implementación de una estrategia integral de continuidad de …€¦ · · 2014-06-02•ejecutar...
TRANSCRIPT

© 2014 VMware Inc. Todos los derechos reservados
Implementación de una estrategia integral de continuidad de negocio y recuperación ante desastres con VMware
VMware vForum, 2014

Temas del programa
• Definición del problema
• Definiciones
• Tecnologías de VMware que proporcionan continuidad del negocio
(BC) y recuperación ante desastres (DR)
– vSphere High Availability y vSphere App HA.
– vSphere Fault Tolerance.
– vSphere Data Protection y vSphere Data Protection Advanced.
– Disponibilidad de vCenter.
– vSphere Replication.
– vCenter Site Recovery Manager.
– vCenter Infrastructure Navigator.
• Más información
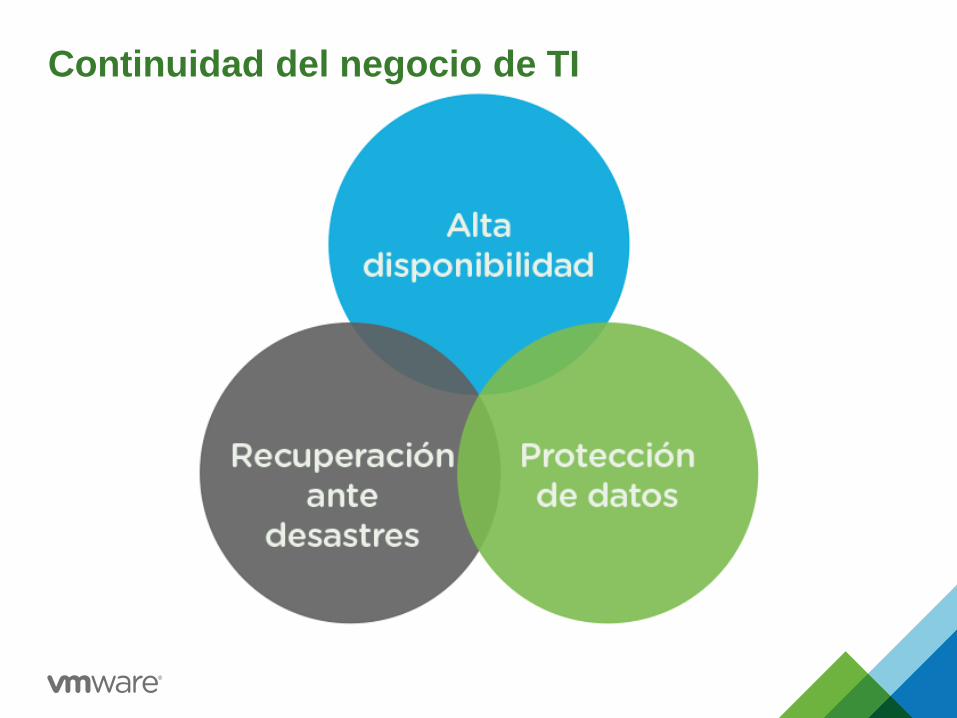
Continuidad del negocio de TI

¿De verdad es un problema?
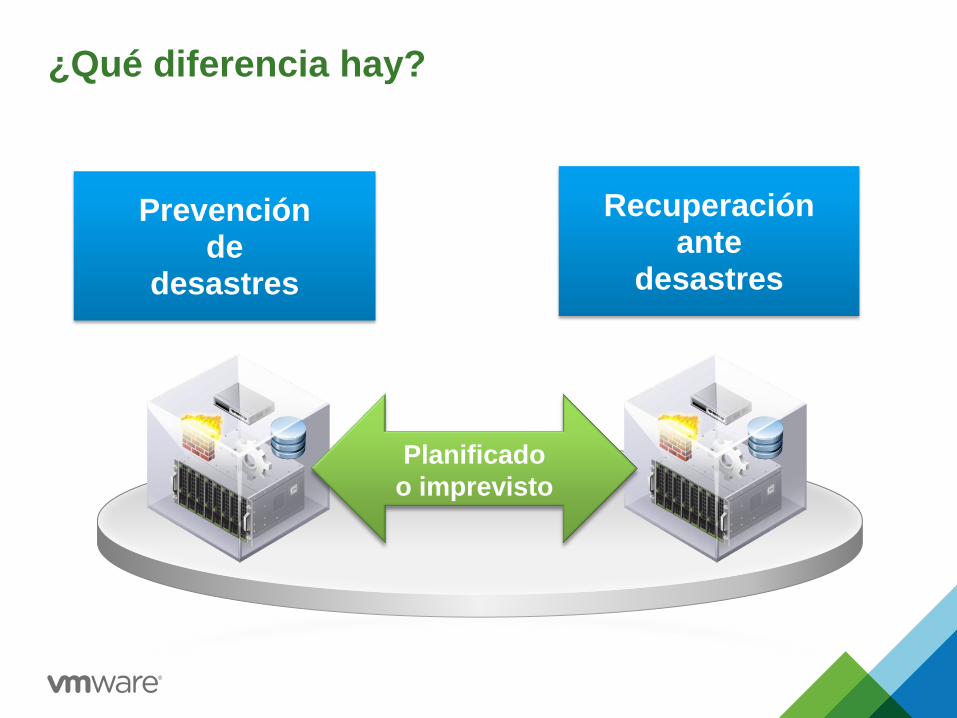
¿Qué diferencia hay?
Prevención de
desastres
Recuperación ante
desastres
Planificado
o imprevisto

Diferencia entre recuperación ante desastres y continuidad del negocio
Ejemplo: Martes, 23 de agosto de 2011 a las 13:51, hora EDT. Terremoto de magnitud 5,8 cerca de Mineral, Virginia (EE. UU.)
¿Se necesitó la funcionalidad de recuperación
ante desastres?
No
¿Se interrumpió la continuidad del negocio?
¡POR SUPUESTO!

Diferencia entre tolerancia a fallos y alta disponibilidad
• Tolerancia a fallos
– Capacidad para recuperarse ante la pérdida de componentes.
– Ejemplo: avería de una unidad de disco duro.
• Alta disponibilidad
Porcentaje de tiempo de actividad
en un año
Tiempo de inactividad
en un año
99 3,65 días
99,9 8,76 horas
99,99 52 minutos
99,999 «cinco nueves» 5 minutos
X

RTO, RPO y MTD
• Objetivo de tiempo de recuperación (RTO)
– El tiempo que se debe tardar en realizar la recuperación.
• Objetivo de punto de recuperación (RPO)
– Cantidad de datos que se pueden perder.
• Tiempo de inactividad máximo tolerable (MTD)
– Tiempo de inactividad que puede transcurrir antes de que se produzcan pérdidas significativas.
– Ejemplos: económicas, de reputación.
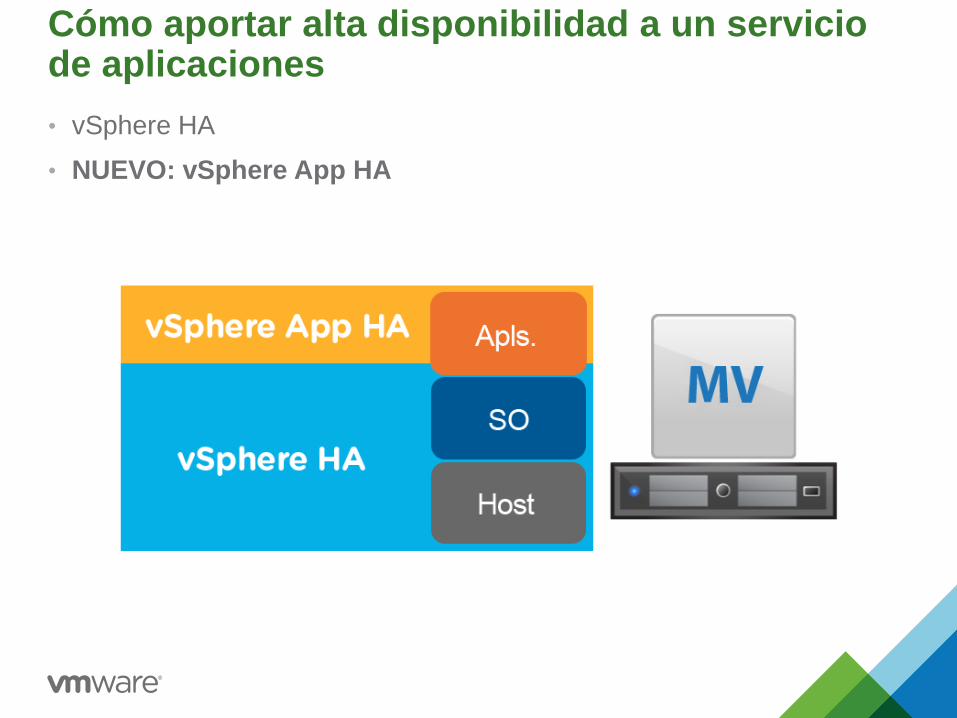
Cómo aportar alta disponibilidad a un servicio de aplicaciones
• vSphere HA
• NUEVO: vSphere App HA
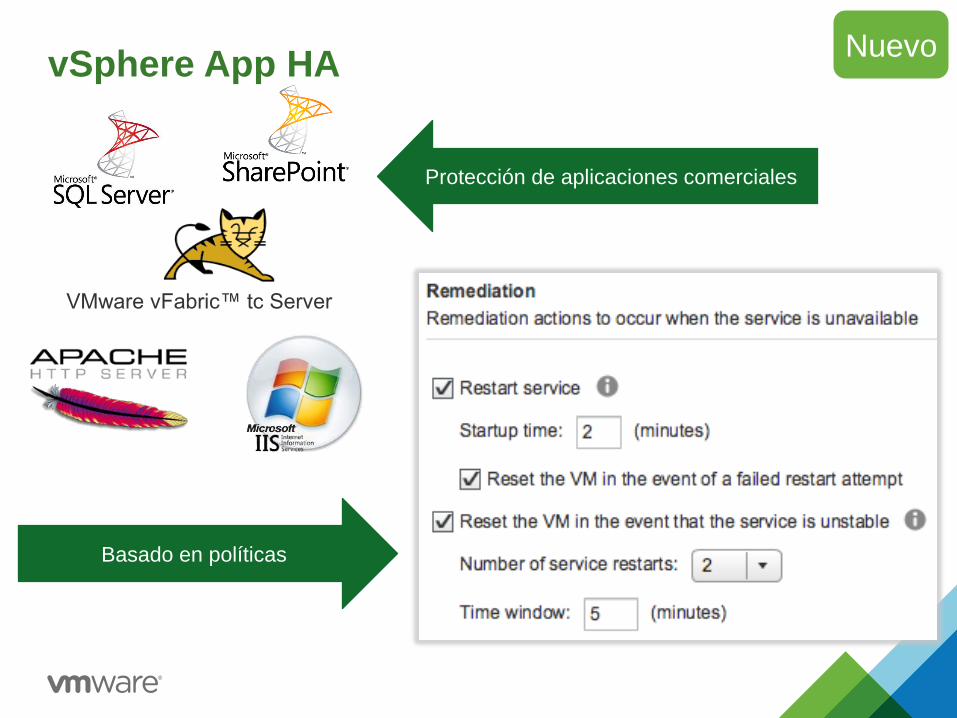
VMware vFabric™ tc Server
vSphere App HA Nuevo
Basado en políticas
Protección de aplicaciones comerciales
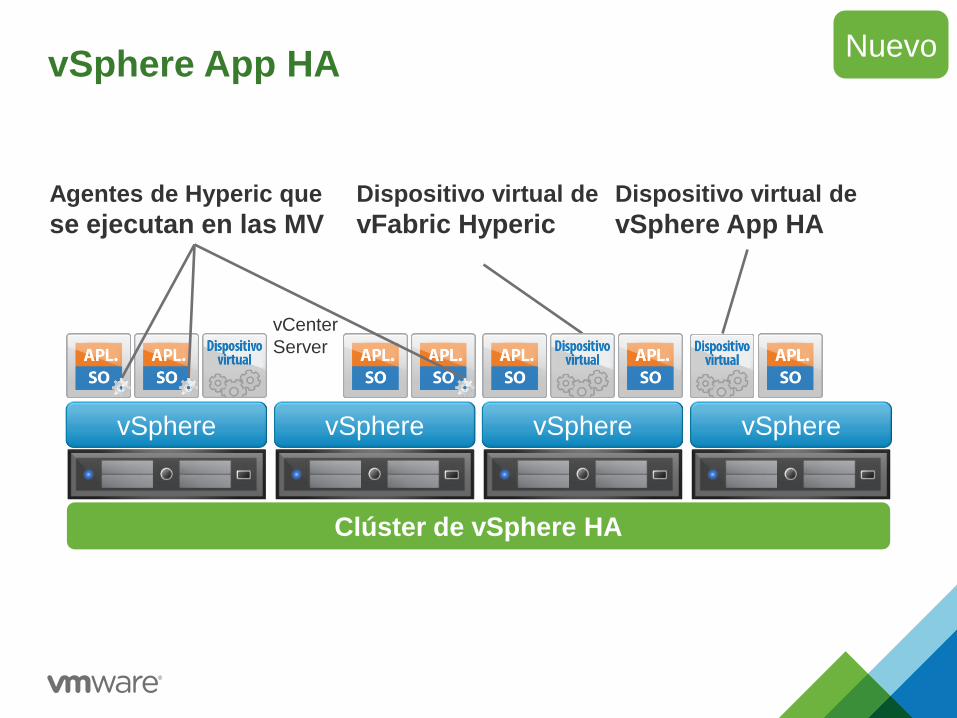
vSphere App HA
Clúster de vSphere HA
Dispositivo virtual de
vFabric Hyperic
Dispositivo virtual de
vSphere App HA
Agentes de Hyperic que
se ejecutan en las MV
vCenter
Server
vSphere vSphere vSphere vSphere
Nuevo
vSphere App HA Nuevo

vSphere High Availability: aspectos importantes
• El objetivo de tiempo de recuperación (RTO) se mide en minutos (no en segundos).
• Requiere almacenamiento compartido.
• Prácticas recomendadas.
– Aplicar control de admisión: política basada en porcentajes.
– Prueba de rendimiento tras un fallo mediante el modo de mantenimiento de host.
– Respuesta de aislamiento: dejar en estado encendido.
– Redundancia de red y almacenamiento.

vSphere Fault Tolerance (FT)
• Sin tiempo de recuperación ni pérdida de datos:
– Solo para fallos de hardware de host;
– No protege contra fallos del sistema operativo y las aplicaciones.
• Funciona bien con vSphere High Availability y vSphere App HA.
• ¿Por qué no conviene usar vSphere FT?
– Requisitos de recursos: ¿la carga de trabajo realmente lo necesita?
– La máquina virtual contiene varias CPU; consulte BCO5065 .
– No hay instantáneas de máquina virtual: se necesita un agente para copias de seguridad.

vSphere Data Protection (copia de seguridad y restauración)
• ¿Con agentes? ¿Sin agentes? ¡Las dos opciones!
– Sin agentes para la mayoría de las cargas de trabajo: es mejor simplificar.
– Agentes para determinadas aplicaciones.
• vSphere Data Protection (VDP) Advanced
– Copia de seguridad y recuperación de VMware para VMware.
– Basado en la tecnología consolidada y probada de EMC Avamar™.
– Copia de seguridad y restauración de máquinas virtuales sin agentes.
– Agentes para protección granular de aplicaciones de nivel 1.
vSphere Data Protection Nuevo

vSphere Data Protection Advanced: aspectos importantes
• Se ha diseñado para entornos de pequeña y mediana empresa.
• Utiliza vSphere API for Data Protection (VADP): instantáneas de máquinas virtuales, función de seguimiento de bloques modificados (CBT).
• Utiliza Windows VSS en VMware Tools.
• Funciona bien con vSphere High Availability, no con vSphere Fault Tolerance.
• RDM: virtual, sí; físico, no.
• ¿Sirve para la recuperación ante desastres?
– Puede ser; depende de los objetivos de tiempo y punto de recuperación.

vSphere Data Protection Advanced: aspectos importantes
• Prácticas recomendadas
– Rellenar previamente DNS, usar siempre FQDN.
– Gestionar las instantáneas de máquina virtual.
– Evitar su implementación en almacenamiento lento.
– No apagar directamente, realizar siempre un cierre controlado del sistema.
– No programar copias de seguridad durante el intervalo de mantenimiento.

Disponibilidad de vCenter
• Ejecutar la aplicación vCenter Server en una máquina virtual.
• Ejecutar la base de datos de vCenter Server en una máquina virtual.
• ¿Se pueden ejecutar las dos en la misma máquina virtual?
• Proteger mediante vSphere High Availability.
– Establecer la prioridad alta para el reinicio de vCenter y la máquina virtual de base de datos.
– Activar la supervisión de aplicaciones y sistemas operativos invitados.
• vSphere App HA puede proteger la base de datos de SQL Server.

Disponibilidad de vCenter
• Realizar copia de seguridad de máquina virtual y base de datos de vCenter Server.
– Copia de seguridad en el nivel de imágenes para la máquina virtual de vCenter Server.
– Copia de seguridad en el nivel de aplicaciones, mediante un agente para realizar la copia de seguridad de la base de datos.
• ¿Por qué no conviene utilizar vSphere FT para vCenter Server?
– vCenter Server requiere un mínimo de 2 vCPU.
– vSphere FT no protege contra fallos de aplicaciones.
• ¿Hay que replicar vCenter Server y sus máquinas virtuales de base de datos?

vSphere Replication: recuperación ante desastres
• Herramienta nativa integrada en la plataforma.
• Replicación de hipervisor previa a la máquina virtual que se gestiona en vCenter.
Posibilidad de seleccionar
el objetivo de punto de recuperación,
de 15 minutos a 24 horas.
Posibilidad de seleccionar
el almacén de datos de destino
(independiente del tipo de disco).
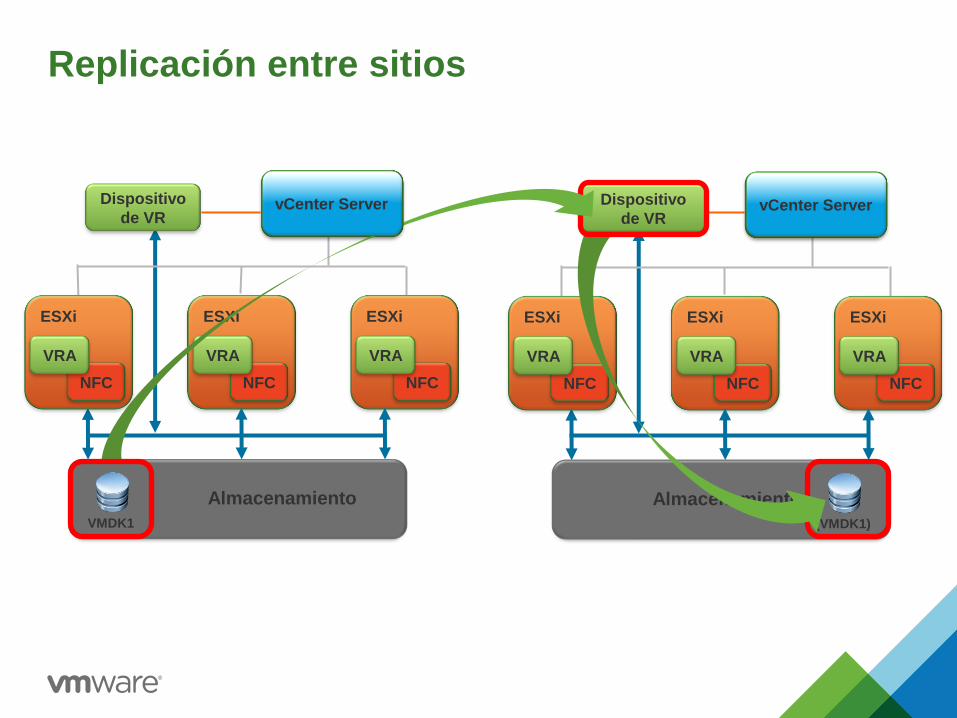
Replicación entre sitios
vCenter Server
ESXi
NFC
VRA
ESXi
NFC
VRA
ESXi
NFC
VRA
Almacena
miento
Almacenamiento
(VMDK1)
vCenter Server
ESXi
NFC
VRA
ESXi
NFC
VRA
ESXi
NFC
VRA
Dispositivo
de VR Dispositivo
de VR
Almacena
miento
Almacenamiento
VMDK1
vCenter Server vCenter Server
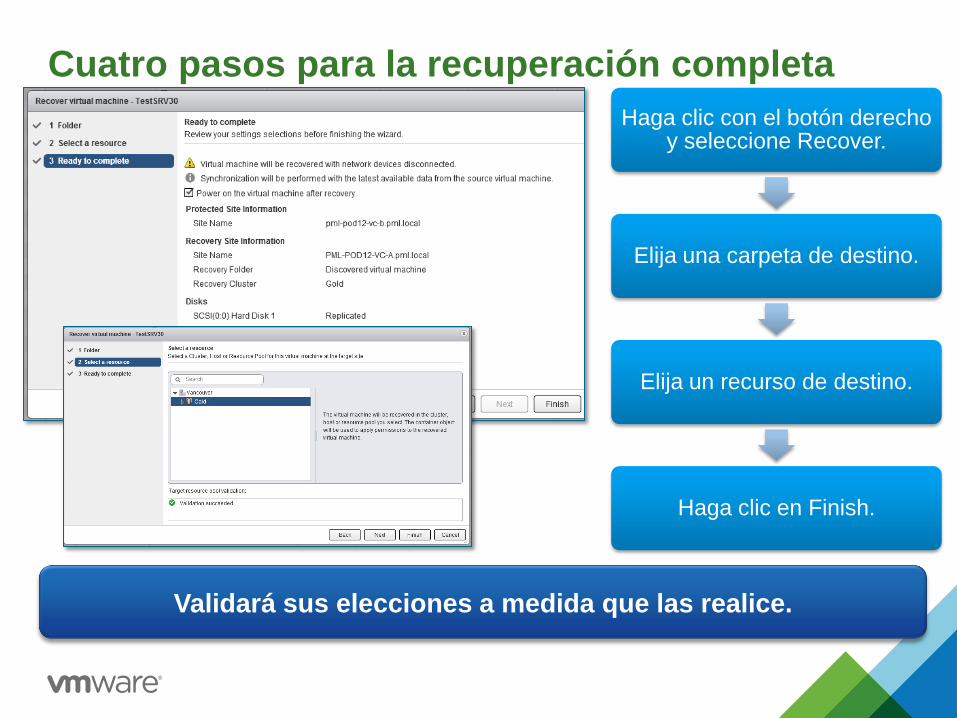
Cuatro pasos para la recuperación completa
Haga clic con el botón derecho y seleccione Recover.
Elija una carpeta de destino.
Elija un recurso de destino.
Haga clic en Finish.
Validará sus elecciones a medida que las realice.
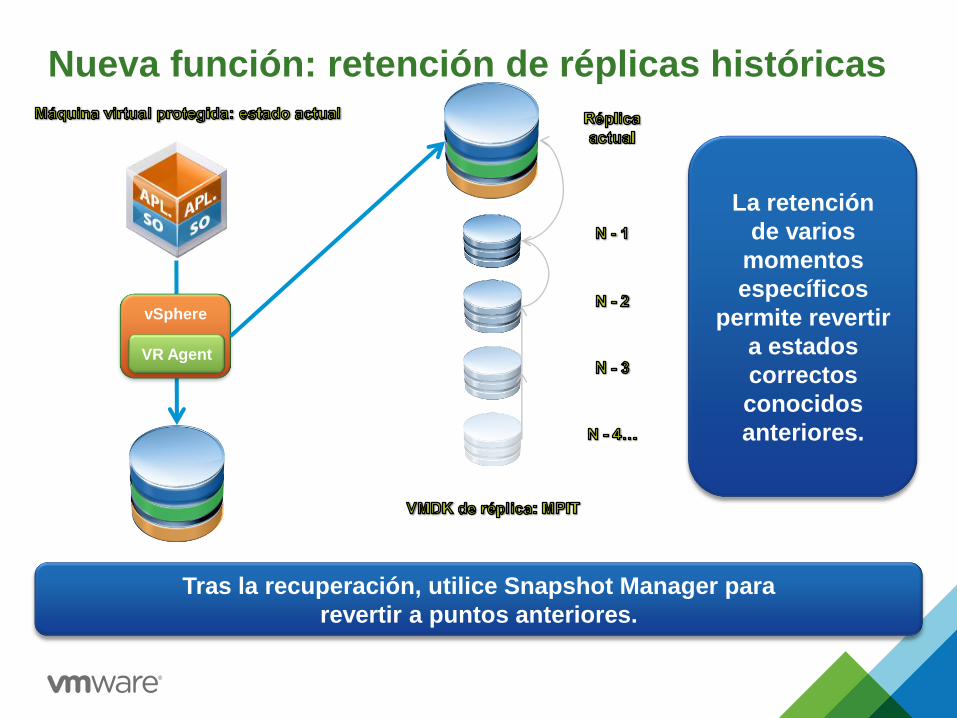
Nueva función: retención de réplicas históricas
vSphere
VR Agent
Tras la recuperación, utilice Snapshot Manager para
revertir a puntos anteriores.
La retención
de varios
momentos
específicos
permite revertir
a estados
correctos
conocidos
anteriores.
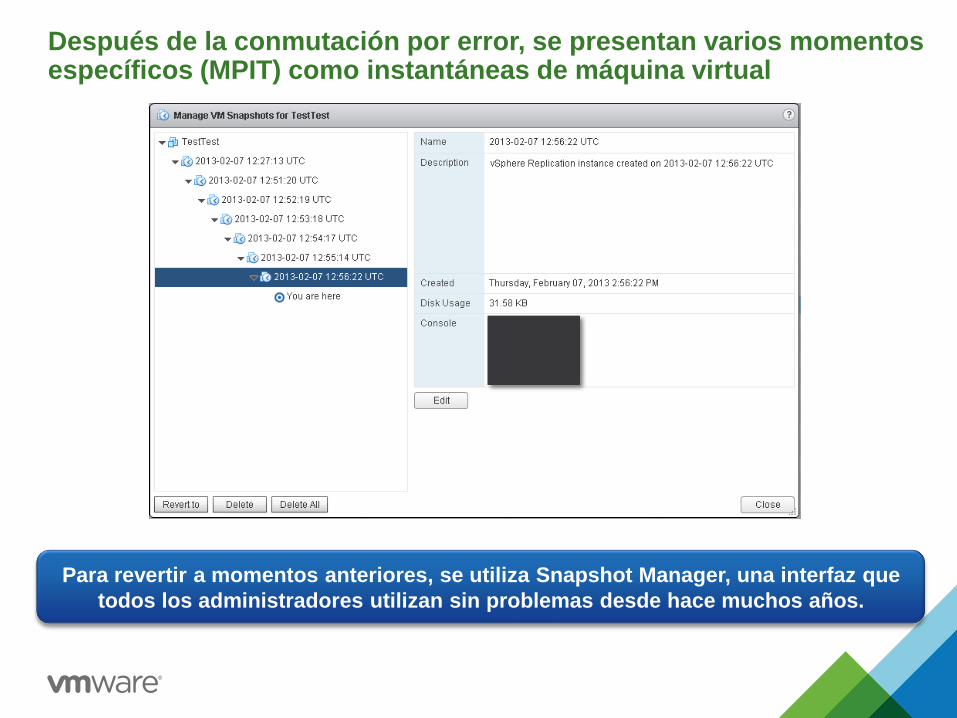
Después de la conmutación por error, se presentan varios momentos específicos (MPIT) como instantáneas de máquina virtual
Para revertir a momentos anteriores, se utiliza Snapshot Manager, una interfaz que
todos los administradores utilizan sin problemas desde hace muchos años.

vSphere Replication: interoperabilidad
vSphere FT:
no funciona con
vSphere Replication
• vSphere FT entra
en conflicto con el nivel
de filtro de disco vSCSI.
vSphere Data
Protection
• En la mayoría de los
casos, ¡sin problemas!
• Si utiliza VSS… es
fundamental que sea
la versión 5.5.
HA, vMotion, DRS
Storage vMotion
y Storage DRS
• ¡Ya compatibles!

vSphere Replication: prácticas recomendadas
• Objetivo de punto de recuperación (RPO)
– ¡Exclusivamente lo necesario!
– No solo porque sea posible…
• Objetivo de tiempo de recuperación (RTO)
– ¡No lo establezca! Sin pruebas ni automatización; proceso manual.
• VSS: ¡exclusivamente si es necesario!
• Consideraciones de ancho de banda
– Resulta muy complicado determinarlo. Antes, ejecutar localmente una prueba de bucle cerrado.
• ¿RDM?
– Es preferible no utilizarlas. Si es imprescindible, utilice opciones compatibles con el entorno virtual.
• Importante: no mezclar ABR con vSphere Replication.
Site Recovery Manager (SRM)
• Motor de recuperación ante desastres.
• Herramienta que utiliza datos replicados externamente (basados en VR o en matrices) para acortar el RTO del plan de continuidad del negocio (BCP).
• Producto que permite probar, automatizar y planificar una recuperación ante desastres repetible y personalizable.
¿En qué consiste?
• No es un motor de replicación.
• No es una herramienta para sistemas que requieren un RPO casi instantáneo.
• No es un clúster ampliado de prevención de desastres.
¿En qué no consiste?
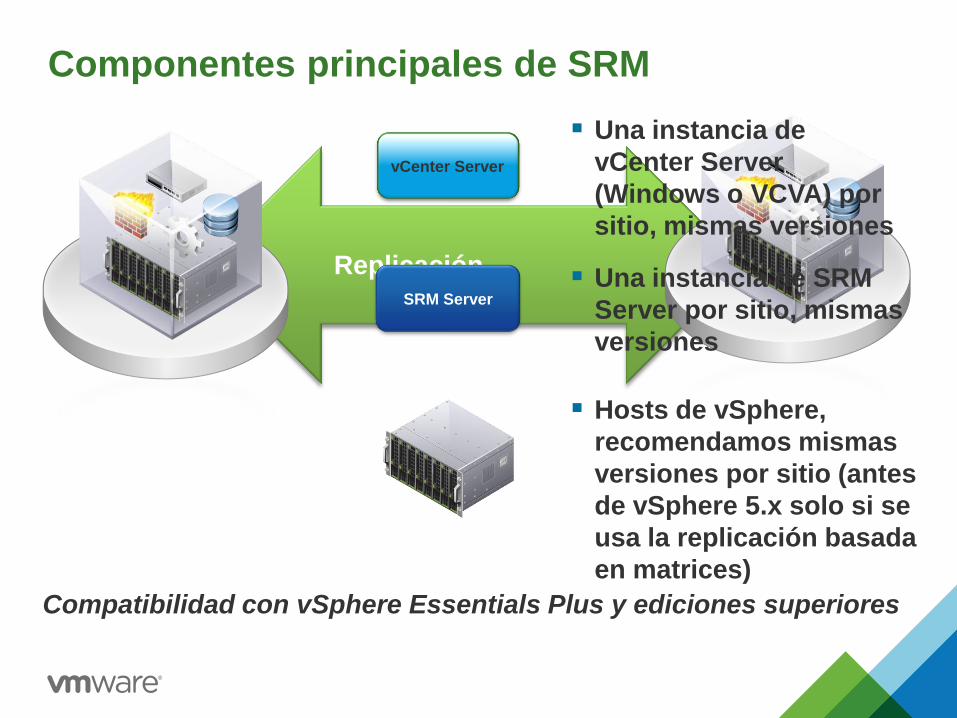
Componentes principales de SRM
Replicación
vCenter Server
SRM Server
Una instancia de
vCenter Server
(Windows o VCVA) por
sitio, mismas versiones
Una instancia de SRM
Server por sitio, mismas
versiones
Hosts de vSphere,
recomendamos mismas
versiones por sitio (antes
de vSphere 5.x solo si se
usa la replicación basada
en matrices)
Compatibilidad con vSphere Essentials Plus y ediciones superiores
vCenter Server
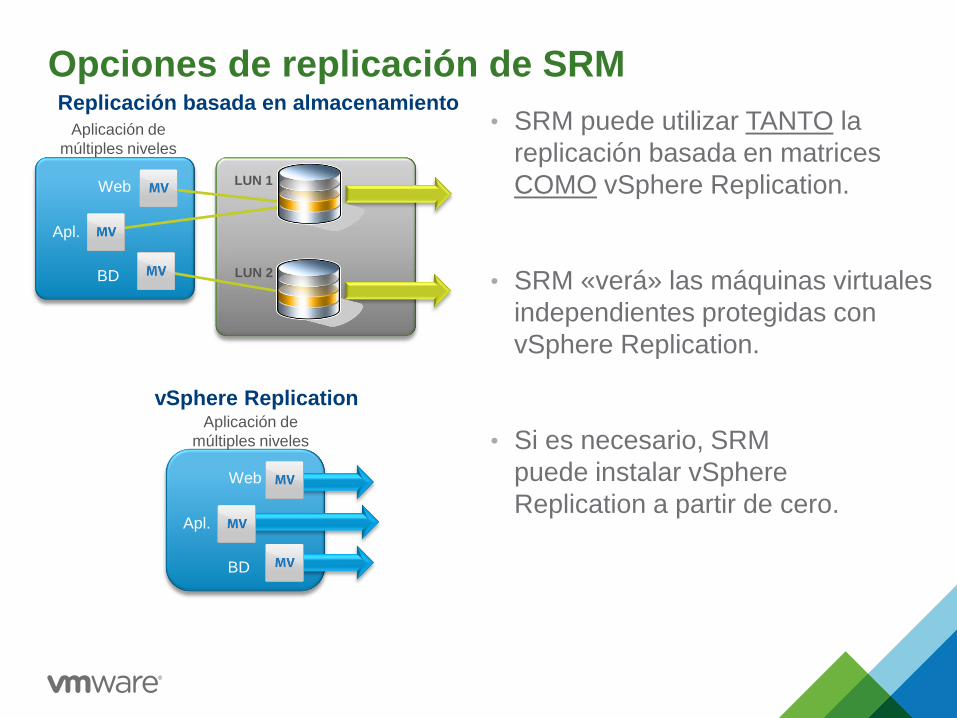
Opciones de replicación de SRM
• SRM puede utilizar TANTO la
replicación basada en matrices
COMO vSphere Replication.
• SRM «verá» las máquinas virtuales
independientes protegidas con
vSphere Replication.
• Si es necesario, SRM
puede instalar vSphere
Replication a partir de cero.
Concentr. LUN 2
Web
Aplicación de
múltiples niveles
BD
Apl.
vSphere Replication
Replicación basada en almacenamiento
LUN 1
Web
BD
Apl.
Aplicación de
múltiples niveles
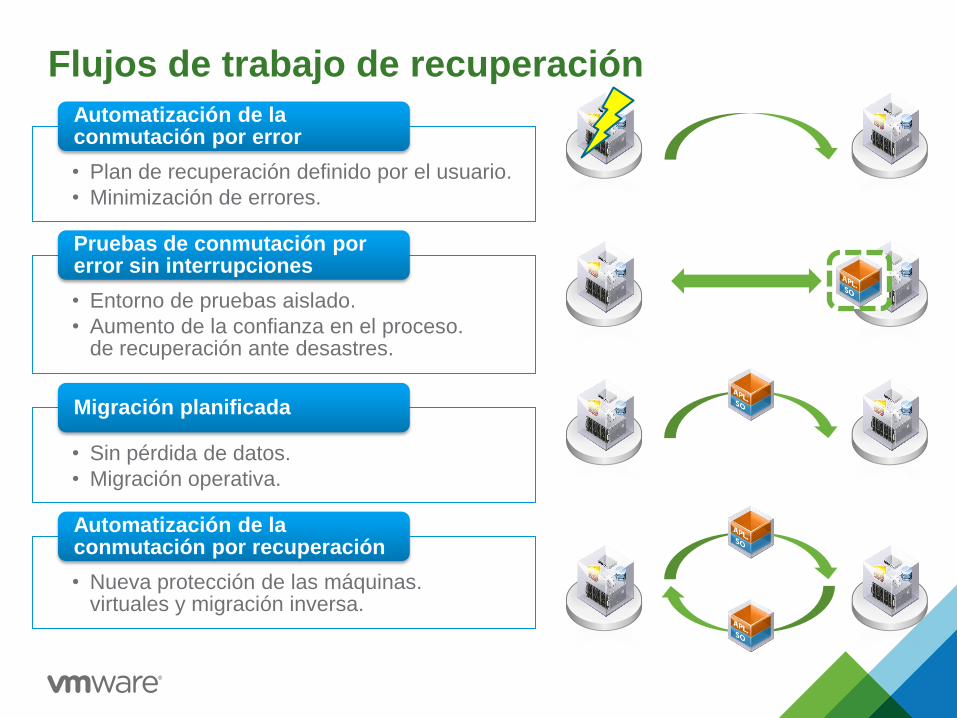
Flujos de trabajo de recuperación
• Plan de recuperación definido por el usuario.
• Minimización de errores.
Automatización de la conmutación por error
• Entorno de pruebas aislado.
• Aumento de la confianza en el proceso. de recuperación ante desastres.
Pruebas de conmutación por error sin interrupciones
• Sin pérdida de datos.
• Migración operativa.
Migración planificada
• Nueva protección de las máquinas. virtuales y migración inversa.
Automatización de la conmutación por recuperación

Interoperabilidad de SRM
• Funciona con vSphere Replication y
replicación basada en matrices (ABR).
• Acepta copias de seguridad,
VADP, etc.
• vSphere HA no presenta ningún
problema en absoluto.
• Acepta vMotion y DRS.
• Acepta Storage vMotion y
Storage DRS, pero no siempre:
– Dependencia de la replicación
• vSphere FT: precaución.
– Solo con la replicación basada
en matrices. El estado de FT
no se recupera.
• Web y vSphere Client.

SRM: algunas prácticas recomendadas
Sin carácter exhaustivo
Se dispone de gran cantidad de material de soporte en blogs, vmware.es y sitios técnicos.
Importantes Diseño del almacenamiento.
Configuración de la red de pruebas.
Realizar pruebas con frecuencia.
Asignar a vCenter el tamaño correcto.
La más importante
Realizar un análisis del impacto empresarial.
RPO, RTO, coste del tiempo de inactividad, interdependencias, carácter esencial de las aplicaciones, prioridades, unidades de conmutación por error, factores externos pasados por alto, adopción por parte del equipo ejecutivo…
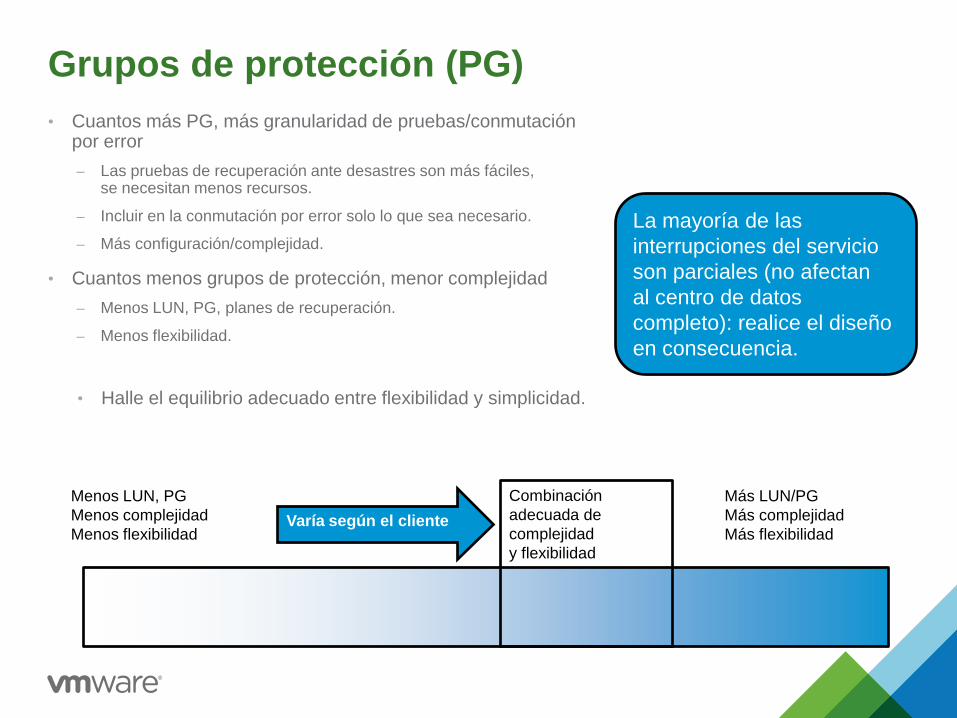
Grupos de protección (PG)
• Cuantos más PG, más granularidad de pruebas/conmutación por error
– Las pruebas de recuperación ante desastres son más fáciles, se necesitan menos recursos.
– Incluir en la conmutación por error solo lo que sea necesario.
– Más configuración/complejidad.
• Cuantos menos grupos de protección, menor complejidad
– Menos LUN, PG, planes de recuperación.
– Menos flexibilidad.
• Halle el equilibrio adecuado entre flexibilidad y simplicidad.
Menos LUN, PG
Menos complejidad
Menos flexibilidad
Más LUN/PG
Más complejidad
Más flexibilidad
Combinación
adecuada de
complejidad
y flexibilidad
Varía según el cliente
La mayoría de las
interrupciones del servicio
son parciales (no afectan
al centro de datos
completo): realice el diseño
en consecuencia.

Red de pruebas
– Utilice una red de área local virtual (VLAN) o una red aislada para el entorno de pruebas.
• La opción predeterminada «Auto» no permite la comunicación de las máquinas virtuales entre hosts.
– En SRM, se puede especificar un conmutador virtual distinto para las pruebas que para la ejecución.
• Se especifica en el plan de recuperación.
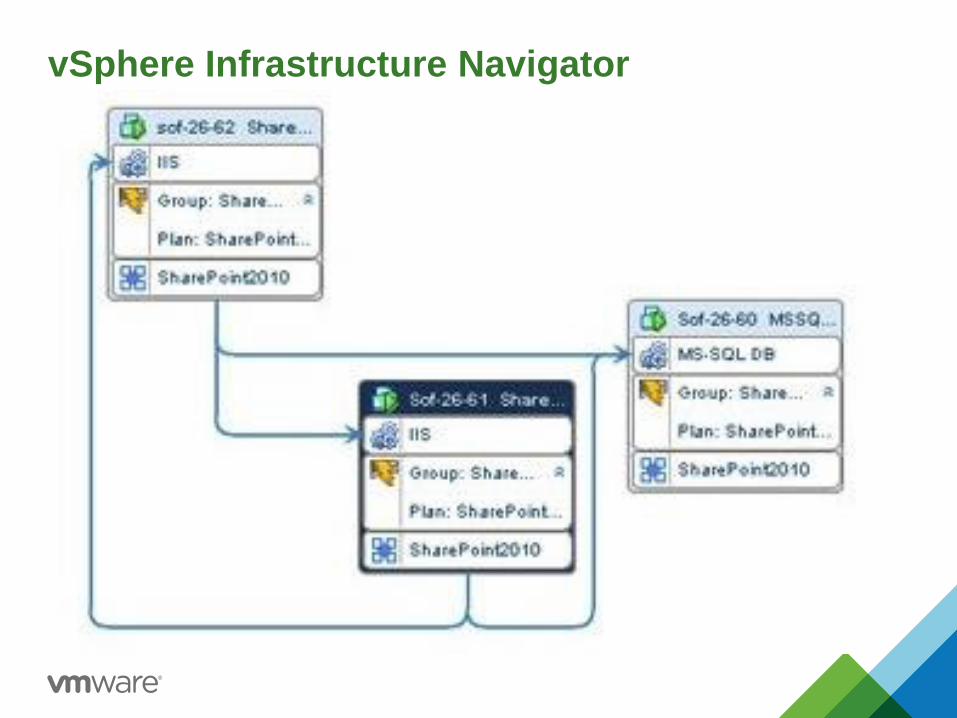
vSphere Infrastructure Navigator
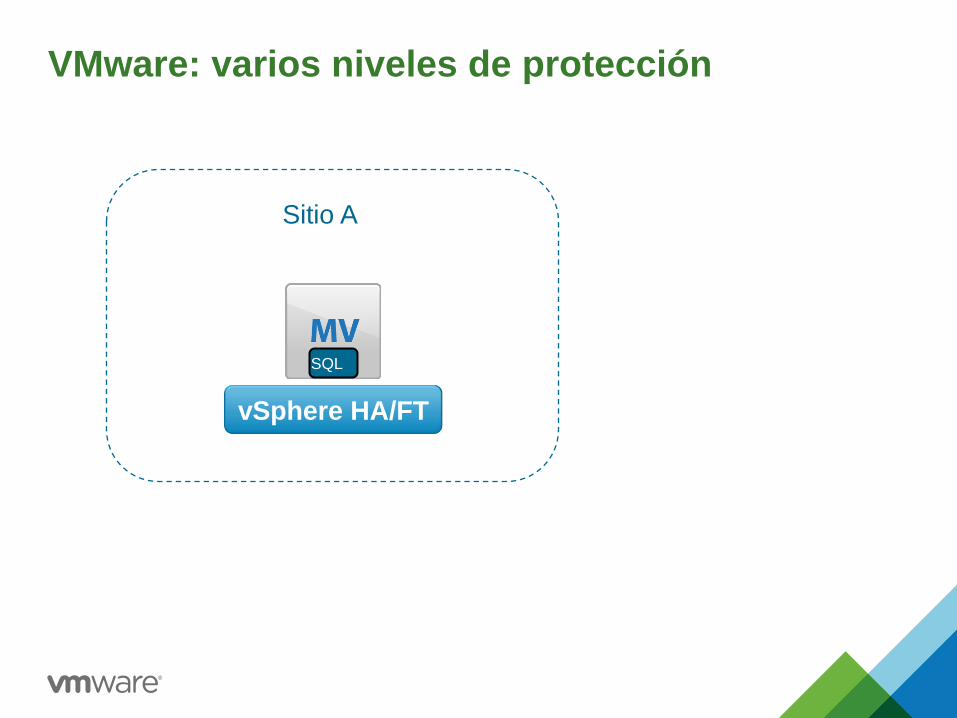
VMware: varios niveles de protección
SQL
vSphere HA/FT
Sitio A
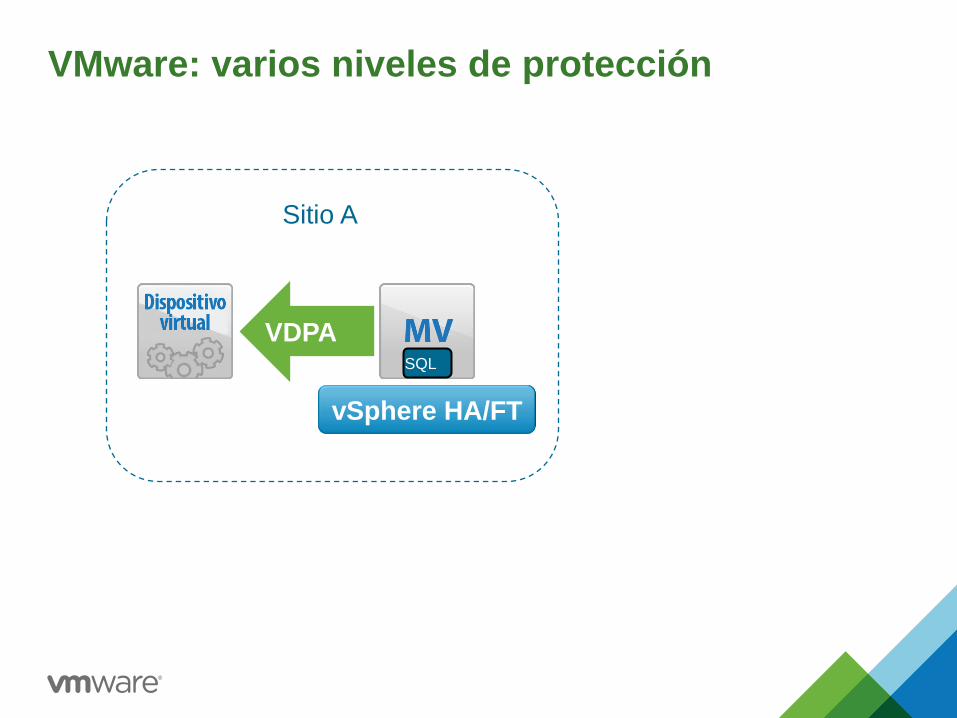
VMware: varios niveles de protección
SQL
vSphere HA/FT
VDPA
Sitio A
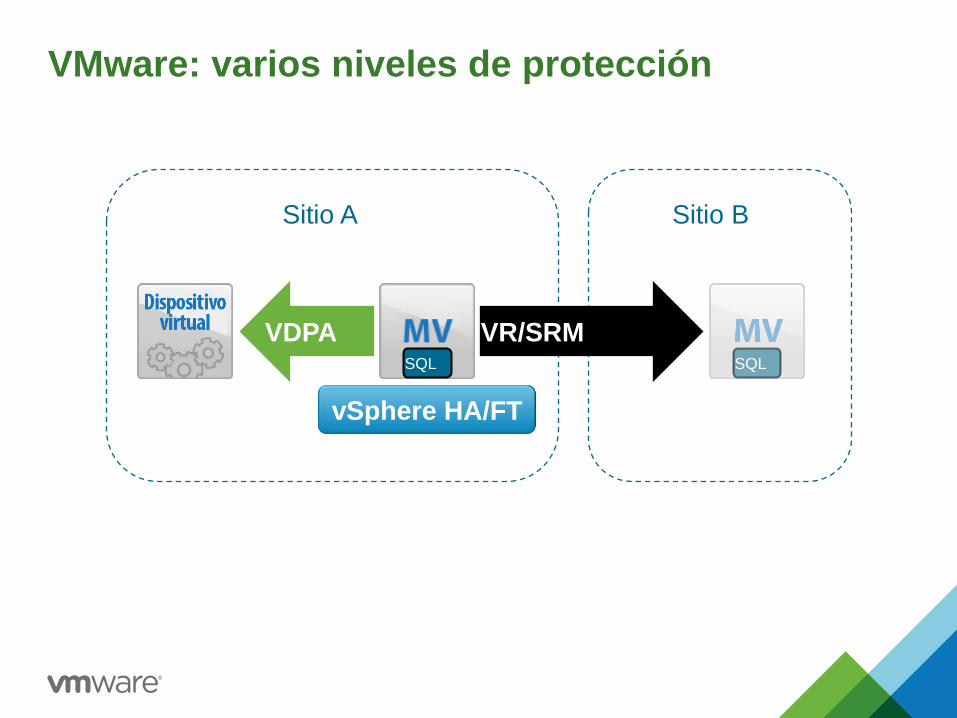
VMware: varios niveles de protección
SQL
vSphere HA/FT
VR/SRM SQL
VDPA
Sitio A Sitio B

Recursos adicionales
Más información
• Participe en un laboratorio de prácticas online
• Solicite una demostración
• Instale una versión de evaluación durante 60 días

Gracias