el lenguaje sql - mitoledo.commitoledo.com/dai/recursos/sql.pdf · se ha empezado a hablar del...
TRANSCRIPT

CAPÍTULO 6
EL LENGUAJE SQL
De los distintos lenguajes que presentaban los primeros SGBDR (Sistemas de Gestión de Bases de Datos Relacionales), ha acabado imponiéndose como estándar, tanto de iure como de facto, el SQL, lenguaje que actualmente ofrecen, aunque con variaciones, la mayor parte de los productos comerciales y que viene siendo objeto, desde hace varios años, de un intenso proceso de normalización.
En este capítulo presentaremos la evolución que ha experimentado este lenguaje, describiendo con detalle las principales sentencias del SQL-92, clasificándolas según afecten a la estática, la dinámica o a otras características del sistema.
1. ORGANISMOS Y GRUPOS QUE SE OCUPAN DE LA ESTANDARIZACIÓN DE LOS LENGUAJES DE BASES DE DATOS
Debido a la importancia de los lenguajes de bases de datos, existen numerosos organismos que se ocupan de su estandarización.
Como ya señalamos en el capítulo 2, en el comité conjunto JTC1, establecido por los organismos ISO e IEC para las Tecnologías de la Información, existe el subcomité 21 que engloba al WG3 que se dedica a las bases de datos.
En Estados Unidos, además del grupo H2 de ANSI, también el NIST (National Institute of Standards and Technology) se ocupa de la estandarización del SQL.
Por otra parte, hay que destacar el denominado SQL Access Group, un consorcio formado por varias decenas de fabricantes de productos con el fin de “definir especificaciones técnicas que permitan a distintos SGBDR y herramientas de aplicación trabajar conjuntamente"; para ello se propone acelerar los esfuerzos de estandarización del lenguaje SQL aportando propuestas a los grupos RDA y SQL.
La Unión Europea, siguiendo las recomendaciones del proyecto EWOS (European Workshop on Open Systems), ha creado en abril de 1991 el EG DBE (Expert Group on Database Enquiry), en el que también desempeña un papel muy relevante el SQL.
Además existen otras asociaciones como X/OPEN, la OSF (Open Software Foundation) o la Asociación Europea de Fabricantes de Ordenadores, que han adoptado extensiones del lenguaje.
Por último, cabe destacar que existen distintos vendedores que han definido sus propios estándares basándose en los aprobados por ANSI e ISO.

2. EVOLUCIÓN DEL LENGUAJE SQL
Como vimos en el capítulo 5, el modelo relacional surge a finales de los años sesenta como resultado de las investigaciones de E.F. Codd en los laboratorios de IBM en San José (California); los trabajos de Codd dieron lugar a una serie de estudios teóricos y prototipos que se extienden a partir de 1970.
El lenguaje SQL surge originariamente con el nombre de SEQUEL (Structured English QUEry Language) implementado en un prototipo de IBM, el SEQUEL-XRM, durante los años 1974-75. Este prototipo evolucionó durante los años 1976-77, pasándose a denominar su lenguaje SEQUEL/2, y cambiando posteriormente este nombre por SQL, debido a motivos legales. Poco después, el SISTEMA R de IBM implementó un subconjunto de este lenguaje.
En 1979 aparece el primer SGBDR comercial basado en SQL -ORACLE-, posteriormente van surgiendo otros productos basados en SQL como son el SQL/DS, DB2, DG/SQL, SYBASE, INTERBASE, INFORMIX, UNIFY, etc. E incluso otros productos que no poseían el SQL como lenguaje base -v.g. INGRES, DATACOM, ADABAS, SUPRA, IDMS/R- ofrecen interfaces SQL; por lo que este lenguaje se convierte en un estándar de facto, aunque con múltiples variantes según los distintos fabricantes.
En 1982 el Comité de bases de datos X3H2 de ANSI presenta un lenguaje relacional estándar basado principalmente en el SQL propio de los productos IBM; en 1986 este organismo aprueba el lenguaje como norma pasando a denominarse SQL/ANS, que también es aprobado, al año siguiente, como norma ISO -ISO (l987)-. En esta norma se especifican dos niveles (I y II) a cumplir, siendo el nivel I un subconjunto de las funcionalidades proporcionadas por el nivel II. Este estándar ha recibido numerosas críticas, ya que resulta ser "una intersección de las instrumentaciones existentes", concebido primordialmente para proteger los intereses de los fabricantes. Así, por ejemplo, en CODD(1985) se afirma que "... desafortunadamente el SQUANS es muy débil, fallando en el soporte de numerosas características que los usuarios realmente necesitan si quieren aprovechar todas las ventajas del enfoque relacional... El SQUANS es incluso menos fiel al modelo relacional que el SQL de algunos suministradores...”.
En 1989 se revisa la versión 1 del estándar -ISO(1989)-, revisión conocida como Addendum, que añade cierta integridad referencial, que se denomina integridad referencial básica, ya que sólo permite definir la opción de modificación y borrado restringidos y no proporciona cambios en cascada. Por otra parte, ya que la norma ISO de 1989 no estandariza las definiciones para SQL embebido en lenguajes de programación -que sólo figuraban en apéndices recomendados-, ANSI define, ese mismo año, un estándar para el lenguaje SQL embebido -ANS1(1989)-. En este mismo año Apple Computer libera el Data Access Language (DAL) para sus ordenadores, (DAL es un dialecto del SQL que soporta varios gestores de bases de datos).
En junio de 1990, IBM anuncia su estándar DRDA (Distributed Relational Database Access) como parte de su arquitectura SAA (System Application Architecture).
En abril de 1991 el SAG (SQL Access Group) completa la 1ª Fase de especificaciones técnicas, que define un estándar para intercambiar mensajes SQL sobre una red OSI, basado en la especialización SQL del RDA de ISO. En junio de 1991 este

grupo realizó una demostración -que constituyó todo un éxito- con más de veinte SGBDR que se intercambiaban datos y consultas. En el mes de noviembre de este mismo año Microsoft anunció ODBC (Open Database Connectivity) basado en el estándar del SAG.
En 1992 este grupo completó su segunda fase, que especificaba un IPA (Interfaz para la Programación de Aplicaciones) CLI (Call Level Interface) y que ampliaba el estándar a más instalaciones cliente/servidor, en la que además de las especificaciones OSI se incluye otros protocolos de red como, por ejemplo, TCP/IP. En noviembre de ese año Borland relanzó el estándar ODAPI (Open Database Application Programming Interface) como IDAPI (Integrated Database Application Programming Interface), con el patrocinio de IBM, Novell y WordPerfect.
En 1992 también se aprueba como norma internacional una nueva versión del SQL, conocida como SQL2 o SQL-92 -ISO(1992)-, en la que se incrementa substancialmente la capacidad semántica del esquema relacional, se añaden nuevos operadores, se mejora el tratamiento de errores y se incluyen normas para el SQL embebido. En esta nueva norma se definen tres niveles de conformidad distintos:
Entry SQL, Intermediate SQL y Full SQL, siendo este último -como su nombre indica- el que ofrece mayores funcionalidades, mientras que el primer nivel es un subconjunto del segundo y éste, a su vez, del tercero.
Este estándar ha sido complementado recientemente con dos nuevas partes que abordan la interfaz de nivel de llamadas (Call-Level Interface), ISO (1995) y la definición de módulos almacenados persistentes (Persistent Stored Modules) ISO (1996). Esta última norma internacional convierte al SQL en un lenguaje computacionalmente completo añadiéndole estructuras de control, manejo de excepciones, etc.
En la actualidad se acaban de aprobar nuevas propuestas para extender el SQL -el llamado SQL3, (véase apartado 9)-, dotándolo, además, de una mayor capacidad semántica, de ciertos principios del paradigma de la orientación al objeto. También se está trabajando sobre una extensión del SQL3 para soportar bases de datos multimedia, conocida como SQL/MM (SQL Multimedia). Debido al tamaño que posee el SQL3 ya se ha empezado a hablar del SQL4, en el que se incluyen aquellas características del lenguaje que no se encuentran todavía definidas completamente o que necesitan una mayor profundización.
3. CONCEPTOS SQL
Aunque el lenguaje SQL se basa en el modelo relacional, incorpora algunos elementos adicionales que facilitan la gestión de datos. En este sentido se introduce el concepto de catálogo, entendido como un conjunto de esquemas, que proporciona un mecanismo adicional para calificar nombres de elementos (catálogo.esquerna.elemento), facilitando así la gestión del espacio de nombres.
Un entorno SQL puede contener cero o varios catálogos y, a su vez, un catálogo uno o varios esquemas. En cada catálogo existe un DEFINITION_SCHEMA que contiene las tablas base sobre las que se define un conjunto de vistas denominado INFORMATION_SCHEMA, esquemas que son autodescriptivos. Las tablas base definidas en el estándar son las siguientes:

USERS, SCHEMATA, DATA_TYPE_DESCRIPTOR, DOMAINS, DOMAINS_CONSTRAINTS, TABLES, VIEWS, COLUMNS, VIEW_TABLE_USAGE, VIEW_COLUMN_USAGE, TABLE_CONSTRAINTS, KEY_COLUMN_USAGE, REFERENTIAL_CONSTRAINTS, CHECK_CONSTRAINTS, CHECK_TABLE_USAGE, CHECK_COLUMN_USAGE, ASSERTIONS, TABLE_PRIVILEGES, COLUMN_PRIVILEGES, USAGE_PRIVILEGES, CHARACTER_SETS, COLLATIONS, TRANSLATIONS, SQL_LANGUAGES
Los nombres de estas tablas son autoexplicativos y se parecen a las presentes en los catálogos de los productos existentes.
El lenguaje introduce también el concepto de agrupamiento (cluster), que sirve para referenciar el conjunto de catálogos a los que se puede acceder en un momento dado.
Por otra parte, merece la pena destacar que en el esquema SQL se puede encontrar, además de tablas, dominios, aserciones, vistas o la concesión y revocación de privilegios, la definición de conjuntos de caracteres (Character Set), así como secuencias de ordenación (Collation) y traducción (Translation) para estos conjuntos de caracteres. Esto permite soportar lenguajes como el japonés, coreano o chino, que superan los 256 caracteres y que pueden obtenerse con una extensión de 8 bits del código ASCII.
4. SENTENCIAS DE DEFINICIÓN
El estándar SQL2 presenta muchas novedades respecto a las versiones anteriores, que no pueden ser tratadas ampliamente en este libro -obsérvese que el estándar tiene alrededor de 500 páginas-; por lo que nos centraremos en los aspectos que nos parecen más interesantes, al contribuir al incremento de la semántica.
Utilizaremos una extensión de la Forma Normal de Backus (BNF) para especificar las cláusulas del lenguaje donde:
< > representa los símbolos no terminales del lenguaje ::= es el operador de definición [] indica elementos opcionales {} agrupa elementos en una fórmula | indica una alternativa ... indica repetición
De los distintos elementos que puede contener un esquema relacional en SQL2, estudiaremos los dominios, aserciones y tablas; tenemos que advertir que presentaremos las opciones y posibilidades que resultan, a nuestro juicio, más interesantes, remitiendo al lector a las referencias bibliográficas para un estudio más exhaustivo de los distintos elementos del lenguaje.
4.1. Esquemas La creación de esquemas se lleva a cabo mediante la sentencia: <definición de esquemas>::=
CREATE SCHEMA <cláusula de nombre del esquema> [<especificación del conjunto de caracteres del esquema>] [<elemento de esquema> ... ]
<cláusula de nombre del esquema>::= <nombre del esquema> | AUTHORIZATION <id. autorización del esquema>

| <nombre del esquema> AUTHORIZATION <id. autorización del esquema>
Podríamos, por ejemplo, Crear el siguiente esquema: CREATE SCHEMA biblioteca
AUTHORIZATION uc3m;
4.2. Dominios El SQL92 soporta la definición de dominios de la siguiente manera: <definición de dominio> ::=
CREATE DOMAIN <nombre de dominio> [ AS ] <tipo de datos1> DEFAULT <opción por defecto> ] <restricción de dominio> ]
donde la opción por defecto puede ser un literal, una función de valor tiempo o fecha, o bien USER, SYSTEM USER o NULL; mientras que se define
<restricción de dominio> ::= [ <definición de nombre de restricción> ] < definición de restricción de verificación> [ <atributos de restricción> ]
en la cual se puede, opcionalmente, dar un nombre a la restricción de dominio de la siguiente forma:
<definición de nombre de restricción> ::= CONSTRAINT <nombre de restricción>
El único elemento obligatorio de la restricción de dominio es la: <definición de restricción de verificación> ::=
CHECK <parent. izq.> <condición> <parent. dcho.>
Así, por ejemplo, se podría definir el siguiente dominio, en el que se quiere especificar, por intensión, que los tipos de documentos válidos en una biblioteca son artículos o libros:
CREATE DOMAIN Tipos_Doc CHAR(1) CONSTRAINT Artículos_o_Libros CHECK (VALUE IN (‘A’,’ L’));
Por lo que respecta a los atributos de restricción, sirven para indicar si la restricción es diferida o inmediata:
<atributos de restricción> ::= <tiempo de verificación de restricción> [ [NOT] DEFERRABLE] | [ [NOT] DEFERRABLE] <tiempo de verificación de restricción> <tiempo de verificación de restricción> INITIALLY DEFERRED | INITIALLY INMEDIATE
Así, si el modo de verificación es inmediato, la restricción se verificará al finalizar cada sentencia, mientras que si es diferido, se verificará al finalizar la transacción (véase apartado 6).
4.3. Tablas Hay que recordar que existe una diferencia fundamental entre una tabla en SQL y
una relación del modelo relacional, ya que mientras que ésta se define como un 1 Como tipos de datos el SQL-92 admite los siguientes: CHARACTER [VARYING] (n), BIT [VARYING] (n), NUMERIC (p,s), DECIMAL (p,s), INTEGER, SMALLINT, REAL, DOUBLE PRECISION, FLOAT (p), DATE, TIME, TIMESTAMP, INTERVAL.

conjunto de tuplas (véase capítulo 5), una tabla es en realidad un multiconjunto de filas, por lo que admite filas repetidas.
En el SQL92 se pueden definir tablas persistentes -que, como su nombre indica, se almacenan en memoria secundaria y permanecen allí cuando termina la sesión en la que fueron creadas- o tablas temporales -que sólo se materializan y tienen existencia en tanto dura la sesión-, tal como indica la definición siguiente:
<definición de tabla> ::= CREATE [ TEMPORARY ] TABLE <nombre de tabla> <paréntesis izq.> <elemento de tabla> [{<coma> <elemento de tabla>} ... ] <paréntesis dcho.>
Los elementos de tabla pueden ser tanto definiciones de columnas como definiciones de restricciones de tabla. Una columna debe definirse sobre un dominio o bien directamente con un tipo de datos, pudiendo presentar además valores por defecto y restricciones de columna:
<definición de columna> ::= <nombre de columna> { <tipo de datos> | <nombre de dominio>} <claúsula de valor por defecto> ] <definición de restricción de columna> ]
Las definiciones de restricción, tanto de columnas como de tablas, presentan, al igual que en el caso de los dominios, la posibilidad de nominar dichas restricciones y de indicar si son inmediatas o diferidas mediante los atributos de restricción:
<definición de restricción de columna> ::= [ <definición de nombre de restricción> ] <restricción de columna> [ <atributos de restricción>
<definición de restricción de tabla> ::= [ <definición de nombre de restricción> <restricción de tabla> [ <atributos de restricción> ]
Las restricciones de columna pueden indicar la obligatoriedad de un valor -escribiendo NOT NULL-, si una columna es clave primaria de la tabla -mediante PRIMARY KEY-, si es clave alternativa, esto es, que sus valores no pueden repetirse en toda la tabla -especificando UNIQUE-, o cualquier otra condición (véase siguiente apartado). En caso de que la clave primaria o las claves alternativas estuviesen compuestas por varios atributos, habría que establecer restricciones de tabla de forma análoga a las de columna anteriormente descritas. En general, podemos considerar las restricciones de columnas como un caso especial de restricciones de tablas, con lo que, por ejemplo, la definición de clave primaria -cuando está compuesta sólo por un atributo- puede realizarse tanto al lado de la columna correspondiente como al finalizar la descripción de atributos.
Un ejemplo de tabla puede ser el siguiente, en la que se definen las editoriales, con una serie de atributos:
CREATE TABLE Editorial (Código_E Códigos, Nombre_E Nombres NOT NULL, Dirección Dirs NOT NULL, Ciudad Lugares NOT NULL, PRIMARY KEY (Código_E), UNIQUE (Nombre_E));

4.4. Restricciones y reglas de integridad Como hemos comentado, en el lenguaje SQL-92 no se cumple la restricción
inherente al modelo relacional teórico -CODD (1970)- de que en una tabla no existan dos filas iguales, ya que es opcional la definición de clave primaria, debido a motivos de compatibilidad con versiones anteriores; esta característica es causa de numerosas críticas [véase, por ejemplo, CODD (1990)].
Por otro lado, el SQL92 sí soporta la regla de integridad de entidad, ya que se asume la definición NOT NULL para las columnas que forman parte de la clave primaria.
En cuanto a la integridad referencial, el SQL92 permite definir claves ajenas, especificando, ya sea a nivel de columna o de tabla, la siguiente restricción:
<definición de restricción referencial> ::= FOREIGN KEY <parent.izq.> <columnas que ref.> <parent.dcho.> REFERENCES <columnas y tabla referenciadas> [ MATCH <tipo de correspondencia> [ <acción referencial disparada>
donde <columnas y tabla referenciadas> ::=
<nombre de tabla> [ <parent.izq.> <lista de columnas de referencia> <parent. dcho.> ]
Es importante destacar que si se especifica sólo el nombre de la tabla referenciada, las columnas referenciadas serán aquellas que componen la clave primaria de dicha tabla -que en este caso tiene, obligatoriamente, que tener definida una clave primaria-.
Pero es interesante observar que el SQL92 permite referenciar una columna o grupo de columnas, sin que sean necesariamente la clave primaria, y sólo se exige que estén definidas como UNIQUE. De esta forma se pueden definir dependencias de inclusión más amplias que las recogidas por la integridad referencial, tal como la propone Codd al presentar el modelo relacional.
La cláusula MATCH permite precisar si se admiten valores nulos en la clave ajena cuando ya existen otros valores no nulos en dicha clave (véase apartado 5.1.3.H de este capítulo).
Por lo que respecta a la acción a tomar en caso de borrado o modificación de los valores de las columnas referenciadas, el SQL92 admite cuatro posibilidades: operación restringida (en caso de no especificar la acción referencial disparada o poner NO ACTION), operación con transmisión en cascada (CASCADE), operación con puesta a nulos (SET NULL), operación con puesta a valor por defecto (SET DEFAULT), tal como se indica a continuación:
<acción referencial disparada> ::= <regla de modificación> [ <regla de borrado> ] | <regla de borrado> [ <regla de modificación> ]
<regla de modificación> ::= ON UPDATE <acción referencial> <regla de borrado> ::= ON DELETE <acción referencial>
<acción referencial> CASCADE | SET NULL | SET DEFAULT | NO ACTION

En la siguiente tabla, Documento, se ha definido, además de la clave primaria compuesta (Tipo, Cod_Doc), una clave alternativa (ISBN), dos restricciones de integridad (la de columna sobre año, y la de tabla, que afecta a los atributos Tipo, ISBN y Nombre_E2) y una clave ajena que referencia a la tabla Editorial:
CREATE TABLE Documento (Tipo Tipos_Doc, Cod_Doc CHAR(4), Titulo CHAR(25) NOT NULL, Idioma Idiomas, Nombre_E Nombres, Año INTEGER(4) CHECK (Año > 1950), Isbn INTEGER(10), PRIMARY KEY (Tipo, Cod_Doc), UNIQUE (Isbn), CHECK ((Tipo = ‘A’ AND Isbn IS NULL AND Nombre_E IS NULL) OR ( Tipo = ‘L’ AND Isbn IS NOT NULL AND Nombre_E IS NOT NULL)), FOREIGN KEY (Nombre_E) REFERENCES TO Editorial ON UPDATE CASCADE ON DELETE NO ACTION));
Otra posibilidad para definir restricciones que afecten a varias tablas la constituyen las aserciones:
<definición de aserción> ::= CREATE ASSERTION <nombre de restricción> <verificación de aserción> [<atributos de restricción>] <verificación de aserción> ::= CHECK <parent. izq.> <condición> <parent. dcho.>
Por ejemplo, si suponemos que no puede haber editoriales cuya sede se encuentre en Madrid que editen libros en francés o en alemán, deberíamos construir la siguiente aserción:
CREATE ASSERTION Idiomas_No_Usados_Por_Editoriales_En_Madrid CHECK (NOT EXISTS (SELECT * FROM Documento NATURAL JOIN Editorial WHERE Idioma IN ('F', 'A') AND Ciudad = 'Madrid'));
4.5. Actualización de esquemas La actualización de esquemas se lleva a cabo mediante las sentencias ALTER
(que permiten la modificación de dominios o de tablas) y las sentencias DROP (para borrar esquemas, tablas, dominios o vistas).
Algunos ejemplos de sentencias de este estilo son: DROP SCHEMA biblioteca;
que borraría todo el esquema (y sus elementos). DROP DOMAIN Tipos_Doc;
2 La restricción de tabla asegura que los artículos no posean ISBN ni editorial, mientras que obliga a que todos los documentos que sean libros tengan un ISBN y una editorial.

que elimina el dominio. ALTER DOMAIN Tipos_Doc
DROP CONSTRAINT Articulos_o_Libros
que permite eliminar una restricción del dominio (lo que también es aplicable a tablas).
DROP TABLE Editorial;
que eliminaría la tabla del esquema (evidentemente, junto con todas las filas que tuviera).
ALTER TABLE EDITORIAL ADD COLUMN Director VARCHAR (30);
que añadiría una columna a la tabla Editorial que permite especificar quién es su director.
ALTER TABLE Editorial ALTER COLUMN Ciudad SET DEFAULT 'Madrid';
que fija un valor por defecto para la columna Ciudad. ALTER TABLE Editorial
DROP COLUMN Dir;
que borra la columna Dir.
4.6. Vistas Como ya hemos señalado, una vista consta de una expresión de consulta sobre
otras vistas y/o tablas: <definición de vista>::=
CREATE VIEW <nombre de tabla> [<parent. izq.> <lista de columna> <parent. dcho.>] AS <expresión de consulta> [WITH CHECK OPTION]
Así podríamos definir sobre la tabla Documento una vista que sólo contuviese los libros de la siguiente manera:
CREATE VIEW Libro AS SELECT * FROM Documento WHERE Tipo = ‘L’;
La cláusula WITH CHECK OPTION permite controlar que sólo se admiten operaciones de inserción y modificación que no atenten contra la expresión de consulta que define la vista. Así, por ejemplo, si en el caso anterior hubiésemos utilizado esta cláusula, no se permitiría cambiar el valor del atributo tipo.
Otro aspecto a tener en cuenta es que, en la actualidad, sólo son actualizables las vistas que proceden de una única tabla (en cuya definición no aparezcan las cláusulas GROUP BY o HAVING).
5. SENTENCIAS DE MANIPULACIÓN
Existen tres maneras de manipular bases de datos SQL:
Interactivamente, esto es, invocando directamente las sentencias SQL.

Por medio de SQL embebido3, en el que se insertan sentencias SQL como huéspedes de un lenguaje anfitrión4.
Por módulos, agrupando sentencias SQL en módulos, que son llamados desde lenguajes anfitriones. ANSI denomina esta forma de manipulación como llamadas explícitas a procedimientos5.
En este apartado presentaremos las principales sentencias de manipulación que permiten actuar de forma interactiva, mientras que en el siguiente resumiremos as características del SQL embebido. En cuanto a la aproximación por módulos, que se proponía ya en el estándar de 1986, no ha tenido mucha repercusión en el mercado, siendo muy pocos los fabricantes que la soportan.
5.1. Recuperación de datos: Sentencia SELECT
5.1.1. PARTES BÁSICAS Para llevar a cabo consultas sobre una base de datos relacional, el lenguaje SQL
propone la sentencia SELECT6 , que consta de las siguientes cláusulas: <especificación de consulta>::=
SELECT [<cuantificador de conjunto>] <lista de selección> <expresión de tabla>
El cuantificador de conjunto permite determinar si en el resultado de la consulta se mantienen filas repetidas (la opción por defecto, ALL) o si se eliminan los duplicados (DISTINCT):
<cuantificador de conjunto>::= DISTINCT | ALL
En cuanto a la lista de selección: <lista de selección> ::=
<asterisco> |<sublista de selección> [ {<coma> <sublista de selección>} ...]
<sublista de selección> ::=
<columna derivada> | <calificador><punto><asterisco>
<columna derivada> ::=
<expresión de valor> [<cláusula as>] <cláusula as> ::= [AS]<nombre de columna>
Una expresión de valor en SQL se refiere a expresiones de valor numéricas, de tira de caracteres, de fecha/tiempo o de intervalo. En todas ellas se pueden combinar referencias a columnas con distintos operadores y funciones que ofrece el lenguaje. Se pueden seleccionar, por tanto, todas las columnas (mediante el asterisco) o alguna de ellas, o bien derivar nuevas columnas a partir de las existentes aplicando diversas funciones u operadores (por ejemplo, sumando el valor de dos columnas).
3 Denominado también por ANSI, en su modelo de referencia, 1lamadas implícitas a procedimientos". 4 El estándar actual admite como lenguajes anfitriones los siguientes: COBOL, BASIC, MUMPS, PASCAL, FORTRAN, ADA, C y PL/I. 5 No debe confundirse con los llamados procedimientos almacenados, que se han estandarizado en el denominado SQL/PSM. 6 Que no se debe confundir con la selección del álgebra relacional, ya que con la sentencia SELECT podemos llevar a cabo cualquier operación del álgebra.

Por otra parte, las cláusulas fundamentales de la sentencia SELECT se encuentran en la expresión de tabla:
<expresión de tabla> ::= <cláusula from> [<cláusula where>] [<cláusula group by>] [<cláusula having>1
la primera permite especificar de dónde se obtienen los datos: <cláusula from> ::=
FROM <referencia de tabla> [{<coma><referencia de tabla>}...]
<referencia de tabla> ::=
<nombre de tabla> [ [AS] <nombre de correlación> [<parent.izq.> <lista de columnas derivadas> <parent.dcho.>]] | <tabla derivada> [AS] <nombre de correlación> [<parent.izq.> <lista de columnas derivadas> <parent.dcho.>]] | <tabla combinada>
Así, en el caso más sencillo podríamos recuperar todas las filas de la tabla Documento con la siguiente sentencia:
SELECT * FROM Documento;
cuyo resultado se puede observar en la figura 7. l. DOCUMENTO
TIPO CÓD-DOC TÍTULO IDIOMA NOMBRE_E AÑO ISBN L 001 CONCEPCIÓN BD E RAMA 1993 84-7897-083-S L 002 AN INTRODUCTION DBS I ADDISON-WESLEY 1995 0-201-54329-X L 003 A GUIDE TO SQL I ADDISON-WESLEY 1996 0-201-58432-1 L 004 RELATIONAL DB I AMISON-WESLEY 1995 0-201-55483-X L 005 ANÁLISIS SI E RAMA 1996 84-7897-2334 L 006 ANÁLISIS DE SI E ANAYA 1993 84-7900-080-1 L 007 COMPILADORES E PARANINFO 1992 84-7884-033-1 A 001 ER MODEL 1 1976 A 002 RELATIONAL MODEL 1 1970 A 003 LENGUAJE SQL3 E 1995 A 004 SQL3 TR.ADEOFFS 1 1995 A 005 BASES DE DATOS E 1996
Figura 7.1 Selección de todas las filas de una tabla
El caso de una tabla derivada se trata de una subconsulta, que puede ser: <subconsulta> ::=
<parent.izq.><expresión de consulta><parent. dcho.> <expresión de consulta> ::=
<expresión de consulta de no combinación> | <expresión de consulta de combinación>
Las consultas que no son combinaciones de tablas incluyen, además de tablas simples, la unión (UNION), intersección (INTERSECT) y diferencia (EXCEPT) de tablas. Así, por ejemplo, si suponemos que existen dos tablas: Editorial (definida anteriormente, véase figura 7.2 a) y otra denominada Librería, que posee los mismos atributos (véase figura 7.2 b), podríamos consultar por aquellas editoriales que no son librerías mediante la sentencia siguiente:
SELECT * FROM Editorial EXCEPT SELECT FROM Librería;

A) EDITORIAL
CÓDIGO NOMBRE DIRECCIÓN CIUDAD 001 RAMA CARRETERA DE CANILLAS 144 MADRID 002 ADDISON-WESLEY SUNSET ST. 4 READING 003 McGRAW-HILL 181AVENUE NEW YORK 004 PARANINFO SOL 3 MADRID 005 ANAYA GOYA 8 MADRID
B) LIBRERÍA
CÓDIGO NOMBRE DIRECCIÓN CIUDAD 001 RAMA CARRETERA DE CANILLAS 144 MADRID 002 ADDISON-WESLEY SUNSET ST. 4 READING 004 PARANINFO SOL 3 MADRID
C) EDITORIAL-LIBRERÍA
CÓDIGO NOMBRE DIRECCIÓN CIUDAD 003 McGRAW-HILL 181 AVENUE NEW YORK 005 ANAYA GOYA 8 MADRID
Figura 7.2. Ejemplo de diferencia en SQL
Como indicamos en el capítulo anterior, este tipo de operaciones requiere que las tablas sean compatibles en dominio. En caso de que sólo algunas columnas de las tablas coincidan en dominio, se puede aplicar una:
<especificación de correspondencia> ::= CORRESPONDING [BY <parent.izq.><lista de columnas de correspondencia><parent.dcho.> ]
En caso de tener una tabla Proyectos como la definida en la figura 7.3a, se podría unir con la tabla documento mediante la siguiente sentencia:
SELECT * FROM Proyecto UNION CORRESPONDING (titulo, idioma, año) SELECT * FROM Documento;
dando como resultado el que aparece en la figura 7.3 b. A) PROYECTOS
TÍTULO IDIOMA AÑO mimo E 1996
ENEAS E 1996 HERÁCLITO I 1995
B) PROYECTOS UNION DOCUMENTO
TÍTULO IDIOMA AÑO CONCEPCIÓN Y DISEÑO DE BD E 1993
AN INTRODUCTION TO DATABSE SYSTEMS I 1995 A GUIDE TOSQL STANDARD I 1996
RELATIONAL DATABASE : SELECTED WRITINGS I 1995 ANÁLISIS Y DISEÑO DE APLICACIONES E 1996
ANÁLISIS DE SI E 1993 COMPILADORES E INTÉRPRETES E 1992 ENTITY RELATIONSHIP MODEL I 1976
THE RELATIONAL MODEL I 1970 LENGUAJE SQL3 E 1995
SQL3 TRADEOFFS I 1995 BASES DE DATOS E 1996
mimo E 1996 ENEAS E 1996
HERÁCLITO 1 1995
Figura 7.3. Ejemplo de unión en SQL
5.1.2. COMBINACIÓN DE TABLAS Por lo que respecta a la combinación de tablas, el lenguaje SQL permite todas las
opciones que hemos discutido en el capítulo anterior; así, se define: <tabla combinada> ::=
<combinación cruzada> | <combinación calificada> | <parent. izq.><tabla combinada><parent. dcho.>
donde <combinación cruzada> ::=

<referencia a tabla> CROSS JOIN <referencia a tabla>
que corresponde al producto cartesiano. En la figura 7.4 se muestra el resultado de la siguiente sentencia:
SELECT * FROM Documento CROSS JOIN Editorial;
lo que sería equivalente a realizar (como en el SQL-89) la siguiente consulta: SELECT Documento.*, Editorial.*
FROM Documento, Editorial;
TIPO CÓD-DOC TÍTULO IDIOMA NOMBRE E AÑO ISBN CÓD NOMBRE-E DIR CIUDAD L 001 CONCEPCIÓN BD E RAMA 1993 84-7894-083-S 001 RAMA CTRA CANILLAS 144 MADRID L 002 INTRODUCTION DBS I ADDISON 1995 0-201-54329-X 002 ADDISON SUNSET 4 READING L 003 A GUIDE TO SQL I ADDISON 1996 0-201-58432-1 003 McGRAW 181 AV NEW YORK L 004 RELATIONAL, DB I ADDISON 1995 0-201-55483-X 004 PARANINFO SOL 3 MADRID ... ... ... ... ... ... ... ... ... ... ...
Figura 7.4. Ejemplo de combinación cruzada en SQL
Otro tipo de combinación es la siguiente: <combinación calificada> ::=
<referencia a tabla> [NATURAL] [<tipo de combinación>] JOIN <referencia a tabla> [<especificación de combinación>]
donde <tipo de combinación> ::=
INNER | <tipo de combinación externa> [OUTER] | UNION
<tipo de combinación externa> ::=
LEFT | RIGHT | FULL
<especificación de combinación> ::=
<condición de combinación | <combinación de columnas nominadas>
<condición de combinación> ::=
ON <condición de búsqueda> <combinación de columnas nominadas>::=
USING <parent.izq.><lista de columnas de combinación> <parent.dcho.>
Así, por ejemplo, podemos realizar la combinación natural de las tablas Documento y Editorial de la siguiente manera:
SELECT * FROM Documento NATURAL JOIN Editorial ON Documento.Nombre_E = Editorial. Nombre;
que también puede hacerse como en el SQL-89 mediante la sentencia:

SELECT Documento.*, Codigo, Dir, Ciudad FROM Documento, Editorial WHERE Documento.Nombre_E = Editorial.Nombre;
y cuyo resultado se presenta en la figura 7.5.
TIPO CÓD_DOC TÍTULO IDIOMA NOMBRE-E AÑO ISBN CÓDIGO DIRECCIÓN CIUDAD L 001 CONCEPCIÓN BD E RA-MA 1993 84-7897-083-S 001 CTRA CANILLAS, 14 MADRID L 002 INTRODUCTION DBS I ADDISON 1995 0-201-54329-X 002 SUNSET ST., 4 READING L 003 A GUIDE TO SQL I ADDISON 1996 0-201-58432-1 002 SUNSET ST., 4 READING L 004 RELATIONAL DB I ADDISON 1995 0-201-55483-X 002 SUNSET ST., 4 READING L 005 ANÁLISIS SI E RA-MA 1996 84-7897-233-1 001 CTRA CANILLAS, 144 MADRID L 006 ANÁLISIS DE Si E ANAYA 1993 84-7900-080-1 005 GOYA, 8 MADRID L 007 COMPILADORES E PARANINFO 1992 84-7884-033-1 004 SOL, 3 MADRID
Figura 7.5. Ejemplo de combinación natural
Cabe destacar que si las dos columnas que representan nombre de editorial (Documento.Nombre_E y Editorial.Nombre) se llamaran igual, podríamos haber usado la siguiente sentencia:
SELECT * FROM Documento NATURAL JOIN Editorial;
Cuando se emplea NATURAL JOIN sin la cláusula ON, se combinan las tablas igualando todas las columnas que tienen el mismo nombre en las tablas; si sólo se quiere utilizar algunas de ellas se emplea la cláusula USING.
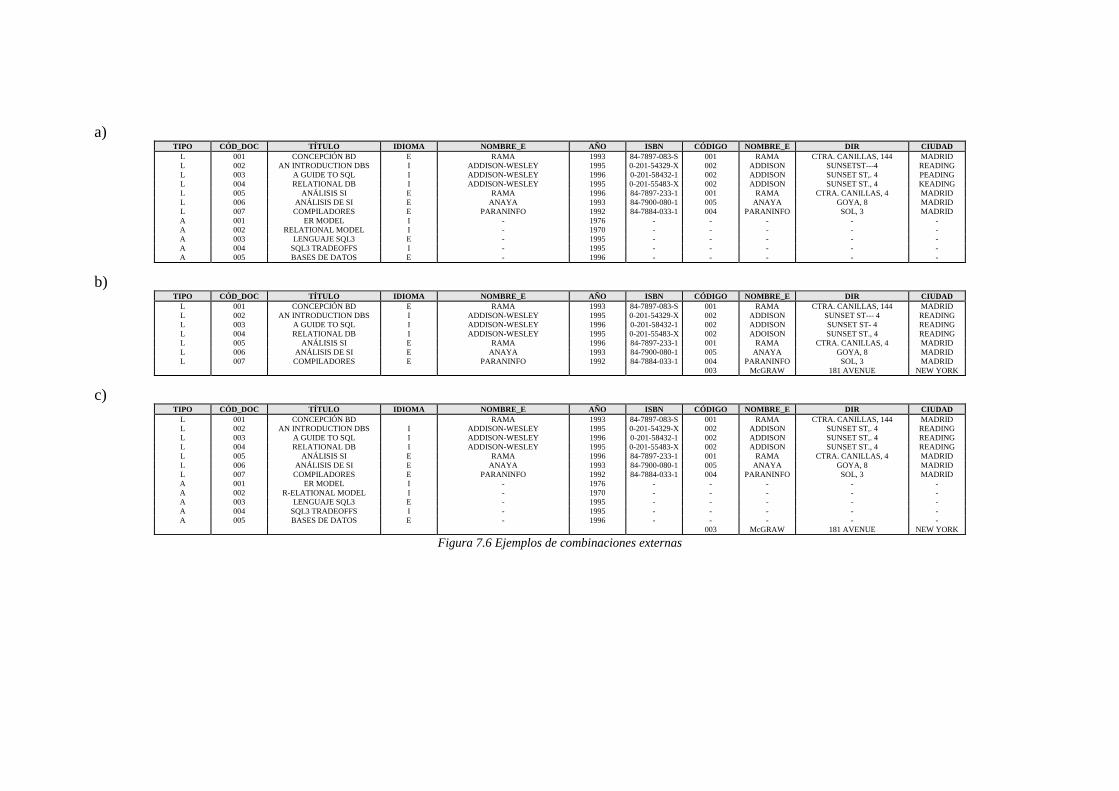
Por la que respecta a las combinaciones externas podemos ver en la figura 7.6 distintas posibilidades. En el primer caso (a), se ha aplicado la siguiente sentencia:
SELECT * FROM Documento LEFT OUTER JOIN Editorial ON Documento. Nombre_E = Editorial. Nombre;
en el caso b) se ha aplicado una combinación externa derecha: SELECT *
FROM Documento RIGHT OUTER JOIN Editorial ON Documento. Nombre_E = Editorial. Nombre;
y en el último caso, una combinación externa completa: SELECT *
FROM Documento FULL OUTER JOIN Editorial ON Documento. Nombre_E = Editorial. Nombre;
a) TIPO CÓD_DOC TÍTULO IDIOMA NOMBRE_E AÑO ISBN CÓDIGO NOMBRE_E DIR CIUDAD
L 001 CONCEPCIÓN BD E RAMA 1993 84-7897-083-S 001 RAMA CTRA. CANILLAS, 144 MADRID L 002 AN INTRODUCTION DBS I ADDISON-WESLEY 1995 0-201-54329-X 002 ADDISON SUNSETST---4 READING L 003 A GUIDE TO SQL I ADDISON-WESLEY 1996 0-201-58432-1 002 ADDISON SUNSET ST,. 4 PEADING L 004 RELATIONAL DB I ADDISON-WESLEY 1995 0-201-55483-X 002 ADDISON SUNSET ST., 4 KEADING L 005 ANÁLISIS SI E RAMA 1996 84-7897-233-1 001 RAMA CTRA. CANILLAS, 4 MADRID L 006 ANÁLISIS DE SI E ANAYA 1993 84-7900-080-1 005 ANAYA GOYA, 8 MADRID L 007 COMPILADORES E PARANINFO 1992 84-7884-033-1 004 PARANINFO SOL, 3 MADRID A 001 ER MODEL I - 1976 - - - - - A 002 RELATIONAL MODEL I - 1970 - - - - - A 003 LENGUAJE SQL3 E - 1995 - - - - - A 004 SQL3 TRADEOFFS I - 1995 - - - - - A 005 BASES DE DATOS E - 1996 - - - - -
b) TIPO CÓD_DOC TÍTULO IDIOMA NOMBRE_E AÑO ISBN CÓDIGO NOMBRE_E DIR CIUDAD
L 001 CONCEPCIÓN BD E RAMA 1993 84-7897-083-S 001 RAMA CTRA. CANILLAS, 144 MADRID L 002 AN INTRODUCTION DBS I ADDISON-WESLEY 1995 0-201-54329-X 002 ADDISON SUNSET ST--- 4 READING L 003 A GUIDE TO SQL I ADDISON-WESLEY 1996 0-201-58432-1 002 ADDISON SUNSET ST- 4 READING L 004 RELATIONAL DB I ADDISON-WESLEY 1995 0-201-55483-X 002 ADOISON SUNSET ST., 4 READING L 005 ANÁLISIS SI E RAMA 1996 84-7897-233-1 001 RAMA CTRA. CANILLAS, 4 MADRID L 006 ANÁLISIS DE SI E ANAYA 1993 84-7900-080-1 005 ANAYA GOYA, 8 MADRID L 007 COMPILADORES E PARANINFO 1992 84-7884-033-1 004 PARANINFO SOL, 3 MADRID 003 McGRAW 181 AVENUE NEW YORK
c) TIPO CÓD_DOC TÍTULO IDIOMA NOMBRE_E AÑO ISBN CÓDIGO NOMBRE_E DIR CIUDAD
L 001 CONCEPCIÓN BD RAMA 1993 84-7897-083-S 001 RAMA CTRA. CANILLAS, 144 MADRID L 002 AN INTRODUCTION DBS I ADDISON-WESLEY 1995 0-201-54329-X 002 ADDISON SUNSET ST,. 4 READING L 003 A GUIDE TO SQL I ADDISON-WESLEY 1996 0-201-58432-1 002 ADDISON SUNSET ST,. 4 READING L 004 RELATIONAL DB I ADDISON-WESLEY 1995 0-201-55483-X 002 ADDISON SUNSET ST., 4 READING L 005 ANÁLISIS SI E RAMA 1996 84-7897-233-1 001 RAMA CTRA. CANILLAS, 4 MADRID L 006 ANÁLISIS DE SI E ANAYA 1993 84-7900-080-1 005 ANAYA GOYA, 8 MADRID L 007 COMPILADORES E PARANINFO 1992 84-7884-033-1 004 PARANINFO SOL, 3 MADRID A 001 ER MODEL I - 1976 - - - - - A 002 R-ELATIONAL MODEL I - 1970 - - - - - A 003 LENGUAJE SQL3 E - 1995 - - - - - A 004 SQL3 TRADEOFFS I - 1995 - - - - - A 005 BASES DE DATOS E - 1996 - - - - - 003 McGRAW 181 AVENUE NEW YORK
Figura 7.6 Ejemplos de combinaciones externas

5.1.3. CLÁUSULA WHERE La cláusula WHERE se define de la siguiente manera: <cláusula WHERE>: : = WHERE <condición de búsqueda>
y sirve para filtrar el resultado de la consulta, ya que en éste no aparecerán las filas que no cumplan la condición de búsqueda, que se define así:
<condición de búsqueda> ::= <término booleano> | <condición de búsqueda> OR <término booleano>
<término booleano> ::=
<factor booleano> | <término booleano> AND <factor booleano>
<factor booleano> ::= [NOT] <test booleano> <test booleano> ::=
. <primario booleano> [ IS [NOT] <valor de verdad7> ]
<primario booleano> ::=
<predicado> | <parent. izq.><condición de búsqueda><parent. dcho.>
El SQL admite distintos tipos de predicados, los más utilizados son los siguientes: A) Predicado de comparación
Es parecido al de los lenguajes de programación, y utiliza los símbolos tradicionales: igual (“=”), distinto menor que (“<”), mayor que (“>”), menor o igual a (“<=”) y mayor o igual a (“>=”)
En la figura 7.7 se obtiene el resultado de aplicar a la tabla Documento la siguiente consulta:
SELECT Titulo, Idioma, Nombre_E, Año FROM Documento WHERE Año > = 1995;
TÍTULO IDIOMA NOMBRE AÑO AN INTRODUCTION TO DBS I ADDISON-WESLEY 1995
A GUIDE TO SQL I ADDISON-WESLEY 1996 RELATIONAL DB I ADDISON-WESLEY 1995
ANÁLISIS SI E RAMA 1996 LENGUAJE SQL3 E 1995
SQL3 TRADEOFFS I 1995 BASES DE DATOS E 1996
Figura 7.7. Ejemplo de predicado de comparación B) Predicado Between
Es un predicado de comparación especial que permite obtener los valores que se encuentran dentro de un intervalo (extremos inclusive). Por ejemplo, en la figura 7.8 se ejecuta la siguiente consulta sobre la tabla Documento:
SELECT Titulo, Idioma, Nombre_E, Año FROM Documento WHERE Año BETWEEN 1976 AND 1993;
TÍTULO IDIOMA NOMBRE AÑO
CONCEPCION BD E RAMA 1993 ANÁLISIS DE SI E ANAYA 1993 COMPILADORES E PARANINFO 1992
E/R MODEL I - 1976 RELATIONAL MODEL I - 1970
Figura 7.8. Ejemplo de predicado Between
7 Recordemos que el lenguaje SQL soporta lógica multivaluada, con los valores de verdad TRUE (cierto), FALSE (falso) y UNKNO" (quizás).

C) Predicado In
Permite comparar un valor con una lista (de valores) o con una subconsulta. Por ejemplo, si quisiéramos consultar los documentos publicados en las editoriales Ra-Ma o Paraninfo, podríamos escribir la siguiente consulta:
SELECT * FROM Documento WHERE Nombre_E IN ('Ra-Ma', 'Paraninfo');
Otro ejemplo podría ser la consulta relativa a los libros publicados por editoriales que se encuentren en Madrid:
SELECT * FROM Documento WHERE Nombre_E IN
(SELECT Nombre FROM Editorial WHERE Ciudad = 'Madrid');
en la que podemos ver cómo se ha anidado una sentencia SELECT dentro de otra. Hay que destacar que esta sentencia puede hacerse de múltiples formas distintas, por ejemplo mediante una combinación de tablas.
Autores como DATE (1995) señalan como inconveniente para los usuarios que una misma consulta pueda expresarse de formas distintas, puesto que los productos pueden dar tiempos de respuesta distintos según se lleve a cabo la consulta. Por ejemplo suele ser más eficiente realizar una consulta combinando tablas que “anidando” sentencias SELECT. D) Predicado Like
Permite utilizar comodines a la hora de consultar la base de datos, para lo que utiliza el carácter “%” para Indicar cero o más caracteres en el patrón de búsqueda, y el carácter “-” para indicar exactamente un carácter.
Así, podríamos consultar por Documentos en cuyo título aparezca “BD” mediante la sentencia siguiente:
SELECT * FROM Documento WHERE Titulo LIKE '%DB %';
y obtendríamos el resultado que se muestra en la figura 7.9. TIPO CÓD-DOC TÍTULO IDIOMA NOMBRE AÑO ISBN
L 002 INTRODUCTION TO DBS I ADDISON-WESLEY 1995 0-201-54329-X L 004 RELATIONAL DB I ADDISON-WESLEY 1995 0-201-55483-X
Figura 7.9. Utilización del predicado Like E) Predicado Null
Sirve para determinar si una columna tiene valores nulos. Así, por ejemplo, si quisiéramos consultar aquellos documentos que no poseen ISBN8, haríamos lo siguiente:
SELECT* FROM Documento WHERE Isbn IS NULL;
8 Obtendríamos sólo los artículos que son los únicos documentos que no poseen ISBN.

F) Predicado Exists
Este predicado es cierto si la cardinalidad de la consulta que tiene asociada es mayor que cero y falso en caso contrario. En el apartado 4.3 lo utilizamos para definir una aserción, y remitimos al lector a MELTON y SIMON (1992) para una mayor explicación sobre este predicado y los que se enuncian a continuación. También nos parece muy interesante consultar las referencias DATE (1990) y DATE (1995) para adentrarse en algunos de los problemas que puede causar la utilización de estos predicados. G) Predicado UNIQUE
Sirve para determinar si existen filas duplicadas en la subconsulta que lleva asociado. H) Predicado Overlaps
Se emplea para contrastar si dos intervalos de tiempo se solapan. I) Predicado de comparación cuantificado
El lenguaje SQL permite también aplicar cuantificadores existenciales y universales en las consultas por medio de las partículas SOME, ANY y ALL. J) Predicado Match
Este predicado, que también se emplea como ya hemos señalado en la definición de clave ajena, se define de la siguiente manera:
<predicado match> ::= <constructor de valor de fila> MATCH [UNIQUE ] [PARTIAL|FULL] <subconsulta de tabla>
En el caso de que no se especifique ningún tipo de correspondencia (ni PARTIAL ni FULL), el predicado es cierto si:
• algún valor del valor de fila (del constructor) es nulo,
• o ningún valor del valor de fila (del constructor) es nulo y todo valor del valor de fila es igual al valor correspondiente en alguna fila de la subconsulta de tabla (o exactamente a una fila si se especifica UNIQUE),
• en caso contrario el predicado es falso.
Si se especifica correspondencia total (FULL), el predicado es cierto si:
• todo valor del valor de fila es nulo, o
• ningún valor del valor de fila es nulo y todo valor del valor de fila es igual al correspondiente valor en alguna fila de la subconsulta,
• en caso contrario es falso.
Si se especifica correspondencia parcial (PARTIAL), el predicado es cierto si:
• todo valor del valor de fila es nulo, o
• todo valor del valor de fila no nulo es igual al correspondiente valor en alguna fila de la subconsulta, en caso contrario es falso.
Para explicar el funcionamiento del predicado vamos a aplicarlo al ejemplo de la figura 7.10, en la que suponemos que la clave primaria de la tabla Libro está compuesta por las columnas Título y Año. En la tabla Escribe tenemos una clave ajena compuesta

por estas mismas columnas que referencia a la tabla Libro. El predicado Match nos serviría para refinar esta referencia, especificando si admitimos o no que una de las columnas que forman la clave ajena, por ejemplo, Año, tomen valores nulos.
LIBRO TÍTULO AÑO EDITORIAL
SELECTED WRITINGS 1990 ADDISON-WESLEY SELECTED WRITINGS 1992 ADDISON-WESLEY
CONCEPCIÓN BD 1993 RAMA ANÁLISIS SI 1996 RAMA
CLAVE AJENA (TÍTULO, AÑO) ESCRIBE
AUTOR TÍTULO AÑO DATE SELECTED WRITINGS 1990 DATE SELECTED WRITINGS 1992
DE MIGUEL CONCEPCIóN DE BD 1993 PIATTINI CONCEPCIóN DE BD 1993 PIATTINI ANÁLISIS SI 1996
Figura 7.10. Ejemplo de utilización de Match
En caso de querer insertar la fila <DATE, Selected Writings, nulo> en la tabla Escribe, si se especifica el tipo de correspodencia total (FULL) siempre daría falso al tener un valor del valor de fila nulo; mientras que si no se especificara ninguna correspondencia o si ésta fuera parcial, el predicado sería cierto.
Si se quiere introducir la fila <DATE, Concepción y Diseño de BD, nulo>, con correspondencia total sería falso, así como con correspondencia parcial, mientras que si no se especifica correspondencia daría cierto.
Por supuesto que si se quiere insertar la fila <DATE, Concepción y Diseño de BD, l889>, daría falso en los tres casos.
5.1.4. CLÁUSULA GROUP BY Esta cláusula permite particionar una tabla en grupos (denominados tablas
agrupadas), de acuerdo a los valores de ciertas columnas: <cláusula group by> ::=
GROUP BY <lista de referencia de columnas de agrupación>
Se suele utilizar en combinación con funciones de agregación como el número de filas de una tabla (COUNT), el valor máximo (MAX), el valor mínimo (MIN), la suma de valores (SUM), la media de valores (AVG).
Ejemplos de utilización de esta cláusula podrían ser los siguientes: SELECT Tipo, MIN (Año)
FROM Documento GROUP BY Tipo;
cuyo resultado se muestra en la figura 7.11. TIPO AÑO L 1992 A 1976
Figura 7.11. Ejemplo de utilización de la cláusula group by
Si quisiéramos saber cuántas editoriales existen en cada ciudad, podríamos hacer: SELECT Ciudad, COUNT (*)
FROM Editorial GROUP BY Ciudad;

5.1.5 CLÁUSULA HAVING Esta cláusula va asociada a la anterior y juega un papel análogo al de la cláusula
WHERE, pero aplicado a tablas agrupadas. <cláusula having> ::=
HAVING <condición de búsqueda>
Así, por ejemplo, si quisiéramos consultar las ciudades en las que se encuentran ubicadas por lo menos dos editoriales, podríamos agrupar las editoriales por ciudades y establecer la condición de que fueran más de dos en la cláusula Having:
SELECT Ciudad, FROM Editorial GROUP BY Ciudad HAVING COUNT (*) >= 2;
5.2. Inserción de datos: Sentencia INSERT La inserción de datos se lleva a cabo mediante la sentencia INSERT: <sentencia de inserción> ::=
INSERT INTO <nombre de tabla> VALUES <columnas y fuente de inserción>
<columnas y fuente de inserción> ::=
[<parent. izq.><lista de columnas de inserción> <parent.dcho.>] <expresión de consulta> | DEFAULT VALUES
Así, por ejemplo, si queremos insertar un nuevo documento en la biblioteca podríamos hacer:
INSERT INTO Documento VALUES (‘L’, 030, 'Una visión actual de CASE', 'E', TAMA', 1995, 84-9876-098-7);
pudiendo también especificar el nombre de las columnas, lo que es muy recomendable, ya que nos permite conseguir una mayor independencia de cara a una posib e reorganización del orden de las columnas o una inclusión de nuevas columnas en la tabla.
5.3. Borrado de datos: Sentencia DELETE La sentencia DELETE permite borrar datos de la tabla: <sentencia de borrado>::=
DELETE FROM <nombre de tabla> [WHERE <condición de búsqueda>]
Así, por ejemplo, Podemos borrar los libros publicados por Addison-Wesley de la siguiente manera:
DELETE FROM Documento WHERE Nombre_E = ‘Addison-Wesley';
5.4. Modificación de datos: Sentencia UPDATE La modificación de datos se lleva a cabo mediante la sentencia UPDATE: <sentencia de actualización> ::=
UPDATE <nombre de tabla> SET <lista de cláusula de set> [WHERE <condición de búsqueda>]
<lista de cláusula de set>::=

<cláusula de set>[{<coma><cláusula de set> ...
<cláusula de set> ::= <columna><operador igual><fuente de actualización>
<fuente de actualización> ::= <expresión de valor>
| <especificación de valor nulo> | DEFAULT
Si quisiéramos aumentar en 1 todos los años de publicación, deberíamos ejecutar la siguiente sentencia:
UPDATE Documento SET Año = Año + 1;
Otro ejemplo podría ser cambiar a idioma inglés todos los libros publicados por RA-MA:
UDATE Documento SET Idioma = ‘I’ WHERE Nombre_E = 'Ra-Ma';
6. SENTENCIAS DE CONTROL: SEGURIDAD EN SQL
6.1. Confidencialidad El lenguaje SQL en la actualidad sólo soporta control de acceso discrecional
aunque existen algunas propuestas para incluir control de acceso obligatorio (véase capítulo 14) en el SQL3. En el modelo de confidencialidad del SQL el creador de un objeto es siempre el propietario del mismo, y tiene todos los privilegios sobre el objeto (salvo que sea una vista, en cuyo caso se limitan los privilegios sobre la vista a los que tenía sobre las tablas subyacentes).
Como ya señalamos en el apartado 4, a la hora de crear un esquema SQL se puede asignar un identificador de autorización por medio de la cláusula de nombre del esquema
Para conceder privilegios se emplea la: <sentencia de concesión>::=
GRANT <privilegios> ON <nombre de objeto> TO <concedido> [<coma><concedido> ... ] [WITH GRANT OPTION]
en la que <privilegios>::-
ALL PRIVILEGES | <lista de acción>
los privilegios pueden ser para consultar o actualizar (borrar, insertar y modificar) tablas, así como para referenciarlas (utilizado en restricciones como la integridad referencial), o para "usar" dominios (Domain), conjuntos de caracteres (Character-Set), ordenaciones (Collation) y traducciones (Translation). Por lo que:
<lista de acción>::= SELECT | DELETE | INSERT [<parent. izq.><lista de columnas><parent. dcho.>] | UPDATE [<parent. izq.><lista de columnas><parent. dcho.>] | REFERENCES [<parent. izq.><lista de columnas><parent. dcho.>]

| USAGE
Un ejemplo de esta sentencia sería la concesión del privilegio de borrar filas de la tabla Empleados al usuario Juan:
GRANT DELETE ON Empleados TO Juan;
En lugar de conceder privilegios a determinados identificadores de usuario, se pueden conceder privilegios a todos mediante la utilización de 'TUBLIC".
Como podemos observar en la definición de la sentencia de concesión, se puede conceder también la posibilidad de conceder privilegios (WITH GRANT OPTION).
Por otra parte, para revocar privilegios se emplea: <sentencia de revocación> ::=
REVOKE [GRANT OPTION FOR] <privilegios> ON <nombre de objeto> FROM <concedido> [{<coma><concedido> ... }]<comportamiento de borrado>
<comportamiento de borrado> ::= CASCADE | RESTRICT
en la que si usamos el comportamiento restringido (RESTRICT) no dejará revocar privilegios que hayan sido concedidos a otros usuarios, mientras que si empleamos la opción en cascada, se borrarán todos los privilegios. Un ejemplo de sentencia de revocación sería:
REVOKE INSERT, UPDATE (Salario) ON Empleado FROM Ana, Pedro CASCADE;
Hay que tener cuidado, ya que a pesar de revocar los privilegios a un usuario, éste puede mantenerlos a través de otro usuario (que les haya concedido los mismos privilegios).
Por otro lado, cualquier borrado de un objeto (tabla, dominio, vista, etc.) causa, como es lógico, la revocación de todos los privilegios sobre el objeto a todos los usuarios.
Otro mecanismo que representa un papel muy importante en la confidencialidad del SQL lo constituyen las vistas, que permiten ocultar información a los usuarios; y, así, conceder privilegios sólo sobre subconjuntos de las tablas.
6.2. Disponibilidad El SQL soporta las transacciones clásicas, tal y como se definen en el capítulo 14,
mediante las sentencias COMMIT y ROLLBACK. Las transacciones se inician al empezar los programas, o bien al ejecutar sentencias de definición o manipulación.
En el próximo apartado examinaremos algunas características de las transacciones, que afectan más a la integridad (control de concurrencia) que a la disponibilidad.

6.3. Integridad
6.3.1. SEMÁNTICA Como ya señalamos en otras ocasiones [véase, por ejemplo, DE MIGUEL y
PIATTINI (1992)], el lenguaje SQL 92 representa un gran avance en cuanto a semántica respecto al lenguaje SQL 89. Como hemos visto, en el estándar actual se soportan, además de la clave primaria, unicidad, no nulos e integridad referencial, las restricciones de verificación (CHECK), los dominios9 (CREATE DOMAIN) y las aserciones (CREATE ASSERTION); sentencias que se incluyen en la definición de los elementos del esquema.
Las restricciones en SQL 92 presentan otra característica que afecta en gran medida a la integridad semántica: la posibilidad de ser diferidas, esto es, de verificarse al final de la transacción en lugar de hacerlo después de la ejecución de cada sentencia de manipulación, como hemos visto para el caso de la integridad referencial. Si la transacción se ha definido como diferible se puede cambiar dinámicamente el momento de su comprobación mediante la sentencia:
SET CONSTRAINTS <lista de nombres de restricciones> {DEFERRED INMEDIATE}
<lista de restricciones> ::=
ALL <nombre de restricción> [{<coma> <nombre de restricción>}... ]
Esto permite definir restricciones que los anteriores estándares no soportaban. Por ejemplo, si se definen dos tablas Empleados y Departamentos, como las siguientes:
Departamentos (N_DEPT, LOCALIDAD, ..., JEFE)
Empleados (CODEMP, NOMBRE, ..., N_DEPT)
en las que JEFE es una clave ajena que referencia a Empleados y se define como no nula, y N_DEPT es una clave ajena que referencia a Departamentos y también se considera no nula. Supongamos que se quiere insertar un nuevo departamento con su jefe correspondiente en un SGBDR con SQL-89. Si se intenta introducir el nuevo departamento, el sistema no lo permitirá al no existir el empleado (que es el jefe) al que referencia; lo mismo sucederá si se quiere introducir en primer lugar el jefe, ya que no existe el departamento correspondiente. Este problema (la “pescadilla que se muerde la cola”) se resuelve definiendo las restricciones como diferidas, e incluyendo las dos inserciones dentro de una misma transacción; ya que se comprobará la consistencia al final de la transacción permitiéndose ambas inserciones, ya que son (en conjunto) semánticamente consistentes. Sin embargo, como señala DATE (1992c), la posibilidad de desactivar dinámicamente las restricciones, limita seriamente el potencial de optimización semántica.
6.3.2. OPERACIONAL El estándar SQL no proporciona, a diferencia de los productos relacionales,
ninguna sentencia para bloquear datos, sino que deja este aspecto a los implementadores (se podría implementar incluso un sistema que soportara completamente el SQL 92 y que utilizara un mecanismo diferente al de los bloqueos).
9 Si bien la definición de dominios no es en sí misma una restricción semántica sino la creación de un elemento del modelo, los dominios permiten incorporar semántica del mundo real.

En la versión actual del estándar se han introducido cuatro niveles de aislan-tiento:
• lectura sin grabar • lectura grabada • lectura repetible • serializable
siendo la opción por defecto esta última (en la que se obliga a la serialidad de las transacciones). Estos niveles de aislamiento se definen en base a tres problemas de concurrencia (parecidos a los tratados en el capítulo 14):
• Lectura "sucia": consiste en que una transacción lleva a cabo una actualización sobre un dato, que es leído entonces por otra transacción. Si la primera transacción se deshace, la segunda ha leído un valor que nunca debería haber existido.
• Lectura no reproducible: una transacción que quiere leer un dato dos veces se encuentra con que ese dato varía (si en medio de las dos lecturas otra transacción ha actualizado ese dato), sin que en la primera transacción se hubiera realizado ninguna actualización.
• Lectura "fantasma": si una transacción recupera todos los datos que satisfacen una condición y después otra transacción incorpora nuevos datos que satisfacen dicha condición, si la primera transacción repite su consulta aparecen nuevos datos ('Tantasinas").
En la tabla de la figura 7.12 se muestran los diferentes niveles de aislamiento según los problemas de concurrencia que evitan.
NIVEL DE AISLAMIENTO
LECTURA “SUCIA”
LECTURA NO. REPETIBLE
LECTURA “FANTASMA”
Lectura no grabada Posible Posible Posible Lectura grabada No posible Posible Posible Lectura repetible No posible No posible Posible
Señalizable No posible No posible No posible Figura 7.12. Niveles de aislamiento del SQL 92
Hay que advertir, sin embargo, de acuerdo con BERENSON et al. (1995), que los problemas que define el estándar son ambiguos e incompletos, pudiendo dar lugar a
muchas anomalías. Estos expertos proponen que se considere obligatorio para todos los niveles evitar el fenómeno de:
Escritura "sucia": si una transacción modifica un dato y otra transacción modifica también ese mismo dato antes de que la primera se grabe o deshaga, si cualquiera de las dos se deshace no queda claro cuál es el valor correcto.
En BERENSON et al (1995) el lector interesado puede encontrar más propuestas para mejorar los niveles de aislamiento del estándar (introduciendo, por ejemplo, el nivel de estabilidad para cursores, que extiende el de lectura grabada para cursores SQL) en función de otros fenómenos como el de actualización perdida.
Mediante la sentencia: <sentencia para determinar transacciones> ::=
SET TRANSACTION <modo de transacción> [ {<coma><modo de transacción>} ...
<modo de transacción> ::=
<nivel de aislamiento> | <modo de acceso de la transacción> | <tamaño del área de diagnóstico>
<nivel de aislamiento> ::= ISOLATION LEVEL <nivel>

<nivel> ::=
READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE
<modo de acceso de la transacción> ::= READ ONLY | READ WRITE
<tamaño del área de diagnóstico> ::= DIAGNOSTICS SIZE <especificación de valor simple>
los administradores pueden fijar, como podemos observar, las características de las transacciones. Por defecto, éstas puede ejecutar tanto operaciones de lectura como de escritura, se aíslan lo más posible de otras (nivel serializable) y utilizan un área de diagnóstico de un tamaño por defecto. El tamaño de esta área indica el número de condiciones que se almacena para cada sentencia SQL que se ejecuta.
Un ejemplo de esta sentencia sería: SET TRANSACTION
READ ONLY ISOLATION LEVEL READ UNCOMMITTED DIAGNOSTICS SIZE 4;
7. SOL EMBEBIDO
Como ya hemos señalado, el lenguaje SQL permite actuar tanto como lenguaje interactivo como lenguaje huésped (embebido), por lo que se dice que tiene la propiedad dual.
Las sentencias SQL se van intercalando con las sentencias del lenguaje anfitrión, precedidas normalmente de la partícula EXEC SQL para que puedan ser distinguidas por los precompiladores. Como puede verse en la figura 7.13, la declaración de variables se introduce en una sección que empieza con la sentencia EXEC SQL BEGIN DECLARE SECTION y finaliza con otra sentencia EXEC SQL END DECLARE SECTION.
Figura 7.13. Ejemplo de un programa con SQL embebido
Las sentencias de manipulación, como se observa en la figura, sufren algunas variaciones, ya que pueden referenciar a variables anfitrión, como podría ser el caso de:

EXEC SQL SELECT Año INTO :Año FROM Documento WHERE Isim = :Isbn;
que rellenaría la variable :Año con el valor del año que figure en la base de datos para el documento cuyo ISBN fuera igual al de la variable anfitrión.
Las variables anfitrión deben tener un tipo adecuado al de la base de datos, y en el estándar se definen las correspondencias para distintos lenguajes. También se introduce la función CAST que permite la conversión explícita de tipos de datos, facilitando la correspondencia entre los tipos del lenguaje SQL y los de lenguajes de programación en los que el SQL pueda actuar de forma huésped.
También es importante destacar que las sentencias SQL deberían ser seguidas por una comprobación de que han devuelto un valor correcto, para lo que se puede utilizar la variable SQLCODE, que se introdujo en el SQL de 1986 y puede tomar los valores siguientes:
• 0 si la operación ha tenido éxito
• 100 si no devuelve datos,
• un valor negativo para indicar que se ha producido algún error.
Sin embargo, como podemos observar, esta variable no es demasiado precisa en la indicación de los errores, lo que ha llevado a que cada fabricante defina sus propios códigos de error adicionales, lo que dificulta enormemente la portabilidad de las aplicaciones. En el SQL-92 se define un nuevo parámetro denominado SQLSTATE que consta de 5 caracteres -los dos primeros indican la clase de error y los 3 últimos la subclase-, existiendo una tabla de códigos que contemplan los distintos tipos de errores que pueden producirse. También se facilita una nueva sentencia GET DIAGNOSTICS que permite a las aplicaciones recuperar información adicional sobre los errores.
También es importante contemplar el tratamiento de excepciones, lo que se lleva a cabo mediante la sentencia WHENEVER:
<declaración de excepciones embebida> ::= WHENEVER <condición> <acción>
donde <condición> ::=
SQLERROR | NOT FOUND
<acción> ::= CONTINUE | GOTO <objetivo>
donde el objetivo es la etiqueta (o un entero) desde donde se reanuda el programa.
Por otro lado hay que tener en cuenta que si bien hay sentencias SQL que implican una sola fila (por ejemplo, una selección por la clave primaria o una inserción), la mayor parte de las sentencias SQL manejará un conjunto de filas, mientras que el lenguaje anfitrión sólo podrá manejarlas de una en una. Para resolver esta discordancia (denominada impedance mismatch), el SQL soporta el mecanism de cursores, ofreciendo mandatos para declararlos (DECLARE CURSOR FOR), abrirlos (OPEN), cerrarlos (CLOSE) y leer los (FETCH).

Por motivos de espacio no podemos analizar todas estas sentencias, a modo d ejemplo presentamos la definición de un cursor, que se lleva a cabo utilizando la sentencia:
<declaración de cursor>::= DECLARE <nombre del cursor> [INSENSITIVE][SCROLL] CURSOR FOR <sentencia>
Por ejemplo, si quisiéramos declarar un cursor para recorrer la tabla Editorial: DECLARE cursor_e CURSOR FOR
SELECT Código, Nombre, Dir, Ciudad FROM Editorial ORDER BY Ciudad DESC;
La cláusula ORDER BY (que también puede utilizarse en el SQL interactivo) permite ordenar los valores ascendentemente (por defecto) o descendentemente.
Si el cursor se declara insensible (INSENSITIVE) no podrá ver los efectos de otras sentencias en la misma transacción mientras permanezca abierto, en caso
contrario no queda determinado cuál sería el efecto. Se introducen también cursores de desplazamiento (scroll cursors), que permiten realizar un FETCH de diversas formas: NEXT, PRIOR, FIRST, LAST, ABSOLUTE n o RELATIVE n, siendo “n” el resultado de evaluar una expresión escalar.
8. SQL DINÁMICO
Otro avance del SQL92 lo constituye la posibilidad de utilizar sentencias SQL dinámicas, esto es, de ejecutar sentencias SQL cuyo contenido se conoce sólo en tiempo de ejecución, como por ejemplo:
SELECT Nombre, Dirección FROM Editorial WHERE Ciudad = ?;
donde mediante el símbolo “?” se indica el parámetro que habrá de pasarse a la sentencia durante su ejecución.
Esta opción resulta muy útil cuando no se conocen todos los elementos de una sentencia SQL en el momento de escribirla, por ejemplo, cuando el usuario va a introducir algunos datos, o en caso de que se esté utilizando alguna facilidad de usuario (hoja de cálculo) que genera sentencias SQL.
9. EL LENGUAJE SOL3
Debido al considerable volumen que ha ido adquiriendo este nuevo estándar (que supera ampliamente las mil páginas) se ha decidido descomponerlo en varias partes con un doble propósito: por un lado, facilitar su aprobación en tiempos más cortos, y, por otro, permitir que los productos soporten algunos conceptos pero no necesariamente todos. El estándar ha quedado estructurado en las siguientes partes:
1. Marco de referencia (SQL/Framework), que es una descripción no técnica de cómo se estructura el nuevo estándar.

2. Fundamentos y Facilidades de Propósito General (SQL/Foundation), que constituye el núcleo del estándar SQL3, incluidos los aspectos de orientación al objeto.
3. Interfaz de nivel de llamada (SQL/CLI, Call Level Interface).
4. Módulos SQL Persistentes (SQL/PSM, Persistent Storage Module)10, en los que se especifican los procedimientos almacenados y la compleción computacional.
5. Vinculaciones a Lenguajes Anfitrión (SQL/Bindings), en las que se especifican las vinculaciones para SQL embebido y SQL dinámico.
6. Especialización XA (SQL/Transaction), que se propone como especialización de la interfaz XA de X/Open.
7. Temporal (SQL/Temporal), en el que se incluyen los principales aspectos del lenguaje TSQL2.
8. Objetos extendidos (SQL/Objects), que abarca los Tipos Abstractos de Datos “Objetos”.
9. Tablas virtuales (SQL/Virtual Table), que permitirá acceder a ficheros utilizando SQL.
Las características más significativas del SQL3 son las siguientes:
• Nuevos tipos de datos (booleano, “objetos grandes”...)
• Reglas activas (disparadores).
• Tipos abstractos de datos, definidos con la sentencia CREATE TYPE, que permite especificar los atributos y operaciones que representan la estructura y el comportamiento de tipos abstractos de datos definidos por el usuario.
• Operador de unión recursiva para expresiones de consulta.
• Cursores sensitivos, que estando abiertos permiten "ver" incluso cambios en los datos no producidos a través de ellos.
• Jerarquía de generalización de tablas (subtablas y supertablas).
• Papeles (roles) de usuario.
Debido a obvias limitaciones de espacio sólo presentaremos dos aspectos que destacan por su interés, al encontrarse presentes en la mayor parte de los productos relacionales: los papeles o roles y los disparadores (triggers).
9.1. Papeles (roles) en SOL3 Entre los aspectos más destacables en cuanto a la confidencialidad, se encuentra la
inclusión de los papeles o "roles" de seguridad, ya presentes en muchos productos, que se definen de la siguiente manera:
<definición de rol> ::= CREATE ROLE <nombre de rol>
asignando los usuarios a los roles mediante la:
10 Como ya hemos señalado, en 1995 y 1996 se han aprobado, respectivamente, las normas SQL/CLI y SQL/PSM adaptadas al SQL-92. En estos momentos se están extendiendo de acuerdo al SQL3 Foundation.

<sentencia de concesión de rol> ::= GRANT <rol concedido> [ { <coma><rol concedido> TO <concedido> [ { <coma>< concedido>
para eliminar a un usuario de un rol se utiliza la: <sentencia de revocación de rol> ::=
REVOKE <rol concedido> [ { <coma><rol concedido> TO <concedido> [ { <coma>< concedido>
mientras que para eliminar un rol, empleamos: <sentencia de borrado de rol> ::=
DROP ROLE <nombre de rol>
9.2. Disparadores en SQL3 El lenguaje SQL3 estandariza los disparadores de la siguiente forma: <definición disparador> ::=
[ CREATE ] TRIGGER [ <nombre disparador> ] <tiempo acción disparador> <evento disparador> ON <nombre tabla> [ REFERENCING <lista de alias para valores antiguos o nuevos> ] <acción disparada> ...
donde el nombre del disparador es un nombre cualificado, y <tiempo de acción>
AFTER | BEFORE | INSTEAD OF11
el evento puede ser: <evento disparador>
INSERT | DELETE | UPDATE [ OF <lista columnas disparador> ]
La lista de alias para los valores antiguos y nuevos es una lista formada por: <alias valores antiguos o nuevos> ::=
OLD [ AS ] <nombre correlación valores antiguos> | NEW [ AS ] < nombre correlación valores nuevos> | OLD_TABLE [ AS ] <alias de tabla de valores viejos> | NEW_TABLE [ AS ] <alias de tabla de valores viejos>
donde los nombres de correlación son identificadores.
La acción disparada consta de: <acción disparada>
[ FOR EACH { ROW | STATEMENT } ] [ WHEN <p.izdo> <condición búsqueda> <p. dcho> ] <sentencia SQL disparada>
<sentencia SQL disparada> ::= <sentencia de procedimiento SQL> | BEGIN ATOMIC <sentencia de procedimiento SQL><pto y coma> .. END
La sentencia SQL disparada es una sentencia de procedimiento SQL que puede ser de borrado (DELETE), modificación (UPDATE) o inserción (INSERT), de control o de diagnóstico.
11 Se deja esta opción para el SQL4.

Por otra parte, el INFORMATION_SCHEMA del SQL3 define las siguientes vistas que describen los disparadores:
• TRIGGERS, identifica los disparadores de un usuario. • TRIGGERED_ACTIONS, identifica las acciones disparadas en un catálogo que posee un
usuario. • TRIGGERED_COLUMNS, por cada esquema de un usuario, identifica las vistas que
dependen de columnas que se describen en un disparador.
En el DEFINITION_SCHEMA se definen las siguientes tablas: • TRIGGERS (TRIGGER_CATALOG, TRIGGER_SCHEMA, TRIGGER_NAME, EVENT - MANIPULATION, EVENT_OBJECT_CATALOG, EVENT_OBJECT_SCHEMA, EVENT_OBJECT_TABLE, ACTION_ORDER, ACTION_CONDITION, ACTION_STATEMENT_LIST, ACTION_ORIENTATION, CONDITION_TIMING, CONDITION_REFERENCE_OLD_TABLE, CONDITION_REFERENCE_NEW_TABLE, COLUMN_LIST_IS_IMPLICIT) • TRIGGERED_COLUMNS (TRIGGER_CATALOG, TRIGGER_SCHEMA,
TRIGGER_NAME, EVENT_OBJECT_CATALOG, EVENT_OBJECT_SCHEMA, EVENT_OBJECT_TABLE, EVENT_OBJECT_COLUMN)
Veamos a continuación un ejemplo de utilización de disparadores:
Sean las dos tablas siguientes:
DEPT (N_DEPT, LOCALIDAD, NUM_EMP)
EMP (COD_EMP, NOMBRE . N_DEPT)
donde se han subrayado las claves primarias y existe una clave ajena N_DEPT de la tabla empleado que referencia a la tabla DEPT.
El atributo NUM_EMP representa el número de empleados del departamento y es, por tanto, un atributo derivado12 que, si se decide almacenar, deberá ser controlado por medio de disparadores como los siguientes:
CREATE TRIGGER borrar_emp AFTER DELETE ON emp FOR EACH ROW ( UPDATE dept.num_emp = dept.num_emp – 1 WHERE dept. n_dept = emp. n_dept);
CREATE TRIGGER insertar_emp
AFTER INSERT ON emp FOR EACH ROW ( UPDATE dept.num_emp = dept.num_emp + 1 WHERE dept.n_dept= emp.n_dept);
CREATE TRIGGER modificar_emp
AFTER UPDATE OF n_dept ON emp REFERENCING OLD_TABLE AS v_emp
NEW TABLE AS n_emp FOR EACH ROW (UPDATE dept
SET num_emp = num_emp + 1 WHERE dept.n_dept = n_emp.n_dept);
(UPDATE dept SET num_emp = num_emp - 1 WHERE dept.n_dept = v_emp.n_dept);
12 Otra posibilidad sería controlar el atributo NUM_EMP mediante una restricción de verificación (por medio de un CHECK) o considerando una función que devuelva el número de empleados de un departamento pero sin necesidad de almacenar dicho número

EJERCICIOS Y PREGUNTAS DE REPASO 7.1. Represente en el modelo E/R un esquema conceptual que refleje los principales
conceptos del lenguaje SQL.
7.2. En el apartado 3.2.4 se cita la posibilidad de borrar un dominio mediante la sentencia DROP, ¿qué alternativas propone para el caso de existir columnas definidas sobre el dominio? Nota: consulte lo que se entiende en el estándar por comportamiento de borrado (drop behavior).
7.3. En el lenguaje SQL-92 las vistas pueden ser creadas (mediante la sentencia CREATE VIEW) y borradas (DROP VIEW); pero, a diferencia de lo que ocurre con las tablas, no se puede modificar su definición (no existe la sentencia ALTER VIEW). Comente cuál cree que es la razón de ello.
7.4. Crear un esquema SQL para la siguiente base de datos que refleja la información necesaria para la gestión del metro:
ESTACIONES (NOMBRE_EST, AÑO, DIRECCIÓN)
LÍNEA (NÚMERO, LÍNEA, COLOR, LONGITUD)
COMPUESTA (NÚMERO_LÍNEA, NOMBRE_EST, ORDEN)
TREN (CÓD_TREN, MODELO, NÚM_VAGONES, LÍNEA, CÓD_COCHERA)
COCHERA (CÓD_COCHERA, NOMBRE_EST, CAPACIDAD)
a) Defina los dominios, claves primarias, alternativas y ajenas, así como las restricciones que estime oportuno.
b) Modifique el esquema anterior de las siguientes formas:
- Añadir una columna JEFE a la tabla ESTACIONES
- Borrar la columna NÚM_VAGONES de la tabla tren
- Añadir la restricción de que CAPACIDAD > 10
c) Crear una vista que represente los trenes de la línea 5 que se guardan en la cochera de la estación de ALUCHE.
d) Llevar a cabo las siguientes consultas:
- Líneas compuestas por más de 30 estaciones.
- Trenes que circulen por las líneas 10, 11 y 8 y que tengan menos de 5 vagones.
- Todos los datos de las estaciones de la línea 1 ordenados ascendentemente por el orden que ocupan en esta línea.
- Estaciones que pertenezcan a más de tres líneas y que no dispongan de cochera.
e) Insertar la estación Islas Filipinas en el año 1998 en Cea Bermúdez.
f) Borrar la estación Avenida de América de la línea 8.
g) Modificar la capacidad de la cochera con código " 111 " a 30 trenes.

7.5. Crear un esquema SQL para la siguiente base de datos que recoge la información necesaria para la gestión de la liga de fútbol:
JUGADOR (DNI, NOMBRE, NACIONALIDAD, DIRECCIÓN, SUELDO, EQUIPO)
EQUIPO (NOMBRE, CIUDAD, DIVISIÓN, PRESIDENTE)
PARTIDO (ID_PARTIDO, FECHA, EQUIPO_LOCAL, EQUIPO_VISITANTE, RESULTADO)
PARTICIPA (DNI_JUGADOR, ID_PARTIDO, FUNCIÓN)
a) Defina los dominios, claves primarias, alternativas y ajenas, así como las restricciones que estime oportuno. Tenga en cuenta que:
- Un jugador sólo puede realizar una función en un determinado partido.
- No se almacenan los datos históricos, por lo que un jugador sólo puede pertenecer a un equipo y éste sólo puede estar en una división.
b) Modifique el esquema anterior de la siguiente forma:
- Añadir una columna ENTRENADOR a la tabla EQUIPO.
- Borrar la columna DIRECCIÓN de la tabla JUGADOR.
c) Crear las aserciones oportunas que permitan especificar lo siguiente:
- Los jugadores que pertenecen a equipos de primera división deben percibir un sueldo mayor o igual a 15.000.000 de pesetas.
- Los jugadores de segunda división no pueden ganar menos de 2.000.000 ni más de 14.000.000 de pesetas.
- En el equipo del Atletic de Bilbao no puede haber jugadores italianos.
- En el equipo que preside "Gil y Gil" no puede haber jugadores angoleños.
d) Insertar filas en las tablas para, por lo menos, quince equipos y sus jugadores, así como unos treinta partidos.
e) Llevar a cabo las siguientes consultas:
- Jugadores que entrena "Capello".
- Suma de los sueldos de los jugadores del "Extrernadura".
- Partidos en los que el "Hércules" ha ganado.
- Equipo en el que juega "Ronaldo".
- Ciudad(es) a la(s) que pertenecen los equipos que más goles han marcado.
- Nombre de los jugadores que han desempeñado la función de delantero.
7.6. Crear un esquema SQL para la siguiente base de datos, que recoge la información necesaria para la gestión de una empresa:
EMPLEADO (CÓD_EMP, DNI, DIR, SUELDO, COMISIÓN, DEPARTAMENTO)
DEPARTAMENTO (CÓD_DEP, NOMBRE, CIUDAD, PRESUPUESTO)
PROYECTO (CÓD_PROY, NOMBRE, PRES_PROY, PROY_SUPERIOR)

TRABAJA (CÓD_EMP, CÓD_PROY, FECHA_INICIO, FECHA_FIN, FUNCIÓN)
f) Defina los dominios, claves primarias, alternativas y ajenas, así como las restricciones que estime oportuno. Tenga en cuenta que:
- Un empleado sólo puede trabajar en un departamento.
- Un empleado puede trabajar en un proyecto con distintas funciones en distintas fechas (interesa recoger toda la información histórica).
- Un proyecto puede formar parte de uno superior.
- El presupuesto de cualquier proyecto en el que trabajan los empleados de un departamento no puede superar el presupuesto del departamento.
- El presupuesto del departamento debe ser superior a la suma de los sueldos y comisiones13 de los empleados del departamento.
g) Modifique el esquema anterior de la siguiente forma:
- Añadir una columna JEFE a la tabla DEPARTAMENTO, que corresponde al código del empleado que es jefe del departamento.
- Modificar la columna PRESUPUESTO para que admita decimales, al cambiar la expresión del presupuesto de pesetas a euros.
h) Llevar a cabo las siguientes consultas:
- Empleado que percibe el sueldo más bajo de la empresa.
- Media de los sueldos del departamento de 1nformática".
- Proyectos en los que ha trabajado "Juan Valdés".
- Departamentos a los que pertenezcan empleados que han trabajado en el proyecto "Atenea- durante el mes de abril de 1998.
- Suma de los presupuestos de todos los subproyectos que pertenezcan al proyecto "Atrio".
- Sueldo de los jefes de los empleados que trabajen actualmente en el proyecto "Kamikaze".
LECTURAS RECOMENDADAS MELTON, J. y SIMON, A. (1992). Understanding the New SQL: A Complete Guide, Morgan Kauffman
Publishers, San Mateo, CA. Es sin duda uno de los mejores libros que existen sobre el lenguaje SQL-92, escrito por el editor del estándar
(Jim Melton). DATE, C.J. y DARWEN, H. (1997). A Guide to the SQL Standard, 4ª edición, Addison-Wesley, Reading, MA. Chris Date se ha caracterizado a lo largo de estos años por una severa crítica al estándar, por considerar que
“pervierte” el modelo relacional. En las distintas ediciones de este libro se presenta un análisis en profundidad de las características del lenguaje.
VENKATRAD, M. y PIZZO, M. (1995). “SQL/CLI New binding style for SQL”, en: SIGMOD RECORD, vol. 24, nº 5, diciembre, pp. 72-76.
Este artículo presenta un resumen sobre el SQL/CLI (Call Level Interface), explicando su importancia en las aplicaciones actuales.
BEECH, D. (1997). “Can SQL3 Be Simplified?”, en: Database Programming & Design, vol. 10, nº 1, enero, pp. 46-50.
David Beech discute cómo pueden incorporarse nuevos conceptos de la orientación al objeto al lenguaje SQL manteniendo al mismo tiempo su principal ventaja: la simplicidad.
13 Téngase en cuenta que para algunos empleados (por ejemplo, analistas, la comisión puede tomar valores nulos).