desarrollo de algoritmos de selección de variables para...
TRANSCRIPT

Desarrollo de algoritmos de selección de variables para clasificadores neuronales:
métodos no estocásticos
AUTOR: Ismael Lapiedra Michel . DIRECTOR: Dr.Eduard Llobet .
FECHA: Mayo / 2004

Indice Ismael Lapiedra Michel
-2-
ÍNDICE 0 · Introducción y antecedentes Pág. 4 1 Objetivos del proyecto Pág. 6 2 · Obtención de los datos y pre-procesado Pág. 7 3 · Métodos existentes para la selección de variables Pág. 18 3.1 Forward selection Pág. 19 3.2 Backward elimination Pág. 20 3.3 Stepwise selection Pág. 21 4 Nuevos métodos para la selección de variables Pág. 23 4.1 Redes neuronales y selección de variables Pág. 23 4.1.1 Red fuzzy ARTMAP Pág. 24 4.1.2 Red probabilística Pág. 25 4.2 Métodos implementados Pág. 28 4.2.1 Fordward –fuzzy ARTMAP Pág. 28 4.2.2 Backward –fuzzy ARTMAP Pág. 28 4.2.3 Stepwise –fuzzy ARTMAP Pág. 29 4.2.4 Fordward –PNN Pág. 29 4.2.5 Backward –PNN Pág. 29 4.2.6 Stepwise –PNN Pág. 29 5 · Análisis de los Datos Pág. 30 5.1. Fichero TABLA.M Pág. 30 5.1.1. ·Forward y Backward con mínimos cuadrados Pág. 30 5.1.2 · Forward , Backward y Stepwise
con la Red Fuzzy Pág. 31 5.1.3 · Forward , Backward y Stepwise con la Red Newpnn Pág. 34 5.2. Fichero VOCS.M Pág. 36 5.2.1. ·Forward y Backward con mínimos cuadrados Pág. 36
5.2.2 · Forward , Backward y Stepwise con la Red Fuzzy Pág. 38
5.2.3 · Forward , Backward y Stepwise con la Red Newpnn Pág. 41

Indice Ismael Lapiedra Michel
-3-
5.3 Discusión: Comparación entre los diferentes métodos de validación (Redes neuronales y método de los mínimos cuadrados) y los diferentes métodos de ejecución (Forward, Backward y Stepwise). Pág. 43
6 Implementación en un entorno gráfico con Matlab. Pág. 47 6.1 Introducción Pág. 47 6.2 Herramientas básicas de diseño de GUI’s Pág. 47 6.2.1.- Push Buttons Pág. 49 6.2.2.- Radio Buttons Pág. 50 6.2.3.- Edit Text Pág. 50 6.2.4.- Static Text Pág. 50 6.2.5.- List Box Pág. 51 6.2.6.- Popup Menu Pág. 51 6.2.7.-.Otros controles Pág. 52
6.3 Programación de GUI’s Pág. 53
6.3.1.- Las Funciones get/set Pág. 55 6.3.2.- Las Funciones uigetfile/uiputfile Pág. 57
6.3.3.- Las Variables Globales Pág. 58
6.4 Estructura del GUI Pág. 58 6.4.1 Menú Principal “Project” Pág. 59 7 · Conclusiones del Proyecto Final de Carrera Pág. 62
7.1. Comentarios sobre los resultados obtenidos Pág. 62 7.2. Conclusiones sobre el mejor método Pág. 62 7.3. Posibles mejoras, continuación del proyecto Pág. 63
8 · Bibliografía Pág. 64 Anexo · Ficheros “ *.m ” Pág. 65

Introducción y antecedentes Ismael Lapiedra Michel
-4-
0 · INTRODUCCIÓN Y ANTECEDENTES
Durante los últimos años, las narices electrónicas [1] han tomado mucha relevancia tanto en el ámbito académico como en el industrial [2,3]. La razón es la posibilidad de hacer medidas directas sin la necesidad, o casi, de un preprocesado, la sencillez a la hora de crear instrumentos móviles y el hecho de que un instrumento sencillo puede utilizarse para diferentes aplicaciones con sólo alterar o modificar las opciones de evaluación de los datos.
El olfato humano es un sentido relativamente poco desarrollado si lo
comparamos a el de otros mamíferos pero aún así es capaz de distinguir aromas y las concentraciones de estos en el ambiente con una precisión de ppm. Un aroma puede estar constituido por una molécula, aunque generalmente lo está por centenares y diferentes. Para captar estas moléculas el hombre dispone de receptores diferentes que captan una parte del espectro de aromas en especial y también, en menor medida, parte del resto del espectro. Esto es lo crea un efecto de solapamiento entre lo captado por cada receptor. De esta manera, por combinación de señales provenientes de estos receptores y tras una etapa de reconocimiento y análisis de la información en el bulbo olfativo y el cerebro[4,5], percibimos los olores en mayor o menor medida.
La necesidad de poder captar estos aromas en productos de nuestra vida
cotidiana esta clara y, es por ello que desde hace más de treinta años [6,7] se han intentado crear sistemas electrónicos que pudiesen simular nuestra capacidad de captar estos compuestos químicos, aunque este concepto no se empezó a desarrollar realmente hasta 1982 [8]. Las aplicaciones más notables se han dado en el campo de la cosmética (perfumes, jabones, etc...), productos alimenticios, bebidas, etc...; donde es de vital importancia porque el trabajo humano es limitado. Para ello se han creado instrumentos llamados olfatos electrónicos cuya definición podría ser [9]: “Un sistema de olfato electrónico es un instrumento que comprende una agrupación de sensores químicos electrónicos con sensibilidades parcialmente solapadas junto a un sistema de reconocimiento de patrones, capaz de analizar y reconocer aromas simples o complejos”.
Como desprendemos de la definición, un sistema de estas características está
compuesto por unos sensores que captan las moléculas químicas volátiles y las transforman en señales eléctricas que después se procesarán con un sistema de reconocimiento de patrones. Otras técnicas de análisis convencionales son la cromatografía de gases y la espectrometría de masas pero los resultados obtenidos no suelen ser adecuados a las necesidades y se necesita de un personal cualificado e instruido en su manejo.
Un ejemplo de sensores estudiados desde los años 70 son los que utilizan
semiconductores y metales catalíticos. Éstos funcionan a altas temperaturas (100-600 ºC) y miden la variación de la conductividad eléctrica en la superficie del conductor en función de la concentración de oxígeno absorbido, que participa en la combustión. A mayor acumulación de moléculas volátiles (aroma), menor concentración de oxígeno absorbido.
Otro ejemplo de materiales son los polímeros conductores que trabajan a
temperatura ambiente (20-60 ºC) [10].

Introducción y antecedentes Ismael Lapiedra Michel
-5-
Una vez hemos extraído la información necesaria con los sensores pasamos al pre-procesado de la información en el que prepararemos los datos obtenidos para ser analizados. La extracción de la información relevante, es el apartado más importante de todos ya que determinará los resultados que queramos obtener. Ese es el fin por el cual hemos estado trabajado ene este proyecto. El hecho de obtener gran cantidad de información de un sistema, nos hace inviable, a veces, su estudio y análisis. Por ello, hemos aplicado estos métodos de selección de variables [11, 12, 13] por los cuales conseguiremos reducir drásticamente la información obtenida, quedándonos únicamente con la más relevante. Cuando los tengamos preparados aplicaremos sistemas de reconocimiento de patrones y obtendremos unos resultados que pueden tener relación con la discriminación de gases o la cuantificación de éstos dependiendo de el método de extracción utilizado y la finalidad.
Figura 1. Esquema de los procedimientos de obtención de resultados mediante algoritmos de reconocimiento de
patrones.
Hoy en día contamos en el mercado con diversos equipos de análisis o narices electrónicas como el FOX 2000, AromaScan, Nordic Sensor, etc... La mayoría de las aplicaciones de éstos son industriales aunque también encontramos medioambientales y de investigación
Como aplicaciones actuales de estas técnicas encontramos la industria
agroalimentaria (capacidad de abstraer los aromas de los vinos, por ejemplo, o el proceso de maduración de la fruta [14]), el control medioambiental o el campo de la medicina.

Objetivos del proyecto Ismael Lapiedra Michel
-6-
1 OBJETIVOS DEL PROYECTO Como ya hemos comentado antes, se está extendiendo el uso de las narices
electrónicas en muchos ámbitos académicos y de la industria. Este hecho hace que se intente estandarizar el mecanismo de medida para que se pueda aplicar a un mayor número de ensayos de diferente tipo con sólo unas pequeñas modificaciones en el tratamiento de los datos.
No obstante, la técnica aún no se ha perfeccionado, en el caso de muchos
campos de aplicación, y este pretende ser el objetivo de este proyecto. Algunos aspectos importantes son la robustez, la potencia de cálculo y la sencillez. La complejidad de los datos adquiridos por estas máquinas hace muy dificultoso el camino para extraer la información más relevante.
La enorme cantidad de datos proporcionada por las narices electrónicas,
pudiéndose hacer extensible a cualquier método de extracción de características de un sistema u a otros campos de la ciencia, hace muy difícil, e incluso a veces imposible, el tratamiento de los datos obtenidos.
Para ello hemos planteado crear e implementar diferentes métodos de selección
de variables o información, para intentar reducir al máximo la cantidad de información con la que partimos a la hora de analizar dichos datos. Básicamente, en este proyecto, buscaremos nuevos métodos y metodologías para la selección de variables y combinaremos éstas junto con las Redes Neuronales. Seguidamente, plasmaremos estas ideas en unos algoritmos de selección, para concluir en unos programas implementados con Matlab que nos permitan reducir la cantidad de información relevante a analizar.
Esta claro que gran parte de esa información estará compuesta por errores,
derivas e interferencias que ocultarán las características importantes del sistema. Con estos métodos pretendemos diferenciar la información importante de la que no lo es tanto y nos camufla la importancia del sistema.
Para probar que con estos programas de selección de variables obtenemos
resultados satisfactorios, se han utilizado dos ficheros de datos para ejecutar las pruebas pertinentes. LA razón por la cual se han utilizado dos ficheros, es que con uno, al tratarse de un fichero pequeño y sin errores, los resultados no nos han mostrado información relevante sobre algunos métodos, mientras que al utilizar el segundo, ya más complicado y grande, hemos podido probar adecuadamente la funcionalidad de éstos.
Finalmente, se ha pretendido reunir y englobar todos los métodos de selección
de variables implementados en un programa de interfície gráfica que interactúe con el usuario con la finalidad de poder ejecutar esos programas de reducción de información a otro tipo de datos. Este programa será de gran ayuda para comprender el enorme potencial que tienen estos métodos así como para ayudar en las tareas docentes y académicas que puedan surgir en este centro.

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-7-
2 · OBTENCIÓN DE LOS DATOS Y PREPROCESADO En este proyecto se ha decidido hacer pruebas con dos tipos de ficheros. El primero es sencillo por que sólo tiene 13 variables o columnas y porque los datos en si están muy claros, o sea, no existen variables que se engloben en dos tipos diferentes o, la posibilidad de errores a la hora de aplicar un método de selección. El segundo, en cambio, consta de 30 variables o columnas que son relativamente más complicadas. Cabe la posibilidad de solapamiento de grupos y, evidentemente, el tamaño es mayor. Como es de esperar, el hecho de operar con un fichero de datos mayor implica más tiempo y la necesidad de mayor potencia de cálculo. A continuación pasaremos a describir cómo se han obtenido los respectivos datos, empezando por el fichero sencillo. Para ello empezaremos describiendo los sensores utilizados y el proceso de toma de datos. Los sensores son del tipo micro-hotplate y están compuestos de diferentes capas de silicio y metales que se depositan sobre las anteriores mediante máscaras [15]. Este proceso es muy delicado y se consiguen capas de nm o µm. También intervienen otros pasos como las oxidaciones en el proceso de elaboración de un sensor, que pasamos a describir gráficamente a continuación:
Figura 2 . Proceso de fabricación de sensores del tipo micro-hotplate.

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-8-
Una vez se tienen los sensores, se pasa a tomar las medidas mediante un equipo compuesto por un ordenador, un sistema para humedecer el aire, aire sintético, CO y NO2. Teniendo en cuenta la necesidad de un control que lo gestione todo. Se intenta mantener una humedad del 20 % y van variando las concentraciones de los diferentes gases así como éstos mismos para ir consiguiendo las medidas. Éstas se irán tomando según muestra esta tabla:
CO[ppm] NO2 [ppm]
Tabla 1. Medidas realizadas combinando CO y NO2 a diferentes concentraciones.
Para obtener y analizar la respuesta dinámica del sensor se va variando o
modulando, ya que se trata de una onda, la temperatura de trabajo del sensor. Una vez tenemos todas las medidas necesarias pasaremos a preprocesar un poco
esa información, así pues aplicamos un método de filtraje de los datos que fue el análisis WAVELET. Este análisis nos proporciona información tanto temporal como frecuencial al contrario de FFT, que únicamente nos proporciona información frecuencial. Dependiendo de la familia de gráficas que utilicemos para descomponer una señal, obtendremos unos determinados coeficientes. Una señal la podemos descomponer en la suma de una secuencia compuesta por coeficientes y otros parámetros tal como sigue:
[ ] [ ] ...k)xW(2a...
3)W(4x
2)W(4x1)W(4x
W(4x)
aaaa1)W(2x
W(2x)aaW(x)a faf(x) j
k2765432 1x0 j +−++
−
−−
+
−
++=+
(1) Donde W(2x) son ondas de nivel 1, W(4x) son ondas de nivel 2 y así
sucesivamente. Una vez hemos obtenido estos coeficientes que componen la señal, los utilizaremos para analizar los datos. Un ejemplo de la representación de los coeficientes de nivel 1, 2 y 3 para una función bior 3.3 (que es la que utilizaremos para todas las medidas) es la siguiente figura:
0 20 40 80 130 0 10 20 40 60

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-9-
figura 3 . Representación de los coeficientes de nivel 1, 2 y 3 fruto de la descomposición de una señal de CO con el método WAVELET. Este método es muy laborioso ya que debemos crear un workspace que se llame
igual que la variable que contiene, en la que están los datos de una medida. Una vez tengamos esto debemos hacerlo para cada una de las medidas (48 en total). Seguidamente aplicar dicho análisis, de forma manual, para cada uno de los ficheros y guardarlos para después agruparlos y crear la tabla final, que posteriormente simplificaremos. Para analizar los datos hemos elegido la función BIOR 3.3 y al tercer nivel de análisis. Éste ha sido en 1-D y no en 2-D. El resultado de todo esto ha sido una tabla de 48 medidas por 45 coeficientes.
Una vez tenemos una tabla con los coeficientes wavelet para cada medida, de
dimensiones 48 por 45 coeficientes, debemos hacer una primera selección de los coeficientes más significativos. Con esto, facilitaremos el análisis y los resultados no variaran sustancialmente.
La primera solución que se me ocurrió fue la de representar cada una de las
medidas, con sus correspondientes coeficientes y observé que todos tenían la misma forma: un pico inicial con unos secundarios seguidamente. Entonces, la solución fue elegir los coeficientes que englobaban el pico inicial y un poco más ya que eso será lo más representativo de cada medida. La representación para la primera medida de CO fue la siguiente:

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-10-
Figura 4 . “Plot” o representación de la 1ª medida de CO respecto los coeficientes. La elección, vista la gráfica, fueron 14 coeficientes que se comprendían entre el
cuarto y el diecisieteavo. En estos coeficientes se encuentran las mayores diferencias entre medidas.
Seguidamente decidimos realizar un ploteado de los resultados en forma polar y
para ello utilizamos la tabla con los 14 coeficientes para cada una de las 48 medidas y con el programa MATLAB, dibujamos cada una de las medidas en forma polar y también todas las agrupaciones de medidas del mismo gas con la misma concentración. Un ejemplo de esto último es este:

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-11-
Figura 5 . Representación polar de diferentes muestras de gases (CO y NO2 a
20 ppm).
En la gráfica hemos representado dos medidas de concentración 20 ppm de CO (pintadas en rojo) y dos medidas de concentración 10 ppm de NO2 (pintadas de azul). En la representación, vemos que si existen diferencias entre cada uno de los grupos de dos medidas y eso nos reafirma que podemos aplicar otros métodos para conseguir una discriminación más determinante tanto entre gases como entre concentraciones.
Finalmente, si cogemos y representamos las medidas nos damos cuenta que la
séptima fila es una fila nula o de ceros, cosa que no nos aporta ninguna información relevante. Es más, nos estorbará en la aplicación de los diferentes métodos. Con lo que se decide eliminar esa columna para más comodidad. Con ello obtenemos una tabla de 13 posiciones o variables (columnas) por 48 filas o medidas. Estos serán los datos que utilizaremos para probar los diferentes métodos. Éstos se representan a continuación: Columns 1 through 11 1.0661 1.2560 0.6310 -0.1725 0.0361 0.0009 0 0.0215 0.1108 0.0217 0.0246 1.0308 1.2269 0.6017 -0.1648 0.0348 0.0009 0 0.0205 0.1060 0.0256 0.0251 1.0052 1.2061 0.5804 -0.1594 0.0338 0.0008 0 0.0200 0.1033 0.0286 0.0250 0.9848 1.1907 0.5643 -0.1553 0.0332 0.0008 0 0.0195 0.1015 0.0315 0.0256 0.7838 1.0251 0.3521 -0.0998 0.0233 0.0006 0 0.0137 0.0681 0.0529 0.0277 0.7617 0.9944 0.3477 -0.0987 0.0228 0.0006 0 0.0134 0.0679 0.0524 0.0218 0.7494 0.9904 0.3435 -0.0979 0.0227 0.0006 0 0.0133 0.0676 0.0507 0.0186 0.7402 0.9833 0.3392 -0.0970 0.0225 0.0006 0 0.0132 0.0671 0.0492 0.0159 0.5729 0.7630 0.2354 -0.0690 0.0163 0.0004 0 0.0095 0.0461 0.0397 0.0013 0.5656 0.7533 0.2357 -0.0691 0.0163 0.0004 0 0.0095 0.0465 0.0388 -0.0002 0.5620 0.7462 0.2352 -0.0690 0.0163 0.0004 0 0.0095 0.0465 0.0395 0.0006 0.5569 0.7423 0.2342 -0.0687 0.0161 0.0004 0 0.0094 0.0465 0.0395 -0.0015 0.4380 0.6232 0.1833 -0.0530 0.0123 0.0003 0 0.0073 0.0358 0.0369 0.0036

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-12-
0.4163 0.6013 0.1833 -0.0535 0.0123 0.0003 0 0.0072 0.0367 0.0335 -0.0033 0.4091 0.5915 0.1824 -0.0531 0.0121 0.0003 0 0.0071 0.0368 0.0324 -0.0045 0.4045 0.5858 0.1831 -0.0534 0.0122 0.0003 0 0.0072 0.0376 0.0325 -0.0046 0.5128 2.0450 -0.0903 0.0009 0.0089 0.0003 0 0.0057 0.0194 0.0510 -0.0344 0.2798 2.1350 0.0119 -0.0108 0.0072 0.0002 0 0.0056 0.0262 0.0003 0.0419 0.2648 2.1243 -0.0039 -0.0067 0.0063 0.0002 0 0.0051 0.0223 -0.0032 0.0392 0.2609 2.1261 -0.0072 -0.0058 0.0061 0.0002 0 0.0049 0.0212 -0.0027 0.0385 0.5345 2.3087 -0.1012 0.0055 0.0081 0.0002 0 0.0054 0.0168 0.0632 -0.0150 0.5439 2.3233 -0.0962 0.0044 0.0082 0.0002 0 0.0056 0.0176 0.0641 -0.0145 0.5462 2.3323 -0.0947 0.0040 0.0084 0.0003 0 0.0056 0.0181 0.0656 -0.0130 0.5462 2.3323 -0.0947 0.0040 0.0084 0.0003 0 0.0056 0.0181 0.0656 -0.0130 0.5680 2.6112 -0.0603 -0.0030 0.0090 0.0003 0 0.0061 0.0222 0.0758 -0.0021 0.6076 2.6529 -0.0364 -0.0095 0.0102 0.0003 0 0.0070 0.0278 0.0771 -0.0010 0.6199 2.6636 -0.0294 -0.0113 0.0106 0.0003 0 0.0072 0.0290 0.0779 -0.0004 0.6309 2.6777 -0.0222 -0.0133 0.0109 0.0003 0 0.0074 0.0301 0.0780 -0.0011 0.8453 2.9777 0.0715 -0.0349 0.0117 0.0003 0 0.0080 0.0246 0.1383 -0.0266 0.9650 3.0755 0.1427 -0.0532 0.0152 0.0004 0 0.0104 0.0360 0.1339 -0.0189 0.9998 3.1064 0.1689 -0.0599 0.0164 0.0005 0 0.0113 0.0399 0.1290 -0.0172 1.0142 3.1178 0.1798 -0.0627 0.0169 0.0005 0 0.0117 0.0413 0.1272 -0.0167 0.3494 0.9441 -0.0744 0.0004 0.0020 0.0001 0 0.0011 -0.0071 0.0530 -0.1536 0.3876 1.0912 -0.0663 -0.0051 0.0037 0.0001 0 0.0022 -0.0002 0.0490 -0.1715 0.4203 1.2322 -0.0615 -0.0091 0.0052 0.0001 0 0.0030 0.0061 0.0482 -0.1858 0.4477 1.3462 -0.0570 -0.0125 0.0063 0.0002 0 0.0037 0.0106 0.0470 -0.1968 0.6543 1.4568 -0.0269 -0.0236 0.0088 0.0002 0 0.0052 0.0147 0.0868 -0.2170 0.7381 1.6268 -0.0133 -0.0281 0.0109 0.0003 0 0.0064 0.0224 0.1054 -0.1999 0.7876 1.7398 -0.0027 -0.0317 0.0122 0.0003 0 0.0073 0.0280 0.1139 -0.1932 0.8498 1.8721 0.0114 -0.0359 0.0139 0.0004 0 0.0082 0.0329 0.1245 -0.1807 1.6258 3.2291 0.9008 -0.2542 0.0540 0.0014 0 0.0331 0.1875 0.0815 -0.0326 1.7072 3.2689 0.9777 -0.2746 0.0585 0.0015 0 0.0356 0.2051 0.0814 -0.0196 1.7389 3.2870 1.0053 -0.2819 0.0603 0.0015 0 0.0368 0.2141 0.0848 -0.0079 1.7706 3.2961 1.0334 -0.2889 0.0619 0.0015 0 0.0376 0.2204 0.0895 0.0032 1.3423 2.6050 0.2512 -0.1016 0.0292 0.0008 0 0.0173 0.0722 0.1243 -0.1347 1.1796 2.9722 0.4833 -0.1485 0.0344 0.0009 0 0.0215 0.1180 0.0961 -0.0555 1.2839 3.0389 0.5544 -0.1662 0.0378 0.0010 0 0.0236 0.1282 0.0933 -0.0479 1.3789 3.0909 0.6245 -0.1835 0.0409 0.0011 0 0.0257 0.1387 0.0909 -0.0404 Columns 12 through 14 0.0479 0.1090 0.0024 0.0491 0.1049 0.0023 0.0506 0.1021 0.0022 0.0522 0.1000 0.0022 0.0609 0.0702 0.0015 0.0577 0.0689 0.0015 0.0582 0.0685 0.0015 0.0576 0.0679 0.0015 0.0454 0.0492 0.0011 0.0441 0.0491 0.0011 0.0445 0.0490 0.0011 0.0431 0.0486 0.0011 0.0319 0.0372 0.0008 0.0303 0.0370 0.0008 0.0286 0.0365 0.0008 0.0293 0.0368 0.0008 0.1280 0.0275 0.0007 0.0715 0.0223 0.0006 0.0709 0.0198 0.0005 0.0700 0.0191 0.0005 0.1282 0.0251 0.0007 0.1271 0.0255 0.0007 0.1278 0.0259 0.0007

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-13-
0.1278 0.0259 0.0007 0.1181 0.0278 0.0007 0.1181 0.0316 0.0008 0.1181 0.0327 0.0008 0.1172 0.0336 0.0009 0.0713 0.0362 0.0009 0.0716 0.0469 0.0012 0.0708 0.0506 0.0013 0.0701 0.0520 0.0013 0.0285 0.0061 0.0002 0.0386 0.0114 0.0003 0.0480 0.0157 0.0004 0.0554 0.0192 0.0004 0.0609 0.0269 0.0006 0.0782 0.0333 0.0008 0.0876 0.0373 0.0009 0.0994 0.0422 0.0010 0.0811 0.1636 0.0037 0.0894 0.1769 0.0039 0.0957 0.1824 0.0040 0.0989 0.1869 0.0041 0.1398 0.0887 0.0020 0.0874 0.1044 0.0024 0.0871 0.1146 0.0026 0.0855 0.1243 0.0028
Como podemos observar, la columna séptima es nula, con lo que nos
desharemos de ella quedándonos con 13 columnas. Por lo que respecta al segundo fichero, es el resultado de las medidas hechas en
una matriz de doce sensores de óxido de estaño en un recipiente donde introduc imos diferentes gases simples o mezclas binarias. Los gases utilizados son: Acetona, Amoníaco y Ortoxileno. Disponemos de en total de 240 ficheros de partida que salen de las 240 medidas hechas con la matriz de los 12 sensores y que son combinaciones de gases repetidas 4 veces y en días diferentes.
El equipo de medida utilizado será:
- Una cámara estanco construida en el laboratorio. - Una matriz de sensores. - Un ventilador para homogeneizar la muestra. - Un termómetro para controlar la temperatura. - Un Higrómetro para controlar la humedad. - Un P.C. - Placa de interfície. - Placa de adquisición. - Un cable de conexión al P.C.
La matriz de sensores se conecta a través de un cable plano a una placa de
interfície. Esta placa está conectada a la placa de adquisición de datos instalada en el PC, que permitirá recoger las variaciones de cada sensor.
Respecto a los sensores utilizados, se trata de sensores químicos del tipo
semiconductor y en concreto de Óxido de estaño. Este tipo de sensores puede clasificarse como sensor químico de tipo modulador, en el que algún parámetro del

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-14-
sensor se modifica debido a la energía del medio, a diferencia de los sensores químicos generadores, que transforman de forma directa esta energía en forma de tensión o de corriente.
El principio de funcionamiento es el detallado a continuación. Cuando el sensor
se calienta a una elevada temperatura, sin la presencia de oxígeno, los electrones atraviesan fácilmente a través de la banda de conducción de las partículas de óxido de estaño. En presencia de oxígeno, las partículas de óxido de estaño absorben este oxígeno y, debido a su elevada electroafinidad, atrapan los electrones que se deslizan por la banda de conducción. Se forma así una barrera de potencial que impide el paso de electrones, haciendo que la resistencia eléctrica aumente.
Cuando el sensor de expone delante de una atmósfera que contiene gases
reductores, como pueden ser gases combustibles, el CO, etc…, las partículas de óxido de de estaño absorben las moléculas de gas reductor, causando así la oxidación entre estas moléculas y el oxígeno absorbido. Esto hace disminuir la barrera de potencial que se habá creado al principio, reduciendo, por tanto, la resistencia eléctrica del sensor.
La reacción entre gases y la superficie de oxígeno varía según la temperatura a
la que esté el sensor, y depende también del grado de actividad del material sensor, es decir de la capa de óxido de estaño.
Para realizar estas medidas, se prepara un recipiente para cada una de ellas. Una
vez tenemos los recipientes preparados con estas proporciones de contaminantes, ya podemos inyectarlas. Para la realización de las medidas se utiliza una metodología estricta. El ventilador de la cámara estará en funcionamiento todo el rato de forma contraria introduciríamos perturbaciones en la lectura del sensor. Así el proceso detallado es el siguiente:
Partimos de una cámara limpia, unos sensores estabilizados y una humedad controlada del 30%.
1. Se carga la jeringuilla con un volumen de líquido contaminante apropiado para la concentración que queremos medir.
2. Se inicia el programa de adquisición de datos, introduciendo todos los datos
sobre el experimento que nos pedirá el programa. Obtendremos una documentación adecuada para cada medida.
3. Se empiezan a adquirir los datos antes de inyectar el contaminante en la cámara. 4. Esperamos unos 10 minutos para asegurarnos que los sensores están totalmente
estabilizados.
5. Se limpia la cámara con la introducción de aire sintético durante un par de
minutos.

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-15-
6. No volveremos a medir hasta pasada una hora para asegurarnos la estabilidad de los sensores.
Una vez obtenidas las medidas en forma de ficheros de datos se deben tratar
para poder operar con ellos. Se debe, por tanto, eliminar las cabeceras del fichero de texto donde tenemos la información de los gases en sí, temperatura, humedad, etc…
También eliminaremos la primera fila de la matriz, en el título, ya que son
nombres y la última fila, porque hay errores. A partir de este fichero elaboraremos la matriz final de datos. Fabricaremos una matriz con tantas filas como ficheros tenemos, o sea 240, y tantas columnas como parámetros por sensor, tenemos 10 parámetros y 12 sensores.
En nuestro caso tenemos 48 filas ya que hemos escogido las 48 mezclas binarias
de una sola prueba. Se ha dicho que se han cogido 48 mezclas binarias y 12 simples, o sea 60, y se han realizado 4 pruebas para todas ellas obteniendo así las 240 filas. Nosotros contaremos con una matriz de 48 filas ya que tratamos sólo una prueba y sólo las mezclas binarias. Nuestro fichero final también cuenta sólo con 30 columnas en vez de 120, para reducir tiempo de cálculo.
La matriz finalmente utilizada será la siguiente:
Columns 1 through 12 0.0005 0.0010 0.0018 0.0049 0.0005 0.0004 0.0059 0.0009 0.0091 0.0136 0.0035 0.0025 0.0060 0.0019 0.0052 0.0043 0.0018 0.0051 0.0095 0.0019 0.0037 0.0090 0.0036 0.0015 0.0004 0.0013 0.0017 0.0027 0.0005 0.0003 0.0033 0.0008 0.0116 0.0211 0.0091 0.0022 0.0007 0.0019 0.0026 0.0059 0.0009 0.0006 0.0096 0.0017 0.0157 0.0225 0.0064 0.0042 0.0030 0.0088 0.0062 0.0213 0.0054 0.0023 0.0130 0.0032 0.0313 0.0439 0.0092 0.0177 0.0185 0.0077 0.0193 0.0137 0.0052 0.0162 0.0315 0.0056 0.0148 0.0282 0.0058 0.0051 0.0011 0.0031 0.0027 0.0105 0.0029 0.0012 0.0042 0.0013 0.0153 0.0248 0.0081 0.0097 0.0011 0.0032 0.0031 0.0110 0.0025 0.0011 0.0071 0.0011 0.0121 0.0166 0.0026 0.0082 0.0005 0.0015 0.0022 0.0043 0.0006 0.0005 0.0066 0.0011 0.0149 0.0225 0.0067 0.0032 0.0061 0.0017 0.0044 0.0041 0.0018 0.0053 0.0080 0.0018 0.0030 0.0076 0.0028 0.0014 0.0088 0.0025 0.0062 0.0054 0.0024 0.0081 0.0146 0.0024 0.0019 0.0065 0.0013 0.0016 0.0041 0.0126 0.0089 0.0266 0.0063 0.0028 0.0191 0.0047 0.0413 0.0572 0.0109 0.0222 0.0012 0.0030 0.0043 0.0106 0.0013 0.0011 0.0120 0.0027 0.0222 0.0318 0.0062 0.0064 0.0027 0.0081 0.0073 0.0198 0.0047 0.0024 0.0272 0.0029 0.0309 0.0397 0.0063 0.0158 0.0035 0.0120 0.0094 0.0260 0.0058 0.0027 0.0144 0.0045 0.0420 0.0548 0.0079 0.0208 0.0008 0.0014 0.0026 0.0070 0.0007 0.0006 0.0085 0.0015 0.0117 0.0174 0.0043 0.0034 0.0028 0.0090 0.0060 0.0202 0.0052 0.0022 0.0105 0.0033 0.0326 0.0453 0.0086 0.0167 0.0173 0.0081 0.0183 0.0131 0.0051 0.0154 0.0262 0.0053 0.0152 0.0296 0.0077 0.0049 0.0016 0.0050 0.0046 0.0148 0.0035 0.0016 0.0066 0.0016 0.0193 0.0251 0.0038 0.0120 0.0085 0.0027 0.0065 0.0055 0.0024 0.0078 0.0144 0.0024 0.0023 0.0068 0.0014 0.0015 0.0038 0.0121 0.0102 0.0254 0.0059 0.0029 0.0356 0.0045 0.0421 0.0551 0.0087 0.0208 0.0006 0.0025 0.0030 0.0068 0.0011 0.0005 0.0078 0.0017 0.0199 0.0276 0.0065 0.0043 0.0176 0.0081 0.0187 0.0135 0.0051 0.0157 0.0361 0.0054 0.0151 0.0289 0.0075 0.0052 0.0012 0.0019 0.0040 0.0103 0.0010 0.0009 0.0149 0.0022 0.0137 0.0218 0.0052 0.0053 0.0013 0.0039 0.0033 0.0128 0.0028 0.0013 0.0045 0.0013 0.0152 0.0204 0.0029 0.0093 0.0008 0.0022 0.0028 0.0067 0.0009 0.0008 0.0074 0.0019 0.0196 0.0270 0.0060 0.0043 0.0003 0.0011 0.0016 0.0022 0.0004 0.0003 0.0044 0.0007 0.0090 0.0166 0.0082 0.0019 0.0004 0.0018 0.0028 0.0051 0.0008 0.0004 0.0081 0.0013 0.0202 0.0303 0.0124 0.0044 0.0017 0.0056 0.0048 0.0165 0.0038 0.0017 0.0069 0.0020 0.0228 0.0292 0.0040 0.0128 0.0004 0.0007 0.0014 0.0033 0.0004 0.0002 0.0035 0.0008 0.0053 0.0087 0.0024 0.0016 0.0123 0.0043 0.0107 0.0085 0.0035 0.0113 0.0215 0.0037 0.0067 0.0146 0.0030 0.0027 0.0011 0.0024 0.0039 0.0094 0.0012 0.0011 0.0171 0.0024 0.0177 0.0262 0.0061 0.0058

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-16-
0.0119 0.0045 0.0104 0.0085 0.0035 0.0110 0.0252 0.0035 0.0074 0.0156 0.0040 0.0029 0.0014 0.0026 0.0041 0.0105 0.0014 0.0010 0.0163 0.0028 0.0159 0.0262 0.0067 0.0073 0.0060 0.0017 0.0044 0.0042 0.0018 0.0053 0.0115 0.0018 0.0031 0.0075 0.0028 0.0015 0.0117 0.0043 0.0103 0.0081 0.0033 0.0106 0.0198 0.0036 0.0062 0.0136 0.0028 0.0025 0.0019 0.0066 0.0045 0.0173 0.0047 0.0019 0.0082 0.0023 0.0261 0.0372 0.0074 0.0150 0.0041 0.0132 0.0088 0.0260 0.0064 0.0027 0.0167 0.0048 0.0439 0.0607 0.0107 0.0218 0.0090 0.0028 0.0063 0.0059 0.0026 0.0085 0.0180 0.0023 0.0028 0.0076 0.0016 0.0019 0.0017 0.0050 0.0038 0.0150 0.0041 0.0016 0.0070 0.0018 0.0205 0.0295 0.0067 0.0132 0.0057 0.0018 0.0050 0.0041 0.0017 0.0048 0.0097 0.0018 0.0037 0.0085 0.0034 0.0015 0.0116 0.0045 0.0100 0.0081 0.0034 0.0105 0.0173 0.0033 0.0072 0.0157 0.0041 0.0028 0.0014 0.0046 0.0036 0.0135 0.0037 0.0015 0.0053 0.0018 0.0222 0.0338 0.0094 0.0121 0.0024 0.0079 0.0064 0.0192 0.0044 0.0021 0.0094 0.0029 0.0298 0.0382 0.0057 0.0151 0.0084 0.0026 0.0059 0.0055 0.0025 0.0079 0.0119 0.0022 0.0029 0.0078 0.0017 0.0017 0.0005 0.0012 0.0022 0.0047 0.0007 0.0005 0.0043 0.0012 0.0154 0.0221 0.0064 0.0034 0.0173 0.0075 0.0183 0.0130 0.0050 0.0152 0.0292 0.0055 0.0139 0.0267 0.0054 0.0045 0.0005 0.0007 0.0013 0.0036 0.0003 0.0002 0.0034 0.0007 0.0056 0.0090 0.0024 0.0016 Columns 13 through 24 0.0006 0.0021 0.0021 0.0077 0.0006 0.0004 0.0061 0.0011 0.0184 0.0242 0.0055 0.0037 0.0062 0.0028 0.0057 0.0048 0.0021 0.0055 0.0096 0.0022 0.0045 0.0110 0.0041 0.0016 0.0004 0.0021 0.0021 0.0035 0.0005 0.0004 0.0035 0.0009 0.0191 0.0322 0.0112 0.0029 0.0008 0.0032 0.0029 0.0077 0.0011 0.0006 0.0101 0.0018 0.0299 0.0373 0.0089 0.0060 0.0030 0.0092 0.0063 0.0214 0.0054 0.0023 0.0130 0.0032 0.0333 0.0453 0.0092 0.0180 0.0188 0.0112 0.0204 0.0158 0.0058 0.0180 0.0317 0.0062 0.0189 0.0350 0.0066 0.0059 0.0012 0.0033 0.0027 0.0106 0.0029 0.0013 0.0043 0.0013 0.0157 0.0253 0.0081 0.0098 0.0012 0.0034 0.0032 0.0111 0.0025 0.0012 0.0071 0.0011 0.0127 0.0172 0.0026 0.0084 0.0006 0.0025 0.0023 0.0058 0.0007 0.0005 0.0067 0.0012 0.0267 0.0358 0.0091 0.0043 0.0062 0.0028 0.0050 0.0047 0.0021 0.0057 0.0081 0.0020 0.0038 0.0098 0.0034 0.0016 0.0089 0.0043 0.0070 0.0066 0.0028 0.0087 0.0146 0.0027 0.0037 0.0100 0.0018 0.0019 0.0042 0.0132 0.0089 0.0267 0.0064 0.0028 0.0191 0.0047 0.0449 0.0598 0.0110 0.0228 0.0013 0.0057 0.0048 0.0138 0.0015 0.0011 0.0125 0.0029 0.0458 0.0541 0.0085 0.0094 0.0027 0.0087 0.0073 0.0198 0.0048 0.0024 0.0272 0.0030 0.0334 0.0412 0.0064 0.0161 0.0036 0.0127 0.0095 0.0260 0.0059 0.0028 0.0145 0.0045 0.0450 0.0577 0.0080 0.0214 0.0009 0.0029 0.0030 0.0104 0.0008 0.0007 0.0091 0.0016 0.0238 0.0306 0.0065 0.0052 0.0029 0.0094 0.0060 0.0203 0.0053 0.0022 0.0105 0.0033 0.0341 0.0466 0.0087 0.0171 0.0176 0.0119 0.0195 0.0146 0.0056 0.0167 0.0264 0.0058 0.0183 0.0355 0.0084 0.0057 0.0017 0.0054 0.0047 0.0149 0.0036 0.0017 0.0066 0.0017 0.0206 0.0261 0.0039 0.0122 0.0087 0.0044 0.0072 0.0067 0.0028 0.0083 0.0144 0.0027 0.0039 0.0100 0.0018 0.0019 0.0038 0.0128 0.0103 0.0255 0.0059 0.0029 0.0356 0.0045 0.0458 0.0578 0.0088 0.0213 0.0007 0.0044 0.0033 0.0087 0.0013 0.0005 0.0078 0.0018 0.0357 0.0439 0.0089 0.0060 0.0178 0.0117 0.0198 0.0150 0.0056 0.0172 0.0361 0.0059 0.0184 0.0347 0.0083 0.0059 0.0013 0.0041 0.0048 0.0148 0.0011 0.0009 0.0155 0.0024 0.0305 0.0399 0.0075 0.0082 0.0013 0.0042 0.0034 0.0129 0.0029 0.0013 0.0046 0.0013 0.0158 0.0208 0.0030 0.0095 0.0009 0.0039 0.0030 0.0088 0.0011 0.0008 0.0075 0.0020 0.0359 0.0434 0.0083 0.0060 0.0004 0.0017 0.0019 0.0029 0.0004 0.0004 0.0045 0.0008 0.0151 0.0262 0.0104 0.0025 0.0005 0.0030 0.0033 0.0066 0.0010 0.0004 0.0082 0.0014 0.0329 0.0440 0.0148 0.0056 0.0018 0.0060 0.0048 0.0165 0.0038 0.0017 0.0069 0.0020 0.0240 0.0302 0.0041 0.0131 0.0004 0.0013 0.0018 0.0050 0.0005 0.0003 0.0037 0.0009 0.0103 0.0153 0.0040 0.0026 0.0126 0.0066 0.0115 0.0099 0.0040 0.0122 0.0216 0.0041 0.0094 0.0195 0.0036 0.0032 0.0012 0.0046 0.0043 0.0124 0.0013 0.0011 0.0179 0.0026 0.0376 0.0459 0.0085 0.0087 0.0121 0.0070 0.0112 0.0096 0.0039 0.0118 0.0253 0.0038 0.0094 0.0200 0.0048 0.0034 0.0014 0.0048 0.0047 0.0138 0.0016 0.0010 0.0181 0.0030 0.0366 0.0478 0.0092 0.0111 0.0061 0.0027 0.0050 0.0048 0.0021 0.0056 0.0115 0.0020 0.0038 0.0096 0.0034 0.0017 0.0118 0.0063 0.0110 0.0096 0.0038 0.0113 0.0199 0.0040 0.0084 0.0179 0.0034 0.0029 0.0020 0.0070 0.0045 0.0174 0.0048 0.0019 0.0082 0.0023 0.0270 0.0379 0.0074 0.0152 0.0042 0.0139 0.0088 0.0261 0.0065 0.0027 0.0168 0.0049 0.0471 0.0632 0.0107 0.0223 0.0092 0.0050 0.0072 0.0069 0.0031 0.0091 0.0182 0.0026 0.0044 0.0115 0.0022 0.0022 0.0017 0.0053 0.0038 0.0150 0.0042 0.0016 0.0070 0.0018 0.0212 0.0301 0.0068 0.0133

Obtención de los datos y preprocesado Ismael Lapiedra Michel
-17-
0.0059 0.0026 0.0055 0.0047 0.0019 0.0052 0.0097 0.0020 0.0044 0.0104 0.0039 0.0016 0.0119 0.0071 0.0110 0.0093 0.0039 0.0114 0.0174 0.0037 0.0092 0.0205 0.0049 0.0032 0.0015 0.0049 0.0036 0.0135 0.0037 0.0015 0.0053 0.0019 0.0227 0.0344 0.0094 0.0122 0.0025 0.0084 0.0065 0.0192 0.0045 0.0021 0.0095 0.0030 0.0314 0.0398 0.0058 0.0155 0.0086 0.0047 0.0068 0.0064 0.0029 0.0084 0.0120 0.0024 0.0043 0.0114 0.0023 0.0021 0.0005 0.0025 0.0024 0.0065 0.0008 0.0005 0.0044 0.0013 0.0289 0.0372 0.0088 0.0046 0.0175 0.0108 0.0192 0.0150 0.0055 0.0165 0.0293 0.0060 0.0174 0.0328 0.0060 0.0052 0.0006 0.0013 0.0017 0.0055 0.0004 0.0003 0.0036 0.0009 0.0109 0.0161 0.0039 0.0025 Columns 25 through 30 0.0150 0.0677 0.0425 0.0820 0.0374 0.0126 0.1284 0.1070 0.1421 0.1160 0.1305 0.1327 0.0116 0.0771 0.0571 0.0799 0.0351 0.0124 0.0391 0.1247 0.0910 0.2353 0.1179 0.0405 0.1426 0.3500 0.2131 0.5539 0.4467 0.1360 0.3852 0.3799 0.4654 0.3089 0.3684 0.4264 0.0359 0.1366 0.0892 0.3631 0.2775 0.0442 0.0359 0.1112 0.0609 0.1356 0.1773 0.0474 0.0174 0.0950 0.0658 0.1498 0.0612 0.0163 0.1761 0.1064 0.1455 0.1452 0.1801 0.1773 0.2811 0.1464 0.1722 0.1279 0.2262 0.3074 0.2285 0.4767 0.3031 0.5576 0.4367 0.2055 0.0534 0.1594 0.1072 0.2298 0.1161 0.0602 0.1030 0.2895 0.1685 0.3187 0.3559 0.1055 0.1370 0.4075 0.2361 0.3225 0.3562 0.1360 0.0296 0.0960 0.0631 0.1131 0.0598 0.0296 0.1307 0.3387 0.1957 0.4589 0.3902 0.1235 0.3659 0.4153 0.4997 0.3702 0.3826 0.4012 0.0445 0.1682 0.0991 0.2181 0.2359 0.0496 0.2554 0.1428 0.1658 0.1086 0.1996 0.2778 0.1605 0.4425 0.2652 0.4023 0.4159 0.1603 0.0394 0.1500 0.0984 0.2501 0.1386 0.0366 0.3777 0.4306 0.5139 0.3909 0.3922 0.4219 0.0462 0.1289 0.0935 0.1496 0.0776 0.0514 0.0388 0.1332 0.0685 0.1454 0.1981 0.0493 0.0340 0.1239 0.0774 0.1905 0.0955 0.0395 0.0117 0.0686 0.0560 0.0687 0.0312 0.0118 0.0188 0.1326 0.1231 0.2837 0.1186 0.0189 0.0503 0.1865 0.1049 0.2182 0.2463 0.0525 0.0128 0.0426 0.0329 0.0562 0.0346 0.0117 0.3138 0.2292 0.2784 0.1979 0.2856 0.3514 0.0503 0.1469 0.1038 0.2277 0.1125 0.0678 0.3236 0.2666 0.3313 0.2825 0.3422 0.3641 0.0832 0.1681 0.1246 0.3231 0.1565 0.0777 0.1873 0.1132 0.1545 0.1570 0.1892 0.1904 0.3123 0.2173 0.2661 0.1743 0.2752 0.3532 0.0675 0.2582 0.1372 0.5101 0.4537 0.0711 0.2253 0.4876 0.2893 0.5180 0.4275 0.1875 0.3367 0.1815 0.2210 0.2138 0.3073 0.3635 0.0627 0.2070 0.1240 0.5045 0.4358 0.0669 0.1078 0.0954 0.1281 0.1042 0.1108 0.1122 0.3075 0.2546 0.3181 0.2625 0.3227 0.3373 0.0425 0.1915 0.1077 0.4166 0.3174 0.0493 0.0901 0.2698 0.1557 0.2470 0.2884 0.0942 0.2903 0.1695 0.2107 0.1938 0.2826 0.3163 0.0156 0.0758 0.0638 0.1588 0.0683 0.0157 0.3707 0.3659 0.4299 0.2645 0.3457 0.4120 0.0148 0.0438 0.0303 0.0486 0.0276 0.0112

Métodos existentes para la selección de variables Ismael Lapiedra Michel
-18-
3 · MÉTODOS EXISTENTES PARA LA SELECCIÓN DE VARIABLES El hecho de encontrar un método eficaz para la selección de variables es una tarea ardua y difícil, que no se resulta nada cómoda debido a la poca información que se puede hallar al respecto. Intentar seleccionar las variables más representativas de un sistema es potencialmente interesante, ya que nos permite reducir la complejidad de los sistemas y poder simplificar el trabajo con éstos. En nuestro caso hemos utilizado dos tipos de ficheros de datos, uno más simple y el otro más complejo para poder calcular y medir la efectividad, así como comparar cada uno de los métodos. Después de una etapa de búsqueda de información sobre los diferentes métodos de selección que encontramos, nos queda la fase más costosa: la implementación de dichos métodos en diferentes programas ejecutables y la creación de una interficie de interacción con el usuario para gestionar los diferentes programas. Con la ayuda de herramientas como Internet, libros, bases de datos y demás medios de búsqueda de información, hemos conseguido aislar tres métodos realmente interesantes tanto por su “facilidad” de implementación como por su eficacia. Estos métodos son los llamados: Forward selection, Backward elimination y Stepwise selection [16,17]. Aunque sólo nos hayamos basado en estos métodos, no quiere decir que sean los únicos ni los más eficientes, pero la complejidad de otros hacían muy difícil su implementación. Recordemos que la complejidad de un método no sólo afecta a su dificultad de implementación, sino también, al tiempo de ejecución, cosa no muy crítica en este tipo de trabajos pero engorrosa como ya veremos más adelante cuando hablemos de los tiempos de ejecución de cada programa. Como introducción decir que dentro de la selección secuencial tenemos de dos tipos: incremental o decremental. En la primera se basan los algoritmos del tipo forward selection y en la segunda se basan los del tipo backward elimination. Un ejemplo de lo dicho anteriormente es el siguiente gráfico donde se muestra como funciona una selección incremental y decremental.
Figura 6. : Selección secuencial: A) incremental, B) decremental.

Métodos existentes para la selección de variables Ismael Lapiedra Michel
-19-
A continuación pasaremos a explicarlos detenidamente. 3.1 Forward selection La traducción literal sería: selección hacia delante o selección incremental, también llamada selección incremental secuencial (SFS) debido a que se basa en un bucle repetitivo y que se ejecuta secuencialmente. El principio es sencillo, consiste en ir eligiendo las variables más representativas de nuestro conjunto de variables, según un método de validación predeterminado, hasta llegar a un máximo predeterminado o una condición a cumplir. Dicha condición puede ser, por ejemplo, la de reducción del error hasta un valor tolerable.
El método tradicional de validación es el de los mínimos cuadrados que consiste en buscar la diferencia entre el valor obtenido, después de operar con la salida y la columna en cuestión (que representa una variable), y la propia salida. Principalmente, los pasos a seguir para obtener ese error son:
- Se elige una columna (representa una variable). - Se realiza un centrado de ésta. - Se hace la pseudo inversa y se multiplica por la salida esperada (también
columna). - Ahora se multiplica por la columna centrada. - Se hace, entonces, un sumatorio del resultado de restar cada una de las filas
de la columna obtenida anteriormente por su valor de salida esperado. - Seguidamente se divide todo este sumatorio por el número menos una de
filas que tenemos en esa columna y obtenemos un error para esa columna. - El proceso se repetirá tantas columnas como tengamos, para obtener los
errores de éstas. - Hay que tener en cuenta que cada vez que se elige una columna se debe
restar ésta a la totalidad de los datos para restar su contribución ya que la estamos descartando del proceso de selección.
Una vez ejecutado este bucle tantas veces como variables o columnas de datos
tengamos, obtenemos un error final para cada columna. Es entonces cuando elegiremos la columna que tenga el error menor, en este caso, para entrar en el sistema de variables seleccionadas. La que tenga el mínimo error ya que será la que mejor describa el sistema por sí sola.
Una vez elegida, volvemos a formar un sistema diferente restándole la
contribución de la columna elegida a las restantes y volviendo a ejecutar el bucle. Se elegirán tantas variables como número hallamos entrado por teclado.
Éste es básicamente el sistema implementado y la descripción del programa que
se ha realizado. Como ventajas de este método podríamos nombrar la sencillez de implementación y entendimiento, el reducido tiempo de cálculo, ya que no se utilizan redes neuronales. Las desventajas pueden ser que el número de variables a elegir es arbitrario y se entra por teclado, una vez una variable es seleccionada no se puede deseleccionar.

Métodos existentes para la selección de variables Ismael Lapiedra Michel
-20-
Este último punto es interesante ya que ésta es la razón por la cual éste método y el siguiente no son del todo efectivos. La solución será fundir estos dos en el llamado stepwise method.
Ahora pasaremos a poner un ejemplo de este método, para facilitar la
comprensión:
Ejemplo
Supongamos que disponemos de un conjunto de 5 variables y queremos seleccionar las 3 variables más relevantes con el algoritmo SFS. Así, X = {X1, X2, X3, X4, X5} por lo que d = 5 y p = 3 (donde p es el número de variables a elegir). La ejecución de SFS (X, 3) será la siguiente:
Inicialmente, Y0 = ∅ y Lo = X = {X1, X2, X3, X4, X5}
En la primera iteración (k = 0), sea ξm = X3 ( o sea, la variable elegida). Entonces,
Y1 = Y0 {X3} = {X3}
L1 = L0 - {X3} = {X1, X2, X4, X5}
En la segunda iteración (k = 1), sea ξm = X1. Entonces,
Y2 = Y1 {X1} = {X1, X3}
L2 = L1 - {X1} = {X2, X4, X5}
En la tercera (y última) iteración (k = 2), sea ξm = X5. Entonces,
Y3 = Y2 {X5} = {X1, X3, X5}
L3 = L2 - {X5} = {X2, X4}
Finalmente Y ← Y3 , por lo que Y = {X1 , X3 , X5 }será el conjunto de 3 variables seleccionado de X por el algoritmo SFS.
3.2 Backward elimination La traducción literal sería: eliminación hacia atrás o eliminación decremental, también llamada selección decremental secuencial (SBS) debido a que se basa en un bucle repetitivo y que se ejecuta secuencialmente. Se trata, básicamente, de un algoritmo top-down que selecciona una variable (para su eliminación) en cada paso.
Este método es igual que el anterior pero en vez de partir de un conjunto las variables elegidas nulas, partimos de la totalidad del grupo y vamos eliminando las que no nos interesan, de forma que nos quedemos con las variables más representativas como en el caso anterior. La condición de parada del programa será, en este caso al igual que en el anterior, haber seleccionado un número determinado de variables

Métodos existentes para la selección de variables Ismael Lapiedra Michel
-21-
entrado por teclado. Haber seleccionado o deseleccionado la totalidad menos ese número de variables. El algoritmo viene a ser el mismo ya que también se ha implementado con el método de validación de los mínimos cuadrados. O sea, una vez obtenemos un error para cada columna o variable, elegiremos para salir del conjunto aquella que su error es mayor ya que representa peor la totalidad del conjunto. Como en el caso anterior, la dificultad de implementación no es muy elevada y el tiempo de ejecución es reducido. Como desventajas, contamos con que las variables deseleccionadas o eliminadas del grupo final, no pueden ser elegidas o incluidas de nuevo en dicho grupo. Otra desventaja es que el número de variables a elegir o deselecciona es arbitrario y se introduce por teclado. A continuación pasaremos a exponer un ejemplo:
Ejemplo
Supongamos que disponemos de un conjunto de 5 variables y queremos seleccionar las 3 variables más relevantes con el algoritmo SBS. Así, X = {X1, X2, X3, X4, X5} por lo que d = 5 y p = 3. La ejecución de SBS ( X, 3) será la siguiente:
Inicialmente,. =oY~
X = {X1, X2, X3, X4, X5}
La última iteración será cuando k = d - p - 1 = 5 - 3 - 1 = 1
En la primera iteración (k = 0), sea ξm = X3. Entonces,
1~Y = oY
~- {X3} = {X1, X2, X4, X5}
En la segunda (y última) iteración (k = 1), sea ξm = X1. Entonces,
2~Y = oY
~ - {X1} = {X2, X4, X5}
Finalmente 235~~~YYYY pd ==← −− , por lo que Y = { X2, X4, X5} será el conjunto de 3
variables seleccionado de X por el algoritmo SBS.
3.3 Stepwise selection Este último método, se puede decir que es una mezcla de los dos anteriores. Se trata de ejecutar primero uno y después otro, tantas veces como queramos. En nuestro caso será un parámetro a entrar por teclado y se introducirá al principio de la ejecución. Se ha decidido empezar por un proceso de Backward, ya que parece ser más rápido que el de Forward. El hecho de ejecutar los dos métodos anteriores en uno permite tanto seleccionar variables (proceso forward selection) como deseleccionarlas (proceso backward elimination). Esto será muy efectivo en el caso de ficheros de datos muy complejos en

Métodos existentes para la selección de variables Ismael Lapiedra Michel
-22-
los que puede haber dife rentes grupos de variables que nos den la solución correcta. El hecho de poder deseleccionar una variable seleccionada anteriormente, nos permite redireccionar el camino en el que se van eligiendo las variables. Si este método se repite varias veces al final llegaremos a una solución óptima. Evidentemente, el hecho de encadenar estos métodos nos traerá una dificultad añadida en su implementación. Esto se resolverá tratando cada método por separado e independiente como una función con sus entradas y salidas respectivas, sin tocar el contenido y tratándolo como una caja oscura en la que no nos interesa el interior. Este método no se ha implementado con el método de validación de los mínimos cuadrados pero si con los dos diferentes tipos de redes neuronales. Esto es debido a que se ha creído que el método de validación es demasiado simple para el método y se obtienen, por consiguiente, los mismos resultados a cada ciclo. El hecho de utilizar redes neuronales nos complica más el método de validación y existen más parámetros en juego que pueden hacer variar el resultado o conjunto de variables escogidas. En este descartaremos el hecho de poner un ejemplo, ya que básicamente es la combinación de los dos anteriores y se observará mejor en los ejemplos prácticos que veremos más adelante.

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-23-
4 NUEVOS MÉTODOS PARA LA SELECCIÓN DE VARIABLES Aunque hasta ahora el único método descrito y probado, para validar, que se ha utilizado ha sido el de los mínimos cuadrados, es lógico pensar que se pueden aplicar a este caso cualquier método de validación existente, en un principio. Todo dependerá de las características que queramos exigir a nuestro programa. El hecho de utilizar un método de validación es simple: bien hemos de aplicar un método para elegir la mejor variable. Para ello, hasta ahora nos basábamos en encontrar una especie de error para cada una de ellas, con la finalidad de eliminar la que menos nos interesara. Esto mismo se puede hacer enfocándose de otra manera. Se pueden aplicar otras técnicas, como las redes neuronales o probabilísticas, para obtener un error entre lo que es y lo predicho. De ahí poder elegir el que nos convenga. Esto es lo que se explicará a continuación. 4.1 Redes neuronales y selección de variables Como ya se ha dicho anteriormente, el hecho de aplicar las redes neuronales a la selección de variables, es una forma de aplicar un método de validación que resulte factible y resolutivo. Las redes neuronales pretenden simular o darnos una predicción de lo que se supone que ellas han aprendido a través de un método de aprendizaje. A través de esta predicción y comparándola con lo que debería darnos obtendremos un acierto o un error. O sea, básicamente, entrenamos la red introduciendo combinaciones entrada (dato)- salida (grupo al que pertenece), correctos y, una vez entrenada la red se prueba introduciendo un dato y esperando una clasificación por parte de la red. Si la califica bien, se considerará acierto y sino fallo. Del estudio de la cantidad de fallos o aciertos de cada columna (variable) respecto a las otras, obtendremos un ganador, el cual seleccionaremos. Como se puede ver, en un principio debería ser suficiente para poder hacer una selección de las variables más importantes. Pero que pasa si obtenemos el mismo número de fallos para una columna que para otra. Eso querría decir que, en un principio, nos da igual cual elegir, aunque sepamos que no es lo mismo. Este pequeño incidente fue una de las razones por las que introducimos un segundo criterio para el caso de las redes Fuzzy. Éste consiste en observar los pesos que se crean dentro de la red y fijarnos en el parámetro interno wija. Dicho parámetro, nos dará un numero mayor o menor dependiendo de la dificultad con la que se ha encontrado la red para obtener una respuesta a esa entrada. Así parece lógico que si dos variables tienen el mismo número de errores en la predicción del grupo al cual pertenecen sus filas, pero diferentes wijas, se pueda discriminar y encontrar un ganador. En este caso, a menor valor de wija, menos le ha costado a la red encontrar la predicción. De la suma de todas las wijas de cada fila obtenemos el valor e toda la columna (variable) que compararemos. Gracias a este nuevo parámetro podemos discriminar perfectamente las variables interesantes de las que no lo son. La introducción de este nuevo criterio de selección, es debida a que la salida de las redes es digital, o está bien (‘100’) o está mal (‘0’) la comparación con la salida real o agrupación a la que pertenece. Con lo que es fácil de

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-24-
que se repita el número de fallos (comprendido entre 0 y 48, correspondiente al número de filas) para os columnas diferentes. En el caso de la segunda red, la probabilística no contaremos con un segundo criterio de selección con lo que el método resultará un poco menos efectivo y los resultados podrán variar respecto al anterior. Seguidamente, pasaremos a describir más exhaustivamente cómo funcionan dichas redes y sus principales características. 4.1.1 Red fuzzy ARTMAP
Estas técnicas fueron creadas para imitar el comportamiento del cerebro humano [18,19]. Las primeras funciones creadas al respecto fueron las ART (1,2 y 3) y se trata de funciones no supervisadas. La red Fuzzy Art surgió de una modificación de la ART1 y básicamente intenta agrupar un cierto número de medidas sin tener ninguna información más que las medidas de entrada.
Su modo de funcionamiento se basa en que cada vez que la red recibe un nuevo
vector de entrada reacciona activando uno y solo uno de los nodos de salida. Cada uno de estos nodos representa cada una de las categorías que se han creado anteriormente con las entradas. En caso de que el nuevo vector de entrada no se corresponda con ningún nodo ya creado, se creará uno nuevo cuyo primer miembro será el nuevo vector.
Para controlar este algoritmo contamos con un parámetro llamado de vigilancia.
Éste puede tomar los valores entre “0” y “1” y, básicamente, la variación de este parámetro designará la rigurosidad con la que el sistema agrupara las muestras. Si ponemos este parámetro a “1” el sistema identificará a cada medida con una clase mientras que si lo ponemos a “0” agrupara a todas las medidas en una clase. También contamos con un parámetro que es el ritmo de aprendizaje, con el que podemos incrementar o disminuir la velocidad de aprender de la red [20].
Otro tipo de red que proviene de la red Artmap es la Fuzzy Artmap. Se trata de
un análisis supervisado donde le introducimos información tanto de las medidas de entrada como de las salidas ideales y en la que también distinguimos una fase de entrenamiento y otra de simulación. Este método tiene unas características principales:
- Aprendizaje rápido con baja carga computacional de las medidas que se presentan en el entrenamiento, lo que permite programar el algoritmo en dispositivos programables de bajo coste, aplicar validaciones cruzadas de orden 1 y probar diferentes combinaciones e parámetros.
- No hay necesidad de obtener muchas muestras para el entrenamiento, una cosa muy interesante en cualquier aplicación experimental en la que sea costosa la obtención de conjuntos de medida extensos. La red presenta una habilidad particular para aprender rápidamente hechos singulares que aparecen muy pocas veces en el conjunto del entrenamiento. Por tanto, en este conjunto, no es necesario que haya el mismo número de medidas de cada clase para que funcione correctamente.

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-25-
- Aprende continuamente las nuevas categorías sin olvidar lo que se ha aprendido antes, una cosa muy útil para adaptarse a las derivas producidas por el sensor.
- En comparación con otros tipos de redes neuronales, Fuzzy Artmap calcula automáticamente el número de neuronas en la capa oculta. Además, maximiza el poder de generalización aprendiendo al 100% el conjunto de entrenamiento.
- No se trata de un método totalmente cerrado como el MLP, sino que se puede analizar los pesos obtenidos internamente y sacar conclusiones, lo que puede dar luz sobre los procesos internos y como influyen en la categorización de los resultados.
- La implementación práctica de la red Fuzzy Artmap presenta un problema que se tiene que tratar con mucho cuidado: La red aprende el 100% de las medidas del conjunto de entrenamiento sacrificando lo mínimo posible la generalización. Pero la presencia de “outliers” o medidas erróneas en el conjunto de entrenamiento puede requerir un incremento del valor del parámetro de vigilancia excesivo, cosa que perjudicará seriamente la capacidad de generalizar de la red. Este problema es una de las razones por las que este tipo de algoritmo se ha utilizado poco en la nariz electrónica, ya que en este tipo de aplicaciones es sumamente difícil identificar medidas erróneas dadas la baja repetitividad de las señales de los sensores.
Para aplicar este método utilizaremos dos funciones llamadas fzmaptrnok y
Fzmaptstok. La primera la utilizaremos para entrenar la red mientras que la segunda para testar o simular la red. Resumiendo: La red Fuzzy Artmap es una red de clasificación con aprendizaje supervisado. En una fase de entrenamiento la red necesita que se le suministre un conjunto de medidas. Cada medida ha de contener un vector de entrada, que detalla los parámetros medidos en cada experiencia y un vector de salida que codifica la categoría que se le tiene que asignar. Posteriormente, en la fase de evaluación sólo se suministra el vector de entrada y la red clasifica esta medida siguiendo los criterios que ha aprendido en la fase de entrenamiento. 4.1.2 Red probabilística Básicamente, la estructura general de este tipo de redes es la misma que en el caso anterior. Su función también es simular el comportamiento del cerebro humano y en concreto la función de las neuronas. Su diferencia reside en el funcionamiento de la neurona en si.
La red probabilística guarda mucha relación con las redes de base radial, ya que se compone de dichas neuronas. El modelo de neurona de base radial lo tenemos a continuación:

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-26-
Figura 7 . modelo de neurona de base radial.
En el podemos ver, como característica más representativa, la función radbas que gobierna la salida. La función de transferencia que representa es la siguiente: radbas (n) =
2ne− Y la gráfica de dicha función es:
Figura 8. Gráfica de la función radbas.
Este tipo de redes pueden ser usadas para la clasificación de problemas, como en el anterior caso. Cuando se presenta una entrada, la primera capa se encarga de calcular las distancias entre el vector entrada y el vector de entrenamiento correspondiente, y produce un vector que nos indica cuan parecido son los dos vectores. La segunda capa suma estas contribuciones para cada clase de entrada para producir, a su salida, un vector de probabilidades. Finalmente, una función de transferencia determinada (radbas), colocada al final de la segunda capa, se encarga de elegir la máxima de estas probabilidades, y produce un uno ‘1’ para esta clase y un cero ‘0’ para las restantes. La arquitectura final de la red es la que se puede ver a continuación:

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-27-
Figura 9. Grafismo de la arquitectura de la red probabilística.
El diseño de las redes de Base Radial puede realizarse muy rápidamente y de dos formas diferentes: - El primer método, newrbe, encuentra la solución exacta. La función newrbe crea redes radial basis con tantas neuronas de este tipo como vectores de entrada en los datos de entrenamiento. - El segundo método, newrb, encuentra la red más pequeña que pueda resolver el problema con un error dado. Típicamente, menos neuronas son necesarias para diseñar mediante la función newrb. Sea como sea, como el número de neuronas radial basis es proporcional a las dimensiones del espacio de entrada, y la complejidad del problema, las redes de base radial pueden llegar a ser mayores que las redes del tipo backpropagation. En nuestro caso en cuestión, las redes neuronales del tipo probabilísticas [21], pueden también ser utilizadas para la clasificación de problemas. Su diseño es sencillo y no depende del entrenamiento. Este tipo de redes generaliza bien. En concreto, el mayor interés que encontramos en este tipo de redes es que no necesita de entrenamiento con lo que se convierte en una herramienta muy rápida de utilizar, al contrario que el anterior tipo de red. Principalmente, su programación consiste únicamente de las siguientes tres líneas: net = newpnn(P,T,0.01);
Y = sim(net,P); Yc = vec2ind(Y);

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-28-
Donde, P es el vector de entrada, T el vector de targets y el Spread (0.01) es un parámetro de ajuste. Finalmente en Yc obtendremos la salida predicha por la red para esa entrada. 4.2 Métodos implementados Una vez descritos los métodos existentes de selección de variables (forward selection, backward elimination y Stepwise selection) y los utilizados para la validación (fuzzy Artmap y Probabilistic neural network), pasaremos a combinar éstos para obtener diferentes casos y sopesar cual de ellos nos dará mejores resultados, o como mínimo en el menor tiempo. Las diferentes combinaciones implementadas se detallan a continuación. 4.2.1 Fordward –fuzzy ARTMAP Se trata de una selección del tipo Forward en la que se ha utilizado un método de validación mediante una red del tipo Fuzzy ARTMAP. Partiremos de un fichero de datos en el que las columnas representarán las diferentes variables y las filas las diferentes medidas realizadas. Mediante un proceso de validación cruzada o leave_one_out, iremos cogiendo cada una de las columnas y obteniendo un error para cada una. Al acabar con todas las columnas existentes, se procederá a elegir la columna (o variable) con error menor y cantidad de wijas menor (parámetro que nos indica la dificultad que se ha encontrado la red para obtener ese error). Una vez elegida la columna, pasaremos a guardarla en un fichero aparte y procederemos a volver a elegir otra columna. La nueva columna se unirá a la ya obtenida y se calculará la nueva tasa de acierto (que se supone será mayor en este caso). Este proceso se repetirá hasta que la tasa de aciertos, que se obtiene de la tasa de error, se mantenga respecto a la tasa de aciertos anterior, queriendo decir que el sistema ya no puede mejorar más aunque se le añadan más variables. En definitiva, obtendremos una serie de variables que representarán al conjunto o sistema con una tasa de acierto máxima. 4.2.2 Backward –fuzzy ARTMAP Se trata de una selección del tipo Backward en la que se ha utilizado un método de validación mediante una red del tipo Fuzzy ARTMAP. Partiremos también de un fichero de datos en el que el objetivo ahora es ir eliminando columnas o variables. Para ello, mediante un proceso de validación cruzada o leave_one_out, iremos sacando cada una de las columnas y calculando un error para el resto de las columnas. Una vez obtenemos los errores, miraremos cual nos hace que esa tasa de acierto sea menor y eliminaremos la columna. Este proceso se repetirá hasta que la tasa de acierto del grupo que nos quede sea menor que la anterior. Eso querrá decir que nuestra tasa de acierto ha disminuido por debajo del máximo calculado inicialmente y que esa última variable

Nuevos métodos para la selección de variables Ismael Lapiedra Michel
-29-
elegida contiene información relevante para el conjunto. Finalmente, esta variable se incluirá otra vez al grupo, como es lógico. 4.2.3 Stepwise –fuzzy ARTMAP Se trata de una selección del tipo Stepwise en la que se ha utilizado un método de validación mediante una red del tipo Fuzzy ARTMAP. Para ello, partiremos de un fichero de datos donde las columnas representen las variables y las filas las medidas. Se trata de encadenar los dos procesos anteriores para permitir que una vez eliminada o seleccionada una variable se pueda volver a incluir en el conjunto. Sabemos que, a veces, una elección no es la óptima, pero con los otros métodos no podemos deshacer lo que hemos hecho. En una función existen mínimos o máximos locales que pueden hacer parar nuestro método y llevarnos a una confusión en los resultados. Por ello se aplica este método, en el que se partirá de un proceso de backward elimination y se pasará a uno de forward selection. Se trata, pues, de encadenar los dos métodos anteriores y ejecutarlos en un bule cerrado tantas veces como nosotros queramos. Los resultados para este método, como veremos más adelante, son muy buenos para el caso de ficheros complicados y con medidas que pueden inducir a errores (mínimos locales). 4.2.4 Fordward –PNN Se trata de una selección del tipo forward en la que se ha utilizado un método de validación mediante una red del tipo Probabilística. Igual que en los casos anteriores se partirá del mismo tipo de fichero pero en este caso se aplicará otro tipo de red para validación del contenido. La única diferencia radicará en la utilización del fichero modificado leave (leave2) y la adecuación de algunas líneas de código, ya que ésta red trabaja con las transpuestas de las matrices utilizadas anteriormente. 4.2.5 Backward –PNN Se trata de una selección del tipo Backward, antes explicada, en la que se ha utilizado un método de validación mediante una red del tipo Probabilística. 4.2.6 Stepwise –PNN Se trata de una selección del tipo Stepwise, antes explicada, en la que se ha utilizado un método de validación mediante una red del tipo Probabilística.

Análisis de los datos Ismael Lapiedra Michel
-30-
5 · ANÁLISIS DE LOS DATOS 5.1. Fichero TABLA.M. Este fichero es el que hemos utilizado inicialmente para probar los diferentes métodos. Se trata de un fichero relativamente pequeño que no nos va a traer complicaciones, ya que todas las medidas están claras y pertenecen a una clase sin ningún tipo de duda. 5.1.1 ·Forward y Backward con mínimos cuadrados. Los resultados que obtenemos de la aplicación de este método son los que se exhiben a continuación: § Para el caso de Forward selection: Escribe el numero de variables a seleccionar recuerda que debe ser menor o igual a 13 ----------------------------------------->4 Finalmente las variables escogidas son: 10 9 2 11 Y la progresion del error: 1.0e+004 * 0.0001 0.0012 0.0200 3.5686 En estos resultados comprobamos que :
- Inicialmente el número de variables es de 13. - Ha seleccionado 4 variables antes de detenerse porque es un dato introducido
por teclado. No tenemos manera de saber cuando podemos parar el método iterativo.
- El error es el asociado a cada una de las variables que han sido seleccionadas. Éste ha sido el mínimo de los calculados y la progresión de los errores asociados a cada una de las variables vemos que es incremental. Es debido a que al quitarle la contribución de las variables a cada ciclo, este parámetro aumenta.
§ En el caso Backward elimination obtenemos: Escribe el numero de variables a seleccionar recuerda que debe ser menor o igual a 13 ----------------------------------------->4

Análisis de los datos Ismael Lapiedra Michel
-31-
Finalmente las variables escogidas son: 7 8 12 13 Y la progresion del error: 1.0e+012 * 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0009 0.7943 2.3789 En estos resultados comprobamos que:
- Inicialmente el número de variables, también, es de 13. - Ha deseleccionado 9 variables antes de detenerse porque es un dato
introducido por teclado. Hemos introducido que el número de variables elegidas finalmente sea de 4.No tenemos manera de saber cuando podemos parar el método iterativo.
- El error es el asociado a cada una de las variables que han sido seleccionadas. Éste ha sido el mínimo de los calculados y la progresión de los errores asociados a cada una de las variables vemos que es incremental.
- Evidentemente, hay 9 errores, ya que hemos ejecutado el proceso iterativo 9 veces para obtener 4 variables, finalmente.
5.1.2 · Forward, Backward y Stepwise con la Red Fuzzy. Los resultados son los siguientes: § Para el caso de Forward selection: Finalmente las variables escogidas son: 4 2 3 1 Y la progresion de la tasa de acierto: 0.1875 0.7500 0.9792 1.0000 En estos resultados vemos que:
- El método acaba eligiendo 4 variables ya que el método se para cuando la progresión del error se detiene, manteniéndose o disminuyendo.
- La progresión del error es ascendiente siempre y se mantiene entre unos límites establecidos: ‘0’, representa el 0% de aciertos, y ‘1’, representa el 100% de aciertos.
§ En el caso de Backward elimination: Finalmente las variables escogidas son: 2 3 10 1

Análisis de los datos Ismael Lapiedra Michel
-32-
Y la progresion de la tasa de acierto: Columns 1 through 10 0.9375 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 Column 11 0.9792 En estos resultados vemos que:
- El método acaba eligiendo también 4 variables ya que el método se para cuando la progresión del error disminuye. Como podemos ver el error aumenta hasta el máximo, se estabiliza y después decae. El primer error corresponde con el inicial del total de la tabla de datos. Los restantes pertenecen a los propios de cada iteración, en este caso, relacionados con la matriz resultante de eliminar la variable no querida.
- El último error pertenece a la última variable que, inicialmente ha sido eliminada, pero al haber descendido el error, respecto del anterior, se procederá a incluirse dentro del grupo de las variables seleccionadas.
- La progresión del error es ascendiente siempre y se mantiene entre unos límites establecidos: ‘0’, representa el 0% de aciertos, y ‘1’, representa el 100% de aciertos.
§ Finalmente, para el método Stepwise, obtenemos: Finalmente obtenemos que: Inicialmente el conjunto de variables total es: ans = 1 2 3 4 5 6 7 8 9 10 11 12 13 Resultado despues de la iteracion numero 1 es: ans = 2 3 10 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 2 es:

Análisis de los datos Ismael Lapiedra Michel
-33-
ans = 2 3 10 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 3 es: ans = 2 3 10 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 4 es: ans = 2 3 10 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Observando estos resultados vemos que:
- El bucle, que contiene un proceso Backward y otro Forward, se ejecuta cuatro veces. El número de veces a ejecutar el buc le es un parámetro arbitrario entrado por teclado.
- Una vez acabamos la primera iteración, acabamos seleccionando las mismas 4 variables, que mantendremos hasta el final. Esto es debido a que el fichero es sencillo y en un solo ciclo obtenemos los resultados deseados.

Análisis de los datos Ismael Lapiedra Michel
-34-
- La tasa de acierto es máxima en todo momento. Por eso no se realizan cambios dentro del grupo de variables seleccionado.
5.1.3 · Forward, Backward y Stepwise con la Red Newpnn. Hemos obtenido lo siguiente: § Para el caso de Forward selection: Finalmente las variables escogidas son: 2 1 Y la progresion de la tasa de acierto:
0.7708 1.0000 En estos resultados podemos ver que:
- Acaba eligiendo menos variables que con el método de validación anterior y eso, en parte, se lo podemos agradecer a un parámetro llamado Spread. Dicho parámetro que se utiliza en este tipo de redes, provoca una variación en el número de variables a elegir ya que aumenta o disminuye la tasa de aciertos haciendo que el sistema sea más o menos riguroso en la clasificación.
- Por ello, el bucle se acaba ejecutando únicamente 2 veces. - El proceso acaba porque llegamos al máximo en la tasa de aciertos.
§ En el caso de Backward elimination: Finalmente las variables escogidas son: 2 1 Y la progresion de la tasa de acierto: Columns 1 through 10 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 Columns 11 through 13 1.0000 1.0000 0.7708 Viendo estos resultados podemos concluir que: - También se acaban eligiendo 2 variables y corresponden a las anteriores. - Por ello, contamos con 13 errores asociados con las 11 variables descartadas, ya que el primer valor corresponde con el inicial total y el último con la última variable finalmente reelegida (1). - Vemos que el proceso para porque se ha descendido de la tasa de acierto anterior que era la máxima.

Análisis de los datos Ismael Lapiedra Michel
-35-
§ Finalmente, para el método Stepwise, obtenemos: Finalmente obtenemos que: Inicialmente el conjunto de variables total es: ans = 1 2 3 4 5 6 7 8 9 10 11 12 13 Resultado despues de la iteracion numero 1 es: ans = 2 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 2 es: ans = 2 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 3 es: ans = 2 1 Y la progresion de la tasa de acierto en el proceso backward: 1

Análisis de los datos Ismael Lapiedra Michel
-36-
Y la progresion de la tasa de acierto en el proceso forward: 1 Resultado despues de la iteracion numero 4 es: ans = 2 1 Y la progresion de la tasa de acierto en el proceso backward: 1 Y la progresion de la tasa de acierto en el proceso forward: 1 Contemplando estos resultados, vemos que:
- Se vuelven a elegir las mismas 2 variables y en el primero ciclo de este método, manteniéndose esta selección hasta el final.
- Esto nos confirma que sólo realizar el primer backward del primer bucle, ya alcanza la combinación acertada. Esto quiere decir que el fichero es sencillo y no contiene mínimos locales.
- La tasa de aciertos se mantiene constante al máximo, como cabe esperar. 5.2. Fichero VOCS.M. Tratamos con un fichero, en este caso, mucho más complejo y grande. Consta de 30 variables entre las que debemos discriminar las menos relevantes. Además, hay medidas que pueden llevarnos a dudas a la hora de clasificarlas dentro de un grupo en concreto. Es en este fichero donde veremos la funcionalidad del método Stepwise. 5.2.1 ·Forward y Backward con mínimos cuadrados. Los resultados que obtenemos de la aplicación de este método son los que se exhiben a continuación: § Para el caso de Forward selection: Escribe el numero de variables a seleccionar recuerda que debe ser menor o igual a 30 ----------------------------------------->4 Finalmente las variables escogidas son: 5 17 29 4

Análisis de los datos Ismael Lapiedra Michel
-37-
Y la progresion del error: 1.2487 1.4294 1.5944 2.2836 En estos resultados comprobamos que:
- Inicialmente el número de variables es de 30. - Ha seleccionado 4 variables antes de detenerse porque es un dato introducido
por teclado. No tenemos manera de saber cuando podemos parar el método iterativo.
- El error es el asociado a cada una de las variables que han sido seleccionadas. Éste ha sido el mínimo de los calculados y la progresión de los errores asociados a cada una de las variables vemos que es incremental. Es debido a que al quitarle la contribución de las variables a cada ciclo, este parámetro aumenta.
- Los valores del error son muchos menores porque tenemos más variables con lo que la contribución de cada una es menor.
§ En el caso Backward elimination obtenemos: Escribe el numero de variables a seleccionar recuerda que debe ser menor o igual a 30 ----------------------------------------->4 Finalmente las variables escogidas son: 9 12 24 27 Y la progresion del error: Columns 1 through 10 3.4846 3.4084 3.4008 3.3916 3.3918 3.3536 3.3218 3.5520 5.4767 5.4737 Columns 11 through 20 6.7781 6.7803 7.1078 7.1105 7.1390 7.1352 8.2666 7.6249 7.3638 7.1475 Columns 21 through 26 6.6698 6.5942 6.2834 6.0607 5.7656 5.6080 En estos resultados comprobamos que:
- Inicialmente el número de variables, también, es de 30. - Ha deseleccionado 26 variables antes de detenerse pya que así se lo hemos
indicado por teclado. Hemos introducido que el número de variables elegidas finalmente sea de 4. No tenemos manera de saber cuando podemos parar el método iterativo.

Análisis de los datos Ismael Lapiedra Michel
-38-
- El error es el asociado a cada una de las variables que han sido seleccionadas. Éste ha sido el mínimo de los calculados y la progresión de los errores asociados a cada una de las variables vemos que es incremental.
- Evidentemente, hay 26 errores, ya que hemos ejecutado el proceso iterativo 26 veces para obtener 4 variables, finalmente.
- Los valores de los errores para este fichero son mucho menores.
5.2.2 · Forward, Backward y Stepwise con la Red Fuzzy. Los resultados son los siguientes: § Para el caso de Forward selection: Finalmente las variables escogidas son: 6 4 20 8 Y la progresion de la tasa de acierto: 0.2292 0.6042 0.8958 0.8958 En estos resultados vemos que:
- El método acaba eligiendo 4 variables ya que el método se para cuando la progresión del error se detiene, manteniéndose o disminuyendo. En este caso se detiene porque la progresión se mantiene y no al máximo valor. Esto nos indica que podríamos encontrarnos dentro de un mínimo (local o final). En un principio, esto indicará que no estamos incluyendo información relevante para definir el sistema. Cuando lleguemos al análisis Stepwise se descubrirá.
- La progresión del error es ascendiente siempre y se mantiene entre unos límites establecidos: ‘0’, representa el 0% de aciertos, y ‘1’, representa el 100% de aciertos.
§ En el caso de Backward elimination: Finalmente las variables escogidas son: Columns 1 through 11 1 2 3 4 5 6 9 10 11 12 13 Columns 12 through 22 14 15 16 17 18 20 21 22 23 27 8 Y la progresion de la tasa de acierto: Columns 1 through 7 0.2292 0.2917 0.4167 0.4583 0.5417 0.5833 0.6042

Análisis de los datos Ismael Lapiedra Michel
-39-
Columns 8 through 10 0.6250 0.6250 0.5417 En estos resultados vemos que:
- El método acaba eligiendo también 22 variables ya que el método se para cuando la progresión del error disminuye. Como podemos ver el error aumenta hasta un valor (0.6250) que no es el máximo, se estabiliza y después decae. El primer error corresponde con el inicial del total de la tabla de datos. Los restantes pertenecen a los propios de cada iteración, en este caso, relacionados con la matriz resultante de eliminar la variable no querida.
- El último error pertenece a la última variable que, inicialmente ha sido eliminada, pero al haber descendido el error, respecto del anterior, se procederá a incluirse dentro del grupo de las variables seleccionadas.
- La progresión del error es ascendiente siempre y se mantiene entre unos límites establecidos: ‘0’, representa el 0% de aciertos, y ‘1’, representa el 100% de aciertos.
- Las variables elegidas son las del caso anterior y además se han elegido 18 más. Esto podría indicar que nos encontramos ante un mínimo local que nos camufla el resultado correcto. Seguramente contaremos con más variables de las necesarias para definir el sistema.
§ Finalmente, para el método Stepwise, obtenemos: Finalmente obtenemos que: Inicialmente el conjunto de variables total es: ans = Columns 1 through 18 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Columns 19 through 30 19 20 21 22 23 24 25 26 27 28 29 30 Resultado despues de la iteracion numero 1 es: ans = Columns 1 through 18 1 2 3 4 5 6 9 10 11 12 13 14 15 16 17 18 20 21 Columns 19 through 22 22 23 27 8 Y la progresion de la tasa de acierto en el proceso backward:

Análisis de los datos Ismael Lapiedra Michel
-40-
0.6250 Y la progresion de la tasa de acierto en el proceso forward: 0.6250 Resultado despues de la iteracion numero 2 es: ans = 1 2 3 4 9 11 12 13 14 15 16 20 21 23 6 Y la progresion de la tasa de acierto en el proceso backward: 0.7500 Y la progresion de la tasa de acierto en el proceso forward: 0.7500 Resultado despues de la iteracion numero 3 es: ans = 1 3 4 9 11 13 14 16 21 23 12 Y la progresion de la tasa de acierto en el proceso backward: 0.7500 Y la progresion de la tasa de acierto en el proceso forward: 0.7500 Resultado despues de la iteracion numero 4 es: ans = 1 3 4 9 11 13 14 16 21 23 12 Y la progresion de la tasa de acierto en el proceso backward: 0.7500 Y la progresion de la tasa de acierto en el proceso forward: 0.7500

Análisis de los datos Ismael Lapiedra Michel
-41-
Observando estos resultados vemos que:
- El bucle, que contiene un proceso Backward y otro Forward, se ejecuta cuatro veces. El número de veces a ejecutar el buce es un parámetro arbitrario entrado por teclado.
- Aquí es donde podemos apreciar la funcionalidad de este método. En el primer bucle elegimos las mismas variables que en el backward pero el hecho de ejecutar otra vez los dos métodos anteriores, hace que evitemos ese mínimo que nos oculta el buen resultado.
- La tasa de acierto no es máxima en todo momento. Pero va en aumento para cada bucle.
5.2.3 · Forward, Backward y Stepwise con la Red Newpnn. Hemos obtenido lo siguiente: § Para el caso de Forward selection: Finalmente las variables escogidas son: 30 21 23 16 22 24 Y la progresion de la tasa de acierto: 0.5208 0.7917 0.8333 0.8542 0.8750 0.8750 En estos resultados podemos ver que:
- El proceso acaba eligiendo 6 variables, con lo que obtenemos 6 tasas de acierto asociados a la elección de estas variables.
- La tasa de acierto no llega a ser máxima (‘1’). § En el caso de Backward elimination: Finalmente las variables escogidas son: 26 27 28 30 25 Y la progresion de la tasa de acierto: Columns 1 through 11 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 Columns 12 through 22 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 0.8958 Columns 23 through 27 0.8958 0.8958 0.8958 0.8958 0.8542

Análisis de los datos Ismael Lapiedra Michel
-42-
Viendo estos resultados podemos concluir que: - Se eligen 5 variables, con lo que obtendremos 25 tasas de acierto + la tasa inicial total + la tasa del último descartado que será reelegido. - Vemos que el proceso para porque se ha descendido de la tasa de acierto anterior que era la máxima. § Finalmente, para el método Stepwise, obtenemos: Finalmente obtenemos que: Inicialmente el conjunto de variables total es: ans = Columns 1 through 18 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Columns 19 through 30 19 20 21 22 23 24 25 26 27 28 29 30 Resultado despues de la iteracion numero 1 es: ans = 26 27 28 30 25 Y la progresion de la tasa de acierto en el proceso backward: 0.8958 Y la progresion de la tasa de acierto en el proceso forward: 0.8958 Resultado despues de la iteracion numero 2 es: ans = 26 27 28 30 25 Y la progresion de la tasa de acierto en el proceso backward: 0.8958 Y la progresion de la tasa de acierto en el proceso forward: 0.8958

Análisis de los datos Ismael Lapiedra Michel
-43-
Resultado despues de la iteracion numero 3 es: ans = 26 27 28 30 25 Y la progresion de la tasa de acierto en el proceso backward: 0.8958 Y la progresion de la tasa de acierto en el proceso forward: 0.8958 Resultado después de la iteración numero 4 es: ans = 26 27 28 30 25 Y la progresion de la tasa de acierto en el proceso backward: 0.8958 Y la progresion de la tasa de acierto en el proceso forward: 0.8958 Contemplando estos resultados, vemos que:
- Se vuelven a elegir las mismas 5 variables que con el método anterior y en el primero ciclo de este método, manteniéndose esta selección hasta el final.
- Esto nos confirma que sólo realizar el primer backward del primer bucle, ya alcanza la combinación acertada.
- La tasa de aciertos se mantiene constante y con valor (0.8958) no máximo, pero igual al obtenido con el método anterior.
5.3. Discusión: Comparación entre los diferentes métodos de validación (Redes neuronales y método de los mínimos cuadrados) y los diferentes métodos de ejecución (Forward, Backward y Stepwise). Para facilitar la comparación entre los diferentes métodos, hemos implementado las siguientes tablas. La primera corresponde a los resultados obtenidos del fichero pequeño TABLA.m y la segunda, corresponden a los resultados obtenidos del fichero VOCS.m, más complicado. En dichas tablas hemos incluido la información que hemos encontrado más relevante para el análisis de los diferentes métodos. Estos parámetros son: el tiempo de ejecución (básico, ya que es un indicativo de la carga computacional

Análisis de los datos Ismael Lapiedra Michel
-44-
que tiene el método), las variables finalmente seleccionadas (indicativo de la funcionalidad del método) y la tasa de acierto (indica no sólo la funcionalidad sino la efectividad). Con todo ello, hay que tener en cuenta que cada método puede o no coincidir con las variables seleccionadas, ya que cada método tiene una forma diferente de encontrarlas. También hay que tener en cuenta que dependiendo del fichero, obtendremos unos u otros resultados. En el análisis de todos estos parámetros debemos tener en cuenta el tiempo que se ha tardado en ejecutar los diferentes métodos, ya que éste puede suponer que un proyecto pueda ser o no viable. A continuación pasaremos a comentar las dos tablas: Fichero TABLA.m:
Método Tiempo de ejecución
Variables seleccionadas
Tasa de acierto
Forward (Mín. Cuadrados)
segundos 10,9,2,11 -----
Backward (Mín. Cuadrados)
segundos 7,8,12,13
-----
Forward-Fuzzy 10 min. 4,2,3,1 100 % Backward-Fuzzy 5 min. 2,3,10,1 100 % Stepwise-Fuzzy 7 min. 2,3,10,1 100 % Forward-PNN 7 min. 2,1 100 % Backward-PNN 4 min. 2,1 100 % Stepwise-PNN 5 min. 2,1 100 %
Tabla 2. Resumen de los datos obtenidos con el fichero TABLA.m
Fichero VOCS.m:
Método Tiempo de ejecución
Variables seleccionadas
Tasa de acierto
Forward (Mín. Cuadrados)
segundos 5,17,29,4 -----
Backward (Mín. Cuadrados)
segundos 9,12,24,27
-----
Forward-Fuzzy 150 min. 6,4,20,8 89.58 % Backward-Fuzzy 60 min. 1,2,3,4,5,6,9,10,11,12,
13,22,14,15,16,17,18, 20,21,22,23,27,8
62.50 %
Stepwise-Fuzzy 100 min. 1,3,4,9,11,13,14,16,21, 23,12
75 %
Forward-PNN 100 min. 30,21,23,16,22,24 87.50 % Backward-PNN 40 min. 26,27,28,30,25 89.58 % Stepwise-PNN 60 min. 26,27,28,30,25 89.58 %
Tabla 3. Resumen de los datos obtenidos con el fichero TABLA.m

Análisis de los datos Ismael Lapiedra Michel
-45-
El primer parámetro, sobre el que podemos extraer conclusiones, es el del tiempo. Como podemos observar, los tiempos de ejecución si tratamos un fichero de datos fácil y pequeño o si, por el contrario, tratamos un fichero grande y difícil, cambian profundamente. Los tiempos del primer fichero nunca superan los 10 minutos, mientras que para un fichero relativamente grande y siempre comparable al primero, como es el segundo, obtenemos tiempos de dos horas y media de ejecución. Como podemos ver el tiempo de ejecución aumenta casi exponencialmente, ya que estamos aplicando una validación cruzada y esto nos aumenta en gran número este tiempo. La diferencia es notable y es un punto frágil para elegir uno u otro método. Dentro de los métodos realizados específicamente a cada fichero, vemos que el más rápido siempre es el de los mínimos cuadrados, pero los resultados de éste no son comparables a los otros métodos. Seguidamente contamos con los obtenidos con la red probabilística y finalmente, con los obtenidos con la red Fuzzy Artmap. Esta diferencia siempre se verá más acusada conforme aumente la dificultad y las dimensiones de las matrices a tratar. A la hora de mirar el tiempo que tarda cada método en particular vemos que el más lento es el Forward selection, seguido del Stepwise selection y finalmente el Backward elimination. Como es de suponer, en el caso de tener que elegir entre 5 o 10 minutos, no tendremos muchos problemas en elegir uno u otro. Pero si estamos hablando de horas de diferencia de un método a otro, el problema es mayor. Así pues el método más rápido es el Backward elimination. Por lo que respecta a las variables seleccionadas, su número será muy interesante comparado con su tasa de acierto, ya que nos permitirá evaluar el método correctamente. En el caso del fichero sencillo, las variables elegidas para el análisis realizado con mínimos cuadrados son diferentes en los dos casos y no se pueden comparar con el resto. A diferencia, el resto de métodos tienen en común dos variables (2,1) y tres más que se van alternando (3,4,10) para el caso de la red Fuzzy Artmap. En todos ellos asolemos un 100 % de tasa de acierto. Viendo estos resultado podemos concluir que en el caso de tratar un fichero relativamente sencillo (100 % de tasa de acierto para todos los métodos), optaremos por seleccionar el método que menos variables seleccione, en este caso cualquiera de los tres métodos implementados con una red probabilística, en concreto el método Backward elimination por su rapidez. En el caso del segundo fichero, el resultado obtenido para el análisis con mínimos cuadrados es el mismo que en el caso anterior. Mirando los resultados de los métodos utilizando la red Fuzzy Artmap para validar, vemos que las variables elegidas en cada caso son muy diferentes. En el caso del método Forward selection elegimos 4 (6, 4, 20, 8) con una tasa del 89.58 % de acierto, mientras que en el caso de la Backward elimination acabamos seleccionando 23 variables ( 1, 2, 3, 4, 5, 6, 9, 10, 11, 12, 13, 22, 14, 15, 16, 17, 18, 20, 21, 22, 23, 27, 8), con una tasa de acierto del 62.50 %. Como hemos visto una gran diferencia entre un método y otro decidimos aplicar una selección Stepwise, en la que obtendremos unos resultados intermedios de 11 variables escogidas ( 1, 3, 4, 9, 11, 13, 14, 16, 21, 23, 12) con un 75 % de tasa de acierto final. La única variable común para los tres métodos será la 4.

Análisis de los datos Ismael Lapiedra Michel
-46-
Si nos fijamos en el método de validación mediante la red Probabilística, vemos que en el caso de el método Forward selection acabamos seleccionando 6 variables (30, 21, 23, 16, 22, 24) con un 87.50 % de tasa de acierto. En el caso del método Backward elimination, se eligen las mismas variables que en el caso del método Stepwise (26, 27, 28, 30, 25) y llegamos también a la misma tasa de acierto del 89.58 %. La única variable común para los tres métodos es la 30. Finalmente, podemos concluir que el método que nos dará mejores resultados a menor número de variables seleccionadas será el Forward selection con validación por red Fuzzy Artmap pero el tiempo de ejecución es muy elevado así que optaremos a considerar como mejor método al Backward elimination o al Stepwise selection con validación por red probabilística por su rapidez en comparación a los otro mé todos.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-47-
6 IMPLEMENTACIÓN EN UN ENTORNO GRÁFICO CON MATLAB 6.1 Introducción
El motivo por el cual se ha elegido este tipo de creador de interficies gráficas ha sido porque, ya que hemos utilizado Matlab para crear nuestros programas, hemos decidido seguir utilizando éste para evitarnos incompatibilidades y problemas que pudieran surgir.
Sin lugar a dudas, Matlab se ha convertido en los últimos años en una
herramienta imprescindible, ya no sólo por su facilidad de manejo en lo que respecta al cálculo matemático, sino también se ha extendido su ámbito de actuación, gracias, en gran parte, a la cantidad de librerías añadidas de diversa funcionalidad. Un ejemplo de ello, lo tenemos en los programas como Simulink. Este programa ampliamente utilizado, que te permite simular circuitos eléctricos y electrónicos de forma fácil y rápida, ha sido una de las estrellas de Matlab en versiones anteriores, gracias a su capacidad de incorporación de nuevos elementos o dispositivos mediante la adición de nuevas librerías.
Una gran ventaja añadida en la nueva versión de Matlab 6, respecto a las
anteriores, son sus herramientas de creación de interficies gráficas de usuario llamadas GUI’s. Estas son herramientas que simplifican la representación de programas, a su vez tan complejos como se quiera, con la simple utilización de botones, listas, menús, etc... O sea, que para ejecutar una función basta con apretar un botón que tenga un enlace a dicha función, con ello nos evitamos el invocar a la función de forma escrita y basta con pulsar virtualmente un botón para ejecutarla. Esto es muy práctico para personas que no estén familiarizadas con los lenguajes de programación y las funciones de Matlab. En un sistema basado en ventanas, botones, listas, etc…, como en el entorno operativo de Windows, todo el mundo se aclara, más o menos.
La creación de estos GUI’s no es muy complicada pero se requiere del
aprendizaje de las herramientas básicas, así como de un nuevas funciones o mejor dicho, requiere de un análisis más exhaustivo de todas las posibilidades que nos brindan las librerías de funciones de Matlab. 6.2 Herramientas básicas de diseño de GUI’s Antes de empezar, decir que la función que se utiliza para llamar al editor de GUI’s desde el workspace es Guide. Como en casi todas las cosa de la vida, el diseño de GUI’s presenta más funcionalidades de las que se han utilizado en este ejemplo. No se aprovecha todo el potencial que esta herramienta de Matlab nos ofrece, ya que el objetivo que nos hemos planteado desde un principio ha sido la sencillez, en contra de la sofisticación, que en la mayoría de los casos comporta pérdida de tiempo y encarecimiento de costes.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-48-
La pantalla inicial que nos aparece al ejecutar la llamada a la herramienta de creación de GUI’s con la escritura de guide, es la siguiente:
Figura 10. GUIDE Quick Start
En dicha pantalla podemos ver que nos ofrece la posibilidad, en primer instancia, de elegir si comenzar una nueva interficie o proseguir con una ya creada. Dentro de la primera, nos ofrece la opción de abrirnos uno en blanco, uno con controles, uno con representación axial y un menú o uno con una pregunta que necesita ser respondida. También te ofrece guardar la figura abierta en un destino a especificar.
Una vez dicho esto, explicar que los GUI’s están pensados para que cada casilla,
cada botón, cada menú, tenga una función asociada cuando el ratón lo presione o seleccione. Cada uno de los tipos de objetos que nos encontramos dentro de los GUI’s consta de varios campos a actuar cuando entramos en el menú de características (“Property inspector”), pero nosotros hemos actuado básicamente sobre los siguientes:
- Callback: Es donde se especifica la función asociada a la que se llama cuando se pulsa o selecciona en el objeto determinado.
- Position: Para modificar la posición y las dimensiones de cada objeto.
- Color: Para modificar el color primario y secundario del bloque.
- String: Se utiliza en bloques donde el usuario entra información por teclado.
- Value : Sobretodo en casillas de exclusión mutua (on/off, etc..).

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-49-
- Visible: Para hacer visible o no el bloque seleccionado.
- Tag : Da un nombre al bloque, una etiqueta con que identificarlo en el código
El menú de parámetros que aparece cuando se aprieta sobre el botón derecho del
ratón y se elige la opción del menú “Property Inspector”, es el siguiente:
Figura 11. Property Inspector
En el podemos observar cada uno de los parámetros descritos con anterioridad. Estos parámetros son comunes para todos los bloques o unidades de control que son los elementos que permiten actuar al usuario.
Las unidades de control más utilizadas en la creación de GUI’s se explican a
continuación: 6.2.1.- Push Buttons
Generan una acción cuando se pulsa sobre ellos. Cuando se hace un clic del ratón, aparecen hundidos, y cuando se deja el botón del ratón, retornan a la posición original, realizándose entonces la llamada o callback asociada.
Figura 12. Push button

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-50-
En esta interfície, los Push buttons se utilizan para ejecutar cada uno de los programas y para salir de la aplicación. También, por ejemplo, para obtener ayuda en el menú principal. 6.2.2.- Radio Buttons
Acostumbran a estar acompañados de otros radio buttons, presentando exclusión mutua. Son casillas de selección (p.e. si/no, 1/2, on/off, etc…). Para ejecutar la acción asociada sólo hará falta apretar sobre él y la casilla se mostrará activada. La propiedad value es la que permite saber si la casilla está activada. También se puede activar desde el propio código.
Figura 13. Radio buttion
En nuestra interfície, no hemos utilizado este tipo de botones. 6.2.3.- Edit Text Es un campo que permite al usuario entrar o modificar cadenas de texto. Se utiliza cuando se quiere un texto como entrada, y la propiedad string es la que que contiene dicha información. Como antes, edit text no es sólo un bloque de entrada sino también de salida.
Figura 14. Edit text
6.2.4.- Static Text
Es parecido al anterior pero aquí no se entra nada por teclado. Se utiliza para etiquetar controles, mostrar información al usuario o para poner títulos como en nuestra interfície.
El usuario no puede modificar el contenido, ni tiene ninguna rutina asociada o
callback. Sólo se actuará sobre el en el campo string, para colocar la información útil para el usuario.
Figura 15. Static text
Los Static text son parecidos a los anteriores, en aspecto únicamente. Éstos últimos no nos sirven, como en el caso anterior, para adquirir información.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-51-
6.2.5.- List Box
Son cajas que muestran una lista de opciones (definidas por el usuario en la propiedad string) y permiten a éste escoger una o más opciones. La propiedad string contendrá las cadenas que el usuario leerá, pero la selección de una de estas opciones activará la propiedad value, que tendrá un índice de acuerdo con que si la opción escogida es la primera (value=1), o la segunda… y así para todas las opciones disponibles.
Figura 16. List box
Los List box no son utilizados en nuestra interfície. 6.2.6.- Popup Menu
La traducción más fiel sería la de menús plegables. En hacer clic sobre la pestaña superior, se despliega un menú que contiene diversas opciones, al estilo de list box. En este caso, pero una vez elegida la opción, el menú vuelve a su estado inicial, mostrando sólo la opción escogida. Con este y a diferencia del list box, sólo se podrá escoger una opción de todas las propuestas.
En cierta manera, no deja de ser un mecanismo de exclusión mutua (escoger una
opción no es más no escoger las restantes). En este sentido, son parecidos a a los radio buttons, pero con una gran ventaja, ya que si el número de opciones es grande, el espacio se reduce sensiblemente. Las propiedades más importantes son string y value . La primera contiene las opciones en si, y la segunda, tiene por valor un índex asociado a cada opción y es el que se tiene que consultar para saber el camino a seguir en el código.
Figura 17. Pop up menu

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-52-
6.2.7.-.Otros controles Existen otros controles, no tan utilizados como los anteriores comentados pero que también se utilizan en este tipo de GUI’s, los cuales pasaremos a comentar a continuación: Toggle buttons, checkboxes, sliders, frames i axes.
Los toggle buttons son parecidos a los radio buttons, solo haciendo un clic, el botón no retorna al estado inicial, sino que se aguanta hundido. Es en el momento de hacer un nuevo clic que el botón vuelve al estado inicial. Esto permite definir dos comportamientos, según el estado del botón, según el valor de la propiedad value.
Figura 18. Toggle button
Los checkbox son parecidos a los radio buttons, solo que los últimos están más encarados a la exclusión mutua. Los checkbox se usan por ejemplo para llenar opciones de un formulario, siendo la propiedad más interesante value, que informa sobre el estado de la casilla, seleccionada o no.
Figura 19. Check box
Los sliders son barras que, horizontalmente o verticalmente, se desplazan en consonancia con una variación numérica dentro de un rango determinado. Así, si se establece un intervalo [-5, 5] i la barra tiene desplazamiento horizontal, el extremo izquierdo equivaldrá a -5 i el derecho a 5. La barra, que se podrá mover por las pestañas de los extremos, dará los valores intermedios de acuerdo con la posición en la que se encuentre.
Figura 20. Slider
Los frames son cuadros que pretenden englobar regiones del GUI. No tienen ninguna función asociada o callback, i en el GUI realizado, en el que se han utilizado, tienen una justificación simplemente visual, ya que engloban menús u opciones relacionadas.
Los axes son unidades que permiten la representación de gráficos o figuras
diversas, obtenidas por medio de instrucciones como plot.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-53-
Figura 21. Axes
Todos los elementos comentados son los que el editor de GUI’s dispone para la realización de interficies. De hecho, se han comentado ya las propiedades más interesantes, más útiles, así como las unidades de control. Ahora es el momento de dar un vistazo a los principales aspectos que se han tenido en cuenta en la programación de las rutinas asociadas a cada bloque de control, las tan nombradas callbacks. 6.3 Programación de GUI’s
Ya conocemos las herramientas interactivas, y por tanto, podemos pasar a describir, a grandes rasgos, como programarlas. Se trata de construir un código, utilizando el lenguaje Matlab, que reaccione ante la acción de activación ( o desactivación), de alguna de las casillas que conforman el GUI. Cabe decir que, en el momento de guardar un documento creado con el editor de interfícies gráficas (Guide), no solo se guarda la figura (fichero .fig), sino que también se guarda un código asociado a la figura (fichero .m), un fichero de rutina de Matlab, como cualquier fichero que se haya podido realizar en alguna de las prácticas a lo largo de este segundo ciclo. Cada vez que se inserta un elemento en el GUI, este se selecciona con el botón derecho, i se elige la opción Edit Callback, que genera una función asociada a la activación del mismo, como se muestra a continuación:
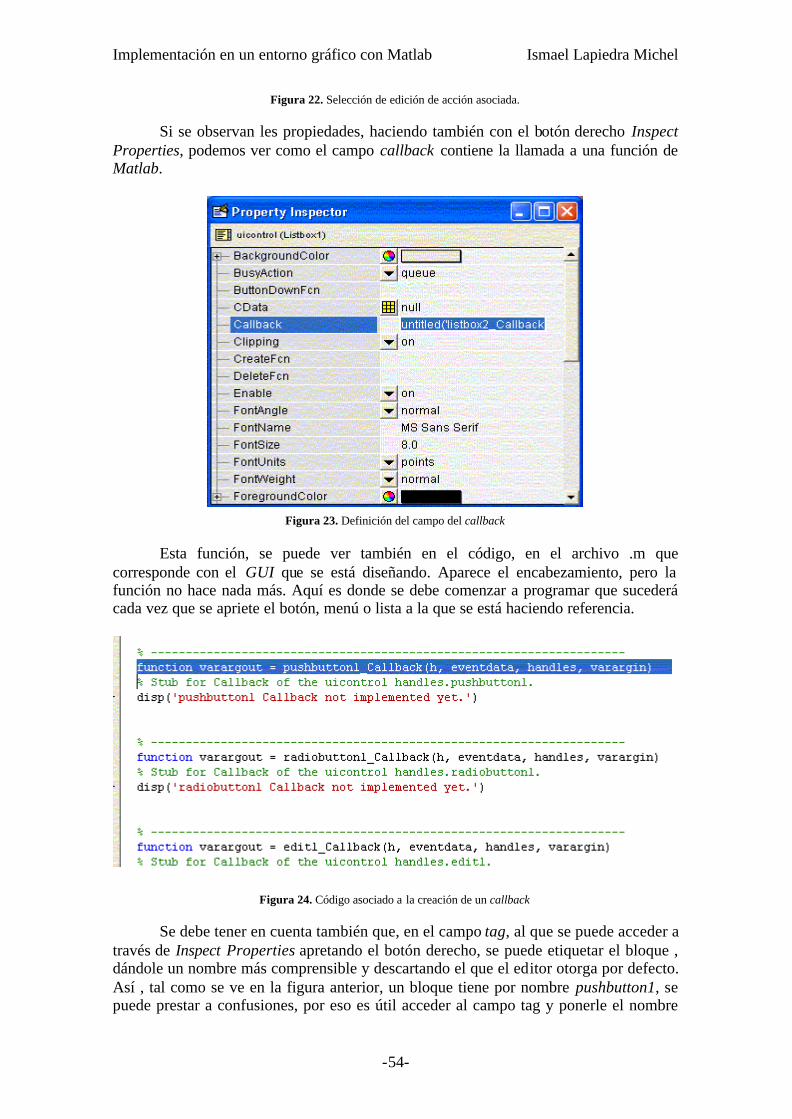
Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-54-
Figura 22. Selección de edición de acción asociada.
Si se observan les propiedades, haciendo también con el botón derecho Inspect Properties, podemos ver como el campo callback contiene la llamada a una función de Matlab.
Figura 23. Definición del campo del callback
Esta función, se puede ver también en el código, en el archivo .m que corresponde con el GUI que se está diseñando. Aparece el encabezamiento, pero la función no hace nada más. Aquí es donde se debe comenzar a programar que sucederá cada vez que se apriete el botón, menú o lista a la que se está haciendo referencia.
Figura 24. Código asociado a la creación de un callback
Se debe tener en cuenta también que, en el campo tag, al que se puede acceder a través de Inspect Properties apretando el botón derecho, se puede etiquetar el bloque , dándole un nombre más comprensible y descartando el que el editor otorga por defecto. Así , tal como se ve en la figura anterior, un bloque tiene por nombre pushbutton1, se puede prestar a confusiones, por eso es útil acceder al campo tag y ponerle el nombre

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-55-
que nosotros creamos más adecuado. Se recomienda variar este parámetro justo después de creado el objeto. Si una vez hecho esto, se le atribuye al elemento una función asociada haciendo Edit Callback, se podrá observar como en el menú de propiedades, la función no tiene como nombre, por ejemplo, pushbutton1_Callback, sino Reset_Callback . Igualmente, en el código, en el archivo .m, a función tomará el nombre respecto a lo que se diga en el campo tag.
Esto será útil porque, una vez introducidos en la programación del código, será
más fácil hacer referencia a un bloque con un nombre más explicativo. Una vez aquí, se supone que se ha hecho todo lo necesario con el bloque de control en el editor (ubicación del bloque, definición de la función asociada, escritura de algún mensaje en el campo string, definición de las opciones a escoger, colores, visibilidad, etc…). Ahora ya se pueden empezar a debatir los aspectos más generales de la programación con Matlab. No se trata de dar un cursillo de programación en Matlab, ya que el código es muy simple.
La programación de GUI’s tiene sus propias funciones, pero de entre todas, se han usado las mínimas i más simples, las que hacen referencia a la entrada/salida de datos. Todo se ha hecho para evitar instrucciones que suspendan la ejecución del código, que la recuperen, que la interrumpan, etc.
Para la sincronización en el flujo normal de ejecución del código, se ha hecho uso, básicamente, de la propiedad que hace visible o no a los elementos, de manera que los parámetros que el usuario puede tocar se modifican uno a uno y en un orden que acostumbra a forzar la invarianza. El usuario irá incorporando parámetros siguiendo una secuencia predeterminada i lógica. 6.3.1.- Las Funciones get/set
Para consultar el estado de una unidad de control, se acostumbra a utilizar la función get, mientras que para actuar sobre ella, la función es set. El formato de las mismas es el que se muestra a continuación:
V = GET(H,'PropertyName') SET(H,'PropertyName',PropertyValue)
Código 1. Funciones d’E/S set & get
Las dos funciones, como se puede ver, requieren de un parámetro, llamado H, i que es el handle. Viene a ser como un identificador, que cada unidad de control tiene, i que se utiliza para hacer referencia a cualquier unidad dentro del código. Si, dentro de una función asociada a un bloque, se hace referencia a este, ya sea para hacer get o set, el handle será h. Si, al contrario, se pretende actuar sobre un bloque A dentro de la función asociada a un bloque B, el handle ya no será h sino handles.nombre_bloque, entendiendo como nombre del bloque el campo tag, al que previamente se ha hecho referencia.
Por ejemplo, si es tiene un GUI con dos menús plegables, que tienen como tag popup_menu1 i popup_menu2, i tienen como funciones asociadas

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-56-
popup_menu1_Callback i popup_menu2_Callback, se tendrá en cuenta lo que figura en la siguiente tabla, que indica como hacer referencia al handle de un bloque determinado en función de la parte del código en la que se está.
Tag handles a popup_menu1_Callback handles a popup_menu2_Callback popup_menu1 H handles.popup_menu1 popup_menu2 handles.popup_menu2 h
Tabla 4. Como hacer referencia a un handle
Una vez solucionada la problemática de los handles, se puede pasar a hablar de PropertyName. Las funciones get y set, permiten actuar sobre la mayoría de lo s campos de cada bloque. Los campos son todas aquellas propiedades que aparecen al seleccionar un elemento con el botón derecho y elegir la opción Inspect Properties. Son campos los que se han comentado antes: callback, string, value, position, color, etc. Pero también lo son otros como FontSize, FontName, Horizontal/allignment, etc. Todos ellos son modificables con las instrucciones ya explicadas, sólo hace falta poner comillas antes y después del nombre de la propiedad (‘string’,’value’,’fontsize’, etc.).
Ahora ya se está capacitado para ejecutar una orden de consulta, de lectura, sobre cualquier bloque de control en cualquier posición del código. La única restricción es que todo esto es válido cuando hace referencia siempre a un único GUI. Si desde, por ejemplo, file1.m se consulta el estado de un push button que de file3.m, se generará un mensaje de error y se parará la ejecución del código. Es el único impedimento, pero siempre existen soluciones, como son las variables globales, de las que se hablará más adelante.
Finalmente, PropertyValue, útil para escribir o actuar sobre un bloque, contendrá aquella información que se quiere depositar en el bloque de destino. Así, si se quiere escribir sobre un Static text una cadena de caracteres, ésta se pondrá entre comillas (‘hola, buen día’), o se quiere forzar a un Popup menu a una determinada opción, se le introducirá un enter (1 ó 2 ó n), o si se actúa sobre un campo que tiene unos valores específicos (como puede ser el campo visible), los valores irán entre comillas (‘on’,’off’). Comentar, ahora sí para concluir, que algunos campos donde el usuario entra en un determinado valor por teclado, i este valor quiere significar un enter, necesitará de la función str2num, que transforma la cadena de texto a valores enteros. Si se encuentra con algún carácter no numérico, no retorna nada. La forma de declararlo en el código es la siguiente:
V = STR2NUM(GET(H,'PropertyName'))
Código 2. Función str2num de conversión de cadenas a enters
Si no se hace así, probablemente v, la variable de salida valga ‘2’ i no 2, como se querría. I si este valor se hace servir como parámetro de entrada de una función que en aquel campo necesita un enter, dará error i se parará la ejecución.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-57-
6.3.2.- Las Funciones uigetfile/uiputfile
Son funciones bastante menos usadas que las anteriores, pero se usan, son interactivas y han resultado nuevas en el momento de iniciar la programación de la interficie. Lo que hacen, a grandes rasgos, es abrir una ventana, como se hace cuando se abre un fichero o cuando se guarda. Estas funciones no hacen precisamente esto, simplemente retornan el nombre i el path, pero con eso es suficiente para cargar o guardar un fichero, eso sí, sin necesidad de ir al menú correspondiente de la ventana ni tener que hacer Ctrl+A ó Ctrl+G. Las funciones tienen el aspecto que es muestra a continuación:
[FILENAME, PATHNAME] = UIGETFILE(FILTERSPEC, TITLE) [FILENAME, PATHNAME] = UIPUTFILE(FILTERSPEC, TITLE)
Código 3. Funciones d’E/S uigetfile & uisetfile
La primera, uigetfile, dará la información suficiente como para que, a partir de pathname i filename, crear una cadena que permita abrir un fichero con ayuda de la función load.
La segunda, uiputfile, permitirá crear un fichero de destino, donde se podrán guardar los resultados que se deseen.
Tanto en un caso como en el otro, filterspec permite definir cual será la extensión de los ficheros. Introduciendo la cadena ‘*.*’, se mostrarán todos los archivos de la carpeta en la que se esté. Por otro lado, title dará la oportunidad de escoger el mensaje que figurará como título de la ventana, es decir, prescindir de un frío y poco explicativo untitled o Open file y poder hacer entender al usuario qué está realmente haciendo (p.e. ‘Cargar workspace’).
Todo esto se muestra en la siguiente figura.
Figura 25. Ejemplo de uso de uigetfile.
Una vez obtenidas las variables de salida de las funciones, con el nombre del fichero (filename) i el path o ruta o directorio al que pertenecen (pathname), solo hace

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-58-
falta construir una cadena de caracteres haciendo, por ejemplo, nombre_completo_fichero = [pathname filename]. Llegados hasta aquí, un simple load o save (nombre_completo_fichero) será suficiente para abrir o guardar los datos. 6.3.3.- Las Variables Globales
La siguiente sorpresa con la que nos encontramos fue la posibilidad, que también ofrece Matlab, de programar y aprovecharse de las ventajas que suponen las variables globales.
Las variables globales suelen ser la fuente de muchos problemas en sistemas críticos, como el control de encoders o tarjetas de adquisición de datos. El caso es, pero, que esta versión de Matlab no és ejecutable en ordenadores de potencia de cálculo media: se hace necesario un buen ordenador, un ordenador rápido. Además, el flujo de ejecución de esta interfície no rivaliza con la velocidad de un ordenador que pueda ejecutar Matlab.
Todos estos motivos son suficientes para no tener miedo a utilitzar las variables globales, solo se pide prudencia para evitar sobrescribir valores.
Las variables globales lo son sólo en aquellas funciones en las que se encuentran
definidas, es decir, que si la variable scores es declarada global a function1 y function3, la variable del mismo nombre variará de forma independiente a function2, donde una vez acabada su ejecución, dicha variable no tendrá valor. Para declarar una función como global, sólo hace falta ir al principio de cada función donde esta se debe utilizar y escribir.
global NOM_VARIABLE_GLOBAL
Código 4. Declaración de variable global
Las variables globales suelen ir en mayúsculas, no solo en la declaración sino también en el momento de hacer referencia a ellas en medio del código.
Todas estas son las principales novedades encontradas al programar les
interfícies con Matlab, en comparación con el que se había estado haciendo en las diversas prácticas de las muchas asignaturas del segundo ciclo que se han servido de Matlab. 6.4 Estructura del GUI
Una vez aclaradas las claves para poder programar las interfícies gráficas, podemos pasar a definir y explicar los objetivos de nuestro proyecto.
Principalmente, nuestro programa debe ser capaz de interactuar con el usuario
de una forma sencilla y explicativa, para adecuar las necesidades de éste al programa. Primeramente, se debe crear un entorno inteligible que nos permita ejecutar los programas sin dificultades y para ello hemos introducido un pequeño botón de ayuda, donde se explica cual debe ser el contenido del workspace para que los programas funcionen correctamente.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-59-
A este botón se le han adjuntado los que ejecutan propiamente los programas,
que en nuestro caso son 8 (igual al número de métodos implementados). En el menú principal también contaremos con un botón de salida del programa. Se ha decidido cargar el workspace directamente, en vez de cargar primero los
targets y después los datos, ya que ahorramos en sencillez y facilidad de ejecución. A continuación pasaremos a describir cada uno de los programas o ventanas de
ejecución de las que nuestro proyecto se compone.
6.4.1 Menú Principal “Project”. Es la ventana que aparece al ejecutar nuestro programa. Realmente es el cuerpo de la interfície, ya que es la única ventana que nos aparecerá en el proceso de ejecución, a parte de la de salida. En dicha ventana podemos observar diferentes botones que cumplen una función específica. El primero de ellos es el de ayuda (color morado), donde se describe cómo debe ser el workspace y las variables que lo componen para que se ejecuten correctamente los programas. Seguidamente, se contemplan los diferentes botones de ejecución de los distintos programas (color azul). Son 8 y corresponden, por orden descendente y de izquierda a derecha, a: • Forward selection: botón que llama a la función que realiza una selección forward (selección de las variables más representativas de una en una, sin posibilidad de deseleccionar, hasta que se acabe el método iterativo o la función de salida se cumpla), donde la validación se basa en un método de mínimos cuadrados. • Backward elimination: botón que llama a la función que realiza una eliminación Backward (eliminación de las variables menos representativas de una en una, sin posibilidad de volver a seleccionar, hasta que se acabe el método iterativo o la función de salida se cumpla), donde la validación se basa, también, en un método de mínimos cuadrados. • Forward_Fuzzy: Botón que permite llamar a la función que realiza una selección forward, donde la validación se basa en redes neuronales y en concreto en redes de tipo fuzzy. • Backward_Fuzzy: Botón que permite llamar a la función que realiza una eliminación Backward, donde la validación se basa en redes neuronales y en concreto en redes de tipo fuzzy.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-60-
• Stepwise_Fuzzy: Botón que permite llamar a la función que realiza una ejecución del tipo stepwise (método que combina los dos métodos anteriores, con lo que permite seleccionar y deseleccionar hasta cumplir una condición de entrada inicial), donde la validación se basa en redes neuronales y en concreto en redes de tipo fuzzy. • Forward_Newpnn: Botón que permite llamar a la función que realiza una selección forward, donde la validación se basa en redes neuronales y en concreto en redes de tipo Newpnn. • Backward_Newpnn: Botón que permite llamar a la función que realiza una eliminación Backward, donde la validación se basa en redes neuronales y en concreto en redes de tipo Newpnn. • Stepwise_Newpnn: Botón que permite llamar a la función que realiza una ejecución del tipo stepwise, donde la validación se basa en redes neuronales y en concreto en redes de tipo Newpnn.
Básicamente el cuerpo del programa son estos botones que permiten ejecutar cada uno de las funciones de forma independiente, al clicar sobre cada uno de estos enlaces, deberemos indicar la ruta de acceso al workspace que contemple los datos que queramos ejecutar. Seguidamente se procederá a ejecutar el método donde se podrá pedir o no algún dato de entrada o alguna condición de parada. Inmediatamente acabada la ejecución, se plasmarán los resultados en la ventana de trabajo principal de Matlab y el sistema quedará preparado para otra ejecución sin necesidad de realizar una limpieza del área de trabajo.
Figura 26. Aspecto del menú principal de la interficie.

Implementación en un entorno gráfico con Matlab Ismael Lapiedra Michel
-61-
Por último, podemos ver que también contamos con un botón de salida (color azul oscuro), que nos permitirá acabar con la ejecución de este programa interactivo si asertamos ante la pregunta de fin de programa. La ventana que nos aparece se muestra a continuación:
Figura 27. Aspecto del menú de salida de la interficie.

Conclusiones del proyecto de fin de carrera Ismael Lapiedra Michel
-62-
7 · CONCLUSIONES DEL PROYECTO DE FIN DE CARRERA 7.1. Comentarios sobre los resultados obtenidos Se ha optado por realizar dos tipos de pruebas ya que inicialmente los resultados han sido demasiado satisfactorios al tratarse de unos datos muy fácilmente clasificables. Al realizar un segundo análisis con datos más inestables, hemos podido comprobar la utilidad del método Stepwise y contrastar los tiempos de ejecución de cada método. Respecto al tipo de método de validación, el ha dado mejores resultados ha sido la red probabilística ya que no necesita de entrenamiento con lo que es mucho más rápida. Una vez implementados todos los métodos, hemos creído conveniente reunir todos esos programas en uno interactivo, para poder ejecutarlo in situ y comprobar los resultados para cualquier fichero de datos. Los resultados de este objetivo han sido satisfactorios. 7.2. Conclusiones sobre el mejor método. Para empezar, debemos concluir que la elección del método a aplicar, en cada caso, dependerá ,en gran medida, del tipo de fichero con el que vayamos a tratar. Si se trata de un fichero en el que las clases para cada una de las variables estén muy bien diferenciadas y el fichero, en si, no sea muy extenso, hemos visto que el tiempo de ejecución no es crítico, valorando especialmente la tasa de aciertos. En este caso, el método que mejor funciona es el Backward elimination utilizando la red probabilística para validar. Si por el contrario, utilizamos un fichero notoriamente más extenso y en el que las clases no están muy bien diferenciadas, el mejor método si dependerá del tiempo de ejecución ya que éste aumentará sensiblemente. El método elegido será el Backward elimination o el Stepwise selection con red probabilística como método de validación. El hecho de poder deseleccionar una variable que previamente habíamos seleccionado, nos abre el camino a optimizar la selección y será de mucha utilidad para los casos en que el fichero sea complicado de clasificar. Un resumen de los resultados lo tenemos en la siguiente gráfico donde podemos ver la tasa de aciertos para cada uno de los métoso al analizar un fichero más difícil:

Conclusiones del proyecto de fin de carrera Ismael Lapiedra Michel
-63-
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
For
war
dSe
lect
ion
Bac
kwar
dE
limin
atio
n
Step
wis
eSe
lect
ion
Por
cent
aje
de a
cier
tos
Fuzzy ArtmapRed probabilísticaSin selección
Figura 28 . Porcentaje de aciertos para todos los métodos en el caso de un fichero complejo.
Como también podemos observar, en el caso de no utilizar ningún método de selección, o sea, entrenamos y testeamos con la totalidad de los datos (toda la matriz), el resultado es mucho peor. En concreto, se obtiene el 23 % de tasa de aciertos, eso quiere decir que el hecho de coger toda la información nos reduce sensiblemente la tasa de aciertos debido a que se introduce mucha información irrelevante y que leva a confusión. Aquí es donde se comprueba que se trata de un fichero cuyas variables no están muy bien clasificadas o enmarcadas en diferentes grupos y su análisis puede llevar a confusiones. 7.3. Posibles mejoras, continuación del proyecto Para finalizar, podríamos intentar introducir posibles mejoras que nos permitieran optimizar los métodos como podrían ser:
- Búsqueda de nuevos o diferentes métodos. - Realizar un programa que fuera menos riguroso a la hora de entrar los datos
para su análisis. El formato que nos exige el programa para los datos es muy específico.
- Buscar otros métodos de validación o incluso otro tipo de redes que puedan ser más rápidas en su predicción.
- Realizar más pruebas o análisis con otros ficheros e intentar concretar más el uso de cada método.

Bibliografía Ismael Lapiedra Michel
-64-
8 · BIBLIOGRAFÍA [1] J.W. Gardner. P.N. Bartlett, A brief history of electronic noises, Sens. Actuators, B 18 (1994) 211. [2] Neotronics Scientific, Western House, 2 Cambridge Road, Stansted Mounfitchet, Essex, CM24 8BZ, U.K.. [3] ALPHA M.O.S., Le St Exupery, 20 av Didier Daurat, 31400 Toulouse, France. [4] J.S. Kauer. Contributions of topography and parallel processing to odour coding in the vertebrate olfactory pathway. Trends Neuroscience. 14 (1991) 79-85. [5] M. Meredith. Neural circuit computation: complex patterns in the olfactory bulb. Brain Res. Bull., 29 (1992) 111-117. [6] W. F. Wilkens, A. D. Hatman. An electronic analog for the olfactory processes, Ann. NY Acad. Sci., 116 (1964), 608. [7] T. M. Buck, F.G. Allen, M. Dalton. Detection of chemical speciesby surface effects on metals and semiconductors, T. Bregman and A. Dravnieks (Eds.), Surface Effects in Detection, Spartan Books Inc., USA. 1965. [8] K. Persaud, G. H. Dodd. Analisys of discrimination mechanisms of the mammalian olfactory system using a model nose, Nature, 299 (1982) 352-355. [9] J. W. Gardner, A brief history of electronic noses, Sensors and Actuators B 18-19 (1994) 211-220. [10] P. T. Moseley, Solid-state gas sensors, Meas. Sci. Technol., 8 (1997) 223-237. [11] Tomas Eklov, Per Martensson, Ingemar Lundstrom. Selection of variables for interpreting multivariate gas sensor data. Elsevier Sciense B.V. Acta 381 (1999) 221-232. [12] Nils Paulsson, Elisabeth Larsson, Fredrik Winquist. Extraction and selection of parameters for evaluation of breath alcohol measurement with an electronic nose. Elsevier Sciense B.V. Acta 84 (2000) 187-197. [13] Lu Xu, Wen-Jun Zhang. Comparison of diffrents methods for variable selection. Elsevier Sciense B.V. Acta 446 (2001) 477-483. [14] J. Brezmes, E. Llobet, X. Vilanova, J. E. Sueiras, X. Correig, Diseño y construcción de un olfato electrónico para la determinación no destructiva del grado de maduración de la fruta. Informe del proyecto de investigación subvencionado por el “ Comité Econòmic de la Fruita” de Catalunya (1997). [15] E. Llobet, J. Brezmes, X. Vilanova, R. Ionescu, S. Al-Khalifa, J.W. Gardner y X. Correig, FFT and Wavelet Analyses of Response Patterns from a Temperature-modulated Micro-hotplate Gas Sensor, 341-344. [16] forward selection: http://www.anc.ed.ac.uk/~mjo/intro/node25.html. [17] Algoritmos subóptimos: http://www-etsi2.ugr.es/depar/ccia/rf/www/tema5_00-01_www/node10.html. [18] H. Demuth, M. Beale, Neural network toolbox for ues with MATLAB, User’s guide version 3.0, The Mathworks, inc. http://www.mathworks.com [19] A. Lober, L.E. Wangen, A. Kowalski, A theoretical foundation for the PLS algorithm. j. Chemometrics, 1987. Vol1, 19 [20] J.W. Gardner, Detection of vapours and odours from a multisensor array using pattern recognition. Part 1: principal conponents and cluster analyses. Sensors and Actuators B (1991) vol 4, 108-116 [21] The Mathworks, inc, MATLAB (versión 6.1), The Mathworks, inc. http://www.mathworks.com

Anexo Ismael Lapiedra Michel
-65-
ANEXO Ficheros ejecutables
A continuación, vamos a presentar una serie de ficheros ejecutables que hemos utilizado en cada uno de los apartados de nuestro proyecto. Éstos nos han servido para minimizar el espacio y el tiempo de análisis que nos ocuparía si no recurriésemos a métodos informáticos. De la ejecución de estos ficheros obtendremos toda la información de este proyecto. Además hemos expuesto los datos de entrada de las funciones que hemos utilizado en cada caso. Forward.m Este fichero realiza un proceso de forward selection a través de una validación por mínimos cuadrados. Partimos de un preprocesamiento de la matriz de targets (target2, es una matriz de targets en base 10 y en una sola fila), calculamos el número de variables que hay y preguntamos el número de variables que se quiere seleccionar. Seguidamente procedemos a ejecutar el bucle tantas veces como variables a seleccionar en el que: aplicamos el método de los mínimos cuadrados para obtener un error, buscamos el error mínimo, seleccionamos la variable a la que corresponde ese error mínimo, la seleccionamos (la eliminamos del grupo de variables y la añadimos al grupo de variables seleccionadas) y eliminamos la contribuc ión de esta variable seleccionada del resto del grupo. Finalmente, representamos por pantalla la selección obtenida junto con el error asociado a cada selección. tar=mncn(target2); w=size(var); disp('Escribe el numero de variables a seleccionar'); disp('recuerda que debe ser menor o igual a');disp(w(2)); input('----------------------------------------->'); p = ans; if (p>14) return end for k=1:p [m n]=size(sensn);
for j=1:n a=0; t=sensn(:,j); tm=mncn(t); ta=PINV(tm); b=ta*tar; sal=b*tm; for i=1:m
c=((sal(i)-tar(i))^2); a=a+c;
end d=a/(m-1); e(j)=sqrt(d);
end for z=1:n
if min(e)==e(z) s=z;

Anexo Ismael Lapiedra Michel
-66-
end end var2(k)=var(s); var(s)=[]; fin(:,k)=sensn(:,s); fin2(k)=e(s); clear e; tar=tar-b*sensn(:,s); sensn(:,s)=[];
end disp('Finalmente las variables escogidas son:'); disp(var2); disp('Y la progresion del error:'); disp(fin2); Backward.m Este fichero se encarga de realizar una backward elimination mediante el método de los mínimos cuadrados. Los pasos a seguir son iguales que en el caso anterior, únicamente deberemos tener en cuenta que: ahora el bucle ya no se ejecuta tantas veces como variables queremos seleccionar sino tantas veces como el total menos las variables a seleccionar que queremos deseleccionar y buscamos el error máximo de la variable a deseleccionar. Por el resto, el programa es igual al anterior. tar=mncn(target2); w=size(var); disp('Escribe el numero de variables a seleccionar'); disp('recuerda que debe ser menor o igual a'); disp(w(2)); input('----------------------------------------->'); p = ans; var2=var; var=[]; if (p>w(2)) return end for k=1:(w(2)-p)
[m n]=size(sensn); for j=1:n
a=0; t=sensn(:,j); tm=mncn(t); ta=PINV(tm); b=ta*tar; sal=b*tm; for i=1:m
c=((sal(i)-tar(i))^2); a=a+c;
end d=a/(m-1); e(j)=sqrt(d);
end for z=1:n
if max(e)==e(z) s=z;
end end

Anexo Ismael Lapiedra Michel
-67-
var(k)=var2(s); var2(s)=[];
final(:,k)=sensn(:,s); fin2(k)=e(s); clear e;
tar=tar-b*sensn(:,s); sensn(:,s)=[];
end disp('Finalmente las variables escogidas son:'); disp(var2); disp('Y la progresion del error:'); disp(fin2); Forward_fuzart Con este fichero pretendemos realizar una selección del tipo forward selection, pero con un método de validación diferente: el de la red Fuzzy Artmap. El programa consta de los siguientes pasos: adecuación de los datos de entrada, bucle general que se ejecutará hasta que la tasa de aciertos ya no aumente más y una representación por pantalla de los datos obtenidos. En el bucle principal tenemos: un primer bucle donde calculamos los errores llamando a la función leave que describiremos más tarde (básicamente se trata de un programa que realiza mediante un proceso de leave-one-out, un cálculo de los errores obtenidos en la diferentes predicciones mediante la red Fuzzy Artmap), buscamos el error mínimo para un número de wijas menor (el número de wijas es un parámetro que nos dice cuanto se ha tenido que esforzar la red para obtener la solución), seleccionamos la variable que obtenemos y actualizamos la tasa de aciertos. Finalmente representamos los datos. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); er=1; k=1; tassa=0; while (er>tassa) [Num_max n]=size(sensn); for j=1:n sensn1(:,k)=sensn(:,j); [error]=leave(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1; end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end r=size(s); for z=r(2):-1:1

Anexo Ismael Lapiedra Michel
-68-
if min(wi)==wi(z) f=s(z); end end else f=s(1); end var2(k)=var(f); var(f)=[]; if (er>tassa)&(k>1) tassa=er; end fin(:,k)=sensn(:,f); er=error1(f); er=(Num_max-er)/Num_max; fin2(k)=er; clear error1; sensn1(:,k)=sensn(:,f); sensn(:,f)=[]; clear wija; k=k+1; if (er==1) disp('Finalmente las variables escogidas son:'); disp(var2); disp('Y la progresion de la tasa de acierto:'); disp(fin2); return end end disp('Finalmente las variables escogidas son:'); disp(var2); disp('Y la progresion de la tasa de acierto:'); disp(fin2); Backward_fuzart En este programa, igual que en el anterior, pretendemos hacer una backward elimination pero ahora con el método de validación a través de una red Fuzzy Artmap. Básicamente es igual que el anterior solo que: calculamos una tasa de aciertos inicial del total de los datos por un proceso de leave-one-out cuando antes era uno, el error para cada una de las variables es representado por el error del conjunto que nos queda al eliminar esta variable y también elegiremos el menor, elegimos la variable seleccionada cuando el número de wijas sea máximo en este caso, una vez salimos del bucle deseleccionamos la última variable ya que se trata de una variable seleccionada después de acabar el bucle y representamos los datos. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); sensfi=sensn; [Num_max n]=size(sensn); w=n; er=1; k=1; [error]=leave(Num_max,sensn,target); tassa=(Num_max-error(1))/Num_max; tassa=1*tassa; while (er>=tassa)

Anexo Ismael Lapiedra Michel
-69-
[Num_max n]=size(sensn); for j=1:n sensn1=sensn; sensn1(:,j)=[]; [error]=leave(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1 end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end r=size(s); for z=r(2):-1:1 if max(wi)==wi(z) f=s(z); end end else f=s(1); end var2(k)=var(f); var(f)=[]; sensn(:,f)=[]; fin=sensn; [error]=leave(Num_max,sensn,target); er=(Num_max-error(1))/Num_max; if (er>tassa) tassa=er; end clear error; clear wija; clear error1; clear wijasto; clear sens1; k=k+1; end k=k-1; var((w+1)-k)=var2(k); sensn(:,((w+1)-k))=sensfi(:,(var2(k))); var2(k)=[]; fin=sensn; disp('Finalmente las variables escogidas son:'); disp(var); Stepwise_fuzart Este programa pretende aplicar el método Stepwise mediante la validación por la red Fuzzy Artmap. Se parte de un preprocesado de los datos, se pregunta cantas veces se

Anexo Ismael Lapiedra Michel
-70-
quiere ejecutar el bucle que comprende un proceso backward elimination y otro forward selection y, finalmente, se representan los datos. Estos datos son tanto las variables escogidas en cada ciclo del bucle como la tasa de acierto en cada iteración. En este bucle principal se llama a las funciones back y ford que no son más que los programas backward_fuzard y forward_fuzart adecuados para encadenarse mediante un bucle cíclico. A continuación se exponen sendos programas con sus respectivos comentarios. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); var2=[]; fin=[]; k=1; disp('Escribe el numero de veces que quieres que se repita el bucle'); input(''); x = ans; o=x; x=x+1; i=1; informetassa1{i}=0; informetassa2{i}=0; informevar{i}=var; informevar2{i}=var2; i=i+1; while (x~=1) [var,var2,fin,sensn,k,tassa]=back(var,var2,fin,sensn,target,k); informetassa1{i}=tassa; [var,var2,fin,sensn,k,tassa]=ford(var,var2,fin,sensn,target,k,tassa); informetassa2{i}=tassa; x=x-1; informevar{i}=var; informevar2{i}=var2; i=i+1; end disp('Finalmente obtenemos que:'); disp(''); disp('Inicialmente el conjunto de variables total es:'); informevar{1} for h=1:o disp('Resultado despues de la iteracion numero'); disp(h); disp('es:'); informevar{(h+1)} end Ford Este programa es igual que el forward_fuzard pero adecuándose las variables para poder encadenarse junto a la función back a un bucle cíclico. Se trata de una función que debe ser llamada dentro de un programa. Consta de unas variables de entrada y otras de salida, que son con las que debemos tener cuidado de tener en buen recaudo. function[var,var2,fin,sensn,k,tassa]=ford(var,var2,fin,sensn,target,k,tassa)

Anexo Ismael Lapiedra Michel
-71-
er=1; v=size(var); b=size(var2); w=v(2)+b(2); while (er<tassa) [Num_max n]=size(fin); sensn1=sensn; for j=1:n sensn1(:,(w+2)-k)=fin(:,j); [error]=leave(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1 end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end for z=1:(r-1) if min(wi)==wi(z) f=s(z); end end else f=s(1); end var((w+2)-k)=var2(f) var2(f)=[]; sensn(:,(w+2)-k)=fin(:,f) er=(Num_max-error1(f))/Num_max; if (er>tassa) tassa=er; end sensn1(:,(w+2)-k)=fin(:,f); fin(:,f)=[]; clear wija; clear error1; clear wijasto; clear error; k=k-1; end clear wijasto; Back Al igual que el caso anterior, este programa es idéntico que el backward_fuzart pero se trata como una función a ser llamada dentro de un programa. También consta de unas variables de entrada y otras de salida que coinciden con el caso anterior. function [var,var2,fin,sensn,k,tassa]= back(var,var2,fin,sensn,target,k)

Anexo Ismael Lapiedra Michel
-72-
sensfi=sensn; er=1; v=size(var); b=size(var2); w=v(2)+b(2); [Num_max n]=size(sensn); [error]=leave(Num_max,sensn,target); tassa=(Num_max-error(1))/Num_max; tassa=1*tassa; while (er>=tassa) [Num_max n]=size(sensn); for j=1:n sensn1=sensn; sensn1(:,j)=[]; [error]=leave(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1 end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end r=size(s); for z=r(2):-1:1 if max(wi)==wi(z) f=s(z); end end else f=s(1); end var2(k)=var(f) var(f)=[]; fin(:,k)=sensn(:,f); sensn(:,f)=[]; [error]=leave(Num_max,sensn,target); er=(Num_max-error(1))/Num_max; if (er>tassa) tassa=er; end clear error; clear wija; clear error1; clear wijasto; clear sens1; k=k+1; end k=k-1; var((w+1)-k)=var2(k); sensn(:,(w+1)-k)=fin(:,k); fin(:,k)=[]; var2(k)=[];

Anexo Ismael Lapiedra Michel
-73-
Leave
Esta función es el alma del proceso de validación mediante redes neuronales del tipo Fuzzy Artmap. Para realizar un análisis supervisado o Fuzzy Artmap utilizamos este código que también consta de un leave_one_out como estructura principal. Empezamos creando las matrices y declaramos las variables que después utilizaremos. El paso siguiente será entrenar la red y simular con las funciones fzmaptrnok y fzmaptstok , respectivamente. Finalmente obtenemos un número de aciertos o de errores según la predicción hecha por la red en comparación con la real.
El proceso de leave_one_out consiste en ir realizando un proceso de entrenamiento y testeo con cada una de las filas de nuestra matriz, así primeramente elegiremos la primera fila para testear y el resto para entrenar. Este proceso se repite para cada una de las filas de nuestra matriz de datos.
function [error,aciert]=leave(Num_max,sensn1,target) A=[]; B=[]; P=[]; t=[]; vigbase=0; vigb=1; lra=1; lrb=1; alfa=0.01; remain=Num_max for i=1:Num_max l=1; for m=1:Num_max if m==i tester=sensn1(m,:); targ=target(m,:); else P(l,:)=sensn1(m,:); t(l,:)=target(m,:); l=l+1; end; end; [viga,wija,wijb,wab]=fzmaptrnok(vigbase,vigb,lra,lrb,alfa,P,t); wija; wijb; wab; [a,ok,nok,nsnc,rateok,viga,wija,vigb,wijb]=fzmaptstok(viga,vigb,lra,l rb,alfa,wija,wijb,wab,tester,targ); ok; nok; rate(i)=rateok; [Num f]=size(wija); wijas(i)=Num-1; viga; A(i,:)=a; remain=Num_max-i end; total=0; tota2=0; for d=1:48 total=total+rate(d); tota2=tota2+wijas(d);

Anexo Ismael Lapiedra Michel
-74-
end aciert=total/100; error(1)=48-aciert; error(2)=tota2; clear rate; clear rateok; clear total; clear tester; clear target; clear P; clear t; clear A; clear B; clear wijb; clear wab; clear viga; Forward_fuzart2 Es igual que el programa forward_fuzart pero llamando a la función leave 2 en vez de a la leave, que describiremos más tarde. Se trata de realizar un proceso de forward selection mediante un método de validación con redes probabilísticas. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); target=ind2vec(target2); sensn=sensn'; er=1; k=1; tassa=0; while (er>tassa) [n Num_max]=size(sensn); for j=1:n sensn1(k,:)=sensn(j,:); [error]=leave2(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1; end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end r=size(s); for z=r(2):-1:1 If min(wi)==wi(z) f=s(z); end end else f=s(1);

Anexo Ismael Lapiedra Michel
-75-
end var2(k)=var(f); var(f)=[]; if (er>tassa)&(k>1) tassa=er; end fin(k,:)=sensn(f,:); er=error1(f); er=(Num_max-er)/Num_max; fin2(k)=er; clear error1; sensn1(k,:)=sensn(f,:); sensn(f,:)=[]; clear wija; k=k+1; if (er==1) disp('Finalmente las variables escogidas son:'); disp(var2); return end end disp('Finalmente las variables escogidas son:'); disp(var2); Backward_fuzart2 Es igual que el programa backward_fuzart pero llamando a la función leave 2 en vez de a la leave, que describiremos más tarde. Se trata de realizar un proceso de backward elimination mediante un método de validación con redes probabilísticas. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); sensn=sensn'; target=ind2vec(target2); sensfi=sensn; [n Num_max]=size(sensn); w=n; er=1; k=1; [error]=leave2(Num_max,sensn,target); tassa=(Num_max-error(1))/Num_max; tassa=1*tassa; while (er>=tassa) [n Num_max]=size(sensn); for j=1:n sensn1=sensn; sensn1(j,:)=[]; [error]=leave2(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1; end end

Anexo Ismael Lapiedra Michel
-76-
if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end r=size(s); for z=r(2):-1:1 if max(wi)==wi(z) f=s(z); end end else f=s(1); end var2(k)=var(f); var(f)=[]; sensn(f,:)=[]; fin=sensn; er=(Num_max-error1(f))/Num_max; if (er>tassa) tassa=er; end clear error; clear wija; clear error1; clear wijasto; clear sens1; k=k+1; end k=k-1; var((w+1)-k)=var2(k); sensn(((w+1)-k),:)=sensfi((var2(k)),:); var2(k)=[]; fin=sensn; disp('Finalmente las variables escogidas son:'); disp(var); Stepwise_fuzart2 Es igual que el programa Stepwise_fuzart pero llamando a las funciones back2 y ford2 en vez de a la back y a la ford, que describiremos más tarde. Se trata de realizar un proceso de Stepwise selection mediante un método de validación con redes probabilísticas. sensn=(sensn-(min(min(sensn)))); sensn=sensn/(max(max(sensn))); sensn=sensn'; target=ind2vec(target2); var2=[]; fin=[]; k=1; disp('Escribe el numero de veces que quieres que se repita el bucle'); input(''); x = ans; o=x; x=x+1; i=1; informetassa1{i}=0; informetassa2{i}=0;

Anexo Ismael Lapiedra Michel
-77-
informevar{i}=var; informevar2{i}=var2; i=i+1; while (x~=1) [var,var2,fin,sensn,k,tassa]=back2(var,var2,fin,sensn,target,k); informetassa1{i}=tassa; [var,var2,fin,sensn,k,tassa]=ford2(var,var2,fin,sensn,target,k,tassa); informetassa2{i}=tassa; x=x-1; informevar{i}=var; informevar2{i}=var2; i=i+1; end disp('Finalmente obtenemos que:'); disp(''); disp('Inicialmente el conjunto de variables total es:'); informevar{1} for h=1:o disp('Resultado despues de la iteracion numero'); disp(h); disp('es:'); informevar{(h+1)} end Ford2 Es igual que el programa Ford pero llamando a la función leave 2 en vez de a la leave, que describiremos más tarde. function[var,var2,fin,sensn,k,tassa]=ford(var,var2,fin,sensn,target,k,tassa) er=1; v=size(var); b=size(var2); w=v(2)+b(2); while (er<tassa) [n Num_max]=size(fin); sensn1=sensn; for j=1:n sensn1((w+2)-k,:)=fin(j,:); [error]=leave2(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1; end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z)); end for z=1:(r-1)

Anexo Ismael Lapiedra Michel
-78-
if min(wi)==wi(z) f=s(z); end end else f=s(1); end var((w+2)-k)=var2(f); var2(f)=[]; sensn((w+2)-k,:)=fin(f,:) er=(Num_max-error1(f))/Num_max; if (er>tassa) tassa=er; end sensn1((w+2)-k,:)=fin(f,:); fin(f,:)=[]; clear wija; clear error1; clear wijasto; clear error; k=k-1; end clear wijasto; Back2 Es igual que el programa Back pero llamando a la función leave 2 en vez de a la leave, que describiremos más tarde. function [var,var2,fin,sensn,k,tassa]=back(var,var2,fin,sensn,target,k) v=size(var); b=size(var2); w=v(2)+b(2); sensfi=sensn; er=1; [n Num_max]=size(sensn); [error]=leave2(Num_max,sensn,target); tassa=(Num_max-error(1))/Num_max; tassa=1*tassa; while (er>=tassa) [n Num_max]=size(sensn); for j=1:n sensn1=sensn; sensn1(j,:)=[]; [error]=leave2(Num_max,sensn1,target); error1(j)=error(1); wijasto(j)=error(2); end r=1; for z=n:-1:1 if min(error1)==error1(z) s(r)=z; r=r+1; end end if (r>2) for z=1:(r-1) wi(z)=wijasto(s(z));

Anexo Ismael Lapiedra Michel
-79-
end r=size(s); for z=r(2):-1:1 if max(wi)==wi(z) f=s(z); end end else f=s(1); end var2(k)=var(f); var(f)=[]; fin(k,:)=sensn(f,:); sensn(f,:)=[]; er=(Num_max-error1(f))/Num_max; if (er>tassa) tassa=er; end clear error; clear wija; clear error1; clear wijasto; clear sens1; k=k+1; end k=k-1; var((w+1)-k)=var2(k); sensn((w+1)-k,:)=fin(k,:); fin(k,:)=[]; var2(k)=[]; Leave2 Básicamente, la estructura es idéntica a la del leave pero se utilizan redes probabilísticas para obtener un error o tasa de acierto. Por ello, consta de un proceso de leave_one_out pero creado y simulado a través de una red propalística. Se utilizan las llamadas a las funciones newpnn (que crea la red) sim (se simula la salida) vec2ind (para cambiar de vector a índice, necesario para operar con este tipo de redes). function [error,aciert]=leave2(Num_max,sens,target) aciert=0; Num_max=48; remain=Num_max for j=1:Num_max l=1; for k=1:Num_max if k==j tester=sens(:,k); targ=target(:,k); else P(:,l)=sens(:,k); t(:,l)=target(:,k); l=l+1; end; end; net = newpnn(P,t,0.01); Y = sim(net,tester);

Anexo Ismael Lapiedra Michel
-80-
Yc = vec2ind(Y); targ=vec2ind(targ); if (Yc==targ) aciert=aciert+1; end; error(1)=48-aciert; error(2)=100; remain=remain-1 end; clear P; clear t; clear tester; clear targ; clear Y; clear Yc;