estadísticas y economía financiera. 1a. edición. eduardo court monteverde y erick rengifo
DESCRIPTION
Este libro constituye un valioso aporte de Eduardo Court y Erick Rengifo a la literatura financiera, ya que presentan de manera muy sencilla y didáctica, los aspectos fundamentales de la teoría estadística y su aplicación a las distintas herramientas y modelos que utilizan los agentes financieros. El mundo moderno genera cada vez más instrumentos y operativas financieras de mayor complejidad y sofisticación. Esto exige a su vez entender y explicar la determinación y medición de los nuevos riesgos que se derivan de ellos, es aquí que las herramientas y modelos (econometría financiera) se constituyen como un buen soporte para la toma de decisiones. Considero este libro de mucha importancia y de lectura necesaria, desde estudiantes hasta profesionales que estén involucrados en el mundo de las finanzas.TRANSCRIPT

EEEEddddduuuardo Coourrt MMoonntteevveerddeErick Williamss RReennggiffoo


ESTADÍSTICAS Y ECONOMETRÍA
FINANCIERA
EDUARDO COURT & ERICK RENGIFO
Revisión Técnica Lic. Enrique Fernando Zabos Pouler

Estadísticas y Econometría Financiera
Court, Eduardo & Rengifo, Erick
Directora General Susana de Luque
Coordinadora de Edición y Producción Luciana Rabuffetti
Edición y Revisión Técnica Lic. Enrique Fernando Zabos Pouler
Diseño Sebastián Escandell Verónica De Luca
Copyright D.R. 2011 Cengage Learning Argentina, una división de Cengage Learning Inc.Cengage Learning™ es una marca registrada usada bajo permiso. Todos los derechos reservados.
Rojas 2128. (C1416CPX) Ciudad Autónoma de Buenos Aires, Argentina. Tel: 54 (11) 4582-0601
Para mayor información, contáctenos en www.cengage.com o vía e-mail a: [email protected]
Impreso en MetroColor S.A. Tirada de 1000 ejemplares
Impreso en Perú
Court, Eduardo & Rengifo, Erick
Estadísticas y Econometría Financiera
1a ed. - Buenos Aires, Cengage Learning Argentina, 2011. 612 p.; 21x27 cm.
ISBN 978-987-1486-48-9
1. Econometría. 2. Estadística. 3. Enseñanza Superior. I. Rengifo Minaya, Erick Williams. II. Título.
CDD 330.015 195
Fecha de catalogación: 14/03/2011
División Latinoamérica
Cono Sur Rojas 2128 (C1416CPX) Ciudad Autónoma de Buenos Aires, Argentina www.cengage.com.ar
México Corporativo Santa Fe 505, piso 12 Col. Cruz Manca, Santa Fe 05349, Cuajimalpa, México DF www.cengage.com.mx
Pacto Andino: Colombia, Venezuela y Ecuador Cra. 7 No. 74-21 Piso 8 Ed. Seguros Aurora Bogotá D.C., Colombia www.cengage.com.co
El Caribe Metro Office Park 3 - Barrio Capellania Suite 201, St. 1, Lot. 3 - Code 00968-1705 Guaynabo, Puerto Rico www.cengage.com
Queda prohibida la reproducción o transmisión total o parcial del texto de la presente obra bajo cualesquiera de las formas, electrónica o mecánica, incluyendo fotocopiado, almacenamiento en algún sistema de recuperación, digitalización, sin el permiso previo y escrito del editor. Su infracción está penada por las leyes 11.723 y 25.446

PARTE
1
Índice
ACERCA DE LOS AUTORES ...................................................................................................................................................................... I PRÓLOGO .........................................................................................................................................................................................................III
Capítulo 1 Estadística descriptiva ............................................................................................................................................11. INTRODUCCIÓN A LAS ESTADÍSTICAS ...........................................................................................................................................12. COLECCIÓN DE DATOS (MUESTREO) ................................................................................................................................................3
2.1. El muestreo probabilístico ...........................................................................................................................................................3 2.1.1. Muestreo aleatorio simple ................................................................................................................................................4 2.1.2. Muestreo sistemático .........................................................................................................................................................5 2.1.3. Muestreo estratificado simple ........................................................................................................................................5
2.2. El muestreo no probabilístico ....................................................................................................................................................6 2.2.1. Muestreo basado en el juicio del analista ...................................................................................................................6 2.2.2. Muestreo basado en la facilidad de acceso a los elementos que forman la base del estudio ..............6 2.2.3. Muestreo basado en un propósito específico ...........................................................................................................63. DISTRIBUCIÓN DE FRECUENCIAS ......................................................................................................................................................74. MEDIDAS DE TENDENCIA CENTRAL .............................................................................................................................................. 11
4.1. El promedio o media ..................................................................................................................................................................... 11 4.2. El promedio ponderado .............................................................................................................................................................. 12 4.3. La mediana ........................................................................................................................................................................................ 13 4.4. La moda .............................................................................................................................................................................................. 13
5. MEDIDAS DE DISPERSIÓN ................................................................................................................................................................... 13 5.1. El rango ................................................................................................................................................................................................14 5.2. Los cuartiles ......................................................................................................................................................................................14

5.3. La desviación media absoluta (DMA) ...................................................................................................................................16 5.4. La varianza y la desviación estándar ................................................................................................................................. 18 5.5. La variable estandarizada (z) .................................................................................................................................................. 20 5.6. Coeficiente de variación ............................................................................................................................................................ 21
6. MEDIDAS DE ASOCIACIÓN ................................................................................................................................................................... 22 6.1. El diagrama de series de tiempo ........................................................................................................................................... 22 6.2. El diagrama de dispersión ......................................................................................................................................................... 22 6.3. El coeficiente de correlación ................................................................................................................................................... 26 6.4. El coeficiente de variación ........................................................................................................................................................ 28
7. PROBLEMAS PROPUESTOS................................................................................................................................................................ 288. ECUACIONES DEL CAPÍTULO ..............................................................................................................................................................31
Capítulo 2 Probabilidades ................................................................................................................................................................. 351. INTRODUCCIÓN .......................................................................................................................................................................................... 352. DEFINICIONES ............................................................................................................................................................................................. 35
2.1. Experimento ..................................................................................................................................................................................... 36 2.2. Variable aleatoria (VA) ................................................................................................................................................................ 36
2.2.1. Variables aleatorias discretas ....................................................................................................................................... 36 2.2.2. Variables aleatorias continuas ..................................................................................................................................... 36
2.3. Espacio muestral............................................................................................................................................................................ 37 2.4. Evento ................................................................................................................................................................................................. 37 2.5. Probabilidad ...................................................................................................................................................................................... 37
3. MÉTODOS PARA CALCULAR LAS PROBABILIDADES ......................................................................................................... 37 3.1. Método clásico ................................................................................................................................................................................. 38 3.2. Método basado en las frecuencias relativas .................................................................................................................. 38 3.3. Método subjetivo ........................................................................................................................................................................... 40
4. CONTEO ........................................................................................................................................................................................................... 40 4.1. El principio de multiplicación ................................................................................................................................................... 40 4.2. Permutaciones .................................................................................................................................................................................41 4.3. Combinaciones .................................................................................................................................................................................41
5. TEORÍA DE CONJUNTOS Y PROBABILIDADES ........................................................................................................................ 42 5.1. Intersección ...................................................................................................................................................................................... 42 5.2. Unión .................................................................................................................................................................................................... 43 5.3. Conjuntos mutuamente excluyentes ................................................................................................................................. 43 5.4. Regla de la suma ............................................................................................................................................................................ 43 5.5. Tablas de contingencias ............................................................................................................................................................. 43 5.6. Diagrama del árbol ........................................................................................................................................................................ 45 5.7. Probabilidad marginal .................................................................................................................................................................. 45 5.8. Probabilidad conjunta ................................................................................................................................................................. 46 5.9. Probabilidad condicional ............................................................................................................................................................ 46 5.10. La regla de la multiplicación......................................................................................................................................................47 5.11. Regla de la multiplicación de eventos independientes ..............................................................................................47
6. EL TEOREMA DE BAYES .........................................................................................................................................................................47

7. INDEPENDENCIA ESTADÍSTICA ........................................................................................................................................................ 49 7.1. La independencia estadística y el tipo de muestreo ................................................................................................. 50
7.1.1. Muestreo con reemplazo ................................................................................................................................................ 50 7.1.2. Muestreo sin reemplazo...................................................................................................................................................518. DISTRIBUCIONES DE PROBABILIDAD .......................................................................................................................................... 52
8.1. Distribuciones de probabilidad discretas.......................................................................................................................... 52 8.1.1. Esperanza matemática .................................................................................................................................................... 53 8.1.2. La varianza y la desviación estándar ......................................................................................................................... 54 8.1.3. La covarianza ...................................................................................................................................................................... 54 8.1.4. El coeficiente de correlación ......................................................................................................................................... 55
8.2. Distribuciones de probabilidad continuas ........................................................................................................................ 569. PROBLEMAS PROPUESTOS................................................................................................................................................................ 5710. ECUACIONES DEL CAPÍTULO ..............................................................................................................................................................61
Capítulo 3 Funciones de distribución de probabilidad discretas ................................................. 651. INTRODUCCIÓN .......................................................................................................................................................................................... 652. DISTRIBUCIÓN BINOMIAL .................................................................................................................................................................... 663. DISTRIBUCIÓN HIPERGEOMÉTRICA .............................................................................................................................................. 724. DISTRIBUCIÓN DE POISSON .............................................................................................................................................................. 755. PROBLEMAS PROPUESTOS................................................................................................................................................................ 786. ECUACIONES DEL CAPÍTULO ............................................................................................................................................................. 82
Capítulo 4 Distribuciones de probabilidad continuas .................................................................................. 851. INTRODUCCIÓN .......................................................................................................................................................................................... 852. LA DISTRIBUCIÓN UNIFORME .......................................................................................................................................................... 873. LA DISTRIBUCIÓN EXPONENCIAL .................................................................................................................................................. 894. LA DISTRIBUCIÓN NORMAL ................................................................................................................................................................915. APROXIMACIÓN DE LA DISTRIBUCIÓN BINOMIAL USANDO LA NORMAL ..........................................................1026. LA DISTRIBUCIÓN CHI CUADRADA ..............................................................................................................................................1077. LA DISTRIBUCIÓN T DE STUDENT ...............................................................................................................................................1118. LA DISTRIBUCIÓN F DE FISHER .....................................................................................................................................................1169. LAS DISTRIBUCIONES DE PROBABILIDAD MUESTRAL ..................................................................................................118
9.1 Distribución muestral de la media y de la proporción .............................................................................................12010. PROBLEMAS PROPUESTOS..............................................................................................................................................................12611. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................131
Capítulo 5 Estadística inferencial: Intervalos de confianza ..............................................................1371. INTRODUCCIÓN ........................................................................................................................................................................................1372. DEFINICIONES ...........................................................................................................................................................................................1383. ESTIMACIÓN PUNTUAL .......................................................................................................................................................................1404. INTERVALOS DE CONFIANZA ..........................................................................................................................................................142
4.1. Intervalos de confianza para la media poblacional (μ) cuando la varianza poblacional (σ2) es conocida .........................................................................................................143

4.2. Intervalos de confianza para la media poblacional (μ) cuando la varianza poblacional no es conocida ...........................................................................................................148
4.3. Intervalos de confianza para el caso de las proporciones ....................................................................................1525. AJUSTES CUANDO EL TAMAÑO DE LA POBLACIÓN ES PEQUEÑA ...........................................................................1546. DETERMINACIÓN DEL TAMAÑO DE LA MUESTRA .............................................................................................................1557. PROBLEMAS PROPUESTOS..............................................................................................................................................................1608. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................163
Capítulo 6 Estadística inferencial: Pruebas de hipótesis para la media ...........................1671. INTRODUCCIÓN ........................................................................................................................................................................................1672. DEFINICIONES ...........................................................................................................................................................................................1673. PRUEBAS DE HIPÓTESIS .................................................................................................................................................................... 171
3.1. Pruebas de hipótesis para la media poblacional (μ), cuando la varianza poblacional (σ 2 ) es conocida ........................................................................................................ 171
3.2. Pruebas de hipótesis para la media poblacional (μ), cuando la varianza poblacional no es conocida ...........................................................................................................177
3.3. Pruebas de hipótesis para las proporciones .................................................................................................................1834. PROBLEMAS PROPUESTOS..............................................................................................................................................................1875. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................191
Capítulo 7 Estadística inferencial: Aplicaciones de la chi cuadrada.......................................1931. INTRODUCCIÓN ........................................................................................................................................................................................1932. PRUEBAS DE HIPÓTESIS DE LA VARIANZA POBLACIONAL ........................................................................................1933. OTRAS APLICACIONES DE LA CHI CUADRADA ....................................................................................................................200
3.1. Independencia estadística ......................................................................................................................................................200 3.2. Pruebas de bondad de ajuste ...............................................................................................................................................203
4. PROBLEMAS PROPUESTOS..............................................................................................................................................................2145. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................219
Capítulo 8 Fundamentos de álgebra lineal .............................................................................................................2231. INTRODUCCIÓN ........................................................................................................................................................................................2232. GENERALIDADES.....................................................................................................................................................................................2243. TIPOS ESPECIALES DE MATRICES ................................................................................................................................................224
3.1. Vectores ...........................................................................................................................................................................................224 3.2. Matriz cuadrada ............................................................................................................................................................................224 3.3. Matriz nula .......................................................................................................................................................................................224 3.4. Matriz identidad ...........................................................................................................................................................................225 3.5. Matriz simétrica ............................................................................................................................................................................225
4. OPERACIONES MATRICIALES BÁSICAS ....................................................................................................................................225 4.1. Matrices transpuestas ..............................................................................................................................................................225 4.2. Suma de matrices ........................................................................................................................................................................226 4.3. Multiplicación de matrices ......................................................................................................................................................226 4.4. Multiplicación escalar ................................................................................................................................................................228 4.5. Producto escalar ..........................................................................................................................................................................228

4.6. Traza de una matriz ...................................................................................................................................................................2295. EL DETERMINANTE DE UNA MATRIZ .........................................................................................................................................229
5.1. Matriz singular ..............................................................................................................................................................................2316. MATRIZ INVERSA ....................................................................................................................................................................................2327. MATRICES IDEMPOTENTES ..............................................................................................................................................................2348. SISTEMA DE ECUACIONES .................................................................................................................................................................2359. DEPENDENCIA LINEAL ........................................................................................................................................................................23610. DERIVADA DE MATRICES ..................................................................................................................................................................23711. PROBLEMAS PROPUESTOS..............................................................................................................................................................23912. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................241
Capítulo 9 El modelo de mínimos cuadrados ordinarios (MCO) univariado..................2471. INTRODUCCIÓN ........................................................................................................................................................................................2472. EL DIAGRAMA DE DISPERSIÓN Y EL MODELO DE MCO UNIVARIADO ...................................................................2483. SUPUESTOS DEL MODELO DE MCO .............................................................................................................................................2554. EL MODELO DE MCO UNIVARIADO ...............................................................................................................................................2605. EL COEFICIENTE DE DETERMINACIÓN (R2) .............................................................................................................................2676. EL ERROR ESTÁNDAR ..........................................................................................................................................................................2717. EL ANÁLISIS DE VARIANZA (ANVA) ............................................................................................................................................2728. PRUEBA DE HIPÓTESIS INDIVIDUALES DE LOS COEFICIENTES DE LA REGRESIÓN .....................................2759. APLICACIÓN USANDO EVIEWS ......................................................................................................................................................281
9.1. Creación de hoja de trabajo e importación de datos ...............................................................................................281 9.2. Análisis preliminar de los datos ...........................................................................................................................................285 9.3. El modelo de MCO ........................................................................................................................................................................289 9.4. Testeo del modelo de equilibrio de activos financieros (Capital Asset Pricing Model - CAPM) ........290
10. PROBLEMAS PROPUESTOS..............................................................................................................................................................29611. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................299
Capítulo 10 El modelo de mínimos cuadrados ordinarios (MCO) multivariado .......3051. INTRODUCCIÓN ........................................................................................................................................................................................3052. EL MODELO DE MCO MULTIVARIADO .........................................................................................................................................3063. PRUEBAS DE BONDAD DE AJUSTE: EL COEFICIENTE DE DETERMINACIÓN (R2) ............................................3114. VARIANZA DE LOS ERRORES ESTIMADOS .............................................................................................................................3125. LA VARIANZA DE LOS ESTIMADORES .......................................................................................................................................3136. PROPIEDADES DE LOS COEFICIENTES ESTIMADOS POR EL MODELO DE MCO ...............................................314
6.1. Insesgamiento ...............................................................................................................................................................................315 6.2. Eficiencia ..........................................................................................................................................................................................315 6.3. Consistencia ...................................................................................................................................................................................315
7. APLICACIÓN: EL MODELO DE VALORACIÓN POR ARBITRAJE (MVA) .....................................................................3168. HIPÓTESIS LINEALES ...........................................................................................................................................................................3219. VARIABLES CUALITATIVAS ..............................................................................................................................................................325
9.1. Variables dummy y los valores extremos (outliers) .................................................................................................32910. NO LINEALIDAD DE LA RELACIÓN ENTRE “Y” Y “X”: REGRESIÓN POLINOMIAL ............................................33211. PROBLEMAS PROPUESTOS..............................................................................................................................................................335

12. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................34013. APÉNDICE ....................................................................................................................................................................................................341
13.1. Derivación algebraica de la varianza de los errores.................................................................................................341 13.2. Derivación de la varianza de los parámetros ...............................................................................................................343 13.3. Demostración formal de las propiedades estadísticas de los parámetros estimados ..........................344
Capítulo 11 Prueba de los supuestos del modelo de MCO ...............................................................3471. INTRODUCCIÓN ........................................................................................................................................................................................3472. SUPUESTOS DEL MODELO DE MCO: UN REPASO ...............................................................................................................3483. SUPUESTO 1: LINEALIDAD ................................................................................................................................................................3494. SUPUESTO 2: E(ε) = 0 ..........................................................................................................................................................................3525. SUPUESTO 3A: HOMOCEDASTICIDAD, VAR(ε) = σ 2 .......................................................................................................352
5.1. El test de heterocedasticidad de White ..........................................................................................................................353 5.2. Consecuencias de la heterocedasticidad ........................................................................................................................357
6. SUPUESTO 3B: NO AUTOCORRELACIÓN, COV(ΕI ΕJ) = 0 ...........................................................................................360 6.1. Posibles causas de la autocorrelación de los errores ..............................................................................................361 6.2. El Test de Durbin-Watson .......................................................................................................................................................361 6.3. El test de Breusch-Godfrey ...................................................................................................................................................363 6.4. Consecuencias de la autocorrelación ...............................................................................................................................365 6.5. Errores estándar ajustados por autocorrelación y heterocedasticidad:
El método de Newey-West .....................................................................................................................................................366 6.6. Mala especificación de la dinámica del modelo ...........................................................................................................367
7. SUPUESTO 4: Ε ~ N(0, Σ 2) ...............................................................................................................................................................368 7.1. El test de normalidad de Jarque-Bera ..............................................................................................................................369 7.2. Consecuencias de no normalidad de los errores ........................................................................................................370 7.3. Posibles causas de no normalidad......................................................................................................................................370
8. SUPUESTO 5: ORTOGONALIDAD ..................................................................................................................................................3719. OTROS PROBLEMAS ASOCIADOS AL MODELO DE MCO .................................................................................................371
9.1. Multicolinealidad ..........................................................................................................................................................................371 9.1.1. Consecuencias de cuasi multicolinealidad .............................................................................................................372 9.1.2. Soluciones al problema de cuasi multicolinealidad .............................................................................................372
9.2. Forma funcional ...........................................................................................................................................................................373 9.2.1. Consecuencias de errores de especificación funcional ..................................................................................373 9.2.2. El test de Ramsey ...........................................................................................................................................................373
9.3. Omisión de variables importantes .....................................................................................................................................375 9.4. Variables redundantes .............................................................................................................................................................377 9.5. Estabilidad de los parámetros estimados ......................................................................................................................379
9.5.1. El test de estabilidad de Chow ...................................................................................................................................380 9.5.2. Test de errores de predicción ......................................................................................................................................38310. PROBLEMAS DEL CAPÍTULO ............................................................................................................................................................38711. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................39012. APÉNDICE ....................................................................................................................................................................................................394
12.1. El modelo de mínimos cuadrados generalizados ........................................................................................................394 12.2. El método de Cochrane-Orcutt ............................................................................................................................................396

Capítulo 12 Modelos de series de tiempo ...............................................................................................................3991. INTRODUCCIÓN ........................................................................................................................................................................................3992. PROCESOS ESTACIONARIOS ............................................................................................................................................................400
2.1. Estacionariedad estricta .........................................................................................................................................................400 2.2. Estacionariedad débil ................................................................................................................................................................401
3. LA AUTOCOVARIANZA, LA AUTOCORRELACIÓN Y EL CORRELOGRAMA............................................................402 3.1. El proceso de ruido blanco ......................................................................................................................................................403 3.2. Pruebas de autocorrelación ..................................................................................................................................................403
4. MODELO DE MEDIAS MÓVILES MA(Q) ........................................................................................................................................4065. MODELOS AUTORREGRESIVOS AR(p) .......................................................................................................................................411
5.1. Estacionariedad de procesos AR(p) ...................................................................................................................................4136. MODELOS ARMA(P,Q) ...........................................................................................................................................................................4207. CRITERIOS DE INFORMACIÓN .........................................................................................................................................................4228. PRONÓSTICOS ..........................................................................................................................................................................................423
8.1. Pronósticos con el modelo AR(p) ........................................................................................................................................424 8.2. Pronósticos con el modelo MA(q) .......................................................................................................................................425 8.3. Pronósticos con el modelo ARMA(p,q) .............................................................................................................................426 8.4. Evaluación de los pronósticos ..............................................................................................................................................427
8.4.1. La media de los errores al cuadrado (Mean Square Error - MSE) ..................................................................428 8.4.2. La media absoluta de los errores (Mean Absolute Error - MAE) ...................................................................428 8.4.3. La media absoluta de errores porcentuales (Mean Absolute Percentage Error - MAPE) ...................428 8.4.4. El coeficiente de desigualdad de Theil (Theil Inequality Coefficient) .........................................................429 8.4.5. Descomposición de los errores de predicción ......................................................................................................4299. LA METODOLOGÍA DE BOX-JENKINS ...........................................................................................................................................43010. PROBLEMAS DEL CAPÍTULO ............................................................................................................................................................43911. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................442
Capítulo 13 Modelos para la volatilidad condicional: Los modelos de heteroscedasticidad condicional autorregresiva .....449
1. INTRODUCCIÓN ........................................................................................................................................................................................4492. MODELOS BÁSICOS DE VOLATILIDAD .......................................................................................................................................4503. MODELOS DE HETEROSCEDASTICIDAD CONDICIONAL AUTORREGRESIVA ......................................................452
3.1. El modelo ARCH(q) ......................................................................................................................................................................453 3.2. Los momentos del modelo ARCH ........................................................................................................................................454 3.3. Detección de la presencia de los efectos ARCH .........................................................................................................455 3.4. El modelo ARCH generalizado, GARCH(p,q) ...................................................................................................................457 3.5. El modelo ARCH-M ......................................................................................................................................................................463
4. LA CURVA DE IMPACTO DE LAS NOTICIAS .............................................................................................................................465 4.1. El modelo TARCH .........................................................................................................................................................................466 4.2. El modelo EGARCH ......................................................................................................................................................................470 4.3. Modelo de componentes ARCH ...........................................................................................................................................476
5. EL PRONÓSTICO DE LA VOLATILIDAD .......................................................................................................................................4806. PROBLEMAS DEL CAPÍTULO ............................................................................................................................................................4847. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................486

8. APÉNDICE ....................................................................................................................................................................................................490 8.1. La ecuación para la media condicional .............................................................................................................................491 8.2. La ecuación para la varianza condicional .......................................................................................................................491 8.3. El modelo ARCH ............................................................................................................................................................................491 8.4. El modelo GARCH(1,1) como un modelo ARMA(1,1) ...................................................................................................495
................................................................496
Capítulo 14 Modelos de Series de Tiempo Multivariados y el Concepto de Cointegración ........................................................................................................499
1. INTRODUCCIÓN ........................................................................................................................................................................................4992. ESTACIONARIEDAD ...............................................................................................................................................................................500
2.1. Tipos de no estacionariedad .................................................................................................................................................501 2.1.1. No estacionariedad en tendencia .............................................................................................................................501 2.1.2. No estacionariedad estocástica ................................................................................................................................504 2.1.3. Diferenciar una serie no estacionaria en tendencia ..........................................................................................505
2.2. Métodos visuales para la detección de no estacionariedad.................................................................................506 2.3. El método aumentado de Dickey-Fuller (ADF) .............................................................................................................507
3. EL MODELO AUTORREGRESIVO MÚLTIPLE (VAR) ..............................................................................................................511 3.1. Generalidades ................................................................................................................................................................................511 3.2. Determinación del orden de rezagos del modelo VAR............................................................................................515 3.3. Interpretación de los resultados obtenidos con el modelo VAR .......................................................................519
3.3.1. Significancia en bloques y la causalidad de Granger .........................................................................................519 3.3.2. Las funciones de impulso-respuesta ......................................................................................................................520 3.3.3. Descomposición de la varianza ..................................................................................................................................524 3.3.4. Pronósticos ........................................................................................................................................................................525
3.4. Una nota de precaución ...........................................................................................................................................................5264. COINTEGRACIÓN .....................................................................................................................................................................................526
4.1. El modelo de corrección de errores ...................................................................................................................................528 4.2. Determinación de la existencia de vectores de cointegración ..........................................................................529
4.2.1. El método de Engle-Granger .......................................................................................................................................529 4.2.2. El método de Johansen ..................................................................................................................................................532
4.3. El modelo VEC: funciones de impulso-respuesta y pronósticos ........................................................................5395. UN EJEMPLO INTEGRAL ......................................................................................................................................................................5446. PROBLEMAS DEL CAPÍTULO ............................................................................................................................................................5557. ECUACIONES DEL CAPÍTULO ...........................................................................................................................................................556
Tablas Estadísticas ...............................................................................................................................................561 Distribución binomial: Tablas de frecuencias relativas ........................................................................................................561 Distribución binomial: Tablas de Frecuencias Acumulativas .............................................................................................567 Distribución Poisson: Tablas de Frecuencia Relativa ............................................................................................................572 Distribución Poisson: Tablas de Frecuencia Relativa ............................................................................................................577 Tabla T de Student...................................................................................................................................................................................582 Tabla T de Student...................................................................................................................................................................................583

Tabla T de Student...................................................................................................................................................................................584 Tabla de Distribución Normal Estándar ........................................................................................................................................585 Estadístico de Durbin-Watson (α=0.05) ......................................................................................................................................586
REFERENCIAS BIBLIOGRÁFICAS ...................................................................................................................................................587


CAPÍTULO
1
Estadística descriptiva
1
CAPÍTULO
1
Estadística descriptiva
1. INTRODUCCIÓN A LAS ESTADÍSTICAS
Este capítulo introduce las nociones básicas de la teoría estadística y sus aplicaciones en la economía
y los negocios. Las estadísticas pueden entenderse como el proceso de recopilar, analizar e interpretar
datos y reportar los resultados. Las estadísticas son usadas en una variedad de circunstancias que
van desde aplicaciones en el ámbito gubernamental, medicina, negocios y economía, entre otros.
Se muestran en este capítulo una serie de técnicas estadísticas que brindarán al lector las he-
rramientas necesarias para la mejor toma de decisiones en ambientes de incertidumbre. El enfoque
del capítulo es teórico-práctico. Se presentarán los conceptos estadísticos y su aplicación a casos
concretos. Se desarrollarán ejemplos numéricos y, a su vez, se presentarán de manera detallada la
forma en que estos problemas pueden ser resueltos con el uso de Microsoft Excel.
El primer aspecto que todo analista realiza para cumplir con sus funciones es el entender el
problema a tratar. Entendido el problema se procede a enumerar una serie de hipótesis que serán
materia de estudio o proyecto. Una vez determinadas las hipótesis se procede a ver la disponibilidad
de datos (sean de fuentes primarias o secundarias) y, de acuerdo a esta disponibilidad, se ajustarán
las hipótesis a aquellas que puedan ser efectivamente testeadas y se determinarán los métodos de
adquisición de datos necesarios. Los métodos de adquisición de los datos pueden ir desde simple
recolección primaria de datos propios de la empresa (estados financieros, inventario permanente
valorizado, los registros de compras y ventas entre otros) hasta la determinación y ejecución de en-
trevistas, búsqueda de datos secundarios por internet, etc.

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
2
Acabado el proceso de adquisición de datos, implica para el analista, el comienzo del análisis
estadístico propiamente dicho. El primer aspecto a considerar en esta nueva etapa es entender los
datos, sus principales características y la determinación y localización de posibles errores que se
pudieran haber cometido. En las siguientes secciones se tratará las formas de presentar los datos
que ayuden a tener una primera visión de los mismos mediante el uso de tablas de frecuencias y de
diversos estadísticos de tendencia central, dispersión y asociación.
Antes de proceder, es necesario introducir dos conceptos que serán de gran ayuda para entender
los conceptos y técnicas que se exponen en este capítulo. En estadísticas se conoce a la totalidad de
datos relacionados a una determinada variable como población. El número de elementos en esta
población se denomina N. A cualquier subconjunto de esta población se le conoce como muestra y su tamaño es representado por la letra n. Por ejemplo, si se está interesado en conocer cuál es el
promedio de los salarios de la población entre los 15 y 64 años de edad de los Estados Unidos, N sería
igual a 205.794.364.1 Si se desea tomar una muestra de la población de 10.000 habitantes, entonces
n sería igual a 10.000.
Población y muestra
Población (N) Muestra (n)
En términos prácticos, trabajar con la totalidad de los datos (N ) es poco eficiente y realista
considerando el tiempo, los recursos económico-financieros y los recursos humanos que serían
necesarios para recolectar dicha información. Por lo tanto, y a no ser que el tamaño de la población
sea pequeño y de fácil acceso, se trabaja con muestras poblacionales de tamaño n. Ahora bien, la
selección de la muestra tiene que hacerse con bastante cuidado, tratando que esta sea una muestra representativa de la población, de tal manera que los resultados obtenidos mediante el análisis
estadístico sean válidos, es decir, que sean no sesgados y eficientes. Se desarrollarán con más detalle
estos términos en las siguientes secciones.
El capítulo se encuentra organizado de la siguiente manera: la sección 2 describe los métodos
de recolección de datos más usados; la sección 3 muestra como generar las distribuciones de frecuen-
cias a partir de datos recolectados; finalmente en las secciones 4, 5, y 6 se presentan las medidas de
1 CENTRAL INTELLIGENCE AGENCY, The World FactBook, valores aproximados a julio del 2009.

CAPÍTULO 1 Estadística descriptiva
3
tendencia central, dispersión y de asociación, respectivamente. La sección 7 presenta una serie de
ejercicios propuestos y la sección 8 incluye la lista de las ecuaciones más importantes del capítulo.
2. COLECCIÓN DE DATOS (MUESTREO)
Como se mencionó anteriormente, en la práctica se trabaja con muestras tomadas de determi-
nadas poblaciones. Asimismo, se aludió que las muestras son la base fundamental del análisis, por
lo que se debe de prestar particular atención en la forma en la que esta se recolecta.
Esta sección presenta los conceptos básicos de la colección de datos, dejando la lectura más
avanzada a los libros y artículos mencionados en la bibliografía.
Algunos de los conceptos que se necesitan se describen a continuación:
Población, también conocida como Universo, contiene todos los posibles elementos de la
variable en estudio.
Muestra, una parte seleccionada de la población.
Censo, se refiere a la recolección de todos los elementos de la población.
Parámetro, una característica de la población. Por ejemplo, la media poblacional (μ), la
desviación estándar poblacional (σ), entre otros.
Estadístico, una característica de la muestra. Por ejemplo, la media muestral ( x ), la des-
viación estándar poblacional (s), entre otros.
Error muestral, es el error que aparece debido al uso de la muestra en vez de la población. Es
importante notar, que este error puede reducirse al incrementarse el tamaño de la muestra
si se usa el muestreo probabilístico que se detalla posteriormente.
Error no muestral, también conocido como sesgo o error direccional, representa los errores
originados en el diseño de la muestra, en una mala comunicación de lo que se quería averiguar
en el caso de una entrevista, entre otros. En este caso, el error no muestral no puede disminuir
simplemente añadiéndose más observaciones a la muestra. Se tienen que hacer revisiones
fundamentales a los procesos, a las entrevistas, etc.
En general, antes de determinar el método de muestreo a utilizar, será necesario entender el
problema que se tiene a mano y se deberá tratar de determinar las características de los datos a reco-
lectar. Por lo general, se sugiere realizar ciertos análisis exploratorios para entender mejor los datos
que se desean recolectar.
Se pueden definir dos métodos de muestreo: el muestreo probabilístico y el muestreo no pro-
babilístico. Ambos tipos de muestreo son tratados a continuación.
2.1. El muestreo probabilístico
En este tipo de muestreo se supone que todos los elementos de la población tienen la proba-
bilidad de ser elegidos. Sin embargo, no todos tendrán necesariamente la misma probabilidad de

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
4
ser elegidos. Este método es el que debe ser utilizado si la intención es la realización de inferencia
estadística. Este método, a su vez, se clasifica en:
2.1.1. Muestreo aleatorio simple
En el muestreo aleatorio simple cada elemento o miembro de la población tiene la misma pro-
babilidad de ser elegido. La forma común en la que se selecciona a los miembros de la población es
creando números aleatorios.
Por ejemplo, si se imagina que se tiene una población de 500 contadores en una determinada
ciudad y que se quiere seleccionar aleatoriamente a 10 de ellos. Se supone que se los tiene identificados
de acuerdo a un número consecutivo que va desde 1 hasta 500. El procedimiento que se seguirá se
describe en la aplicación Excel que presenta a continuación.
Primero se creará la cantidad de números aleatorios deseados (en nuestro caso 10). La creación
se basa en la distribución uniforme (0,1) con lo que se asegura que los números generados estarán
entre 0 y 1. Se multiplica cada uno de los números generados por el tamaño de la población para
obtener el número correlativo que permitirá identificar al contador seleccionado por este proceso
es decir, los números resultantes representan la identificación de los contadores a ser seleccionados.
Por lo normal, se aproximan los números del paso anterior al número inmediato inferior.
Por ejemplo, el primer número aleatorio presentado en la aplicación Excel 1, es igual a 191. Esto
significa que el contador cuyo número de identificación es 191 será seleccionado para nuestra muestra.
Generación de Números Aleatorios

CAPÍTULO 1 Estadística descriptiva
5
2.1.2. Muestreo sistemático
El muestreo sistemático se basa en determinar aleatoriamente un número (conocido como
semilla), que se usa para determinar los elementos u observaciones de una población que serán se-
leccionados. Por ejemplo, se selecciona un número al azar entre 1 y 10, por ejemplo 4. Este número
implica que las observaciones que se seleccionarán serán basadas en los múltiplos de este número.
Se seleccionarán las observaciones 4, 8, 12, etc.
El principal problema de este método es conocido como el de estacionalidad. El problema
de estacionalidad ocurre cuando en los datos existen ciertos patrones determinísticos que se repiten
de acuerdo a una determinada frecuencia. Un ejemplo clásico es el referido a la venta de helados.
Las mayores ventas de helados se producen durante todos los veranos, mientras que las ventas más
bajas se dan en el invierno. Si se desean determinar las ventas promedio en unidades de una empresa
dedicada a producir helados durante los 10 últimos años, usando datos trimestrales y usando un
muestreo sistemático, se puede correr el riesgo que el número semilla coincida exactamente o con el
verano (que generaría que el promedio sea inflado) o con el invierno (que haría que el promedio esté
subvaluado). De ahí la importancia de conocer los datos con los que se está trabajando para prever
todo tipo de problemas que pudieran aparecer y determinar la mejor manera de solucionarlos.
2.1.3. Muestreo estratificado simple
Muchas veces la población a estudiar tiene cierta estructura que puede ser identificada a priori.
Por ejemplo, si se desea hacer un análisis del nivel de ingresos de la población de un determinado
país, se pueden identificar distintos niveles de ingresos de acuerdo a determinados estudios sobre
los niveles socio-económicos.
Esta estructura de la población debe ser considerada al momento de recolectar los datos para
hacer que la muestra resultante sea representativa de la población. Es decir, lo que se trata de replicar
es la estructura (o estratos) existente en los datos para luego al interior de cada estrato aplicar un
muestreo aleatorio simple.
Se analiza el siguiente ejemplo desarrollado con valores hipotéticos:
Nivel socio-económico Población Ingresos (en miles de U.M.) Muestra 1 Muestra 2(muestreo estratificado)
A 1.000 (10%) 125 10 (10%) 10 (10%)B 3.000 (30%) 70 80 (80%) 30 (30%)C 6.000 (60%) 25 10 (10%) 60 (60%)
Esta tabla presenta la población y, en paréntesis, el porcentaje respecto al total. Por ejemplo, 10%
de la población pertenece al nivel socio-económico A. Asimismo, presenta valores de dos muestras
hipotéticas de 100 habitantes cada una. Entre paréntesis se encuentra el porcentaje de la misma
respecto al total de la muestra. Por ejemplo, en la muestra 1 se seleccionaron a 80 personas del nivel
B, lo que representa el 80% del total de la muestra.

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
6
La expresión U.M. se refiere a unidades monetarias.
Primero, se supone que el muestreo es completamente aleatorio y que, por azar, el resultado
de la selección resulta sesgado (por diversos motivos, como facilidad de acceso a las observaciones,
o simplemente por motivos aleatorios). Se supone que esos datos corresponden a la Muestra 1 en la
Tabla 1. Aquí se puede observar que el nivel socio-económico B está sobre representado mientras
que el nivel C está sub representado con respecto a la población. Si se desearan construir estadísticos
con esta muestra los resultados estarían sesgados hacia los valores de la clase B.
Por otro lado, la muestra hallada usando un muestreo estratificado simple, la estructura funda-
mental de la población se ha preservado, generándose de esta manera la representatividad necesaria
de la muestra. Es importante notar que en el muestreo estratificado simple, una vez que los estratos
han sido formados, para seleccionar a los elementos que comprenderán cada uno de los estratos se
aplica una muestra aleatoria simple.
2.2. El muestreo no probabilístico
En este caso no todos los elementos de la población tienen la probabilidad de ser seleccionados.
En este tipo de muestreo se utiliza bastante la intuición y la experiencia del analista y, por lo general,
es utilizado para realizar estudios exploratorios, cuyos resultados no son usados para realizar infe-
rencia acerca de los parámetros poblacionales.
Se pueden identificar los tipos de muestreos no probabilísticos que se citan a continuación.
2.2.1. Muestreo basado en el juicio del analista
Este tipo de muestreo depende de lo que el analista considere como importante para la cons-
trucción de la muestra. Por ejemplo, un auditor contable puede decidir no aplicar ningún muestreo
probabilístico como los mencionados anteriormente y, en vez de eso, determinar en base a su expe-
riencia, qué documentos solicitar para su análisis.
2.2.2. Muestreo basado en la facilidad de acceso a los elementos que forman la base del estudio
Este muestreo se construye en base a la disponibilidad y facilidad de acceso a los elementos
que constituyen la población. Por ejemplo, si un grupo de estudiantes desea construir una muestra
para entender de manera preliminar (exploratoria) los hábitos de consumo de café de los clientes de
Starbucks; estos pueden concentrar sus esfuerzos en una determinada área geográfica que les sea
de fácil acceso.
2.2.3. Muestreo basado en un propósito específico
En este tipo de muestreo, los miembros de la muestra son seleccionados con el propósito explícito
de ayudar a responder alguna pregunta relevante en el estudio. Por ejemplo, si se desea determinar la

CAPÍTULO 1 Estadística descriptiva
7
calidad de un libro básico de introducción a las finanzas, se puede seleccionar a un grupo de alum-
nos de pregrado con nociones mínimas de finanzas. Si estos estudiantes entienden los conceptos
presentados en el libro, esto será una señal que podrá ser fácilmente entendido por estudiantes con
cierto nivel de conocimientos de la materia.
3. DISTRIBUCIÓN DE FRECUENCIAS
Si el analista cuenta con los datos necesarios para realizar su trabajo, lo primero a hacer será
entender los datos con los que se cuenta. Se supone que los datos se refieren a las ventas en unidades
de los últimos 10 años los que se muestran a continuación:
Año Ventas (miles de unidades)20X0 2.54020X1 2.56020X2 2.61220X3 2.63020X4 2.72020X5 2.76020X6 2.78520X7 2.80420X8 2.83120X9 2.935
Una manera bastante fácil y útil para tener un mejor entendimiento de los datos es el crear una
tabla de frecuencias. Las tablas de frecuencias presentan la información agrupada de acuerdo a
rangos predeterminados. Una posible tabla de frecuencias tiene la siguiente forma:
Tabla de frecuencias
Clases Frecuencia Frecuencia relativa (%)
Frecuencia acumulada
Frecuencia relativa acumulada
2 20% 2 20%(2.600, 2.700] 2 20% 4 40%(2.700, 2.800] 3 30% 7 70%(2.800, 2.900] 2 20% 9 90%(2.900, 3.000] 1 10% 10 100%
0 0% 10 100%Total 10 100%
Los elementos característicos de una tabla de frecuencias son los siguientes:
a. Clases: son los rangos en los que se separan los datos. Por ejemplo, (2.600, 2.700] in-
dica que se deben seleccionar las observaciones mayores que 2.600 (no incluyendo
2.600) y menores o iguales a 2.700 (incluyendo 2.700).

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
8
b. Límites de las clases: son los valores que definen el mínimo y máximo valor a incluir
en una determinada clase. Por ejemplo, en la clase (2.600, 2.700], los límites son 2.600
y 2.700.
c. Rango de las clases: es la diferencia entre el límite máximo y el mínimo. Por ejemplo,
en (2.600, 2.700] el rango sería 2.700 - 2.600 = 100. Es importante notar que el rango
de todas las clases no tiene que ser necesariamente el mismo, aunque se sugiere que si lo
sea por motivos de presentación.
d. Marca de clases: Es el punto medio de cada clase. Se calcula sumando el límite infe-
rior al superior y dividiendo el resultado entre 2. Por ejemplo, el valor medio de la clase
(2.600, 2.700] es igual a (2.600 + 2.700)/2 = 2.650. Estos valores son importantes para
graficar el polígono de frecuencias que se detallará posteriormente.
Es importante notar que una tabla de frecuencias está bien estructurada si las clases satisfacen
las siguientes características:
a. Las clases deben ser mutuamente excluyentes, es decir, los límites entre clases jamás
deben pertenecer a más de una clase. Por ejemplo, las clases (2.600, 2.700] y (2.700,
2.800] son mutuamente excluyentes ya que los límites de una clase no están incluidas
en la otra: 2.700 está incluida en la primera clase pero no lo está en la segunda. Nótese
que “]” significa que el límite está incluido en una clase en particular y, “(” implica que
el límite no está incluido en una clase en particular.
b. Las clases deben ser exhaustivas, es decir, todas las observaciones en la muestra deben
estar incluidas en alguna de las clases. Como puede advertirse en la Tabla 3, todos los
valores de Tabla 2 han sido incluidos. La forma de verificar esto es simplemente verifi-
car que el total de la columna “frecuencia” corresponda al número de observaciones de
la muestra (en nuestro caso 10).
A continuación se describen los resultados presentados en la Tabla 3.
a. La primera columna (clases) contiene las clases en las que se dividirán las observacio-
nes.
b. La segunda columna (frecuencia) describe el número de observaciones que caen en
una determinada clase. Por ejemplo, se observan dos años con ventas entre (2.600,
2.700]. Nótese que la suma de esta columna debe ser igual al tamaño de la muestra.
c. La tercera columna (frecuencia relativa) describe el porcentaje de observaciones en
una determinada clase. Por ejemplo, el 20% de las ventas fueron entre (2.600, 2.700].
Adviértase que la suma de esta columna debe ser igual al 100%.
d. La cuarta columna (frecuencia acumulada) describe el número de observaciones que
son menores o iguales al límite superior de una determinada clase. Por ejemplo, se ob-
servan 7 años con ventas menores o iguales a 2.800.

CAPÍTULO 1 Estadística descriptiva
9
e. La quinta columna (frecuencia relativa acumulada) describe el porcentaje de observa-
ciones que son menores o iguales al límite superior de una determinada clase. Por ejem-
plo, se observan que el 70% de las ventas fueron menores o iguales a 2.800.
Cuando se utilizan los valores de la Tabla 3, se pueden generar algunos gráficos que son de
bastante ayuda:
a. El histograma: muestra la información contenida en la primera columna de la Tabla 3,
es decir presenta las frecuencias.
b. El gráfico de las frecuencias relativas acumuladas: muestra la información de la
quinta columna de la Tabla 3. Nótese que el máximo valor de las frecuencias relativas
acumuladas es 100%.
0,00%20,00%40,00%60,00%80,00%
100,00%
0
1
2
3
4
2500 2600 2700 2800 2900 3000 More
Freq
uenc
ia
Límites
Histograma y frecuencias relativas acumuladas
Frequency Cumulative %
c. El polígono de frecuencias: muestra la misma información que el histograma, pero de
manera más intuitiva, en el sentido que supone que las frecuencias varían gradualmente
conforme las observaciones aumentan o disminuyen en el eje de los límites. Para reali-
zar este gráfico se usan los valores medios de las clases como puntos que se ponen en la
parte superior de cada rectángulo. El polígono de frecuencias se obtiene uniendo estos
puntos.

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
10
01234
2500 2600 2700 2800 2900 3000 More
Freq
uenc
ia
Límites
Histograma y polígono
Frequency Frequency
de frecuencias
A continuación se presenta la forma en que se pueden realizar estas tablas por medio de Excel.
Tabla de frecuencias
Una vez que se tiene un entendimiento de las características básicas de los datos obtenidos me-
diante el análisis presentado en esta sección, se procederá a analizar determinados estadísticos que

CAPÍTULO 1 Estadística descriptiva
11
proporcionarán un mayor entendimiento de ciertas características claves de los datos en términos
de sus medidas de tendencia central, dispersión y asociación.
4. MEDIDAS DE TENDENCIA CENTRAL
Las medidas de tendencia central permiten al analista determinar los valores típicos de los datos.
En esta sección se analizarán los estadísticos más importantes: el promedio, el promedio ponderado,
la media y la moda. Se presentarán los estadísticos para las poblaciones y para las muestras. Para esto
se debe recordar que para el tamaño de la población se utilizará N y para el tamaño de la muestra n.
4.1. El promedio o media
El promedio o media es también conocido como la media aritmética. La media poblacional,
que a partir del momento se identificará con la letra griega “μ” (mu), se calcula de la siguiente manera:
1
N
iix
N (1)
Por otra parte, si se trata de la media muestral, para una muestra de tamaño n, este estadístico
estará dado por:
1
n
iix
xn
(2)
Donde: x representa el promedio muestral, xi la variable de interés, n el número de observa-
ciones en la muestra y ∑ el operador de suma.
Se supone que se tienen los datos de las ventas anuales correspondientes a los 10 últimos años
de una determinada corporación (los datos se encuentran en la Tabla 2) y que desea conocer las
ventas anuales promedio:
Por lo tanto, x = 2.718. Es decir, que la venta anual promedio durante los últimos 10 años es
igual 2.718 U.M.
El principal problema de este estadístico es que es muy susceptible a valores extremos. Para
entender este problema, se supone que las ventas en unidades del año 20X9 han sido 5.450 en vez de
2.935. El efecto de este cambio se puede notar a continuación:

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
12
Por lo tanto, x = 2.969. Como se puede apreciar, la existencia de un valor extremo, tiende a
mover el promedio en la dirección de dicha variable. Dicho de otra manera, un valor mucho mayor
que las demás observaciones, tiende a empujar el valor promedio hacia la derecha, mientras que la
existencia de un valor extremo mucho menor que las otras observaciones moverá la media hacia la
izquierda. Este problema se acentúa cuanto más lejano sea el valor.
Una forma de solucionar este problema es no considerar los valores extremos en el cálculo del
promedio o utilizar otro estadístico como la mediana.
4.2. El promedio ponderado
El promedio considera que toda la información tiene la misma ponderación o importancia en
el cálculo del estadístico. Sin embargo, muchas veces cada observación tiene diferente peso o pon-
deración. Es eso exactamente lo que considera el promedio ponderado. La fórmula del promedio
ponderado es:
1
n
i ii
x x (3)
Donde:
1
1n
ii
(4)
En la fórmula anterior, x representa el promedio ponderado y i la ponderación de cada
observación.
Un ejemplo típico en este caso es el cálculo de la rentabilidad de un portafolio. Si se imagina que
se tiene la siguiente composición de un determinado portafolio: 10% en renta fija, 70% en acciones
y 20% en metales como el oro. Si los rendimientos ganados por cada clase de activo financiero son
2%, 10% y 35%, respectivamente, el promedio ponderado sería calculado de la siguiente manera:
Es decir, que la rentabilidad promedio del portafolio es igual a 14,2%.

CAPÍTULO 1 Estadística descriptiva
13
4.3. La mediana
La mediana representa el valor medio de los datos debidamente ordenados ya sea de manera
ascendente o descendente. Si el número de observaciones es impar, la mediana se encuentra en la
posición (n + 1)/2 y si el número de observaciones es par la mediana corresponde al promedio de las
dos observaciones centrales que se localizan en las posiciones (n/2) y [(n/2) + 1].
Se supone que se tienen las siguientes observaciones en orden ascendente: 1, 4, 7, 10 y 15. En este
caso n (número de observaciones) es igual a 5, por lo tanto, la mediana se encuentra en la posición
(5 + 1)/2 = 3, es decir, la mediana de esta muestra es igual a 7.
Por otro lado, si se tiene la siguiente muestra ordenada de manera ascendente: 1, 4, 7, 10, 15,
18; las posiciones de los valores que determinarán la media son 6/2 = 3 y (6/2) + 1 = 4. Por lo tanto,
la mediana será igual a (7 + 10)/2 = 8,5.
La ventaja de la mediana respecto al promedio es que es inmune a los valores extremos. Por
ejemplo, si se toma la primera serie del primer párrafo de este ejemplo y se reemplaza el último valor
15 por 25. La nueva serie resultante será: 1, 4, 7, 10, 25. Como se puede ver la mediana sigue siendo
7 independientemente de los valores extremos.
4.4. La moda
La moda corresponde al valor que se observa más frecuentemente en la muestra. Si una serie
tiene una sola moda se llamara unimodal; si tiene dos modas se llamará bimodal y si tiene más de
dos modas se llamará multimodal.
Si se tiene la siguiente serie: 2, 4, 3, 5, 3, 1 y 9 la moda será 3, es decir, el número que aparece
más frecuentemente en esta serie es el número 3. En este caso, esta serie es unimodal.
5. MEDIDAS DE DISPERSIÓN
Las medidas de dispersión permiten al analista determinar cuán dispersos son los valores de
los datos respecto a alguna medida de tendencia central, usualmente el promedio. Estas medidas
de dispersión son de gran uso en las finanzas ya que la dispersión de los valores de las observaciones
está asociada con el nivel de riesgo o incertidumbre asociada con la variable observada. Se tratará
este tema en detalle en las siguientes secciones de este capítulo.
A continuación se analizarán algunos de los estadísticos de dispersión más importantes: el
rango, los cuartiles, la desviación media absoluta, la varianza y la desviación estándar, la variable
estandarizada y el coeficiente de variación.

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
14
Para un mejor entendimiento de los conceptos se utilizarán los datos de la presente tabla:
Año Gastos en publicidad (miles de U.M.)20X0 11020X1 11520X2 12720X3 13820X4 14720X5 15020X6 17520X7 16020X8 17020X9 180
5.1. El rango
El rango se calcula de la siguiente manera:
Rango = valor máximo – valor mínimo
El rango de las observaciones presentadas en la Tabla 4 será: 180 – 110 = 70. Es importante
recalcar que el rango, al solo usar los valores extremos, sufre del mismo problema que el promedio.
Es decir, su valor es sensible a los valores extremos.
5.2. Los cuartiles
Los cuartiles dividen los datos en cuatro grupos, cada uno de los cuales contiene el 25% de las
observaciones de la muestra. La estrategia para calcular los cuartiles es el siguiente:
a. Encontrar la posición de cada uno de los límites de los cuartiles ( pQ1 , pQ2 y pQ3 ) de la
siguiente manera:
(5)
Se advierte que la posición del segundo cuartil corresponde a la ubicación de la mediana, es
decir que el segundo cuartil será siempre igual a la mediana.
b. Una vez localizada la posición se procede a determinar el valor que corresponde a la
posición encontrada en el paso a. En caso que esta posición no sea un número entero se
procede a realizar una interpolación lineal tal como se explica a continuación.

399
1. INTRODUCCIÓN
Los modelos de series de tiempo tratan de explotar la información contenida en la historia de
las mismas variables. Estos modelos son conocidos como modelos en forma reducida o no estruc-
turales, ya que no han sido derivados de un modelo teórico económico o financiero. Estos modelos
son de bastante uso en finanzas, porque usualmente las predicciones obtenidas con estos modelos
son mejores que las obtenidas con los modelos estructurales.
Este capítulo introduce de manera bastante práctica los principales modelos de series de tiempo.
Se empezará presentando en la sección 2 la definición de un proceso estocástico, la definición de
procesos fuerte y débilmente estacionarios. La sección 3 trata sobre las autocovarianzas, autocorre-
laciones y el correlograma. También esta sección introduce los principales métodos para detectar las
autocorrelaciones. A continuación se desarrollan, en las secciones 4, 5 y 6, los modelos autorregresi-
vos AR(p), los modelos de medias móviles MA(q), y los modelos ARMA(p,q), respectivamente. La
sección 7 está destinada a la forma matemática de determinar el orden de los modelos de series de
tiempo mediante los criterios de información. La sección 8 desarrolla el tema de los pronósticos y
la forma de verificar su calidad. La sección 9 presenta el método de Box-Jenkins para el trabajo con
modelos de series de tiempo. Se muestra este método mediante el desarrollo de un ejemplo numérico
usando EViews. Finalmente, en las secciones 10 y 11 se encuentran los ejercicios y ecuaciones del
capítulo, respectivamente.
CAPÍTULO
12
Modelos de series de tiempo

400
ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
2. PROCESOS ESTACIONARIOS
Un concepto clave en los modelos de series de tiempo es el conocido como procesos estocásticos. Un proceso estocástico es una secuencia de números aleatorios. El proceso estocástico se escribirá
como { yi } para i = 1, 2,… Si este índice representa tiempo, el proceso estocástico se llamará serie de
tiempo. Si se asigna un posible valor de y por cada i se estará construyendo una posible realización
del proceso estocástico.
El principal problema en los modelos de series de tiempo es que en la realidad solo se observa
el proceso estocástico en una de sus varias posibles realizaciones. Por lo tanto, solo se puede obtener
un set de estadísticos (media, varianza, etc.) dadas las observaciones disponibles. En teoría, si se
pudieran observar todas las posibles realizaciones del proceso estocástico, se podrían calcular los
parámetros poblacionales (tal como la media poblacional) simplemente como el promedio de todas
las realizaciones.
Sin embargo, la realidad no se muestra de distintas maneras: solo existe una realización de
la realidad. Esto inmediatamente presenta una limitación que se debe tratar de solucionar. En esta
sección del capítulo se tratará el concepto de estacionariedad, que en síntesis significa que todas
las observaciones de la series de tiempo provienen de la misma distribución de probabilidad y que,
si a su vez el proceso no es muy persistente, cada observación contendrá información valorable que
no está presente en ninguna de las otras observaciones, por lo que los estadísticos obtenidos de las
observaciones serán consistentes con sus respectivos parámetros poblacionales. Por ejemplo, la media
de estas observaciones en el tiempo será consistente con la media poblacional.
El concepto de estacionariedad tiene dos versiones: la estacionariedad estricta y la estaciona-
riedad débil, que se procede a explicar a continuación.
2.1. Estacionariedad estricta
Un proceso estocástico { yi } con i = 1, 2,…T es estrictamente estacionario si, para un número
real finito r y para cualquier conjunto de subíndices i1 , i
2 ,…, i
T :
1 2 1 2, ,..., 1 , ,..., 1( ,..., ) ( ,..., )i i i i r i r i rT Ty y y T y y y TF y y F y y (1)
Es decir, que la distribución conjunta de { yi } con i = 1, 2,…T, depende solo de la distancia r y
no de i, es decir, la probabilidad conjunta de ( y1, y
11 ) es la misma que ( y
51 , y
61 ) (nótese que en este
caso r = 10). Lo importante para la distribución es la posición relativa de la secuencia. Además, esto
quiere decir que la probabilidad que y caiga en algún intervalo en particular es siempre la misma.
Por lo tanto, si un proceso estocástico es estrictamente estacionario: la media, la varianza y otros
momentos de la distribución serán los mismos para todo i. Ejemplos de series estrictamente estacio-
narias incluyen los procesos independientes e idénticamente distribuidos (i.i.d.).
Muchos procesos son no estacionarios simplemente porque tienen una tendencia determinística.
Es decir, que si se remueve la tendencia, la serie de tiempo se convertirá en una serie estacionaria. A
dichas series se les conoce como series estacionarias con tendencia. Asimismo, si se tiene una serie
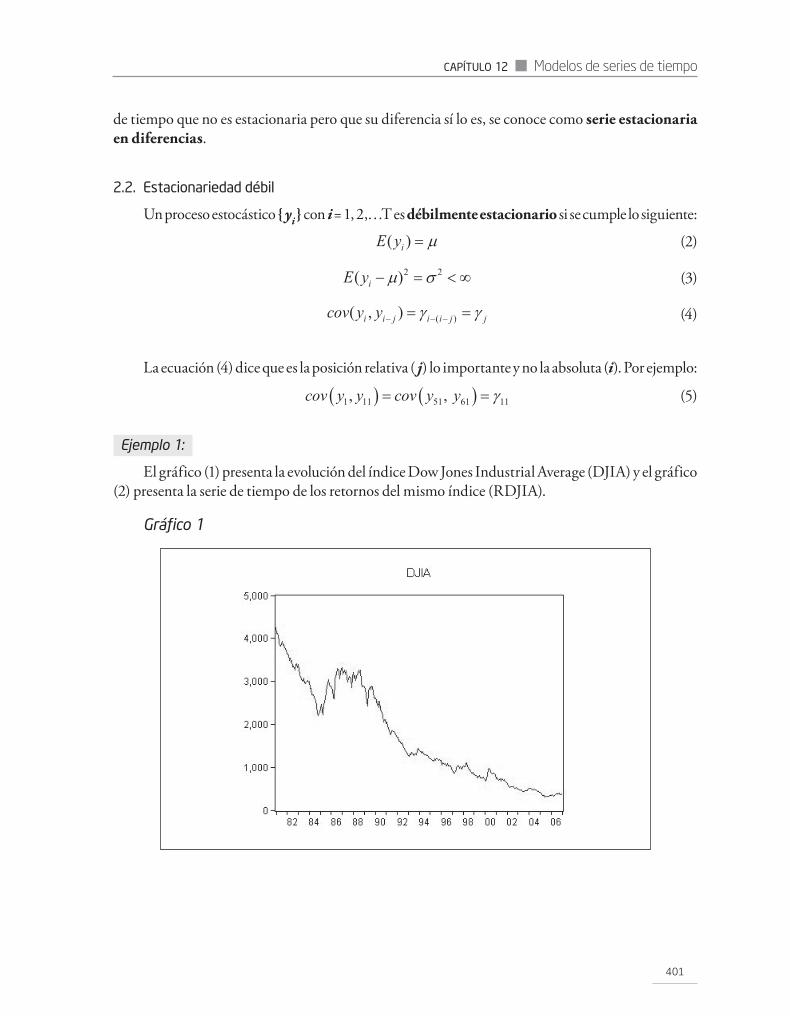
CAPÍTULO 12 Modelos de series de tiempo
401
de tiempo que no es estacionaria pero que su diferencia sí lo es, se conoce como serie estacionaria en diferencias.
2.2. Estacionariedad débil
Un proceso estocástico { yi } con i = 1, 2,…T es débilmente estacionario si se cumple lo siguiente:
( )iE y (2)
2 2( )iE y (3)
( )( , )i i j i i j jcov y y (4)
La ecuación (4) dice que es la posición relativa ( j) lo importante y no la absoluta (i). Por ejemplo:
1 11 51 61 11, , cov y y cov y y (5)
El gráfico (1) presenta la evolución del índice Dow Jones Industrial Average (DJIA) y el gráfico
(2) presenta la serie de tiempo de los retornos del mismo índice (RDJIA).

402
ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
Como se puede observar el gráfico de los precios (DJIA) es un proceso no estacionario, mientras
que el gráfico de los retornos (RDJIA) parece serlo. Una forma fácil de ver por qué la primera serie
es no estacionaria es tomando un intervalo de un tamaño fijo en dos puntos distantes y calcular el
promedio. Se asume por ejemplo, que se toman las siguientes observaciones del DJIA: 1982 hasta
1984 y del 2002 al 2004 (intervalos de 3 años cada uno). De acuerdo al concepto de estacionariedad,
si se hace esto y la serie es en realidad estacionaria, se esperaría que las medias sean iguales. Sin em-
bargo, solo observando el gráfico se advierte que este no será el caso, puesto que el índice estaba entre
3.638,06 y 2.278,20 entre enero de 1982 y diciembre de 1984 y, entre 616,53 y 421,98 entre enero
del 2002 y diciembre del 2004. En cambio si se observa la serie de los retornos, las medias estarán
bastante cercanas en los mismos intervalos de tiempo, lo que puede indicar que efectivamente esta
serie de tiempo es estacionaria. Posteriormente se presentará la forma econométrica de determinar
la estacionariedad de las series.
3. LA AUTOCOVARIANZA, LA AUTOCORRELACIÓN Y EL CORRELOGRAMA
Se supone que el subíndice i representa el tiempo, por lo tanto, el proceso estocástico { yi } , i =
1, 2,…T será una serie de tiempo. La autocovarianza se expresa como γj y se la define como:
( )( , )i i j i i j jcov y y (6)
Como se mencionó anteriormente, la autocovarianza solo depende de j (la posición relativa).
La varianza de la serie de tiempo {yi } será igual a:
0( , ) ( )i i i i icov y y var y (7)

CAPÍTULO 12 Modelos de series de tiempo
403
Por lo tanto, la autocorrelación de orden j ( ρj ) se definirá como el ratio entre la autocovarianza
de orden j y la varianza:
0
( , )( )
j i i jj
i
cov y yvar y
(8)
Con j = 1, 2,… Si j = 0, ρj = 1. Ahora bien, si se grafica la evolución en el tiempo de ρ
j , se estará
construyendo lo que se conoce como el correlograma.
3.1. El proceso de ruido blanco
El proceso de ruido blanco (White Noise Process) es un proceso débilmente estacionario con
media constante y no autocorrelación. Es decir, en un proceso de ruido blanco se cumple:
( )iE y (9)
-( , ) 0 0i i j jcov y y j (10)
20( , ) i icov y y (11)
3.2. Pruebas de autocorrelación
Se recuerda que la autocorrelación muestral se calcula de la siguiente manera:
1
1ˆ ( ) ( )n
j t t jt j
y y y yn j
(12)
Obsérvese que se divide entre n - j y no entre n, para que el estadístico sea insesgado. Esto es im-
portante si se está trabajando con una muestra pequeña. Sin embargo, si la muestra es lo suficientemente
grande n - j será bastante aproximado a n. La media de la serie se calcula como es usual:
1
n
ity
yn
(13)
Se sigue a nivel muestral y se define la autocorrelación muestral como:
0
ˆˆ
ˆj
j (14)
Dado esto, se presentan a continuación los test empleados para determinar la presencia de
autocorrelación. El primer método se basa en la siguiente propiedad asintótica:
ˆ (0, )mdn N I (15)

404
ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
Donde: 1 2ˆ ˆ ˆ ˆ( , ,..., )m . Esta ecuación establece que las autocorrelaciones ρ asintóticamente
se distribuyen como una normal estándar. Por lo tanto, se pueden construir intervalos de confianza
para la autocorrelación poblacional de la siguiente manera:
/21zn
(16)
Si el nivel de confianza deseado es del 90% (nivel de significancia α = 10%), el valor de zα/2 será
igual a 1,645.1 Por lo tanto, el intervalo de confianza para las autocorrelaciones poblacionales será:
11,645n
(17)
Existen otros métodos que permiten determinar la existencia de autocorrelaciones hasta un
determinado orden (m), que se presentan a continuación.
El método de Box-Pierce y el método de Ljung-Box permiten testear la siguiente hipótesis nula:
0 1 2 3: ... 0mH (18)
El test de Box-Pierce se calcula mediante:
2 2 2
1 1( ) ( ) ( )
m m
j jj j
Box Pierce Q n n m (19)
El test de Ljung-Box:
22 2
1 1
2( ) ( 2) ( ) ( )m m
jj
j j
nLjung Box Q n n n mn j n j
(20)
Ambas pruebas se distribuyen como una chi cuadrada debido a que ˆn es asintóticamente
independiente y distribuida como una normal estándar. Por lo tanto, la suma al cuadrado de estos
números es asintóticamente chi-cuadrada. Los grados de libertad de esta distribución son iguales a
m, que representa el número de rezagos deseados.
El método de Ljung-Box es preferido cuando el tamaño de la muestra es pequeño. Como se
puede observar, la diferencia entre estos dos métodos desaparece conforme n (número de observa-
ciones) se incrementa.
1 Se recomienda al lector remitirse al capítulo 5 para un detallado tratamiento de los intervalos de confianza.

CAPÍTULO 12 Modelos de series de tiempo
405
El problema con ambos test es que no existe una metodología clara para seleccionar el número de
rezagos (m). Si se escoge un m muy pequeño, el riesgo que no se estén capturando autocorrelaciones
de orden superior aumentará. Por otro lado, si el número m es demasiado grande las propiedades
asintóticas del test se pueden perder y la distribución no será más la chi cuadrada.
En esta parte se presenta un ejemplo ficticio que permite entender cómo es que estos test son
utilizados en la práctica. Se parte del hecho que se han calculado las tres primeras autocorrelaciones
de los retornos de algún instrumento financiero. Se supone que el número de observaciones es igual
a 50 y que el nivel de confianza deseado es igual al 90%. Finalmente, se asume que las autocorrela-
ciones obtenidas son las siguientes: 1 2 3ˆ ˆ ˆ1, 25; 0, 22; 0,02 .Primero, se estima el intervalo de confianza para las autocorrelaciones:
11,645 0,2326;0,232650
Con base en este intervalo de confianza, solo la primera autocorrelación no está en el intervalo.
Por lo que este será un indicio de la presencia de autocorrelación de primer orden.
Ahora se presenta la forma en que las pruebas de Box-Pierce y Ljung-Box son calculadas:
2 2 2 2
1
ˆ( ) ( ) ( 50 1,25) ( 50 0,22) ( 50 0,02)
( ) 80,565
m
jj
Box Pierce Q n
Box Pierce Q (21)
2
1
2 2 2
2 ˆ( ) ( )
50 2 50 2 50 2( ) ( 50 1,25) ( 50 0, 22) ( 50 0,02)50 1 50 2 50 3
( ) 85,55
m
jj
nLjung Box Q nn j
Ljung Box Q
Ljung Box Q
(22)
La hipótesis nula en este caso es:
0 1 2 3: 0H (23)
Esto significa que se prueba la no existencia de autocorrelación de hasta tercer orden. Se conoce
que ambas pruebas se distribuyen como una chi cuadrada con 3 grados de libertad (m = 3). Si se
desea un nivel de significancia del 10% (es una prueba no direccional, por lo que cada cola será igual
al 5%), el valor crítico superior de la chi cuadrada para estos grados de libertad será igual a 7,8148.

406
ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
Por lo tanto, como los valores de las pruebas son 80,565 y 85,55, para el Box-Pierce and Ljung-Box,
respectivamente; se rechazará la hipótesis nula. Lo que significa que existe autocorrelación signifi-
cativa hasta el tercer rezago.
El valor crítico, se ha hallado usando el comando de Excel “PRUEBA.CHI.INV” o “CHIINV”,
según se trate de la versión en español o inglés. La siguiente aplicación muestra la forma de usar Excel
para hallar este valor crítico:
Valores críticos de la chi cuadrada
n 50
nivel de confianza 0,9
rezagos (m) 3
α/2 0,05
grados de libertad 3
Chi_inferior 0,351846
Chi_superior 7,814728
Se advierte que se tienen dos valores críticos porque se trata de una prueba no direccional.
En las siguientes secciones se comienzan a presentar varios modelos de series de tiempo.
4. MODELO DE MEDIAS MÓVILES MA(q)
El proceso de medias móviles o (MA) por sus siglas en inglés (Moving Averages) es un modelo
que supone que la variable puede ser explicada por un cierto número de rezagos (q) de los errores,
es decir:
1 1 2 2 ...t t t t q t qy u u u u (24)
Donde los errores (u) son i.i.d. con media cero y varianza σ 2. A partir de esta sección se cambia
el uso del subíndice i por t para referirse al tiempo. Se puede reescribir esta ecuación de la siguiente
manera:
1
q
t j t j tj
y u u (25)
Antes de continuar, se define el siguiente operador matemático L, que será de gran utilidad en
lo que queda del capítulo:
mt t mL y y (26)

CAPÍTULO 12 Modelos de series de tiempo
407
Por ejemplo, Lyt y
t-1 , L2y
t y
t-2 . Si se emplea esta notación en la ecuación (26):
1
qj
t j t tj
y L u u (27)
Finalmente, si se define:
21 2( ) 1 ... q
qL L L L (28)
La ecuación (27) se puede escribir como:
( )t ty L u (29)
En la ecuación (28) se requiere que todas las raíces características de ( )L caigan fuera del
círculo unitario; es decir, que cada raíz de r en la siguiente ecuación característica sea mayor que
uno en valor absoluto:
21 21 ... 0q
qr r r (30)
Esta condición, conocida como la condición de invertibilidad, asegura que el modelo MA(q),
representado como un modelo AR(∞) converja a cero, es decir, que ( ( )L )-1 tienda a cero. En otras
palabras, esta condición asegura que el modelo MA(q) no es explosivo. Esta condición es muy pa-
recida a la condición de estacionariedad del modelo AR(p) que se discutirá en la próxima sección.
También, esta condición será de vital importancia al momento de trabajar con modelos ARMA(p,q).
La estrategia a seguir cuando se trabaja con series de tiempo es determinar la función de auto-
correlación presentada en la ecuación (8). Para eso se necesitan los siguientes componentes: la media,
la varianza y las autocovarianzas. La estrategia presentada para este modelo será la misma que la que
se utilizará para los otros modelos de series temporales.
Para mostrar la técnica se supone el siguiente modelo MA(3):
1 1 2 2 3 3t t t t ty u u u u (31)
Se recuerda que se asumió que u es un ruido blanco con media cero y varianza σ 2. Se calcula el
valor esperado de esta ecuación. Se toma la esperanza matemática a ambas partes de la ecuación (31):
1 1 2 2 3 3
1 1 2 2 3 3
( ) ( )( ) ( ) ( ) ( ) ( ) ( )t t t t t
t t t t t
E y E u u u uE y E E u E u E u E u
(32)
Como los errores son ruidos blancos con media cero, ecuación (32) será igual a:
( )tE y (33)

408
ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
A continuación se calcula la varianza de y. Se recuerda que la varianza se define como:
2 2
0( ) [( ) ]t t t tvar y E y E y E y (34)
Sin perder generalidad en este proceso, se asume que μ = 0 y se desarrolla la ecuación (34):
2 2
0 1 1 2 2 3 3( ) [ ] [( ) ]t t t t t tvar y E y E u u u u (35)
Si se opera:
02 2 2 2 2 2 2t 1 t-1 2 t-2 3 t-3 1 t t-1E[(u + ×u + ×u + ×u +(2× ×u ×u +otros términos cruzados)] (36)
Se analiza el primer término cruzado que se presenta en la ecuación (2 θ1 u
t u
t-1 ). Para esto
se recuerda que la covarianza se define como:
( ) ( ) ( ) ( ) ( )t t j t t j t t j t t jcov u u E u u E u E u E u u , (37)
Asimismo, como los errores son ruidos blancos, la autocovarianza de los errores es cero, obsér-
vese la ecuación (10). Por lo tanto, cuando se aplique el operador de la esperanza a cada uno de los
términos cruzados en la ecuación (36), estos serán iguales a cero. Lo que queda por ver ahora es qué
pasa con los primeros elementos de la ecuación (36):
02 2 2 2
02
0
=
=
=
2 2 2 2 2 2 2t t 1 t-1 2 t-2 3 t-3
2 2 2t 1 2 3
2 2 2t 1 2 3
var(y ) E(u )+ × E(u )+ × E(u )+ × E(u )var(y )var(y ) (1+
(38)
Ahora, lo que queda por calcular son las autocovarianzas de este modelo. Para eso se recuerda que:
,( ) ( ) ( ) ( ) ( )t t j t t j t t j t t jcov y y E y y E y E y E y y (39)
En esta ecuación se sigue con el supuesto que μ = 0, es decir que E(yt ) = E(y
t-1 ) = 0. Se procede
a calcular la autocovarianza de primer orden:
1 1 1 1 2 2 3 3 1 1 2 2 3 3 4( ) ( ) [( ) ( )]t t t t t t t t t t t tcov y y E y y E u u u u u u u u , (40)
Si se opera:
2 2 2t t-1 t t-1 1 t-1 1 2 t-2 2 3 t-3cov(y y )= E(y y )= E[ érminos cruzados], (41)

CAPÍTULO 12 Modelos de series de tiempo
409
De nuevo, al aplicar el operador de la esperanza a los términos cruzados estos desaparecerán de
la ecuación. Se analiza la primera parte de esta ecuación:
12 2 2
12
1
= =
= = + +
= =
2 2 21 t-1 1 2 t-2 2 3 t-3
1 1 2 2 3
1 1 2 2 3(
t t-1cov(y y ),
t t-1cov(y y ),
t t-1cov(y y ),
(42)
Se hace lo mismo para determinar las autocovarianzas de orden superior:
2 2 1 1 2 2 3 3 2 1 3 2 4 3 5( ) ( ) [( ) ( )]t t t t t t t t t t t ty y E y y E u u u u u u u u ,cov (43)
2 2t t-2 t t-2 2 t-2 1 3 t-3cov(y y )= E(y y )= E[ érminos cruzados], (44)
Si se opera, se obtiene:
t t-2cov(y y ), 2
2
2
= =
= =
= =
2 22 t-2 1 3 t-3
2 22 1 32
2 1 3
t t-2cov(y y ),
t t-2cov(y y ), (45)
La autocovarianza de tercer orden:
3 3 1 1 2 2 3 3 3 1 4 2 5 3 6( ) ( ) [( ) ( )]t t t t t t t t t t t tcov y y E y y E u u u u u u u u , (46)
2t t-3 t t-3 3 t-3cov(y y )= E(y y )= E[ érminos cruzados], (47)
Por lo tanto:
3
3
= =
= =
2t t-3 3 t-3
2t t-3 3
cov(y y )cov(y y )
,,
(48)
Como se puede apreciar, las covarianzas de orden mayor a 3 solo tendrán elementos cruzados,
por lo que las covarianzas serán iguales a cero:
t t- j t t- jcov(y y )= E(y y )= 0 j > 3 , (49)
Finalmente, se calculan las autocorrelaciones de acuerdo a la ecuación (8):
11
0
21 1 2 2 3 1 1 2 2 3
2 2 2 2 2 2 21 2 3 1 2 3
= (50)

ESTADÍSTICAS Y ECONOMETRÍA FINANCIERA
Este libro de los profesores Eduardo Court y Erick Rengifo ofrece un análisis riguroso y exhaustivo de la compleja interacción entre la estadística, econometría y los mercados
--
Joseph QuinlanChief Market Strategist and Managing Director
for Global Wealth and Investment Management at US Trust. US Trust is the private Wealth management arm of Bank of America
Este libro constituye un valioso aporte de Eduardo Court y Erick Rengifo a la literatura -
-
Hector ALonso Bueno Luján Gerente de Riesgos de Empresas y Corporaciones, BBVA Banco Continental
Global Risk Management - BBVA Group
División Latinoamérica
Cono Sur Rojas 2128 (C1416 CPX) Buenos Aires, Argentina www.cengage.com.ar
México Corporativo Santa Fe 505, piso 12 Col. Cruz Manca, Santa Fe 05349, Cuajimalpa, México DF www.cengage.com.mx
Pacto Andino: Colombia, Venezuela y Ecuador Cra. 7 N° 74-21, Piso 8, Ed. Seguros Aurora Bogotá D.C., Colombia www.cengage.com.co
El Caribe Metro Office Park 3 - Barrio Capellania Suite 201, St. 1, Lot. 3 - Code 00968-1705 Guaynabo, Puerto Rico www.cengage.com