

Planificación Temporal
• La planificación temporal para proyectos de desarrollo de software puede verse desde dos perspectivas bastante diferentes.
– La fecha final de lanzamiento del sistema basado en computadora ya ha sido (irrevocablemente) establecida.
• La organización del software se ve forzada a distribuir el esfuerzo dentro del marco prescrito.
– El segundo asume que se han estudiado limites cronológicos aproximados pero que la fecha final es fijada por la organización del software.
• El esfuerzo se distribuye para hacer un mejor uso de los recursos y la fecha final se define después de un cuidadoso análisis del elemento de software.
• Desdichadamente, la primera perspectiva se encuentra bastante mas a menudo que la segunda.

Estimación y Planificación
• Estimación=predicción de duración, esfuerzo y costos requeridos para realizar todas las actividades y constituir todos los productos asociados con el proyecto.
• La planificación es el proceso de:
– Selección de una estrategia para la obtención de producto final.
– Definición de actividades a realizar para lograr ese objetivo.
– Coordinación de concurrencia y solapamiento de dichas actividades.
– Asignación de recursos a las mismas.

Estimación y Planificación
• Estimación: Predicción cuantitativa de
aspectos del Proyecto.
• Planificación: Organización de gente y
tareas.
• La Planificación es el primer paso en la
realización de un proyecto informático y en
gran parte, el responsable del éxito o fracaso
del mismo.

Observaciones Acerca de la
Estimación
• La estimación la lleva a cabo el gestor del
proyecto
• La estimación y planificación temporal de un
proyecto software requiere:
- Experiencia.
- Buena información histórica.
- Coraje de confiar en las métricas y la
experiencia.

Observaciones Acerca de la
Estimación
• Hay cuatro factores que influyen
significativamente en las estimaciones:
– La complejidad del proyecto.
– El tamaño del proyecto.
– El grado de incertidumbre estructural.
• Se han definido requisitos?
• Separabilidad de funciones.
• Acotado.
• ¿La información que se maneja es clara?
– Disponibilidad de información histórica.

Observaciones Acerca de la
Estimación
• Complejidad del proyecto
• La complejidad es relativa a la experiencia en proyectos anteriores.
• Existen medidas sobre la complejidad de proyectos basadas en el diseño y código (métricas técnicas).
• En la fase de estimación no son aplicables porque no hay ni diseño ni código.
• Por eso hay que utilizar medidas más subjetivas (ej. PF).

Observaciones Acerca de la
Estimación
• Tamaño del proyecto
• En los proyectos grandes, crece la
interdependencia entre los componentes del
proyecto.
• Interdependencia descomposición del
producto en elementos muy grandes dificulta
el proceso de estimación

Observaciones Acerca de la
Estimación
• Grado de incertidumbre estructural
• Estructura:
– Grado en que los requisitos se han definido.
– Facilidad con la que se pueden compartimentalizar
funciones.
– Naturaleza jerárquica de la información a procesar.
• Incertidumbre estructural baja mejor
descomposición del producto mejor
estimación.

Observaciones Acerca de la
Estimación
• Información histórica
• “Aquellos que no pueden recordar el pasado,
están condenados a repetirlo”.
• La existencia de métricas del software de
proyectos anteriores facilita la estimación.
• En cualquier caso, la estabilidad de los
requisitos por parte del cliente es fundamental
para la estimación

El Proceso de Planificación del
Proyecto
• El objetivo de la planificación del proyecto de
software es proporcionar un marco de trabajo
que permita al gestor hacer estimaciones
razonables de recursos, coste y programa de
trabajo.
• Estas estimaciones se hacen al comienzo del
proyecto
Hay que actualizarlas según progresa éste

Ámbito del Software y Factibilidad
• La primera actividad de la planificación del proyectoes determinar el ámbito del software
• Recordemos que ámbito:
– Contexto. ¿Cómo encaja el software a construir en unsistema, producto o contexto de negocios mayor y quélimitaciones se imponen como resultado del contexto.
– Objetivos de información. ¿Qué objetos de datos visibles al cliente se obtienen del software? ¿Qué objetos de datos son requeridos de entrada?
– Función y rendimiento. ¿Qué función realiza el software para transformar la información de entrada en una salida? ¿Hay características de rendimiento especiales que abordar?

Ámbito del Software y Factibilidad
• El cliente es el único que puede ayudarnos a
determinar el ámbito.
• Por tanto la comunicación con el cliente es
fundamental.
• La comunicación se puede iniciar con las
preguntas de contexto libre.
• Hay tres grupos dentro de estas preguntas

Ámbito del Software y Factibilidad
• El primer grupo se centra en el cliente, los
objetivos globales y los beneficios:
– - ¿Quién está detrás de la solicitud de este trabajo?
– - ¿Quién utilizará esta solución?
– - ¿Cuál será el beneficio económico de una buena
solución?
– - ¿Hay otro camino para la solución?

Ámbito del Software y Factibilidad
• El segundo grupo permiten comprender mejor el problema y que el cliente exprese sus percepciones sobre una solución:
• ¿Cómo caracterizaría (el cliente) un resultado correcto que se generaría con una solución satisfactoria?
• ¿Con qué problemas se enfrentará esta solución?
• ¿Puede mostrarme (o describirme) el entorno en el que se utilizará la solución?
• ¿Hay aspectos o limitaciones especiales de rendimiento que afecten a la forma en que se aborde la solución?

Ámbito del Software y Factibilidad
• El último grupo se centra en la efectividad de la
reunión. Se denominan metacuestiones:
– ¿Es usted la persona apropiada para responder a estas
preguntas? ¿Son oficiales sus respuestas?
– Son relevantes mis preguntas para su problema.
– ¿Estoy realizando muchas preguntas?
– ¿Hay alguien más que pueda proporcionar información
adicional?
– ¿Hay algo más que debiera preguntarle?
• Estas preguntas y otras similares ayudan a romper
el hielo y a iniciar la comunicación esencial

Ámbito del Software y Factibilidad
• Veamos un ejemplo de ámbito
• Se va a desarrollar un sistema automático de gestión de pasos a nivel.
– El sistema identifica al tren cuando se encuentra a 1 km del paso a nivel.
– Una vez identificado se enciende una luz roja, suena una campana y se baja la barrera.
– La señal debe bajarse en 30 sg. (el tren llega en 72 sg., ya que circula a 50 km/h).
– Después de que el último vagón del tren pase a 10 m. del paso a nivel, se levanta la barrera, deja de sonar la campana, y cuando la barrera está elevada se apaga la luz roja.
• El planificador del proyecto examina la especificación del ámbito y extra todas las funciones principales del software, así como el rendimiento y las restricciones.

Actividades asociadas ... Ámbito del software
Función Rendimiento Restricciones Detectar tren 1 km. Detectar último 10 m. después paso vagón Bajar barrera 30 sg.
Subir barrera lo más rápido posible
Encender luz 1 sg. Apagar luz 1 sg. Sonar campana 1 sg. Para campana 1 sg.
La función no es independiente del rendimiento y/o las restricciones
1. e.g. no es lo mismo bajar la barrera en 30 sg. Que en 15 sg.
2. e.g. no es lo mismo detectar el último vagón que detectar al tren
cuando pase a 500 m. después del paso.

Actividades asociadas ... Ámbito del software
• Además del ámbito el software interactúa con otros elementos
• Por tanto el concepto de interfaz también es vital para la planificación temporal
• Interfaz:
– Hardware.
– Software.
– De usuario.
– Procedimientos.
• Otro aspecto importante durante la estimación es el de la fiabilidad del
• Software
• Nótese que se mide a posteriori, pero estamos en estimación
• En función del tipo de aplicación este factor se vuelve más o menos crítico ( ej. Juego, control de avión)

Recursos
• La segunda tarea de la planificación del desarrollo desoftware es la estimación de recursos requeridos paraacometer el esfuerzo de desarrollo, Estos recursos son:
– Personas.
– Componentes software reutilizables.
– Herramientas de hardware/software.
• Cada recurso queda especificado mediante cuatro características:
– Descripción del recurso.
– Informe de disponibilidad.
– Fecha cronológica en la que se requiere el recurso.
– Tiempo durante el que será aplicado el recurso.
• Las dos últimas características son la ventana temporal

Recursos
• Respecto al personal hay que especificar su posición en la organización y su especialidad
• El número de personas requerido debe estimarse como veremos en este tema
• Gran parte de la reutilización del software se debe a la tecnología de componentes, Respecto a la planificación, tenemos cuatro tipos de componentes:
– Ya desarrollados.
– Ya experimentados.
– Con experiencia parcial.
– Nuevos.

Estimación de Proyectos de
Software
• Estimar el costo del software es vital
• Las estimaciones nunca podrán ser exactas
• Cuanto mejor estimemos, más rentable será nuestroproyecto
• Estimar es difícil, ya que:
– Los requisitos iníciales no están totalmente delimitados.
– Puede que necesitemos utilizar tecnologías nuevas.
• Las personas involucradas en el proyecto pueden tener distintos grados de experiencia.

Estimación de Proyectos de
Software
• Técnicas de estimación
• - Retrasar la estimación lo máximo posible. Cuanto más la retrasemos, más precisa será.
• Estimación por analogía. Utilizar el costo de proyectos similares ya terminados.
• Precio para ganar. El costo se estima en todo el dinero que el cliente puede gastar en el proyecto.
• Técnicas de descomposición. Estiman el costo descomponiendo el producto y/o el proceso.
• Modelos empíricos. Modelos de regresión que relacionan esfuerzo con tamaño o funcionalidad

Técnicas de Descomposición
• La técnica de descomposición basada en el problema, sebasa en la descomposición del producto en funciones yestimar el tamaño del software
• Por tanto, la primera estimación que sirve de base para todaslas demás, es la estimación del tamaño del software
• Podemos considerar tres tamaños del software:
– Tamaño en LDC.
– Tamaño en PF.
– Tamaño en Punto Objeto (PO)
• En cualquier caso, la precisión de la estimación depende de:
– El grado en el que el planificador ha estimado adecuadamente el tamaño del producto a construir.

Modelos de Estimación de Costos
de Proyectos Informáticos

Métrica
Una métrica es, pues, una asignación
de valor a un atributo de una entidad
propia del software, ya sea un
producto o un proceso.

• Cuando hablamos de un atributo nos referimos a una determinada característica que pretendemos medir y cuantificar.
• Cuando hablamos de un producto nos referimos, por ejemplo, a un código, un diseño, una especificación, etc.
• Cuando se habla de un proceso se hace referencia a una etapa de la construcción del software y a la manera de llevarlo a cabo: un diseño, unas pruebas, etc.
Métrica

• En general, se puede decir que las diferentes
métricas intentan evaluar tres grandes
magnitudes generales:
• La calidad y el tamaño (a menudo del producto)
y la productividad (frecuentemente del proceso
de construcción del producto), aunque lo hacen
desde muchos puntos de vista diferentes.
Métrica

• Las métricas del producto, que miden diferentes
aspectos del software obtenido, a menudo a
partir de código fuente expresado en un
lenguaje informático determinado.
• Las métricas del proceso, que intentan medir
determinados atributos que hacen referencia al
entorno de desarrollo del software y tienen en
cuenta la manera de construirlo.
Métricas del producto y del
proceso

• La calidad de un producto, según la definición
del estándar ISO 8402, es el conjunto de
funcionalidades y características de un producto
o servicio que se centran en su capacidad de
satisfacer las necesidades, ya sea implícitas o
bien explicitadas claramente, de un cliente o
usuario.
Métricas de calidad y de
productividad

• Las métricas de calidad se asocian a unos
determinados atributos medibles, no siempre
evidentes, para reconocer la presencia o
ausencia de calidad.
• Las métricas de productividad recogen la
eficiencia del proceso de producción de
software y relacionan el software que se ha
construido con el esfuerzo que ha costado
elaborarlo.
Métricas de calidad y de
productividad

• A menudo las diferentes unidades de medida se combinan en indicadores resumidos, como ejemplos podemos encontrar, entre otros, los siguientes:
– Líneas de código por persona y día (indicador de productividad).
– Horas para implementar un punto de función (indicador de productividad).
– Número de errores por cada mil líneas de código (indicador de calidad).
– Importe monetario por cada millar de líneas de código (indicador de costo).
– Páginas de documentación por cada mil líneas de código (indicador de documentación).
Métricas de calidad y de
productividad

• La medida habitual del costo es, evidentemente,
la cantidad de dinero que cuesta producir un
software determinado; mientras que las medidas
habituales del esfuerzo se reducen siempre al
trabajo que lleva a cabo un profesional en una
determinada unidad de tiempo: un día (persona-
día), un mes (persona-mes) o un año (persona-
año).
El esfuerzo y la medida de la
productividad

• En primer lugar, se habló de hombre-mes como
la tarea que llevaba a cabo un hombre durante
un mes de trabajo. Ésta es la denominación
habitual, que se puede encontrar a menudo
abreviada con la sigla MM, proveniente de la de
nominación inglesa man-month.
Problemas terminológicos del
hombre-mes

• Más adelante, pareció que la denominación era claramente sexista y se buscaron otros nombres como éstos:
– Persona-mes: un mes de trabajo de una persona del equipo con independencia del género.
– Staff-month: un mes de trabajo de una persona del equipo de proyecto.
– Engineering-month: un mes de trabajo en la actividad de ingeniería del software, que incluye, como ya sabemos, el análisis, el diseño, la programación y las pruebas para producir una determinada aplicación o un sistema de información.
Problemas terminológicos del
hombre-mes

El mito del hombre-mes
En resumidas cuentas, llegamos a la conclusión de que los meses y
los hombres (o las mujeres) no son intercambiables.

Con el objetivo de medir la productividad del
proceso de construcción de software de
aplicación, debe darse la posibilidad de
determinar las salidas que sean útiles para
relacionarlas después con el volumen del
trabajo o el esfuerzo que representa desarrollar
un producto de software determinado
Hasta aca
Métricas orientadas al tamaño y
a la función

se han propuesto también otras unidades de
medida que, en lugar del tamaño, intentan tener
en cuenta la dificultad intrínseca de construir un
software determinado; es decir, métricas que se
refieren no al tamaño del producto final
obtenido, sino a las funcionalidades que éste
incorpora.
Métricas orientadas al tamaño y
a la función

• La medida más utilizada para determinar el
tamaño de un proyecto informático ha sido,
durante mucho tiempo, la de las líneas de
código del software final obtenido.
• Algunas definiciones:
– LOC: líneas de código. Es la más habitual y antigua.
– KLOC: miles de líneas de código.
– DSI: instrucciones de código fuente realmente
entregadas, y su múltiplo KDSI.
Las líneas de código

• La medida más utilizada para determinar el tamaño de un proyecto informático ha sido, durante mucho tiempo, la de las líneas de código del software final obtenido.
• Algunas definiciones:
– NCSS: líneas de código fuente sin tener en cuenta los comentarios, y su múltiplo KNCSS
– NSLOC: nuevas líneas de código fuente, tal como se realiza en el modelo COCOMO 2 para que se tenga en cuenta que sólo deben contarse las líneas de código nuevas sin contar las que incorpore automáticamente el entorno de programación
Las líneas de código

• Las ratios de productividad también proceden de los años setenta y ochenta (de la informática y de los lenguajes que existían entonces). Estas ratios, que actúan como estándares de la profesión y que han sido mencionadas de paso, son las siguientes:
a) 10 LOC por día y persona ocupada en el proyecto, según Barry W. Boehm a principios de los años ochenta.
b) 350 NCSS por persona y mes, según datos de comienzos de los años noventa en los proyectos de la empresa Hewlett Packard recogidos por Robert O. Grady.
Líneas de código, productividad y
lenguajes de programación
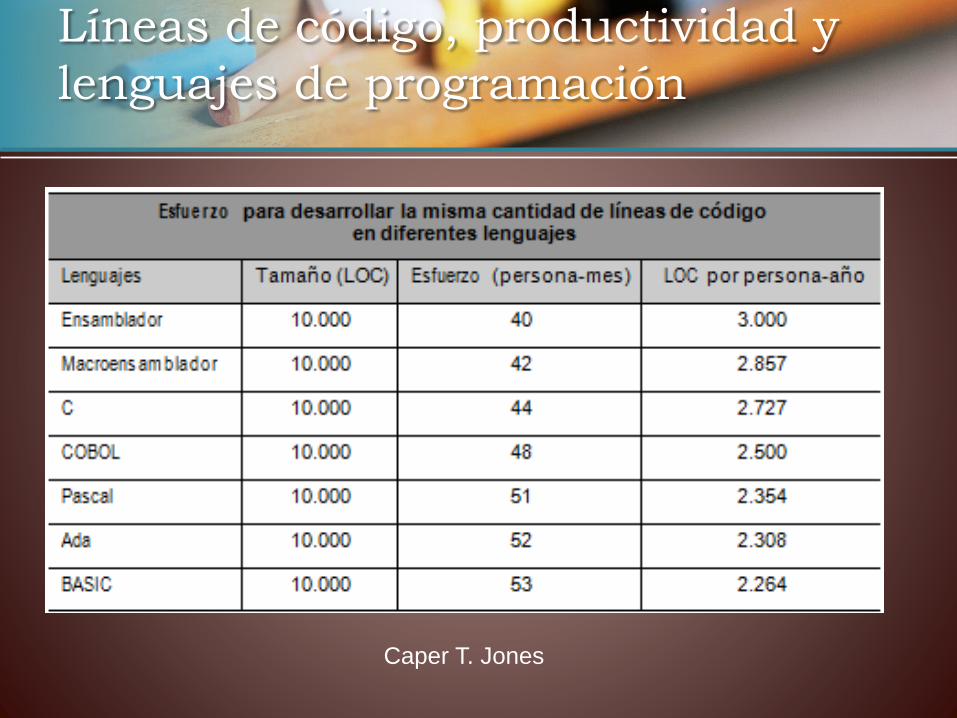
Líneas de código, productividad y
lenguajes de programación
Caper T. Jones
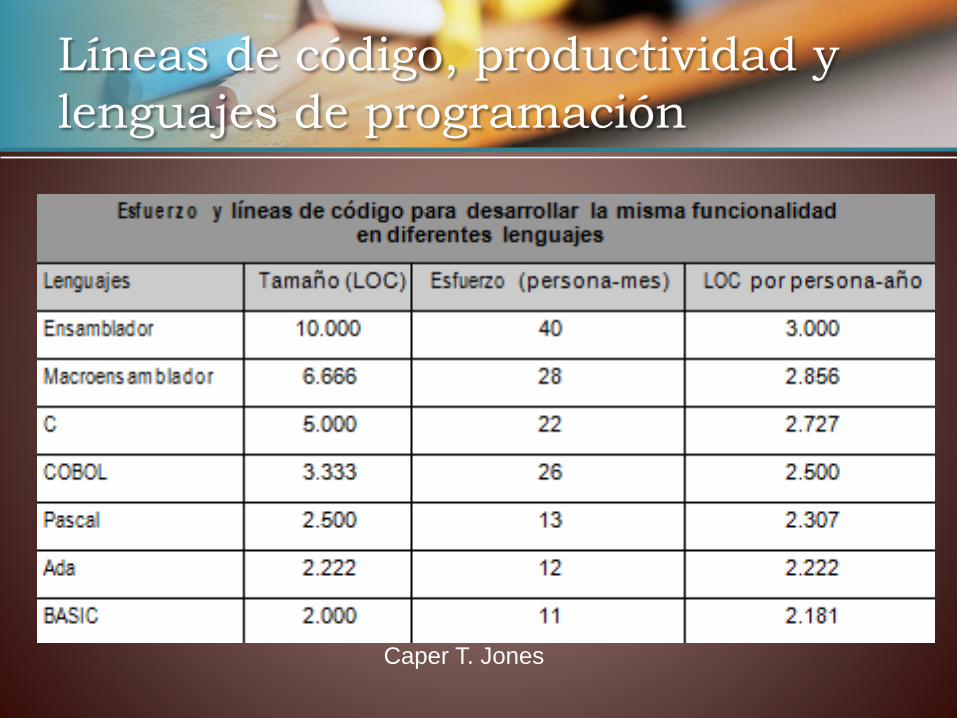
Líneas de código, productividad y
lenguajes de programación
Caper T. Jones

44
Métricas basadas en la Función
• La métrica del punto de función (PF) se puede utilizar como medio para predecir el tamaño de un sistema obtenido a partir de un modelo de análisis. Para visualizar esta métrica se utiliza un modelo funcional, el cual se evaluar para determinar las siguientes medidas clave que son necesarias para el cálculo de la métrica de punto de función:
– Número de entradas del usuario
– Número de salidas del usuario
– Número de consultas del usuario
– Número de archivos
– Número de interfaces externas

45
• La cuenta total debe ajustarse utilizando la siguiente ecuación:
PF = cuenta-total x (0,65 + 0,01 x Fi)
• Donde cuenta-total es la suma de todas las entradas PF obtenidas de la figura y Fi (i=1 a 14) son los "valores de ajuste de complejidad".
Métricas basadas en la Función

• Para el ejemplo descrito en la figura se asume que la Fi es 44 (un producto moderadamente complejo), por consiguiente:
PF = 50 x (0,65 + 0,01 x 44) = 54.5
Factor de ponderación
Parámetro de medición Cuenta Simple Media Compl.
Número de entradas del
usuario
3 X 3 4 6 = 9
Número de salidas del usuario 2 X 4 5 7 = 8
Número de consultas del
usuario
2 X 3 4 6 = 6
Número de archivos 1 X 7 10 15 = 7
Número de interfaces externas 4 X 5 7 10 = 20
Cuenta total 50
Cálculo de puntos de función

• Basándose en el valor previsto del PF obtenido del
modelo de análisis, el equipo del proyecto puede
estimar el tamaño global de implementación de las
funciones de interacción.
• Asuma que los datos de los que se dispone indican que
un PF supone 60 líneas de código (se utilizará un
lenguaje orientado a objetos) y que en un esfuerzo de
un mes-persona se producen 12 PF.
Métricas basadas en la Función

Los puntos de función y la
productividad

Relación entre puntos de función
y líneas de código

La única manera segura de poder tener unos estándares de productividad buenos y dignos de
ser utilizados es no depender de lo que dicen libros y artículos (con datos obtenidos en condiciones a menudo bien diferentes) y
disponer de los datos de productividad propios, datos que pueden haber sido obtenidos en
proyectos anteriores del mismo tipo (en cuanto a aplicación y tecnología) y con equipos de desarrollo de calificaciones y características
personales conocidos.
……….?

Ing. José Luis Cerrón Pérez
Modelos de Estimación de Costos de
Proyectos Informáticos

• La gestión de un proyecto informático de gestión
empieza con la calificación del proyecto, que
pretende, en primer lugar, obtener una idea del
volumen de trabajo que costará construir la
aplicación (estimación) y, en segundo lugar,
planificar en el tiempo las diferentes actividades
que es necesario llevar a cabo (planificación).
Estimación de costos

• La primera de estas etapas se conoce también
con el nombre de estimación de costos de un
proyecto informático, ya que a partir del
esfuerzo de trabajo estimado se obtendrá el
presupuesto. Del mismo modo, después de la
planificación y el reparto en el calendario de las
tareas que se deben a realizar, se obtienen los
plazos, etapa que también se conoce con el
nombre de tiempo de desarrollo del proyecto.
Estimación de costos

• La mayor parte del costo del software se
encuentra hoy en el costo de las horas de
análisis, diseño, programación y prueba que se
deben utilizar para obtenerlo. Por ello, cuando
aquí se habla de estimación de costos se hace
referencia, exclusivamente, al esfuerzo humano
que ha sido necesario, es decir, a las horas de
trabajo requeridas para construir el software.
Estimación de costos

• En palabras de de Marco:
“No hay modelos de costo transportables. Si esperas que alguien en otro lugar desarrolle un conjunto de fórmulas que puedas utilizar para prever el coste en tu propia instalación, probablemente tendrás que esperar para siempre.”
T. de Marco (1982, pág. 155).
Estimación de costos

• De Marco propone dos definiciones sucesivas
muy realistas de lo que es una estimación:
– Definición implícita de estimación: una estimación es
la predicción más optimista que tiene una
probabilidad no nula de llegar a ser cierta.
– Definición propuesta por de Marco: una estimación es
una predicción que tiene la misma probabilidad de
estar por encima que de estar por debajo del
resultado real.
Estimación de costos

En resumidas cuentas, estimar la carga de trabajo
que es necesario llevar a cabo para la
construcción de software de aplicación es una
tarea que normalmente debe fracasar.
Estimación de costos

Momento de la estimación y
grado de exactitud
Fuente: Gráfico adaptado de Cost Models for Future Life Cycle Process: COCOMO 2.0 de B.W. Boehm

Modelos de estimación
La idea de los modelos de estimación es la de
proporcionar sistemas y métodos generales
para proceder a realizar la estimación de costos
en la construcción de software de aplicación.

Modelos de estimación
Los diferentes modelos de estimación de costes
y/o esfuerzos en la construcción de software se
pueden dividir en cinco grandes grupos
principales:
1. Modelos con base histórica.
2. Modelos con base estadística.
3. Teóricos.
4. Compuestos.
5. Basados en estándares.

Modelos de estimación
Modelos con base histórica.
– Los modelos de base histórica son los más
antiguos y, en cierta manera, primitivos.
– A menudo se basan en la analogía con otros
proyectos parecidos y se fundamentan casi
exclusivamente en la experiencia profesional (la
“historia”) de los que efectúan la estimación.

Modelos de estimación
Modelos con base estadística.
• A partir del estudio estadístico de los datos reales
disponibles tomados de un conjunto más o menos
numeroso de proyectos ya acabados, obtienen
fórmulas que relacionan las diferentes unidades de
medida del software, a menudo las líneas de
código (LOC) y el esfuerzo (generalmente medido
en hombre-mes).

Modelos de estimación
Teóricos.
• Estos modelos, más que basarse en datos
estadísticos disponibles, lo que hacen es partir de
una serie de ideas generales sobre el proceso de
construcción de software y, sobre esta teoría,
elaboran fórmulas que relacionan diferentes
métricas de software.

Modelos de estimación
Compuestos.
• Estos modelos intentan obtener las ventajas de los
dos sistemas anteriores: estadísticos y teóricos. Es
decir, se parte de una serie de planteamientos
teóricos y se complementan o corrigen con datos
estadísticos obtenidos de proyectos reales ya
acabados.

Los modelos COCOMO
COCOMO es el modelo de construcción de costes
más conocido y utilizado de los modelos
algorítmicos compuestos que se basan sobre
todo en datos estadísticos, pero también en
ecuaciones analíticas y en un ajuste fruto de la
opinión de expertos.

El COCOMO clásico de 1981
• El COCOMO clásico lo forman, en realidad, tres
modelos diferentes, que tienen en cuenta
diferentes grados de complejidad:
• El COCOMO básico es un modelo estático válido para
obtener una estimación rápida del esfuerzo (meses-hombre)
en función del tamaño (KLOC) al inicio del ciclo de vida.

El COCOMO clásico de 1981
• El COCOMO clásico lo forman, en realidad, tres
modelos diferentes, que tienen en cuenta
diferentes grados de complejidad:
• El COCOMO intermedio añade al cálculo del esfuerzo en
función del tamaño, el efecto de unos atributos que influyen
en el coste (CDA), con los cuales se quiere tener en cuenta
el tipo de aplicación y tecnología, las calificaciones y la
experiencia del personal, el entorno de diseño y
programación y las herramientas de las que dispone, etc.

El COCOMO clásico de 1981
• El COCOMO clásico lo forman, en realidad, tres
modelos diferentes, que tienen en cuenta
diferentes grados de complejidad:
• El COCOMO adelantado incorpora todas las características
de la versión intermedia, pero en lugar de evaluar los CDA
con un único valor para todo el ciclo de vida, tiene en cuenta
diferentes CDA para cada fase* de la construcción del
software.

El COCOMO clásico de 1981
• Las ecuaciones del modelo COCOMO tienen siempre la forma general que mostramos a continuación:
• E = a · Lb · CDA
• T = c · Ed
– E es el esfuerzo (en personas-mes).
– L son las líneas de código (en KLOC)
– T es el tiempo de desarrollo del proyecto (en meses)
– CDA los cost driven attributes.
– Finalmente a, b, c y d son coeficientes que el modelo proporciona como resultado del análisis de los datos de sesenta y tres proyectos realizados entre 1965 y 1980.

El COCOMO clásico de 1981
• Además de los tres modelos, COCOMO tiene
en cuenta varios tipos de proyecto, ya que no
se obtienen los mismos datos de productividad
en todos los casos.
a) Orgánico.
b) Semiacoplado.
c) Encajado.

El COCOMO clásico de 1981
• Los coeficientes que corresponden al modelo
básico.

El COCOMO clásico de 1981
• Los coeficientes que corresponden al modelo
intermedio.
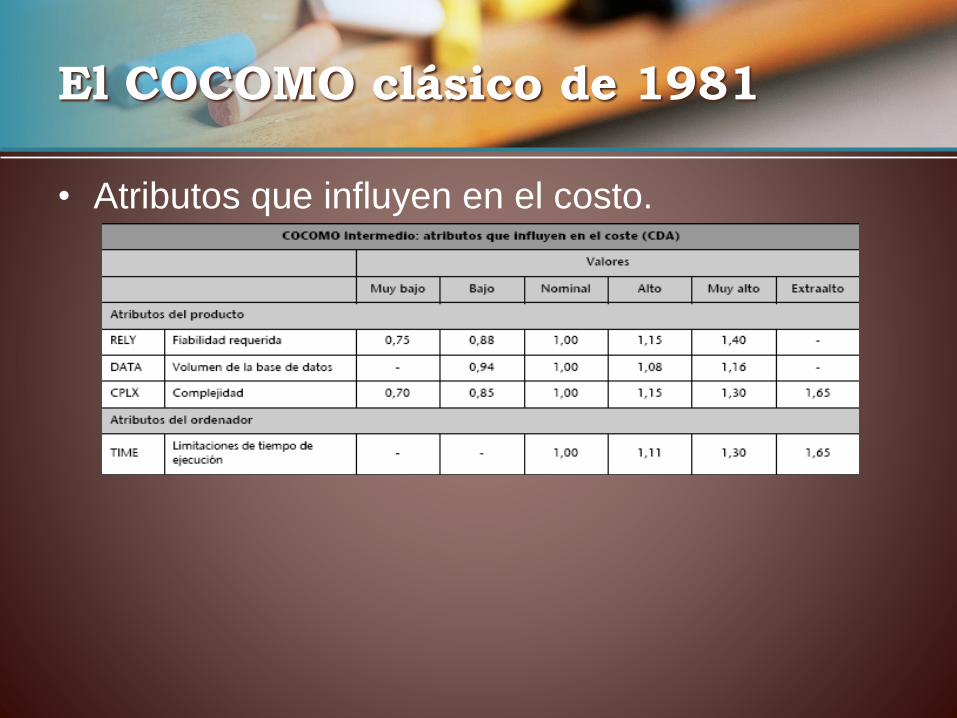
El COCOMO clásico de 1981
• Atributos que influyen en el costo.

El COCOMO clásico de 1981

El COCOMO clásico de 1981
• En resumidas cuentas, el modelo COCOMO es
el más serio y completo de los que existen,
aunque los resultados que se obtienen pueden
haber quedado obsoletos por la evolución y los
cambios que ha sufrido la informática en los
últimos veinte años.

El COCOMO II de los años
noventa y a partir del 2000
• El nuevo modelo COCOMO II tiene como
objetivo principal desarrollar un modelo de
estimación de costos y planificación del
software especialmente adecuado para los
ciclos de vida.
• el COCOMO II incluye tres modelos que
corresponden a diferentes fases y modalidades
del futuro ciclo de vida.

El COCOMO II de los años
noventa y a partir del 2000
• Modelo de composición de aplicaciones:
– incluye el uso de prototipos para disminuir los
riesgos potenciales que surgen con las interfaces
gráficas de usuario típicas de herramientas RAD y
otras herramientas actuales de productividad y de la
orientación a objetos.
– En este modelo se definen unos puntos objeto que
vendrían a ser una adaptación y modernización de
los puntos de función

El COCOMO II de los años
noventa y a partir del 2000
• Modelo de diseño primerizo :
– intenta obtener una primera aproximación en las
fases iniciales del ciclo de vida, cuando todavía se
conocen pocas de las características y datos
definitivos del proyecto.
– Utiliza como primitivas de salida tanto las líneas de
código como los clásicos puntos de función.

El COCOMO II de los años
noventa y a partir del 2000
• Modelo de postarquitectura:
– Se aplica cuando se considera que el proyecto
dispone ya de requerimientos estables. Por otra
parte, también utiliza como primitivas de salida las
líneas de código y los puntos de función.
– Además, tiene en cuenta indicadores de la
reutilización de software, cinco factores de escala y
hasta diecisiete factores específicos diferentes

Uso de estándares de
productividad
• No es fácil, en la práctica, encontrar cuál es el
modelo que más se ajusta a la realidad del
proyecto informático que todavía está por
empezar y que preocupa al jefe de proyecto
que debe llevar a cabo la estimación de las
cargas y los costos.

Uso de estándares de
productividad
• En lugar de cuantificar cada actividad o conjunto
de estas características funcionales en líneas de
código o puntos de función y buscar modelos
que conviertan estas métricas en esfuerzo
(meses-hombre), es suficiente disponer
directamente, para cada actividad, del esfuerzo
estándar que ha requerido en otros proyectos
anteriores.

Uso de estándares de
productividad
• Según la opinión de un experto como Jones, se
dan las equivalencias prácticas siguientes:
– 1 FP = 100 LOC.
– FP elevado a 0,4 = meses de desarrollo.
– FP/150 = número de personas que son necesarias
para el desarrollo.
– FP/500 = número de personas necesarias para el
mantenimiento futuro.

Uso de estándares de
productividad
• Según la opinión de un experto como Jones, se
dan las equivalencias prácticas siguientes:
– FP elevado a 1,15 = número de páginas de
documentación.
– FP elevado a 1,2 = número de casos de prueba que
se realizan.
– FP elevado en 1,25 = potencial de errores (en
proyectos nuevos).
– FP elevado a 0,25 = número de años que seguirá en
uso la aplicación.

¡Tengamos una noche
maravillosa!







