciar estas dos alternativas, en el desarrollo de este trabajo se habla de gestión de pesos
globales cuando se hace referencia la primera de ellas y gestión de pesos
condicionados cuando se habla de la segunda. La Tabla 9 resume y expone conjuntamente las ideas generales mencionadas en
los párrafos anteriores para proporcionar una mayor aclaración de las diferencias existentes entre las distintas alternativas.
Tabla 9. Alternativas planteadas para el análisis del resultado de la cooperación.
Alternativas Coopera Aprende Pondera su aportación al conjunto
Modifica su ponderación ante objetos diferentes
Cooperación basada en decisión mayoritaria - - - Cooperación basada en la gestión de pesos globales - Cooperación basada en la gestión de pesos condicionados
Con el objetivo de analizar las tres alternativas y comparar los resultados que
proporcionan cada una de ellas ante la misma situación se ha realizado un programa en MatLab que permite la simulación del sistema. En el capítulo de resultados se especifican los experimentos llevados a cabo mediante diversas simulaciones, que permiten evaluar la calidad de los resultados que proporciona cada alternativa y extraer las conclusiones oportunas. Para la realización del programa en MatLab se parte de una serie de premisas que sirven para simular el escenario real, interpretar los resultados obtenidos en las simulaciones y valorar la calidad del sistema simulado. Estas condiciones previas sobre las que se sustentan las simulaciones son las siguientes:
Se definen tres clases para identificar: coches, personas y entornos. Esto implica que, al igual que el sistema real implementado en la plataforma hardware, los

70 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
resultados de la identificación en las simulaciones clasificarán cada objeto detectado dentro de una de las tres clases definidas.
Para facilitar la elaboración de los algoritmos se trabaja con matrices. La mayoría de las matrices tienen un tamaño variable en función del número de nodos de la red, aunque también se definen matrices de tamaño fijo.
Para simular el escenario donde trabajan los nodos se definen tres probabilidades para cada uno de ellos: probabilidad de identificar correctamente un coche, una persona y un entorno. Estas tres probabilidades se consideran probabilidades de acierto para cada categoría y se generan de manera aleatoria permitiendo definir un valor mínimo y máximo. Mediante la definición de estos límites es posible simular situaciones homogéneas donde los nodos tienen altas o bajas tasas de acierto o bien situaciones heterogéneas donde existen nodos con probabilidades de acierto dispares entre sí. Además, el objeto a detectar se determina de manera aleatoria de esta forma se simula que ha pasado un coche, una persona o se ha detectado un objeto del entorno.
Con el objetivo trabajar con un escenario más realista y poder determinar la categoría final cuando el nodo ha cometido un fallo en la identificación se define un vector de tendencias de tamaño variable pues tiene tantos elementos como nodos tiene la red [1 x nodos]. Cada elemento es una probabilidad aleatoria que sirve para que el nodo ante un fallo de identificación proporcione una de las dos categorías restantes teniendo en cuenta la probabilidad indicada en ese vector de tendencias. De esta forma, se consigue que cada nodo tienda a identificar una categoría determinada cada vez que se falla en la identificación de un determinado tipo de objeto. Estas probabilidades deben tomar valores que se alejen del 50% para que la tendencia ante el fallo sea realmente una tendencia y no una mera distribución uniforme entre dos valores. Por ejemplo, si el nodo 1 falla a la hora de identificar coche y tiene una probabilidad asignada en su vector de tendencias del 70% implica que dará como resultado persona 7 de cada 10 veces y entorno 3 de cada 10, mostrando una tendencia a identificar persona cuando falla en la identificación de un coche. Esta condición trata de simular el comportamiento real de los nodos de la red que, de forma general, mostrarán una tendencia ante un determinado tipo de objeto en cada situación de fallo.
Se entiende que la solución cooperativa es el resultado de valorar las soluciones parciales de cada nodo de forma conjunta basándose en la decisión llevada a cabo por cada una de las alternativas propuestas -mayoría, pesos globales y pesos condicionados-.
Para cada alternativa propuesta se implementa un algoritmo que evalúa los aciertos, los fallos y los empates ocasionados al obtener la solución cooperativa.

Desarrollo y experimentación 71
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Las identificaciones parciales de cada nodo se definen a través de una matriz [3x1], donde cada fila representa a una categoría. La fila 1 representa la categoría coche, la fila 2 representa la categoría persona y por último, la fila 3 representa la categoría entorno. Cada uno de los tres elementos de la matriz puede tomar dos valores 1 o 0, y sólo puede haber un único 1 dentro de la matriz ya que éste indica la categoría a la que pertenece el objeto detectado por el nodo.
[100] ⇒ 𝐶𝑜𝑐ℎ𝑒 [
010] ⇒ 𝑃𝑒𝑟𝑠𝑜𝑛𝑎 [
001] ⇒ 𝐸𝑛𝑡𝑜𝑟𝑛𝑜
Se define una matriz de identificaciones que contiene las matrices de identificaciones parciales de cada nodo, de forma que cada elemento de esta matriz es una matriz de identificación parcial. El tamaño de la matriz de identificaciones es variable, pues contiene tantas filas como nodos existan en la red [nodos x 1].
𝑀𝑎𝑡𝑟𝑖𝑧 𝑑𝑒 𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑐𝑎𝑐𝑖𝑜𝑛𝑒𝑠 =
[
[100]
[100]
⋮
]
Siguiendo con el formato de la matriz de identificaciones, se crea también una matriz de identificación cooperativa. En este caso, esta matriz tiene un tamaño fijo [3x1] pues cada fila representa el resultado cooperativo obtenido mediante cada alternativa. La fila 1 representa la matriz de identificación cooperativa para el algoritmo de consenso por mayoría, la fila 2 da el resultado del algoritmo por pesos globales y la fila 3 el de los pesos condicionados.
𝑀𝑎𝑡𝑟𝑖𝑧 𝑑𝑒 𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑐𝑎𝑐𝑖ó𝑛 𝑐𝑜𝑜𝑝𝑒𝑟𝑎𝑡𝑖𝑣𝑎 =
[
[100]
[100]
[010]
]
Identificación nodo 1
Identificación nodo 2
Resultado cooperativo alg. 1
Resultado cooperativo alg. 2
2
Resultado cooperativo alg. 3

72 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Una vez definidos todos los conceptos anteriormente propuestos se procede a explicar cómo funcionan cada uno de los tres algoritmos implementados.
IV.1 Algoritmo 1: Decisión por consenso mayoritario
Este es el algoritmo más sencillo de los tres propuestos y no implica ningún tipo de aprndizaje. Consiste en hacer una revisión de las identificaciones parciales de cada nodo analizando cada submatriz de la matriz de identificaciones para contar cuántos nodos han dado como resultado la categoría coche, cuántos han dado como resultado la categoría persona y cuántos la categoría entorno. De forma que el resultado de la cooperación será aquella categoría más votada (Figura 34).
En caso de que dos o tres categorías estén igualadas en número de votos
(aportaciones), se indicará que se ha producido un empate y que por tanto el resultado no podrá valorarse ni como acierto ni como fallo. En contraposición, si hay una categoría más votada que las otras dos, el resultado de la cooperación será dicha categoría y podrá ser valorado a posteriori como acierto, en caso de que coincida con el objeto que había que identificar, o como fallo en caso contrario.
Figura 34. Flujograma del algoritmo cooperativo por consenso mayoritario.
Indicar el número de nodos en la red
Todos evaluados?
Alg. Mayoría Determinar la categoría más votada
Analizar matriz de identificación del
nodo
SÍ
NO
Más votado coche?
Más votado persona?
NO
Resultado cooperativo = coche
SÍ
Más votado entorno?
NO
Resultado cooperativo = persona
SÍ
Resultado cooperativo = entorno
SÍ
Indicar empate
Fin Mayoría
NOActualizar la
categoría correspondiente
Result. cooperativo =objeto a detectar?
Hay empate?
SÍ
NO
EMPATE ACIERTO FALLO
NO
SÍ

Desarrollo y experimentación 73
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
IV.2 Algoritmo 2: Decisión mediante pesos globales
Este algoritmo intenta conseguir que el sistema aprenda para que mejore con el tiempo. Para conseguirlo asigna un peso a cada nodo para que el resultado parcial de cada nodo tenga más o menos influencia sobre el resultado cooperativo de la identificación. Esta influencia es valorada de manera general, es decir, sin tener en cuenta el objeto que debe identificar puesto que únicamente el nodo tomará una decisión parcial que tendrá mayor o menor peso en la decisión final del sistema completo.
Para determinar la aportación que realiza cada nodo a la decisión final es
necesario evaluar la matriz de identificación parcial del propio nodo (submatriz de la matriz de identificaciones) y el peso asignado a dicho nodo. La aportación viene determinada por la multiplicación de dicha matriz por dicho peso, de forma que el resultado será una nueva matriz Mg [3x1] en la que un elemento será igual al valor del peso del nodo y el resto serán valores nulos, debido a que la submatriz de identificación parcial sólo tiene un único elemento que vale 1 siendo el resto 0. Siguiendo este criterio, el resultado de la identificación vendrá dado por la expresión (3).
𝑀𝑔 ≡ 𝑀𝑎𝑡𝑟𝑖𝑧 𝑟𝑒𝑠𝑢𝑙𝑡𝑎𝑑𝑜 𝑝𝑒𝑠𝑜𝑠 𝑔𝑙𝑜𝑏𝑎𝑙𝑒𝑠 = ∑ 𝛼𝑛 ∙ 𝑀𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑐𝑎𝑐𝑖𝑜𝑛𝑒𝑠(𝑛,1) (3)
𝑛𝑜𝑑𝑜𝑠
𝑛=1
Si se expande la ecuación anterior se obtiene la expresión (4) en la que puede
apreciarse el aspecto de la nueva matriz [3x1] que contiene las aportaciones a cada categoría.
𝑀𝑔 = 𝛼1 ∙ [𝐶1
𝑃1
𝐸1
] + 𝛼2 ∙ [𝐶2
𝑃2
𝐸2
] + ⋯+ 𝛼𝑛 ∙ [
𝐶𝑛
𝑃𝑛
𝐸𝑛
] = [
𝛼1 ∙ 𝐶1 + 𝛼2 ∙ 𝐶2 + ⋯+ 𝛼𝑛 ∙ 𝐶𝑛
𝛼1 ∙ 𝑃1 + 𝛼2 ∙ 𝑃2 + ⋯+ 𝛼𝑛 ∙ 𝑃𝑛
𝛼1 ∙ 𝐸1 + 𝛼2 ∙ 𝐸2 + ⋯+ 𝛼𝑛 ∙ 𝐸𝑛
] (4)
Siguiendo este algoritmo la solución cooperativa vendrá dada por la categoría
que mayor contribución tenga, es decir, si tras aplicar la ecuación se obtiene que el elemento de mayor valor es el de la primera fila el resultado cooperativo será la categoría coche, si el mayor valor está en la segunda fila será persona y si está en la tercera fila será entorno. En caso de que dos o tres elementos de la matriz tengan el mismo valor entonces se indicará que se ha producido un empate y ese ensayo no podrá contabilizarse posteriormente ni como un acierto ni como un fallo. El último paso del algoritmo es actualizar los pesos en función del resultado obtenido, siendo este proceso el que contribuye al aprendizaje. La Figura 35 muestra el flujograma que describe el funcionamiento de este algoritmo.

74 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 35. Flujograma del algoritmo cooperativo usando pesos globales.
Para la actualización de los pesos se define la tasa de aprendizaje que sirve para
indicar con qué factor se deben modificar los pesos de cada nodo. Esta tasa es variable, ya que puede ser modificada a la hora de realizar las simulaciones pero, a su vez es común para todos los nodos, es decir, sólo se define un único valor para esta variable. Cabe destacar también que la actualización se lleva a cabo analizando las identificaciones parciales de cada uno de los nodos, de forma que se pueda valorar cada uno de ellos de manera independiente. Si la identificación del nodo coincide con el resultado de la identificación cooperativa, es decir, ha contribuido a la solución del conjunto, entonces ese nodo recibe una gratificación o recompensa consistente en aumentar el valor de su peso, en caso contrario sufre una penalización que consiste en disminuir el valor de su peso. El incremento del peso se realiza sumando la tasa de aprendizaje al valor del peso actual, sin embargo, el decremento
Indicar el número de nodos en la red
Todos nodos evaluados?
Alg. Pesos globales
NOInicializar pesos para
cada nodo
Multiplicar cada peso por su matriz de
identificación parcial
Acumular en la matriz resultado pesos globales
NO
Analizar la matriz resultado pesos
globales
SÍ
Mayor valor en fila 1?
Mayor valor en fila 2?
SÍ
NO
Resultado cooperativo = coche
Mayor valor en fila 3?
Resultado cooperativo = persona
Resultado cooperativo = entorno
SÍ SÍ
NO
Indicar empate
Fin Pesos globales
Almacenar resultado en la matriz de identificación
cooperativa
Result. cooperativo =objeto a detectar?
Hay empate?
SÍ
NO
EMPATE ACIERTO FALLO
NO
SÍ
Actualizar pesos globales

Desarrollo y experimentación 75
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
del peso se lleva a cabo restando la mitad de la tasa de aprendizaje. La decisión de que el factor de penalización y el factor de recompensa no se vean afectados en la misma proporción se debe a que se intenta reducir la simetría en la evolución de los pesos minimizando así el número de empates que pueden producirse. En la Figura 36 se muestra el flujograma que define las acciones llevadas a cabo para actualizar los pesos globales.
Figura 36. Flujograma de actualización de pesos para el algoritmo de pesos globales.
IV.3 Algoritmo 3: Decisión mediante pesos condicionados
Este algoritmo, al igual que el algoritmo anterior y a diferencia del primero, implementa un sistema capaz de aprender. Sin embargo, la aportación final de cada nodo no depende de un único peso, sino que se definen un conjunto de pesos para cada nodo –pesos condicionados-. Por este motivo no basta con asignar un peso a cada nodo sino que se debe definir una nueva matriz de tamaño fijo [3x3] -puesto que hay tres categorías posibles de identificación- que contenga los pesos condicionados. Cada nodo debe tener asignada una matriz de pesos condicionados. La expresión (5) muestra la matriz de pesos condicionados para el nodo n.
Extraer la identificación parcial
del nodo 1
Resultado = resultado
cooperativo?
Actualizar pesos globales
Peso = Peso + tasa de aprendizaje
Peso = Peso – (tasa de aprendizaje / 2)
SÍ
NO
Extraer la identificación parcial
del siguiente nodo
Todos nodos evaluados?
Fin Actualizar pesos globales
NO
SÍ

76 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
𝑀𝛼,𝑛 ≡ 𝑀𝑎𝑡𝑟𝑖𝑧 𝑑𝑒 𝑝𝑒𝑠𝑜𝑠 𝑐𝑜𝑛𝑑𝑖𝑐𝑖𝑜𝑛𝑎𝑑𝑜𝑠 = [
𝛼𝐶𝑛𝛼𝐶/𝑃𝑛
𝛼𝐶/𝐸𝑛
𝛼𝑃/𝐶𝑛𝛼𝑃𝑛
𝛼𝑃/𝐸𝑛
𝛼𝐸/𝐶𝑛𝛼𝐸/𝑃𝑛
𝛼𝐸𝑛
] (5)
En la matriz de pesos condicionados la diagonal se corresponde con los pesos de
la forma An donde A representa una categoría – coche (C), persona (P) o entorno (E)-
y n representa el número de nodo. El resto de pesos son de tipo A/Bn donde A y B representan dos categorías diferentes y n el número de nodo. De esta forma se debe
interpretar que An es la contribución del nodo n al resultado de la categoría A
cuando se identifica un objeto de tipo A. Mientras que se interpreta A/Bn como la contribución del nodo n al resultado de la categoría A cuando se identifica un objeto
de tipo B. Por ejemplo, C1 es la contribución del nodo 1 a la categoría coche cuando
se identifica un coche mientras que C/P1 es la contribución del nodo 1 a la categoría coche cuando identifica persona. Esta idea surge como consecuencia de la premisa de que un nodo puede ser bueno identificando unos tipos de objetos y no tan bueno identificando otros. De esta forma, no se está considerando si un nodo es bueno o malo de manera global sino que se considera si un nodo es bueno o malo en función del tipo de objeto que se esté identificando.
Para comprender mejor la distribución de pesos es importante conocer cómo se
crea la matriz resultado por pesos condicionados Mc. El concepto es prácticamente el mismo que el que se usa en el algoritmo de pesos globales pero, en vez de utilizar un único peso para cada nodo, se debe utilizar una matriz de pesos condicionados para cada uno. La expresión (6) especifica el cálculo de esta matriz.
𝑀𝑐 ≡ 𝑀𝑎𝑡𝑟𝑖𝑧 𝑟𝑒𝑠𝑢𝑙𝑡𝑎𝑑𝑜 𝑝𝑒𝑠𝑜𝑠 𝑐𝑜𝑛𝑑𝑖𝑐𝑖𝑜𝑛𝑎𝑑𝑜𝑠 = ∑ 𝑀𝛼,𝑛 ∙ 𝑀𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑐𝑎𝑐𝑖𝑜𝑛𝑒𝑠(𝑛,1) (6)
𝑛𝑜𝑑𝑜𝑠
𝑛=1
Al expandir la ecuación anterior se obtiene la expresión (7.2), en la que puede
apreciarse las aportaciones a cada categoría en la nueva matriz Mc [3x1].
𝑀𝑐 = [
𝛼𝐶1𝛼𝐶/𝑃1
𝛼𝐶/𝐸1
𝛼𝑃/𝐶1𝛼𝑃1
𝛼𝑃/𝐸1
𝛼𝐸/𝐶1𝛼𝐸/𝑃1
𝛼𝐸1
] ∙ [𝐶1
𝑃1
𝐸1
] + ⋯+ [
𝛼𝐶𝑛𝛼𝐶/𝑃𝑛
𝛼𝐶/𝐸𝑛
𝛼𝑃/𝐶𝑛𝛼𝑃𝑛
𝛼𝑃/𝐸𝑛
𝛼𝐸/𝐶𝑛𝛼𝐸/𝑃𝑛
𝛼𝐸𝑛
] ∙ [
𝐶𝑛
𝑃𝑛
𝐸𝑛
] (7.1)
𝑀𝑐 = [
𝛼𝐶1∙ 𝐶1+𝛼𝐶/𝑃1
∙ 𝑃1 + 𝛼𝐶/𝐸1∙ 𝐸1 + ⋯+ 𝛼𝐶𝑛
∙ 𝐶𝑛+𝛼𝐶/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐶/𝐸𝑛
∙ 𝐸𝑛
𝛼𝑃/𝐶1∙ 𝐶1 + 𝛼𝑃1
∙ 𝑃1 + 𝛼𝑃/𝐸1∙ 𝐸1 + ⋯+ 𝛼𝑃/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝑃𝑛∙ 𝑃𝑛 + 𝛼𝑃/𝐸𝑛
∙ 𝐸𝑛
𝛼𝐸/𝐶1∙ 𝐶1+𝛼𝐸/𝑃1
∙ 𝑃1 + 𝛼𝐸1∙ 𝐸1 + ⋯+ 𝛼𝐸/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝐸/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐸𝑛
∙ 𝐸𝑛
] (7.2)
Al igual que en el algoritmo anterior, la solución cooperativa vendrá dada por la
categoría que mayor contribución tenga en la matriz Mc –matriz resultado por pesos condicionados-. Esto implica que si tras aplicar la ecuación se obtiene que el

Desarrollo y experimentación 77
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
elemento de mayor valor es el de la primera fila entonces el resultado cooperativo será la categoría coche, si el mayor valor está en la segunda fila será persona y si está en la tercera fila será entorno. Podría producirse un empate en caso de que dos o tres elementos de la matriz tengan el mismo valor, en cuyo caso ese ensayo no podrá contabilizarse ni como un acierto ni como un fallo. El último paso del algoritmo es el que proporciona el aprendizaje y consiste en actualizar los pesos en función del resultado obtenido. En la Figura 37 se puede observar el flujograma que describe el funcionamiento de este algoritmo, nótese que en términos de funcionalidad es prácticamente igual que el flujograma que describe el algoritmo que usa pesos globales, la diferencia reside en que la multiplicación de los pesos por la identificación en este caso se produce mediante la multiplicación de dos matrices.
Figura 37. Flujograma del algoritmo cooperativo usando pesos condicionados.
Indicar el número de nodos en la red
Todos nodos evaluados?
Alg. Pesos condicionados
NOInicializar pesos para
cada nodo
Multiplicar la matriz de pesos del nodo por su matriz de
identificación parcial
Acumular en la matriz resultado pesos globales
NO
Analizar la matriz resultado pesos
globales
SÍ
Mayor valor en fila 1?
Mayor valor en fila 2?
SÍ
NO
Resultado cooperativo = coche
Mayor valor en fila 3?
Resultado cooperativo = persona
Resultado cooperativo = entorno
SÍ SÍ
NO
Indicar empate
Fin Pesos condicionados
Almacenar resultado en la matriz de identificación
cooperativa
Result. cooperativo =objeto a detectar?
Hay empate?
SÍ
NO
EMPATE ACIERTO FALLO
NO
SÍ
Actualizar pesos condicionados

78 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Del mismo modo que en el caso del algoritmo anterior, para la actualización de los pesos se hace uso de la tasa de aprendizaje que se usa para indicar con qué factor se deben modificar los pesos de cada nodo. El valor de la tasa se aprendizaje se decide antes de iniciar la simulación y en este caso, para comparar este algoritmo con el algoritmo que trabaja con pesos globales, se utiliza el mismo valor que en el caso anterior.
Sin embargo, la actualización de los pesos es en general un procedimiento
diferente que el usado por el algoritmo de pesos globales a pesar de que coinciden en que se lleva a cabo analizando la identificación parcial de cada nodo. La diferencia reside en el hecho de tener más de un peso asignado a cada nodo, lo que implica que se debe analizar qué pesos aumentan y/o disminuyen en cada caso. Para determinar cómo deben variar los pesos en cada caso se tiene que tener en mente el aspecto de la matriz Mc de forma que se deben analizar las variaciones de cada peso para las distintas situaciones, teniendo en cuenta la contribución de cada uno de ellos al resultado de la cooperación. Según esto, se definen dos situaciones diferentes: que la identificación cooperativa sea una determinada categoría y la identificación parcial del nodo coincida con dicha categoría -el nodo contribuye positivamente- o bien que la identificación parcial del nodo no coincida con la categoría indicada tras la cooperación -el nodo contribuye negativamente-. En la Figura 38 se observan ambas situaciones siendo explicadas con más detalle en el siguiente párrafo.
Figura 38. Ej. de actualización de pesos para el algoritmo de pesos condicionados.
A la vista de la figura anterior se puede decir que el hecho de que el nodo
contribuya de forma positiva implica aumentar el peso de la categoría resultante y
𝑀𝑐 = [
𝛼𝐶1∙ 𝐶1+𝛼𝐶/𝑃1
∙ 𝑃1 + 𝛼𝐶/𝐸1∙ 𝐸1 + ⋯ + 𝛼𝐶𝑛
∙ 𝐶𝑛+𝛼𝐶/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐶/𝐸𝑛
∙ 𝐸𝑛
𝛼𝑃/𝐶1∙ 𝐶1 + 𝛼𝑃1
∙ 𝑃1 + 𝛼𝑃/𝐸1∙ 𝐸1 + ⋯ + 𝛼𝑃/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝑃𝑛∙ 𝑃𝑛 + 𝛼𝑃/𝐸𝑛
∙ 𝐸𝑛
𝛼𝐸/𝐶1∙ 𝐶1+𝛼𝐸/𝑃1
∙ 𝑃1 + 𝛼𝐸1∙ 𝐸1 + ⋯ + 𝛼𝐸/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝐸/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐸𝑛
∙ 𝐸𝑛
] (7.2)
Resultado de la cooperación = coche
Resultado del nodo = coche
Aumentar la contribución a la fila 1
Disminuir la contribución a las filas 2 y 3
𝑀𝑐 = [
𝛼𝐶1∙ 𝐶1+𝛼𝐶/𝑃1
∙ 𝑃1 + 𝛼𝐶/𝐸1∙ 𝐸1 + ⋯ + 𝛼𝐶𝑛
∙ 𝐶𝑛+𝛼𝐶/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐶/𝐸𝑛
∙ 𝐸𝑛
𝛼𝑃/𝐶1∙ 𝐶1 + 𝛼𝑃1
∙ 𝑃1 + 𝛼𝑃/𝐸1∙ 𝐸1 + ⋯ + 𝛼𝑃/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝑃𝑛∙ 𝑃𝑛 + 𝛼𝑃/𝐸𝑛
∙ 𝐸𝑛
𝛼𝐸/𝐶1∙ 𝐶1+𝛼𝐸/𝑃1
∙ 𝑃1 + 𝛼𝐸1∙ 𝐸1 + ⋯ + 𝛼𝐸/𝐶𝑛
∙ 𝐶𝑛 + 𝛼𝐸/𝑃𝑛∙ 𝑃𝑛 + 𝛼𝐸𝑛
∙ 𝐸𝑛
] (7.2)
Resultado de la cooperación = coche
Resultado del nodo = persona
Aumentar la contribución a la fila 1 (coche)
Disminuir la contribución a la fila 2 (persona)
CONTRIBUCIÓN POSITIVA
CONTRIBUCIÓN NEGATIVA

Desarrollo y experimentación 79
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
disminuir los pesos de las otras dos categorías condicionadas a la categoría resultante. Siguiendo el ejemplo de la Figura 38, si la cooperación determina que la
solución es coche entonces, si el nodo también decidió coche, se le debe incrementar C
y disminuir P/C y E/C. Por el contrario, si el nodo contribuye de forma negativa, es decir, su resultado no coincide con el resultado de la cooperación, entonces se debe disminuir el peso asociado a la categoría determinada por el nodo y aumentar el peso correspondiente a la categoría de la cooperación condicionado la que determinó el propio nodo. Por ejemplo, si el resultado de la cooperación indica que el objeto es
un coche y el nodo determina que es una persona entonces se debe disminuir P y
aumentar C/P. El incremento del peso es entendido como una recompensa y se realiza sumando la tasa de aprendizaje al valor del peso actual, sin embargo, el decremento del peso se produce para penalizar y se lleva a cabo restando la mitad de la tasa de aprendizaje. En la Figura 39 se muestra el flujograma que define las acciones que deben realizarse para actualizar los pesos en este algoritmo.
Figura 39. Flujograma de actualización de pesos para el algoritmo de pesos condicionados.
Extraer la identificación parcial
del nodo 1
Resultado = resultado
cooperativo?
Actualizar pesos condicionados
αA =αA + tasa de aprendizaje
αA =αA – (tasa de aprendizaje / 2)
SÍ
NO
Extraer la identificación parcial
del siguiente nodo
Todos nodos evaluados?
Fin Actualizar pesos condicionados
NO
SÍ
αA/B = αA/B – (tasa de aprendizaje / 2)
αA/C = αA/C – (tasa de aprendizaje / 2)
αA/B =αA/B + tasa de aprendizaje
Res. cooperativo = A
Resultado = B

80 Desarrollo y experimentación
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
V. Referencias
[33] Microchip, «Especificaciones dsPIC33FJ64MC802,» [En línea]. Available:
http://www.microchip.com/wwwproducts/Devices.aspx?dDocName=en532314. [Último
acceso: Enero 2014].
[34] Microwave Solutions, «Radar MDU4200,» [En línea]. Available: http://docs.microwave-
solutions.com/createPdf.php?id=MDU4200. [Último acceso: Enero 2014].
[35] Telegesis, «Módulo ZigBee ETRX2HR-PA,» [En línea]. Available:
http://www.telegesis.com/product_range_overview/etrx-2_pa.htm. [Último acceso:
Noviembre 2013].
[36] J. M. Hernando Rábanos, Transmisión por radio. Cuarta edición., Madrid: Editorial
Universitaria Ramón Areces, 2003.
[37] I. International Communication Union, «Unión Internacional de Telecomunicaciones.
Página en español.,» [En línea]. Available: http://www.itu.int/es/Pages/default.aspx.
[Último acceso: Diciembre 2013].

Resultados 81
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Resultados
Los resultados de este trabajo se han obtenido mediante la realización de varios experimentos desarrollados a partir de las simulaciones realizadas en MatLab. El objetivo de dichas simulaciones es determinar cómo responde cada algoritmo y cuál es el predice los mejores resultados.
Las simulaciones realizadas permiten comparar distintas metodologías de una
forma rápida y bastante fiable, sin embargo, en ocasiones el hecho de simular puede distorsionar la realidad debido a las depreciaciones en determinadas variables del entorno que pueden llegar a ser altamente influyentes. A pesar de estos posibles inconvenientes, la simulación sigue siendo una herramienta de gran potencial que en general proporciona buenos resultados. No obstante, se debe tener muy presente que los resultados mostrados son fruto de algoritmos probabilísticos por lo que se deben considerar únicamente orientativos.
Para verificar el comportamiento del sistema, y debido a la gran cantidad de
variables que influyen en cada simulación, ha sido necesario realizar varios experimentos evaluando el sistema desde distintos puntos de vista. A continuación se ponen de manifiesto los resultados obtenidos. Posteriormente, en el capítulo de conclusiones se expondrán las discusiones para cada experimento.
I. Caso 1: Influencia de la calidad individual de los nodos sobre los
aciertos, fallos y empates producidos en el sistema cooperativo.
En primer lugar se ha comparado la respuesta de los tres algoritmos para tres situaciones diferentes, que están directamente relacionadas con la calidad de los resultados asociados a cada nodo. Es decir, se realizan tres experimentos distintos: uno de ellos analiza el caso en el que todos los nodos tienen probabilidades de acierto bajas, posteriormente en otro experimento se fuerza a que todos tengan probabilidades de acierto altas y por último se analiza el comportamiento ante la coexistencia de nodos con alta probabilidad de acierto junto con nodos de baja probabilidad de acierto. Los resultados obtenidos en cada experimento mostrarán el número de aciertos, fallos y empates proporcionados por el sistema cooperativo para 30 situaciones diferentes en las cuales el tamaño de la red se ve modificado.
Para que todos los resultados obtenidos en esta fase sean comparables entre sí se
ha de mantener un criterio común para el resto de variables. Se realizan 1000 ensayos por cada situación de forma que los resultados obtenidos, a pesar de estar basados en

82 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
probabilidades, se acerquen más a los posibles resultados reales como consecuencia de repetir 1000 veces el experimento para cada situación -tamaño de red-. Otros factores que permanecen constantes durante las simulaciones y que sólo tienen influencia sobre los algoritmos con aprendizaje son el peso inicial de las matrices de pesos y la tasa de aprendizaje que se han inicializado con 0.5 y 0.01 respectivamente.
I.1 Experimento 1. Nodos con probabilidades de acierto bajas
Para este experimento se ha forzado a que los nodos presenten tasas de acierto comprendidas entre el 40 y el 60% para todas las categorías. Estos valores implican la simulación de una red cuyos elementos, de forma individual, proporcionan resultados coincidentes con el objeto a detectar sólo entre un 40 y un 60% de las identificaciones que realizan. La gráfica de la Figura 40 revela los resultados obtenidos con los tres algoritmos para el caso de que los nodos tengan una probabilidad de acierto baja (40-60%).
Figura 40. Resultados exp. 1. Nodos con probabilidades de acierto bajas (40-60%).
5 10 15 20 25 3010
200
400
600
800
1000
X: 6
Y: 608
Nº Nodos
Algoritmo 1. Decisión por consenso mayoritario
X: 19
Y: 810
5 10 15 20 25 3010
200
400
600
800
1000
Nº Nodos
Algoritmo 2. Decisión por pesos globales
X: 5
Y: 594X: 15
Y: 800
5 10 15 20 25 3010
200
400
600
800
Nº Nodos
Algoritmo 3. Decisión por pesos condicionados
X: 21
Y: 571
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates

Resultados 83
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
En la figura anterior se han marcado, para los distintos algoritmos, las situaciones en las que la red cooperativa es capaz de proporcionar tasas de acierto que rondan la tasa de acierto máxima que tienen algunos de los nodos de la red a nivel individual (60%). Además también se han marcado las situaciones en las que la red cooperativa alcanza probabilidades de acierto próximas al doble de la probabilidad de acierto mínima que tienen algunos nodos a nivel individual (80%). Como ya se ha mencionado al inicio de este capítulo, el análisis de estos resultados se llevará a cabo en el capítulo de conclusiones para facilitar la comparativa de todos los experimentos así como la consecución de las conclusiones más significativas a nivel general.
I.2 Experimento 2. Nodos con probabilidades de acierto altas
En este caso, se parte de una situación más favorable que en el caso anterior, puesto que se ha forzado a que los nodos presenten tasas de acierto comprendidas entre el 80 y el 90% para todas las categorías. Estos valores implican la simulación de una red cuyos elementos, de forma individual, proporcionan resultados coincidentes con el objeto a detectar en un 80-90% de las identificaciones que realizan.
La gráfica de la Figura 41 revela los resultados obtenidos para este caso. En ella
se han marcado las situaciones en las que la red cooperativa proporciona el valor mínimo de aciertos para cada uno de los tres algoritmos. Además también se han señalado las situaciones en las que de forma cooperativa se alcanza un número de aciertos próximo al 100%. Al igual que en el caso anterior los resultados obtenidos serán analizados con detalle en el capítulo de conclusiones.

84 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 41. Resultados exp. 2. Nodos con probabilidades de acierto altas (80-90%).
I.3 Experimento 3. Nodos con probabilidades de acierto dispares entre sí
En este caso, a diferencia de los casos anteriores se dispone de una red muy heterogénea donde los nodos presentan probabilidades de acierto que pueden distar en gran medida de la del resto de nodos con los que coexisten dentro de la misma red. Para este experimento se ha forzado a que los nodos de la simulación presenten tasas de acierto comprendidas entre el 40 y el 90% para todas las categorías. El amplio margen comprendido entre esos valores está directamente relacionado con la heterogeneidad que presenta la red, puesto que pueden formar parte de la misma red nodos que tengan una probabilidad de acierto del 40% con nodos que acierten un 90% de las identificaciones. Con este tipo de red se intenta visualizar el comportamiento del sistema cooperativo y comprobar si la influencia de los nodos que proporcionan un gran número de aciertos puede enmascarar las identificaciones erróneas llevadas a cabo por los nodos con probabilidades de acierto más bajas.
5 10 15 20 25 3010
200
400
600
800
1000
X: 2
Y: 721
Nº Nodos
Algoritmo 1. Decisión por consenso mayoritario
X: 7
Y: 994
5 10 15 20 25 3010
200
400
600
800
1000
X: 2
Y: 721
Nº Nodos
Algoritmo 2. Decisión por pesos globales
X: 6
Y: 995
5 10 15 20 25 3010
200
400
600
800
1000
X: 2
Y: 830
Nº Nodos
Algoritmo 3. Decisión por pesos condicionados
X: 6
Y: 995
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates

Resultados 85
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
En el caso de los experimentos 1 y 2, en los que se trabaja con redes más homogéneas, los resultados obtenidos tras la ejecución de distintas pruebas no distan mucho entre sí, es decir, aunque los valores cambian se mantiene la tendencia y el comportamiento del sistema. Sin embargo, en el caso del experimento 3, donde se trabaja con una red muy heterogénea, la diferencia entre unas pruebas y otras se hace más notable y significativa. De hecho las diferencias pueden ser apreciables en dos pruebas consecutivas cuyos resultados se muestran en las siguientes figuras. Tanto la gráfica de la Figura 42 como la de la Figura 43 muestran resultados obtenidos al ejecutar dos simulaciones sobre un sistema con este tipo probabilidades de acierto -comprendidas entre un 40 y un 90%- para dos pruebas diferentes: Prueba 1 y Prueba 2.
Figura 42. Resultados exp. 3: Prueba 1. Nodos con probabilidades acierto 40-90%.
5 10 15 20 25 3010
200
400
600
800
1000
X: 12
Y: 902
X: 2
Y: 345
Nº Nodos
Algoritmo 1. Decisión por consenso mayoritario
5 10 15 20 25 3010
200
400
600
800
1000
X: 9
Y: 900
X: 2
Y: 345
Nº Nodos
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
200
400
600
800
1000
X: 5
Y: 543
Nº Nodos
Algoritmo 3. Decisión por pesos condicionados
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates

86 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 43. Resultados exp.3: Prueba 2. Nodos con probabilidades acierto 40-90%.
II. Caso 2: Evolución del aprendizaje para distintos tipos de redes
En este segundo caso se analiza cómo evoluciona el aprendizaje a medida que se van realizando las modificaciones de los pesos. Como ya se ha visto en los experimentos anteriores, tras una detección, el sistema cooperativo puede acertar, fallar o simplemente empatar, es decir, en este último caso, los nodos que forman la red no son capaces de proporcionar una única solución. Por este motivo, para poder visualizar cómo varía la probabilidad de acierto del sistema, no basta con que éste se ejecute una única vez sino que se debe disponer de información procedente de varias ejecuciones consecutivas para determinar cuál es la probabilidad de acierto del propio sistema ante unas condiciones dadas de forma que no proporcione un único
5 10 15 20 25 3010
200
400
600
800
1000
X: 8
Y: 899
Nº Nodos
X: 2
Y: 422
Algoritmo 1. Decisión por decisión mayoritaria
5 10 15 20 25 3010
200
400
600
800
1000
X: 5
Y: 923
Nº Nodos
X: 2
Y: 422
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
200
400
600
800
1000
X: 4
Y: 925
Nº Nodos
X: 2
Y: 536
Algoritmo 3. Decisión por pesos condicionados
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates

Resultados 87
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
resultado para evaluar el comportamiento. Esto supone que antes de modificar las matrices de pesos se llevarán a cabo varias identificaciones manteniendo las características del sistema y variando los objetos que emulan el objeto real que debe ser identificado para determinar así la probabilidad de acierto del sistema cooperativo.
Al igual que en el caso 1, se realizarán experimentos que tengan en cuenta el
tamaño de la red y la calidad individual de los nodos pero además se analiza una nueva dimensión que representa la evolución del aprendizaje. Teniendo en cuenta estos criterios de estudio se ha optado por realizar otros 3 experimentos: Experimento 4, 5 y 6.
En las tres simulaciones correspondientes a estos tres experimentos se muestra
la evolución del aprendizaje analizando el comportamiento de los tres algoritmos. Se evalúa la probabilidad de acierto del sistema cooperativo para tres tamaños de red diferentes (3, 8 y 13 nodos) frente al número de modificaciones que sufren los pesos (evoluciones). El experimento 4 se realiza con nodos de baja calidad al igual que el experimento 1 cuyas probabilidades de acierto oscilan entre un 40 y un 60%. Para el experimento 5 se dispone de nodos de mejor calidad pues éstos se definen con probabilidades de acierto comprendidas entre 80 y 90% manteniendo el criterio del experimento 2. Y por último, para el experimento 6 se crea una red heterogénea que contiene nodos cuyas probabilidades de acierto se encuentran entre el 40 y el 90% del mismo modo que se realizó el experimento 3. El resto de parámetros de simulación se mantienen constantes inicializando la tasa de aprendizaje y los pesos iniciales con los valores de 0.01 y 0.5 respectivamente. Además se analizan 30 evoluciones en cada experimento, es decir, los pesos del sistema sufren 30 modificaciones en cada simulación teniendo en cuenta que se realizan 1000 ejecuciones entre cada evolución, de esta forma se puede obtener una probabilidad de acierto más precisa al realizar un número elevado de identificaciones antes de proceder a la modificación de los pesos.
II.1 Experimento 4. Nodos con probabilidades de acierto bajas
Para este experimento se ha forzado a que los nodos presenten tasas de acierto comprendidas entre el 40 y el 60% para todas las categorías. Estos valores implican la simulación de una red cuyos elementos, de forma individual, proporcionan resultados coincidentes con el objeto a detectar sólo entre un 40 y un 60% de las identificaciones que realizan.
La gráfica de la Figura 44 revela los resultados obtenidos con los tres algoritmos
para el caso de que los nodos tengan una probabilidad de acierto baja (40-60%). Hay que tener en cuenta que los valores iniciales para cada tamaño de red son los mismos

88 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
en los tres algoritmos, es por esto por lo que estos sólo se han marcado en la gráfica correspondiente al algoritmo 1.
Figura 44. Resultados exp. 4: Prueba 1. Nodos con prob. de acierto bajas (40-60%).
Otro nuevo experimento del mismo tipo revela los resultados mostrados en la
Figura 45.
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.508
X: 1
Y: 0.588
X: 1
Y: 0.69
X: 30
Y: 0.51
X: 30
Y: 0.598
X: 30
Y: 0.674
Nº evoluciones
Algoritmo 1. Decisión por consenso mayoritario
Pro
b.a
cie
rto
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 30
Y: 0.542
X: 30
Y: 0.686
X: 30
Y: 0.711
Nº evoluciones
Pro
b.a
cie
rto
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 30
Y: 0.555
X: 30
Y: 0.743 X: 30
Y: 0.696
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 3. Decisión por pesos condicionados
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos

Resultados 89
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 45. Resultados exp. 4: Prueba 2. Nodos con prob. de acierto bajas (40-60%).
II.2 Experimento 5. Nodos con probabilidades de acierto altas
En este caso, se parte de una situación más favorable que en el caso anterior, puesto que se fuerza a que los nodos presenten tasas de acierto comprendidas entre el 80 y el 90% para todas las categorías.
La gráfica de la Figura 46 muestra los resultados obtenidos para este caso. Se
observa que los resultados obtenidos alcanzan probabilidades de acierto muy próximas e incluso iguales al 100%.
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.491
X: 1
Y: 0.652
X: 1
Y: 0.758
X: 30
Y: 0.505
X: 30
Y: 0.657
X: 30
Y: 0.75
Nº evoluciones
Algoritmo 1.Decisión por consenso mayoritario
Pro
b.
acie
rto
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1X: 30
Y: 0.794
X: 30
Y: 0.732
X: 30
Y: 0.541
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1X: 30
Y: 0.803
X: 30
Y: 0.736
X: 30
Y: 0.547
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 3. Decisión por pesos condicionados
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos

90 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 46. Resultados exp. 5. Nodos con probabilidades de acierto altas (80-90%).
II.3 Experimento 6. Nodos con probabilidades de acierto dispares entre sí
En este experimento, al igual que en el experimento 3 y a diferencia del resto de experimentos realizados, se dispone de una red muy heterogénea donde los nodos presentan probabilidades de acierto que pueden llegar a ser muy distintas de las de otros nodos con los que coexisten dentro de la misma red.
Para este experimento se ha forzado a que las tasas de acierto estén
comprendidas entre el 40 y el 90% para todas las categorías. La heterogeneidad de la
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 1
Y: 1
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 1. Decisión por consenso mayoritario
X: 1
Y: 0.939
X: 1
Y: 0.994
X: 30
Y: 0.932
X: 30
Y: 1
X: 30
Y: 0.996
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 2. Decisión por pesos globales
X: 30
Y: 0.945
X: 30
Y: 0.998
X: 30
Y: 1
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 30
Y: 0.997
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 3. Decisión por pesos condicionados
X: 30
Y: 1
X: 30
Y: 0.941
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos

Resultados 91
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
red está directamente relacionada con las diferentes probabilidades de acierto que pueden tomar los nodos. Con este tipo de red se intenta visualizar el comportamiento del sistema cooperativo comprobando si la influencia de los nodos que proporcionan un gran número de aciertos puede enmascarar las identificaciones erróneas llevadas a cabo por los nodos con probabilidades de acierto más bajas.
Figura 47. Resultados exp. 6: Prueba 1. Nodos con prob. de acierto 40-90%.
La Figura 48 muestra otra prueba dentro del mismo experimento. En este caso
los nodos presentan probabilidades de acierto individuales más bajas que en la prueba 1 de este mismo experimento.
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.898X: 1
Y: 0.77
X: 1
Y: 0.96X: 30
Y: 0.954
X: 30
Y: 0.912
X: 30
Y: 0.776
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 1. Decisión por consenso mayoritario
0 5 10 15 20 25 300
0.2
0.4
0.6
0.8
1
X: 30
Y: 0.973
X: 30
Y: 0.932X: 30
Y: 0.802
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
0.2
0.4
0.6
0.8
1
X: 30
Y: 0.97
X: 30
Y: 0.931
X: 30
Y: 0.785
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 3. Decisión por pesos condicionados
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos

92 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Figura 48. Resultados exp. 6: Prueba 2. Nodos con prob. de acierto 40-90%.
III. Caso 3: Influencia de la tasa de aprendizaje para distintos tipos de
redes
En este caso se realizan varios experimentos que sirven para analizar la influencia de la tasa de aprendizaje para varios tamaños de red con nodos de distintas calidades (tasas de acierto individuales). Los experimentos de este caso se realizan del mismo modo que se realizaron los del caso 2. Es decir, se evalúa el número de evoluciones que sufren las matrices de pesos frente a la probabilidad de acierto, teniendo presente que entre cada evolución se realizan 1000 ensayos. La diferencia con respecto al caso 2 es que en el caso 3 se mantiene constante el tamaño de la red para cada experimento y lo que se ve modificado para cada curva es la tasa de aprendizaje. Es necesario especificar que las matrices de pesos se inicializan con el valor 0.5.
5 10 15 20 25 3010
0.5
1
Nº evoluciones
Pro
b.
acie
rto
Algortimo 1. Decisión por consenso mayoritarioX: 1
Y: 0.939X: 1
Y: 0.826
X: 1
Y: 0.598
X: 30
Y: 0.95X: 30
Y: 0.772
X: 30
Y: 0.603
5 10 15 20 25 3010
0.5
1
X: 30
Y: 0.975
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 2. Decisión por pesos globales X: 30
Y: 0.873
X: 30
Y: 0.696
5 10 15 20 25 3010
0.5
1
Nº evoluciones
Pro
b.
acie
rto
Algoritmo 3. Decisión por pesos condicionadosX: 30
Y: 0.973 X: 30
Y: 0.866
X: 30
Y: 0.6633 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos
3 nodos
8 nodos
13 nodos

Resultados 93
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Mediante este procedimiento es posible estudiar la influencia de la tasa de aprendizaje sobre el número de aciertos que proporciona el sistema cooperativo para analizar posteriormente si es más aconsejable modificar los pesos con incrementos más grandes o más pequeños.
III.1 Experimento 7. Sistema cooperativo formado por 3 nodos (40-60%)
Para este experimento se parte de una red de 3 nodos sobre la que se analiza la probabilidad de acierto del sistema cooperativo para cada evolución. Los nodos tienen tasas de acierto individuales que oscilan entre el 40 y el 60%, por lo que se consideran nodos de baja calidad. La Figura 49 muestra los resultados obtenidos para cada algoritmo durante la realización de este experimento.
Figura 49. Resultados exp. 7. Red de 3 nodos con probabilidades de acierto 40-60%.
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
3 NODOS. Algoritmo 1. Decisión por consenso mayoritario
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 20
Y: 0.5975
X: 20
Y: 0.5765
Nº evoluciones
3 NODOS. Algoritmo 2. Decisión por pesos globales
Pro
b.
acie
rto
X: 20
Y: 0.618
X: 1
Y: 0.529
X: 1
Y: 0.541
X: 1
Y: 0.52
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 20
Y: 0.512
Nº evoluciones
Pro
b.
acie
rto
3 NODOS. Algoritmo 3. Decisión por pesos condicionados
X: 20
Y: 0.583
X: 20
Y: 0.556
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05

94 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
III.2 Experimento 8. Sistema cooperativo formado por 8 nodos (40-60%)
Para este experimento se parte de las mismas premisas que en experimento 7, la única diferencia en la especificación de la red reside en el número de nodos que forman la red. En este caso se dispone de 8 nodos trabajando de forma cooperativa frente a los 3 nodos que formaban la red en la prueba anterior.
La Figura 50 muestra los resultados obtenidos con el experimento 8.
Figura 50. Resultados exp. 8. Red de 8 nodos con probabilidades de acierto 40-60%.
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
8 NODOS. Algoritmo 1. Decisión por consenso mayoritario
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.5875
Nº evoluciones
8 NODOS. Algoritmo 2. Decisión por pesos globales
Pro
b.
acie
rto
X: 1
Y: 0.5925
X: 1
Y: 0.5745
X: 20
Y: 0.6645
X: 20
Y: 0.666X: 20
Y: 0.6455
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
8 NODOS. Algoritmo 3. Decisión por pesos condicionados
X: 20
Y: 0.6665
X: 20
Y: 0.6115X: 20
Y: 0.49tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05

Resultados 95
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
III.3 Experimento 9. Sistema cooperativo formado por 3 nodos (40-90%)
Para este experimento se parte de un sistema semejante al del experimento 7 puesto que la red está formada por 3 nodos. Sin embargo, la calidad de los nodos es mayor puesto que para esta prueba se ha forzado a que los nodos tengan tasas de acierto que toman valores entre el 40 y el 90%. El cambio de esta condición implica la que la red esté formada por nodos que pueden producir un número de aciertos más elevado. La Figura 51 refleja los resultados obtenidos tras la realización de este experimento.
Figura 51. Resultados exp. 9. Red de 3 nodos con probabilidades de acierto 40-90%.
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
3 NODOS. Algoritmo 1. Decisión por consenso mayoritario
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.686
Nº evoluciones
Pro
b.
acie
rto
3 NODOS. Algoritmo 2. Decisión por pesos globales
X: 1
Y: 0.6965
X: 1
Y: 0.6995
X: 20
Y: 0.7645
X: 20
Y: 0.7235
X: 20
Y: 0.7335
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 20
Y: 0.772
Nº evoluciones
Pro
b.
acie
rto
3 NODOS. Algoritmo 3. Decisión por pesos condicionados
X: 20
Y: 0.7325X: 20
Y: 0.708
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05

96 Resultados
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
III.4 Experimento 10. Sistema cooperativo formado por 8 nodos (40-90%)
Para esta prueba se parte de una red semejante a la utilizada en el experimento 8 pero en este caso los 8 nodos que forman el sistema cooperativo pueden alcanzar de forma individual tasas de acierto más elevadas puesto que sus probabilidades de acierto están comprendidas entre el 40 y el 90%.
Figura 52. Resultados exp. 10. Red de 8 nodos con probabilidades acierto 40-90%.
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
8 NODOS. Algoritmo 1. Decisión por consenso mayoritario
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
X: 1
Y: 0.9
Nº evoluciones
Pro
b.
acie
rto
8 NODOS. Algoritmo 2. Decisión por pesos globales
X: 1
Y: 0.8985
X: 1
Y: 0.905
X: 20
Y: 0.9405X: 20
Y: 0.9335
X: 20
Y: 0.927
2 4 6 8 10 12 14 16 18 2010
0.2
0.4
0.6
0.8
1
Nº evoluciones
Pro
b.
acie
rto
8 NODOS. Algoritmo 3. Decisión por pesos condicionadosX: 20
Y: 0.9425
X: 20
Y: 0.936
X: 20
Y: 0.9315
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05
tasa aprendizaje = 0.01
tasa aprendizaje = 0.03
tasa aprendizaje = 0.05

Conclusiones 97
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Conclusiones
En este apartado se analizarán los resultados obtenidos en los experimentos desarrollados, especificando las conclusiones propias de cada uno de los casos analizados. Además, con el objetivo de determinar los puntos débiles y fuertes de cada algoritmo, se expondrán unas conclusiones generales que sirvan como base para la implementación real del sistema cooperativo.
I. Conclusiones Caso 1: Influencia de la calidad individual de los nodos
sobre los aciertos, fallos y empates producidos en el sistema cooperativo
Como es de esperar y a la vista de las gráficas expuestas en el apartado I del capítulo de Resultados, se puede afirmar que la calidad -en términos de probabilidad de acierto- de los nodos que forman la red está altamente vinculada con el resultado del sistema cooperativo.
I.1 Conclusiones del experimento 1
Si se dispone de nodos que individualmente proporcionan identificaciones erróneas de forma frecuente (Figura 40), es decir, nodos con probabilidades de acierto bajas, entonces el sistema cooperativo no es capaz de mejorar su comportamiento hasta que no dispone de una red de un tamaño considerable.
De hecho la Figura 40, expuesta en el apartado I.1 del capítulo de resultados,
muestra cómo para alcanzar la probabilidad del 60%, que es la probabilidad máxima de acierto que un único nodo puede obtener, se deben utilizar 6 nodos para el caso del algoritmo 1 (consenso mayoritario) y 5 nodos para el caso del algoritmo 2 (pesos globales). Si se desea mejorar aún más los resultados, llegando a alcanzar tasas de acierto que doblen la probabilidad de acierto mínima individual, son necesarios 19 nodos para el algoritmo 1 y 15 nodos para el algoritmo 2. No obstante, y a pesar de necesitar redes de tamaño tan elevado, superar el 95% es una tarea prácticamente imposible. Sin embargo, un factor muy importante a tener en cuenta es que, a pesar de que ambos algoritmos requieren redes grandes, el algoritmo 2 es capaz de disminuir la incertidumbre del sistema debido a que reduce de forma muy significativa el número de empates producidos en comparación con los que se producen con el uso del algoritmo 1.

98 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Por otro lado se observa cómo el algoritmo 3, ajeno a la evolución que siguen tanto el 1 como el 2, no es capaz de proporcionar una respuesta cooperativa coherente, sino que prácticamente muestra un comportamiento aleatorio que no sigue ningún criterio a medida que aumenta el tamaño de la red.
Todo esto supone que cuando todos los nodos de la red de forma individual
tienen una tasa de fallo muy elevada, ninguno de los tres algoritmos es lo suficientemente adecuado como para proporcionar buenos resultados de forma cooperativa sin requerir la implementación de una red de tamaño considerable. El hecho de requerir una red grande implica aumentar el coste del sistema de forma notable, pues se debe recordar que cada nodo está compuesto por un radar, una plataforma hardware Tecalum, un módulo ZigBee y una antena. Sin embargo, hay que tener en cuenta que la situación de la que se parte es una situación muy desfavorable ya que disponer de nodos con tasas de acierto que, en ningún caso superan el 60%, debe considerarse como una situación inaceptable cuya implementación real debe ser rechazada ya que ninguno de los nodos es capaz de acercarse a tasa de acierto que puedan considerarse adecuadas. Para solucionar este problema e intentar conseguir nodos que mejoren su tasa individual de acierto es aconsejable modificar la orientación y/o localización de los nodos o ajustar su ganancia. Si realizando cambios físicos sobre los nodos se consigue que, al menos algunos de ellos, mejoren sus resultados individuales entonces el sistema se convertirá en otro sistema con características más semejantes a las analizadas en la experimento 3 con lo que la implementación real podría llevarse a cabo.
I.2 Conclusiones del experimento 2
En este caso la situación es completamente opuesta a la anterior, puesto que se parte de nodos que de por sí, de forma individual, son capaces de proporcionar resultados con una alta probabilidad de acierto. Esta situación es muy favorable, y a pesar de que ninguno de los nodos proporciona tasas de acierto que superen el 90%, al combinarse creando un sistema cooperativo son capaces de generar identificaciones correctas prácticamente el 100% de las veces con un tamaño de red aceptable: en torno a 7 nodos en el caso del algoritmo 1 y unos 6 nodos al implementar tanto el algoritmo 2 como el algoritmo 3 (Ver Figura 41 en apartado I.2 del capítulo de resultados).
En esta situación, a diferencia de lo que ocurría en el caso anterior, el algoritmo
3 sí presenta un comportamiento coherente. Sin embargo, debido a la complejidad computacional que requiere, sigue siendo más favorable implementar un sistema real basado en el algoritmo 2 ya que la gestión de pesos globales es mucho más sencilla que gestionar todos los pesos que aparecen en el caso de tener en cuenta los pesos condicionados. Además, aunque la incertidumbre se reduce más en el caso del

Conclusiones 99
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
algoritmo 3, ésta puede considerarse nula a partir de dos nodos para el caso del algoritmo 2 con lo que se puede afirmar que ambos algoritmos también tienen un comportamiento semejante al considerar ese criterio. No obstante, como característica favorable propia del algoritmo 3, cabe destacar, que éste es el que proporciona el mínimo número de aciertos más alto, es decir, a la vista de la Figura 41, el algoritmo 3 acierta como mínimo 830 casos de cada 1000 frente a los otros dos algoritmos cuyos mínimos son inferiores situándose en 721 aciertos de cada 1000.
I.3 Conclusiones del experimento 3
Como ya se ha mencionado anteriormente, la situación que describe el experimento 3 es mucho menos previsible que las anteriores. El hecho de que los nodos de la red puedan ser muy distintos entre sí hace que se incremente grado de heterogeneidad de la red y que los resultados varíen entre las distintas pruebas. La Figura 42 y la Figura 43, mostradas anteriormente en el apartado I.3 del capítulo de resultados, sirven cómo comprobante de cuán dispares pueden ser los resultados cooperativos manteniendo las probabilidades de acierto de los nodos entre el 40 y el 90%. El hecho de aumentar o disminuir el margen de acierto de los nodos implica generar situaciones que tiendan hacia resultados del tipo del experimento 1 o resultados del tipo del experimento 2. Este hecho se hace significativamente influyente en el caso del algoritmo 3 que presenta un comportamiento inestable ya que los resultados obtenidos en la prueba 1 distan muchísimo de los obtenidos en la prueba 2. Por otro lado, al comparar únicamente el comportamiento de los algoritmos 1 y 2 se observa que, a pesar de que existan situaciones más favorables que otras, la tendencia para ambos algoritmos se mantiene en todas las pruebas. Sin embargo, el algoritmo 2 consigue resultados que rondan o superan el 90% con menos nodos que el algoritmo 1. Esta afirmación puede comprobarse en la Tabla 10 cuyos datos han sido extraídos de las Figura 42 y Figura 43 mostradas en el apartado I.3 del capítulo de resultados. Se observa que el algoritmo 2 requiere 9 nodos frente a los 12 requeridos por el algoritmo 1 para la prueba 1 y ese margen de diferencia se sigue mantiene en la prueba 2 pues el algoritmo 2 necesita 5 nodos para superar el 90% mientras que el algoritmo 1 necesita 3 nodos más. Además, del mismo modo que en las comparaciones anteriores, el algoritmo 2 reduce el nivel de incertidumbre al minimizar de forma casi absoluta el número de empates que se generan.
Tabla 10. Comparativa experimento 3: Probabilidades ≥ 90 %.
Experimento 3. Probabilidades de acierto ≥ 90%
Tipo de algoritmo Prueba 1 Prueba 2
Algoritmo 1. Mayoría 12 nodos 8 nodos
Algoritmo 2. Pesos globales 9 nodos 5 nodos
Algoritmo 3. Pesos condicionados 17 nodos 4 nodos

100 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Otro aspecto destacable en el experimento 3 pero que difiere del experimento 1, es que el algoritmo 3 siempre tiende a mejorar su comportamiento a medida que aumenta el tamaño de la red. Esto supone que a pesar de que su comportamiento es prácticamente aleatorio con tamaños de red más aceptables, a medida que aumenta el número de nodos que cooperan el sistema tiende a estabilizarse proporcionando tasas de acierto muy elevadas. La Figura 53, que se muestra a continuación, pone de manifiesto esta conclusión ya que muestra la comparativa entre ambos experimentos y permite visualizar cómo en el caso del experimento 3 se revela una tendencia creciente en la curva de aciertos.
Figura 53. Comparativa del algoritmo3. Exp. 1 vs. Prueba 1 del exp. 3.
II. Conclusiones Caso 2: Evolución del aprendizaje para distintos tipos de
redes
A la vista de las gráficas expuestas en el apartado II del capítulo de Resultados, de forma general se puede afirmar los algoritmos 2 y 3 muestran una tendencia a mejorar sus resultados a medida que transcurre el tiempo, ya que tras sufrir las modificaciones de sus pesos con las distintas evoluciones que sufren, proporcionan mejores resultados en la mayoría de los casos. Por su parte el algoritmo 1 muestra resultados que se mantienen más o menos constantes a medida que se incrementa el
5 10 15 20 25 3010
200
400
600
800
1000
X: 6
Y: 608
Nº Nodos
Algoritmo 1. Decisión por consenso mayoritario
X: 19
Y: 810
5 10 15 20 25 3010
200
400
600
800
1000
X: 5
Y: 594
Nº Nodos
Algoritmo 2. Decisión por pesos globales
X: 15
Y: 800
5 10 15 20 25 3010
200
400
600
800
X: 21
Y: 571
Nº Nodos
Algoritmo 3. Decisión por pesos condicionados
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates
5 10 15 20 25 3010
200
400
600
800
1000
X: 12
Y: 902
X: 2
Y: 345
Nº Nodos
Algoritmo 1. Decisión por consenso mayoritario
5 10 15 20 25 3010
200
400
600
800
1000
X: 9
Y: 900
X: 2
Y: 345
Nº Nodos
Algoritmo 2. Decisión por pesos globales
5 10 15 20 25 3010
200
400
600
800
1000
X: 5
Y: 543
Nº Nodos
Algoritmo 3. Decisión por pesos condicionados
aciertos
fallos
empates
aciertos
fallos
empates
aciertos
fallos
empates
SIMULACIÓN 1
SIMULACIÓN 3
Tendencia creciente

Conclusiones 101
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
número de identificaciones que realiza, lo cual es el resultado esperado al no poseer ningún tipo de aprendizaje. Sin embargo, la evolución del aprendizaje también mantiene una relación directa con la calidad de los nodos en términos de tasa de acierto puesto que los resultados que se obtienen son algo diferentes para los experimentos 4, 5 y 6 que se diferencian en la calidad de los nodos que forman la red cooperativa. Para poder analizar cómo evoluciona el aprendizaje se han definido dos nuevas variables. Por un lado se analiza la pendiente de la curva que relaciona la probabilidad de acierto con el número de evoluciones y que representa por tanto las variaciones en el número de aciertos entre la primera y la última evolución. Por otro lado se analiza la probabilidad de acierto media -promedio- que se obtiene con cada algoritmo para cada tamaño de red en cada experimento de forma que se puede evaluar si se ha producido alguna mejora cuando se trabaja con diferentes tamaños para implementar el sistema cooperativo.
Cabe destacar que las posibles desviaciones que se producen a lo largo de las
evoluciones son debidas a que los resultados obtenidos se basan en cálculos probabilísticos y que por tanto se crearán situaciones más favorables en unos casos que en otros. Sin embargo, la tendencia general es la que debe analizarse a la hora de extraer las conclusiones acerca de la evolución del aprendizaje.
II.1 Conclusiones del experimento 4
La Tabla 11 muestra las probabilidades de acierto, mostradas anteriormente en la Figura 44 del apartado II.1 del capítulo de resultados, y que fueron obtenidas desde el inicio de la simulación hasta alcanzar las 30 evoluciones para cada uno de los tres tamaños de red correspondientes a cada uno de los tres algoritmos. Se incluyen los valores de la pendiente y del promedio para evaluar la calidad de los algoritmos.
Tabla 11. Análisis de pendientes y promedios para la prueba 1 del experimento 4.
Alg.1. Consenso mayoría Alg.2. Pesos globales Alg.3. Pesos condicionados
Evolución 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos
1 0,508 0,588 0,690 0,508 0,588 0,690 0,508 0,588 0,690
2 0,502 0,613 0,700 0,502 0,678 0,734 0,521 0,677 0,747
3 0,516 0,582 0,695 0,516 0,649 0,727 0,550 0,681 0,741
4 0,515 0,612 0,664 0,515 0,682 0,720 0,529 0,684 0,713
5 0,540 0,589 0,693 0,540 0,667 0,733 0,565 0,690 0,747
6 0,504 0,598 0,698 0,544 0,681 0,731 0,545 0,675 0,751
7 0,481 0,608 0,728 0,481 0,682 0,763 0,521 0,682 0,788
8 0,499 0,611 0,677 0,499 0,690 0,731 0,537 0,692 0,753
9 0,519 0,594 0,719 0,519 0,679 0,758 0,564 0,695 0,758
10 0,522 0,607 0,701 0,522 0,692 0,742 0,557 0,707 0,745
11 0,528 0,599 0,691 0,528 0,679 0,728 0,567 0,690 0,730

102 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
12 0,512 0,588 0,705 0,535 0,676 0,755 0,552 0,678 0,745
13 0,539 0,614 0,685 0,563 0,697 0,731 0,578 0,705 0,736
14 0,492 0,601 0,686 0,492 0,663 0,734 0,531 0,665 0,718
15 0,519 0,584 0,701 0,519 0,686 0,732 0,557 0,679 0,745
16 0,534 0,596 0,688 0,534 0,679 0,729 0,573 0,684 0,738
17 0,519 0,593 0,693 0,519 0,685 0,723 0,569 0,685 0,725
18 0,497 0,610 0,677 0,536 0,698 0,713 0,539 0,686 0,721
19 0,511 0,580 0,690 0,547 0,667 0,727 0,542 0,673 0,728
20 0,497 0,604 0,695 0,545 0,682 0,736 0,533 0,690 0,737
21 0,488 0,589 0,698 0,537 0,681 0,734 0,536 0,672 0,730
22 0,497 0,607 0,722 0,541 0,697 0,751 0,545 0,706 0,764
23 0,500 0,595 0,704 0,553 0,678 0,737 0,553 0,686 0,752
24 0,518 0,588 0,696 0,561 0,659 0,732 0,566 0,674 0,717
25 0,501 0,604 0,680 0,547 0,687 0,728 0,552 0,695 0,724
26 0,498 0,606 0,691 0,548 0,681 0,733 0,539 0,700 0,737
27 0,514 0,630 0,691 0,558 0,708 0,728 0,563 0,720 0,729
28 0,497 0,582 0,678 0,548 0,676 0,722 0,544 0,669 0,745
29 0,496 0,604 0,668 0,539 0,684 0,708 0,537 0,716 0,724
30 0,510 0,598 0,674 0,542 0,686 0,711 0,555 0,696 0,743
Promedio 0,509 0,599 0,693 0,531 0,678 0,731 0,548 0,685 0,737
Pendiente 0,01% 0,03% -0,05% 0,11% 0,33% 0,07% 0,16% 0,36% 0,18%
Recordando que para este experimento cada nodo, de forma individual, tenía
asociadas unas probabilidades de acierto que oscilaban entre el 40 y el 60% y a la vista de los resultados que se han obtenido, se observa cómo las probabilidades de acierto medias superan el 50% en todos los casos e incluso en algunos llegan a superar el valor máximo que podría proporcionar cada nodo de forma individual. Esto hace que se pueda afirmar que el sistema cooperativo formado por nodos de este tipo puede proporcionar mejores resultados que los obtenidos sin formar la red cooperativa.
Además, es destacable el hecho de que las pendientes del algoritmo 1 sean
prácticamente nulas y no ocurra lo mismo para los algoritmos 2 y 3. Este comportamiento es el esperado debido a que el algoritmo 1 no implementa ningún tipo de aprendizaje al estar basado en la decisión por mayoría, lo cual hace que su tendencia se mantenga prácticamente constante a medida que se producen nuevas identificaciones. Sin embargo, las pendientes de los algoritmos 2 y 3 presentan una ligera pendiente positiva que determina cómo evoluciona el aprendizaje en cada caso. La tendencia a incrementar la probabilidad de acierto a medida que crece el número de evoluciones está limitada por un valor máximo alcanzable para cada caso que influye directamente sobre el margen de mejora que tiene cada algoritmo para proporcionar tasas de acierto más elevadas. Este valor máximo es desconocido y diferente para cada caso puesto que está condicionado, entre otros factores, por las probabilidades de acierto de los nodos que forman la red, la tendencia que tenga cada nodo a la hora de identificar un objeto u otro cuando genera una detección

Conclusiones 103
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
errónea y la secuencia de los objetos que se deben identificar. No obstante, a pesar de ninguno de estos dos algoritmos demuestra un aprendizaje altamente significativo, si se combina el tamaño de red adecuado con la implementación de un algoritmo con aprendizaje es posible alcanzar tasas de acierto significativamente altas en comparación con los resultados que podrían obtenerse con un único nodo trabajando de forma aislada.
Como conclusión y a la vista de los resultados obtenidos en el experimento, se
puede confirmar que la implementación de un sistema cooperativo puede producir mejoras importantes a la hora de realizar identificaciones. Por ejemplo en este caso con nodos de baja calidad (40-60% de aciertos), la mayor mejora se ha obtenido con redes de 8 nodos en la que, sin usar aprendizaje, es posible alcanzar una probabilidad de acierto media equivalente a la tasa de acierto máxima individual de cada nodo (60%), pero que incluso se ve mejorada en casi un 10% si se incorpora algún tipo de aprendizaje (67.8% y 68.5% respectivamente para los algoritmos 2 y 3). El hecho de que se obtengan mayores pendientes para redes de 8 nodos que para las redes de 13 nodos es debido a que a medida que se aumenta el tamaño de la red se dispone de mejor margen para la mejora como consecuencia de que el sistema cuenta con más opiniones que hacen que los resultados se acerquen más al valor máximo admisible que puede alcanzar la red. Esto implica que el hecho de proporcionar aprendizaje a la red cooperativa permite reducir el número de nodos en la red sin que la probabilidad de acierto se degrade en gran medida.
Las mismas conclusiones pueden obtenerse para la prueba 2 del mismo
experimento cuyos resultados se mostraron en la Figura 45 del apartado II del capítulo de resultados y cuyos valores pueden observarse de nuevo en la Tabla 12 en la que se incluyen los valores para la pendiente y el promedio.
Tabla 12. Análisis de pendientes y promedios para la prueba 2 del experimento 4.
Alg.1. Consenso mayoría Alg.2. Pesos globales Alg.3. Pesos condicionados
Evolución 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos
1 0,491 0,652 0,758 0,491 0,652 0,758 0,491 0,652 0,758
2 0,527 0,635 0,777 0,527 0,677 0,803 0,535 0,700 0,799
3 0,507 0,634 0,775 0,536 0,702 0,810 0,527 0,701 0,821
4 0,517 0,633 0,736 0,517 0,726 0,777 0,544 0,736 0,794
5 0,513 0,608 0,748 0,513 0,684 0,791 0,528 0,697 0,803
6 0,488 0,611 0,758 0,493 0,684 0,791 0,514 0,699 0,803
7 0,517 0,626 0,748 0,517 0,710 0,797 0,554 0,719 0,806
8 0,512 0,646 0,763 0,512 0,725 0,803 0,527 0,726 0,809
9 0,488 0,629 0,768 0,488 0,708 0,810 0,512 0,722 0,823
10 0,500 0,607 0,739 0,500 0,683 0,800 0,526 0,710 0,811
11 0,510 0,655 0,743 0,541 0,724 0,781 0,517 0,728 0,788
12 0,508 0,639 0,751 0,508 0,692 0,792 0,527 0,724 0,803

104 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
13 0,512 0,609 0,750 0,512 0,682 0,787 0,528 0,703 0,784
14 0,500 0,646 0,748 0,500 0,715 0,785 0,513 0,738 0,791
15 0,491 0,616 0,772 0,514 0,689 0,824 0,508 0,717 0,823
16 0,514 0,642 0,751 0,514 0,693 0,797 0,544 0,715 0,798
17 0,498 0,645 0,754 0,498 0,714 0,807 0,527 0,735 0,805
18 0,507 0,611 0,746 0,507 0,678 0,782 0,553 0,685 0,780
19 0,490 0,624 0,775 0,490 0,682 0,815 0,536 0,710 0,807
20 0,496 0,625 0,746 0,496 0,698 0,796 0,541 0,699 0,795
21 0,533 0,643 0,725 0,565 0,722 0,771 0,558 0,735 0,776
22 0,499 0,651 0,766 0,533 0,733 0,815 0,523 0,726 0,805
23 0,500 0,640 0,759 0,540 0,704 0,797 0,535 0,715 0,800
24 0,493 0,647 0,758 0,542 0,725 0,803 0,543 0,716 0,807
25 0,488 0,627 0,766 0,521 0,718 0,805 0,524 0,715 0,814
26 0,504 0,641 0,738 0,537 0,704 0,795 0,543 0,717 0,805
27 0,511 0,662 0,765 0,546 0,735 0,810 0,542 0,734 0,823
28 0,503 0,664 0,765 0,544 0,737 0,802 0,543 0,748 0,809
29 0,517 0,647 0,759 0,567 0,725 0,805 0,555 0,732 0,814
30 0,505 0,657 0,750 0,541 0,732 0,794 0,547 0,736 0,803
Promedio 0,505 0,636 0,755 0,520 0,705 0,797 0,532 0,716 0,802
Pendiente 0,05% 0,02% -0,03% 0,17% 0,27% 0,12% 0,19% 0,28% 0,15%
Nótese que en la Tabla 11 se muestra una situación anómala para el algoritmo 2
puesto que a pesar de tener implementado un tipo de aprendizaje, este algoritmo para redes de 13 nodos no presenta una pendiente similar a la obtenida con otros tamaños de red sino que prácticamente se mantiene una tendencia a lo largo de las evoluciones (pendiente de 0.07%). Sin embargo, en los resultados mostrados en la Tabla 12 que equivalen a otra simulación del mismo tipo no se aprecia esta anomalía ya que la pendiente de de 0.12% por lo que se demuestra que este hecho es un caso aislado ya que en general esa pendiente debe tener un valor más alejado del 0% debido a la existencia del aprendizaje. Esta situación que se manifiesta en la Prueba 1 del experimento 4 (Figura 44 y Tabla 11) y que conlleva a pensar que el algoritmo 2 no muestra una evolución en el aprendizaje puede deberse a que la secuencia de objetos identificados durante las 1000 ejecuciones del algoritmo junto con el conjunto de probabilidades de acierto asignado a esos 13 nodos han proporcionado unas tasas de acierto próximas al valor máximo alcanzable por lo que la mejora no puede ser muy significativa ya que el algoritmo apenas tiene margen para mejorar.

Conclusiones 105
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
II.2 Conclusiones del experimento 5
La Tabla 13 recoge los valores mostrados en la Figura 46 del apartado II.2 del capítulo de resultados y cuyos valores fueron obtenidos para el caso en el que los nodos tenían unas tasas de acierto individuales que oscilaban entre el 80 y el 90%.
Tabla 13. Análisis de pendientes y promedios para el experimento 5.
Alg.1. Consenso mayoría Alg.2. Pesos globales Alg.3. Pesos condicionados
Evolución 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos
1 0,939 0,994 1,000 0,939 0,994 1,000 0,939 0,994 1,000
2 0,950 0,991 1,000 0,950 0,991 1,000 0,957 0,992 1,000
3 0,939 0,999 1,000 0,939 0,999 1,000 0,947 0,999 1,000
4 0,934 0,998 1,000 0,934 0,998 1,000 0,941 0,998 1,000
5 0,942 0,996 1,000 0,942 0,997 1,000 0,942 0,997 1,000
6 0,935 0,997 0,998 0,935 0,998 0,998 0,935 0,999 0,999
7 0,939 0,994 1,000 0,939 0,995 1,000 0,949 0,995 1,000
8 0,942 0,992 0,999 0,942 0,994 0,999 0,956 0,995 0,999
9 0,937 0,991 1,000 0,937 0,992 1,000 0,953 0,993 1,000
10 0,946 0,993 1,000 0,946 0,996 1,000 0,961 0,995 1,000
11 0,939 0,998 1,000 0,939 0,999 1,000 0,951 0,998 1,000
12 0,944 0,991 0,999 0,944 0,993 0,999 0,954 0,996 0,999
13 0,928 0,996 1,000 0,928 0,996 1,000 0,943 0,997 1,000
14 0,948 0,999 1,000 0,954 1,000 1,000 0,958 1,000 1,000
15 0,941 0,998 1,000 0,951 0,998 1,000 0,954 0,998 1,000
16 0,934 0,995 1,000 0,941 0,996 1,000 0,947 0,997 1,000
17 0,938 0,997 1,000 0,945 0,997 1,000 0,953 0,998 1,000
18 0,932 0,991 1,000 0,940 0,993 1,000 0,941 0,993 1,000
19 0,952 0,995 1,000 0,957 0,997 1,000 0,961 0,997 1,000
20 0,934 0,991 1,000 0,943 0,993 1,000 0,943 0,991 1,000
21 0,935 0,995 1,000 0,948 0,998 1,000 0,946 0,996 1,000
22 0,930 0,998 1,000 0,943 0,998 1,000 0,941 0,999 1,000
23 0,930 0,997 1,000 0,942 0,997 1,000 0,946 0,997 1,000
24 0,944 0,994 0,999 0,945 0,995 0,999 0,957 0,996 1,000
25 0,935 0,992 0,999 0,953 0,993 0,999 0,944 0,994 0,999
26 0,951 0,994 1,000 0,958 0,994 1,000 0,957 0,995 1,000
27 0,945 0,995 1,000 0,952 0,996 1,000 0,957 0,998 1,000
28 0,943 0,995 1,000 0,952 0,996 1,000 0,953 0,998 1,000
29 0,939 0,999 1,000 0,947 0,999 1,000 0,958 0,999 1,000
30 0,932 0,996 1,000 0,945 0,998 1,000 0,941 0,997 1,000
Promedio -0,02% 0,01% 0,00% 0,02% 0,01% 0,00% 0,01% 0,01% 0,00%
Pendiente 0,939 0,995 1,000 0,944 0,996 1,000 0,950 0,996 1,000
A partir de estos resultados se puede afirmar que, con una red formada por
nodos con altas tasas de acierto, las identificaciones realizadas son correctas en la mayoría de los casos puesto que los resultados son superiores al 95% prácticamente ante cualquier situación. Sin embargo, los valores de las pendientes rondan el 0% lo

106 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
que implica que apenas influye el aprendizaje. El hecho de trabajar con nodos con altas tasas de acierto hace que el aprendizaje no mejore mucho los resultados que de por sí, sólo con la cooperación, ya rondan unos valores muy elevados.
II.3 Conclusiones del experimento 6
La Tabla 14 recoge los valores asociados a las Figura 47 y Figura 48 del apartado II.3 del capítulo de resultados y cuyos valores fueron obtenidos para el caso en el que la red mostraba un cierto grado de heterogeneidad al estar formada por nodos cuyas tasas de acierto individuales variaban entre el 40 y el 90%.
Tabla 14. Análisis de pendientes y promedios para la prueba 1 del experimento 6.
Alg.1. Consenso mayoría Alg.2. Pesos globales Alg.3. Pesos condicionados
Evolución 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos
1 0,770 0,898 0,960 0,770 0,898 0,960 0,770 0,898 0,960
2 0,774 0,915 0,971 0,774 0,933 0,987 0,784 0,928 0,978
3 0,773 0,894 0,961 0,773 0,919 0,973 0,779 0,923 0,968
4 0,770 0,899 0,967 0,770 0,929 0,981 0,777 0,930 0,970
5 0,762 0,909 0,952 0,783 0,933 0,963 0,772 0,934 0,962
6 0,790 0,900 0,963 0,790 0,923 0,984 0,799 0,934 0,972
7 0,762 0,903 0,963 0,762 0,939 0,977 0,779 0,927 0,974
8 0,779 0,891 0,960 0,779 0,923 0,970 0,788 0,917 0,967
9 0,778 0,902 0,969 0,778 0,938 0,983 0,783 0,934 0,976
10 0,764 0,913 0,966 0,795 0,942 0,975 0,777 0,935 0,973
11 0,757 0,897 0,965 0,788 0,935 0,975 0,766 0,925 0,970
12 0,754 0,876 0,966 0,794 0,908 0,979 0,766 0,912 0,976
13 0,793 0,895 0,960 0,815 0,935 0,975 0,805 0,924 0,969
14 0,791 0,906 0,959 0,816 0,933 0,981 0,801 0,944 0,970
15 0,758 0,897 0,964 0,798 0,927 0,975 0,769 0,928 0,967
16 0,758 0,902 0,969 0,781 0,944 0,982 0,763 0,928 0,973
17 0,725 0,901 0,965 0,763 0,942 0,979 0,738 0,935 0,971
18 0,771 0,897 0,977 0,803 0,935 0,987 0,776 0,935 0,984
19 0,774 0,903 0,963 0,803 0,940 0,977 0,785 0,939 0,970
20 0,758 0,906 0,959 0,785 0,934 0,975 0,766 0,930 0,969
21 0,771 0,890 0,959 0,795 0,931 0,974 0,774 0,926 0,970
22 0,769 0,891 0,967 0,796 0,928 0,979 0,774 0,917 0,974
23 0,742 0,921 0,974 0,761 0,945 0,982 0,750 0,939 0,977
24 0,769 0,894 0,970 0,797 0,932 0,979 0,773 0,927 0,976
25 0,760 0,889 0,967 0,791 0,932 0,977 0,765 0,920 0,972
26 0,772 0,909 0,963 0,794 0,941 0,979 0,776 0,923 0,970
27 0,781 0,890 0,961 0,815 0,921 0,974 0,791 0,908 0,976
28 0,760 0,896 0,962 0,791 0,938 0,977 0,770 0,924 0,973
29 0,795 0,905 0,956 0,815 0,939 0,974 0,799 0,925 0,974
30 0,776 0,912 0,954 0,802 0,932 0,973 0,785 0,931 0,970
Promedio 0,02% 0,05% -0,02% 0,11% 0,11% 0,04% 0,05% 0,11% 0,03%
Pendiente 0,769 0,900 0,964 0,789 0,932 0,977 0,777 0,927 0,972

Conclusiones 107
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Tabla 15. Análisis de pendientes y promedios para la prueba 2 del experimento 6.
Alg.1. Consenso mayoría Alg.2. Pesos globales Alg.3. Pesos condicionados
Evolución 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos 3 Nodos 8 Nodos 13 Nodos
1 0,598 0,826 0,939 0,598 0,826 0,939 0,598 0,826 0,939
2 0,590 0,796 0,954 0,590 0,875 0,963 0,646 0,866 0,969
3 0,622 0,789 0,959 0,700 0,869 0,967 0,664 0,842 0,969
4 0,584 0,794 0,960 0,672 0,865 0,980 0,647 0,858 0,970
5 0,581 0,770 0,956 0,669 0,840 0,981 0,660 0,833 0,978
6 0,579 0,778 0,956 0,653 0,840 0,976 0,663 0,867 0,974
7 0,566 0,774 0,935 0,654 0,838 0,962 0,661 0,862 0,958
8 0,582 0,788 0,958 0,690 0,848 0,972 0,693 0,876 0,972
9 0,585 0,795 0,947 0,671 0,846 0,966 0,680 0,862 0,963
10 0,586 0,772 0,951 0,677 0,836 0,969 0,701 0,860 0,970
11 0,566 0,795 0,960 0,654 0,873 0,977 0,657 0,881 0,976
12 0,617 0,781 0,959 0,695 0,864 0,976 0,703 0,866 0,971
13 0,575 0,806 0,965 0,681 0,877 0,982 0,686 0,881 0,981
14 0,566 0,799 0,943 0,677 0,867 0,971 0,682 0,866 0,966
15 0,594 0,785 0,951 0,676 0,875 0,968 0,676 0,874 0,961
16 0,615 0,787 0,955 0,676 0,866 0,976 0,670 0,874 0,966
17 0,605 0,781 0,965 0,695 0,880 0,981 0,693 0,879 0,976
18 0,592 0,796 0,953 0,674 0,877 0,973 0,680 0,880 0,965
19 0,593 0,768 0,965 0,685 0,850 0,981 0,673 0,858 0,978
20 0,593 0,783 0,951 0,686 0,876 0,971 0,688 0,883 0,970
21 0,584 0,799 0,941 0,672 0,882 0,964 0,678 0,881 0,959
22 0,577 0,794 0,954 0,664 0,868 0,975 0,650 0,883 0,972
23 0,588 0,794 0,961 0,682 0,880 0,981 0,651 0,899 0,976
24 0,608 0,800 0,946 0,696 0,881 0,968 0,694 0,884 0,964
25 0,611 0,785 0,950 0,686 0,875 0,976 0,686 0,891 0,972
26 0,587 0,795 0,926 0,674 0,876 0,952 0,662 0,888 0,951
27 0,554 0,784 0,951 0,648 0,885 0,974 0,662 0,886 0,973
28 0,585 0,787 0,952 0,670 0,868 0,973 0,667 0,873 0,971
29 0,601 0,807 0,949 0,688 0,886 0,968 0,653 0,896 0,965
30 0,603 0,772 0,950 0,696 0,873 0,975 0,663 0,866 0,973
Promedio 0,02% -0,18% 0,04% 0,33% 0,16% 0,12% 0,22% 0,13% 0,11%
Pendiente 0,590 0,789 0,952 0,672 0,865 0,971 0,670 0,871 0,968
A la vista de los resultados obtenidos en el experimento 6, se observa cómo el
algoritmo 2 y el algoritmo 3 presentan comportamientos similares. En ambos casos se obtiene mayor influencia del aprendizaje en redes formadas por 3 u 8 nodos, en función de si los nodos que forman la red presentan probabilidades que tienden a valores más bajos de forma general; aunque los resultados siempre presentan mayor tasa de acierto media con redes de 13 nodos debido a que disponen de más opiniones al ser redes más grandes. Sin embargo, tanto para redes de 8 nodos como redes de 13 nodos prácticamente se iguala e incluso se supera el 90% por lo que el conjunto de 8 nodos puede considerarse más apropiado frente al de 13 nodos para formar el sistema cooperativo puesto que muestra un comportamiento más estable para

108 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
distintas simulaciones y a su vez proporciona resultados que rondan o superan el porcentaje máximo individual que cada nodo podría proporcionar de forma aislada enmascarando el mal comportamiento de los nodos que únicamente proporcionan aciertos en un 40% de las identificaciones.
Por otro lado, es aconsejable la inclusión del aprendizaje en el sistema puesto
que, a pesar de que el algoritmo 1 –consenso mayoritario sin aprendizaje- muestra unos resultados semejantes a los obtenidos mediante los algoritmos 2 y 3, podría darse el caso de que los nodos, al formar una red heterogénea, tiendan a situaciones con nodos de peor calidad en cuyo caso el aprendizaje podría beneficiar al conjunto tal y como ha quedado demostrado en el experimento 4.
III. Conclusiones Caso 3: Influencia de la tasa de aprendizaje para
distintos tipos de redes
A la vista de las gráficas expuestas en el apartado III del capítulo de Resultados, se puede afirmar que el algoritmo 1, como era de esperar, no muestra ningún tipo de variación notable durante la evolución de estos ensayos como consecuencia de su falta de aprendizaje. Por otro lado, de forma general se puede afirmar también que el algoritmo 2 presenta un comportamiento más estable que el algoritmo 3 ante distintas condiciones de ensayo.
Otro factor destacable es que la calidad de los nodos en términos de
probabilidad de acierto individual tiene una influencia directa sobre el comportamiento del sistema ante variaciones de la tasa de aprendizaje. El hecho de que los nodos de forma individual presenten tasas de acierto elevadas hace que el sistema sea menos sensible a variaciones de dicho parámetro. Debido a este motivo no se han realizado experimentos con redes cuyos nodos presentasen tasas de acierto superiores al 80% ya que los experimentos 9 y 10 con nodos de 40-90% han sido suficientes para comprobar esta afirmación.
Por otro lado, no se debe olvidar que se trabaja con simulaciones basadas en
cálculos probabilísticos lo cual puede ocasionar pequeñas desviaciones a lo largo de las evoluciones creándose situaciones más favorables en unos casos que en otros. Debido a esto, sólo la tendencia general de las curvas obtenidas es lo que debe tenerse en cuenta a la hora de extraer las conclusiones de estos análisis.
III.1 Conclusiones del experimento 7
A la vista de los resultados mostrados en la Figura 49 del apartado III.1 del capítulo de resultados, se puede afirmar el comportamiento del algoritmo 2 presenta

Conclusiones 109
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
algunas diferencias sobre el comportamiento del algoritmo 3. De hecho, trabajar con pesos globales (algoritmo 2) para determinados valores de tasa de aprendizaje supone obtener mejores resultados que los que se pueden obtener al trabajar con pesos condicionados (algoritmo 3). El algoritmo 2, a parte de denotar un comportamiento poco estable como consecuencia del trabajo cooperativo de sólo 3 nodos, presenta tendencias más o menos crecientes para todos los casos analizados en este experimento. Sin embargo, el algoritmo 3 tiene un comportamiento muy ligado a la tasa de aprendizaje ya que si este parámetro toma valores demasiado grandes el comportamiento del algoritmo se ve perjudicado tal y como demuestra la tendencia ligeramente decreciente que se pone de manifiesto al trabajar con una tasa de aprendizaje de 0.05.
Por tanto, al trabajar con un sistema formado por 3 nodos el algoritmo 2
proporciona unos resultados mejores que el algoritmo 3 a pesar de que su comportamiento sea más inestable a lo largo del tiempo ya que presenta variaciones más grandes entre una evolución y la siguiente como consecuencia del escaso número de opiniones con las que cuenta el sistema cooperativo. A pesar de este pequeño inconveniente, el algoritmo 2 es más sencillo y menos costoso computacionalmente que el algoritmo 3 y además sus resultados demuestran que es posible alcanzar tasas de acierto que superan a la tasa de acierto máxima individual de cada nodo de la red.
III.2 Conclusiones del experimento 8
Los resultados del experimento 8 pueden observarse en la Figura 50 del apartado III.2 del capítulo de resultados. Estos resultados demuestran que la red de 8 nodos analizada en este experimento tiene un comportamiento semejante a la red de 3 nodos analizada en el experimento 7. No obstante, existen diferencias relevantes. Por un lado, el algoritmo 2 es capaz de proporcionar resultados más estables como consecuencia de aumentar el tamaño de la red. De esta forma se puede afirmar que un sistema de este tipo es capaz de mejorar sus resultados de forma progresiva hasta alcanzar la estabilidad.
Por su parte, los inconvenientes del algoritmo 3 se hacen más notables a medida
que aumenta el tamaño de la red, mostrándose pendientes significativamente más decrecientes a medida que se aumenta el valor de la tasa de aprendizaje. Este hecho hace que el algoritmo 3 empeore su tasa de acierto entre una evolución y la siguiente cuando los pesos se ven modificados a intervalos más grandes, es decir, cuando se trabaja con tasas de aprendizaje más elevadas.

110 Conclusiones
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
III.3 Conclusiones de los experimentos 9 y 10
A la vista de los resultados mostrados en las Figura 51 y Figura 52 de los apartados III.3 y III.4 del capítulo de resultados es posible extraer conclusiones conjuntas para el experimento 9 y el experimento 10. Los resultados de dichos experimentos demuestran la existencia de comportamientos semejantes en ambos casos.
Es cierto que, en el experimento 9, el comportamiento de los tres algoritmos
tiende a ser más inestables que en el caso del experimento 10 debido a que en el primero de ellos la red está formada sólo por 3 nodos y en el segundo se dispone de un sistema que tiene en cuenta las opiniones de 8 nodos. Sin embargo ambos experimentos demuestran que la calidad individual de los nodos influye de forma muy significativa sobre el comportamiento del sistema final, ya que en el algoritmo 3 no se aprecian tendencias decrecientes. Esto significa que los nodos con altas tasas de acierto son capaces de enmascarar el comportamiento de aquellos nodos que producen mayor número de fallos sin que se vea altamente influenciado por el valor de la tasa de aprendizaje.
IV. Conclusiones generales
En este apartado se exponen las conclusiones globales del comportamiento del sistema extraídas como consecuencia de la realización de múltiples pruebas para cada uno de los experimentos anteriormente mencionados. Estas conclusiones podrán servir como pautas a tener en cuenta a la hora de implementar el sistema real.
En primer lugar es destacable el hecho de que tanto el algoritmo 2 como el
algoritmo 3, es decir, los algoritmos que incorporan aprendizaje a través de la gestión de los pesos, proporcionan menos incertidumbre que el algoritmo 1 que no presenta ningún tipo de aprendizaje. Esta afirmación queda demostrada en el caso 1 estudiado en el capítulo de resultados (apartado I de dicho capítulo), ya que tanto el algoritmo de pesos globales como el de pesos condicionados anulan casi por completo el número de empates que se producen en el sistema cooperativo. Por este motivo se puede decir que ambos algoritmos son más fiables que el primero ya que siempre proporcionan un resultado para el sistema cooperativo. Sin embargo, entre el algoritmo 2 y 3, el primero de ellos es el que proporciona un comportamiento más estable ante variaciones en la calidad individual de los nodos, además requiere menos nodos que el algoritmo 1 para obtener niveles de probabilidad de acierto semejantes. Por todo esto, se puede afirmar que el algoritmo 2 es el que proporciona mejores resultados al analizar la influencia de la calidad individual de los nodos.

Conclusiones 111
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Además presenta una complejidad y un coste computacional mucho menor que el algoritmo 3, un factor muy importante a tener en cuenta a la hora de implementar el algoritmo en el dsPIC de la plataforma Tecalum.
Por otro lado, las escasas diferencias entre el comportamiento del algoritmo 2 y
el comportamiento del algoritmo 3 cuando se analiza la evolución del aprendizaje, conllevan a concluir que el algoritmo 2 vuelve a ser el elegido. El algoritmo 3 no presenta mejoras significativas respecto al 2 y el comportamiento con la gestión de pesos globales se ha demostrado que es más inestable ante variaciones de calidad individual de los nodos y tamaño de la red. Además, las redes formadas por 8 nodos presentan un comportamiento adecuado ante las circunstancias estudiadas en el caso 2 del capítulo de resultados (apartado II de dicho capítulo) y no merece la pena la formación de redes de gran tamaño ya que el límite establecido por la propia gestión de un sistema probabilístico conlleva la disminución del margen de mejora por lo que los algoritmos con aprendizaje no pueden mostrar todas sus capacidades si los resultados iniciales se aproximan a dicho valor máximo. Por todo esto, es recomendable trabajar con redes de tamaño medio cuyos nodos tengan implementados el algoritmo 2.
En relación a la tasa de aprendizaje, los resultados mostrados en el apartado III
del capítulo de resultados que analiza la influencia de este parámetro para distintos tipos de red (Caso 3), demuestran que es aconsejable trabajar con tasas de aprendizaje pequeñas para que la evolución del aprendizaje más progresiva y el algoritmo no entre en una situación de inestabilidad que le lleve a la degradación. Además, los resultados obtenidos demuestran también que el comportamiento del algoritmo 2 presenta un comportamiento más homogéneo y predecible ante distintos tipos de red, ya que el algoritmo 3 es más propenso a la degradación. Por todo esto se aconseja trabajar con tasas de aprendizaje pequeñas (muy cercanas a 0.01) así como la selección del algoritmo 2 para la implementación del sistema cooperativo.


Trabajos futuros 113
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Trabajos futuros
Tal y como ha quedado demostrado en el apartado de conclusiones, con el trabajo elaborado hasta este momento, el algoritmo que hace uso de los pesos globales –algoritmo 2- parece más adecuado que el algoritmo que tiene en cuenta los pesos condicionados –algoritmo 3- puesto que el primero de ellos tiene un comportamiento más predecible ante cualquier circunstancia a la vez que proporciona unos resultados relativamente buenos. Sin embargo, el sentido común parece dictaminar que el concepto que intenta gestionar el algoritmo 3 debería proporcionar mejores resultados que los que puede proporcionar el algoritmo 2, ya que la gestión de pesos condicionados intenta tener en cuenta muchos más aspectos relacionados con el comportamiento de los nodos ante identificaciones erróneas. El hecho de que esta situación no se produzca es debido a que el entorno tiene una gran influencia sobre el comportamiento del algoritmo 3 y las simulaciones realizadas no han incluido toda la información necesaria para llevar a cabo un buen desarrollo de este algoritmo. Por todo esto, una de las tareas que podrían llevarse a cabo en futuros trabajos sería la modelización del entorno y la creación de un modelo más predictivo basado en el filtro de Kalman con el objetivo de proporcionar situaciones más reales de cara a la simulación. Del mismo modo, se podría analizar de nuevo la gestión de los pesos condicionados mediante la implementación de redes bayesianas e incluso la realización de un análisis con lógica difusa para el estudio de las fronteras.
Por otro lado, desde el punto de vista de la aplicación sería posible incorporar
nuevos agentes al sistema. La misión de estos agentes sería proporcionar información adicional al sistema para favorecer la identificación. Estos nuevos tipos de agentes podrían ser agentes meteorológicos o agentes oyentes.
Un agente meteorológico podría encargarse de realizar mediciones de humedad
con el fin de determinar la presencia de lluvia, ya que la lluvia puede distorsionar en algunos casos la señal de eco del radar generando identificaciones erróneas. Otra labor del agente meteorológico podría ser la medición de la temperatura del entorno y de los objetos presentes en el mismo. Así, se podría determinar la presencia de un cuerpo caliente en las inmediaciones del radar lo cual supondría la presencia de una persona, animal o coche. Por su parte el agente oyente dispondría de un micrófono direccional cuya información recogida podría ser de gran utilidad a la hora de discriminar entre vehículos y personas. Toda la información obtenida a través de los nuevos agentes debería incluirse como nuevos atributos en los árboles de decisión con el fin de determinar una solución a partir de la información procedente de los radares, los micrófonos y los sensores de humedad y de temperatura.

114 Trabajos futuros
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
Una acción muy importante y que podría mejorar en gran medida los resultados obtenidos hasta este momento sería la inclusión en el sistema de un mecanismo que permita el rediseño de los árboles de decisión en tiempo de ejecución. La modificación de los árboles de decisión es una labor que se ha sido desarrollada de forma paralela a este trabajo en el Trabajo Fin de Máster titulado “Sistema de inteligencia embebida con autoaprendizaje basado en una arquitectura de árbol de decisión dinámico y adaptativo” [4]. La fusión del rediseño de los árboles de decisión junto con la implementación de un sistema cooperativo podría incrementar la tasa de acierto del sistema de forma considerable a medida que el sistema incorpora nuevos objetos a su propia fuente de conocimiento. De hecho, uno de los principales inconvenientes encontrados durante la realización de este trabajo ha sido el hecho de que el sistema siempre tiene que proporcionar una identificación correspondiente a alguna de las tres categorías que se definieron: coche, persona o entorno. Sin embargo, en ocasiones, la incertidumbre o entropía con la que se determinan ciertas identificaciones pueden ocasionar que el sistema tienda a aprender de situaciones poco favorables. La posibilidad de poder incluir nuevas categorías cuando el sistema proporciona resultados poco fiables favorece el aprendizaje del sistema cooperativo ya que siempre aprenderá a partir de situaciones favorables.
Otra tarea importante que se debería realizar con el objetivo de validar el
funcionamiento del sistema sería su implementación sobre la plataforma hardware Tecalum. De esta forma sería posible comprobar su funcionalidad sobre una situación real de funcionamiento con el fin de verificar los resultados obtenidos en las simulaciones.

Bibliografía 115
Modelo de aprendizaje cooperativo basado en arquitectura multiagente para sistemas con inteligencia
embebida.
BIBLIOGRAFÍA
J. T. Palma Méndez, R. Marín Morales. Inteligencia Artificial: técnicas, métodos y aplicaciones. Madrid, Universidad de Murcia. Editorial McGraw Hill, 2008.
A. P. Engelbrecht. Computational Intelligence. Second Edition. Chichester (England). Editorial Wiley, 2007.
S. J. Russel, P. Norvig. Artificial Intelligence: A Modern Approach. New Jersey. Editorial Prentice-Hall, 1995.
E. Bonabeau, M. Dorigo, G. Theraulaz. Swarm Intelligence: From Natural to Artificial Intelligence. New York. Editorial Oxford University Press, 1999.
D. Roldán. Comunicaciones Inalámbricas. Madrid. Editorial RA-MA, 2004.
J. M. Hernando Rábanos. Transmisión por radio. Cuarta edición. Madrid. Editorial Universitaria Ramón Areces, 2003.