
1
CURSO
11/12
DETEC
CIÓN DE ATA
QUES EN RED
ES IN
ALÁMBRICAS
N
EFTA
LÍ RODRÍGUEZ GÁLVEZ
ESTUDIOS DE INGENIERÍA
DE TELECOMUNICACIÓN
PROYECTO DE FIN DE CARRERA
Detección de ataques en redes inalámbricas
CURSO: 2011/2012
Neftalí Rodríguez Gálvez
LOMO: PORTADA:

2

3
ESTUDIOS DE INGENIERÍA DE TELECOMUNICACIÓN
DETECCIÓN DE ATAQUES EN REDES INALÁMBRICAS
REALIZADO POR:
Neftalí Rodríguez Gálvez
DIRIGIDO POR:
José Camacho Páez
DEPARTAMENTO:
Teoría de la Señal, Telemática y Comunicaciones
Granada, Septiembre de 2012

4

5
DETECCIÓN DE ATAQUES EN REDES INALÁMBRICAS
Neftalí Rodríguez Gálvez
PALBRAS CLAVE: Red, inalámbrica, WEP, WPA, seguridad, 802.11, ataques, análisis
multivariante.
RESUMEN:
Hoy en día las redes inalámbricas han tomado gran relevancia en la vida cotidiana. Por
consiguiente, ha surgido la necesidad de ofrecer un elevado nivel de seguridad al usuario para
que la información transmitida a través de dichas redes se mantenga segura. En este proyecto,
se presenta el análisis del tráfico de una red doméstica para la detección de patrones de
distintos ataques gracias al análisis exploratorio de datos. Se busca así detectar que se está
produciendo un ataque a la red e incluso saber de qué tipo de ataque se trata.
KEYWORDS: Network, Wireless, WEP, WPA, security, 802.11, attacks, Multivariate analysis
ABSTRACT:
Nowadays, wireless networks are very used in our society. Due to this fact, we need security in
wireless transmissions. In order to offer this security, the traffic transmitted in a home network
is analyzed in this project. We should recognize that an attack against the private information
is being produced. The main objective is to capture the transmitted information in the network
and detect an attack using the exploratory data analysis.

6
ÍNDICE
CAPÍTULO I ………………………………….. 9
1. INTRODUCCIÓN Y OBJETIVOS ……………………………………… 11
2. PROTOCOLO 802.11 ……………………………………… 12
2.1. TÉCNICAS DE ACCESO AL MEDIO ………………………………………………… 13
2.2. ARQUITECTURAS DE RED ………………………………………………… 18
2.3. FUNCIONES DE COORDINACIÓN ………………………………………………… 20
2.3.1. FUNCIÓN DE COORDINACIÓN DISTRIBUIDA (DCF) ………………………. 21
2.3.2. FUNCIÓN DE COORDINACIÓN PUNTUAL (PCF) ………………………. 21
2.4. FORMATO TRAMA MAC ………………………………………………… 27
2.5. CRIPTOGRAFÍA ………………………………………………… 31
2.4.1. CÓDIGOS ……………………………………………………. 31
‐ Basados en clave simétrica ..…………………………………………………. 32
‐ Basados en clave asimétrica ..…………………………………………………. 33
2.4.2. CIFRADO ……………………………………………………. 33
2.4.3. RESUMEN DEL MENSAJE ……………………………………………………. 34
2.6. SEGURIDAD ………………………………………………… 35
2.6.1. WEP ……………………………………………………. 35
2.6.2. WPA Y WPA2 ……………………………………………………. 37
3. ATAQUES DE INTRUSIÓN ……………………………………… 41
3.1. DEBILIDADES DEL PROTOCOLO WEP ………………………………………………… 41
3.1.1. CONFIDENCIALIDAD ……………………………………………………. 42
3.1.2. INTEGRIDAD ……………………………………………………. 43
3.1.3. CONTROL DE ACCESO ……………………………………………………. 43
3.2. TIPOS DE ATAQUES …………………………………………………. 44
3.3. ATAQUES ACTIVOS …………………………………………………. 45

7
3.3.1. ATAQUE DE DEAUTENTICACIÓN …………………………………………………. 45
3.3.2. ATAQUE DE RE‐INYECCIÓN DE SOLICITUDES ARP …………………………. 45
3.3.3. HOMBRE EN EL MEDIO (MAN‐IN‐THE‐MIDDLE) …………………………… 46
3.3.4. ATAQUE DE REDIRECCIÓN IP ….…………………………………………………. 47
3.3.5. ATAQUE DE REACCIÓN ….……………………………….……………………………. 48
CAPÍTULO II …………………………………. 48
4. HERRAMIENTAS DE CAPTURA DE TRÁFICO ………………………… 51
4.1. WIRESHARK …..………………………………………………… 51
4.2. LIBPCAP …..………………………………………………… 53
4.3. SUITE AIRCRACK …..………………………………………………… 54
4.4. MDK3 …..………………………………………………… 55
4.5. WIFISLAX Y WIFIWAY …..………………………………………………… 55
4.6. MATLAB …..………………………………………………… 56
5. HERRAMIENTAS DE CLASIFICACIÓN: ANÁLISIS MULTIVARIANTE . . 57
5.1. ANÁLISIS EXPLORATORIO DE DATOS …..………………………………………………… 57
5.2. CLASIFICADORES …..………………………………………………… 59
5.2.1. ALGORITMOS DE CLASIFICACIÓN POR VECINDAD ….…………………. 60
5.2.2. ÁRBOLES DE CLASIFICACIÓN ….………………………………………………………. 62
5.2.3. ANÁLISIS DISCRIMINANTE LINEAL ….…………………………….…………. 63
5.2.4. ANÁLISIS DISCRIMINANTE POR MÍNIMOS CUADRADOS PARCIALES … 64
5.2.5. REDES BAYESIANAS ….…………………………………………………………………. 64
5.2.6. MÁQUINAS DE VECTORES SOPORTE ….……………………………………………. 66
6. DISEÑO DE LAS PRUEBAS ……………………………… 66

8
CAPÍTULO III ……………………………….. 73
7. ANÁLISIS DE RESULTADOS …………………………..…… 75
8. CONCLUSIONES Y TRABAJO FUTURO ……………………………… 106
BIBLIOGRAFÍA ……………………………… 108
ANEXO I: CAPTURA DE PAQUETES CON LIBPCAP ……………………………………………….. 109
ANEXO II: ANÁLISIS EXPLORATORIO DE DATOS ……………………………………………….. 115
ANEXO III: CÓDIGO MATLAB KNN ……………………………………………….. 121
ANEXO IV: CÓDIGO MATLAB ÁRBOLES DE CLASIFICACIÓN ……………………………………… 127
ANEXO V: CÓDIGO MATLAB PLS‐DA ……………………………………………….. 130
ANEXO VI: CÓDIGO MATLAB LDA Y QDA ……………………………………………….. 136
ANEXO VII: CÓDIGO MATLAB REDES BAYESIANAS ……………………………………………….. 141

9
CAPÍTULO I
INTRODUCCIÓN

10

11
1. INTRODUCCIÓN Y OBJETIVOS
Cuando se habla de sistemas de comunicación se puede diferenciar claramente entre sistemas
cableados o sistemas inalámbricos. Los sistemas cableados son más rápidos, fiables y seguros
que los inalámbricos, pero en contraposición, los sistemas inalámbricos ofrecen una
comodidad que no ofrecen los sistemas cableados.
Las redes cableadas ofrecen unas ventajas claras pero al mismo tiempo presentan unos
inconvenientes como el precio o la ausencia de movilidad. En un escenario en el que los
equipos son fijos y hay un pequeño número de componentes, el despliegue de una red
cableada no es muy costoso, pero esa no es la realidad hoy en día. En la actualidad se necesita
una libertad móvil que es impensable para una red cableada. Los ordenadores fijos se han
sustituido por ordenadores portátiles y ha aparecido una amplia gama de dispositivos móviles
que precisan de acceso a Internet o a la red correspondiente (teléfonos móviles inteligentes,
tabletas, etc.)
Para poder comenzar a desplegar redes inalámbricas el instituto europeo de estándares de
telecomunicaciones (ETSI ‐ The European Telecommunications Standards Institute) publica el
primer estándar para las redes inalámbricas de área local (WLANs ‐ Wireless Local Area
Networks) en 1995. El protocolo que realmente tiene éxito y es el que comienza a utilizarse de
forma global es el llamado 802.11. Este protocolo ha sido también la referencia para
desarrollos posteriores. El protocolo 802.11 presenta una serie de características a la hora de
modular la señal conservando la interoperabilidad, adaptando el esquema de modulación a la
estructura de red correspondiente, obteniendo así una optimización en la transmisión de
tramas. Sin embargo, el protocolo 802.11 no presenta protecciones de seguridad relativas a la
autenticación, cifrado o integridad de datos, lo que produce grandes problemas de seguridad.
Al mismo tiempo que se desarrolla el protocolo 802.11 surge la manera de acceder a la
información de forma ilícita. Para evitar este acceso no deseado aparece el protocolo de
privacidad equivalente cableada (WEP ‐ Wired Equivalent Privacy) , con el que se consigue
hacer frente a estos problemas. Este protocolo ha tenido que incorporar una serie de
algoritmos y de protecciones de clave ya que se probó su vulnerabilidad. El protocolo WEP es
actualmente utilizado en redes inalámbricas para la protección de la información, si bien es
cada vez más sustituido por protocolos más seguros como WPA, WPA2, etc.
La finalidad principal de este proyecto es comprobar que la seguridad en redes 802.11 no tiene
que restringirse a medidas preventivas de seguridad criptográfica, sino que un buen
complemento a dicha criptografía pueden ser las estrategias de detección. Para probar esto, se
selecciona un protocolo de criptografía débil, WEP, para ver la capacidad para mejorar su
seguridad sin incurrir en la complejidad y la carga computacional de un sistema de criptografía
como WPA2.
Para poder detectar ataques a este tipo de redes se utiliza el análisis exploratorio de datos,
basado en la toma de observaciones de determinadas variables. Una vez se tiene el grupo de
observaciones, se realiza un análisis para distinguir si las variables medidas tienen información
de discriminación. Una vez realizado este análisis se procede al entrenamiento de los

12
clasificadores preparándolos así para la clasificación de nuevas observaciones. El análisis
exploratorio de datos es una pieza importante en el análisis de las variables ya que si no se
realiza, obteniendo variables que realmente tengan información discriminatoria, se puede
llegar a resultados erróneos.
2. PROTOCOLO 802.11
El instituto de ingenieros eléctricos y electrónicos (IEEE ‐ Institute of Electrical and Electronic
Engineers) consiste en una gran sociedad profesional sin ánimo de lucro interesada en la
investigación y el desarrollo tecnológico. El proyecto 802 fue iniciado en 1980 con el objetivo
de fijar unos estándares para la tecnología en redes de área local LAN (Local Area Networks) al
ver el incremento en el uso de redes inalámbricas. Estos estándares están enfocados a definir
las reglas para las capas física y de enlace del modelo de interconexión de sistemas abiertos
(OSI – Open System Interconnection).
La capa física se encarga de la definición del medio físico por el que se transmite la información
(ya sea guiado o no guiado) y la forma en la que se transmite dicha información (codificación,
modulación, etc.). Por otro lado la capa de enlace se encarga del control de flujo, detección de
errores, el acceso al medio, topología de red, la distribución ordenada de las tramas y el
direccionamiento físico. El protocolo 802 hace una subdivisión de la capa de enlace en otras
dos que son la de control de enlace lógico (LLC – Logical Link Control) y la del control de acceso
al medio (MAC – Medium Access Control). Por un lado LLC funciona como interfaz entre la
capa MAC y el resto de capas superiores, realizando control de flujo de errores. Por otro lado,
la subcapa MAC está más orientada a la gestión de la capa física. A cada uno de los dispositivos
de la red se le asigna una dirección física (MAC) con la que pueden ser identificados de forma
unívoca dentro de la red.
Cuando más de un equipo comparte un mismo medio para realizar las transmisiones, se puede
producir el efecto de colisión. Una colisión se produce cuando se encuentran dos paquetes en
el medio y la información se pierde o deteriora. Para evitar este efecto indeseable aparecen los
protocolos multi‐acceso que básicamente se dividen en dos técnicas principales: basadas en
contención y libres de colisión o planificadas. Las técnicas planificadas se basan en un
controlador central que permite el acceso a la comunicación basándose en una serie de
turnos. En el caso de las tecnologías basadas en contención, los usuarios pueden transmitir
siempre que tengan algo que enviar usando una serie de métodos para evitar colisiones.
En primer lugar se presentan las técnicas de acceso al medio por contención y más tarde se
presentan las funciones de coordinación utilizadas dentro de una red inalámbrica.
El objetivo principal es el establecimiento de un orden o control para la transmisión de
información en una red. De esta forma a lo largo del tiempo se han sucedido nuevas técnicas.
El propio desarrollo de las redes ha producido que vayan apareciendo nuevas técnicas de
forma que sean ajustables a las necesidades presentadas.

13
2.1. TÉCNICAS DE ACCESO AL MEDIO
La primera técnica de contención que apareció fue llamada ALOHA y fue desarrollada por la
universidad de Hawaii en 1970. Esta técnica consiste en la transmisión de información cuando
haya algo que enviar. Cada nodo transmite cuando tiene algo que transmitir sin tener en
cuenta la información que ya esté en la red. Al haber colisiones, se produce un
desaprovechamiento del ancho de banda del canal debido a que la información transmitida no
es correcta y debe retransmitirse.
Para poder analizar lo que ocurre en una red que hace uso de ALOHA puro se utiliza una
distribución de Poisson para representar el número de intentos de transmisión. Se define el
intervalo de vulnerabilidad como el tiempo que garantiza que una trama no colisiona con otra.
De esta forma la expresión para la probabilidad de que se produzca colisión es:
!
Teniendo en cuenta que k es el número de colisiones y que μ es el número medio de intentos
de transmisión durante el intervalo de vulnerabilidad. Si se asigna k=0 (lo que se
correspondería con la ausencia de colisiones), se obtiene una expresión para la eficiencia del
sistema (S), expresada como el número de tramas transmitidas por unidad de tiempo de
trama.
0
Observando que G es el número de intentos de transmisión por parte de todas las estaciones
por unidad de tiempo de trama. En el caso de ALOHA, el intervalo de vulnerabilidad es 2X,
siendo X el tiempo de trama. En la figura 1 se puede observar de dónde se obtiene el máximo
de 2X. Si se supone que una trama se transmite en un tiempo X, en el caso de que dos tramas
colisionen, el medio queda desaprovechado el tiempo desde que se inicia la transmisión de
una de las tramas hasta que termina la transmisión de la otra de las tramas involucrada en la
colisión. Pueden colisionar en instantes anteriores o posteriores pero el caso más desfavorable
sería que colisionasen cuando se está terminando de transmitir una de las tramas, de forma
que el tiempo de desaprovechamiento del canal será el tiempo de transmisión de una de las
tramas más el tiempo de transmisión de la otra: X + X = 2X. Éste es el intervalo de
vulnerabilidad. Gracias a esto, se puede aproximar μ=2G, ya que será el número medio de
intentos en 2X. Por lo tanto:
Como mejora a esta técnica aparece ALOHA ranurado, que se basa en que las estaciones no
pueden transmitir siempre que tengan algo que transmitir, sino en instantes determinados de
tiempo. De esta forma, una estación no podrá transmitir cuando otra lo esté haciendo. Las
colisiones serán producidas cuando dos estaciones comiencen a transmitir al mismo tiempo. El
intervalo de vulnerabilidad se reduce a la mitad: X, y en este caso la eficiencia viene dada por
la siguiente expresión:

14
Figura 1: Comparación entre el intervalo de vulnerabilidad para aloha puro y ranurado.
Con la técnica ALOHA ranurado se mejora la eficiencia del sistema pero ésta sigue siendo
reducida.
Una mejora tanto para aloha puro como ranurado sería que las estaciones estuvieran dotadas
de la capacidad necesaria para detectar la existencia de transmisiones en el medio. Esta nueva
idea es lo que se introduce con las técnicas de acceso múltiple con sondeo de portadora
(CSMA: Carrier Sense Multiple Acces). De esta forma, una estación procederá a transmitir si
detecta que no hay otra estación que ha comenzado antes a transmitir.
Las técnicas CSMA tienen tres variantes principales que son:
‐ 1‐persistente.
‐ no‐persistente.
‐ p‐persistente.
CSMA 1‐persistente consiste en la transmisión por parte de la estación en caso de que detecte
que el canal se encuentra libre. Si el canal se encuentra ocupado, se mantiene a la escucha
hasta que encuentra el canal libre.
Por otro lado, en la variante no‐persistente si el canal se encuentra ocupado, la estación
espera un tiempo aleatorio antes de volver a escuchar el canal.

15
Finalmente, CSMA p‐persistente consiste en transmitir con una probabilidad p si el canal se
encuentra libre. De esta forma decide transmitir en la siguiente ranura temporal con una
probabilidad de 1‐p. Si el canal se encuentra ocupado se queda a la escucha hasta que éste
esté libre.
Gracias a la capacidad de las estaciones de escuchar el canal, la eficiencia de las técnicas CSMA
es superior a las técnicas aloha. Aun así se sigue desaprovechando el canal debido a que al
producirse una colisión, las estaciones no detectan que se ha producido y siguen
transmitiendo. De esta forma se desaprovecha todo ese tiempo.
La eficiencia de la técnica 1‐persistente es la más baja ya que se producirán mucha cantidad de
colisiones al transmitir todas cuando ven el canal libre. Con no‐persistente se logra repartir
estos intentos de transmisión a lo largo del tiempo lo que produce una mejora en la eficiencia.
Finalmente la eficiencia del método p‐persistente dependerá del valor de p, pero permite que
realizando una buena elección del valor p se consiga una mayor distribución temporal de los
intentos de transmisión con lo que se consigue que haya menos colisiones.
Con el objetivo de solventar el problema del desaprovechamiento de tiempo al no poder
detectar colisiones cuando son producidas aparece la técnica CSMA con detección de colisión
(CSMA/CD, CSMA with Collision Detection). De esta forma, las estaciones son dotadas de la
capacidad de detectar colisiones y poder parar la transmisión en cuanto una colisión se
produzca.
Para el análisis de la eficiencia de esta técnica es necesario definir el concepto intervalo de
contención (τ) que será el tiempo máximo que tarda una estación en darse cuenta de que se
ha producido una colisión. Este tiempo será 2∙tp, siendo tp el tiempo de propagación que
tardan las señales en viajar entre las dos estaciones más alejadas. Suponiendo el peor de los
casos con dos estaciones A y B que desean transmitir. La estación A comienza la transmisión
pero esta tarda un tiempo tp en llegar a B, por lo que B no sabe que A ha comenzado a
transmitir y comienza también a transmitir.
De esta forma, al pasar un tiempo tp detecta la colisión y detiene la transmisión, sin embargo,
A no sabe que se ha producido la colisión y continuará transmitiendo hasta que vuelve a pasar
un tiempo tp. De esta forma tenemos una cota superior para ese intervalo de contención.

16
Figura 2: Transmisión en CSMA/CD.
En la figura 2 se puede observar un esquema de los eventos principales producidos con
CSMA/CD. Gracias a este esquema aclaratorio la eficiencia se puede estimar como sigue:
2
Donde R es el número medio de intervalos de contención antes de conseguir transmitir con
éxito la trama, ttrama el tiempo de transmisión y tp el tiempo de propagación del medio.
Para poder calcular esto será necesaria una expresión para R por lo que se define la
probabilidad de una transmisión con éxito como Pexito. Teniendo en cuenta que N es el número
de estaciones en el medio y que P es la probabilidad de transmisión de una estación en un
momento dado:
é 11
Teniendo la probabilidad Péxito ya se puede estimar el valor esperado del número de intervalos
de contención:
é 1 é
1 é
é
Con esto se simplifica la expresión de la eficiencia:
1
1 21 é
é
Definiendo a como tp/ttrama.

17
CSMA/CD presenta unas mejoras evidentes frente a CSMA. No obstante, su aplicación a
medios de comunicación inalámbricos no es adecuada debido a una serie de problemas a
tener en cuenta que pueden provocar un desaprovechamiento del medio: el problema del
nodo oculto y el del nodo expuesto.
Problema del nodo oculto: Para analizar este efecto se toma como referencia una red formada
por un punto de acceso y dos estaciones inalámbricas (figura 3). En la imagen se observan las
estaciones, el punto de acceso y el rango de cobertura que tiene cada dispositivo. En este caso
la estación A puede intercambiar información con el punto de acceso y la estación C puede
hacer lo mismo. El problema se produce cuando la estación A y C escuchan el canal al mismo
tiempo y lo detectan libre. Las dos estaciones comienzan a transmitir pero no pueden detectar
las colisiones debido a la cobertura de cada una de ellas. Este efecto es el llamado problema
del nodo oculto ya que las estaciones A y C no se pueden detectar entre ellas. Esto produce en
muchos casos un desaprovechamiento indeseable del canal.
Figura 3: Problema del nodo oculto.
Problema del nodo expuesto: En este caso se utiliza el escenario mostrado en la figura 4. En
este caso se presentan las estaciones A, B y C y por otro lado dos puntos de acceso (PA1 y
PA2). Dentro de la cobertura de la estación B se encuentran tanto PA1 como PA2, de esta
forma, si B quiere transmitir información a PA1, PA2 detectará el medio ocupado y si desea
transmitir información a C no lo hará. Este efecto es indeseable ya que no habría problemas en
la comunicación si se enviaran ambas informaciones.

18
Figura 4: Problema del nodo expuesto.
Para combatir estos problemas, surge la técnica que finalmente es la utilizada por el protocolo
802.11 llamada “acceso múltiple por detección de portadora con evasión de colisiones”
(CSMA/CA – Collision Avoidance). En este caso las estaciones que deseen transmitir tienen
primero que avisar su intención y recibir por parte del punto de acceso el permiso de
realizarlo. En caso contrario tienen que esperar.
2.2. ARQUITECTURAS DE RED
El estándar 802.11 define tres tipos de arquitecturas de red que se presentan a continuación:
BSS – Basic Service Set Conjunto de servicio básico: Consiste en el establecimiento
de un punto central en la red llamado punto de acceso a través del cual se comunican
los distintos dispositivos inalámbricos de la red (Figura 5).
Figura 5: BSS.

19
IBSS – Independent Basic Service Set Conjunto de servicios básico independiente:
En este caso los equipos de la red se comunican entre sí sin necesidad de
intermediario, en forma de ad‐hoc (Figura 6).
Figura 6: IBSS / ad‐hoc.
ESS – Extended Service Set Conjunto de servicios extendido: Está formado por un
conjunto de BSS interconectados entre sí con un sistema de distribución.
Figura 7: ESS.
El estándar 802.11 trabaja con el modo ad‐hoc (IBSS) o en modo infraestructura (BSS/ESS). O
bien se transmitirá la información directamente entre estaciones, o bien a través de un punto
de acceso. En caso de realizarlo a través de un punto de acceso (BSS/ESS) será necesario llevar
a cabo un proceso de asociación con el punto de acceso para un intercambio posterior de
información. Este proceso se divide en dos: uno de autenticación y otro de asociación. Debido
a estos dos subprocesos, se crean tres estados posibles para una estación dentro de una red
inalámbrica:
Estado 1: Sin autenticación y sin asociación: La estación no está conectada a la red
inalámbrica.
Estado 2: Con autenticación pero sin asociación: La estación desea hacer uso de la red
pero todavía no ha terminado el proceso de asociación por completo.

20
Estado 3: Con autenticación y con asociación: El cliente ha sido autenticado utilizando
una clave correcta, ha sido asociado y puede hacer uso de la red.
En primer lugar la estación se encuentra en el estado 1. Para salir de este estado tiene que
realizar el proceso de autenticación con el punto de acceso, pasando así al estado 2. Si en el
estado 2 se produce una notificación de de‐autenticación, la estación vuelve al estado 1. Sin
embargo, si se produce un proceso de asociación o de re‐asociación, la estación pasa al estado
3 en el que puede comunicarse con el punto de acceso intercambiando la información
necesaria. Una vez la estación está en el estado 3, si se produce una notificación de des‐
asociación, se pasa al estado 2 y si lo que se produce es una notificación de des‐autenticación,
se pasa al estado 1. Esta estructura es de gran relevancia a la hora de realizar el estudio de los
ataques posteriores, teniendo claro que no es lo mismo la autenticación que la asociación. Un
diagrama de bloques aclarativo se presenta en la figura 8.
Figura 8: Estados de una estación para comunicación en una red infraestructura.
2.3. FUNCIONES DE COORDINACIÓN
En el estándar 802.11 se establecen las siguientes funciones de coordinación para la gestión de
una red:
DCF – Distributed Coordination Function. Función de coordinación distribuida.
PCF – Point Coordination Function. Función de coordinación puntual.

21
2.3.1 FUNCIÓN DE COORDINACIÓN DISTRIBUIDA (DCF)
Esta función es un componente indispensable en el protocolo 802.11 ya que no es opcional a
diferencia de la función PCF. Establece el envío de mensajes para la coordinación de los envíos
de información dentro de la red. Con la función de coordinación distribuida no existe una
garantía de calidad de servicio ya que no existe una pre‐asignación de recursos, ni plazos
conocidos ni garantía de recepción correcta de la información.
Esta función puede ser dividida en cuatro partes principales que se abordarán a continuación
que son:
Detección de portadora: ¿Cómo se detecta que se está produciendo una transmisión
de información?
Métodos de transmisión: ¿Qué hacer cuando se pretende transmitir? ¿Qué mensajes
enviar?
Espaciado entre tramas: ¿Tengo que respetar algún tiempo de espera?
Fragmentación.
DETECCIÓN DE PORTADORA
Lo primero que tiene que ser especificado es cómo llevar a cabo la detección de la portadora.
802.11 presenta dos tipos distintos de detección de portadora:
Detección de portadora física (PCS – Physical Carrier Sensing).
Detección de portadora virtual (VCS – Virtual Carrier Sensing).
La detección de portadora física se realiza escuchando el canal durante todo el tiempo para ver
si éste se encuentra ocupado o libre. Esto se conoce como “evaluación de la libertad del canal”
(CCA – Clear Channel Assessment ). La CCA establece que la estación no puede transmitir hasta
que el canal se encuentre libre. Una vez especificada la forma de detección física, será
necesario establecer de forma virtual que el medio se encuentra ocupado, y esto se lleva a
cabo gracias a un nuevo concepto llamado “vector de asignación de red” (NAV – Network
Allocation Vector) que contiene el tiempo estimado que durará la transmisión por parte de la
estación emisora, por lo que será el tiempo que estará ocupado el medio. De esta forma las
estaciones no intentarán transmitir durante este tiempo (aunque perciban libre el medio).
Sería una forma de “reservar” el medio durante un tiempo determinado.
Hay que tener en cuenta que tanto la detección de portadora física como la virtual se
encuentran en funcionamiento de forma simultánea. Cada una trabaja en una capa de defensa
por lo que si una falla, se espera que la otra lleve a cabo la detección con éxito. Gracias a esta
doble defensa se refuerza la protección contra colisiones.

22
MÉTODOS DE TRANSMISIÓN
Una vez queda definido cómo realizar la detección de portadora, aparece el problema de cómo
transmitir y qué transmitir. 802.11 establece dos métodos de transmisión: básico y método
basado en intercambio de mensajes RTS/CTS.
En el caso del método básico se considera una estación que tiene la intención de transmitir
información al punto de acceso. Al detectar el medio libre, envía una trama de datos
conteniendo el temporizador NAV para reservar la ocupación del canal. A este mensaje
responde el punto de acceso con un mensaje ACK (Acknowledgement) con el que confirma la
correcta recepción del mensaje. Este intercambio de mensajes se muestra en la figura 9.
Figura 9: Entorno DCF.
El segundo método de transmisión consiste en el esquema llamado “4‐handshake”, que
consiste en un método de evasión de colisiones y está basado en realizar primero un
intercambio de mensajes RTS/CTS con el temporizador NAV. Este procedimiento consiste en el
cálculo del tiempo previsto de ocupación del canal por parte de una estación y la siguiente
solicitud mediante un mensaje RTS (Request To Send) de la intención de transmitir. Los
mensajes RTS son cortos con el objetivo de que si se produce una colisión, no esté el medio
ocupado de forma no efectiva mucho tiempo. Si el punto de acceso está disponible para recibir
los datos, responde con un mensaje CTS (Clear To Send). Ese mensaje es recibido por todas las
estaciones, de esta forma el resto de estaciones sabrán que el medio está ocupado y esperarán
a que termine la transmisión. Un esquema del intercambio de mensajes se muestra en la figura
10.

23
Figura 10: Entorno DCF.
ESPACIO ENTRE TRAMAS
En una red en la que se intercambia información como puede ser una red inalámbrica como la
tratada en este trabajo, las tramas enviadas serán de distintos tamaños y distinto nivel de
importancia. Para poder establecer un orden de envíos y prioridades, aparece un tiempo entre
tramas llamado “Espacio entre tramas” (IFS – InterFrame Space). Se utilizan cuatro tipos
diferentes de IFS que se especifican a continuación:
SIFS – Short InterFrame Space “Espacio corto entre tramas”. Este tiempo es
utilizado cuando se quiere llevar a cabo la transmisión de paquetes cortos y de alta
prioridad, como por ejemplo, paquetes ACK o CTS.
PIFS – Pcf InterFrame Space “Espacio entre tramas PCF”. Establece el tiempo entre
tramas correspondientes a la función de coordinación puntual (PCF).
DIFS – Dcf InterFrame Space “Espacio entre tramas DCF”. Este tiempo es el utilizado
en el caso de tener la intención de transmitir tramas de datos utilizando la función de
coordinación distribuida (DCF).
EIFS – Extended InterFrame Space “Espacio ampliado entre tramas”. Este tiempo es
el utilizado tras errores de transmisión.
Los IFSs se ordenan de menor a mayor prioridad: SIFS < PIFS < DIFS < EIFS. Los valores de estos
tiempos son fijos y utilizados según el caso del que se trate la transmisión. La duración de éstos
depende de la velocidad de la red utilizada. De esta forma ocurrirá que habrá paquetes que
serán transmitidos antes que otros dependiendo de su prioridad. Aparece también un tiempo
de contención llamado “Backoff time” junto con una ventana de contención. Este tiempo de
contención selecciona de forma aleatoria su valor entre los valores mínimo y máximo para la
ventana de contención. Las estaciones a transmitir deberán esperar ese tiempo aleatorio de
Backoff después de esperar el temporizador DIFS.

24
De esta forma, el diagrama de un intercambio de mensajes con dos estaciones y el punto de
acceso sobre la línea del tiempo quedaría como se muestra en la figura 11:
Figura 11: Intercambio DCF, 4‐handshake con temporizadores.
En el momento que una estación detecta el medio libre, se selecciona un valor para el
intervalo de Backoff entre 0 y el valor máximo de la ventana de contención y comienza la
cuenta atrás. La cuenta atrás se suspende en caso de ocuparse el medio de forma que la
estación volverá a quedarse en espera, reanudando la cuenta atrás en ese punto cuando el
canal vuelve a quedar vacío. Cuando la cuenta llega a 0, se envía el paquete. Si se produce una
colisión, se duplica el tamaño máximo de la ventana de contención y se repite el proceso. De
esta forma si dos estaciones detectan al mismo tiempo el medio libre, esperarán un tiempo de
Backoff distinto, por lo que en cuanto una de ellas comience la transmisión la otra parará su
tiempo de Backoff evitando así la colisión de paquetes RTS/CTS como se muestra en la figura
12:

25
Figura 12: Intervalos de Backoff.
FRAGMENTACIÓN
Como ya se ha mostrado anteriormente, las transmisiones inalámbricas son poco fiables, por
lo que un error en la transmisión de un contenido demasiado extenso conllevaría una pérdida
de tiempo inadecuada para la red. En el caso de tener la intención de transmitir una unidad de
datos de servicios MAC (MSDU – MAC Service Data Unit) de excesivo tamaño, será necesario
proceder a una fragmentación en unidades de datos de protocolo MAC (MPDU – MAC
Protocolo Data Unit).
El contenido de una MSDU se divide en fragmentos. A cada fragmento se le añade una
cabecera MAC y el CRC con lo que está listo para ser enviado (MPDU). Una MSDU se ha
enviado correctamente cuando todos los fragmentos correspondientes hayan sido enviados y
confirmados. De esta forma se envía un paquete ACK para la confirmación de recepción de un
fragmento. También se añade un temporizador para los envíos de los fragmentos, de forma
que se esperará un tiempo para recibir el ACK, en caso de no recibirlo se reenvía el fragmento.
También existe un límite para retransmisiones, que al ser superado, se cancela el envío de la
MSDU dejando el medio libre.
Para ejemplificar todas las partes de la función coordinada distribuida presentadas en este
documento, se muestra en la figura 13 un diagrama en el que se muestran el intercambio de
información entre una estación y el punto de acceso. En este ejemplo la estación fragmenta la
MSDU en dos fragmentos que envía (recibiendo el correspondiente ACK). Se hace uso de el
método de transmisión basado en el intercambio de paquetes RTS/CTS.

26
Figura 13: Intercambio de mensajes con fragmentación.
2.3.2. FUNCIÓN DE COORDINACIÓN PUNTUAL (PCF)
Además de la función DCF, el estándar para redes inalámbricas define adicionalmente un
método de acceso al medio opcional conocido como “función de coordinación puntual” (PCF –
Point Coordination Function). Este método es implementado sobre la arquitectura DCF y está
basado en el funcionamiento de ésta. La diferencia principal reside en que la DCF está basada
en contención y la PCF es una técnica de acceso al medio planificada.
La función PCF se basa en centralizar las comunicaciones dentro de la red definiendo un punto
como el punto de coordinación (PC – Point Coordinator), que se encarga de coordinar el
acceso al medio inalámbrico. Este modo de gestión tiene una prioridad más alta que el DCF, ya
que no será necesario esperar el tiempo DIFS para realizar una transmisión. Existe un
protocolo llamado “MAC inalámbrico de fundamento distribuido” (DFWMAC – Distributed
Foundation Wireless Media Access Control) que está basado en la división del tiempo en
períodos llamados supertramas, donde se produce alternancia de períodos de contención (CP
– Contention Period) y períodos libres de contención (CFP – Contention Free Period). Una
super‐trama está formada por un período CFP seguido de un período CP y la gestión es la
siguiente: En los períodos libres de contención se hace uso de PCF mientras que en los
períodos de contención se utiliza DCF.
El principio de una super‐trama se indica con una trama de alerta (beacon) que consisten en
un mensaje cuyo objetivo es la sincronización de los relojes locales de las estaciones. De esta
forma, el punto de coordinación es el encargado de enviar los mensajes “beacon” con los que
inicia un período CFP en el que el punto de coordinación pregunta a una estación si tiene
intención de transmitir.
En caso de que, pasado un tiempo PIFS no se haya recibido respuesta, se pregunta a otra
estación o se finaliza el período CFP. De esta forma se consigue que el canal no se mantenga
desocupado durante un tiempo superior a PIFS, pero aún así se pueden producir colisiones si,
por ejemplo, una estación no recibe la señal de alerta. En este caso no sabrá que se está
trabajando en modo PCF y creerá que se está trabajando en modo DCF, con lo que enviará
información en intervalos de tiempo que no le corresponden.

27
2.4. FORMATO TRAMA MAC:
Uno de los aspectos más importantes de este estudio consiste en conocer la estructura real de
los paquetes que van a ser capturados en una red inalámbrica para su posterior
procesamiento. Con este objetivo se muestra a continuación el formato de las tramas MAC con
una explicación de sus campos con la meta de entender cuándo y cómo son utilizados.
Las tramas que pueden aparecer en una red inalámbrica pueden ser de 3 tipos distintos:
Tramas de administración: Tramas relacionadas con el proceso de asociación y
autenticación de las estaciones y cualquier tipo de señalización necesaria en la red
(beacons).
Tramas de datos.
Tramas de control: Son las generadas por las funciones de coordinación y por las
confirmaciones (RTS, CTS, ACK, etc.).
Las tramas MAC están formadas por 3 campos principales que son: la cabecera, el cuerpo y un
campo llamado FCS, obteniendo así la trama mostrada en la figura 14. El campo FCS consiste
en 4 bytes para suma de comprobación (checksum). El cuerpo del mensaje consiste en la
información procedente de capas superiores correspondiente con el contenido de la
comunicación y podrá estar protegido con seguridad o no. En caso de que no lo esté se puede
analizar su contenido en texto plano y en caso de que lo esté, será necesario descifrarlo para
poder ver su contenido. El campo que va a ser analizado a fondo será la cabecera MAC, ya que
su información es visible sin necesidad de descifrarlo y se puede extraer información de gran
relevancia de dicha cabecera.
Figura 14: Estructura principal de una trama MAC.
La cabecera MAC está formada por una serie de campos que se muestran en la figura 15. El
campo de control de trama se detalla a continuación bit a bit. El resto de campos de la
cabecera son los siguientes:
Duración: Tiempo para transmitir la trama y recibir la confirmación (ACK). Este tiempo
es el que define el NAV especificado anteriormente.
Direcciones 1, 2, 3 y 4: Están formadas por direcciones físicas de 48 bits. El valor de
éstas depende del origen y destino del paquete. Las asignaciones específicas se
explican a continuación.
El campo de control de secuencia se utiliza para la identificación y orden de los
fragmentos MPDUs correspondientes a una MSDU.

28
Figura 15: Cabecera de trama MAC.
El campo de control de trama se divide en los campos mostrados en la figura 16, distinguiendo
entre:
V 2 bits de versión, que serán generalmente 0. En caso de no serlo, no se está
siguiendo el estándar, por lo que se podría estar utilizando un estándar de un
fabricante concreto.
Tipo Se indica el tipo de trama que es distinguiendo entre los tres presentados
anteriormente: administración, datos o control. El significado de los campos de tipo se
encuentra en la tabla 1.
Subtipo Concreta dentro del tipo, cuál es la función concreta de la trama. El
significado de los valores de los subtipos más importantes se muestra en la tabla 1.
toDs Si tiene valor 1 indica que la trama viene del sistema de distribución (caso
contrario 0). Los valores con más detalle se encuentran en la tabla 2.
FromDs Si tiene valor 1 indica que la trama va destinada al sistema de distribución
(caso contrario 0). Los valores con más detalle se encuentran en la tabla 2.
MF Más fragmentos: En caso de que el paquete haya sido fragmentado, todos los
fragmentos llevan este campo a 1 excepto el último.
Re Se pone a 1 para indicar que se está produciendo una retransmisión, en caso
contrario su valor es 0.
Pot Con el valor 1 indica que el dispositivo que envía la trama se encuentra
trabajando en un modo de ahorro de energía (en caso contrario 0).
MD Más datos: En caso de estar trabajando en modo de ahorro de energía, este bit
a 1 indica que el punto de acceso tiene tramas almacenadas para ser enviadas.
W WEP: Si este bit se encuentra a 1, indica que el contenido del cuerpo de la trama
está cifrado.
O Orden: En caso de estar a 1, las tramas siguen un orden estricto.
Figura 16: Campo control de trama.

29
TIPO Bits (3‐2)
Descripción Subtipo Bits (7‐6‐5‐4)
Descripción
00 Administración 0000 Solicitud de asociación
00 Administración 0001 Respuesta asociación
00 Administración 0010 Solicitud re‐asociación
00 Administración 1010 Disociación
00 Administración 1011 Autenticación
00 Administración 1100 Des‐autenticación
01 Control 1011 RTS
01 Control 1100 CTS
01 Control 1101 ACK
10 Datos 0000 Datos
Tabla 1: Tipos y subtipos de trama MAC.
Valor del campo “toDs”
Valor del campo “fromDs”
Descripción
0 0 Comunicación directa entre estaciones: Entorno ad‐hoc.
0 1 Comunicación desde el punto de acceso a las estaciones (desde el sistema de distribución).
1 0 Comunicación desde las estaciones al punto de acceso (hacia el sistema de distribución).
1 1 Comunicación entre puntos de acceso.
Tabla 2: Interpretación de los valores de los campos “toDs” y “fromDs”.
Un punto importante a tener en cuenta a la hora de interpretar la información recibida es que
la lectura se debe de hacer de derecha a izquierda y por parejas. Los valores se representan
como números hexadecimales, un ejemplo podría ser “40 42”. La interpretación se obtendría
como se muestra en la figura 17.

30
Figura 17: Interpretación de valores hexadecimales.
Según se muestra en la figura 17, la interpretación sería la siguiente: Se trata de una trama de
administración, concretamente una solicitud de re‐asociación. Es una solicitud enviada por
parte de una estación hacia un punto de acceso. O bien es el último fragmento de una serie de
envíos, o bien no está fragmentado. No se trata de una re‐transmisión ni se trabaja en modo
ahorro de potencia. Finalmente el contenido se encuentra cifrado y no sigue un orden estricto.
Finalmente, los campos de direcciones MAC necesitan una especial atención, ya que
dependiendo de la trama las direcciones se corresponden con unos dispositivos u otros. En
primer lugar, el campo de dirección 4 es opcional y habrá casos que no contendrá nada. Los
casos posibles son los siguientes:
En una comunicación modo ad‐hoc (IBSS) , la comunicación se realiza directamente
entre estaciones sin tener que pasar por el punto de acceso, se indica con los bits
“toDS = 0” y “FromDS=0”. En este caso el orden es el siguiente:
o Dirección 1: Dirección MAC destino a donde tiene que llegar la información.
o Dirección 2: Dirección MAC origen de donde sale la información.
o Dirección 3: BSSID (Número identificativo de la red).
o Dirección 4: No se usa.
En el caso de realizar la comunicación en modo infraestructura desde una estación
(toDS = 1, fromDS = 0) el orden es el siguiente:
o Dirección 1: BSSID.
o Dirección 2: Origen.
o Dirección 3: Destino.
o Dirección 4: No se usa.

31
Para una comunicación en modo infraestructura desde un punto de acceso (toDS = 0,
fromDS = 1) el orden es el siguiente:
o Dirección 1: Destino.
o Dirección 2: BSSID.
o Dirección 3: Origen.
o Dirección 4: No se usa.
Cuando la comunicación se realiza entre estaciones móviles correspondientes a
distintas BSS (toDS = 1, fromDS = 1):
o Dirección 1: BSSID origen.
o Dirección 2: BSSID destino.
o Dirección 3: Destino.
o Dirección 4: Origen.
2.5. CRIPTOGRAFÍA
En las redes cableadas la información se transmite a través de enlaces cableados y no es
necesario prestar tanta atención a la criptografía. Sin embargo, las redes inalámbricas se basan
en difusión a través del aire, por lo que será necesario prestar especial atención a la integridad,
confidencialidad y autenticación del mensaje. En esta sección se va a presentar en primer lugar
los tipos de códigos existentes, cómo se realiza el cifrado y, finalmente, se presentan métodos
de comprobación de integridad de los mensajes.
Dos importantes términos en este ámbito son: “texto plano” y “texto cifrado”. Los mensajes
que pueden ser entendidos al ser leídos son los llamados “texto plano”. El cifrado consiste en
un método en el que el texto plano es convertido en una correspondiente forma ininteligible
llamada texto cifrado, que podrá ser enviado a través de un medio inseguro. El proceso de
conversión del texto cifrado de nuevo a texto plano es llamado descifrado.
2.5.1. CÓDIGOS
Los códigos se pueden clasificar en dos grandes categorías que son los códigos de clave
simétrica y los de clave asimétrica. La diferencia principal entre estos dos tipos se basa en las
claves utilizadas a la hora de realizar el cifrado y el descifrado de datos.
En el caso de códigos de clave simétrica se utiliza una única clave compartida secreta tanto
para el cifrado como para el descifrado. Sin embargo los códigos de clave asimétrica hacen uso
de dos claves: una de ellas es para el cifrado y otra para el descifrado de la información. Las
dos claves están matemáticamente relacionadas y una de ellas se define como la clave pública
y la otra como la clave privada. En la figura 18 se muestra de forma gráfica la división de
códigos.

32
Figura 18: Criptografía.
BASADOS EN CLAVE SIMÉTRICA
Los códigos basados en clave simétrica pueden ser de dos tipos distintos: basados en cifrado
de flujo o en cifrado de bloques.
En el cifrado de flujo, los datos son cifrados dígito a dígito. En este caso se hace uso de una
clave de longitud menor que el tamaño del mensaje de texto plano. Con esta clave se obtiene
un flujo de clave pseudo‐aleatorio que es utilizado posteriormente junto con el texto plano
aplicando una operación lógica XOR. Como resultado se obtiene el texto cifrado.
Por otro lado, el cifrado de bloques procesa grupos de bits de tamaño fijo. Un bloque de
símbolos de texto plano con tamaño m>1 se cifran para crear un bloque de texto cifrado del
mismo tamaño. Como consecuencia, al estar trabajando con bloques de tamaño fijo m, la clave
tendrá también tamaño m. En el caso de ser necesario el cifrado de mensajes de tamaño
superior a m, se puede hacer uso de varios modos de operación desarrollados . El modo de
operación más simple es el llamado “Libro de código electrónico” (ECB ‐ Electronic CodeBook).
El mensaje de texto plano se divide en bloques de n bits y se cifran con una clave de ese
tamaño. El problema de este método aparece cuando se hace uso de bloques repetidos de
texto plano de n bits a lo largo del mensaje. De esta forma habrá réplicas de bloques de texto
cifrado. La ventaja del cifrado de flujo frente al de bloque reside en que el de flujo puede cifrar
datos de varios tamaños mientras que el de bloque está limitado a un tamaño fijo.
El principal problema de la criptografía con uso de clave simétrica es que el intercambio de la
clave compartida tiene que realizarse a través de un modo seguro de transmisión. Pero no
siempre se puede asegurar la confidencialidad cuando se realizan envíos de la clave, por lo que
la seguridad de la transmisión se vuelve vulnerable a ataques. Para evitar este problema
aparece la criptografía basada en clave asimétrica.

33
BASADOS EN CLAVE ASIMÉTRICA
En este caso, como ya se ha comentado anteriormente, se hace uso de un par de claves: una
pública (que suele estar disponible) y otra privada (que se mantiene secreta). Si se hace uso de
este tipo de códigos con fines de confidencialidad, la clave pública es usada para cifrar el
mensaje y la privada para descifrarlo. En el caso de autentificación, la clave privada es usada
para cifrar el mensaje y la pública para descifrarlo, lo que quiere decir que cualquiera que
tenga la clave pública puede descifrar el mensaje.
Una de las primeras aplicaciones para los códigos basados en clave asimétrica es la utilización
conjunta de éstos con códigos de clave simétrica. Las claves simétricas se cifran con una clave
pública de manera que pueden ser transmitidas de forma segura a la parte con la clave privada
asociada.
Otra aplicación para las claves asimétricas es las firmas y certificados digitales. En el caso de las
firmas digitales se hace uso de tres algoritmos. Uno de ellos realiza la generación de una clave
pública y una correspondiente clave privada de forma aleatoria. Un segundo algoritmo se
encarga de “firmar” los mensajes haciendo uso de la clave privada. Finalmente un algoritmo
verificador de firma será el encargado de recibir los mensajes, y con la firma y la clave pública
decidir si son aceptados o rechazados.
Por otro lado se encuentran los certificados digitales, que son creados a partir de una clave
privada dada y pueden ser verificados con la correspondiente clave pública. Esto simplemente
establece que hay un mismo poseedor que conserva la clave pública y la privada.
Principalmente los certificados digitales aparecen para ofrecer seguridad en el entorno de una
red a grande escala, ya que en estos casos es difícil distribuir claves públicas de forma segura.
Un certificado digital es un mecanismo que tiene el objetivo de unir una identidad a una clave
pública (y a su clave privada asociada). El poseedor (con la correspondiente identidad) de la
llave pública puede ser un individuo, una organización o un dispositivo.
Estos certificados se gestionan y mantienen por medio de la confianza en una tercera parte: el
certificado de autoridad (CA – Certificate Authority). El CA establece la unión de firma digital, la
identidad de los datos del poseedor y la clave pública. La firma digital, los datos de identidad y
la clave pública forman el certificado digital.
2.5.2. CIFRADO
Hay varios métodos de llevar a cabo el cifrado pero algunos de los más utilizados son los
siguientes:
RC4: El algoritmo RC4 es el utilizado en el protocolo WEP (especificado más adelante) y
está basado en códigos de clave simétrica, específicamente códigos de flujo. Su rapidez
y simplicidad hace que su uso sea muy extendido. Se divide en dos fases principales: La
fase de generación del flujo de clave y la fase de cifrado. La generación de flujo de
clave consiste en una serie de estados y operaciones de mezclado que resultan en un
flujo de bits pseudo‐aleatorios. La semilla de estas operaciones es la clave simétrica

34
que se genera utilizando un vector de inicialización de 24 bits y una clave de 40 bits (en
total 64 bits). Posteriormente se posibilitó el uso de una clave de 104 bits, obteniendo
un tamaño total de 128 bits. Una vez la tabla de estados ha sido inicializada, los valores
se utilizan para generar el flujo de clave. La segunda fase se basa en realizar una
operación lógica XOR del texto plano con el flujo de clave generado.
DES: Estándar de cifrado de datos (Data Encryption Standard). Consiste en un código
basado en clave simétrica de bloques y es vulnerable a ataques de fuerza bruta debido
a que la longitud de la clave está limitada a 64bits. Para fortalecer este código apareció
el triple‐DES que consiste en 3 códigos DES repetidos en el que se hace uso de 3 claves
de 56 bits.
AES: Estándar de cifrado avanzado (Advanced Encryption Standard). Se trata de un
código basado también en clave simétrica de bloques que fue el sucesor de DES. En
este caso el tamaño de bloque es de 128 bits y la longitud de las claves es de 128, 192
ó 256 bits. Cuanto más larga sea la clave, más difícil será descifrarla por lo que más
seguridad se proporciona.
2.5.3. RESUMEN DEL MENSAJE:
El resumen del mensaje consiste en una transformación de un mensaje de cualquier longitud a
un valor numérico. Existen dos formas típicas de comprobación de la integridad de un
mensaje: suma de comprobación (checksum) y comprobación de redundancia cíclica (CRC –
Cyclic Redundancy Checks).
La suma de comprobación se lleva a cabo enviando los datos y la suma de comprobación. Si se
ha producido un cambio en el mensaje, al calcular la suma de comprobación no coincidirá con
la que transporta el mensaje con lo que se detectará dicha modificación. Por otro lado la
comprobación de redundancia cíclica sigue un procedimiento similar al de la suma de
comprobación pero la diferencia es que el valor se obtiene realizando una larga división en
lugar de una suma. No obstante, la seguridad proporcionada por los citados métodos no
siempre asegura la integridad de los mensajes por lo que existen algoritmos adicionales más
seguros como se muestra a continuación:
MD5 – Message Digest 5 (Resumen de mensaje): En este algoritmo se utiliza una clave
que no es enviada a través de la red. La clave es utilizada para obtener el resumen del
mensaje llamado el “valor hash”. En la “función de hash” se utiliza información sobre
el punto de acceso (como la dirección IP) produciendo un resultado de longitud fija. El
receptor utiliza la misma clave teniéndola almacenada y realiza la “función de hash”. El
“valor de Hash” consiste en una representación basada en un número de 32 dígitos
hexadecimal. Aunque haya sido diseñado para seguridad, se ha demostrado que tiene
importantes vulnerabilidades, ya que puede presentar dos resúmenes de mensaje
iguales provenientes de dos mensajes distintos.

35
SHA – Secure Hash Algoritm (Algoritmo de Hash seguro): Se considera que es el
sucesor de MD5. El estándar de procesado de información presenta cuatro algoritmos
de seguridad SHA: SHA‐1, SHA‐256, SHA‐384 y SHA‐512. Los cuatro algoritmos son
iterativos con funciones de hash en una dirección que pueden procesar un mensaje
con una longitud máxima de 264 ‐ 2128 bits para producir una representación
condensada como resumen del mensaje de 160 – 512 bits. El mensaje de entrada se
procesa en bloques de 512 – 1024 bits. Cada algoritmo SHA procesa el mensaje en dos
estados: pre‐procesamiento y el cálculo de valor de hash.
2.6. SEGURIDAD
Una de las cuestiones más importantes en las redes inalámbricas es que la información
transmitida a través de una red inalámbrica llegue a su destinatario y no pueda ser utilizada
por dispositivos no autorizados. El estándar 802.11 no establece reglas específicas de
seguridad por lo que éstas han tenido que ir siendo desarrolladas de forma posterior y
gradualmente por medio de actualizaciones 802.11a, 802.11b, etc.
En un primer momento los fabricantes comenzaron a crear listas de direcciones MAC en los
puntos de acceso de forma que sólo podían acceder a la información de la red los equipos cuya
dirección MAC estuviese incluida en la lista. Con el estándar 802.11b aparece la “Privacidad
equivalente a cableado” (WEP – Wired Equivalent Privacy) con el que se establece una serie de
reglas para mantener la seguridad en la red. Al demostrar la vulnerabilidad de dicho estándar
se comienza a trabajar en el desarrollo del estándar que supliría los defectos de WEP que
posteriormente recibe el nombre de “acceso protegido Wi‐Fi 2” (WPA2 – Wi‐Fi Protected
Access) en la actualización del estándar 802.11i. Mientras se desarrolla dicha actualización,
aparece el llamado “acceso protegido Wi‐fi” (WPA) que está basado en WEP pero que cubre
las vulnerabilidades de éste. A continuación se especifican los detalles de dichos estándares.
2.6.1. WEP
En cuanto a la autenticación WEP presenta dos modos de operación: sistema abierto o clave
compartida.
Con el sistema abierto, la autentificación se establece mediante la transmisión de dos
mensajes. Si se consideran dos dispositivos inalámbricos A y B, el dispositivo A envía una
petición de autenticación y B responde a esta petición mediante “success” (éxito) o “failure”
(fallo). Al ser abierto por la respuesta será siempre éxito a no ser que se cree una lista de
direcciones MAC en el punto de acceso como se comentó anteriormente. En ese caso que el
dispositivo se encuentre en la lista recibirá el mensaje de éxito y en caso contrario el de fallo.
En el caso de autenticación con clave compartida, sólo los dispositivos que conocen la clave
compartida pueden autentificarse. El proceso de autentificación se lleva a cabo por medio de
“four‐way handshake”. El dispositivo A envía una petición de autentificación al dispositivo B. El
dispositivo B genera un texto aleatorio de 128 octetos y se lo envía a A. A cifra el texto usando

36
RC4 y envía el resultado a B. Una vez recibido en B, éste comprueba el “valor de
comprobación de integridad” (ICV – Integrity Check Value ) y, en caso de ser correcto, B envía
un código de estado indicando éxito. En caso contrario, indicará error.
Aunque parezca más robusto el método de clave compartida, se ha demostrado que es más
débil. Esto se debe a que si se capturan los mensajes del “four‐way handshake” se puede
obtener la clave, con lo que la red queda vulnerable.
Para calcular el ICV se utiliza un código CRC de 32 bits. Con esto se busca que se pueda
detectar si se ha producido una modificación del mensaje durante la transmisión, ya sea una
modificación debido a algún error en la transmisión o una modificación debido a un ataque.
Suponiendo un mensaje M, se calcula el código CRC de 32 bits, que se concatena con dicho
mensaje obteniendo el texto plano:
| , "|" ó .
Para el proceso de cifrado se utiliza la clave WEP (K) y un vector de inicialización (IV). El cifrado
RC4 genera una secuencia pseudo‐aleatoria (flujo de clave) que es función de la clave y del
vector de inicialización. El texto cifrado (C) se obtiene realizando la operación lógica XOR al
flujo de clave y al texto plano (figura 19):
⊕ 4 ,
Figura 19: Cifrado WEP.
El receptor del texto cifrado lo único que tendrá que hacer será realizar la operación inversa
para obtener el texto plano:
⊕ 4 , ⊕ 4 , ⊕ 4 ,
Ahora se separa el mensaje del código CRC para realizar la comprobación de integridad del
mensaje. Se calcula en el receptor el código CRC de 32 bits del mensaje y se comprueba con el

37
código CRC recibido. Si estos códigos coinciden, el mensaje no ha sido modificado. En caso
contrario, el mensaje se descarta al ser erróneo.
Finalmente hace falta resaltar que el principal problema que aparece con WEP es el efecto
llamado “reutilización del IV” que se explica en detalle más adelante.
Las claves WEP originales tenían una longitud de 40 bits (WEP‐40). Se consideró que eran
demasiado cortas para algunos propósitos más serios. Se incrementó la longitud hasta 104 bits
pero esto no hizo tampoco mucho para incrementar la seguridad. El tiempo necesario para
averiguar la clave de una longitud de 40 bits ronda los 3‐5 minutos y para una clave de 104 bits
unos 10‐15 minutos.
2.6.2. WPA y WPA2
Demostrada la vulnerabilidad de WEP en todos los aspectos, aparece WPA2 para ofrecer la
seguridad necesaria en una red inalámbrica. Presenta mejoras tanto en autenticación como en
integridad y cifrado del mensaje como se muestra a continuación.
En este caso también se establecen dos modos de autenticación: “clave pre‐compartida” ( Pre‐
Shared Key ‐ PSK) y 802.1X. En el modo PSK se utiliza una clave secreta común para la estación
y el punto de acceso que es introducida de forma manual en cada equipo antes de realizar la
conexión. Una vez las dos partes conocen la clave se lleva a cabo un proceso de “four‐way
handshake”. El hecho de tener que establecer estas contraseñas de forma manual en los
dispositivos hace que este modo sea ideal para redes de tamaño reducido.
Por otro lado se encuentra 802.1X que es un protocolo de la capa 2 que proporciona control
de acceso en redes basadas en puertos. Es más complejo que el modo PSK y está pensado para
redes más grandes que necesiten mayor seguridad. El protocolo utilizado para llevar a cabo el
proceso de autentificación es el protocolo de autentificación extensible (Extensible
Authentification Protocol ‐ EAP). EAP consiste en un estándar de internet para autentificación
de cliente de red. EAP fue inicialmente una extensión del protocolo punto‐a‐punto (PPP –
Point‐to‐Point Protocol). El objetivo de desarrollo de EAP fue poder realizar una negociación en
los puntos finales de la comunicación para poder seleccionar el mecanismo de autentificación
adecuado. Esto significa que es posible adoptar un nuevo mecanismo de autentificación sin ser
necesaria la extensión de PPP. 802.1X define cómo se encapsulan los paquetes EAP en tramas
de capa 2 y establece tres entidades envueltas en el proceso de autentificación (figura 20):
Solicitante: Es el software incorporado en el cliente inalámbrico.
Autenticador: Punto de acceso, donde se ejecuta el software del Servidor de
autenticación de red (NAS – Network Authentication Server). El NAS se utiliza ya que el
servidor de autenticación no tiene por qué residir en la capa 2. El NAS bloquea los
paquetes de capa 3 del cliente hasta que está completamente autenticado.
Servidor de autentificación: Normalmente suele ser RADIUS.

38
Figura 20: Componentes 802.1X
Un punto de acceso anuncia sus capacidades de seguridad en tramas de señalización o como
respuesta a peticiones de prueba. El solicitante selecciona el punto de acceso deseado y se
autentica con el punto de acceso por medio del sistema abierto. Una vez en este punto,
comienza el intercambio de paquetes EAP (el resto de comunicación se mantiene bloqueada
hasta que la comunicación EAP termine). El suplicante y el servidor de autenticación llevan a
cabo la autenticación usando uno de los métodos disponibles por EAP.
Tras la autentificación con éxito, el cliente y el servidor de autentificación generan una clave
secreta común llamada la clave de sesión maestro (MSK – Master Session Key). El solicitante
deriva la llave maestra por parejas (PMK – Pairwise Master Key) de la MSK. El servidor de
autentificación transfiere la clave al Autentificador, habilitándolo para derivar también la PMK.
El solicitante y el autenticador llevan a cabo un intercambio “handshake de 4 caminos” que
establece el código y la clave de transición por parejas (PTK – Pairwise Transient Key). Otras
claves se derivan de la PTK. Una vez realizado este procedimiento, 802.1X desbloquea el
puerto y admite paquetes de datos de la red. El solicitante y el autenticador ya pueden
intercambiar tramas de forma segura.
Los mensajes que viajan en la red inalámbrica son encapsulados en paquetes EAPOL (EAP Over
LAN). Los que son transmitidos en la red de cable se encapsulan en paquetes RADIUS (sobre
TCP/IP). El autenticador es el responsable del encapsulado y de‐encapsulado de los paquetes
EAPOL y RADIUS. La relación entre EAP y 802.1X está resumida en la figura 21.

39
Figura 21: EAP sobre LAN.
Algunos métodos EAP actuales se describen a continuación:
EAP‐PSK: Autentificación basada en clave pre‐compartida.
EAP‐MD5: Un método de autentificación mínima basado a partir de la función MD5. La
autentificación no es mutua, esto significa, que solo la autentificación del cliente es
llevada a cabo. Es vulnerable a ataques.
EAP‐MSCHAPv2: La versión 2 de Mircrosoft CHAP consiste en un protocolo de
autentificación de handshake con retos. Mientras que la versión 1 consistía en un
mecanismo de autentificación solo para el cliente, la versión 2 permite la
autentificación tanto del cliente como del servidor.
EAP‐LEAP: El EAP ligero es una propiedad del protocolo EAP de Cisco. EAP ligero
provee autentificación mutua basada en la contraseña de una respuesta al reto.
EAP‐PEAP: El protocolo EAP protegido es un protocolo de propiedad co‐desarrollado
por Microsoft, Cisco y seguridad RSA. PEAP provee la autentificación segura mutua del
cliente y del servidor.
EAP‐TLS: Seguridad en la capa de transporte (TLS – Transport Layer Security) está
basada a partir de un certificado de autentificación mutua. Los certificados tanto del
cliente como del servidor se intercambian.
EAP‐TTLS: Seguridad de la capa de transporte tunelado (TTLS – Tunneled Transport
Layer Security) es una extensión de TLS. Los cliente son autentificados
En cuanto al cifrado e integridad aparecen dos tipos distintos. Una vez se descubren las
vulnerabilidades de WEP quedan las redes desprotegidas en contra de ataques, por lo que se
necesita fortalecer esta seguridad hasta que aparezca la actualización WPA2. De esta forma
surge el protocolo de integridad de clave temporal (TKIP – Temporal Key Integrity Protocol).

40
Después aparece el protocolo de código en modo cifrado contador con autenticación de
mensajes enlazados por bloques (CCMP):
TKIP: Aparece con WPA y está basado en WEP pero mejorando la seguridad en los
aspectos que WEP era más vulnerable: generación de clave, colisiones de IV y
falsificación de mensajes. De esta forma se utiliza un cifrado RC4 de 128 bits por trama
que se obtiene como función de una clave temporal, la dirección MAC del cliente y el
IV. Para mantener la integridad del mensaje se incluye un mensaje de comprobación
de integridad (MIC – Message Integrity Check) en cada trama. El algoritmo utilizado
para obtener este valor es el llamado algoritmo “Michael” y se aplica a la dirección
origen, destino, el campo de prioridad, tres octetos reservados y el texto plano del
mensaje. De esta forma ofrece mucha más seguridad a la hora de detectar
modificaciones en el mensaje. También se incluye un campo para evitar los ataques
simples de retransmisiones que se llama el contador de secuencia TKIP (TSC – TKIP
Sequence Counter), desechando todas las tramas en las que no se incremente este
valor.
CCMP: Este protocolo está basado en el modo contador del estándar de cifrado
avanzado (AES – Advanced Encryption Standard) para confidencialidad y en el CBC‐
MAC (CCM) para integridad. En la figura 22 se muestra de forma visual la
transformación de la trama pasando de una original a una trama CCMP. El valor MIC se
obtiene con el texto plano del mensaje, se añade una cabecera CCMP y se añade una
secuencia de comprobación de trama (FCS – Frame Check Sequence). La cabecera
CCMP contiene un IV, un identificador de clave y un número de paquete. Para cada
sesión se genera una clave temporal. El proceso de encapsulación CCMP comienza con
la construcción del campo de datos de autenticación adicional (AAD – Additional
Aunthentication Data). El número de paquete, el segundo campo de dirección y el
campo de prioridad de la cabecera MAC se usan para construir el bloque CCM nonce.
Figura 22: Trama CCMP.

41
3. ATAQUES DE INTRUSIÓN
Una vez estudiado y analizado el funcionamiento principal de las redes inalámbricas 802.11 y
la protección de éstas, se procede al análisis de los ataques de intrusión que se pueden llevar a
cabo en dichas redes inalámbricas. Para el estudio de estos ataques de intrusión se comienza
con el análisis de los principales objetivos de seguridad del protocolo WEP y la posterior
comprobación de las vulnerabilidades del protocolo relacionadas con dichos objetivos de
seguridad.
También se realiza una diferenciación en los tipos de ataques entre pasivo y activo. Esta
diferenciación se realiza en base al tráfico de la red, con lo que se designará ataque activo al
que introduzca un tráfico adicional al normal de la red y ataque pasivo al que no introduzca
tráfico, sino que se limite a escuchar e interpretar la información recibida.
De esta forma se presenta una amplia variedad de ataques que pueden ser llevados a cabo
para conseguir tanto la clave secreta de una red como información privada.
3.1. DEBILIDADES DEL PROTOCOLO WEP
Con el desarrollo del protocolo WEP se busca ofrecer robustez en los siguientes aspectos de las
transmisiones:
Confidencialidad: El principal objetivo del protocolo WEP es evitar el espionaje.
Control de acceso: Proporciona un acceso protegido a la infraestructura de red
inalámbrica.
Integridad de los datos: Se pretende evitar la manipulación de los mensajes
transmitidos. Éste es el objetivo principal del campo de suma de comprobación.
La longitud de las claves también está establecida en el estándar WEP. Se da lugar a dos
versiones:
Una versión clásica formada por claves de 40 bits que son vulnerables a ataques de
“fuerza bruta”.
Una versión de 104 bits que evita el éxito de los ataques por “fuerza bruta” pero que
también es vulnerable. Esta versión, aunque haga uso de 104 bits, se llama la versión
de 128 bits.
A continuación se presentan las vulnerabilidades relacionadas con los objetivos de seguridad
WEP.

42
3.1.1. CONFIDENCIALIDAD
La primera vulnerabilidad presentada y una de las más importantes del protocolo WEP está
relacionada con la confidencialidad y con la reutilización del valor IV. A continuación se
muestra que en contraposición al objetivo de conseguir confidencialidad en las transmisiones,
se han desarrollado técnicas que se aprovechan de esta vulnerabilidad.
Cuando dos paquetes se cifran usando el mismo IV ocurre lo siguiente:
1 → ⨁ 4 ,
2 → ⨁ 4 ,
Si estos dos textos cifrados se le aplica la operación lógica XOR ocurre lo siguiente:
⨁ ⨁ 4 , ⨁ ⨁ 4 , ⨁
Esto se produce ya que RC4 depende sólo del valor IV y de la clave, de forma que cuando se
aplica XOR, se obtiene la operación XOR de los textos planos de ambos paquetes. Esto facilita
el descifrado de uno de ellos teniendo conocimiento del otro.
También es importante que, como se ha explicado anteriormente, el IV no sólo se usa para
elaborar el texto cifrado, sino que se añade de forma visible al paquete sin ser cifrado, lo cual
produce que pueda ser leído por cualquier equipo conozca o no la clave secreta, permitiendo
así que un atacante detecte rápidamente dos mensajes con el mismo IV. La mayoría de las
redes que usan WEP varían el valor IV para cada paquete transmitido, de forma que no ocurra
esto. Pero hay que tener en cuenta que WEP no obliga a realizar esta variación sino que es
voluntaria. Depende de la forma en la que la tarjeta inalámbrica lleve a cabo las variaciones de
IV el que sea más o menos vulnerable la red.
Otro factor a tener en cuenta es que el campo IV tiene un número limitado de posibles valores
ya que hay 24 bits destinados a dicho campo. Exactamente hay 224 IV´s posibles, por lo que en
algún momento comienzan a repetirse. Además hay algunas tarjetas inalámbricas que cuando
la wifi es reiniciada comienzan a numerar desde el principio, por lo que los iniciales se
repetirán más.
Existen varios métodos para descubrir el contenido de los mensajes una vez se han obtenido
dos mensajes con el mismo IV. Por ejemplo, el atacante se puede aprovechar de la estructura
de un paquete IP, ya que su contenido, al menos en la parte de las cabeceras, será predecible
con lo que podrá obtener el texto plano de los mensajes en tratamiento.
Una vez el atacante ha descubierto el contenido de los textos planos con su IV correspondiente
puede crear su propio diccionario de correspondencias con el objetivo de obtener la clave. De
esta forma, registrará los flujos de clave almacenándolos con su correspondiente valor IV.
Cuantos más datos formen la tabla, más posibilidades tendrá el atacante de descifrar la clave
secreta. El tamaño del diccionario no dependerá del tamaño de la clave, sino del tamaño del IV
que por el estándar se encuentra fijado a 24 bits. Con este tipo de ataque se demuestra que el
protocolo WEP es vulnerable en el aspecto de la confidencialidad (el objetivo principal para el

43
que fue desarrollado). Para evitar estos tipos de ataques, las redes deben procurar no repetir
el valor IV de los paquetes o repetirlo lo menos posible.
3.1.2. INTEGRIDAD
En este apartado se muestra que se pueden realizar modificaciones en el mensaje sin que sea
detectable a través de la suma de comprobación. Para demostrar esto, se supone que se
intercepta un mensaje cifrado C (correspondiente al mensaje sin cifrar M) que se envía de una
estación a otra dentro de una red inalámbrica.
⊕ 4 ,
, ⨁ 4 ,
Debido a las propiedades de la operación XOR se puede encontrar un texto cifrado C’ que
descifra el mensaje ⨁ , siendo el valor Δ elegido aleatoriamente por el atacante. El
atacante intercepta el mensaje enviado por el cliente y lo modifica sin que se vea afectado el
CRC. De esta forma la víctima recibe un mensaje modificado por parte del atacante. El texto
cifrado C’ se obtiene de la siguiente forma:
⨁ ⟨Δ, Δ ⟩ 4 , ⨁ ⟨ , ⟩ ⨁ ⟨Δ, Δ ⟩
4 , ⨁ ⟨ ⨁ Δ, ⨁ Δ ⟩ 4 , ⨁ ⟨ , ⨁ Δ ⟩
4 , ⨁ ⟨ , ′ ⟩
De esta forma se obtiene un texto cifrado para ⨁ Δ. El atacante sólo necesita conocer el
texto cifrado original y la diferencia de texto plano deseada (Δ). Se puede realizar una
modificación de los datos transmitidos sin que ésta pueda ser percibida y, además, no es
necesario el conocimiento completo de M.
3.1.3. CONTROL DE ACCESO
Finalmente se muestra otra forma de atacar pero en este caso a la seguridad del control de
acceso (el último de los propósitos para los que se diseñó el protocolo WEP). En este caso lo
que se hace es elaborar un paquete y cifrarlo de forma que pueda ser aceptado en la red sin
ocasionar alarma.
Como se ha mostrado en el primer caso, se puede obtener el flujo de clave de un mensaje si se
produce la reutilización del valor IV. Si un atacante averigua el texto plano de un texto cifrado,
el flujo de clave lo puede obtener de la siguiente forma:
⨁ ⨁ ⨁ 4 , 4 ,
Una vez consigue el flujo de clave, ya puede crear un texto cifrado para un mensaje M’ que
será enviado a la víctima haciéndole pensar que proviene de un usuario legítimo de la red:

44
⟨ , ′ ⟩ ⨁ 4 ,
Este nuevo texto cifrado tendrá que utilizar el mismo valor de IV con el que se ha obtenido el
flujo de clave. Además al no levantar sospecha por reutilizar un valor IV, ya que esto es posible
en el protocolo WEP, el atacante no será descubierto. Así se puede burlar el mecanismo de
control de acceso del protocolo WEP.
3.2. TIPOS DE ATAQUES
Una buena forma de clasificar los ataques realizados a redes que utilizan seguridad WEP es
según el tráfico que inyectan a la red. De esta forma los ataques se dividen en pasivos y
activos.
En un ataque pasivo el atacante escucha el tráfico de la red a escondidas desde la distancia con
una antena direccional y una aplicación como un analizador de protocolo o un olfateador
(sniffer). De esta forma se puede capturar tráfico de la red usado posteriormente para realizar
estudios. Este tipo de ataques son muy difíciles de detectar en una red, ya que no introducen
tráfico adicional. Para llevar a cabo un ataque pasivo, el atacante no necesita conectarse a la
red inalámbrica, ni asociarse ni autenticarse. Existen aplicaciones de propósito específico que
permitirán obtener, por ejemplo, el número de usuario y contraseña a páginas de internet, FTP
o sesiones Telnet. Al obtener esta información de acceso, el atacante puede dañar la red o
acceder a información privada.
En el caso del ataque activo, el atacante no se dedica sólo a escuchar el tráfico de la red, sino
que lleva a cabo una función en la red. Principalmente hay dos tipos de ataques activos: La
denegación del servicio y “forzar la entrada”.
En el caso de ataques por denegación de servicio, lo que se realiza es una denegación de la
conexión por parte de usuarios legítimos al punto de acceso. En este ámbito se puede desde
bloquear el acceso de un usuario a los servicios proporcionados a la red inalámbrica hasta
deshabilitar una cuenta de forma que el usuario no pueda acceder a la red. Este tipo de
ataques son muy comunes y fáciles de realizar. En el momento que un equipo se conecta a la
red es vulnerable a ataques de este tipo. Por otro lado se encuentran los ataques basados en
forzar la entrada. En este caso lo que se busca es causar un daño a la red o adquirir
información privada.
En muchos casos el procedimiento llevado a cabo a la hora de realizar un ataque de intrusión
consiste en realizar primero un ataque activo para posicionarse adecuadamente, y luego
efectuar un ataque pasivo para recopilar la información que se está buscando. Por ejemplo, un
atacante podría irrumpir en un equipo de forma que recopile contraseñas de una red en la que
los usuarios entran cada mañana. Los ataques pasivos también se usan para conseguir
información necesaria para poder llevar a cabo un ataque activo. Los ataques pasivos y activos
pueden ser combinados para la obtención de resultados exitosos en casos concretos,
dependiendo de la situación.

45
3.3. ATAQUES ACTIVOS
A continuación se presentan algunos ataques activos de distinta naturaleza y procedimiento,
de forma que puedan ser comparadas distintas estrategias de ataque de cara a poder
caracterizar ataques comunes llevados a cabo en redes inalámbricas.
3.3.1. ATAQUE DE DEAUTENTICACIÓN
El proceso de autenticación de un equipo a un punto de acceso protegido por WEP se lleva a
cabo por medio del envío de 6 paquetes:
Envío de la petición de sondeo a la dirección de difusión. Esta petición contiene un
número identificador de conjunto de servicio extendido (ESSID – Extended Service Set
IDentifier).
Respuesta por parte del punto de acceso con la dirección MAC del punto de acceso y
otras opciones.
ACK por parte del cliente como respuesta de sondeo.
El punto de acceso envía el texto de desafío al cliente.
El cliente lo decodifica y lo cifra usando la clave compartida, enviándolo como
respuesta al punto de acceso.
El punto de acceso verifica que el texto de desafío es correcto y envía una respuesta
exitosa de autentificación. En caso de que no sea correcto, se lo indica al cliente.
En este tipo de ataques, se presta especial atención a los paquetes intercambiados con el texto
del desafío, ya que lo que se realiza es un cifrado haciendo uso de la clave compartida, de
forma que si se realiza un ataque adecuado, esta clave podrá ser obtenida.
En este ataque se obtiene la dirección MAC del blanco y se le envía un paquete de
deautenticación al cliente como si fuera de parte del punto de acceso. Esto produce una
pérdida del servicio por parte del cliente que comenzará un proceso de autenticación que
aprovecha el atacante para obtener la información deseada. Por lo general se produce un
elevado tráfico adicional en la red producido por las solicitudes de deautenticación alterando
así el tráfico normal, provocando que el usuario se vuelva a asociar al punto de acceso. No
obstante, este ataque se puede llevar a cabo también con un número reducido de paquetes
como se mostrará en las pruebas. Esta técnica es también muy utilizada en redes protegidas
por los protocolos WPA y WPA2 haciendo uso de diccionarios.
3.3.2. ATAQUE RE‐INYECCIÓN DE SOLICITUDES ARP
Otro ataque muy común consiste en escuchar de forma pasiva esperando el envío de un
paquete ARP. A este paquete se responde y se captura la respuesta cifrada por parte del
punto de acceso, obteniendo así el valor IV. Lo más característico de este tipo de ataque es

46
que no provoca la condición de negación del servicio a los clientes asociados al punto de
acceso, lo que hace que sea muy comúnmente utilizado. Normalmente se lleva a cabo de
forma exitosa en redes inalámbricas pequeñas o lentas porque sólo es necesario un equipo y
no necesita ser muy activo. Si no hay ningún cliente detectado no se puede llevar a cabo este
ataque.
Básicamente lo que hace es buscar paquetes ARP encriptados enviados a la dirección de
difusión por parte de clientes asociados. Una vez se obtiene dicho paquete, se envía miles de
veces una copia de dicho paquete ARP (todas con el mismo IV) desde el equipo atacante al
punto de acceso obteniendo por parte de éste una respuesta con un nuevo IV. Cada vez que se
envía el paquete se genera una respuesta por parte del punto de acceso con un paquete
cifrado. El tiempo estimado que será necesario para obtener una clave será entre 10 y 15
minutos.
Al enviar tantas veces un mismo paquete lo que se hace es duplicar el dato IV en todos los
paquetes. Para detectar este tipo de ataques será necesario observar un incremento en los IVs
duplicados, una cantidad elevada de recepción de tramas duplicadas y un incremento radical
en la cantidad de paquetes ARP o de difusión. Una buena forma de hacer frente a este tipo de
ataque es limitando la cantidad de respuestas que se envían a tramas duplicadas.
3.3.3. ATAQUE HOMBRE EN EL MEDIO (MIM – Man In the Middle)
El principio básico de este ataque consiste en el establecimiento de un punto de acceso falso
que se interpone entre la comunicación del cliente con el punto de acceso real. El punto de
acceso falso lo que hace es imitar al punto de acceso real para que los clientes se puedan
comunicar con él sin sospechar que se está produciendo una intrusión.
Lo que buscará el punto de acceso falso será que los clientes se desconecten del punto de
acceso original y se conecten al falso. Esto se consigue produciendo una denegación del
servicio (provocando la nueva autenticación del cliente) o emitiendo la señal con una fuerza
superior al punto de acceso original.
Lo normal es que los clientes de una red inalámbrica se conecten al punto de acceso que les
conceda la señal con mayor potencia. Para que no se detecte que se está realizando una
intrusión, el punto de acceso falso crea un puente a otra conexión de red. Así, el atacante
toma el control de la conexión del cliente de la red inalámbrica llevando a cabo las acciones
que desee como miembro de dicha red.
El procedimiento se basa en poner en funcionamiento el punto de acceso falso en un canal que
se encuentre a una distancia mínima de 5 canales del punto de acceso original. Una vez
colocado, se configura en modo máster y con una dirección ESSID igual a la del punto de
acceso que se pretende atacar. Cuando ya está configurado, se añade ruido al canal donde
transmite el punto de acceso original. Esto se puede ejecutar usando la herramienta “Void11”
o “Mdk3”. Ambas herramientas consisten en añadir ruido a un canal produciendo
inundaciones de paquetes de deautenticación, autenticación o asociación, tanto en los clientes
como en los puntos de acceso. Más adelante se habla de forma más detenida de Mdk3 que

47
será el empleado en las pruebas. Otra forma de añadir ruido a la red consiste en producir
colisiones:
Capa física: Produciendo ruido físico en el canal de transmisión de los mensajes,
consiguiendo así un descenso en la calidad del servicio.
Capa de enlace: Produciendo confusiones gracias al campo NAV
La idea es conseguir que el cliente se desconecte de la red. Al ser desconectado, el cliente
vuelve a conectarse a la red pero en este caso lo hará con la señal que le ofrezca mayor
calidad, que en este caso será la del punto de acceso falso. El punto de acceso falso se
introduce en la comunicación y toma el control de la red adquiriendo la información que desee
como contraseñas y nombres de usuarios.
Este tipo de ataques se pueden prevenir si se crea una lista estática de puntos de acceso y de
direcciones ESSID y BSSID autorizadas con los correspondientes canales de transmisión.
Primero se comprueba si la dirección ESSID o BSSID es correcta y en el caso que lo sea, se
comprueba si el canal de transmisión es correcto.
También se puede realizar el almacenamiento de las direcciones BSSID / ESSID con la fuerza de
transmisión y el canal por el que transmiten, para detectar cualquier anormalidad en las
transmisiones. Una última opción sería la detección del incremento radical de solicitudes de
deautenticación, asociación o de autenticación.
3.3.4. ATAQUE DE REDIRECCIÓN IP
Como se ha comentado, para descifrar los paquetes de una red protegida por el protocolo
WEP es necesario tener conocimiento de la clave secreta. En un principio el atacante no
conoce la clave por lo que no puede descifrarlos, pero puede aprovecharse de que el punto de
acceso sí puede. La idea principal entonces es conseguir que el punto de acceso descifre los
mensajes para el atacante. Para el ataque que se presenta en este apartado se necesita que el
punto de acceso trabaje como router con acceso a internet, escenario muy común en las redes
domésticas de hoy en día.
Este ataque es el llamado “redirección IP” y a rasgos generales consiste en realizar una
modificación en la dirección destino del paquete sin que se detecte dicha modificación.
Consiguiendo así que el paquete sea recibido por un servidor de internet controlado por el
atacante. El punto de acceso descifrará el paquete y lo enviará a dicho servidor sin accionar
ningún tipo de alarma y sin desecharlo. Para que no sea detectada la modificación, será
necesario realizar la modificación no sólo al campo de la dirección IP destino, sino también al
CRC.
Como el único cambio que se realiza es el de la dirección IP de destino, y si la dirección antigua
es conocida, se puede calcular la diferencia del valor de la suma de comprobación que hay que
introducir para que el paquete no sea desechado por el punto de acceso. Se define X como el
código CRC del paquete original, DS como la palabra superior de 16 bits de la dirección IP
destino original, Di la inferior y DS’ Di’ las correspondientes a la nueva dirección IP destino. La

48
nueva suma de comprobación que deberá sustituir a X (teniendo en cuenta que tanto la suma
como la resta son en complemento a 1)será:
′ ′
A continuación se presentan tres posibilidades distintas basadas en el conocimiento de la suma
de comprobación del paquete. Dependiendo del caso a tratar se actuará de una manera u otra:
En el caso de que la suma de comprobación del paquete original sea conocida será
necesario simplemente calcular X’ como se indica en la expresión anterior y realizar la
operación XOR al campo de suma de comprobación del paquete: ⊕ ′.
Si por el contrario no se dispone de dicho valor, la tarea se dificulta un poco. Se define
σ = X’ – X y ∆ = ′ ⊕ . No es suficiente el conocimiento de σ para calcular ∆. Hay
varios valores de X y X’ cuya resta es σ que producirán distintos ∆. La idea en este caso
es probar varias posibilidades hasta dar con la correcta. En caso de error, no hay
ningún problema ya que lo único que sucede es que el punto de acceso desecha el
paquete.
Buscar que el CRC final sea igual al original compensando el cambio de dirección IP
destino con otros campos del paquete. Esta compensación se busca en los campos de
la cabecera IP que no afecten a la emisión correcta del paquete IP como por ejemplo,
la dirección IP origen. En el caso de modificar la dirección IP origen lo que se hace es
restar σ a la palabra inferior de 16 bits de la original, compensando así la modificación
realizada. Otra opción sería que el atacante disponga de un rango de direcciones IP
destino en internet. En este caso se buscará:
′ ′
3.3.5. ATAQUE DE REACCIÓN
El ataque de reacción es válido sólo para redes que hacen uso del protocolo TCP/IP. No es
necesario que tengan acceso a internet por lo que podrán ser utilizados incluso en los casos
que no sea posible utilizar el ataque de redirección IP. La idea de este ataque es aprovechar
las respuestas del receptor del mensaje para descifrar el texto plano P desconocido
correspondiente a un texto cifrado C. En una red TCP, cuando el receptor recibe el paquete y
comprueba que la suma de comprobación es correcta, envía una confirmación (ACK). El ACK es
característico por su tamaño, por lo que no será necesario descifrar el mensaje para detectar
que se trata de un paquete ACK.
Resaltar que la suma de comprobación TCP consiste en la suma en complemento a 1 de las
palabras de 16 bits del mensaje. El nuevo texto cifrado se obtendrá realizando: ,
siendo ∆ todo ceros excepto en la posición i e “i+16” que será 1 (eligiendo arbitrariamente i).
Al recibir un ACK después de haber enviado el nuevo texto cifrado, se obtiene un bit del texto
plano. Lo único que será necesario hacer es repetir el procedimiento para muchas
posibilidades de i obteniendo así el texto plano.

49
CAPÍTULO II
MATERIALES Y MÉTODOS

50

51
Una vez presentados los principios teóricos en los que se basa la seguridad en una red
inalámbrica y los tipos de ataques existentes, se procede al análisis de los materiales y
métodos utilizados en las pruebas del presente proyecto. En un primer lugar se presentan las
herramientas de captura de tráfico en red utilizadas. También se procederá a la explicación
detallada del software necesario para llevar a cabo los ataques. Después se presenta el análisis
multivariante utilizado para poder interpretar los datos correspondientes al tráfico de la red a
tratar y las herramientas de clasificación de tráfico. Finalmente se presenta la explicación
detallada del diseño de las pruebas realizadas.
4. HERRAMIENTAS DE CAPTURA DE TRÁFICO EN RED
Para poder obtener datos relevantes en una red inalámbrica con los que trabajar será
necesaria alguna herramienta de captura de tráfico. En la actualidad existen varias
herramientas de este tipo entre las que destacan: Wireshark, la librería libpcap y airodump
(de aircrack). Para añadir ruido a un canal determinado se hace uso de la herramienta Mdk3.
También es necesario un sistema operativo que soporte dichas herramientas. En el presente
proyecto se utiliza el sistema Wifiway, pero también se presenta Wifislax ya que se suele
utilizar para auditoría de redes inalámbricas. Finalmente se realiza una descripción de la
herramienta Matlab utilizada para el análisis de datos y clasificación.
4.1. WIRESHARK
Wireshark (http://www.wireshark.org/) es un analizador de paquetes de red basado en la
librería libpcap cuyo objetivo es capturar los paquetes de la red y mostrar los datos de la forma
más detallada posible. Hoy en día es posiblemente el mejor analizador de paquetes de
software libre. Puede ser utilizado para solucionar problemas en una red, examinar problemas
de seguridad, aprender sobre protocolos, etc. Además puede ser utilizado tanto en redes
cableadas como en inalámbricas y en sistemas operativos UNIX o Windows. Su antecesor fue
“Ethereal” que apareció en una primera versión de prueba que fue perfeccionada hasta que se
desarrolló finalmente la primera versión de Wireshark. Algunas de las características
principales son:
Captura paquetes de datos de forma directa de una interfaz de red.
Muestra mucha información de los protocolos utilizados en el encapsulado del
paquete.
Las capturas pueden ser almacenadas en formato .cap.
Permite realizar un filtrado de recepción de paquetes. Por ejemplo, si lo que se
pretende es sólo analizar los paquetes IP en una red, permite crear un filtro de tal
manera que sólo se muestren los paquetes IP.
Puede descifrar mensajes cifrados utilizando la clave conocida por el usuario.
No realiza ningún tipo de alteración ni modificación en la red. Simplemente muestra
por pantalla los paquetes que están en movimiento.

52
Para poner el programa en funcionamiento será necesario instalarlo e iniciarlo. Una vez
iniciado se selecciona la interfaz de la que obtener los paquetes y se comienza con la captura
mostrando por pantalla todos los paquetes recibidos. En la figura 23 se observa la interfaz de
Wireshark donde se muestran tanto los paquetes como la información más relevante de cada
paquete como las direcciones de origen y destino, el protocolo utilizado, la información, etc.
Figura 23: Wireshark.
Si se selecciona uno de los paquetes, en la parte inferior del programa se muestra la
información desplegable de cada uno de los protocolos utilizados en la elaboración del
paquete. Por ejemplo, en la figura 24 se muestra el contenido de un paquete TCP/IP con los
campos de la cabecera IP como la versión, el tamaño de cabecera, el número de identificación,
etc.
Figura 24: Contenido del paquete con wireshark.
En el caso concreto de este proyecto, el uso de Wireshark no será para la captura y análisis
exhaustivo e individual de los paquetes de la red inalámbrica, sino para tener una idea general
de lo que está sucediendo en la red. También para observar de forma clara la estructura de los
paquetes bit a bit aclarando así la estructura a seguir a la hora de elaborar el código de
programación con la librería libpcap. Para capturar todos los paquetes que están siendo
intercambiados en la zona de cobertura inalámbrica, será necesario poner la tarjeta
inalámbrica en modo monitor, lo que se corresponde con modo promiscuo en las redes
cableadas. La forma de llevar a cabo esto se explica más adelante con el conjunto de
herramientas “Aircrack”.

53
4.2. LIBRERÍA LIBPCAP
La librería libpcap (http://www.tcpdump.org/) consiste en una serie de funciones escritas en
determinados lenguajes de programación que proporcionan una gestión de una red a alto
nivel realizando la captura de paquetes a nivel de usuario. Es software libre y permite la
elaboración de programas capaces de realizar la captura de paquetes en una red permitiendo
el análisis de estos. En el presente proyecto la herramienta de captura de paquetes en la red
inalámbrica y de caracterización de dichos paquetes ha sido la librería libpcap. Wireshark ha
sido utilizado de forma complementaria para obtener información específica, pero el trabajo
ha sido realizado directamente en C con esta librería. Este mecanismo se utiliza incluso para
capturar paquetes que no van destinados al dispositivo desde el que se está realizando el
estudio. De esta forma se puede “olfatear” la información transmitida en la red inalámbrica.
Los programas elaborados con la librería libpcap suelen tener una estructura para que se
pueda obtener la información adecuada. Esta esquematización está basada en los siguientes
pasos:
Inicialización: En esta primera etapa del programa se hacen uso de funciones
especiales para poder detectar las tarjetas inalámbricas disponibles y obtener
información relevante de la red, como puede ser la dirección de red, máscara de red,
etc.
Filtrado: Una característica importante de esta librería consiste en la definición de
filtros para el procesado sólo de paquetes que sean relevantes al estudio indicado. En
el proyecto aquí estudiado no se ha hecho uso de filtros ya que lo que interesa es
observar todo el tráfico de la red, pero es interesante el conocimiento de esta
posibilidad que ofrece libpcap. De esta forma se pueden filtrar los paquetes por el
protocolo utilizado, por ejemplo, TCP.
Bucle de captura de paquetes: En este bucle los aspectos más relevantes a definir
serán el número máximo de paquetes a capturar, el modo de captura o el tiempo
máximo de captura de paquetes. De esta forma se captura el paquete y se le aplica
una función definida por el usuario en el código C.
Salida: Finalmente se termina la captura de paquetes y se procede a la interpretación
de los datos obtenidos. Esta librería ofrece la posibilidad de realizar un volcado
completo de la información obtenida de los paquetes para la posterior lectura del
fichero.

54
4.3. SUITE AIRCRACK
La suite Aircrack (http://www.aircrack‐ng.org/) es un conjunto de herramientas utilizadas para
la inyección de paquetes en una red inalámbrica, la captura de paquetes y la realización de
ataques cuyo objetivo es la obtención de las claves secretas de redes inalámbricas. A
continuación se muestran las rutinas principales de la suite:
Airmon: Se utiliza para poner en modo monitor la interfaz deseada de la siguiente
forma:
“airmon‐ng start interfaz”
Siendo interfaz la que se quiere poner en modo monitor.
Airodump: Programa de captura de paquetes 802.11. Se utiliza para observar la
información de los paquetes que se mueven en la red, pero también se utiliza para
recibir los paquetes junto con los IV mientras se está realizando un ataque con alguna
otra herramienta de la suite Aircrack. Se ejecuta de forma paralela al ataque pudiendo
así almacenar tantos IV como sea posible para proceder más tarde al descifrado de la
clave. El uso es el siguiente:
“Airodump opciones interfaz”
Las opciones más importantes disponibles son las siguientes:
o ‐‐ivs: Almacenar solo los IVs capturados.
o ‐‐write <Prefijo> = ‐w <Prefijo>: Fichero en el que se hace el volcado de los
datos.
o ‐‐ netmask <máscara>: Filtrado de puntos de acceso por la máscara.
o ‐‐ bssid <bssid>: Filtrado de puntos de acceso por bssid.
o ‐c <canal>: Realiza la captura de paquetes en un canal determinado.
Aircrack: Descifrador de claves WEP y WPA utilizando las capturas obtenidas por
airodump como entrada:
“aircrack ‐q ‐n [longitud clave WEP] ‐b [BSSID] [fichero].cap”
Activando el modo silencioso con “‐q”, especificando la longitud de la clave WEP con “‐
n [longitud clave WEP]”, el BSSID y el fichero obtenido de las capturas de airodump.
Aireplay: Es un programa de inyección de paquetes 802.11. Se utiliza para generar
tráfico que es capturado al mismo tiempo por airodump obteniendo el fichero usado
posteriormente por aircrack para obtener la clave. Las opciones que hay que añadir a
la hora de utilizar esta herramienta dependen del ataque que se quiera realizar. El
comando general es el siguiente:
“aireplay‐ng <opciones> <interfaz>”
Las opciones específicas se explican en el diseño de las pruebas.

55
4.4. MDK3
MDK3 es un programa que permite añadir ruido a un canal inalámbrico. Las opciones
disponibles son las siguientes:
Inundación de peticiones de deautenticación a los clientes inalámbricos.
Mdk3 <interfaz> d
Inundación de peticiones de autenticación a los puntos de acceso, de forma que se
saturen produciendo una denegación de servicio a los clientes legítimos. El
procedimiento se lleva a cabo creando una gran cantidad de clientes virtuales que
solicitan autenticación.
Mdk3 <interfaz> a –a <BSSID punto de acceso>
Inundación de puntos de acceso falsos, creando confusión a los clientes dentro del
mismo canal.
Cualquiera de estas opciones producirá un descenso en la calidad de la señal recibida, incluso
la denegación de servicio.
4.5. WIFISLAX Y WIFIWAY
Tanto Wifislax (http://www.wifislax.com/) como Wifiway (http://www.wifiway.org/) son
configuraciones específicas (imágenes) de un sistema operativo Linux cuya principal aplicación
es la auditoría de redes inalámbricas. Están dotados de un conjunto de herramientas
instaladas por defecto de fácil manejo para el usuario en varios idiomas, con el objetivo de que
un usuario sin muchos conocimientos informáticos pueda probar la seguridad de su propia red
inalámbrica ante los ataques más comunes que se producen hoy en día. Dispone de programas
con los que no será necesario ni siquiera escribir todos los comandos arriba descritos, sino que
proporciona interfaces de usuario mucho más simples con las que se puede llevar a cabo un
ataque simplemente pulsando botones del programa. Son sistemas operativos en continuo
desarrollo ya que las tecnologías inalámbricas están en continuo progreso y se trata de
software libre.
También tiene soporte para la mayoría de las tarjetas inalámbricas presentes en el mercado
internacional actual, actualizándose a aquellas que van apareciendo a lo largo del tiempo.
Básicamente las dos herramientas pueden ser utilizadas con los mismos fines pero en el caso
de este proyecto se ha optado por Wifiway 3.0.1. Estas herramientas se pueden instalar
directamente en el disco duro de un ordenador o pueden ser utilizados como live CD o incluso
desde dispositivos de almacenamiento. Otra opción es utilizarlos a través de una máquina
virtual. El único problema de este caso es que no se puede utilizar la tarjeta inalámbrica de un
ordenador portátil normal, sino que será necesario utilizar una tarjeta inalámbrica conectada
mediante el puerto USB. En la figura 25 se muestra la máquina virtual trabajando con el
sistema operativo Wifiway (escritorio).

56
Figura 25: Escritorio de Wifiway con la máquina virtual VMware.
4.6. MATLAB
Matlab (http://www.mathworks.es/) es un entorno de programación muy utilizado en la
actualidad. La esencia de los cálculos de MATALAB se basa en el uso de matrices. De esta
forma se consigue que los cálculos requieran menos esfuerzo computacional usando
propiedades algebraicas. No sólo resulta útil por la sencillez de los cálculos, sino también por la
interfaz intuitiva con la que se trabaja. Permite la programación de funciones y archivos
ejecutables obteniendo los resultados por pantalla de una forma rápida y sencilla. Tiene gran
aplicación en el análisis de señales y para la representación de gráficos. Al permitir la
elaboración de programas por parte del usuario, se han ido incorporando a lo largo de su
desarrollo una gran variedad de funcionalidades conforme se han ido desarrollando nuevas
versiones. Además, dispone de una página web oficial en la que los usuarios pueden compartir
programas elaborados por ellos mismos para un uso específico. También se pone a disposición
del usuario una serie de “Toolbox” para la ampliación de las funciones básicas de la
herramienta a campos específicos, por ejemplo, relacionados con el análisis exploratorio de
datos.

57
5. HERRAMIENTAS DE CLASIFICACIÓN: ANÁLISIS
MULTIVARIANTE
El análisis multi‐variante comprende un conjunto de técnicas para el análisis de conjuntos de
datos de más de una variable. La mayoría de estas técnicas son de desarrollo muy reciente
debido a las necesidades computacionales para ser llevadas a cabo. Estas técnicas aparecen al
tener la necesidad de analizar o investigar conjuntos de datos de tamaño muy amplio con la
dificultad computacional que conlleva. Con este objetivo se presenta el análisis exploratorio de
datos que comprende una serie de técnicas descritas a continuación.
5.1. ANÁLISIS EXPLORATORIO DE DATOS.
La idea es realizar una serie de observaciones a las variables de un experimento generando así
amplios conjuntos de datos que luego son analizados y clasificados. De esta forma, se obtiene
una matriz en la que las filas contienen las observaciones realizadas a esas variables y las
columnas a las distintas variables como se muestra en la siguiente matriz (2 dimensiones):
1 …⋮ ⋮ ⋮ ⋮ …
… ⋮ … ⋮
⋮ ⋮ …⋮ ⋮
…
… ⋮ ⋮ …
En el caso de ser de más de dos dimensiones habría que añadir varias matrices de forma que la
matriz sería de dimensión T, siendo T la cantidad total de dimensiones. Para poder
comprender este tipo de análisis se puede pensar en la medida de una serie de variables en la
población de distintos países de Europa. De esta forma se podría obtener información sobre el
por qué de la esperanza de vida en algunos países es mayor que en otra. Las observaciones se
podrían ir tomando en un número de personas de cada país y las variables pues podrían ser
componentes alimenticios, bebidas, actividad laboral y actividad física. Teniendo un número
suficiente de observaciones se podría generalizar el comportamiento en dichas poblaciones
dependiendo de esas variables. También se podrían separar las variables por dimensiones. Por
ejemplo en una dimensión se encontrarían las correspondientes a las características
personales de cada persona (edad, peso, estatura, etc.). Una segunda dimensión podrían ser
características alimenticias como pueden ser la cantidad de hidratos de carbono que ingiere,
de proteínas, verduras, etc. La tercera dimensión serían variables correspondientes a las
actividades físicas llevadas a cabo por la persona y así sucesivamente.
Este proyecto se centra en el estudio de dichas matrices en dos dimensiones ya que lo que se
busca es la caracterización del tráfico normal y el tráfico producido mientras se produce un
ataque. En este enfoque se aplicarán técnicas basadas en estructuras latentes como es el
análisis por componentes principales (PCA – Principal Component Analysis). La función
principal de la técnica PCA es la compresión o reducción de datos, con lo que se busca la

58
eliminación de las variables que no son de gran relevancia para el objetivo del estudio. En una
segunda fase se utilizan una serie de técnicas de clasificación que se explican más adelante.
Con la técnica PCA, se puede conseguir la reducción de un número elevado de variables a un
número más reducido y conceptualmente más coherente de variables. La base para realizar el
cambio de variables es la variabilidad de los datos, para esto se hace uso de conceptos como
media, varianza (suma de los cuadrados de las desviaciones con la media) y covarianza
(permite detectar similitudes entre variables). Las nuevas variables serán las llamadas
“componentes principales” (PC – Principal Components) que se trata de una combinación
lineal de las variables originales. Gracias a esta reducción se puede realizar un análisis con
menos carga computacional y de una manera más sencilla pero eficiente. Suponiendo un
conjunto de datos X de dimensiones NxM, la idea es descomponerlo en una matriz de
puntuaciones P, una matriz de carga C y una de residuos E:
Las dimensiones de la matriz P serán NxA, las de C serán MxA y finalmente las de E serán NxM,
designando A como el número de componentes principales en el conjunto de datos a analizar.
P indica la distribución de los datos observados, C indica las relaciones entre variables y E
indica aquellas observaciones o variables que no siguen en el modelo PCA. Se busca encontrar
las direcciones que maximizan la varianza.
Un detalle importante en el análisis exploratorio de datos es el estudio de los gráficos de
dispersión que lo que hacen es presentar la distribución de las observaciones. En estos gráficos
se puede observar las nubes correspondientes a datos relacionados entre sí dependiendo de
las variables tratadas. Esta especie de nubes dará lugar a la identificación clara de dichas
clases, pudiendo caracterizar así un perfil en el experimento. La idea es representar en un
gráfico bidimensional dos componentes principales, una iría en el eje x y otra en el eje y.
Además de permitir la detección de clases dentro de los datos en estudio, permite también
comprender de forma clara la estructura de los datos para poder utilizar más adelante otras
herramientas como MEDA u oMEDA.
Una vez realizado el estudio con PCA y de los gráficos de dispersión se presenta una
herramienta llamada MEDA (métodos de datos faltantes para el análisis exploratorio de datos
– Missing‐data methods for Exploratory Data Analysis). Esta herramienta se utiliza para la
relación de los factores comunes con las componentes principales del experimento. Esta
herramienta permite la representación de las dependencias entre variables por medio de una
representación como la de la figura 26. En dicha figura se presenta un estudio realizado en
distintas partes de España en cuanto a la alimentación de los habitantes y los ataques al
corazón producidos. De esta forma el gráfico meda representa las dependencias entre las
variables con distintas tonalidades de gris, de menor a mayor oscuridad en orden creciente de
dependencia.

59
Cerdo Ternera Pollo Pavo Conejo Ataques al
corazón
Cerdo
Ternera
Pollo
Pavo
Conejo
Ataques al corazón
Figura 26: Gráfico MEDA.
Gracias a este gráfico el analizador del estudio se puede hacer una idea de las relaciones que
existen entre los consumos de algunos tipos de carnes y otros según la región y también el
riesgo de sufrir un paro cardíaco dependiendo de los tipos de carnes ingeridos. No obstante,
en todo caso se detectan relaciones entre variables sin causalidad, aunque el dominio del
problema puede indicar dicha causalidad, que sería confirmada con las pruebas adecuadas.
Finalmente, para complementar todas estas herramientas se presenta oMEDA que consiste en
un algoritmo MEDA basado en observaciones al que se le añade una variable diseñada por el
analizador de forma que se pueda asignar una serie de pesos direccionables dependiendo de
las observaciones que se pretendan analizar de forma individual. De esta forma si se quieren
comparar dos agrupaciones detectadas con el diagrama de dispersión se le asigna a la variable
añadida por ejemplo 1 a los datos correspondientes a una agrupación, ‐1 a los datos
correspondientes a otra agrupación y 0 en el resto de posiciones. El resultado es un diagrama
de bandas que muestra las variaciones entre ambas agrupaciones.
5.2. CLASIFICADORES
Una vez hecho el análisis multivariable es momento de hablar de clasificadores ya que será
una parte importante también en este proyecto. Una vez caracterizado el experimento, el
clasificador debe ser capaz de recibir una nueva muestra y poder clasificarlo en la clase
correspondiente de forma que el error producido en la clasificación sea lo menor posible. Hay
muchos tipos de clasificadores pero básicamente se dividen en dos grupos principales:
clasificación supervisada y clasificación no supervisada.
En la clasificación supervisada se cuenta con clases bien definidas gracias a agrupaciones
realizadas con anterioridad utilizando muestras y las herramientas propuestas. Este tipo de

60
clasificación se divide en dos fases principales. En una primera fase se utiliza un conjunto de
entrenamiento o aprendizaje (para el diseño del clasificador) y otro conjunto que será utilizado
para test o clasificación. De esta forma se obtiene el modelo de regla general para la
clasificación. En la segunda fase se procede a la clasificación de las muestras de las que no se
conoce la clase a la que pertenecen. En el caso de la clasificación no supervisada no existe el
conocimiento anterior a la clasificación por lo que no se puede realizar el entrenamiento
comentado. La idea aquí es poder distinguir las agrupaciones o modelos de forma que se
puedan separar distintas clases sin conocimiento previo. El proyecto aquí presentado se centra
en las técnicas de clasificación supervisada ya que proporcionará resultados de forma más
precisa al tener la capacidad de crear un grupo de entrenamiento.
Hay muchos tipos de clasificadores pero a continuación se presentan los más importantes.
Cada uno tiene una metodología distinta a la hora de resolver el problema de clasificación y la
variación en la efectividad depende de los problemas que se traten.
5.2.1. ALGORITMOS DE CLASIFICACIÓN POR VECINDAD
Esta técnica es una de las más conocidas y está basada en criterios de vecindad. Una de las
ventajas principales de este tipo de clasificación es la simplicidad conceptual ya que la idea es
realizar la clasificación de una muestra basándose en la clase a la que pertenecen los vecinos
más próximos. En muchas ocasiones, es razonable estimar que si las observaciones más
cercanas pertenecen a una clase determinada, la nueva observación pertenecerá a esa misma
clase. En este apartado se presenta tanto la regla del vecino más próximo como la de los K
vecinos más próximos, prosiguiendo con algunas variaciones existentes.
La regla del vecino más próximo (NN – Nearest Neighbour) se basa simplemente en asignar a
una nueva observación la clase de la observación más cercana a ésta. Esta forma de
clasificación puede producir errores en el caso de que, por ejemplo, la nueva observación se
posicione en la zona de transición entre dos agrupaciones. Lo que ocurrirá entonces es que
puede ser clasificada de forma correcta o incorrecta, lo que no da mucha seguridad a la hora
de realizar la clasificación.
Como mejora a esta técnica aparece la regla de los K vecinos más cercanos (KNN – K Nearest
Neighbors) que no se limita al más cercano, sino a realizar un sondeo de los K vecinos más
cercanos y asignar la clase por mayoría. El número K se establece a partir de un grupo de
observaciones de entrenamiento de forma que se haga uso del valor óptimo. En caso de no
seleccionar un buen valor de K se puede obtener una efectividad inferior que con el método
NN. Una vez se obtiene una nueva observación, se detectan las K observaciones más cercanas
a éstas y se someten a un proceso de votación. La clase ganadora será a la que corresponderá
la nueva observación. En caso de empate se definen una serie de métodos de resolución de
empates como puede ser asignar la clase de la observación más cercana o seleccionar la clase
cuyas observaciones se encuentren en media más cercanas a la nueva observación. En la figura
27 se muestra un ejemplo de clasificación KNN con K = 5. En este caso se obtiene una nueva
observación y realizando el recuento de los 5 vecinos más próximos se le asigna la clase 2 ya
que es la que obtiene más votos.

61
Figura 27: Clasificador KNN, K=5.
Además de estos métodos también se presentan 3 variedades del KNN:
Regla K‐NN con rechazo: En esta variante, cuando se obtiene una nueva observación,
se realiza la votación de los K vecinos más próximos como antes pero en este caso si el
número máximo obtenido en la votación no supera un umbral, la nueva observación
queda sin clasificación. De esta forma hay una alta probabilidad de que las
observaciones que finalmente sean clasificadas, queden clasificadas de forma correcta.
Las observaciones que quedan sin clasificación se corresponden con zonas de
fronteras de decisión y son asignadas a la clase de rechazo R. Llamando T al número
total de clases del experimento, el umbral se selecciona entre los valores K/T y K. Este
método se puede utilizar en casos en los que se necesite una alta precisión en la
clasificación, estudiando de forma individual las observaciones no clasificadas.
Regla K‐NN por distancia media: Esta variación se basa simplemente en asignar al
nuevo caso la clase que se encuentre en media a menor distancia entre los K vecinos.
De esta forma tendrá más relevancia la distancia de las observaciones que la propia
votación de las clases. Puede llevar a error en el caso de que una observación nueva
quede demasiado cerca de una observación de una clase que no le corresponde, ya
que se le asignará esa aunque haya un grupo de observaciones más numeroso de su
clase que estén más lejanas.

62
Clasificador de la distancia mínima: Este tipo de clasificador no se basa en los K
vecinos más próximos, sino que selecciona un representante de cada clase con el que
se va a asignar la clase a las nuevas observaciones. A la nueva observación se le
asignará la clase cuyo representante se encuentre más cercano a dicha observación. La
efectividad en la clasificación de este método dependerá radicalmente de la selección
del representante de cada clase, ya que si no está bien elegido puede suponer un error
muy elevado.
K‐NCN – K Nearest Centroid Neighbourhood (Vecino centroide más cercano):
Dependiente de la distribución espacial de los prototipos de su alrededor. No sólo
tiene en cuenta los vecinos más próximos sino que se tiene en cuenta cómo se
encuentran distribuidos (vecindad envolvente).
Estos son los casos más generales de clasificación por vecindad, pero en este entorno se han
desarrollado también métodos de asignación de pesos a los casos ya que no todas las
observaciones tienen la misma importancia a la hora de influenciar a la clasificación de una
nueva observación. Un tipo de peso muy común consiste en multiplicar el voto por la inversa
de la distancia a la nueva observación. De esta forma los casos que se encuentren más
cercanos tendrán más influencia en la decisión que los más lejanos, pero todos afectarán de
una manera u otra.
5.2.2. ÁRBOLES DE CLASIFICACIÓN:
Los métodos basados en árboles de clasificación son ampliamente conocidos gracias a su
simplicidad y sus buenos resultados. El árbol de clasificación se elabora a partir de un nodo raíz
y se desarrolla de la parte superior a la inferior por medio de los nodos intermedios
terminando con los nodos hoja que son los finales (donde se asigna la clase). Los nodos que
salen de otro nodo son sus nodos hijos y para los nodos hijos dicho nodo será el nodo padre.
Cada rama que sale de un nodo a los hijos tiene una variable de decisión correspondiente con
una variable del problema que se esté tratando que queda sometida a un umbral. El árbol se
construye utilizando los datos de entrenamiento (al ser un sistema de clasificación
supervisada). Una vez terminada la elaboración del árbol se puede llevar a cabo un proceso de
clasificación de una nueva observación, que comienza en el nodo raíz y se va moviendo desde
arriba hacia abajo dependiendo de los valores de las variables involucradas en el experimento
llegando finalmente a un nodo hoja donde se le asigna la clase correspondiente.
Esta estructura en árbol se muestra en la figura 28, donde se supone un experimento simple
de selección de enfermedades dependiendo de componentes en la sangre. La persona a tratar
se encuentra enferma y lo que se busca con este experimento es detectar de forma rápida en
una primera prueba de sangre si se trata de anemia o diabetes. Si no es ninguna de las dos
pues se considera que es otra enfermedad para la que habrá que realizar pruebas concretas
posteriores. De esta forma las tres clases serán diabetes, anemia y otras enfermedades. El
nodo raíz es persona enferma y las variables involucradas son g (nivel de glucosa en sangre)
con su correspondiente umbral x, y la variable h (nivel de hierro en sangre) con su

63
correspondiente umbral y. Se comienza desde persona enferma y se desciende con el nivel de
glucosa, que en caso de estar por encima del umbral se detecta que la persona sufre de
diabetes (nodo hoja). En caso de estar por debajo se llega al nodo intermedio y se continúa
con el proceso de clasificación observando el nivel de hierro en sangre. En caso de ser superior
al umbral se detecta que la persona sufre de anemia y en caso de estar por debajo se clasifica
como “otras enfermedades”.
Figura 28: Árbol de clasificación.
El caso mostrado en la figura 28 es muy simple para comprender el funcionamiento de los
árboles de clasificación pero en un experimento más complejo se pueden dar muchas más
clases y varios nodos hoja pueden estar etiquetados con el mismo nombre de clase. La
complejidad del árbol de clasificación es el número de clases involucrados en el experimento.
En el ejemplo de la figura 28 la complejidad sería de 3. Una característica importante de los
árboles de clasificación es que viendo el camino recorrido desde el nodo raíz hasta el nodo
hoja se puede conocer información de relevancia para el experimento. En el ejemplo anterior
se podría conocer que la persona sufre de anemia, pero además si se analiza el camino
recorrido se sabe que su nivel de glucosa se mantiene por debajo de un umbral.
También presenta algunos problemas ya que si por ejemplo en la primera variable de decisión
del nodo raíz los valores límite se encuentran cercanos, podría ocurrir que una nueva
observación fuera mal clasificada desde el principio condicionando su recorrido a lo largo del
árbol de forma errónea.
5.2.3. ANÁLISIS DISCRIMINANTE LINEAL
El análisis discriminante se basa en la utilización de las llamadas funciones discriminantes que
son funciones matemáticas obtenidas gracias al grupo de observaciones de entrenamiento. La
variable dependiente (bloque Y) está etiquetada con las clases del experimento y las variables
independientes (bloque X) son las tomadas en el experimento para cada observación. Se basa
en encontrar relaciones lineales entre estas últimas variables de forma que puedan ser

64
clasificadas nuevas observaciones por medio de la discriminación de dichas funciones. Ninguna
variable discriminante puede ser combinación lineal de otras variables discriminantes. Para
encontrar las combinaciones lineales de las variables que más discriminen entre los grupos se
utilizan expresiones como la siguiente (funciones discriminantes):
… , , … , , .
En particular, en el Análisis Discriminante de Ficher, la función debe maximizar el criterio:
11∑ ̅
11∑ ∑ ̅
∈
Siendo di = u’xi; i=1, …, n, que se corresponde con los valores de la función discriminante.
5.2.4. ANÁLISIS DISCRIMINANTE POR MÍNIMOS CUADRADOS PARCIALES
En un primer lugar se diseñó la técnica de mínimos cuadrados parciales (PLS – Partial Least
Squares) como herramienta de regresión estadística. Hoy en día es una de las técnicas de
regresión más utilizadas. La modificación de dicho método con propósitos de clasificación es la
llamada análisis discriminante por mínimos cuadrados parciales (PLS‐DA – Partial Least Squares
‐ Discriminant Analysis).
Como en el Análisis Discriminante Lineal, en PLS‐DA el bloque Y describe las clases a las que
pertenecen las observaciones. En un problema de clasificación de más de dos clases será
necesario crear una matriz Y con tantas columnas como clases.
5.2.5. REDES BAYESIANAS
Se basan en el estudio de las relaciones de dependencia entre un conjunto de variables.
Antiguamente los cálculos se realizaban a mano pero en la actualidad existen una serie de
técnicas útiles para el aprendizaje de la estructura como de parámetros correspondientes a
una clase determinada. Las redes bayesianas trabajan básicamente con probabilidades
obtenidas de un estudio de dependencias entre variables. De esta forma, se representa con
una forma similar al árbol pero con implicaciones distintas como se muestra en la figura 29. En
dicha figura se observa un experimento psicológico en el que se distinguen los nodos padres
que son los situados más arriba que no están apuntados por ninguna flecha, los nodos hijos
que son los apuntados por las flechas y las razones de dependencia. Las relaciones entre
variables en este tipo de redes quedan descritas por la posición de la flecha utilizada. La
variable apuntada por una flecha es dependiente de la variable donde se sitúa el origen de la
flecha. De esta forma, una variable puede ser dependiente de una o varias variables pudiendo
tener así más de un nodo padre.

65
Figura 29: Red Bayesiana.
En las redes Bayesianas se distingue entre 3 tipos principales de nodos:
Nodos en secuencia: suponiendo que el nodo es B, y otros nodos A y C: “ ABC “
Nodos divergentes: “A B C”
Nodos convergentes: “A B C”
Al realizar la representación de dependencias que muestra la figura 29, se puede hablar
también de probabilidades condicionales. De esta forma se puede hablar de la probabilidad de
un nodo hijo habiéndose dado el caso del nodo padre. A la probabilidad del padre de un nodo
de la red se le llama Pa ( ). Por ejemplo, en la red de la figura 29, Pa(salud) = Alimentación,
Ejercicio físico. La generalización de probabilidades de un nodo dependerá de la probabilidad
de su nodo padre. De esta forma la probabilidad conjunta está compuesta por una serie de
productos de probabilidades como se muestra a continuación:
1, 2, … , , .
Uno de los clasificadores Bayesianos más utilizados es el llamado clasificador Bayesiano simple.
Este clasificador lo que hace es utilizar la regla de Bayes para la obtención de la probabilidad
posterior de cada clase (Ci), suponiendo que A es la probabilidad a priori de las variables:
| |
Si se suponen las variables como independientes, lo único que se hace es multiplicar dicha
expresión para todos los valores de A.

66
5.2.6. MÁQUINAS DE VECTORES SOPORTE
La mayoría de herramientas de clasificación buscan principalmente obtener el mínimo error
posible. En este ámbito las SVM realizan un enfoque distinto ya que su objetivo no es obtener
el mínimo error, sino que lo que se busca es que los resultados sean lo más fiables posibles,
asumiendo el posible error producido. Para ello, un concepto característico de las SVM es el de
margen, que es el espacio de separación entre las clases. Se busca que el margen sea lo mayor
posible.
Las SVM son clasificadores lineales. No obstante, por medio de la introducción de funciones
kernel, pueden convertirse en clasificadores no lineales. Se parte de funciones sencillas con el
objetivo de encontrar una solución óptima. El siguiente paso es la ampliación del tipo de
funciones sin apenas aumentar la complejidad del proceso.
6. DISEÑO DE LAS PRUEBAS
La red disponible para la realización de las pruebas es una red doméstica inalámbrica con un
punto de acceso (router). Los equipos que se conectan a la red son 3 ordenadores portátiles y
1 dispositivo móvil (figura 30). La seguridad de dicha red es una clave WEP de 128 bits que
protege la información privada de la red. Se busca realizar una serie de observaciones de
duración determinada en las que se captura las siguientes variables para la caracterización del
tráfico de la red: nº de paquetes de difusión, nº de solicitudes de autenticación, nº de
solicitudes de deautenticación,nº de CTS y nº total de paquetes capturados. Durante la captura
de paquetes se trabaja con tráfico normal de la red y se aplican 3 ataques distintos
produciendo así alteraciones en el tráfico. Con esas variables se utilizan las técnicas de
clasificación multivariante explicadas anteriormente caracterizando así distintos tipos de
tráfico siendo capaces posteriormente de clasificar nuevas observaciones en el tráfico
correspondiente, ya sea tráfico normal o tráfico producido por uno de los ataques.
Figura 30: Red para la realización de las pruebas.

67
A continuación se presenta el diseño de las pruebas desde la captura de los paquetes y toma
de observaciones hasta la clasificación. En el siguiente capítulo se presentan los resultados de
dichas pruebas y su correspondiente análisis.
6.1. CAPTURA DE PAQUETES
La captura de paquetes se realiza por medio de la ejecución de un fichero de programación en
C con la librería libpcap escrito y compilado bajo el sistema operativo Linux. En el anexoI se
presenta el código utilizado debidamente comentado. Con este programa, se obtienen una
serie de observaciones de los paquetes transmitidos en la red. Las capturas duran 30 segundos
durante los cuales se capturan todos los paquetes realizando un reconocimiento del tipo de
paquete que es. En el análisis subsiguiente, cada intervalo de 30 segundos se corresponde con
una observación.
El código principal del fichero comienza abriendo el dispositivo inalámbrico en modo
promiscuo y se extrae la dirección de red y la máscara de red. Se inicia la captura en el
dispositivo controlada por tiempo (30 segundos) y se captura paquete a paquete. A cada
paquete se le aplica una función que analiza en primer lugar el campo de control de trama
distinguiendo entre trama de administración, control o datos y dentro de esos tipos se
distinguen los subtipos:
Administración: Solicitud y respuesta de asociación.
Administración: Solicitud de autenticación y de deautenticación.
Control: RTS, CTS y ACK.
Datos.
También es necesario analizar si se trata de un paquete difusión, por lo que primero se
observan los bits “toDs” y “FromDs” del campo control de trama para ver si la comunicación se
está realizando entre estaciones, de una estación a un punto de acceso, de un punto de acceso
a una estación o entre puntos de acceso, ya que dependerá de esto la posición de la dirección
MAC destino del paquete. Una vez se detecta la posición de esta información simplemente se
extrae y se analiza incrementando así la variable correspondiente. Una vez se conoce toda la
información correspondiente a los paquetes capturados durante 30 segundos, se realiza un
volcado de los datos a un fichero de texto. Este fichero de texto está inicialmente vacío y se va
rellenando de valores numéricos con una estructura determinada. Los valores de las variables
correspondientes a una observación se almacenan en forma de fila separados por un espacio.
De esta forma en el fichero de texto se observan una cantidad de filas numéricas formadas por
valores separados por un espacio, lo que es similar a la matriz explicada en el apartado
anterior para realizar el estudio PCA. Se ha elegido esta estructura de almacenamiento debido
al posterior análisis con la herramienta Matlab. Al estar los datos con dicha configuración,

68
pueden ser utilizados de forma rápida y sencilla por dicha herramienta sin causar problemas
adicionales de compatibilidades.
Una vez elaborado el código C se crea un ejecutable y se lleva al sistema operativo Wifiway.
Wifiway se va a utilizar a través de la máquina virtual VMware. Se crea una nueva partición en
el equipo con el sistema operativo Wifiway 3.0.1 con las configuraciones correspondientes de
forma que se pueda utilizar Windows 7 al mismo tiempo que se trabaja desde la máquina
virtual con Wifiway. El mayor problema de la máquina virtual es que no reconoce la tarjeta
inalámbrica del ordenador portátil por lo que se trabaja con una tarjeta inalámbrica externa
cuya comunicación se realiza por medio del puerto USB. Una vez se arranca Wifiway se pone la
interfaz wlan0 en modo monitor y se ejecuta el programa de captura. Para poner la interfaz en
modo monitor se usa el siguiente comando:
" 0"
Será necesario disponer de un fichero de texto vacío en el mismo directorio con el nombre
indicado en el programa de captura para el almacenamiento de los datos obtenidos. Una vez
en este punto se procede a la distinción de 4 tipos de tráfico en función de los ataques a
analizar. Estos ataques se realizan durante la captura de paquetes.
6.2. EJECUCIÓN DE ATAQUES
Como se ha comentado, se va a hacer distinción entre 4 tipos distintos de tráfico en la red
inalámbrica. El primer tipo de tráfico es el tráfico normal en el que no se realiza ningún tipo de
alteración. Los otros tres restantes se presentan a continuación mostrando los comandos
utilizados para llevarlos a cabo: Ataque de deautenticación, de inyección y hombre en el medio
(Man in the middle). Como la información correspondiente a la estructura de dichos ataques
ya ha sido comentada, se procede a la presentación de la ejecución de los ataques. Paralelo a
la ejecución del programa de captura y a la realización de cualquiera de los ataques, se
necesitará un terminal abierto en el que se estén capturando las respuestas ya que se trabaja
con la herramienta Aircrack. El comando utilizado es:
“airodump‐ng –c 12 ‐‐bssid 14:D6:4D:93:E4:4C –w out mon0”
En el commando airodump se especifica el canal por el que se transmite la información de la
red (12) el bssid del punto de acceso (14:D6:4D:93:E4:4C), el fichero de salida (out) y la interfaz
con la que se captura el tráfico (mon0).
Para el ataque de inundaciones de solicitudes de deautenticación se utiliza el comando:
“aireplay‐ng ‐0 0 –a 14:D6:4D:93:E4:4C mon0”
La opción “‐0” indica ataque de deautenticación de la suite Aircrack y el siguiente 0 indica que
se estén mandando solicitudes de deautenticación continuamente. Este número puede ser
cambiado por un número específico pero para que sea más efectivo se realiza la inundación de

69
tantas solicitudes como sea posible. Con la opción “‐a” se indica la dirección MAC del punto de
acceso y finalmente se añade la interfaz a través de la que se realizan las comunicaciones. Al
ejecutar el comando se comienza a producir una inundación de desautenticaciones hasta que
el ataque es parado por el atacante. Para la detección de este ataque será muy interesante la
variable “solicitud de deautenticación” de las obtenidas en las observaciones, ya que se
debería producir un incremento radical en su valor.
De forma adicional se presenta una modificación en la ejecución en este ataque para que no
pueda ser detectado por el total de paquetes de la red. Esta opción permite el envío de un
número determinado de paquetes de deatenticación a baja tasa en lugar de estar en envío
continuo. De esta forma se necesita más tiempo para obtener la clave de la red pero no
levantará tantas alarmas. En este caso el comando es:
“aireplay‐ng ‐0 3 –a 14:D6:4D:93:E4:4C mon0”
En el caso del ataque por inyección el comando es el siguiente:
“aireplay‐ng ‐3 –b 14:D6:4D:93:E4:4C –h 5C:AC:4C:24:17:4B mon0”
Con la opción “‐3” se indica el reenvío estándar de peticiones ARP, luego con “‐b” se indica la
dirección MAC del punto de acceso y con “‐h” la dirección MAC de un cliente asociado a la red
terminando con la interfaz utilizada. La variable interesante que podría alertar que se está
produciendo un ataque de estas características sería “paquete ARP”. El problema que surge
con esta variable es que hace falta desencriptar el mensaje WEP para ver si se trata de un
paquete ARP ya que esa información no se encuentra disponible en la cabecera 802.11. Dado
que las solicitudes ARP son de difusión y suelen producir un ACK al ser recibidas, una
alternativa indirecta y menos costosa sería observar estas variables ya que esta información si
puede ser obtenida sin necesidad de realizar el descifre del mensaje.
Finalmente se presenta el ataque man in the middle. Como se comentó anteriormente, la
forma de detectar este ataque es analizando la producción anormal de ruido en el canal de
transmisión de la red inalámbrica. Esto puede ser producido de varias maneras. En este caso
concreto se lleva a cabo un ataque man in the middle introduciendo ruido a través de
colisiones producidas por una inundación de solicitudes de asociación al punto de acceso. Se
realiza una sucesión de creación de clientes inalámbricos falsos que van mandando peticiones
de asociación al punto de acceso produciendo así un incremento de tráfico recibido por el
punto de acceso que provoca colisiones por las que la calidad de las comunicaciones en ese
canal se verá afectada. Como ya se comentó la herramienta es Mdk3 y el comando:
“mdk3 a –a 14:D6:4D:93:E4:4C”
Indicando como en el resto de ataques la dirección MAC del punto de acceso. La variable
relevante en este caso será la de “solicitud de asociación”.

70
6.3. ANÁLISIS MULTIVARIANTE
Una vez se obtienen las observaciones de las distintas variables, es momento de analizar el
gráfico de dispersión, y realizar un estudio de las dependencias con PCA, MEDA y oMEDA. Este
análisis se lleva a cabo con la herramienta Matlab y con una serie de códigos que se presentan
en el anexo x.
Para poder realizar el estudio con PCA primero se hace un pre‐procesamiento a los datos para
que queden centrados en la media, para lo que se usa el código “preprocess2D.m”. De la
ejecución de dicho código se obtienen los datos pre‐procesados con los que se puede realizar
el estudio de dependencias. En primer lugar se observan los gráficos de dispersión con el
código “plot_scores_pca.m” que muestra un gráfico como el que se ha explicado
anteriormente. Si no hay una diferenciación clara en el gráfico de los distintos grupos de
tráficos quiere decir que las variables utilizadas no tienen poder discriminativo, por lo que
habrá que rediseñar el conjunto de variables capturadas. Si se obtienen los tráficos bien
diferenciados se puede proceder con el estudio de MEDA. Para obtener el diagrama MEDA se
usa el código “meda_pca.m” al que hay que introducirle como argumento los datos pre‐
procesados, las componentes principales a tener en cuenta, el tipo de pre‐procesamiento
utilizado, un umbral para la discretización de la matriz MEDA, el tipo de gráfico a mostrar y las
variables. El tipo de gráfico a mostrar podrá ser en niveles de grises dependiendo si existe
mayor o menor dependencia o también puede ser directamente discretizado de forma que
aparezca blanco donde no hay dependencia y negro donde sí la hay. En el gráfico obtenido con
este código se pueden obtener resultados para la compresión del experimento
Finalmente, una vez se ha caracterizado el experimento, se puede continuar con oMEDA, cuyo
código es “omeda_pca.m”, de forma que se realice un estudio concreto de algún aspecto de
relevancia para el experimento. En el caso de este proyecto será interesante observar qué
variables se incrementan desde el tráfico normal al producido con un ataque, de forma que
quede bien claro la variable a tener en cuenta. También se puede ver la tendencia general de
alguna agrupación en concreto o la comparación entre dos tipos de tráficos de ataques. Para la
ejecución de oMEDA, se introduce por argumento un vector con el que se dan distintos pesos
a las observaciones dependiendo desde donde hacia dónde se quiere ver la variación en las
variables. Por ejemplo, si se quiere ver lo que cambia del tráfico normal al tráfico del ataque 1,
se asignaría ‐1 a las observaciones de tráfico normal, 1 a las observaciones de tráfico de ataque
1 y 0 al resto de observaciones. Al ejecutarlo se obtiene el diagrama de bandas aclaratorio.
Todos los códigos correspondientes tanto al análisis PCA, MEDA y oMEDA pertenecen a la
“Exploratory Data Analysis Toolbox” de Matlab [9]”.
6.4. CLASIFICADORES
Una vez hemos explorado los datos y considerado que las variables capturadas tienen
información discriminativa, se hace uso de una serie de códigos de Matlab para la aplicación
de los clasificadores explicados anteriormente en este documento. A continuación se muestra
el procedimiento a seguir en cada caso dependiendo del clasificador a utilizar. Primero se

71
realiza un entrenamiento del clasificador procediendo después a clasificar nuevas
observaciones de la red. Una vez clasificadas las nuevas observaciones se realiza un estudio del
error producido por cada uno de los clasificadores pudiendo así comparar la efectividad de
unos y otros. La métrica del error es bastante sencilla pero efectiva y consiste en realizar una
comparación entre la clase asignada por el clasificador a la nueva observación y la clase que
debería haber sido asignada. Se suman todos los casos en los que el clasificador haya hecho
bien su trabajo y se divide por el número total de nuevas observaciones clasificadas,
obteniendo así un porcentaje de error del total. Siendo M el número total de nuevas
observaciones a clasificar y C el número de nuevas observaciones bien clasificadas, el cálculo
del error se realiza con la siguiente expresión:
% 100
Para el algoritmo del vecino más próximo y para el del K vecinos más próximos se utiliza el
mismo código Matlab “knnclassify.m” (códigos correspondientes a los algoritmos basados en
vecindad en el anexo III). A este código hay que introducir por argumento tanto los datos para
la calibración (observaciones y etiquetas indicando la clase a la que pertenecen) como el
número K y las nuevas observaciones a ser clasificadas con lo que se obtiene un vector que
contiene las clases correspondientes a las nuevas observaciones clasificadas. Para la distinción
de clases se va a utilizar el valor 1 para el tráfico normal, 2 para el tráfico correspondiente al
ataque de deautenticación, 3 para el de re‐inyección de peticiones ARP y 4 para el de man‐in‐
the‐middle. Con este mismo código se puede realizar un estudio y comparación de los dos
algoritmos simplemente cambiando los valores de K. Para K=1 se estará trabajando con el
algoritmo del vecino más próximo y con un valor de K superior se estará trabajando con el
algoritmo de los K vecinos más próximos por votación. Para el caso de los K vecinos más
próximos se debería dividir las observaciones en dos grupos, uno para comprobar qué K es el
más adecuado para este experimento y otro para el entrenamiento del clasificador. La
importancia de ver qué valor de K es el óptimo para este experimento es fundamental porque
la efectividad de la clasificación va a depender directamente de la elección de dicho valor y no
hay un valor generalizado, ya que dependerá de la distribución de las observaciones. Se
utilizará un conjunto de observaciones para el entrenamiento del clasificador. A continuación
se tomará otro conjunto de observaciones con las que se evaluará el valor óptimo de K al
realizar la clasificación gracias al estudio del error. Finalmente se procederá a la clasificación de
una tercera tanda de observaciones, con las que, usando el valor óptimo obtenido de K se
llegará al cálculo final del error.
En el caso del árbol de clasificación (códigos correspondientes en el anexo IV) primero se
utiliza un comando para el entrenamiento del clasificador obteniendo así el árbol y después se
hace uso de otro para la clasificación. El código para el entrenamiento es “classregtree.m” y el
de clasificación “eval.m”, que usa el árbol obtenido por el anterior código para la clasificación
de las nuevas observaciones.
Para el análisis discriminante lineal (códigos correspondientes en el anexo VI) se usa
“classify.m” indicando “linear” entre los argumentos, y para el cuadrático simplemente se
cambia “linear” por “quadratic”. Si el clasificador a utilizar es el bayesiano, la función es
“NaiveBayes.fit.m” obteniendo así la red de Bayes (anexo VII) y evaluándola posteriormente

72
para las nuevas observaciones con la función “predict.m”. Si el clasificador a utilizar es pls‐da,
se utiliza más de un código Matlab. El código para la creación del modelo pls‐da se encuentra
bajo el nombre de “clasiPlsda.m” (anexo V) y de ese código se obtiene el modelo pls‐da de los
datos de entrenamiento. Para poder evaluar las nuevas observaciones obteniendo la
clasificación se usa el código “plspred.m” (perteneciente a la toolbox PLS‐DA [11])al que hay
que introducir por argumento las nuevas observaciones y el modelo pls‐da obtenido con la
función anterior. A la clasificación obtenida se le puede calcular el error pero de forma
adicional se puede introducir como argumento a la función “plspred.m” las clases
correspondientes de las nuevas observaciones y el código calcula el porcentaje de éxito, por lo
que el de error será 100‐% (éxito).

73
CAPÍTULO III
PRUEBAS

74

75
Una vez realizadas todas las pruebas explicadas en el capítulo anterior se procede a la
presentación de los resultados y conclusiones obtenidas con las correspondientes correcciones
a lo largo del proceso.
7. ANÁLISIS DE RESULTADOS
En cuanto a la captura de paquetes de la red se han tomado medidas finalmente de las
variables: ACK, paquetes de difusión, solicitud de autenticación, solicitud de deautenticación,
CTS y número total de paquetes capturados durante el período. Se han realizado en total 350
observaciones de las 7 variables. La duración de las observaciones ha sido de 30 segundos y se
han realizado en tandas de 10 observaciones con 60 segundos entre tandas. Se ha esperado
60 segundos entre tandas para que no se mezclen las observaciones correspondientes a
tráficos distintos. El tiempo de parada entre una observación y la siguiente dentro de las 10 ha
sido de 5 segundos (figura 31). Cada tanda de 10 observaciones se corresponde con un tipo de
tráfico distinto. Así se ha ido rotando entre tráfico normal, ejecución del ataque 1, ejecución
del ataque 2 y ejecución del ataque 3. La figura 32 muestra una captura durante la toma de
datos realizando el ataque 1:
Figura 31: Estructura de las observaciones.

76
Figura 32: Ataque de deautenticación.
En la pantalla superior en negro se está ejecutando el código, en la intermedia se está
produciendo las solicitudes de deautenticación al punto de acceso y en la más baja se está
utilizando airodump para la captura de respuestas. Las observaciones obtenidas se presentan
en la tabla 3:
Tipo de tráfico
Nº ACK
Nº paq Broad.
Solicitud autentic.
Solicitud deaunt.
CTS Total paquetes
TN (1) 4142 154 0 1 10 8347
TN (1) 4138 157 0 0 10 8097
TN (1) 4327 151 0 0 10 8494
TN (1) 5943 163 0 0 14 11811
TN (1) 4619 153 0 0 10 9183
TN (1) 4866 158 0 0 15 9423
TN (1) 4457 150 0 0 8 8677
TN (1) 6224 152 0 0 11 11655
TN (1) 7802 148 0 0 9 14910
TN (1) 4415 154 0 0 15 8549
A1 (2) 4367 8061 0 7905 12 16356
A1 (2) 4271 8131 2 7971 11 16357
A1 (2) 4292 8129 0 7976 13 16205
A1 (2) 3924 8099 0 7946 9 15444
A1 (2) 4299 8170 2 8015 10 16286
A1 (2) 3904 8210 0 8053 12 15581
A1 (2) 4299 8089 0 7936 13 16233
A1 (2) 4115 7948 0 7799 12 15771
A1 (2) 3736 8097 0 7946 12 15161
A1 (2) 4358 6488 0 6337 10 14936
A2 (3) 3693 5341 0 0 11 12385
A2 (3) 3493 13046 0 0 9 19749
77
A2 (3) 3703 13368 0 0 13 20361
A2 (3) 3397 12663 0 0 7 19047
A2 (3) 3813 13453 0 0 12 20562
A2 (3) 3628 13020 0 0 13 19998
A2 (3) 3739 14122 0 0 11 21293
A2 (3) 3495 13398 0 0 9 20109
A2 (3) 3783 13258 0 0 12 20485
A2 (3) 3286 11226 0 0 9 17592
A3 (4) 4228 317 786 0 13 9161
A3 (4) 4425 152 848 0 13 9526
A3 (4) 4348 156 843 0 12 9421
A3 (4) 3739 150 726 0 11 8108
A3 (4) 4256 157 836 0 10 9286
A3 (4) 4239 153 825 0 13 9195
A3 (4) 4688 154 879 0 13 9979
A3 (4) 3937 147 770 0 12 8569
A3 (4) 4171 156 808 0 11 9034
A3 (4) 4147 150 780 0 13 8843
TN (1) 3591 152 23 0 12 7229
TN (1) 3294 151 0 0 9 6622
TN (1) 3883 151 0 0 11 7816
TN (1) 3436 155 0 0 13 6858
TN (1) 3375 153 0 0 14 6701
TN (1) 3542 161 0 0 13 6986
TN (1) 3644 151 0 0 9 7251
TN (1) 3656 152 0 0 15 7224
TN (1) 3926 168 0 0 13 7844
TN (1) 3791 150 0 0 14 7636
A1 (2) 3631 7963 0 7812 12 15140
A1 (2) 3515 8135 0 7984 11 14999
A1 (2) 3955 8078 0 7932 14 15673
A1 (2) 3835 8097 0 7943 8 15477
A1 (2) 3425 8150 0 8001 9 14894
A1 (2) 3873 8157 0 8003 12 15696
A1 (2) 3627 8087 0 7931 12 15217
A1 (2) 3402 8104 0 7923 11 14876
A1 (2) 3508 8147 0 7967 12 15062
A1 (2) 3836 5833 0 5683 11 13410
A2 (3) 3444 161 0 0 14 6895
A2 (3) 3668 152 0 0 12 7391
A2 (3) 3436 158 0 0 14 6935
A2 (3) 3603 505 0 0 14 7549
A2 (3) 2061 9886 0 0 8 13907
A2 (3) 1942 9920 0 0 8 13700
A2 (3) 2362 9358 0 0 7 14043
A2 (3) 1926 8958 0 0 9 12735
A2 (3) 2009 9685 0 0 6 13635
A2 (3) 2011 9009 0 0 9 12958

78
A3 (4) 3643 324 689 0 14 8005
A3 (4) 3647 152 703 0 16 7885
A3 (4) 3947 154 757 0 13 8500
A3 (4) 4457 155 800 0 13 9270
A3 (4) 3824 152 725 0 12 8188
A3 (4) 3869 151 759 0 11 8434
A3 (4) 4197 156 818 0 12 9115
A3 (4) 4126 150 812 0 12 9009
A3 (4) 3938 160 800 0 13 8749
A3 (4) 4706 151 895 0 16 10092
TN (1) 3866 156 23 0 8 7632
TN (1) 4302 150 0 0 12 8545
TN (1) 3745 153 0 0 10 7442
TN (1) 3765 156 0 0 13 7507
TN (1) 3562 156 0 0 11 7120
TN (1) 3662 155 0 0 13 7330
TN (1) 3269 157 0 0 14 6513
TN (1) 3659 158 0 0 10 7184
TN (1) 3265 155 0 0 11 6509
TN (1) 3306 161 0 0 14 6711
A1 (2) 3358 7934 0 7774 17 14502
A1 (2) 3246 8124 0 7973 9 14473
A1 (2) 3561 8074 0 7921 14 15083
A1 (2) 3601 8072 0 7922 13 15243
A1 (2) 3687 8088 0 7936 12 15347
A1 (2) 3679 8112 0 7951 13 15361
A1 (2) 3757 8089 0 7936 13 15508
A1 (2) 3503 8102 0 7944 13 14949
A1 (2) 3317 8097 0 7946 11 14657
A1 (2) 3673 8190 0 7995 12 15384
A2 (3) 3845 276 0 119 13 7813
A2 (3) 3676 149 0 0 11 7294
A2 (3) 3843 166 0 0 12 7555
A2 (3) 2870 6170 0 0 11 11689
A2 (3) 1875 9772 0 0 10 13444
A2 (3) 2166 9468 0 0 8 13613
A2 (3) 2050 9188 0 0 8 13136
A2 (3) 2224 9532 0 0 8 13803
A2 (3) 1955 9124 0 0 7 12992
A2 (3) 2172 9139 0 0 8 13362
A3 (4) 3744 343 734 0 11 8380
A3 (4) 3989 183 794 0 14 8782
A3 (4) 3279 152 646 0 14 7169
A3 (4) 3818 162 744 0 15 8297
A3 (4) 3417 154 670 0 13 7448
A3 (4) 3322 154 623 0 11 7073
A3 (4) 3672 160 694 0 13 7839
A3 (4) 3807 153 692 0 13 7981

79
A3 (4) 3798 154 712 0 15 8088
A3 (4) 3712 157 701 0 9 7934
TN (1) 3941 153 24 0 10 7768
TN (1) 3594 162 2 0 11 7024
TN (1) 3562 151 0 0 14 7218
TN (1) 4241 150 0 0 12 8584
TN (1) 3953 152 0 0 10 7996
TN (1) 3617 157 0 0 14 7163
TN (1) 4200 154 0 0 13 8309
TN (1) 4762 166 0 0 14 9292
TN (1) 3332 158 0 0 10 6582
TN (1) 3903 154 0 0 15 7587
A1 (2) 3919 7965 0 7808 13 15639
A1 (2) 3578 8089 0 7936 10 14917
A1 (2) 3506 8093 0 7937 11 14858
A1 (2) 3243 8108 0 7960 14 14503
A1 (2) 3575 8103 0 7946 12 15003
A1 (2) 3280 8151 0 7998 11 14338
A1 (2) 3442 8078 0 7925 12 14644
A1 (2) 3694 8130 0 7980 15 15226
A1 (2) 3418 8146 0 7988 14 14699
A1 (2) 3292 8102 0 7950 11 14383
A2 (3) 3644 537 2 129 14 7576
A2 (3) 2338 9631 0 1 10 14167
A2 (3) 2263 9410 0 0 6 13808
A2 (3) 2230 9359 0 0 7 13678
A2 (3) 2134 9384 0 0 9 13471
A2 (3) 2163 9897 0 0 10 14012
A2 (3) 2153 9493 0 0 8 13641
A2 (3) 2495 9943 0 0 6 14700
A2 (3) 2004 8046 0 0 4 11953
A2 (3) 2186 9652 0 0 9 13814
A3 (4) 4313 328 822 0 15 9482
A3 (4) 3592 158 701 0 11 7807
A3 (4) 4162 150 809 0 14 9031
A3 (4) 4293 164 792 0 15 9060
A3 (4) 4224 161 786 0 10 8951
A3 (4) 4063 160 760 0 11 8633
A3 (4) 4184 157 768 0 14 8803
A3 (4) 3852 153 714 0 11 8148
A3 (4) 4068 154 753 0 6 8591
A3 (4) 3835 152 714 0 12 8127
TN (1) 4201 158 17 0 10 8202
TN (1) 4012 151 0 0 10 7695
TN (1) 3868 153 0 0 13 7518
TN (1) 3964 155 0 0 12 7754
TN (1) 4330 151 0 0 12 8370
TN (1) 4525 151 0 0 14 8676

80
TN (1) 5054 159 1 0 13 9454
TN (1) 4786 147 0 0 11 9078
TN (1) 4660 157 2 0 12 9127
TN (1) 4571 150 0 0 10 8902
A1 (2) 5173 7834 0 7685 10 17920
A1 (2) 4989 8061 0 7907 11 17668
A1 (2) 4479 8087 0 7934 11 16792
A1 (2) 4438 8019 0 7870 11 16520
A1 (2) 4618 7980 0 7829 14 17109
A1 (2) 3648 8093 0 7944 12 15229
A1 (2) 4055 8147 0 7993 12 16199
A1 (2) 4151 8065 0 7915 9 17009
A1 (2) 4339 8025 0 7877 11 17495
A1 (2) 4049 6091 0 5943 15 14183
A2 (3) 4196 156 0 0 11 8385
A2 (3) 4182 155 0 0 12 8285
A2 (3) 2446 7077 0 0 8 11869
A2 (3) 2267 8860 0 0 7 13214
A2 (3) 2134 8064 0 0 4 12483
A2 (3) 2277 9083 0 0 8 13594
A2 (3) 2161 9002 0 0 10 13410
A2 (3) 2188 9088 0 0 9 13412
A2 (3) 2390 9203 0 0 5 13918
A2 (3) 2446 8639 0 0 6 13539
A2 (3) 2374 8433 0 0 6 13103
A2 (3) 2419 9077 0 0 7 13669
A2 (3) 2510 8690 0 0 9 13504
A2 (3) 2204 8457 0 0 7 12717
A2 (3) 2333 7665 0 0 7 12114
A2 (3) 2374 7938 0 0 5 12471
A2 (3) 2119 8053 0 0 8 12166
A2 (3) 2036 8303 0 0 7 12239
A2 (3) 1973 7959 0 1 7 11768
A2 (3) 1723 9224 0 0 8 12651
A3 (4) 3831 356 815 0 14 8961
A3 (4) 3704 155 558 0 12 7062
A3 (4) 3666 150 582 0 13 7177
A3 (4) 3612 160 757 0 12 8158
A3 (4) 3508 178 736 0 13 7937
A3 (4) 4548 147 889 0 12 9903
A3 (4) 3579 180 731 0 9 7974
A3 (4) 3787 151 746 0 12 8278
A3 (4) 3701 173 731 0 10 8104
A3 (4) 3377 152 518 0 14 7435
TN (1) 3322 165 0 0 12 6619
TN (1) 3717 165 0 0 10 7545
TN (1) 3795 151 0 0 11 7624
TN (1) 3834 160 0 0 10 7592

81
TN (1) 3817 152 0 0 15 7651
TN (1) 3740 168 0 0 11 7343
TN (1) 3641 153 0 0 13 7202
TN (1) 3448 155 0 0 13 6947
TN (1) 4066 156 0 0 14 8023
TN (1) 3968 154 0 0 13 7716
A1 (2) 3988 7963 0 7806 10 15745
A1 (2) 4104 8072 0 7926 14 15910
A1 (2) 3523 8157 0 7994 15 14489
A1 (2) 3869 8089 0 7941 11 15589
A1 (2) 3947 8127 0 7954 13 15865
A1 (2) 3912 8084 0 7938 12 15723
A1 (2) 3867 8086 0 7935 14 15715
A1 (2) 3717 8124 0 7959 15 15359
A1 (2) 3667 8143 0 7982 13 15561
A1 (2) 3812 6540 0 6382 14 14034
A3 (4) 3991 154 809 0 13 8978
A3 (4) 3466 151 686 0 12 7594
A3 (4) 3553 156 665 0 13 7557
A3 (4) 3424 151 630 0 14 7220
A3 (4) 3336 159 640 0 11 7189
A3 (4) 3671 158 724 0 12 8025
A3 (4) 3756 156 748 0 13 8263
A3 (4) 3698 151 677 0 13 7774
A3 (4) 3948 156 754 0 11 8479
A3 (4) 3663 155 739 0 15 8112
TN (1) 3619 159 23 0 12 7250
TN (1) 4039 153 0 0 13 7955
TN (1) 4016 151 0 0 10 7972
TN (1) 3730 152 0 0 13 7409
TN (1) 3712 160 2 0 10 7443
TN (1) 4096 158 0 0 14 8355
TN (1) 3597 151 0 0 12 7559
TN (1) 3618 152 0 0 12 7200
TN (1) 3799 154 0 0 8 7662
TN (1) 3792 166 0 0 11 7530
A1 (2) 3467 7919 0 7760 10 14613
A1 (2) 3448 8084 0 7943 13 14498
A1 (2) 3597 8092 2 7936 9 14971
A1 (2) 3581 8086 0 7937 9 15197
A1 (2) 3788 8108 0 7960 14 14939
A1 (2) 3433 8111 0 7963 12 14584
A1 (2) 3675 8100 0 7936 10 14734
A1 (2) 3409 8095 0 7936 9 14443
A1 (2) 3399 8056 0 7902 9 14496
A1 (2) 3710 8027 0 7868 12 15327
A2 (3) 3678 292 0 140 9 7369
A2 (3) 2297 8730 0 0 8 13226
82
A2 (3) 2091 9170 0 0 10 13342
A2 (3) 1959 9095 0 0 8 12870
A2 (3) 2035 9433 0 0 10 13429
A2 (3) 2270 8851 0 0 7 13291
A2 (3) 2461 9528 0 0 11 14326
A2 (3) 2071 9346 0 0 8 13431
A2 (3) 2280 9733 0 0 10 14240
A2 (3) 2211 8619 0 0 5 13014
A3 (4) 3436 301 693 0 13 7821
A3 (4) 3764 172 764 0 10 8355
A3 (4) 3815 143 794 0 14 8599
A3 (4) 3643 167 754 0 14 8183
A3 (4) 3404 150 685 0 12 7531
A3 (4) 3424 160 705 0 15 7670
A3 (4) 3513 145 762 0 14 8100
A3 (4) 3423 158 693 0 13 7595
A3 (4) 3427 155 699 0 10 7632
A3 (4) 3350 158 684 0 13 7499
TN (1) 3847 171 0 0 15 7710
TN (1) 4149 163 0 0 14 8310
TN (1) 4535 152 0 0 10 9032
TN (1) 4380 152 0 0 13 8716
TN (1) 4502 157 0 0 11 9111
TN (1) 4174 153 0 0 12 8363
TN (1) 3743 158 0 0 11 7405
TN (1) 3586 154 0 0 15 7204
TN (1) 3507 146 0 0 10 6871
TN (1) 4171 159 0 0 9 7885
A1 (2) 4383 7739 0 7591 11 16154
A1 (2) 3784 8086 0 7936 13 15544
A1 (2) 4122 7983 0 7815 14 16029
A1 (2) 3424 8082 0 7933 13 14584
A1 (2) 4065 8023 0 7863 12 15907
A1 (2) 3739 8075 0 7936 13 15365
A1 (2) 4435 7982 0 7827 11 16756
A1 (2) 4832 8020 0 7872 13 17435
A1 (2) 3889 8043 0 7894 9 15601
A1 (2) 4242 8000 0 7856 13 16219
A2 (3) 4022 4372 0 115 9 12144
A2 (3) 2447 8741 0 0 10 13413
A2 (3) 2011 10404 0 0 6 14298
A2 (3) 2345 10011 0 0 7 14638
A2 (3) 2147 9868 0 0 9 14120
A2 (3) 2338 10594 0 0 8 15185
A2 (3) 2345 9718 0 0 11 14323
A2 (3) 2526 10188 0 0 6 15119
A2 (3) 2287 9891 0 0 9 14377
A2 (3) 2438 10012 0 0 6 14844

83
A3 (4) 4442 340 888 0 11 9989
A3 (4) 4756 174 999 0 12 10767
A3 (4) 3921 161 785 0 12 8645
A3 (4) 4066 157 838 0 16 9107
A3 (4) 3755 149 767 0 11 8365
A3 (4) 3687 154 746 0 11 8177
A3 (4) 4006 161 816 0 14 8921
A3 (4) 3695 163 748 1 13 8193
A3 (4) 3453 151 689 0 11 7596
A3 (4) 3987 156 667 0 12 8627
TN (1) 4132 155 0 0 14 8076
TN (1) 3850 154 0 0 16 7760
TN (1) 3619 158 0 0 11 7414
TN (1) 4128 151 0 0 12 8365
TN (1) 3761 157 0 0 14 7583
TN (1) 3428 154 0 0 13 6962
TN (1) 3750 156 0 0 12 7652
TN (1) 5224 148 0 0 12 10427
TN (1) 4248 134 0 0 11 8552
TN (1) 3893 155 0 0 15 8173
A1 (2) 4115 7869 0 7721 9 15931
A1 (2) 3786 8033 0 7878 15 15454
A1 (2) 4566 7864 0 7716 9 16902
A1 (2) 3875 8067 0 7916 13 15668
A1 (2) 3572 8113 0 7960 14 15319
A1 (2) 3707 8114 0 7967 10 15710
A1 (2) 3988 8145 0 7994 11 16201
A1 (2) 3993 8096 0 7952 14 16064
A1 (2) 4558 7970 0 7817 12 17187
A1 (2) 4043 8062 0 7909 13 16116
A2 (3) 2106 9536 0 128 12 13691
A2 (3) 2030 10430 0 0 9 14559
A2 (3) 2183 9953 0 0 3 14319
A2 (3) 2249 10873 0 1 7 14818
A2 (3) 1958 9190 0 0 5 13080
A2 (3) 1930 10683 0 0 9 14522
A2 (3) 1866 10759 0 0 7 14348
A2 (3) 2009 10846 0 0 10 14748
A2 (3) 2026 10279 0 0 8 13833
A2 (3) 1782 9128 0 0 8 12322 Tabla 3: Observaciones obtenidas analizando el tráfico.
En la primera columna de la tabla 3 se denominan los siguientes tipos de tráfico:
TN – Tráfico normal, cuyo valor numérico de identificación en Matlab será 1.
A1 – Ataque de deautenticación, valor numérico 2.
A2 – Ataque de inyección, valor numérico 3.
A3 – Ataque de hombre en el medio, valor numérico 4.
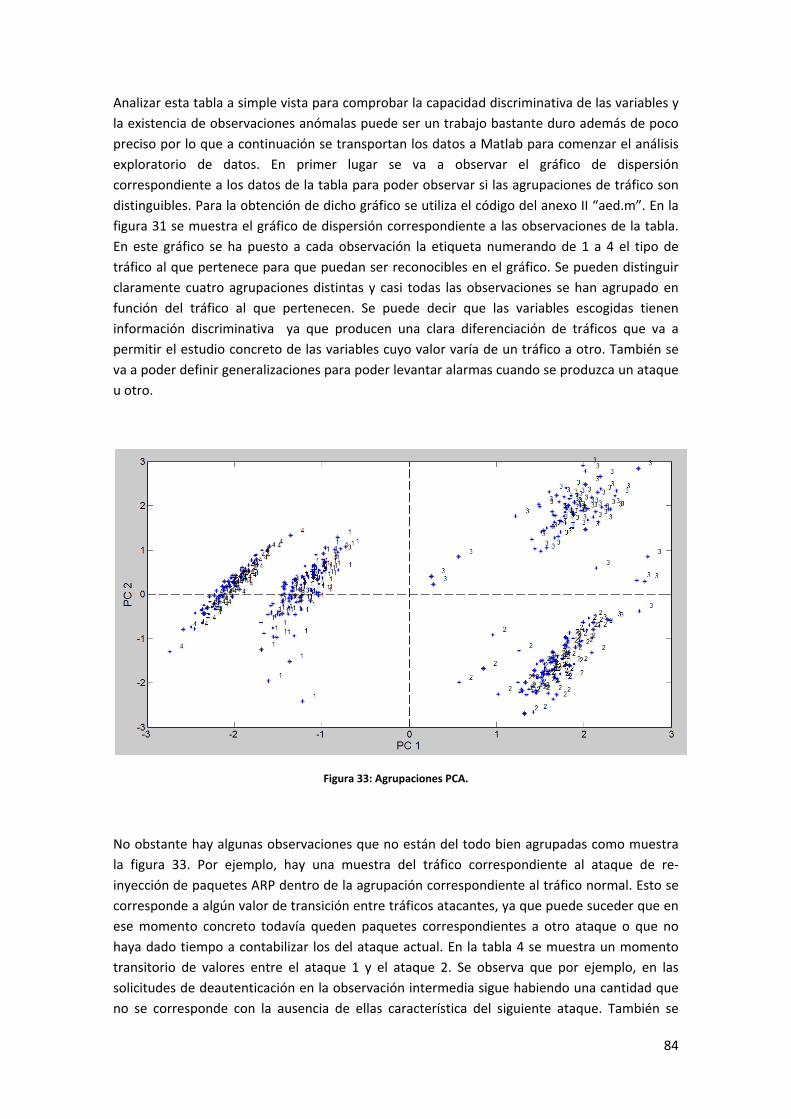
84
Analizar esta tabla a simple vista para comprobar la capacidad discriminativa de las variables y
la existencia de observaciones anómalas puede ser un trabajo bastante duro además de poco
preciso por lo que a continuación se transportan los datos a Matlab para comenzar el análisis
exploratorio de datos. En primer lugar se va a observar el gráfico de dispersión
correspondiente a los datos de la tabla para poder observar si las agrupaciones de tráfico son
distinguibles. Para la obtención de dicho gráfico se utiliza el código del anexo II “aed.m”. En la
figura 31 se muestra el gráfico de dispersión correspondiente a las observaciones de la tabla.
En este gráfico se ha puesto a cada observación la etiqueta numerando de 1 a 4 el tipo de
tráfico al que pertenece para que puedan ser reconocibles en el gráfico. Se pueden distinguir
claramente cuatro agrupaciones distintas y casi todas las observaciones se han agrupado en
función del tráfico al que pertenecen. Se puede decir que las variables escogidas tienen
información discriminativa ya que producen una clara diferenciación de tráficos que va a
permitir el estudio concreto de las variables cuyo valor varía de un tráfico a otro. También se
va a poder definir generalizaciones para poder levantar alarmas cuando se produzca un ataque
u otro.
Figura 33: Agrupaciones PCA.
No obstante hay algunas observaciones que no están del todo bien agrupadas como muestra
la figura 33. Por ejemplo, hay una muestra del tráfico correspondiente al ataque de re‐
inyección de paquetes ARP dentro de la agrupación correspondiente al tráfico normal. Esto se
corresponde a algún valor de transición entre tráficos atacantes, ya que puede suceder que en
ese momento concreto todavía queden paquetes correspondientes a otro ataque o que no
haya dado tiempo a contabilizar los del ataque actual. En la tabla 4 se muestra un momento
transitorio de valores entre el ataque 1 y el ataque 2. Se observa que por ejemplo, en las
solicitudes de deautenticación en la observación intermedia sigue habiendo una cantidad que
no se corresponde con la ausencia de ellas característica del siguiente ataque. También se

85
observa un valor intermedio de paquetes de difusión y de ACK. Estos valores son los que
producen esas observaciones intermedias que será interesante eliminar para no provocar
confusiones en el modelo presentado.
Tipo de tráfico
Nº ACK
Nº paq Broad.
Solicitud autentic.
Solicitud deautent
CTS Total paquetes
A1 (2) 4043 8062 0 7909 13 16116
A2 (3) 2106 9536 0 128 12 13691
A2 (3) 2030 10430 0 0 9 14559 Tabla 4: Valores correspondientes a momentos transitorios entre ataques.
Una vez se ha confirmado el uso de las variables y de las observaciones, se puede continuar
con el estudio MEDA y oMEDA pero en este caso se hace de forma individual de los distintos
tráficos producidos por ataques y el tráfico normal de la red. Así, se va a ir analizando los tres
ataques por separado con los gráficos MEDA y oMEDA para seguir obteniendo resultados
relevantes.
En primer lugar se comienza con el ataque de deautenticación que, recordando, de forma
teórica debería producir un incremento en el número de solicitudes de deautenticación de la
red inalámbrica. En la figura 34 se muestra tanto el gráfico MEDA discretizado (a) como el
oMEDA (b). En el gráfico MEDA se muestra la dependencia en las variaciones tanto de los
paquetes de difusión (BROAD) con los de deautenticación (DEAUTH) y con el total de paquetes.
Se ha producido un incremento en los paquetes de deautenticación lo cual está muy
relacionado con el incremento de paquetes de difusión y por consiguiente, con el total de
paquetes que se mueven en la red. Esto revela que la mayoría de los paquetes son de
deautenticación y de difusión. La inundación de paquetes de deautenticación enviados en el
ataque son de difusión por lo que es normal que se produzca un incremento en ambas
variables.
El gráfico oMEDA comparando las observaciones del ataque 1 con las de tráfico normal
muestra incluso más información ya que se ve de forma clara de cuánto incremento es el
cambio en las variables y además se aprecia una nueva variable a tener en cuenta que es el
incremento en las solicitudes de autenticación. Aunque no aparecían en el gráfico MEDA
también tienen relevancia ya que han sido producidas por las deautenticaciones enviadas. Una
vez los clientes se deautentican, necesitan re‐autenticarse de nuevo lo que produce este
incremento en las solicitudes de autenticación. Observando estos datos se puede detectar un
ataque de deautenticación simplemente observando la cantidad de solicitudes de
deautenticación producidas. Otra opción más robusta sería observar ese incremento pero que
fuera acompañado tanto de incremento de los paquetes de difusión, de las solicitudes de
asociación y del total de paquetes en la red. El problema de observar sólo el total de paquetes
en la red es que no se podría saber si es de deautenticación o se trata de otro ataque. Si se
observa el cambio en el resto de variables sí que se puede concluir no sólo que se esté
produciendo un ataque, sino que el ataque es de deautenticación.

86
(a) (b)
Figura 34: Ataque 1 a) Gráfico MEDA, b) Gráfico oMEDA.
Una vez caracterizado este ataque se continúa con el ataque de re‐inyección de paquetes ARP
observando también los gráficos MEDA y oMEDA. De forma teórica se proponía la idea de
observar los paquetes de difusión para ya que se va a realizar una gran cantidad de tráfico de
peticiones ARP que son de difusión. En la figura 35 se muestran estos gráficos, el de la
izquierda (a) es el gráfico MEDA y el de la derecha (b) el oMEDA. El gráfico MEDA muestra
variaciones en los paquetes de difusión relacionadas con las variaciones producidas en los
paquetes ACK, los CTS y el total de paquetes de la red. En el gráfico oMEDA se puede observar
las diferencias en las variables entre el tráfico normal y el ataque 2. Como era de esperar, se
produce un incremento tanto en los paquetes de difusión como en el total de paquetes, esto
está producido por la gran cantidad de paquetes ARP de la red. Pero hay otras dos variables en
las que se produce variación que quizás es un poco inesperada, que son los ACK y los CTS.
Tanto los paquetes ACK como los CTS disminuyen durante la ejecución del segundo ataque.
Esto viene producido porque el punto de acceso va a estar ocupado con las peticiones ARP y
las respuestas. Este ataque se podría detectar fijándose en un decremento significativo de
paquetes ACK acompañado de un aumento significativo de los paquetes de difusión. También
podría ser detectado con el total de paquetes en tránsito en la red pero como se ha
comentado en el caso anterior, si se detecta observando sólo esa variable, se podrá identificar
que se está produciendo un ataque pero no se sabrá cuál.
(a) (b)
Figura 35: Ataque 2 a) Gráfico MEDA, b) Gráfico oMEDA.

87
Finalmente se muestra el ataque correspondiente a man‐in‐the‐middle, donde la observación
principal se iba a realizar en las solicitudes de autenticación. En la figura 36 se muestra los
gráficos MEDA (a) y oMEDA (b) utilizados para el análisis. En este caso es el gráfico oMEDA el
que ofrece información de mayor relevancia ya que muestra un incremento considerable en
las solicitudes de autenticación. En este caso el incremento o decremento en el resto de
variables no es suficiente como para poder generalizar una regla. De esta forma, se puede
detectar este ataque observando un incremento importante en los paquetes de solicitudes de
autenticación acompañado del incremento en el total de paquetes.
(a) (b)
Figura 36: Ataque 3 a) Gráfico MEDA, b) Gráfico oMEDA.
Al haber realizado el análisis de los tres ataques se pueden observar las diferencias en los
incrementos y decrementos de variables que caracterizan un tráfico concreto. No obstante,
hay una variable con la que se puede identificar que se está produciendo un ataque en los tres
casos y dicha variable es el total de paquetes. Al estar trabajando con ataques activos que
inyectan tráfico adicional a la red, todos son detectables por la cantidad total de paquetes de
forma que se podrá detectar que se está produciendo un ataque sin la necesidad de observar
el resto de variables. No obstante, éste no será el caso en todos los ataques. Para poder
trabajar también con un ataque que no produzca este incremento, se ha pensado en ejecutar
el ataque de deautenticación a baja tasa. De esta forma se pretende realizar el ataque pero de
una forma mucho más lenta para no levantar sospechas en cuanto al total de paquetes. El
atacante va recopilando la información obtenida necesitando más tiempo para descifrar la
clave. El comando utilizado para este ataque es el mismo que antes pero en la opción “‐0”
seguida de un “0” que era para indicar envíos continuos de solicitudes de deautenticación, se
propone cambiar el “0” por “3” con la idea de enviar cantidades limitadas de solicitudes de
deautenticación. El comando queda como sigue:
“aireplay‐ng ‐0 3 –a 14:D6:4D:93:E4:4C mon0”
Se toma así una nueva tanda de observaciones de 30 segundos separadas por 5 segundos en
los que no se captura tráfico. A este nuevo tráfico se le asigna el valor numérico 5 para la
identificación con Matlab. Se ha intercalado la toma de observaciones con tráfico normal y
tráfico correspondiente al ataque a baja tasa como se muestra en la tabla 5:

88
Tipo de tráfico ACK Difusión Autenticación Deaut. CTS Nº total de paquetes
TN 4142 154 0 1 10 8347
TN 4138 157 0 0 10 8097
TN 4327 151 0 0 10 8494
TN 5943 163 0 0 14 11811
TN 4619 153 0 0 10 9183
TN 4866 158 0 0 15 9423
TN 4457 150 0 0 8 8677
TN 6224 152 0 0 11 11655
TN 7802 148 0 0 9 14910
TN 4415 154 0 0 15 8549
TN 3591 152 23 0 12 7229
TN 3294 151 0 0 9 6622
TN 3883 151 0 0 11 7816
TN 3436 155 0 0 13 6858
TN 3375 153 0 0 14 6701
TN 3542 161 0 0 13 6986
TN 3644 151 0 0 9 7251
TN 3656 152 0 0 15 7224
TN 3926 168 0 0 13 7844
TN 3791 150 0 0 14 7636
TN 3866 156 23 0 8 7632
TN 4302 150 0 0 12 8545
TN 3745 153 0 0 10 7442
TN 3765 156 0 0 13 7507
TN 3562 156 0 0 11 7120
TN 3662 155 0 0 13 7330
TN 3269 157 0 0 14 6513
TN 3659 158 0 0 10 7184
TN 3265 155 0 0 11 6509
TN 3306 161 0 0 14 6711
TN 3941 153 24 0 10 7768
TN 3594 162 2 0 11 7024
TN 3562 151 0 0 14 7218
TN 4241 150 0 0 12 8584
TN 3953 152 0 0 10 7996
TN 3617 157 0 0 14 7163
TN 4200 154 0 0 13 8309
TN 4762 166 0 0 14 9292
TN 3332 158 0 0 10 6582
TN 3903 154 0 0 15 7587
A. baja tasa (A5) 4723 259 0 128 9 8978
A. baja tasa (A5) 4837 258 0 128 10 9731
A. baja tasa (A5) 4660 269 0 128 12 9245
A. baja tasa (A5) 5088 276 0 128 14 10025
A. baja tasa (A5) 4571 262 0 128 11 9073
A. baja tasa (A5) 4429 265 0 128 10 8736
A. baja tasa (A5) 5424 258 0 128 8 10694

89
A. baja tasa (A5) 4931 277 0 128 14 9758
A. baja tasa (A5) 5925 268 0 134 11 11622
A. baja tasa (A5) 5289 280 0 128 11 10566
A. baja tasa (A5) 5280 221 0 71 13 10093
A. baja tasa (A5) 5331 176 0 38 13 10457
A. baja tasa (A5) 6080 217 0 89 9 11721
A. baja tasa (A5) 7047 265 0 128 11 13672
A. baja tasa (A5) 5464 268 0 128 8 10790
A. baja tasa (A5) 4914 270 0 128 12 9576
A. baja tasa (A5) 5395 274 0 128 13 10533
A. baja tasa (A5) 3491 292 2 128 8 7059
A. baja tasa (A5) 1553 298 0 128 11 3364
A. baja tasa (A5) 1440 291 0 128 9 3135
A. baja tasa (A5) 1408 294 0 128 9 3095
A. baja tasa (A5) 1348 291 0 128 13 2962
A. baja tasa (A5) 1360 294 0 128 12 3009
A. baja tasa (A5) 1354 291 0 128 16 2950
A. baja tasa (A5) 2270 299 0 128 14 4764
A. baja tasa (A5) 2665 307 0 128 10 5558
A. baja tasa (A5) 3016 292 0 128 11 6191
A. baja tasa (A5) 2663 289 0 128 10 5390
A. baja tasa (A5) 2819 294 0 128 12 5693
A. baja tasa (A5) 9781 205 0 128 12 18964
A. baja tasa (A5) 9046 141 0 54 7 17823
A. baja tasa (A5) 9794 107 0 23 8 19181
A. baja tasa (A5) 7891 177 0 76 8 15235
A. baja tasa (A5) 4009 191 0 48 14 7935
A. baja tasa (A5) 4463 276 0 128 11 8852
A. baja tasa (A5) 4374 273 0 128 9 8547
A. baja tasa (A5) 4631 259 0 128 13 9259
A. baja tasa (A5) 3901 266 0 128 12 7734
A. baja tasa (A5) 4937 270 0 128 8 9732
A. baja tasa (A5) 3985 271 0 128 12 7970
TN 4201 158 17 0 10 8202
TN 4012 151 0 0 10 7695
TN 3868 153 0 0 13 7518
TN 3964 155 0 0 12 7754
TN 4330 151 0 0 12 8370
TN 4525 151 0 0 14 8676
TN 5054 159 1 0 13 9454
TN 4786 147 0 0 11 9078
TN 4660 157 2 0 12 9127
TN 4571 150 0 0 10 8902
TN 3322 165 0 0 12 6619
TN 3717 165 0 0 10 7545
TN 3795 151 0 0 11 7624
TN 3834 160 0 0 10 7592
TN 3817 152 0 0 15 7651

90
TN 3740 168 0 0 11 7343
TN 3641 153 0 0 13 7202
TN 3448 155 0 0 13 6947
TN 4066 156 0 0 14 8023
TN 3968 154 0 0 13 7716
TN 3619 159 23 0 12 7250
TN 4039 153 0 0 13 7955
TN 4016 151 0 0 10 7972
TN 3730 152 0 0 13 7409
TN 3712 160 2 0 10 7443
A. baja tasa (A5) 5007 277 0 128 12 9981
A. baja tasa (A5) 4414 263 0 128 10 8797
A. baja tasa (A5) 4326 262 0 128 7 8536
A. baja tasa (A5) 4364 273 0 128 10 8704
A. baja tasa (A5) 4221 258 0 128 9 8382
A. baja tasa (A5) 4382 277 0 128 10 8785
A. baja tasa (A5) 4132 278 0 128 10 8260
A. baja tasa (A5) 4420 270 0 128 15 8756
A. baja tasa (A5) 4567 159 0 37 8 8914
A. baja tasa (A5) 4115 268 0 128 11 8141
A. baja tasa (A5) 3974 263 0 128 11 7863
A. baja tasa (A5) 5056 276 0 128 8 9953
A. baja tasa (A5) 4115 211 0 62 10 8090
A. baja tasa (A5) 4847 275 0 128 10 8926
A. baja tasa (A5) 6846 266 0 128 10 13132
A. baja tasa (A5) 5113 259 0 128 10 10049
A. baja tasa (A5) 4473 261 0 128 7 8723
A. baja tasa (A5) 4406 273 0 128 13 8663
A. baja tasa (A5) 4292 278 0 128 10 8557
A. baja tasa (A5) 4233 194 0 44 11 8412
A. baja tasa (A5) 4729 258 0 128 12 9518
A. baja tasa (A5) 3865 188 0 53 11 7673
A. baja tasa (A5) 4519 276 0 128 10 9088
A. baja tasa (A5) 4291 268 0 128 12 8584
A. baja tasa (A5) 4566 271 0 128 10 9152
TN 4096 158 0 0 14 8355
TN 3597 151 0 0 12 7559
TN 3618 152 0 0 12 7200
TN 3799 154 0 0 8 7662
TN 3792 166 0 0 11 7530
TN 3847 171 0 0 15 7710
TN 4149 163 0 0 14 8310
TN 4535 152 0 0 10 9032
TN 4380 152 0 0 13 8716
TN 4502 157 0 0 11 9111
TN 4174 153 0 0 12 8363
TN 3743 158 0 0 11 7405
TN 3586 154 0 0 15 7204

91
TN 3507 146 0 0 10 6871
TN 4171 159 0 0 9 7885
TN 4132 155 0 0 14 8076
TN 3850 154 0 0 16 7760
TN 3619 158 0 0 11 7414
TN 4128 151 0 0 12 8365
TN 3761 157 0 0 14 7583
TN 3428 154 0 0 13 6962
TN 3750 156 0 0 12 7652
TN 5224 148 0 0 12 10427
TN 4248 134 0 0 11 8552
TN 3893 155 0 0 15 8173
A. baja tasa (A5) 3717 274 0 128 13 7464
A. baja tasa (A5) 5019 256 0 128 9 10063
A. baja tasa (A5) 4384 260 0 128 13 8707
A. baja tasa (A5) 4282 278 0 128 8 8549
A. baja tasa (A5) 3985 278 0 128 9 7933
A. baja tasa (A5) 3724 287 0 128 13 7434
A. baja tasa (A5) 3952 268 0 128 9 7849
A. baja tasa (A5) 4615 271 0 128 13 9050
A. baja tasa (A5) 3442 275 0 128 11 6877
A. baja tasa (A5) 3517 285 0 128 14 7148
A. baja tasa (A5) 4048 177 0 35 11 8110
A. baja tasa (A5) 4821 274 0 128 8 9741
A. baja tasa (A5) 3938 277 0 128 13 7983
A. baja tasa (A5) 4270 263 0 128 12 8609
A. baja tasa (A5) 4458 260 0 128 13 8961
A. baja tasa (A5) 4333 267 0 128 12 8732
A. baja tasa (A5) 4089 270 0 128 11 8259
A. baja tasa (A5) 4833 277 0 128 13 9727
A. baja tasa (A5) 4078 216 0 82 10 8204
A. baja tasa (A5) 4077 264 0 128 11 8197
A. baja tasa (A5) 4243 178 0 37 13 8384
A. baja tasa (A5) 4483 192 0 57 13 8952
A. baja tasa (A5) 3946 288 0 128 8 7927
A. baja tasa (A5) 4341 276 0 128 11 8710
A. baja tasa (A5) 4636 270 2 128 9 9344
A. baja tasa (A5) 4271 268 0 128 7 8571
A. baja tasa (A5) 4506 257 0 128 14 9034
A. baja tasa (A5) 5242 227 0 96 11 10213
A. baja tasa (A5) 4138 282 0 128 12 8287
A. baja tasa (A5) 4647 279 0 128 11 9065
A. baja tasa (A5) 4791 274 0 128 13 9633
A. baja tasa (A5) 5334 277 0 128 8 10610
A. baja tasa (A5) 4497 276 0 128 9 8845
A. baja tasa (A5) 4659 263 0 128 9 9325
Tabla 5: Observaciones correspondientes al tráfico producido por el ataque de deautenticación a baja tasa.

92
En la figura 37 se muestra el gráfico de dispersión incluyendo en el conjunto de observaciones
aquellas que se corresponden al tráfico del ataque de deautenticación pero con baja tasa
(añadiendo las observaciones correspondientes al ataque de baja tasa al fichero donde se
encontraban las observaciones del resto de ataques). Ocurre un fenómeno llamativo ya que las
observaciones etiquetadas como 5 y las observaciones etiquetadas como 1 se agrupan
creando un mismo grupo, sin embargo no aparecen mezcladas con las observaciones
etiquetadas por 2 que correspondía al tráfico del ataque de deautenticación a alta tasa. A
simple vista no se distingue el tráfico del nuevo ataque del tráfico normal de la red lo cual lleva
a un análisis más exhaustivo que permita la diferenciación y detección de ataques a baja tasa.
Figura 37: Gráfico de dispersión con las nuevas observaciones producidas por el ataque a baja tasa.
Se trabaja entonces sólo con las observaciones de tráfico normal y con las del nuevo ataque
para observar las diferencias y poder establecer reglas de generalización de detección. El
nuevo gráfico de dispersión se muestra en la figura 38. En este caso el análisis de las
componentes principales sí que muestra dos agrupaciones claramente diferenciadas entre el
tráfico normal (1) y el tráfico producido por el nuevo ataque (5). Ya se puede proseguir con los
gráficos MEDA y oMEDA para obtener más información de lo que está ocurriendo.

93
Figura 38: Gráfico de dispersión con tráfico normal (1) frente a nuevo ataque (5).
En la figura 39 se muestran los gráficos MEDA (a) y oMEDA (b). De forma teórica se supone que
no se debería obtener gran cambio en el total de paquetes pero se debe observar una
diferencia en las solicitudes de deautenticación o en otras variables para que el ataque pueda
ser detectado. El gráfico MEDA ya hace ver algo interesante, ya que sólo muestra
dependencias entre las solicitudes de deautenticación y los paquetes de difusión. El punto
clave se encuentra en el gráfico oMEDA en el que se puede observar un incremento de en total
de paquetes prácticamente despreciable y no detectable. Sin embargo, se mantiene la
diferencia radical tanto en solicitudes de deautenticación como en los paquetes de difusión lo
cual muestra que será necesario observar en una red inalámbrica estas variables y no el total
de paquetes en la red, ya que un ataque a baja tasa es igualmente efectivo pero no activa
alarmas en cuanto al tráfico total de la red.
(a) (b)
Figura 39: Ataque 1 baja tasa a) Gráfico MEDA, b) Gráfico oMEDA.

94
Como última etapa del proyecto se muestran los resultados correspondientes al trabajo con
los clasificadores ya mencionados realizando una comparación de efectividad para el caso
concreto de los tráficos aquí analizados. Para el entrenamiento de los clasificadores se han
utilizado las observaciones mostradas con anterioridad pero para la clasificación de nuevas
observaciones se han vuelto a realizar observaciones en la red con el mismo procedimiento
seguido inicialmente para que las condiciones sean lo más similares posible. En este caso se
han obtenido un total de 138 observaciones siendo 40 de tráfico normal, 38 de tráfico
correspondiente al ataque 1, 30 al ataque 2 y otras 30 al ataque 3. Las nuevas observaciones
se presentan en la tabla 6:
Tipo de tráfico
Nº ACK Nº paq Broad.
Solicitud autentic.
Solicitud deaunt.
CTS Total paquetes
TN (1) 3405 148 0 0 12 6746
TN (1) 3835 149 0 0 11 7699
TN (1) 3792 159 0 0 12 7667
TN (1) 3668 146 0 0 13 7461
TN (1) 3608 173 0 0 11 7343
TN (1) 3777 146 0 0 10 7619
TN (1) 4014 148 0 0 10 8117
TN (1) 3462 180 0 0 14 7067
TN (1) 3738 155 0 0 12 7458
TN (1) 3463 152 0 0 13 6949
A1 (2) 4162 7964 0 7820 15 15835
A1 (2) 3830 8296 0 8142 10 15135
A1 (2) 4006 8213 0 8056 14 15722
A1 (2) 4018 8300 0 8135 11 15805
A1 (2) 3630 8319 0 8144 14 14989
A1 (2) 3922 8242 0 8064 11 15595
A1 (2) 3740 8285 0 8118 11 15355
A1 (2) 3944 8172 0 8009 14 15872
A1 (2) 3922 8270 0 8109 11 15829
A1 (2) 3758 8108 0 7966 11 15424
A2 (3) 3705 333 0 187 10 6724
A2 (3) 3119 14156 0 0 13 20273
A2 (3) 3290 14445 0 0 14 20755
A2 (3) 2762 14406 0 0 11 19826
A2 (3) 3161 14344 0 0 12 20601
A2 (3) 1916 14872 0 0 12 18678
A2 (3) 2034 14753 0 0 13 18804
A2 (3) 1781 14949 0 0 12 18463
A2 (3) 1658 14926 0 0 16 18235
A2 (3) 1959 14435 0 0 11 18315
A3 (4) 3107 369 627 0 12 7160
A3 (4) 2309 159 480 0 10 5218
A3 (4) 2439 161 509 0 15 5511
A3 (4) 2896 153 592 0 11 6509
A3 (4) 2043 160 444 0 15 4726
A3 (4) 2567 150 540 0 13 5825

95
A3 (4) 5330 164 1075 0 12 11802
A3 (4) 4184 143 838 0 9 9232
A3 (4) 6513 143 1275 0 11 14319
A3 (4) 4187 145 853 0 9 9318
TN (1) 3879 196 23 0 13 7954
TN (1) 5389 164 0 0 9 10782
TN (1) 3544 155 0 0 12 7232
TN (1) 7050 131 0 0 9 14416
TN (1) 4107 150 0 0 13 8262
TN (1) 3734 181 0 0 14 7672
TN (1) 4010 149 0 0 12 7918
TN (1) 3994 157 0 0 12 7842
TN (1) 4063 148 0 0 13 8077
TN (1) 2788 158 0 0 12 5662
A1 (2) 1680 8096 0 7936 15 11454
A1 (2) 1654 8218 0 8069 13 11443
A1 (2) 1569 8243 0 8088 12 11368
A1 (2) 1487 8309 0 8150 12 11377
A1 (2) 1673 8317 0 8163 15 11707
A1 (2) 1327 8278 0 8122 13 10978
A1 (2) 1332 8299 0 8133 15 11018
A1 (2) 1255 8311 0 8155 10 10836
A1 (2) 1523 8298 0 8145 13 11306
A1 (2) 1358 8255 0 8099 11 10986
A2 (3) 1300 352 0 203 10 2858
A2 (3) 1292 176 0 0 13 2856
A2 (3) 1313 203 0 0 17 2999
A2 (3) 1399 231 0 0 12 3146
A2 (3) 1351 179 0 0 13 2959
A2 (3) 1306 13392 0 0 10 16151
A2 (3) 1219 14877 0 0 14 17447
A2 (3) 1238 15004 0 0 14 17665
A2 (3) 1331 15018 0 0 14 17889
A2 (3) 1293 14992 0 0 12 17698
A3 (4) 1370 405 322 0 9 3567
A3 (4) 1427 168 355 0 14 3577
A3 (4) 1354 173 326 0 15 3328
A3 (4) 1414 189 354 0 14 3536
A3 (4) 1451 206 346 0 13 3540
A3 (4) 1958 157 434 0 12 4576
A3 (4) 1341 153 335 0 15 3365
A3 (4) 1574 170 379 0 13 3845
A3 (4) 1693 167 428 0 14 4276
A3 (4) 1303 165 226 0 12 3089
TN (1) 1345 167 0 0 15 2903
TN (1) 1533 231 7 1 12 3412
TN (1) 2832 192 0 0 16 5540
TN (1) 3759 156 0 0 13 7163

96
TN (1) 3535 170 0 0 16 7001
TN (1) 2162 172 0 0 13 4459
TN (1) 1394 176 0 0 14 3034
TN (1) 1408 167 0 0 13 3004
TN (1) 1738 216 0 0 16 3642
TN (1) 1636 171 0 0 16 3439
A1 (2) 1467 8117 0 7977 17 11122
A1 (2) 1550 8287 0 8168 15 11360
A1 (2) 1496 8277 0 8150 15 11270
A1 (2) 1466 8302 0 8186 15 11288
A1 (2) 1434 8268 0 8163 16 11176
A1 (2) 1312 8249 0 8122 16 10963
A1 (2) 1561 8313 0 8171 12 11443
A1 (2) 1471 8294 0 8165 13 11375
A1 (2) 1532 8358 0 8198 13 11502
A1 (2) 1346 6835 0 6703 10 9535
A2 (3) 1448 9492 0 0 16 12437
A2 (3) 1397 15033 0 0 10 17876
A2 (3) 1303 14997 0 0 14 17644
A2 (3) 2048 14535 0 0 14 18391
A2 (3) 6372 12175 0 0 12 23542
A2 (3) 6103 10935 0 0 9 22943
A2 (3) 6700 11048 0 0 9 23697
A2 (3) 6114 10069 0 0 524 22300
A2 (3) 7023 11308 0 0 6 23577
A2 (3) 6350 11183 0 0 12 21608
A3 (4) 9734 241 1581 0 13 19481
A3 (4) 9769 140 1581 0 11 19316
A3 (4) 9797 145 1342 0 12 17866
A3 (4) 9938 148 1532 0 10 19139
A3 (4) 9880 157 1916 0 13 21391
A3 (4) 9727 141 2080 0 10 22221
A3 (4) 9972 150 1632 0 13 19779
A3 (4) 10826 173 1798 0 184 21966
A3 (4) 11680 133 1810 0 473 23487
A3 (4) 11151 139 2117 0 404 24698
TN (1) 11733 150 19 0 700 22442
TN (1) 11613 132 0 0 134 20437
TN (1) 11784 148 0 0 158 21387
TN (1) 11963 148 0 0 13 21472
TN (1) 11636 162 0 0 13 23109
TN (1) 11723 142 0 0 168 21636
TN (1) 11288 137 0 0 9 20958
TN (1) 11677 150 0 0 79 21997
TN (1) 11634 158 0 0 12 22937
TN (1) 11730 148 0 0 10 20735
A1 (2) 10861 7940 0 7799 12 29423
A1 (2) 11437 7975 0 7831 106 29908

97
A1 (2) 11163 7981 0 7842 12 29463
A1 (2) 11191 7894 0 7755 483 30543
A1 (2) 11336 7998 0 7847 13 29040
A1 (2) 11387 7994 0 7848 11 28795
A1 (2) 11565 7715 0 7565 12 27787
Tabla 6: Nuevas observaciones a clasificar.
En primer lugar se comienza con los algoritmos basados en vecindad. Si se asigna el valor 1 a K
y se ejecuta el código del anexo III, se obtiene un vector formado por los números
correspondientes a las clases asignadas por el clasificador. En la tabla 7 se muestra la clase a la
que deberían pertenecer las observaciones y la clase a la que pertenecen finalmente. En rojo
se indican las observaciones mal clasificadas:
Clase a la que deberían pertenecer Clase asignada por el clasificador
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 1
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3

98
3 3
4 4
4 1
4 1
4 1
4 1
4 1
4 4
4 4
4 1
4 4
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 1
3 1
3 1
3 1
3 1
3 3
3 3
3 3
3 3
3 3
4 1
4 1
4 1
4 1
4 1
4 1
4 1

99
4 1
4 1
4 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
1 1
1 1
1 1
1 1
1 1

100
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2 Tabla 7: Clasificación realizada por el clasificador NN.
Se observa que principalmente las confusiones se producen entre el tráfico normal y el tráfico
producido por el ataque man‐in‐the‐middle. En cuanto al error, se obtiene un error del
23.3577% que es un error bastante alto por lo que no se recomienda el uso de este
clasificador. Ahora se varía el valor de K y se procede a una calibración inicial del método para
obtener el valor de K óptimo para este experimento. Se toman las 350 observaciones utilizadas
para el análisis multivariante anterior y se dividen en: 200 observaciones para el
entrenamiento y 150 para la clasificación con distintos valores de K. El valor usado para la
clasificación de las nuevas observaciones (u observaciones futuras) será el óptimo obtenido en
el proceso de calibración. Los valores de K obtenidos con sus correspondientes valores de error
se muestran en la tabla 8, cuya gráfica correspondiente se muestra en la figura 40:
Valor de K Error (%)
2 4
3 3
4 3
5 0,6667
6 0,6667
7 2
8 2
9 2,6667
10 2,6667
11 3,333
12 3,333
13 3,333 Tabla 8: Estudio del valor óptimo de K.

101
Figura 40: Error frente a valores de K.
En función a los valores de error, se selecciona el valor K=5, que aplicándolo al conjunto de
nuevas observaciones se obtiene un error del 24.0876%, lo que es superior al valor obtenido
con K=1. En este caso el clasificador KNN no ofrece resultados mejores que en NN. Una vez
realizado el cálculo con los algoritmos basados en vecindad, se prosigue con el resto de
algoritmos. Para el algoritmo PLS‐DA será necesario seguir un procedimiento similar al seguido
con los basados en vecindad. En este caso, uno de los argumentos de la función es determinar
las variables latentes del modelo. Se toman de nuevo las 350 observaciones utilizadas para el
análisis multivariante inicial y divididas en 200 observaciones para el entrenamiento y 150 para
la clasificación con distintos valores de variables latentes. En función de las 350 observaciones
se obtienen los valores de error mostrados en la tabla 9 dependiendo del valor de variables
latentes.
Valor de variables latentes Error (%)
1 60,58
2 56,9343
3 47,4453
4 43,0657
5 40,8759
6 38,6861
7 38,6861
8 38,6861
9 38,6861 Tabla 9: Error obtenido dependiendo del valor de variables latentes asignado.
El error producido en la clasificación es decreciente conforme aumenta el valor de variables
latentes hasta que llega a un punto en el que se estabiliza. El valor óptimo se selecciona como
6 y se realiza la clasificación de las nuevas observaciones obteniendo un error del 17,5182%.
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
0 2 4 6 8 10 12 14
error (%)
K
Error frente a K

102
En la tabla 10 se muestra los resultados de error obtenidos para los diferentes tipos de
clasificadores.
Tipo de clasificador Error (%)
NN 23,3577
KNN (K=5) 24,0876
Árbol de clasificación 5,1095
LDA 6,5693
QDA 6,5693
PLS‐DA 17,5182
Red bayesiana 10,9489 Tabla 10: Comparación de errores obtenidos con los distintos clasificadores.
Como se observa en la tabla, el algoritmo que mejor ha respondido en la clasificación de las
observaciones ha sido el de “árbol de clasificación”, si bien su rendimiento es muy cercano al
de LDA y QDA. A continuación se muestra una tabla donde se presentan la clase en la que
deberían haber sido clasificadas las observaciones y la clase que ha sido asignada por el
clasificador. Las clasificaciones erróneas se muestran en rojo:
Clase a la que deberían pertenecer Clase asignada por el clasificador
1 2
1 1
1 1
1 2
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 3
3 3
3 3
3 3
3 3
3 3
3 3

103
3 3
3 3
3 3
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 3
3 1
3 1
3 3
3 1
3 3
3 3
3 3
3 3
3 3
4 4
4 4
4 4
4 4
4 4
104
4 4
4 4
4 4
4 4
4 1
1 1
1 3
1 1
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
3 3
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
4 4
1 1
1 1
1 1

105
1 1
1 1
1 1
1 1
1 1
1 1
1 1
2 2
2 2
2 2
2 2
2 2
2 2
2 2 Tabla 11: Clasificación realizada por el clasificador “árbol de clasificación”.
El mejor método de clasificación para el caso concreto mostrado en este proyecto es la
utilización de un clasificador basado en “árbol de clasificación”, seguido de cerca por las
técnicas de análisis discriminante. Consiguiendo que la gran mayoría de las nuevas
observaciones sean clasificadas de forma correcta.
También hay que evaluar las observaciones obtenidas en el caso de ataque de baja tasa. Se
aplican los distintos clasificadores para la diferenciación de tráfico normal y tráfico producido
por ataque de deautenticación a baja tasa. En primer lugar se repite el procedimiento seguido
anteriormente para los algoritmos basados en vecindad. En este caso se utiliza un conjunto de
observaciones correspondientes al tráfico normal y la ataque de baja tasa. En total se disponen
de 189 observaciones divididas en: 80 observaciones (40 tráfico normal + 40 ataque de baja
tasa) para el entrenamiento del clasificador, 50 observaciones (25 tráfico normal + 25 ataque
de baja tasa) para la selección del valor óptimo de K y finalmente 59 observaciones (25 tráfico
normal + 34 ataque de baja tasa) para la nueva clasificación. En la tabla 12 se muestran los
resultados de error obtenidos dependiendo del valor de K:
K Error (%)
1 16
2 16
3 18
4 20
5 26
6 26
7 38
8 36 Tabla 12: Error en función de K.
Para K=2 se clasifican las nuevas observaciones obteniendo un error del 18,6441%, obteniendo
también para el caso NN (K=1) un error del mismo valor. Se repite el proceso también para el

106
caso del clasificador PLS‐DA en función de las variables latentes obteniendo los resultados de
error en función de L (número de variables latentes del modelo) de la tabla 13:
L Error (%)
1 24
2 8
3 10
4 4
5 4
6 4 Tabla 13: Error en función de las variables latentes del modelo.
Seleccionando el valor L=4 se obtiene un error en la clasificación del nuevo grupo de
observaciones del 3,3898%. En la tabla 14 se muestran los resultados comparativos
correspondientes a los errores de clasificación producidos al hacer uso de los distintos
clasificadores en el caso del ataque de baja tasa:
Tipo de clasificador Baja tasaError (%)
3 ataques anteriores Error (%)
NN 18,6441 23,3577
KNN (K=2) 18,6441 24,0876
Árbol de clasificación 0 5,1095
LDA 3,3898 6,5693
QDA 0 6,5693
PLS‐DA 3,3898 17,5182
Red bayesiana 0 10,9489 Tabla 14: Comparación de errores obtenidos con los distintos clasificadores para el ataque a baja tasa y para los
cálculos obtenidos en el caso de los 3 ataques.
En esta última tabla se observa que los datos de exactitud en la clasificación son muy
superiores a los obtenidos anteriormente. Se vuelven a obtener datos mejores en árbol de
clasificación y QDA y los peores datos se obtienen para los algoritmos basados en vecindad.
8. CONCLUSIONES Y TRABAJO FUTURO
Al haber llevado a cabo el diseño y ejecución de las pruebas mostradas en este documento se
pueden sacar una serie de conclusiones a continuación expuestas. En primer lugar es posible
caracterizar el tráfico producido por un ataque contra la seguridad de una red inalámbrica.
Esto va a permitir poder activar alarmas dentro de la red si esto se produce. Además, es
posible identificar el tipo de ataque que se está produciendo. Esto puede ser útil para llevar a
cabo una acción en contra de un ataque concreto.

107
Se ha podido comprobar la efectividad del análisis multivariante con los métodos explicados
“PCA”, “MEDA” y “oMEDA” tanto para la detección de agrupaciones en los tipos de tráfico
como para la detección de variables importantes y de observaciones y variables irrelevantes.
Se han podido detectar las variables de mayor relevancia centrando así la atención en esas
variables y no en las que no ofrecen información decisiva, lo cual aumenta la eficiencia del
estudio. También se ha comprobado la efectividad de los clasificadores estudiados, capaces de
aprender de un conjunto de datos de entrenamiento, pudiendo así realizar una clasificación de
nuevas observaciones.
Para el trabajo futuro se propone la elaboración de las respuestas por parte del punto de
acceso a los ataques aquí analizados, de forma que si se produce un ataque, el propio punto de
acceso cambie la contraseña de la red y la distribuya entre los equipos conectados o active una
alarma indicando al administrador de la red que se ha intentado acceder a la información
personal. También se puede extender este estudio a tantos ataques como se desee, ya que se
disponen de las herramientas de análisis adecuadas para ser llevado a cabo, por ejemplo la
caracterización del ataque de redirección IP o el de reacción.
También se puede trabajar con los ataques utilizados en redes protegidas con seguridad WPA y
WPA2 ya que cada vez se va utilizando de forma más generalizada este tipo de seguridad en
redes inalámbricas. Se propone el uso del análisis exploratorio de datos y los clasificadores
para poder realizar un estudio similar al aquí presentado pero con seguridad WPA/WPA2.
La información transmitida en una red inalámbrica ofrece una serie de facilidades como la
movilidad y la comodidad que no ofrecen las redes cableadas. Sin embargo, la información va
a estar en peligro si no se toman las medidas de seguridad y protección oportunas, lo cuál va a
llevar a una actualización continua de las tecnologías de protección de las redes inalámbricas al
mismo tiempo que surgen ataques en contra de los protocolos de seguridad.

108
BIBLIOGRAFÍA
[1] Alan Holt y Chi‐yu Huang, 802.11 Wireless networks: security and analysis, Springer.ISBN
978‐1‐84996‐274‐2.
[2] http://www.wi‐foo.com/
[3] “Wireless attacks from an intrusion detection perspective”, SANS Institute, November
2006.
[4] “Break WEP Faster with Statistical Analysis”, École Polytechnique Fédérale de Lausanne,
June 2006.
[5] Kim H. Esbensen. Multivariate Data Analysis: in practice. Camo. ISBN: 82‐993330‐3‐2.
[6] Izaskun Pellejero. Fundamentos y aplicaciones de seguridad en redes WLAN. Marcombo.
ISBN 84‐267‐1405‐6
[7] Pedro García Teodoro. Transmisión de datos y redes de computadores. Pearson Educación,
2007. ISBN: 9788420539195 8420539198.
[8] Krishna Sankar. Cisco Wireless LAN Security. Cisco Press. ISBN: 1‐58705‐154‐0
[9] Exploratory Data Analysis Toolbox. Descargable desde la url
http://wdb.ugr.es/~josecamacho/downloads.php
[11] Toolbox PLS‐DA, programas descargables desde la url
http://www.mathworks.com/matlabcentral/fileexchange/30685‐pls‐regression‐or‐
discriminant‐analysis‐with‐leave‐one‐out‐cross‐validation‐and‐
prediction/content/PLS/plspred.m
[12] Basilio Sierra Araujo. Aprendizaje automático: Conceptos básicos y avanzados. Pearson.
ISBN 10: 84‐8322‐318‐X. ISBN 13: 978‐84‐8322‐815‐5.

109
ANEXO I: CAPTURA DE PAQUETES CON LIBPCAP
Código C basado en librería libpcap para la captura de paquetes:
“capturaPaquetes.c”
#include <stdio.h> #include <stdlib.h> #include <errno.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <pcap.h> #include <netinet/if_ether.h> #include <netinet/ip.h> #include <netinet/tcp.h> #include <time.h> // Variables static int count = 1; static int paqArp = 0; static int paqAck = 0; static int paqBroad = 0; static int paqSolAso = 0; // Contabilidad de los paquetes de solicitud de asociación. static int paqResAso = 0; // Contabilidad de los paquetes de respuesta de asociación. static int paqAut = 0; // Contabilidad de los paquetes de autenticación. static int paqDeauth = 0; // Contabilidad de los paquetes de deautenticación. static int paqRts = 0; // Contabilidad de los paquetes RTS. static int paqCts = 0; // Contabilidad de los paquetes CTS. static int registroDatos = 0; // Función para el volcado de datos a un fichero de texto de forma que puedan ser introducidos como variable en matlab. void volcado(void) { FILE *pf; // Se abre el fichero. En caso de devolver 0 es que se ha producido error. if((pf = fopen("2606.txt", "a"))==0) {printf("Error abriendo el fichero....");exit(0);} else { // En caso contrario se añaden todos los datos numericos separados por un espacio terminando con un salto de línea para que la siguiente vez se escriba en otra fila. fprintf(pf, "%u %u %u %u %u %u %u\n", paqAck, paqBroad, paqAut, paqDeauth, paqRts, paqCts, count); // Se cierra el fichero. fclose(pf); } } // Función ejecutada cada vez que se capture un paquete. Lo que hace es analizar las cabeceras para indicar el tipo de paquete que es.

110
void examenPaquete(u_char *useless, const struct pcap_pkthdr* pkthdr, const u_char* packet) { int i; char *aux1, *aux2, *aux3; char *puntero; // (1 byte) /* Usamos este puntero para ir llevando la cuenta. */ char *auxiliar; int tipo, subtipo, punteroAux, valor, deauth, radioTapHeader; // Se incrementa el contador para saber cuántos paquetes van. count++; // Se inicializan las variables valor=0; deauth=0; radioTapHeader=0; // Se hace que el puntero apunte a la dirección donde se encuentra el valor de la longitud de la cabecera Tap. puntero = packet + 2; // Se extrae el valor de la longitud radioTapHeader = *puntero; // Los archivos tienen una cabecera radiotap que sumandola a la dirección de comienzo del paquete se puede continuar analizando el contenido. puntero = packet + radioTapHeader; // Ahora puntero apunta al principio de la cabecera 802.11 en el que se mira en primer lugar el tipo y subtipo: punteroAux = *puntero; // se guarda en punteroAux lo que hay en la zona de memoria apuntada por puntero. tipo = punteroAux & 0x0F; // 4 bits correspondientes al tipo subtipo = punteroAux & 0xF0; // 4 bits correspondientes al subtipo // Para hacer la clasificación, hay tres tipos dependiendo del valor de tipo: 0 (Admin), 4 (control), 8 ó 12 (datos). if (tipo==0) // Bits 3 y 2 del campo "control de trama" a 00 ‐‐> 0000 ‐‐> Administración // Una vez se conoce el tipo, se analizan los subtipos relacionados con este proyecto: switch(subtipo) { case 0: // En este caso 0 ‐‐> 0000 0000 ‐‐> Solicitud de asociación paqSolAso++;break; case 16: // En este caso 16 ‐‐> 0001 0000 ‐‐> Respuesta de asociación paqResAso++;break; case 176: // En este caso 176 ‐‐> 1011 0000 ‐‐> Solicitud de autenticación paqAut++;break; case 192:

111
// En este caso 192 ‐‐> 1100 0000 ‐‐> Solicitud de deautenticación paqDeauth++;break; } } else { if (tipo==4) {// Bits 3 y 2 del campo "control de trama" a 01 ‐‐> 0100 ‐‐> control switch(subtipo) { case 176: // En este caso 176 ‐‐> 1011 0000 ‐‐> campo control de trama: 1011 0100 ‐‐> RTS paqRts++;break; case 192: // En este caso 192 ‐‐> 1100 0000 ‐‐> campo control de trama: 1100 0100 ‐‐> RTS paqCts++;break; case 208: // En este caso 208 ‐‐> 1101 0000 ‐‐> campo control de trama: 1101 0100 ‐‐> ACK paqAck++;break; } } else // Bits 3 y 2 del campo "control de trama" a 10 ó 11 ‐‐> 1000 / 1100 ‐‐> datos {// Paquete de datos, no se hace nada } } // Para saber si el paquete es broadcast o no hay que mirar si están activos los bits "toDs o FromDs", detectar la posición mac destino y ver si es broadcast // En primer lugar el puntero apunta a la cabecera 802.11 puntero = packet + radioTapHeader + 1; // Se selecciona el valor de los campos "toDs y FromDs" punteroAux = *puntero & 0x03; // Ahora dependiendo del valor obtenido se analiza la dirección mac destino switch(punteroAux) { case 0: // En este caso tenemos fromDs 0 toDs 0, Sta‐>Sta // Tendremos entoces la siguiente asignacion de direcciones MAC // MAC1 ‐> Destino. // MAC2 ‐> Origen. // MAC3 ‐> BSSID. // La dirección a la que hay que acceder de la cabecera 802.11 está a 4 bytes de diferencia de la incial: saltando el campo control de trama y nav. aux1 = packet + radioTapHeader + 4; // Con un bucle for se recorren los 6 valores numéricos de la dirección MAC destino y si todos tienen el valor 255 es que el destino es broadcast. for ( i = 1; i <=6 ; i++) {

112
valor = *aux1; valor = valor & 0xff; if(valor!=255) {// No es broadcast, por lo que se sale del bucle for break;} // En el caso de estar en la última posición y es 255 sí que es un paquete broadcast por lo que se incrementa el contador if(i==6 && valor==255) {paqBroad++;} aux1 = aux1 + 1; } break; case 1: // En este caso tenemos fromDs 0 toDs 1, Sta‐>AP // Tendremos entoces la siguiente asignacion de direcciones MAC // MAC1 ‐> BSSID. // MAC2 ‐> Origen. // MAC3 ‐> Destino. // Al ser la dirección MAC 3 la de destino, hay que desplazarse 2 (control de trama) + 2 (NAV) + 6 (direcc. mac 1) + 6 (direcc. mac 2) = 16 aux1 = packet + radioTapHeader + 16; // Con un bucle for se recorren los 6 valores numéricos de la dirección MAC destino y si todos tienen el valor 255 es que el destino es broadcast. for ( i = 1; i <=6 ; i++) { valor = *aux1; valor = valor & 0xff; if(valor!=255) {// No es broadcast, por lo que se sale del bucle for break;} // En el caso de estar en la última posición y es 255 sí que es un paquete broadcast por lo que se incrementa el contador if(i==6 && valor==255) {paqBroad++;} aux1 = aux1 + 1; } break; case 2: // En este caso tenemos fromDs 1 toDs 0, AP‐> Sta // Tendremos entoces la siguiente asignacion de direcciones MAC // MAC1 ‐> Destino. // MAC2 ‐> BSSID. // MAC3 ‐> Origen // La dirección se encuentra en la misma posición que en el primer caso. aux1 = packet + radioTapHeader + 4; // Con un bucle for se recorren los 6 valores numéricos de la dirección MAC destino y si todos tienen el valor 255 es que el destino es broadcast. for ( i = 1; i <=6 ; i++) { valor = *aux1; valor = valor & 0xff; if(valor!=255) {// No es broadcast, por lo que se sale del bucle for

113
break;} // En el caso de estar en la última posición y es 255 sí que es un paquete broadcast por lo que se incrementa el contador if(i==6 && valor==255) {paqBroad++;} aux1 = aux1 + 1; } break; case 3: // En este caso tenemos fromDs 1 toDs 1, AP‐> AP // Comunicación entre puntos de acceso return; } } int main(int argc, char **argv) { // Se indica el nombre de la interfaz de la que se capturan los paquetes, en este caso será wlan0 en modo monitor ‐‐> mon0 char *dev="mon0"; char errbuf[PCAP_ERRBUF_SIZE]; pcap_t* descr; bpf_u_int32 maskp; // Máscara de subred bpf_u_int32 netp; // Dirección de red int aux; int contador = 0; time_t t1,t2; int tiempo = 0; // Si el dispositivo no se encuentra se muestra por pantalla el error y se sale del programa if (dev == NULL) {fprintf(stderr," %s\n",errbuf); exit(1);} else { // Si el dispositivo se encuentra se continua con el programa printf("Abriendo %s en modo promiscuo\n",dev);} // Se extrae la direccion de red y la mascara pcap_lookupnet(dev,&netp,&maskp,errbuf); // Se inicia la captura para lo que se necesita especificar el dispositivo y // además hay que ver si se produce error. En caso de error, éste se muestra // por pantalla y el programa termina. if((descr=pcap_open_live(dev, BUFSIZ, 1, ‐1, errbuf))==NULL) {printf("pcap_open_live(): %s \n", errbuf);exit(‐1);} // Si no hay error se inicia el programa de captura pero en primer lugar // hay que tomar medida de los tiempos ya que será necesario tenerlos en // cuenta para que se estén capturando paquetes durante un tiempo determinado. (void) time(&t1); (void) time(&t2); // Se utiliza un bucle while con el que controlar el número máximo de períodos // de toma de muestras que se quieren llevar a cabo. while(contador<100) {

114
// Contador será quien llevará un control del bucle while contador++; // Se ponen todas las variables a 0 que serán modificadas en las capturas de los paquetes. count = 0; paqArp = 0; paqAck = 0; paqBroad = 0; paqSolAso = 0; paqResAso = 0; paqAut = 0; paqDeauth = 0; paqRts = 0; paqCts = 0; // Se toman los tiempos antes de entrar al bucle de control de tiempo. (void) time(&t1); (void) time(&t2); tiempo = (int) t2‐t1; // Se capturan los paquetes durante un periodo de 30 segundos. while (tiempo < 30) { // Se captura un paquete aplicándole la función definida más arriba "examenPaquete" pcap_loop(descr, 1, examenPaquete, NULL); // Se toma el tiempo 2 para la comprobación temporal (void) time(&t2); // Se resta el tiempo actual con el incial para ver si han pasado 30 segundos. tiempo = (int) t2‐t1; } // Una vez se han capturado todos los paquetes durante los 30 segundos se realiza el volcado de los datos. volcado(); // Se para el programa 5 segundos y se continúa con el bucle. sleep(5); } return 0; }

115
ANEXO II: ANÁLISIS EXPLORATORIO DE DATOS
“aed.m”
% Datos con baja tasa incluida muestras = load('observacionesTresAtaques.txt'); % Etiquetas incluido baja tasa (5) observaciones5 = { 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3}; variables = {'ACK', 'BROAD', 'AUT', 'DEAUTH', 'RTS', 'CTS', 'TOTALPAQ'}; [muestrasp,average,scale] = preprocess2D(muestras , 2); %% Análisis de variables con PCA fig_h = plot_scores_pca(muestrasp, 1:2, 2, observaciones5); %% Análisis MEDA medaTNA1(); %medaTNA2(); %medaTNA3(); % Muestra la gráfica meda en tonos de grises

116
[meda_map,meda_dis] = meda_pca(datosp,1:2,2, 0.1, 1, variables'); % Muestra la gráfica meda discretizada [meda_map,meda_dis] = meda_pca(datosp,1:2,2, 0.1, 2, variables'); %% Análisis oMEDA % Dummy para ver la evaluación de las variables dummyTotal = [ -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; -0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; 0.3; ]; % Dummy para ver la variación de variables entre tráfico normal y ataque 1 dummyTNaA1 = [ -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1;

117
0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0]; % Dummy para ver la variación de variables entre tráfico normal y ataque 2 dummyTNaA2 = [ -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 0;0;0;0;0;0;0;0;0;0; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1 ];

118
% Dummy para ver la variación de variables entre tráfico normal y ataque 3 dummyTNaA3 = [ -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 0;0;0;0;0;0;0;0;0;0; 0;0;0;0;0;0;0;0;0;0; ]; % Quitar comentario al tráfico que se quiera analizar omeda_vec = omeda_pca(muestrasp, 1:2, muestrasp, dummyTNaA1, 2, 1, variables'); %omeda_vec = omeda_pca(muestrasp, 1:2, muestrasp, dummyTNaA2, 2, 1, variables'); %omeda_vec = omeda_pca(muestrasp, 1:2, muestrasp, dummyTNaA3, 2, 1, variables'); %% AHORA COMPARACIÓN DEL TRÁFICO NORMAL Y EL ATAQUE 5 % Datos con baja tasa incluida muestras = load('2606 bajaTasa.txt'); % Etiquetas incluido baja tasa (5) observaciones5 = { 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1;

119
2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5}; variables = {'ACK', 'BROAD', 'AUT', 'DEAUTH', 'RTS', 'CTS', 'TOTALPAQ'}; %% Análisis PCA [muestrasp,average,scale] = preprocess2D(muestras , 2); fig_h = plot_scores_pca(muestrasp, 1:2, 2, observaciones5); % Ahora se seleccionan sólo las observaciones del tráfico normal y las % correspondientes al ataque de baja tasa. datosComp = load('TN-A1bajaTasa.txt'); observaciones = { 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1;

120
1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5}; % Análisis PCA [datosp,average,scale] = preprocess2D(datosComp , 2); fig_h = plot_scores_pca(datosp, 1:2, 2, observaciones); % Análisis MEDA [meda_map,meda_dis] = meda_pca(datosp,1:2,2, 0.1, 1, variables'); [meda_map,meda_dis] = meda_pca(datosp,1:2,2, 0.1, 2, variables'); dummy = [ -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; -1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1]; % Análisis oMEDA omeda_vec = omeda_pca(datosp, 1:2, datosp, dummy, 2, 1, variables');

121
ANEXO III: CÓDIGO MATLAB KNN
“knn.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]); % Clases a las que corresponden dichas observaciones para comprobar si el % clasificiador ha obtenido la clase real a la que pertenece la

122
% observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Valor de K para el la clasificación basada en los k vecinos más cercanos k = 1; % Obtención de las clases asignadas por el clasificador resultado = knnclassify (clasificar, datos, etiquetas, k); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(resultado) contador = contador + 1; if(resultado (i) ~= grupos (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:80, [1:4 6:7]); % Conjunto de datos para la selección del valor óptimo de K selK = datos(81:130, [1:4 6:7]); % Conjunto de datos para la selección del valor óptimo de K clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento:

123
et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de % seleccion de k et2 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Valor de K para el la clasificación basada en los k vecinos más cercanos k = 1; % Obtención de las clases asignadas por el clasificador resultado = knnclassify (clasif, entrenamiento, et1, k); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(resultado) contador = contador + 1; if(resultado (i) ~= et3 (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100

124
“seleccionK.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se separa el conjunto de datos en 2 grupos para poder realizar el % entrenamiento del clasificador y la obtención del valor óptimo de K con % el que posteriormente se clasifican las nuevas muestras. entre = datos(1:200, :); clasi = datos(201:350, :); % Etiquetas de las clases a las que corresponden las observaciones que % serán usadas para el entrenamiento del clasificador etiquetasEntre = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Etiquetas de las clases a las que corresponden las observaciones que % serán usadas para la obtención del valor óptimo de K etiquetasClasi = [ 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Valor variable del que depende la eficiencia en la clasificación % realizada por el clasificador k = 21;

125
% Obtención de las clases asignadas por el clasificador prueba = knnclassify (clasi, entre, etiquetasEntre, k); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(prueba) contador = contador + 1; if(prueba (i) ~= etiquetasClasi (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100
“seleccionKbajaTasa.m”
datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:80, [1:4 6:7]); % Conjunto de datos para la selección del valor óptimo de K selK = datos(81:130, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de % seleccion de k et2 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ];

126
% Valor variable del que depende la eficiencia en la clasificación % realizada por el clasificador k = 8; % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación prueba = knnclassify (selK, entrenamiento, et1, k); error = 0; contador = 0; for i=1:length(prueba) contador = contador + 1; if(prueba (i) ~= et2 (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100

127
ANEXO IV: CÓDIGO MATLAB ÁRBOLES DE CLASIFICACIÓN
“arbol.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]); % Clases a las que corresponden dichas observaciones para comprobar si el

128
% clasificiador ha obtenido la clase real a la que pertenece la % observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Se usan los datos de entrenamiento para obtener el árbol que % posteriormente se usa para la clasificación arb = classregtree(datos, etiquetas); % Clasificación de las nuevas variables yfit = eval(arb, clasificar); resultado = round (yfit); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(resultado) contador = contador + 1; if(resultado (i) ~= grupos (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:130, [1:4 6:7]); % Conjunto de datos para la clasificación de las nuevas observaciones clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1;

129
1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; arb = classregtree(entrenamiento, et1); yfit = eval(arb, clasif); resultado = round (yfit); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(resultado) contador = contador + 1; if(resultado (i) ~= et3 (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100

130
ANEXO V: CÓDIGO MATLAB PLS‐DA
“clasiPlsda.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]);

131
% Clases a las que corresponden dichas observaciones para comprobar si el % clasificiador ha obtenido la clase real a la que pertenece la % observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Metaparámetro L con el que se determina el número de variables latentes % del modelo. L = 6; % Obtención del modelo PLS-DA a partir de los datos de entrenamiento. pls_model = plsda(datos, etiquetas, L, 'da'); yfit = plspred(clasificar, pls_model, grupos); % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(yfit.Yp) contador = contador + 1; if(yfit.Yp (i) ~= grupos (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:80, [1:4 6:7]); % Conjunto de datos para la selección del valor óptimo de L selK = datos(81:130, [1:4 6:7]);

132
% Conjunto de datos para la clasificación de las nuevas observaciones clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de % seleccion de L et2 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; pls_model = plsda(entrenamiento, et1, 4, 'da'); yfit = plspred(clasif, pls_model, et3); error = 0; contador = 0; for i=1:length(yfit.Yp) contador = contador + 1; if(yfit.Yp (i) ~= et3 (i)) error = error + 1; end end error = (error / contador) * 100

133
“seleccionL.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se separa el conjunto de datos en 2 grupos para poder realizar el % entrenamiento del clasificador y la obtención del valor óptimo de L con % el que posteriormente se clasifican las nuevas muestras. entre = datos(1:200, :); clasi = datos(201:350, :); % Etiquetas de las clases a las que corresponden las observaciones que % serán usadas para el entrenamiento del clasificador etiquetasEntre = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Etiquetas de las clases a las que corresponden las observaciones que % serán usadas para la obtención del valor óptimo de L etiquetasClasi = [ 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Metaparámetro L con el que se determina el número de variables latentes % del modelo. L=10;

134
% Obtención del modelo PLS-DA a partir de los datos de entrenamiento. pls_model = plsda(datos, etiquetas, L, 'da'); yfit = plspred(clasificar, pls_model, grupos) % Variable para la obtención del error error = 0; contador = 0; % Bucle que recorre el vector de clases obtenidas por el clasificador % comprobando si coincide con la clase a la que realmente pertenece la % observación for i=1:length(yfit.Yp) contador = contador + 1; if(yfit.Yp (i) ~= etiquetasClasi (i)) % En el caso de que el clasificador falle, se incrementa la % variable error error = error + 1; end end % Cálculo del error (%) dividiendo el número de fallos producidos por el % clasificador entre el número total de observaciones. error = (error / contador) * 100
“seleccionLbajatasa.m”
% Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:80, [1:4 6:7]); % Conjunto de datos para la selección del valor óptimo de L selL = datos(81:130, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de % seleccion de L et2 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5

135
]; L=10; pls_model = plsda(entrenamiento, et1, L, 'da'); yfit = plspred(selL, pls_model, et2); error = 0; contador = 0; for i=1:length(yfit.Yp) contador = contador + 1; if(yfit.Yp (i) ~= et2 (i)) error = error + 1; end end error = (error / contador) * 100

136
ANEXO VI: CÓDIGO MATLAB LDA Y QDA
“lda.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]); % Clases a las que corresponden dichas observaciones para comprobar si el

137
% clasificiador ha obtenido la clase real a la que pertenece la % observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Se aplica el clasificador LDA a las nuevas muestras clase = classify(clasificar, datos, etiquetas, 'linear'); error = 0; contador = 0; for i=1:length(clase) contador = contador + 1; if(clase (i) ~= grupos (i)) error = error + 1; end end error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:130, [1:4 6:7]); % Conjunto de datos para la clasificación de las nuevas observaciones clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ];

138
% Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; clase = classify(clasif, entrenamiento, et1, 'linear'); error = 0; contador = 0; for i=1:length(clase) contador = contador + 1; if(clase (i) ~= et3 (i)) error = error + 1; end end error = (error / contador) * 100
“qda.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4;

139
1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]); % Clases a las que corresponden dichas observaciones para comprobar si el % clasificiador ha obtenido la clase real a la que pertenece la % observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Se aplica el clasificador QDA a las nuevas muestras clase = classify(clasificar1, datos1, etiquetas, 'quadratic'); error = 0; contador = 0; for i=1:length(clase) contador = contador + 1; if(clase (i) ~= grupos (i)) error = error + 1; end end error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt');

140
% Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:130, [1:4 6:7]); % Conjunto de datos para la clasificación de las nuevas observaciones clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; clase = classify(clasif, entrenamiento, et1, 'quadratic'); error = 0; contador = 0; for i=1:length(clase) contador = contador + 1; if(clase (i) ~= et3 (i)) error = error + 1; end end error = (error / contador) * 100

141
ANEXO VII: CÓDIGO MATLAB REDES BAYESIANAS
“baye.m”
% Se cargan los datos correspondientes a las observaciones de tráfico % normal y los tres ataques datos = load('observacionesTresAtaques.txt'); datos = datos(:, [1:4 6:7]); % Se crean también las etiquetas que indican a qué grupo corresponde cada % observación distinguiendo de forma numérica entre: % 1 -> Tráfico normal % 2 -> Ataque 1 % 3 -> Ataque 2 % 4 -> Ataque 3 etiquetas = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3; 4; 4; 4; 4; 4; 4; 4; 4; 4; 4; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 3; 3; 3; 3]; % Se cargan también las nuevas observaciones que el clasificador debe % clasificar clasificar = load('nuevasObservaciones.txt'); clasificar = clasificar(:, [1:4 6:7]);

142
% Clases a las que corresponden dichas observaciones para comprobar si el % clasificiador ha obtenido la clase real a la que pertenece la % observación. grupos = [1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2;2;2;2; 3;3;3;3;3;3;3;3;3;3; 4;4;4;4;4;4;4;4;4;4; 1;1;1;1;1;1;1;1;1;1; 2;2;2;2;2;2;2]; % Se crea la red bayesiana aplicada posteriormente a las observaciones a % clasificar nb = NaiveBayes.fit(datos, etiquetas); % Clasificación de las nuevas observaciones cpre = predict(nb, clasificar); error = 0; contador = 0; for i=1:length(cpre) contador = contador + 1; if(cpre (i) ~= grupos (i)) error = error + 1; end end error = (error / contador) * 100 %% Parte correspondiente a la clasificación con ataque de baja tasa. datos = load('datosTN-A1bajatasa.txt'); % Conjunto de datos para el entrenamiento del clasificador entrenamiento = datos(1:130, [1:4 6:7]); % Conjunto de datos para la clasificación de las nuevas observaciones clasif = datos(131:189, [1:4 6:7]); % Clases a las que corresponden las observaciones para el grupo de % entrenamiento: et1 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1;

143
1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; % Clases a las que corresponden las observaciones para el grupo de nuevas % observaciones a clasificar et3 = [ 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 1; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5; 5 ]; nb = NaiveBayes.fit(entrenamiento, et1); cpre = predict(nb, clasif); error = 0; contador = 0; for i=1:length(cpre) contador = contador + 1; if(cpre (i) ~= et3 (i)) error = error + 1; end end error = (error / contador) * 100

144







