facultad de ciencias fÍsicas y matemÁticas … · escuela academico profesional de informatica...
TRANSCRIPT

Universidad Nacional de Trujillo
FACULTAD DE CIENCIAS FÍSICAS Y MATEMÁTICAS
ESCUELA ACADEMICO PROFESIONAL DE INFORMATICA
INFORME FINAL DE TRABAJO DE GRADUACION
“DISEÑO DE UN MODELO COMPUTACIONAL BASADO EN
ALGORITMOS DE AGRUPAMIENTO PARA MEJORAR EL TIEMPO DE
RESPUESTA Y LA CORRESPONDENCIA DE RESULTADOS DE UN
SISTEMA DE BUSQUEDA DE INFORMACION BIBLIOGRAFICA”
Autores:
- DE LA CRUZ MANTILLA, AZUCENA SARAI
- LINARES VALDIVIA, JUAN CARLOS
Asesor:
- ING. CHRISTIAN ARAUJO GONZÁLEZ
2014 TRUJILLO – PERU

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 1
INDICE
INDICE ...................................................................................................................... 1
LISTA DE FIGURAS.................................................................................................... 3
RESUMEN ................................................................................................................ 4
I. PLAN DE INVESTIGACION........................................................................................ 5
1.1. REALIDAD PROBLEMÁTICA.............................................................................. 5
1.2. ENUNCIADO DEL PROBLEMA .......................................................................... 5
1.3. HIPÓTESIS......................................................................................................... 6
1.4. OBJETIVOS ........................................................................................................ 6
1.4.1. OBJETIVO GENERAL .................................................................................. 6
1.4.2. OBJETIVOS ESPECIFICOS ........................................................................... 6
1.5. JUSTIFICACION.................................................................................................. 6
1.6. LIMITACIONES .................................................................................................. 7
II. MARCO TEORICO..................................................................................................... 8
2.1. DISEÑO CONCEPTUAL ..................................................................................... 8
2.2. MODELO COMPUTACIONAL ........................................................................... 9
2.3. ALGORITMOS DE AGRUPAMIENTO................................................................. 11
2.3.1. ALGORITMO .............................................................................................. 11
2.3.2. AGRUPAMIENTO DE OBJETOS.................................................................. 11
2.3.3. ALGORITMOS DE AGRUPAMIENTO.......................................................... 12
2.3.4. APLICACIÓN DE LOS ALGORITMOS DE AGRUPAMIENTO........................ 13
2.4. CLASIFICACION DE LOS ALGORITMOS DE AGRUPAMIENTO .......................... 14
2.4.1. ALGORITMOS DE AGRUPAMIENTO PARTICIONAL .................................. 14
2.4.2. ALGORITMOS DE AGRUPAMIENTO JERÁRQUICO.................................... 18
2.4.3. ALGORITMOS DE AGRUPAMIENTO BORROSO ........................................ 19
2.4.4. ALGORITMOS DE AGRUPAMIENTO BASADOS EN LA DENSIDAD ........... 24
2.4.5. ALGORITMOS DE AGRUPAMIENTO BASADO EN GRID ............................ 26
2.4.6. ALGORITMOS DE AGRUPAMIENTO BASADO EN MODELOS ................... 28
2.4.7. ALGORITMOS DE AGRUPAMIENTO GEOGRÁFICO O ESPACIAL .............. 28
2.4.8. ALGORITMOS DE AGRUPAMIENTO EN DATOS DISTRIBUIDOS .............. 29
2.5. SISTEMA DE BUSQUEDA DE INFORMACION BIBLIOGRAFICA ........................ 30
III. DISEÑO DE LA INVESTIGACION .............................................................................. 32 3.1. TIPO DE INVESTIGACION ................................................................................. 32
3.2. DISEÑO DE LA INVESTIGACION ....................................................................... 32
3.3. POBLACION Y MUESTRA ................................................................................. 32
3.3.1. POBLACION ............................................................................................... 32
3.3.2. MUESTRA .................................................................................................. 32

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 2
3.4. VARIABLES DE ESTUDIO .................................................................................. 33
3.5. TECNICAS E INSTRUMENTOS .......................................................................... 33
IV. RESULTADOS ........................................................................................................... 34
4.1. ANALISIS COMPARATIVO DE ALGORITMOS DE AGRUPAMIENTO................. 34
4.1.1. ANALISIS DE LOS ALGORITMOS SEGÚN LOS CRITERIOS.......................... 35
4.1.2. RESULTADOS DEL ANALISIS COMPARATIVO ........................................... 38
4.1.3. CONCLUSIONES DEL ANALISIS COMPARATIVO ....................................... 39
4.2. DISEÑO DEL MODELO PROPUESTO ................................................................ 39
4.2.1. ENFOQUE DEL DISEÑO ............................................................................. 39
4.2.2. DEFINICION DEL MODELO ........................................................................ 41
4.2.3. DESCRIPCION DEL MODELO ..................................................................... 42
4.3. CASO DE ESTUDIO ............................................................................................ 46
V. REFERENCIAS BIBLIOGRAFICAS .............................................................................. 47
5.1. BIBLIOGRAFÍA GENERAL .................................................................................. 47
5.2. BIBLIOGRAFÍA ESPECÍFICA ............................................................................... 48
5.3. WEBGRAFÍA...................................................................................................... 49
ANEXO ..................................................................................................................... 50
PICTOGRAFIA ........................................................................................................... 51
CASO DE USO........................................................................................................... 52

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 3
LISTA DE FIGURAS
Figura 1. Agrupamiento Particional.
Figura 2. Agrupamiento Jerárquico.
Figura 3. Agrupamiento Borroso o Difuso.
Figura 4. Agrupamiento basado en Densidad.
Figura 5. Agrupamiento basado en Grid.
Figura 7. Tabla de las variables de estudio.
Figura 8. Cuadro Comparativo.
Figura 9. Enfoque del Modelo Computacional Propuesto
Figura 10. Fases del modelo computacional

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 4
RESUMEN
Los usuarios buscan información específica de acuerdo a sus necesidades
específicas. Ellos pueden hacer búsquedas ya sea mediante motores de búsqueda o
bases de datos particulares de sistemas de bibliotecas o algún otro Sistema de
Información.
Sin embargo, los resultados de dichas consultas, pueden saturar a un usuario
por la abundancia de resultados y tiempo de respuesta, causando pérdida de
efectividad del sistema de búsqueda.
Para resolver este problema, la siguiente tesis, propone un modelo
computacional basado en algoritmos de agrupamiento que divide el conjunto de datos
en pequeños grupos con características comunes, lo cual permite minimizar el tiempo
de búsqueda y proporcionar información adecuada a los intereses del usuario.
Dando como resultado efectividad orientada a este tipo de sistemas, y a modo
de prueba se implementó en un prototipo de software a partir del modelo propuesto.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 5
I. PLAN DE INVESTIGACION
1.1. REALIDAD PROBLEMÁTICA
Cada día es más fácil acceder a nuevas fuentes de información, los usuarios
requieren buscar información específica de acuerdo a sus necesidades
particulares.
Los usuarios pueden hacer búsquedas, ya sea mediante motores de
búsqueda o también mediante accesos a bases de datos particulares de
bibliotecas o sistemas de información.
Esta facilidad de acceso a distintas fuentes de información, trae consigo la
dificultad de causar una sobresaturación de información al usuario, debido a
la abundancia de resultados que se puede obtener al efectuar una consulta
determinada.
Otros problemas ocurren cuando la búsqueda produce demasiados
resultados, con lo que aparte de consumir mucho tiempo de cómputo, el
usuario se puede saturar ante demasiados resultados.
Estas dificultades aún persisten cuando los usuarios efectúan consultas en
las bibliotecas, por que usan vocabularios controlados y normalizados al
incluir nuevos materiales a sus sistemas de información, y estos vocabularios
no necesariamente son conocidos por usuarios finales.
El usuario, al intentar obtener resultados no nulos, usualmente adopta una
estrategia de búsqueda general, pero esto implica que muchos de los
resultados de la búsqueda que haga no serán relevantes y el orden en que
estos resultados son retornados no necesariamente será el más adecuado
para él.
Características del problema:
Los resultados de la búsqueda son retornados en orden alfabético y no
específicamente lo que el usuario desea encontrar en el sistema.
La búsqueda produce demasiados resultados con lo que consume
tiempo de cómputo y ejecuta instrucciones demás.
Existe sobresaturación de información y abundancia de resultados, que
en determinados casos no corresponde con lo que el usuario desea
buscar en el sistema

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 6
1.2. ENUNCIADO DEL PROBLEMA
¿Cómo mejorar el tiempo de respuesta y correspondencia de resultados de
un sistema de búsqueda de información bibliográfica?
1.3. HIPÓTESIS
El diseño de un modelo computacional basado en algoritmos de
agrupamiento permitirá mejorar el tiempo de respuesta y la correspondencia
de resultados del sistema de búsqueda de información bibliográfica.
1.4. OBJETIVOS
1.4.1. OBJETIVO GENERAL
Diseñar un modelo computacional basado en algoritmos de
agrupamiento para mejorar el tiempo de respuesta y correspondencia de
resultados de un sistema de búsqueda de información bibliográfica.
1.4.2. OBJETIVOS ESPECIFICOS
Analizar los algoritmos de agrupamiento y su utilidad en la optimización y aplicación.
Diseñar un algoritmo con el rendimiento de los algoritmos que se tiene de base para este tipo de problemas.
Comparar y evaluar los resultados de los algoritmos realizados en las consultas hechas al sistema de búsqueda de información bibliográfica.
Implementar el modelo computacional diseñado anteriormente para la
realización de pruebas.
Validar la optimización de los resultados de las consultas realizadas
sobre el modelo computacional.
1.5. JUSTIFICACION
Desde el punto de vista de ciencia de la computación:
Se justifica esta investigación porque se va a hacer un estudio y análisis
riguroso de distintos tipos de algoritmos de agrupamiento, base para diseñar
el modelo computacional que se va a aplicar e implementar. El problema a
investigar corresponde a la ciencia computacional el cual está en el marco y
área de la investigación, esta investigación debería llegar a conclusiones que
supusieran un avance en el conocimiento científico de la materia estudiada.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 7
Desde el punto de vista operativa
Esta tesis se justifica en que, al ser implementado, permitiría mejorar el
tiempo de respuesta y la correspondencia de resultados de los sistemas de
búsqueda de información bibliográfica, como en la biblioteca central de la
Universidad Nacional de Trujillo.
1.6. LIMITACIONES
El trabajo tiene las siguientes limitaciones:
a. El estudio consiste en diseñar un modelo computacional basado en algoritmos de agrupamiento, pero se elijara solo un algoritmo para
comprobar y evaluar el diseño.
b. Este diseño se aplicara solo en el sistema de búsqueda de información bibliográfica de la biblioteca central de la UNT, por medio de una base de datos local.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 8
II. MARCO TEORICO
2.1. DISEÑO CONCEPTUAL
Según el Diccionario RAE, el diseño es la traza o delineación de una figura,
concepción original de un objeto, proyecto o plan; y descripción o bosquejo
de verbal de algo.
El diseño se define como el proceso previo de configuración mental, "pre-
figuración", en la búsqueda de una solución en cualquier campo.
El verbo "diseñar" se refiere al proceso de creación y desarrollo para
producir un nuevo objeto (proceso, servicio, conocimiento o entorno) para
uso humano.
El sustantivo "diseño" se refiere al plan final o proposición determinada
fruto del proceso de diseñar.
Según David Martínez Coronel en su trabajo [25], la fase del diseño
conceptual es una serie de actividades mediante la cual se determinan y
definen el marco conceptual al que serán referidos los datos, los instrumentos
para su captación, los criterios de validación para la revisión y depuración de
inconsistencias, y el esquema para la presentación de resultados.
Etapas del proceso de diseño
Según Dioclecio Moreira Camelo en su tesis doctoral [11], nos dice que la
clasificación más aceptada por la comunidad científica divide el diseño en las
siguientes:
a. Clarificación de las tareas: conjunto de información describe los
requisitos y restricciones del problema de diseño.
b. Diseño conceptual: abstracción de las funciones del sistema y de su
estructura física para conducir a la formación de un nuevo producto.
c. Diseño preliminar: construcción de una disposición general del sistema
de diseño según los principios de seguridad, legislación, coste, factores
técnicos, estéticos, etc.
Diseño de detalle: selección de los materiales, definición de las dimensiones,
de las superficies, de los flujos, de las tolerancias, de los dibujos técnicos y de
la documentación para la producción.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 9
2.2. MODELO COMPUTACIONAL
Según Dioclecio Moreira Camelo en su tesis doctoral [11], desde el punto de
vista computacional, el diseño conceptual consiste en buscar y combinar ideas
para formar alternativas de diseño.
Los modelos Computacionales conducen o automatizan algunas tareas del
proceso de diseño.
Estos modelos provienen de los métodos cognitivo, epistemológico y
metodológico, a partir de los cuales se han desarrollado.
Con los avances de las tecnologías informáticas, se ha logrado explicitar,
racionalizar, almacenar y manipular cada vez mejor el conocimiento utilizado
durante el desarrollo de un producto en los modelos computacionales.
La mayoría de los modelos computacionales parte de las intenciones de un
producto como datos de entrada y propone una o más soluciones para las
mismas.
Estas intenciones pueden ser un conjunto de requerimientos o de
funciones que deben ser realizados por los componentes físicos.
En el caso de que no se consiga atender a dichas funciones, habitualmente
se descomponen en otras más simples para facilitar su entendimiento y
permitir la búsqueda de soluciones.
Para describir los modelos, se han agrupado según la forma en que
descomponen y relacionan las funciones, y más genéricamente el
comportamiento y las estructuras de un diseño, en base a los siguientes
métodos:
• Árbol de funciones: descompone los requerimientos de función en base
a una organización jerárquica (árbol) de funciones y sub-funciones,
antes o durante la síntesis.
• Relación del flujo de las entradas y salidas: considera la relación
existente entre las entradas y salidas de flujos o de movimiento para
encontrar posibles sub-funciones dentro de una base de conocimientos.
• Relaciones de causa y efecto (causal): esta categoría considera que para
alcanzar un determinado efecto se debe tener una causa anterior.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 10
• Características: considera las características mínimas para un producto,
que son las dimensiones de un espacio de diseño formado por un
número finito de particiones.
• Agentes: proceso computacional que utiliza agentes inteligentes para
conseguir una mejor integración y funcionalidad en entornos de
ejecución distribuidos. En estos sistemas, cada agente se encarga de una
tarea específica para interactuar con otros agentes que realizan otras
tareas.
Redes neuronales: paradigma inspirado en el sistema nervioso biológico
que consiste en un gran conjunto de procesadores interconectados
(neuronas) que trabajan de forma simultánea para resolver problemas
específicos.
• Adbucción: método que proviene de la lógica que describe una solución
de diseño (hechos) a través de conocimientos sobre el diseño (axiomas)
y de las propiedades de otras soluciones de diseño (teoremas).
• Métodos evolutivos: métodos concebidos a partir de la abstracción
genética. Este método detecta la abstracción más favorable y, a partir
de ella, cambia los parámetros (funciones) por medio de algoritmos de
mutación o recombinación que descomponen los parámetros.
Además del método de razonamiento, también se describen los modelos
computacionales a través de los siguientes aspectos:
• Planteamiento del modelo, es decir qué se resuelve,
• La base que utilizan para resolver un problema de diseño,
• Su algoritmo de síntesis,
• Los métodos de evaluación y
• Hasta donde llegan en la formación de la solución.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 11
2.3. ALGORITMOS DE AGRUPAMIENTO
2.3.1. ALGORITMO
Según Carlos López García en su libro [15], los algoritmos son una
herramienta que permite describir claramente un conjunto finito de
instrucciones, ordenadas secuencialmente y libres de ambigüedad, que
debe llevar a cabo un computador para lograr un resultado previsible.
Vale la pena recordar que un programa de computador consiste de
una serie de instrucciones muy precisas y escritas en un lenguaje de
programación que el computador entiende (Logo, Java, Pascal, etc.).
Un Algoritmo es una secuencia ordenada de instrucciones, pasos o
procesos que llevan a la solución de un determinado problema.
Los hay tan sencillos y cotidianos como seguir la receta del médico,
abrir una puerta, lavarse las manos, etc.; hasta los que conducen a la
solución de problemas muy complejos.
En términos generales, un Algoritmo debe ser
Realizable: El proceso algorítmico debe terminar después de una
cantidad finita de pasos. Se dice que un algoritmo es inaplicable
cuando se ejecuta con un conjunto de datos iniciales y el proceso
resulta infinito o durante la ejecución se encuentra con un obstáculo
insuperable sin arrojar un resultado.
Comprensible: Debe ser claro lo que hace, de forma que quien ejecute
los pasos (ser humano o máquina) sepa qué, cómo y cuándo hacerlo.
Debe existir un procedimiento que determine el proceso de ejecución.
Preciso: El orden de ejecución de las instrucciones debe estar
perfectamente indicado. Cuando se ejecuta varias veces, con los
mismos datos iniciales, el resultado debe ser el mismo siempre. La
precisión implica determinismo.
2.3.2. AGRUPAMIENTO DE OBJETOS
El tesista Allan Roberto Avendaño Sudario especifica en su documento
[12], que una de las técnicas utilizadas para comprender la naturaleza de
las colecciones de objetos, consiste en dividirlas en pequeños grupos de
elementos que compartan cierto grado de similitud entre sí.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 12
Este enfoque ha sido utilizado en diversas áreas científicas y
comerciales, incluyendo la organización de resultados de búsqueda y
marketing.
Es así, que se han utilizado para analizar el comportamiento histórico
de los usuarios en la Web o en las bibliotecas al agrupar manualmente los
libros de acuerdo a los tópicos tratados.
Para agrupar elementos no es necesario plantear un análisis previo en
el que se determine, por ejemplo, la independencia de las variables o de
la supervisión de un experto que determine la similitud. Sin embargo, es
necesario seleccionar las variables relevantes que describan con precisión
la naturaleza de los objetos.
Otro de los requerimientos durante el agrupamiento de objetos es la
métrica de distancia. La cual es una expresión matemática en la que se
evalúan las características de los objetos para determinar la proximidad
entre estos.
2.3.3. ALGORITMOS DE AGRUPAMIENTO
Según la página web [17], un algoritmo de agrupamiento (en inglés,
clustering) es un procedimiento de agrupación de una serie de vectores
de acuerdo con un criterio.
Esos criterios son por lo general distancia o similitud. La cercanía se
define en términos de una determinada función de distancia, como la
euclídea, aunque existen otras más robustas o que permiten extenderla a
variables discretas.
La medida más utilizada para medir la similitud entre los casos es las
matriz de correlación entre los n x n casos. Sin embargo, también existen
muchos algoritmos que se basan en la maximización de una propiedad
estadística llamada verosimilitud.
Generalmente, los vectores de un mismo grupo (o clústeres)
comparten propiedades comunes. El conocimiento de los grupos puede
permitir una descripción sintética de un conjunto de datos
multidimensional complejo. De ahí su uso en minería de datos.
Esta descripción sintética se consigue sustituyendo la descripción de
todos los elementos de un grupo por la de un representante
característico del mismo.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 13
2.3.4. APLICACIÓN DE LOS ALGORITMOS DE AGRUPAMIENTO
Según Carlos Eduardo Bedregal Lizárraga en su tesis [23], las técnicas
de agrupamiento encuentran aplicación en diversos ámbitos. Las técnicas
de agrupamiento de datos fueron inicialmente desarrolladas en biología y
zoología para la construcción de taxonomías. La necesidad de varias
disciplinas científicas de organizar grandes cantidades de datos en grupos
con significado ha hecho del agrupamiento de datos una herramienta
valiosa en el análisis de datos.
Un sin número de entidades han sido objeto de aplicaciones de
agrupamiento de datos: enfermedades, huellas digitales, estrellas,
consumidores e imágenes. Entre las principales aplicaciones de
agrupamiento de datos tenemos la segmentación de imágenes, la minería
de datos, la recuperación de información, el procesamiento del lenguaje
natural y el reconocimiento de objetos.
a. Segmentación de imágenes. Componente fundamental en muchas
aplicaciones de visión computacional, consiste en el
particionamiento de una imagen para la identificación de regiones,
cada una de las cuales es considerada homogénea con respecto a
alguna propiedad de la imagen. Para cada píxel de la imagen se
define un vector de características compuesto por lo general de
funciones de intensidad y ubicación del píxel.
b. Reconocimiento de objetos. Cada objeto es representado en
términos de un conjunto de imágenes del objeto obtenidas desde
un punto de vista arbitrario. Entonces, a través de técnicas de
agrupamiento es posible seleccionar e identificar al conjunto de
vistas de un objeto que sean cualitativamente similares.
c. Procesamiento del lenguaje natural. Técnicas de agrupamiento son
también utilizadas para el reconocimiento de caracteres y del habla.
Sistemas dependientes o independientes del sujeto capaz de
reconocer lexemas y morfemas para identificar caracteres escritos y
discursos hablados.
d. Minería de datos. Es necesario desarrollar algoritmos que puedan
extraer información significante de la gran cantidad de datos
disponibles. La generación de información útil, o conocimiento, a
partir de grandes cantidades de datos es conocida como minería de
datos.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 14
2.4. CLASIFICACION DE LOS ALGORITMOS DE AGRUPAMIENTO
Según Ignacio Javier Benítez Sánchez en su tesis sustenta la siguiente
clasificación:
2.4.1. ALGORITMOS DE AGRUPAMIENTO PARTICIONAL
Un algoritmo de agrupamiento particional obtiene una partición
simple de los datos en vez de la obtención de la estructura del clúster tal
como se produce con los dendogramas de la técnica jerárquica. En la
figura 1 se muestra un ejemplo de clustering particional.
Figura 1. Agrupamiento Particional.
El clustering particional organiza los objetos dentro de k clusters de tal
forma que sea minimizada la desviación total de cada objeto desde el
centro de su clúster o desde una distribución de clusters. La desviación de
un punto puede ser evaluada en forma diferente según el algoritmo, y es
llamada generalmente función de similitud.
Los métodos particionales tienen ventajas en aplicaciones que
involucran gran cantidad de datos para los cuales la construcción de un
dendograma resultaría complicada.
El problema que se presenta al utilizar algoritmos particionales es la
decisión del número deseado de clusters de salida. Las técnicas
particionales usualmente producen clusters que optimizan el criterio de
función definido local o globalmente.
En la práctica, el algoritmo se ejecuta múltiples veces con diferentes
estados de inicio y la mejor configuración que se obtenga es la que se
utiliza como el clustering de salida.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 15
a. Chain-map o Algoritmo de las distancias encadenadas
El algoritmo Chain-map es uno de los algoritmos de agrupamiento más
sencillos. Dado el conjunto de objetos, en forma de vectores, en donde
cada elemento es el valor de una característica, el algoritmo comienza
seleccionando un objeto cualquiera de los disponibles.
A continuación se ordenan todos los demás objetos formando una
cadena según proximidad, como se puede ver en (a), en donde el
subíndice i indica que se ha seleccionado al objeto i como al primero de la
cadena.
Zi (0) ; z i(1) ; : : : ; zi (N- 1)…………………..(a)
El procedimiento consiste en calcular todas las distancias euclídeas
entre el objeto k y el inmediatamente anterior (k- 1), y disponerlas en la
cadena por el orden establecido.
Las distancias Euclídeas pequeñas indican que los objetos pertenecen a
una misma clase, mientras que un gran salto en el valor de la distancia
Euclidea, significa una transición de un grupo a otro. De esta forma se
obtiene una agrupación de todos los objetos en grupos, sin necesidad de
definir previamente el número de estos.
Sí que es preciso determinar, sin embargo, a partir de qué valor de
salto cuantitativo de la distancia euclídea se considera que se ha saltado
de un clúster a otro.
Este algoritmo Chain-map, aunque no es el óptimo en algunos casos, sí
es muy recomendable en todos como un paso previo para la iniciación de
otros algoritmos de clustering, y para la estimación inicial del número de
grupos a buscar.
b. Max-min
El algoritmo Max-min tampoco necesita predefinir el número inicial de
grupos o clusters a buscar. El procedimiento que sigue es el siguiente:
Se selecciona uno de los objetos al azar, quedando asignado como
patrón del grupo A1.
Se calculan todas las distancias euclídeas de todos los objetos
restantes con respecto al objeto patrón del grupo A1. El objeto con
la distancia euclídea más grande (el más alejado de A1), queda
seleccionado como patrón de un segundo grupo A2.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 16
A continuación se calculan todas las distancias euclídeas de todos
los objetos restantes con respecto al objeto patrón del nuevo grupo
A2. De las dos distancias obtenidas para cada objeto, se selecciona
la más pequeña.
De todo el conjunto de distancias así formado, se selecciona la
mayor, y si esta es mayor que la distancia, ponderada por un factor
f, entre los patrones de los grupos A1 y A2, entonces se crea un
nuevo grupo, A3 (b).
El mismo procedimiento se repite, creando nuevos grupos hasta
que la respectiva distancia máxima ya no sea mayor que el valor
medio de todas las distancias entre patrones de todos los grupos
creados.
Se recalculan por última vez todas las distancias euclídeas de los
objetos restantes a todos los respectivos patrones de todos los
grupos creados, asignando cada objeto como perteneciente al
clúster que tenga más cercano (menor distancia euclídea).
dmax > f d(z1; z2); 0 < f < 1 ……………………………(b)
El inconveniente de este algoritmo es la apropiada elección del factor
de ponderación f, ya que interviene directamente en la creación de un
mayor o menor número de grupos o clases distintas.
c. K-means
El algoritmo de K-medias o k-means es muy conocido y muy usado, por
su eficacia y robustez. Su nombre hace referencia al número K de clases o
grupos a buscar, que debe definirse con antelación. El procedimiento del
algoritmo es el siguiente:
Se comienza seleccionando K objetos al azar del conjunto total y
asignándolos como patrones o centroides de las K clases que se van
a buscar.
A continuación, se calculan todas las distancias euclídeas de todos
los objetos restantes a todos los K centroides, y se asigna la
pertenencia a cada objeto al clúster que tenga más cercano.
Entonces se recalcula el centroide de cada clúster, como la media
de todos los objetos que lo componen, buscando minimizar el valor
de una función de coste, que es un sumatorio de todos los

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 17
sumatorios de las distancias euclídeas de los objetos de cada clase
al centroide de su respectiva clase, como se puede ver en (c).
Los dos pasos anteriores se repiten sucesivamente hasta que los
centros de todos los grupos permanezcan constantes, o hasta que
se cumpla alguna otra condición de parada.
J =∑ (∑ ‖𝑧𝑗 − 𝑐𝑖‖𝑗,𝑧𝑗∈𝐴𝑖)𝑘
𝑖=1 … … … (c)
La eficacia del algoritmo K-means depende de la idoneidad del
parámetro K. Si este es mayor o menor que el número real de grupos, se
crean grupos ficticios o se agrupan objetos que deberían pertenecer a
clusters distintos.
El cual genera k grupos de elementos. Este número debe ser
seleccionado ante del procesamiento; además, debe ser mayor que dos y
menor que el número de elementos que componen la colección.
El objetivo de este algoritmo consiste en minimizar el promedio
cuadrado de la distancia de cada documento con el centroide de cada
grupo.
d. PAM
PAM (Partitioning Around Medoids) es una extensión del algoritmo K-
means, en donde cada grupo o clúster está representado por un medoide
en vez de un centroide.
El medoide es el elemento más céntrico posible del clúster al que
pertenece; similar al centroide, pero no necesariamente, ya que el
centroide representa el valor patrón o medio del conjunto, que no
siempre coincide con el más céntrico. El procedimiento para el
agrupamiento es similar al del K-means.
e. CLARA
El algoritmo CLARA (Clustering Large Applications) divide la base de
datos original en muestras de tamaño s, aplicando el algoritmo PAM
sobre cada una de ellas, seleccionando la mejor clasificación de las
resultantes. Este algoritmo está indicado para bases de datos con gran
cantidad de objetos, y su principal motivación es la de minimizar la carga
computacional, en detrimento de una agrupación optima y precisa.
Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 18
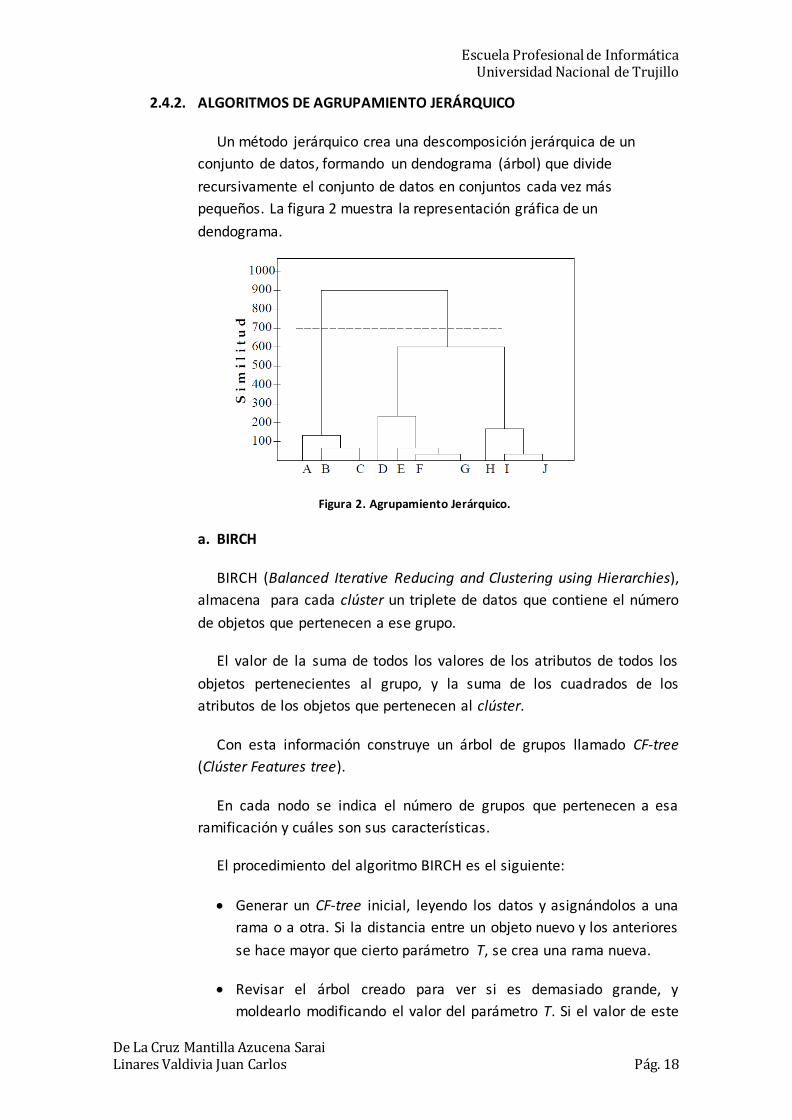
2.4.2. ALGORITMOS DE AGRUPAMIENTO JERÁRQUICO
Un método jerárquico crea una descomposición jerárquica de un
conjunto de datos, formando un dendograma (árbol) que divide
recursivamente el conjunto de datos en conjuntos cada vez más
pequeños. La figura 2 muestra la representación gráfica de un
dendograma.
Figura 2. Agrupamiento Jerárquico.
a. BIRCH
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies),
almacena para cada clúster un triplete de datos que contiene el número
de objetos que pertenecen a ese grupo.
El valor de la suma de todos los valores de los atributos de todos los
objetos pertenecientes al grupo, y la suma de los cuadrados de los
atributos de los objetos que pertenecen al clúster.
Con esta información construye un árbol de grupos llamado CF-tree
(Clúster Features tree).
En cada nodo se indica el número de grupos que pertenecen a esa
ramificación y cuáles son sus características.
El procedimiento del algoritmo BIRCH es el siguiente:
Generar un CF-tree inicial, leyendo los datos y asignándolos a una
rama o a otra. Si la distancia entre un objeto nuevo y los anteriores
se hace mayor que cierto parámetro T, se crea una rama nueva.
Revisar el árbol creado para ver si es demasiado grande, y
moldearlo modificando el valor del parámetro T. Si el valor de este

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 19
parámetro se aumenta, las ramas del árbol se juntan al no haber
distinción de grupos.
Aplicar algún procedimiento de clustering, como el K-means, sobre
la información contenida en los nodos de cada nivel.
Redistribuir los datos según los centroides descubiertos en el paso
anterior, logrando un mayor refinamiento en el agrupamiento.
Las principales desventajas del algoritmo BIRCH son su secuencialidad,
lo cual puede provocar asignación a distintos clusters de objetos
replicados, colocados en distintos lugares de la secuencia, y la fuerte
dependencia del parámetro T.
De forma que una mala elección de este valor puede generar la
creación de falsas agrupaciones, o ramificaciones duplicadas, o la
asignación de objetos a un mismo nodo, cuando deberán estar en nodos
distintos.
b. CURE
CURE (Clustering Using REpresentatives) es un algoritmo que se basa
en la selección de más de un elemento representativo de cada clúster.
Como resultado, CURE es capaz de detectar grupos con múltiples formas
y tamaños.
Es un algoritmo de tipo aglomerativo, que comienza considerando
todos los objetos como grupos independientes, y a partir de ahí combina
sucesivamente los objetos, agrupándolos en clusters.
De cada uno de estos grupos, almacena los objetos extremos,
desplazándolos hacia el centro del clúster mediante un factor de
acercamiento que es el valor medio de todos los elementos que
componen el grupo.
2.4.3. ALGORITMOS DE AGRUPAMIENTO BORROSO
Los algoritmos de agrupamiento borroso se basan todos en una
partición no-exclusiva de las pertenencias de los objetos a los distintos
clusters. En una partición clásica (exclusiva) todos los objetos del
conjunto son asignados (pertenecen) a un único clúster y sólo uno,
cumpliendo los grupos formados las propiedades que se muestran en las
expresiones (d), (e) y (f).

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 20
𝐴𝑖 ∩ 𝐴𝑗 = ∅ , 1 ≤ 𝑖 ≠ 𝑗 ≤ 𝑐 …………. (d)
∅ ∁ 𝐴𝑖 ∁ 𝑍 , 1 ≤ 𝑖 ≤ 𝑐 …………. (e)
⋃ 𝐴𝑖 𝑐𝑖=1 = 𝑍 …………. (f)
La expresión (d) indica que la intersección de los elementos de dos
clusters distintos debe generar como resultado el conjunto vacío (c es el
número de grupos). Las expresiones (e) y (f) indican que ningún grupo es
el conjunto vacío, y que la unión de todos los elementos de todos los
grupos da como resultado el conjunto total de objetos (Z).
Si se genera una matriz de pertenencias U = [𝜇1𝑘]de dimensiones c x N
(c número de clusters, N número de objetos), se define un espacio de
particiones clásicas como el conjunto de la expresión (g).
Mℎ𝑐 = {𝑈 ∈ 𝑅𝑐𝑥𝑁|𝜇
1𝑘∈ {0,1} , ∀𝑖, 𝑘 ; ∑ 𝜇
1𝑘= 1,𝑐
𝑖=1 | ∀𝑘 ;
0 < ∑ 𝜇1𝑘
< 𝑁, ∀𝑖 𝑁𝑘=1
}…….. (g)
Figura 3. Agrupamiento Borroso o Difuso.
En una partición clásica, los valores de todo 𝜇1𝑘 sólo pueden ser 0 o 1.
Sin embargo, en una partición borrosa, los elementos 𝜇1𝑘 de la matriz de
pertenencias U, pueden tomar cualquier valor entre cero y uno. La
partición borrosa se define según la expresión (h), que tiene las mismas
propiedades que la partición clásica (g), pero incorporando la posibilidad
de que las pertenencias puedan adquirir valores dentro del rango [0; 1].
M𝑓𝑐 = {𝑈 ∈ 𝑅𝑐𝑥𝑁|𝜇
1𝑘∈ {0,1} , ∀𝑖, 𝑘 ; ∑ 𝜇
1𝑘= 1,𝑐
𝑖=1 | ∀𝑘 ;
0 < ∑ 𝜇1𝑘
< 𝑁, ∀𝑖 𝑁𝑘=1
}…………… (h)

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 21
En ambas particiones se requiere que la suma de todas las
pertenencias de un único objeto a todos los clusters ha de sumar uno.
Este es un requerimiento no-posibilista.
Aunque no es tan usada, también existe la variante posibilista de
partición, en donde no se exige que la suma de pertenencias para cada
objeto sea exactamente igual a uno, sino que al menos la pertenencia de
algún objeto a un determinado clúster sea mayor de cero.
En los algoritmos que se detallan a continuación se usa la partición
borrosa no-posibilista (suma de pertenencias en cada objeto ha de ser
igual a uno).
a. Algoritmo de las c-medias o fuzzy c-means
El algoritmo FCM o Fuzzy c-means, está basado en la minimización de
la función objetivo definida en (i), que es una medida ponderada del error
cuadrático que se comete al definir los elementos ci como centroides de
los c clusters.
𝐽(𝑍; 𝑈; 𝐶) = ∑ ∑ (𝜇𝑖𝑘)𝑚‖𝑧𝑘 − 𝑐𝑖‖𝐵2𝑁
𝐾=1𝐶𝐼=1 …………………(i)
Los elementos implicados en esta función son: Z, que es el número de
objetos; la matriz de pertenencias U, cuyos elementos μik aparecen
elevados a un factor de `borrosidad' m, que puede tomar cualquier valor
mayor de uno; y la matriz C de centroides de los clusters. La expresión
‖𝑧𝑘 − 𝑐𝑖‖𝐵2 es una medida de la distancia, como se puede ver en (j).
‖𝑧𝑘 − 𝑐𝑖‖𝐵2 = (𝑧𝑘 − 𝑐𝑖)
𝑇 𝐵 (𝑧𝑘 − 𝑐𝑖) = 𝐷𝑖𝑘𝐵2 ……..(j)
Cuando a B se le da de valor la matriz identidad, se tiene como
resultado la distancia euclídea elevada al cuadrado. Si B se sustituye por
la inversa de la matriz de covarianzas, el resultado es la distancia de
Mahalanobis.
El resultado de minimizar esta función objetivo, mediante igualación a
cero de las respectivas derivadas parciales, produce dos expresiones para
obtener los valores de los centroides y de las pertenencias, mostradas en
las expresiones (k) y (l).
𝜇𝑖𝑘 = 1
∑ (𝐷𝑖𝑘𝐵
2
𝐷𝑗𝑘𝐵2 )
2𝑚−1
𝑐𝑗=1
, 1 ≤ 𝑖 ≤ 𝑐, 1 ≤ 𝑘 ≤ 𝑁 … … … . . (k)

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 22
𝑐𝑖 = ∑ (𝜇𝑖𝑘)𝑚𝑧𝑘
𝑁𝑘=1
∑ (𝜇𝑖𝑘)𝑚𝑁𝑘=1
, 1≤ 𝑖 ≤ 𝑐 … … … … … … … … … … … … … . . (𝑙)
Partiendo de estas expresiones, el algoritmo FCM sigue los siguientes
pasos:
Inicializar la matriz de pertenencias U con valores aleatorios, pero
que cumplan con los requisitos definidos en (h).
Calcular los centros de los clusters según expresión (l).
Hallar todas las distancias de los objetos a los respectivos centros
de sus grupos (j).
Recalcar toda la matriz de particiones U aplicando la expresión (k)
cuando 𝐷𝑗𝑘𝐵2 para todo i, k, y aplicando la solución expuesta (m)
para cualquier otro caso.
Verificar si se cumple la condición de parada. Si no se cumple,
volver a empezar desde el segundo paso del algoritmo.
La condición de parada es que la variación en la matriz de
pertenencias de la nueva iteración respecto a la calculada en la
iteración anterior esté por debajo de un valor umbral 𝜀 tal y como
se indica en (n). El parámetro " suele tener un valor pequeño,
normalmente 0:001 o menor, indicando que la nueva matriz de
pertenencias debe ser muy similar a la anterior para que se pare el
algoritmo.
𝜇𝑖𝑘 = 0 𝑠𝑖 𝐷𝑖𝑘𝐵 > 0 … … … … … … … … … … (𝑚)
𝜇𝑖𝑘 ∈ [0,1], 𝑐𝑜𝑛 ∑ 𝜇𝑖𝑘 = 1 𝑝𝑎𝑟𝑎 𝑒𝑙 𝑟𝑒𝑠𝑡𝑜𝑐
𝑖=1
‖𝑈(𝑘) − 𝑈(𝑘−1)‖ < 𝜀 … … … … … … … … … … . (𝑛)
b. Algoritmo de Gustafson-Kessel o GK
El algoritmo GK es una variante del algoritmo FCM, propuesta por
Gustafson y Kessel en 1979. Esta consiste en asignar distintas clases de
normas B a los distintos grupos o clases, con lo cual se obtienen
agrupaciones con distintas formas.
Así pues, se define un vector B que contiene c normas, y se modifica la
función objetivo a minimizar de forma que quede como en (o).

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 23
𝐽(𝑍; 𝑈; 𝐶; 𝐵) = ∑ ∑ (𝜇𝑖𝑘)𝑚‖𝑧𝑘 − 𝑐𝑖‖𝐵𝑖
2𝑁𝐾=1
𝐶𝐼=1 ……………….(o)
Para obtener una solución viable, el rango de posibles valores de los
elementos Bi se limita estableciendo un valor fijo para su determinante,
como se puede ver en: |𝐵𝑖| = 𝜌𝑖 ,𝜌 > 0
El resultado de minimizar la función objetivo resulta en una nueva
expresión para el cálculo de las normas (p), en donde la variable Fi
representa la matriz de covarianzas de la clase i, y se puede obtener
usando la expresión (q).
La fórmula para el cálculo de los centroides se mantiene como en el
FCM (l), y la nueva expresión para calcular las pertenencias a las clases es
como la anterior (k), pero incorporando el hecho de que hay una norma
distinta para cada grupo, como se puede ver en (r).
𝐵𝑖 = [𝜌𝑖 det(𝐹𝑖)]1𝑛𝐹𝑖
−1 … … … … … … … … … … … … … … … . . (𝑝)
𝐹𝑖 =∑ (𝜇𝑖𝑘)𝑚(𝑧𝑘 − 𝑐𝑖)(𝑧𝑘 − 𝑐𝑖)𝑇𝑁
𝑘=1
∑ (𝜇𝑖𝑘)𝑚𝑁𝑘 =1
… … … … … … … … … (𝑞)
𝜇𝑖𝑘 = 1
∑ (𝐷𝑖𝑘𝐵𝑖
2
𝐷𝑗𝑘𝐵𝑖
2 )
2𝑚−1
𝑐𝑗=1
, 1 ≤ 𝑖 ≤ 𝑐, 1 ≤ 𝑘 ≤ 𝑁 ≤ 𝑁 … … (𝑟)
Los pasos que sigue el algoritmo son, pues, los siguientes:
Inicializar la matriz de pertenencias U con valores aleatorios.
Calcular los centros de los grupos, según la expresión (l).
Calcular la matriz de covarianzas de cada clase (q).
Calcular todas las distancias, aplicando la norma correspondiente en
cada caso, según (p) y (j).
Hallar todos los nuevos valores de la matriz de pertenencia,
siguiendo el mismo procedimiento descrito para el FCM, y teniendo
en cuenta que hay una norma distinta para cada cluster (r).
Verificar la condición de parada, que es la misma que en el caso del
FCM (n). Si no se cumple, volver al paso 2 del algoritmo.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 24
c. Algoritmo de estimación de la máxima probabilidad o FMLE
El algoritmo FMLE (Fuzzy Maximum Likelihood) es otra variante del
FCM que incluye una norma con un término exponencial, que se calcula
mediante el uso de las expresiones (s), (t) y (u).
𝐷𝑖𝑘𝐺𝑖
2 = √𝑑𝑒𝑡(𝐺𝑖)
𝑃𝑖
𝑒𝑥𝑝 [1
2(𝑧𝑘 − 𝑐𝑖)
𝑇𝐺𝑖−1(𝑧𝑘 − 𝑐𝑖)] … … … . (𝑠)
𝐺𝑖 = ∑ 𝜇𝑖𝑘(𝑧𝑘 − 𝑐𝑖)(𝑧𝑘 − 𝑐𝑖)𝑇𝑁
𝑘=1
∑ 𝜇𝑖𝑘𝑁𝑘 =1
… … … … … … … … … … . . (𝑡)
𝑃𝑖 = 1
𝑁∑ 𝜇𝑖𝑘
𝑁
𝑘=1
… … … … … … … … … … … … … … … … … … … . (𝑢)
Al igual que el algoritmo GK, cada grupo o clase tiene su propia norma
asociada, que se calcula de la forma que se ha mostrado. El resto del
procedimiento es similar a la secuencia de pasos del algoritmo GK.
2.4.4. ALGORITMOS DE AGRUPAMIENTO BASADOS EN LA DENSIDAD
Los algoritmos basados en densidad obtienen clusters basados en
regiones densas de objetos en el espacio de datos que están separados
por regiones de baja densidad (estos elementos aislados representan
ruido). En la figura 4 se muestra un ejemplo de agrupamiento basado en
densidad.
Figura 4. Agrupamiento basado en Densidad.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 25
Este tipo de métodos es muy útil para filtrar ruido y encontrar clusters
de diversas formas. La mayoría de los métodos de particionamiento,
realizan el proceso de agrupamiento con base en la distancia entre dos
objetos. Estos métodos pueden encontrar solo clusters esféricos y se les
dificulta hallar clusters de formas diversas.
a. GDBSCAN
El algoritmo GDBSCAN (Generalized Density Based Spatial Clustering of
Applications with Noise) está basado en la densidad de los grupos
formados.
Al buscar formas densas que pueden ocupar zonas geográficas, este es
también un algoritmo clasificado como de clustering geográfico.
El principio en que se basa es que para que se reconozca un cluster en
una zona, esta debe rebasar cierto límite o threshold de densidad.
Este valor de densidad es una relación entre el número de objetos y el
área que ocupan en el conjunto considerado como perteneciente a un
único cluster.
Los grupos detectados (o inicializados) son considerados como objetos
o cuerpos geométricos, con sus propias características, como son el
centro de gravedad, el área total, la densidad, etc.
Todos los objetos pueden compararse entre sí para establecer
relaciones de distancia entre los centros de los clusters, o si hay un
solapamiento entre regiones, con lo cual se puede plantear la fusión o
reorganización de los distintos grupos.
Normalmente se realiza un proceso iterativo, en el que a cada objeto
de la base de datos se le calcula si pertenece o no a alguno de los clusters
reconocidos, y a qué distancia se encuentra de todos ellos.
Si este objeto no se asigna como perteneciente a ningún grupo, se
considera como ruido y se pasa al siguiente elemento, hasta completar un
barrido de todos los objetos. Finalizado el proceso, si la condición de
parada no se satisface, se vuelve a empezar variando las condiciones
iniciales.
El resultado final es un mapa geográfico de densidades, en donde las
zonas con mayor densidad de objetos se agrupan para formar clusters

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 26
geométricos, con sus propios valores definiendo su forma, densidad y
situación en el espacio de coordenadas.
b. DENCLUE
DENCLUE (DENsity-based CLUstEring) usa el concepto de las funciones
de influencia para catalogar la influencia que cada objeto ejerce sobre los
elementos cercanos.
Estas funciones de influencia son similares a las funciones de
activación usadas para redes neuronales: superado cierto valor umbral de
distancia entre objetos (distancia euclídea), la salida cambia de un estado
a otro, normalmente entre un estado inactivo (0) y otro activo (1).
El valor umbral viene definido por funciones de activación, como la
gaussiana o la sigmoidal.
La densidad se computa como la suma de todas las funciones de
influencia de todos los objetos.
Los clusters se determinan mediante la detección de los atractores, o
máximos locales de densidad. Se consigue así un algoritmo de
agrupamiento robusto, capaz de manejar datos ruidosos o erróneos.
2.4.5. ALGORITMOS DE AGRUPAMIENTO BASADO EN GRID
Recientemente un número de algoritmos de agrupamiento han sido
presentados para datos espaciales, estos son conocidos como algoritmos
basados en Grid.
Figura 5. Agrupamiento basado en Grid.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 27
Estos algoritmos cuantifican el espacio en un número finito de celdas y
aplican operaciones sobre dicho espacio.
La mayor ventaja de este método es su veloz procesamiento del
tiempo, el cual generalmente es independiente de la cantidad de objetos
a procesar. En la figura se muestra un ejemplo de agrupamiento basado
en Grid.
a. STING
STING (STatistical INformation Grid) particiona el espacio según
niveles, en un número finito de celdas con una estructura jerárquica
rectangular.
De cada celda extrae la información de los objetos que allí encuentra,
que es: media, varianza, mínimo y máximo de los valores y tipo de
distribución de los objetos encontrados.
Con cada nivel se vuelven a particionar las celdas, construyendo un
árbol jerárquico a semejanza del algoritmo BIRCH.
Acabada la partición del espacio hasta el nivel de detalle deseado, los
clusters se forman asociando celdas con información similar mediante
consultas especializadas.
b. CLIQUE
CLIQUE (CLustering In QUEst) también realiza particiones del espacio
según niveles, pero en esta ocasión cada nivel nuevo es una dimensión
más, hasta alcanzar la n dimensiones o características de los objetos.
La estructura de partición es en forma de hiper-rectángulos.
El funcionamiento es el siguiente: comienza con una única dimensión,
y la divide en secciones, buscando las más densas, o aquellas donde se
encuentran más objetos.
A continuación incluye la segunda dimensión en el análisis,
particionando el espacio en rectángulos, y buscando los más densos.
Luego sigue con cubos en tres dimensiones, y así sucesivamente.
Cuando acaba con todas las características o dimensiones de los
objetos, se definen los clusters y las relaciones entre ellos mediante
semejanza de densidades y otra información extraída, en todos los niveles
o dimensiones.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 28
2.1.1. ALGORITMOS DE AGRUPAMIENTO BASADO EN MODELOS
a. Expectation-Maximization
El algoritmo de Expectation-Maximization o EM, asigna cada objeto a
un cluster predefinido, según la probabilidad de pertenencia del objeto a
ese grupo concreto.
Como modelo se usa una función de distribución gaussiana, siendo el
objetivo el ajuste de sus parámetros, según cómo los distintos objetos del
conjunto se ajustan a la distribución en cada cluster.
El algoritmo de EM puede identificar grupos o clases de distintas
formas geométricas, si bien implica un alto coste computacional, para
conseguir un buen ajuste de los parámetros de los modelos .
2.1.2. ALGORITMOS DE AGRUPAMIENTO GEOGRÁFICO O ESPACIAL
a. GRAVIclust
El GRAVIclust es un algoritmo de clustering geográfico, que busca
conjuntos geográficos definidos por el área, el centro y el radio del área
localizada (con lo cual los grupos tienen una forma más o menos circular).
La densidad de cada grupo, es decir, las zonas más concurridas son las
que más probabilidad tienen de formar un cluster de datos.
Como medida de similitud se usa la distancia euclídea, siendo la
función objetivo a optimizar la mostrada en la expresión (v)
𝐽 = ∑ ∑ 𝑑(𝑝, 𝐿𝑖)
𝑝∈𝐶𝑖
𝑘
𝑖=1
… … … … … . . (𝑣)
En donde k es el número de clusters a buscar, p es un objeto
perteneciente al cluster Ci, y d es la distancia del objeto p al centro de
gravedad de la agrupación Ci, llamado Li. El objeto p pertenece
únicamente al conjunto cuya distancia al centro de gravedad Li sea
menor.
La búsqueda se perfecciona en sucesivas iteraciones, buscando los
centros de los clusters formados mediante el cálculo del centro de masas
(o centro de gravedad) de todos los objetos que componen el cluster
correspondiente.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 29
2.1.3. ALGORITMOS DE AGRUPAMIENTO EN DATOS DISTRIBUIDOS
a. Collective Principal Component Analysis
En [22] se propone un algoritmo para el agrupamiento de objetos cuyas
características se encuentran distribuidas entre varios nodos de una red,
lo que se conoce como datos heterogéneamente distribuidos.
Para ello se basa en la técnica del PCA (Principal Components Analysis),
la cual busca una representación reducida de los datos que contenga la
información más relevante para permitir la agrupación (el Principal
Components).
El nombre resultante es el de CPCA (Collective Principal Components
Analysis). Cada nodo local realiza el agrupamiento sobre sus
características, y envía la información con los datos más representativos
obtenidos a una unidad central.
Allí se vuelve a aplicar el procedimiento de clustering sobre los datos
recibidos; los resultados son enviados de vuelta a todos los nodos, que
vuelven a aplicar la tarea de agrupación tomando como patrones los
datos recibidos. Los clusters locales resultantes son vueltos a enviar a la
unidad central.
b. RACHET
RACHET (Recursive Agglomeration of Clustering Hierarchies by
Encircling Tactic) es un algoritmo de clustering jerárquico diseñado para
conjuntos de objetos distribuidos homogéneamente (con todas sus
características o dimensiones) en distintos nodos en una red.
Cada nodo genera primero un dendograma (árbol jerárquico de
agrupamiento) local, según los objetos contenidos en él.
A continuación todos los dendogramas locales son enviados a una
unidad central, pero para reducir costes de comunicación, lo que se envía
es una aproximación de los resultados en forma de resúmenes
estadísticos de ciertos indicadores, como el número de objetos en cada
grupo o la distancia euclídea media de todos los datos al centroide del
grupo.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 30
2.2. SISTEMA DE BUSQUEDA DE INFORMACION BIBLIOGRAFICA
Según en la página web [18], un sistema informático es un sistema que
permite almacenar y procesar información; como todo sistema, es el conjunto
de partes interrelacionadas: en este caso, hardware, software y recursos
humanos.
El hardware incluye computadoras o cualquier tipo de dispositivo
electrónico inteligente, que consisten en procesadores, memoria, sistemas de
almacenamiento externo, etc.
El software incluye al sistema operativo, firmware y aplicaciones, siendo
especialmente importante los sistemas de gestión de bases de datos. Por
último el soporte humano incluye al personal técnico que crean y mantienen
el sistema (analistas, programadores, operarios, etc.) y a los usuarios que lo
utilizan.
La información bibliográfica se extiende como una visión de conjunto de
todas las publicaciones en alguna categoría, intenta dar una visión de
conjunto completa de la literatura.
Las bibliografías se pueden ordenar de diferentes maneras, de igual modo
a los catálogos de biblioteca. Las bibliografías anotadas ofrecen descripciones
aproximadas de las fuentes, construyendo protocolos o argumentos, que son
de gran utilidad para los autores. Creando estas anotaciones, generalmente
unas cuantas frases, se establece un resumen que da pistas sobre la idoneidad
de cada fuente antes de escribir una obra.
a. Recuperación de la información
En el área de extracción de información, las técnicas de agrupamiento de
documentos son utilizadas con diversos fines. Es así, que en lugar de listar los
resultados en la forma tradicional, los documentos resultantes de una
búsqueda son agrupados de acuerdo a la similitud de los términos que
contienen.
El resultado del proceso de agrupamiento de objetos son grupos cuyos
elementos comparten características comunes. Los algoritmos se clasifican de
acuerdo a las características del agrupamiento, descritas a continuación.
De acuerdo a la relación que existe entre los grupos. Los algoritmos de
particionamiento generan grupos sin una estructura explícita que relacione se
relacionen con otros grupos. Por el contrario, los algoritmos jerárquicos

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 31
organizan los grupos en categorías y consecuentemente son organizados en
sub-categorías.
El tesista Allan Roberto Avendaño Sudario específica en su documento [12],
que con la aparición de los medios electrónicos ha aumentado la generación
de documentos y, de igual manera, la capacidad de almacenamiento de los
dispositivos electrónicos, aunque sigue siendo mínima la extracción de
información contextual de los documentos.
El proceso de extracción de información consiste en representar,
almacenar, organizar y acceder a documentos relevantes tomados a partir de
una colección de documentos sin estructurar (generalmente en lenguaje
natural), con el objetivo de satisfacer las necesidades de los usuarios.
Estos sistemas de extracción de información además, brindan el soporte a
los usuarios al filtrar los resultados en grupos de documentos
automáticamente creados. Las técnicas de agrupamiento o clustering
permiten obtener grupos de documentos similares entre sí, sin la supervisión
de expertos.
Es por esto que estas técnicas son empleadas para que los usuarios finales
tengan una visión global de las características de colecciones de objetos con
mayor facilidad.
b. Stemming
Stemming es un método para reducir una palabra a su raíz o (en inglés) a
un stem o lema. Hay algunos algoritmos de stemming que ayudan en sistemas
de recuperación de información. Algoritmos utilizados para desechar prefijos
y sufijos: Paice/Husk, S-stemmer / n-gramas y Técnicas lingüísticas
Morfológicamente las palabras están estructuradas en prefijos, sufijos y la
raíz. La técnica de Stemming lo que pretende es eliminar las posibles
confusiones semánticas que se puedan dar en la búsqueda de un concepto,
para ello trunca la palabra y busca solo por la raíz.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 32
III. DISEÑO DE LA INVESTIGACION
3.1. TIPO DE INVESTIGACION
Investigación aplicada
3.2. DISEÑO DE LA INVESTIGACION
Para el análisis se aplicara el diseño de contrastación Pre-experimental a
post-prueba único y un grupo de control.
Este diseño incluye dos grupos, uno (G1) recibe el tratamiento
experimental y el otro no (G2). Cuando concluya la manipulación, a ambos
grupos se le realiza una medición sobre la variable dependiente en estudio.
El diseño se diagrama de la siguiente manera:
𝐺1 𝑋 𝑂1
𝐺2 − 𝑂2
Dónde:
- X: Modelo computacional basado en algoritmos de agrupamiento.
- G1: Grupo experimental.
- G2: Grupo Control.
- O1: Medición al aplicar X a G1.
- O2: Medición sin aplicar X a G2.
3.3. POBLACION Y MUESTRA
3.3.1. POBLACION
Nuestra población corresponde a todos los datos de los sistemas
documentarios, catálogos, bibliotecarios, librerías y demás sistemas de
información.
3.3.2. MUESTRA
Se tomará como muestra los datos del sistema de búsqueda de
información bibliográfica de la Biblioteca Central de la Universidad
Nacional de Trujillo.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 33
3.4. VARIABLES DE ESTUDIO
Figura 7. Tabla de las variables de estudio.
3.5. TECNICAS E INSTRUMENTOS
En la presente investigación se utilizan las siguientes técnicas e
instrumentos que permitan probar los objetivos planteados:
• Observación directa de un sistema de búsqueda de información
bibliográfica diseñado tradicionalmente.
• Técnica de análisis comparativo entre algoritmos de agrupamiento.
• Comparación de características técnicas de la aplicación en base a
criterios.
• Evaluación y Verificación.
• Investigación y consulta bibliográfica.
• Desarrollo humano.
TIPO DE VARIABLE NOMBRE DE LA VARIABLE INDICADORES
Independiente Modelo computacional basado
en algoritmos de agrupamiento.
- Análisis de los
algoritmos de
agrupamiento
Dependiente
Mejora del tiempo de respuesta
y correspondencia de los
resultados del sistema de
búsqueda de información
bibliográfica.
- Tiempo de respuesta
- Correspondencia de
resultados

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 34
IV. RESULTADOS
4.1. ANALISIS COMPARATIVO DE ALGORITMOS DE AGRUPAMIENTO
En esta sección se analizara los tipos de algoritmos de agrupamiento según
criterios que optimicen nuestro modelo computacional para el sistema de
búsqueda de información bibliográfica, y también se presentara un cuadro
comparativo que resumirá el análisis de los algoritmos de agrupamiento
según los criterios.
Los algoritmos de agrupamiento que se analizaran serán los siguientes:
1. Algoritmos Particionales
2. Algoritmos Jerárquicos
3. Algoritmos Borrosos
4. Algoritmos basado en la Densidad
5. Algoritmos basado en Grid
Para este análisis comparativo se tomara en cuenta los siguientes criterios
de comparación, según Hernández Valadez Edna en su Tesis [26]:
a. Correspondencia de resultados, este criterio se ajusta en la fase de
evaluación, está dado por el nivel de concordancia que tiene la
búsqueda que realiza el usuario con los resultados que arroja el sistema.
b. Complejidad computacional, es la eficiencia que tienen los algoritmos,
estableciendo su efectividad de acuerdo al tiempo de corrida, al espacio
requerido y los recursos que utiliza.
c. Similitud entre clústeres y dentro de cada clúster, es la distancia que hay
entre dos objetos de diferentes clústeres y del mismo clúster
respectivamente.
d. Escalabilidad, es la capacidad que tienen ciertos algoritmos para realizar
agrupamiento de grandes cantidades de datos.
e. Insensibilidad al orden de entrada, es la capacidad que tienen ciertos
algoritmos para devolver los mismos clústeres, independientemente del
orden de entrada del mismo conjunto de datos.
f. Datos ruidosos, algunos algoritmos de agrupamiento son sensibles a
tales datos, como datos faltantes, desconocidos o erróneos.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 35
4.1.1. ANALISIS DE LOS ALGORITMOS SEGÚN LOS CRITERIOS
A continuación se analizara cada tipo de los algoritmos de
agrupamiento seleccionados según los criterios que se han definido:
1. Algoritmos de Agrupamiento Particionales
a. Correspondencia de resultados, las técnicas particionales
usualmente producen clústeres que optimizan el criterio de función
definido, es decir favorecen este criterio para la optimización y
concordancia de resultados con la búsqueda.
b. Complejidad computacional, la complejidad típica de la mayoría de
este tipo de algoritmos es O(n).
c. Similitud entre clústeres y dentro de cada clúster, fallan cuando los
objetos de un grupo o clúster están cerca del centroide de otro
clúster, también cuando los grupos tienen diferentes tamaños y
formas.
d. Escalabilidad, los métodos particionales tienen ventajas en
aplicaciones que involucran gran cantidad de datos, a diferencia de
los que utilizan dendogramas como los jerárquicos.
e. Insensibilidad al orden de entrada, en este tipo de algoritmos no
varía los resultados si es que se ponen en diferente orden el mismo
conjunto de datos que son captados por el algoritmo.
f. Datos ruidosos, en algunos casos puede afectar al algoritmo si es
que faltan algunos atributos a los datos.
2. Algoritmos de Agrupamiento Jerárquicos
a. Correspondencia de resultados, crea una descomposición jerárquica
de un conjunto de datos, formando un dendograma, el sistema
podría arrojar algunos resultados que no sean muy relevantes para
el usuario.
b. Complejidad computacional: La complejidad típica de este tipo de
algoritmos es O (n2 log n).
c. Similitud entre clústeres y dentro de cada clúster, este tipo de
algoritmos tiene varios grados de similitud, porque divide
recursivamente el conjunto de datos en conjuntos cada vez más
pequeños, haciendo que la similitud varié.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 36
d. Escalabilidad, utilizar un dendograma resulta complicado para
grandes cantidades de datos.
e. Insensibilidad al orden de entrada, puede variar el dendograma
cuando se altera el orden de entrada del conjunto de datos.
f. Datos ruidosos, el algoritmo es capaz de aceptar datos dañados o
con atributos faltantes.
3. Algoritmos de Agrupamiento Borrosos
a. Correspondencia de resultados, en este tipo de algoritmos, los
objetos pueden pertenecer a dos o más clústeres, por lo que los
resultados que arroje el sistema puede pertenecer a distintos
grupos, y no tenga concordancia con la búsqueda.
b. Complejidad computacional, este tipo de algoritmos tiene
complejidad computacional de O(n log n).
c. Similitud entre clústeres y dentro de cada clúster, el grado de
similitud entre clústeres se puede medir s iempre y cuando los
objetos no pertenezcan a un mismo clúster.
d. Escalabilidad, por ser un derivado de los algoritmos particionales
también tienen ventaja con respeto a grandes cantidades de datos,
con otros algoritmos.
e. Insensibilidad al orden de entrada, en este tipo de algoritmos no
varía los resultados si es que se ponen en diferente orden el mismo
conjunto de datos que son captados por el algoritmo.
f. Datos ruidosos, el algoritmo es capaz de aceptar datos dañados o
con atributos faltantes.
4. Algoritmos de Agrupamiento basado en Densidad
a. Correspondencia de resultados, este tipo de algoritmos utiliza
funciones de densidad, el cual podría beneficiar la correspondencia
de los resultados puesto que arrojaría resultados que tengan buena
similitud entre ellos.
b. Complejidad computacional, la complejidad típica de este tipo de
algoritmos es O(n log n).

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 37
c. Similitud entre clústeres y dentro de cada clúster, por ser basado en
funciones de densidad estos algoritmos tiene alto grado de similitud
de los objetos dentro de un clúster, y bajo grado de similitud entre
objetos de distintos clústeres.
d. Escalabilidad, en algunos casos presenta dificultades en la
escalabilidad con grandes cantidades de datos, y en específico con
datos de alta dimensionalidad.
e. Insensibilidad al orden de entrada, en este tipo de algoritmos no
varía los resultados si es que se ponen en diferente orden el mismo
conjunto de datos que son captados por el algoritmo.
f. Datos ruidosos, este tipo de métodos es muy útil para filtrar ruido y
encontrar clústeres de diversas formas, clasifica a los datos ruidosos
en un solo clúster.
5. Algoritmos de Agrupamiento basado en Grid
a. Correspondencia de resultados, el algoritmo agrupa los datos sin
utilizar alguna función predefinida, es decir de forma arbitraria,
haciendo que el sistema arroje resultados que no tengan ninguna
correspondencia con la búsqueda.
b. Complejidad computacional, la implementación es sencilla, la
complejidad típica de este tipo de algoritmos es O(n).
c. Similitud entre clústeres y dentro de cada clúster, este tipo de
algoritmos tiene muy baja similitud entre clústeres y dentro de cada
clúster.
d. Escalabilidad, con este tipo de algoritmos se pueden agrupar
grandes cantidades de datos aunque tengan alta dimensional.
e. Insensibilidad al orden de entrada, en este tipo de algoritmos no
varía los resultados si es que se ponen en diferente orden el mismo
conjunto de datos que son captados por el algoritmo.
f. Datos ruidosos, este algoritmo acepta toda clase de datos, incluso
datos dañados o con atributos faltantes.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 38
4.1.2. RESULTADOS DEL ANALISIS COMPARATIVO
CUADRO COMPARATIVO
El presente Cuadro comparativo está basado en las características de los
algoritmos de agrupamiento presentadas en el análisis anterior.
Algoritmos a b c d e f
Particionales
Jerárquicos
Borrosos
Basado en
Densidad
Basado en
Grid
Figura 8. Cuadro Comparativo.
Leyenda:
a. Correspondencia de resultados
b. Complejidad computacional
c. Similitud entre clústeres y dentro de cada clúster
d. Escalabilidad
e. Insensibilidad al orden de entrada
f. Datos ruidosos
: Si Cumple
: No Cumple
: Parcialmente

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 39
4.1.3. CONCLUSIONES DEL ANALISIS COMPARATIVO
Del cuadro comparativo anterior se pueden resumir las siguientes
conclusiones:
- Los algoritmos basados en Grid son los que en más criterios tiene
ventaja sobre los demás algoritmos, sin embargo ciertos criterios
son mucho más importantes que otros para nuestro caso de
estudio, los algoritmos basados en Grid no tienen ventaja en esos
criterios que podrían optimizar mejor nuestro caso de estudio.
- A partir del punto anterior los criterios más significantes o que tiene
más peso son los primeros: a, b y c sin dejar de lado los otros d, e y
f que también tienen un buen aporte.
- Los algoritmos Particionales son los que tienen ventaja en criterios
con mayor importancia que son la correspondencia de resultados,
complejidad computacional y similitud de objetos entre clústeres
diferentes y dentro de cada clúster.
- Entre los algoritmos particionales el que es más reconocido es el
algoritmos K-means, nuestro modelo computacional estará basado
en este algoritmo.
4.2. DISEÑO DEL MODELO PROPUESTO
La presente investigación se orienta al uso de algoritmos de agrupamiento
para desarrollar un modelo computacional, que nos permita mejorar el
tiempo de respuesta y la correspondencia de resultados de un sistema de
búsqueda de información bibliográfica.
El modelo computacional estará basado, como se concluyó anteriormente,
en los algoritmos de agrupamiento particionales y en específico en el
algoritmo k-means.
4.2.1. ENFOQUE DEL DISEÑO
La fase inicial de la investigación se enfocó en la comprensión de la
problemática, haciendo algunas pruebas de consultas al sistema de
búsqueda de información bibliográfica de la biblioteca central de la
Universidad Nacional de Trujillo.
Este modelo computacional una vez implementado proveerá una
herramienta académica a los usuarios, la cual a partir de una

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 40
representación lógica de los documentos y la agrupación automática de
los mismos, proporcionara información relevante de acuerdo a la
búsqueda del usuario y sus intereses.
Figura 9. Enfoque del Modelo Computacional Propuesto
Los algoritmos de agrupamiento, también llamada de segmentación,
es útil para el descubrimiento de las distribuciones de datos y los
patrones en ellos. Se trata de un proceso de agrupación de objetos en
clases de objetos similares. Estos algoritmos están sujetos dentro un
enfoque por procedimientos o imperativo, el sistema hace un llamado a
este algoritmo que es procedimiento.
El sistema de información bibliográfica analiza los objetos recuperados
(documentos), usando los intereses señalados por el usuario y las
recomendaciones propuestas sobre dichos objetos; y emplea algoritmos
de agrupamiento que permiten organizar automáticamente la
información, a partir de sus similitudes. Para seleccionar los contenidos se
han empleado diversos enfoques, entre los que destaca en el área de
Recuperación de Información mediante el cual se representa el carácter
temático de los objetos.
ALGORITMOS:
IMPERATIVO O
POR
PROCEDIMIENTOS
+ +
MODELO COMPUTACIONAL DE
BUSQUEDA DE INFORMACION
BIBLIOGRAFICA UTILIZANDO
ALGORITMOS DE AGRUPAMIENTO
TECNICA A
UTILIZAR:
ALGORITMOS DE
AGRUPAMIENTO
PARTICIONAL:
K-MEANS
- RECUPERACION
De INFORMACION DE UN SISTEMA
DE INFORMACION - TECNICAS DE
RECUPERACION DE
INFORMACION: STEMMING

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 41
4.2.2. DEFINICION DEL MODELO
A continuación se propondrá los pasos o las fases que tiene nuestro
modelo computacional:
Fase I: Representación lógica de los documentos,
Fase II: Captación de las consulta del usuario
Fase III: Agrupación de los documentos
Fase IV: Salida de los resultados
Figura 10. Fases del modelo computacional
FASE I:
Representación lógica de los
documentos, los cuales deben
estar depurados.
FASE II:
Captación de la consulta del
usuario, entrada de la consulta
para ejecutar el algoritmo.
FASE III:
Agrupación de los documentos,
utilización de las técnicas de
agrupamiento según la
consulta.
FASE IV:
Salida de los resultados,
contenido debe de tener alta
correspondencia con el área de
interés.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 42
4.2.3. DESCRIPCION DEL MODELO
El modelo se puede describir a través de sus tareas básicas:
representación lógica de los documentos, representación de las
necesidades de los usuarios, agrupación de los documentos:
1. Representación lógica de los documentos
El sistema provee un espacio de búsqueda y recuperación de
información adaptada a las necesidades de los usuarios, se
representara documentos en sistemas destinados al agrupamiento,
la clasificación o la visualización de grandes colecciones.
La representación de documentos es fundamental para poder
procesar estos y es una fase previa en el tiempo a la recuperación
de información, pero es parte integrante del conjunto.
El objetivo de la representación de documentos es la traducción
de los mismos a términos del sistema. Esta representación se lleva a
cabo mediante un conjunto de fases que contribuyen mediante
ciertas simplificaciones y generalizaciones a presentar una vista
lógica de los documentos que permita su comparación con las
consultas. Es por tanto un proceso imprescindible para la
recuperación de información.
En general podríamos equiparar la representación de
documentos al análisis documental, aunque con algunos matices. El
primero de ellos hace referencia al ámbito automatizado en que
tienen lugar estos procesos. Las representaciones que generaremos
serán aptas para su procesamiento por parte de aplicaciones
informáticas según diversos modelos. Además la representación de
los documentos se hace en torno a criterios temáticos, y para ser
más exactos, en torno a criterios temáticos analíticos.
Se tienen las siguientes fases:
1. Elección y selección de elementos de representación
El término “elemento de representación” hace referencia a la
unidad de sentido mínima utilizada para representar un
documento, pueden tomar la forma de un descriptor unitérmino,
un descriptor sintagmático, una agrupación de palabras, el
elemento de representación está formado por tanto de una o más
palabras que forman un descriptor u otra construcción con valor

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 43
representativo, de manera que cada una de las palabras que forman
dicho elemento de representación no poseen carga de significación
autónoma.
2. Creación del léxico de la colección
Entendemos por léxico de la colección al conjunto cerrado de
elementos de representación base de entre el que podremos elegir
los términos de indización para cada uno de los documentos
concretos de la colección. Es fundamental escoger un léxico
adecuado para la colección, que refleje correctamente el significado
de los documentos y cuyo número de términos no sea
excesivamente elevado.
3. Indización Automática
Existen dos opciones consolidadas a tener en cuenta a la hora de
representar los documentos. Podemos optar por la representación
binaria, propia del modelo booleano clásico y del probabilístico de
independencia binaria, o por la representación ponderada de los
documentos, que es propia del modelo de espacio vectorial y de
casi todos los modelos más modernos.
La representación binaria implica que la única información que
consignamos acerca de los elementos de representación es la de si
están o no presentes en el documento, básicamente estamos
renunciando a la posibilidad de ponderar los documentos, ya que
utilizaremos todas las unidades de representación que hayan
superado el filtro de la eliminación de palabras vacías y el de
reducción de la dimensionalidad.
La representación ponderada de los documentos incluye un
conjunto de procedimientos destinados a averiguar el valor
representativo de un término, una raíz o un sintagma en el contexto
de un documento, y en el contexto de la colección.
Este conjunto de procedimientos se puede identificar
básicamente con la indización tal y como se entiende en
Recuperación de Información Automatizada. Lo fundamental de
elegir una representación ponderada de los términos reside en el
hecho de que podamos representar los documentos en torno a la
importancia que tiene cada uno de los elementos que los
conforman.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 44
Durante la fase de indización se asignan los pesos que
cuantifican la importancia relativa de cada “elemento de
representación” en su función de descripción de los contenidos de
un documento. Se trata, por tanto, de ponderar la carga semántica
y la capacidad descriptiva de los elementos de representación de un
documento, y no tan sólo de seleccionar un conjunto de trazos
descriptivos
2. Captación de las consulta del usuario
El usuario hace la consulta, se ingresan los términos de búsqueda
para que el sistema tenga el parámetro de entrada para el
algoritmo, se refiere al contexto del proceso de
interacción persona-ordenador
- La interfaz gráfica de usuario, es un programa informático que
actúa de interfaz de usuario, utilizando un conjunto de imágenes
y objetos gráficos para representar la información y acciones
disponibles en la interfaz. Su principal uso, consiste en
proporcionar un entorno visual sencillo para permitir la
comunicación con el sistema operativo de una máquina o
computador.
Morfológicamente las palabras están estructuradas en prefijos,
sufijos y la raíz. La técnica de Stemming lo que pretende es eliminar
las posibles confusiones semánticas que se puedan dar en la
búsqueda de un concepto, para ello trunca la palabra y busca solo
por la raíz.
3. Agrupación de los documentos:
Una vez que los documentos se han caracterizado, el modelo los
agrupa utilizando el algoritmo de agrupamiento k-means, propuesto
por McQueen en el 2007, el cual es ampliamente utilizado por su
facilidad, rapidez y efectividad.
El modelo sigue una forma fácil y simple para dividir los
documentos en k grupos de documentos similares de una misma
área de investigación, donde k representa el número de áreas de
investigación.
La idea principal es definir k centroides (uno para cada grupo),
estos k centroides representan los documentos más relevantes de
cada área de investigación.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 45
Ahora bien, una vez que se ha establecido el número de grupos,
se eligen k documentos que representarán los centroides (centros)
iniciales de cada clúster.
En este paso es importante seleccionar documentos cuyo
contenido tenga una alta correspondencia con el área de
investigación, por lo tanto si los documentos no son los apropiados,
la clasificación podría ser ineficiente.
Se pueden identificar cuatro pasos en el algoritmo:
Paso 1. Inicialización: Se definen el conjunto de objetos para
particionar, el número de grupos y un centroide por cada
grupo. Algunas implementaciones del algoritmo estándar
determinan los centroides iniciales de forma aleatoria;
mientras que algunos otros procesan los datos y determinan
los centroides mediante de cálculos.
Paso 2. Clasificación: Para cada objeto de la base de datos, se
calcula su distancia a cada centroide, se determina el
centroide más cercano, y el objeto es incorporado al grupo
relacionado con ese centroide.
Paso 3. Cálculo de centroides: Para cada grupo generado en el
paso anterior se vuelve a calcular su centroide.
Paso 4. Condición de convergencia: Existe varias condiciones
de convergencia, converger cuando alcanza un número de
iteraciones dado, converger cuando no existe un intercambio
de objetos entre los grupos, o converger cuando la diferencia
entre los centroides de dos iteraciones consecutivas es más
pequeño que un umbral dado. Si la condición de convergencia
no se satisface, se repiten los pasos dos, tres y cuatro del
algoritmo.
4. Salida de los resultados
Una vez realizado el agrupamiento el sistema habrá filtrado los
objetos recuperados (documentos), usando los intereses señalados
por el usuario, este paso se seleccionaron documentos cuyo
contenido tenga una alta correspondencia con el área de
investigación, por lo tanto si los documentos no son los apropiados,
la clasificación podría ser ineficiente.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 46
4.3. CASO DE ESTUDIO
El presente caso de estudio estará orientado a desarrollar un diseño de
un modelo computacional basado en algoritmos de agrupamiento para
mejorar el tiempo de respuesta y la correspondencia de resultados de un
sistema de búsqueda de información bibliográfica para la Universidad
Nacional de Trujillo.
En el anexo se detalla el desarrollo del caso a mayor detalle
respectivamente.
El software permitirá a un usuario final plantear una consulta general y
obtener los resultados de su consulta en forma agrupada. El usuario define
como parámetro de entrada adicional, el número de grupos que desea
obtener.
Para el desarrollo del prototipo se utilizara la colección de datos del
sistema de información bibliográfico de la biblioteca central de la
universidad nacional de Trujillo que consta alrededor de 4500 libros, 1500
revistas y periódicos entre otros.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 47
IV. REFERENCIAS BIBLIOGRAFICAS
5.4. BIBLIOGRAFÍA GENERAL
[1] Sergio López García. (2001). Algoritmo de Agrupamiento Genético Borroso basado en el Algoritmo de las C-Medias Borroso. http://oa.upm.es/786/1/09200116.pdf
[2] José L. Díez, José L. Navarro y A. Sala. Algoritmos de Agrupamiento en la identificación de Modelos Borrosos.http://riai.isa.upv.es/CGI-
BIN/articulos%20revisados%202004/num2/601/riai-2004601impr.pdf
[3] J. Pérez, M. F. Henriques, R. Pazos, L. Cruz, G. Reyes, J. Salinas, A. Mexicano. Mejora al Algoritmo de Agrupamiento k-Means mediante un nuevo criterio de convergencia y su aplicación a bases de datos poblacionales de cáncer. http://www.tlaio.org.mx/EventosAnteriores/TLAIOII/T2_5_A27iJPO.pdf
[5] Andrea Villagra, Ana Guzmán, Daniel Pandolfi y Guillermo Leguizamón. Análisis de medidas no-supervisadas de calidad en clusters obtenidos por k-means y particle swarm optimization (PSO).
http://www.palermo.edu/ingenieria/Cica2009/Papers/20.pdf
[6] Andrea Villagra. Meta-heurísticas aplicadas a Clustering.
[7] Marcelo Barroso, Gonzalo Navarro y Nora Reyes. Combinando Clustering con aproximación espacial para Búsquedas en espacios métricos. http://www.dcc.uchile.cl/~gnavarro/ps/cacic05.pdf
[9] Carlos Ruiz, Martha Zorrilla, Ernestina Menasalvas y M. Spiliopoulou. Clustering Semi-Supervisado sobre datos procedentes de una plataforma e-
learning. http://personales.unican.es/zorrillm/PDFs/caepia07.pdf
[11] Dioclécio Moreira Camelo. (2007). Modelado y desarrollo de un modelo computacional de síntesis interactivo y multirrelacional para guiar la actividad de diseño en la fase conceptual. www.tdx.cat/bitstream/10803/10557/1/moreira.pdf
[13] Cristina García Cambronero, Irene Gómez Moreno. Algoritmos de Aprendizaje: KNN & KMEANS. http://www.it.uc3m.es/jvillena/irc/practicas/08-09/06.pdf
[14] Elmer A. Fernández. Clustering (Agrupamiento). Universidad Católica de Córdoba.
[15] Juan Carlos López García. Algoritmos y Programación. Universidad Católica
de Córdoba. Eduteka.
[16] Silberschatz Korth Sudarshan. Fundamentos de bases de datos. Mac Graw
Hill.

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 48
[25] Martínez C. David. (2005). Diseño Conceptual. http://www.inegi.org.mx/inegi/spc/doc/INTERNET/21-
%20Manual%20para%20el%20Dise%C3%B1o%20Conceptual.pdf
5.5. BIBLIOGRAFÍA ESPECÍFICA
[4] Andrés Marín, John W. Branch B. Aplicación de dos nuevos Algoritmos para agrupar resultados de Búsquedas en Sistemas de Catálogos Públicos en línea
(OPAC). http://aprendeenlinea.udea.edu.co/revistas/index.php/RIB/article/view/1918/
1572
[8] Eugenio Yolis. Algoritmos Genéticos aplicados a la Categorización Automática de Documentos. http://laboratorios.fi.uba.ar/lsi/yolis -tesisingenieriainformatica.pdf
[10] Matylin Giugni O., Luis León G., Joaquín Fernández. ClusterDoc, un sistema de recuperación y recomendación de Documentos Basado en
Algoritmos de Agrupamiento. http://www.redalyc.org/pdf/784/78415900002.pdf
[12] Allan Roberto Avendaño Sudario. Sistema de agrupamiento y búsqueda de contenidos de la blogosfera de la ESPOL, utilizando HADOOP como plataforma de procesamiento masivo y escalable de datos. Año 2009.
http://www.dspace.espol.edu.ec/bitstream/123456789/8141/3/SISTEMA%20DE%20AGRUPAMIENTO%20Y%20B%C3%9ASQUEDA%20DE%20CONTENIDOS%20
DE%20LA%20BLOGOSFERA%20DE%20LA%20ESPOL%2c%20UTILIZANDO%20HADOOP%20COMO%20PLATAFORMA%20DE%20PROCESAMIENTO%20MASIVO%2
0Y%20ESCALABLE%20DE%20DATOS%20%28BONSAI%29.pdf
[23] Bedregal L. Carlos. (2008). Agrupamiento de datos utilizando tecnicas mam-som
[24] Benítez S. Ignacio. (2006). Técnicas de Agrupamiento para el Analisis de Datos Cuantitativos y Cualitativos.
[26] Hernández Valadez Edna. (2006). Algoritmo de clustering basado en entropía para descubrir grupos en atributos de tipo mixto.
http://www.cs.cinvestav.mx/TesisGraduados/2006/tesisEdnaHernandez.pdf
[27] Estudio comparativo de métodos de agrupamiento no supervisado de latidos de señales ECG. Diego Hernán Peluffo Ordóñez
http://www.bdigital.unal.edu.co/2112/1/Diegohernanpeluffoordonez.2009.pdf
[29] Marta Millán. Segmentación o Clustering. http://ocw.univalle.edu.co/ocw/ingenieria-de-sistemas-telematica-y-
afines/descubrimiento-de-conocimiento-en-bases-de-datos/material-1/Segmentacion08.pdf-e-introduccin

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 49
[30] Dra. Silvia Schiaffino. Clustering. http://www.exa.unicen.edu.ar/catedras/optia/public_html/clustering.pdf
[31] Damaris Pascual González Algoritmos de Agrupamiento basados en
densidad y Validación de clusters..
http://www.cerpamid.co.cu/sitio/files/DamarisTesis.pdf [32] J. Pérez, M. F. Henriques, R. Pazos, L. Cruz, G. Reyes, J. Salinas, A. Mexicano. Mejora al Algoritmo de Agrupamiento k-Means mediante un nuevo criterio de convergencia y su aplicación a bases de datos poblacionales de cáncer. http://www.tlaio.org.mx/EventosAnteriores/TLAIOII/T2_5_A27iJPO.pdf
5.6. WEBGRAFÍA
[17] Algoritmo de agrupamiento. Recuperado en Octubre del 2014, a partir de
http://es.wikipedia.org/wiki/Algoritmo_de_agrupamiento
[18] Sistema. Recuperado en Octubre del 2014, a partir de http://es.wikipedia.org/wiki/Sistema
[19] ¿Cómo funcionan los sistemas de búsqueda de información? Recuperado en Octubre del 2014, a partir de http://www2.ual.es/ci2bual/como-funcionan-buscadores-como-google-y-las-bases-de-datos/#sthash.5X0NfDhP.dpuf
[20] Servicio de información bibliográfica y referencia. Recuperado en Octubre
del 2014, a partir de http://sabus.usal.es/docu/pdf/Informacbibl.PDF
[21] Sistema de información. Recuperado en Octubre del 2014, a partir de http://es.wikipedia.org/wiki/Sistema_de_informaci%C3%B3n
[22] Titulo, Resumen e Introduccion. http://es.slideshare.net/cristiandiazv/titulo-resumen-e-introduccin
[28] Criterios de Calidad. http://personal.lobocom.es/claudio/moddat004.htm

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 50
ANEXO
ASPECTOS GENERALES DEL CASO
DESCRIPCION DE LA EMPRESA:
DESCRIPCION
La Universidad Nacional de Trujillo fue fundada durante la época republicana por el
General Simón Bolívar, los primeros ambientes donde funcionó la universidad fueron
dentro del colegio fundado por obispos El Salvador.
La Universidad Nacional de Trujillo, es una institución educativa que imparte educación
superior gratuita como lo establece la Constitución del Estado, tiene personería
jurídica de Derecho Público Interno, regida por la ley 23733 y su Estatuto.
Se dedica al estudio, la investigación, la difusión del saber y la cultura así como a la
extensión universitaria y proyección social. Tiene autonomía académica, normativa,
administrativa y económica dentro de la ley
MISION:
La Universidad Nacional de Trujillo en el año 2011, será una institución moderna,
acreditada, reconocida a nivel nacional e internacional por realizar investigación
científico - tecnológica con enfoque interdisciplinario, por ser aliada estratégica en el
proceso de desarrollo sostenido de la Región La Libertad, y del país y contar con una
gestión administrativa flexible e innovadora.
VISION:
Ser una institución educativa pública que forma profesionales y académicos de pre y
postgrado altamente competitivos realizando investigación científica con proyección y
extensión a la comunidad de la región La Libertad y del país.
UBICACIÓN:
Campus Universitario: Av. Juan Pablo II Ciudad Universitaria S/N. 044 Trujillo - Perú .
Local Central: Diego de Almagro 344, Trujillo

Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 51
Usuario realiza una consulta al
sistema de información
bibliográfico.
El sistema arroja los
resultados esperados por el
usuario.
El sistema basado en
nuestro modelo
computacional ejecuta el
algoritmo de agrupamiento.
PICTOGRAFICO
Biblioteca Central de la Universidad Nacional de Trujillo
Escuela Profesional de Informática Universidad Nacional de Trujillo
De La Cruz Mantilla Azucena Sarai Linares Valdivia Juan Carlos Pág. 52
CASO DE USO
SISTEMA DE INFORMACION BIBLIOGRAFICO
DE LA BIBLIOTECA CENTRAL
Realizar una
búsqueda
bibliográfica
Agregar nueva
bibliografía.
Actualizar una
bibliografía.
Administrador
Usuario