Download - analisis de datos en ingenieria

UNIVERSIDAD DEL NORTEDIVISION DE INGENIERIAS
DEPARTAMENTO DE INGENIERIA INDUSTRIAL
ANÁLISIS DE DATOS EN INGENIERIA I
TALLER
1. Para hacer más sencillos todos los análisis respectivos recurrimos al software
estadístico Statgraphics, el cual es una herramienta que permite automatizar de
forma clara y sencilla todos nuestros cálculos. En el archivo adjunto de Excel, y de
Statgraphics, están resumidos todos los cálculos hechos durante la investigación.
a) Nuestra variable de interés son tiempos de atención, en minutos.
En primer lugar, hacemos el respectivo gráfico de líneas:
1
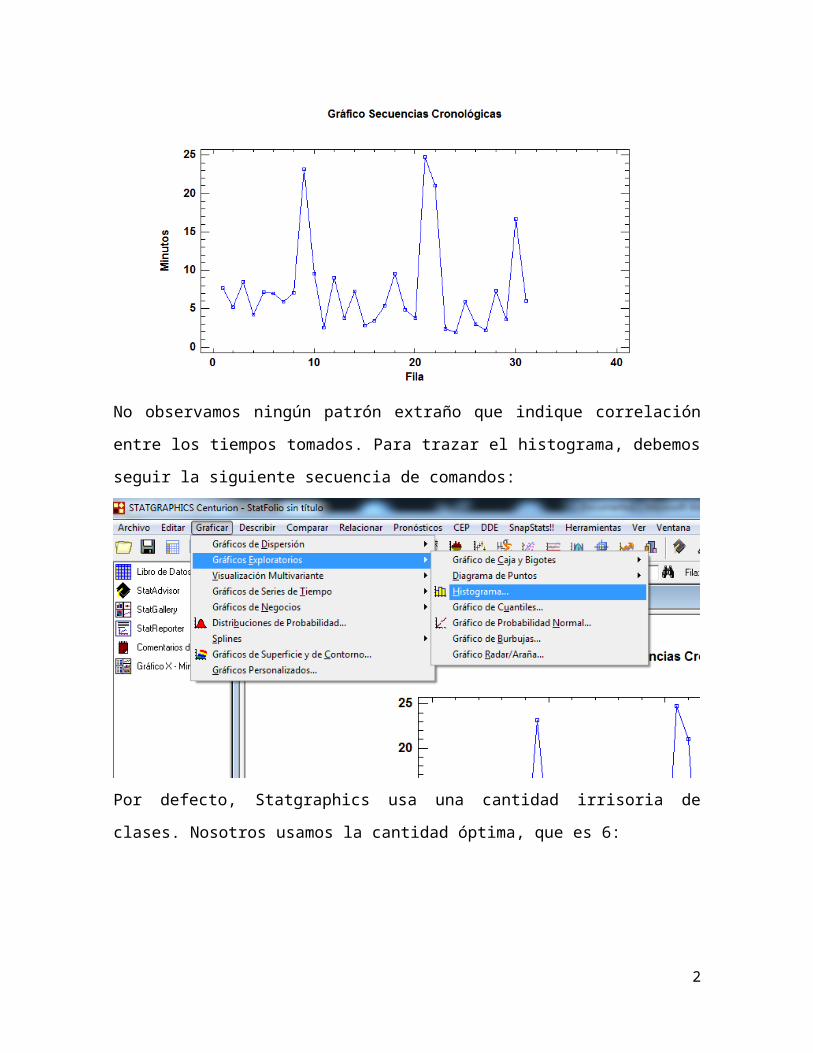
No observamos ningún patrón extraño que indique correlación entre los tiempos
tomados. Para trazar el histograma, debemos seguir la siguiente secuencia de
comandos:
Por defecto, Statgraphics usa una cantidad irrisoria de clases. Nosotros usamos la
cantidad óptima, que es 6:
2

Este histograma será analizado de manera detallada en incisos posteriores.
b) Para este paso, nos valemos de Microsoft Excel.
Medidas de Centralización:
CentralizaciónMedia 7,51
Mediana 5,93Moda 2,4
3
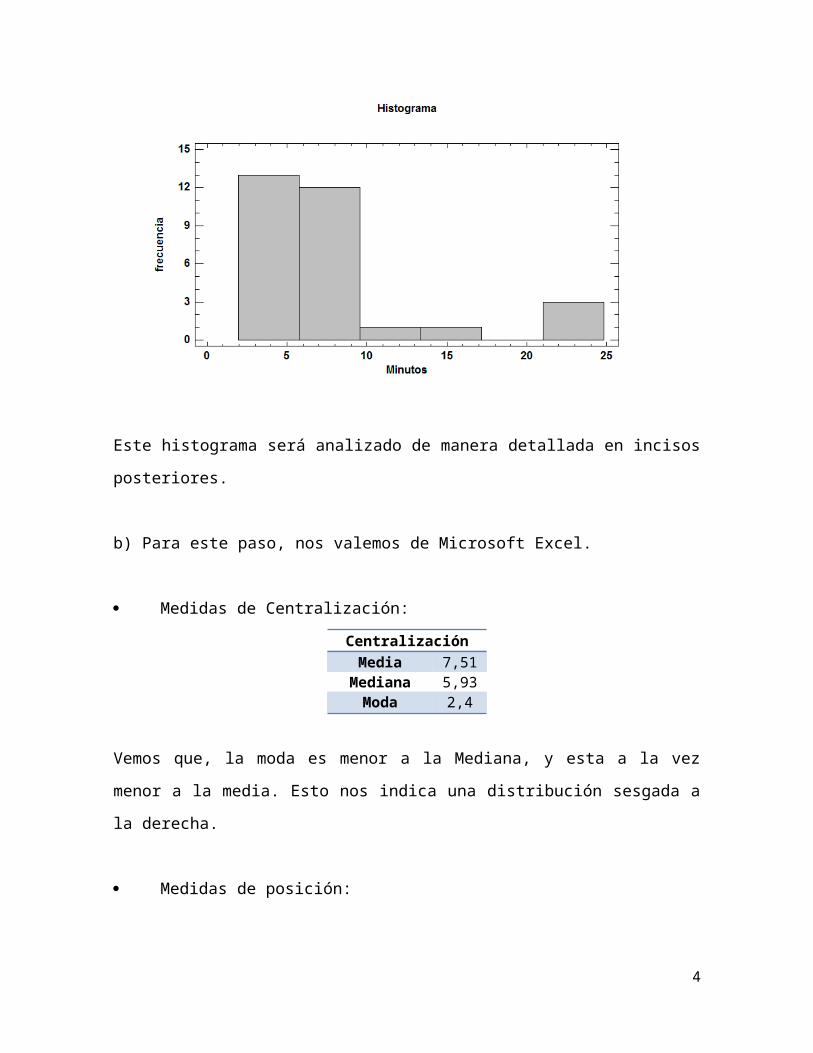
Vemos que, la moda es menor a la Mediana, y esta a la vez menor a la media.
Esto nos indica una distribución sesgada a la derecha.
Medidas de posición:
PosiciónCuartil 1 3,70Cuartil 2 5,93Cuartil 3 8,12
Según los resultados, el 75% de los datos se encuentra entre 3,7 y 8,12. Esto
supone una alta variabilidad entre los datos.
Medidas de dispersión:
DispesiónVarianza 35,80
Desviación 5,98Coef var 0,17
Rango InterQ 4,42
Tenemos un coeficiente de variación relativamente pequeño, lo que indica que la
dispersión dentro del rango inter cuartil es pequeña.
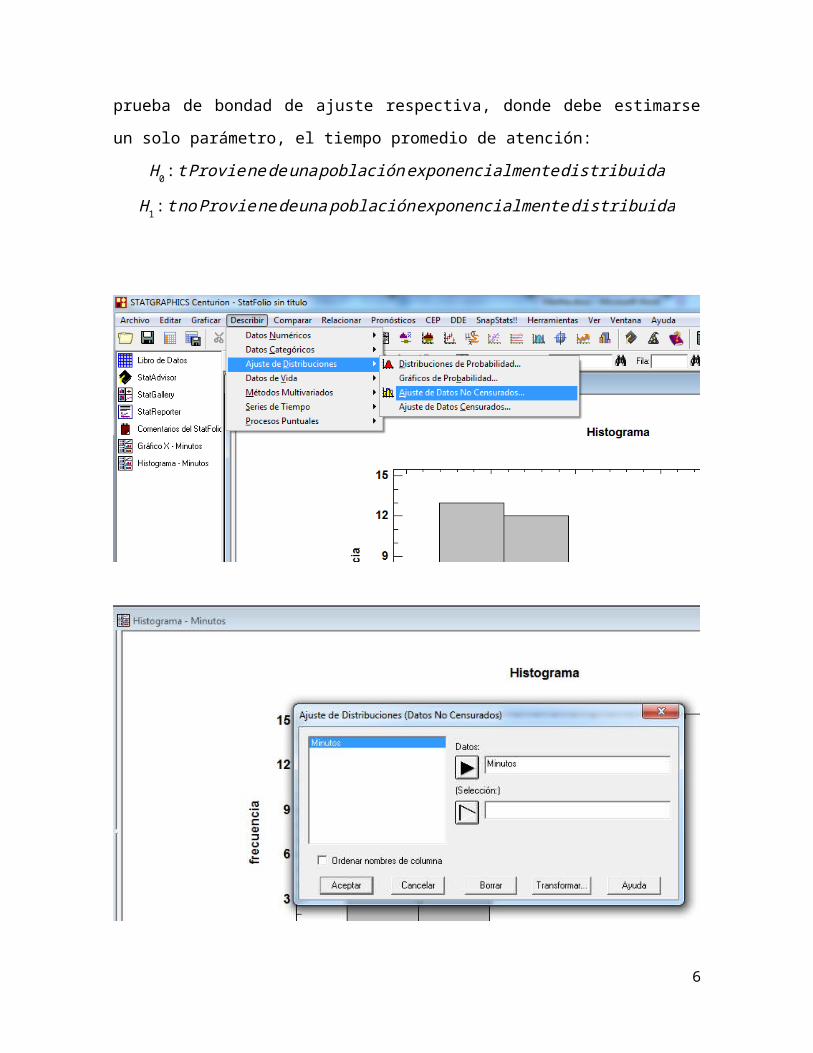
c) Dado el sesgo hacia la derecha en la distribución, y el hecho de trabajar con
tiempos, podemos suponer que se trata de una distribución exponencial. Así,
procedemos a hacer la prueba de bondad de ajuste respectiva, donde debe
estimarse un solo parámetro, el tiempo promedio de atención:
4

H 0 : t Proviene deuna poblaciónexponencialmente distribuida
H 1: t no Proviene deuna poblaciónexponencialmente distribuida
5
6
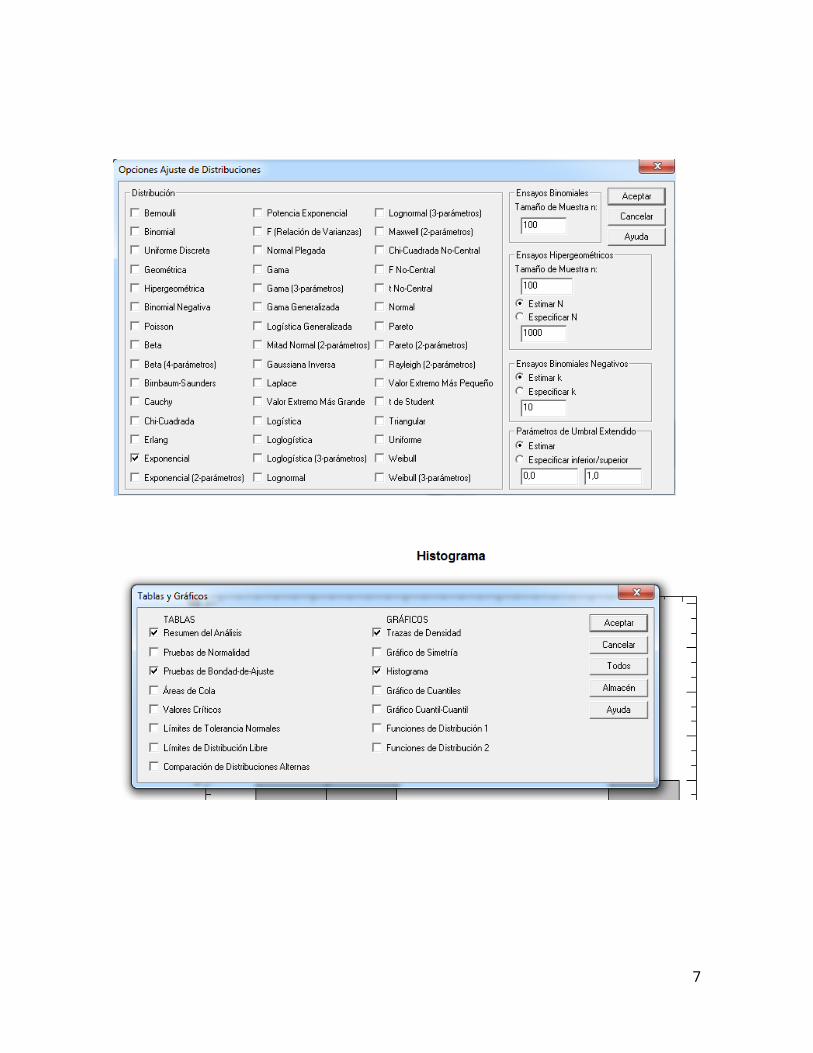
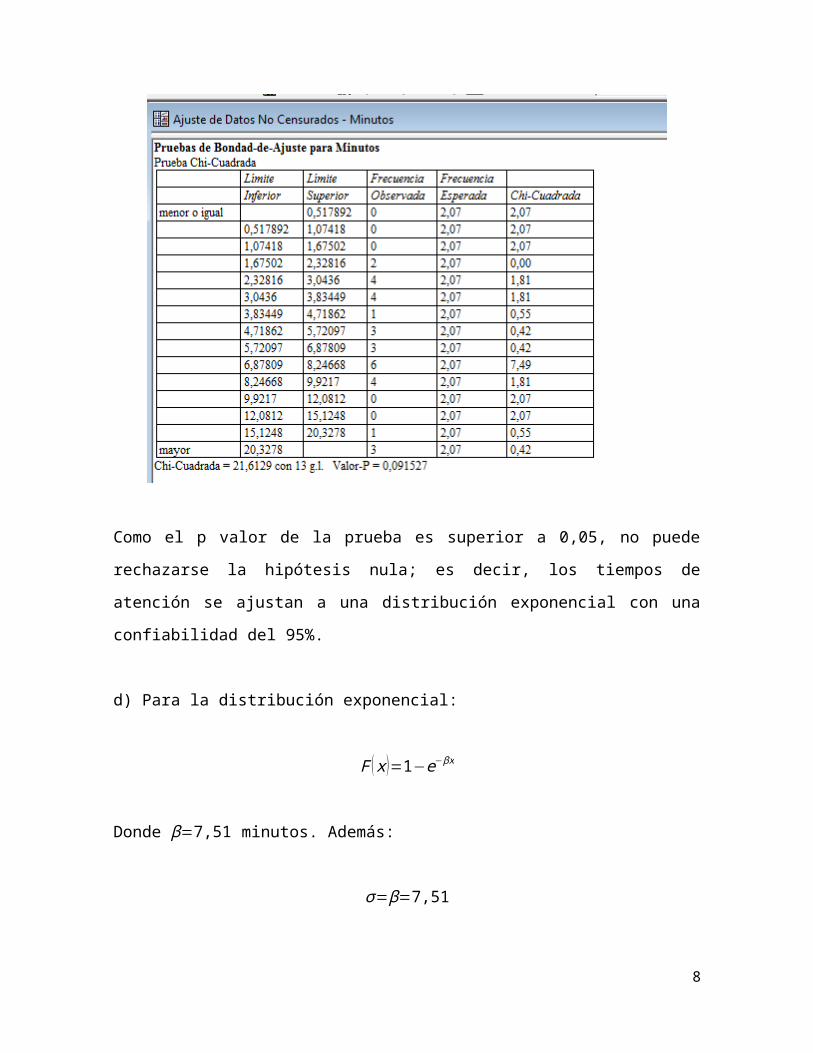
Como el p valor de la prueba es superior a 0,05, no puede rechazarse la hipótesis
nula; es decir, los tiempos de atención se ajustan a una distribución exponencial
con una confiabilidad del 95%.
d) Para la distribución exponencial:
F ( x )=1−e−βx
Donde β=7,51 minutos. Además:
σ=β=7,51
Los límites para dos desviaciones de distancia de la media son:
LI=7,51−2∗7,51=−7,51 ; LI=7,51+2∗7,51=22,53
7
En la muestra, hay 29 datos que cumplen esta condición, lo que representa un
93,5% del total. Usando la distribución exponencial:
F ( X=22,53 )=1−e−7,51(22,53)=1
Así, hay un distanciamiento significativo en ambos resultados. Esto podemos
atribuirlo al hecho de que el tamaño de la muestra es relativamente pequeño.
e) Los primeros 16 datos fueron tomados durante la mañana, mientras que los
otros dos durante la tarde. Así, procederemos a hacer una prueba de medias:
H 0 :umañana=uTarde
H 1: umañana≠uTarde
Para automatizar la prueba, nos valemos nuevamente de Statgraphics.
8

9
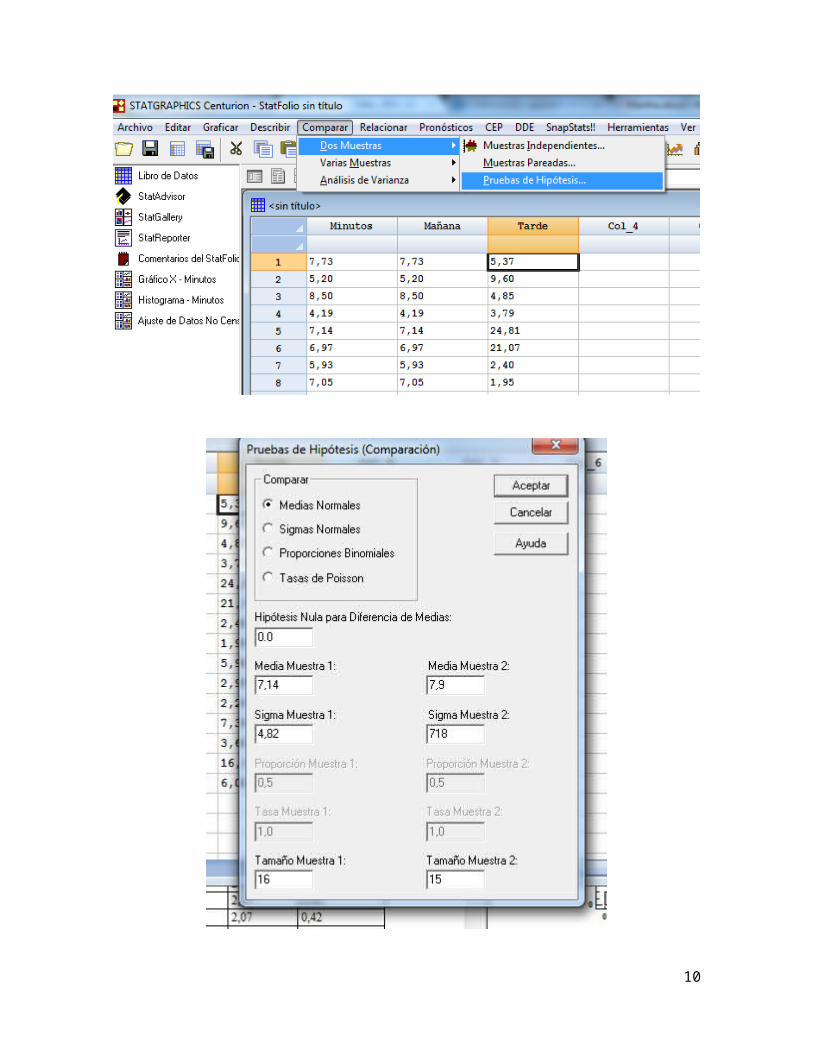
Vemos que la conclusión es no rechazar la hipótesis nula con alfa del 5%, por lo
que la media en el tiempo de atención es independiente de la hora del día.
2. Para este punto, evaluamos el mismo proceso. Sin embargo, la variable a
estudiar no fue el tiempo de atención, sino la cantidad de entidades que llegaban
al sistema cada 10 minutos.
Planteamos las hipótesis:
H 0 :Las llegadas siguenunadistribución Poisson
H 1: Las llegadasno siguenunadistribución Poisson
Volvemos a hacer la prueba de bondad de ajuste en Statgraphics:
10

El p valor de la prueba es 0,477>0,05. Esto nos lleva a concluir, que, en efecto, las
entidades que llegan en un período de 10 minutos se ajustan a una distribución
Poisson.
11
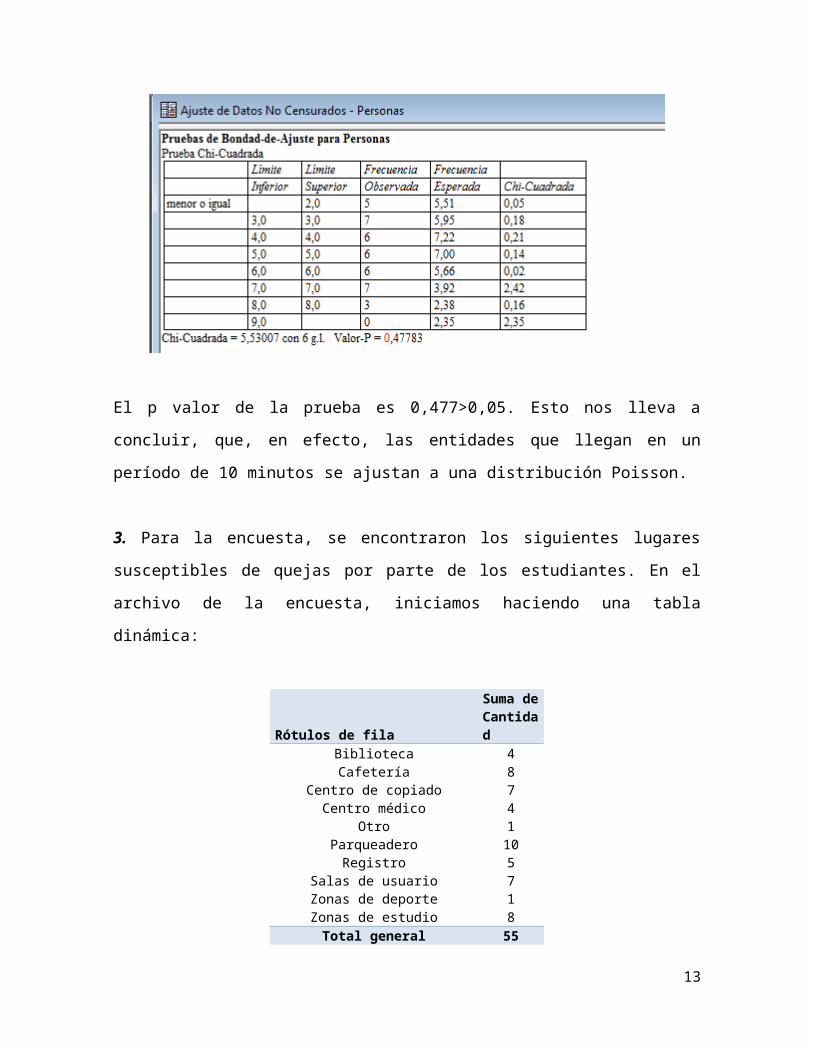
3. Para la encuesta, se encontraron los siguientes lugares susceptibles de quejas
por parte de los estudiantes. En el archivo de la encuesta, iniciamos haciendo una
tabla dinámica:
Rótulos de filaSuma de Cantidad
Biblioteca 4Cafetería 8
Centro de copiado 7Centro médico 4
Otro 1Parqueadero 10
Registro 5Salas de usuario 7Zonas de deporte 1Zonas de estudio 8
Total general 55
Ordenamos las frecuencias de mayor a menor, y acumulamos:
Ítem f F F RelativaParqueadero 10 10 0,18181818
Cafetería 8 18 0,32727273Zonas de estudio 8 26 0,47272727
Centro de copiado
733 0,6
Salas de usuario 7 40 0,72727273Registro 5 45 0,81818182
Biblioteca 4 49 0,89090909Centro médico 4 53 0,96363636
Otro 1 54 0,98181818Zonas de deporte
155 1
Haciendo el respectivo gráfico de Pareto
12
Parquea
dero
Cafeter
ía
Zonas
de estu
dio
Centro
de copiad
o
Salas
de usu
ario
Regist
ro
Bibliotec
a
Centro
méd
ico Otro
Zonas
de dep
orte.000
.200
.400
.600
.800
1.000
1.200
.182.327
.473.600
.727.818
.891.964 .982 1.000
F Relativa
Ítem
Acum
ulad
o
De las 10 causas asignables encontradas, 6 acumulan el 82% de todas las quejas.
Estas 6 causan representan un 60% del total de causas. Podemos interpretar este
resultado de la siguiente manera: En particular, no hay una causa única de queja,
y puede resultar normal que alguna de estas causas presenten fallas en ciertos
momentos del tiempo, pero no permanentemente, ya que de ser así, esto se
hubiese visto reflejado en el gráfico. Por ejemplo si registro siempre prestara un
mal servicio, la gran mayoría de los encuestados se habría quejado de este lugar.
Sin embargo, esto no ocurrió.
:
13







