
How productive is MT post-editing? Studying translation and MT post-editing
productivity in a real industrial setting
Carla Parra Escartín
Hermes Traducciones y Servicios Lingüísticos
9 May 2016 – Rome, EXPERT Business Case

1. How do translators work?
2. A glance at MT evaluation
3. How is MT used in real commercial settings?
4. Does MT boost translators’ productivity?
Agenda

How do translators work?

Productivity!

On average, a professional translator…
Translates 2500-3000 words per day
Proofreads 1000 words per hour
Post-edits ???? words per day
How many WORDS a day?

How do translators translate?

CAT tools
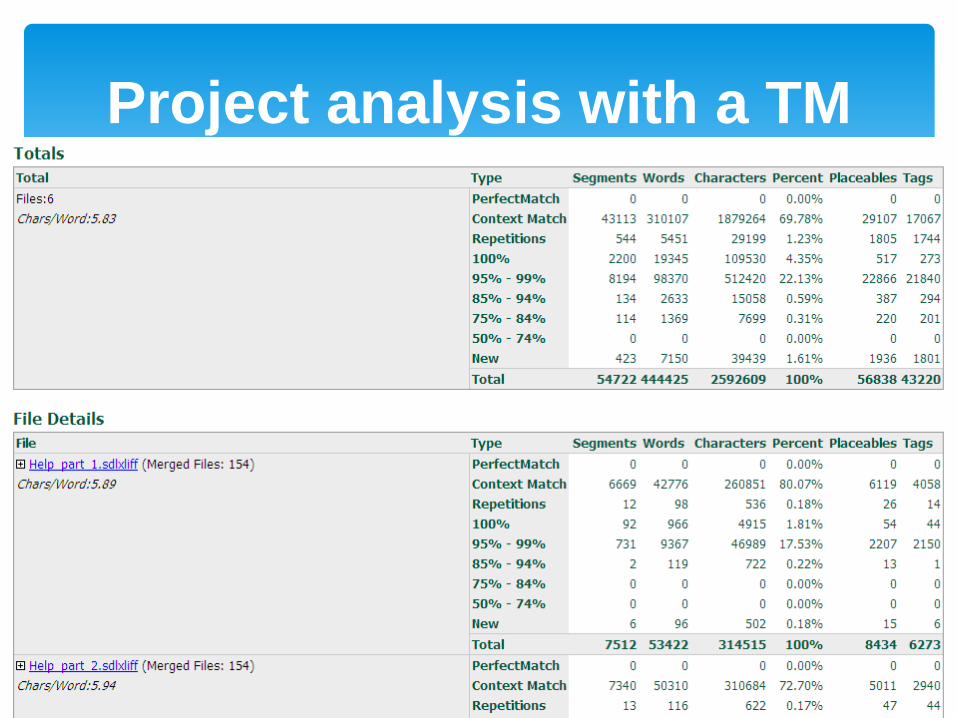
Project analysis with a TM

A glance at MT evaluation

FLUENCY:
To what extent is a target side
translation grammatically well
formed, without spelling errors
and experienced as using
natural/intuitive language by a
native speaker?
1. Incomprehensible
2. Disfluent
3. Good
4. Flawless
Human evaluation
ADEQUACY:
How much of the meaning
expressed in the gold standard
translation or the source is also
expressed in the target
translation?
1. None
2. Little
3. Most
4. Everything

1. Lexical evaluation metrics:
BLEU, TER, WER, NIST, ROUGE, PER, GTMe, METEOR
2. Syntactic evaluation metrics
3. Semantic evaluation metrics
Automatic evaluation

Bilingual Evaluation Understudy
Assumptions:
The closer an MT output is to professional human translation, the
better it is
Even if there are many ways of translating the same text, most of
them will have some phrases in common.
It measures the closeness of the MT output to one or more reference
human translations
It counts the number of n-grams co-occurring in both the reference
and the MT output.
Acceptable correlation with human scores for translations
BLEU

Translation Error Rate
Minimum number of edits to transform output to match a
reference translation (~ post-editing effort):
Substitutions
Insertions
Deletions
𝑻𝑬𝑹 =𝒔𝒖𝒃𝒔𝒕𝒊𝒕𝒖𝒕𝒊𝒐𝒏𝒔 + 𝒊𝒏𝒔𝒆𝒓𝒕𝒊𝒐𝒏𝒔 + 𝒅𝒆𝒍𝒆𝒕𝒊𝒐𝒏𝒔
𝒓𝒆𝒇𝒆𝒓𝒆𝒏𝒄𝒆 𝒍𝒆𝒏𝒈𝒕𝒉
TER

MT in commercial settings

Machine Translation Post-Editing (MTPE) has
become a reality in commercial settings
Clients try to impose discounts (DRAFT
translation is provided!)
How can we assess MT output to determine a fair
compensation for the post-editor?
MT: the new trend in translation

MTPE discounts estimation
When negotiating MTPE discounts, two main strategies are used for MT
output evaluation:
1. Annotation of a sample of the MT output (manual evaluation)
2. Post-edition of a sample to generate:
Automatic evaluation metrics
Time spent
(Key strokes)
Good MT evaluation is CRITICAL to avoid underpayments / potential
mistrust by translators

Does Machine Translation boost
translators’ productivity?

1. Could we use a target-side Fuzzy Match Score to evaluate
MT output?
2. Are automatic metrics able to reflect productivity gains?
Establishment of productivity gain thresholds
1 experiment, 2 studies

Is the MT output quality good enough for post-editing?
Does it allow to post-edit faster than translating from scratch?
Are automatic metrics able to reflect productivity gains?
How should one interpret a BLEU score improvement from
45 to 50 in terms of productivity?
Does a TER value of 40 justify any discount?
Could we use the Fuzzy Match Score as an evaluation
metric?
Many questions…

Real production environment
Ten in-house translators
English Spanish
memoQ CAT tool
Productivity enhancement features disabled
Experiment settings

1. Real translation request
2. In-house MT engine available
3. Word volume to engage
translators for several hours
4. Significant word counts for
each TM match band
5. Repetitions and internal
leverage segments deleted to
avoid skewing
Text used

Systran’s rule-based MT engine
3 years of in-house customization
MT engine
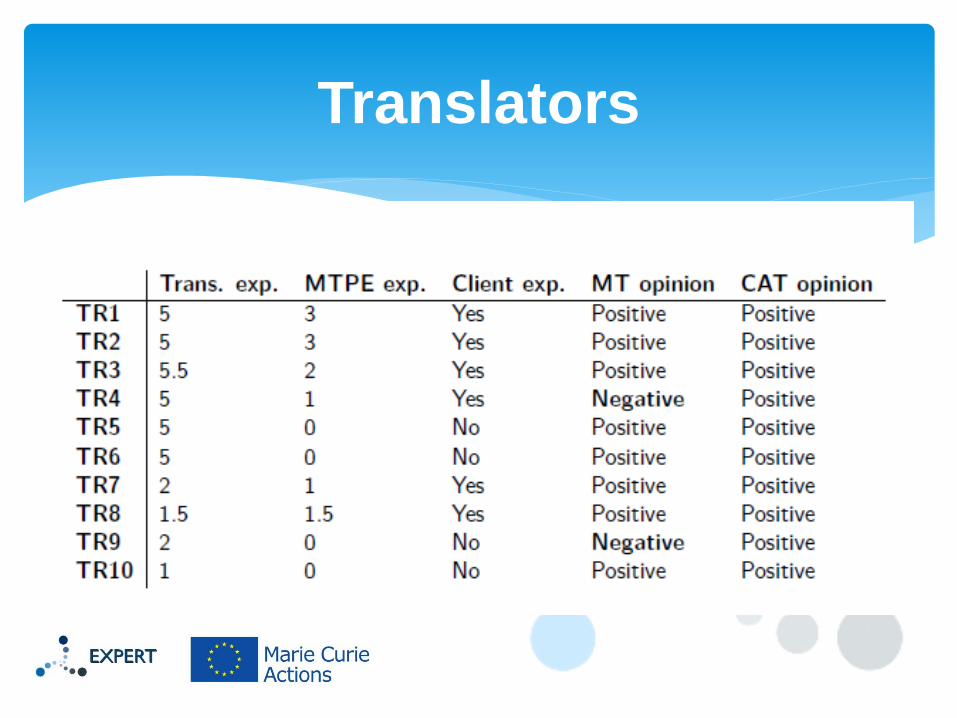
Translators

CAT environment

Some data had to be discarded:
Segments with exceptionally long times (> 10 minutes): 6
Segments with unnaturally high productivity (> 5 words/second): 29
Translator 5 data series: under-editing
Translator 8 data series: activated productivity enhancement tools
Data analysis

Translators are used to the usage of Translation Memory
leverage using the source-side Fuzzy Match Score:
They instantly acknowledge that TM fuzzy matches of 60%
are not worth editing
They would consider it fair to accept discounts for 80%
matches
MTPE tasks could benefit greatly from the familiarity of
source-side FMS to MTPE evaluation as a target-side FMS
Fuzzy match scores for MT evaluation

Based on the Sørensen-Dice coefficient using 3-grams.
It does not depend on traditional tokenization: instead of word
n-grams, it computes character n-grams
2 ∗ (𝑀𝑇_𝑜𝑢𝑡𝑝𝑢𝑡 ∩ 𝑃𝐸_𝑜𝑢𝑡𝑝𝑢𝑡)
(𝑀𝑇_𝑜𝑢𝑡𝑝𝑢𝑡_𝑠𝑖𝑧𝑒 + 𝑃𝐸_𝑜𝑢𝑡𝑝𝑢𝑡_𝑠𝑖𝑧𝑒)∗ 100
Fuzzy match scores for MT evaluation
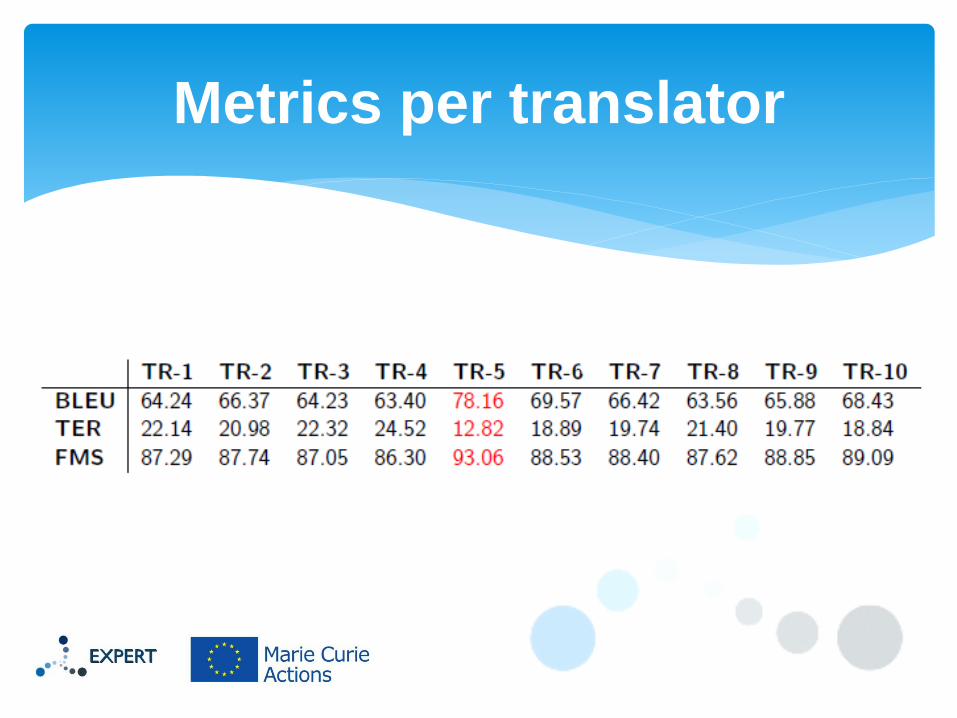
Metrics per translator

Each translator’s translation-from-scratch throughput was
used
Great variability (473-1701 words per hour)
TR1 translated faster than post-editing 75-84% fuzzy matches
Productivity
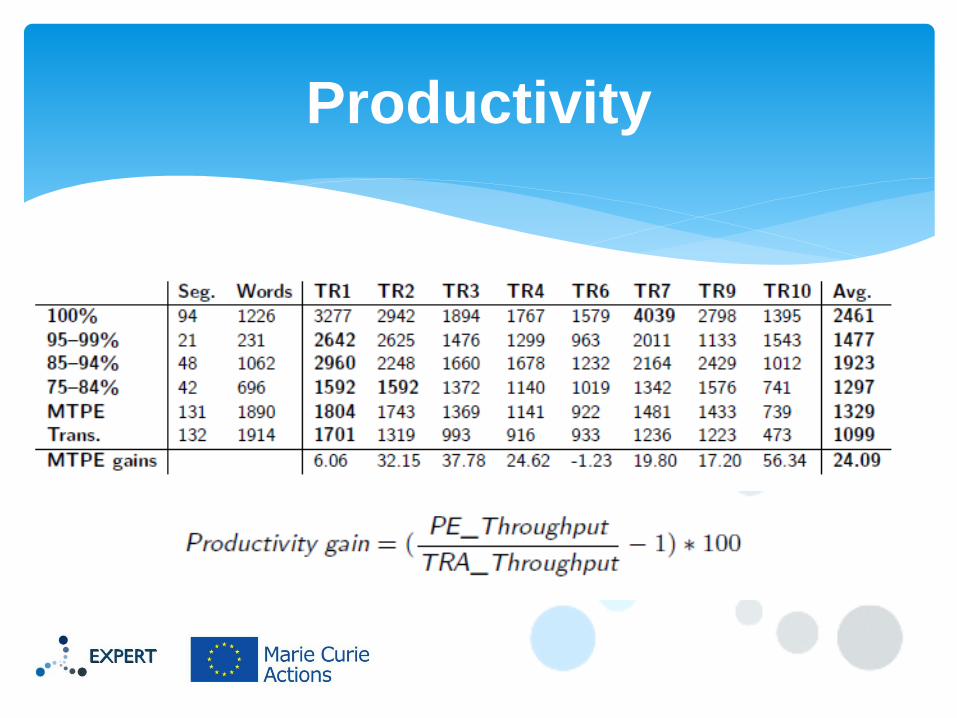
Productivity

All translators but TR6 are faster in MTPE
Biggest gain by the least experienced translator (TR10)
Smallest gain by the most experienced translator (TR1)
The rest do not follow this trend
Productivity

Mature MT engines allow experienced post-editors to do
MTPE faster than the lowest TM matches
All translators with MTPE throughput higher than the 75–
84% band (TR1, TR2, TR7), had previous MTPE
experience
Translators faster with the 75–84% band (TR6, TR9) had no
previous MTPE experience
Productivity

MTPE can improve productivity even when the fastest
translators work with content which allow for higher than usual
translation throughputs
Productivity

BLEU, TER and FMS agree that
the four less experienced
translators performed less edits
to MT output
95–99% band lies between the
two nearest bands but
undergoes a loss in productivity
For evaluation purposes, each
tag was converted to a single
token
MT evaluation metrics
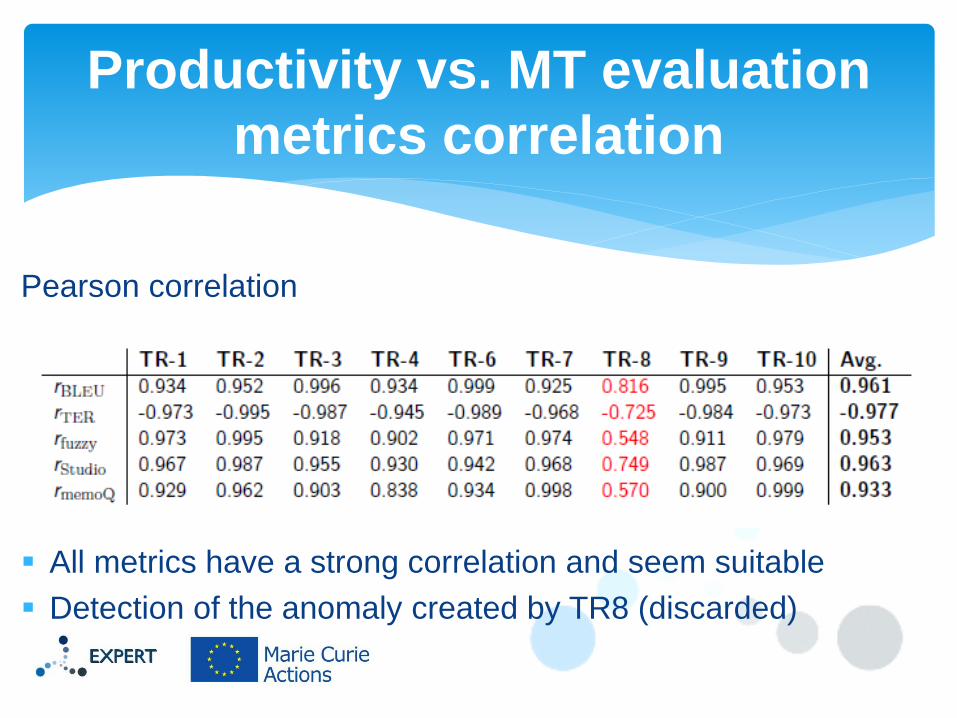
Pearson correlation
All metrics have a strong correlation and seem suitable
Detection of the anomaly created by TR8 (discarded)
Productivity vs. MT evaluation
metrics correlation

MT quality may be assessed using a fuzzy score mirroring TM leverage (3-
grams, Sørensen-Dice)
It correlates with productivity as well as or even better than BLEU and
TER:
It is easier to estimate and does not depend on tokenization
It is more familiar to all parties in the translation industry
It can be used to evaluate all types of MT output notwithstanding its type
Conclusion
(FMS vs. BLEU and TER)
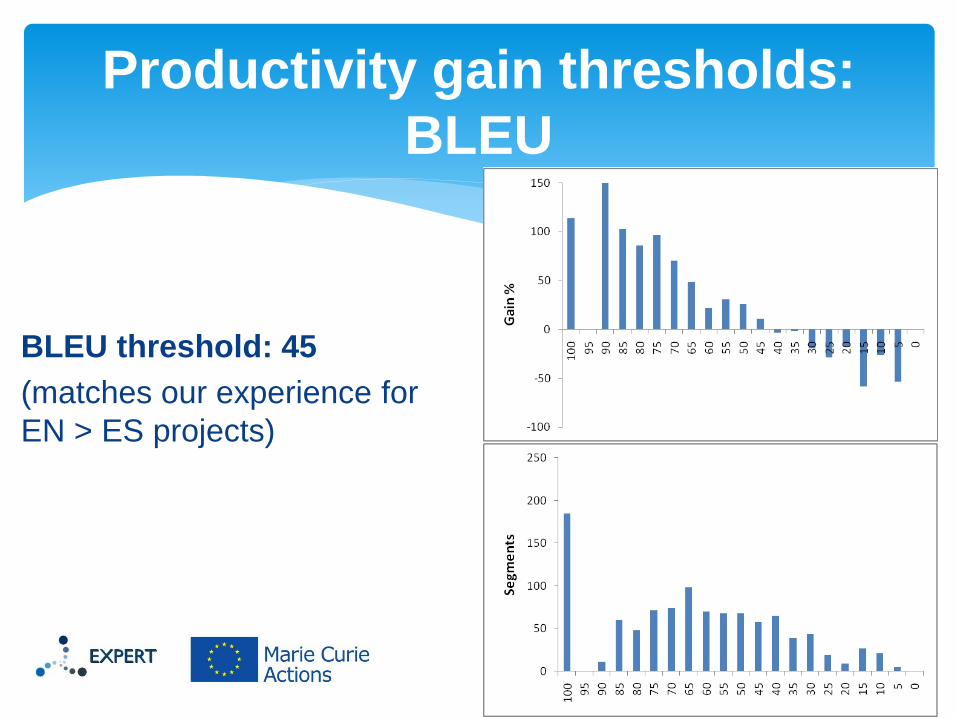
BLEU threshold: 45
(matches our experience for
EN > ES projects)
Productivity gain thresholds:
BLEU
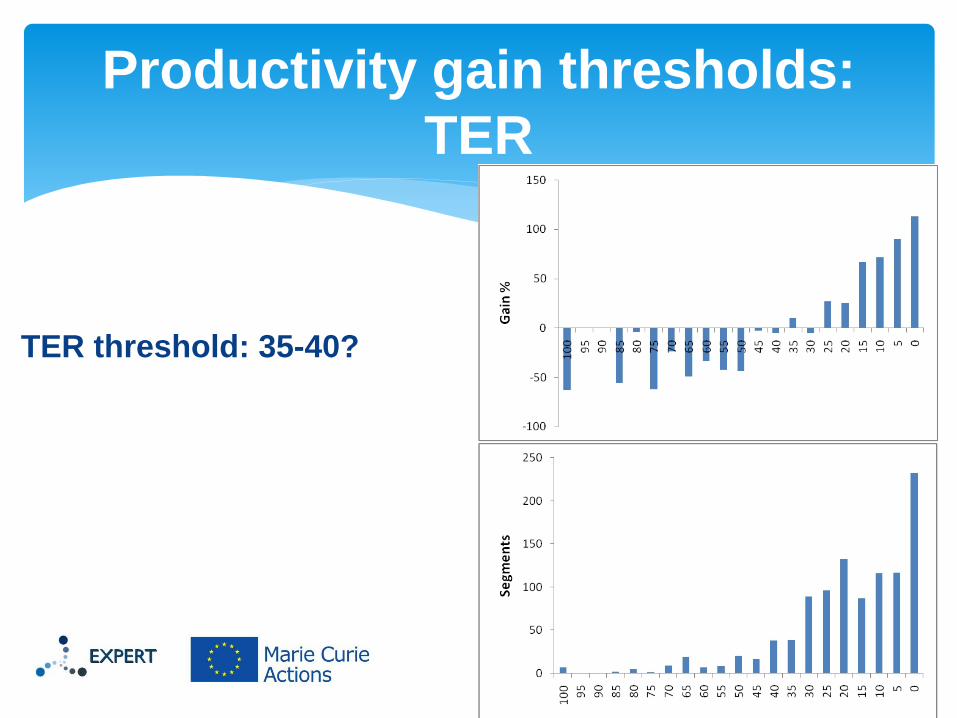
TER threshold: 35-40?
Productivity gain thresholds:
TER
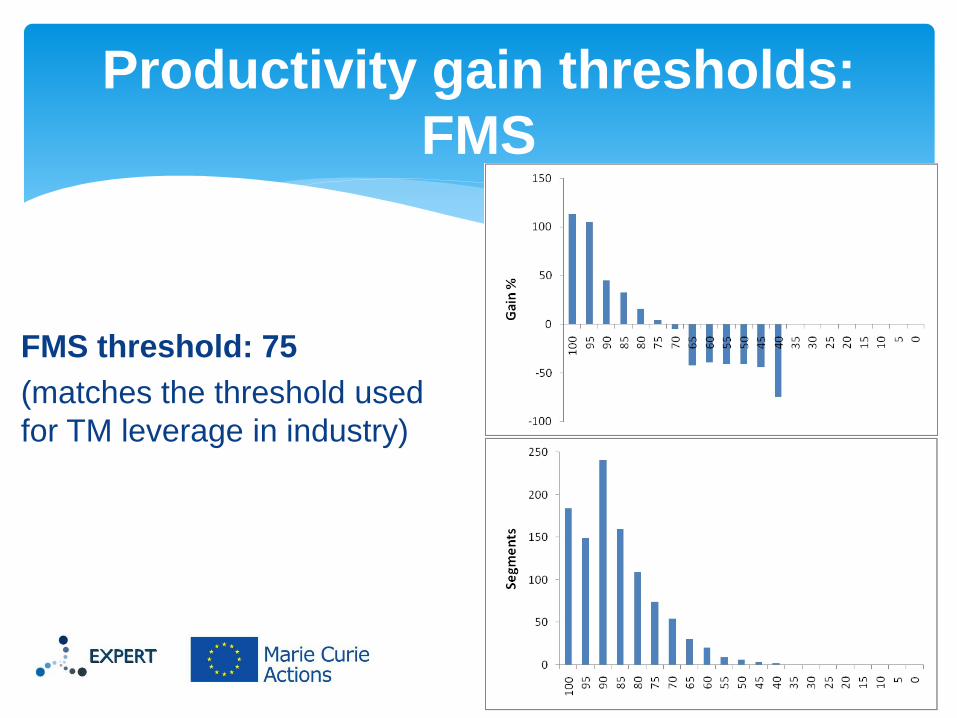
FMS threshold: 75
(matches the threshold used
for TM leverage in industry)
Productivity gain thresholds:
FMS

When equal amount of text edits are required, is MTPE faster
or slower than editing TM matches?
Hypothesis:
MTPE segments are slower to post-edit due to higher effort
spent deciding the text that needs fixing, and also because
translators may be more confident with TMs than with MT.
Productivity and cognitive effort
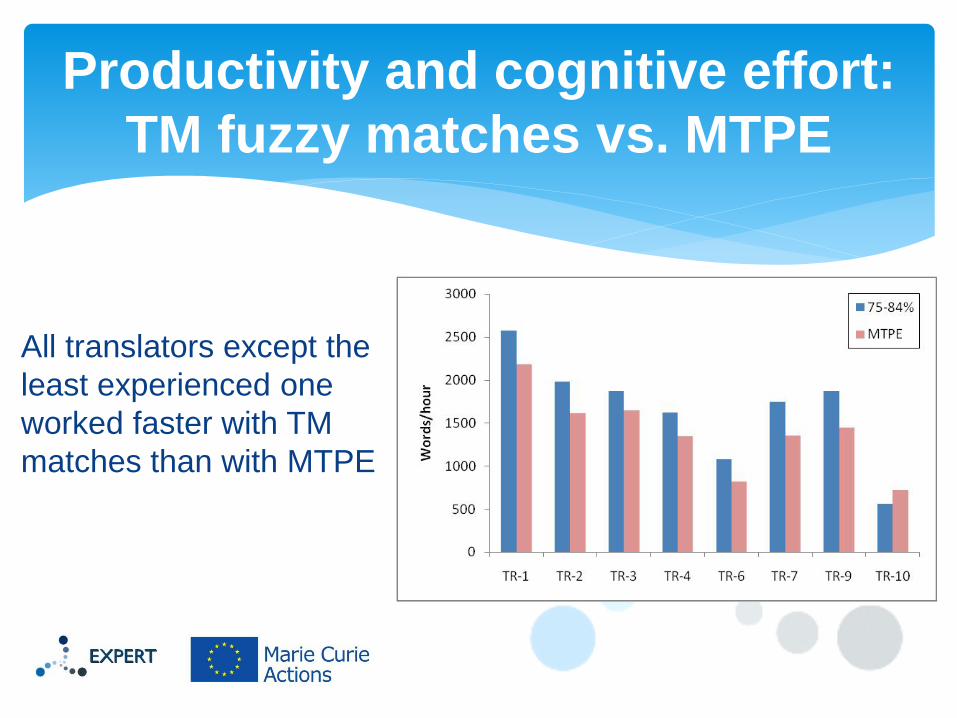
All translators except the
least experienced one
worked faster with TM
matches than with MTPE
Productivity and cognitive effort:
TM fuzzy matches vs. MTPE
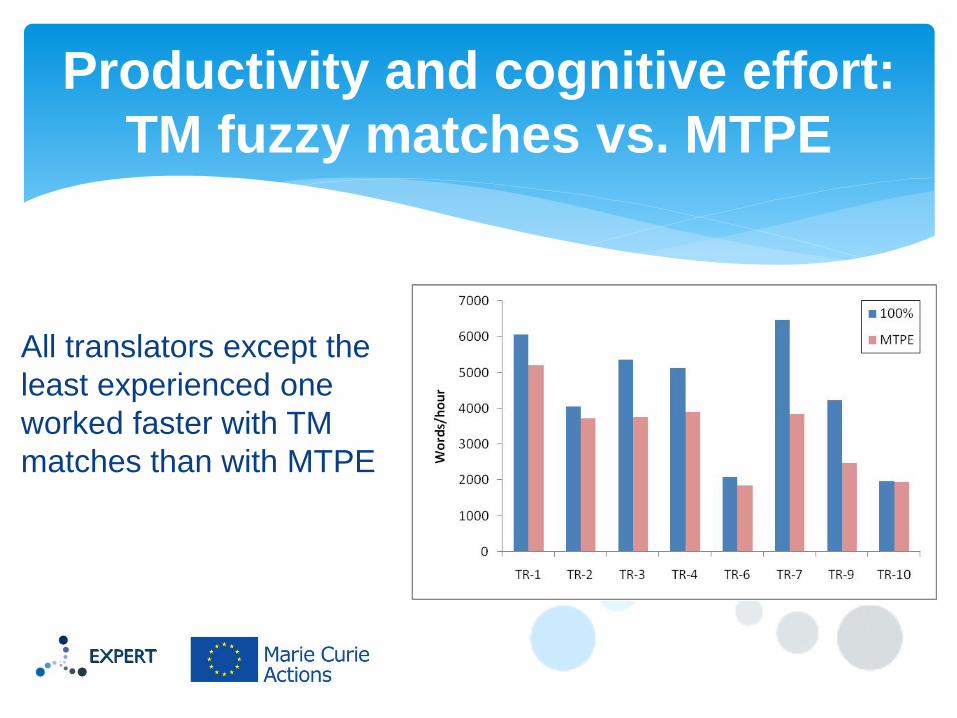
All translators except the
least experienced one
worked faster with TM
matches than with MTPE
Productivity and cognitive effort:
TM fuzzy matches vs. MTPE

Productivity gain thresholds for EN > ES:
BLEU: 45
TER: 35-40?
FMS: 75
Source-side FMS pricing system due to TM leverage cannot be
directly applied to target-side FMS in MTPE
Conclusion
(Productivity thresholds)


Parra Escartín, Carla; Arcedillo, Manuel. 2015. Living on the edge: productivity gain
thresholds in machine translation evaluation metrics. Proceedings of the Fourth
Workshop on Post-editing Technology and Practice, pp. 46-56. Miami (Florida), 4 November
Parra Escartín, Carla; Arcedillo, Manuel. 2015. Machine translation evaluation made
fuzzier: A study on post-editing productivity and evaluation metrics in commercial
settings. Proceedings of the MT Summit XV, Research Track, pp. 131-144. Miami (Florida),
30 October - 3 November.
Parra Escartín, Carla; Arcedillo, Manuel. A fuzzier approach to machine translation
evaluation: A pilot study on post-editing productivity and automated metrics in
commercial settings. Proceedings of the ACL 2015 Fourth Workshop on Hybrid Approaches
to Translation (HyTra), pp. 40–45, Beijing, China, July 31, 2015. Association for
Computational Linguistics.
Bibliography







