§entro pe investigacion y &e - cs.cinvestav.mxf1a.pdf · modelos rígidos e inanimados en...
TRANSCRIPT



§ENTRO pe INVESTIGACION Y &E fSTLPíOS AVANZADOS DEL
S. P. N.I l i L I O T E C A
INGENIERIA ELECTRICA

CENTRO DE INVESTIGACION Y DE ESTUDIOS AVANZADOS DEL I.P.N. DEPARTAMENTO DE INGENIERIA ELECTRICA. SECCION DE COMPUTACION.
IMPLEMENTACION DE UN SISTEMA PARA EL DESARROLLO DE
PROTOTIPOS DE SOFTWARE
T E S I S
QUE PARA OBTENER EL. TITULO DE :
M A E S T R O E N C I E N C I A S
ESPECIALIDAD EN INGENIERIA ELECTRICA. OPCION COMPUTACION.
PRESENTA :
ING. ALEJANDRO PENA CASANOVA.
TRABAJO DIRIGIDO POR EL DR. JOSEF KOLAR SABOR.
BECARIO DE CONACYT. „.. v MEXICO D.F.. 1989CENTRO DL l’iVEST'.GACI?* Y ESTUDIOS AY> ¡ í¿A 0 U v U
I. P. N.B I B L I O T E C A
INGENIERÍA ELECTRICA


########## INDICE GENERAL * * * * * * * * * *CENTRO DE INVESTIGACION Y 0fi
ESTUDIOS AVANZADOS DEL
INTRODUCCION. i. P . N .B I B L I O T E C A
INGENIERIA ELECTRICA
CAPITULO 1 CICLO DE VIDA DEL DESARROLLO DE SISTEMAS UTILIZANDO
PROTOTIPOS.
1.1 Introducción a los Prototipos.......................... 11.2 Métodos de definición de requerimientos............... 21.3 Prototipos y recursos utilizados.......................31.4 Ciclo de desarrollo tradicional de sistemas........... 31.5 Ciclo de desarrollo de sistemas utilizando
prototipos.................................. 4 ........... 4
CAPITULO 2 ESTRUCTURA DEL SISTEMA PROLAN.
2.1 Componentes del sistema PROLAN......................... 62.2 Lenguaje PROLAN y uso del compilador................... 7
2.2.1 Descripción del lenguaje PROLAN................. 72.2.1.1 BLOQUES TIPO HEADING Y
FOOTING................................... 72. 2.1.2 Bloques tipo BLOCK....................... 82. 2.1.3 Bloques tipo REPORT......................92. 2.1.4 Bloques tipo SCREEN......................92.2.1.5 Componentes de un bloque
C Instrucciones).......................... 112. 2.1.6 Directivas al compilador................ 142.2.1.7 Otros elementos del lenguaje
PROLAN....................................152.2.2 Ejecución del Compilador.........................16
2.3 Uso del Programa Intérprete de prototipos.............172.4 Uso del Programa Generador Automático
de Código PROLAN........................... V ...........172.4.1 Modificar un archivo existente.................. 182.4.2 Crear un archivo nuevo...........................182.4.3 Editar un bloque................................. 182.4.4 Ver un bloque < SHOWME >........................ 222.4.5 Generar código fuente PROLAN.................... 222.4.6 Salvar código intermedio........................ 232.4.7 Listado de bloques
definidos ✓ no definidos.........................232.4.8 Establecer Directivas............................232.4.9 Limpiar area de trabajo........ .................23

2.4.10 Fin de la sesión.......................t ....... 23AX .......23A
CAPITULO 3 IMPLEMENT ACION DEL COMPILADOR PROLAN.
3.1 Definición de la gramática PROLAN......................243.2 Breve introducción a LEX................................243.3 Breve introducción a YACC...............................273.4 Estructuras de datos más importantes...................293.5 Archivo de especificaciones para LEX................... 313.6 Archivo de especificaciones para YACC..................353.7 Rutina principal del compilador PROLAN............... 36
CAPITULO 4- IMPLEMENTACI0N DEL INTERPRETE.
4.1 Introducción................................. - -........384.2 Implementadón de las rutinas del intérprete..........40
CAPITULO 5 IMPLEMENT ACION DEL PROGRAMA GENERADOR AUTOMATICO DE
CODIGO PROLAN
5.1 Introducción............................................. 435.2 Modificar un Archivo Existente......................... 445.3 Crear un Archivo Nuevo.................................. 455. 4 Editar un Bloque............................ ............ 45
5.4.1 Función editorCD;................................. 465.5 Mostrar un Bloque CShowme).................. ...........505.6 Generación de Código PROLAN.............................505.7 Salvar Código Intermedio................................ 515.8 Reporte de bloques
definidos / no definidos................................ 515.9 Establecer Directivas................................... 515.10 Limpiar Area de Trabajo...............................51
CAPITULO 6 UNA AMPLIACION DEL SISTEMA PROLAN.
6.1 Introducción............................................ 536.2 Descripción del Procedimiento..........................536.3 Rutinas Estándar........................................ 576 . * Caso Práctico...............C t W í W iVVtSfl6» íiW f 5 t................. 5®
ESTUDIOS AVANZADOS DEL
!. P. N.B I B L I O T E C A
INGENIERIA ELECTRICA

CONCLUSIONES...................................................................... 63
BIBLIOGRAFIA.
CENTRO Dc INVESTIGACION Y Bfi ESTUDIOS AVANZADOS DEL
i. P. N. B I B L I O T E C A
INGENIERIA ELECTRICA

========== INTRODUCCION ==========
Uno de los mayores problemas que se presentan durante el desarrollo de sistemas computar izados es, la definición por parte de los usuarios, analistas y coordinadores de proyectos de los requerimientos de información del sistema. Regularmente esos requerimientos sufren cambios radicales durante el desarrollo del proyecto tal que, muchas veces surgen controversias como : "éstoestá, incompleto”, "ésto no sirve”, "ésto no es lo que pedí”, etc..
Esto lleva a la conclusión de que, la mayoría de las técnicas actuales de definición de sistemas fallan ó no trabajan adecuadamente. Existen tres puntos principales que se han detectado en donde todas las técnicas de análisis tienen problemas para manejarlos adecuadamente y son :
- Los usuarios tienen dificultades extremas en preescribir en una forma total y final sus requerimientos de información.
- Las técnicas gráficas y narrativas de documentación son inadecuadas para comunicar en una forma dinámica la aceptabilidad de una aplicación propuesta.
- La comunicación muchas veces es muy reducida entre los miembros de un proyecto debido a la cantidad de tareas que tienen que realizar cada uno de ellos.
Actualmente técnicas de definición utilizadas tales como; análisis estruc turado y lenguajes de especificación Cver 161^ no han sido exitosas en la solución de estos problemas fundamentales.
La definición de requerimientos por medio de la construcción de modelos de aplicaciones ofrece una solución viable y exitosa a los problemas de definición. El uso de prototipos es un método para extraer, presentar y refinar los requerimientos de los usuarios por medio de la construción de un modelo de trabajo del proyecto final rápidamente, en contexto y paulatinamente ir afinando las soluciones conforme hay más entendimiento sobre ciertas partes del problema. Por lo tanto, el uso de prototipos puede eficientemente y efectivamente resolver el problema de la definición de requerimientos. Esta técnica de definición de requerimientos es relativamente nueva y surgió apenas en esta década de los QO's, como una inovación sobre las técnicas tradicionales (ver Í6JJ>.
La flexibilidad de tener un modelo dinámico de trabajo para absorber los cambios hechos por los usuarios en todo momento durante el proceso de definición quita muchas preocupaciones a los desarrolladores de los sistemas y no produce sorpresas de cambios
I - í

inesperados. Por ésto, un prototipo de trabajo nos proporciona una visión más amplia de los cambios hechos a los requerimientos que modelos rígidos e inanimados en hojas de papel.
En estos momentos de gran avance tecnológico las areas de aplicación computac ional cada vez son más y se hace necesario el desarrollo de lenguajes de programación orientados a objetivos cauda vez más específicos tales como ; manipulación simbólica, disefío de software, manejo de robots, etc.
Este trabajo de tesis trata de cubrir varios objetivos en el ramo de construcción de compiladores y en el uso de herramientas para la construcción de prototipos dinámicos de software. En particular, se desarrolló un sistema integral para el desarrollo de prototipos de software llamado PROLAN CPROioíype LANguageJ el cual, corre en computadoras tipo ”PC” compatibles con l.B.H. yconsta de : Un compilador para el lenguaje, un intérprete decódigo objeto y un programa generador interactivo automático decódigo fuente PROLAN.
Los objetivos principales que se persiguen son :
- Proporcionar a las personas involucradas en el desarrollo desistemas computar izados, una herramienta sencilla de usar que les ayude a generar los prototipos de sus sistemas ya en la computadora, de una manera rápida y fácil. Ya que, actualmente na existe un lenguaje ó herramienta orientado específicamente a este fin.
- También se intenta hacer notar, que existen herramientas las cuales, hacen factible que personas con conocimientos de computación y teoría de compiladores, puedan diseñar e implementar sus propios lenguajes para cubrir objetivos específicos.
El trabajo fué logrado de la siguiente manera ;
- El sistema PROLAN empezó a ser im.plementado tomando como base las especificaciones sintácticas y semánticas de un lenguaje especializado en el desarrollo de prototipos dinámicos de software. Estas especificaciones fueron hechas a través de varios experimentos iniciales por el Dr. Josef Kolar Sabor Cver Eltrabajo inició como proyecto de la materia de compiladores' éinterpretes que se da en esta escuela. Esta primera fase consistió de la creación del analizador léxico utilizando LEX Cver II].?, secreó el analizador sintáctico utilizando YACC Cver 111.? y ,selogró la generación del código intermedio mediante la inclusión de acciones semánticas durante el proceso de análisis. También se logró en esta fase un tratamiento efectivo de errores sintácticos, utilizando facilidades del paquete YACC.
1 - 2

- Posteriormente como parte de un proyecto de laboratorio, se terminó de conceptualizar y se implementó un programa intérprete, el cual se ajustó al código intermedio generado por el compilador. Con el objeto de darle un tratamiento final a este código para generarnos el prototipo de un sistema.
- Después ya como trabajo de tesis, se diseñó e implementó un programa generador interactivo de código fuente PROLAN. Esto fué con el objeto de que la programación fuera más rápida y fácil.
- Finalmente se elaboró el bosquejo de implementación de un programa en lenguaje "C". El cual tomará como entrada un programa fuente en PROLAN y lo convertirá a un programa en lenguaje "C Entonces este programa generado nos servirá como un esqueleto de base para poder desarrollar nuestro sistema final de producción.
Los temas a tratar son los siguientes :
El capitulo 1 trata el ciclo de vida del desarrollo de un sistema de software utilizando prototipos dinámicos.
El capítulo 2 trata la estruc tura del sistema PROLAN así como del uso del compilador, intérprete y del programa generador de código automático desde el punto de vista del usuario.
El capítulo 3 trata la implementación del compilador para el lenguaje PROLAN utilizando herramientas para la construcción de compiladores tales como LEX y YACC.
El capítulo 4 trata de la implementación del intérprete para el código objeto generado por el compilador.
El capítulo 5 trata de la implementación del programa generador interactivo automático de código fuente PROLAN.
En el capítulo 6 se da el bosquejo de implementación de un programa, que converirá código fuente PROLAN a código fuente "C".
Finalmente se presentan las conclusiones relativas al desarrollo de este trabajo.
1 - 3

CAPITULO 1
CICLO DE VIDA DEL DESARROLLO DE SISTEMAS UTILIZANDO PROTOTIPOS
1.1 Introducción a los Prototipos.
La mayoría de los métodos recomendados para definir requerimientos de sistemas administrativos están diseñados para establecer un conjunto de requerimientos final, completo, correcto y consistente antes que el sistema sea diseñado, construido, visto ó experimentado por el usuario. Aún con el uso de estas técnicas rigurosas en muchos casos, los usuarios continúan rechazando aplicaciones aún antes de ser implementadastotalmente, ésto trae como consecuencia un tiempo exesivo que se pierde y un monto considerable de trabajo extra para ajustar lo que está hecho con las necesidades ac tuales. En el peor de los casos en lugar de re troal inventar el sistema éste es abandonado. Las personas que desarrollan sistemas construyen y prueban de acuerdo a especificaciones pero los usuarios aceptan ó rechazan de acuerdo a las realidades actuales de operación.
Las técnicas rigurosas actuales de definición de modelos tales como: diseño estructurado ó lenguajes de definición de problemas no son exitosas para definir muchas aplicaciones de negocios. Hay un gran número de problemas de análisis en los cuales la incertidumbre de los requerimientos, problemas de comunicación ó la personalidad de los participantes involucrados hacen que las especificaciones preliminares sean inapropiadas ó inadecuadas. El resultado no sólo es caro en tiempo y costo sino que es costoso en la desmoralización y frustración de los participantes.
Un modelo alterno para la definición de requerimientos es, recolectar un conjunto inicial de necesidades e implementar rápidamente esas necesidades en la computadora con el propósito, de expanderlas y refinarlas en común acuerdo con los usuarios involucrados.
Este tipo de modelo es llamado aplicación de prototipos. También, es nombrado modelado de sistemas ó desarrollo heurístico. El ofrece una alternativa más atractiva y fácil de usar que las técnicas tradicionales de desarrollo de proyectos.
Muchas técnicas de preespecificaciones tienen sus origenes al trabajar fácilmente con ”problemas de juguete". Estos problemas, tienen las siguientes características :
- Son pequeños CA menudo un diagrama de ellos llena una solapágina?.
- Una especificación exacta es proporcionada.
- Una solución exacta puede ser proporcionada inmediatamente
í

Día con día los proyectos de software no son ”problemas de juguete";
- Son grandes Cmuy grandes2.
- Las especificaciones son imprecisas y volátiles.- Las soluciones están en los ojos de cada persona.- Los participantes varían en nivel de habilidades y a menudo
ejecutan diferentes tareas a la ves.
1.2 Métodos de definición de requerimientos.
Definición rigurosa. Se refiere a una estrategia para determinar los requerimientos de una aplicación preescribiendo en detalle todas las necesidades antes de cualquier disefío conceptual, implementación , operación y se basa en :
- Entrevistas.- Observación.
- Revisión de procedimientos y sistemas existentes.- Investigación de poli ticas relevantes.- Ideas relevantes.
Todas estas herramientas son utilizadas para generar un modelo lógico del sistema propuesto. Modelos físicos son generalmente rehuidos siendo inapropiados en la fase de análisis. Herramientas modernas como diseño estructurado y lenguajes de definición de problemas son comunmente utilizadas para auxiliar en el análisis, documentación y presentación de requerimientos. '
Aplicación de prototipos. Se refiere a una estrategia para ejecutar determinación de requerimientos en donde las necesidades del usuario son extraídas, presentadas y desarrolladas construyendo un modelo de trabajo del sistema final rápidamente y en contexto. Aunque la misma técnica rigurosa es aplicada inicialmente para obtener un inicial entendimiento del problema, el modelo difiere significativamente en que. al tener un entendimiento inicial del problema un intento es hecho para implementar rápidamente un modelo del problema. Entonces, ese modelo sirve como un medio de comunicación entre las partes involucradas. El modelo es entonces gradualmente expandido y refinado en lo que los participantes incrementan la comprensión del problema y posibles soluciones. La figura 1.1 muestra los cuatro pasos básicos del modelo de prototipos.
2

GURA 1.1 MODELO DE LOS CUATRO PASOS EL CUAL PERMITE AL USUARIO EXPERIMENTAR CON LA SOLUCION ANTES DE ESTAR TOTALMENTE DE ACUERDO CON ELLA.

Identificación de necesidades básicas. Determinar las metas fundamentales y objetivos de una aplicación. Varios problemas de negocios a ser resueltos por el sistema, elementos de datos, relaciones entre registros y funciones a ser ejecutadas.
Desarrollo de un modelo de trabajo. Rápidamente construir un modelo de trabajo el cual nos de los campos claves definidos en elprimer paso. Es muy importante entregar el primer modelorápidamente para mantener a los usuarios interesados en elproceso.
Deroost- ración en contexto / Solicitar refinamientos yextenciones. Presentar el modelo a todas las partes interesadas desde el que va a ser el capturista de datos hasta el gerente divisional y solicitar de una manera agresiva requerimientos adicionales. Explicar claramente cada parte del prototipo y hacer que los usuarios den sus puntos de vista y mejoras al modelo.
Pr otot i po Hecho. Continuar iterando entre las demostraciones y revisiones hasta que la funcionalidad sea entendida por todas las partes involucradas, probar el prototipo intentando ejecutar el servicio que va a dar.
Esta distinción entre preespecificación y prototipos es muy importante ya que, representan diferentes filosofías de como atacar el problema de definición de requerimientos. Aquellas organizaciones que seleccionen la mejor técnica tendrán mejores resultados.
1.3 Prototipos y recursos utilizados.
Hacha literatura actual se pregunta el tamaño de instalaciones y el número de gente que se necesita para el desarrollo de prototipos. Un típico escenario podría ser un solo analista y una terminal de -video para atender a un usuario. Varias pantallas podrían ser rápidamente generadas, siguiendo el ciclo iterativo de prototipos. El usuario podría ser satisfecho y la aplicación podría entonces ser completada por producciones ya para la implementación.
1.4 Ciclo tradicional de desarrollo sistemas.
La mayoría de los centros modernos de computación ejecutan el desarro lio de nuevos sistemas utilizando un enfoque estructurado llamado SDLC CCiclo de vida del desarrollo estructurado de sistemas, ver I6J.> ilustrado en la figura 1.2. Esta técnica permite alcanzar metas graduales con fases específicas para permitir puntos de verificación , control de calidad, y puntos de discusión'entre las partes involucradas. Los pasos exactos y sus propiedades de implementación varían levemente según la organización. Entonces, a continuación se mencionan las metas genéricas y objetivos de cada fase de un SDLC.
3

SURA 1.2 CICLO DE UIDA DEL DESARROLLO ESTRUCTURADO DE SISTEMAS (SDLC).

Factibilidad Determina la factibilidad técnica,operacional y costo-beneficio de la aplicación propuesta.
Definición Determina los requerimientos queel sistema debe cubrir.
Disefio preliminar Determina una solución físicalos requerimientos.
Diseño detallado Proporciona una especificaciónexacta para la construción de cada componente del sistema.
Implementación Construye, prueba y verifica sistema..
Conversión Convierte el actual modo de ope - ración al del nuevo sistema.
Producción Opera el sistema día a día.
Mantenimiento Revisa el sistema para correc -dones operacionales.
Todas las técnicas es truc turadas están de acuerdo en que la fase más importante del desarrollo de un sistema, es la definición del mismo. Es decir, si esta fase es hecha incorrectamente todas las demás fases lo más seguro es que no sirvan para nada ya que, si no está entendido correctamente el problema de poco servirá lo que se impl emente.
1.5 Ciclo de desarrollo de sistemas utilizando prototipos.
Realmente el ciclo SDLC de desarrollo de sistemas no se altera al útil i zar prototipos pues éstos son solamen te utilizados en la fase de definición de requerimientos. Pero, al utilizar prototipos se minimiza el costo del ciclo de vida, el tiempo de £mplementacíón y los r iesgos del proyecto ya que, los prototipos proporcionan un modelo de definición heurístico. Se considera heurístico, porque al tener patrones de soluciones de una manera rápida tenemos la facilidad de obtener un aprendizaje de la solución al problema ó problemas de una manera acelerada.
4
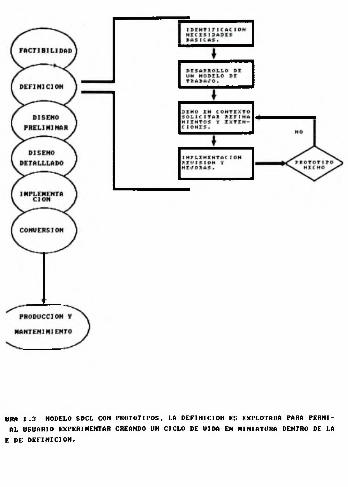
URA 1.3 NODELO SDCL CON PROTOTIPOS, LA DEFINICION ES EXPLOTADA PARA PERNI- AL USUARIO EXPERINENTAR CREANDO UN CICLO DE UIDA EN MINIATURA DENTRO DE LA E DE DEFINICION.

La jigura 1.3 nos muestra el modelo SDLC con la estrategia de prototipos. Dentro de la fase de definición derequerimientos, la definición es explotada de modo que el usuario pueda crear un ciclo de vida 'en miniatura dentro de ésta. Entonces, con ésto se logra que se pueda experimentar paradescubrir hasta las últimas necesidades.
5

CAPITULO 2
ESTRUCTURA DEL SISTEMA PROLAN
2.1 Componentes del sistema PROLAN.
Basándonos en los conceptos expuestos en el capítulo 1* se diseñó e implementó un sistema especializado en el desarrollo de prototipos de software. El sistema se desarrolló de acuerdo a las siguientes fases :
- Definición sintáctica y semántica de un lenguaje de programación especializado en el desarrollo de prototipos de software C llamado PROLANJ>.
- Construcción de un compilador para el lenguaje PROLAN el cual. genera un código objeto.
- Construcción de un programa intérprete el cual, toma como entrada el código generado por el compilador y lo ejecuta éste.
- Construcción de un programa generador automático interactivo de código PROLAN.
En la figura 2.1 se presenta la estructura y la relación entre las partes del sistema PROLAN.
El objetivo principal del desarrollo del lenguaje PROLAN fué crear un lenguaje simple de carácter descriptivo en el cual, se pudieran expresar fácil y rápidamente los formatos de menúes,pantallas en general y reportes igual que la lógica de control entre ellos. Para desarrollar los prototipos el sistema es totalmente autosuficiente ó sea que para su uso no se requiere ninguna información fuera de la sintaxis y la semántica dellenguaje PROLAN.
Sin perder de vista el objetivo principal. En el lenguaje PROLAN se deja abierta la posibilidad de incluir herramientas que hagan posible su uso para el desarrollo del sistema a producir mediante una secuencia de transformaciones en que. se reemplazan gradualmente las partes del prototipo por los módulos definitivos del sistema. Estas herramientas harían de PROLAN un lenguaje de semántica extensible lo que, permitiría enriquecerlo poroperaciones que no estén incluidas en su definición de base.
Sin embargo estas extensiones ya no se pueden implementar utilizando solamente el lenguaje PROLAN y nos llevan a lanecesidad de incluir también algún lenguaje procedural. Las características más importantes del sistema PROLAN son su simplicidad, eficiencia de uso y su gran flexibilidad. Debido a ésto, se logró crear un sistema altamente portátil que se puede
6

P R O T O T I P O D E U N S I S T E M O .
FIGURA 2.1 ESTRUCTURA DEL SISTEHA PROLAN.

implementar y ajustar fácilmente para cualquier computador utilizando lenguajes de programación comúnes. Por supuesto, para lograr estas metas se han incluido solamente las operaciones de base. Por lo tanto, el sistema no trata de competir con paquetes profesionales de diseño de pantallas y reportes como Dbase-III, Story-Board, Viev ,etc.
2.2 Lenguaje PROLAN y uso del compilador.
2.2.1 Descripción del lenguaje PROLAN.
Un programa en el lenguaje PROLAN está compuesto de bloques de instrucciones separados entre si por el símbolo ’ Cpunto y comcO. Los bloques representan agrupaciones de diferentes tipos de instrucciones los cuales pueden ser de cinco tipos diferentes :
- HEADING- FOOTING- BLOCK- REPORT- SCREEN
2.2.1.1 BLOQUES TIPO HEADING Y FOOTING.
Los bloques HEADING definen los encabezados estándar los cuales, se colocan en forma, automática en cada pantalla y /o reporte. El contenido de los bloques está definido por su cuerpo el cual, contiene instrucciones. Los bloques FOOTING definen los pies de página estándar los cuales. al igual que los bloques anteriores se incluyen automáticamente en todas las pantallas y repor tes.
Los bloques HEADING y FOOTING no tienen nombre y se definen de la siguiente manera en un programa PROLAN.HEADING
FOOTING
En donde su cuerpo está representado por instrucciones.
Se pueden definir varios bloques HEADING y/o FOOTING en el mismo programa siendo válido el bloque desde el lugar de su
7

definición hasta que se encuentre otra redefinición de otro bloque HEADING ó FOOTING. Ejemplo.
HEADING— este es heading_l
FOOTING— este es footing_l
i
SCREEN A ;
REPORT B : A ;
HEADING— este es heading_2
FOOTING— este es footing_2
SCREEN E ;
REPORT F s E ;
En este programa PROLAN la pantalla A y el reporte E tendrán incluidos el heading_l y el foóting_l. Mientras que la pantalla E y el reporte F tendrán incluidos el heading_2 y el footing_2.
2. 2.1.2 Bloques tipo BLOCK.
Los bloques tipo BLOCK representan alguna unidad de texto en general y el cual, se puede referir solamente por su nombre y se hará la inclusión dinámica de sus instrucciones en el lugar donde fué referenciado. Estos bloques se definen de la siguiente manera:
BLOCK Nombre_de1_B 1oque

En donde Nombre_del_Bloque »s un identificador el cual representa el nombre con el que es nombrado dicho bloque.
Ejemplo del uso de un bloque tipo BLOCK :
BLOCK El23 ;
SCREEN F ;El 23
Entonces todo el código del bloque El 23 será incluidodinámicamente en la pantalla F.
2.2.1.3 Bloques tipo REPORT.
Los bloques tipo REPORT definen una unidad de texto que se va a imprimir en forma de un reporte. Estos bloques serán enviados a disco a la hora de ejecución del prototipo. Es tos bloques se definen de la siguiente manera :
REPORT Nombre_del _t> loque t B1 oque _s i guíente ;
El Nornbre_del_Bloque es un ident ificador el cual, define el nombre del reporte y el Bloque_siauiente también es un identificador que define el nombre de un bloque tipo SCREEN ó REPORT al cual, será transferido el control automáticamente después que el reporte sea ejecutado. Ejemplo :
REPORT XASD s ALTAS ;
Después de que este reporte sea ejecutado el control se transferirá al bloque ALTAS.
2. 2.1.4 Bloques tipo SCREEN.
Los bloques tipo SCREEN definen alguna unidad de texto que aparecerá en la pantalla a la hora de ejecución del prototipo y estos bloques se definen de la siguiente manera :
9

SCREEN Nornbre_ de l_b loque t Lista_opciones_sucesores {
El Nornbre_del_bloque es un identificador que define el nombre de la pantalla. Después del caracter * sigue la Lista_opciones_sucesores la cual, puede ser vacía. Esta lista se ofrece con el propósito de tener puntos de continuación a la hora de ejecución del prototipo.
La Lista_opciones_sucesores que se presenta con las pantallas es básicamente una lista de parejas separadas por comas. Los elementos de las parejas están separados por el caracter ’ CguiónJ y son de la forma opción-pantalla ú opción-reporte. El primer elemento de la pareja define un caracter que puede teclear el usuario cuando se le haya presentado la pantalla actual y la segunda parte representa el nombre de la pantalla ó el reporte adonde se va a pasar el control en caso de que el usuario haya tecleado este caracter. A continuación, se da una explicación más detallada de ésto.
La opción puede expresarse en forma de un identificador ó número, pero sólo se toma en cuenta el primer caracter. También puede usarse cualquier caracter encerrado entre apóstrofes ó bien, la forma Nnúrnero en la cual, número es el valor ASCII del caracter desado. Existe una opción implícita que se puede usar con cualquier pantalla ó reporte y ésta se solicita tecleando el caracter IMPRET Cpor default ESC ASCII 27.}. ésto es explicado más adelante en la sección correspondiente a directivas del compilador 2.2.1.6J>, lo que causa el regreso a la pantalla dinámicamente precedente.
Existe la opción reservada \255~sucesor la cual, ocaciona que si lo tecleado no corresponde a ninguna opción dentro de la cadena opción-sucesor, ocasionará que se seleccione ésta.
La segunda parte de la pareja en la mayoría de los casos, hace referencia a alguna pantalla ó reporte mencionando su nombre. En el caso del separador ’ ■’ Csigno de igual} este nombre no representa ninguna parte del prototipo sino, algún procedimiento externo que se ejecutará al pedir la opción correspondiente. Esta posibilidad se incluye para poder realisar la transformación gradual del prototipo en el sistema completo de producción Cno implementada aúrO .
Cada programa en PROLAN ¿iene que definir un bloque tipo SCREEN nombrado MAIN. El bloque con este nombre por definición representa el menú principal con el que comienza la ejecución del prototipo. Además, el lenguaje tiene definido un bloque ficticio implícito llamado END que significa el fin de la ejecución del prototipo y éste puede ser invocado en laLista_opc i ones_ sucesores de las pantallas y/o como el B1oque_s i gu i ente de un reporte.
Ejemplo de un bloque tipo SCREEN :10

SCREEN MAIN t AFF-ALTAS, B-BAJAS, *6*-REPORTE, \67-CONSULTAS, 100-NOMINA, \255-EHD }
i
Después de que esta pantalla sea ejecutada, si tecleamos A el control se pasará al bloque ALTAS, si tecleamos B el control se pasará al bloque BAJAS, sí tecleamos el número 6 se pasará el control al bloque REPORTE, si tecleamos la letra C CASCII 67J el control se pasará al bloque CONSULTAS, si tecleamos el número 1 el control se pasará al bloque NOMINA y finalmente si lo tecleado no corresponde a ninguna opción de las anteriores el prototipo terminará su ejecución.
Todos los bloques tipo SCREEN serán enviados a la pantalla ó al dispositivo de salida estándar a la hora de ejecutar el prototipo.
2. 2.1.5 Componentes de un bloque CInstrucciones).
El cuerpo de cualquier bloque tiene la estructura de una secuencia de instrucciones separadas entre sí por espacios en blanco. A continuación se explican los diferentes tipos de instrucciones que hay en el lenguaje PROLAN.
Inclusión de un bloque. Si el componente es un identificador éste tiene que ser el nombre de algún bloque del programa. Típicámente sería de tipo BLOCK aunque también se permite hacer referencias a cualquier otro tipo de bloques. No se impone ningún límite respecto a la profundidad de referencias entre bloques únicamente se pide evitar las referencia cíclicas.
Línea de código. Este componente tiene la forma. :
Cldent-ificador Lista_de_parametros)
Si el componente tiene la forma de una línea de código entonces se supone que el Identificador inicial representa el nombre de algún procedimiento externo a ejecutarse. El compilador asegura que los argumentos del código se hacen accesibles a este procedimiento en alguna forma estándar durante la ejecución del prototipo. Las líneas de código facilitan entonces el diseño y uso de operaciones no incluidas en el intérprete de prototipos.
La línea de código formada por CCURSOR x,y^> representa un ejemplo del uso de este tipo de componente, la rutinacorrespondiente posiciona el cursor en cualquier lugar de la
lí

pantalla sin que salga ningún texto. La linea formada por la instrucción CFRAME xí.yí - x2,y2J> os otro ejemplo el cual, permite dibujar marcos definiendo sus puntos extremos superior y derecho inferior. El uso de estos componentes tiene sentido solamente para los bloques tipo SCREEN.
Para separar los argumentos en las líneas de código se pueden utilizar los signos ; *,'CcomcD, *-’CguionJ ó bién, ’ * unespacio en blanco que, simplemente delimita los elementos léxicos. El compilador no hace diferencia entre estos caracteres en su papel de separadores. Ejemplo :
(COPY Z1 Z2 Z3 Z4> es equivalente a (COPY Z1-Z2-Z3-Z4) ó a (COPY Zl, Z2, Z3, Z4).
Líneas de texto. Las líneas de texto incluidas en un bloque son los elementos más típicos dentro del cuerpo de éstos y pueden ser de tres tipos :
- Líneas alineadas a la izquierda.- Líneas alineadas a la derecha.
- Líneas centradas.
El formato típico de una línea de texto es :
Al irisación Renglón , Columna " T e x t o .... " Pos i ci criamiento
La alineación de las líneas se determina por el primer caracter no vacío de la línea de texto y el cual puede ser :'<’ , *>' ó y los cúales significan :
< Líneas alineadas a la izquierda.
> Líneas alineadas a la derecha.
* Líneas centradas.
La alineación a la izquierda es implícita entonces el uso del caracter ’< ’ es opcional.
Las líneas alineadas a la izquierda ó a la derecha puedencontener la especificación del número de Renglón y del número deColumna ó sea las coordenadas de colocación de la línea en la pantalla ó en el reporte. Las líneas centradas pueden contenersolamente la especificación del Renglón dado que la Columna se calcula automáticamente en base de la capacidad de una línea CSCRNWD ó PAGEWD - véase la semántica de las direc tivas delcompilador 2.2.1.6^ y la longitud actual del texto de la línea.
12

El valor absoluto del número de Renglón tiene que estar incluido en el intervalo < 1 , SCRNLN > para las líneas que se dirigen a la pantalla y entre < 1 , PAGELN > para las dirigidas a la impresora CSCRNLN y PAGELN son valores que se definen útil izando las directivas del compilador. Véase la subsección2. 2.1. 6J>.
Si el número de Renglón no tiene signo, se interpreta como el número de orden del Renglón contando desde arriba. Si el número de Renglón tiene signo negativo se interpreta como el número de orden pero contando las líneas desde abajo. Si el número tiene el signo positivo se interpreta como posición relativa al último Renglón precedente en que se colocó algún texto durante la ejecución del prototipo. El valor por default del Renglón es +1.
El valor absoluto del número de Columna tiene que estar incluido en el intervalo < 1 , SCRNWD > para las líneas que se dirigen a la pantalla y entre < 1, PAGEWD > para las líneas que se dirigen a la impresora CSCRNWD y PAGEWD son valores que se definen utilizando las directivas del compilador. Véase la subsección 2.2.1.6J>. Dado que la semántica del número de Columna depende del tipo de alineación vamos a considerar primero el caso de la alineación a la izquierda.
Si el número de Columna no tiene signo, se interpreta como el número de orden de la Columna contando a partir de la izquierda en que se coloca el inicio del texto de la línea. Si el número de Columna tiene el signo positivo ó negativo, se interpreta como posición relativa a la última Columna precedente en que se colocó el inicio de algún texto durante la ejecución del prototipo. El valor por default de la Columna es +0.
En el caso de alineación a la derecha, la interpretación del número de Columna es semejante sólo que, el conteo comienza a partir del lado derecho Cío que influye en el posicionamiento relativoJ y además se determina la posición del último caracter del texto de la línea.
Las líneas de texto puden ser terminadas opcionalmente por el caracter CSubrayadoJ el cual, representa el posicionamientodel cursor después de que se haya presentado la pantalla completa. Los valores de default son Renglón 24, Columna 78. Este caracter sólo tiene sentido entonces para los bloques tipo SCREEN. En la página siguiente se muestran ejemplos de todo ésto :
íB

Líneas de texto Salida correspondiente
12945478 PO 12945(378 PO 12B45Ó7IP
•'12345 LINEA 1"
"12345 LINEA 2"
"12345 LINEA 3"
"12345 LINEA 4"
"12345 LINEA 5"
"12345 LINEA 1"
"12345 LINEA 2"
"12345 LINEA 3"
2.2.1.6 Directivas al compilador.
Las directivas al compilador definen una serie de valores los cuales, serán usados a la hora de compilación de programa fuente y en. la interpretación del prototipo. Las direc tivas se definen al inicio de un programa en PROLAN y fuera de cualquier bloque, éstas directivas tienen alcance, global y sólo deben ser definidas una sola vez. El formato típico de una direc tiva es el siguiente :
++ Nombre ■ Número
Las directivas se definen en una sola línea y pueden ir encualquier posición de ésta con la condición de que, haya blancosCcero ó más? a la izquierda de los caracteres ' . Nombre puedeser cualquiera de los siguientes :
PAGELNPAGEWDSCRNLNSCRNWDIMPRETFILEMD
La direc tiva FILEND no lleva el signo de *=’ ni ningún valor 14
12345 LINEA 1
12345 LINEA 2
12345 LINEA 3
12345 LINEA 1
12345 LINEA 2
12345 LINEA 3
12345 LINEA 4
12345 LINEA 5

y sirve para marcar el fin lógico de un programa PROLAN, en el
punto donde esta directiva sea encontrada. Esta direc t iva puede servirnos para propósitos de depuración de programas.
La directiva PAGELN define el número máximo de líneas quetendrá un reporte el valor de default es 60.
La direc tiva PAGEWD define el número máximo de columnas que tendrá un reporte el valor por default es 80.
La direc tiva SCRNLN define el número máximo de líneas quetendrán las pantallas el valor por default es 24.
La directiva SCRNWD define el número máximo de columnas que tendrán las pantallas el valor por default es 80.
La directiva IMPRET define el caracter el cual, durante laejecución de una pantalla si lo tecleamos, nos regresará a la pantalla dinámicamente precedente a la que se está ejecutando actualmente, el valor por default es CESC ASCII 27.>.
2.2.1.7 Otros elementos del lenguaje PROLAN.
Comentar i d e . Tienen la forma. :
— Cualquier Texto
Pueden ir en cualquier parte del programa inclusive fuera de algún bloque y sirven de documentación. También, pueden ir en cualquier parte de una línea sólo se pide que haya blancos Ccero ó más} a la izquierda de los caracteres
Los Identificadores en PROLAN se pueden formar xisando letras, dígitos, y los caracteres ’ (subrayado} y '.'CpuntoZ. No hay límite para el número de caracteres que forman un identificador solamente la longitud de una línea de programa fuente. Ejemplo de identificadores :
Los números en PROLAN se suponen enteros decimales sin signo, aunque se deja abierta la posibilidad de uso de números reales para modificaciones posteriores del lenguaje PROLAN.
Las cadenas de texto en PROLAN se forman encerrando entre comillas ’"* los caracteres deseados. Para que se pueda incluir cualquier caracter en la cadena se permite el uso del escape ’V seguido por el código ASCII del caracter deseado. También se permiten las construcciones :
A_L_T_A_S B_A. J. A_S REPORTE
stV\\
tabulador comí lias backslash
15

Palabras reservadas. Las palabras HEADING, FOOTING, BLOCK, REPORT, SCREEN, END, CURSOR y FRAME. Son reservadas del lenguaje y solamente deben de ser usadas en los lugares especificados anteriormente de lo contrario, pueden surgir resultados impredecibles dentro de un programa PROLAN.
2.2.2 Ejecución del Compilador.
Una vez que tenemos un programa escrito en PROLAN hecho por nosotros 6 hecho por el programa generador automático de código PROLAN Cver sección 2 . entonces, estamos listos para dar este programa como entrada al programa compilador el cuál, checard su construcción léxica, sintáctica y semántica y si no hay problemas y nosotros queremos, podemos generar el código objeto y/o ejecutar desde este punto el prototipo del sistema.
La forma de ejecutar el compilador es como sigue :
PROLAN Nombre del programa -Paraml -Param2 -Param3 ..-PararonNombre del programa. Se refiere al nombre del archivo el cual
contiene el código fuente PROLAN, este nombre debe darse completo inclusive si el nombre contiene alguna extensión. Si el nombre es omitido el compilador leerá el programa directamente del teclado.
Los párametros son directivas dadas al compilador y pueden ser uno ó varios de los mencionados a continuación. Cabe aclarar que los párametros pueden ir en cualquier orden y también pueden ser escritos en letras mayúsculas y/o minúsculas.
I Este párametro indica al compilador que imprima el código fuente al momento de estar compilando. Si este párametro no es dado y ocurre algún error de compilación automáticamente esa línea será desplegada en la pantalla, las líneas sondesplegadas con su respectivo número de línea.
E Este párametro indica al compilador que si la compilación fue correcta ejecute en este momento el prototipo del sistema es decir, nosotros podemos desde este momento ver nuestro prototipo final sin necesidad de generar el código objeto.
G Este párametro ocasiona que si no hay problemas en la compiloción, sea generado el código objeto respectivo el cual, servirá como entrada al programa intérprete de prototipos. El uso de este parámetro ocasiona que sea creado un archivo con el mismo nombre del archivo que se dió como entrada, pero con extensión . OBB en el cual, será escrito el código objeto generado Cver 3.C Este parámetro sólo sirve al personal de caracter técnico ya que, al darlo ocaciona que. el código objeto generado por el compilador sea desplegado en la pantalla en código ASCII estándar. Es decir, se despliegan los contenidos de las tablas BTAB y LTAB Cver generación del código objeto sección 3.4.).
16

Ejemplo si damos lo siguiente
PROLAN XI23.pro -I -E -GSerá compilado el programa que se encuentra en el archivo en
disco X123.pro el cual, debe estar escrito en lenguaje PROLAN y será impreso el código fuente a la hora de compilación, será ejecutado el prototipo del sistema y además, será creado el archivo X123.0BB el cual, contendrá el código objeto y servirá como entrada al intérprete de prototipos (ver uso del intérprete de prototipos sección 2.3J.
En caso de que existan errores de compilación, el compilador indicará claramente que errores son y .en donde están ocurriendo.
2.3 Uso.del Programa Intérprete de prototipos.
ESte programa toma como entrada un archivo con extensión . OBB generado por el compilador y ejecuta el prototipo. La forma de ejecutar este programa es la siguiente :
INTOBB nombre
En donde nombre es el nombre del archivo el cual contiene el código objeto a ejecutarse, el archivo debe tener extensión .OBB pero a la hora de dar el nombre si se desea no es necesario dar la extensión. Si dentro del programa a ejecutarse existen bloques tipo REPORT entonces será creado un archivo con extensión .RPT el cual contendrá todos los reportes que se generen durante la ejecución del prototipo para que posteriormente nosotros lo enviemos a nuestra impresora de preferencia.
Si ponemos por ejemplo :
INTOBB V_678Será ejecutado el archivo V_JE.78.0BB y si existen reportes será creado el archivo V_678.RPT el cual, contendrá todos los reportes del prototipo ejecutado.
2. 4 Uso del programa Generador Automático de Código PROLAN.
Uno de los módulos más importantes del sistema PROLAN es el programa generador automático de código PROLAN, con este programa, cualquier persona con pocos ó ningún conocimiento del lenguajepuede hacer el prototipo de todo un sistema de una manera interactiva fácil y rápida entonces, como mencionamos anteriormente este programa nos podrá generar el código fuente PROLAN el cuál, servirá como entrada al compilador PROLAN sin
17

necesidad de programar línea por línea.
La forma de ejecutar este programa es :
GENAUTAl ejecutar este programa aparecerá el siguiente menú el cual
es el menú principal del programa : .
lí1 Modificar un archivo existente.[21 Crear un archivo nuevo.[31 Editar un bloque.[41 Ver un bloque < Showme >[51 Generar código fuente PROLAN.[61 Salvar código intermedio.[71 Listado de bloques definidos/no definidos. [81 Establecer directivas.[91 Limpiar area de trabajo.[01 Fin de la sesión.
2. 4.1 Modificar un archivo existente.
Esta opción nos permite modificar el prototipo de un sistema el cual, debe estar guardado en un archivo con extensión .INT Cver la opción Salvar código intermedio 2.4.6-> es decir, en esta opción hay que dar el nombre de un archivo sin dar la extensión y si el archivo existe será cargado a memoria y podremos hacer las modificaciones respectivas De lo contrario, el programa enviará un mensaje de que no existe ese archivo.
2.4.2 Crear un archivo nuevo.Cuando vamos a crear un prototipo por primera vez es decir,
es la primera vez que vamos a trabajar con el generador automático es necesario, seleccionar esta opción con el objeto de que el prototipo que vamos a crear ó ya creamos pueda ser guardado en disco. Con esta opción será creado un archivo con extensión .INT en el cuál, podrá ser guardado el prototipo que hayamos hecho Cver la opción Salvar código intermedio 2.4.6.), si el archivo ya existe en disco el programa preguntará si se desea destruir lo que ya tiene y el usuario debe seleccionar lo correcto.
2.4.3 Editar un bloque.
Como lo hemos expresado este programa generador automático de código PROLAN es un programa en el cual, podemos hacer de una manera interactiva el prototipo de todo un sistema de softxoare y después podemos generar el código fuente PROLAN respectivo. Por todo ésto entonces este programa tiene incluido un editor de pantalla completa en el cual, podemos editar ó dibujar nuestras pantallas y/o nuestros reportes.
Í 8

Al seleccionar esta opción nos será preguntado el nombre del bloque a editar, si este bloque ya existe inmediatamente nos será mostrado ya dentro del editor, si este bloque no existe el programa nos preguntará si deseamos crearlo ó no. Si seleccionamos que si, el programa preguntará de que tipo queremos que sea el bloque el cual, podrá ser solamente de cualquiera de los siguientes tipos . HEADING, FOOTING, BLOCK, REPORT, SCREEN. Cver descripción del lenguaje PROLAN 2.2.1.) Una ves seleccionado el tipo, el programa nos pasa al editor en donde podemos empezar a editar nuestro bloque.
Uso del editor. Al entrar al editor existe una línea en la parte in/erior de la pantalla en donde está escrito el nombre del bloque que estamos editando, de que tipo es, patrón de edición (ver establecer direc ti vas 2.4.8.? y otros datos de ayuda general.
El número máximo de líneas y columnas de nuestro editor depende del tipo de bloque que estamos editando y de las directivas, los bloques tipo REPORT son regidos por lasdirectivas PAGEWD y PAGELN, los bloques tipo SCREEN son regidos por las directivas SCRNWD y SCRNLN las cátales, definen el número máximo de columnas y de líneas en las reportes y pantallasrespec tivamente Cver establecer directivas 2.4.8.).
Los bloqxjes tipo HEADING, FOOTING y BLOCK están regidos por el patrón de edición es decir, dependiendo de como esté puesto el patrón de edición ya sea en modo pantalla ó reporte podemos editar estos bloques, ésto es debido a que estos bloques pueden ser usados tanto en pantallas como en reportes entonces. esnecesario poder editar un bloque de éstos bajo los parámetros deuna pantalla ó de un reporte (ver establecer directivas 2.4.8.?.
En la edición podemos utilizar las siguientes teclas (El símbolo ,A* significa la tecla CONTROL.? :
Teclas de Movimiento del cursor.
FLECHA HACIA ARRIBA Nos mueve el cursor una posición haciaarriba.
FLECHA HACIA ABAJO Nos mueve el cursor una posición hacia abajo.
FLECHA A LA DERECHA Nos mueve el cursor una posición hacia la derecha.
FLECHA A LA IZQUIERDA Nos mueve el cursor una posición, hacia la izquierda.
19

HOME P0si.ci.0Tu3. e 1 cursor en el primer carac ter de la línea en l a cual se encuentra el cursor.
END Posiciona el cursor en el último caracter de la lineaen la cual se encuentra el cursor.
Teclas de Borrado de texto.
DEL Nos borra el caracter que se encuentra en la posicióndel cursor y nueve todo el texto de la línea, una posición a la izquierda.
* Y Borra la línea completa en la cual, estáposicionado el cursor y mueve todo el texto abajo del cursor una línea hacia arriba.
BACKSPACE Borra el caracter que está situado a la izquierda del cursor y mueve toda la línea un carac ter a la izquierda.
Teclas de movimiento de texto.
* C Centra toda la línea en la cual está posicionado elcursor. Si estamos editando una pantalla, la línea es centrada entre el intervalo < 1 , SCRNWD > y siestamos editando un reporte la línea es centrada en el intervalo < 1 , PAGEWD >. Si estamos editandootro tipo de bloque entonces, el centrado es en base al patrón de edición actual Cveáse establecer directivas 2.4.8J>. También esta tecla causa que a la hora de generar código PROLAN esta línea sea una línea centrada Cver líneas de texto 2.2.1.5.).
A R Esta tecla ocasiona que toda la línea en donde estáel cursor sea traslada hacia la derecha es decir, el último caracter de la línea se hace coincidir con el margen derecho, SCRNWD para las pantallas y PAGEWD para los reportes.
* L Esta tecla ocaciona que toda la línea sea trasladadahacia la izquierda es decir, se hace coincidir elprimer carac ter de la línea con la posición 1 en cualquier tipo de bloque.
RETURN Si oprimimos esta tecla cuando el editor está enmodo ”insert”, se abre una línea en blanco en la posición siguiente de donde está el cursor y
20

posiciona éste en la columna 1 de la nueva línea. Si se oprime cuando el editor está en modo "overwrite", se posiciona el cursor en la columna í de la línea siguiente.
Otras Teclas y su función.
J Esta tecla causa que la línea en donde está elcursor, sea una línea alineada a la izquierda a la hora de generar código PROLAN Cver líneas de texto 2.2.1.5.?. Todas las líneas si no se indica otra cosa son inicialmente alineadas a la izquierda CdefaultD.
* K Esta tecla causa que la línea en donde está elcursor sea una línea alineada a la derecha a la hora de generar código PROLAN Cver líneas de texto 2.2.1.5J,
A A Esta tecla causa que en la línea donde está el cursorsea agregado al último el caracter *_*Csubrayado} Cver líneas de texto 2.2.1.5.?. Este caracter no se ve sólo hasta la generación del código PROLAN. Esta tecla actúa alternativamente quitando y poniendo dicho caracter si la oprimimos más de una vez.
~ I Esta tecla ocasiona que nosotros podamos hacerinclusiones de otros bloques con tan sólo indicar su nombre Cver bloques tipo BLOCK descripción del lenguaje PROLAN 2. 2.1.1.?.. Cualquier tipo de bloque puede ser incluido exepto bloques tipo HEADING y FOOTING ya que, como recordáramos, éstos bloques no tienen nombre a la hora de generar código PROLAN. Cver bloques tipo HEADING y FOOTING 2. 2.1.1,?.
A F Esta tecla nos permite incluir cualquier n-úmero demarcos CFrames} en el bloque que estaumos editando Cver Líneas de código en descripción del lenguaje PROLAN 2. 2.1. 5J).
* O Esta tecla sólo es permitida cuando estamos editandoun bloque tipo SCREEN y aquí, podemos definir toda la cadena de Opciones_sucesores de este bloque Cver bloques, tipo SCREEN en descripción del lenguaje PROLAN 2. 2.1.4.X
2 í

* s Esta tocia sólo os permiti da cu ando estamos editando un bloque tipo REPORT y define el bloque al cual, va a ser transferido el control despues de ser ejecutado este bloque. Cver bloques tipo REPORT en descripción del lenguaje PROLAN 2.2.1.3^.
IMS Con esta tecla alternamos el modo Insert del editor con el modo Overwrite.
Con esta tecla terminamos la edición y volvemos al menú principal del programa.
2.4.4 Ver un bloque < SHOWME >.
Con esta opción podemos ver como quedará un bloque a la horade la interpretación del prototipo es decir, en este punto esinterpretado todo el código del bloque en cuestión incluyendomarcos e inclusiones de otros bloques es decir, se hace unaexpansión completa de todas las instrucciones que componen el bloque y dicha expansión es con el objeto de ir teniendo una idea exacta de como va quedando nuestro prototipo. Al interpretarse el bloque entramos a otro editor pero en el cual, sólo funcionan las teclas de movimiento del cursor y la tecla *• Q CCONTROL Q2 ya que. en este prunto no podemos modificar nada sino solamente ver.
El objetivo de entrar a un editor es que, un reporte ó una pantalla puede ser más grande que la pantalla normal de video entonces, con esta posibilidad nosotros podemos ver nuestra pantalla ó reporte completos.
2. 4.5 Generar código fuente PROLAN.
Esta opción como su nombre lo indica, nos genera el código fuente PROLAN del prototipo que ac tualmente está en la memoria de la computadora. Esta opción creará un archivo con el mismo nombre dado en las opciones 1 y/o 2 Cver secciones 2.4.1 y 2.4.2J> pero, con extensión .PRO el cual, podrá ser dado como entrada al compilador PROLAN. Si ninguna de estas opciones fué seleccionada entonces, será creado un archivo llamado ÑAMEME. PRO el cual, deberá ser renombrado por el usuario posteriormente para evitar perder el código PROLAN generado.
Cabe aclarar que lo generado por el programa se encuentra en código ASCII estándar por lo tanto, este código lo podemos accesar con el editor de nuestra preferencia y podemos efectuar cambios sobre él si es que asi lo deseamos.
22

2.4.6 Salvar código intermedio.
Si modificamos el prototipo de un sistema ó creamos unprototipo nuevo entonces, con el propósito de volver hacer modificaciones ó conservar este prototipo es necesario, guardarlo en disco. Al seleccionar esta opción el prototipo será almacenado en el archivo seleccionado en la opción Modificar un archivo existente ó en la opción Crear un archivo nuevo Cver secciones2.4.1 y 2.4.2J). Si ninguna de estas opciones ha sido seleccionada entonces será creado un archivo Herniado ÑAMEME. INT el cual, deberáser renombrado posteriormente para evitar perder el códigointermedio de nuestro prototipo.
2.4.7 Listado de bloques definidos / no definidos.
~Se entiende por un bloque definido aquel bloque el cual, ya se conoce de que tipo va a ser. Si un bloque sólo ha sido referenciado en alguna parte de la creación del prototipo pero no se ha definido su tipo entonces, se dice que este bloque sólo ha sido referenciado. Si un bloque sólo ha sido referenciado no se generará su código PROLAN respectivo ya que. no se cuenta con ninguna información para hacer algo al respecto. Esta opción nos permite saber qué bloques ya han sido definidos y cuáles no con el objeto, de que llevemos un buen control del diseño de nuestro prototipo.
2.4.8 Establecer Directivas.
Estas directivas funcionan exactamente igual que las definidas en Directivas al compilador Cver descripción del lenguaje PROLAN 2. 2.1.6.) y nos definen los límites máximos del n-úmero de columnas y numero de renglones que pueden tener los reportes y las pantallas. Solo falta explicar la directiva PATRON DE EDICION, esta directiva fué creada con el objeto siguiente :
Debido a que los bloques HEADING, FOOTING Y BLOCK podemos utilizarlos dentro de pantallas y/o reportes indistintamente entonces, como los límites máximos de columnas y renglones de éstos pueden ser diferentes, tenemos la necesidad de ver un bloque de este tipo dentro de los límites de una pantalla ó reporte dependiendo de donde los vamos a utilizar en nuestro prototipo y con esta opción podemos lograr ésto.
2.4.9 Limpiar area de trabajo.
Si durante la sesión de trabajo tenemos necesidad de borrar todo el prototipo que está actualmente en la memoria de la computadora ó vamos a iniciar la creación de uno nuevo entonces, debemos seleccionar esta opción. Cabe aclarar que esta opción sólo
23

borra el prototipo de la memoria de la computadora y no del disco es decir, si ya guardamos algo en disco ésto no será afectado de ninguna manera. Debemos tener mucho cuidado al usar esta opción pues si lo que hemos hecho no lo hemos guardado lo perderemos de una manera irrecuperable.
2.4.10 Fin de la sesión.
Con esta opción finaliza la ejecución del generador automático de código PROLAN. Antes de terminar definitivamente,el programa preguntará al usuario si está seguro de querer finalizar Esto es con el objeto de que se reflexione un poco por si existen cosas que se hicieron y no fueron guardadas adecuadamente.
23A

CAPITULO 3
IMPLEMENTACION DEL COMPILADOR PROLAN
3.1 Definición de la gramática PROLAN.
En el capítulo 2, presentamos el lenguaje PROLAN desde el punto de vista del usuario final. Entonces en este capítulo, damos sus características utilizando un enfoque técnico. La definición formal del lenguaje nos resultó más simple y conveniente ut ilizando una gramática libre de contexto. Pero, PROLAN es en realidad un lenguaje regular. La gramática PROLAN se puede transformar fácilmente en una gramática LLC1). En base de la cual, podemos construir el analizador sintáctico usando las ideas principales del método de descenso recursivo reemplazando las llamadas recursivas por ciclos iterativos.
Sin embargo, este compilador fué hecho utilizando las herramientas computar izadas LEX y YACC para la construcción de los analizadores léxico y sintáctico respectivamente, basados directamente en la gramática que se presenta en la figura 3.1. La gramática la presentamos en el formato Bachus Naur Form. C para más información ver 131 y resultó natural separar la parte léxica de la gramática del lenguaje ya que, esta separación corresponde a la metodología que se utilizó para la construcción del compilador.
3.2 Breve introducción a LEX.
Un compilador está compuesto básicamente de un analizador léxico CSCANNERX un analizador sintáctico CPARSERJ), un proceso de análisis semántico y la generación de código objeto. El analizador léxico se encarga de detectar grupos de caracteres los cuales, están lógicamente ligados llamados TOKENS ó símbolos terminales de una gramática dada. El analizador sintáctico se encarga de checar la correcta construción de un programa en un lenguaje el cual, está regido por una gramática. El análisis semántico checa el sentido de las construcciones hechas en los pasos anteriores y finalmente el código objeto que se genera es el producto final del proceso de compilación. En nuestro caso particular, logramos la generación del código objeto mediante rutinas semánticas específicas las cuales, son ejecutadas directamente durante el análisis sintáctico. Cabe hacer mención que, YACC construye un PARSER que utiliza el método LALRC13 para el reconocimiento de una gramática CPara más información ver 111J>.
El paquete computar izado LEX genera un programa en lenguaje "C" el cual, es un reconocedor de patrones. Es decir, al ejecutarse este programa toma como entrada un archivo fuente lo lee y nos reconocerá todos los TOKENS contenidos en él de acuerdo a los patrones que nosotros deseamos que reconozca.
24

FIGURA 3.1 Gramática del lenguaje PROLAN.
Parte Sintáctica i
<progra/h>
<blocks>
<op_list>
<op_cases>
<option>
<op_sop>
<body>
<com.pon&nt>
<text_line>
<l_alnd_line>
<opt _l_a l nd><r_alnd_line>
<c»nt_lin&>
<blocks>
<blochs> f <block>
<block>
HEADING <body>
FOOTING <body>
BLOCK id ; <body>
REPORT id i id ; <body>
SCREEN id <op_list> } <body>
: <op_cases> | e
<op_cases> , <option> <op_sop> id<option> <op_sep> idid | num | opchar ] opnum
* I -
<body> j <componont>
<component>
id ,<text_line>
<code_line>
<l_alnd_line>
<r_aLnd_line>
<cent_line>
<opt_l_alnd> <l_r_line> <opt_curs>
< I *
> <l_r_line> <opt_curs>■ <c_lin&> <opt_curs>

<r_nxum>
< c _ n v j n >
<c_lino>
<opt_cvxs>
< cod e_ lin e>
<code_args>
<separator>
<code_arg>
<r_nvm> , <c_n\tm> , siring , <c_n\tm> , siring
<r_nwn> , siringsiring
num | + num | - numnum | 4 num | - num<r_nvm> , siring
siring
- I *
C CURSOR num , nunO CFRAME num , num - num , nunOCid <code_args'>')
<code_args> <separator> <cod&_arg>
<code_arg>
' \ - \ £
num | id | siring

P a r t e l é x i c a t
<id>
<id_next>
<id_chax>
<num>
<opchar>
<opn\un>
<string>
<comm&nt>
<di reetive>
<letter> <id_next>
e | <id_next> <id_char>
<letter> \ <digit> | _ | •<digit> | <num> <digit>
* <any_chaurac ter> *
\<nwn>
"<any_character> ..........."— <any_character> . . <end_o/_line>
++ PAGELN ■ <nwn>♦+ PAGEWD ■ <n-um>4+ SCRNLN ■ <nvm>++ SCRNWD ■ <num>++ IMPRET ■ <nxim>++ FILEND
A B C D E F 11 6 1 H 1 I 1J K L M N o 11 p 1 Q 1 R 1S T U V W X 1 ^ 1 z 1 a jb c d e f g 1 * 1 i 1 J 1k 1 m n o p 1 «i 1 r 1 s 1t U V w X y 1 * 1
<digit> 0 I 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<letter>

LEX acepta como entrada un archivo llamado deespecificaciones el cual, consiste de tres partes separadas porlineas las cuales inician con los caracteres 'XX' CDos signos deporcentaje}. A continuación se presenta un ejemplo gráfico deésto :
X<pr írnera_parte>X XXsegunda_partepatrón_lP&tr ón_2
patróri_n acci ón_n a ejecutarseXXtercera_parte
La prirner& parte es opcional y puede contener líneas que controlan las dimensiones de ciertas tablas globales. definiciones como macros y también, código global en lenguaje "C”. Esta parte va precedida por una línea que inicie con 'X<* Csignos de porcentaje y llave que abre2 y terminada por una línea que inicie con ’X>’ (signos de porcentaje y llave que cierraO. Aunque la pr irnera_parte de la especificación para LEX sea vacía, los separadores XX entre la prirnera_parte y la segunda_parte no pueden ser omitidos.
La segurida_parte de la especificación consiste de una tabla de patrones a reconocer y de acciones a ejecutarse en caso de que ésto suceda. Las acciones pueden ser un solo estatuto en ”C” ó varios estatutos encerrados entre ’< >' (llaves). La acción puede también consistir de una ’|’ (barra verticalJ> la cual, indica que el patrón actual usará la misma acción que el próximo patrón.
La tercera_parte y el separador XX precedente a ésta es, opcional. Esta parte puede contener código en lenguaje "C” el cual, es usado tal como es. Usualmente contiene funciones locales que son parte de las acciones que segunda_parte invoca.
Del archivo de especificaciones, LEX construye una función en lenguaje "C” llamada YYLEXO y la guarda en un archivo en disco llamado LEXYY.C. Si esta función es ligada con otro programa y llamador; el estándar input será leído 'hasta su fin, detectando patrones. Las acciones asociadas con los patrones son ejecutadas. Si^.estas acciones contienen un estatuto return, YYLEXO retornará posiblemente con un valor asociado al patrón detectado (Para una mayor í nf ormac i ó n ver tí JS>.
25
acción_l a ejecutarse acción_2: a ejecutarse

Para demostrar el funcionamiento de las partes que se incluyen en un archivo de especificaciones para LEX, damos el siguiente ejemplo :
Queremos construir un compilador el cual, nos analize un programa basado en la siguiente gramática. En este momento nos centraremos en el analizador léxico y posteriormente en el analizador sintáctico. La gramática la presentamos en el formato B. N. F. .
<product>
factor
<expr> ♦ Cproduct> <expr> - <product> <product>
<product> * <factor> <product> S <factor>
<factor>
ID NUMC <expr>~>
En donde + - * ✓ O ID y NUM son TOKENS ó símbolos terminales de la gramática. Los cuales, serán detectados por el analizador léxico generado por LEX. Se supone que, ID está formado por letras y dígitos iniciando con una letra y NUM está formado por cualquier combinación de los dígitos entre 0 y 9. Entonces, el archivo de especificaciones de entrada para LEX sería el siguiente :
/* Ejemplo ésta es parte 1 */ ffinclude <ytab. h>
K>
XX
return PLUS; retxirn MI ÑUS; return MUL;return D1V; /* parte 2 */return LPÁR; return RPAR; return NUM; '< imprimeidCJ;return ID;>
<[0-9J>+< [a-zA-Z3>+
XX26
<expr>

S* p a r te 3 */
imprimeidCJ<
printfC"\n Identificador 5feM,yy texO;
Entonces LEX nos generará una función YYLEXO en lenguaje ”C” la cual, nos detectará estos patrones y ejecutará las acciones asociadas a cada uno de ellos.
3.3 Breve introducción a YACC.
YACC construye un analizador sintáctico ó PARSER para analizar una gramática dada. El método de análisis que utiliza un analizador hecho por medio de este paquete computar izado es LALRC1) Cpara más información ver I1Í5. Un PARSER es una máquina de stack el cual, consiste de un stock "grande" para manejar los estados de una matriz de transición y derivar un nuevo estado para cada combinación posible del estado actual y el próximo TOKEN leído de la entrada, una tabla de acciones definidas por el usuario las cuales, serán ejecutadas en ciertos puntos del reconocimiento, y finalmente, una rutina principal que controla todo ésto. El resultado es puesto en una función llamada YYPARSEO la cual, es escrita en un archivo en disco llamado YTAB.C. Esta función llama a la función del analizador léxico YYLEXO repetidamente hasta que detecta el fin del archivo de entrada y de esta forma se realiza una compilación de un archivo de entrada
Podemos visualizar la función de un PARSER de la siguiente manera :
stack matriz de transición
27

YACC acepta una gramática especificada en La forma B. N. F. como la que dimos para el ejemplo en cuestión.
Al igual que LEX, la entrada para YACC consiste de trespartes separadas por los mismos caracteres '906'.
La primera_parte de YACC es con el objeto de determinar que símbolos van a ser terminales ya que, no hay forma de diferenciarlos de los no terminales y ésto se logra anteponiendo la palabra XTOKEN seguida del nombre del símbolo terminal. Al igual que en LEX, en esta parte se puede incluir código global en lenguaje ”C ’\ También en esta parte se designa la jerarquía de operadores si es que estamos trabajando con gramáticas en las cuales se deba especificar ésto.
La segunda_parte consiste de todas las producciones de la gramática en forma B.N.F. y opcionalmente código en ”C” encerrado entre ’< >* C llaves? en cualquier punto que se desee delreconocimiento con lo cual, se logran las acciones semánticascorrespondientes.
La tercera_parte consiste de rutinas locales en lenguaje ”C" las cuales, regularmente son invocadas en la segurida_parte.
Ejemplo de la entrada a YACC para construir el analizador sintáctico del lenguaje dado en el ejemplo anterior :
x</* Analizador sintáctico del ejemplo */
ttinclude <ytctb.h> /* Parte í de YACCX>XTOKEN PLUS /# signo + */XTOKEN MI ÑUS /# signo - */XTOKEN MUL /# signo # */XTOKEN DIV /* signo / */XTOKEN NUM /# constante numérica, entera *sXTOKEN ID /# identi/icador */XTOKEN LPAR /* C */XTOKEN RPAR /# J> */
product
factor
exp PLUS product
exp MI NUS product product
product MUL factor /* Parte £ de YACC */ product DIV factor
factor
ID
28
exp

| NUM
| LPAR exp RPAR
mainCJ(
yyparseCl; /* parte 3 de YACC #/>
Esta entrada para YACC nos generará la función YYPARSEO la cual, ligada con la rutina YYLEXO nos da un compilador para la gramática especificada. Obviamente no hemos incluido ninguna acción semántica durante el reconocimiento de la gramática ya que. sólo se trata de una breve introducción a éstos paquetes.
Entonces de manera similar al ejemplo, se construyeron los analizadores léxico y sintáctico para nuestro lenguaje PROLAN. Se anexan más adelante listados de los archivos de especificaciones y además una explicación de las rutinas que conforman el compilador completo.
3.4 Estructuras de datos más importantes.
La generación del código objeto se logra mediante el uso de las rutinas semánticas ejecutadas durante el análisis sintáctico las cuales, trabajan sobre las estructuras más importantes del proceso de compilación y en las cuales, se guarda el código objeto, dichas estructuras son :
- La tabla de bloques CBTABJ>- La tabla de líneas <TLTABJ>
En la tabla BTAB se encuentra información general relativa a cada bloque y en la tabla LTAB se encuentran las instrucciones ó cuerpo de cada bloque. La relación gráfica entre estas tablas es la siguiente :
29

TABLA BTAB TABLA LTAB
Cada registro en La tabLa de bloques tiene los campos siguientes
Nombre del bloque, sirve como clave en la tabla BTAB, los bloques de tipo HEADING y FOOTING tienen el nombre vacío.
De t errni na que tipo de bl oque es C HEADING, FOOTING, BLOCK, REPORT, SCREEN?.
BLKID
BTYPE
DFLAG
FRSTL, LASTL
HEAD, FOOT
OPCNS
SUCCS
Determina si el bloque ha sido definido ó solamente referenciado.
Apuntadores a la primera y última línea en la tabla LTAB del cuerpo del bloque.Apuntan a los corresponden a BTAB.
bloques HEADING y FOOTING que este bloque en esta misma tabla
cadena de caracteresApuntador al inicio de la mencionados como opciones.
Apuntador al inicio de la cadena de los bloques sucesores que corresponden a las opciones.
Cabe mencionar que los componentes del registro de la tabla BTAB corresponden exactamente a los datos incluidos en un bloque tipo SCREEN. Para los otros tipos de bloques, se usan únicamente algunos de los componentes mencionados.
Cada registro en la tabla de líneas LTAB tiene los campos siguientes :
LTYPE Tipo de línea (.Texto, Identificador, CódigoJ>. 30

ALGN Tipo de alineación de la línea CIzquierda, Derecha, Centradaú.
SGNRNUM Signo del renglón.
RNUM Número de renglón.
SGNCNUM Signo de la columna.
CNUM Número de columna.
LTEXT Contenido textual de la línea.
OPTCURS Indica si el cursor será posicionado ó no al fin de la línea durante la ejecución del prototipo.
La es truc tura del registro corresponde otra vez al caso más común ó sea, a una línea de texto. Para el almacenamiento de los demás tipos de componentes posibles del cuerpo del bloque Clíneas de código y referencias a otros bloques2 se utilizan los campos arriba mencionados en forma, específica.
El contenido de las tablas BTA6 y LTAB completado con algunos valores más, representa el código objeto generado por el compilador. Naturalmente este código no se genera si se descubre algún error en el programa. El compilador sefíala varios tipos de errores sintácticos que en general, no considera graves ya que, intenta y puede recuperarse rápidamente de cada uno de el los.
Para el recuperamiento y detección de errores sintácticos se utilizaron facilidades del mismo paquete YACC <para más información ver 111 . Sin embargo el compilador detecta cualquier uso de algún bloque no definido considerándolo un error grave. Otro error grave ocurre si hay referencias cíclicas entre los bloques Ceste chequeo no ha sido implementado aún?.
3.5 ARCHIVO DE ESPECIFICACIONES PARA LEX.
Como vimos anteriormente, en la primera_parte del archivo de especificaciones para LEX Cver introducción a LEX 3.2.?, se definen variables globales, inclusiones y otros parámetros complementarios los cuales, son la parte general del analizador léxico que LEX nos generará. Las siguientes variables y estructuras son definidas en esta parte Cse mencionan las más importantes J>;- Se definen e inicial izan con valores de default las directivas
globales del compilador CPAGELN, PAGEWD, SCRNLN, SCRNWD, IMPRETD.- Se define e inicializa la tabla BTAB la cual, contendrá la información general de cada bloque. Esta tabla es inicializada en sus primeras 8 posiciones con las palabras reservadas del lenguaje PROLAN. La matriz es un arreglo de es truc turas y la definimos de la siguiente manera :
31

struct- opc i ones {int opcionval;struct opciones *nextop;
sucesores <int succval;struct sucesores *nextsucc;
Wdefine MAXTABstruct stabi
char *blkid;char btype;char dflsg;int. frstl;int. last Isint headsint. footsstruct opeiones struct sucesores
JbtabtMAXTAB]-<{"end",{"heading". i"footing". •( "block ", {"report." , ■( "screen",<"cursor", i"frame"?
♦openss—
NULL,NULL, NULL,NULL, NULL,NULL, NULL,NULL, NULL,NULL, NULL,NULL, NULL,NULL, NULL,NULL,
NULL, NULL, NULL, NULL, NULL. NULL, NULL: NULL,
NULL,NULL NULL,NULL NULL,NULL NULL,NULL NULL,NULL NULL,NULL NULL,NULL NULL,NULL
, NULL,NULL, NULL,NULL, .NULL,NULL, NULL,NULL, .NULL,NULL, NULL,NULL, .NULL,NULL, ,NULL,NULL,
NULL >, NIJLL> , NULL}, N!JLL>, NULL}, NULL > t NULL}» NULL >
También se definen otros valores y variables adicionales los cuales, son fácilmente localizados en el listado que se anexa.
La segunda_parte del archivo de los patrones que detectan los símbolos PROLAN y ciertas acciones ó llamados a cuando el patrón es detectado. A con patrones más relevantes y las acciones la construcción del patrón mencionado, archivo de especificaciones anexado al funciones relevantes invocadas en esta grandes rasgos en la tercera_parte„
especificaciones contiene, terminales de la gramática funciones que se ejecutan tinuación se explican los ejecutadas Csi se desea ver favor de ver el listado del final del capítulo2. Las parte serán, explicadas a
Detección de comentar ios. Solamente se checa su construcción léxica y se deshecha, no se toma ninguna acción.
- Detección de directivas. Se invoca la función procdirO; la cual, altera los valores de default de las directivas del compilador. No se regresa ningún valor al analizador sintáctico
32
200

a menos que. mea detectada la directiva FILEND la cual, detecta el fin lógico de un archivo PROLAN Cver directivas al compilador sección 2.2.1.6.). Si este directiva es encontrada se invoca la función errfinalO; la cual, nos emite los errores que hubo a nivel léxico y avisa al analizador sintáctico que el archivo de entrada terminó.
- Caracter entre apostrofes (OPCHAR). Se extrae el valor ASCII del caracter y se guarda en una variable global y se avisa al analizador sintáctico de esta detección.
- Detección de líneas de texto ó strings. Se invoca la función procesastringO; la cual, expande los caracteres de escape y valores ASCII dentro de una cadena de caracteres y retorna un valor al analizador sintáctico.
- Identificador. Al detectar un identificador se invoca la función procidenO; la cual, busca el identi ficador en la tabla de símbolos BTAB. Si no existe lo da de alta y si existe sólo nos regresa la posición del identificador en la tabla. Esa posición es almacenada en una variable global.
- Constante numérica entera. Se extrae el valor numérico de la constante, se almacena en una variable global y si el valor está en el intervalo O < Constante < 255 se envía al analizador sintáctico un valor de lo contrario se envía otro. Esto es con el objeto de diferenciar las constantes tipo "BYTE” de las otras.
- Constante real. Se extrae el valor de la constante real y se almacena en una variable global y se avisa al analizador sintáctico de que detectamos una constante de este tipo. Hasta este momento las constantes de este tipo no se utilizan en el lenguaje PROLAN pero, se detectan para futuras aplicaciones y/o modificaciones del lenguaje.
- Retorno de carro. Cuando el retorno de carro es detec tado se invoca la rutina procerrorO; la cual trata los errores léxicos a nivel de líneas.
Como se mencionó anteriormente, la tercera_parte del archivo de especificaciones de LEX consta de rutinas en lenguaje "C" las cuales, son regularmente invocadas en la segunda_parte. A continuación se explica de una manera general la implementación y el funcionamiento de las rutinas más importantes de esta parte CPara mayor información sobre estas rutinas favor de ver los listados que se anexan al fin del capí tulo>.
Rutina procerrorO; Esta rutina trabaja básicamente con la estructura siguiente :
struct- errores*int posicion; int error;
>errorest];
33

De cada línea de código fuente PROLAN que va siendo compilada, se guardan, todos los errores léxicos que van ocurriendo para que al detectar el fin de la línea sean desplegados en el dispositivo de salida estándar. Solamente se despliega el número del error y de que error se trata. El campo posicion no es utilizado actualmente.
Rutina procesastringO; Esta rutina lo que hace es expander los caracteres de escape que se encuentran en una línea de texto y nos genera una variable tipo string la cual, contiene ya el código expandido llamacLa stringreal. Ejemplo :
"\"\065\076\069JANI:>RO\032PENA\032CASANQVA\" " string original
"ALEJANDRO PENA CASANÒVA"
Rutina procidenO; Esta rutina da de alta un identificador en la tabla BTAB si es que no se encuentra en ella. Si ya se encuentra en la tabla solamente nos retorna en que posición se encuentra. Esta rutina efectúa una búsqueda con centinela. A continuación, se da recortado el algoritmo de este tipo de búsqueda
p ro ce d u re c » » a r c h ( » l# n i» n lo ) ;
i : in te g e r ;
b e g in
tablaC n » l 1 . n o in k r* :* l em ento ;
v h i l e í t a b la ! i 1. nom bre <> •lom ento)
i f < i == n+1>
re tu rn < i >;
En este punto solamente es conocido el nombre del bloque y los otros campos de la tabla BTAB son inicializados con NULL CnulosJ.
Rutina procdirO; La función de esta rutina es alterar los valores de las directivas del compilador. También checa que los valores de estas directivas estén dentro de los límites permitidos
34
procesastri ngC) ;
contenido de stringreal

3.6 Archivo de especificaciones para YACC.
Como mencionamos anteriormente, La pr imera_parte del archivo de especificaciones para YACC contiene la descripción de qué símbolos van a ser TOKENS. Entonces en esta parte estamos describiendo todos los símbolos terminales ó TOKENS del lenguaje PROLAN Cpara mayor información ver el listado de este archivo él cual, se anexa al fin del capítulo2
En la segurida_parte del archivo de especificaciones se encuentra la descripción de la gramática que va a reconocer el analizador sintáctico. En esta parte también, se ejecutan todas las acciones semánticas correspondientes. Las acciones semánticas más importantes son aquellas que generan el código objeto. Dichas acciones van llenando como lo hemos explicado las tablas BTAB y LTAB. Debido a que, las rutinas semánticas son muchas y se ejecutan en puntos muy diversos favor de ver el listado al fin del capítulo.
La tercera_parte del archivo de especificaciones contiene, rutinas y definición de variables muy importantes para todo el compilador en general. A continuación se explican las definiciones de variables y ruti nos más importantes.- En este punto es definida la tabla LTAB en la cual, se guardarán las líneas ó sea las instrucciones ó cuerpo de los bloques. Dicha tabla se define como sigue :
efine MAXLTAB 2000struct slirieí
char ltype; char algn; char sgnrnum; int- rnurn; char sgncnurn; i nt cnurn; char »Itext: char opt-curs;
íltabíMAXLTAB];
- En este punto son definidas otras variables auxiliares en el proceso de compilación. Una de ellas que vale la pena mencionar es la variable errf la cual, indica si existió ó no un error fatal para no liberar al usuario el código objeto repectivo.
Función inoptionO; Como podemos ver, las cadenas de opciones y sucesores de la tabla BTAB son listas ligadas creadas dinámicamente en memoria principal. Entonces durante el análisis sintáctico se van obteniendo los valores de estas cadenas y esta rutina da de alta al fin de la lista ligada las opciones que van siendo detectadas.
35

Función insuccO; Esta rutina trabaja exac tomante igual que la anterior sólo que, da de alta las direcciones de los bloques sucesores que corresponden a las opciones arriba mencionadas en su respectiva lista ligada.
3.7 Rutina principal del compilador PROLAN.
Entonces como hemos visto LEX nos genera la función YYLEXO la cual, es el analizador léxico y YACC genera la función YYPARSEO la cual, es el analizador sintáctico por lo tanto, fué necesario crear una rutina principal que controlara el funcionamiento de compilador en general. A continuación se da un esquema jerarquizado de este funcionamiento y se explican a grandes rasgos la rutina principal y otras rutinas auxiliares Cpara mayor información, ver los listados anexados en este capítuloZ.
Función mainO; Es la función principal que controla el compilador PROLAN. Esta rutina inicia su funcionamiento leyendo los parámetros de la línea de comandos Cver Ejecución del compilador 2.2.2). Dependiendo de los parámetros leídos se prenden las banderas para ejecutar las acciones correspondientes. Junto con los parámetros se lee el nombre del archivo de entrada y se abre de lectura. Si no se da ningún nombre, la lectura se hace sobre el dispositivo estándar de entrada.
El siguiente paso es invocar a la función YYPARSEC) la cual, se encarga del análisis sintáctico correspondiente y a la vez
36

invoca a la función YYLEXO hasta que el archivo de entrada es leído totalmente. Si durante la compiloción se detectan errores de tipo irrecuperables ésto queda reflejado en la bandera de errores y si esta bandera está prendida entonces, no se sigue adelante con el proceso de compilación y el programa termina en este punto con un mensaje.
Después se checa que todos los bloques de l,a tabla BTAB hayan sido definidos. Si hay bloques no definidos se despliega una lista de éstos y el programa termina en este punto.
Otro chequeo muy importante es el que se encarga de que no existan referencias cíclicas entre los llamados de bloques. Si existen, tampoco se liberará el código objeto respectivo ya que, ésto ocasionaia transtornos graves al programa intérprete Ceste chequeo no está implementado aúrO.
Si no ha habido ningún problema hasta este punto, se ejecutan las rutinas correspondientes a los párametros dadas al compilador en la línea de comandos Cver Ejecución del compilador 2.2.2) y el programa termina su ejecución de una manera normal.
Función interpreteO; Esta función nos interpreta el código objeto generado por nuestro compilador. Su implementación es comentada en el capítulo siguiente.
Función generacO; Esta función pasa el código objeto que se encuentra en las tablas BTAB y LTAB a un archivo en disco. Esto se logró utilizando las funciones estándar del lenguaje ”C” de lectura y escri tura. La escritura a disco es hecha en código ASCII estándar por lo tanto, los archivos en disco con extensión .OBB generados en este punto podrán ser listados sin ningún problema en la pantalla ó en la impresora.
Función imcodigoO; Esta función barre secuencialmente la tabla BTAB y la tabla LTAB y nos despliega en la pantalla sus contenidos en un formato puramente técnico. Esto es con el objeto de checar que el código objeto esté siendo generado de una manera correcta.
57








CAPITULO A-
IMPLEMENTACION DEL INTERPRETE
<4.1 Introducción.
Como hornos visto, el compilador genera un código objeto durante el proceso de compilación y éste código debe de ser ejecutado ó interpretado por un programa, independiente el cual, fué escrito en lenguaje ”C" en su totalidad.
£1 intérprete inicia su traJbajo cargando del disco el código objeto generado por el compilador y ajustando apropiadamente algunos valores complementarios Cdirec tivas, dirección del bloque MAIN, etc.2. Después inicia la ejecución del prototipo utilizando el bloque MAIN como el bloque inicial.
La interpretación del código objeto se puede ver en dos niveles. El primer nivel Cel más alto2 es un ciclo interpretativo típico que asegura el paso de control entre los bloques del programa, sus ”instrucciones” representan los registros de la tabla BTAB y su orden de ejecución se determina dinámicamente por las opciones del usuario. Este ciclo contiene además el manejo de un stach en el que se guarda la secuencia dinámica de bloques CMenúes} para que se pueda resolver la opción IMPRET del usuario Cver Directivas al compilador 2.2.1.6). A continuación se presenta el esqueleto comentado del primer niuel del intérprete.
procedure INTERPRET;var IC : instruct ion_couriter ;
OF' : option_character ;i : integer?
beginF'USH ("bloque END"); í fondo del stack >IC := "bloque MAIN"; -í el menú principal >while IC O "bloque END" dobegin
EJECUTE (IC); í ejecuta el bloque en segundo >. i nivel >
OP := "le opción del usuario" if OP = IMPRET
then POP (IC) i regresa al predecesor >else begin
i := "numero de orden de OP entre las opciones del bloque IC"
F’USH (IC); i guarda el predecesor iIC : - SUCCtil; í el i-ésirno sucesor >
endend ( del ciclo de interpretación >
end.38

El segundo nivel del intérprete se encarga de la ejecución de un solo bloque. Las "instrucciones" de éste nivel se guardan en los registros de LTAB y su .orden de ejecución es secuencial. En éste nivel, las referencias a otros bloques se ejecutan como llamadas a subrut inas y entonces el intérprete, visa otro stach para el manejo de las llamadas anidadas. El algoritmo de la ejecución de un bloque se presenta recortado y comentado de la forma, siguiente :
procedure EXECUTE( IC : instruction_counter );var i , fin : pointers_to_LTAB; < en BTAB Í
k : instructi on_counter;IR : LTAB_record_type í registro de instrucción >subr : boolean;
beginPU8H2 ( FRSTtlCJ LASTtIC] ) < pareja inicial >while not STACK2_EMPTY dobegin
POP2 ( i 8<S< fin ); subr s= false; while i <= fin and not subr do beg i n
IR := LTABIil; •( se saca la instruccióri >if IR = "referencia al bloque k"
then beginsubr := true; i := i+1;PUSH2 ( i ?•<?< fin ); { pendientes de ejecutar í PUSH2 < FR9T [ k ] ?<?< LAST C k 1 ) ;
end else begin
"Ejecuta la instrucción en IR"; i := i + 1;
endend
. end end
A grandes rasgos éstas son las dos rutinas básicas del programa intérprete y se utilizan algunas funciones estándar del lenguaje "C" para auxilio de la interpretación. A continuación se da una explicación mas detallda de la implementac ión de las rutinas que conforman el programa intérprete y se anexa el listado de éstas al fin del capitulo.
39

4.2 Implementación de las rutinas del intérprete.
Visto como un árbol jerarquizado el intérprete sería de la siguiente manera :
Función mainO; Cprimer nivel de interpretación^. Esta rutina inicia su funcionamiento cargando el código objeto de disco a la memoria principal de la computadora, en las tablas BTAG y LTAB y formando las estructuras dinámicas correspondientes principalmente a las List-as_opciones_5ucesore=. Posteriormente, busca un bloque en la tabla BTAB llamado MAIN el cual, es el bloque de inicio de ejecución. En éste primer nivel de ejecución se maneja un stack el cual, contiene direcciones de bloques de la tabla BTAB para poder accesar la pantalla precedente cuando se oprime el caracter correspondiente a la opción IMPRET. Al fondo de éste stack se encuentra el bloque ficticio END el cual, es el fin lógico de un programa PROLAN. Cabe aclarar que, las pantallas y los reportes son "dibujados” primero en una matriz de caracteres de dos dimensiones llamada MATRIXI1001I200] y después, ésta matriz es enviada directamente a la memoria del video si se trata de una pantalla ó a disco si se trata de un reporte. Esto se hizo asi con el objeto de poder trasladar si se desea el código del intérprete a otras computadoras y/o a otros lenguajes sin necesidad de hacer cambios radicales.
40

Antes de ejecutar un bloque en el segundo nivel, se checan sus campos correspondientes a sus HEADING y FOOTING y se ejecutan éstos. Después se ejecuta el bloque en cuestión en segundo nivel invocando la función executeO; pasándole como parámetro su dirección en BTAB. Cabe aclarar que sus HEADING y/o FOOTING son ejecutados exactamente de la misma manera. Entonces como vimos en el árbol jerarquizado la interpretación final de una "instrucción" ó decodificación la lleva a cabo, la función decodificaO; . La cual, recibe como parámetros, direcciones de la tabla LTAB. De ésta forma entonces, se lleva a cabo la interpretación de un bloque.
Si el tipo de bloque recién ejecutado en primer nivel es detipo REPORT, no se guarda en el stack la dirección de éste.Solamente, se extrae la dirección del bloque siguiente a ejecutar.
Si el bloque recién ejecutado en primer nivel es de tipoSCREEN, se guarda su dirección en el stock y se busca de acuerdoal caracter tecleado por el usuario cual es el bloque sucesor deéste en su Lista_opciones_sucesores. Si el bloque siguiente aejecutar se trata de un programa, externo, se procesa éste ydespués el control es retornado a nuestro intérprete de prototipos Césta opción no ha sido implementada aún?. Si se trata de la opción correspondiente a IMPRET, se saca del tope del stack la dirección del próximo bloque a ejecutar.
Esta rutina entonces terminará cuando sea encontrado como bloque a ejecutarse el bloque ficticio END.
Función executeO; C segundo nivel de interpretación?. A ésta rutina le llega como parámetro una dirección en la tabla BTAB el cual, es el bloque actual a ejecutarse. En éste nivel se utiliza otro stack para poder resolver las inclusiones a otros bloques. Estas inclusiones se tratan como llamados a subrutinas y lamecánica de funcionamiento es la siguiente :
Se guardan inicialmente en el stack las direcciones de inicio y fin del código del bloque ejecutándose. éstas direcciones corresponden a la tabla LTAB. Se ejecuta instrucción por instrucción y se pasa a la función decodif icaO; La dirección de cada una de ellas para su interpretación final. Si durante el proceso se detecta una línea que represente la inclusión dinámica de otro bloque entonces, se guardan en el stack las direcciones de retorno representadas por los limites inicial y final de las instrucc iones que aún no fxan sido ejecutadas del bloque actual, los límites inicial y final del código del bloque a incluir y se sigue el proceso normal. Este segundo ciclo interpretativo terminará cuando el stack de éste nivel esté vacío.
Función decodif icaO; Cdecodif icación de instrucciones?. A esta función, le llega como parámetro una dirección en la tabla LTAB la cual, corresponde a la instrucción que actualmente está siendo ejecutada. El "código de operación" corresponde■ al campo LTYPE y los operandos están en los otros campos dependiendo de que instrucción se trata. Si se trata de dibujar un marco Cframe? se invoca la función borderO; pasándole los parámetros respectivos. Si se trata de una línea de texto se hacen una serie de cálculos y
4Í

actualización de valores basados en mi alineamiento paradeterminar la posición de despliegue de la línea en cuestión en lamatriz de formación de las pantallas y/o los reportes. Si se tratade un posicionamiento de cursor se actualizan las nuevascoordenadas y si se trata de una línea de código se invoca la función correspondiente y se le pasan sus parámetros respectivos Cno i mpl ementado aún). Para mayor información rerni t irse al listado anexo.
42



CAPITULO 5
IMPLEMENT ACION DEL PROGRAMA GENERADOR AUTOMATICO DE CODIGO PROLAN
5.1 Introducción.
Como hemos visto hasta ahora, PROLAN es un lenguaje sumamente sencillo y fácil por lo cual no cuesta mucho esfuerzo entender su gramática y su filosofía. Aún con todos éstos atributos se creó un programa en lenguaje ”C” el cual, es un programa generador interactivo automático de código PROLAN. Con el objeto de que. personas con conocimientos muy básicos del lenguaje PROLAN sean capaces de crear prototipos de sus sistemas de una manera relativamente fácil, interactiva y rápida.
Cabe hacer mención solamente de una diferencia en la definición de las tablas BTAB y LTAB. La filosofía de uso es la misma pero, aquí la tabla LTAB está compuesta de estructuras netamente dinámicas ya que. la construcción del código fuente para un prototipo de ésta manera requiere de alta flexibilidad en el uso de las estructuras de datos. Entonces, la relación gráfica entre las tablas BTAB y LTAB es ahora la siguiente :
Cada una de éstas es truc turas es creada y/o modificada en diferentes opciones del programa generador automático de código. A continuación se explica a grandes rasgos la implementación de cada una de las opciones del programa generador automático de código PROLAN y de las ru t i nos ctsoc i adas a ellas.
43

El programa es controlado por la función mainO; por medio de un menú general. En ésta función se definen variables yestructuras utilizadas en las diferentes opciones. Entonces, lastablas BTAB y LTAB quedan definidas de la siguiente manera :
¿define MAXTAB 200
struct =t ab{char *blkid;char btype; struct 1tab ichar dflag char ltype;st. r uct 1 tab * f r st 1 ; ------------- ► cha r a 1 gn ;struct ltab *:frstinc;------------ ► char sgnrnum;struct ltab *frstframe;----------*• int. rnurn;int head; char sgncnurnint. foot: int cnurn;struct opc_succ *frstopsucc; char *ltext:
}btabIMAXTAB1 ; char optcurs;struct ltab *next1cod;
Ist-r uct opc_succ char *opsucc;struct opc_succ *nextopsucc;
5.2 Modificar un Archivo Existente.
Se pide el nombre del archivo, se ignora la extensión si es que se da y se le agrega la extensión .INT. También, en éste punto se abre para escritura un archivo con el mismo nombre pero, con extensión .PRO. En el ¿ual, se grabará el código PROLAN si así se desea Cver Generar código fuente PROLAN 5.6->. Si el archivo con extensión .INT se encuentra en el direc torio, se carga en la memoria de la computadora llenando las tablas BTAB y LTAB respectivamente además, de otros valores complementarios como directivas. El código es cargado de disco invocando la función cargacodigoO; .
Función cargacodigoO; Lo primero que hace ésta rutina, es invocar la función liberaareasO; posteriormente lee de disco el código intermedio que corresponde a un prototipo y llena y/o forma todas las es truc turas que conforman las tablas BTAB y LTAB en la memoria principal de la computadora.
Función liberaareasO; Esta función libera ó devuelve a la computadora el espacio ocupado por las es truc turas en la memoria de ella. Es decir, deja las tablas BTAB y LTAB disponibles para almacenar un nuevo prototipo.
44

5.3 Crear un Archivo Nuevo.
En éste punto se crea’un archivo nuevo en el cual, podrá ser guardado el prototipo que se encuentre en memoria. Se pide el nombre y se le agrega la extensión . INT, se busca que el archivo no exista previamente en el directorio. Si existe, el usuario será advertido de ésto y si se desea destruir su contenido. También en éste punto se crea un archivo con extensión .PRO en el cual, se escribirá el código PROLAN si es que el usuario lo desea generarCver Generar código fuente PROLAN 5.6J>.
5.4 Editar un Bloque.
Podemos decir, que ésta es la opción más importante del programa ya que, en ésta opción el usuario puede hacer de una forma interactiva sus pantallas y/o sus reportes. En ésta opción, se tuvo que crear un editor de pantalla completa e incluir el intérprete de prototipos con el objeto de pasar un bloque en código objeto a formato comprensible por el •usuario en el editor de pantalla. La forma en que se implementó ésta opción es la siguiente :
1.-Se pide el bloque a editar y se busca si existe en la tabla BTAB invocando la función procidenO; Cver implementación del compilador capítulo 3.?.
2. -Si el bloque existe en la tabla BTAB se pasa éste bloque alintérprete y las líneas de texto son desplegadas en una matriz en sus coordenadas correspondientes. Esto se hace invocando la función interpreteO; Cver implementación del intérpretecapítulo 4J>. Posteriormente se invoca la función editorO; pasándole como parámetro la matriz recién llenada por el intérprete y allí, el usuario puede crear y/o modificar las líneas de texto a su antojo y usar otras instrucciones. Cabe aclarar que en éste punto de interpretación sólo soninterpretadas las líneas de texto ya que, son las que se pueden modificar por medio del editor. Es decir, en éste punto los efectos de las inclusiones a otros bloques y los fromes no son vistos. Sólo pueden ser modificados sus parámetros Cver Mostrar un bloque <Showme> 5.5.?.
3.-Si el bloque no existe y sí el usuario lo quiere crear, se crea uno nuevo y entonces, el usuario puede meter el cuerpo de instrucciones por medio del editor de pantalla.
4.-Al terminar la edición, se altera la estructura correspondiente a líneas de texto invocando la función genltabO; . Es decir, se elimina totalmente la estructura anterior y se crea una nueva con lo que está actualmente en la matriz que se editó. Esto es con el objeto de reflejar los cambios hechos. También, durante la edición se pueden alterar las otras estructuras que componen la tabla LTAB. A continuación se explica más a detalle ésto.
45

5.4.1 Función editorO;
La estructura de datos con La cual trabaja nuestro editor de pantalla, es una matriz rectangular de tamaño máximo 100 filas y 200 columnas. Pero, nosotros podemos viajar a cualquier coordenada de ésta matriz en la pantalla del video ya que, están implementados ”scrolls" tanto hacia Los lados como hacia arriba 6 hacia abajo. Los tamaños máximos del número de columnas y renglones que se pueden editar en un momento determinado están dados por las directivas Cver Establecer directivas 5.9J>. El algoritmo general recortado del editor es el siguiente :
program EDITOR;
tecla : char; í tecla oprimida >>;,y : integer; { coordenadas actuales del cursor í
beg i nwhile( read(tecla en la hegin
case(tecla)valorl : acción!; valor2 : acciori2; valor3 : accion3; valor4 : accion4;
valorn : accionn; end;
end;genera ó altera la estructura de líneas de texto;
end
Aquí dentro del editor- están incluidas las acciones para alterar las estructuras de inclusiones de bloques, frames y estructuras de opciones_sucesores. Son opciones de altas, bajas y consultas a éstas estructuras y cualquier cambio que se haga sobre ellas ocasionará que la estructura en cuestión sea alterada. Más adelante explicaremos la implementación general de cada una de éstas funciones.
Los ”scrolls” de pantalla son hechos a través de las funciones estándar del lenguaje "C" puttextO; y movetextO; las cuales, nos permiten escibir y/o mover textos directamente a la memoria del video de la computadora Cpara más información ver 15]?. Ya que. éstos movimientos son muy utilizados en el editor a continuación se explica brevemente como son logrados éstos.
Es importante mencionar que durante el proceso de edición se manejan 2 tipos de coordenadas. Unas corresponden a la posición del cursor dentro del video de la computadora y las otras corresponden a la posición en donde nos encontramos actualmente dentro de la matriz de edición.
posición x, y > O QlJIT )
< acciones sobre la matriz en las > { coordenadas x,y u otras acciones >
46

Scrool_hacia_abajo. Se mueve todo el texto del video comprendido entre las coordenadas C2,í 24,802 a las coordenadas Cí,1,23,802. Con ésto logramos que desaparezca lo que hay en la línea 1 y se duplique lo que hay en la línea 24. Entonces simplemente reemplazamos la línea 24 del video con el contenido de la línea inmediatamente superior de la matriz de edición.
Scrool_hacia_arriba. Se mueve todo el texto del video comprendido entre las coordenadas Cí,í 23,802 a las coordenadasC2,l,24,802. Con ésto logramos que desaparezca lo que hay en la línea 24 y se duplique lo que hay en la línea 1. Entonces simplemente reemplazamos la línea 1 del video con el contenido de la línea inmediatamente inferior de la matriz de edición.
Scrool_hacia_la_derecha. Se mueve todo el texto del video comprendido entre las coordenadas Cí,l 24,792 a las coordenadasCí,2,24,802. Con ésto logramos que desaparezca lo que hay en lacolumna 80 y se duplique lo que hay en la columna 1. Entonces simplemente reemplazamos la columna 1 del vídeo con el contenido de la columna inmediatamente inferior de la matriz de edición.
Scrool_hacia_la_izquierda. Se mueve todo el texto del video comprendido entre las coordenadas CI,2 24,802 a las coordenadasCí,1,24,792. Con ésto logramos que, desaparezca lo que hay en la columna 1 y se duplique lo que hay en la columna 80. Entonces simplemente reemplazamos la columna 80 del video con el contenido de la columna inmediatamente superior de la matriz de edición.
A continuación se explica de una manera general la implementación de las rutinas que corresponden a las acciones y algunas otras de apoyo. Las cuales, son ejecutadas en el editor dependiendo de alguna tecla ó combinación de teclas oprimidas por el usuario. Se entiende por línea y columna actual aquellas en donde está posicionado el cursor y si se efectúa algún cambio en la memoria del video también, éste cambio será hecho sobre la matriz de edición.
Función leeteclaO; Esta función lee direc tómente del "buffer" del teclado en la posición del cursor la tecla ó combinación de ellas y nos regresa un código.
Función imiineaO; Esta función imprime una línea de texto de longitud 80 caracteres ya sea en la posición 1 ó en la 24 de la memoria del video.
Función imcolO; Esta función imprime una columna de texto de longitud 24 caracteres ya sea en la posición 1 ó en la 80. de la memoria del video.
Función procesauaO; Esta función es invocada cuando elusuario oprime la flecha hacia arriba. Esta tecla traslada el cursor una posición hacia arriba en el video. Si es necesario ejecuta un scrol1_hacia_abajo.
Función procesadaO; Esta función es invocada cuando elusuario oprime la flecha hacia abajo. Esta tecla traslada el
47

cursor una posición hacia abajo en el video. Sí es necesarioejecuta un scroll_hacia_arriba.
Función procesalaO; Esta función es invocada cuando el usuario oprime la flecha hacia la izquierda. Esta tecla traslada el cursor una posición hacia la izquierda en el video. Si es necesario ejecuta un scroll_hacia_la_derecha.
Función procesaraO; Esta función es invocada cuando el usuario oprime la flecha hacia la derecha. Esta tecla traslada el cursor una posición hacia la derecha en el video. Si es necesario ejecuta un scroll_hacia_la_izquierda.
Función procesaasciistdO; Esta función se ejecuta cuando se detecta un caracter comprendido entre los valores 32 y 126 del código ASCII estándar y además, el editor se encuentra en modo ”overwri te”. Su función es reemplazar lo que hay en la posición x.y del video y de la matriz de edición con el caracter leído.
Función procesaasciiintO; Esta función se ejecuta cuando se detecta un caracter comprendido entre los valores 32 y 126 del código ASCII estándar y además , el editor se encuentra en modo ”inserí”. Su función es recorrer el texto de la línea una posición a la derecha a partir de las coordenadas x,y del video y de la matriz de edición y poner en esa posición el caracter leído.
Función procesadelO; Esta función es invocada al detectar la tecla DEL. Esta función borra el caracter que se ericuentra en la posición del cursor. Esto se logra recorriendo todo el texto de la línea de la matriz de edición que se encuentra a la derecha de las coordenadas x. y una posición a la izquierda.
Función procesaretinsO; Esta función se ejecuta al digitar la tecla RETURN y el editor está en modo ”insert”. Lo que se hace es abrir una línea nueva en la posición siguiente a donde está el cursor por medio de un recorrimiento físico de todas las líneas de texto un lugar haci a abajo.
Función procesaretCD; Esta función se ejecuta al digitar la tecla RETURN y el editor está en modo "overwrite”. Lo que se hace es trasladar el cursor una línea hacia abajo y en ¿a columna 1.
Función procesadellineO; Esta función se ejecuta cuando el usuario oprime la combinación de teclas ~Y. Lo que se hace es eliminar totalmente la línea en donde se encuentra el cursor por medio de un recorrimiento físico de todas las líneas de texto una posición hacia arriba a partir de donde está el cursor.
Función procesahomeCD; Esta función se ejecuta al digitar la tecla HOME. Se busca el primer caracter diferente de blanco de izquierda a derecha de la línea actual y se modifican entonces las coordenadas poniendo allí el cursor.
Función procesaendO; Esta función se ejecuta al digitar la tecla END. Se busca el primer caracter diferente de blanco de derecha a izquierda de la línea actual y se modifican entonces las coordenadas poniendo allí el cursor.
48

Función procesabackO; Esta función se ejecuta al detectar la tecla BACKSPACE y se implementó haciendo una invocación primero de la función procesalaO; y después de la función procesadelO; .
Función procesacent-fO; Esta función es ejecutada al detectarse la combinación de teclas "‘C. Lo que se hace es centrar físicamente la línea actual entre los margenes <1,SCRNWD> para las pantallas y <1,PAGEWD> para los reportes. Esto se logra efectuando cálculos entre la longitud del texto de la línea y los margenes. Además, se prende una bandera en la posición 0 lo cual indicará que ésta sea una línea centrada a la hora de generar el código PROLAN.
Función procesalef ifO; Esta función es ejecutada aldetectarse la combinación de teclas *L. Lo que se hace estrasladar físicamente toda la línea actual hacia la izquierda haciendo coincidir el primer caracter no vacío con la posición 1 del video y de la matriz de edición.
Función procesarightfO; Esta función es ejecutada aldetectarse la combinación de teclas ~R. Lo que se hace estrasladar físicamente toda la línea actual hacia la derecha haciendo coincidir el último caracter no vacío con la posiciónSCRNWD del video y de la matriz de edición para las pantallas ycon la posición PAGEWD para los reportes.
Función procesaleftlCD; Esta función es ejecutada aldetectarse la combinación de teclas ^J. Lo que se hace es prender una bandera en la posición 0 de la línea actual que indicará que ésta sea una línea alineada a la izquierda a la hora de generar el código PROLAN.
Función procesarightlO; Esta función es ejecutada aldetectarse la combinación de teclas ~K. Lo que se hace es prender una bandera en la posición O de la línea actual que indicará que ésta sea una línea alineada a la derecha a la hora de generar el código PROLAN.
Función procesa_ulO; Esta función es ejecutada al detec tarse la combinación de teclas ~A. Lo que se hace es prender una banderaen la posición 0 de la línea actual que indicará que el cursorserá posicionado al fin de la línea a la hora de la interpretación del código objeto del prototipo.
Función incluyebO; Esta función se invoca al detectar lacombinación de teclas '‘I. Al 'hacerlo nos pasamos del editor a unmentí el cual, nos permite hacer altas, bajas y consultas a unalista simplemente ligada. La cual, corresponde a las inclusiones de bloques del bloque que estamos actualmente editando.
Función incluyefO; Esta función se invoca al detectar lacombinación de teclas ~F Al hacerlo nos pasamos del editor a unmenú el cual, nos permite hacer altas, bajas y consultas a unalista simplemente ligada. La cual, corresponde a las inclusiones de marcos Cframes2 del bloque que estamos actualmente editando.
49

Función incluyeosO; Esta función se invoca al detectar lacombinación de teclas *0. Al hacerlo nos pasamos del editor a unmenú el cual, nos permite hacer altas, bajas y cónsul tas a una lista simplemente ligada. La cual, corresponde a laLista_opcic<nes_sucesores del bloque que estamos actualmenteeditando.
Función genltabO; Esta función es ejecutada cuando sedetecta la combinación de teclas ~Q. Esto significa fin de la edición y entonces se destruye totalmente la lista ligada que corresponde a las líneas de texto del bloque recién editado y se genera una nueva con el contenido de las líneas que hay en la matriz de edición.
5.5 Mostrar un Bloque CShowme).
Esta opción fué creada con el objeto de que, el usuario pueda ver un bloque de código ejecutado totalmente. Es decir, a diferencia de la opción anterior edición de un bloque, no se pueden ver las inclusiones a otros bloques ni los fromes incluidos. Por lo tanto, ésta opción nos permite ver como quedará totalmente un bloque de código a la hora de ejecución del prototipo. La forma en que se implementó ésta opción es la siguiente :
Se pasa el bloque a mostrar al intérprete con una bandera la cual dice que estamos en modo "showme". Con el objeto de que, ejecute las inclusiones dinámicas de otros bloques de código y los fromes. Entonces, el intérprete llena la matriz correspondiente y entramos al editor pero en el cual, sólo funcionan las teclas de movimiento de cursor ya que en éste punto no podemos modificar nada.
5.6 Generación de Código PROLAN.
Esta es otra de las opciones más importantes de éste programa y nos sirve, para generar el código fuente PROLAN invocando la función gencpO; .
Función gencpO; Esta función escribe el código fuente PROLAN en un archivo en disco el cual tiene extensión .PRO y que fuépreviamente abierto en la opción 1 ó 2 del menú principal. Al seleccionar ésta opción se explotan las tablas BTAB y LTAB asícomo otros valores adicionales tales como directivas. Esto es conel objeto, de posarlas al formato del lenguaje PROLAN. Como primer punto se escriben en el archivo las direc tivas con sus valoresactuales ya que, éstas directivas regirán sobre todo el prototipo. Después, se barre secuencialmente la tabla de bloques BTAB para saber de que tipo de bloques se trata y se plasma en el archivo de código PROLAN junto con las líneas de su cuerpo las cuales, sonobtenidos de las estructuras dinámicas con las que está construida la tabla LTAB.
50

5.7 Salvar Código Intermedio.
; Con el objeto de que ún prototipo pueda ser modificado ó aumentado "es necesario, guardar las tablas BTAB, LTAB y demás parámetros en un archivo en disco y en un formato tal que, pueda ser recuperado posteriormente. Esto se logra invocando la función guardacO; .
Función guardacO; Esta función trabaja sobre un archivo con extensión . INT el cual, fué previamente abierto en las opciones 1 ó 2 del menú principal. La tabla BTAB y las estructuras que conforman la tabla LTAB, son almacenadas de una forma especial tal que. luego puedan ser recuperadas para volver a crear las es truc turas en la memoria de la computadora. Cabe aclarar que no se hace encriptación alguna del código que se escribe a disco. Es decir, se hace en ASCII estándar y por lo tanto puede ser visto ó editado por otros medios.
5.8 Reporte de bloques definidos / no definidos.
El campo DFLAG de la tabla BTAB nos indica si un bloque ha sido definido ó solamente referenciado. Entonces, ésta opción trabaja netamente sobre la tabla BTAB de una manera secuencial y nos reporta en la pantalla aquellos bloques según el estado del indicador antes mencionado. Todo ésto lo hace la función i mbloquesdndC) ; .
5.9 Establecer Directivas.
Las directivas como fué explicado en la descripción dellenguaje PROLAN C2.2.1.63 nos indican el número máximo de líneas ycolumnas que van a tener ios pantallas y los reportes. Estasdirectivas están vigentes a la hora de editar un bloque y a lahora de mostrar los bloques. También, cabe aclarar que los valores de las directivas serán tomados tal cual a la hora de generar el código PROLAN y así serán grabados en el archivo respectivo.
5.10 Limpiar Area de Trabajo.
Esta opción significa que podemos iniciar una nueva sesión de trabajo es decir, eliminar totalmente el prototipo que se encuentra en la memoria de la computadora. Esto se logra, eliminando ó limpiando los apuntadores de la tabla BTAB a las estructuras dinámicas que conforman la tabla LTAB. Entonces, el espacio que ocupan las estructuras es devuelto a la memoria libre de la computadora. También, son eliminados todos los bloques de la tabla BTAB. Todo ésto es hecho por la función liberaareasO; Cver5.2S>. Es importante estar seguro de que el prototipo que está en memoria ha sido previamente salvado ya que. todo el trabajo hecho hasta éste punto se perderá de una manera irrevocable.
51












CAPITULO 6
UNA AMPLIACION DEL SISTEMA PROLAN
6.1 Introducción.
Estando concientes de la rápidez del lenguaje PROLAN para generar prototipos básicos de sistemas de software. Seria ideal poder utilizar el código que hace ésto, para poder generar un esqueleto de nuestro sistema firval de producción en una herramienta ó lenguaje de alto nivel. El cual pudiésemos expander según nuestras necesidades de desarrollo, ya sea agregando código adicional ó funcionalidad y dinamismo a las pantallas y/o reportes generados por medio del lenguaje PROLAN.
Considero que, el proceso de pasar un programa escrito en lenguaje PROLAN a cualquier otro, variaría según el lenguaje de que se trate. ya que es necesario analizar a detalle que construcciones son equivalentes, si el lenguaje es estructurado ó no, si es declarativo ó procedural y además si existe factibilidad en la transformación.
En este capítulo se presentan a detalle los pasos necesarios para poder implementar un programa en lenguaje "C". El cual sea capaz de transformar un programa escrito en lenguaje PROLAN, a otro programa, en lenguaje "C", que haga exactamente lo mismo a la hora de ejecución. Además en este nuevo programa sería factible agregar y/o modificar el código de acuerdo a nuestras necesidades tal y como lo mencionamos anteriormente.
6.2 Descripción del procedimiento.
Para iniciar la conversión del lenguaje PROLAN al lenguaje"C", sería necesario primero compilar el código fuente escrito por el usuario ó hecho a través del programa generador automático. Esto es con el objeto de trabajar sobre el código objeto generado por el compilador. Específicamente hablando necesitaríamos trabajar sobre las tablas de bloques BTAB y la de líneas LTABCpara más información de estas tablas ver capítulo 3 2. Elpropósito de trabajar con el código objeto en lugar del código fuente, es que el código objeto ya se encuentra libre de errores de sintaxis, se encuentran hechas las ligas lógicas entre todos los módulos del programa y además se encuentra en una forma tal que. solamente decodificando los códigos de operación de las diversas instrucciones y accesando sus operandos podemostransformar todo ésto a sus construcciones equivalentes en ellenguaje "C".
53

Una vez generado el código objeto de un programa fuente en PROLAN, procederemos a explotarlo y a escribir en un archivo en disco su código fuente respectivo en lenguaje "CM. Entonces el algoritmo general es el siguiente :- Iniciar la lectura de la tabla de bloques BTAB de una manera secuencial.
- Determinar que tipo de bloque se trata, si se trata de un bloquetipo HEADING, FOOTING, ó BLOCK, abrimos el inicio de unprocedimiento en lenguaje "C" con el mismo nombre de este bloque. Como los bloques HEADING y FOOTING no tienen nombre, formamos uno nosotros mismos. Posteriormente aplicamos el proceso de explotación de sus líneas de instrucciones que se encuentran en la tabla LTAB Céste proceso se explica mós adelante2. De esta formacreamos un procedimiento ya en lenguaje "C" equivalente a unbloque de los tipos mencionados arriba. Su esqueleto en lenguaje *’C" será el siguiente :
nombre()instruccionl ■ instruecion2í instruccionS;
instruccionn;
- Si el bloque que estamos analizando es de tipo REPORT ó SCREEN su equivalente en "C" consta de dos partes. La primera parte consiste de su contenido textual ó cuerpo y la segunda parte llamada parte de control contiene la invocación a sus encabezados y pies de página estándar Csi es que tiene}, la invocación a su cuerpo y el control de las transferencias según las opciones del usuario. El objetivo de que un bloque de este tipo tenga dos partes en "C" es que, en cualquier otro bloque podemos hacer referencias dinámicas a él y entonces el llamado sería solamente a su contenido textual y no a su control. Entonces la primera parte de estos bl oques es f ormada por l a exp lo tac i ón de sus instrucciones en la tabla LTAB y la segunda parte es formada por la explotación de sus cadenas de opciones-sucesores en los bloques tipo SCREEN y por el bloque siguiente a ejecutarse en los bloques tipo REPORT Cpara más información ver capítulo 2 Entonces elesqueleto de su primera parte en lenguaje "C" será el siguiente :
cuerpo()instruccionl; inst.ruccion2; ínstruccionS;
instrucciomn
54

Esta primera parte será igual para los bloques REPORT y SCREEN pero, la segunda parte tendrá una pequeña diferencia. A continuación se muestra como será el esqueleto en lenguaje "C" de la segunda parte ó parte dé control para un bloque tipo SCREEN :
nombre(><
TIPOBLOQUE = TIPÜSCREEN; heading(> ; footing(); cuerpo() ; c=getch<): switch(c)<
case opcionl : <return(sucesor 1); > case opcion2 : <return(sucesor2); > case opciortS : <return <sucesor3) ? >
case opcionn : {return(sucesorn); }
Para un bloque tipo REPORT, la segunda parte serÁ lasiguiente :
nombre()TIPOBLÜGUE=TIPOREPORT; h e a d i n g O ; footing()5 cuerpo()5ret ur n (b1oque s i gu i ente):
Estos bloques serán invocados por la rutina controlCD; la cual, es una rutina estándar Cmás adelante se explica ésto}, escrita en lenguaje "C" y es la que se encargará de asegurar el paso del control entre los bloques.
- La formación de la parte de control de un bloque se forma de la siguiente manera :
Primero se prende una bandera global, la cual nos servirá para saber que tipo de bloque estamos ejecutando. Después se checan los apuntadores a sus encabezados y pies de página estándar. Si tienen algún valor se generan invocaciones a ellos. Después se genera una invocación al cuerpo de este bloque. Posteriormente para los bloques tipo SCREEN, se genera una estructura de cases dependiendo del contenido de su cadena opciones-sucesores. Siempre estará presente en »sta estructura la opción IMPRET. Para los bloques tipo REPORT, se genera solamente una invocación al bloque siguiente.
55

- La explotación de las instrucciones de un bloque en la tabla LTAB, nos da como resultado la transformación de cada una de ellas en su equivalente en lenguaje "C". A continuación se muestran las acciones para lograr ésto i
Sí se detecta una línea de codigo.se crea la siguiente instrucción en "C” i
nombre(parí,par2,...parn);
En domde nombre representa una rutina la cual, es responsabilidad del usuario ponerla al alcance del programa..
Si se detecta una línea tipo cursor se crea la siguiente instrucción en "C" *
cursor(reng,col):
En donde cursorO; será una rutina estándar hecha en lenguaje "C". Esta rutina afectará las coordenadas de posicionamiento de cusor que se utilizan para pedir la opción del usuario después de que sea ejecutada una pantalla.
Si se detecta una línea tipo frarne se crea la siguiente instrucción en "C" :
frarne (par 1, par2, par3, par4> ;
En donde frameO; será una rutina estándar hecha en lenguaje "C". Esta rutina nos generará los marcos en las pantallas.
Si se detecta una línea tipo identificador, se crea la siguiente instrucción en "C", tomando en cuenta las siguientes consideraciones :
Si el bloque al cual se hace referencia es un bloque de tipo REPORT ó SCREEN se genera una instrucción que representa la invocación al contenido textual ó cuerpo de ese bloque :
cuerpo();
Si el bloque referenciado es de otro tipo, se genera un llamado al nombre de ese bloque :
nombre();
56

Entonces hemos llegado al tratamiento de las ins trucc iones ó líneas más típicas dentro de los bloques y son las líneas de texto. Eventual mente el equivalente en lenguaje "C" de este tipo de líneas, serán dos instrucciones. La primera representa el contenido textual de la línea más las coordenadas en la cual será puesta esa línea durante la ejecución del programa. La segunda instrucción será una invocación a la rutina estándar cursorO; en caso de que esta línea tenga incluida la opción de posicionamiento de cursor Cpara más información ver capítulo 2 D. Entonces el equivalente en lenguaje "CM será de la siguiente manera :
desp1 i ega1(reng1,col 1,texto)¡ cursor(reng2,col 2);
En donde rengl, coll, reng2, col2, pueden ser calculados de dosmaneras diferentes :
La primera es generar en lenguaje "C" la instrucción con suscoordenadas definitivas. Es decir, durante el proceso degeneración de código en "C", podemos simular por medio delintérprete la ejecución completa de un bloque en particular con el objeto de determinar las coordenadas definitivas de sus líneas de texto. La otra forma es pasar las coordenadas que dió el usuarioy generar una rutina estándar que estará incluida en nuestrosprogramas en "C" y se encargará del cálculo del posicionamientode las líneas de texto a la hora de ejecución del programa.
6.3 Rutinas estándar-
Como hemos mencionado anteriormente podemos tener creadas de antemano ciertas rutinas, las cuales serán incluidas en todoprograma en "C" creado en forma automática. Esto es con el objetode facilitarnos el trabajo. A continuación se explica de unamanera general que rutinas podrían ser y su funcionamiento :
Rutina cursorO; Esta rutina se encargará de afectar unas variables globales, las cuales indicarán en donde va a posicionarse el cursor después de que sea ejecutado un bloque de código tipo SCREEN.
Rutina f rameO; Esta rutina se encargará de dibujarnos los marcos durante la ejecución de las pantallas.
Rutina despliegalC3; Esta rutina se encargará de desplegar las líneas de texto tanto en las pantallas como en los reportes de acuerdo a los paramétros que reciba.
Rutina mainO; Esta rutina será el inicio de ejecución de nuestro programa y su función será poner la rutina endO; en el fondo del stack de control del flujo del programa, y pasar elcontrol a la rutina controlO; indicando en que función va ainiciar la ejecución del programa Cmás adelante ejemplificaremos
57

ésto}.
Rutina controlO; Está rutina estándar tiene la función de asegurar el paso de control entre los bloques a la hora de ejecución del programa. Esta rutina trabaja básicamente sobre un stack de apuntadores a función y su algoritmo general recortado es el siguiente :
Algoritmo que asegura el flujo de control entre los bloques en un programa en "C" hecho en forma automática a partir de un programa en PROLAN.
control(fune i on)ap_fun función ? /* tipo apuntador a función *■/ap_fun stackti? /* arreglo de apuntadores a función */ap_fun ic,aux: /* tipo apuntador a función */
ic=función? while(ic O end)í
aux=(*ic)(); /* ejecuta la función apuntada por icy regresa un valor el cual es la función siguiente a ejecutarse
i f (TIPOBLÜQUE = = TIPÜREPÜRT)< / *ic=aux? break?
if (TIPOBLOQIJEc == TIPOSCREEN) <pantalla ejecutada se guarda en el stack su di recc i ór¡
*/push(ic);iftaux == iropretf)?
ic = popO? /* opción IMPRET */ else
i c=aux?
: si lo ejecutado fue un reporte no se guarda guarda nada en el stack
6. A Caso Práctico.Con base en lo expuesto anteriormente se expone a
continuación el esqueleto general en lenguaje "C" que generaríamos a partir de un programa fuente escrito en PROLAN.
El código PROLAN es el siguiente :
58

+ + pagel ri = 24 + + pagewd = 80 + + Ecrrilri = 24 +•+ scrnwd = 80 ++ impret = 27
HEADING(frame 2,2-23,80) bll
FOOTING(frame 1,1-24,80) reporte
BLOCK falls(cursor 24,79)
REPORT reporte:end :< 2 , 33 , "CINVESTAV"< 7 , 11 , "1.-altas"< 8 , 11 , "2.-bajas"altas
SCREEN altas :=4, "este es altas"
SCREEN bajas ;. 2 , "esta es bajas" bll
SCREEN main : a-altas, b-bajas, r-reporte, f-enc bl 1< 2 , 33 , "CINVESTAV"< 7 , 11 , "1.-altas"< 8 , 11 , "2.-bajas"< 11 , 18 ,"a-altas b-bajas r-reporte f-fin
El esqueleto en código "C" sería el siguiente :
opcion ?"
59

int pageln=24, pagewd=30,scrnln=24, /* las mismas directivas */ scrnwd=80, i mpret=27;
I M P R E T F O O /* función para controlar la opcion IMPRET */’
END (){
exit (0) ; /* control de algún fin eventual */
BLOQUES<)/* código del heading */
f r a m e ( 2 , 2 , 2 3 , S O ) ;
b 11 ();/* i n c 1u s io n d i nárnic a3 /* del b l o q u e bll
bll()/* código del bloqueí
cursor(24,79);>
BLOQUE10<)/* código de1 foot i ng */ frame <1 - 1,24,80):reportel 1 O : /* inclusion dinámica del cuerpo */
>/=•' del bloque reporte * '
reportellO /* código del cuerpo del bloque reporte */desp1 i ega1< reng,co1,texto):despliegal(reng,col,texto); /* líneas de texto */desp1 i ega1(reng,co1,texto):altasl2();/* inclusión dinámica del cuerpo */
>/* del bloque altas */
reporteO /* código de control del bloque reporte *■/
TIPOBLOQUE=TIPOREPORT;BLOQUES() ;BLOQUE1GO; /* invoca sus encabezados y pies de página */report-ellO /* invoca a su cuerpo */return(END);/* bloque sucesor */
del cuerpo */
bll */
60

altasl2() /* código del' cuerpo del bloque sitas */<
desp1 i ega1(reng,col,texto);t>a jas 13 ( > ; /* inclusion dinámica del cuerpo del */
> /* bloque bajas */
altas O /* código de control del bloque altas */TIPOBLOQUE=TIPOSC:REEN;BLOQUES O ; /* invoca sus encabezados y pies de página */BLOQUE10();altasl2() /* invoca a su cuerpo */ c=getch(); switch(c)<
CASE 27 : {return ( irnpretf) ; > /* no tiene cadena opcion-sucesor} * /
bajaslSO /* código del cuerpo del bloque bajas */ desp1 i ega1<reng,co1,texto);b 11 (> ; / * inclusión dinámica de cuerpo del */
5 /* bloque bll */
bajas O /* código de control del bloque bajas */í
TIPOBLOQUE = TIPOSCREEÑ;BLOQUES():BL0QUE1CK); /* invoca sus encabezados y pies de página */ bajaslSO /* invoca a su cuerpo */ c = getch (); 'switch (c)<
CASE 27 : íreturn < irnpretf) 5 > ' no tiene cadena opciones } sucesores
rnainprototipol4()/* código del cuerpo del bloque rnainprototipo */í
bll O ; /* inclusión dinámica del bloque bll */ desp1 i ega1< reng,c o 1, texto) :desp1 i ega1(reng,co1,texto):/* 1í neas de texto */ despliegal< reng.col,texto); desp1 i ega1(reng,co1,texto);cursor(reng,col)j /* la línea anterior tiene la opción
optcurs
61

mainprototipo<) /* código de control del bloque rnain del */{ /* prototipo *■/
TIPOBLOQUE = TIPOSCREEN;BLOQUES();BLOQUE10 O 5 /* invoca sus encabezados y pies de página */ mainprototipol4()/* invoca su cuerpo */ c=getch(); switch (c)í
CASE 97 : <return(altas);>CASE 98 : <return(bajas)j3/* cadena opcion-sucesor */CASE 114 : {return(reporte);>CASE 102 : <return(END);>CASE 27 : {return ( irnpretf) ; }
>
rnainO /* rutina principal del programa */push(END); /* coloca el fin en el fondo del stack */control(mainprototipo); /* pasa el control a la rutina
> que se encarga del paso entrebloques
*/
Como se puede ver, los bloques de código son creados en un orden diferente a como están en el programa fuente PROLAN. Esto es debido a que los bloques son extraídos de la tabla BTAB y no directamente del archivo fuente. Pero, en un lenguaje como "C", ésto no nos ocasiona problema alguno. Se menciona esta situación por si alguna persona intenta implementar en otros lenguajes el programa convertidor, tenga presente este detalle.
Los nombres de los bloques tipo HEADING y FOOTING sonformados por la palabra BLOQUE seguida por el número querepresenta su posición en la tabla BTAB. Con ésto aseguramos lacreación de nombres únicos durante el proceso. Los nombres de loscuerpos de código de los bloques tipo REPORT y SCREEN son formados agregando al nombre que ya tienen el mismo número mencionado.
Si quisiéramos pasar el código PROLAN a un lenguaje como PASCAL. Básicamente el proceso seria igual. Solo sería necesario tomar en cuenta el orden en el cual son creados los bloques de código fuente, ya que en un lenguaje como éste el orden de los procedimiento si tiene relevancia importante. También sería necesario crear el funcionamiento de apuntadores a funciones, ya que en este lenguaje no existen este tipo de apuntadores de una manera explícita.
62

========== CONCLUSIONES ========== e
De acuerdo con la mayoría de las personas involucradas en el área de desarollo de sistemas computarizados. La fase de análisis en especial, el módulo de definición de un sistema ó problema, a resolver es la fase más importante de todo el ciclo de construcción de un sistema. Ya que, si esta fase es hecha de una manera incorrec ta todo el resto del trabajo no servirá de mucho porque probablemente, no cubra los objetivos propuestos ó no resuelva en su totalidad las necesidades planteadas. Por éso, es muy importante el uso de herramientas adecuadas y la total atención de todas las personas involucradas durante esta fase.
Durante el transcurso de mi experiencia profesional he visto, que muchos departamentos de desarrollo de aplicaciones computar izadas orientadas a cubrir necesidades de usuarios finales, no ponen mucha atención en la aplicación de técnicas adecuadas y útiles en la fase de análisis. Esto es debido a muchos factores y uno de los principales es que actualmente no existe en el mercado una amplia gama, de herramientas orientadas a estos fines. El trabajo aquí desarrollado trata de dar una alternativa más a los desarrolladores de sistemas de la utilización de la técnica de prototipos para la definición de requerimientos y/o sistemas.
Cabe aclarar que hasta la fecha del desarrollo de este trabajo no existen en México paquetes computar izados con las caractertsticas y enfoques del que aquí presentamos. Por lo tanto, consideramos que, este trabajo representa una buena aportación para maximizar la eficiencia del ciclo de desarrollo de sistemas con el objeto de lograr resultados cada vez más óptimos.
Otra meta que trata de cubrir este trabajo es dar a conocer alas personas interesadas en el desarrollo de compiladores paralenguajes particulares que. con conocimintos básicos decomputación, teoría de compiladores y uso de herramientas computarizadas orientadas a estos fines. Es de alguna manera no muy difícil, crear nosotros mismos nuestros propios programas compiladores para nuestras aplicaciones particulares.
A pesar de ser relativamente limitada nuestra experiencia con la versión actual del sistema presentado, ya se ha comprobado su gran utilidad. Es un sistema relativamente simple ___y fácil de implementar y usar. Quedaron sin construirse, funciones más complejas dentro del editor del generador automático de código, llamados a subrutinas y programas externos a la hora deinterpretar el código objeto respec tivo. Esto es debido a que el lenguaje PROLAN es propenso a ser expandido sintáctica y semánticamente y en este punto, nuestro objetivo era tener una versión inicial de base con el objeto de empezar a aplicarlo en el trabajo real. Por lo tanto, quedg^abierta a la imaginación de las

personas interesadas la expansión del lenguaje de acuerdo a las
necesidades de aplicación del mismo.
El tamaRo de memoria ocupada por el compilador está determinado por el dimensionamiento de las tablas BTAB y LTAB queen la versión presentada aquí, se almacenan en la memoriaprincipal de la computadora Ctanto para el compiladof, intérprete y generador automático de código2. En caso de escasez de memoria el almacenamiento directo de LTAB en un archivo en disco norepresentaría problema alguno. Solamente causaría cierta degradación en el tiempo de ejecución del prototipo Cías pantallas saldrían con cierto retraso debido a que habría que traer elcódigo desde disco2. Entonces con ésto se lograría que PROLAN no tuviera en teoría limitaciones en el número de instrucciones que tuvieran los bloques.
El sistema no incluye las facilidades que se pueden usar en las herramientas orientadas a la generación de reportes ó al diseño de pantallas Cejem. facilidades para captura de los datos, sus formatos, validación automática, etc.2. Lo que se puede ver como una desventaja en el caso de que se use no solo para el desarrollo del prototipo sino también para su transformación gradual en el sistema final de producción.
Hasta ahora, el desarrollo de estas facilidades esresponsabilidad del usuario. Su inclusión en el sistema está actualmente anticipada en la forma de las llamadas líneas de código en el programa fuente. Se necesita más experiencia con el sistema para poder decidir qué facilidades vale la pena adicionarle sin que se pierdan sus ventajas principales : Lasimplicidad y la eficiencia.
Como mencionamos anteriormente, el compilador para el lenguaje PROLAN fué construido utilizando las herramientas computar izadas LEX y YACC las cuales, están orientadas a estos fines. Realmente el tener herramientas de este tipo proporcionan una gran ayuda y una disminución sustancial en el tiempo que se invierte en la implementación de analizadores léxicos y sintác ticos. Por lo tanto, se puede invertir más tiempo en la optimización de otros módulos de nuestros compiladores.
Algunas ampliaciones que podrían se factibles hacer sobre el sistema PROLAN son:
- Manejo óptimo de memoria. Se podría tener en disco el código objeto representado por las tablas BTAB y LTAB y tener sólo en memoria principal el código correspondiente al bloq^ que está siendo actualmente ejecutado.
- Manejo de colores de base en los textos de las pantallas.
64

~ Manejo de otros tipos de menúes Charras, etc.2.
- Manejo de pantallas de captura mediante la manipulación de campos.
- 1 rn.plementación del intérprete en lenguajes como PASCAL y BASIC, para poder aprovechar las ventajas inherentes a ellos*
- Manejo de ventanas.
- Programas que transformen código fuente PROLAN a otros lenguajes como : PASCAL, BASIC, DBASE-II1, etc.
65

BIBLIOGRAFIA
H l Schreiner, A.T. - Friedman, H.G.Jr. : Introduction toCompiler Construetion with UNIX. Englewood Cliffs, New Jersey U.S.A., Prentice Hall, 1935.
121 Tremblay J.P. - Sorenson P. 6. : Theory and Practice ofCompiler Writing. U.S.A., Me. Graw-Hill, 1985.
13] Aho A.V. - Ullman J.D. : Principles of Compiler Design.Princenton, New Jersey U.S.A., Addison-Wesley, 1977.
[41 Kolar S. J. : Un sistema portátil para el desarrollo deprototipos de software. México D. F. , México. 1988.
[5] Borland International : Reference Guide Turbo-C ver. 1.5.Scotts Valley, California U.S.A. , Borland International, 1987.
[61 Boar B.H. : Prototyping Aplications. New York, U.S.A., Willey 1984.

El jurado designado por la Sección de Computación del
departamento de Ingeniería Eléctrica del Centro de Investigación y
ele■ Estudios Avanzados del Instituto Politécnico Nacional, aprobó
ésta tesis el día 11 de Abril de 1989.


