
Carlos Tenreiro
Apontamentos de
Teoria das Probabilidades
Coimbra, 2002


Nota previa
Os presentes apontamentos tem por base as notas do curso de
Teoria das Probabilidades que leccionamos no segundo semestre dos
anos lectivos de 2000/01 e 2001/02, a alunos do Ramo Cientıfico,
especializacao em Matematica Pura, do terceiro ano da licenciatura
em Matematica da Universidade de Coimbra. Uma versao prelimi-
nar destes apontamentos foi utilizada como texto de apoio ao curso
no ultimo dos anos lectivos referidos.
Ao longo dos dez capıtulos que constituem este texto, desenvol-
vemos temas habituais num primeiro curso de Teoria das Probabi-
lidades, cujo principal objectivo e o estabelecimento dos teoremas
limite classicos: leis dos grandes numeros de Kolmogorov e teorema
do limite central de Lindeberg.
Estando os alunos ja familiarizados com topicos como o do pro-
longamento de medidas, da integracao relativamente a uma me-
dida, dos espacos Lp de Lebesgue, das medidas produto, da trans-
formacao de medidas, ou dos teoremas de Radon-Nikodym e da
decomposicao de Lebesgue, a abordagem as probabilidades feita
nesta disciplina, e fortemente influenciada por tal facto.
Ao fazermos referencia a um dos resultados anteriores, ou a ou-
tro qualquer resultado de Medida e Integracao que sabemos ser do
conhecimento do aluno, remetemos o leitor para os nossos Apon-
tamentos de Medida e Integracao (Coimbra, 2000) que neste texto
designaremos pelas iniciais AMI.
Carlos Tenreiro


Indice
I Distribuicoes de probabilidade 1
1 Espacos de probabilidade 3
1.1 Modelo matematico para uma experiencia aleatoria . . . . . . . . . . . . 3
1.2 Propriedades duma probabilidade . . . . . . . . . . . . . . . . . . . . . . 7
1.3 Modelacao de algumas experiencias aleatorias . . . . . . . . . . . . . . . 8
1.4 Algumas construcoes de espacos de probabilidade . . . . . . . . . . . . . 14
1.5 Produto de espacos de probabilidade . . . . . . . . . . . . . . . . . . . . 16
1.6 Probabilidade condicionada . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.7 Produto generalizado de probabilidades . . . . . . . . . . . . . . . . . . 22
1.8 Breve referencia a simulacao de experiencias aleatorias . . . . . . . . . . 24
1.9 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2 Variaveis aleatorias e distribuicoes de probabilidade 29
2.1 Variaveis aleatorias e suas leis de probabilidade . . . . . . . . . . . . . . 29
2.2 Classificacao das leis de probabilidade sobre Rd . . . . . . . . . . . . . . 34
2.3 Funcao de distribuicao duma variavel aleatoria real . . . . . . . . . . . . 36
2.4 Funcao de distribuicao dum vector aleatorio . . . . . . . . . . . . . . . . 41
2.5 Transformacao de vectores absolutamente contınuos . . . . . . . . . . . 43
2.6 Distribuicoes condicionais . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.7 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3 Independencia 49
3.1 Independencia de classes de acontecimentos aleatorios . . . . . . . . . . 49
3.2 Independencia de variaveis aleatorias . . . . . . . . . . . . . . . . . . . . 51
3.3 Soma de variaveis aleatorias independentes . . . . . . . . . . . . . . . . 54
3.4 Leis zero-um de Borel e de Kolmogorov . . . . . . . . . . . . . . . . . . 57
3.5 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
i

ii Apontamentos de Teoria das Probabilidades
4 Integracao de variaveis aleatorias 61
4.1 Esperanca matematica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.2 Momentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.3 Covariancia e correlacao . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.4 Integracao de vectores aleatorios . . . . . . . . . . . . . . . . . . . . . . 70
4.5 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
II Leis dos grandes numeros 73
5 Convergencias funcionais de variaveis aleatorias 75
5.1 Convergencia quase certa . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.2 Convergencia em probabilidade . . . . . . . . . . . . . . . . . . . . . . . 76
5.3 Convergencia em media de ordem p . . . . . . . . . . . . . . . . . . . . . 78
5.4 Convergencia funcional de vectores aleatorios . . . . . . . . . . . . . . . 81
5.5 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
6 Leis dos grandes numeros e series de variaveis aleatorias independen-
tes 83
6.1 Generalidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.2 Primeiras leis dos grandes numeros . . . . . . . . . . . . . . . . . . . . . 85
6.3 Leis fracas dos grandes numeros . . . . . . . . . . . . . . . . . . . . . . . 88
6.4 Leis fortes e series de variaveis independentes . . . . . . . . . . . . . . . 89
6.5 Lei forte dos grandes numeros de Kolmogorov . . . . . . . . . . . . . . . 92
6.5.1 Necessidade da condicao de integrabilidade . . . . . . . . . . . . 92
6.5.2 Suficiencia da condicao de integrabilidade . . . . . . . . . . . . . 93
6.6 O teorema das tres series . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.7 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
III Teorema do limite central 99
7 Funcao caracterıstica 101
7.1 Integracao de variaveis aleatorias complexas . . . . . . . . . . . . . . . . 101
7.2 Definicao e primeiras propriedades . . . . . . . . . . . . . . . . . . . . . 102
7.3 Derivadas e momentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
7.4 Injectividade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
7.5 Formulas de inversao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7.6 Independencia e soma de vectores aleatorios . . . . . . . . . . . . . . . . 108
ATP, Coimbra 2002

Indice iii
7.7 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
8 Vectores aleatorios normais 111
8.1 Definicao e existencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
8.2 Funcao caracterıstica e independencia das margens . . . . . . . . . . . . 112
8.3 Continuidade absoluta . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
8.4 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
9 Convergencia em distribuicao 117
9.1 Definicao e unicidade do limite . . . . . . . . . . . . . . . . . . . . . . . 117
9.2 Caracterizacoes e primeiras propriedades . . . . . . . . . . . . . . . . . . 118
9.3 Relacoes com os outros modos de convergencia . . . . . . . . . . . . . . 121
9.4 O teorema de Prohorov . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
9.5 O teorema da continuidade de Levy–Bochner . . . . . . . . . . . . . . . 125
9.6 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
10 O teorema do limite central 129
10.1 Preliminares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
10.2 O teorema do limite central classico . . . . . . . . . . . . . . . . . . . . 132
10.3 O teorema do limite central de Lindeberg . . . . . . . . . . . . . . . . . 134
10.4 O teorema do limite central multidimensional . . . . . . . . . . . . . . . 137
10.5 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
Tabela de valores da distribuicao normal standard 139
Bibliografia Geral 143
Indice Remissivo 144
ATP, Coimbra 2002


Parte I
Distribuicoes de probabilidade
1


Capıtulo 1
Espacos de probabilidade
Modelo matematico para uma experiencia aleatoria. Propriedades duma probabilidade.
Modelacao de algumas experiencias aleatorias. Algumas construcoes de espacos de pro-
babilidade. Produto infinito de espacos de probabilidade. Probabilidade condicionada.
Teorema de Bayes. Produto generalizado de probabilidades. Breve referencia a simula-
cao de experiencias aleatorias.
1.1 Modelo matematico para uma experiencia aleatoria
Em 1933 A.N. Kolmogorov1 estabelece as bases axiomaticas do calculo das proba-
bilidades. O modelo proposto por Kolmogorov permitiu associar o calculo das proba-
bilidades a teoria da medida e da integracao, possibilitando assim a utilizacao dos
resultados e tecnicas da analise no desenvolvimento da teoria das probabilidades.
Ao conjunto das realizacoes possıveis duma experiencia aleatoria Kolmogorov
comecou por associar um conjunto Ω, a que chamamos espaco dos resultados ou
espaco fundamental, em que cada elemento ω ∈ Ω caracteriza completamente uma
realizacao possıvel da experiencia aleatoria. Identificou os acontecimentos aleatorios
associados a experiencia com subconjuntos do espaco fundamental, associando a cada
acontecimento o conjunto dos pontos ω ∈ Ω que correspondem a resultados da ex-
periencia aleatoria favoraveis a realizacao desse acontecimento. Como casos extremos
temos o acontecimento impossıvel e o acontecimento certo representados natu-
ralmente pelos conjuntos ∅ e Ω, respectivamente. Os subconjuntos singulares de Ω
dizem-se acontecimentos elementares.
As operacoes usuais entre conjuntos, reuniao, interseccao, diferenca, etc, permitem
exprimir ou construir acontecimentos em funcao ou a partir de outros acontecimentos:
1Kolmogorov, A.N., Grundbegriffe der Wahrscheinlichkeitrechnung, 1933.
3

4 Apontamentos de Teoria das Probabilidades
A∪B ≡ acontecimento que se realiza quando pelo menos um dos acontecimentos A ou
B se realiza; A ∩ B ≡ acontecimento que se realiza quando A e B se realizam; Ac ≡acontecimento que se realiza quando A nao se realiza; A − B ≡ acontecimento que se
realiza quando A se realiza e B nao se realiza;⋃∞
n=1 An ≡ acontecimento que se realiza
quando pelo menos um dos acontecimentos An se realiza;⋂∞
n=1 An ≡ acontecimento
que se realiza quando todos os acontecimentos An se realizam; lim inf An ≡ aconteci-
mento que se realiza quando se realizam todos os acontecimentos An com excepcao
dum numero finito deles; lim sup An ≡ acontecimento que se realiza quando se realiza
um infinidade de acontecimentos An.
Finalmente, com a axiomatizacao do conceito de probabilidade, Kolmogorov estabe-
lece regras gerais a que deve satisfazer a atribuicao de probabilidade aos acontecimentos
duma experiencia aleatoria.
Concretizemos este procedimento, considerando a experiencia aleatoria que consiste
no lancamento de um dado equilibrado. Representando por “i” a ocorrencia da face
com “i” pontos, o espaco dos resultados e Ω = 1, 2, 3, 4, 5, 6. Os acontecimentos
aleatorios “saıda de numero par”, “saıda de numero inferior a 3”, etc., podem ser
identificados com os subconjuntos do espaco dos resultados 2, 4, 6, 1, 2, etc., respe-
ctivamente. Em resposta as perguntas “qual e a probabilidade de sair um numero par no
lancamento de um dado?” e “qual e a probabilidade de sair um numero multiplo de 3 no
lancamento de um dado?”, esperamos associar a cada um dos conjuntos 2, 4, 6 e 3, 6,um numero real que exprima a maior ou menor possibilidade de tais acontecimentos
ocorrerem. Uma forma natural de o fazer, sera associar a um acontecimento a proporcao
de vezes que esperamos que esse acontecimento ocorra em sucessivas repeticoes da
experiencia aleatoria. Sendo o dado equilibrado, e atendendo a que em sucessivos
lancamentos do mesmo esperamos que o acontecimento 2, 4, 6 ocorra tres vezes em
cada seis lancamentos e que o acontecimento 3, 6 ocorra duas vezes em cada seis
lancamentos, poderıamos ser levados a associar ao primeiro acontecimento o numero
3/6 e ao segundo o numero 2/6.
A definicao de probabilidade de Kolmogorov que a seguir apresentamos, e moti-
vada por consideracoes do tipo anterior relacionadas com o conceito frequencista de
probabilidade, isto e, com as propriedades da frequencia relativa de acontecimentos
aleatorios em sucessivas repeticoes duma experiencia aleatoria. Em particular, se por
P(A) denotarmos a probabilidade do acontecimento A, P(A) devera ser um numero
real do intervalo [0, 1], com P(Ω) = 1 e P(A ∪ B) = P(A) + P(B), se A e B sao
incompatıveis, isto e, se A ∩ B = ∅. Estamos agora ja muito perto de nocao de
probabilidade considerada por Kolmogorov. Alem da propriedade de aditividade sobre
P, Kolmogorov assume que P e σ-aditiva. O domınio natural de definicao duma tal
ATP, Coimbra 2002

1 Espacos de probabilidade 5
aplicacao e assim uma σ-algebra. Recordemos que uma classe A de partes de Ω e
uma σ-algebra se contem o conjunto vazio, e e estavel para a complementacao e para a
reuniao numeravel. Uma σ-algebra contem claramente Ω, e e estavel para a interseccao
numeravel bem como para a interseccao e reuniao finitas.
Definicao 1.1.1 Uma probabilidade P sobre uma σ-algebra A de partes de Ω e uma
aplicacao de A em [0, 1] tal que:
a) P (Ω) = 1;
b) Para todo o An ∈ A, n = 1, 2, . . . disjuntos dois a dois
P( ∞⋃
n=1
An
)=
∞∑
n=1
P(An) (σ-aditividade).
Ao terno (Ω,A,P) chamamos espaco de probabilidade. Quando a uma ex-
periencia aleatoria associamos o espaco de probabilidade (Ω,A,P) dizemos tambem
que este espaco e um modelo probabilıstico para a experiencia aleatoria em causa.
Os elementos de A dizem-se acontecimentos aleatorios. Fazendo em b), A1 = Ω e
An = ∅, para n ≥ 2, obtemos P(Ω) = P(Ω) +∑∞
n=2 P(∅), o que implica P(∅) = 0. Por
outras palavras, uma probabilidade e uma medida definida num espaco mensuravel
(Ω,A) em que a medida de todo o espaco e igual a unidade (ver AMI, §2.1).A axiomatizacao da nocao de probabilidade, nao resolve o problema da atribuicao
de probabilidade aos acontecimentos de uma experiencia aleatoria particular. Apenas
fixa as regras gerais a que uma tal atribuicao deve satisfazer.
Nos exemplos que a seguir consideramos, a associacao dum modelo probabilıstico
as experiencias aleatorias que descrevemos pode ser feita de forma simples.
Exemplo 1.1.2 Retomando o exemplo do lancamento de um dado equilibrado, como
todos os elementos de Ω = 1, 2, 3, 4, 5, 6 tem a mesma possibilidade de ocorrer, sera
natural tomar P definida em A = P(Ω) por P(x) = 1/6, para x ∈ Ω. Duma forma
geral, se o espaco Ω dos resultados duma experiencia aleatoria e finito e todos os seus
elementos tem a mesma possibilidade de ocorrer, sera natural tomar
P(A) =♯A
♯Ω, para A ⊂ Ω,
isto e,
P(A) =numero de resultados favoraveis a A
numero de resultados possıveis,
que nao e mais do que a definicao classica de probabilidade.
ATP, Coimbra 2002

6 Apontamentos de Teoria das Probabilidades
Exemplo 1.1.3 Suponhamos que extraımos ao acaso um ponto do intervalo real [a, b].
Neste caso Ω = [a, b]. Sendo o numero de resultados possıveis infinito, nao podemos
proceder como no exemplo anterior. No entanto, como intervalos com igual compri-
mento tem a mesma possibilidade de conter o ponto extraıdo, sera natural tomar para
probabilidade dum subintervalo ]c, d] de [a, b], o quociente entre o seu comprimento e
o comprimento de [a, b], isto e, P(]c, d]) = (d − c)/(b − a), para a ≤ c < d ≤ b. Mais
geralmente, se Q e uma regiao mensuravel de Rd com volume 0 < λ(Q) < +∞, onde λ e
a medida de Lebesgue em Rd, a extraccao ao acaso dum ponto de Q pode ser modelada
pela probabilidade
P(A) =λ(A)
λ(Q)=
volume de A
volume de Q, para A ∈ B(Q),
dita probabilidade geometrica.
Exercıcios
1. (Paradoxo dos dados2) No lancamento de tres dados equilibrados, 9 e 10 pontos podem
ser obtidos de seis maneiras diferentes: 1 2 6, 1 3 5, 1 4 4, 2 2 5, 2 3 4, 3 3 3, e 1 3 6, 1 4
5, 2 2 6, 2 3 5, 2 4 4, 3 3 4, respectivamente. Como pode este facto ser compatıvel com a
experiencia que leva jogadores de dados a considerarem que a soma 9 ocorre menos vezes
que a soma 10?
2. (Paradoxo do dia de aniversario) Se nao mais que 365 pessoas estao a assistir a um
espectaculo, e possıvel que todas elas tenham um dia de aniversario diferente. Com 366
pessoas e certo que pelo menos duas delas tem o mesmo dia de aniversario. Admitindo que
os nascimentos se distribuem uniformemente pelos 365 dias do ano, e que ha n (≤ 365)
pessoas a assistir ao espectaculo, calcule a probabilidade pn de pelo menos duas delas
terem o mesmo dia de aniversario. Verifique que p23 > 0.5 e que p56 > 0.99.
Suponha agora que tambem esta a assistir ao espectaculo. Qual e a probabilidade qn de
alguem com seu dia de aniversario estar tambem a assistir ao espectaculo? Verifique que
q23 < 0.059 e que q56 < 0.141.
3. Num segmento de recta de comprimento L dois pontos sao escolhidos ao acaso. Qual e a
probabilidade da distancia entre eles nao exceder x, com 0 ≤ x ≤ L?
4. Qual e a probabilidade das raızes da equacao quadratica x2 + 2Ax + B = 0 serem reais,
se (A, B) e um ponto escolhido ao acaso sobre o rectangulo [−R, R]× [−S, S]?
5. Suponhamos que extraımos ao acaso um ponto x do intervalo [0, 1], e que nao estamos
interessados em x mas no seu quadrado y. Se pretendemos calcular a probabilidade de y
pertencer ao subintervalo ]c, d] de [0, 1], conclua que devera tomar Ω = [0, 1] e P tal que
P(]c, d]) =√
d −√c, para 0 ≤ c ≤ d ≤ 1.
2Este problema foi colocado a Galileu Galilei, o que o levou a escrever Sopra le scoperte dei dadi
(Sobre uma descoberta acerca de dados) entre 1613 e 1623.
ATP, Coimbra 2002

1 Espacos de probabilidade 7
1.2 Propriedades duma probabilidade
As propriedades seguintes sao consequencia do facto duma probabilidade ser uma
medida definida num espaco mensuravel (Ω,A) em que a medida de todo o espaco e
igual a unidade. A sua demonstracao e deixada ao cuidado do aluno.
Proposicao 1.2.1 (Aditividade finita) Se A1, . . . , An sao acontecimentos aleatorios
disjuntos dois a dois, entao P(⋃n
k=1 Ak) =∑n
k=1 P(Ak).
Proposicao 1.2.2 Para A,B ∈ A, temos:
a) P(Ac) = 1 − P(A);
b) Se A ⊂ B, entao P(B − A) = P(B) − P(A);
c) Se A ⊂ B, entao P(A) ≤ P(B) (monotonia);
d) P(A ∪ B) = P(A) + P(B) − P(A ∩ B).
Proposicao 1.2.3 (Subaditividade completa) Se An ∈ A, para n = 1, 2, . . ., entao
P(⋃∞
n=1 An) ≤ ∑∞n=1 P(An).
Proposicao 1.2.4 (Continuidade) Se An ∈ A, para n = 1, 2, . . ., e An → A entao
P(An)→P(A).
Dizemos que uma funcao de conjunto P definida numa classe B de partes de Ω,
e ascendentemente contınua (resp. descendentemente contınua) em A ∈ B,
se para toda a sucessao (An) em B com An ↑ A (resp. An ↓ A), se tem P(An) →P(A). P diz-se ascendentemente contınua (resp. descendentemente contınua) se for
ascendentemente contınua (resp. descendentemente contınua) em todo o A ∈ B.
Do resultado seguinte fica claro que quando exigimos que uma probabilidade seja
nao so aditiva mas tambem σ-aditiva, o que estamos a exigir a P e uma propriedade de
continuidade. Recordemos que uma semi-algebra C de partes dum conjunto Ω e um
semi-anel de partes de Ω que contem Ω, isto e, e uma classe nao-vazia de subconjuntos
de Ω que contem Ω, que e estavel para a interseccao finita, e o complementar de qualquer
elemento de C e reuniao finita disjunta de elementos de C (ver AMI, §1.2).
Teorema 1.2.5 Seja P uma funcao de conjunto nao-negativa e aditiva numa semi-
-algebra B de partes de Ω com P(Ω) = 1. As afirmacoes seguintes sao equivalentes:
i) P e σ-aditiva em B;
ii) P e ascendentemente contınua;
iii) P e ascendentemente contınua em Ω;
iv) P e descendentemente contınua;
v) P e descendentemente contınua em ∅.
ATP, Coimbra 2002

8 Apontamentos de Teoria das Probabilidades
Exercıcios
1. (Formula de Daniel da Silva ou da Inclusao-Exclusao:) Se A1, . . . , An, para n ≥ 2,
sao acontecimentos, mostre que
P( n⋃
i=1
Ai
)=
n∑
i=1
P(Ai) −∑
1≤i<j≤n
P(Ai ∩ Aj)
+∑
1≤i<j<k≤n
P(Ai ∩ Aj ∩ Ak) + . . . + (−1)n+1P(A1 ∩ . . . ∩ An).
2. (Paradoxo das coincidencias3) Numa festa de natal os n funcionarios de uma empresa
decidem dar entre si presentes. Cada um tras um presente que e misturado com os outros
e distribuıdo ao acaso pelos funcionarios. Este procedimento e utilizado acreditando-se
que a probabilidade pn de alguem receber o seu proprio presente e pequena se o numero de
funcionarios e grande. Calcule pn e mostre que pn→1 − e−1. Verifique que pn ≈ 0.6321,
para n ≥ 7.
(Sugestao: Utilize a formula de Daniel da Silva aplicada aos acontecimentos Ai =“o
i-esimo funcionario recebe o seu presente”.)
3. (Desigualdades de Bonferroni) Se A1, . . . , An sao acontecimentos, mostre que:
(a) P( n⋃
i=1
Ai
)≥
n∑
i=1
P(Ai) −∑
1≤i<j≤n
P(Ai ∩ Aj).
(b) P( n⋃
i=1
Ai
)≤
n∑
i=1
P(Ai) −∑
1≤i<j≤n
P(Ai ∩ Aj) +∑
1≤i<j<k≤n
P(Ai ∩ Aj ∩ Ak).
4. Se (An) e uma sucessao de acontecimentos mostre que P(⋂∞
n=1 An) = 1 sse P(An) = 1,
para todo o n ∈ N.
1.3 Modelacao de algumas experiencias aleatorias
Dando continuidade ao paragrafo 1.1, apresentamos agora mais alguns exemplos de
modelacoes de experiencias aleatorias.
Exemplo 1.3.1 Consideremos n lancamentos sucessivos duma moeda equilibrada. Se
representarmos por 1 a saıda de “cara” e por 0 a saıda de “coroa”, o espaco dos
resultados e Ω = 0, 1n = (x1, . . . , xn) : xi = 0 ou 1. Tal como no Exemplo 1.1.2,
sendo a moeda equilibrada, todos os elementos de Ω tem a mesma possibilidade de
ocorrer. Poderemos assim tomar P definida em A = P(Ω) por
P((x1, . . . , xn)) = 1/2n, para (x1, . . . , xn) ∈ 0, 1n.
3Este problema e pela primeira vez considerado por Pierre Remond de Montmort em Essay d’Analyse
sur les Jeux de Hazard, 1708.
ATP, Coimbra 2002

1 Espacos de probabilidade 9
Exemplo 1.3.2 Consideremos agora n lancamentos sucessivos duma moeda nao neces-
sariamente equilibrada, isto e, em cada lancamento a probabilidade de obtermos 1 (cara)
e p e a probabilidade de obtermos 0 (coroa) e 1 − p. Qual e o espaco de probabilidade
que devemos associar a esta experiencia aleatoria? O espaco dos resultados e, tal como
no exemplo anterior, Ω = 0, 1n. No entanto, os elementos de Ω nao tem agora,
para p 6= 1/2, a mesma possibilidade de ocorrer. Para determinarmos a probabilidade
que devemos associar a esta experiencia, tentemos reduzir-nos ao exemplo anterior
considerando uma experiencia auxiliar que consiste em n extraccoes sucessivas de uma
bola dum saco com ℓ bolas identicas em que ℓp estao numeradas com 1 e ℓ(1 − p)
sao numeradas com 0 (se p e racional e sempre possıvel determinar ℓ; por exemplo, se
p = 0.1 basta tomar ℓ = 10 e passamos a ter uma experiencia que consiste na repeticao
n vezes duma outra, esta com 10 resultados igualmente provaveis, em que um deles e
do tipo 1 e os restantes sao de tipo 0). A ocorrencia do acontecimento (x1, . . . , xn)com
∑ni=1 xi = k, corresponde na experiencia auxiliar a ocorrencia de um conjunto
de resultados elementares em numero de (ℓp)k(ℓ(1 − p))n−k. Sendo ℓn o numero total
de acontecimentos elementares, e sendo estes igualmente provaveis, entao P devera ser
dada por
P(x1, . . . , xn)) = (ℓp)k(ℓ(1 − p))n−k/ℓk = pk(1 − p)n−k,
isto e,
P(x1, . . . , xn)) = p∑n
i=1 xi(1 − p)n−∑n
i=1 xi ,
para (x1, . . . , xn) ∈ 0, 1n.
Exemplo 1.3.3 Consideremos n repeticoes, sempre nas mesmas condicoes, duma ex-
periencia aleatoria com k resultados possıveis 1, . . . , k, sendo p1, . . . , pk as respectivas
probabilidades de ocorrencia, onde∑k
i=1 pi = 1. Seguindo o raciocınio anterior o espaco
dos resultados e Ω = 1, . . . , kn e P devera ser dada por
P((x1, . . . , xn)) = p∑n
i=1 1I1(xi)
1 . . . p∑n
i=1 1Ik(xi)
k ,
para (x1, . . . , xn) ∈ 1, . . . , kn, onde 1IA representa a funcao indicatriz do conjunto A.
Nos exemplos que a seguir apresentamos nao e simples, sem mais, associar ou mesmo
garantir a existencia dum modelo probabilıstico para a experiencia aleatoria em causa.
Os dois primeiros casos sao classicos tendo sido considerados por Carl Friedrich Gauss4
e por Francis Galton5, respectivamente. Em ambos, a probabilidade P e definida pela
exibicao da sua densidade f , dita de probabilidade, relativamente a medida de
4Gauss, C.F., Theoria motus corporum celestium in sectionibus conicis solem ambientium, 1809.5Galton, F., Typical laws of heredity in man, 1877.
ATP, Coimbra 2002

10 Apontamentos de Teoria das Probabilidades
Lebesgue, isto e, P = fλ (ver AMI, §7.1). O ultimo exemplo e ilustrativo duma
classe de modelos probabilısticos conhecidos por processos estocasticos. A teoria
dos processos estocasticos nao sera desenvolvida neste curso.
Exemplo 1.3.4 (Distribuicao dos erros de medida) Consideremos o erro x = y−µ cometido ao tomarmos o valor observado y como medida do verdadeiro valor µ, des-
conhecido. Por razoes que detalharemos no Capıtulo 9, a experiencia aleatoria que
consiste na observacao de y, pode ser descrita pela probabilidade definida, para a ≤ b,
por
P(]a, b]) =
∫
]a,b]
1√2πσ2
e−(x−µ)2/(2σ2)dλ(x),
onde o parametro σ > 0 pode ser interpretado como uma medida da precisao das
observacoes. Na Figura 1.1 apresentam-se os graficos da funcao integranda anterior
para varios valores de σ, a que chamamos densidade normal de parametros µ e
σ2.
-4 -2 2 4
0.2
0.4
0.6
0.8
σ = 0.5
σ = 1
σ = 2
µ µ µ+ µ+
Figura 1.1: Densidade normal univariada
Exemplo 1.3.5 (Densidade normal bivariada) Quando se estuda a relacao entre
as alturas dos filhos (y) e dos pais (x) convenientemente normalizadas, e habitual
descrever as observacoes realizadas (x, y), atraves da probabilidade definida, para a ≤ b
e c ≤ d, por
P(]a, b]×]c, d]) =
∫
]a,b]×]c,d]
1
2π√
1 − ρ2e−(x2−2ρxy+y2)/(2(1−ρ2))dλ(x)dλ(y),
onde o parametro ρ ∈ ]− 1, 1[ quantifica a associacao ou dependencia existente entre
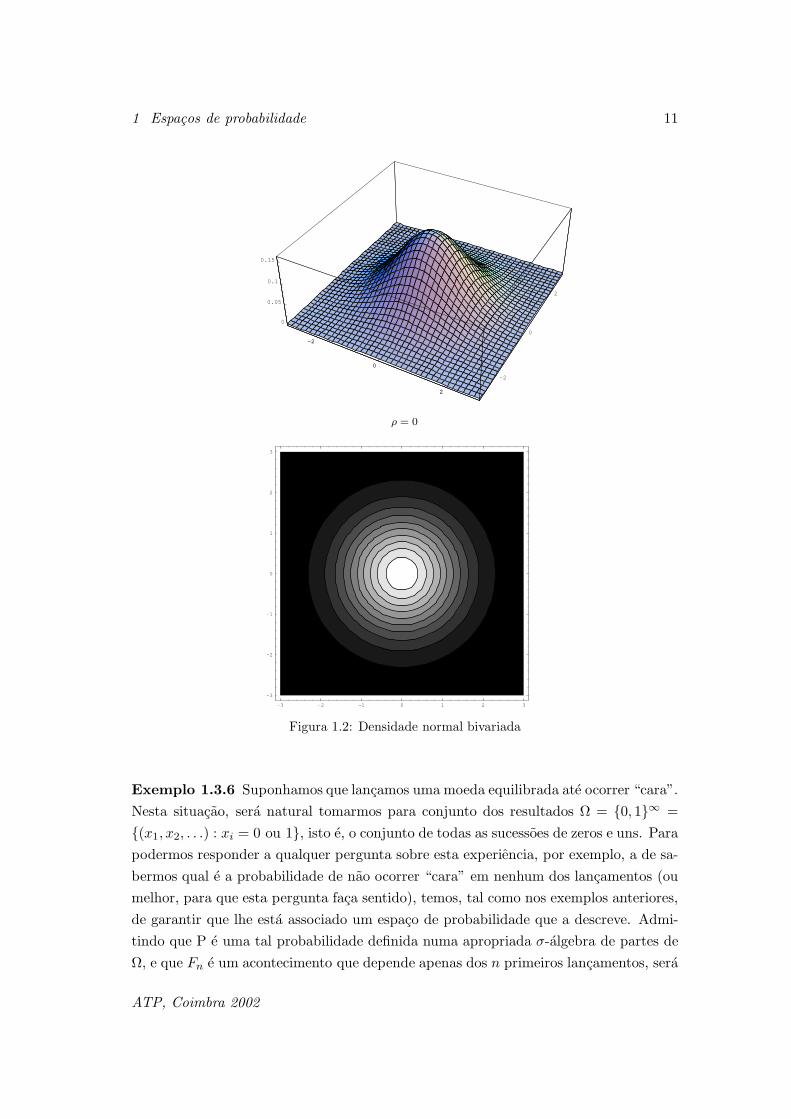
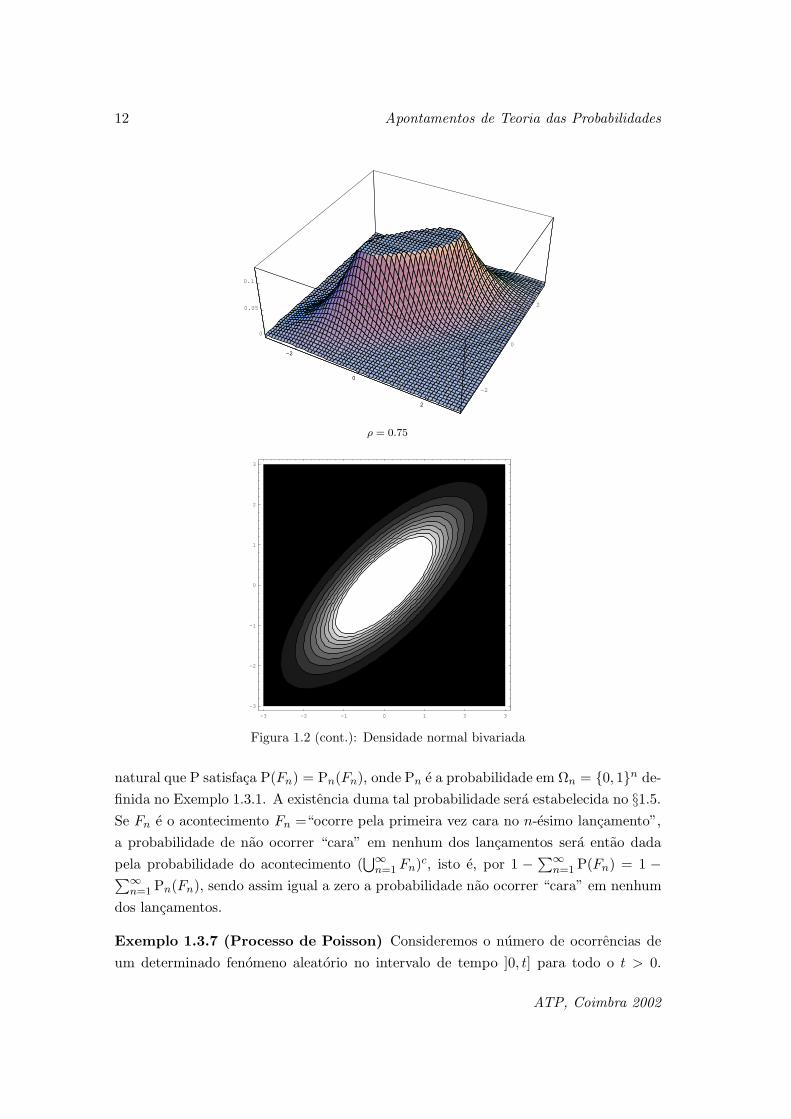
as quantidades numericas em estudo. Nas Figuras 1.2 e 1.3, e para os valores ρ = 0
e ρ = 0.75, respectivamente, apresentam-se o grafico e as curvas de nıvel relativos a
funcao integranda anterior.
ATP, Coimbra 2002
1 Espacos de probabilidade 11
-2
0
2
-2
0
2
0
0.05
0.1
0.15
-2
0
2
ρ = 0
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
Figura 1.2: Densidade normal bivariada
Exemplo 1.3.6 Suponhamos que lancamos uma moeda equilibrada ate ocorrer “cara”.
Nesta situacao, sera natural tomarmos para conjunto dos resultados Ω = 0, 1∞ =
(x1, x2, . . .) : xi = 0 ou 1, isto e, o conjunto de todas as sucessoes de zeros e uns. Para
podermos responder a qualquer pergunta sobre esta experiencia, por exemplo, a de sa-
bermos qual e a probabilidade de nao ocorrer “cara” em nenhum dos lancamentos (ou
melhor, para que esta pergunta faca sentido), temos, tal como nos exemplos anteriores,
de garantir que lhe esta associado um espaco de probabilidade que a descreve. Admi-
tindo que P e uma tal probabilidade definida numa apropriada σ-algebra de partes de
Ω, e que Fn e um acontecimento que depende apenas dos n primeiros lancamentos, sera
ATP, Coimbra 2002
12 Apontamentos de Teoria das Probabilidades
-2
0
2
-2
0
2
0
0.05
0.1
-2
0
2
ρ = 0.75
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
Figura 1.2 (cont.): Densidade normal bivariada
natural que P satisfaca P(Fn) = Pn(Fn), onde Pn e a probabilidade em Ωn = 0, 1n de-
finida no Exemplo 1.3.1. A existencia duma tal probabilidade sera estabelecida no §1.5.Se Fn e o acontecimento Fn =“ocorre pela primeira vez cara no n-esimo lancamento”,
a probabilidade de nao ocorrer “cara” em nenhum dos lancamentos sera entao dada
pela probabilidade do acontecimento (⋃∞
n=1 Fn)c, isto e, por 1 − ∑∞n=1 P(Fn) = 1 −
∑∞n=1 Pn(Fn), sendo assim igual a zero a probabilidade nao ocorrer “cara” em nenhum
dos lancamentos.
Exemplo 1.3.7 (Processo de Poisson) Consideremos o numero de ocorrencias de
um determinado fenomeno aleatorio no intervalo de tempo ]0, t] para todo o t > 0.
ATP, Coimbra 2002

1 Espacos de probabilidade 13
Pensemos, por exemplo, na chegada de chamadas a uma central telefonica, na chegada
de clientes a uma caixa de supermercado, na emissao de partıculas por uma substancia
radioactiva, etc. Se o fenomeno ocorre nos instantes t1, t2, t3, . . . com t1 < t2 < t3 < · · ·,o resultado da experiencia nao e mais do que uma funcao de ]0,+∞[ em N0, cujo grafico
e apresentado na Figura 1.3. O conjunto Ω dos resultados possıveis da experiencia pode
ser assim identificado com o conjunto das funcoes escalonadas de ]0,+∞[ em N0, nao-
-decrescentes e contınuas a direita.
6
-
1
2
3
numero deocorrencias
0 t1 t2 t3 tempo
b
r b
r b
r
Figura 1.3: Acontecimento elementar dum processo de Poisson
Admitamos que: H1) a probabilidade de se verificarem k ocorrencias num determinado
intervalo de tempo finito depende apenas da sua amplitude; H2) dados dois intervalos
de tempo finitos e disjuntos, a probabilidade de se verificarem k ocorrencias num deles
nao nos da qualquer informacao sobre a probabilidade de se verificarem j ocorrencias no
outro; H3) nao ha ocorrencias simultaneas. Poderıamos demonstrar que as hipoteses
anteriores determinam, numa apropriada σ-algebra de partes de Ω, uma famılias de
probabilidades indexada por um parametro real λ > 0 que pode ser interpretado como
o numero medio de chegadas num intervalo de tempo unitario.
Exercıcios
1. Vou lancar dois dados equilibrados n vezes consecutivas e aposto com outro jogador que
pelo menos um par de 6 ira sair. Para que o jogo me seja favoravel deverei lancar o dado
24 ou 25 vezes?
2. (Problema da divisao das apostas6) Dois jogadores jogam uma serie de partidas justas
ate que um deles obtenha 6 vitorias. Por motivos exteriores ao jogo, este e interrompido
quando um dos jogadores somava 5 vitorias e o outro 3 vitorias. Como devemos dividir
o montante apostado por ambos os jogadores?
6Este problema e o anterior foram colocados por Antoine Gombaud, chevalier de Mere, a Blaise
Pascal. O problema da divisao das apostas e resolvido por este e por Pierre de Fermat numa celebre
ATP, Coimbra 2002

14 Apontamentos de Teoria das Probabilidades
3. Eu e outro jogador aceitamos lancar sucessivamente dois dados nas condicoes seguintes:
eu ganho se tirar 7 pontos, ele ganha se tirar 6 pontos e e ele que lanca em primeiro lugar.
Que probabilidade tenho eu de ganhar?
4. (Problema da ruına do jogador7) A e B tem cada um 12 moedas e jogam com tres
dados. Se saem 11 pontos, A da uma moeda a B, e se saem 14 pontos, B da uma moeda
a A. Ganha aquele que primeiro ficar com todas as moedas. Qual e a probabilidade de
A ganhar?
(Sugestao: Para m ∈ −12, . . . , 12, denote por pm a probabilidade de A ganhar quando
possui 12 + m moedas, e verifique que pm satisfaz uma relacao de recorrencia linear.)
5. Uma caixa contem b bolas brancas e p bolas pretas. Uma bola e extraıda ao acaso da
caixa, e sem ser nela reposta, uma segunda bola e extraıda ao acaso. Qual o espaco de
probabilidade que associa a experiencia descrita? Qual e a probabilidade: De ambas as
bolas serem brancas? Da primeira bola ser branca e da segunda ser preta? Da segunda
ser preta? Da segunda ser preta, sabendo que a primeira bola e branca?
1.4 Algumas construcoes de espacos de probabilidade
Recordamos neste paragrafo construcoes de espacos de probabilidade ja nossas co-
nhecidas da disciplina de Medida e Integracao. Alguns dos exemplos apresentados nos
paragrafos anteriores sao casos particulares das construcoes seguintes.
Exemplo 1.4.1 Se Ω = ωi : i ∈ I, com I finito ou numeravel, e pi, i ∈ I, sao
numeros reais nao-negativos com∑
i∈I pi = 1, entao
P(A) =∑
i:ωi∈A
pi, para A ∈ P(Ω),
e uma probabilidade em (Ω,P(Ω)). As probabilidades consideradas nos Exemplos 1.1.2,
1.3.1 e 1.3.2, sao casos particulares desta. No caso em que I = 1, 2, . . . , n e pi = 1/n,
para todo o i ∈ I, obtemos a definicao classica de probabilidade.
Exemplo 1.4.2 Se F : R→R e uma funcao nao-decrescente, contınua a direita com
F (x)→ 0 ou 1, se x→−∞ ou x→+∞, respectivamente, entao existe uma e uma so
probabilidade P sobre (R,B(R)) tal que
P(] −∞, x]) = F (x), para todo o x ∈ R.
troca de correspondencia no verao de 1654. A resolucao do problema por Pascal e publicada em Traite
du Triangle Arithmetique, 1665. Este problema era ja na altura classico, sendo referido por Luca
Paccioli em Summa de arithmetica, geometria, proportioni et proportionalita, 1494.7Este problema e o anterior sao dois dos problemas resolvidos por Christian Huygens em De ratioci-
niis in aleae ludo (Sobre a logica do jogo de dados), 1657. O problema da ruına do jogador foi colocado
por Pascal a Fermat, tendo chegado posteriormente ao conhecimento de Huygens.
ATP, Coimbra 2002

1 Espacos de probabilidade 15
F diz-se funcao de distribuicao de P (ver AMI, §2.9). A probabilidade definida no
Exemplo 1.1.3 e um caso particular desta, em que F (x) = (x−a)/(b−a), se a ≤ x ≤ b,
F (x) = 0, se x < 0, e F (x) = 1, se x > b.
Exemplo 1.4.3 O exemplo anterior pode ser generalizado ao caso multidimensional.
Para x = (x1, . . . , xd) e y = (y1, . . . , yd) em Rd, escrevemos x ≤ y (resp. x < y) se
xi ≤ yi (resp. xi < yi) para todo o i = 1, . . . , d. Tal com em R, os conjuntos dos pontos
x tais que a < x ≤ b ou dos pontos x tais que x ≤ b, serao denotados por ]a, b] ou
]−∞, b], respectivamente. Dado um rectangulo semi-aberto a esquerda ]a, b], denotamos
por V o conjunto dos seus vertices, isto e, o conjunto dos pontos da forma (x1, . . . , xd)
com xi = ai ou xi = bi, para i = 1, . . . , d. Se x ∈ V , designamos por sgn(x) o sinal de
x, que e definido por sgn(x) = (−1)♯i:xi=ai. Dada uma funcao F : Rd→R, tal que: i)
F e nao-decrescente, isto e, F ]a, b] =∑
x∈V sgn(x)F (x) ≥ 0, se a < b; ii) F e contınua
a direita, isto e, limx→y, y≤x
F (x) = F (y), para todo o y ∈ Rd; iii) F (x) → 0 ou 1, se
mini=1,...,d xi→−∞ ou +∞, respectivamente; entao existe uma e uma so probabilidade
P sobre (Rd,B(Rd)) tal que
P(] −∞, x]) = F (x), para todo o x ∈ Rd.
F diz-se funcao de distribuicao de P. A demonstracao da existencia de P pode ser
encontrada em Billingsley, 1986, pg. 177–180. A unicidade e consequencia imediata do
lema da igualdade de medidas (cf. AMI, §2.6).
Exemplo 1.4.4 Se µ e uma medida em (Ω,A) e f e uma aplicacao B(R)-mensuravel
definida em (Ω,A), nao-negativa com∫
fdµ = 1, entao
P(A) =
∫
Afdµ, para A ∈ A,
e uma probabilidade. P diz-se probabilidade com densidade f relativamente a µ, e f
diz-se densidade de probabilidade de P relativamente a µ (ver AMI, §7.1).
Note que a construcao descrita no Exemplo 1.4.1 e um caso particular desta se
tomarmos f =∑
i∈I pi1Iωi e µ a medida contagem em Ω. Verifique que o mesmo
acontece com as construcoes consideradas nos Exemplos 1.1.3, 1.3.4 e 1.3.5. No caso
da extraccao ao acaso dum ponto do intervalo [a, b], P tem densidade f relativamente
a medida de Lebesgue em R, onde
f(x) =
1
b − a, se a ≤ x ≤ b
0, senao(1.4.5)
A densidade assim definida diz-se densidade uniforme sobre o intervalo [a, b].
ATP, Coimbra 2002

16 Apontamentos de Teoria das Probabilidades
Exemplo 1.4.6 Se Q e uma probabilidade num espaco mensuravel (E,B), e f e uma
aplicacao mensuravel de (E,B) em (Ω,A), entao P definida por
P(A) = Q(f−1(A)), para A ∈ A,
e uma probabilidade, dita probabilidade imagem de Q por f (ver AMI, §7.1). Este
e, em particular, o caso da probabilidade definida no Exercıcio 1.1.5 (porque?).
Exemplo 1.4.7 Se Pi e uma probabilidade sobre (Ωi,Ai), para i = 1, . . . , d, po-
demos definir sobre o espaco produto (Ω,A) = (∏d
i=1 Ωi,⊗d
i=1 Ai) a probabilidade
P =⊗d
i=1 Pi, dita probabilidade produto das probabilidade P1, . . . ,Pd (ver AMI,
§§6.1, 6.2). Sabemos que P e a unica probabilidade sobre (Ω,A) que satisfaz
P(A1 × . . . × Ad) =d∏
i=1
Pi(Ai),
para todo o Ai ∈ Ai, i = 1, . . . , d. A probabilidade construıda no Exemplo 1.3.2 e um
caso particular desta bastando tomar, para i = 1, . . . , n, (Ωi,Ai) = (0, 1,P(0, 1))e Pi(1) = p = 1 − Pi(0). O mesmo acontece com a probabilidade definida no
Exemplo 1.3.5 quando ρ = 0.
1.5 Produto de espacos de probabilidade
No Exemplo 1.3.6, deixamos em aberto a questao da existencia de uma probabilidade
definida num produto infinito de espacos de probabilidade verificando propriedades
semelhantes as da probabilidade produto definida num produto finito de espacos de
probabilidade (cf. Exemplo 1.4.7). Respondemos neste paragrafo a essa questao.
No que se segue, (Ωt,At,Pt), t ∈ T , e uma qualquer famılia de espacos de proba-
bilidade, e vamos denotar por∏
t∈T Ωt, o produto cartesiano dos espacos anteriores,
isto e, o conjunto de todos os elementos da forma (ωt, t ∈ T ), onde ωt ∈ Ωt, para
t ∈ T . Quando T = 1, . . . , n ou T = N escrevemos habitualmente Ω1 × . . . × Ωn ou
Ω1 × Ω2 × . . ., respectivamente. Se Ωt = Ω, para todo o t ∈ T , usamos a notacao ΩT ,
Ωn ou Ω∞, respectivamente.
Sendo S ⊂ T , e πS a aplicacao projeccao de∏
t∈T Ωt em∏
t∈S Ωt definida por
πS(ωt, t ∈ T ) = (ωt, t ∈ S), todo o subconjunto de∏
t∈T Ωt da forma π−1S (A), com
A ⊂ ∏t∈S Ωt, diz-se cilindro de base A. Um tal cilindro diz-se de dimensao finita
se S e finito.
Definicao 1.5.1 Chamamos σ-algebra produto das σ-algebras At, t ∈ T , a σ-algebra⊗
t∈T At, gerada pelos cilindros de dimensao finita cujas bases sao rectangulos men-
ATP, Coimbra 2002

1 Espacos de probabilidade 17
suraveis. Por outras palavras, se
S =π−1
S (A) : S ⊂ T, ♯S < ∞, A =∏
t∈S
At com At ∈ At, para t ∈ S
=∏
t∈S
At : At ∈ At e At = Ωt excepto para um numero finito de ındices
=⋃
S⊂T, ♯S<∞π−1
S
( ∏
t∈S
At
),
entao ⊗
t∈T
At = σ(S).
O espaco mensuravel (∏
t∈T Ωt,⊗
t∈T At) diz-se produto dos espacos mensuraveis
(Ωt,At), t ∈ T . Como anteriormente, denotamos a σ-algebra anterior por A1⊗
. . .⊗An
ou A1⊗A2
⊗. . ., quando T = 1, . . . , n ou T = N. Se At = A, para todo o t ∈ T ,
usaremos as notacoes AT , An ou A∞.
Proposicao 1.5.2 A σ-algebra produto⊗
t∈T At e a σ-algebra gerada pelas aplicacoes
projeccao πS :∏
t∈T Ωt→(∏
t∈S Ωt,⊗
t∈S At), com S ⊂ T finito.
Dem: Como σ(πS ;S ⊂ T, ♯S < ∞) = σ(∪S⊂T,♯S<∞π−1S (
⊗t∈SAt)), obtemos S ⊂
σ(πS ;S ⊂ T, ♯S < ∞), ou ainda,⊗
t∈SAt ⊂ σ(πS;S ⊂ T, ♯S < ∞). Para estabelecer
a inclusao contraria vamos mostrar que π−1S (
⊗t∈SAt) ⊂ ⊗
t∈SAt. Como⊗
t∈SAt ⊂σ(
∏t∈T At) e π−1
S (∏
t∈S At) ⊂ S, obtemos π−1S (
⊗t∈SAt) = π−1
S (σ(∏
t∈T At)) =
σ(π−1S (
∏t∈T At)) ⊂ σ(S) =
⊗t∈SAt.
Proposicao 1.5.3⊗
t∈T At e tambem gerada pelas aplicacoes πt :∏
t∈T Ωt→(Ωt,At),
com t ∈ T .
Dem: Para S ⊂ T finito e At ∈ At, para t ∈ S, temos π−1S (
∏t∈S At) = ∩t∈Sπ−1
t (At) ∈σ(πt; t ∈ T ). Assim, S ⊂ σ(πt; t ∈ T ), e tambem
⊗t∈S At ⊂ σ(πt; t ∈ T ). A inclusao
contraria e imediata pela proposicao anterior.
Proposicao 1.5.4 Uma aplicacao f = (ft, t ∈ T ) : (E,F) → (∏
t∈S Ωt,⊗
t∈S At) e
mensuravel sse ft : (E,F)→(Ωt,At) e mensuravel para todo o t ∈ T .
Dem: Sendo f mensuravel, a mensurabilidade de ft, para t ∈ T , e consequencia da
proposicao anterior, uma vez que ft = πt f . Reciprocamente, para A =∏
t∈T At, com
At ∈ At e At = Ωt, excepto para um conjunto finito S de ındices, temos f−1(A) =
x ∈ E : ft(x) ∈ At, t ∈ S = ∩t∈Sf−1t (At) ∈ F , pela mensurabilidade de cada uma
das aplicacoes ft.
ATP, Coimbra 2002

18 Apontamentos de Teoria das Probabilidades
A proposicao anterior permite-nos concluir, em particular, que a σ-algebra gerada
por f , σ(f), nao e mais do que a σ-algebra gerada pela famılia de aplicacoes ft, t ∈ T ,
isto e, σ(f) = σ(ft, t ∈ T ).
O resultado seguinte estabelece a existencia duma probabilidade sobre⊗
t∈T At
que sobre os cilindros de dimensao finita cujas bases sejam rectangulos mensuraveis∏
t∈S At, coincide com a probabilidade produto⊗
t∈S Pt.
Teorema 1.5.5 Existe uma unica probabilidade P sobre (∏
t∈T Ωt,⊗
t∈T At) tal que
para todo o S ⊂ T finito, e A =∏
t∈S At, com At ∈ At para t ∈ S,
P(π−1S (A)) =
∏
t∈S
Pt(At) =(⊗
t∈S
Pt
)(A).
A probabilidade P denota-se por⊗
t∈T Pt e denomina-se probabilidade produto das
probabilidades Pt, t ∈ T . O espaco (∏
t∈T Ωt,⊗
t∈T At,⊗
t∈T Pt) diz-se produto
cartesiano dos espacos de probabilidade (Ωt,At,Pt), t ∈ T .
Dem: Seguindo a demonstracao apresentada em Monfort, 1980, pg. 105–108, limitamo-
-nos a dar conta das suas principais etapas. O primeiro passo da demonstracao consiste
em mostrar que S e uma semi-algebra de partes de Ω =∏
t∈T Ωt e que P definida pela
formula anterior e aı aditiva e satisfaz P(Ω) = 1. Usando o Teorema 1.2.5, estabelece-se
a seguir a σ-aditividade de P em S. Finalmente, utilizando o teorema do prolonga-
mento (ver AMI, §2.5), concluımos que existe um unico prolongamento σ-aditivo de P
a⊗
t∈T At, o que conclui a demonstracao.
Exercıcios
1. Suponha que lanca uma moeda um numero infinito de vezes sempre nas mesmas condicoes
e que em cada lancamento a probabilidade de obter “cara” e igual a p ∈ ]0, 1[. Calcule a
probabilidade:
(a) de nao ocorrer “cara” em nenhum dos lancamentos;
(b) de ocorrer “cara” um numero infinito de vezes;
(c) de obter uma infinidade de vezes uma sequencia particular e finita de “caras” e
“coroas”.
2. Uma moeda equilibrada e lancada ate ocorrer “cara” pela primeira vez, e suponhamos
que estamos interessados no numero de lancamentos efectuados.
(a) Que espaco de probabilidade associaria a esta experiencia?
(b) Sendo E o acontecimento “ocorrencia de “cara” pela primeira vez depois dum
numero par de “coroas”” e F o acontecimento “ocorrencia de “cara” pela primeira
vez depois dum numero ımpar de “coroas””, calcule a probabilidade de E e de F .
ATP, Coimbra 2002

1 Espacos de probabilidade 19
1.6 Probabilidade condicionada
Retomemos o Exemplo 1.1.2 e suponhamos agora que lancamos o dado e que, apesar
de nao sabermos qual foi a face que ocorreu, sabemos que saiu face par, isto e, ocorreu o
acontecimento B = 2, 4, 6. Com esta nova informacao sobre a experiencia aleatoria,
o espaco de probabilidade inicialmente considerado nao e mais o espaco adequado a
descricao da mesma. Sera natural substituir a probabilidade P pela probabilidade PB
definida por PB(A) = ♯A ∩ B/♯B.
Duma forma geral, se (Ω,A,P) e o espaco de probabilidade associado a uma ex-
periencia aleatoria, e se sabemos que B ∈ A, com P(B) > 0, se realiza ou vai realizar,
a probabilidade dum acontecimento A ∈ A depende naturalmente “da sua relacao com
B”. Por exemplo, se A ⊃ B, A realizar-se-a, e se A ∩ B = ∅, A nao se realizara. Sera
assim natural medir a probabilidade de A se realizar por um numero proporcional a
P(A ∩ B), isto e, devemos associar a esta experiencia o novo espaco de probabilidade
(Ω,A,PB) onde
PB(A) =P(A ∩ B)
P(B), para A ∈ A.
Notemos que PB e efectivamente uma probabilidade sobre A.
Definicao 1.6.1 Para B ∈ A, com P(B) > 0, e A ∈ A, PB(A) diz-se probabilidade
condicionada de A sabendo B ou probabilidade condicionada de A dado B.
PB(A) denota-se tambem por P(A|B).
O conhecimento de P(B) e de PB(A) permitem calcular a probabilidade da inter-
seccao A∩B. O resultado seguinte generaliza tal facto a interseccao dum numero finito
de acontecimentos.
Teorema 1.6.2 (Formula da probabilidade composta) Se A1, . . . , An, com n ≥2, sao acontecimentos aleatorios com P(A1 ∩ . . . ∩ An−1) > 0, entao
P(A1 ∩ . . . ∩ An) = P(A1)P(A2|A1)P(A3|A1 ∩ A2) . . . P(An|A1 ∩ . . . ∩ An−1).
Dem: Para n = 2 o resultado e consequencia imediata da definicao de probabilidade
condicionada. Para n > 2, se A1, . . . , An sao acontecimentos aleatorios com P(A1 ∩. . .∩An−1) > 0, basta ter em conta que P(A1∩ . . .∩An) = P(A1∩ . . .∩An−1)P(An|A1∩. . . ∩ An−1).
Consideremos agora um acontecimento B cuja realizacao esta relacionada com a
dos acontecimentos de uma famılia finita A1, . . . , An de acontecimentos disjuntos dois
a dois, e admitamos que conhecemos as probabilidades P(B|Ai) de B na eventualidade
ATP, Coimbra 2002

20 Apontamentos de Teoria das Probabilidades
do acontecimento Ai se realizar. O resultado seguinte mostra como efectuar o calculo
da probabilidade de B desde que conhecamos a probabilidade de cada um dos aconteci-
mentos Ai.
Teorema 1.6.3 (Formula da probabilidade total) Sejam A1, . . . , An acontecimen-
tos aleatorios dois a dois disjuntos de probabilidade positiva e B ∈ A tal que B ⊂A1 ∪ . . . ∪ An. Entao
P(B) =n∑
i=1
P(Ai)P(B|Ai).
A modelacao duma experiencia aleatoria consiste, como vimos ate agora, na fixacao
dum espaco de probabilidade que descreve completamente (ou acreditamos que des-
creve) a experiencia em causa. A realizacao dum acontecimento aleatorio particular,
nao tras qualquer informacao suplementar sobre futuras realizacoes da experiencia uma
vez que acreditamos que esta e completamente descrita pelo espaco de probabilidade
considerado. Outra perspectiva e no entanto possıvel. Se admitirmos que o espaco de
probabilidade considerado nao descreve completamente a experiencia em causa, mas que
a descreve apenas de uma forma aproximada, a realizacao dum acontecimento aleatorio
particular pode melhorar o conhecimento que temos sobre a experiencia aleatoria. Nesse
caso sera de todo o interesse saber como devemos calcular a probabilidade dum acon-
tecimento a luz desta nova informacao.
Retomando os comentarios que precederam o resultado anterior, significa isto que se
conhecermos as probabilidades P(·|Ai) para i = 1, . . . , n, e as probabilidades α1, . . . , αn
de cada um dos acontecimentos A1, . . . , An, respectivamente, sera natural considerar
numa primeira abordagem a modelacao da experiencia aleatoria o espaco de proba-
bilidade (Ω,A,Pα) onde, para C ∈ A, Pα e definida por Pα(C) =∑n
i=1 αiP(C|Ai)
(verifique que, para todo o i, Pα(·|Ai) = P(·|Ai) e Pα(Ai) = αi ). Se admitirmos
que a realizacao dum acontecimento B nos vai permitir conhecer melhor o fenomeno
aleatorio em estudo, e que as probabilidades P(·|Ai) nao sao alteradas com a observacao
de B, devemos entao, numa segunda etapa, substituir α1, . . . , αn por β1, . . . , βn, onde
βi = Pα(Ai|B), e considerar o novo espaco de probabilidade (Ω,A,Pβ) onde Pβ(C) =∑n
i=1 βiP(C|Ai), para C ∈ A. Os αi e os βi dizem-se probabilidades a priori e a
posteriori dos Ai, respectivamente.
O resultado seguinte permite concluir que cada βi, pode ser calculado a partir das
probabilidades a priori α1, . . . , αn e das probabilidades condicionais P(·|A1), . . . ,P(·|An).
Mais precisamente, βi = P(B|Ai)αi/∑n
j=1 αjP(B|Aj), para i = 1, . . . , n.
ATP, Coimbra 2002

1 Espacos de probabilidade 21
Teorema 1.6.4 (Teorema de Bayes) Nas condicoes do teorema anterior, se P(B) >
0, entao, para i = 1, . . . , n,
P(Ai|B) =P(B|Ai)P(Ai)∑n
j=1 P(Aj)P(B|Aj).
Os dois resultados anteriores sao validos para uma infinidade numeravel de aconteci-
mentos A1, A2, . . . com probabilidades positivas. Em particular, se (Ai) e uma particao
de Ω, a condicao B ⊂ A1 ∪ A2 ∪ . . ., e sempre verificada.
Exercıcios
1. Demonstre os Teoremas 1.6.3 e 1.6.4.
2. Uma urna contem r bolas brancas e s bolas pretas. Uma bola e extraıda ao acaso da
urna, e e de seguida reposta na urna com mais t bolas da sua cor. Este processo e repetido
novamente. Qual e a probabilidade: Da segunda bola extraıda ser preta? Da primeira
bola ser branca sabendo que a segunda e branca?
3. Numa determinada especie animal, os especimes com genotipos PP e PC sao pretos e
os especimes com genotipos CC sao castanhos. Um animal de cor preta, que sabemos
resultar dum cruzamento PC × PC, e cruzado com um animal castanho, sendo os tres
descendentes deste cruzamento todos pretos.
(a) Quais as probabilidades do progenitor preto ter genotipos PP e PC, respectiva-
mente?
(b) Calcule as probabilidades anteriores, no caso do progenitor de cor preta resultar
dum cruzamento PP × PC.
(c) Poderao as probabilidades anteriores ser calculadas no caso de apenas sabermos que
o progenitor de cor preta resultou dum cruzamento PC × PC ou PP × PC?
4. (Paradoxo do teste para despiste duma doenca rara) Um teste ao sangue e uti-
lizado para despiste duma doenca rara: em 98.5% dos casos o teste da um resultado
positivo quando a doenca esta presente (sensibilidade do teste); em 97.5% dos casos o
teste da um resultado negativo quando a doenca nao esta presente (especificidade do
teste); 0.41% da populacao sofre dessa doenca.
(a) Qual a probabilidade do teste indicar que uma pessoa sofre da doenca, sem sabermos
nada acerca dessa pessoa?
(b) Qual a probabilidade de efectivamente estar doente uma pessoa cujo teste indica
que sofre dessa doenca?
(c) Calcule a probabilidade do teste fornecer um diagnostico correcto.
5. Um homem acusado num caso de paternidade possui uma caracterıstica genetica presente
em 2% dos adultos do sexo masculino. Esta caracterıstica so pode ser transmitida de
pai para filho e quando presente no progenitor e sempre transmitida para cada um dos
seus descendentes. Admitindo que a probabilidade p do homem ser o pai da crianca em
ATP, Coimbra 2002

22 Apontamentos de Teoria das Probabilidades
causa e de 0.5, determine a probabilidade do homem ser pai da crianca sabendo que esta
possui a referida caracterıstica genetica. Calcule esta ultima probabilidade para p = 0.01
e p = 0.001.
6. Um saco contem duas moedas: uma normal com cara de um lado e coroa do outro, e
outra com cara dos dois lados. Uma moeda e tirada ao acaso do saco.
(a) Se pretendesse calcular a probabilidade de obter cara em dois lancamentos da mo-
eda, qual era o espaco de probabilidade que consideraria?
(b) A moeda tirada do saco e lancada n vezes, e os resultados obtidos sao todos cara.
Qual e a probabilidade da moeda que lancamos ser a que tem cara nos dois lados?
(c) Se pretendesse calcular a probabilidade de obter cara nos proximos dois lancamentos
da moeda, qual era o espaco de probabilidade que consideraria?
(Sugestao: Utilize o Teorema de Bayes.)
7. (Probabilidade das causas) Sobre uma mesa estao sete urnas em tudo identicas que
denotamos por U0, . . . , U7, contendo a urna Ui, i bolas pretas e 6 − i bolas brancas.
De uma das urnas escolhida ao acaso, sao feitas duas tiragens com reposicao, tendo-se
observado duas bolas brancas. Qual e a composicao mais provavel da urna escolhida?
1.7 Produto generalizado de probabilidades
Dados dois espacos de probabilidade (Ω1,A1,P1) e (Ω2,A2,P2), sabemos ja que
e possıvel definir no produto cartesiano (Ω1 × Ω2,A1 ⊗ A2) uma unica probabilidade
P1 ⊗ P2 que satisfaz (P1 ⊗ P2)(A1 × A2) = P1(A1)P2(A2), para todo o A1 ∈ A1 e
A2 ∈ A2. Grosso modo, e tendo em mente os Exemplos 1.3.1, 1.3.2 e 1.3.5 (com ρ = 0),
podemos dizer que um resultado particular (x, y) da experiencia aleatoria descrita pela
probabilidade P1 ⊗ P2 resulta da realizacao de duas experiencias aleatorias descritas
pelas probabilidades P1 e P2, respectivamente, em que a probabilidade de ocorrencia
de y como resultado da segunda experiencia nao depende da ocorrencia do resultado x
na primeira experiencia.
Tal situacao nao se verifica no Exemplo 1.3.5 quando ρ 6= 0. Na modelacao da
experiencia aleatoria aı descrita, em vez de optarmos por definir uma probabilidade P
no produto cartesiano dos espacos associados as alturas normalizadas dos pais e dos
filhos, poderiamos optar por decompor o problema em dois problemas mais simples,
comecando por modelar a experiencia aleatoria associada a observacao das alturas nor-
malizadas dos pais atraves duma probabilidade P1 com densidade normal de parametros
0 e 1 (por exemplo), isto e,
P1(A1) =
∫
A1
1√2π
e−x2/2dλ(x),
para A1 ∈ B(R), modelando a seguir a experiencia aleatoria associada a observacao das
alturas dos filhos correspondentes a um progenitor cuja altura normalizada e igual a x,
ATP, Coimbra 2002

1 Espacos de probabilidade 23
-4 -2 2 4
0.1
0.2
0.3
0.4
0.5
0.6
x = −2 x = 0 x = 1
ρ = 0.75
Figura 1.4: Densidade da probabilidade de transicao no caso normal bivariado
por uma probabilidade P12(x, ·) com densidade normal cujos parametros dependem de
x. Tomando a densidade normal de parametros ρx e 1 − ρ2, obterıamos
P12(x,A2) =
∫
A2
1√2π(1 − ρ2)
e−(y−ρx)2/(2(1−ρ2))dλ(y),
para A2 ∈ B(R).
Colocado num contexto geral, o problema que naturalmente se levanta e saber se
e possıvel a partir duma probabilidade P1 definida sobre (Ω1,A1), e duma famılia de
probabilidades P12(x, ·) sobre (Ω2,A2) indexada por x ∈ Ω1, definir uma probabilidade
P sobre A1⊗A2 que preserve as interpretacoes anteriores atribuıdas a P1 e a P12, isto e,
P1(A1) devera ser a probabilidade P de A1×Ω2, e P12(x,A2) devera ser a probabilidade
condicional de Ω1 × A2 dado x × Ω2, sempre que este ultimo acontecimento tenha
probabilidade nao-nula.
O resultado seguinte estabelece a possibilidade de definir uma tal probabilidade
sobre A1 ⊗A2. Note que quando a famılia de probabilidades P12(x, ·), x ∈ Ω1, se reduz
a um unico elemento P2, a probabilidade P nao e mais do que P1 ⊗ P2.
Definicao 1.7.1 Chamamos probabilidade de transicao sobre Ω1 × A2, a uma
aplicacao P12 de Ω1×A2 em [0, 1] tal que para todo o x ∈ Ω1, P1
2(x, ·) e uma probabilidade
sobre (Ω2,A2), e para todo o A2 ∈ A2, P12(·, A2) e A1-mensuravel.
Teorema 1.7.2 Sejam (Ω1,A1,P1) um espaco de probabilidade, (Ω2,A2) um espaco
mensuravel e P12 uma probabilidade de transicao sobre Ω1 × A2. Entao, existe uma
unica probabilidade P sobre A1 ⊗A2 tal que
P(A1 × A2) =
∫
A1
P12(x,A2)dP1(x),
para todo o A1 ∈ A1 e A2 ∈ A2.
ATP, Coimbra 2002

24 Apontamentos de Teoria das Probabilidades
Dem: A formula anterior define P sobre a semi-algebra A1 ×A2 de partes de Ω1 ×Ω2.
Alem disso, P(Ω1×Ω2) = 1 e P e σ-aditiva em A1×A2 (para estabelecer a σ-aditividade
de P adapte a demonstracao do Teorema 6.2.1 de AMI, sobre a existencia da medida
produto). Para concluir basta agora usar o teorema do prolongamento (cf. AMI, §2.6)que garante a existencia de um e um so prolongamento σ-aditivo de P a A1 ⊗A2.
Exercıcios
1. (Problema do concurso das portas) E-lhe proposto o seguinte jogo. Tem a sua frente
tres portas das quais uma contem um premio, estando as outras duas vazias. Comeca por
escolher um das portas. Sem lhe ser dada nenhuma informacao sobre o que contem a porta
que escolheu, uma das outras duas, a que nao tem o premio, e aberta. E-lhe agora pedido
para escolher entre as duas portas fechadas restantes. Qual o espaco de probabilidade
que devemos associar a esta experiencia? Calcule a probabilidade de ganhar o premio
considerando cada uma das seguintes estrategias:
(a) na segunda escolha mantem a porta inicialmente escolhida;
(b) na segunda escolha muda de porta;
(c) na segunda escolha escolhe ao acaso uma nova porta (entre as duas que ainda estao
fechadas).
2. Retome os Exercıcios 1.6.2 e 1.6.6. Identifique os modelos de probabilidade associados as
experiencias aleatorias aı descritas.
3. Mostre que a probabilidade definida no Exemplo 1.3.5 e um caso particular do produto
generalizado de probabilidades, podendo ser definida a partir duma probabilidade P1
sobre B(R) com densidade normal de parametros 0 e 1, e duma probabilidade de transicao
P12 sobre R × B(R), onde P1
2(x, ·) tem densidade normal de parametros ρx e 1 − ρ2 (ver
Figura 1.4).
1.8 Breve referencia a simulacao de experiencias aleatorias
Algumas das experiencias aleatorias descritas no §1.1 podem ser facilmente simu-
ladas com a ajuda dum computador. Na base de todo o processo esta a simulacao da
extraccao ao acaso de pontos do intervalo ]0, 1[ (ver Exemplo 1.1.3). E por ela que
comecamos.
Os algoritmos utilizados para esse fim passam pela obtencao duma sucessao x0, x1, x2,
. . . , xn, . . . de inteiros entre 1 e m−1, com m “grande”, que pareca comportar-se como se
da extraccao ao acaso de pontos do conjunto 1, . . . ,m−1 se tratasse. O metodo mais
usado para gerar uma tal sucessao, e o metodo de congruencia linear. Comecando
com uma “semente” x0, xn+1 e obtido de xn atraves da formula
xn+1 = axn + b (mod m),
ATP, Coimbra 2002

1 Espacos de probabilidade 25
onde a e b sao constantes convenientemente escolhidas, de modo que se obtenha, por
um lado, uma sucessao com um perıodo grande, e, por outro lado, que a sucessao imite
a extraccao ao acaso de pontos de 1, . . . ,m−1. Para obter uma sucessao de numeros
em ]0, 1[ basta dividir cada xn por m. Os numeros assim obtidos dizem-se numeros
pseudo-aleatorios, ou mais simplesmente, numeros aleatorios.
Sendo a sucessao anterior completamente determinada pela semente x0, para obter
diferentes sucessoes, diferentes valores de x0 tem de ser escolhidos, ou pelo utilizador,
ou, de forma automatica, com base no relogio do computador. A partir da funcao
“random” do compilador de Pascal dum computador Compaq (Workstation Alpha
Unix) obtivemos os seguintes 50 numeros aleatorios (primeiras seis casas decimais):
0.750923, 0.514810, 0.989085, 0.676017, 0.582768, 0.992278, 0.900570, 0.276358,
0.154543, 0.896320, 0.631060, 0.799246, 0.093678, 0.344508, 0.520097, 0.426544,
0.189514, 0.070280, 0.458262, 0.145676, 0.270472, 0.428466, 0.193471, 0.095973,
0.438925, 0.171107, 0.073370, 0.986646, 0.940340, 0.777523, 0.356934, 0.691263,
0.292333, 0.346020, 0.367280, 0.875102, 0.338298, 0.267851, 0.151460, 0.492841,
0.164171, 0.782520, 0.292087, 0.257849, 0.127028, 0.812184, 0.684393, 0.316542,
0.882464, 0.142655.
Quando nada e dito em contrario o compilador atras referido usa o numero 7774755
como semente. Para uma semente (numero natural) escolhida pelo utilizador devera
utilizar a instrucao “seed(semente)”, e para uma semente baseada no relogio da maquina
use “seed(wallclock)”.
Utilizando o gerador de numeros aleatorios podemos tambem simular a experiencia
descrita no Exemplo 1.1.2. Se for r o numero aleatorio gerado, basta associar-lhe a
face do dado com o numero ⌊6r⌋+ 1, onde ⌊x⌋ denota a parte inteira de x. Por outras
palavras, ocorre a face i do dado se r pertence ao subintervalo [(i − 1)/6, i/6[ de [0, 1[.
A partir dos numeros aleatorios anteriores obtemos os resultados seguintes resultados
para o lancamento simulado dum dado equilibrado:
5, 4, 6, 5, 4, 6, 6, 2, 1, 6, 4, 5, 1, 3, 4, 3, 2, 1, 3, 1, 2, 3, 2, 1, 3,
2, 1, 6, 6, 5, 3, 5, 2, 3, 3, 6, 3, 2, 1, 3, 1, 5, 2, 2, 1, 5, 5, 2, 6, 1
De forma analoga, ainda a partir dos numeros aleatorios anteriores, obtemos os
resultados seguintes para o lancamento simulado duma moeda equilibrada:
1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0
As tecnicas que conjugam os metodos de simulacao anterior e a interpretacao fre-
quencista de probabilidade para efectuar calculos sao conhecidos na literatura como
ATP, Coimbra 2002

26 Apontamentos de Teoria das Probabilidades
metodos de Monte Carlo. Alguns exemplos sao apresentados nos exercıcios seguin-
tes.
Exercıcios
1. Como poderia simular num computador a extraccao ao acaso dum ponto do quadrado
[0, 1]×[0, 1]? Utilizando a interpretacao frequencista de probabilidade (que justificaremos
mais a frente), como poderia calcular de forma aproximada a area do cırculo inscrito nesse
quadrado?
2. Simule as experiencias descritas nos Exercıcios 1.1.1 e 1.3.1 num computador, e ensaie
uma resposta as pergunta feitas nesses exercıcios apenas com base nessa simulacao.
3. Escreva um algoritmo para simular a extraccao ao acaso dum ponto do intervalo [a, b[,
para a e b quaisquer.
4. No casino de Monte Carlo a roda da roleta e dividida em 37 casas iguais, 18 vermelhas,
18 pretas e uma verde. Se um jogador aposta 1 euro na cor vermelha tem probabilidade
18/37 de ganhar e 19/37 de perder. Por simulacao, e para n = 200, 1000 e 2000, obtenha
aproximacoes para a probabilidade do ganho lıquido do jogador ao fim de n partidas ser
nao-negativo.
1.9 Bibliografia
Billingsley, P. (1986). Probability and Measure, Wiley.
James, B.R. (1981). Probabilidades: um curso de nıvel intermediario, IMPA.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Kolmogorov, A.N. (1950). Foundations of the Theory of Probability, Chelsea Publishing
Company (traducao do original Grundbegriffe der Wahrscheinlichkeitrechnung,
datado de 1933).
Monfort, A. (1980). Cours de Probabilites, Economica.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
Sobre a historia das Probabilidades (e nao so)
Borel, E. (1950). Elements de la Theorie des Probabilites, Editions Albin Michel.
Hald, A. (1990). A History of Probability and Statistics and their applications before
1750, Wiley.
Hald, A. (1998). A History of Mathematical Statistics from 1759 to 1930, Wiley.
ATP, Coimbra 2002

1 Espacos de probabilidade 27
Sobre numeros aleatorios e simulacao de experiencias aleatorias
Grycko, E., Pohl, C., Steinert, F. (1998). Experimental Stochastics, Springer.
Knuth, D.E. (1981). The Art of Computer Programming, vol. II, Addison-Wesley.
Tompson, J.R. (2000). Simulation: a Modeler’s Approach, Wiley.
ATP, Coimbra 2002


Capıtulo 2
Variaveis aleatorias e
distribuicoes de probabilidade
Variaveis aleatorias e suas distribuicoes de probabilidade. Classificacao das distri-
buicoes de probabilidade sobre Rd. Funcao de distribuicao duma variavel aleatoria real
e dum vector aleatorio. Transformacao de vectores aleatorios absolutamente contınuos.
Distribuicoes condicionais.
2.1 Variaveis aleatorias e suas leis de probabilidade
Observado um resultado particular duma experiencia aleatoria, estamos por vezes
interessados nao no resultado em si mesmo, mas numa funcao desse resultado. Pense
no que acontece quando joga ao Monopolio e lanca os dados: interessa-lhe a soma dos
pontos obtidos e nao os pontos ocorridos em cada um dos dados. Por outras palavras,
sendo (Ω,A,P) um modelo probabilıstico para a experiencia aleatoria em causa, e
observado um ponto ω ∈ Ω, interessamo-nos por uma funcao de ω. Surge assim de
forma natural a nocao de variavel aleatoria.
Definicao 2.1.1 Chamamos variavel aleatoria em (E,B), onde E e um conjunto
nao-vazio munido duma σ-algebra B de partes de E, a toda a aplicacao mensuravel X
com valores em (E,B) definida num espaco de probabilidade (Ω,A,P).
Uma variavel aleatoria (v.a.) X diz-se variavel aleatoria real (v.a.r.) se E =
R, vector aleatorio (ve.a.) se E = Rd para algum numero natural d, sucessao
aleatoria se E = R∞, e processo estocastico ou funcao aleatoria se E = RT com
T um conjunto infinito de ındice. De acordo com a Proposicao 1.5.4, se Xt, t ∈ T ,
e uma famılia qualquer de variaveis aleatorias reais definidas num mesmo espaco de
probabilidade, entao X = (Xt, t ∈ T ) e uma variavel aleatoria em (RT ,B(R)T ).
29

30 Apontamentos de Teoria das Probabilidades
Definicao 2.1.2 Se X e uma variavel aleatoria definida em (Ω,A,P) com valores em
(E,B), chamamos lei de probabilidade ou distribuicao de probabilidade de X, a
medida imagem de P por X. Denotando por PX uma tal medida, temos PX = PX−1,
isto e,
PX(B) = P(X−1(B)) = P(ω ∈ Ω : X(ω) ∈ B), para B ∈ B.
Por simplicidade de escrita, escreveremos P(X ∈ B) em vez de P(ω ∈ Ω : X(ω) ∈B). PX e claramente uma probabilidade sobre (E,B). Se X e Y sao variaveis aleatorias
com valores num mesmo espaco mensuravel (mas nao necessariamente definidos num
mesmo espaco de probabilidade), escrevemos X ∼ Y sempre que X e Y tenham a
mesma distribuicao, isto e, sempre que PX = PY . Se X e Y estao definidas num mesmo
espaco de probabilidade e X = Y P-quase certamente (q.c.), isto e, P(X = Y ) = 1,
entao X ∼ Y . O recıproco nao e verdadeiro (ver Exercıcio 2.1.7).
Notemos que a σ-algebra X−1(B), que nao e mais do que a σ-algebra gerada por
X, σ(X) (cf. AMI §3.6), contem toda a “informacao” sobre X necessaria ao calculo da
sua distribuicao de probabilidade. Quando afirmamos que uma variavel aleatoria tem
distribuicao µ sobre (E,B), estamos a dizer que existe um espaco de probabilidade de
base (Ω,A,P) e uma variavel aleatoria X nele definida tal que PX = µ. Normalmente
apenas (E,B, µ) tem interesse e nenhum relevo e assumido pelo espaco de base (ver
Exercıcio 2.1.1).
Exemplo 2.1.3 Consideremos um espaco de probabilidade (Ω,A,P) e seja A ∈ A,
com P(A) = p. A funcao X = 1IA, e uma v.a. com valores em (0, 1, P(0, 1)).Claramente σ(X) = σ(A) = ∅, A,Ac,Ω e a lei de probabilidade PX de X e dada por
PX(B) = 0 se B = ∅, PX(B) = p se B = 1, PX(B) = 1− p se B = 0 e PX(B) = 1
se B = 0, 1. Qualquer variavel aleatoria com esta distribuicao sera representada por
B(p). Assim, indicamos X ∼ B(p) e dizemos que X e uma variavel de Bernoulli de
parametro p. Dizemos tambem que X tem (ou segue) uma lei (ou distribuicao) de
Bernoulli de parametro p.
Proposicao 2.1.4 Se X e uma variavel aleatoria em (E,B) e g : (E,B) → (F, C) e
uma aplicacao mensuravel, a distribuicao PX de X e g determinam a distribuicao de
g(X). Mais precisamente, Pg(X) e a medida imagem de PX por g:
Pg(X) = PX g−1.
Dem: Para C ∈ C, Pg(X)(C) = P(X−1(g−1(C))) = PX(g−1(C)) = (PX g−1)(C).
Se X1, . . . ,Xn sao variaveis aleatorias definidas num mesmo espaco de probabilidade
com valores em (E1,B1), . . . (En,Bn), respectivamente, sabemos que X = (X1, . . . ,Xn)
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 31
e uma variavel aleatoria com valores em (∏n
i=1 Ei,⊗n
i=1 Bi). O resultado anterior per-
mite concluir que conhecendo a distribuicao PX de X conhecemos tambem as dis-
tribuicoes PXj ditas distribuicoes marginais de X, uma vez que Xj = πj X
com πj : (∏n
i=1 Ei,⊗n
i=1 Bi)→ (Ej ,Bj) a projeccao πj(x1, . . . , xn) = xj. As variaveis
aleatorias Xj dizem-se margens de X.
O conhecimento das distribuicoes marginais de X nao permite, duma forma ge-
ral, caracterizar a distribuicao de X. Com efeito, os vectores (X1,X2) e (Y1, Y2)
com valores em (0, 12,P(0, 12)) e distribuicoes distintas definidas, para (i, j) ∈0, 12, por P(X1,X2)((i, j)) = 1/8, se i = j, P(X1,X2)((i, j)) = 3/8, se i 6= j, e
P(Y1,Y2)((i, j)) = 1/4, para todo o (i, j), tem por distribuicoes marginais variaveis de
Bernoulli de parametro 1/2.
A seguir apresentamos alguns exemplos importantes de variaveis aleatorias que estao
relacionadas com os espacos de probabilidade considerados no Capıtulo 1.
Exemplo 2.1.5 Considere um modelo probabilıstico (Ω,A,P) que descreva a repeticao
n vezes duma experiencia sempre nas mesmas condicoes. Cada experiencia tem dois
resultados possıveis que vamos designar por “sucesso” e “insucesso”, sendo p ∈ [0, 1] a
probabilidade de sucesso em cada experiencia. Se X e a v.a. que nos da o numero de
sucessos obtidos nas n repeticoes da experiencia, entao PX e uma probabilidade sobre
(0, 1, . . . , n,P(0, 1, . . . , n)), com
PX(k) =(n
k
)pk(1 − p)n−k, para k = 0, 1, . . . , n.
Dizemos que X segue uma distribuicao binomial de parametros n e p, e indicamos
X ∼ B(n, p).
20 40 60 80 100
0.02
0.04
0.06
0.08
0.1
0.12
p = 0.1
p = 0.5 p = 0.8
Figura 2.1: Distribuicao binomial (n = 100)
ATP, Coimbra 2002

32 Apontamentos de Teoria das Probabilidades
(Obs: A distribuicao binomial e um modelo para problemas de amostragem com re-
posicao, como no caso dum problema controlo de qualidade em que um lote de pecas
e aceite se uma amostra escolhida ao acaso do lote nao contiver “muitas” pecas defei-
tuosas.)
Exemplo 2.1.6 Seja (Ω,A,P) o modelo probabilıstico que descreve n repeticoes, sem-
pre nas mesmas condicoes, duma experiencia aleatoria com k resultados possıveis
1, . . . , k, sendo p1, . . . , pk as respectivas probabilidades, onde∑k
i=1 pi = 1 (ver Exemplo
1.3.3). Para i = 1, . . . , k, denotemos por Xi o numero de ocorrencias do resultado i nas
n repeticoes da experiencia. X = (X1, . . . ,Xk) e um vector aleatorio em 0, 1, . . . , nk,
e, para (x1, . . . , xk) ∈ 0, 1, . . . , nk, temos
PX((x1, . . . , xk)) =n!
x1! . . . xk!px11 . . . pxk
k .
Dizemos neste caso que X e um ve.a. multinomial de parametros n ∈ N e (p1, . . . , pk),
e indicamos X ∼ M(n, p1, . . . , pk).
Exemplo 2.1.7 Se X e uma v.a. com valores no intervalo [a, b] (a < b), cuja distri-
buicao de probabilidade tem densidade, relativamente a medida de Lebesgue em R,
dada por (1.4.5), dizemos que X e uma v.a. uniforme sobre o intervalo [a, b] e
escrevemos X ∼ U([a, b]) (ver Exemplo 1.1.3).
Exemplo 2.1.8 Se X e uma v.a. real cuja densidade de probabilidade e normal de
parametros µ e σ2 (cf. Exemplo 1.3.4), dizemos que X e uma v.a. normal de parame-
tros µ e σ2 e escrevemos X ∼ N(µ, σ2). Se µ = 0 e σ2 = 1, X diz-se normal
standard, ou, por razoes que veremos mais a frente, normal centrada e reduzida.
(Obs: A distribuicao normal e a mais usada das distribuicoes de probabilidade, des-
crevendo, por exemplo, o efeito global aditivo de um numero elevado de pequenos efeitos
independentes, como e o caso dos erros de instrumentacao. A justificacao teorica para
o papel de relevo que esta distribuicao assume na modelacao deste tipo de fenomenos
aleatorios, e o denominado teorema do limite central que estudaremos no Capıtulo 9.)
Exemplo 2.1.9 Se (X,Y ) e um ve.a. em R2 com densidade de probabilidade dada por
f(x, y) =1
2πσ1σ2
√1 − ρ2
exp
(− 1
2(1 − ρ2)
((x − m1)
2
σ21
−2ρ(x − m1)(y − m2)
σ1σ2+
(y − m2)2
σ22
)),
para (x, y) ∈ R2, dizemos que (X,Y ) e um ve.a. normal de parametros m1,m2 ∈ R,
σ1, σ2 > 0 e −1 < ρ < 1 (ver Exemplo 1.3.5).
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 33
Exercıcios
1. Se X e uma v.a. com valores em (E,B), sabemos que a sua lei de probabilidade e uma
probabilidade sobre (E,B). Mostre agora que se Q e uma probabilidade sobre (E,B),
existe uma v.a. X com valores em (E,B) definida num apropriado espaco de probabilidade
(Ω,A, P) tal que PX = Q.
2. Sejam Pn, n ∈ N, medidas de probabilidade sobre (E,B) e P definida em (Ω,A) =
(E∞,B∞) por P = ⊗∞n=1Pn. Considere a sucessao (Xn) definida, para ω = (ω1, ω2, . . .)
∈ Ω, por Xn(ω) = ωn (projeccao), e mostre que PXn = Pn, para todo o n ∈ N.
3. Sejam T um qualquer conjunto de ındices e X = (Xt, t ∈ T ) e Y = (Yt, t ∈ T ) variaveis
aleatorias com valores em (⊗t∈T Et,⊗t∈TBt). Mostre que X ∼ Y sse (Xt1 , . . . , Xtn) ∼(Yt1 , . . . , Ytn), para todo o n ∈ N e t1, . . . , tn ∈ T .
4. Determine a lei de probabilidade da variavel aleatoria que nos da a soma dos pontos
obtidos no lancamento de dois dados equilibrados.
5. Se X e uma v.a. binomial de parametros n e p, mostre que n − X e uma v.a. binomial
de parametros n e 1 − p.
6. Retome o Exercıcio 1.8.4 e denote por Sn o ganho lıquido do jogador ao fim de n partidas.
Apresente uma formula para o calculo de P(Sn ≥ 0). Utilize-a quando n = 200, 1000 e
2000. Compare os resultados com os obtidos por simulacao.
7. Sejam X e Y variaveis aleatorias definidas em (Ω,A, P) = ([0, 1],B([0, 1]), λ) por
X(ω) = ω e Y (ω) = 1 − ω.
Mostre que X ∼ Y e no entanto P(X = Y ) = 0.
8. Considere um modelo probabilıstico (Ω,A, P) que descreva a repeticao duma experiencia
sempre nas mesmas condicoes. Cada experiencia tem dois resultados possıveis que vamos
designar por “sucesso” e “insucesso”, sendo p ∈ [0, 1] a probabilidade de sucesso em cada
experiencia. Seja X a v.a. que nos da o numero de lancamentos efectuados para obtermos
o primeiro sucesso. Mostre que X tem uma distribuicao geometrica de parametro
p ∈ [0, 1], isto e,
PX(k) = (1 − p)k−1p, para k ∈ N.
9. No contexto do exercıcio anterior seja X a v.a. que nos da o numero de insucessos observa-
dos antes de obtermos o r-esimo sucesso. Mostre que X tem uma distribuicao binomial
negativa, dita tambem distribuicao de Pascal, e escrevemos X ∼ BN(r, p), isto e,
PX(k) = (k+r−1r−1 )pr(1 − p)k, para k ∈ N0.
10. Para cada n ∈ N, seja Xn uma v.a. binomial de parametros n ∈ N e pn ∈ ]0, 1[, onde
npn→λ > 0, e X uma v.a. de Poisson de parametro λ, isto e, PX e uma probabilidade
sobre (N0,P(N0)) definida por
PX(n) = e−λ λn
n!, para n ∈ N0.
ATP, Coimbra 2002

34 Apontamentos de Teoria das Probabilidades
(a) Para todo o k ∈ N, mostre que
PXn(k)PXn(k − 1) →
λ
k.
(b) (Convergencia da binomial para a Poisson) Para todo o k ∈ N0, conclua que
PXn(k)→PX(k),o que justifica a designacao de lei dos acontecimentos raros que e atribuıda a dis-
tribuicao de Poisson.
(Obs: A distribuicao de Poisson e usada em problemas de filas de espera para descre-
ver o numero de chegadas de clientes a um posto de atendimento num determinado
intervalo de tempo, ou, mais geralmente, para representar a realizacao de aconte-
cimentos independentes que ocorrem com frequencia constante. E tambem usada
para descrever o numero de defeitos em pecas semelhantes de um dado material.)
2.2 Classificacao das leis de probabilidade sobre Rd
No paragrafo anterior vimos exemplos de leis de probabilidade discretas, como as
dos Exemplos 2.1.3, 2.1.5 e 2.1.6, e de leis de probabilidade absolutamente contınuas,
como as dos Exemplos 2.1.7, 2.1.8 e 2.1.9. Recordemos que uma medida ν sobre B(Rd)
se diz: absolutamente contınua relativamente a medida de Lebesgue, e escrevemos
ν ≪ λ, se para todo o A ∈ B(Rd) com λ(A) = 0, entao ν(A) = 0; discreta, se existe S
quando muito numeravel tal que ν(Sc) = 0; difusa, se ν(x) = 0, para todo o x ∈ Rd;
alheia relativamente a medida de Lebesgue, e escrevemos ν ⊥ λ, se existe A ∈ B(Rd)
tal que ν(A) = λ(Ac) = 0; singular, se e difusa e alheia relativamente a medida de
Lebesgue.
O teorema da decomposicao de Lebesgue ja nosso conhecido da disciplina de Me-
dida e Integracao, e que enunciamos de seguida para medidas finitas, permitir-nos-a
classificar de forma simples as leis de probabilidade sobre Rd (ver AMI, §8.6).
Teorema da decomposicao de Lebesgue: Se ν e uma medida finita em (Rd,B(Rd)),
entao ν = ν0 + ν1 onde ν0 e ν1 sao medidas em Rd tais que ν0 ⊥ λ e ν1 ≪ λ. A
decomposicao anterior de ν, a que chamamos decomposicao de Lebesgue de ν em
relacao a λ, e unica.
Teorema 2.2.1 Seja X um vector aleatorio em (Rd,B(Rd)). Entao existem medidas
νac, νd e νs sobre B(Rd) tais que
PX = νac + νd + νs,
onde νac ≪ λ, νd e discreta e νs e singular. A decomposicao anterior e unica. A νac,
νd e νs, chamamos parte absolutamente contınua, discreta e singular de PX ,
respectivamente.
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 35
Dem: Pelo teorema da decomposicao de Lebesgue, PX = ν0 + ν1, onde ν0 ⊥ λ e
ν1 ≪ λ. Denotando por S, o conjunto dos pontos x para os quais ν0(x) 6= 0, um
tal conjunto e quando muito numeravel (porque?). Tomando agora, para A ∈ B(Rd),
ν2(A) = ν0(A ∩ S) e ν3(A) = ν0(A ∩ Sc), obtemos ν0 = ν2 + ν3, com ν2 discreta
e ν3 singular. Atendendo a unicidade da decomposicao PX = ν0 + ν1, basta, para
concluir, mostrar a unicidade da decomposicao ν0 = ν2 + ν3. Suponhamos entao que
ν0 = ν ′2 + ν ′
3, com ν ′2 discreta e ν ′
3 singular. Sendo S′ quando muito numeravel tal que
ν ′2((S
′)c) = 0, e ν3 e ν ′3 difusas, temos ν2(A) = ν2(A∩(S∪S′)) =
∑x∈A∩(S∪S′) ν2(x) =
∑x∈A∩(S∪S′) ν ′
2(x) = ν ′2(A ∩ (S ∪ S′)) = ν ′
2(A), para A ∈ B(Rd). Finalmente, sendo
ν2 finita, ν3 = ν0 − ν2 = ν0 − ν ′2 = ν ′
3.
Definicao 2.2.2 Se X e uma variavel aleatoria em (Rd,B(Rd)) e νac, νd e νs as partes
absolutamente contınua, discreta e singular de PX , respectivamente, dizemos que X (ou
a sua lei de probabilidade) e absolutamente contınua se νd = νs = 0, discreta se
νac = νs = 0, e singular se νac = νd = 0.
Atendendo ao teorema de Radon-Nikodym (ver AMI, §8.4), sabemos que νac ad-
mite a representacao νac(A) =∫A fdλ, A ∈ B(Rd), para alguma funcao f mensuravel
de (Rd,B(Rd)) em (R,B(R)), nao-negativa e integravel. A funcao f , que e unica a
menos dum conjunto de medida de Lebesgue nula, chamamos derivada de Radon-
Nikodym de νac relativamente a λ. Assim, X e absolutamente contınua sse PX(A) =∫A fdλ, para todo o A ∈ B(Rd), para alguma funcao f mensuravel, nao-negativa com∫fdλ = 1. Neste caso f diz-se densidade de probabilidade de X (ou de PX).
Tendo em conta a definicao de medida discreta, podemos dizer que X e discreta
sse existe um subconjunto S de Rd, quando muito numeravel, tal que PX(S) = 1. Ao
mais pequeno conjunto S (no sentido da inclusao) com estas propriedades chamamos
suporte de X (ou de PX) e denotamo-lo por SX . Claramente, SX = x ∈ Rd :
PX(x) > 0. A funcao g : Rd → R definida por g(x) = PX(x)1ISX(x), diz-se
funcao de probabilidade de X. Notemos que g e a derivada de Radon-Nikodym de
PX relativamente a medida contagem definida em Rd.
Como veremos de seguida, subvectores de vectores absolutamente contınuos sao
absolutamente contınuos e subvectores de vectores discretos sao ainda discretos.
Teorema 2.2.3 Se (X1, . . . ,Xd) e um vector aleatorio absolutamente contınuo de den-
sidade f , entao, para todo o i1, . . . , im ⊂ 1, . . . , d, (Xi1 , . . . ,Xim) e absolutamente
contınuo de densidade
g(xi1 , . . . , xim) =
∫
Rd−m
f(x1, . . . , xd)dλd−m,
onde λd−m representa a medida de Lebesgue em Rd−m.
ATP, Coimbra 2002

36 Apontamentos de Teoria das Probabilidades
Dem: Para B ∈ B(Rm), temos P(Xi1,...,Xim )(B) = P((X1, . . . ,Xd) ∈ π−1
i1,...,im(B)) =∫π−1i1,...,im
(B) f(x1, . . . , xd)dλd =∫
1IB(xi1 , . . . , xim)f(x1, . . . , xd)dλd =∫
Rm 1IB(xi1 , . . . ,
xim)∫
Rd−m f(x1, . . . , xd)dλd−mdλm =∫B g(xi1 , . . . , xim)dλm.
Teorema 2.2.4 Se (X1, . . . ,Xd) e um vector aleatorio discreto com suporte S e funcao
de probabilidade g, entao, para todo o i1, . . . , im ⊂ 1, . . . , n, (Xi1 , . . . ,Xim) e dis-
creto com suporte πi1,...,im(S) e funcao de probabilidade
h(xi1 , . . . , xim) =
∫
Rd−m
g(x1, . . . , xd)dµd−m
=∑
(x1,...,xd)∈π−1i1,...,im
((xi1,...,xim ))
g(x1, . . . , xd),
onde µd−m representa a medida contagem em Rd−m.
Exercıcios
1. Seja (X, Y ) o ve.a. definido no Exemplo 2.1.9. Mostre que X ∼ N(m1, σ21).
2. Se X ∼ M(n, p1, . . . , pk), mostre que Xi ∼ B(n, pi), para i = 1, . . . , k.
3. Considere os vectores aleatorios (X, Y ) de densidade
f(x, y) =1
2πe−(x2+y2)/2,
e (U, V ) de densidade
g(x, y) =1
πe−(x2+y2)/21I(]−∞, 0]×]−∞, 0])∪ ([0, +∞[×[0, +∞[)(x, y),
para (x, y) ∈ R2. Mostre que X ∼ U e Y ∼ V , e, no entanto, (X, Y ) 6∼ (U, V ).
2.3 Funcao de distribuicao duma variavel aleatoria real
Apresentamos neste paragrafo um instrumento importante no estudo da distribuicao
de probabilidade duma variavel aleatoria real X definida num espaco de probabilidade
(Ω,A,P).
Definicao 2.3.1 Chamamos funcao de distribuicao de X, e denotamo-la por FX ,
a funcao de distribuicao de PX , isto e,
FX(x) = PX(] −∞, x]) = P(X ≤ x), x ∈ R.
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 37
Proposicao 2.3.2 FX satisfaz as seguintes propriedades:
a) FX e nao-decrescente e contınua a direita.
b) FX(x)→0 ou 1, se x→−∞ ou x→+∞, respectivamente.
c) PX(a) = FX(a) − FX(a−), PX(]a, b]) = FX(b) − FX(a), PX([a, b]) = FX(b) −FX(a−), PX(]a, b[) = FX(b−) − FX(a) e PX([a, b[) = FX(b−) − FX(a−), para todo o
−∞ < a < b < +∞.
d) FX e contınua em x ∈ R sse PX(x) = 0.
e) O conjunto dos pontos de descontinuidade de FX e quando muito numeravel.
f) FX caracteriza PX (isto e, FX = FY sse X ∼ Y )
Dem: Demonstraremos apenas a alınea f). A demonstracao das restantes alıneas fica
ao cuidado do aluno. Se X ∼ Y entao PX = PY e consequentemente FX = FY .
Reciprocamente, se FX = FY para a, b ∈ R, temos PX(]a, b]) = FX(b) − FX(a) =
FY (b) − FY (a) = PY (]a, b]), ou ainda, PX = PY pelo lema da igualdade de medidas
(ver AMI, §2.6).
Notemos que, atendendo a alınea d), X e difusa sse FX e contınua em R. Alem
disso, das alıneas d) e e), e da decomposicao de Lebesgue, concluımos que a parte
discreta de PX tem por suporte o conjunto dos pontos de descontinuidade de FX .
O resultado seguinte da-nos duas caracterizacoes da continuidade absoluta duma
variavel aleatoria real em termos da sua funcao de distribuicao. A sua demonstracao
fica como exercıcio.
Teorema 2.3.3 Se X e uma variavel aleatoria real, sao equivalentes as seguintes pro-
posicoes:
i) X e absolutamente contınua.
ii) FX(x) =∫]−∞,x] fdλ, para alguma funcao nao-negativa e mensuravel f , com∫
fdλ = 1.
O resultado anterior e o teorema da diferenciacao de Lebesgue que a seguir enun-
ciamos (ver Rudin, 1974, pg. 176, e AMI, §9.3), permitem-nos, no caso de X ser abso-
lutamente contınua, garantir a diferenciabilidade quase em todo o ponto de FX , bem
como relacionar F ′X com a densidade de probabilidade de X.
Teorema da diferenciacao de Lebesgue: Se F (x) =∫]−∞,x] f dλ, para x ∈ R, onde
f : R →R e B(R)-mensuravel e integravel, entao F possui derivada em quase todo o
ponto de R e F ′ = f , λ-q.t.p.
Teorema 2.3.4 Se X e uma variavel aleatoria real absolutamente contınua de densi-
dade f , entao FX possui derivada em λ-quase todo o ponto de R e F ′X = f , λ-q.t.p.
ATP, Coimbra 2002

38 Apontamentos de Teoria das Probabilidades
Mesmo no caso em que X nao e necessariamente uma v.a. absolutamente contınua,
e possıvel obter o resultado seguinte (ver Rudin, 1974, pg. 176).
Teorema 2.3.5 Se X e uma variavel aleatoria real entao FX possui derivada em λ-
quase todo o ponto de R e F ′X = fac, λ-q.t.p., onde fac e a derivada de Radon-Nikodym
da parte absolutamente contınua de PX .
Terminamos este paragrafo estabelecendo duas condicoes suficientes para a conti-
nuidade absoluta duma variavel aleatoria em termos da sua funcao de distribuicao.
Teorema 2.3.6 Se X e uma variavel aleatoria real e FX satisfaz pelo menos uma das
condicoes a)∫
F ′Xdλ = 1 ou b) FX e continuamente diferenciavel em R, entao X e
absolutamente contınua.
Dem: a) Atendendo aos Teoremas 2.2.1 e 2.3.5, podemos escrever PX = F ′Xλ+νd +νs.
Se F ′X e tal que
∫F ′
Xdλ = 1, obtemos entao PX(R) = 1+νd(R)+νs(R), ou ainda, νd =
νs = 0, isto e, X e absolutamente contınua. b) Pelo teorema fundamental do calculo,∫]a,b] F
′Xdλ =
∫]a,b] F
′X(t)dt (integral de Riemann) = FX(b) − FX(a) = PX(]a, b]), para
todo o a < b em R. Como F ′X e nao-negativa concluımos que F ′
X e λ-integravel e que∫
F ′Xdλ = 1.
Exercıcios
1. Sejam a ∈ R e X uma v.a. constantemente igual a a (dizemos que X e degenerada).
Mostre que PX = δa, isto e, a lei de probabilidade de X e a medida de Dirac no ponto
a, e determine a funcao de distribuicao FX de X .
2. Seja X uma v.a. uniforme discreta sobre o conjunto 1, 2, . . . , n, isto e, X toma valores
no conjunto 1, 2, . . . , n e
PX(j) = 1/n, para j = 1, . . . , n.
Determine a funcao de distribuicao de X .
3. Sejam U uma v.a.r. centrada e reduzida, isto e, U ∼ N(0, 1), e X definida por X =
σU + µ, com µ ∈ R e σ > 0 fixos. Mostre que X ∼ N(µ, σ2).
4. Sejam X uma v.a. uniforme sobre o intervalo [a, b], e Y a v.a.r. definida em ([0, 1],B([0, 1]), λ)
por Y (ω) = (1 − ω)a + ωb.
(a) Determine a funcao de distribuicao de X .
(b) Mostre que Y ∼ X .
5. Denotemos por X a v.a. que descreve a “extraccao ao acaso dum ponto do intervalo
[0, 1]”. Determine a funcao de distribuicao de X2 e conclua que X2 e absolutamente
contınua. Descrevera X2 a extraccao ao acaso dum ponto do intervalo [0, 1]?
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 39
6. Sendo X uma v.a. normal de parametros 0 e 1, mostre que X2 admite por densidade de
probabilidade
f(x) =
1√2π
x−1/2 e−x/2, se x ≥ 0
0, se x < 0.
7. Considere a v.a. X de ([0, 1],B([0, 1), λ) em (R,B(R)), definida por X(ω) = ω, se 0 ≤ω < 1/2, X(ω) = 1/2, se 1/2 ≤ ω ≤ 3/4, e X(ω) = 2ω, se 3/4 < ω ≤ 1. Determine
a funcao de distribuicao de X e identifique as partes absolutamente contınua, discreta e
singular de PX .
8. Dizemos que uma v.a.r. X tem uma distribuicao exponencial de parametro λ > 0, e
escrevemos X ∼ E(λ), se admite uma densidade de probabilidade da forma
f(x) =
λe−λx, se x > 0
0, se x ≤ 0.
1 2 3 4
0.2
0.4
0.6
0.8
1
1.2
1.4
λ = 1.5
λ = 1
λ = 0.5
Figura 2.2: Distribuicao exponencial
(a) Determine a funcao de distribuicao FX .
(b) Mostre que se U ∼ U([0, 1[), entao, para λ > 0, X ∼ − 1λ ln(1 − U).
(Obs: A distribuicao exponencial e usada como modelo para o tempo de funcionamento
duma componente ou sistema, quando assumimos que o numero de falhas por unidade de
tempo e constante, ou para descrever o tempo que medeia entre chegadas consecutivas
de clientes a um posto de atendimento, quando assumimos que o numero de chegadas
por unidade de tempo e constante.)
9. (Representacao de Skorokhod duma v.a.r.) Sejam X uma v.a.r. com funcao de
distribuicao F e
F←(x) = infs ∈ R : F (s) ≥ x,para x ∈]0, 1[ (F← diz-se inversa generalizada de F ou funcao quantil de F ).
(a) Mostre que:
i. F←(x) ≤ u sse x ≤ F (u), para u ∈ R; ii. Se U ∼ U(]0, 1[), entao F←(U) ∼ X .
ATP, Coimbra 2002

40 Apontamentos de Teoria das Probabilidades
(b) Se X esta definida num espaco de probabilidade (E,F , Q), mostre que existe uma
v.a. real Y definida em (]0, 1[,B(]0, 1[), λ) tal que X ∼ Y .
(c) Sendo F contınua, mostre que:
i. F (F←(x)) = x; ii. F (X) ∼ U([0, 1]).
10. Se X e uma v.a.r. com funcao de distribuicao F contınua em R e estritamente crescente
quando 0 < F (x) < 1, sabemos do exercıcio anterior que F−1(U) ∼ X , quando U ∼U(]0, 1[). Atendendo a que pode simular uma v.a. uniforme sobre o intervalo ]0, 1[ (ver
§1.8), implemente a simulacao das variaveis aleatorias reais seguintes cuja densidade de
probabilidade se indica (ver Figuras 2.3-2.6):
(a) Cauchy de parametros α e β:
f(x) = (βπ(1 + (x − α)2/β2))−1, x ∈ R (α ∈ R, β > 0);
(b) Laplace de parametros α e β:
f(x) = βe−β|x−α|/2, x ∈ R (α ∈ R, β > 0);
-4 -2 2 4
0.1
0.2
0.3
0.4
β = 1.5
β = 1
β = 0.75
α α α+ α+
Figura 2.3: Distribuicao de Cauchy
-4 -2 2 4
0.1
0.2
0.3
0.4
0.5
0.6
0.7
β = 1.5
β = 1
β = 0.75
α α α+ α+
Figura 2.4: Distribuicao de Laplace
ATP, Coimbra 2002
2 Variaveis aleatorias e distribuicoes de probabilidade 41
(c) Logıstica de parametros α e β:
f(x) = e−(x−α)/β(1 + e−(x−α)/β)−2/β, x ∈ R (α ∈ R, β > 0);
(d) Weibull de parametros α e β:
f(x) = αββxβ−1e−(αx)β
, x ≥ 0 (α, β > 0).
-6 -4 -2 2 4 6
0.05
0.1
0.15
0.2
0.25
0.3
β = 1.5
β = 1
β = 0.75
α α α α+ α+ α+
Figura 2.5: Distribuicao logıstica
0.5 1 1.5 2 2.5 3
0.2
0.4
0.6
0.8
1
1.2
β = 3
β = 1.5
β = 1
Figura 2.6: Distribuicao de Weibull (α = 1)
2.4 Funcao de distribuicao dum vector aleatorio
Neste paragrafo generalizamos a nocao de funcao de distribuicao ao caso multivari-
ado. A notacao que a seguir utilizamos foi introduzida no Exemplo 1.4.3.
Definicao 2.4.1 Chamamos funcao de distribuicao do vector aleatorio X = (X1, . . . ,
Xd), e denotamo-la por FX , a funcao de distribuicao de PX , isto e,
FX(x) = PX(] −∞, x]) = P(X ≤ x), x ∈ Rd.
ATP, Coimbra 2002

42 Apontamentos de Teoria das Probabilidades
Proposicao 2.4.2 FX goza das seguintes propriedades:
a) FX e contınua a direita e nao-decrescente coordenada a coordenada;
b) FX(x)→0 ou 1, se mini=1,...,d xi→−∞ ou +∞, respectivamente;
c) Para a ≤ b, PX(]a, b]) =∑
x∈V sgn(x)FX(x), onde V e o conjunto dos vertices
de ]a, b];
d) FX caracteriza PX .
Dem: As alıneas a) e b) obtem-se como no caso real. A alınea c) e consequencia da
decomposicao ]a, b] =]−∞, b]−⋃di=1]−∞, (b1, . . . , bi−1, ai, bi+1, . . . , bd)] e da Formula
de Daniel da Silva. A alınea d) obtem-se de c) e do lema da igualdade de medidas.
Sendo FX contınua a direita e nao-decrescente coordenada a coordenada, a con-
tinuidade de F num ponto e equivalente a continuidade a esquerda nesse ponto. No
resultado seguinte estabelecemos uma condicao necessaria e suficiente para que um
ponto de Rd seja ponto de continuidade de FX .
Teorema 2.4.3 Sejam X um vector aleatorio em Rn, x ∈ Rd, fixo, e fr(] −∞, x]) a
fronteira de ] −∞, x]. Entao FX e contınua em x sse PX(fr(] −∞, x])) = 0.
Dem: Sendo (ǫn) uma sucessao em Rd com 0 ≤ ǫn ↓ 0, temos, para x ∈ Rd, ]−∞, x]−]−∞, x − ǫn] ↓ fr(] −∞, x], e assim PX(fr(] −∞, x])) = FX(x) − lim FX(x − ǫn), o que
permite concluir.
No caso real, a continuidade de FX em R e condicao necessaria e suficiente para que
X seja difusa. Como podemos concluir do resultado anterior, no caso multidimensional
a continuidade de FX em Rd apesar de suficiente nao e condicao necessaria para que
X seja difuso.
Aplicacoes sucessivas do teorema da diferenciacao de Lebesgue, permitem gene-
ralizar o Teorema 2.3.4 ao caso multidimensional.
Teorema 2.4.4 Se X e um vector aleatorio em Rd absolutamente contınuo de funcao
de distribuicao FX , entao∂dFX
∂x1 . . . ∂xdexiste em λ-quase todo o ponto de Rd e e uma
versao da densidade de probabilidade de X.
Terminamos este paragrafo, notando que conhecida a funcao de distribuicao dum
vector X, podemos facilmente obter a funcao de distribuicao dum seu subvector.
Teorema 2.4.5 Se FX e a funcao de distribuicao de (X1, . . . ,Xd), entao para
i1, . . . , im ⊂ 1, . . . , d, a funcao de distribuicao de (Xi1 , . . . ,Xim) e dada por
F(Xi1,...,Xim )(xi1 , . . . , xim) = lim FX(x1, . . . , xd),
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 43
onde o limite anterior e tomado quando xj → +∞, para todo o j ∈ 1, . . . , d \i1, . . . , im.
Exercıcios
1. Se U ∼ N(0, 1), mostre que o ve.a. (U, 0) em R2 e difuso e estude a sua funcao de
distribuicao quanto a continuidade.
2. Se (X, Y ) e um ve.a. em R2 com funcao de distribuicao F , mostre que ∂2F∂x∂y esta definida
em quase todo o ponto de R2 e e nao-negativa. Alem disso, mostre que se F e de classe
C2 entao (X, Y ) e absolutamente contınuo.
2.5 Transformacao de vectores absolutamente contınuos
Suponhamos que X e Y sao vectores aleatorios em Rd tais que Y = g(X) com
g : U →V , bijectiva entre os abertos U e V , e g e g−1 de classe C1. Mostramos neste
paragrafo que Y e absolutamente contınuo se X o for, e determinamos a densidade de
probabilidade de Y em funcao da de X. Um tal resultado e uma consequencia imediata
do teorema da mudanca de variavel no integral de Lebesgue que recordamos de seguida
(ver AMI, §§7.3, 7.4).
Teorema da mudanca de variavel: Nas condicoes anteriores, seja f : U → R
B(U)-mensuravel. Se f e nao-negativa, entao
∫
Vfdλ =
∫
V(f g−1)(x)|det(Jg−1(x))|dλ(x),
onde Jg−1(x) representa a matriz jacobiana de g−1 no ponto x. Alem disso, para f qual-
quer, a λ-integrabilidade de f e equivalente a λ-integrabilidade de (fg−1)(·)|det(Jg−1(·))|,e nesse caso vale a igualdade anterior.
Teorema 2.5.1 Nas condicoes anteriores, se X e absolutamente contınuo com densi-
dade f , entao Y e absolutamente contınuo e uma versao da sua densidade de probabi-
lidade e dada por
h(x) =
(f g−1)(x)|det(Jg−1(x))|, se x ∈ V
0 se x /∈ V.
Dem: Para B ∈ B(V ), temos PY (B) = P(g(X) ∈ B) = P(X ∈ g−1(B)) =∫g−1(B) fdλ =∫
U f1Ig−1(B)dλ =∫V (f1Ig−1(B) g−1)(x)|det(Jg−1(x))|dλ(x) =
∫V (f g−1)(x)1IB(x)
|det(Jg−1(x))|dλ(x) =∫B(f g−1)(x)|det(Jg−1(x))|dλ(x).
ATP, Coimbra 2002

44 Apontamentos de Teoria das Probabilidades
Uma aplicacao interessante do resultado anterior surge na determinacao da densi-
dade de probabilidade da soma de duas variaveis aleatorias X e Y com valores em Rd,
quando o vector (X,Y ) tem por densidade (x, y) → f(x)g(y), com f e g densidades
de probabilidade em Rd. Pelo teorema anterior, o vector (X + Y, Y ) tem por densi-
dade (u, v)→ f(u − v)g(v), e pelo Teorema 2.2.3 a densidade h de X + Y e dada por
h(u) =∫
f(u − v)g(v)dλ(v), a que chamamos convolucao das densidades f e g, e
que denotamos por f ⋆ g. Voltaremos a este assunto no Capıtulo 4.
Exercıcios
1. Retome o Exercıcio 2.3.5. Use o Teorema da transformacao de variaveis aleatorias abso-
lutamente contınuas para determinar a densidade de probabilidade de X2.
2. Sejam (X, Y ) o ve.a. definido no Exercıcio 2.2.3, e Z = X + Y . Mostre que Z ∼ N(0, 2).
3. Seja (X, Y ) um ponto escolhido ao acaso no quadrado [0, 1] × [0, 1]. Determine a distri-
buicao de Z = X + Y , dita distribuicao triangular sobre o intervalo [0, 2].
4. Se (X, Y ) e um ve.a. com valores em (R2,B(R2)) e densidade f , mostre que as v.a.
Z1 = XY e Z2 = X/Y sao absolutamente contınuas com densidades
g1(z) =
∫f(u, z/u)/|u| dλ(u), para z ∈ R,
e
g2(z) =
∫f(zv, v)|v| dλ(v), para z ∈ R,
respectivamente. Se (X, Y ) e o ve.a. definido no Exercıcio 2.2.3, conclua que Z2 possui
uma distribuicao de Cauchy de parametros 0 e 1.
5. Sejam (X, Y ) o ve.a. definido no Exercıcio 2.2.3 e Z = X2 + Y 2.
(a) Mostre que, para A ∈ B(R),
P(Z ∈ A) =
∫ ∫1IA(x2 + y2)
1
2πe−(x2+y2)/2dλ(x)dλ(y).
(b) Conclua que Z segue uma lei exponencial de parametro 1/2.
6. (Metodo de Box-Muller para simulacao de variaveis normais1) Seja (U, V ) um
ve.a. com distribuicao uniforme sobre o rectangulo [0, 1[×[0, 1[.
(a) Determine a densidade de probabilidade do vector (R, Θ) = (√−2 ln(1 − U), 2πV )
e conclua que Θ possui uma distribuicao uniforme sobre o intervalo [0, 2π[ e que R
possui uma distribuicao de Rayleigh, isto e, R tem por densidade
fR(r) = re−r2/21I[0,+∞[(r).
(b) Mostre que X = R cosΘ possui uma distribuicao normal standard.
1Box, G.E.P., Muller, M.E., Ann. Math. Stat., 29, 610–611, 1958.
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 45
2.6 Distribuicoes condicionais
Dada uma probabilidade P1 sobre (Rn,B(Rn)) e uma probabilidade de transicao Q
sobre Rn×B(Rm), sabemos do §1.7 que existe um vector aleatorio (X,Y ) definido num
espaco de probabilidade (Ω,A,P) tal que PX = P1 e
P(X,Y )(A × B) =
∫
AQ(x,B)dPX(x), (2.6.1)
para todo o A × B ∈ B(Rn) × B(Rm).
O problema que agora consideramos pode ser visto como o inverso do anterior.
Dado um vector aleatorio (X,Y ) definido num espaco de probabilidade (Ω,A,P) e
com valores em (Rn × Rm,B(Rn) ⊗ B(Rm)), sera possıvel escrever a sua distribuicao
de probabilidade na forma (2.6.1) para alguma probabilidade de transicao Q sobre
Rn × B(Rm)? A resposta a esta questao e afirmativa mas a sua justificacao completa
ultrapassa largamente os objectivos deste curso2. Vamos contentar-nos com algumas
respostas parciais.
Admitamos em primeiro lugar que X e discreto. Tomando, para B ∈ B(Rm),
Q(x,B) =
P(Y ∈ B|X = x), se P(X = x) > 0
ν(B), se P(X = x) = 0,
onde ν e uma probabilidade fixa sobre B(Rm), concluımos que Q e uma probabilidade
de transicao sobre Rn × B(Rm) e, para A × B ∈ B(Rn) × B(Rm),
∫
AQ(x,B)dPX(x)
=∑
x∈A:P(X=x)>0
P(Y ∈ B|X = x)P(X = x)
=∑
x∈A:P(X=x)>0
P(X = x, Y ∈ B)
= P(X,Y )(A × B).
O mesmo acontece quando (X,Y ) e um vector absolutamente contınuo com densi-
dade f , bastando definir
Q(x,B) =
∫
B
f(x, y)
fX(x)dλ(y), se fX(x) > 0
ν(B), se fX(x) = 0,
2No caso das variaveis X e Y tomarem valores em espacos gerais, o resultado pode nao ser verdadeiro
(ver Hennequin e Tortrat, 1965, pg. 236–238).
ATP, Coimbra 2002

46 Apontamentos de Teoria das Probabilidades
onde fX(x) =∫
f(x, y)dλ(y) e ν e uma probabilidade fixa sobre B(Rm). Com efeito,
∫
AQ(x,B)dPX(x)
=
∫
A
∫
B
f(x, y)
fX(x)dλ(y)fX(x) dλ(x)
=
∫
A×Bf(x, y) dλ(y)dλ(x)
= P(X,Y )(A × B),
para A × B ∈ B(Rn) × B(Rm). A aplicacao y→fY (y|X = x) = f(x,y)fX(x) , que nao e mais
do que uma versao de derivada de Radon-Nikodym de Q(x, ·) relativamente a λ, diz-se
densidade condicional de Y dado X = x. A densidade de (X,Y ) pode ser assim
obtida a partir de fX e de fY (·|X = ·) pela formula f(x, y) = fX(x)fY (y|X = x).
Definicao 2.6.2 Sejam X e Y sao vectores aleatorios definidos num espaco de proba-
bilidade (Ω,A,P) com valores em (Rn,B(Rn)) e (Rm,B(Rn)), respectivamente. Toda a
probabilidade de transicao Q sobre Rn × B(Rm) satisfazendo
∫
AQ(x,B)dPX(x) = P(X,Y )(A × B),
para todo o A × B ∈ B(Rn) × B(Rm), e dita lei ou distribuicao condicional de Y
dado X, e e denotada por PY (·|X = ·). A PY (·|X = x) chamamos lei ou distri-
buicao condicional de Y dado X = x.
Observemos que no caso particular em que X e discreto, e tal como a notacao
sugere, PY (·|X = x), para x ∈ Rn com P(X = x) > 0, e efectivamente a distribuicao
de probabilidade de Y quando Y e considerada definida no espaco de probabilidade
(Ω,A,P(·|X = x)).
Notemos tambem que se PY,1(·|X = ·) e PY,2(·|X = ·) sao distribuicoes condicionais
de Y dado X, entao PY,1(·|X = x) = PY,2(·|X = x), para PX-quase todo o ponto x de
Rn.
Exercıcios
1. Sejam X uma v.a. com valores em Rn e Y = g(X) com g : R
n → Rm uma aplicacao
mensuravel. Determine PY (·|X = ·).
2. Seja (X, Y ) um ve.a. em R2 com X ∼ N(0, 1) e cuja distribuicao condicional de Y dado
X = x tem uma distribuicao N(x, 1). Prove que Y ∼ N(0, 2).
ATP, Coimbra 2002

2 Variaveis aleatorias e distribuicoes de probabilidade 47
3. Um ponto X e escolhido ao acaso do intervalo [a, b] e a seguir um ponto Y e escolhido
ao acaso do intervalo [X, b]. Mostre que a densidade de probabilidade de Y e dada, para
y ∈ R, por
fY (y) =1
b − aln
(b − a
b − y
)1I[a,b[(y).
4. Um animal poe um certo numero X de ovos segundo uma distribuicao de Poisson de
parametro λ. Cada um desses ovos, independentemente dos outros, da origem a um
novo animal com probabilidade p. Denotando por Y o numero de crias de cada ninhada,
determine a distribuicao de Y .
(Sugestao: Comece por determinar a distribuicao condicional de Y dado X = n.)
2.7 Bibliografia
Hennequin, P.L., Tortrat, A. (1965). Theorie des Probabilites et Quelques Applications,
Masson.
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Rudin, W. (1974). Real and Complex Analysis, McGraw-Hill.
ATP, Coimbra 2002


Capıtulo 3
Independencia
Independencia de acontecimentos aleatorios, de classes e de variaveis aleatorias. Cara-
cterizacoes da independencia duma famılia de variaveis aleatorias. Distribuicao da
soma de variaveis aleatorias independentes. Leis zero-um de Borel e de Kolmogorov.
3.1 Independencia de classes de acontecimentos aleatorios
Introduzimos neste capıtulo uma das mais importantes nocoes que abordamos neste
curso. Trata-se da nocao de independencia cujas implicacoes serao exploradas neste e
nos proximos capıtulos.
Se A e B sao acontecimentos aleatorios dum espaco de probabilidade (Ω,A,P),
com P(B) > 0, a probabilidade condicionada P(A|B) pode ser interpretada como a
probabilidade do acontecimento A quando sabemos que o acontecimento B se realizou.
O facto de sabermos que B se realizou, pode, ou nao, alterar a probabilidade P(A)
do acontecimento A, isto e, pode, ou nao, verificar-se a igualdade P(A|B) = P(A), ou
ainda, P(A ∩ B) = P(A)P(B). Tal facto motiva a definicao seguinte.
Definicao 3.1.1 Os acontecimentos aleatorios At, t ∈ T , onde T denota um qualquer
conjunto de ındices, dizem-se independentes, se para qualquer conjunto finito de
ındices distintos t1, . . . , tn ∈ T , P (⋂n
k=1 Atk) =∏n
k=1 P(Atk).
Notemos que os acontecimentos duma famılia podem ser dois a dois independentes
sem serem (colectivamente) independentes. Para ilustrar tal situacao, considere, por
exemplo, Ω = 0, 12, A = P(Ω) e P tal que P((i, j)) = 1/4, para (i, j) ∈ Ω, e os
acontecimentos A = (0, 0), (0, 1), B = (0, 0), (1, 0) e C = (0, 0), (1, 1).A nocao de independencia de acontecimentos aleatorios pode, de forma natural, ser
extendida a uma famılia arbitraria de classes.
49

50 Apontamentos de Teoria das Probabilidades
Definicao 3.1.2 Dizemos que as subclasse nao-vazias Ct, t ∈ T , de A sao indepen-
dentes, quando, para qualquer conjunto finito de ındices distintos t1, . . . , tn ∈ T , e de
acontecimentos At1 ∈ Ct1 , . . . , Atn ∈ Ctn , os acontecimentos Atk , k = 1, . . . , n, forem
independentes.
No resultado seguinte lancamos mao das nocoes de π-sistema e de d-sistema. Re-
cordemos que um π-sistema e uma classe de partes de Ω que e estavel para a interseccao
finita, enquanto que um d-sistema, ou sistema de Dynkin, contem Ω e e estavel para a
complementacao e para a reuniao numeravel disjunta (ver AMI, §1.2).
Teorema 3.1.3 Sejam Ct, t ∈ T , subclasses nao-vazias de A, tais que:
a) Ct e um π-sistema, para todo o t ∈ T ;
b) Ct, t ∈ T , sao independentes.
Entao as σ-algebras σ(Ct), t ∈ T , sao independentes.
Dem: Para t1, . . . , tn ∈ T , distintos, e At1 , . . . , Atn fixos em Ct1 , . . . , Ctn , respectiva-
mente, consideremos a classe L = A ∈ A : P(AAt2 . . . Atn) = P(A)P(At1) . . . P(Atn).L e um d-sistema e, sendo Ct1 , . . . , Ctn independentes, Ct1 ⊂ L. Consequentemente,
d(Ct1) ⊂ L. Sendo Ct1 um π-sistema, d(Ct1) = σ(Ct1) (cf. AMI, Teorema 1.3.3), o que
prova que σ(Ct1), Ct2 , . . . , Ctn sao independentes. Repetindo o raciocınio para as clas-
ses Ct2 , . . . , Ctn , σ(Ct1) concluımos que σ(Ct2), Ct3 , . . . , Ctn , σ(Ct1) sao independentes, e
finalmente que σ(Ct1), σ(Ct2), . . . , σ(Ctn) sao independentes.
Corolario 3.1.4 Os acontecimentos At, t ∈ T , sao independentes sse as σ-algebras
σ(At), t ∈ T , o forem.
Teorema 3.1.5 Sejam Bt, t ∈ T , sub-σ-algebras de A independentes e P uma particao
de T . Entao as σ-algebras BS = σ(Bt, t ∈ S), S ∈ P, sao ainda independentes.
Dem: Para S ∈ P, seja CS = ⋂α∈K : Bα ∈ Bα,K ⊂ S,K finito. Vamos pro-
var que CS, S ∈ P, e uma famılia de π-sistemas independentes com σ(CS) = BS , o
que permite concluir pelo teorema anterior. 1) CS e claramente um π-sistema. 2) Se-
jam agora S1, . . . , Sk ∈ P distintos (logo disjuntos) e Ai ∈ CSi , i = 1, . . . , k. Entao
Ai =⋂
αi∈KiBi
αi, com Bi
αi∈ Bαi e Ki ⊂ Si finito. Uma vez que P(
⋂ki=1 Ai) =
P(⋂k
i=1
⋂αi∈Ki
Biαi
) =∏k
i=1
∏αi∈Ki
P(Biαi
) =∏k
i=1 P(Ai), concluımos que CS , S ∈ P,
e uma famılia de π-sistemas independentes. 3) Claramente CS ⊂ BS , e tambem
σ(CS) ⊂ BS. Por outro lado, Bα ⊂ CS, para α ∈ S, e tambem⋃
α∈S Bα ⊂ CS . Assim,
BS = σ(Bα, α ∈ S) = σ(⋃
α∈S Bα) ⊂ σ(CS).
Exercıcios
1. Utilizando a definicao, mostre que se A e B sao acontecimentos aleatorios independentes,
tambem o sao os pares de acontecimentos A e Bc, Ac e B, e Ac e Bc.
ATP, Coimbra 2002

3 Independencia 51
2. Mostre que A1, . . . , An sao acontecimentos independentes sse para todo o j ∈ 1, . . . , ne I ⊂ 1, . . . , n − j com P(
⋂i∈I Ai) > 0, entao P(Aj |
⋂i∈I Ai) = P(Aj).
3. Se An, n ≥ 1, sao acontecimentos independentes, mostre que P(⋂∞
n=1 An) =∏∞
n=1 P(An).
4. Sejam (Ω,A) o produto dos espacos mensuraveis (Ωn,An), n ∈ N, e P uma probabilidade
sobre A. Para n ∈ N e An ∈ An, considere os acontecimentos
Bn = Ω1 × . . . × Ωn−1 × An × Ωn+1 × . . .
e as probabilidades Pn definidas em (Ωn,An) por Pn(An) = P(Bn). Mostre que os
acontecimentos Bn, n ≥ 1, sao independentes sse P = ⊗∞n=1Pn.
5. Se An, n ≥ 1, sao acontecimentos independentes, mostre que ∪ni=1Ai e ∪∞i=n+1Ai sao
independentes, com n ∈ N fixo.
6. Para s > 1, fixo, sejam ζ(s) =∑∞
n=11
ns , e X uma variavel aleatoria com valores em N
tal que P(X = n) = 1ζ(s)
1ns , para n ∈ N.
(a) Para p ∈ N, considere o conjunto Ep = X e divisıvel por p, e mostre que P(Ep) =
1/ps.
(b) Mostre que os conjuntos Ep, com p primo, sao independentes.
(c) Estabeleca a formula de Euler: 1ζ(s) =
∏p primo
(1 − 1
ps
).
3.2 Independencia de variaveis aleatorias
As variaveis aleatorias que consideramos neste paragrafo estao definidos sobre um
mesmo espaco de probabilidade (Ω,A,P), podendo, no entanto, tomar valores em
espacos mensuraveis diversos. No que se segue, T e um qualquer conjunto de ındices.
Definicao 3.2.1 Dizemos que Xt, t ∈ T , e uma famılia de variaveis aleatorias
independentes se σ(Xt), t ∈ T , forem σ-algebras independentes.
Uma caracterizacao da independencia duma qualquer famılia Xt, t ∈ T , de variaveis
aleatorias em termos da distribuicao da variavel aleatoria (Xt, t ∈ T ), e apresentada no
resultado seguinte. Fica assim clara a relacao estreita entre as nocoes de independencia
da famılia Xt, t ∈ T , de variaveis aleatorias e a forma produto para a distribuicao de
probabilidade da variavel aleatoria (Xt, t ∈ T ).
Teorema 3.2.2 As variaveis aleatorias Xt, t ∈ T , onde cada Xt toma valores em
(Et,Bt), sao independentes sse P(Xt,t∈T ) =⊗
t∈T PXt .
Dem: Comecemos por notar que como a σ-algebra⊗
t∈T Bt e gerada pelos conjuntos do
tipo π−1S (
∏t∈S Bt), com Bt ∈ Bt, t ∈ T , e S ⊂ T finito, a igualdade de medidas expressa
no enunciado e equivalente a igualdade P(Xt,t∈S) =⊗
t∈S PXt , para todo o subconjunto
ATP, Coimbra 2002

52 Apontamentos de Teoria das Probabilidades
finito S de T . Suponhamos entao que Xt, t ∈ T , sao variaveis aleatorias independentes,
e para S ⊂ T finito, consideremos Bt ∈ Bt, para t ∈ S. Como P(Xt,t∈S)(∏
t∈T Bt) =
P(⋂
t∈SXt ∈ Bt) =∏
t∈S P(Xt ∈ Bt) =⊗
t∈S PXt(∏
t∈T Bt), concluımos que
P(Xt,t∈T ) =⊗
t∈T PXt . Reciprocamente, sejam S ⊂ T finito, e At ∈ σ(Xt), para t ∈ S.
Por definicao de σ-algebra gerada por Xt, At = X−1t (Bt), com Bt ∈ Bt. Assim,
P(⋂
t∈S At) = P((Xt, t ∈ S) ∈ ∏t∈S Bt) = P(Xt,t∈S)(
∏t∈S Bt) =
⊗t∈S PXt(
∏t∈S Bt) =
∏t∈S PXt(Bt) =
∏t∈S P(At), ou seja, Xt, t ∈ T , sao independentes.
Nos dois resultados seguintes apresentamos caracterizacoes da independencia das
margens dum vector aleatorio em termos da sua funcao de distribuicao e, no caso
deste ser absolutamente contınuos, da sua densidade de probabilidade. Um resultado
do mesmo tipo, mas em termos da sua funcao de probabilidade, vale para vectores
aleatorios discretos.
Teorema 3.2.3 Seja (X1, . . . ,Xn) um vector aleatorio em Rn com funcao de distri-
buicao F(X1,...,Xn). As variaveis aleatorias reais X1, . . . ,Xn sao independentes sse
F(X1,...,Xn) =
n∏
i=1
FXi ,
onde FXi denota a funcao de distribuicao da variavel aleatoria Xi. Alem disso, se
F(X1,...,Xn) =∏n
i=1 Gi, onde cada Gi e uma distribuicao de probabilidade em R, entao
Gi = FXi , para i = 1, . . . , n, e as variaveis aleatorias X1, . . . ,Xn sao independentes.
Dem: 1) Se X1, . . . ,Xn sao independentes, P(X1,...,Xn) =⊗n
i=1 PXi , o que implica que
F(X1,...,Xn)(x1, . . . , xn) = P(X1,...,Xn)(∏n
i=1] − ∞, xi]) =⊗n
i=1 PXi(∏n
i=1] − ∞, xi]) =∏n
i=1 PXi(] − ∞, xi]) =∏n
i=1 FXi(xi), para (x1, . . . , xn) ∈ Rn. Reciprocamente, se
F(X1,...,Xn) =∏n
i=1 FXi , entao P(X1,...,Xn) e⊗n
i=1 PXi coincidem sobre o π-sistema dos
borelianos da forma∏n
i=1]−∞, xi], que gera B(Rn). Pelo lema da igualdade de medida,
P(X1,...,Xn) e⊗n
i=1 PXi coincidem sobre B(Rn) (cf. AMI, §2.6), o que atendendo ao teo-
rema anterior e equivalente a independencia das variaveis X1, . . . ,Xn. 2) Suponhamos
agora que F(X1,...,Xn) =∏n
i=1 Gi, onde cada Gi e uma distribuicao de probabilidade em
R. Assim, para i = 1, . . . , n, e xi ∈ R, FXi(xi) = limxj→+∞
j 6=i
F(X1,...,Xn)(x1, . . . , xn) =
limxj→+∞
j 6=i
∏nk=1 Gk(xk) = Gi(xi). Alem disso, F(X1,...,Xn) =
∏ni=1 Fi, o que pela primeira
parte da demonstracao e equivalente a independencia de X1, . . . ,Xn.
Teorema 3.2.4 Seja (X1, . . . ,Xn) um vector aleatorio em Rn com densidade de proba-
bilidade f(X1,...,Xn). As variaveis aleatorias reais X1, . . . ,Xn sao independentes sse
f(X1,...,Xn) =n∏
i=1
fXi ,
ATP, Coimbra 2002

3 Independencia 53
onde fXi denota a densidade de probabilidade da variavel aleatoria Xi. Alem disso,
se f(X1,...,Xn) =∏n
i=1 gi, onde cada gi e uma densidade de probabilidade em R, entao
gi = fXi, para i = 1, . . . , n, e as variaveis aleatorias X1, . . . ,Xn sao independentes.
Dem: 1) Se X1, . . . ,Xn sao independentes, o teorema de Fubini (ver AMI, §6.4) per-
mite concluir que P(X1,...,Xn) = (∏n
i=1 fXi)λn, ou ainda, f(X1,...,Xn) =∏n
i=1 fXi . Re-
ciprocamente, e ainda pelo teorema de Fubini, se f(X1,...,Xn) =∏n
i=1 fXi , concluımos
que P(X1,...,Xn) =⊗n
i=1 PXi , isto e, X1, . . . ,Xn sao independentes. 2) Se f(X1,...,Xn) =∏n
i=1 gi, onde cada gi e uma densidade de probabilidade em R, entao, para i = 1, . . . , n
e xi ∈ R, fXi(xi) =∫
Rn−1
∏nj=1 gj(xj)dλn−1 = g(xi)
∏nj=1j 6=i
∫g(xj)dλ = g(xi). Assim,
f(X1,...,Xn) =∏n
i=1 fXi , o que pela primeira parte da demonstracao e equivalente a
independencia das variaveis X1, . . . ,Xn.
Terminamos este paragrafo com uma caracterizacao da independencia de dois vec-
tores aleatorios em termos de distribuicoes condicionais.
Teorema 3.2.5 Sejam X e Y sao vectores aleatorios com valores em (Rn,B(Rn)) e
(Rm,B(Rm)), respectivamente. X e Y sao independentes sse PY (·|X = x) e inde-
pendente de x, para PX-quase todo o ponto x. Neste caso PY (·|X = x) = PY , para
PX -quase todo o ponto x.
Dem: Basta ter em conta que, para A ∈ B(Rn) e B ∈ B(Rm), P(X,Y )(A × B) =∫A PY (B|X = x) dPX(x) e PX(A)PY (B) =
∫A PY (B) dPX(x).
Exercıcios
1. Dada uma famılia de acontecimentos aleatorios At, t ∈ T , mostre que 1IAt , t ∈ T , sao
independentes sse os acontecimentos At, t ∈ T , o forem.
2. Se Xt : (Ω,A, P) → (Et,Bt), com t ∈ T , sao variaveis aleatorias independentes, e ft :
(Et,Bt) → (Ft, Ct), sao aplicacoes mensuraveis, mostre que ft Xt, t ∈ T , sao tambem
variaveis aleatorias independentes.
3. Sejam X1, . . . , Xn sao v.a. reais independentes, e m < n natural. Mostre que:
(a) Os vectores aleatorios (X1, . . . , Xm) e (Xm+1, . . . , Xn), sao independentes;
(b)∑m
i=1 Xi e∑n
i=m+1 Xi sao v.a. independentes.
4. (Construcao de v.a. independentes) Mostre que as variaveis aleatorias (Xn) definidas
no Exercıcio 2.1.2 sao independentes.
5. Dadas variaveis aleatorias Xi : (Ωi,Ai, Pi)→(Ei,Bi), para i = 1, . . . , n, mostre que existe
um espaco de probabilidade (Ω,A, P) e variaveis aleatorias independentes Yi : (Ω,A, P)→(Ei,Bi), i = 1, . . . , n, tais que Yi ∼ Xi para todo o i.
ATP, Coimbra 2002

54 Apontamentos de Teoria das Probabilidades
6. Dada uma sucessao (Xn) de v.a.r. identicamente distribuıdas, mostre que existem v.a.r.
Y1, Y2, . . . , Z1, Z2, . . ., definidas num mesmo espaco de probabilidade que satisfazem: a)
Xn ∼ Yn ∼ Zn, para todo o n ∈ N; b) Y1, Y2, . . . , Z1, Z2, . . . sao independentes.
7. Mostre que o resultado expresso no exercıcio anterior continua valido para uma qualquer
sucessao (Xn) de v.a.r. nao necessariamente identicamente distribuıdas.
8. (Metodo de Box-Muller para simulacao de variaveis normais, II) Sejam R e Θ as
variaveis aleatorias definidas no Exercıcio 2.5.6. Mostre que X = R cosΘ e Y = R sin Θ,
sao variaveis independentes com distribuicoes normal standard.
3.3 Soma de variaveis aleatorias independentes
Se X e Y sao variaveis aleatorias com valores em Rd, absolutamente contınuas e
independentes, isto e, se (X,Y ) e um vector com densidade (x, y)→fX(x)fY (y), vimos
no §2.5 que a soma X + Y e uma variavel absolutamente contınua cuja densidade e a
convolucao das densidades fX e fY , isto e,
fX+Y (x) = (fX ⋆ fY )(x) =
∫fX(x − y)fY (y)dλ(y).
No caso discreto e tambem possıvel obter uma formula do tipo anterior. Com efeito,
se X e Y sao variaveis discretas e independentes com funcoes de probabilidade gX e
gY , temos, para x ∈ Rd,
gX+Y (x) =∑
y∈Rd
P(X + Y = x, Y = y)
=∑
y∈Rd
P(X = x − y, Y = y)
=∑
y∈Rd
gX(x − y)gY (y)
=: (gX ⋆ gY )(x),
a que chamamos convolucao das funcoes de probabilidade gX e gY .
Se denotarmos agora por Sn = X1 + . . . + Xn, a soma de n variaveis aleatorias
independentes e identicamente distribuıdas, com densidade ou funcao de probabilidade
comum f , a densidade ou funcao de distribuicao fSn de Sn pode ser obtida por inducao
a partir de fSn−1 e de f , pois Sn = Sn−1 + Xn, e Sn−1 e Xn sao independentes.
Nos casos seguintes e simples obter a distribuicao de Sn pelo metodo anterior.
Exemplo 3.3.1 Se X1, . . . ,Xn sao v.a. independentes com Xi ∼ N(0, 1), entao
fSn(x) =1√2nπ
e−x2/(2n), para x ∈ R.
ATP, Coimbra 2002

3 Independencia 55
-10 -5 5 10
0.05
0.1
0.15
0.2
0.25
n = 2
n = 4
n = 8
n = 20
Figura 4.1: Distribuicao da soma de n v.a. i.i.d. N(0, 1)
Exemplo 3.3.2 Se X1, . . . ,Xn sao v.a. independentes com Xi ∼ B(p), entao
fSn(x) =
(nx
)px (1 − p)n−x, se x ∈ 0, 1, . . . , n
0, caso contrario.
10 20 30 40 50 60 70 80
0.025
0.05
0.075
0.1
0.125
0.15
0.175
n = 20
n = 40
n = 80
n = 120
Figura 4.2: Distribuicao da soma de n v.a. i.i.d. B(1/3)
Exemplo 3.3.3 Se X1, . . . ,Xn sao v.a. independentes com Xi ∼ E(λ), temos
fSn(x) =
λe−λx (λx)n−1
(n−1)! , se x ≥ 0
0, se x < 0.
ATP, Coimbra 2002

56 Apontamentos de Teoria das Probabilidades
10 20 30 40
0.05
0.1
0.15
0.2
n = 5
n = 10
n = 15
n = 20
n = 25
Figura 4.3: Distribuicao da soma de n v.a. i.i.d. E(1)
No primeiro exemplo Sn ∼ N(0, n), enquanto que no segundo Sn ∼ B(n, p), o que
seria de esperar atendendo a definicao de distribuicao binomial. No ultimo exemplo,
dizemos que Sn possui uma distribuicao de Erlang de parametros n e λ.
Exercıcios
1. Estabeleca os resultados enunciados nos exemplos anteriores.
2. Se X1, . . . , Xn sao v.a. independentes com distribuicoes geometricas de parametro p,
mostre que Sn = X1 + . . . + Xn verifica Sn ∼ Y + n, onde Y ∼ BN(n, p) (ver Exercıcio
2.1.9).
3. Sejam X e Y independentes, e Z = X + Y . Determine a densidade de Z quando:
(a) X ∼ E(µ) e Y ∼ E(λ);
(b) X ∼ N(m1, σ21) e Y ∼ N(m2, σ
22).
4. Dizemos que uma v.a.r. X tem uma distribuicao do qui-quadrado com n graus de
liberdade (n ∈ N), e escrevemos X ∼ χ2n, se admite uma densidade de probabilidade da
forma
f(x) =
1
Γ(n/2)2n/2 xn/2−1e−x/2, se x ≥ 0
0, se x < 0,
onde Γ(α) =∫∞0 xα−1e−xdx, para α > 0, e a funcao Gamma. Mostre que se X1, X2, . . . , Xn
sao v.a. normais standard independentes, entao X21 + X2
2 + . . . + X2n ∼ χ2
n.
(Sugestao: Tenha em conta o Exercıcio 2.3.6 e a igualdade∫ 1
0xp−1(1−x)q−1dx = Γ(p)Γ(q)
Γ(p+q) ,
valida para p, q > 0.)
5. Sejam X1, . . . , Xn v.a.r. independentes e Y1, . . . , Yn v.a.r. independentes, com Xi ∼ Yi
para i = 1, . . . , n. Mostre que∑n
j=1 Xj ∼ ∑nj=1 Yj . Verifique que a hipotese de inde-
pendencia e essencial para a validade do resultado.
ATP, Coimbra 2002

3 Independencia 57
3.4 Leis zero-um de Borel e de Kolmogorov
Atendendo ao teorema de Borel-Cantelli ja nosso conhecido da disciplina de Medida
e Integracao, sabemos que, sob certas condicoes sobre a sucessao de acontecimentos
(An), o acontecimento An i.o. = lim sup An, isto e, o acontecimento que se realiza
quando se realiza uma infinidade de acontecimentos An, tem probabilidade zero. Mais
precisamente:
Teorema 3.4.1 (de Borel–Cantelli1) Se os acontecimentos aleatorios An, n ≥ 1,
satisfazem∑∞
n=1 P(An) < +∞, entao P(An i.o.) = 0.
No caso dos acontecimentos (An) serem independentes este resultado pode ser pre-
cisado. Mostramos de seguida que a probabilidade do acontecimento An i.o. so pode
tomar dois valores possıveis: zero ou um.
Teorema 3.4.2 (Lei zero-um de Borel2) Se os acontecimentos aleatorios An, n ≥1, sao independentes entao
P(An i.o.) =
0 sse
∑∞n=1 P(An) < +∞
1 sse∑∞
n=1 P(An) = +∞.
Dem: Pelo teorema de Borel-Cantelli, basta mostrar que∑∞
n=1 P(An) = +∞ implica
P(An i.o.) = 1. Tal e equivalente a provar que P(⋃∞
k=n Ak) = 1, para todo o n ∈ N.
Atendendo a independencia dos acontecimentos Ack, k ∈ N, e a desigualdade 1 − x ≤
exp(−x), valida para todo o x ∈ [0, 1], obtemos P(⋂∞
k=n Ack) = lim P(
⋂mk=n Ac
k) =
lim∏m
k=n P(Ack) = lim
∏mk=n(1 − P(Ak)) ≤ lim
∏mk=n exp(−∑m
k=n P(Ak)) = exp(−∑∞
k=n P(Ak)) = 0.
Como veremos de seguida, a propriedade exibida pelo acontecimento An i.o. da sua
probabilidade so poder tomar dois valores, zero ou um, e partilhada por uma classe mais
vasta de acontecimentos aleatorios. Um tal resultado e conhecido como lei zero-um de
Kolmogorov.
Definicao 3.4.3 Uma σ-algebra B ⊂ A, diz-se P-trivial se P(A) = 0 ou P(A) = 1,
para todo o A ∈ B.
Claramente ∅,Ω e P-trivial para toda a probabilidade P.
Lema 3.4.4 Uma sub-σ-algebra B de A e P-trivial sse e independente de si propria.
1Cantelli, F.P., Rend. Accad. Naz. Lincei., 26, 295–302, 1917.2Borel, E, Rend. Circ. Mat. Palermo, 27, 247–271, 1909.
ATP, Coimbra 2002

58 Apontamentos de Teoria das Probabilidades
Dem: Se B e independente de si propria, entao para todo o A ∈ B, P(A) = P(A∩A) =
P(A)P(A), ou seja, P(A) = 0 ou P(A) = 1. Reciprocamente, se B e P-trivial e A e B sao
elementos de B com P(A) = 0 ou P(B) = 0, entao P(A ∩ B) ≤ min(P(A),P(B)) = 0.
Se P(A) = P(B) = 1, sabemos que P(A ∩ B) = 1, para toda a probabilidade P. Em
ambos os casos, P(A ∩ B) = P(A)P(B).
Teorema 3.4.5 (Lei zero-um de Kolmogorov3) Sejam B1,B2, . . . sub-σ-algebras in-
dependentes de A, e B∞ a σ-algebra assintotica associada a sucessao (Bn), isto e,
B∞ =∞⋂
n=1
σ(Bk, k ≥ n).
Entao B∞ e P-trivial.
Dem: Consideremos n ≥ 2, e denotemos por Bn a σ-algebra σ(Bk, k ≥ n). Pelo
Teorema 3.1.5, as σ-algebras B1,B2, . . . ,Bn−1,Bn sao independentes, e por maioria
de razao, sao ainda independentes as σ-algebras B1,B2, . . . ,Bn−1,B∞ pois B∞ ⊂ Bn.
Sendo n qualquer, isto significa que B1,B2, . . . ,B∞ sao independentes, sendo, pelo
Teorema 3.1.5, tambem independentes as σ-algebras σ(Bk, k ≥ 1) e B∞. Finalmente,
como B∞ ⊂ σ(Bk, k ≥ 1), concluımos que B∞ e independente de si propria, ou seja,
que B∞ e P-trivial.
Teorema 3.4.6 Seja B uma sub-σ-algebra P-trivial de A. Uma variavel aleatoria X
B-mensuravel com valores em (R,B(R)) e degenerada, isto e, X e P-q.c. constante.
Dem: Seja X B-mensuravel com valores em R. Como X−1(] −∞, x]) = X ≤ x ∈ B,
entao P(X ≤ x) = 0 ou 1, para todo o x ∈ R. Seja c = supx ∈ R : P(X ≤ x) = 0.Se c = −∞ entao P(X ≤ x) = 1, para todo o x ∈ R, e assim P(X = −∞) =
lim P(X ≤ −n) = 1. Se c = +∞, entao P(X ≤ x) = 0, para todo o x ∈ R, e assim
P(X = +∞) = 1 − lim P(X ≤ n) = 1. Se c ∈ R, concluımos que P(X ≤ x) = 0, para
todo o x < c e P(X ≤ x) = 1, para todo o x > c. Consequentemente, P(X = c) =
P(X ≤ c) − P(X < c) = lim P(X ≤ c + 1/n) − lim P(X ≤ c − 1/n) = 1 − 0 = 1.
Se X1,X2, . . . e uma sucessao de variaveis aleatorias reais independentes, e
Sn = X1 + . . . + Xn,
estudaremos mais a frente o comportamento assintotico das sucessoes
Sn e Sn/n.
3Kolmogorov, A.N., Grundbegriffe der Wahrscheinlichkeitrechnung, Berlin, 1933.
ATP, Coimbra 2002

3 Independencia 59
De acordo com o resultado seguinte, estas sucessoes ou convergem ou divergem quase
certamente, isto e, o conjunto dos pontos w ∈ Ω onde convergem ou tem probabilidade
zero ou ou tem probabilidade um. Alem disso, sendo Sn/n convergente, a variavel
aleatoria limite e quase certamente degenerada. Mais precisamente:
Corolario 3.4.7 Nas condicoes anteriores, se (an) e uma sucessao de numeros reais
com an→+∞, entao:
a) Sn e Sn/an convergem ou divergem quase certamente;
b) lim supSn/an e lim inf Sn/an, sao quase certamente constantes.
Exercıcios
1. Se An, n ≥ 1, sao acontecimentos independentes e An → A, mostre que P(A) = 0 ou
P(A) = 1.
2. Sejam Xn, n ≥ 1, variaveis de Bernoulli, com
P(Xn = 1) = pn = 1 − P(Xn = 0), para n ∈ N.
(a) Mostre que limXn = 0 = (lim supAn)c, onde An = X−1n (1) para n ∈ N.
(b) Conclua que P(limXn = 0) = 1 se∑∞
n=1 pn < +∞.
(c) Se Xn, n ≥ 1 sao independentes, mostre que P(limXn = 0) = 1 sse∑∞
n=1 pn < +∞.
3.5 Bibliografia
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
Williams, D. (1991). Probability with Martingales, Cambridge University Press.
ATP, Coimbra 2002


Capıtulo 4
Integracao de variaveis aleatorias
Esperanca matematica duma variavel aleatoria real e suas principais propriedades. Mo-
mentos duma variavel aleatoria real. Parametros de dispersao e de forma. Desigual-
dade de Markov e suas consequencias. Covariancia e correlacao. Integracao de vectores
aleatorios.
4.1 Esperanca matematica
Introduzimos neste paragrafo o primeiro dos parametros de resumo da distribuicao
de probabilidade duma variavel aleatoria real X de que falaremos neste capıtulo. Para
motivar a definicao que dele apresentaremos, suponhamos, em primeiro lugar, que X
e uma variavel discreta que toma os valores x1, . . . , xn com probabilidades p1, . . . , pn,
onde p1 + . . . + pn = 1. Pretendendo resumir a distribuicao de probabilidade de X
atraves dum parametro que descreva o centro duma tal distribuicao, e natural recor-
rer a analogia deste problema com o da definicao do centro de massa dum sistema
discreto de pontos materiais com massas pi em xi. Somos assim levados a definir um
tal parametro por∑n
i=1 xipi. No caso de X ser absolutamente contınua com densi-
dade de probabilidade f , vale o mesmo tipo de analogia, sendo natural definir um
tal parametro de resumo por∫
xf(x)dx, isto e, como o centro de massa dum sistema
contınuo de pontos materiais com densidade de massa f(x) em x.
Lancando mao da nocao de integral duma funcao real relativamente a uma medida
(ver AMI, §§4.1–4.3), as duas formulas anteriores podem ser escritas de forma unificada
como o integral da funcao identidade relativamente a PX ,
∫x dPX(x),
onde (Ω,A,P) e o espaco de probabilidade onde admitimos que X esta definida, ou
ainda, pelo teorema da mudanca de variavel (ver AMI, §7.2), como o integral de X
61

62 Apontamentos de Teoria das Probabilidades
relativamente a medida de probabilidade P,
∫XdP.
No contexto das probabilidades o integral anterior e denominado e denotado duma
forma especial.
Definicao 4.1.1 Chamamos esperanca matematica (tambem dita valor medio,
valor esperado ou media) da variavel aleatoria real X, que denotamos por E(X), ao
integral
E(X) =
∫XdP,
sempre que este integral exista.
Pelas razoes ja avancadas, dizemos que a esperanca matematica, como parametro
de resumo da distribuicao de probabilidade duma variavel aleatoria, e um parametro
de localizacao.
Recordemos, que se X e uma variavel aleatoria com valores em ([0,+∞],B([0,+∞])),
sabemos que o integral de X relativamente a medida de probabilidade P e um elemento
de [0,+∞]. Se X toma valores em (R,B(R)), X admite a decomposicao X = X+−X−,
onde X+ = X ∨ 0 e X− = X ∧ 0, sao ditas parte positiva e parte negativa de X,
respectivamente. Tal decomposicao permite generalizar a nocao de integral a X atraves
da formula ∫XdP =
∫X+dP −
∫X−dP,
sempre que∫
X+dP < +∞ ou∫
X−dP < +∞. Se alem disso∫
XdP < ∞, dizemos
que X e P-integravel, ou simplesmente que X e integravel.
Claramente, a esperanca matematica existe quando e so quando uma das variaveis
X+ ou X− for integravel, e existe e e finita quando e so quando X for integravel.
Mostramos a seguir que a esperanca matematica duma funcao mensuravel de X
depende unicamente dessa funcao e da distribuicao de probabilidade de X. Em par-
ticular, a esperanca matematica duma variavel aleatoria real depende apenas da sua
distribuicao de probabilidade.
Teorema 4.1.2 Se X e uma variavel aleatoria com valores em (E,B) e g e uma
aplicacao mensuravel de (E,B) em (R,B(R)), entao E(g(X)) existe sse∫
g dPX existe
e nesse caso
E(g(X)) =
∫g(x) dPX (x).
ATP, Coimbra 2002

4 Integracao de variaveis aleatorias 63
Dem: Se g e nao-negativa, pelo teorema da mudanca de variavel (ver AMI, §7.2) ob-
temos E(g(X)) =∫
g(X)dP =∫
g XdP =∫
gd(PX−1) =∫
gdPX . Sendo g qualquer,
basta considerar a decomposicao g = g+ − g− e ter em conta que (g X)+ = g+(X)
e (g X)− = g−(X). (Apresente uma demonstracao alternativa usando a Proposicao
2.1.4.)
No caso de X ser uma variavel aleatoria em Rd discreta ou absolutamente contınua
(mais precisamente se PX nao tem parte singular), o resultado anterior permite obter
formulas para o calculo de E(g(X)). Assim, se X e discreta com PX =∑∞
i=1 piδxi ,
onde pi = P(X = xi), entao
E(g(X)) =∞∑
i=1
pi
∫g(x)dδxi (x) =
∞∑
i=1
pig(xi).
Se X e absolutamente contınua com densidade f , entao
E(g(X)) =
∫g(x)dPX (x) =
∫g(x)f(x)dλ(x).
As propriedades que a seguir enunciamos sao consequencia imediata das proprieda-
des do integral.
Teorema 4.1.3 Sejam X e Y variaveis aleatorias reais definidas num mesmo espaco
de probabilidade.
a) X e integravel sse |X| e integravel, e nesse caso |E(X)| ≤ E(|X|).b) Se X e Y sao integraveis, e α, β ∈ R, entao αX+βY e integravel e E(αX+βY ) =
αE(X) + βE(Y ).
c) Se |X| ≤ Y , com Y integravel entao X e integravel.
d) Se |X| ≤ M , q.c., com M > 0, entao X e integravel. Alem disso, se X = a,
q.c., com a ∈ R, entao E(X) = a.
O resultado seguinte permite simplificar o calculo da esperanca matematica, no caso
das variaveis aleatorias integraveis e simetricas.
Teorema 4.1.4 Se X e integravel e simetrica relativamente a a ∈ R, isto e, se X−a ∼−(X − a), entao E(X) = a.
Dem: Atendendo a que a esperanca matematica duma variavel aleatoria real depende
apenas da sua distribuicao de probabilidade, concluımos que E(X −a) = E(−(X −a)),
ou ainda, E(X) = a.
Se X e discreta com funcao de probabilidade simetrica relativamente a a, ou abso-
lutamente contınua com densidade de probabilidade simetrica relativamente a a, entao
X e claramente simetrica relativamente a a.
ATP, Coimbra 2002

64 Apontamentos de Teoria das Probabilidades
Notemos que a hipotese de integrabilidade e essencial para a validade do resul-
tado anterior. Por exemplo, se X e uma variavel aleatoria de Cauchy com densidade
f(x) = (π(1 + x2))−1, para x ∈ R, X e simetrica relativamente a origem e no entanto
X nao possui esperanca matematica. Com efeito,∫
(x∧ 0)dPX(x) =∫
(x∨ 0)dPX(x) =∫[0,+∞[
xπ(1+x2)
dλ(x) = 2π lim
∫ n0
2x1+x2 dλ(x) = 2
π lim∫ n0
2x1+x2 dx (integral de Riemann) =
2π lim ln(1 + n2) = +∞.
Apresentamos agora alguns exemplos de calculo da esperanca matematica.
Exemplos 4.1.5 1. Se X e uma variavel de Bernoulli de parametro p, entao E(X) =
0 × (1 − p) + 1 × p = p.
2. Se X e uma variavel de Poisson de parametro λ, temos E(X) =∑∞
n=0 ne−λ
λn/n! = e−λλ∑∞
n=0 λn/n! = λ.
3. Se X e uma v.a. normal de parametros m e σ2, entao E(X) = m. Para jus-
tificarmos esta afirmacao, e tendo em conta que X ∼ σU + m, com U ∼ N(0, 1),
basta mostrar que E(U) = 0, ou ainda, atendendo a simetria de U relativamente a
origem, que U e integravel. Tal e verdade, pois tomando M > 0 tal que x ≤ ex,
para x ≥ M , obtemos E(|U |) =∫
R|u|fU (u)dλ(u) = 2√
2π
∫[0,+∞[ ue−u2/2dλ(u) ≤ M +
2√2π
∫[M,+∞[ e
−u2/2+udλ(u) = M + 2e1/2√2π
∫[M,+∞[ e
−(u−1)2/2dλ(u) ≤ M + e1/2 < +∞.
Exercıcios
1. Suponhamos que lancamos sucessivamente uma moeda equilibrada e seja X o numero de
lancamentos efectuados ate ocorrer a primeira cara. Determine a distribuicao de X , bem
como o numero medio de lancamentos necessarios para obter a primeira cara.
2. Para cada uma das seguintes v.a. calcule a respectiva esperanca matematica:
(a) Binomial de parametro n e p.
(b) Geometrica de parametro p.
(c) Exponencial de parametro λ.
(d) Uniforme sobre o intervalo [a, b].
3. Deduza uma formula que lhe permita calcular a esperanca matematica duma variavel
aleatoria Y , a partir das densidades fY (·|X = ·) e fX , e aplique-a ao calculo da esperanca
matematica da v.a. Y definida no Exercıcio 2.6.3.
4. No casino de Monte Carlo a roda da roleta possui 37 divisoes iguais, numeradas de 0
a 36, podendo um jogador apostar um euro num dos numeros com excepcao do 0. Ele
recebe 36 euros se a bola para nesse numero, obtendo assim ganho lıquido de 35 euros, e
perde o que apostou caso contrario. Qual e o seu ganho (lıquido) medio? Um jogo que
decorre em varias partidas identicas diz-se justo (no sentido classico), se o nosso ganho
lıquido medio for nulo, ou de forma equivalente, se o valor que pagamos para jogar cada
uma das partidas (aposta), for igual ao nosso de ganho ilıquido medio. Caso contrario,
ATP, Coimbra 2002

4 Integracao de variaveis aleatorias 65
dizemos que o jogo nos e favoravel ou desfavoravel, consoante o nosso ganho lıquido
medio for positivo ou negativo, respectivamente. Para que valor da aposta e o jogo da
roleta justo?
5. (Paradoxo de Sao Petersburgo1) Pedro joga contra Paulo, e pagara a este uma
quantia que depende do resultado duma serie de lancamentos duma moeda equilibrada:
se ocorre “coroa” nos n−1 primeiros lancamentos e “cara” no n-esimo lancamento, Paulo
recebe 2n euros. Por sua vez, Paulo pagara inicialmente uma quantia Q a Pedro. Devera
o Paulo aceitar pagar 15 euros por partida para jogar? Verifique que independentemente
do valor Q pago pelo Paulo, o seu ganho medio lıquido por partida e superior a Q. Sera
possıvel determinar Q de modo que o jogo seja justo? Simule este jogo num computador
e ensaie uma resposta a pergunta anterior com base unicamente nessa simulacao.
4.2 Momentos
Da disciplina de Medida e Integracao conhecemos os espacos vectoriais Lp(Ω,A,P),
com 0 < p < +∞, das variaveis aleatorias reais X de potencia p integravel, isto e, tais
que E|X|p < +∞ (cf. AMI, §5.2). Identificando variaveis aleatorias que coincidem a
menos dum conjunto de probabilidade P nula, obtemos os espacos Lp(Ω,A,P), que sao
espacos de Banach para a norma ||X||p = E1/p|X|p se p ≥ 1, e sao espacos metricos
com distancia d(X,Y ) = ||X − Y ||pp, para 0 < p < 1. Para 0 < p < q < +∞ sabemos
tambem que Lq ⊂ Lp.
A par da esperanca matematica que estudamos no paragrafo anterior e que definimos
para toda a variavel aleatoria de L1, definimos neste paragrafo outros parametros de
resumo da distribuicao de probabilidade duma variavel aleatoria que tem um papel
importante no seu estudo.
Definicao 4.2.1 Sejam p ∈ N e X ∈ Lp. Chamamos momento de ordem p de X
a E(Xp), e momento centrado de ordem p de X a µp = E(X − E(X))p.
Atendendo a desigualdade de Holder (cf. AMI, §5.3), para p ≤ q, e valida a desi-
gualdade µ1/pp ≤ µ
1/qq .
Como parametros de resumo da distribuicao de probabilidade duma variavel aleato-
ria, particular interesse tem para nos o momento de primeira ordem, ja estudado no
paragrafo anterior, e o momento centrado de segunda ordem. Este ultimo, por razoes
que decorrem da sua definicao e um parametro de dispersao (em torno da media) da
distribuicao de probabilidade duma variavel aleatoria.
1Este jogo conceptual foi pela primeira vez estudado por Nicolaus Bernoulli, que o discute com
Montmort numa troca de correspondencia entre 1713 e 1716. O jogo torna-se conhecido atraves dum
artigo de Daniel Bernoulli, primo de Nicolaus, publicado na revista da Academia Imperial de Ciencias
de Sao Petersburgo em 1738.
ATP, Coimbra 2002

66 Apontamentos de Teoria das Probabilidades
Definicao 4.2.2 Se X ∈ L2, chamamos variancia de X, que denotamos por Var(X),
ao seu momento centrado de segunda ordem, Var(X) = E(X − E(X))2. A σ(X) =√Var(X), chamamos desvio-padrao de X.
As demonstracoes das propriedades da variancia expressas nas proposicoes seguintes
sao deixadas ao cuidado do aluno.
Proposicao 4.2.3 Se X ∈ L2, entao Var(X) = 0 sse X e quase certamente constante.
Proposicao 4.2.4 Se X ∈ L2 e a, b ∈ R, entao:
a) Var(X) = E(X2) − E2(X);
b) Var(aX + b) = a2Var(X).
As formulas anteriores sao de grande utilidade no calculo da variancia. Para as
variaveis aleatorias consideradas nos Exemplos 4.1.5, efectuamos agora o calculo da
sua variancia.
Exemplos 4.2.5 1. Se X e uma variavel de Bernoulli de parametro p, entao E(X2) =
0 × (1 − p) + 1 × p = p, e portanto Var(X) = p − p2 = p(1 − p).
2. Se X e uma variavel de Poisson de parametro λ, comecemos por efectuar o
calculo de E(X(X −1)) =∑∞
n=0 n(n−1)e−λ λn/n! = λ2e−λ∑∞
n=2 λn−2/(n−2)! = λ2.
Assim, Var(X) = λ.
3. Se X ∼ N(m,σ2), sabemos que X ∼ σU + m, com U ∼ N(0, 1), e portanto
Var(X) = Var(σU + m) = σ2Var(U) = σ2E(U2), pois E(U) = 0. Finalmente, inte-
grando por partes, obtemos E(U2) =∫
x2 1√2π
e−x2/2dλ(x) =∫
1√2π
e−x2/2dλ(x) = 1,
donde Var(X) = σ2 (ver Figura 1.1). Em particular concluımos que a variavel normal
de parametros 0 e 1 tem media zero e variancia unitaria. Toda a variavel aleatoria com
esta propriedade diz-se centrada e reduzida.
Terminamos este paragrafo fazendo referencia a outros dois parametros de resumo
da distribuicao de probabilidade duma variavel aleatoria que nos dao indicacao sobre
a forma da distribuicao de X. Sao por isso ditos parametros de forma.
Definicao 4.2.6 Se X ∈ L3 chamamos coeficiente de assimetria de X a β1 =
µ3/µ3/22 . Se X ∈ L4 chamamos coeficiente de achatamento de X a β2 = µ4/µ
22.
Notemos que se X ∈ L3 e simetrica relativamente a a ∈ R, entao β1 = 0. Se
β1 > 0 dizemos que X tem assimetria positiva, e se β1 < 0 dizemos que X tem
assimetria negativa. O coeficiente de achatamento que traduz “o peso nas caudas”
ATP, Coimbra 2002

4 Integracao de variaveis aleatorias 67
da distribuicao de X e habitualmente comparado com o da distribuicao normal para a
qual β2 = 3.
-4 -2 2 4
0.1
0.2
0.3
0.4
0.5
-4 -2 2 4
0.05
0.1
0.15
0.2
0.25
0.3
-4 -2 2 4
0.1
0.2
0.3
0.4
-4 -2 2 4
0.1
0.2
0.3
0.4
0.5
0.6
0.7 µ2 ≈ 0.65
µ3 ≈ 0.76
µ4 ≈ 2.53
β1 ≈ 1.47
β2 ≈ 6.06
N(0, 1) µ2 = 1
µ3 = 0
µ4 = 3
β1 = 0
β2 = 3
µ2 ≈ 1.44
µ3 = 0
µ4 ≈ 4.26
β1 = 0
β2 ≈ 2.04
µ2 ≈ 1.04
µ3 ≈ −1.06
µ4 ≈ 4.33
β1 ≈ −1
β2 ≈ 4
Figura 3.1
Exercıcios
1. Se X e uma variavel de quadrado integravel com media m e variancia σ2 > 0, mostre
que U = (X − m)/σ e uma v.a. centrada e reduzida.
2. Para cada uma das seguintes v.a. calcule a variancia respectiva:
(a) Geometrica de parametro p.
(b) Uniforme sobre o intervalo [a, b].
(c) Exponencial de parametro λ.
3. Seja Y a v.a. definida no Exercıcio 2.6.2. Sem explicitar a distribuicao de Y , calcule E(Y )
e Var(Y ).
4. Se X e uma v.a.r. de quadrado integravel, mostre que E(X) e a v.a. constante que melhor
aproxima X no sentido de L2, isto e,
∀ a ∈ R, E(X − E(X))2 ≤ E(X − a)2.
5. Se X ∼ N(m, σ2), mostre que X ∈ Lp para todo o p ≥ 1.
6. Seja X uma v.a.r. absolutamente contınua com densidade de probabilidade
f(x) =
1√2π σ x
exp
(− (lnx − m)2
2σ2
), se x > 0
0 , se x ≤ 0,
onde m ∈ R e σ > 0. Dizemos neste caso que X segue uma distribuicao log-normal de
parametros m e σ, e escrevemos X ∼ LN(m, σ).
ATP, Coimbra 2002

68 Apontamentos de Teoria das Probabilidades
(a) Para c > 0 e α > 0, mostre que cXα ∼ LN(ln c + αm, ασ).
(b) Prove que E(X) = exp(m + σ2/2).
(c) Utilizando as alıneas anteriores, calcule os momentos de ordem k, k ∈ N, e a
variancia de X .
7. (a) (Desigualdade de Bienayme-Tchebychev2) Mostre que se X e uma variavel
aleatoria real integravel, entao para todo o α > 0,
P(|X − E(X)| ≥ α) ≤ Var(X)
α2.
(Sugestao: Comece por verificar que 1I|X−E(X)|≥α ≤ (X − E(X))2/α2.)
(b) Mostre que a desigualdade anterior e optima no sentido em que para qualquer α > 0,
existe uma variavel aleatoria X que verifica a igualdade.
(c) Conclua que para qualquer variavel aleatoria de quadrado integravel, a probabi-
lidade do seu desvio relativamente a media ser superior ou igual a k vezes o seu
desvio-padrao, nao e superior a 1/k2 (se k = 3 obtemos 1/k2 = 0.111 . . ., e para
k = 5 obtemos 1/k2 = 0.04).
4.3 Covariancia e correlacao
Se (X,Y ) e um vector aleatorio em R2, os parametros de resumo das distribuicoes de
X e de Y que estudamos no paragrafo anterior, sao tambem parametros de resumo da
distribuicao de (X,Y ). Contrariamente a tais parametros que incidem unicamente so-
bre as distribuicoes marginais do vector, vamos neste paragrafo estudar um parametro
de resumo da distribuicao de (X,Y ) que, como veremos, nos da uma medida da de-
pendencia linear (afim) entre as variaveis X e Y .
Para tal vamos lancar mao das propriedades particulares do espaco de Banach
L2(Ω,A,P). Este espaco vectorial, e um espaco com produto interno definido por
〈X,Y 〉 = E(XY ). Como ||X||2 =√
〈X,X〉, dizemos que L2 e um espaco de Hil-
bert. Sabemos tambem que em L2 e valida a propriedade seguinte conhecida como
desigualdade de Cauchy-Schwarz:
Teorema 4.3.1 Se X,Y ∈ L2 entao |E(XY )| ≤√
E(X2)√
E(Y 2). Alem disso, tem-
se a igualdade sse X e Y sao linearmente dependentes.
Sempre que X e Y nao sejam constantes, a quantidade E(XY )/√
E(X2)√
E(Y 2) ∈[−1, 1] surge assim como uma medida natural da dependencia linear entre X e Y . Se
pretendemos avaliar nao so a dependencia linear mas tambem a dependencia afim, o
coeficiente anterior deixa de ser indicado para o efeito.
2Bienayme, I.-J., C. R. Acad. Sci. Paris, 37, 309–324, 1853.2Tchebychev, P.L., J. Math. Pures et Appl., Ser. 2, 12, 177–184, 1867.
ATP, Coimbra 2002

4 Integracao de variaveis aleatorias 69
Definicao 4.3.2 Se X,Y ∈ L2, chamamos covariancia de (X,Y ) ao numero real
Cov(X,Y ) = E((X − E(X))(Y − E(Y ))).
Se alem disso X e Y sao de variancia nao-nula, chamamos coeficiente de correlacao
de (X,Y ) ao numero do intervalo [−1, 1] dado por
ρ(X,Y ) =Cov(X,Y )
σ(X)σ(Y ).
Notemos que se X,Y ∈ L2, entao Cov(X,Y ) = E(XY ) − E(X)E(Y ) e Var(X) =
Cov(X,X). Alem disso, Var(X + Y ) = Var(X) + Var(Y ) + 2Cov(X,Y ). O calculo
anterior da variancia da soma simplifica-se se X −E(X) e Y −E(Y ) sao ortogonais (no
sentido do produto interno de L2), uma vez que neste caso Cov(X,Y ) = 0. Dizemos
entao que X e Y sao nao-correlacionadas. Neste caso Var(X + Y ) = Var(X) +
Var(Y ). A generalizacao das duas igualdades anteriores a soma dum numero finito
de variaveis X1, . . . ,Xn ∈ L2, e simples, obtendo-se Var(∑n
i=1 Xi) =∑n
i=1 Var(Xi) +
2∑
1≤i<j≤n Cov(Xi,Xj), e tambem, Var(∑n
i=1 Xi) =∑n
i=1 Var(Xi), se as variaveis sao
duas a duas nao-correlacionadas.
Do resultado seguinte concluımos que duas variaveis reais independentes sao, em
particular, nao-correlacionadas. Reparemos ainda que a integrabilidade do produto de
duas variaveis independentes e consequencia da integrabilidade de cada um dos factores.
Teorema 4.3.3 Se X e Y sao variaveis aleatorias reais integraveis e independentes,
entao XY e integravel e E(XY ) = E(X)E(Y ).
Dem: Sejam entao X e Y variaveis aleatorias reais integraveis e comecemos por mos-
trar que XY e ainda integravel. Com efeito, pelo teorema de Fubini, E(|XY |) =∫|xy| dP(X,Y ) =
∫|xy| dPX ⊗ PY =
∫|x||y| dPXdPY =
∫|x| dPX
∫|y| dPY < +∞.
Utilizando os mesmos argumentos obtemos E(XY ) = E(X)E(Y ).
Terminamos este paragrafo estabelecendo um resultado que reforca a interpretacao
do coeficiente de correlacao entre duas variaveis aleatorias, como uma medida da de-
pendencia afim entre essas variaveis.
Teorema 4.3.4 Se X,Y ∈ L2 sao de variancia nao-nula, entao:
a) ρ(aX + c, bY + c) = ρ(X,Y ), para a, b > 0 e c ∈ R;
b) ρ(X,aX + b) = a/|a|, para a 6= 0 e b ∈ R;
c) ρ(X,Y ) = ±1 sse existem a, b, c ∈ R, com ab 6= 0, tais que
aX + bY + c = 0, P-q.c.
ATP, Coimbra 2002

70 Apontamentos de Teoria das Probabilidades
Dem: As duas primeiras alıneas obtem-se directamente da definicao de ρ. Para estabe-
lecer c), consideremos a variavel aleatoria Z = Y/σ(Y ) − Xρ(X,Y )/σ(X) que satisfaz
σ2(Z) = 1 − ρ2(X,Y ). Basta agora usar a alınea b) e a Proposicao 4.2.3.
Exercıcios
1. Mostre que a covariancia e uma funcao bilinear, isto e, se X1, . . . , Xn, Y1, . . . , Ym sao
variaveis de quadrado integravel e a1, . . . , an, b1, . . . , bm numeros reais, entao
Cov( n∑
i=1
aiXi,
m∑
j=1
bjYj
)=
n∑
i=1
m∑
j=1
aibjCov(Xi, Yj).
2. Mostre que se X1, . . . , Xn sao variaveis aleatorias reais integraveis e independentes, entao∏ni=1 Xi e integravel e E
(∏ni=1 Xi
)=
∏ni=1 E(Xi).
3. Verifique que o coeficiente de correlacao pode ser igual a 0 para variaveis nao necessa-
riamente independentes. Para tal considere X em L3 simetrica relativamente a origem e
Y = X2.
4.4 Integracao de vectores aleatorios
As nocoes de integracao de variaveis aleatorias que ate agora estudamos, podem
ser extendidas de forma natural ao caso dos vectores aleatorios. No que se segue,
denotaremos por || · || a norma euclideana de Rd.
Definicao 4.4.1 Um vector aleatorio X = (X1, . . . ,Xd) com valores em (Rd,B(Rd))
diz-se integravel se E||X|| < +∞. Nesse caso, chamamos esperanca matematica
de X ao vector de Rd dado por
E(X) = (E(X1), . . . ,E(Xd)).
Claramente, a nocao de integrabilidade nao depende da norma considerada ser a
euclideana. Alem disso, X e integravel sse ||X|| e integravel, ou ainda, sse cada uma
das variaveis aleatorias Xi, i = 1, . . . , d, e integravel.
Para 0 < p < +∞, podemos definir o espaco vectorial real dos vectores aleatorios
X com valores em Rd de potencia p integravel, isto e, tais que E||X||p < +∞. Um
tal conjunto e denotado por Lp(Ω,A,P, Rd), ou simplesmente por Lp. Claramente, a
aplicacao X→E(X), de L1 em Rd, e uma aplicacao linear.
A par da esperanca matematica, a nocao que a seguir introduzimos e um dos
parametros de resumo duma distribuicao de probabilidade mais utilizados no caso mul-
tidimensional. E a generalizacao natural a este contexto, da nocao real de variancia.
ATP, Coimbra 2002

4 Integracao de variaveis aleatorias 71
Definicao 4.4.2 Se X ∈ L2, chamamos matriz de covariancia de X = (X1, . . . ,Xd)
(dita tambem matriz de dispersao ou de variancia-covariancia) a matriz
CX = [Cov(Xi,Xj)]1≤i,j≤d.
A matriz de covariancia e simetrica e semi-definida positiva, pois Var(∑d
i=1 λiXi) =
λT CXλ, para todo o λ ∈ Rd.
Da alınea c) do Teorema 4.3.4 sabemos que a matriz de covariancia C(X,Y ) dum
vector aleatorio em R2 nos da informacao sobre o tipo de distribuicao de (X,Y ). Mais
precisamente, sabemos que se C(X,Y ) possui caracterıstica 1 entao a distribuicao de
(X,Y ) esta concentrada numa recta, nao sendo, por isso, absolutamente contınua.
Generalizamos a seguir este resultado ao caso dum vector aleatorio em Rd:
Teorema 4.4.3 Sejam X um ve.a. em Rd de quadrado integravel e CX a sua matriz
de covariancia. Se car(CX) = r, entao a distribuicao de X esta concentrada num
subespaco afim de Rd de dimensao r.
Exercıcios
1. Seja U = (X, Y ) o ve.a. definido no Exemplo 2.1.9. Calcule E(U) e CU .
2. Sejam A uma matriz real de tipo n × m e b um vector em Rn. Se X e um ve.a. em Rm
de quadrado integravel, mostre que a esperanca matematica e a matriz de covariancia de
X e AX + b se encontram relacionadas da seguinte forma:
E(AX + b) = AE(X) + b e CAX+b = ACXAT .
3. Demonstre o Teorema 4.4.3. Conclua que no caso em que car(CX) = d, X pode ser ou
nao absolutamente contınuo.
4.5 Bibliografia
Hennequin, P.L., Tortrat, A. (1965). Theorie des Probabilites et Quelques Applications,
Masson.
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Monfort, A. (1980). Cours de Probabilites, Economica.
ATP, Coimbra 2002


Parte II
Leis dos grandes numeros
73


Capıtulo 5
Convergencias funcionais de
variaveis aleatorias
Convergencia quase certa, em probabilidade e em media de ordem p duma sucessao de
variaveis aleatorias. Relacoes entre os diversos modos de convergencia. Principais pro-
priedades e caracterizacoes. Teorema da convergencia dominada em Lp. Convergencias
funcionais de vectores aleatorios.
5.1 Convergencia quase certa
Neste capıtulo X,X1, X2, . . . representam variaveis aleatorias reais definidas sobre
um mesmo espaco de probabilidade (Ω,A,P).
Definicao 5.1.1 Dizemos que (Xn) converge para X quase certamente, e escre-
vemos Xnqc−→ X, se
P(ω ∈ Ω : lim Xn(ω) = X(ω)) = 1.
Dizer que a sucessao (Xn) converge para X quase certamente e assim dizer que a
menos dum conjunto com probabilidade nula, a sucessao (Xn) converge pontualmente
para X. Por outras palavras, existe N ∈ A, com P(N) = 0, tal que limXn(ω) = X(ω),
para todo o ω ∈ N c.
Das propriedades dos conjuntos de probabilidade nula, verificamos assim que as
propriedades da convergencia quase certa duma sucessao de variaveis aleatorias sao
essencialmente iguais as da convergencia pontual. Uma das excepcoes e o da nao unici-
dade do limite quase certo. No entanto, mesmo esta propriedade pode ser recuperada
atraves da identificacao de variaveis aleatorias que coincidem a menos dum conjunto
de probabilidade nula, isto e, identificando variaveis quase certamente iguais.
75

76 Apontamentos de Teoria das Probabilidades
Proposicao 5.1.2 Se Xnqc−→ X e Xn
qc−→ Y , entao X = Y q.c..
No resultado seguinte apresentamos uma caracterizacao da convergencia quase certa
bastante util quando pretendemos estabelecer a existencia do limite quase certo.
Teorema 5.1.3 Seja (Xn) uma sucessao de variaveis aleatorias reais. As condicoes
seguintes sao equivalentes:
(i) Xnqc−→ X, para alguma variavel aleatoria real X;
(ii) (Xn) e de Cauchy quase certamente, isto e,
supn,m≥k
|Xn − Xm| qc−→ 0, k→+∞.
Dem: A implicacao (i) ⇒ (ii) e obvia. Estabelecamos a implicacao recıproca. Sendo
(Xn) de Cauchy quase certamente, concluımos que existe N ∈ A com P(N) = 0 tal
que para todo o w ∈ N c a sucessao (Xn(ω)) e de Cauchy em R. Definindo X(ω) =
lim Xn(ω), para ω ∈ N c e X(ω) = 0, para ω ∈ N , temos claramente Xnqc−→ X.
Exercıcios
1. Sendo f uma funcao contınua real de variavel real, prove que se Xnqc−→ X , entao
f(Xn) qc−→ f(X).
2. Mostre que as seguintes condicoes sao equivalentes:
(i) Xnqc−→ X ;
(ii) ∀ ǫ > 0 P(⋂∞
k=1
⋃∞n=k|Xn − X | ≥ ǫ
)= 0;
(iii) ∀ ǫ > 0 P(⋃∞
n=k|Xn − X | ≥ ǫ)→0, k→+∞.
3. Diz-se que uma sucessao (Xn) de v.a.r. converge quase completamente para uma v.a.r.
X quando∑∞
n=1 P(|Xn − X | ≥ ǫ) < +∞, para todo o ǫ > 0.
(a) Prove que a convergencia quase completa implica a convergencia quase certa.
(b) Mostre que se as variaveis (Xn) sao independentes, as convergencias quase certa e
quase completa sao equivalentes.
(Sugestao: Use a lei zero-um de Borel.)
5.2 Convergencia em probabilidade
Definicao 5.2.1 Dizemos que (Xn) converge para X em probabilidade, e escre-
vemos Xnp−→ X, se
∀ ǫ > 0 P(ω ∈ Ω : |Xn(ω) − X(ω)| ≥ ǫ)→0.
ATP, Coimbra 2002

5 Convergencias funcionais de variaveis aleatorias 77
Tal como para a convergencia quase certa, se X e Y sao limite em probabilidade
duma sucessao de variaveis aleatorias entao X e Y coincidem a menos dum conjunto
com probabilidade nula.
Comecemos por relacionar este modo de convergencia com a convergencia quase
certa introduzida no paragrafo anterior.
Teorema 5.2.2 Se Xnqc−→ X, entao Xn
p−→ X.
Dem: Tendo em conta a inclusao ω : lim Xn(ω) = X(ω) ⊂ ⋃n∈N
⋂k≥nx : |Xk(ω) −
X(ω)| < ǫ, valida para todo o ǫ > 0, obtemos, por hipotese, P(⋃
n∈N
⋂k≥nω :
|Xk(ω)−X(ω)| < ǫ) = 1, ou ainda, lim P(⋂
k≥nx : |Xk(ω)−X(ω)| < ǫ) = 1. Assim
lim P(ω : |Xn(ω) − X(ω)| < ǫ) = 1, o que permite concluir.
Apresentamos a seguir duas caracterizacoes importantes da convergencia em proba-
bilidade. A segunda delas permite utilizar no estudo da convergencia em probabilidade
resultados da convergencia quase certa.
Teorema 5.2.3 Seja (Xn) uma sucessao de variaveis aleatorias reais. As condicoes
seguintes sao equivalentes:
(i) Xnp−→ X, para alguma variavel aleatoria real X;
(ii) (Xn) e de Cauchy em probabilidade, isto e,
∀ ǫ > 0 supn,m≥k
P(|Xn − Xm| ≥ ǫ)→0, k→+∞.
Dem: A implicacao (i) ⇒ (ii) e consequencia imediata da inclusao |Xn −Xm| ≥ ǫ ⊂|Xn−X| ≥ ǫ/2∪|Xm−X| ≥ ǫ/2. Para estabelecer a implicacao recıproca, comece-
mos por mostrar que sendo (Xn) de Cauchy em probabilidade existe uma subsucessao
(Xnk) que e de Cauchy quase certamente. Com efeito, sendo (Xn) de Cauchy em proba-
bilidade, existe uma subsucessao (nk) de (n) tal que P(|Xnk+1−Xnk
| ≥ 2−k) < 2−k,
para todo o k ∈ N. Pelo teorema de Borel-Cantelli concluımos que P(N) = 0, onde
N = lim sup|Xnk+1− Xnk
| ≥ 2−k. Dado ω ∈ N c, existe assim ℓ ∈ N tal que
|Xnk+1(ω) − Xnk
(ω)| < 2−k, para todo o k ≥ ℓ. Tomando agora r > s ≥ ℓ obtemos
|Xnr (ω)−Xns(ω)| ≤ ∑r−1j=s |Xnj+1(ω)−Xnj (ω)| < 2−ℓ+1, o que prova que (Xnk
) que e
de Cauchy quase certamente. Finalmente, sendo X a variavel aleatoria real que satisfaz
Xnk
qc−→ X, cuja existencia e assegurada pelo Teorema 5.1.3, e usando uma vez mais o
facto de (Xn) ser de Cauchy em probabilidade, concluımos que Xnp−→ X.
Teorema 5.2.4 Xnp−→ X sse toda a subsucessao de (Xn) possui uma subsucessao que
converge quase certamente para X.
ATP, Coimbra 2002

78 Apontamentos de Teoria das Probabilidades
Dem: Se Xnp−→ X, como toda a subsucessao de (Xn) converge em probabilidade para
X, basta provar que existe uma subsucessao de (Xn) que converge quase certamente
para X. Tal facto e uma consequencia de (Xn) ser de Cauchy em probabilidade e
do teorema anterior. Reciprocamente, suponhamos que toda a subsucessao de (Xn)
possui uma subsucessao que converge quase certamente para X. Dado ǫ > 0, qualquer,
pretendemos provar que a sucessao xn = P(|Xn−X| ≥ ǫ), converge para zero. Para tal
basta provar que toda a sua subsucessao admite uma subsucessao que converge para
zero. Seja entao (xn′) uma qualquer subsucessao de (xn). Por hipotese, a subsucessao
(Xn′) de (Xn) admite uma subsucessao (Xn′′) que converge quase certamente, e por
maioria de razao em probabilidade, para X. Assim, P(|Xn′′ − X| ≥ ǫ) → 0, ou seja,
xn′′ → 0.
Terminamos este paragrafo com uma caracterizacao da convergencia quase certa
que nos sera muito util no proximo capıtulo.
Teorema 5.2.5 (Xn) converge quase certamente sse supj≥1 |Xn+j − Xn| p−→ 0.
Dem: Consequencia do Teorema 5.1.3 e do Exercıcio 5.2.4.
Exercıcios
1. Se Xnp−→ X e Xn
p−→ Y , entao X = Y q.c..
2. Considere a sucessao (Xn) definida em ([0, 1[,B([0, 1[), λ) por Xn = 1I[ k2m , k+1
2m [, se n =
2m + k com m = 0, 1, 2, . . . e k ∈ 0, 1, . . . , 2m − 1. Mostre que Xn converge em proba-
bilidade para a v.a. nula, mas nao quase certamente.
3. Sendo f uma funcao real de variavel real contınua, prove que se Xnp−→ X , entao
f(Xn) p−→ f(X).
(Sugestao: Use o Teorema 5.2.4.)
4. Seja (Xn) uma sucessao monotona de v.a. reais. Mostre que Xnp−→ X sse Xn
qc−→ X .
5.3 Convergencia em media de ordem p
Definicao 5.3.1 Se X1,X2, . . ., sao variaveis aleatorias em Lp, com 0 < p < +∞,
dizemos que (Xn) converge para a variavel aleatoria X em media de ordem p,
e escrevemos XnLp−→ X, se
||Xn − X||pp = E|Xn − X|p→0.
A convergencia em media de ordem 2 diz-se tambem convergencia em media qua-
dratica sendo denotada por mq−→.
ATP, Coimbra 2002

5 Convergencias funcionais de variaveis aleatorias 79
Reparemos que a variavel aleatoria limite X esta necessariamente em Lp pois |X|p ≤2p(|Xn−X|p + |Xn|p). O que referimos para os modos de convergencia anteriores sobre
a unicidade do limite, vale tambem para o limite em media de ordem p.
A desigualdade de Tchebychev-Markov que estabelecemos a seguir generaliza a de-
sigualdade de Bienayme-Tchebychev estabelecida no Exercıcio 4.2.7, permitindo-nos
mostrar que a convergencia em probabilidade e implicada pela convergencia em media
de ordem p.
Teorema 5.3.2 (desigualdade de Tchebychev-Markov1) Se X e uma variavel
aleatoria real e p > 0, entao para todo o α > 0,
P(|X| ≥ α) ≤ E|X|pαp
.
Dem: Como, para α > 0, 1I|X|≥α ≤ |X|p/αp, obtemos P(|X| ≥ α) = E(1IX≥α) ≤E|X|p/αp.
Teorema 5.3.3 Para 0 < p < +∞, se XnLp−→ X entao Xn
p−→ X.
Para diferentes valores de p, os diferentes modos de convergencia em media de ordem
p estao relacionados como se descreve a seguir.
Teorema 5.3.4 Para 1 ≤ p < q < +∞, se XnLq−→ X, entao Xn
Lp−→ X.
Dem: Consequencia da desigualdade ||X||p ≤ ||X||q que obtemos directamente da desi-
gualdade de Holder (cf. AMI, §5.3).
A convergencia em media de ordem p nao e em geral consequencia das convergencias
quase certa ou em probabilidade. Tal ocorre, no entanto, sob certas condicoes sobre a
sucessao de variaveis aleatorias como as que explicitamos no resultado seguinte.
Teorema 5.3.5 (da convergencia dominada em Lp) Se
a) Xnqc−→ X ou Xn
p−→ X;
b) |Xn| ≤ Y, P-q.c., para todo o n, com Y ∈ Lp para algum 0 < p < +∞;
entao X ∈ Lp e XnLp−→ X.
Dem: Bastara considerar o caso em que Xnp−→ X. Provemos em primeiro lugar que
|X| ≤ Y , quase certamente. Para δ > 0 temos, P(|X| > Y + δ) ≤ P(|X| > |Xn| + δ) ≤P(|Xn−X| > δ) → 0, quando n→+∞. Sendo δ > 0 qualquer, concluımos que P(|X| ≤
1Markov, A.A., Ischislenie Veroiatnostei, 1913. Este e o livro de Markov sobre Calculo de Probabi-
lidades.
ATP, Coimbra 2002

80 Apontamentos de Teoria das Probabilidades
Y ) = 1. Tomemos agora ǫ > 0, qualquer. Uma vez que E(Y p) < +∞, existe M > 0
tal que E(Y p1I2Y >M) < ǫ. Assim, E|Xn −X|p = E(|Xn −X|p1I|Xn−X|≤ǫ)+ E(|Xn −X|p1Iǫ<|Xn−X|≤M) + E(|Xn − X|p1I|Xn−X|>M) < ǫp + MpP(|Xn − X| > ǫ) + 2pǫ, o
que permite concluir uma vez que P(|Xn − X| > ǫ) → 0.
Notemos, em particular, que sob as condicoes do teorema anterior com p = 1, vale
a convergencia das esperancas matematicas respectivas, isto e, E(Xn) → E(X). Este
resultado e o ja nosso conhecido teorema da convergencia dominada de Lebesgue
(cf. AMI, §4.4).Terminamos com uma caracterizacao da convergencia em media de ordem p analoga
as que ja obtivemos para a convergencia quase certa e para a convergencia em proba-
bilidade.
Teorema 5.3.6 Seja (Xn) uma sucessao de variaveis aleatorias em Lp, para algum
0 < p < +∞. As condicoes seguintes sao equivalentes:
(i) XnLp−→ X, para alguma variavel aleatoria real X;
(ii) (Xn) e de Cauchy em Lp, isto e,
supn,m≥k
||Xn − Xm||p→0, k→+∞.
Dem: A implicacao (i) ⇒ (ii) e consequencia de || · ||pp, para 0 < p < 1, e || · ||p, para
1 ≤ p < +∞, verificarem a desigualdade triangular (cf. §4.2). Sendo agora (Xn)
de Cauchy em Lp, da desigualdade de Tchebychev-Markov concluımos que (Xn) e de
Cauchy em probabilidade. Pelo Teorema 5.2.3 existe um subsucessao (Xnk) de (Xn) tal
que Xnk
qc−→ X, para alguma variavel aleatoria real X. Pelo lema de Fatou (cf. AMI,
§4.4) temos entao E|Xn − X|p ≤ lim inf E|Xn − Xnk|p, o que permite concluir usando
uma vez mais o facto de (Xn) ser de Cauchy em Lp.
Exercıcios
1. Conclua a desigualdade de Tchebychev-Markov e optima no sentido em que para qualquer
α > 0, existe uma variavel aleatoria X que verifica a igualdade.
2. Considere a sucessao (Xn) definida no Exercıcio 5.2.2. Mostre que Xn converge em media
de ordem p mas nao quase certamente.
3. Considere a sucessao (Xn) definida em ([0, 1],B([0, 1]), λ) por Xn = n1I[0, 1n ]. Mostre que
Xn converge quase certamente para a funcao nula, mas nao em media de ordem p.
4. Seja (Xn) uma sucessao de v.a. em Lp com XnLp−→ X . Mostre que ||Xn||p→||X ||p.
5. Seja (Xn) uma sucessao de v.a.r. de quadrado integravel. Mostre que E(Xn) → µ e
Var(Xn)→0 sse Xnmq−→ µ.
ATP, Coimbra 2002

5 Convergencias funcionais de variaveis aleatorias 81
6. Seja (Xn) uma sucessao de v.a. nao-correlacionadas com P(Xn = 1) = P(Xn = −1) =
1/2. Mostre que∑n
j=1 Xj/n mq−→ 0.
7. Se E|X |p < +∞, para algum p > 0, mostre que lim np P(|X | ≥ n) = 0.
(Sugestao: Use o teorema da convergencia dominada.)
8. Sejam (Xn) v.a.r. independentes de quadrado integravel com media zero e∑∞
n=1 E(X2n) <
∞. Mostre que∑∞
k=1 Xk converge em media quadratica e quase certamente2 (isto e,
Sn =∑n
k=1 Xk converge em media quadratica e quase certamente para alguma v.a.r. S).
5.4 Convergencia funcional de vectores aleatorios
Para terminar este capıtulo, notemos que as nocoes de convergencia consideradas
para sucessoes de variaveis aleatorias reais podem ser extendidas sem dificuldade ao
caso de sucessoes de vectores aleatorios definidos num mesmo espaco de probabilidade.
No que se segue, denotaremos por ||·|| a norma euclideana de Rd. No entanto, a definicao
seguinte nao depende da norma considerada em Rd.
Definicao 5.4.1 Se (Xn) e (X) sao vectores aleatorios definidos num mesmo espaco
de probabilidade, dizemos que (Xn) converge para X P-quase certamente (resp.
em probabilidade ou em media de ordem p) e escrevemos Xnqc−→ X (resp. p−→,
Lp−→), se ||Xn − X|| qc−→ 0 (resp. p−→, Lp
−→).
Atendendo a que a convergencia duma sucessao de vectores aleatorios segundo qual-
quer um dos modos anteriores e equivalente a convergencia das respectivas margens,
versoes vectoriais dos resultados apresentados nos paragrafos anteriores podem assim,
sem excepcao, ser obtidos.
5.5 Bibliografia
Billingsley, P. (1986). Probability and Measure, Wiley.
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Lukacs, E. (1975). Stochastic Convergence, Academic Press.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
2Khintchine, A., Kolmogorov, A.N., Mat. Sb., 32, 668–676, 1925.
ATP, Coimbra 2002


Capıtulo 6
Leis dos grandes numeros e series
de variaveis aleatorias
independentes
Leis dos grandes numeros para variaveis de quadrado integravel. Leis fracas de Kol-
mogorov e de Khintchine. Leis fortes e series de variaveis aleatorias. Lei forte de
Kolmogorov. O teorema das tres series.
6.1 Generalidades
Sendo (Ω0,A0,P0) um modelo probabilıstico para uma determinada experiencia
aleatoria E , e A ∈ A0 um acontecimento aleatorio, o conceito frequencista de proba-
bilidade a que fizemos alusao no §1.1, estabelece que a probabilidade P0(A) do acon-
tecimento A e o limite, num sentido a precisar, da frequencia relativa de ocorrencia
do acontecimento A em sucessivas repeticoes, sempre nas mesmas condicoes, da ex-
periencia aleatoria em causa.
Dito por outras palavras, para o modelo probabilıstico (Ω,A,P) com
Ω =
∞⊗
n=1
Ω0, A =
∞⊗
n=1
A0 e P =
∞⊗
n=1
P0,
que descreve a repeticao, sempre nas mesmas condicoes, da experiencia E , e sendo
Sn =∑n
k=1 Xk, onde Xk e a variavel aleatoria definida em (Ω,A,P) que toma valor
1 ou 0, consoante, A ocorra ou nao na k-esima repeticao da experiencia, o numero de
ocorrencias de A nas primeiras n repeticoes de E , o conceito frequencista de probabili-
dade pode ser traduzido pela convergencia
Sn
n→P0(A),
83

84 Apontamentos de Teoria das Probabilidades
segundo um modo de convergencia estocastica a precisar.
Duma forma geral, sendo (Xn) uma sucessao de variaveis aleatorias reais definidas
num mesmo espaco de probabilidade, um resultado que estabelece a convergencia
Sn
n− µn
M−→ Y
para alguma sucessao (µn) de numeros reais e para alguma variavel aleatoria Y , ondeM−→ representa um dos modos de convergencia em probabilidade, quase certa, ou em
media de ordem p, e conhecido como lei dos grandes numeros. Quando a con-
vergencia envolvida e a convergencia em probabilidade, o resultado e dito lei fraca dos
grandes numeros. Quando a convergencia e a convergencia quase certa, o resultado e
dito lei forte dos grandes numeros. Se a convergencia utilizada for a convergencia
em media de ordem p, dizemos que temos uma lei dos grandes numeros em media
de ordem p.
Com excepcao do proximo paragrafo em que estabelecemos leis dos grandes numeros
para sucessoes de variaveis aleatorias nao necessariamente independentes, admitiremos
ao longo deste capıtulo que as variaveis (Xn) sao independentes mas nao necessari-
amente identicamente distribuıdas. Neste contexto, e tendo em mente a lei zero-um
de Kolmogorov, sabemos que a existir o limite de Sn/n segundo um dos modos de
convergencia anteriores, a variavel limite e necessariamente degenerada (ver Exercıcio
6.1.2).
Definicao 6.1.1 Dizemos que a sucessao (Xn) obedece a uma lei dos grandes
numeros para o modo de convergencia M se
Sn
n− µn
M−→ 0,
para alguma sucessao (µn) de numeros reais.
Por simplicidade, sempre que (Xn) obedeca a uma lei dos grandes numeros deno-
taremos por (µn) uma das sucessoes que satisfaz a definicao anterior.
Exercıcios
1. Mostre que (Xn) obedece a uma lei dos grandes numeros para o modo de convergencia
M sse existe uma sucessao (νn) de numeros reais tal que 1n
∑ni=1(Xi − νi)
M−→ 0.
2. Mostre que se a sucessao (Xn) de variaveis aleatorias independentes verifica Sn/n −µn
M−→ Y , para alguma sucessao de numeros reais (µn) e alguma v.a.r. Y , entao Y e
quase certamente constante.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 85
3. Seja (Xn) uma sucessao de v.a.r. com |Xn| ≤ M , para todo o n ∈ N. Mostre que se (Xn)
obedece a uma lei fraca dos grandes numeros entao µn − 1n
∑ni=1 E(Xi)→0.
4. Considere a sucessao (Xn) satisfazendo P(Xn = n2) = 1/n2 e P(Xn = −n2/(n2 − 1)) =
1 − 1/n2.
(a) Mostre que E(Xn) = 0 e∑∞
n=1 P(Xn = n2) < ∞.
(b) Use o Lema de Borel-Cantelli para mostrar que Sn/n qc−→ −1.
(c) Conclua que o resultado estabelecido no exercıcio anterior nao e valido para esta
sucessao.
5. Sejam (Xn) e (Yn) sucessoes de v.a.r. independentes (nao necessariamente definidas num
mesmo espaco de probabilidade) com Xn ∼ Yn. Mostre que se (Xn) obedece a uma lei
dos grandes numeros para o modo de convergencia M, o mesmo acontece com (Yn).
6.2 Primeiras leis dos grandes numeros
Neste paragrafo obtemos leis dos grandes numeros usando tecnicas baseadas no
calculo de momentos de ordem superior ou igual a segunda. Em paragrafos posteriores,
e a custa de tecnicas de demonstracao mais elaboradas, mostraremos que no caso das
sucessoes de variaveis aleatorias independentes tais leis podem ser obtidas para variaveis
nao necessariamente de quadrado integravel.
No resultado seguinte estabelecemos uma condicao necessaria e suficiente para a
validade duma lei dos grandes numeros em media quadratica duma qualquer sucessao
(Xn) de variaveis de quadrado integravel.
Teorema 6.2.1 1 Seja (Xn) uma sucessao de variaveis aleatorias reais de quadrado
integravel. (Xn) obedece a uma lei dos grandes numeros em media quadratica sse
Var(Sn)/n2→0. Neste caso µn − 1n
∑ni=1 E(Xi)→0.
Dem: Se Var(Sn)/n2→0 entao Sn/n− µnmq−→ 0, com µn = E(Sn/n), o que estabelece
a suficiencia da condicao anterior para a validade duma lei dos grandes numeros em
media quadratica. A condicao e tambem necessaria pois Var(Sn/n) ≤ E(Sn/n − µn)2
(cf. Exercıcio 4.2.4).
Atendendo ao Teorema 5.3.3, e sob as condicoes do teorema anterior, a condicao
Var(Sn)/n2 → 0 e tambem suficiente para a validade duma lei fraca dos grandes
numeros. No entanto, notemos que esta pode ser obtida via desigualdade de Bie-
nayme-Tchebychev, pois para ǫ > 0,
P(|Sn/n − E(Sn/n)| ≥ ǫ) = P(|Sn − E(Sn)| ≥ nǫ)
≤ 1
n2ǫ2Var(Sn).
1Markov, A.A., Izv. Mat. Fiz. Ob. pri Kazanskom Univ., Ser. 2, 15, 135, 1906.
ATP, Coimbra 2002

86 Apontamentos de Teoria das Probabilidades
No caso particular em que (Xn) e uma sucessao de variaveis aleatorias reais de
quadrado integravel com E(Xk) = µ, para todo o k ∈ N, a condicao Var(Sn)/n2 → 0
e necessaria e suficiente para que Sn/n mq−→ µ. Alem disso, se as variaveis da su-
cessao sao duas a duas nao-correlacionadas, a condicao Var(Sn)/n2 → 0 reduz-se a∑n
k=1 Var(Xk)/n2→0. Estas condicoes sao, em particular, satisfeitas por uma sucessao
de variaveis independentes e identicamente distribuıdas de quadrado integravel.
Terminamos este paragrafo mostrando que sob condicoes mais restritivas que as ate
aqui consideradas, sao tambem validas leis fortes dos grandes numeros. Comecaremos
por admitir que as variaveis (Xn) sao independentes e que possuem momentos de quarta
ordem uniformemente limitados.
Teorema 6.2.2 Se (Xn) e uma sucessao de variaveis aleatorias reais independentes
com supk∈N E(X4k ) < +∞, entao (Xn) obedece a uma lei forte dos grandes numeros
com µn − 1n
∑ni=1 E(Xi)→0.
Dem: Basta demonstrar o resultado para E(Xn) = 0, para todo o n ∈ N. Pela in-
dependencia das variaveis (Xn) e da desigualdade de Holder temos E(S4n) ≤ n(3n −
2) supk∈N E(X4k). Usando agora a desigualdade de Tchebychev-Markov obtemos
∑∞n=1 P(|Sn/n| ≥ ǫ) ≤ E(S4
n)/(ǫ4n4) < +∞, o que, pelo Exercıcio 5.1.3, permite
concluir.
No resultado seguinte, utilizando uma tecnica de demonstracao conhecida por meto-
do das subsucessoes, estabelecemos uma lei forte dos grandes sob condicoes menos
restritivas que as anteriores. Admitiremos que as variaveis (Xn) sao duas a duas nao-
-correlacionadas e que possuem momentos de segunda ordem uniformemente limitados.
Teorema 6.2.3 Seja (Xn) uma sucessao de variaveis aleatorias reais de quadrado in-
tegravel duas a duas nao-correlacionadas com supk∈N E(X2k) < +∞. Entao (Xn) obe-
dece a uma lei forte dos grandes numeros com µn − 1n
∑ni=1 E(Xi)→0.
Dem: Sem perda de generalidade suponhamos que E(Xn) = 0, para todo o n ∈ N.
Denotando Yn = Sn/n, comecaremos por estabelecer o resultado para a subsucessao
de (Ynn) de (Yn), Numa segunda fase extendemo-lo a toda a sucessao. temos E(Y 2n ) =
E(S2n)/n2 =
∑nk=1 E(X2
k)/n2 ≤ γ/n, onde γ = supk∈N E(X2k). Assim,
∑∞n=1 E(Y 2
n2) ≤∑∞
n=1 γ/n2 < +∞, ou ainda, E(∑∞
n=1 Y 2n2) < +∞, e consequentemente
∑∞n=1 Y 2
n2 <
+∞, quase certamente. Concluımos assim que lim Yn2 = 0, q.c.. Para demonstrar que
lim Yn = 0, q.c., consideremos, para n ∈ N, p(n) ∈ N tal que p(n)2 < n ≤ (p(n) + 1)2.
Assim, E(Yn − p(n)2
n Yp(n)2)2 = E( 1
n
∑nk=p(n)2+1 Xk) ≤ (n − p(n)2)γ/n2 ≤ (2p(n) +
1)γ/n2 ≤ (2√
n+1)γ/n2 ≤ 3γ/n3/2, e tal como atras E(∑∞
n=1(Yn−p(n)2
n Yp(n)2)2) < +∞,
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 87
o que implica que lim(Yn− p(n)2
n Yp(n)2) = 0, q.c. Como lim Yp(n)2 = 0, q.c. e p(n)2/n ≤ 1,
concluımos finalmente que lim Yn = 0, q.c.
No caso particular em que (Xn) e uma sucessao de variaveis aleatorias reais de qua-
drado integravel duas a duas nao-correlacionadas com E(Xk) = µ, para todo o k ∈ N,
concluımos que a condicao supk∈N E(X2k) < +∞ e suficiente para que Sn/n qc−→ µ.
Estas condicoes sao, em particular, satisfeitas por uma sucessao de variaveis indepen-
dentes e identicamente distribuıdas de quadrado integravel.
Exercıcios
1. Estabeleca leis fracas e fortes dos grandes numeros para cada uma das seguintes sucessoes
de variaveis aleatorias:
(a) (Xn) e uma sucessao de variaveis de Bernoulli de parametro p duas a duas nao-
correlacionadas.2
(b) (Xn) e uma sucessao de v.a.r. duas a duas nao-correlacionadas com Xn uma variavel
de Bernoulli de parametro pn.3
(c) (Xn) e uma sucessao de v.a.r. de quadrado integravel, duas a duas nao-correlacionadas
com Var(Xn) ≤ γ.4
2. Seja (Xn) uma sucessao de v.a.r. com |Xn| ≤ M , para todo o n ∈ N. Mostre que
a condicao Var(Sn)/n2 → 0 e necessaria para a validade duma lei fraca dos grandes
numeros.
3. Sejam (Xn) uma qualquer sucessao de v.a.r. e p ≥ 1. Mostre que:
(a) Xnqc−→ 0 ⇒ Sn/n qc−→ 0;
(b) XnLp−→ 0 ⇒ Sn/n Lp
−→ 0.
(c) Verifique que Xnp−→ 0 ; Sn/n p−→ 0, considerando (Xn) com P(Xn = 2n) = 1/n
e P(Xn = 0) = 1 − 1/n.
4. (Velocidade de convergencia em probabilidade) Sejam (Xn) uma sucessao de v.a.r.
i.i.d. de quadrado integravel e µ = E(X1).
(a) Mostre que bn(Sn/n−µ) p−→ 0 (resp. mq−→), para toda a sucessao (bn) satisfazendo
bn/n1/2→0.
(b) Tomando Xn ∼ N(0, 1), conclua que o resultado anterior nao e, em geral, valido
para bn = n1/2.
2Lei fraca de Bernoulli, J., Ars Conjectandi, Basel, 1713.2Lei forte de Borel, E., Rend. Circ. Mat. Palermo, 27, 247–271, 1909.3Lei fraca de Poisson, S.D., Recherches sur la Probabilite des Judgements, Paris, 1837.4Lei fraca de Tchebychev, P.L., J. Math. Pures et Appl., Ser. 2, 12, 177–184, 1867 (reproduzido em
Oeuvres de P.L. Tchebychev, Vol. 1, 28, 687–694).
ATP, Coimbra 2002

88 Apontamentos de Teoria das Probabilidades
6.3 Leis fracas dos grandes numeros
Neste paragrafo discutimos a convergencia em probabilidade de Sn/n sob condicoes
parcialmente mais fracas que as consideradas no paragrafo anterior. Em particular,
verificaremos que e possıvel obter leis fracas dos grandes numeros sob condicoes menos
restritivas sobre os momentos das variaveis em questao. No que se segue limitar-nos-
-emos a estabelecer condicoes suficientes para a validade duma lei fraca dos grandes
numeros. No caso de existirem condicoes necessarias e suficientes indica-las-emos.
Teorema 6.3.1 (Lei fraca de Kolmogorov5) Seja (Xn) uma sucessao de variaveis
aleatorias reais independentes satisfazendo as condicoes seguintes para alguma sucessao
(an) de numeros reais:
a)∑n
k=1 P(|Xk − ak| > n)→0;
b) 1n2
∑nk=1 E((Xk − ak)
21I|Xk−ak |≤n)→0.
Entao, (Xn) obedece a uma lei fraca dos grandes numeros com µn = 1n
∑nk=1E((Xk−
ak)1I|Xk−ak|≤n) − ak.
Dem: Basta considerar o caso ak = 0, para todo o k. Para k e n naturais, consideremos
as variaveis aleatorias X ′n,k = Xk1I|Xk|≤n e S′
n =∑n
k=1 X ′n,k. Para ǫ > 0, temos por a),
P(|S′n −Sn| ≥ ǫ) ≤ ∑n
k=1 P(X ′n,k 6= Xk) =
∑nk=1 P(|Xk| > n) → 0. Como Sn/n−µn =
(Sn − S′n)/n + (S′
n − E(S′n))/n, basta agora mostrar que (S′
n − E(S′n))/n p−→ 0. Tal
facto e consequencia de b) pois para ǫ > 0, P(|S′n −E(S′
n)|/n ≥ ǫ) ≤ Var(S′n)/(ǫ2n2) =
ǫ−2n−2∑n
j=1 E(X2j 1I|Xj |≤n) → 0.
Kolmogorov mostra ainda que as condicoes anteriores alem de suficientes sao tambem
necessarias para a validade duma lei fraca dos grandes numeros quando a sucessao (an)
e substituıda por uma sucessao (mn) de medianas de (Xn), isto e, mn e um numero
real para o qual P(Xn < mn) ≤ 1/2 e P(Xn ≤ mn) ≥ 1/2.
Teorema 6.3.2 6 Seja (Xn) e uma sucessao de variaveis aleatorias reais independentes
e identicamente distribuıdas. (Xn) obedece a uma lei fraca dos grandes numeros sse
nP(|X1| > n) → 0. Neste caso podemos tomar µn = E(X11I|X1|≤n).
Dem: Para estabelecer a suficiencia da condicao nP(|X1| > n) → 0, vamos mostrar que
se verifica a condicao b) do teorema anterior para an = 0. Com efeito E(X211I|X1|≤n) ≤∑n
k=1 k2P(k − 1 < |X1| ≤ k) ≤ 2∑n
i=1 iP(i − 1 < |X1| ≤ n) ≤ 2∑n
i=1 iP(|X1| > i− 1),
o que permite concluir. Reciprocamente, se (Xn) obedece a uma lei fraca dos grandes
5Kolmogorov, A.N., Math. Ann., 99, 309–319, 1928.6Kolmogorov, A.N., Math. Ann., 102, 484–488, 1929.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 89
numeros sabemos da observacao anterior que nP(|X1 − m| > n)→ 0, onde m e uma
mediana de X1. Sendo esta condicao equivalente a nP(|X1| > n) → 0, fica concluıda a
demonstracao.
Notemos que as condicoes impostas no resultado anterior, nao implicam a inte-
grabilidade das variaveis aleatorias (Xn) (ver Exercıcio 6.3.2). No caso destas serem
integraveis vale o resultado seguinte.
Teorema 6.3.3 (Lei fraca de Khintchine7) Se (Xn) e uma sucessao de variaveis
aleatorias reais independentes, identicamente distribuıdas e integraveis, entao Sn/n p−→µ, onde µ = E(X1).
Dem: Sendo X1 integravel, as hipoteses do Teorema 6.3.2 sao trivialmente verificadas
(ver Exercıcio 5.3.7).
Exercıcios
1. Seja (Xn) uma sucessao de v.a.r. independentes com∑n
k=1 E|Xk|1+δ/n1+δ → 0, para
algum 0 < δ ≤ 1. Mostre que (Xn) obedece a uma lei fraca dos grandes numeros com
µn =∑n
k=1 E(Xk)/n.
2. Seja (Xn) uma sucessao de v.a.r. i.i.d. com P(X1 = k) = P(X1 = −k) = ck2 ln k , para
k = 2, 3, . . ., onde c = 12
(∑∞k=2
1k2 ln k
)−1.
(a) Verifique que nP(|X1| > n)→0 e E|X1| = +∞.
(b) Mostre que Sn/n p−→ 0.
3. Sendo X uma variavel aleatoria real, mostre que:
(a) Para p > 0 vale a igualdade E|X |p =∫]0,+∞[
p yp−1P(|X | > y)dλ(y).
(Sugestao: Utilize o teorema de Fubini.)
(b) A condicao n P(|X | > n)→0 implica que E|X |p < +∞, para todo o 0 < p < 1.
4. Se (Xn) e uma sucessao de v.a.r. i.i.d. com distribuicoes de Cauchy de parametros 0 e 1,
mostre que (Xn) nao obedece a uma lei fraca dos grandes numeros.
6.4 Leis fortes e series de variaveis independentes
Contrariamente ao caso da lei fraca dos grandes numeros, nao e conhecida uma
condicao necessaria e suficiente para a validade duma lei forte dos grandes numeros
para variaveis independentes mas nao necessariamente identicamente distribuıdas.
7Khintchine, A., C. R. Acad. Sci. Paris, 188, 477–479, 1929.
ATP, Coimbra 2002

90 Apontamentos de Teoria das Probabilidades
No paragrafo 6.2 estabelecemos uma primeira lei forte para sucessoes de variaveis
aleatorias duas a duas nao-correlacionadas com momentos de segunda ordem uniforme-
mente limitados. Neste paragrafo vamos obter uma lei forte para sucessoes de variaveis
aleatorias independentes sob condicoes menos restritivas que as consideradas no Teo-
rema 6.2.2. Para tal vamos utilizar a relacao entre a convergencia quase certa da media
empırica Sn/n e a convergencia da serie∑∞
k=1 Xk/k que estabelecemos no resultado
seguinte.
Lema 6.4.1 (de Kronecker) Se (xn) e uma sucessao de numeros reais tal que∑∞
k=1 xk/k converge, entao∑n
k=1 xk/n→0.
Dem: Dado ǫ > 0, existe por hipotese n0 ∈ N tal que para n ≥ n0, |rn| < ǫ, onde
rn =∑∞
k=n+1 xk/k. Assim, como∑n
k=1 xk =∑n
k=1(rk−1 − rk)k =∑n−1
k=1 rk + r0 − nrn,
obtemos para n ≥ n0, |∑n
k=1 xk/n| ≤∑n0−1
k=1 |rk|/n + |r0|/n + |rn| +∑n
k=n0|rk|/n <
ǫ(3 + (n − n0 + 1)/n) < 4ǫ.
O resultado que a seguir estabelecemos permite obter condicoes suficientes para a
convergencia quase certa duma serie de variaveis aleatorias independentes e, por maioria
de razao, via lema de Kronecker, condicoes suficientes para uma lei forte dos grandes
numeros. Para tal necessitamos duma generalizacao da desigualdade
P(|Sn| ≥ ǫ
)≤ 1
ǫ2
n∑
k=1
E(X2k),
que podemos obter como aplicacao directa da desigualdade Bienayme-Tchebychev (ver
Exercıcio 4.2.7).
Lema 6.4.2 (Desigualdade maximal de Kolmogorov8) Sejam X1, . . . ,Xn sao va-
riaveis aleatorias reais independentes com media zero e Sk = X1 + . . . + Xk, para
k = 1, . . . , n. Entao, para todo o ǫ > 0,
P(
max1≤k≤n
|Sk| ≥ ǫ)≤ 1
ǫ2
n∑
k=1
E(X2k).
Dem: Para ǫ > 0, definamos os acontecimentos disjuntos E1 = |S1| ≥ ǫ e Ek =
|S1| < ǫ, . . . , |Sk−1| < ǫ, |Sk| ≥ ǫ, para 2 ≤ k ≤ n, que satisfazem⋃n
k=1 Ek =
max1≤k≤n |Sk| ≥ ǫ. Pela desigualdade de Markov temos P(Ek) ≤ ǫ−2E(Sk1IEk)2.
Usando agora a independencia entre Sk1IEke Sn−Sk, podemos ainda escrever E(S2
k1IEk)
≤ E(S2k1IEk
+ (Sn − Sk)21IEk
) = E(S2k1IEk
+ 2Sk(Sn − Sk)1IEk+ (Sn − Sk)
21IEk) =
E(Sn1IEk)2. Finalmente, P(max1≤k≤n |Sk| ≥ ǫ) =
∑nk=1 P(Ek) ≤ ∑n
k=1 ǫ−2E(Sn1IEk)2
≤ ǫ−2E(S2n).
8Kolmogorov, A.N., Math. Ann., 99, p. 309–319, 1928.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 91
Teorema 6.4.3 (Criterio de Kolmogorov) Sejam (Xn) variaveis aleatorias reais
independentes de quadrado integravel com E(Xn) = 0, para todo o n ∈ N. Se a serie∑∞
n=1 Var(Xn) e convergente, entao a serie∑∞
n=1 Xn converge quase certamente.
Dem: Atendendo ao Teorema 5.2.5, para mostrar que Sn =∑n
k=1 Xk converge quase
certamente basta mostrar que supj≥1 |Sn+j − Sn| p−→ 0. Pela desigualdade maximal
de Kolmogorov e para ǫ > 0, qualquer, podemos obter P(supj≥1 |Sn+j − Sn| ≥ ǫ) =
limN→+∞ P(max1≤j≤N |Sn+j − Sn| ≥ ǫ) ≤ limN→+∞ P(max1≤j≤N |∑n+jk=n+1 Xk| ≥ ǫ) ≤
∑∞k=n+1 Var(Xk)/ǫ
2, o que permite concluir.
Como aplicacao directa do criterio anterior obtemos um primeiro conjunto de condi-
coes suficientes para a convergencia duma serie de variaveis aleatorias independentes
de quadrado integravel.
Teorema 6.4.4 Sejam (Xn) variaveis aleatorias reais independentes de quadrado in-
tegravel. Se as series∑∞
n=1 E(Xn) e∑∞
n=1 Var(Xn) sao convergentes entao a serie∑∞
n=1 Xn converge quase certamente.
Uma segunda consequencia do criterio de Kolmogorov e uma lei forte geral para
variaveis independentes de quadrado integravel mas nao necessariamente identicamente
distribuıdas, sob condicoes menos restritivas que as do Teorema 6.2.3.
Teorema 6.4.5 9 Sejam (Xn) variaveis aleatorias reais independentes de quadrado in-
tegravel. Se a serie∑∞
k=1 Var(Xk)/k2 e convergente, entao Sn/n − µnqc−→ 0, onde
µn = 1n
∑nk=1 E(Xk).
Dem: Como por hipotese∑∞
k=1 Var(Xk/k) < +∞, pelo criterio de Kolmogorov con-
cluımos que∑∞
k=1(Xk − E(Xk))/k converge quase certamente. Do Lema 6.4.1 deduzi-
mos o pretendido.
Exercıcios
1. Seja (Xn) uma sucessao de v.a.r. satisfazendo P(Xn = n2) = P(Xn = −n2) = 1/(2n2)
e P(Xn = 0) = 1 − 1/n2. Conclua que a condicao estabelecida no Teorema 6.4.5 nao e
necessaria para a validade duma lei forte dos grandes numeros.
2. Sejam (Xn) e (Yn) sucessoes de v.a.r. independentes (nao necessariamente definidas
num mesmo espaco de probabilidade) com Xn ∼ Yn. Mostre que∑
Xn converge quase
certamente sse∑
Yn converge quase certamente.
3. (Velocidade de convergencia quase certa) Sejam (Xn) uma sucessao de v.a.r. i.i.d.
de quadrado integravel e µ = E(X1).
9Kolmogorov, A.N., C. R. Acad. Sci. Paris, 191, 910–912, 1930.
ATP, Coimbra 2002

92 Apontamentos de Teoria das Probabilidades
(a) Mostre que se∑
a2n/n2 < ∞ para alguma sucessao de numeros reais (an) entao
an(Sn/n − µ) qc−→ 0.
(b) Conclua que n1/2(lnn)−1/2−ǫ(Sn/n− µ) qc−→ 0, para todo o ǫ > 0.
6.5 Lei forte dos grandes numeros de Kolmogorov
Mostramos neste paragrafo que se (Xn) e uma sucessao de variaveis aleatorias reais
e independentes e identicamente distribuıdos, a condicao E|X1| < +∞ e necessaria e
suficiente para que Sn/n convirja quase certamente para um valor real µ, ou de forma
equivalente, para que (Xn) obedeca a uma lei forte dos grandes numeros com µn = µ.
Trata-se da lei forte dos grandes numeros de Kolmogorov.
6.5.1 Necessidade da condicao de integrabilidade
A necessidade da condicao de integrabilidade para a validade duma lei forte dos
grandes numeros cuja variavel limite nao e constantemente infinita, e estabelecida a
custa dos resultados seguintes.
Lema 6.5.1 Se Y e uma variavel aleatoria real entao∞∑
n=1
P(|Y | > n) ≤ E|Y | ≤ 1 +∞∑
n=1
P(|Y | > n).
Dem: Pelo Exercıcio 6.3.3 temos E|Y | =∫[0,+∞[ P(|Y | > y)dy =
∑∞n=0
∫[n,n+1[ P(|Y | >
y)dy, o que permite concluir.
Lema 6.5.2 Sejam (Xn) variaveis aleatorias reais independentes e identicamente dis-
tribuıdas. As condicoes seguintes sao equivalentes:
i) E|X1| < +∞;
ii) lim Xn/n = 0, q.c.;
iii) ∀ǫ > 0∑∞
n=1 P(|X1| > ǫn) < +∞.
Dem: Para ǫ > 0, tomando Y = X1/ǫ no lema anterior obtemos a equivalencia entre
as condicoes i) e iii). A equivalencia entre as condicoes ii) e iii) e uma consequencia
imediata da equivalencia entre as convergencias quase certa e quase completa para zero
da sucessao (Xn/n) (ver Exercıcio 5.1.3).
Teorema 6.5.3 Sejam (Xn) variaveis aleatorias reais independentes e identicamente
distribuıdas e µ ∈ R tais que Sn/n qc−→ µ. Entao E|X1| < +∞.
Dem: Como por hipotese, Xn/n = (Sn − Sn−1)/nqc−→ 0, o resultado e consequencia
do Lema 6.5.2.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 93
6.5.2 Suficiencia da condicao de integrabilidade
Estamos agora em condicoes de estabelecer o principal resultado deste capıtulo.
Teorema 6.5.4 (Lei forte de Kolmogorov10) Seja (Xn) uma sucessao de variaveis
aleatorias reais independentes e identicamente distribuıdas. Entao, existe µ ∈ R tal que
Sn/n qc−→ µ sse E|X1| < +∞. Nesse caso µ = E(X1).
Dem: Atendendo ao Teorema 6.5.3 basta mostrar que Sn/n qc−→ E(X1), quando
E|X1| < +∞. Sem perda de generalidade vamos admitir que E(X1) = 0. Conside-
remos as variaveis X ′n = Xn1I|Xn|≤n, para n ≥ 1. Pelo Lema 6.3.1,
∑∞n=1 P(Xn 6=
X ′n) =
∑∞n=1 P(|Xn| > n) < +∞, e assim, pelo teorema de Borel-Cantelli, P(Xn 6=
X ′n i.o.) = 1. Concluımos assim que existe N ∈ A com P(N) = 0 tal que para todo
o ω ∈ N c as sucessoes (Xn(ω)) e (X ′n(ω)) coincidem para n suficientemente grande.
Bastara assim provar que S′n/n qc−→ 0, onde S′
n =∑n
k=1 X ′n. Para tal vamos lancar
mao do Teorema 6.4.5, mostrando que a serie∑∞
k=1 Var(X ′k)/k
2 e convergente. Ora∑∞
k=1 Var(X ′k)/k
2 ≤ ∑∞k=1 E(X2
11I|X1|≤k)/k2 =
∑∞k=1
∑kj=1 E(X2
1 1Ij−1<|X1|≤j)/k2
=∑∞
j=1
∑∞k=j E(X2
11Ij−1<|X1|≤j)/k2, onde
∑∞k=1
1k2 ≤ 2,
∑∞k=j
1k2 ≤ 1
j−1 , para
j ≥ 2, e E(X211Ij−1<|X1|≤j) ≤ jE(|X1|1Ij−1<|X1|≤j). Assim,
∑∞k=1 Var(X ′
k)/k2 ≤
2E(|X1|1I|X1|≤1) +∑∞
j=2j
j−1 E(|X1|1Ij−1<|X1|≤j) ≤ 2∑∞
j=1 E(|X1|1Ij−1<|X1|≤j) =
2E|X1| < +∞.
Exercıcios
1. Sejam (Xn) v.a.r. i.i.d. em Lp. Mostre que 1n
∑ni=1 Xp
iqc−→ E(Xp
1 ).
2. Denotemos por Xn = 1n
∑ni=1 Xi e σ2
n = 1n−1
∑ni=1(Xi − Xn)2, a media empırica e
variancia empırica, das v.a.r. X1, . . . , Xn. Mostre que se (Xn) sao variaveis i.i.d. de
quadrado integravel com variancia σ2, entao E(σ2n) = σ2 e σ2
nqc−→ σ2.
3. Retome os Exercıcios 1.8.4 e 2.1.6. Conclua que Snqc−→ −∞.
4. (Integracao pelo metodo de Monte Carlo, I) Sejam (Un) uma sucessao de v.a.
i.i.d. uniformemente distribuıdas sobre o intervalo [0, 1], e f uma funcao real mensuravel
definida em [0, 1] tal que∫[0,1] |f |dλ < +∞. Mostre que 1
n
∑ni=1 f(Ui)
qc−→∫[0,1] fdλ.
5. (Integracao pelo metodo de Monte Carlo, II) Sejam U1, V1, U2, V2, . . . v.a. i.i.d.
uniformemente distribuıdas sobre o intervalo [0, 1], e f : [0, 1] → [0, 1] uma funcao men-
suravel. Para n ∈ N, defina Zn = 1If(Un)>Vn, e mostre que 1n
∑ni=1 Zi
qc−→∫[0,1]
fdλ.
6. (Velocidade de convergencia quase certa11) Sejam (Xn) uma sucessao de v.a.r. i.i.d.
e p ∈]1, 2[. Mostre que n1−1/p(Sn/n− µ) qc−→ 0 para algum µ ∈ R sse E|X |p < ∞. Neste
caso µ = E(X1).
10Kolmogorov, A.N., Grundbegriffe der Wahrscheinlichkeitrechnung, Berlin, 1933.11Marcinkiewicz, J., Zygmund, A., Fund. Math., 29, 60–90, 1937.
ATP, Coimbra 2002

94 Apontamentos de Teoria das Probabilidades
(Sugestao: Retome as demonstracoes dos Teoremas 6.5.3 e 6.5.4, mostrando no primeiro
caso que Xn/n1/p qc−→ 0 e no segundo que S′n/n1/p qc−→ 0, onde S′n =∑n
k=1Xk1I|Xk|≤k1/p.)
6.6 O teorema das tres series
No Teorema 6.4.4 obtivemos condicoes suficientes para a convergencia quase certa
duma serie de variaveis aleatorias independentes. De seguida aprofundamos este as-
sunto comecando por mostrar que no caso das variaveis aleatorias serem limitadas as
condicoes anteriores sao tambem necessarias. Para tal lancamos mao da desigualdade
seguinte devida a Kolmogorov.
Lema 6.6.1 Sejam X1, . . . ,Xn variaveis aleatorias reais independentes com media
zero, Sk = X1 + . . . + Xk, e suponhamos que existe γ > 0 tal que |Xk| ≤ γ q.c.,
para k = 1, . . . , n. Entao, para todo o ǫ > 0,
P(
max1≤k≤n
|Sk| ≥ ǫ)≥ 1 − (ǫ + γ)2∑n
k=1 E(X2k)
.
Dem: Sejam Ek, para 1 ≤ k ≤ n, os acontecimentos definidos na demonstracao da
desigualdade maximal de Kolmogorov, e Dk, para 0 ≤ k ≤ n, os acontecimentos
D0 = Ω e Dk = |S1| < ǫ, . . . , |Sk−1| < ǫ, |Sk| < ǫ, para 1 ≤ k ≤ n. Claramente
max1≤k≤n |Sk| ≥ ǫ =∑n
k=1 Ek = Dcn. Para k ≥ 1, Dk e Ek sao disjuntos e Dk +Ek =
Dk−1, o que permite escrever Sk−11IDk−1+ Xk1IDk−1
= Sk1IDk−1= Sk1IDk
+ Sk1IEk,
onde S0 = 0. Usando a independencia entre Sk−11IDk−1e Xk e entre 1IDk−1
e Xk
temos E(S2k−11IDk−1
) + E(X2k)P(Dk−1) = E(S2
k1IDk) + E(S2
k1IEk). Alem disso, como
P(Dk−1) ≥ P(Dn) e |Sk1IEk−1| ≤ (ǫ + γ)1IEk
, obtemos E(S2k−11IDk−1
) + E(X2k)P(Dn) ≤
E(S2k1IDk
)+(ǫ+γ)2P(Ek). Finalmente, somando todas as inequacoes anteriores obtemos∑n
k=1 E(X2k)P(Dn) ≤ E(S2
n1IDn)+ (ǫ + γ)2P(Dcn) ≤ (ǫ + γ)2, o que permite concluir.
Estabelecemos em primeiro lugar a recıproca do criterio de Kolmogorov para varia-
veis uniformemente limitadas.
Teorema 6.6.2 Sejam (Xn) variaveis aleatorias reais independentes tais que supk∈N
|Xk| ≤ γ q.c., para alguma constante γ > 0, e E(Xk) = 0 para todo o k ∈ N. Entao∑∞
n=1 Xn converge quase certamente sse a serie∑∞
n=1 Var(Xn) e convergente.
Dem: Tendo em conta o Teorema 6.4.3, basta mostrar que∑∞
n=1 Var(Xn) e conver-
gente quando∑∞
n=1 Xn converge quase certamente. Neste caso, para todo o ǫ > 0
P(supj≥1 |Sn+j−Sn| ≥ ǫ) → 0 (cf. Teorema 5.2.5). Ora, pelo Lema 6.6.1, P(supj≥1 |Sn+j
−Sn| ≥ ǫ) = limN→+∞ P(max1≤j≤N |Sn+j −Sn| ≥ ǫ) ≥ 1− (ǫ+2γ)2/∑∞
k=n+1 Var(Xk),
obtendo-se uma contradicao se∑∞
n=1 Var(Xn) = +∞.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 95
Passemos agora ao estudo da serie nao centrada no caso das variaveis da sucessao
serem uniformemente limitadas.
Teorema 6.6.3 Sejam (Xn) variaveis aleatorias reais independentes tais que supk∈N
|Xk| ≤ γ q.c., para alguma constante γ > 0. Entao a serie∑∞
n=1 Xn converge quase
certamente sse as series∑∞
n=1 E(Xn) e∑∞
n=1 Var(Xn) sao convergentes.
Dem: Pelo Teorema 6.4.3 basta mostrar que a convergencia quase certa da serie∑
Xn
implica a convergencia das series∑
E(Xn) e∑
Var(Xn). Sabemos do Exercıcio 3.2.6
que existem variaveis aleatorias reais independentes Y1, Z1, Y2, Z2, . . . definidas num
mesmo espaco de probabilidade com Xn ∼ Yn ∼ Zn, para todo o n ∈ N. Alem
disso, se∑
Xn e quase certamente convergente, tambem o sao as series∑
Yn e∑
Zn
(cf. Exercıcio 6.6.2). Consideremos agora as variaveis Un = Yn − Zn, para n ∈ N
(notemos que Un ∼ −Un, pelo que esta tecnica e conhecida por simetrizacao). Tais
variaveis sao independentes, com E(Un) = 0, |Un| ≤ 2γ, q.c. e alem disso∑
Un e quase
certamente convergente. Pelo Teorema 6.6.2 concluımos que∑
Var(Un) < +∞, ou
ainda∑
Var(Xn) < +∞, uma vez que Var(Un) = Var(Yn) + Var(Zn) = 2Var(Xn).
Novamente pelo Teorema 6.6.2,∑
(Xn − E(Xn)) converge quase certamente, o que
implica a convergencia da serie∑
E(Xn), pois E(Xn) = Xn − (Xn − E(Xn)), para
n ∈ N.
Finalmente, no caso geral das variaveis nao serem uniformemente limitadas e valido
o seguinte resultado.
Teorema 6.6.4 (das tres series12) Se (Xn) e uma sucessao de variaveis aleatorias
reais independentes entao∑∞
n=1 Xn converge quase certamente sse para algum c > 0
as tres series seguintes sao convergentes:
a)∞∑
n=1
P(|Xn| > c); b)∞∑
n=1
E(Xn1I|Xn|≤c); c)∞∑
n=1
Var(Xn1I|Xn|≤c).
Dem: Comecamos por notar que a convergencia da serie a) e, pela lei zero-um de Borel,
equivalente a condicao P(|Xn| > c i.o.) = 0, ou ainda a P(Xn 6= Xn1I|Xn|≤c i.o.) = 0.
Assim, a menos dum conjunto de pontos ω com probabilidade nula as sucessoes (Xn(ω))
e (Xn(ω)1I|Xn|≤c(ω)) coincidem para n suficientemente grande, o que implica que a
convergencia quase certa de∑
Xn e equivalente a convergencia quase certa da serie∑
Xn1I|Xn|≤c. Por outro lado, a convergencia das series b) e c) e, pelo Teorema
6.6.3, equivalente a convergencia quase certa de∑
Xn1I|Xn|≤c. Concluımos assim
que a convergencia das series a), b) e c) implica a convergencia quase certa de∑
Xn.
12Kolmogorov, A.N., Math. Ann., 99, p. 309–319, 1928.
ATP, Coimbra 2002

96 Apontamentos de Teoria das Probabilidades
Reciprocamente, se∑
Xn converge quase certamente, entao como |Xn| > c i.o. ⊂lim sup Xn 6= 0, para c > 0 qualquer, concluımos que P(|Xn| > c i.o.) = 0, o que,
como ja referimos e equivalente a convergencia da serie a). Repetindo o raciocınio ante-
rior, concluımos que a convergencia quase certa de∑
Xn e equivalente a convergencia
quase certa da serie∑
Xn1I|Xn|≤c, o que, por sua vez, e equivalente as convergencia
das series b) e c).
Terminamos este paragrafo mostrando que as condicoes necessarias e suficientes
anteriores para a convergencia quase certa da serie∑∞
n=1 Xn, sao tambem necessarias
e suficientes para a sua convergencia em probabilidade.
Lema 6.6.5 (Desigualdade de Levy) Sejam X1, . . . ,Xn variaveis aleatorias reais e
independentes, Sk = X1 + . . . + Xk, para k = 1, . . . , n, e ǫ, δ > 0. Se
max1≤i≤n
P(|Xi + . . . + Xn| ≥ ǫ/2) ≤ δ,
entao
P(
max1≤k≤n
|Sk| ≥ ǫ)≤ δ
1 − δ.
Dem: Sejam Ek, k ≥ 1, os conjuntos definidos na demonstracao da desigualdade
maximal de Kolmogorov. Pela independencia dos acontecimentos Ek e |Sn −Sk| ≥ ǫ/2
temos P(max1≤k≤n |Sk| ≥ ǫ, |Sn| ≤ ǫ/2) =∑n
k=1 P(Ek, |Sn| ≤ ǫ/2) ≤ ∑nk=1 P(Ek, |Sn−
Sk| ≤ ǫ/2) =∑n
k=1 P(Ek)P(|Sn −Sk| ≤ ǫ/2) ≤ δP(max1≤k≤n |Sk| ≥ ǫ). Por outro lado,
P(max1≤k≤n |Sk| ≥ ǫ, |Sn| > ǫ/2) ≤ P(|Sn| > ǫ/2) ≤ δ, o que permite concluir.
Teorema 6.6.6 (de Levy13) Se (Xn) e uma sucessao de variaveis aleatorias reais e
independentes entao Sn =∑n
k=1 Xk converge quase certamente sse converge em proba-
bilidade.
Dem: Consequencia imediata do Teorema 5.2.5 e da desigualdade de Levy.
Exercıcios
1. Recorde a natureza das series∑
1/n e∑
(−1)n/n. Considere uma sucessao (Xn) de v.a.r.
i.i.d. com P (Xn = −1) = P (Xn = 1) = 1/2. Estude a convergencia da serie∑
Xn/n.
2. Sendo (Xn) uma qualquer sucessao de v.a.r., mostre que se∑∞
n=1 E(|Xn|) < ∞, entao∑∞n=1 Xn converge quase certamente.
3. Sejam . . . , Y1, Y0, Y−1, . . . uma sucessao de v.a.r. i.i.d. com E(Yn) = 0 e α0, α1, . . . uma
sucessao de numeros reais com∑ |αn| < ∞.
(a) Para n ∈ N, mostre que∑∞
j=0 αjYn−j converge quase certamente.
(b) Definindo Xn =∑∞
j=0 αjYn−j , para n ∈ N, mostre que Xn = αXn−1 + Yn.
13Levy, P., Theorie de l’Addition des Variables Aleatoires, Paris, 1937.
ATP, Coimbra 2002

6 Leis dos grandes numeros e series de v.a. independentes 97
6.7 Bibliografia
Chow, Y.S., Teicher, H. (1997). Probability Theory: Independence, Interchangeability,
Martingales, Springer.
Chung, K.L. (1974). A Course in Probability Theory, Academic Press.
Durrett, R. (1996). Probability: Theory and Examples, Duxbury Press.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Kolmogorov, A.N. (1950). Foundations of the Theory of Probability, Chelsea Publishing
Company.
Loeve, M. (1977). Probability Theory I, Springer.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
Revesz, P. (1968). The Laws of Large Numbers, Academic Press.
ATP, Coimbra 2002


Parte III
Teorema do limite central
99


Capıtulo 7
Funcao caracterıstica
Integracao de variaveis aleatorias complexas. Funcao caracterıstica dum vector aleatorio.
Derivadas e momentos. Injectividade. Formulas de inversao. Aplicacoes a caracteri-
zacao da independencia e ao estudo da distribuicao da soma de vectores aleatorios.
7.1 Integracao de variaveis aleatorias complexas
Como bem sabemos, o conjunto dos numeros complexos pode ser identificado com
o conjunto R2 dos pontos do plano, associando-se a cada complexo z = x + i y o par
ordenado (x, y). A x chamamos parte real de z, e escrevemos x = Re(z) e a y parte
imaginaria de z que denotamos por y = Im(z). Considerando em R2 a norma euclide-
ana e em C a norma do modulo (|z| =√
x2 + y2), concluımos facilmente que os abertos
de cada um dos conjuntos podem ser tambem identificados, o mesmo acontecendo re-
lativamente as σ-algebras de Borel B(C) e B(R2).
Toda a funcao complexa Z definida num conjunto Ω pode escrever-se na forma
Z = Re(Z) + i Im(Z), onde Re(Z) e Im(Z) sao funcoes reais definidas, para ω ∈ Ω,
por Re(Z)(ω) = Re(Z(ω)) e Im(Z)(ω) = Im(Z(ω)). As observacoes preliminares ante-
riores implicam que uma funcao Z definida num espaco de probabilidade (Ω,A,P) com
valores em (C,B(C)) e uma variavel aleatoria sse a funcao de (Ω,A,P) em (R2,B(R2))
definida por (Re(Z), Im(Z)) e tambem uma variavel aleatoria, ou ainda, sse Re(Z)
e Im(Z) sao variaveis aleatorias reais. Neste caso dizemos que Z e uma variavel
aleatoria complexa.
Tendo em conta o que atras foi dito, a definicao de esperanca matematica duma
variavel aleatoria complexa surge agora de forma natural.
Definicao 7.1.1 Uma variavel aleatoria complexa Z diz-se integravel se Re(Z) e
Im(Z) o forem, e nesse caso, a sua esperanca matematica e dada por
E(Z) = E(Re(Z)) + iE(Im(Z)).
101

102 Apontamentos de Teoria das Probabilidades
Teorema 7.1.2 a) O conjunto das variaveis aleatorias complexas integraveis e um
espaco vectorial complexo (com a soma e produto escalar definidos da forma habitual).
b) A aplicacao Z→E(Z) desse espaco em C e linear.
Dem: Basta ter em conta que o conjunto das variaveis aleatorias reais integraveis e um
espaco vectorial real e a linearidade da esperanca matematica para variaveis aleatorias
reais.
Teorema 7.1.3 Uma variavel aleatoria complexa Z e integravel sse |Z| o for, e nesse
caso |E(Z)| ≤ E(|Z|).
Dem: A primeira afirmacao resulta das desigualdades |Re(Z)| ≤ |Z|, |Im(Z)| ≤ |Z|e |Z| ≤ |Re(Z)| + |Im(Z)|. A desigualdade |E(Z)| ≤ E(|Z|) e valida se E(Z) =
0. Se E(Z) 6= 0, seja w = E(Z)/|E(Z)|. Entao |E(Z)| = w−1E(Z) = E(w−1Z) =
E(Re(w−1Z)) (pois |E(Z)| e real) ≤ E(|w−1Z|) = E(|Z|).
Antes de terminarmos este curto paragrafo sobre a integracao de variaveis aleatorias
complexas, observemos que outros resultados que enunciamos relativos a esperanca
matematica de variaveis aleatorias reais, sao tambem validos para variaveis aleatorias
complexas. Tais resultados podem ser estabelecidos a partir dos correspondentes re-
sultados para variaveis aleatorias reais, considerando separadamente as partes reais e
imaginarias das variaveis aleatorias intervenientes.
7.2 Definicao e primeiras propriedades
A nocao de funcao caracterıstica que introduzimos a seguir e, como veremos ao
longo deste capıtulo, um instrumento essencial no estudo da distribuicao dum vector
aleatorio. Para x = (x1, . . . , xd) e y = (y1, . . . , yd) em Rd, denotaremos por 〈x, y〉 o
produto interno usual em Rd, isto e, 〈x, y〉 =∑d
j=1 xjyj.
Definicao 7.2.1 Chamamos funcao caracterıstica dum vector aleatorio X em Rd
(ou funcao caracterıstica de PX), a funcao de Rd em C definida por
φX(t) = E(e i 〈t,X〉), para t ∈ Rd.
Notemos que como |e i 〈t,X〉| = 1, a esperanca matematica anterior esta bem definida.
Teorema 7.2.2 Se φX e a funcao caracterıstica dum vector aleatorio X entao:
a) φX(0) = 1;
b) |φX(t)| ≤ 1, para todo o t ∈ Rd;
c) φ−X(t) = φX(t), para todo o t ∈ Rd;
d) φX e uma funcao contınua.
ATP, Coimbra 2002

7 Funcao caracterıstica 103
Dem: As alıneas a), b) e c) sao consequencia imediata da definicao de funcao carac-
terıstica. A continuidade de φX resulta da continuidade sob o sinal de integral.
Atendendo a alınea c) anterior, a funcao caracterıstica duma variavel aleatoria
simetrica relativamente a origem e uma funcao real. Neste caso φX(t) = E(cos(〈t,X〉)),para t ∈ Rd.
O calculo da funcao caracterıstica duma variavel aleatoria pode revelar-se um tra-
balho arduo. Tal e o caso do segundo dos exemplos seguintes.
Exemplos 7.2.3 1. Se X e uma v.a. de Bernoulli de parametro p, entao φX(t) =
e i t.1p + e i t.0(1 − p) = 1 − p(1 − e i t), para t ∈ R.
2. Se X e uma v.a. normal centrada e reduzida, entao φX(t) = e−t2/2, para t ∈R. Com efeito, como φX(t) = E(cos(tX)) = 1√
2π
∫cos(tx)e−x2/2 dλ(x) e φ′
X(t) =−1√2π
∫x sin(tx)e−x2/2 dλ(x) = −tφX(t), obtemos a equacao diferencial φ′
X(t)/φX (t) =
−t, que possui como solucao φX(t) = ece−t2/2, ou ainda, φX(t) = e−t2/2, uma vez que
φX(0) = 1.
As funcoes caracterısticas de subvectores dum vector X podem ser obtidas facil-
mente a partir de φX . Faceis de obter sao tambem as funcoes caracterısticas de trans-
formacoes afins dum vector X.
Teorema 7.2.4 Se X = (X1,X2) e um vector aleatorio em Rp+q, entao
φX1(t1) = φX(t1, 0) e φX2(t2) = φX(0, t2),
para todo o t1 ∈ Rp e t2 ∈ Rq.
Teorema 7.2.5 Sejam X um vector aleatorio sobre Rp+q, A uma matriz real de tipo
p × q e b ∈ Rp. Entao φAX+b(t) = e i 〈t,b〉φX(AT t), para t ∈ Rp.
Como aplicacao deste ultimo resultado, podemos obter a funcao caracterıstica duma
variavel Y ∼ N(m,σ2), pois Y ∼ σX + m, com X ∼ N(0, 1), e assim
φY (t) = e i tmφX(σt) = e i tme−σ2t2/2, t ∈ R.
Exercıcios
1. Demonstre os Teoremas 7.2.4 e 7.2.5.
2. Para as seguintes v.a. calcule a sua funcao caracterıstica:
(a) Variavel constantemente igual a m;
ATP, Coimbra 2002

104 Apontamentos de Teoria das Probabilidades
(b) Binomial de parametros n e p;
(c) Poisson de parametro λ;
(d) Exponencial de parametro λ;
(e) Uniforme sobre o intervalo [−a, a].
3. Seja (X, Y ) o vector aleatorio com densidade
f(x, y) =1
2π√
1 − ρ2e−(x2−2ρxy+y2)/(2(1−ρ2)),
onde ρ ∈ ]− 1, 1[ (ver Exemplo 1.3.5). Calcule φ(X,Y ) e φY .
(Sugestao: Use o Exercıcio 1.7.3.)
4. Mostre que sao equivalentes as seguintes proposicoes: i) P(X ∈ Z) = 1; ii) φX e periodica
de perıodo 2π; iii) φX(2π) = 1.
5. Prove que se PX e difusa, entao φX(t) < 1, para todo o t ∈ R \ 0.
7.3 Derivadas e momentos
Uma aplicacao importante das funcoes caracterısticas e agora abordada. Trata-se
do calculo dos momentos dum vector aleatorio.
Teorema 7.3.1 Se X e um vector aleatorio sobre Rd com E||X||m < +∞, para algum
m ∈ N, entao φX possui derivadas parciais de ordem m e, para t ∈ Rd,
∂mφX
∂tj1 . . . ∂tjm
(t) = i mE(Xj1 . . . Xjme i 〈t,X〉).
Dem: Comecemos por estabelecer o resultado para m = 1. Sendo ei o i-esimo vector
da base canonica de Rd, temos, para t ∈ Rd e h ∈ R, (φX(t + hej1) − φX(t))/h =
E(e i 〈t,X〉(e i hXj1 −1)/h), onde |e i 〈t,X〉(e i hXj1 −1)/h| ≤ |(e i hXj1 −1)/h| ≤ |Xj1| ≤ ||X||,uma vez que |e i x − 1| ≤ |x|, para todo o x ∈ R. Como e i 〈t,X〉(e i hXj1 − 1)/h →e i 〈t,X〉 iXj1 e X e integravel, do teorema da convergencia dominada concluımos que∂φX∂tj
(t) = iE(Xj1ei 〈t,X〉). Suponhamos agora que o resultado e verdadeiro para o
natural k e provemos que ainda valido para k + 1. Para t ∈ Rd e h ∈ R, temos
( ∂kφX∂tj1 ...∂tjk
(t+hejk+1)− ∂kφX
∂tj1 ...∂tjk(t))/h = i kE(Xj1 . . . Xjk
e i 〈t,X〉(e i hXjk+1 −1)/h). Uma
nova aplicacao do teorema da convergencia dominada permite concluir.
Tendo em conta o resultado sobre a derivacao sob o sinal de integral, concluımos,
do resultado anterior, que as derivadas parciais de ordem m de φX sao contınuas.
No caso das variaveis aleatorias reais obtemos o corolario seguinte:
ATP, Coimbra 2002

7 Funcao caracterıstica 105
Corolario 7.3.2 Se X e uma variavel aleatoria real com E|X|m < +∞, para algum
m ∈ N, entao
φ(k)X (0) = i kE(Xk), para k = 1, . . . ,m.
A nao existencia da derivada de ordem k de φX na origem, implica assim a nao
integrabilidade de Xk. Ainda no contexto real, e possıvel provar que a existencia da
derivada de ordem m de φX na origem, implica a existencia do momento de ordem m
de X quando m e par, e do momento de ordem m − 1 de X quando m e ımpar (ver
Metivier, 1972, pg. 157 e seguintes).
Exercıcios
1. Utilize o Corolario 7.3.2 para calcular a media e variancia das seguintes variaveis:
(a) Binomial de parametros n e p;
(b) Poisson de parametro λ;
(c) Exponencial de parametro λ.
2. Se X ∼ N(0, 1), mostre que E(X2n−1) = 0 e E(X2n) = (2n)!/(2nn!), para todo o n ∈ N.
3. Retome o Exercıcio 7.2.3 e calcule C(X,Y ).
7.4 Injectividade
Neste paragrafo mostraremos que a funcao caracterıstica dum vector aleatorio cara-
cteriza a sua distribuicao de probabilidade. Fa-lo-emos a partir dos dois resultados
auxiliares seguintes, onde por Nσ denotaremos um vector aleatorio sobre Rd de densi-
dade
gσ(u) =1
(√
2πσ2 )de−||u||2/(2σ2) =
d∏
j=1
1√2πσ2
e−u2j/(2σ2), (7.4.1)
para u = (u1, . . . , ud), onde || · || denota a norma euclideana em Rd. Atendendo a forma
da sua densidade, Nσ e um vector aleatorio com margens independentes que seguem
distribuicoes normais de media zero e variancia σ2. Comecemos por determinar a funcao
caracterıstica deste vector.
Lema 7.4.2 Para t ∈ Rd,
φNσ(t) = e−σ2||t||2/2.
Dem: Atendendo a forma produto (7.4.1) da densidade de Nσ podemos dizer que Nσ ∼(N1σ , . . . , Ndσ), onde, para i = 1, . . . , d, Niσ e uma variavel aleatoria normal de media
zero e variancia σ2, e alem disso, tais variaveis sao independentes. Assim, para t ∈
ATP, Coimbra 2002

106 Apontamentos de Teoria das Probabilidades
Rd, φNσ(t) = E(e i 〈t,Nσ〉) = E(e i∑d
j=1 tjNjσ) = E(∏d
j=1 e i tjNjσ) =∏d
j=1 E(e i tjNjσ) =∏d
j=1 φNjσ(tj) =∏d
j=1 e−σ2t2j/2 = e−σ2||t||2/2.
Lema 7.4.3 Se X e um vector aleatorio em Rd e h e uma funcao limitada e contınua
de Rd em R, entao
E(h(X)) =1
(2π)dlimσ→0
∫h(x)
∫φX(u)e− i 〈u,x〉−σ2||u||2/2dλ(u)dλ(x).
Dem: Comecemos por notar que E(h(X)) = limσ→0
∫h(x)
∫gσ(x − y) dPX(y)dλ(x).
Com efeito, pelo teorema da mudanca de variavel e pelo teorema da convergencia domi-
nada, temos∫
h(x)∫
gσ(x−y) dPX(y)dλ(x) =∫ ∫
h(x)σ−dg1(σ−1(x−y)) dPX (y)dλ(x)
=∫ ∫
h(y+uσ)g1(u) d(PX⊗λ)(y, u) →∫ ∫
h(y)g(u) d(PX⊗λ)(y, u) =∫
h(y) dPX (y) =
E(h(X)). Para concluir vamos agora mostrar que∫
gσ(x−y) dPX(y) = (2π)−d∫
φX(u)
e− i 〈x,u〉−σ2||u||2/2dλ(u). Para tal, notemos que as funcoes gσ e φNσ estao relacionadas
pela igualdade gσ(x) = φN1/σ(−x)/(σ
√2π)d, para x ∈ Rd, o que permite escrever∫
gσ(x−y) dPX(y) =∫
φN1/σ(y−x)/(σ
√2π)d dPX(y) = (σ
√2π)−d
∫ ∫e i 〈y−x,u〉g1/σ(u)
dλ(u) dPX (y) = (2π)−d∫
e− i 〈x,u〉−σ2||u||2/2∫
e i 〈y,u〉 dPX(y) dλ(u) = (2π)−d∫
φX(u)
e− i 〈x,u〉−σ2||u||2/2 dλ(u).
Teorema 7.4.4 Se X e Y sao vectores aleatorios em Rd (nao necessariamente defini-
dos sobre o mesmo espaco de probabilidade), entao φX = φY sse X ∼ Y .
Dem: Provaremos que o conhecimento de φX implica o conhecimento de PX(A) para
todo o A ∈ B(Rd), ou equivalentemente, para todo o rectangulo A semi-aberto a es-
querda. Conhecendo φX , sabemos pelo lema anterior que conhecemos E(h(X)) para
toda a funcao limitada e contınua em Rd. Dado agora um rectangulo A semi-aberto a
esquerda, sabemos que existe uma sucessao (hn) de funcoes contınuas e limitadas com
0 ≤ hn ≤ 1 e hn → 1IA, o que, pelo teorema da convergencia dominada, implica que
E(hn(X)) → E(1IA(X)) = PX(A).
Exercıcios
1. Sendo X um vector aleatorio em Rd, mostre que φX e uma funcao real sse X e simetrico
relativamente a origem (i.e. X ∼ −X).
2. Sendo X e Y vectores aleatorios em Rd, mostre que X ∼ Y sse 〈a, X〉 = 〈a, Y 〉, para
todo o a ∈ Rd.
ATP, Coimbra 2002

7 Funcao caracterıstica 107
7.5 Formulas de inversao
Dos resultados anteriores, sabemos que para A ∈ B(Rd) e sendo (hn) uma sucessao
de funcoes contınuas e uniformemente limitadas com hn → 1IA, vale a igualdade
PX(A) = limn→+∞
limσ→0
1
(2π)d
∫hn(x)
∫φX(u)e− i 〈u,x〉−σ2||u||2/2dλ(u)dλ(x).
Esta igualdade da-nos uma primeira formula de inversao da funcao caracterıstica de X,
permitindo explicitar PX em funcao de φX .
Apesar de existirem outras formulas de inversao mais expeditas que a anterior em
termos de calculo efectivo, limitar-nos-emos, no que se segue, a apresentar uma formula
de inversao da funcao caracterıstica no caso desta ser integravel a Lebesgue.
Teorema 7.5.1 Seja X um vector aleatorio em Rd. Se φX e integravel a Lebesgue,
entao X e absolutamente contınuo e admite uma densidade de probabilidade contınua
e limitada dada, para x ∈ Rd, por
g(x) =1
(2π)d
∫φX(u)e− i 〈u,x〉dλ(u).
Dem: Comecemos por notar que sendo φX integravel, a funcao g dada pela formula
anterior e limitada e contınua. Alem disso, g e real pois g = g. Tendo em conta o Lema
7.4.3 e o teorema da convergencia dominada, E(h(X)) = 1(2π)d
∫h(x)
∫φX(u)e− i 〈u,x〉
dλ(u)dλ(x) =∫
h(x)g(x) dλ(x), para todo a funcao h contınua e limitada em Rd de
suporte compacto. Dado agora um rectangulo A semi-aberto a esquerda, existe uma
sucessao de funcoes (hn) contınuas de suporte compacto com hn → 1IA e 0 ≤ hn ≤1IE , onde E e um rectangulo fechado que contem A (esta majoracao e essencial para
podermos aplicar o teorema da convergencia dominada, uma vez que nao provamos
ainda que g e λ-integravel). Pelo teorema da convergencia dominada, obtemos PX(A) =
E(1IA(X)) = lim E(hn(X)) = lim∫
hn(x)g(x) dλ(x) =∫A g(x) dλ(x), o que permite
concluir que PX = g λ, como pretendıamos (a integrabilidade e nao-negatividade de g
e consequencia desta igualdade).
Exercıcios
1. Se X e uma v.a. de Cauchy de parametros 0 e 1, mostre que φX(t) = e−|t|, para t ∈ R.
Conclua que E|X | = +∞.
2. Se X e tal que P(X ∈ Z) = 1, mostre que, para todo o n ∈ Z,
P(X = n) =1
2π
∫ 2π
0
e− i tnφX(t) dλ(t).
ATP, Coimbra 2002

108 Apontamentos de Teoria das Probabilidades
7.6 Independencia e soma de vectores aleatorios
Iniciamos este paragrafo apresentando uma caracterizacao da independencia das
margens dum vector aleatorio em termos da sua funcao caracterıstica.
Teorema 7.6.1 Seja X = (X1,X2) um vector aleatorio sobre Rp+q. X1,X2 sao inde-
pendentes sse
φX(t1, t2) = φX1(t1)φX2(t2),
para todo o t1 ∈ Rp e t2 ∈ Rq.
Dem: Procedendo como na demonstracao do Lema 7.4.2, concluımos facilmente que a
independencia dos vectores X1 e X2 implica a forma produto anterior para a funcao
caracterıstica de X. Reciprocamente, sejam Y1 e Y2 vectores independentes definidos
num espaco de probabilidade (Ω′,A′,P′) com Yi ∼ Xi, para i = 1, 2, e Y = (Y1, Y2).
Pela primeira parte da demonstracao e por hipotese, φY (t1, t2) = φY1(t1)φY2(t2) =
φX1(t1)φX2(t2) = φX(t1, t2), para todo o t1 ∈ Rp e t2 ∈ Rq. Assim, X ∼ Y , ou
ainda, PX = P′Y = P′
Y1⊗ P′
Y2= PX1 ⊗ PX2, o que permite concluir que X1 e X2 sao
independentes.
O resultado seguinte, tem um papel importante no estudo da distribuicao duma
soma de vectores aleatorios independentes. A sua demonstracao e deixada ao cuidado
do aluno.
Teorema 7.6.2 Sejam X1, . . . ,Xn vectores aleatorios com valores em Rd definidos
num mesmo espaco de probabilidade. Se X1, . . . ,Xn sao independentes , entao
φ∑nj=1 Xj
(t) =
n∏
j=1
φXj (t),
para todo o t ∈ Rd.
Usando este resultado, concluımos facilmente que qualquer combinacao linear nao-
-nula de variaveis aleatorias normais independentes X1, . . . ,Xn, com Xj ∼ N(mj , σ2j ),
e ainda uma variavel aleatoria normal, uma vez que, para t ∈ R, e a1, . . . , an ∈ R,
φ∑nj=1 ajXj
(t) = e i t∑n
j=1 ajmje−∑n
j=1 σ2j a2
j t2/2,
que nao e mais do que a funcao caracterıstica duma variavel aleatoria normal de media∑n
j=1 ajmj e variancia∑n
j=1 σ2j a
2j , sempre que pelo menos um dos aj seja diferente de
zero.
Exercıcios
1. Verifique que o recıproco do Teorema 7.6.2 e falso, considerando X1 = . . . = Xn = X ,
com X uma variavel de Cauchy de parametros 0 e 1.
ATP, Coimbra 2002

7 Funcao caracterıstica 109
2. Use o Teorema 7.6.2 para calcular a funcao caracterıstica duma v.a. binomial de parametros
n e p.
3. Se X1, . . . , Xn sao v.a. independentes com distribuicoes de Poisson de parametros λ1, . . . , λn,
mostre que∑n
j=1 Xj e ainda uma v.a. de Poisson de parametro∑n
j=1 λj .
4. Dizemos que uma v.a. real X tem uma distribuicao Gama de parametros α > 0 e
β > 0, e escrevemos X ∼ Gama(α, β), se admite uma densidade de probabilidade da
forma
f(x) =
βα
Γ(α) xα−1e−xβ, se x ≥ 0
0, se x < 0,
onde Γ e a funcao Gama (ver Exercıcio 3.3.4).
(a) Sabendo que uma v.a. X com uma distribuicao Gama de parametros α > 0 e β > 0,
tem por funcao caracterıstica
φX(t) =βα
(β − i t)α,
mostre que se X1, . . . , Xn sao v.a.r. i.i.d. com Xj ∼ Gama(αj , β), entao∑n
j=1 Xj ∼Gama(
∑nj=1 αj , β).
(b) Verifique que as distribuicoes exponencial e do qui-quadrado sao casos particula-
res da distribuicao Gama. Mais precisamente χ2n = Gama(n/2, 1/2) e E(λ) =
Gama(1, λ).
7.7 Bibliografia
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Lukacs, E. (1964). Fonctions Caracteristiques, Dunod, Paris.
Metivier, M. (1972). Notions Fondamentales de la Theorie des Probabilites, Dunod.
ATP, Coimbra 2002


Capıtulo 8
Vectores aleatorios normais
Definicao de vector aleatorio normal. Funcao caracterıstica e independencia das mar-
gens. Continuidade absoluta.
8.1 Definicao e existencia
Como sabemos, uma variavel aleatoria real diz-se normal centrada e reduzida,
se e absolutamente contınua relativamente a medida de Lebesgue sobre R e admite uma
versao da densidade de probabilidade da forma
f(x) =1√2π
exp(−x2
2
), x ∈ R.
A nocao de variavel aleatoria normal que a seguir introduzimos, e, como veremos,
mais geral do que a que consideramos nos capıtulos anteriores.
Definicao 8.1.1 Dizemos que uma variavel aleatoria real X e normal, se
X ∼ σU + m,
para algum σ,m ∈ R, onde U e uma variavel aleatoria normal centrada e reduzida.
Claramente E(X) = m e Var(X) = σ2. Se σ 6= 0, a nocao de variavel normal agora
introduzida e precisamente a nocao anteriormente considerada, uma vez que neste caso
X possui uma densidade de probabilidade dada por
f(x) =1√
2πσ2exp
(−(x − m)2
2σ2
), x ∈ R.
Se σ = 0, X e degenerada. Estamos assim a incluir na famılia das variavel aleatoria
normais as variaveis degeneradas. Tal como atras, indicaremos X ∼ N(m,σ2), e facil-
mente se deduz que a funcao caracterıstica de X e dada por
φX(t) = exp( i tm) exp(−t2σ2/2), t ∈ R.
111

112 Apontamentos de Teoria das Probabilidades
Definicao 8.1.2 Um vector aleatorio X em Rd diz-se normal, ou que possui uma
distribuicao normal, se 〈a,X〉 =∑d
i=1 aiXi e uma variavel aleatoria normal, para
todo o a ∈ Rd.
Por outras palavras, um vector aleatorio diz-se normal se qualquer combinacao
linear das suas margens for uma variavel aleatoria normal. Se X1, . . . ,Xd sao variaveis
aleatorias normais independentes e nao-degeneradas, sabemos do capıtulo anterior que
qualquer combinacao linear delas ainda uma variavel aleatoria normal. Nesse caso
(X1, . . . ,Xd) e um vector aleatorio normal. Como podemos concluir do Exercıcio 3
seguinte, um vector aleatorio com margens normais nao e necessariamente normal.
Exercıcios
1. Mostre que as margens dum vector aleatorio normal sao normais.
2. Mostre que o vector Nσ com densidade de probabilidade dada por (7.4.1) e normal.
3. Considere o vector aleatorio (U, V ) definido no Exercıcio 2.2.3. Prove que U + V nao e
uma v.a. normal, apesar de U e V o serem.
4. Sejam X um vector aleatorio normal em Rp, A uma matriz real de tipo d× p, e m ∈ Rd.
Prove que AX + m e um vector aleatorio normal em Rd.
8.2 Funcao caracterıstica e independencia das margens
Se X e um vector aleatorio de quadrado integravel com margens independentes,
sabemos ja que a sua matriz de covariancia CX e diagonal. Mostramos a seguir que no
caso dos vectores aleatorios normais, a condicao recıproca e tambem verdadeira.
Comecemos por determinar a funcao caracterıstica dum vector aleatorio normal.
Teorema 8.2.1 Se X e um vector aleatorio normal em Rd, a sua funcao caracterıstica
e dada por
φX(t) = exp( i 〈t,E(X)〉) exp(−〈t,CX t〉/2), t ∈ Rd.
Dem: Sendo X normal, 〈t,X〉 e uma variavel normal para t ∈ Rd. Assim, φX(t) =
φ〈t,X〉(1) = exp( i E(〈t,X〉)) exp(−Var(〈t,X〉)/2). Para concluir basta agora notar que
E(〈t,X〉) = 〈t,E(X)〉 e Var(〈t,X〉) = 〈t,CX t〉.
Concluımos do resultado anterior que, analogamente ao caso real, a distribuicao
dum vector aleatorio normal e caracterizada pela sua esperanca matematica e pela sua
matriz de covariancia. A notacao X ∼ N(m,Σ), indica assim que X e um vector
aleatorio normal de media m e matriz de covariancia Σ.
ATP, Coimbra 2002

8 Vectores aleatorios normais 113
Estamos agora em condicoes de estabelecer a caracterizacao ja anunciada da inde-
pendencia das margens dum vector aleatorio normal.
Teorema 8.2.2 Se X = (X1, . . . ,Xd) e um vector aleatorio normal em Rd, entao
X1, . . . ,Xd sao variaveis aleatorias reais independentes sse Cov(Xi,Xj) = 0 para todo
o i 6= j.
Dem: Sendo X1, . . . ,Xd variaveis independentes, sabemos ja que sao duas a duas
nao correlacionadas. Reciprocamente, se Cov(Xi,Xj) = 0, para i 6= j, entao φX(t) =
exp( i∑d
j=1 E(Xj)tj) exp(−∑dj=1 t2jVar(Xj)/2) =
∏dj=1 exp( i E(Xj)tj) exp(−t2jVar(Xj)
/2) =∏d
j=1 φXj(tj), para t ∈ Rd. O Teorema 7.6.1 permite agora concluir.
Exercıcios
1. Seja (X, Y ) um ve.a. absolutamente contınuo de densidade
f(x, y) =1
2π
((√
2 e−x2/2 − e−x2
)e−y2
+ (√
2 e−y2/2 − e−y2
)e−x2),
para (x, y) ∈ R2. Prove que:
(a) X e Y sao v.a. normais;
(b) Cov(X, Y ) = 0;
(c) X e Y nao sao v.a. independentes.
2. Utilizando o Teorema 8.2.1:
(a) resolva o Exercıcio 8.1.4;
(b) mostre que (X1, . . . , Xd) e normal quando X1, . . . , Xd sao v.a.r. normais e indepen-
dentes.
8.3 Continuidade absoluta
Neste paragrafo apresentamos uma caracterizacao da continuidade absoluta dum
vector aleatorio normal em termos da sua matriz de covariancia.
Lema 8.3.1 Sejam X um vector aleatorio normal sobre Rd nao-degenerado com media
m e matriz de covariancia Σ, e k = car(Σ). Entao existe uma matriz A de tipo d × k
com AAT = Σ, tal que X ∼ AY + m, onde Y ∼ N(0, Ik).
Dem: Sendo Σ a matriz de covariancia de X, Σ e simetrica e semi-definida positiva.
Existe entao uma matriz ortogonal P (P T = P−1) que diagonaliza Σ, isto e, P T ΣP =
D, com D = diag(λ1, . . . , λd), onde λi > 0, para i = 1, . . . , k, e λi = 0, para i =
k + 1, . . . , d, sao os valores proprios de Σ. Tomando agora
ATP, Coimbra 2002

114 Apontamentos de Teoria das Probabilidades
A = P
√λ1 0
. . .
0√
λk
0 0 0
, (8.3.2)
temos Σ = AAT , com A uma matriz de tipo d× k. Alem disso, se Y ∼ N(0, Ik), e facil
verificar que X ∼ AY + m.
Teorema 8.3.3 Seja X um vector aleatorio normal sobre Rd com matriz de covariancia
CX . Entao:
a) Se car(CX) = 0, X e degenerado.
b) Se 0 < car(CX) < d, X e singular e PX esta concentrada num subespaco afim
de dimensao k.
c) Se car(CX) = d, X e absolutamente contınuo e tem por versao da densidade de
probabilidade
fX(x) =1√
(2π)d det(CX)exp
(−1
2〈x − E(X),C−1
X (x − E(X))〉), x ∈ R
d.
Dem: a) Se car(CX) = 0, temos Var(Xi) = 0, para todo o i = 1, . . . , d, e portanto
todas variaveis Xi sao degeneradas. b) Se 0 < car(CX) = k < d, pelo lema anterior
existe A de tipo d × k dada por (8.3.2), tal que X ∼ AY + E(X), onde Y ∼ N(0, Ik).
Para S = Ay + E(X) : y ∈ Rk, temos PX(S) = PAY +E(X)(S) = PY (Rk) = 1
e λd(S) = 0. X esta assim concentrada no subespaco afim S de dimensao k e e
alheia relativamente a medida de Lebesgue sobre Rd. Alem disso, PX e difusa pois,
para x = Ay + E(X) ∈ S, PX(x) = P(AY = Ay) = P(Y = y) = 0. X e as-
sim um vector difuso. c) Pelo Lema 8.3.1, existe A invertıvel de tipo d × d tal que
AAT = CX e X ∼ AY + E(X), com Y ∼ N(0, Id). Utilizando agora a formula
de transformacao de vectores aleatorios absolutamente contınuos, obtemos fX(x) =
fY (A−1(x−E(X)))|det(A−1)| = |det(A)|−1(2π)−d/2 exp(−(A−1(x−E(X)))T (A−1(x−E(X)))/2) = ((2π)d det(CX))−1/2 exp(−〈x − E(X),C−1
X (x − E(X))〉/2).
Exercıcios
1. O vector (X, Y ) segue uma distribuicao normal sobre R2 de densidade
f(x, y) = k exp(−(x2 − xy + y2/2)/2), (x, y) ∈ R2.
(a) Determine k e o coeficiente de correlacao de (X, Y ).
(b) Sejam U e V as v.a.r. definidas, para a ∈ R, por U = 3X + aY e V = aX − Y.
Determine a de modo que U e V sejam independentes e nesse caso calcule E(UV )2.
ATP, Coimbra 2002

8 Vectores aleatorios normais 115
2. Mostre que o vector (X, Y ) definido no Exemplo 2.1.9 e um vector aleatorio normal.
3. Sejam X1, . . . , Xn v.a.r. independentes com distribuicao normal de media 0 e variancia
σ2 > 0, e Y o vector aleatorio sobre Rn definido por Y = AX, com X = (X1, . . . , Xn)T
e A uma matriz ortogonal de ordem n (note que A possui por linhas (resp. colunas)
vectores ortonormados). Sejam ainda Xn e σ2n as media e variancia empıricas das variaveis
X1, . . . , Xn (ver Exercıcio 6.5.2).
(a) Mostre que Y ∼ X .
(b) Se a primeira linha de A e igual a (1/√
n, . . . , 1/√
n), mostre que∑n
k=2 Y 2k =∑n
i=1(Xi − Xn)2.
(c) Conclua que:
i. Xn e σ2n sao variaveis independentes;
ii.(n − 1) σ2
n
σ2 ∼ χ2n−1.
8.4 Bibliografia
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Metivier, M. (1972). Notions Fondamentales de la Theorie des Probabilites, Dunod.
Monfort, A. (1980). Cours de Probabilites, Economica.
ATP, Coimbra 2002


Capıtulo 9
Convergencia em distribuicao
Convergencia em distribuicao de vectores aleatorios. Algumas caracterizacoes. Relacoes
com os outros modos de convergencia. Os teoremas da seleccao de Helly, de Prohorov.
e da continuidade de Levy–Bochner. O teorema de Cramer–Wold.
9.1 Definicao e unicidade do limite
A nocao de convergencia duma sucessao (Xn) de vectores aleatorios para um vector
aleatorio X que estudamos neste capıtulo e de natureza distinta das convergencias
funcionais consideradas no Capıtulo 5. Para tais modos de convergencia interessam os
valores particulares que tomam os vectores Xn e X em pontos do conjunto onde estao
definidos. Para a nocao de convergencia que a seguir introduzimos, interessam apenas
as probabilidades com que esses vectores tomam tais valores.
Se X e uma variavel aleatoria em Rd, denotaremos por FX a sua funcao de distri-
buicao e por C(FX) o conjunto dos pontos de continuidade de FX . Salvo indicacao em
contrario, ao longo deste capıtulo (Xn) e X sao vectores aleatorios em Rd. Como ja
sabemos, e com excepcao do caso real, o conjunto dos pontos de descontinuidade de
FX pode ser nao-numeravel. No entanto, tal como no caso real, C(FX) e denso em Rd,
uma vez que∏d
i=1 C(FXi) ⊂ C(FX), onde X = (X1, . . . ,Xd).
Definicao 9.1.1 Dizemos que uma sucessao (Xn) de vectores aleatorios, nao necessa-
riamente definidos num mesmo espaco de probabilidade, converge em distribuicao
(ou em lei) para X, e escrevemos Xnd−→ X, se
lim FXn(x) = FX(x), ∀ x ∈ C(FX).
Notemos que seria desapropriado impor que a condicao anterior fosse verificada para
todo o ponto de Rd como ilustra o exemplo da sucessao Xn = 1/n que, segundo um
117

118 Apontamentos de Teoria das Probabilidades
qualquer modo de convergencia aceitavel, devera convergir para X = 0. Reparemos que
FXn(x) converge para FX(x), para todo o x ∈ R, com excepcao do ponto x = 0, unico
ponto de descontinuidade de FX . No caso da sucessao Xn = −1/n, FXn(x) converge
para FX(x), para todo o x ∈ R.
O exemplo da sucessao Xn = (−1)nX, onde X ∼ N(0, 1), e ilustrativo da diferenca
entre a nocao de convergencia agora introduzida e as anteriormente estudadas, uma vez
que Xn ∼ X, e no entanto Xn nao converge em probabilidade para X.
Terminamos este paragrafo estabelecendo a unicidade do limite em distribuicao no
sentido seguinte:
Proposicao 9.1.2 Se Xnd−→ X e Xn
d−→ Y , entao X ∼ Y .
Dem: Por hipotese FX(x) = FY (x), para todo o x ∈ C(FX)∩C(FY ). Atendendo agora
a que C(FX)∩C(FY ) e denso em Rd (porque?) e que FX e FY sao contınuas a direita,
concluımos que FX = FY , ou seja, X ∼ Y .
Exercıcios
1. Se X = (X1, . . . , Xd) e ve.a. em Rd, mostre que∏d
i=1 C(FXi ) ⊂ C(FX).
(Sugestao: Tenha em conta o Teorema 2.4.3.)
2. Sejam (Xn) e X v.a. definidas por Xn = αn e X = α, onde (αn) e α, sao numeros reais.
Mostre que Xnd−→ X sse αn→α.
3. Sejam (Xn) uma sucessao de v.a. independentes com distribuicao exponencial de parame-
tro 1 e Mn =∨n
i=1 Xi, para n ∈ N. Mostre que Mn − lnn d−→ Y, onde P(Y ≤ x) =
exp(−e−x), para x ∈ R.
4. Sejam (Xn) e X ve.a. em Rd com densidades de probabilidade (fn) e f , respectivamente,
tais que: a) |fn| ≤ |g|, λ-q.c., para alguma funcao integravel g; b) lim fn = f , λ-q.c..
Mostre que Xnd−→ X.
9.2 Caracterizacoes e primeiras propriedades
Estabelecemos neste paragrafo caracterizacoes importantes e algumas propriedades
da convergencia em distribuicao. Qualquer uma destas caracterizacoes pode ser usa-
da para definir convergencia em distribuicao para variaveis aleatorias com valores em
espacos metricos gerais nos quais a nocao de funcao de distribuicao se revela desprovida
de sentido.
Teorema 9.2.1 As proposicoes seguintes sao equivalentes:
i) Xnd−→ X;
ATP, Coimbra 2002

9 Convergencia em distribuicao 119
ii) E(f(Xn))→E(f(X)), para toda a funcao f contınua e limitada de Rd em R.
iii) E(f(Xn))→E(f(X)), para toda a funcao f uniformemente contınua e limitada
de Rd em R.
iv) PXn(A)→PX (A), para todo o A ∈ B(Rd), com PX(fr(A)) = 0.
Dem: As implicacoes ii) ⇒ iii) e iv) ⇒ i), sao claramente verdadeiras. Para estabelecer
iii) ⇒ iv), consideremos A ∈ B(Rd), com PX(fr(A)) = 0, e consideremos a funcao
uniformemente contınua
ϕ(t) =
1, se t ≤ 0
1 − t, se 0 < t < 1
0, se t ≥ 1.
Para p ∈ N, tomemos as funcoes fp(y) = ϕ(p d(y,A)) e gp(y) = ϕ(1 − p d(y,Ac)),
definidas para y ∈ Rd, onde d(y,A) denota a distancia de y a A. Para p ∈ N, te-
mos E(gp(Xn)) ≤ E(1IA(Xn)) ≤ E(fp(Xn)), para n ∈ N, e por hipotese E(gp(X)) ≤lim inf PXn(A) ≤ lim inf PXn(A) ≤ E(fp(X)), uma vez que gp e fp sao uniforme-
mente contınuas. Pelo teorema da convergencia dominada, gp → 1Iint(A) e fp → 1IA,
o que implica PX(int(A)) ≤ lim inf PXn(A) ≤ lim inf PXn(A) ≤ PX(A), ou ainda,
PX(A) ≤ lim inf PXn(A) ≤ lim inf PXn(A) ≤ PX(A), uma vez que PX(fr(A)) = 0. Fi-
nalmente, e no caso d = 1, vamos estabelecer a implicacao i) ⇒ ii). Sejam a, b ∈ C(FX)
tais que PX(]a, b]) > 1 − ǫ, com ǫ > 0 fixo a partida. Por hipotese, e para n ≥ n1,
temos PXn(]a, b]) = FXn(b)−FXn(a) = (FXn(b)−FX(b))+(FX (b)−FX(a))+(FX (a)−FXn(a)) > 1 − 2ǫ, ou ainda, P(Xn /∈ ]a, b]) < 2ǫ. Seja agora f uma funcao contınua e
limitada em R. Sendo f uniformemente contınua em [a, b] existe um conjunto finito de
pontos a = a0 < a1 < . . . < ak = b tal que |f(x)−f(aj)| < ǫ, para x ∈ [aj−1, aj [, onde os
aj podem ser tomados em C(FX). A funcao escalonada g =∑k
j=1 f(aj)1I]aj−1,aj ] satisfaz
|f(x) − g(x)| < ǫ, para todo o x ∈ ]a, b]. Assim, |E(f(Xn)) − E(g(Xn))| ≤ E(|f(Xn) −g(Xn)|1IXn∈]a,b]) + E(|f(Xn) − g(Xn)|1IXn /∈]a,b]) ≤ ǫ + supx∈R |f(x)|P(Xn /∈]a, b]) <
ǫ(1 + 2 supx∈R |f(x)|). De forma analoga, |E(f(X)) − E(g(X))| < ǫ(1 + supx∈R |f(x)|).Tendo agora em conta a definicao de g, E(g(Xn)) =
∑kj=1 f(aj)(FXn(aj)−FXn(aj−1)),
obtendo-se uma expressao analoga para E(g(X)). Existe entao n2 ∈ N, tal que
|E(g(Xn)) − E(g(X))| < ǫ, para n ≥ n2. Finalmente, para n ≥ max(n1, n2), obte-
mos |E(f(Xn)) − E(f(X))| < 3ǫ(1 + supx∈R |f(x)|).
Tal como para os outros modos de convergencia estudados, a convergencia em dis-
tribuicao e preservada por transformacoes contınuas.
Teorema 9.2.2 Se Xnd−→ X entao g(Xn) d−→ g(X), para toda a funcao contınua de
Rd em Rk.
ATP, Coimbra 2002

120 Apontamentos de Teoria das Probabilidades
Dem: Sendo f : Rk → R contınua e limitada, temos por hipotese E((f g)(Xn)) →E((f g)(X)), ou ainda E(f(g(Xn))) → E(f(g((X))). Tendo em conta teorema anterior
concluımos que g(Xn) d−→ g(X).
No caso dos vectores aleatorios (Xn) e X serem absolutamente contınuos, se as den-
sidades de probabilidade de fXn de Xn sao uniformemente limitadas por uma funcao
integravel, a convergencia λ-quase em todo o ponto de fXn para fX , implica a con-
vergencia em distribuicao de Xn para X (ver Exercıcio 9.1.4). Como se mostra a seguir,
esta convergencia em distribuicao pode ser obtida sob condicoes menos restritivas.
Teorema 9.2.3 (de Scheffe1) Sejam (Xn) e X sao vectores aleatorios absolutamente
contınuos em Rd com densidades (fXn) e fX , respectivamente. Se fXn →fX , λ-q.t.p.,
entao Xnd−→ X.
Dem: Para x ∈ Rd, temos |FXn(x) − FX(x)| ≤∫]−∞,x] |fn(t) − f(t)|dλ(t) ≤
∫|fn(t) −
f(t)|dλ(t). Ora∫|fn−f |dλ =
∫(f −fn)+dλ+
∫(f −fn)−dλ, e como 0 =
∫(f−fn)dλ =∫
(f−fn)+dλ−∫
(f−fn)−dλ, concluımos que∫|fn−f |dλ = 2
∫(f−fn)+dλ. O resultado
e agora consequencia do teorema da convergencia dominada, pois (f − fn)+ ≤ f e
(f − fn)+ → 0, λ.q.c.
Exercıcios
1. Retome a demonstracao, feita no caso real, da implicacao i) ⇒ ii) do Teorema 9.2.1.
Adapte-a ao caso multidimensional.
2. Sejam Xn, para n ∈ N, uma v.a. uniforme sobre o conjunto i/n : i = 1, . . . , n. Mostre
que Xnd−→ U([0, 1]).
3. Se (Xn) e uma sucessao de v.a.r. com Xn ∼ N(mn, σ2n), onde mn → m e σn → σ > 0,
mostre que Xnd−→ N(m, σ2).
4. Para n ∈ N, seja Xn uma v.a. uniformemente distribuıda sobre o intervalo [an, bn], onde
an→a e bn→b, com a ≤ b. Mostre que Xnd−→ U([a, b]).
5. Se (Xn) e X sao v.a. que tomam valores em N0, mostre que Xnd−→ X sse P(Xn = j)→
P(X = j), para todo o j ∈ N0.
6. (Convergencia da binomial para a Poisson) Sejam Xn ∼ B(n, pn) com npn →λ ∈]0, +∞[, e X v.a. de Poisson de parametro λ. Mostre que Xn
d−→ X .
(Sugestao: Use o Exercıcio 2.1.10.)
7. Verifique que o recıproco do teorema de Scheffe nao e verdadeiro, mostrando que a su-
cessao (Xn) de v.a.r. absolutamente contınuas com densidades fXn(x) = (1− cos(2nπx))
1I[0,1](x), satisfaz Xnd−→ U([0, 1]), e no entanto fXn nao converge λ-q.t.p. para 1I[0,1].
1Scheffe, H., Ann. Math. Statist., 28, 434–458, 1947.
ATP, Coimbra 2002

9 Convergencia em distribuicao 121
8. (Teorema de Scheffe para variaveis discretas) Sejam (Xn) e X v.a. que tomam
valores num conjunto finito ou numeravel S. Mostre que se P(Xn = j) → P(X = j),
para todo o j ∈ S, entao Xnd−→ X . Verifique que a recıproca nao e em geral verdadeira
considerando Xn = 1/n e X = 0.
9.3 Relacoes com os outros modos de convergencia
Com decorre da propria definicao, quando falamos em convergencia em distribuicao
de Xn para X os vectores aleatorios X,X1,X2, . . . nao necessitam de estar definidos
num mesmo espaco de probabilidade. No entanto, quando tal acontece a convergencia
em distribuicao pode ser relacionada com os outros tipos de convergencia ja estudados.
Teorema 9.3.1 Se Xnp−→ X, entao Xn
d−→ X.
Dem: Consequencia da caracterizacao ii) dada no Teorema 9.2.1 e do teorema da
convergencia dominada.
Recordemos que a convergencia em probabilidade e a mais fraca das convergencias
funcionais estudadas. Assim qualquer das convergencias qc−→ ou Lp−→, implica a con-
vergencia em distribuicao.
No caso particular da variavel limite ser degenerada, mostramos a seguir que a
convergencia em distribuicao e equivalente a convergencia em probabilidade.
Teorema 9.3.2 Se Xnd−→ a, com a ∈ Rd, entao Xn
p−→ a.
Dem: Comecemos por estabelecer o resultado para d = 1. Neste caso, se X = a,
FX = 1I[a,+∞[, e assim lim FXn(x) = 0, se x < a, e lim FXn(x) = 1, se x > a. Dado ǫ > 0,
temos P(|Xn −a| < ǫ) = P(a− ǫ < Xn < a+ ǫ) ≥ FXn(a+ ǫ/2)−FXn(a− ǫ) → 1. Para
d > 1, basta ter em conta que se Xnd−→ a, entao πi(Xn) d−→ πi(a), para i = 1, . . . , d, e
pela primeira parte da demonstracao obtemos πi(Xn) p−→ πi(a), para i = 1, . . . , d, ou
equivalentemente, Xnp−→ a.
9.4 O teorema de Prohorov
O objectivo principal deste paragrafo e a obtencao do teorema de Prohorov sobre
a caracterizacao da compacidade sequencial duma sucessao de vectores aleatorios. Por
outras palavras, pretendemos caracterizar as sucessoes de vectores aleatorios para as
quais toda a sua subsucessao possui uma subsucessao convergente em distribuicao.
A importancia dum resultado deste tipo sera clara quando, no proximo paragrafo,
caracterizarmos a convergencia em distribuicao duma sucessao de vectores aleatorios
ATP, Coimbra 2002

122 Apontamentos de Teoria das Probabilidades
a partir das respectivas funcoes caracterısticas. No entanto, e para ja, o resultado se-
guinte, cuja demonstracao deixamos ao cuidado do aluno, indica-nos que a compacidade
sequencial duma sucessao de vectores aleatorios e uma propriedade necessaria, mas nao
suficiente, para a sua convergencia em distribuicao. Ele e consequencia do seguinte
facto sobre sucessoes de numeros reais: uma sucessao (xn) converge para x ∈ R sse
toda a subsucessao de (xn) admite uma subsucessao que converge para x.
Teorema 9.4.1 Sejam (Xn) e X vectores aleatorios em Rd. Xnd−→ X sse toda a
subsucessao de (Xn) admite uma subsucessao que converge em distribuicao para X.
O teorema de Prohorov estabelece que as sucessoes de vectores aleatorios cujas
subsucessoes admitem uma subsucessao convergente, sao precisamente as sucessoes li-
mitadas em probabilidade no sentido da definicao seguinte.
Definicao 9.4.2 Uma sucessao (Xn) de vectores aleatorios em Rd diz-se limitada em
probabilidade se para todo o ǫ > 0, existe M > 0 tal que
PXn(] − M,M ]) = FXn ] − M,M ] > 1 − ǫ, ∀n ∈ N.
Notemos mais uma vez a analogia com o caso das sucessoes de numeros reais:
uma sucessao (xn) e limitada sse toda a sua subsucessao admite uma subsucessao
convergente. Reparemos tambem que impor que uma sucessao de vectores aleatorios
seja limitada em probabilidade quando estudamos a sua convergencia em distribuicao
nao e demasiadamente restritivo, uma vez que (Xn) e limitada em probabilidade sempre
que Xnd−→ X, para algum vector aleatorio X. No entanto, o facto de (Xn) ser limitada
em probabilidade nao implica so por si a convergencia em distribuicao da sucessao para
algum vector aleatorio. Um exemplo disso e o da sucessao Xn = X, se n e par, e
Xn = Y , se n e ımpar, com X 6∼ Y .
O teorema da seleccao de Helly que estabelecemos a seguir e de importancia fun-
damental na demonstracao do teorema de Prohorov. A notacao que usamos sobre a
funcao de distribuicao dum vector aleatorio foi introduzida no Exemplo 1.4.3.
Lema 9.4.3 Sejam D1, . . . ,Dd subconjuntos numeraveis e densos em R e (Xn) uma
sucessao de vectores aleatorios tais que lim FXn(y) existe para todo o y ∈ ∏di=1 Di.
Entao existe uma funcao F∞ nao-decrescente, contınua a direita, com 0 ≤ F∞ ≤ 1, tal
que lim FXn(x) = F∞(x), para todo o x ∈ C(F∞).
Dem: Para x ∈ D =∏d
i=1 Di, definamos F∞(x) = lim FXn(x). Claramente, 0 ≤F∞(x) ≤ 1, para todo o x ∈ D. Para x ∈ Rd\D, definamos F∞(x) = infy>x,y∈D F∞(y).
ATP, Coimbra 2002

9 Convergencia em distribuicao 123
Como F∞(y) : y > x, y ∈ D e limitado em R, o ınfimo anterior e um elemento do
intervalo [0, 1]. Assim, 0 ≤ F∞ ≤ 1, e F∞(x1) ≤ F∞(x2), se x1 ≤ x2. i) Verifiquemos
que F∞ e contınua a direita em todo o ponto x ∈ Rd. Dado ǫ > 0, tomemos x′ > x com
x′ ∈ D tal que F∞(x) + ǫ ≥ F∞(x′). Dado agora y ∈ ]x, x′] temos F∞(y) ≤ F∞(x′),
e portanto F∞(x) + ǫ ≥ F∞(y) ≥ infy>x F∞(y). Fazendo tender ǫ para zero, obte-
mos F∞ ≥ infy>x F∞(y), ou ainda, F∞ = infy>x F∞(y). ii) Verifiquemos que F∞ e
nao-decrescente. Se a, b ∈ D sao tais que a < b, e sendo V o conjunto dos vertices
de ]a, b], temos 0 ≤ FXn ]a, b] =∑
x∈V sgn(x)FXn(x) → ∑x∈V sgn(x)F∞(x) = F∞]a, b].
Dados agora a, b ∈ Rd com a < b, tomemos an ≥ a e bn ≥ b, com an, bn ∈ D,
an → a e bn → b. Denotando por Vn o conjunto dos vertices de ]an, bn], temos
0 ≤ F∞]an, bn] =∑
xn∈Vnsgn(xn)F∞(xn) → ∑
xn∈V sgn(x)F∞(x) = F∞]a, b]. iii) Veri-
fiquemos finalmente que lim FXn(x) = F∞(x), para todo o x ∈ C(F∞). Sejam entao x ∈C(F∞) e (ai) e (bi) em D tais que ai ↑ x e bi ↓ x. Assim, FXn(ai) ≤ FXn(x) ≤ FXn(bi)
e F∞(ai) = lim inf FXn(ai) ≤ lim inf FXn(x) ≤ lim sup FXn(x) ≤ lim sup FXn(bi) =
F∞(bi). Tomando agora limite em i quando i tende para +∞ e tendo em conta que
x ∈ C(F∞), obtemos F∞(x) ≤ lim inf FXn(x) ≤ lim sup FXn(x) ≤ F∞(x), o que prova
o pretendido.
Teorema 9.4.4 (da seleccao de Helly2) Se (Xn) e uma sucessao de vectores aleato-
rios em Rd, entao existem uma subsucessao (Xnk) de (Xn) e uma funcao F∞ : Rd→R
contınua a direita, nao-decrescente com 0 ≤ F∞ ≤ 1, tais que
lim FXnk(x) = F∞(x), ∀x ∈ C(F∞).
Dem: Tendo em conta o Teorema 9.4.3, e sendo D = Qd = ai : i ∈ N, basta mos-
trar que existe uma subsucessao (Xnk) para a qual existe o limite lim FXnk
(ai), para
todo o i ∈ N. Sendo (FXn(a1)) limitada, comecemos por tomar uma sua subsucessao
(FXn(1,k)(a1)) convergente. De forma analoga seja (FXn(2,k)
(a2)) uma subsucessao con-
vergente da sucessao limitada (FXn(1,k)(a2)). As sucessoes (FXn(2,k)
(a1)) e (FXn(2,k)(a2))
sao ambas convergentes. Repetindo este processo, determinamos (FXn(i,k)(ai)) conver-
gente tal que as sucessoes (FXn(i,k)(a1)),...,(FXn(i,k)
(ai−1)) sao convergentes. Tomemos
entao a sucessao diagonal (FXn(k,k)). Para cada i ∈ N, (FXn(k,k)
(ai)) e convergente, pois
FXn(k,k)(ai) : k ≥ i ⊂ FXn(i,k)
(ai) : k ≥ i, e (FXn(i,k)(ai)) e convergente. Basta
entao tomar nk = n(k, k).
Sendo a funcao F∞, cuja existencia e estabelecida no resultado anterior, nao-
decrescente e contınua a direita, e possıvel associar-lhe uma e uma so medida µ∞
2Helly, E., Sitzungsber. Nat. Kais. Akad. Wiss., 121, 265–297, 1912.
ATP, Coimbra 2002

124 Apontamentos de Teoria das Probabilidades
sobre (Rd,B(Rd)) tal que
µ∞(]a, b]) = F∞]a, b] =∑
x∈V
sgn(x)F∞(x),
para todo o a, b ∈ Rd, onde V e o conjunto dos vertices de ]a, b] (cf. Billingsley, 1986, pg.
177–180). Sempre que µ∞(Rd) = 1, µ∞ e uma probabilidade, e nesse caso Xnd−→ X,
onde X e um qualquer vector aleatorio que tenha µ∞ como distribuicao de probabili-
dade. Caso contrario, temos µ∞(Rd) < 1 nao existindo por isso o limite em distribuicao
da sucessao (Xn) (ver Exercıcio 9.4.6). Dizemos neste caso que ocorre uma “perda de
probabilidade no infinito”. Um exemplo simples de tal situacao e o da sucessao Xn = n.
Teorema 9.4.5 (de Prohorov3) Seja (Xn) e uma sucessao de vectores aleatorios em
Rd. (Xn) e limitada em probabilidade sse toda a subsucessao de (Xn) possui uma
subsucessao convergente em distribuicao.
Dem: Suponhamos que (Xn) e limitada em probabilidade,e provemos que toda a sua
subsucessao possui uma subsucessao convergente em distribuicao. Como qualquer
subsucessao duma sucessao limitada em probabilidade e ainda limitada em probabi-
lidade, basta que mostremos que (Xn) possui uma subsucessao convergente em dis-
tribuicao. Pelo teorema da seleccao de Helly, existe uma subsucessao (Xnk) de (Xn)
e uma funcao F∞ : Rd → R contınua a direita, nao-decrescente com 0 ≤ F∞ ≤ 1,
tais que lim FXnk(x) = F∞(x), ∀x ∈ C(F∞). Para concluir basta provar que a me-
dida finita µ∞ associada a F∞ e uma probabilidade. Para ǫ > 0, existe M > 0
tal que PXnk(] − M,M ]) > 1 − ǫ, ∀ k ∈ N. Tomando agora a < −M e b > M
tais que V ⊂ C(F∞) onde V e o conjunto dos vertices do rectangulo ]a, b], temos
µ∞(]a, b]) =∑
x∈V sgn(x)F∞(x) = limk∑
x∈V sgn(x)FXnk(x) = limk PXnk
(]a, b]) ≥limk PXnk
(] − M,M ]) ≥ 1 − ǫ. Sendo ǫ > 0 qualquer concluımos que µ∞(Rd) = 1.
Reciprocamente, suponhamos por absurdo que (Xn) nao e limitada em probabili-
dade. Tendo em conta o Exercıcio 9.4.4, existem ǫ > 0 e uma sucessao (nk) de
numeros naturais estritamente crescente tais que PXnk(] − K,K]) ≤ 1 − ǫ, para todo
o k ∈ N, onde K = (k, . . . , k). Por hipotese, existe (Xnk′) subsucessao de (Xnk
) tal
que Xnk′d−→ X, para algum vector aleatorio X em Rd. Para quaisquer a, b ∈ Rd
tais que V ⊂ C(FX), onde V e o conjunto dos vertices do rectangulo ]a, b], temos
PX(]a, b]) =∑
x∈V sgn(x)FX(x) = lim∑
x∈V sgn(x)FXnk′
(x) = lim PXnk′
(]a, b]) ≤ 1−ǫ,
o que e falso quando fazemos maxi ai → −∞ e mini bi → +∞.
Exercıcios
1. Se Xn = αn, com αn ∈ R, mostre que (Xn) e limitada em probabilidade sse (αn) e
limitada.3Prohorov, Yu.V., Theory Probab. Appl., 1, 157–214, 1956.
ATP, Coimbra 2002

9 Convergencia em distribuicao 125
2. Mostre que se Xnd−→ X entao (Xn) e limitada em probabilidade.
3. Prove que (Xn) e limitada em probabilidade sse cada uma das sucessoes coordenadas de
(Xn) e limitada em probabilidade.
4. Prove que (Xn) e limitada em probabilidade sse limk→+∞ lim supn PXn(] − K, K]c) = 0,
com K = (k, . . . , k).
5. Mostre que se (Xn) e (Yn) sao limitadas em probabilidade, entao (XnYn) e limitada em
probabilidade.
6. Sejam (Xn) e uma sucessao de vectores aleatorios em Rd, F∞ a funcao cuja existencia e
assegurada pelo Teorema 9.4.4 e µ∞ a medida sobre (Rd,B(Rd)) que lhe esta associada.
Para i = 1, . . . , d, consideremos as funcoes coordenada
F∞,i(xi) = limxj→+∞
j 6=i
F∞(x1, . . . , xi−1, xi, xi+1, . . . , xd).
(a) Conclua que o conjunto Ei dos pontos de descontinuidade de F∞,i e quando muito
numeravel.
(b) Mostre que Ec1 × . . . × Ec
d ⊂ C(F∞).
(c) Prove que se µ∞(Rd) < 1, entao (Xn) nao converge em distribuicao.
9.5 O teorema da continuidade de Levy–Bochner
Como veremos neste paragrafo, o teorema de Prohorov permite-nos caracterizar a
convergencia em distribuicao duma sucessao de vectores aleatorios apenas em termos
das funcoes caracterısticas respectivas. Uma tal caracterizacao sera de grande utilidade
no estudo da distribuicao assintotica da soma de vectores aleatorios independentes uma
vez que, como vimos anteriormente, a funcao caracterıstica e bem mais util para esse
efeito do que a funcao de distribuicao.
Teorema 9.5.1 Seja (Xn) uma sucessao de vectores aleatorios em Rd.
a) Se Xnd−→ X, entao φXn(t)→φX(t), para todo o t ∈ Rd.
b) Se (Xn) e limitada em probabilidade e φXn(t)→φ∞(t), para todo o t ∈ Rd, entao
φ∞ = φX para algum vector aleatorio X em Rd e Xnd−→ X.
Dem: a) Para t ∈ Rd fixo, sendo as funcoes x → sin(〈t, x〉) e x → cos(〈t, x〉), contınuas
e limitadas em Rd, concluımos pelo Teorema 9.2.1 que E(sin(〈t,Xn〉) → E(sin(〈t,X〉)e E(cos(〈t,Xn〉) → E(cos(〈t,X〉), uma vez que Xn
d−→ X, ou ainda, φXn(t)→ φX(t).
b) Comecemos por mostrar que φX = φ∞. Sendo (Xn) limitada em probabilidade,
existe, pelo teorema de Prohorov, uma subsucessao (Xnk) de (Xn) tal que Xnk
d−→ X,
para algum vector aleatorio X. Pela alınea a) obtemos φXnk(t) → φX(t), para todo o
t ∈ Rd, e portanto φX = φ∞. Mostremos agora que Xnd−→ X. Para tal, consideremos
ATP, Coimbra 2002

126 Apontamentos de Teoria das Probabilidades
uma qualquer subsucessao (Xn′) de (Xn), e provemos que ela admite uma subsucessao
convergente para X. Com efeito, sendo (Xn′) limitada em probabilidade, existe (Xn′′)
subsucessao de (Xn′) com Xn′′ → Y , para algum vector aleatorio Y , o que implica que
φXn′′ (t) → φY (t), para todo o t ∈ Rd. Assim, φY = φ∞ = φX , ou ainda, X ∼ Y .
Mostramos agora que a condicao de (Xn) ser limitada em probabilidade pode ser
substituıda por uma hipotese de continuidade na origem da funcao limite φ∞. Um tal
resultado e conhecido como teorema da continuidade de Levy–Bochner.
Lema 9.5.2 Se X e uma variavel aleatoria real, entao para todo o r > 0,
P(|X| ≥ 2r) ≤ r
∫ 1/r
−1/r(1 − φX(t))dλ(t).
Dem: Para r > 0 temos,∫ 1/r−1/r(1 − φX(t))dλ(t) =
∫ 1/r−1/r
∫(1 − e i tx) dPX(x)dλ(t) =
∫ ∫ 1/r−1/r(1−e i tx) dλ(t)dPX(x) =
∫R\0 2(1−sin(x/r)/(x/r))/r)dPX (x) ≥
∫|x|≥2r 1/rdPX
= P(|X| ≥ 2r)/r, pois 1 − sin(x/r)/(x/r) ≥ 1/2, se |x| ≥ 2r.
Teorema 9.5.3 (de Levy–Bochner4) Seja (Xn) uma sucessao de vectores aleatorios
em Rd. Se φXn(t)→φ∞(t), para todo o t ∈ Rd, onde φ∞ e contınua na origem, entao
Xnd−→ X para algum vector aleatorio X em Rd e φX = φ∞.
Dem: Atendendo ao Teorema 9.5.1, basta demonstrar que se φXn(t)→φ∞(t), para todo
o t ∈ Rd, onde φ∞ e contınua na origem, entao a sucessao (Xn) e limitada em probabi-
lidade. Comecemos por demonstrar tal facto no caso real utilizando o Exercıcio 9.4.4.
Pelo Lema 9.5.2 e para k > 0, temos PXn(] − k, k]c) ≤ P(|Xn| ≥ k) ≤ (k/2)∫ 2/k−2/k(1 −
φXn(t))dλ(t), onde 1 − φXn(t) → 1 − φ∞(t) e |1 − φXn(t)| ≤ 2. Pelo teorema da con-
vergencia dominada obtemos lim supPXn(] − k, k]c) ≤ (k/2)∫ 2/k−2/k(1 − φ∞(t)) dλ(t) =
∫ 1−1(1 − φ∞(2t/k)) dλ(t). Pela continuidade de φ∞ na origem, uma nova aplicacao
do teorema da convergencia dominada permite finalmente concluir que limk lim supn
PXn(] − k, k]c) = 0. Para estabelecer o resultado no caso multivariado, vamos lancar
mao do Exercıcio 9.4.3. Tendo em conta a primeira parte da demonstracao, bastara de-
monstrar que para cada uma das sucessoes coordenadas (Xn,i) de (Xn), a sucessao das
funcoes caracterısticas (φXn,i) converge pontualmente para uma funcao contınua na ori-
gem. Tal e com efeito verdade uma vez que φXn,i(s) = φXn(sei) → φ∞(sei) =: φ∞,i(s),
para s ∈ R, onde ei representa o i-esimo vector da base canonica de Rd, e φ∞,i e
contınua na origem pela continuidade na origem de φ∞.
4Levy, P., C. R. Acad. Sci. Paris, 175, 854–856, 1922.4Bochner, S., Math. Ann., 108, 378–410, 1933.
ATP, Coimbra 2002

9 Convergencia em distribuicao 127
Notemos que a continuidade na origem da funcao limite e essencial para a validade
do resultado como o comprova o exemplo da sucessao Xn ∼ U([−n, n]). Atendendo
a que a funcao caracterıstica dum vector aleatorio e uma funcao contınua, concluımos
do resultado anterior que o limite φ∞ duma sucessao de funcoes caracterısticas e uma
funcao contınua se o for na origem.
Corolario 9.5.4 Xnd−→ X sse φXn(t)→φX(t), para todo o t ∈ Rd.
Sabemos ja que a distribuicao dum vector aleatorio e caracterizada pelas distri-
buicoes de probabilidade das variaveis aleatorias reais 〈a,X〉, para todo o a ∈ Rd (ver
Exercıcio 7.4.2). O resultado seguinte aponta no mesmo sentido relativamente a con-
vergencia em distribuicao, sendo importante no estudo da convergencia em distribuicao
de sucessoes de vectores aleatorios, pois permite faze-lo a partir da convergencia em
distribuicao de variaveis aleatorias reais.
Teorema 9.5.5 (de Cramer–Wold5) Sejam (Xn) e X vectores aleatorios em Rd.
Entao Xnd−→ X sse 〈a,Xn〉 d−→ 〈a,X〉, para todo o a ∈ Rd.
Dem: Se Xnd−→ X, entao sendo g(x) = 〈a, x〉 contınua, para a fixo em Rd, concluımos,
pelo Teorema 9.2.1 que g(Xn) d−→ g(X), isto e, 〈a,Xn〉 d−→ 〈a,X〉. Reciprocamente,
dado t ∈ Rd, temos φXn(t) = φ〈t,Xn〉(1) → φ〈t,X〉(1) = φX(t), e portanto Xnd−→ X.
Exercıcios
1. Sejam (Xn) e X ve.a. normais. Mostre que Xnd−→ X sse E(Xn)→E(X) e CXn →CX .
2. (Teorema de Slutsky6) Sejam (Xn), (Yn) e X ve.a. em Rd com Xnd−→ X e Xn−Yn
p−→0. Prove que Yn
d−→ X .
3. Sejam (Xn), (Yn) e X v.a.r. tais que Xnd−→ X e Yn
p−→ c, com c ∈ R. Prove que: a)
Xn + Ynd−→ X + c; b) YnXn
d−→ cX .
4. (Metodo delta) Sejam X1, X2, . . . ve.a. em Rd tais que
√n (Xn − µ)
d−→ N(0, Σ),
com µ ∈ Rd, Σ uma matriz de covariancia e g : Rd→Rp.
(a) Se limx→µ g(x) = α ∈ Rp, prove que g(Xn) p−→ α.
(b) Se g e diferenciavel em µ com derivada g′(µ), mostre que
√n (g(Xn) − g(µ))
d−→ N(0, g′(µ)Σ g′(µ)T ).
(Sugestao: Tenha em conta que se g e diferenciavel em µ, entao para h ∈ Rd, g(µ + h) =
g(µ) + g′(µ)h + r(h), onde limh→0 r(h)/||h|| = 0.)
5Cramer, H., Wold, H., J. London Math. Soc., 11, 290–295, 1936.6Slutsky, E., Metron, 5, 1–90, 1925.
ATP, Coimbra 2002

128 Apontamentos de Teoria das Probabilidades
9.6 Bibliografia
Billingsley, P. (1968). Convergence of Probability Measures, Wiley.
Billingsley, P. (1986). Probability and Measure, Wiley.
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
ATP, Coimbra 2002

Capıtulo 10
O teorema do limite central
O teorema do limite central classico e de Lindeberg. A condicao de Liapounov. O
teorema do limite central multidimensional.
10.1 Preliminares
Se X1, . . . ,Xn, . . . sao variaveis aleatorias independentes e identicamente distribuıdas
com distribuicoes normais de media µ e variancia σ2, sabemos pela lei fraca dos grandes
numeros que1
nSn
p−→ µ,
onde
Sn = X1 + . . . + Xn.
Sendo a convergencia em distribuicao implicada pela convergencia em probabilidade, a
distribuicao assintotica de Sn/n e assim degenerada. No entanto, para todo o n ∈ N,
sabemos que
1
nSn ∼ N
(µ,
σ2
n
),
ou ainda,Sn/n − µ√
σ2/n∼ N(0, 1).
Concluımos assim que apesar de Sn/n possuir uma distribuicao assintotica degenerada,
Sn/n convenientemente normalizada (centragem e reducao) possui uma distribuicao
assintotica nao-degenerada:
S⋆n =
Sn − E(Sn)√Var(Sn)
d−→ N(0, 1). (10.1.1)
129

130 Apontamentos de Teoria das Probabilidades
O facto de uma tal distribuicao assintotica ser normal, nao e, como veremos neste
capıtulo, uma propriedade exclusiva das variaveis normais. Indıcios de tal facto sao
ja nossos conhecidos (ver, por exemplo, o §3.3). Para algumas distribuicoes de proba-
bilidade ja estudadas, apresentamos a seguir, para alguns valores de n, os graficos da
densidade ou da funcao de probabilidade da variavel S⋆n. A tracejado surge tambem o
grafico da densidade normal centrada e reduzida.
-4 -2 2 4
0.1
0.2
0.3
0.4
n = 3
n = 9
n = 21
n = 35
Figura 9.1: Distribuicao de S⋆n quando X1, . . . , Xn ∼ B(1/3)
-4 -2 2 4
0.2
0.4
0.6
0.8
1
n = 2
n = 3
n = 5
n = 10
n = 20
Figura 9.2: Distribuicao de S⋆n quando X1, . . . , Xn ∼ χ2
1
ATP, Coimbra 2002
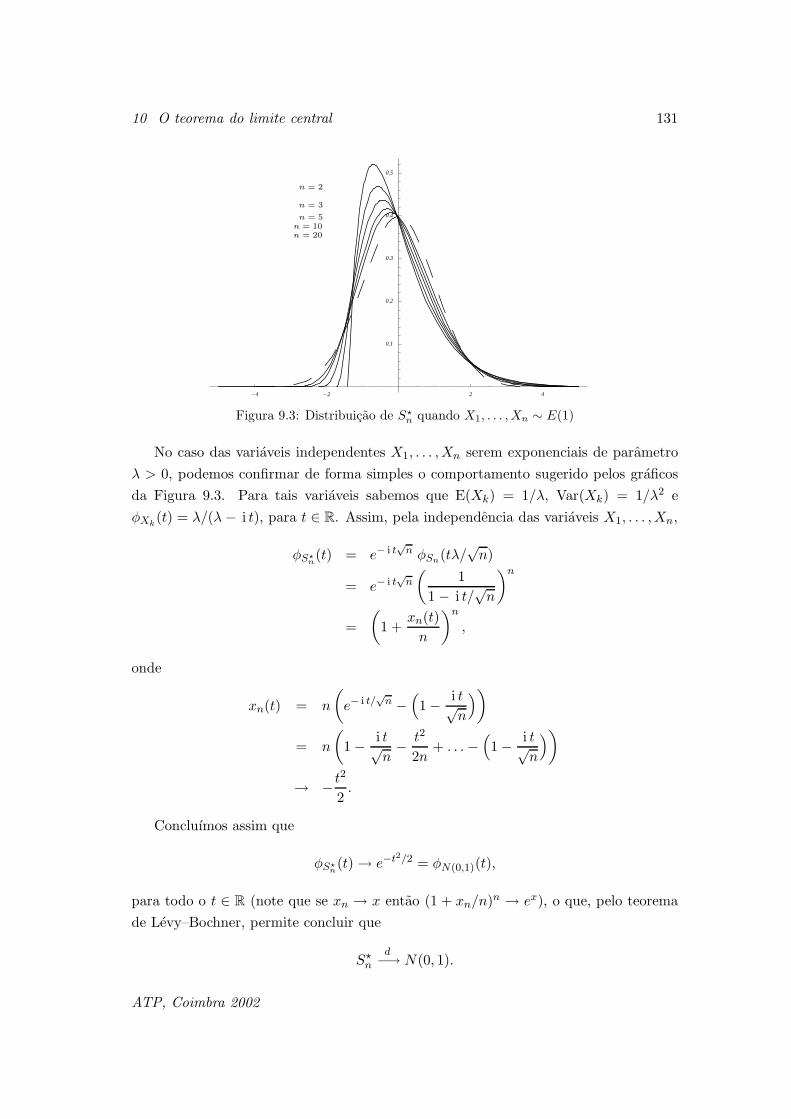
10 O teorema do limite central 131
-4 -2 2 4
0.1
0.2
0.3
0.4
0.5
n = 2
n = 3
n = 5n = 10n = 20
Figura 9.3: Distribuicao de S⋆n quando X1, . . . , Xn ∼ E(1)
No caso das variaveis independentes X1, . . . ,Xn serem exponenciais de parametro
λ > 0, podemos confirmar de forma simples o comportamento sugerido pelos graficos
da Figura 9.3. Para tais variaveis sabemos que E(Xk) = 1/λ, Var(Xk) = 1/λ2 e
φXk(t) = λ/(λ − i t), para t ∈ R. Assim, pela independencia das variaveis X1, . . . ,Xn,
φS⋆n(t) = e− i t
√n φSn(tλ/
√n)
= e− i t√
n
(1
1 − i t/√
n
)n
=
(1 +
xn(t)
n
)n
,
onde
xn(t) = n
(e− i t/
√n −
(1 − i t√
n
))
= n
(1 − i t√
n− t2
2n+ . . . −
(1 − i t√
n
))
→ − t2
2.
Concluımos assim que
φS⋆n(t) → e−t2/2 = φN(0,1)(t),
para todo o t ∈ R (note que se xn → x entao (1 + xn/n)n → ex), o que, pelo teorema
de Levy–Bochner, permite concluir que
S⋆n
d−→ N(0, 1).
ATP, Coimbra 2002

132 Apontamentos de Teoria das Probabilidades
Nos proximos paragrafos mostraremos que a convergencia em distribuicao (10.1.1)
ocorre para uma vasta famılia de variaveis aleatorias. Um resultado deste tipo e conhe-
cido como teorema do limite central ou teorema central do limite, designacao
esta devida a G. Polya (1920)1, onde a palavra “central” realca a importancia que um
tal resultado teve na investigacao em probabilidades ate meados do seculo XX.
Exercıcios
1. Sejam X1, X2, . . . variaveis i.i.d. com P(Xi = ±1) = 1/2. Mostre que Sn/√
n d−→ N(0, 1).
Suponha agora que, partindo dum ponto inicial, uma partıcula se desloca uma unidade
para a esquerda ou para a direita com probabilidade 0.5, em cada segundo. De uma
aproximacao para a probabilidade de ao fim de uma hora a partıcula se encontrar a uma
distancia superior a 200 unidades do ponto inicial.
2. Sejam X1, X2, . . . variaveis aleatorias independentes com distribuicoes de Poisson de
parametro λ > 0. Prove que (Sn − nλ)/√
nλ d−→ N(0, 1).
3. Sejam (Yn) uma sucessao de v.a.r. e (an) uma sucessao de numeros reais tais que an(Yn−µ) d−→ Y , com µ ∈ R e Y uma v.a.r.. Mostre que bn(Yn − µ) p−→ 0, para toda a sucessao
de numeros reais (bn) com bn/an → 0.
4. Seja (Xn) uma sucessao de v.a.r. de quadrado integravel satisfazendo (10.1.1). Mostre
que se n/√
Var(Sn) → +∞, entao (Xn) obedece a uma lei fraca dos grandes numeros
com µn =∑n
i=1 E(Xi)/n.
5. Seja (Xn) uma sucessao de v.a.r. i.i.d. de quadrado integravel com media µ satisfazendo
(10.1.1). Mostre que bn(Sn/n−µ) p−→ 0, para toda a sucessao de numeros reais (bn) com
bn/n1/2 → 0 (ver Exercıcio 6.2.4), mas que n1/2(Sn/n − µ) p−→6 0.
10.2 O teorema do limite central classico
Neste paragrafo estabelecemos a convergencia em distribuicao (10.1.1) para variaveis
aleatorias independentes e identicamente distribuıdas de quadrado integravel.
Para que possamos generalizar os argumentos utilizados no paragrafo anterior a
outras distribuicoes, e essencial o resultado seguinte que nao e mais do que um desen-
volvimento de Taylor duma funcao caracterıstica em que o resto e apresentado numa
forma que nos sera util.
Lema 10.2.1 Se E|X|n < +∞, para algum n ∈ N, entao para todo o t ∈ R,
φX(t) =
n∑
k=0
( i t)k
k!E(Xk) + un(t),
1Polya, G., Math. Z., 8, 171–180, 1920.
ATP, Coimbra 2002

10 O teorema do limite central 133
onde
|un(t)| ≤ E
( |tX|n+1
(n + 1)!∧ 2|tX|n
n!
).
Dem: Para n ≥ 0 vale a igualdade
∫ x
0(x − s)ne i sds =
xn+1
n + 1+
i
n + 1
∫ x
0(x − s)n+1e i sds.
Por inducao podemos entao obter
e ix =
n∑
k=0
( i x)k
k!+
i n+1
n!
∫ x
0(x − s)ne i sds,
para n ≥ 1. Por um lado, a ultima parcela do segundo membro da igualdade anterior
e, em modulo, majorada por∫ x0 |x − s|nds/n! ≤ |x|n+1/(n + 1)!. Por outro lado, e
atendendo a primeira das igualdades anteriores, e majorada por |∫ x0 (x − s)n−1e i sds −
xn/n|/(n−1)! ≤ 2|x|n/n!. Assim, integrando ambos os membros da segunda igualdade
depois de tomar x = tX, obtemos o pretendido.
Teorema 10.2.2 (do limite central classico2) Sejam (Xn) variaveis aleatorias in-
dependentes e identicamente distribuıdas de quadrado integravel, com E(X1) = µ e
Var(X1) = σ2 > 0. EntaoSn − nµ
σ√
n
d−→ N(0, 1).
Dem: Basta considerar o caso em que µ = 0 e σ = 1. Denotemos por φn a funcao
caracterıstica de Sn/√
n e por φ a funcao caracterıstica de X1. Para t ∈ R, temos
φn(t) = φSn(t/√
n) = φn(t/√
n), onde pelo Lema 10.2.1, φ(t/√
n) = 1+ i tE(X1)/√
n+
i 2t2E(X1)2/(2n) + vn(t) = 1 − t2/(2n) + vn(t), com n|vn(t)| ≤ E(|tX1|3/(6n1/2) ∧
|tX1|2) → 0 (porque?). Assim, φn(t) = (1+(−t2/2+nvn(t))/n)n → e−t2/2 = φN(0,1)(t),
o que permite concluir.
Reescrevendo a variavel aleatoria (Sn−nµ)/√
n na forma√
n (Sn/n−µ), o teorema
anterior estabelece que√
n (Sn/n − µ) d−→ N(0, σ2). Em particular Sn/n p−→ µ (cf.
Exercıcio 10.2.5), isto e, o teorema do limite central classico implica a lei fraca dos
grandes numeros. Alem disso, estabelecendo a forma da distribuicao assintotica de Sn,
o teorema do limite central da-nos uma informacao mais precisa sobre o comportamento
assintotico de Sn do que a lei fraca dos grandes numeros.
2Laplace, P.S., Mem. Acad. Sci. Paris, 10, 353–415 e 559–565, 1810 (reproduzidos em Oeuvres de
Laplace, 12, 301–345 e 349–353).
ATP, Coimbra 2002

134 Apontamentos de Teoria das Probabilidades
Exercıcios
1. (Convergencia da binomial para a normal3) Para n ∈ N, Seja Yn uma v.a. binomial
de parametros (n, p) com 0 < p < 1. Mostre que
Yn − np√np(1 − p)
d−→ N(0, 1).
Determine K ∈ N, de modo que a probabilidade de em 1000 lancamentos duma moeda
equilibrada obter entre 500−K e 500+K caras, seja aproximadamente 0.99. Se em 1000
lancamento duma moeda forem observadas 455 caras, poderemos considerar essa moeda
equilibrada?
2. Retome os Exercıcios 1.8.4 e 2.1.6. Mostre que
√n (Sn/n + 1/37)
d−→ N(0, σ2),
onde σ2 = (372 − 1)/372. Obtenha uma aproximacao para P(Sn ≥ 0), quando n =
200, 1000 e 2000. Compare os resultados com os obtidos nos exercıcios referidos.
3. (Convergencia do χ2 para a normal) Se Yn e uma variavel com uma distribuicao do
qui-quadrado com n graus de liberdade, mostre que (Yn − n)/√
2n d−→ N(0, 1).
4. Sejam (Xn) uma sucessao de v.a.r. i.i.d. com momentos finitos de quarta ordem, µ =
E(X1), σ2 = Var(X1) e τ = E(X1 − µ)4.
(a) Mostre que√
n( 1n
∑ni=1(Xi − µ)2 − σ2) d−→ N(0, τ − σ4).
(b) Conclua que√
n(σ2n − σ2) d−→ N(0, τ − σ4), onde σ2
n e a variancia empırica das
variaveis X1, . . . , Xn (ver Exercıcio 6.5.2).
5. Utilizando a tecnica das funcoes caracterısticas demonstre a lei fraca dos grande numeros
de Khintchine (ver Teorema 6.3.3).
10.3 O teorema do limite central de Lindeberg
Vamos neste paragrafo generalizar o Teorema 10.2.2 ao caso em que as variaveis
aleatorias X1,X2, . . ., apesar de independentes e de quadrado integravel nao sao neces-
sariamente identicamente distribuıdas. Denotaremos µk = E(Xk), σ2k = Var(Xk) e
s2n = Var(Sn) = σ2
1 + . . . + σ2n.
Definicao 10.3.1 Dizemos que a sucessao (Xn) de variaveis aleatorias independentes
e de quadrado integravel satisfaz a condicao de Lindeberg se
∀ ǫ > 01
s2n
n∑
k=1
E((Xk − µk)21I|Xk−µk |>ǫsn)→0.
3de Moivre, A., Approximatio as Summam Terminorum Binomii (a + b)n in Seriem Expansi, 1733,
e The Doctrine of Chances, 1738.
ATP, Coimbra 2002

10 O teorema do limite central 135
Comecemos por notar que uma sucessao de variaveis aleatorias independentes e
identicamente distribuıdas de quadrado integravel satisfaz a condicao de Lindeberg.
Para ǫ > 0, e pelo teorema da convergencia dominada, temos
1
s2n
n∑
k=1
E((Xk − µk)21I|Xk−µk|>ǫsn)
=1
nσ2
n∑
k=1
E((Xk − µk)21I|Xk−µk |>ǫσ
√n)
=1
σ2E((X1 − µ1)
21I|X1−µ1|>ǫσ√
n)→0.
A condicao de Lindeberg impoe que para cada k, a variavel aleatoria Xk deve estar
concentrada num intervalo centrado na sua media e cuja amplitude deve ser pequena
quando comparada com sn. A proposicao seguinte da enfase a esta interpretacao,
expremindo-a em termos de variancias.
Proposicao 10.3.2 Se (Xn) satisfaz a condicao de Lindeberg entao∨n
k=1 σ2k
s2n
→0.
Dem: Para ǫ > 0, basta notar que σ2k/s
2n = E((Xk −µk)
21I|Xk−µk|≤ǫsn)/s2n + E((Xk −
µk)21I|Xk−µk |>ǫsn)/s
2n ≤ ǫ2 +
∑nk=1 E((Xk − µk)
21I|Xk−µk|>ǫsn)/s2n.
Para que possamos generalizar os argumentos utilizados na demonstracao do teo-
rema de limite central classico a variaveis aleatorias nao sao necessariamente identica-
mente distribuıdas e importante e lema seguinte sobre a comparacao de produtos de
numeros complexos.
Lema 10.3.3 Para n ∈ N, sejam a1, . . . , an, b1, . . . , bn numeros complexos em modulo
inferiores ou iguais a 1. Entao
∣∣∣n∏
i=1
ai −n∏
i=1
bi
∣∣∣ ≤n∑
i=1
|ai − bi|.
Dem: Basta ter em conta que o resultado e valido para n = 2 e que |∏ni=1 ai−
∏ni=1 bi| =
|a1∏n
i=2 ai − b1∏n
i=2 bi| ≤ |a1 − b1| + |∏ni=2 ai −
∏ni=2 bi|.
Teorema 10.3.4 (de Lindeberg4) Sejam (Xn) variaveis aleatorias reais indepen-
dentes e de quadrado integravel com Var(Xn) > 0 para n suficientemente grande. Se
(Xn) satisfaz a condicao de Lindeberg, entao
Sn − E(Sn)
sn
d−→ N(0, 1).
ATP, Coimbra 2002

136 Apontamentos de Teoria das Probabilidades
Dem: Basta demonstrar o resultado para variaveis centradas. Sendo φk a funcao ca-
racterıstica de Xk, pela independencia das variaveis X1, . . . ,Xn, obtemos, φSn/sn(t) =
∏nk=1 φXk/sn
(t) =∏n
k=1 φk(t/sn), para t ∈ R. Com o objectivo de mostrar que∏n
k=1 φk(t/sn) → e−t2/2, para todo o t ∈ R, provaremos que An = |∏nk=1 φk(t/sn) −
exp(∑n
k=1(φk(t/sn) − 1))| → 0 e que Bn = |∑nk=1(φk(t/sn) − 1)) + t2/2| → 0. Pelo
Lema 10.3.3, An ≤ ∑nk=1 |φk(t/sn)− exp(φk(t/sn)− 1))| =
∑nk=1 | exp(φk(t/sn)− 1)−
1 − (φk(t/sn) − 1)|, uma vez que | exp(z − 1)| ≤ 1, quando |z| ≤ 1. Pelo Lema 10.2.1 e
pela Proposicao 10.3.2, obtemos ainda |φk(t/sn) − 1| ≤ E(|tXk|2/(2sn) ∧ 2|tXk|/sn) ≤t2E(X2
k)/(2s2n) ≤ (t2/2)∨n
k=1 σ2k/s
2n → 0. Assim, e tendo agora em conta que | exp(z)−
1 − z| ≤ 2|z|2, quando |z| ≤ 1/2, obtemos finalmente, An ≤ ∑nk=1 2|φk(t/sn) − 1|2 ≤
∑nk=1 2|φk(t/sn)−1|(t2/2)∨n
k=1σ2k/s
2n ≤ t2(∨n
k=1σ2k/s
2n)
∑nk=1(t
2/2)σ2k/s2
n = (t4/2)∨nk=1
σ2k/s
2n → 0. Pelo Lema 10.2.1 temos agora, para ǫ > 0, Bn =
∑nk=1 E(|t|3|Xk|3/(6s3
n)∧t2X2
k/s2n) ≤ |t|2 ∑n
k=1 E(X2k1I|Xk|>ǫsn)/s
2n + |t|3 ∑n
k=1 E(|Xk|31I|Xk|≤ǫsn)/(6s3n) ≤ |t|2
∑nk=1 E(X2
k1I|Xk|>ǫsn)/s2n + |t|3ǫ/6. Sendo ǫ > 0 qualquer, a condicao de Lindeberg
permite agora concluir.
Em 1935, W. Feller5 e P. Levy6, trabalhando independentemente, estabelecem
condicoes necessarias para a validade do teorema do limite central mostrando que,
na presenca da condicao apresentada na Proposicao 10.3.2, a condicao de Lindeberg
e tambem necessaria para que se tenha Sn−E(Sn)sn
d−→ N(0, 1) (ver Feller, 1971, pg.
518–521; sobre a prioridade da descoberta ver Le Cam, 1986.).
A condicao que a seguir apresentamos, apesar de mais restrictiva que a condicao de
Lindeberg, e normalmente simples de utilizar, em particular para δ = 1.
Proposicao 10.3.5 Se (Xn) e uma sucessao de variaveis aleatorias reais independen-
tes que, para algum δ > 0, satisfaz a condicao
1
s2+δn
n∑
k=1
E|Xk − µk|2+δ→0,
dita de condicao de Liapounov7entao (Xn) satisfaz a condicao de Lindeberg.
Exercıcios
1. Mostre que∨n
k=1 σ2k/s2
n→0 sse s2n→∞ e σ2
n/s2n→0.
4Lindeberg, J.W., Math. Z., 15, 211–225, 1922.5Feller, W., Math. Z., 40, 521–559, 1935.6Levy, P., J. Math. Pures Appli., 14, 347–402, 1935.7Liapounov, A., Bull. Acad. Sci. St. Petersbourg, 13, 359–386, 1900, e Mem. Acad. Sci. St. Peters-
bourg, 12, 1–24, 1901.
ATP, Coimbra 2002

10 O teorema do limite central 137
2. Demonstre a Proposicao 10.3.5.
3. Sejam X1, X2, . . . v.a. independentes com Xn ∼ U([−n, n]). Mostre que Sn/Var(Sn) d−→N(0, 1), onde
(Sugestao: Use o facto de 1nλ+1
∑nk=1 kλ→ 1
λ+1 .)
10.4 O teorema do limite central multidimensional
Neste paragrafo obtemos, via teorema de Cramer–Wold, versoes multivariadas dos
teoremas do limite central classico e de Lindeberg.
Teorema 10.4.1 Se (Xn) e uma sucessao de vectores aleatorios independentes e iden-
ticamente distribuıdos de quadrado integravel com media µ e matriz de covariancia Σ,
entaoSn − E(Sn)√
n
d−→ N(0,Σ).
Dem: Sem perda de generalidade supomos que os vectores Xk sao centrados. Pelo
Teorema 9.5.5, basta mostrar que, para todo o a ∈ Rd, 〈a, Sn/√
n〉 d−→ 〈a,X〉, onde
X ∼ N(0,Σ), ou de forma equivalente, 〈a, Sn/√
n〉 d−→ N(0, aT Σa). Ora, 〈a, Sn/√
n〉 =∑n
k=1〈a,Xk〉/√
n, onde 〈a,Xk〉, k = 1, 2, . . ., sao variaveis reais independentes com
media 0 e variancia aT Σa. Se aT Σa > 0, o resultado e assim consequencia do Teorema
10.2.2. Se aT Σa = 0, 〈a,Xk〉 = 0, q.c., para k = 1, 2, . . ., e 〈a, Sn/√
n〉 ∼ N(0, 0) =
N(0, aT Σa).
Teorema 10.4.2 Seja (Xn) uma sucessao de vectores aleatorios independentes de qua-
drado integravel com medias µn e matrizes de covariancia Σn. Se
1
n(Σ1 + . . . + Σn)→Σ,
e
∀ ǫ > 01
n
n∑
k=1
E(||Xk − µk||21I||Xk−µk||>ǫ√
n)→0,
entaoSn − E(Sn)√
n
d−→ N(0,Σ).
Exercıcios
1. Demonstre o Teorema 10.4.2.
2. Para n ∈ N, seja Xn ∼ M(n, p1, . . . , pk) com∑k
i=1 pi = 1. Mostre que (Xn−E(Xn))/√
n
e assintoticamente normal.
ATP, Coimbra 2002

138 Apontamentos de Teoria das Probabilidades
3. Seja (Xn) uma sucessao de ve.a. i.i.d. com momentos de ordem 2k, para k ∈ N fixo.
(a) Estabeleca a normalidade assintotica do vector dos k primeiros momentos empıricos
(∑n
i=1 Xℓi /n; ℓ = 1, . . . , k).
(b) Usando o Exercıcio 9.5.4 e a normalidade assintotica estabelecida na alınea anterior,
resolva novamente a alınea (b) do Exercıcio 10.3.4.
10.5 Bibliografia
Araujo, A., Gine, E. (1980). The Central Limit Theorem for Real and Banach Valued
Random Variables, Wiley.
Feller, W. (1971). An Introduction to Probability Theory and its Applications, Vol. 2,
Wiley.
James, B.R. (1981). Probabilidades: um curso de nıvel intermediario, IMPA.
Le Cam, L. (1986). The central limit theorem around 1935, Statistical Science, 1, 78–96.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
ATP, Coimbra 2002

Tabela 1
Valores da funcao de distribuicao
normal standard
139

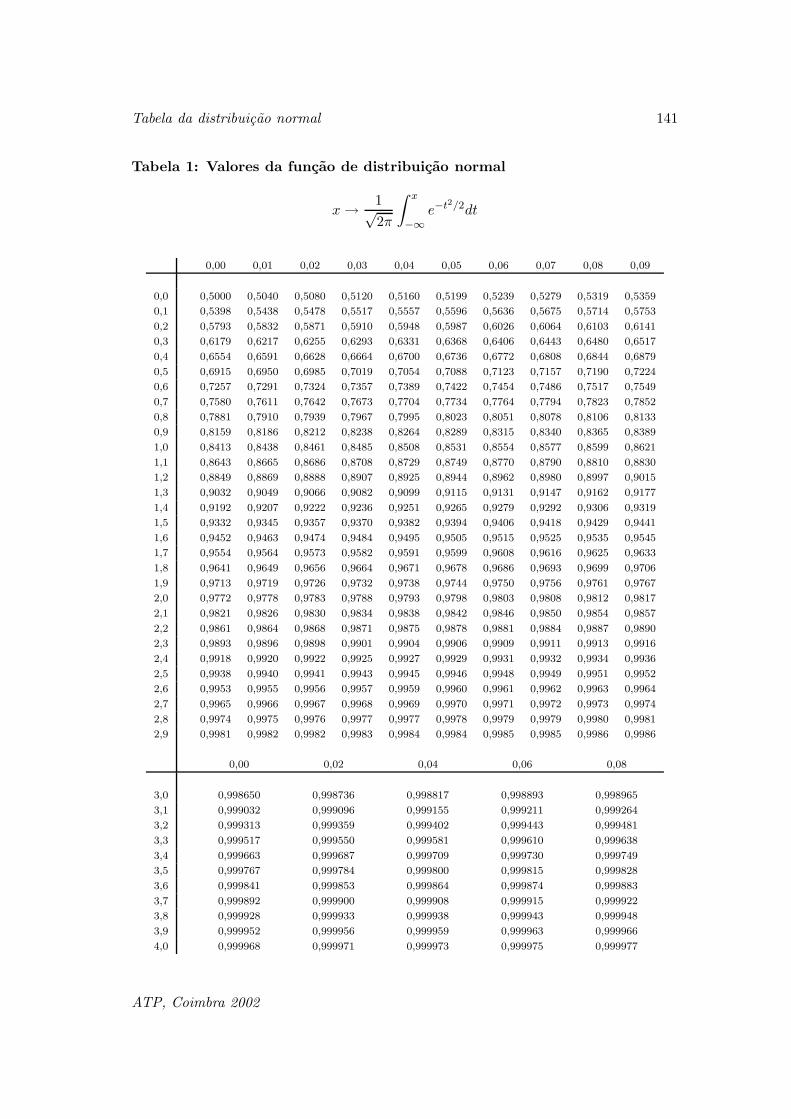
Tabela da distribuicao normal 141
Tabela 1: Valores da funcao de distribuicao normal
x → 1√2π
∫ x
−∞e−t2/2dt
0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,5359
0,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,5753
0,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,6141
0,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,6517
0,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,6879
0,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,7224
0,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,7549
0,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,7852
0,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,8133
0,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,8389
1,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,8621
1,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,8830
1,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,9015
1,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,9177
1,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,9319
1,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,9441
1,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,9545
1,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,9633
1,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,9706
1,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,9767
2,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,9817
2,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,9857
2,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,9890
2,3 0,9893 0,9896 0,9898 0,9901 0,9904 0,9906 0,9909 0,9911 0,9913 0,9916
2,4 0,9918 0,9920 0,9922 0,9925 0,9927 0,9929 0,9931 0,9932 0,9934 0,9936
2,5 0,9938 0,9940 0,9941 0,9943 0,9945 0,9946 0,9948 0,9949 0,9951 0,9952
2,6 0,9953 0,9955 0,9956 0,9957 0,9959 0,9960 0,9961 0,9962 0,9963 0,9964
2,7 0,9965 0,9966 0,9967 0,9968 0,9969 0,9970 0,9971 0,9972 0,9973 0,9974
2,8 0,9974 0,9975 0,9976 0,9977 0,9977 0,9978 0,9979 0,9979 0,9980 0,9981
2,9 0,9981 0,9982 0,9982 0,9983 0,9984 0,9984 0,9985 0,9985 0,9986 0,9986
0,00 0,02 0,04 0,06 0,08
3,0 0,998650 0,998736 0,998817 0,998893 0,998965
3,1 0,999032 0,999096 0,999155 0,999211 0,999264
3,2 0,999313 0,999359 0,999402 0,999443 0,999481
3,3 0,999517 0,999550 0,999581 0,999610 0,999638
3,4 0,999663 0,999687 0,999709 0,999730 0,999749
3,5 0,999767 0,999784 0,999800 0,999815 0,999828
3,6 0,999841 0,999853 0,999864 0,999874 0,999883
3,7 0,999892 0,999900 0,999908 0,999915 0,999922
3,8 0,999928 0,999933 0,999938 0,999943 0,999948
3,9 0,999952 0,999956 0,999959 0,999963 0,999966
4,0 0,999968 0,999971 0,999973 0,999975 0,999977
ATP, Coimbra 2002


Bibliografia Geral
Sobre Teoria das Probabilidades
Billingsley, P. (1986). Probability and Measure, Wiley.
Chow, Y.S., Teicher, H. (1997). Probability Theory: Independence, Interchangeability,
Martingales, Springer.
Chung, K.L. (1974). A Course in Probability Theory, Academic Press.
Durrett, R. (1996). Probability: Theory and Examples, Duxbury Press.
Feller, W. (1971). An Introduction to Probability Theory and its Applications, Vol. 2,
Wiley.
Hennequin, P.L., Tortrat, A. (1965). Theorie des Probabilites et Quelques Applications,
Masson.
James, B.R. (1981). Probabilidades: um curso de nıvel intermediario, IMPA.
Jacod, J., Protter, P. (2000). Probability Essentials, Springer.
Kallenberg, O. (1997). Foundations of Modern Probability, Springer.
Kolmogorov, A.N. (1950). Foundations of the Theory of Probability, Chelsea Publishing
Company (traducao do original Grundbegriffe der Wahrscheinlichkeitrechnung
datado de 1933).
Laha, R.G., Rohatgi, V.K. (1979). Probability Theory, Wiley.
Loeve, M. (1977). Probability Theory I, Springer.
Metivier, M. (1972). Notions Fondamentales de la Theorie des Probabilites, Dunod.
Monfort, A. (1980). Cours de Probabilite, Economica.
Resnick, S.I. (1999). A Probability Path, Birkhauser.
143

144 Apontamentos de Teoria das Probabilidades
Sobre alguns temas especıficos
Araujo, A., Gine, E. (1980). The Central Limit Theorem for Real and Banach Valued
Random Variables, Wiley.
Billingsley, P. (1968). Convergence of Probability Measures, Wiley.
Gnedenko, B.V., Kolmogorov, A.N. (1968). Limit Distributions for Sums of Indepen-
dent Random Variables, Addison-Wesley.
Le Cam, L. (1986). The central limit theorem around 1935, Statistical Science, 1, 78–96.
Lukacs, E. (1964). Fonctions Caracteristiques, Dunod.
Lukacs, E. (1975). Stochastic Convergence, Academic Press.
Revesz, P. (1968). The Laws of Large Numbers, Academic Press.
Williams, D. (1991). Probability with Martingales, Cambridge University Press.
Sobre Teoria da Medida e Integracao
Cohn, D.L. (1980). Measure Theory, Birkhauser.
Fernandez, P.J. (1976). Medida de Integracao, IMPA.
Halmos, P.R. (1950). Measure Theory, D. Van Nostrand Company.
Rudin, W. (1974). Real and Complex Analysis, McGraw-Hill.
Sobre a historia das Probabilidades (e nao so)
Borel, E. (1950). Elements de la Theorie des Probabilites, Editions Albin Michel.
Hald, A. (1990). A History of Probability and Statistics and their applications before
1750, Wiley.
Hald, A. (1998). A History of Mathematical Statistics from 1759 to 1930, Wiley.
Sobre simulacao de experiencias aleatorias
Grycko, E., Pohl, C., Steinert, F. (1998). Experimental Stochastics, Springer.
Knuth, D.E. (1981). The Art of Computer Programming, vol. II, Addison-Wesley.
Tompson, J.R. (2000). Simulation: a Modeler’s Approach, Wiley.
ATP, Coimbra 2002

Indice Remissivo
acontecimento
aleatorio, 3, 5
certo, 3
elementar, 3
impossıvel, 3
acontecimentos aleatorios
incompatıveis, 4
independentes, 49
Bernoulli, D., 65
Bernoulli, J., 87
Bernoulli, N., 65
Bienayme, I.-J., 68
Bochner, S., 126
Borel, E., 57, 87
Box-Muller
metodo de, 44, 54
Cantelli, F.P., 57
cilindro
de base A, 16
de dimensao finita, 16
coeficiente
de achatamento, 66
de assimetria, 66
de correlacao, 69
condicao
de Liapounov, 136
de Lindeberg, 134
convergencia
da binomial para a Poisson, 34, 120
em distribuicao, 117
caracterizacoes da, 118
propriedades da, 119, 121
em media de ordem p, 78, 81
em media quadratica, 78, 81
em probabilidade, 76, 81
quase certa, 75, 81
quase completa, 76
convolucao
de densidades de probabilidade, 44, 54
de funcoes de probabilidade, 54
covariancia, 69
e independencia, 113
matriz de, 71
Cramer, H., 127
d-sistema, 50
de Moivre, A., 134
densidade condicional, 46
densidade de probabilidade, 10, 15, 35, 43
normal bivariada, 10
normal univariada, 10
uniforme, 15
desigualdade
de Bienayme-Tchebychev, 68
de Cauchy-Schwarz, 68
de Levy, 96
de Tchebychev-Markov, 79
maximal de Kolmogorov, 90
desvio-padrao, 66
distribuicao
145

146 Apontamentos de Teoria das Probabilidades
absolutamente contınua, 35
binomial, 31
binomial negativa, 33
condicional, 46
da soma de variaveis reais, 54
de Bernoulli, 30
de Cauchy, 40
de Erlang, 56
de Laplace, 40
de Pascal, 33
de Poisson, 33
de Rayleigh, 44
de Weibull, 41
degenerada, 38
discreta, 35
do qui-quadrado, 56
exponencial, 39
funcao de, 15
geometrica, 33
log-normal, 67
logıstica, 41
marginal, 31
multinomial, 32
normal, 32, 111, 112
singular, 35
suporte da, 35
triangular, 44
uniforme, 32
uniforme discreta, 38
distribuicao de probabilidade, 30
espaco
de probabilidade, 5, 14
dos resultados, 3
fundamental, 3
esperanca matematica, 62, 70, 101
calculo da, 64
propriedades da, 63, 102
experiencia aleatoria, 3, 5
modelacao de uma, 5, 6, 8–12, 20
simulacao de uma, 24
formula
da probabilidade composta, 19
da probabilidade total, 20
de Daniel da Silva, 8
Feller, W., 136
Fermat, P., 13
funcao
caracterıstica, 102
calculo da, 103
derivadas e momentos da, 104
dum vector normal, 112
formulas de inversao, 107
injectividade, 106
propriedades da, 102
de distribuicao, 15, 36, 41
propriedades da, 37, 42
de probabilidade, 35
quantil, 39
Galileu Galilei, 6
Galton, F., 9
Gauss, C.F., 9
Helly, E., 123
Huygens, C., 14
independencia
caracterizacoes, 51–53
de acontecimentos aleatorios, 49
de classes, 50
de variaveis aleatorias, 51
jogo justo, 64
Khintchine, A., 81, 89
ATP, Coimbra 2002

Indice Remissivo 147
Kolmogorov, A.N., 3, 4, 58, 81, 88, 90, 91,
93, 95
Levy, P., 126, 136
Laplace, P.S., 133
lei dos grandes numeros
em media de ordem p, 84
em media quadratica, 85
lei forte dos grandes numeros, 84, 86
de Borel, 87
de Kolmogorov, 93
lei fraca dos grandes numeros, 84
de Bernoulli, 87
de Khintchine, 89
de Markov, 85
de Poisson, 87
de Tchebychev, 87
lei zero-um
de Borel, 57
de Kolmogorov, 58
Lindeberg, J.W., 136
media empırica, 93, 115
metodo
das subsucessoes, 86
de Box-Muller, 44, 54
de congruencia linear, 24
de Monte Carlo, 26, 93
Marcinkiewicz, J., 93
Markov, A.A., 85
medida, 5
absolutamente contınua, 34
alheia, 34
difusa, 34
discreta, 34
singular, 34
modelo probabilıstico, 5
Montmort, P.R., 8, 65
numeros pseudo-aleatorios, 25
Polya, G., 132
Paccioli, L., 14
parametros
de dispersao, 65
de forma, 66
de localizacao, 62
paradoxo
das coincidencias, 8
de Sao Petersburgo, 65
do dia de aniversario, 6
do teste para despiste duma doenca
rara, 21
Pascal, B., 13
π-sistema, 50
Poisson
distribuicao de, 33
processo de, 12
Poisson, S.D., 87
probabilidade, 5
a posteriori, 20
a priori, 20
conceito frequencista de, 4
condicionada, 19
das causas, 22
de transicao, 23
definicao classica de, 5, 14
densidade de, 10, 15
espaco de, 5, 14
geometrica, 6
imagem, 16
produto, 16, 18
produto generalizado de, 22
propriedades duma, 7
problema
da divisao das apostas, 13
da ruına do jogador, 14
ATP, Coimbra 2002

148 Apontamentos de Teoria das Probabilidades
do concurso das portas, 24
processo estocastico, 29
produto
de espacos de probabilidade, 18
de espacos mensuraveis, 17
generalizado de probabilidades, 22
infinito de probabilidades, 16
Prohorov, Yu.V., 124
rectangulo
mensuravel, 17
semi-aberto a esquerda, 15
representacao de Skorokhod, 39
Scheffe, H., 120
semi-algebra, 7
semi-anel, 7
σ-algebra, 5
assintotica, 58
gerada, 18
produto, 16
trivial, 57
Silva, D., 8
simetrizacao, 95
simulacao de variaveis, 39, 40
de Cauchy, 40
de Laplace, 40
de Weibull, 41
exponenciais, 39
logısticas, 41
normais, 44, 54
sucessao
aleatoria, 29
de Cauchy em Lp, 80
de Cauchy em probabilidade, 77
de Cauchy quase certamente, 76
limitada em probabilidade, 122
Tchebychev, P.L., 68, 87
teorema
da continuidade de Levy–Bochner, 126
da convergencia dominada, 79, 80
da decomposicao de Lebesgue, 34
da diferenciacao de Lebesgue, 37
da mudanca de variavel, 43
da seleccao de Helly, 123
das tres series, 95
de Bayes, 20
de Borel-Cantelli, 57
de Cramer–Wold, 127
de Prohorov, 124
de Scheffe, 120
de Slutsky, 127
do limite central, 132
do limite central classico, 133, 137
do limite central de Lindeberg, 135,
137
variavel aleatoria, 29
absolutamente contınua, 35
binomial, 31
binomial negativa, 33
centrada e reduzida, 66
complexa, 101
de Bernoulli, 30
de Cauchy, 40
de Laplace, 40
de Pascal, 33
de Poisson, 33
de Rayleigh, 44
de Weibull, 41
degenerada, 38
discreta, 35
do qui-quadrado, 56
exponencial, 39
geometrica, 33
independencia de, 51
ATP, Coimbra 2002

Indice Remissivo 149
integravel, 62, 70, 101
log-normal, 67
logıstica, 41
momentos de uma, 65
multinomial, 32
nao-correlacionadas, 69
normal, 111, 112
real, 29
simulacao duma, 40
singular, 35
suporte da, 35
triangular, 44
uniforme discreta, 38
variancia, 66
calculo da, 66
empırica, 93, 115
propriedades da, 66
vector aleatorio, 29
margens dum, 31
Wold, H., 127
Zygmund, A., 93
ATP, Coimbra 2002







