centro nacional de investigación y desarrollo tecnológico eduardo ortiz... · agradecimientos a...
TRANSCRIPT

cenidet
Centro Nacional de Investigación y Desarrollo Tecnológico
Departamento de Ciencias Computacionales
TESIS DE MAESTRÍA EN CIENCIAS
Analizador de Estructuras de Navegación Aplicando Minería de Uso Web y Minería de Estructura Web
presentada por
Eduardo Ortiz Hernández Ing. en Sistemas Computacionales por el I. T. de Minatitlán
como requisito para la obtención del grado de:
Maestría en Ciencias en Ciencias de la Computación
Director de tesis:
Dr. Juan Gabriel González Serna
Co-Director de tesis: Dr. José Antonio Zárate Marceleño
Jurado: Dra. Azucena Montes Rendón - Presidente
Dr. Hugo Estrada Esquivel - Secretario M.C. Andrea Magadán Salazar - Vocal
Dr. Juan Gabriel González Serna - Vocal Suplente
Cuernavaca, Morelos, México. 27 de octubre de 2008



DEDICATORIA
A mis padres
Francisco y Rosa Elia, por todo el amor, confianza y apoyo que siempre he recibido,
han estado siempre a mi lado, ésto es de ustedes.
A mis hermanos
Jazmin y Miguel Ángel, por los momentos y alegrías,
y por que los tendré siempre conmigo.
A toda mi gran familia, Ortiz Ortiz y Hernández Ortiz A todos los que formamos ese núcleo,
una base sobre la que sabemos que podemos apoyarnos en todo momento.

AGRADECIMIENTOS A CONACYT por el apoyo económico otorgado para la realización de este trabajo de maestría.
Al Centro Nacional de Investigación y Desarrollo Tecnológico por brindarme la oportunidad para seguir en esta formación continua.
A mi director de tesis, el Dr. Juan Gabriel González Serna por brindarme su consejo y ayuda para terminar este trabajo de tesis. A mi codirector de tesis, el Dr. José Antonio Zárate Marceleño por sus valiosos comentarios y consejos.
A los revisores de este trabajo de tesis de investigación, la Dra. Azucena Montes Rendón, el Dr. Hugo Estrada Esquivel y la M.C. Andrea Magadán Salazar, por su tiempo dedicado, observaciones y comentarios para mejorar este trabajo, y su apoyo personal para culminar esta meta.
A las personas que me han rodeado en mi vida. Matilde, por tu compañía, cariño y confianza, y porque estamos cumpliendo esta meta que nos propusimos desde un principio. A todos mis amigos de mi terruño, Leonardo, Laura, Héctor, Erick, Héctor Martin, Mercedes, Enrique; y a los que me brindaron su amistad en mi estancia en esta ciudad, Laura, Jorge, Claudia, Pedro, Janet, Edgar Omar, Catalina, Rafael, Itzel, Oscar, Omar, Rubi, José Luis, Israel. Mil gracias a todos.

RESUMEN
Cada día cientos de organizaciones lanzan sus sitios Web, esperando integrarse y darse a conocer en la red mundial. Estos sitios se diseñan y estructuran de acuerdo al propósito y usuarios al que va dirigido.
Un punto importante en las tareas de diseño y rediseño de un sitio Web es el análisis de cómo es usado el sitio (minería de uso Web), así como las conexiones y relaciones entre las páginas que lo conforman (minería de estructura Web).
La minería de uso Web es la aplicación de técnicas de minería de datos a los archivos de bitácoras de los servidores Web, con la finalidad de producir patrones de navegación que revelen los caminos más comunes en que los usuarios navegan dentro del sitio.
Por otro lado, la minería de estructura Web tiene como objetivo generar un compendio estructural sobre un sitio utilizando técnicas de minería de datos aplicadas sobre los hipervínculos de cada página que conforma el sitio Web. Este tipo de técnicas puede ser usado para revelar la estructura de navegación del sitio.
La Web, con su propiedad de hipertexto, presenta una estructura que se puede describir mediante grafos. La visualización de dicha estructura es de capital importancia para comprender los resultados de la minería Web. Sin embargo, las propuestas actuales que intentan visualizar la estructura de un sitio Web no han logrado un correcto equilibrio entre los aspectos de visualización y minería uso y estructura Web.
El enfoque que se presenta en este trabajo es conjuntar los resultados de la minería de uso obteniendo los patrones de navegación de los usuarios y de estructura Web sobre un sitio, de la cual el resultado es la estructura de navegación del mismo, en una herramienta que permita mostrar sus resultados apoyados en una visualización gráfica. Al utilizar esta herramienta se establecen las pautas para mejorar el diseño de la estructura del sitio Web, proponiendo éstas al administrador del sitio para que las pueda aplicar en las tareas de diseño y rediseño que fueron mencionadas anteriormente.

ABSTRACT Everyday hundred of organizations launch their websites, hoping to make them known and integrated into the global network. These sites are designed and structured according to the purpose and users whom is directed.
An important point at the tasks of designing and redesigning a Web site is the analysis of how the site is used (Web usage mining), as well as the connections and relations between the pages (Web structure mining).
Web mining usage is the application of data mining techniques to Web servers logs files, in order to produce navigation patterns that reveal the most common ways in which users navigate through the site.
On the other hand, Web mining structure aims to generate structural information about a site using data mining techniques applied on each Web site page hyperlink. Such techniques can be used to reveal the navigation structure of the site.
The hypertext property of the Web, presents a structure that can be described as a graph. Viewing this structure is crucial to understand the results of Web mining. However, currents proposals that try to visualize the structure of a Web site have not achieved a correct balance between the aspects of visualization, Web mining usage and Web mining structure.
The approach that is presented in this thesis is to combine the results of obtaining mining use patterns and the navigation structure of a Web site, of which the outcome is the navigation structure, in a tool that allows showing their results supported by a graphic visualization.
By using this tool, it sets out the guidelines for improving the design of a Web site, proposing them to the webmaster so that design and redesign tasks can be implemented that were mentioned above.

i
TABLA DE CONTENIDO
CAPÍTULO 1 INTRODUCCIÓN ........................................................................................................................ 1
1.1. ANTECEDENTES .................................................................................................................................... 2 1.2. DESCRIPCIÓN DEL PROBLEMA .................................................................................................................. 2 1.3. OBJETIVOS .......................................................................................................................................... 2 1.4. JUSTIFICACIÓN Y BENEFICIOS ................................................................................................................... 3 1.5. ESTADO DEL ARTE ................................................................................................................................. 4
1.5.1. ScentViz....................................................................................................................................... 4 1.5.2. Web Knowledge and Information Visualization (WEBKIV) ......................................................... 5 1.5.3. Visual Web Mining ...................................................................................................................... 7 1.5.4. Web Knowledge and Discovery System (WEBKVDS) ................................................................... 8 1.5.5. Navigation Visualizer .................................................................................................................. 9 1.5.6. WebPatterns ............................................................................................................................... 9 1.5.7. WebViz ...................................................................................................................................... 10 1.5.8. Comparación de los trabajos relacionados ............................................................................... 11
1.6. ORGANIZACIÓN DEL DOCUMENTO DE TESIS .............................................................................................. 13
CAPÍTULO 2 MARCO TEÓRICO .................................................................................................................... 14
2.1. SITIO WEB ................................................................................................................................................ 15 2.2. MINERÍA WEB ........................................................................................................................................... 15
2.2.1. Minería de uso Web ...................................................................................................................... 16 2.2.2. Minería de contenido Web ............................................................................................................ 17 2.2.3. Minería de estructura Web ........................................................................................................... 18
2.3. ESTRUCTURA DE NAVEGACIÓN ...................................................................................................................... 19 2.3.1. Estructuras secuenciales ............................................................................................................... 20 2.3.2. Estructuras hipertextuales ............................................................................................................ 20 2.3.3. Estructuras jerárquicas ................................................................................................................. 20
CAPÍTULO 3 ANÁLISIS Y DISEÑO ................................................................................................................. 22
3.1. ANÁLISIS .................................................................................................................................................. 23 3.1.1. Introducción .................................................................................................................................. 23 3.1.2. Descripción general ....................................................................................................................... 23
3.2. DISEÑO .................................................................................................................................................... 26 3.2.1. Introducción .................................................................................................................................. 26 3.2.2. Diseño arquitectónico ................................................................................................................... 26 3.2.3. Diseño conceptual ......................................................................................................................... 27
CAPÍTULO 4 IMPLEMENTACIÓN ................................................................................................................. 52
4.1. INTRODUCCIÓN .................................................................................................................................. 53 4.2. INTRODUCCIÓN AL PATRÓN DE DISEÑO STRUTS 2 ...................................................................................... 53
4.2.1. Secuencia de una petición en Struts 2 ...................................................................................... 54 4.3. CARACTERÍSTICAS GENERALES DE LA IMPLEMENTACIÓN .............................................................................. 57
4.3.1. El paquete analizadorWebSite .................................................................................................. 57 4.3.2. La base de datos ....................................................................................................................... 58 4.3.3. Las clases de acción .................................................................................................................. 59 4.3.4. El paquete analizadorWebSite.util ........................................................................................... 60
4.4. IMPLEMENTACIÓN DEL MÓDULO DE MINERÍA DE USO WEB ......................................................................... 62 4.4.1. Validación de conexión a la base de datos ............................................................................... 62 4.4.2. Solicitud de la información del sitio Web a analizar ................................................................. 63 4.4.3. Preprocesamiento de archivos Log ........................................................................................... 63

ii
4.4.4. Sesionización de archivos Log ................................................................................................... 65 4.4.5. Procesamiento de minería de uso Web .................................................................................... 68
4.5. IMPLEMENTACIÓN DEL MÓDULO DE MINERÍA DE ESTRUCTURA WEB .............................................................. 70 4.5.1. Recolección de la estructura del sitio Web ............................................................................... 70 4.5.2. Procesamiento de minería de estructura Web ......................................................................... 71
4.6. IMPLEMENTACIÓN DEL MÓDULO PROCESAMIENTO DEL GRAFO Y EXTRACCIÓN DE RESULTADOS. .......................... 73 4.6.1. Visualización gráfica utilizando TouchGraph ............................................................................ 74
CAPÍTULO 5 PRUEBAS ................................................................................................................................ 76
5.1. INTRODUCCIÓN.......................................................................................................................................... 77 5.2. HIPÓTESIS ................................................................................................................................................ 77 5.3. DESCRIPCIÓN DEL PLAN ............................................................................................................................... 77
5.3.1. Características a ser probadas ...................................................................................................... 77 5.3.2. Enfoque ......................................................................................................................................... 77 5.3.3. Criterio pasa / no pasa de casos de prueba .................................................................................. 77 5.3.4. Criterios de suspensión y requerimientos de reanudación ............................................................ 77 5.3.5. Tareas de pruebas ......................................................................................................................... 78 5.3.6. Liberación de pruebas ................................................................................................................... 78 5.3.7. Requisitos ambientales ................................................................................................................. 78 5.3.8. Responsabilidades ......................................................................................................................... 79 5.3.9. Riesgos .......................................................................................................................................... 79
5.4. CASOS DE PRUEBAS .................................................................................................................................... 79 5.4.1. Características a probar ................................................................................................................ 79 5.4.2. Pruebas de procesamiento de minería de uso Web ...................................................................... 80 5.4.3. Pruebas de procesamiento de minería de estructura Web ........................................................... 80 5.4.4. Pruebas de procesamiento del grafo y visualización de resultados .............................................. 80
5.5. PROCEDIMIENTO DE PRUEBAS ....................................................................................................................... 80 5.5.1. Prueba PRUEBA-01-Pruebas de procesamiento de minería de uso Web ...................................... 81 5.5.3. Prueba PRUEBA-04-Pruebas de procesamiento y visualización del grafo de resultados .............. 84
5.4. RESULTADOS DE PRUEBAS ............................................................................................................................ 85 5.3. ANÁLISIS DE RESULTADOS .......................................................................................................................... 107
CAPÍTULO 6 CONCLUSIONES .................................................................................................................... 110
6.1. CONCLUSIONES........................................................................................................................................ 111 6.2. APORTACIONES ....................................................................................................................................... 112 6.3. TRABAJOS FUTUROS.................................................................................................................................. 112
ANEXOS ................................................................................................................................................... 114
ANEXO A FORMATOS DE ARCHIVOS DE BITÁCORA .................................................................................... 115 ANEXO B PANTALLAS DE LA APLICACIÓN ................................................................................................... 117
REFERENCIAS ........................................................................................................................................... 121

iii
LISTADO DE FIGURAS Figura 1. Visualización de DiskTree. ............................................................................................................. 4 Figura 2. Arquitectura de WebKIV. ............................................................................................................... 6 Figura 3. Arquitectura de Visual Web Mining. .............................................................................................. 7 Figura 4. Arquitectura de WEBKVDS. ........................................................................................................... 8 Figura 5. Clasificación de minería Web. ...................................................................................................... 16 Figura 6. Esquema de ejemplo de una estructura de navegación lineal. .................................................... 20 Figura 7. Esquema de ejemplo de una estructura de navegación hipertextual. .......................................... 20 Figura 8. Esquema de ejemplo de una estructura de navegación jerárquica. ............................................. 21 Figura 9. Diagrama de casos de uso para realizar un análisis de un sitio Web. ........................................... 23 Figura 10. Arquitectura del analizador de estructuras de navegación. ....................................................... 27 Figura 11. Diagrama de casos de uso “Realizar análisis de un sitio Web” (CU-1) ........................................ 27 Figura 12. Diagrama de actividades del caso de uso “Realizar análisis de un sitio Web” (CU-1). ................ 28 Figura 13. Diagrama de casos de uso introducir la información del sitio Web a analizar (CU-1.1). ............. 29 Figura 14. Diagrama de actividades del caso de uso “Introducir la información del sitio Web” CU-1.1. ..... 30 Figura 15. Diagrama de casos de uso “Procesar análisis del sitio Web” (CU-1.2). ....................................... 31 Figura 16. Diagrama de casos de uso de Realizar proceso de minería de uso Web (CU-1.2.1). ................... 31 Figura 17. Diagrama de actividades del caso de uso Realizar preprocesamiento de los archivo de bitácora
(CU-1.2.1.1). ..................................................................................................................................... 32 Figura 18. Diagrama de actividades del caso de uso “Realizar sesionización del archivo de bitácora” (CU-
1.2.1.2). ............................................................................................................................................ 33 Figura 19.Diagrama de actividades del caso de uso “Realizar procesamiento de minería de uso Web” (CU-
1.2.1.3). ............................................................................................................................................ 34 Figura 20. Diagrama de casos de uso “Realizar proceso de minería de estructura Web” (CU 1.2.2). .......... 35 Figura 21. Diagrama de actividades “Recolectar la estructura Web” (CU-1.2.2.1). ..................................... 36 Figura 22. Diagrama de actividades del caso de uso “Ejecutar proceso de minería de estructura Web” (CU-
1.2.2.2). ............................................................................................................................................ 36 Figura 23. Diagrama de casos de uso “Procesar y visualizar grafo de resultados” (CU-1.3)......................... 37 Figura 24. Diagrama de actividades del caso de uso "Procesar y visualizar grafo de resultados" (CU-1.3). . 37 Figura 25. Diagrama de módulos de la aplicación. ..................................................................................... 38 Figura 26. Módulo de minería de uso Web. ............................................................................................... 39 Figura 27. Módulo de minería de estructura Web. ..................................................................................... 47 Figura 28. Módulo de extracción y reunión de resultados. ......................................................................... 49 Figura 29. Módulo visualizador gráfico de resultados. ............................................................................... 50 Figura 30. Ventana de Wikibrowser. .......................................................................................................... 50 Figura 31. Arquitectura de Struts 2. ........................................................................................................... 53 Figura 32. Secuencia de una petición en Struts 2. ...................................................................................... 54 Figura 33. Paquete analizadorWebSite. ..................................................................................................... 57 Figura 34. Diagrama relacional de la base de datos.................................................................................... 59 Figura 35. Diagrama de clases del paquete analizadorWebSite.actions. .................................................... 60 Figura 36. Diagrama de clases del paquete analizadorWebSite.util. .......................................................... 61 Figura 37. Diagrama de secuencia del inicio de la aplicación. ..................................................................... 62 Figura 38. Diagrama de secuencia para introducir la información del sitio Web a analizar. ....................... 63 Figura 39. Diagrama de clases de analizadorWebSite.preprocesamiento para la limpieza de los archivos
log. ................................................................................................................................................... 64 Figura 40. Diagrama de secuencia para realizar preprocesamiento del archivo de bitácora. ...................... 65 Figura 41. Diagrama de clases de analizadorWebSite.preprocesamiento para sesionizar archivos Log. .... 66 Figura 42. Diagrama de secuencia para realizar sesionización por minutos del archivo de bitácora. .......... 67 Figura 43. Diagrama de secuencia para realizar sesionización por peticiones del archivo de bitácora........ 67 Figura 44. Diagrama de secuencia para realizar sesionización por heurística del archivo de bitácora. ....... 68 Figura 45. Diagramas de clases de analizadorWebSite.mineriaUso. ........................................................... 69

iv
Figura 46. Diagrama de secuencia para realizar procesamiento de minería de uso Web. ........................... 70 Figura 47. Diagrama de clases de minería de estructura Web. ................................................................... 71 Figura 48. Diagrama de secuencia para realizar minería de estructura Web. ............................................. 72 Figura 49. Diagrama de clases del paquete analizadorWebSite.extraccionResultados. .............................. 73 Figura 50. El paquete com.touchgraph. ...................................................................................................... 74 Figura 51. Etiqueta para integrar el applet a la página Web. ...................................................................... 75 Figura 52. Ventana donde se proporciona la información del sitio Web a analizar. ................................... 86 Figura 53. Ventana de información de los archivos de bitácora cargados. ................................................. 86 Figura 54. Ventana de selección de los tipos de documentos Web a filtrar. ............................................... 87 Figura 55. Peticiones almacenadas en la BD ............................................................................................... 88 Figura 56. Ventana de selección de algoritmo de sesionización. ................................................................ 89 Figura 57. Ventana de muestra de las sesiones de usuario encontradas. ................................................... 89 Figura 58. Muestra de las sesiones encontradas en la base de datos. ........................................................ 89 Figura 59. Peticiones con identificador de sesión 7. ................................................................................... 90 Figura 60. Muestra del llenado de la tabla catalogo. .................................................................................. 90 Figura 61. Muestra del llenado de la tabla cliente. ..................................................................................... 91 Figura 62. Ventana de selección de algoritmo de sesionización. ................................................................ 92 Figura 63. Ventana de muestra de las sesiones de usuario encontradas. ................................................... 92 Figura 64. Muestra de las sesiones encontradas en la base de datos. ........................................................ 92 Figura 65. Peticiones con identificador de sesión 7. ................................................................................... 93 Figura 66. Muestra del llenado de la tabla catalogo. .................................................................................. 93 Figura 67. Muestra del llenado de la tabla cliente. ..................................................................................... 94 Figura 68. Ventana de selección de algoritmo de sesionización. ................................................................ 95 Figura 69. Ventana de muestra de las sesiones de usuario encontradas. ................................................... 95 Figura 70. Muestra de las sesiones encontradas en la base de datos. ........................................................ 96 Figura 71. Peticiones con identificador de sesión 7. ................................................................................... 96 Figura 72. Muestra del llenado de la tabla catalogo. .................................................................................. 97 Figura 73. Muestra del llenado de la tabla cliente. ..................................................................................... 97 Figura 74. Ventana de usuario para procesamiento de minería de uso Web. ............................................. 98 Figura 75. Reglas de asociación almacenadas en la tabla reglas. ................................................................ 99 Figura 76. Elementos antecedentes de las reglas. ...................................................................................... 99 Figura 77. Elementos consecuentes de las reglas. ...................................................................................... 99 Figura 78. Ventana de usuario para procesamiento de minería de estructura Web. ................................ 100 Figura 79. Muestra del llenado de la tabla nodos. .................................................................................... 101 Figura 80. Muestra del llenado del la tabla entradas. .............................................................................. 101 Figura 81. Muestra del llenado de la tabla salidas.................................................................................... 102 Figura 82. Ventana de llenado de los campos gradoglobalessalida, gradolocalesentrada, gradolocalessalida
de la tabla nodos. ........................................................................................................................... 103 Figura 83. Muestra del llenado de la tabla “caminosinalcanzables”. ........................................................ 103 Figura 84. Grafo con la estructura del sitio Web. ..................................................................................... 105 Figura 85. Tablas con las reglas de asociación encontradas y los caminos inalcanzables. ......................... 106 Figura 86. Tabla con el reporte estructural del sitio. ................................................................................ 106 Figura 87. Pantalla de error de conexión a la base de datos (error.jsp). ................................................... 117 Figura 88. Pantalla de inicio de análisis de un sitio Web (inicio.jsp). ........................................................ 117 Figura 89. Pantalla de introducción de la información del sitio Web a analizar (infoSitio.jsp). ................. 118 Figura 90. Pantalla de selección de las extensiones a eliminar (preprocesamiento.jsp). .......................... 118 Figura 91. Pantalla de selección de algoritmo de sesionización (sesionizacion.jsp). ................................. 119 Figura 92. Pantalla de minería de uso Web (mineriaUso.jsp). .................................................................. 119 Figura 93. Pantalla de minería de estructura Web (mineriaEstructura.jsp). ............................................. 120

v
LISTADO DE TABLAS
Tabla 1. Tabla comparativa de trabajos relacionados. ............................................................................... 12 Tabla 2. Descripción del caso de uso “Realizar análisis de un sitio Web” (CU-1). ........................................ 28 Tabla 3. Descripción del caso de uso introducir la información del sitio Web a analizar (CU-1.1). .............. 29 Tabla 4. Descripción del caso de uso realizar preprocesamiento del archivo de bitácora (CU-1.2.1.1). ...... 32 Tabla 5. Descripción del caso de uso “Realizar sesionización de los archivos de bitácora” (CU-1.2.1.2). .... 33 Tabla 6. Descripción del caso de uso “Realizar procesamiento de minería de uso Web” (CU-1.2.1.3). ....... 34 Tabla 7. Descripción del caso de uso “Recolectar estructura del sitio Web” (CU-1.2.2.1). .......................... 35 Tabla 8. Descripción del caso de uso “Ejecutar proceso de minería de estructura Web” (CU-1.2.2.2). ....... 36 Tabla 9. Descripción del caso de uso “Procesar grafo y visualizar resultados” (CU-1.3). ............................. 37 Tabla 10. Parámetros de soporte y confianza. ........................................................................................... 45 Tabla 11. Tablas que conforman la base de datos. ..................................................................................... 58 Tabla 12. Tareas de pruebas. ..................................................................................................................... 78 Tabla 13. Requisitos de hardware. ............................................................................................................. 79 Tabla 14. Requisitos de software. .............................................................................................................. 79 Tabla 15. Caso de prueba PRUEBA-01-01. .................................................................................................. 85 Tabla 16. Caso de prueba PRUEBA-01-02. .................................................................................................. 87 Tabla 17. Caso de prueba PRUEBA-01-02 (sesionización por número de peticiones). ................................. 88 Tabla 18. Caso de prueba PRUEBA-01-02 (sesionización por minutos). ...................................................... 91 Tabla 19. Caso de prueba PRUEBA-01-02 (sesionización por heurística). ................................................... 94 Tabla 20. Caso de prueba PRUEBA-01-03. .................................................................................................. 98 Tabla 21. Caso de prueba PRUEBA-02-01. ................................................................................................ 100 Tabla 22. Caso de prueba PRUEBA-02-02. ................................................................................................ 103 Tabla 23. Caminos inalcanzables .............................................................................................................. 104 Tabla 24. Caso de prueba PRUEBA-03-01. ................................................................................................ 105 Tabla 25. Pruebas de sesionización. ......................................................................................................... 108 Tabla 26. Información generada del procesamiento de minería de estructura Web. ............................... 109

vi
GLOSARIO
Apache License
Es un tipo de licencia de software autorizado por la Apache Software Foundation (ASF). Esta licencia requiere la preservación de avisos o anuncios de derechos de autor, delimitando o especificando el alcance de los derechos y obligaciones, sin embargo no es una licencia copyleft (copia permitida), aunque que permite el uso de código fuente para el desarrollo de aplicaciones libres (open source) y propietarias [ASF Licences 2007].
ASP Del inglés Active Server Pages, es decir, Páginas Activas de Servidor. Es una tecnología de lado servidor de Microsoft para páginas Web creadas dinámicamente.
CGI Del inglés Common Gateway Interface, es decir, Interfaz Común de Pasarela. Es una tecnología que permite a un cliente solicitar datos de un programa ejecutado en un servidor Web.
CVS Del inglés Concurrent Versions System, es decir Sistema de Versiones Concurrentes. Es un sistema ampliamente usado para el control de código abierto. Permite que múltiples personas contribuyan a un conjunto de documentos, registrando las diferentes versiones de esos documentos. Muchos proyectos de código abierto permiten a usuarios anónimos leer desde los repositorios CVS, pero restringen el acceso a los desarrolladores.
HTML Del inglés HyperText Markup Language, es decir, Lenguaje de Marcas Hipertextuales. Es un lenguaje de marcación diseñado para estructurar textos y presentarlos en forma de hipertexto, el cual es el formato estándar de las páginas Web.
IP Del inglés Internet Protocol, es decir Protocolo de Internet. Es un protocolo orientado de datos, usado para la comunicación a través de una red (Internet) entre el origen y destino, de paquetes conmutados.
JSP Del inglés Java Server Pages, es decir, Páginas de Servidor de Java. Es una tecnología para crear aplicaciones Web. Es un desarrollo de la compañía Sun Microsystems y su funcionamiento se basa en scripts, que utilizan una variante del lenguaje java.
PHP Del inglés Hypertext Preprocessor, es decir, Preprocesador de Hipertexto. Es un lenguaje de programación usado frecuentemente para la creación de aplicaciones para servidores o creación de contenido dinámico para sitios Web.
URI Del inglés Uniform Resource Identifier, es decir, Identificador Uniforme de Recurso. Es una cadena de caracteres usada para identificar unívocamente un recurso (servicio, página, documento, dirección de correo electrónico, etc.). Ejemplo: http://www.cenidet.edu.mx/index.html.

vii
URL Del inglés Uniform Resource Locator, es decir, Localizador Uniforme de
Recurso. Es una cadena de caracteres, de acuerdo a un formato estándar, que se usa para nombrar recursos, por su localización. Ejemplo: http://www.cenidet.edu.mx.
VTK Del inglés Visualization Toolkit, es decir, Conjunto de Herramientas de Visualización, es un sistema de software libre para gráficas en 3D por computadora, procesamiento de imágenes y visualización.

1
CAPÍTULO 1 INTRODUCCIÓN

Capítulo 1 Introducción
2
1.1. Antecedentes La World Wide Web (WWW) es un medio de difusión donde se puede obtener una gran cantidad de información, es por ello un área fértil para el área de investigación de minería de datos, denominando a este campo del conocimiento minería Web.
Los sitios Web en muchas ocasiones son utilizados para establecer la imagen de una compañía u organización y promover o vender bienes o servicios. Además, el éxito de un sitio Web afecta y refleja directamente el éxito de la organización. En este trabajo de tesis, se propone emplear los conocimientos de minería Web para mejorar la estructura de un sitio Web, basado en minería de uso y minería de estructura Web.
1.2. Descripción del problema Uno de los principales problemas de un sitio Web es atraer a los usuarios para que éste sea cada vez más visitado. Una vez que el usuario accedió, el sitio debe estar estructurado correctamente para que la navegación sea rápida, intuitiva y natural, lo que ayudará a mejorar la experiencia de navegación y que el usuario permanezca en el sitio una mayor cantidad de tiempo.
A pesar de los esfuerzos de los diseñadores Web, aún existen muchos sitios difíciles de usar. Por ejemplo, la empresa de investigación Forrester Research ha reportado que 65% de todas las compras en Internet terminan en fracaso [Souza 2000], y que 40% de todos los visitantes no regresan a un sitio Web debido a los problemas de diseño [Manning 1998]. Claramente, la usabilidad del sitio Web es uno de los factores más importantes. De acuerdo a los reportes de [Nielsen 2002], algunos de los factores que generan un bajo nivel de usabilidad incluyen un mal diseño del sitio Web y una estructura de navegación complicada, la cual causa que los usuarios se pierdan.
Una razón de estos problemas es la falta de entendimiento de la forma en que los usuarios navegan en el sitio Web. Una solución atractiva es desarrollar una herramienta computacional que emplee minería de uso Web para búsqueda de patrones de navegación y minería de estructura Web que apliquen las técnicas de minería de datos sobre los hipervínculos del sitio, con el fin de proponer recomendaciones a la estructura de navegación.
1.3. Objetivos El objetivo de la tesis es mejorar la navegación de los usuarios en un sitio Web. Para lograr esto se propone desarrollar una herramienta que aplique minería de uso para identificar los patrones de navegación de los usuarios, minería de

Capítulo 1 Introducción
3
estructura Web para obtener la estructura simplificada del sitio analizado y visualizar los resultados de manera gráfica, lo cual proporciona la posibilidad de rediseñar la estructura para optimizar la navegación en el sitio en base a la interpretación de éstos patrones.
1.4. Justificación y beneficios El análisis de las estructuras de navegación es necesario para descubrir los patrones y entender el comportamiento de navegación de los visitantes del sitio Web. Los administradores de los sitios Web carecen de herramientas que permitan visualizar efectivamente los patrones interesantes de navegación obtenidos de la información de uso Web del sitio.
De acuerdo a [Hassan 2004], las estructuras de navegación hipertextuales, si bien ofrecen mayor libertad y dinamismo a la navegación pueden ocasionar confusión, provocando que el usuario se sienta “perdido”. Además, en este tipo de estructuras hay que tener precaución para que ninguna página quede descolgada o de difícil acceso.
Por otro lado, es necesario mantener un equilibrio entre el ancho y profundidad de la jerarquía en las estructuras de navegación jerárquicas. Las estructuras jerárquicas muy profundas pueden provocar que las páginas finales queden muy distanciadas de la página origen y por tanto difíciles de encontrar o recuperar. En contraste, aquellas muy anchas pueden desorientar y confundir al usuario al ofrecer demasiadas opciones de navegación desde una misma página [Hassan 2004].
Al proponer a los administradores una herramienta que permita visualizar efectivamente los patrones de navegación obtenidos al hacer minería de uso Web, éstos conocerán el estado actual de las actividades que los usuarios llevan a cabo en el sitio.
Utilizando estos resultados, se proporciona la posibilidad de auxiliar en el rediseño de los sitios Web al proponer una nueva estructura, sugiriendo mejores ubicaciones para los documentos más solicitados o estableciendo rutas más cortas hacia ellos, enlaces en los patrones de navegación encontrados, entre otros.
Por lo tanto, esta herramienta beneficiará a los usuarios del sitio Web al facilitarles la navegación entre los recursos del sitio, permitiéndoles que ésta sea de manera más cómoda y natural.

Capítulo 1 Introducción
4
1.5. Estado del arte Existen muchas herramientas de minería de uso Web que muestran los resultados en forma de reportes, pero muy pocas hacen visualización de éstos integrándolos con minería de estructura Web. Los trabajos que se presentan a continuación tratan de presentar de manera conjunta éstas dos clasificaciones de minería Web.
1.5.1. ScentViz ScentViz [Chi 2002] fue el primer trabajo en mostrar la minería de uso y estructura Web juntos, mapeando los patrones de navegación que muestran cómo navegan los usuarios a través del sitio, obtenidos de la minería de uso sobre los objetos o páginas del sitio Web.
Sobre las páginas del sitio Web se aplica el algoritmo UBL (del inglés Usage-Based Layout, Diseño basado en el Uso) [Chi 1998], el cual permite reducir el grafo Web a un modelo jerárquico derivado de los datos de uso. Al aplicar éste algoritmo, si una página es enlazada por varias páginas distintas, sólo el primer enlace encontrado con el algoritmo de búsqueda se almacena para representarlo en el grafo.
La técnica de visualización que representa al sitio Web está en forma de disco, denominado DiskTree (Figura 1), donde el centro del grafo es la página raíz (home page), y cada línea representa un hipervínculo a otra página dentro del sitio. Los hipervínculos de un salto se encuentran en el primer círculo concéntrico del grafo, los hipervínculos de dos saltos están en el segundo y así consecutivamente. Estas líneas que representan a los hipervínculos tienen una tonalidad verde, mientras más brillante y gruesa sea la línea, indica un mayor uso del hipervínculo. Para cada nodo en el círculo concéntrico, el sistema destina un espacio angular proporcional al número de hijos de ese nodo. La información detallada de uso se visualiza al lado de cada nodo al pasar el mouse sobre ellos.
Figura 1. Visualización de DiskTree.

Capítulo 1 Introducción
5
ScentViz también permite visualizar la evolución de uso del sitio Web. Ésta se lleva a cabo mediante la técnica time tube (“tubo” o periodo de tiempo), la cual representa el tiempo sobre el eje horizontal y usa múltiples cortes para mostrar intervalos específicos de tiempo.
1.5.2. Web Knowledge and Information Visualization (WEBKIV) WebKIV [Niu 2002] es una herramienta que presenta una vista simultánea de la estructura, contenido y navegación del sitio Web. WebKIV tiene las siguientes características:
1. Visualización de la estructura Web: provee herramientas para visualizar estructuras pequeñas y grandes (hasta 70000 nodos), con controles que soportan el desplegado de la estructura de manera abstracta y de manera detallada.
2. Visualización de la navegación Web: permite visualizar de forma estática y dinámica, los patrones de usuario individuales y de manera conjunta en un grafo.
a. Visualización estática: Representa lo que los usuarios han hecho, realizando minería de datos sobre las bitácoras de acceso del servidor del sitio Web.
b. Visualización dinámica: Representa lo que los usuarios están haciendo, mediante puntos que simbolizan a cada usuario navegando en el sitio Web, donde un punto que se mueve a otro lugar indica el camino que siguió el usuario. Un punto detenido en un nodo del grafo representa que el usuario está viendo la página Web específica, donde el tiempo que tarda el punto indica el tiempo que el usuario está en la página Web. El punto desaparecerá si el usuario se ha detenido por cierta cantidad de tiempo. En este caso, el sistema mantiene una cuenta en cada hipervínculo que atraviesan los usuarios. Se utiliza una escala de grises en estos hipervínculos los cuales, mientras éstos sean más utilizados, más oscura será la línea.
3. Evaluación de resultados de la minería Web: Se aplican las técnicas de minería Web en la bitácora de acceso Web y se usan los resultados (por ejemplo las reglas de asociación) para mejorar la navegación de los usuarios, creando y utilizando los modelos de compresión de navegación (NCM) [Niu 2002]. La visualización gráfica permite sobreponer los patrones de navegación y compararlos con aquellos construidos mediante NCM.

Capítulo 1 Introducción
6
Arquitectura de WebKIV La arquitectura de WebKIV (ver Figura 2) consta de cuatro componentes básicos:
Figura 2. Arquitectura de WebKIV.
1. Colección de datos: Utiliza 3 diferentes tipos de datos, la topología del sitio Web que es obtenida mediante un Web crawler1, los datos de la bitácora del servidor y los resultados de la aplicación de minería Web mediante alguna de las técnicas existentes.
2. Análisis de los datos: Se aplica un algoritmo de árbol radial2 a los datos de la estructura del sitio Web.
3. Transformación de datos: Cada página Web es representada por un cuadrado, cada hipervínculo está representado por una línea y mediante un punto se representa un usuario navegando en la visualización dinámica.
WebKIV utiliza un algoritmo de árbol radial, el cual es usado para construir la estructura del sitio Web en un plano de dos dimensiones al igual que ScentViz [Chi 2002], y donde se presentan los resultados del sistema, existiendo aún dificultades de visualización, a pesar de contar con herramientas de zoom y desplazamiento.
1 Un Web crawler es un programa que inspecciona páginas de la Web de forma metódica y
organizada, visitando una URL, identificando los hipervínculos en dicha página, para visitar éstas páginas, de manera recurrente. 2 Un árbol radial un árbol acíclico jerárquico, donde cada nivel de la jerarquía es representado por
un círculo concéntrico de nodos alrededor del nodo central.

Capítulo 1 Introducción
7
1.5.3. Visual Web Mining El prototipo Visual Web Mining [Youssefi 2003] es una aplicación de las técnicas de visualización de información sobre los resultados obtenidos de la minería de uso Web.
Visual Web Mining utiliza un Web crawler para recuperar las páginas del sitio Web. Además, a partir de los archivos de bitácoras se extraen las sesiones de usuario. Sobre estas sesiones se aplica un algoritmo de minado de secuencias denominado cSPADE3.(SPADE continuo). La salida que genera este algoritmo son secuencias contiguas con un soporte mínimo dado. Estas secuencias son importadas a una base de datos. Posteriormente se ejecutan diferentes consultas de estos datos de acuerdo a algún criterio, por ejemplo el soporte de cada patrón, longitud de los patrones, etc.
Para visualizar los resultados se recurre la herramienta Visualization Toolkit
(VTK), un software libre para gráficas en computadora en 3D, procesamiento de imágenes y visualización, extendiéndola a una nueva librería llamada vtkGraph, mediante la cual permite visualizar la estructura del sitio y se mapea con los datos de uso Web. La Figura 3 muestra la arquitectura del sistema Visual Web Mining.
Figura 3. Arquitectura de Visual Web Mining.
3 SPADE es un algoritmo para descubrir de forma más rápida patrones secuenciales, utilizando
propiedades combinatorias para descomponer el problema original en pequeños subproblemas que son resueltos en memoria principal usando técnicas de búsqueda eficientes, y posteriormente operaciones simples de unión [Zaki 2001].

Capítulo 1 Introducción
8
1.5.4. Web Knowledge and Discovery System (WEBKVDS) WEBKVDS [Zaïane 2004] propone una herramienta de visualización para grafos representando la estructura Web y los patrones. La herramienta está compuesta principalmente de dos partes: FootPath y Web Graph Algebra.
FootPath muestra una representación en 2D de un grafo que denominan Web Graph (una imagen en forma de disco donde el centro es la raíz de la estructura del sitio, y los nodos de cada nivel desplegados en un perímetro circular, cada nivel alejado sucesivamente del centro), donde se combinan la estructura Web y los datos de uso (estadísticas del número de visitas, uso de hipervínculos, tiempo promedio por página) con los patrones de navegación encontrados.
A su vez, Web Graph Algebra es un método diseñado para manipular y combinar grafos Web y sus capas mediante un conjunto de operaciones disponibles al usuario, que le permitan descubrir nuevos patrones de una manera ad-hoc. Mediante la aplicación de estos operadores, es posible obtener datos tales como:
Encontrar páginas de entrada o de salida del sitio Web.
Visualización consecutiva de meses.
Encontrar páginas de contenido4.
La Figura 4 muestra la arquitectura del sistema WEBKVDS.
Figura 4. Arquitectura de WEBKVDS.
Los operadores de Web Graph Algebra son una importante aportación, sin embargo, su utilización puede ser confusa al intentar obtener resultados específicos.
4 Una página de contenido, es aquella que los usuarios de un sitio Web buscan y quieren ver, por
lo cual el tiempo que el usuario permanece en ellas es considerablemente mayor que en una página que apunta a muchas páginas (conocidas como páginas “hub”, éstas funcionan como un punto de conexión hacia las demás páginas).

Capítulo 1 Introducción
9
1.5.5. Navigation Visualizer Navigation Visualizer [Herder 2005] es una herramienta de análisis de minería de uso Web haciendo uso de los resultados obtenidos con el servidor proxy del sistema Scone5 que utiliza bitácoras de acceso de manera similar a las bitácoras en los servidores Web, difiriendo en que el proxy recoge los datos de un grupo de usuarios accediendo a diferentes servidores Web. Cada usuario se registra al usar el navegador y el sistema Scone analiza y almacena todas las acciones del usuario [Herder 2006].
Navigation Visualizer permite modelar el grafo de navegación. El grafo consiste de las páginas, representadas por nodos y los hipervínculos, representados por sus arcos, en un plano de dos dimensiones. Este grafo se puede usar para representar diferentes alternativas de navegación de usuarios, tales como:
Todas las páginas de un sitio Web visitadas por un grupo de usuarios.
Todas las páginas en la Web que son visitadas por algún usuario en un cierto intervalo de tiempo.
Todas las páginas en la Web que son visitadas por un grupo de usuarios en un cierto intervalo de tiempo.
Todas las páginas en la Web que son visitadas por algún usuario en una sesión.
Navigation Visualizer es un sistema que plantea de una manera distinta la
aplicación de minería de datos sobre el uso y la estructura del sitio Web, al utilizar información de un servidor proxy, del cual debería ser delimitado a los registros de navegación del sitio Web que está siendo analizado.
1.5.6. WebPatterns WebPatterns [Oosthuizen 2006] es un prototipo de una herramienta de minería de uso Web combinado con técnicas de visualización de información para presentar sus resultados de manera gráfica.
WebPatterns fue creado con el objetivo de realizar estudios de minería sobre sitios Web organizacionales. Estos tipos de sitios son de un tamaño relativamente pequeño que varían de decenas a centenas de páginas. Debido a esta cantidad de nodos, se considera una representación visual en forma de árbol radial, similar a DiskTree [Chi 2002].
5 Scone es un conjunto de herramientas en Java publicadas bajo licencia de GNU GPL para
investigación y desarrollo de sistemas de ayuda orientados a la Web, enfocadas en incrementar la navegación y orientación en la Web [Scone 2007].

Capítulo 1 Introducción
10
El prototipo WebPatterns está implementado en una arquitectura de 3 capas: la capa de aplicación, la capa de presentación y la capa de datos.
a) Capa de aplicación
Implementada como un servicio Web separado, con los algoritmos de minería de uso Web (algoritmo de extracción de reglas de asociación y algoritmo de análisis de secuencias) escritos en Java y ejecutándose en un servidor Sun.
b) Capa de presentación El diseño de la interfaz de usuario muestra los resultados de la aplicación de los algoritmos de minería de uso Web (extracción de reglas de asociación y análisis de secuencias) en un grafo radial. Las páginas asociadas y las rutas encontradas, respectivamente, están apoyadas visualmente por colores que permiten su fácil identificación. Además incorpora filtros para criterios específicos, tales como el “periodo” del análisis realizado o la “selección de página” que permite al usuario especificar que parte del sitio Web se despliega gráficamente.
La capa de aplicación está implementada en C# y FlowChart .NET para el componente de elaboración del grafo radial.
c) Capa de datos La capa de datos está implementada como una base de datos Oracle, la cual fue instalada también en el servidor Sun.
1.5.7. WebViz El sistema WebViz [Zaïane 2007] es una revisión de WEBKVDS [Zaïane 2004], en el cual se incluye tres principales aportaciones:
a) Nuevos operadores de Web Graph Algebra Uno de los enfoques de WEBKVDS, es el de la posibilidad de aplicar operadores sobre el grafo de visualización de los resultados de minería de uso Web. Los operadores adicionales que incluye WebViz permiten encontrar las páginas del sitio Web con un número mayor de hipervínculos salientes y entrantes; estas notaciones son análogas a las páginas de contenido y páginas hub6.
6 Una página autoritativa es aquella que es reconocida por proveer información valiosa, confiable y
útil en un tema específico. La estructura de la Web mediante los hipervínculos puede proveer de una gran cantidad de información para encontrar páginas autoritativas. De manera específica, la creación de un hipervínculo por un autor a una página Web representa un respaldo o aprobación implícita a la página a la que está dirigida el hipervínculo; realizando un minado del conjunto de éstos enlaces, es posible obtener páginas con gran relevancia y calidad.

Capítulo 1 Introducción
11
b) Optimización del algoritmo para el grafo DiskTree
El grafo en el que WebViz visualiza sus resultados, sigue la estructura de Disktree [Chi 2002], en el cual el nodo raíz (la página principal) se ubica al centro, y los nodos se dibujan en diferentes radios alrededor del nodo raíz. Para cada nivel, las ubicaciones de los nodos se deciden por el número total de nodos de ese nivel n,
sobre un ángulo determinado por 3600
𝑛. Sin embargo, se presentan problemas de
oclusión cuando un nodo tiene mucho más hijos que otros nodos en el mismo nivel. La optimización del algoritmo trata de eliminar este problema asignando más espacio a los subárboles más grandes, calculando recursivamente el ángulo de los nodos de los niveles internos hasta que se alcanza la raíz. La fórmula utilizada es la siguiente:
𝐴𝑝 =𝐴𝑚𝑖𝑛 + 𝐴𝑚𝑎𝑥
2
Donde 𝐴𝑝 representa el ángulo para el padre, 𝐴𝑚𝑖𝑛 y 𝐴𝑚𝑎𝑥 representan el
ángulo máximo de los nodos hijos.
c) Interfaz de usuario mejorada El diseño de la interfaz de usuario ha sido mejorado con respecto a WEBKVDS, añadiendo las siguientes características:
Tamaño del nodo, para representar las visitas de la página.
Color de nodo, para indicar el tiempo promedio de vista de la página.
Anchura del arco, para mostrar el uso del hipervínculo.
Color del arco, para representar el porcentaje de uso del hipervínculo (con respecto a los demás hipervínculos que comparten la misma página de inicio).
1.5.8. Comparación de los trabajos relacionados Al hacer el estudio del estado del arte, se han encontrado varios trabajos que realizaban procesamiento de minería de uso sobre los sitios Web con la finalidad de descubrir los patrones de navegación, que ayudaran a entender como los usuarios navegaban a través de él. ScentViz [Chi 2002] fue el primero en englobar a la minería de uso Web mostrando los patrones de navegación sobre un grafo que representa la estructura del sitio Web, utilizando DiskTree.
La visualización propuesta por [Chi 2002] generó gran influencia sobre los demás trabajos. Sobre esta misma línea, WebKIV [Niu 2002], WEBKVDS [Zaïane 2004] actualizado en WebViz [Zaïane 2007] y WebPatterns [Oosthuizen 2006], los cuales fueron mejorando las capacidades de visualización. Mientras que las investigaciones de Visual Web Mining [Youssefi 2003] y Navigation Visualizer
Capítulo 1 Introducción
12
[Herder 2005] optaron por diferentes modos de visualización, en 3D y un grafo dirigido, respectivamente.
Un factor que debe ser considerado es la importancia de mostrar la estructura del sitio Web analizado y no sólo los datos de uso Web. Un problema con la visualización de las estructuras de sitios Web es que no son necesariamente jerárquicos por naturaleza; debido a que pueden existir muchos hipervínculos, la estructura puede representarse de mejor manera por un grafo dirigido que por un árbol. Por otro lado, algunos grafos de visualización en el estado del arte son poco claros o con problemas de oclusión de los nodos que representan las páginas del sitio, lo que los hace difíciles de entender para poder aplicar el conocimiento adquirido de este tipo de herramientas en la reestructuración del sitio. En esta tesis se propone representar los resultados en un grafo dirigido dinámico, que permita facilitar su interpretación.
Asimismo, además del grafo del sitio Web, se aplicará minería de estructura
Web sobre los hipervínculos que componen las páginas que conforman el sitio, con la finalidad de proporcionar información detallada de la estructura, la cual contiene datos como las páginas inalcanzables, o las menos interconectadas con todo el sitio Web [Madria 1999].
El conjunto de características de los trabajos relacionados junto con la
propuesta de solución del tema de tesis han sido clasificadas en una tabla comparativa, la cual concluye el reporte del estado del arte.
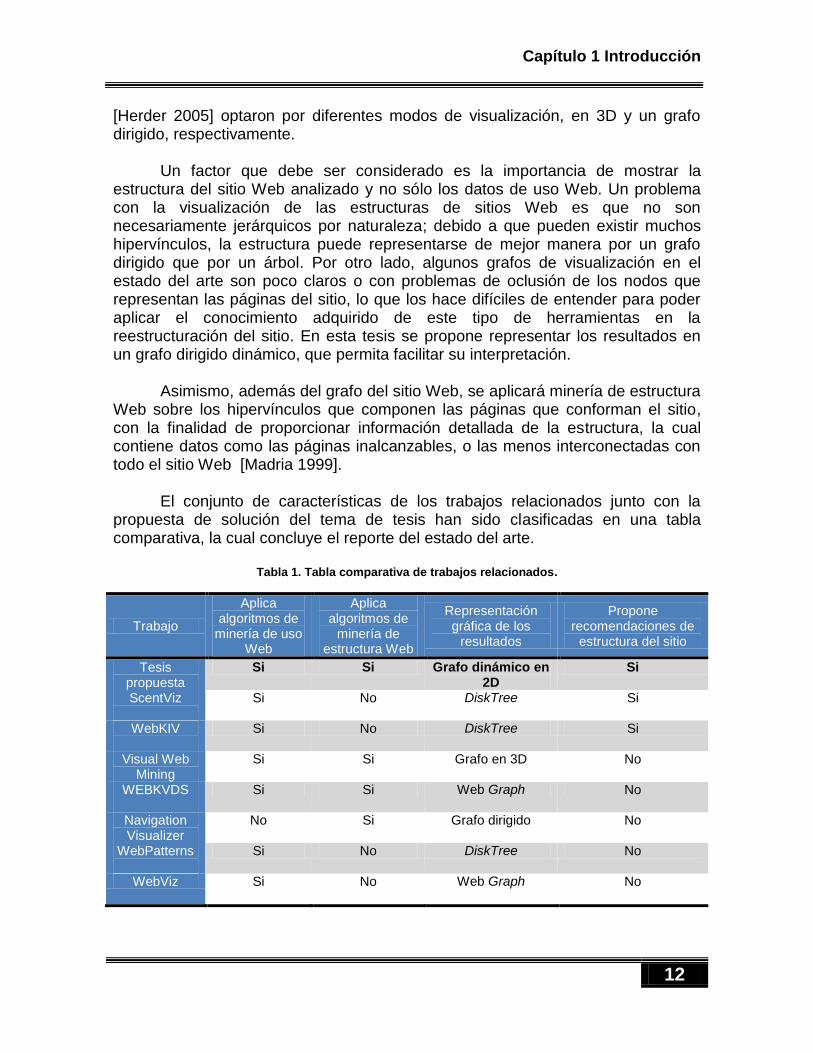
Tabla 1. Tabla comparativa de trabajos relacionados.
Trabajo
Aplica algoritmos de
minería de uso Web
Aplica algoritmos de
minería de estructura Web
Representación gráfica de los
resultados
Propone recomendaciones de
estructura del sitio
Tesis propuesta
Si Si Grafo dinámico en 2D
Si
ScentViz
Si No DiskTree Si
WebKIV
Si No DiskTree Si
Visual Web Mining
Si Si Grafo en 3D No
WEBKVDS
Si Si Web Graph No
Navigation Visualizer
No Si Grafo dirigido No
WebPatterns
Si No DiskTree No
WebViz Si No Web Graph
No

Capítulo 1 Introducción
13
1.6. Organización del documento de tesis El documento se encuentra organizado en 6 capítulos, los cuales presentan la siguiente información:
Capítulo 2 “Marco Teórico”, describe los fundamentos teóricos de la Web, y las investigaciones del campo de la minería de datos que se han aplicado en este campo de investigación.
Capítulo 3 “Análisis y Diseño”, se muestran los casos de uso, diagramas de actividad, y secuencia que representan el análisis y diseño del analizador de sitios Web.
Capítulo 4 “Implementación”, explica información detallada de la arquitectura y los diferentes módulos que la conforman. Se describen los paquetes que se desarrollaron y las clases que las conforman.
Capítulo 5 “Pruebas”, describe las pruebas realizadas al analizador de sitios Web. Comprueba el cumplimiento de los objetivos propuestos mediante los casos de prueba.
Capítulo 6 “Conclusiones”, se presentan las conclusiones derivadas de este trabajo, las principales aportaciones y los posibles trabajos futuros que se pueden realizar a partir de esta investigación.
Finalmente se incluye una sección de anexos: Anexo A, formatos de
archivos de bitácora; Anexo B, pantallas de la aplicación.

14
CAPÍTULO 2 MARCO TEÓRICO

Capítulo 2 Marco Teórico
15
2.1. Sitio Web Un sitio Web es una serie o colección de páginas que definen la estructura del mismo y se identifican por una única dirección Uniform Resource Locator (URL) [Cooley 1999a].
Un sitio Web puede ser modelado como un grafo dirigido con nodos Web y arcos Web, donde los nodos corresponden a archivos con contenidos de páginas (tales como HTML, PHP, ASP, CGI, JSP, etc.), y los arcos corresponden a los links (hipervínculos) interconectando a las páginas Web [Lee 2006].
Formalmente un grafo Web dirigido G = (N,A) puede ser representado con
una función de arco 𝑥𝑖𝑗 ∶ 𝑁𝑘 → 0,1 , ∀ 𝑖, 𝑗 ∈ 𝑁, la cual consiste de un conjunto
finito N de nodos, un conjunto finito de arcos A de pares ordenados de nodos Web, y los elementos de arcos Web (𝑖, 𝑗), donde 𝑖, 𝑗 ∈ 𝑁 = 0, 1, 2, 3, … , 𝑛 − 1 , y
𝑛 = 𝑁 corresponde a la cardinalidad de las páginas Web. Existe una relación donde los nodos corresponden a las páginas Web y los arcos a cada Uniform Resource Identifier 7 (URI) [Faloutsos 1999], [Garofalakis 1999].
Entonces, un sitio Web consiste de una página de inicio (homepage) que puede ser accedida por su nombre de dominio y muchos otros contenidos Web enlazados cada uno (que pueden ser localizados con su correspondiente URI o haciendo clic en los hiperenlaces dentro de la página Web). Los contenidos Web (páginas, incluyendo la página homepage) de un sitio Web pueden ser representados como un grafo que consiste de un conjunto de nodos con arcos asociados [Garofalakis 1999], [Lee 2004a]. Aquí, un contenido Web corresponde a un nodo, mientras que los hipervínculos dentro del sitio Web entre los contenidos Web son los arcos dirigidos de los grafos.
Si se transforman los contenidos Web de un sitio en su correspondiente árbol, es posible encontrar un conjunto de caminos a través del cual cualquier página Web de un sitio puede ser accedida desde la página homepage y todas las otras páginas dentro del sitio [Lee 2006].
2.2. Minería Web Se refiere a la aplicación de técnicas de minería de datos sobre la World Wide Web con el fin de obtener conocimiento de la información disponible en Internet, ésta se divide en tres áreas de acuerdo a su aplicación (ver Figura 5): minería de uso Web, minería de contenido Web y minería de estructura Web [Cooley 2000], y se explican a continuación.
7 Uniform Resource Identifier: es una cadena de caracteres usada para identificar unívocamente un
recurso (servicio, página, documento, dirección de correo electrónico, etc.). Ejemplo: http://www.cenidet.edu.mx/index.html.

Capítulo 2 Marco Teórico
16
Figura 5. Clasificación de minería Web.
2.2.1. Minería de uso Web La minería de uso Web es la aplicación de técnicas de minería de datos sobre las extensas bitácoras de acceso Web con la finalidad de producir resultados que puedan ser usados en tareas de diseño Web [Lee 2006].
Una bitácora de acceso de un servidor Web contiene registros de accesos de los usuarios. Cada registro representa una petición de una página de un usuario Web. Un registro típicamente contiene la dirección IP del cliente, la hora y fecha en que es recibida la petición, la dirección URI del objeto solicitado, el protocolo de la petición, el código de retorno del servidor indicando el estado de control de la petición, y el tamaño de la página si la petición es exitosa [Fu 1999].
Los algoritmos principalmente utilizados en la minería de uso Web son generación de reglas de asociación, generador de patrones secuenciales, y de agrupamiento (clustering).
2.2.1.1. Generador de reglas de asociación
De acuerdo con [Cooley 1999b] las técnicas de generación de reglas de asociación descubren las correlaciones entre los objetos que se encuentran en una base de datos de transacciones. En el contexto de la minería de uso Web una transacción es un grupo de accesos a páginas Web, siendo un objeto un acceso a una página singular. Un ejemplo de una regla de asociación es:
45% de los visitantes que accedieron a la página /pagina1.html también accedieron a la página /página2.html.
El porcentaje reportado en el ejemplo se define como confianza. La
confianza determina la precisión de la regla ya que refleja el grado con el que los ejemplos pertenecientes a la zona del espacio delimitado por el antecedente verifican la información indicada en el consecuente de la regla [Cooley 1999b].

Capítulo 2 Marco Teórico
17
2.2.1.2. Generador de patrones secuenciales
El objetivo de un generador de patrones secuenciales es descubrir patrones en forma inter-transacción tales que, la presencia de un conjunto de objetos es seguida por otro objeto en un periodo de tiempo del conjunto de transacciones ordenadas. En las bitácoras de transacciones de un servidor Web, las visitas de los clientes son registradas por un periodo de tiempo. El periodo de tiempo asociado con una transacción en este caso será determinado y agregado a ésta durante la limpieza de datos o los procesos de identificación de transacciones. El descubrimiento de patrones secuenciales en las bitácoras de acceso de los servidores Web permite a las organizaciones con sitios Web predecir los patrones de visita y ayudar a seleccionar los anuncios dirigidos a los grupos de usuarios en que se basaron estos patrones [Cooley 1997]. El objetivo es determinar relaciones entre los objetos tales como:
60% de los clientes que hicieron una orden en /compañía/producto1.html también hicieron una orden en /compañía/producto4.html dentro de 15 días.
2.2.1.3. Agrupamiento
Permite agrupar a clientes u objetos de datos con características similares. El agrupamiento de información del cliente o de los objetos puede facilitar el desarrollo y ejecución de estrategias de mercadeo [Fu 1999].
2.2.2. Minería de contenido Web La minería de contenido Web es el proceso utilizado para la extracción de conocimiento a partir del contexto de los sitios Web, por ejemplo, del contenido de los documentos o su descripción [Cooley 2000]. La minería de contenido Web es usada por los motores de búsqueda o agentes para hacer recomendaciones que permitan ayudar a los usuarios a encontrar lo que están buscando.
Básicamente, el contenido Web consiste de datos no estructurados tales como textos, datos semiestructurados como documentos HTML y datos estructurados como los encontrados en tablas o bases de datos de páginas HTML [Kosala 2000].
La heterogeneidad y falta de estructura que existe en muchos de los recursos en la Web por ejemplo, los documentos de hipertexto, hacen que el descubrimiento automático, organización y manejo de la información de la Web sea difícil [Madria 1999].

Capítulo 2 Marco Teórico
18
Dentro de la minería de contenido Web se pueden diferenciar dos puntos de vista diferentes de acuerdo a [Cooley 1997]: recuperación de información (RI) y base de datos (BD). El objetivo de la minería de contenido Web desde el punto de vista de RI es principalmente el de asistir o mejorar la búsqueda de información, o bien filtrar la información a los usuarios, basándose en inferencias o perfiles de usuario, mientras que el objetivo desde el punto de vista de BD, trata principalmente de modelar los datos de la Web e integrarlos, de modo que se puedan efectuar búsquedas mediante querys (solicitudes) sofisticadas, utilizando palabras clave.
2.2.3. Minería de estructura Web Es el proceso de uso de la teoría de grafos para analizar los nodos y su estructura de conexión en un sitio Web. Ésta línea de investigación está inspirada por el estudio de las redes sociales y análisis de citas o referencias [Kautz 2000], [Chakrabarti 2000], aplicado a la Web. De acuerdo a los datos que analiza, la minería de estructura Web puede ser enfocada de dos formas distintas.
El primer enfoque está dirigido a la estructura de los hipervínculos dentro de la Web. Trata de descubrir el modelo subyacente a las estructuras de hipervínculos de la Web, según [Kosala 2000]. Este modelo está basado sobre la topología de hipervínculos incluyendo o no una descripción de éstos hipervínculos. El modelo puede ser usado también para categorizar páginas Web y generar información tal como la similitud y relación entre diferentes sitios Web. Esta información puede inferir conocimiento interesante como podría ser la identificación de páginas autoritativas o grupos de páginas autoritativas, y la identificación de páginas que apuntan a muchas páginas autoritativas, los cuales se les denomina hubs.
Se han propuesto algunos algoritmos para modelar la topología de la Web tales como HITS [Kleinberg 1998], PageRank [Brin 1998] y mejoras sobre HITS añadiendo información a la estructura de los hipervínculos [Chakrabarti 1999]. Estos modelos son aplicados principalmente para calcular el rango de calidad o relevancia de cada página Web. Algunos ejemplos de este tipo son el sistema Clever [Chakrabarti 1999] y Google [Brin 1998]. Otras aplicaciones de los modelos incluyen la categorización de páginas Web [Chakrabarti 1998] y descubrimiento de comunidades en la Web [Kumar 1999].
El segundo enfoque, y en el cual está fundamentada la tesis, es extraer la estructura dentro de un sitio Web, utilizando los hipervínculos que contienen los documentos que lo conforman. En este caso, algunos trabajos como el de [Madria 1999], en el cual se materializan los datos de la Web como tuplas Web almacenadas en tablas. Las tuplas Web, representando a los grafos dirigidos, están comprendidas por los objetos Web (nodos y hipervínculos), con el objetivo de generar un reporte de la estructura sobre el sitio Web.

Capítulo 2 Marco Teórico
19
La información estructural generada incluye:
La frecuencia de los hipervínculos locales en las tuplas Web de una tabla. Los hipervínculos locales conectan a los diferentes documentos Web en un sitio. Esto informa acerca de los documentos interrelacionados dentro del sitio. También permite medir la completes del sitio Web en el sentido que la mayoría de la información estrechamente relacionada está disponible en el mismo sitio.
La frecuencia de las tuplas Web en una tabla Web que contiene los hipervínculos que son globales (los hipervínculos que se dirigen a sitios Web diferentes). Esto mide la visibilidad de los documentos Web y la habilidad para relacionarse con documentos similares dentro de diferentes sitios Web. Por ejemplo, en el caso de un artículo de investigación, debe tener más hipervínculos externos debido a que se debe referir a otros artículos relacionados. Esto expresa la habilidad del artículo de investigación de hacer referencia cruzada a otros trabajos relacionados.
Medir el grado de hipervínculos de entrada y el de salida de cada documento Web. Un valor alto de hipervínculos de entrada puede ser un signo de un documento muy popular. De manera similar, un valor alto de hipervínculos de salida puede significar un documento luminoso. El grado de hipervínculos de salida también mide la conectividad del sitio.
Algunos de los puntos importantes en la minería de estructura Web son los
términos como caminos inalcanzables, circuitos o ciclos repetitivos. Un camino inalcanzable es cuando una página Web no puede ser accedida. Un circuito o ciclo es una secuencia de hipervínculos que comienza y termina en el mismo nodo. Con la finalidad de generar una estructura Web, los circuitos y ciclos repetitivos deben ser detectados y removidos, sin ello un usuario Web puede perderse en el ciberespacio [Cooley 1999b].
2.3. Estructura de navegación Una estructura de navegación se refiere a la estructura del sitio Web, esto es, a las conexiones y relaciones entre las páginas que lo conforman. Una estructura de navegación también es conocida como una estructura de información [Hassan 2004].
Un sitio Web puede encontrarse estructurado de forma muy diversa, solapar diferentes tipos de estructuras y contener subestructuras diferentes a la estructura general. Las estructuras de navegación más comunes son:

Capítulo 2 Marco Teórico
20
2.3.1. Estructuras secuenciales
Las páginas se encuentran interrelacionadas de forma lineal (ver Figura 6). Esta estructura se utiliza en tareas de navegación o interacción en las que es necesario que el usuario complete cada uno de los pasos ordenadamente (por ejemplo, un carrito de compras, el proceso de registro como usuario, etc.) o para la segmentación de bloques de información de naturaleza secuencial (artículos, comics, diapositivas, etc.).
Figura 6. Esquema de ejemplo de una estructura de navegación lineal.
Este tipo de estructura es muy sencilla por lo que no provoca desorientación alguna al usuario en la navegación [Hassan 2004].
2.3.2. Estructuras hipertextuales
El hipertexto es la base sobre la que se asienta la Web. En una estructura hipertextual (ver Figura 7) las páginas se enlazan por similitud o relación directa entre los contenidos, permitiendo al usuario que se encuentra visualizando una página 'saltar' hacia otras que le puedan interesar por contener información relacionada [Hassan 2004].
Figura 7. Esquema de ejemplo de una estructura de navegación hipertextual.
2.3.3. Estructuras jerárquicas
Probablemente la organización jerárquica es la estructura de información más común en sitios Web (ver Figura 8), debido en gran medida a su popularización por grandes portales y directorios temáticos. La organización en forma de árbol, por un lado resulta lo suficientemente flexible y escalable como para posibilitar la organización de grandes cantidades de páginas, y por otro resulta muy orientativa para el usuario en su navegación [Hassan 2004].

Capítulo 2 Marco Teórico
21
Figura 8. Esquema de ejemplo de una estructura de navegación jerárquica.
Normalmente, las estructuras jerárquicas se utilizan junto a las hipertextuales, permitiendo al usuario una vez llegado a una página de una rama, “saltar” hacia páginas de otras ramas pero relacionadas temáticamente con la página actual.

22
CAPÍTULO 3 ANÁLISIS Y
DISEÑO

Capítulo 3 Análisis y Diseño
23
3.1. Análisis
3.1.1. Introducción Esta sección detalla las propiedades y los requerimientos que debe cumplir la herramienta de analizador de Estructuras de Navegación Aplicando Minería de Uso Web y Minería de Estructura Web.
3.1.1.1. Ámbito El producto de software que se desarrollará en esta tesis, se describe como una aplicación que se clasifica en administración y mantenimiento de sitios Web. Como tal, se propone para uso de los administradores de los sitios, que le permita realizar un análisis de la estructura de navegación al conocer como está siendo utilizado por los usuarios y la conexión existente entre todos los documentos que conforman al sitio Web. Ésta aplicación se utilizará sobre sitios Web ya implementados y puestos en funcionamiento.
3.1.2. Descripción general
3.1.2.1 Perspectiva del producto A partir de la descripción del problema y objetivos planteados para esta tesis, se requiere del desarrollo de una aplicación para analizar la estructura de navegación de un sitio a partir del uso de técnicas de minería de uso y de estructura Web, con la finalidad de obtener el estado actual y mostrar recomendaciones de la estructura a partir de los resultados obtenidos.
3.1.2.2. Funciones del producto El producto de software que se desarrollará deberá realizar las siguientes funciones (ver Figura 9):
Figura 9. Diagrama de casos de uso para realizar un análisis de un sitio Web.

Capítulo 3 Análisis y Diseño
24
a) Introducir la información del sitio Web a analizar. b) Procesar el análisis del sitio Web. c) Mostrar resultados del análisis.
3.1.2.3. Descripción de las funciones Los usuarios interactuarán con la aplicación, donde podrán introducir la información del sitio Web a analizar, ejecutar el análisis, y los resultados obtenidos mostrarlos al usuario. Función 1. Introducir la información del sitio Web a analizar Este es el primer paso que debe realizar el usuario al utilizar la aplicación. La información que se debe introducir del sitio Web a analizar se divide en dos partes:
a) Introducir los archivos de bitácora: El usuario debe especificar la ubicación de los archivos de bitácora para el análisis del sitio.
b) Introducir la ubicación del sitio Web (URL): El usuario debe especificar la URL del sitio.
Función 2. Ejecutar el análisis El usuario da la instrucción de iniciar el análisis del sitio Web con la información introducida. Esta sección es la parte medular de la aplicación, llevándose a cabo los procesamientos de minería para los datos de uso y de la estructura Web. Función 3. Mostrar los resultados del análisis La información generada será mostrada al usuario de la aplicación.
3.1.2.4. Usuarios de la herramienta
a) Administrador del sitio Web: También conocido como webmaster, es el encargado o responsable del sitio Web. El administrador actúa como coordinador y supervisor de las actividades de diseño, desarrollo y programación del sitio.
b) Usuario del sitio Web: Se refiere a la persona que entra al sitio, para navegar entre las páginas y utilizar los servicios y contenidos que el sitio Web publique. Los usuarios del sitio son usuarios indirectos del software que se desarrollará.

Capítulo 3 Análisis y Diseño
25
3.1.2.5. Limitaciones de la herramienta La implementación de la aplicación que se desarrollará, no está sujeta a un entorno de aplicaciones en particular. Sin embargo, una buena elección de las herramientas facilitará el desarrollo y permitirá la integración del producto final.
El producto de software final, será de tipo Web. Una aplicación de éste tipo, se ejecuta en un servidor Web y utiliza páginas Web como la interfaz de usuario. La elección de esta modalidad de desarrollo de aplicaciones, sobre una aplicación de escritorio o en modo stand-alone, se da en base a sus siguientes ventajas:
Compatibilidad multiplataforma: Los clientes de la aplicación Web se comunican con el servidor enviando y recibiendo información por medio de un navegador Web. Estos navegadores están desarrollados con características de compatibilidad entre ellos, a pesar de estar ejecutándose sobre varias plataformas (Microsoft Windows, Linux, Mac OS X).
Actualización: Las aplicaciones basadas en Web están siempre actualizadas con la última versión sin requerir que el usuario tome acciones proactivas.
Inmediatez de acceso: Una aplicación Web no necesita ser descargada, instalada y configurada.
Menos requerimientos de recursos: Las aplicaciones basadas en Web tienen menos demandas de memoria RAM por parte del usuario final, que los programas instalados localmente.
Desarrollar aplicaciones sin restricción del lenguaje de programación: Una vez que las aplicaciones han sido separadas de las computadoras locales y sistemas operativos específicos, estas aplicaciones pueden ser escritas en una gran variedad de lenguajes de programación. No se está limitado a un lenguaje de programación que esté soportado por el sistema operativo subyacente.
Múltiples usuarios concurrentes: Las aplicaciones basadas en Web pueden ser utilizadas por múltiples usuarios al mismo tiempo.
La implementación de la aplicación utilizará la plataforma de Java con una
arquitectura que permita la creación de la aplicación Web, tal como fue mencionado anteriormente. Es por ello que se utilizará la versión Java 5 Enterprise Edition (Java 5 EE, anteriormente conocido como Java 2 Platform, Enterprise Edition o J2EE hasta la versión 1.4). Esta especificación permite elaborar una aplicación empresarial portable entre plataformas y escalable, integrando tecnologías tales como Enterprise Java Beans, servlets y portlets, Java Server Pages (JSP), entre otras.

Capítulo 3 Análisis y Diseño
26
Asimismo, será necesaria la utilización de un sistema manejador de base de datos, tal como MySQL.
3.2. Diseño
3.2.1. Introducción Describir la estructura del Analizador de Estructuras de Navegación Aplicando Minería de Uso Web y Minería de Estructura Web, los datos y las interfaces entre los componentes del sistema. La fase de diseño que a continuación se describe, está dividida en dos, diseño arquitectónico y conceptual.
3.2.2. Diseño arquitectónico El diseño arquitectónico corresponde al proceso que identifica los subsistemas que conforman un sistema y la infraestructura de control y comunicación. La salida de este proceso de diseño es una descripción de la arquitectura de software [Sommerville 2004].
La arquitectura de la aplicación que se realiza está definida por el patrón de diseño Modelo Vista Controlador (MVC), el cual divide una aplicación interactiva en 3 áreas: procesamiento, salida y entrada. Para esto, utiliza las siguientes abstracciones:
Modelo: Encapsula los datos y las funcionalidades. El modelo es independiente de cualquier representación de salida y/o comportamiento de entrada. El modelo está conformado por componentes de Java Enterprise Edition tales como Servlets, Java Beans entre otros.
Vista: Muestra la información al usuario. Pueden existir múltiples vistas del modelo. Cada vista tiene asociado un componente controlador. Las interfaces de usuario están conformadas por las páginas Web en lenguaje de marcado de hipertexto (HTML), páginas JSP y las hojas de estilo en cascada (CSS).
Controlador: Reciben las entradas, usualmente como eventos que codifican los movimientos o pulsación de botones del ratón, pulsaciones de teclas, etc. Los eventos son traducidos a solicitudes de servicio para el modelo o la vista.
De acuerdo con el patrón de diseño MVC, la arquitectura del analizador de estructuras de navegación se puede visualizar en la Figura 10.
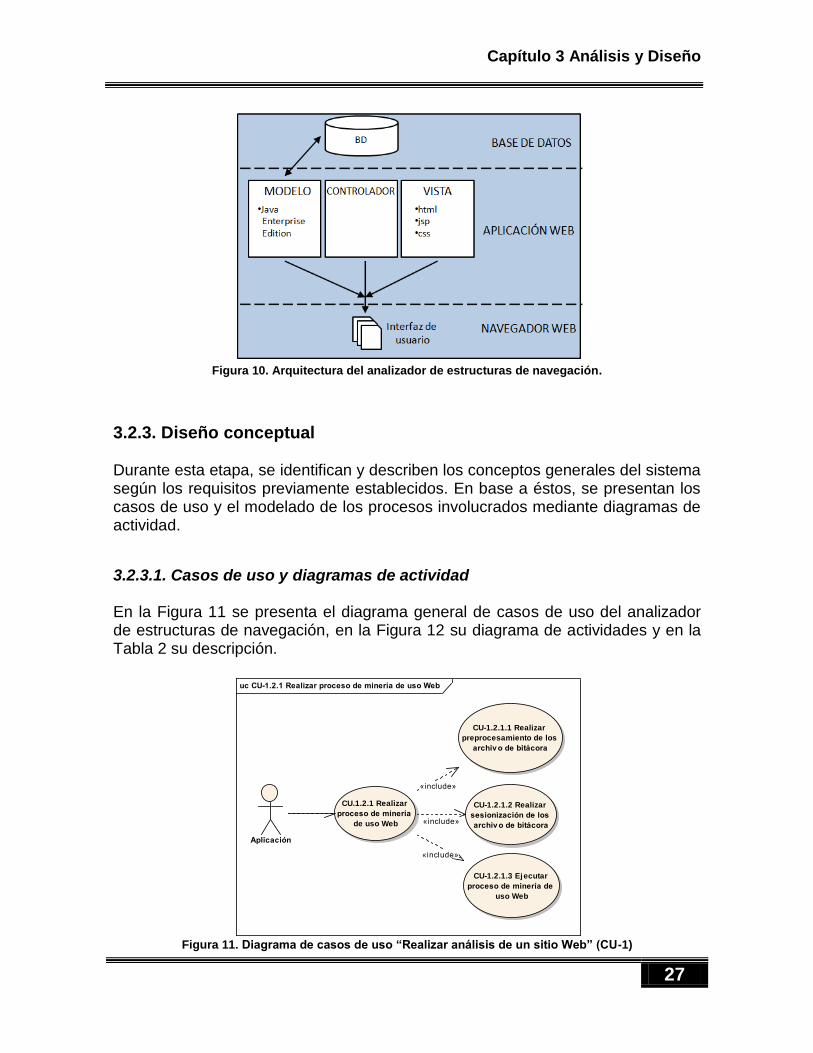
Capítulo 3 Análisis y Diseño
27
Figura 10. Arquitectura del analizador de estructuras de navegación.
3.2.3. Diseño conceptual Durante esta etapa, se identifican y describen los conceptos generales del sistema según los requisitos previamente establecidos. En base a éstos, se presentan los casos de uso y el modelado de los procesos involucrados mediante diagramas de actividad.
3.2.3.1. Casos de uso y diagramas de actividad En la Figura 11 se presenta el diagrama general de casos de uso del analizador de estructuras de navegación, en la Figura 12 su diagrama de actividades y en la Tabla 2 su descripción.
Figura 11. Diagrama de casos de uso “Realizar análisis de un sitio Web” (CU-1)
uc CU-1.2.1 Realizar proceso de minería de uso Web
Aplicación
CU.1.2.1 Realizar
proceso de minería
de uso Web
CU-1.2.1.1 Realizar
preprocesamiento de los
archiv o de bitácora
CU-1.2.1.2 Realizar
sesionización de los
archiv o de bitácora
CU-1.2.1.3 Ejecutar
proceso de minería de
uso Web
«include»
«include»
«include»

Capítulo 3 Análisis y Diseño
28
El usuario interactúa con la aplicación para realizar el análisis de un sitio Web, este caso de uso está compuesto por la Introducción de la información del sitio, Procesar el análisis del sitio Web y Procesar grafo y visualizar resultados.
Tabla 2. Descripción del caso de uso “Realizar análisis de un sitio Web” (CU-1).
ID: CU-1 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 12.
Nombre del caso de uso:
Realizar análisis de un sitio Web.
Actores: Usuario, Aplicación. Descripción: Permite al usuario realizar el análisis de un sitio Web.
Precondiciones: Poscondiciones: 1. Se obtendrá el análisis de la estructura de navegación de un sitio
Web. Escenario de
éxito: 1. El usuario inicia el análisis de la estructura de navegación de un sitio Web. 2. El sistema solicita la información del sitio a analizar. 3. Se realiza el procesamiento del análisis del sitio. 4. Se realiza el procesamiento del grafo del sitio. 5. Se muestra el grafo al usuario y los resultados. 6. Terminar.
Escenario de fracaso:
1. El usuario inicia el análisis de la estructura de navegación de un sitio Web. 2. El sistema solicita la información del sitio a analizar. 3. La información del sitio Web no es válida 4. Terminar.
Incluye: CU-1.1: Introducir la información del sitio Web a analizar. CU-1.2: Procesar análisis del sitio Web. CU-1.3: Procesar grafo y visualizar resultados.
Suposiciones:
Figura 12. Diagrama de actividades del caso de uso “Realizar análisis de un sitio Web” (CU-1).
act CU-1 Realizar análisis de un sitio Web
Sis
tem
aU
su
ari
o
Iniciar el análisis
de un sitio Web
Solicitar información
del sitio Web a
analizar
Información válida
Procesar análisis
del sitio Web
Extraer y
v isualizar
resultados
Proporcionar
información
Si
No

Capítulo 3 Análisis y Diseño
29
La Figura 13 muestra el caso de uso Introducir la información del sitio Web a analizar, la Figura 14 su diagrama de actividades y en la Tabla 3 su descripción. La información necesaria para realizar un análisis a un sitio Web son los archivo de bitácora y su dirección URL.
Figura 13. Diagrama de casos de uso introducir la información del sitio Web a analizar (CU-1.1).
Tabla 3. Descripción del caso de uso introducir la información del sitio Web a analizar (CU-1.1).
ID: CU-1.1 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 14.
Nombre del caso de uso:
Introducir la información del sitio Web a analizar.
Actores: Usuario, Aplicación.
Descripción: Permite que el usuario introduzca que sitio Web se analizará. Precondiciones:
Poscondiciones: 1. Se obtendrá los archivos de bitácora la dirección URL del sitio Web. Escenario de
éxito: 1. El sistema solicita introducir los archivos de bitácora. 2. El usuario selecciona los archivos de bitácora que se encuentran en su equipo. 3. El sistema transfiere los archivos de bitácora bajo el protocolo HTTP al servidor. 4. El sistema identifica el formato de cada archivo de bitácora. 5. El usuario proporciona la URL del sitio Web a analizar. 6. El sistema verifica la URL, si es válida la guarda. 7. Terminar.
Escenario de fracaso 1:
1. El sistema solicita introducir los archivos de bitácora. 2. El usuario selecciona los archivos de bitácora que se encuentra en su equipo. 3. El sistema transfiere los archivos de bitácora bajo el protocolo HTTP al servidor. 4. Hubo un error al cargar los archivos de bitácora. 5. Terminar.
Escenario de 1. El sistema solicita introducir los archivos de bitácora.
uc CU-1.1 Introducir la información del sitio Web a analizar
Usuario
CU-1.1 Introducir la
información del sitio
Web a analizar
CU-1.1.1 Introducir
archiv os de bitácora
Introducir dirección
URL del sitio Web
«include»
«include»

Capítulo 3 Análisis y Diseño
30
fracaso 2: 2. El usuario selecciona los archivos de bitácora que se encuentra en su equipo. 3. El sistema transfiere los archivos de bitácora bajo el protocolo HTTP al servidor. 4. El sistema identifica el formato de cada archivo de bitácora. 5. El formato del archivo de bitácora no es válido. 6. Terminar.
Escenario de fracaso 3
1. El sistema solicita introducir los archivos de bitácora. 2. El usuario selecciona los archivos de bitácora que se encuentra en su equipo. 3. El sistema transfiere los archivos de bitácora bajo el protocolo HTTP al servidor. 4. El sistema identifica el formato de cada archivo de bitácora. 5. El usuario proporciona la URL del sitio Web a analizar. 6. El sistema verifica la URL. 7. La URL proporcionada no es válida. 8. Terminar.
Incluye: CU-1.1.1: Introducir archivos de bitácora. CU-1.1.2: Introducir URL del sitio Web.
Suposiciones:
Figura 14. Diagrama de actividades del caso de uso “Introducir la información del sitio Web” CU-1.1.
El diagrama de la Figura 15 muestra el caso de uso Procesar análisis del
sitio Web. Este caso incluye el Realizar proceso de minería de uso Web y Realizar proceso de minería de estructura Web.
act CU-1.1 Introducir la información del sitio Web a analizar
Sis
tem
aU
su
ari
o
Solicitar
archiv os log
Proporcionar
archiv os log
Cargar
archiv o de
bitácora
Error al cargar
los archivos
logIdentificar
formato de
archiv o log
Error al identificar
el formato del
archivo log
Guardar
archiv os
log
Solicitar URL
del sitio Web
Escribir URL
del sitio Web
Buscar
URL
Existe URL
Guardar
URL
Final
No No Si
SiSi No

Capítulo 3 Análisis y Diseño
31
Figura 15. Diagrama de casos de uso “Procesar análisis del sitio Web” (CU-1.2).
La Figura 16 muestra el diagrama de casos de uso de Realizar proceso de
minería de uso Web. Este caso de uso lo componen los casos Realizar preprocesamiento de los archivos de bitácora, Realizar sesionización de los archivos de bitácora y Ejecutar proceso de minería de uso Web.
Figura 16. Diagrama de casos de uso de Realizar proceso de minería de uso Web (CU-1.2.1).
En la Figura 17 se muestra el diagrama de actividades del caso de uso
preprocesamiento del archivo de bitácora, el cual está conformado de la eliminación de las peticiones irrelevantes y de los formatos de documentos Web (formatos de archivos tales como imágenes o sonidos que se desean filtrar del archivo de bitácora). La Tabla 4 muestra la descripción del caso de uso.
uc CU-1.2 Procesar el análisis de un sitio Web
Aplicación
CU-1,2 Procesar
análisis del sitio
Web
CU-1.2.1 Realizar
proceso de minería
de uso Web
CU-1.2.2. Realizar
proceso de minería
de estructura Web
«include»
«include»
uc CU-1.2.1 Realizar proceso de minería de uso Web
Aplicación
CU.1.2.1 Realizar
proceso de minería
de uso Web
CU-1.2.1.1 Realizar
preprocesamiento de
los archiv o de bitácora
CU-1.2.1.2 Realizar
sesionización de los
archiv o de bitácora
CU-1.2.1.3 Ejecutar
proceso de minería
de uso Web
«include»
«include»
«include»

Capítulo 3 Análisis y Diseño
32
Tabla 4. Descripción del caso de uso realizar preprocesamiento del archivo de bitácora (CU-1.2.1.1).
ID: CU-1.2.1.1. El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 17.
Nombre del caso de uso:
Realizar preprocesamiento de los archivos de bitácora.
Actores: Usuario, Aplicación. Descripción: Permite realizar el preprocesado de los archivos de bitácora antes de
aplicar minería de uso Web. Precondiciones: 1. Los archivos de bitácora almacenados en el servidor.
Poscondiciones: 1. Se obtendrá los archivos de bitácora con las peticiones de documentos Web irrelevantes, peticiones fallidas y las que son llevadas a cabo por robots eliminadas.
Escenario de éxito:
1. El sistema solicita los formatos de los documentos Web a filtrar. 2. El usuario selecciona los formatos de documentos Web que serán eliminados. 3. El sistema elimina las peticiones de los formatos de documentos Web seleccionados por el usuario. 4. El sistema filtra las peticiones fallidas. 5. El sistema elimina las peticiones llevadas a cabo por robots. 6. Terminar.
Incluye:
Suposiciones:
Figura 17. Diagrama de actividades del caso de uso Realizar preprocesamiento de los archivo de
bitácora (CU-1.2.1.1).
act CU-1.2.1.1 Realizar preprocesamiento de los archiv os de bitácora
Ap
lic
ac
ión
Us
ua
rio
Solicitar los
formatos de los
documentos Web a
filtrar
Seleccionar los
formatos de los
documentos Web a
filtrar
Filtrar los tipos
de documentos
Web
seleccionados
Identificación y
eliminación de
las peticiones
fallidas
Identificación y
eliminación de las
peticiones llev adas
a cabo por robots

Capítulo 3 Análisis y Diseño
33
En la Figura 18 se muestra el diagrama de actividades del caso de uso Realizar sesionización de los archivos de bitácora, y en la Tabla 5 su descripción. Tabla 5. Descripción del caso de uso “Realizar sesionización de los archivos de bitácora” (CU-1.2.1.2).
ID: CU-1.2.1.2 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 18.
Nombre del caso de uso:
Realizar sesionización de los archivos de bitácora.
Actores: Usuario, Aplicación. Descripción: Identificar las sesiones de usuario de los archivos de bitácora.
Precondiciones: 1. Los archivos de bitácora almacenados en el servidor. 2. Los archivos de bitácora preprocesados correctamente.
Poscondiciones: 1. Se obtendrán las sesiones de usuario identificadas de los archivos de bitácora, almacenándolas en una base de datos.
Escenario de éxito:
1. El sistema solicita la selección del algoritmo de sesionización. 2. El usuario selecciona el algoritmo de sesionización (en base a un tiempo máximo, por número máximo de peticiones, o por método heurístico). 3. El sistema solicita un valor de umbral para las opciones de sesionización 1 y 2. 4. El usuario proporciona el valor de umbral, si es necesario. 5. El sistema lleva a cabo el proceso de identificación de las sesiones en base al algoritmo seleccionado y lo almacena en una base de datos. 6. Terminar.
Incluye:
Suposiciones:
Figura 18. Diagrama de actividades del caso de uso “Realizar sesionización del archivo de bitácora”
(CU-1.2.1.2).
act CU-1.2.1.2 Realizar sesionización de los archiv os de bitácora
Ap
lic
ac
ión
Us
ua
rio
Solicitar la selección
del algoritmo de
sesionización
Seleccionar
algoritmo de
sesionización
Solicitar v alor de
umbral
Proporcionar
v alor del umbral
Realizar
sesionización

Capítulo 3 Análisis y Diseño
34
La Figura 19 muestra el diagrama de actividades del caso de uso Realizar procesamiento de minería de uso Web, y en la Tabla 6 su descripción.
Tabla 6. Descripción del caso de uso “Realizar procesamiento de minería de uso Web” (CU-1.2.1.3).
ID: CU-1.2.1.3 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 19.
Nombre del caso de uso:
Realizar sesionización de los archivos de bitácora.
Actores: Usuario, Aplicación. Descripción: Obtener los patrones de navegación del sitio mediante el algoritmo de
extracción de reglas de asociación. Precondiciones: 1. Los archivos de bitácora almacenados en el servidor.
2. Los archivos de bitácora preprocesados correctamente. 3. Las sesiones de usuario identificadas y almacenadas en la base de datos.
Poscondiciones: 1. Se obtendrán los patrones de uso del sitio Web. Escenario de
éxito: 1. Solicitar el valor mínimo de soporte para la extracción de reglas de asociación. 2. El usuario proporciona el valor mínimo de soporte. 3. Solicitar el valor mínimo de confianza para la extracción de reglas de asociación. 4. El usuario proporciona el valor mínimo de confianza. 5. El sistema lleva a cabo el proceso de extracción de reglas de asociación. 6. Terminar.
Incluye:
Suposiciones:
Figura 19.Diagrama de actividades del caso de uso “Realizar procesamiento de minería de uso Web”
(CU-1.2.1.3).
act CU-1.2.1.3 Ejecutar proceso de minería de uso Web
Ap
lic
ac
ión
Us
ua
rio
Solicitar
v alor mínimo
de soporte
Proporcionar
v alor mínimo
de soporte
Solicitar v alor
mínimo de
confianza
Proporcionar
v alor mínimo
de confianza
Ejecutar
proceso de
extracción de
reglas de
asociación

Capítulo 3 Análisis y Diseño
35
La Figura 20 muestra el diagrama de casos de uso Realizar proceso de minería de estructura Web. Este se compone de Recolectar estructura del sitio Web y Ejecutar proceso de minería de estructura Web.
Figura 20. Diagrama de casos de uso “Realizar proceso de minería de estructura Web” (CU 1.2.2).
La Figura 21 muestra el diagrama de actividades del caso de uso
Recolectar la estructura del sitio Web, y en la Tabla 7 su descripción.
Tabla 7. Descripción del caso de uso “Recolectar estructura del sitio Web” (CU-1.2.2.1).
ID: CU-1.2.2.1 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 21.
Nombre del caso de uso:
Recolectar estructura del sitio Web.
Actores: Usuario, Aplicación. Descripción: Permite obtener la estructura del sitio Web que conforman las páginas
y sus hipervínculos y almacenarlos en una base de datos. Precondiciones: 1. La URL del sitio Web.
Poscondiciones: 1. La estructura del sitio Web. Escenario de
éxito: 1. El sistema realiza la recolección de la estructura del sitio 2. Se almacena la estructura del sitio en la base de datos. 3. Terminar.
Incluye:
Suposiciones:
uc CU-1.2.2 Realizar proceso de minería de estructura Web
Aplicación
CU-1.2.2 Realizar
proceso de minería
de estructura Web
CU-1.2.2.1
Recolectar
estructura del sitio
Web
CU-1.2.2.2 Ejecutar
proceso de minería
de estructura Web
«include»
«include»

Capítulo 3 Análisis y Diseño
36
Figura 21. Diagrama de actividades “Recolectar la estructura Web” (CU-1.2.2.1).
La Figura 22 muestra el diagrama de actividades del caso de uso ejecutar proceso de minería de estructura Web, y en la Tabla 8 su descripción.
Tabla 8. Descripción del caso de uso “Ejecutar proceso de minería de estructura Web” (CU-1.2.2.2).
ID: CU-1.2.2.2 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 22.
Nombre del caso de uso:
Ejecutar proceso de minería de estructura Web.
Actores: Aplicación.
Descripción: Permite obtener un reporte con información acerca de la estructura del sitio Web.
Precondiciones: 1. La estructura del sitio Web almacenada en la base de datos.
Poscondiciones: 1. Reporte con información de la estructura del sitio Web. Escenario de
éxito: 1. El sistema accede a la base de datos donde se encuentra almacenado cada documento Web que conforma el sitio y sus hipervínculos, para obtener la siguiente información: a. Encontrar caminos inalcanzables en el sitio Web. b. Calcular el grado de hipervínculos locales de entrada y salida. c. Calcular el grado de hipervínculos globales de salida. 2. Terminar.
Incluye:
Suposiciones:
Figura 22. Diagrama de actividades del caso de uso “Ejecutar proceso de minería de estructura Web”
(CU-1.2.2.2).
act CU-1.2.2.1 Recolectar estructura del sitio Web
Ap
lic
ac
ión
Recolección de la
estructura del sitio
Web
Almacenar la
estructura en la
BD
act CU-1.2.2 Realizar proceso de minería de estructura Web
Ap
lic
ac
ión
Encontrar caminos
inalcanzables en el
sitio Web
Calcular el grado de
hiperv ínculos locales
de entrada y de salida
Calcular el grado de
hiperv ínculos
globales de salida

Capítulo 3 Análisis y Diseño
37
La Figura 23 muestra el diagrama de casos de uso Procesar grafo y visualizar resultados, la Figura 24 su diagrama de actividades y en la Tabla 9 su descripción.
Figura 23. Diagrama de casos de uso “Procesar y visualizar grafo de resultados” (CU-1.3).
Tabla 9. Descripción del caso de uso “Procesar grafo y visualizar resultados” (CU-1.3).
ID: CU-1.3 El diagrama de actividades que incluye los escenarios de éxito y los escenarios de fracaso se muestra en la Figura 24.
Nombre del caso de uso:
Procesar grafo y visualizar resultados.
Actores: Aplicación. Descripción: Permite mostrar un grafo con la estructura del sitio y los resultados del
análisis. Precondiciones: 1. Procesamiento de minería de uso Web
2. Procesamiento de minería de estructura Web Poscondiciones: 1. Grafo final de resultados.
Escenario de éxito:
1. Recuperar la estructura del sitio Web de la base de datos. 2. Generar el grafo de la estructura del sitio Web. 3. Recuperar los patrones de navegación 4. Recuperar el reporte de la estructura del sitio Web.
Incluye:
Suposiciones:
Figura 24. Diagrama de actividades del caso de uso "Procesar y visualizar grafo de resultados" (CU-
1.3).
uc CU-1.3 Procesar grafo y v isualizar resultados
Aplicación
Procesar grafo y
v isualizar resultados
act Procesar grafo y v isualizar resultados
Ap
lic
ac
ión
Recuperar la
estructura del
sitio Web
Generar el
grafo de la
estructura del
sitio Web
Recuperar los
patrones de
nav egación de
usuario
Recuperar el
reporte de la
estructura del
sitio Web

Capítulo 3 Análisis y Diseño
38
3.2.3.2. Modelo general de la aplicación Después del análisis de requerimientos y planteamiento de casos de uso, se llega al planteamiento general del analizador de estructuras de navegación. Para lograr una comprensión más clara, el modelo se dividirá en módulos (ver Figura 25).
Figura 25. Diagrama de módulos de la aplicación.
Los módulos que componen el analizador de estructuras de navegación son el minero de estructura Web, el minero de uso Web, la extracción y reunión de resultados y el visualizador gráfico de resultados. A continuación se describe cada uno de los módulos, mostrando el flujo de datos y sus funciones.
3.2.3.3. Módulo de minería de uso Web En este módulo se describen las funciones que desempeñará el minero de uso Web en el analizador de estructuras de navegación. Incluye la recolección de los archivos de bitácora, el preprocesamiento, la división en sesiones de usuario de los archivos de bitácora y el procesamiento de minería. La Figura 26 muestra el diagrama de este módulo.

Capítulo 3 Análisis y Diseño
39
Figura 26. Módulo de minería de uso Web.
3.2.3.3.1. Preprocesamiento La fase de preprocesamiento se compone de las actividades que se mencionan a continuación [Hernández 2005]:
Identificación del formato de la bitácora.
Identificación y eliminación de peticiones irrelevantes.
Identificación y eliminación de peticiones fallidas.
Identificación y eliminación de peticiones llevadas a cabo por robots.
a) Identificación del formato de la bitácora Una bitácora de acceso de un servidor Web contiene registros de accesos de los usuarios. Cada registro representa una petición de una página de un usuario. Un registro típicamente contiene la dirección IP del cliente, la hora y fecha en que es recibida la petición, la dirección URI del objeto solicitado, el protocolo de la petición, el código de retorno del servidor indicando el estado de control de la petición, y el tamaño de la página si la petición es exitosa. Los parámetros o la ubicación de estos pueden variar de acuerdo al formato de la bitácora. La aplicación debe identificar cual tipo de bitácora se está utilizando. El analizador de estructuras de navegación permitirá el uso de los siguientes formatos:

Capítulo 3 Análisis y Diseño
40
Common Log Format (CLF).
Extended Common Log Format (ECLF).
Performance Log Format (PLF). En el anexo A se explican las características de cada tipo de formato.
b) Identificación y eliminación de peticiones irrelevantes Entre los obstáculos más comunes están los servidores proxy de las redes locales, las cachés locales en las computadoras y los firewalls que impiden que todas las peticiones de los usuarios se registren en las bitácoras de acceso de los servidores Web y con esto se distorsiona la imagen de accesos reales. Por ejemplo, una página que ha sido registrada solamente una vez en la bitácora de accesos pudo haber sido solicitada varias veces por varios usuarios en una red local.
La primera actividad de la limpieza es determinar qué información contenida en el archivo de accesos no es de utilidad para el análisis, estos criterios se establecen tomando en cuenta que los únicos datos interesantes, son aquellos que representan de forma exacta los accesos de los usuarios. En base a esta premisa, la metodología propone eliminar todas las peticiones realizadas sobre archivos que representan imágenes, audio y video.
Para lograr la eliminación de estas solicitudes se debe analizar cada línea de entrada en el archivo log, el objetivo de este análisis es identificar y separar cada uno de los elementos registrados en una solicitud de acceso (usuario, recurso solicitado, lugar desde donde se originó la petición, número de bytes transmitidos, navegador, etc.), cuando se ha identificado cada elemento se debe analizar la información sobre el recurso solicitado y determinar si es un elemento irrelevante para el análisis de la información. Cada elemento irrelevante debe ser eliminado de los registros, con esto se logra obtener información que represente solamente los accesos de los usuarios.
c) Identificación y eliminación de peticiones fallidas Cuando un usuario solicita un recurso que no existe dentro del sitio Web, el usuario recibe en su navegador una página de error y el servidor Web registra en su bitácora de accesos esta petición con un código especial que indica que la petición falló. Por cada petición solicitada al servidor Web éste envía un código de respuesta al dispositivo cliente, si el código es menor o igual a 400, indica que la solicitud no tuvo errores; si el código recibido fue mayor a 400, indica que hubo un error en la solicitud. Estos códigos de error se guardan en la bitácora de accesos junto con la información sobre la petición.

Capítulo 3 Análisis y Diseño
41
d) Identificación y eliminación de peticiones llevadas a cabo por robots Los robots de Internet son lanzados al ciberespacio con una cantidad inicial de direcciones Web o URI, por medio de las cuales va enriqueciendo y aumentando el número de sitios y páginas que visitará en la próxima ronda. El propósito fundamental de estos robots suele ser alimentar las bases de datos de buscadores como Yahoo8 y Google9 por mencionar algunos.
De lo anterior, se deduce que las peticiones realizadas por un robot de Internet representan información que no es de importancia para el proceso de minería Web, por lo que debe desecharse. Aunque podría servir para otro tipo de análisis como el determinar las palabras claves que los buscadores utilizan para localizar algún sitio.
3.2.3.3.2. Identificación de sesiones de usuario
Después de que los datos han sido limpiados y las peticiones almacenadas en la base de datos, éstas deben ser divididas en grupos lógicos es decir, deben ser identificadas las sesiones de usuario. El objetivo de la identificación de sesiones de usuario es crear grupos significativos de peticiones para cada usuario [Hernández 2005].
Una vez que los inicios de sesión (forzosamente una página HTML, PHP, CGI, ASP ó cualquier otro objeto contenedor) han sido identificados, le sigue el proceso para localizar los recursos que están involucrados en cada visita al sitio Web.
Este proceso de identificación de sesiones puede darse de acuerdo a tres enfoques: tiempo mínimo, número de peticiones mínimas y por método heurístico.
a) Identificación de sesiones de usuario en base a un tiempo máximo
Este enfoque recibe como parámetro de entrada un número que se refiere al tiempo que máximo que ha de transcurrir para que una sesión de usuario sea tomada como válida; es decir, una vez que se han identificado los inicios de cada una de las sesiones, es posible comenzar a identificar las peticiones que están involucradas con cada una de ellas. A partir del inicio de sesión, es necesario localizar la siguiente petición que contiene información suficiente para ser considerada como candidata para integrarse a la sesión de usuario.
En [Cooley 2000] se han estudiado los métodos para identificar los recursos
que los usuarios han visitado en un período de tiempo, y se determinó en base a
8 Yahoo, http://www.yahoo.com
9 Google, http://www.google.com

Capítulo 3 Análisis y Diseño
42
análisis estadísticos como valor óptimo un tiempo de treinta minutos de duración de una sesión de usuario. Algoritmo: Identificación de sesiones basándose en tiempos de duración.
1 Inicio (Minutos)
2 Datos_Inicio_Sesiones: Vector con claves de registros que representan los inicios de sesión, Identificador de Sesiones, Navegador y Fecha del los inicios de sesión
3 Datos_Inicio_Sesiones = Identificar_Datos_Inicio_sesión ();
4 Para cada ClaveInicioS, IDSesión_R, Navegador_R Y Fecha_Hora_R contenidos en Datos_Inicio_Sesiones
5 Inicio
6
Actualizar (IDSesion = IDSesión_R cuando (Host=Host_R) Y (Fecha_Hora > Fecha_Hora_R) Y (Fecha_Hora <Fecha_Hora_R +Minutos));
9 Fin
10 Fin
b) Identificación de sesiones de usuario por número máximo de peticiones El segundo enfoque propuesto se basa en construir sesiones de usuario tomando como base un parámetro que indica el número máximo de peticiones que pueden estar incluidas dentro de una sesión de usuario.
Para cada uno de los inicios de sesión identificados, se toma la siguiente petición que contiene información suficiente para ser tomada como candidata para integrarse a la sesión. Este mismo proceso se sigue hasta que el número máximo de peticiones incluidas en una sesión de usuario es igual o menor al número máximo permitido. Algoritmo: Identificación de sesiones basándose en número de peticiones por sesión.
1 Inicio (número_registros)
2 Datos_Inicio_Sesiones: Vector con claves de de registros que representan los inicios de sesión, Identificador de Sesiones, Navegador y Fecha del los inicios de sesión
3 ClaveR: Vector que contiene claves de registros de peticiones.
4 Datos_Inicio_Sesiones = Identificar_Datos_Inicio_sesión ();
5 Para cada ClaveInicioS, IDSesión_R y Navegador_R contenidos en Datos_Inicio_Sesiones
6 Inicio
7
ClaveR = Seleccionar (Clave donde (Clave > ClaveInicioS) Y (Navegador=Navegador_R) con un límite = número _ registros);
9 Para cada ClaveR
10 Inicio
11 Actualizar (IDSesión = IDSesión_R cuando (Clave = ClaveR))
12 Fin
13 Fin
14 Fin

Capítulo 3 Análisis y Diseño
43
c) Identificación de sesiones de usuario por método heurístico Lograr una identificación de sesiones exacta es complicado debido a la existencia de cachés locales y proxys. Analizando las bitácoras, se pueden identificar las direcciones IP que pueden llevar a cabo varias peticiones en tiempos realmente cortos y lo más curioso es que estas peticiones son realizadas por agentes navegadores distintos, con esto es posible inducir que el que está llevando a cabo dichas peticiones es un servidor proxy.
Este tercer y último enfoque se basa en un método heurístico que tiene como objetivo identificar sesiones de usuario y como una solución a la problemática que representan los proxy. Algoritmo: Enfoque heurístico.
1 Heurística ( )
2 Inicio
3 Datos_Inicio_Sesiones: Vector con Objetos que contienen claves de de registros que representan los inicios de sesión, Identificador de Sesiones, Recurso Solicitado, Referencia, Navegador y Fecha del los inicios de sesión;
4 Datos_Inicio_Sesiones = Identificar_Datos_Inicio_sesión ();
5 Para cada Objeto del Vector Datos_Inicio_Sesiones
6 Inicio 7 Localizar las 4 peticiones inmediatas al inicio de sesión que contengan el recurso
solicitado por el inicio de sesión en la referencia(): Con el objeto de identificar frames;
8 Crear Objetos con los valores localizados(Clave, idsesion, Host, Recurso, Referencia, Tiempo, Navegador);
Agregar los Objetos a Datos_Inicio_Sesiones; 10 Fin 11 Mientras Datos_Inicio_Sesiones Contenga Elementos 12 Inicio 13
ObjetoAux = VectorIdSesion.obtenerObjeto (); Seleccionar (Clave, Host, Recurso, Referencia, Fecha_Hora, Navegador cuando (IDSesión=0) Y (Fecha_Hora < ObjetoAux.Fecha_Hora + 30minutos) Y (Navegador = ObjetoAux.Navegador) Y (Referencia = ObjetoAux.Recurso) Y (Host = ObjetoAux.Host) Con un límite de 1;
14 Si se localizaron Datos
15 Inicio
16
ObjetoNuevo con (Clave, IDSesión, Host, Recurso, Referencia, Fecha_Hora, Navegador);
Actualizar (Sesión = IDSesión) de ObjetoNuevo;
Eliminar de Datos_Inicio_Sesiones (ObjetoAux);
Agregar a de Datos_Inicio_Sesiones (ObjetoNuevo);
17 Fin
18 Fin
19 Fin

Capítulo 3 Análisis y Diseño
44
3.2.3.3.3. Motor de minería de uso Web El motor de minería de uso Web está compuesto por la técnica denominada generación de reglas de asociación. El objetivo de esta técnica es descubrir relaciones o asociaciones del tipo atributo-valor que ocurren frecuentemente en un conjunto de datos. La idea de utilizar reglas de asociación para aplicar a conjuntos de elementos en grandes bases de datos fue propuesta por primera vez en el artículo “Mining Association Rules between Sets of Items in Large Databases” [Agrawal 1993]. Las reglas de asociación han sido muy utilizadas en análisis de carritos de compra. Véase el siguiente ejemplo: Las personas que compran grabadoras de CDs compran CDs vírgenes: Grabadoras de CDs → CD virgen con [un soporte de 10% y una confianza de 70%]. Un 10% de soporte indica que un 10% del total de los carritos de compra aparecen una grabadora de CDs y CDs vírgenes, mientras que una confianza del 70% indica que en ese porcentaje de carritos de compra en los que aparece una grabadora de CDs también se encuentran CDs vírgenes. Los parámetros de soporte y confianza sirven para evaluar la calidad de una regla de asociación.
a) Ítems frecuentes, soporte y confianza Un ítem o artículo es un elemento individual en el contexto de la minería de datos; para la minería Web es el equivalente a una página del sitio que se está analizando.
El descubrimiento de conjuntos de ítems frecuentes se puede utilizar para identificar el grupo de páginas que son solicitadas juntas en un gran número de sesiones de usuario. Los siguientes son ejemplos ficticios de ítems frecuentes:
La página /A.html y la página /B.html fueron accedidas juntas en al menos el 50% de las sesiones de usuario durante el mes de marzo del 2000.
La página /A.html y la página /B.html fueron accedidas juntas en al menos el 40% de las sesiones de usuario durante el mes de abril del 2000.
Como puede observarse, cada conjunto de ítems contiene un valor conocido
como soporte que representa el porcentaje de accesos. Cualquier conjunto de ítems frecuentes puede separarse en n reglas de asociación, donde un indicador de dirección es agregado a la regla. Un conjunto de ítems frecuentes formado por los elementos A y B da paso a la formación de dos posibles reglas de asociación representadas por A B y B A.
Una sesión dada en el mes de marzo del 2000 que solicitó la página /A.html tiene un 83% de probabilidad de solicitar la página /B.html.

Capítulo 3 Análisis y Diseño
45
Una sesión dada en el mes de marzo del 1999 que solicitó la página /B.html tiene un 89% de probabilidad de solicitar la página /A.html.
El segundo conjunto de ítems frecuentes presentado arriba, ahora puede ser visto como sigue:
Una sesión dada en el mes de abril del 2000 que solicitó la página /A.html tiene un 66% de probabilidad de solicitar la página selección/B.html.
Una sesión dada en el mes de abril del 2000 que solicitó la página /B.html tiene un 92% de probabilidad de solicitar la página /A.html.
Puesto que a partir de un conjunto de ítems frecuentes pueden formarse 2
reglas de asociación y aunque las dos reglas de asociación involucran a los mismos elementos, el porcentaje de probabilidad cambia de una a otra y esto se debe al orden de aparición de los elementos, esta probabilidad de acceso se conoce como nivel de confianza de la regla.
No debe confundirse el soporte con la confianza. Mientras que la confianza es una media de la efectividad de la regla, el soporte se refiere al peso desde el punto de vista estadístico de la regla. Además del peso estadístico, otra motivación para las restricciones del soporte viene del hecho que por lo general se está interesado en reglas que tienen un soporte por encima del umbral mínimo. Si el soporte no es lo suficientemente alto, significa que la regla no es útil [Agrawal 1993].
b) Parámetros de soporte y confianza Los valores de soporte y confianza mínimos son proporcionados por el usuario; de acuerdo a estos parámetros, el número de reglas de asociación variará. La siguiente tabla detalla estas variaciones.
Tabla 10. Parámetros de soporte y confianza.
Alto Bajo Valores típicos recomendados
Soporte mínimo
* Pocos conjuntos frecuentes * Pocas reglas válidas que ocurren con frecuencia
* Muchas reglas válidas que ocurren raramente
2-10%
Confianza mínima
* Pocas reglas, pero todas “casi ciertas lógicamente”
* Muchas reglas, pero muchas de ellas muy inciertas
70-90%

Capítulo 3 Análisis y Diseño
46
c) Algoritmo A-priori para generación de reglas de asociación El algoritmo A-priori [Agrawal 1994], es una optimización del algoritmo en [Agrawal 1993], al descomponer el problema en dos subproblemas: 1. Encontrar todos los conjuntos (itemsets), que tienen un soporte por encima del soporte mínimo dado. El soporte para un conjunto de elementos es el número de transacciones que contienen a éste. Los conjuntos de elementos que tienen un soporte por encima del umbral se denominan conjuntos de elementos grandes (large intemsets) y los demás, conjuntos de elementos pequeños (small itemsets). 2. Utilizar los conjuntos de elementos grandes para generar las reglas deseadas. La idea general es, si ABCD y AB son conjuntos de elementos grandes, entonces es posible determinar si la regla AB → CD mantiene:
𝐶𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎 𝐴𝐵 → 𝐶𝐷 =𝑠𝑜𝑝𝑜𝑟𝑡𝑒(𝐴𝐵𝐶𝐷)
𝑠𝑜𝑝𝑜𝑟𝑡𝑒(𝐴𝐵)
Si 𝐶𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎 𝐴𝐵 → 𝐶𝐷 > 𝐶𝑜𝑛𝑓𝑖𝑎𝑛𝑧𝑎_𝑚𝑖𝑛𝑖𝑚𝑎, entonces la regla es válida (la regla tendrá soporte mínimo, ya que ABCD pertenece a los conjuntos de elementos grandes.
En este algoritmo, el paso clave del descubrimiento de conjuntos frecuentes se basa en el principio “A priori”, es decir, cualquier subconjunto de un conjunto de ítems frecuentes, debe ser frecuente. Si existe algún conjunto “infrecuente”, entonces no hay necesidad de generar su conjunto potencia.
3.2.3.4. Módulo de minería de estructura Web Este módulo describe las funciones que desempeñará el minero de estructura Web. La Figura 27 muestra el diagrama que lo describe.
3.2.3.4.1. Recolección La fase de recolección se realiza mediante un tipo de programa conocido como web crawler que tiene como objetivo inspeccionar todas las páginas del sitio Web que se analizará, de forma metódica y automatizada, almacenando únicamente la estructura que conforman el sitio en una base de datos en base a los hipervínculos.
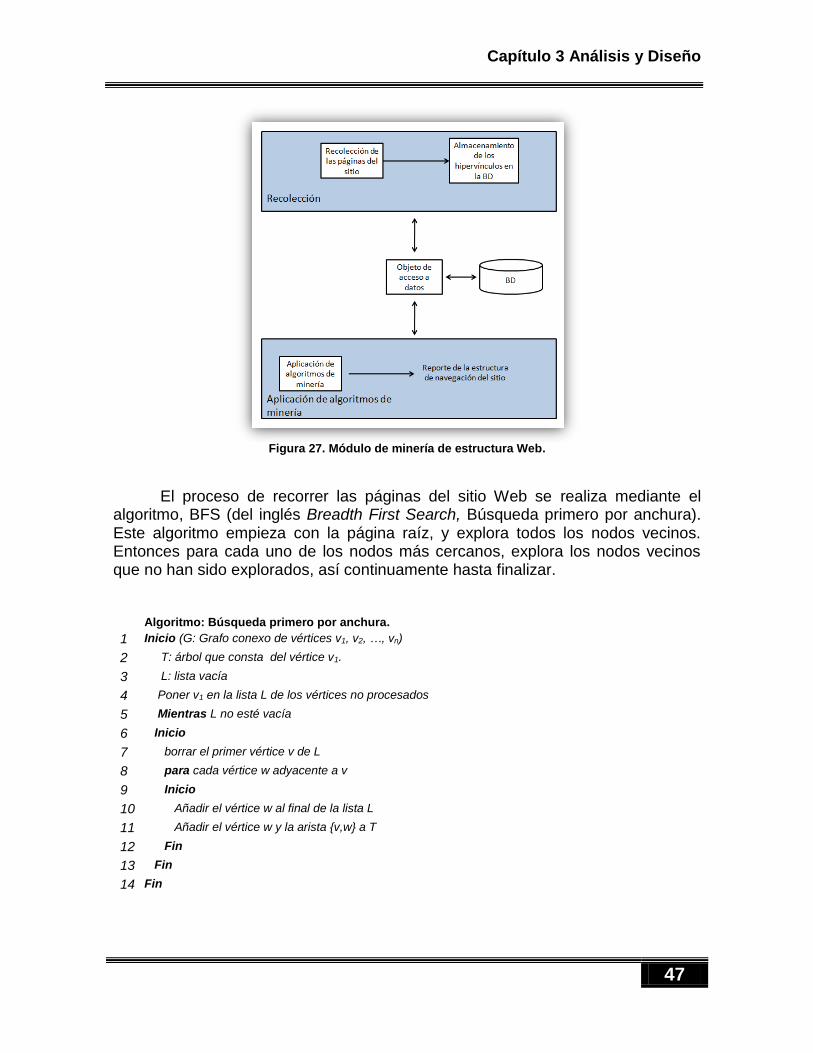
Capítulo 3 Análisis y Diseño
47
Figura 27. Módulo de minería de estructura Web.
El proceso de recorrer las páginas del sitio Web se realiza mediante el
algoritmo, BFS (del inglés Breadth First Search, Búsqueda primero por anchura). Este algoritmo empieza con la página raíz, y explora todos los nodos vecinos. Entonces para cada uno de los nodos más cercanos, explora los nodos vecinos que no han sido explorados, así continuamente hasta finalizar.
Algoritmo: Búsqueda primero por anchura.
1 Inicio (G: Grafo conexo de vértices v1, v2, …, vn)
2 T: árbol que consta del vértice v1.
3 L: lista vacía
4 Poner v1 en la lista L de los vértices no procesados
5 Mientras L no esté vacía
6 Inicio
7 borrar el primer vértice v de L
8 para cada vértice w adyacente a v
9 Inicio
10 Añadir el vértice w al final de la lista L
11 Añadir el vértice w y la arista {v,w} a T
12 Fin
13 Fin
14 Fin

Capítulo 3 Análisis y Diseño
48
3.2.3.4.2. Motor de minería de estructura Web El enfoque de la minería de estructura Web que se aplica en este trabajo es el de extraer la estructura de un sitio Web, utilizando los hipervínculos que contienen los documentos que lo conforman. En este caso, existen algunos trabajos como el de [Madria 1999], en el cual se materializan los datos de la Web como tuplas Web almacenadas en tablas; las tuplas Web representan a los grafos dirigidos y están comprendidas por los objetos Web (nodos e hipervínculos), con el objetivo de generar un reporte de la estructura sobre el sitio Web. La información estructural generada en este procesamiento incluirá:
Caminos inalcanzables: Algunos de los puntos importantes en la minería de estructura Web son los términos como caminos inalcanzables. Un camino inalcanzable es cuando una página Web no puede ser accedida. Estos caminos inalcanzables deben ser detectados y removidos, sin ello un usuario Web puede perderse en el ciberespacio [Cooley 1999b].
El grado de hipervínculos locales de entrada y el de salida de cada documento Web: Un valor alto de hipervínculos de entrada puede ser un signo de un documento muy popular. De manera similar, un valor alto de hipervínculos de salida puede significar un documento luminoso. El grado de hipervínculos de salida también mide la conectividad del sitio.
El grado de hipervínculos de salida globales en cada documento Web: Los hipervínculos globales son los que se dirigen a sitios Web diferentes. Esto mide la visibilidad de los documentos Web y la habilidad para relacionarse con documentos similares dentro de diferentes sitios Web. Por ejemplo, en el caso de un artículo de investigación, debe tener más hipervínculos externos debido a que se debe referir a otros artículos relacionados. Esto expresa la habilidad del artículo de investigación de hacer referencia cruzada a otros trabajos relacionados.
3.2.3.5. Módulo de extracción y reunión de resultados Este módulo, mostrado en la Figura 28, se encarga de hacer un reporte de las recomendaciones sobre la estructura de navegación del sitio Web. Estas recomendaciones están basadas sobre los patrones de navegación encontrados en la minería de uso Web, conjuntamente con el reporte de la estructura de navegación, resultado de la minería de estructura Web.

Capítulo 3 Análisis y Diseño
49
Figura 28. Módulo de extracción y reunión de resultados.
3.2.3.6. Módulo visualizador gráfico de resultados Después de haber analizado un sitio Web, los patrones de navegación y la estructura del sitio Web se deben mostrar al usuario, tarea que tiene encargada este módulo (ver Figura 29). Debido al tipo de resultados, y coincidiendo con lo investigado en el estado del arte, se propone una visualización en forma de grafo. En este trabajo de tesis se añade una característica única sobre las demás herramientas de análisis de sitios mediante minería Web, esto es, un grafo interactivo, apoyándose en la herramienta Touchgraph.
TouchGraph es una herramienta realizada en Java para visualización de redes de información interrelacionada, similar a productos de información comercial como InXight10, TheBrain11 y ThinkMap12. Las redes en TouchGraph son mostradas como grafos interactivos, característica que le permite variedad de transformaciones. Mediante la imagen visual, un usuario tiene la disponibilidad de navegar a través de redes de gran tamaño, y explorar formas diferentes de acomodo de los componentes de la red en la pantalla. Las soluciones de visualización que provee TouchGraph permiten mostrar relaciones entre personas, organizaciones e ideas [Touchgraph 2008].
10
InXigth, http://www.inxight.com 11
TheBrain, http://www.thebrain.com 12
ThinkMap, http://www.thinkmap.com
Capítulo 3 Análisis y Diseño
50
Figura 29. Módulo visualizador gráfico de resultados.
El proyecto TouchGraph está dividido en dos modalidades, propietario y de
código abierto, de las cuales sólo se explicará ésta última, debido a que fue la utilizada como base en este trabajo de tesis.
3.2.3.6.1. TouchGraph de código abierto: La versión TouchGraph de tipo open source está desarrollada bajo la licencia Apache Software Foundation (ASF) para los componentes antiguos, y disponibles para su descarga en el sitio http://sourceforge.net/projects/touchgraph/.
Figura 30. Ventana de Wikibrowser.

Capítulo 3 Análisis y Diseño
51
El proyecto TouchGraph está disponible en código abierto bajo el sistema CVS. Este repositorio incluye algunas aplicaciones como un visualizador gráfico de los enlaces que conforman una wiki13, denominado WikiBrowser (ver Figura 30). A lo largo de este capítulo, se realizaron las importantes etapas de análisis y diseño, siendo más extensa esta última, donde se incluyo el diseño conceptual con la definición de los casos de uso y diagramas de actividades. Esta etapa fue revisada continuamente por que sienta las bases de la implementación realizada.
13
Una wiki (del hawaiano wiki wiki, rápido) es un sitio web colaborativo que puede ser editado por varios usuarios. Los usuarios de una wiki pueden crear, editar, borrar o modificar el contenido de una página Web, de forma interactiva, fácil y rápida.

52
CAPÍTULO 4 IMPLEMENTACIÓN

Capítulo 4 Implementación
53
4.1. Introducción En el presente capítulo se aborda la descripción de la etapa de implementación de la herramienta que este trabajo de tesis presenta. Las etapas que lo componen son el módulo de implementación de minería de uso, el de minería de estructura Web, la extracción y reunión de resultados y la visualización gráfica de resultados.
Una de las principales características de desarrollo de esta herramienta es que la aplicación está basada en el esquema cliente – servidor y se utiliza el patrón de diseño Struts 2, por lo cual se incluye una breve introducción para familiarizarse con éste modelo de desarrollo de aplicaciones Web.
4.2. Introducción al patrón de diseño Struts 2 Struts 2 es un patrón de diseño creado para el desarrollo de aplicaciones Web dentro de su ciclo de vida completo, incluyendo construcción, desarrollo y mantenimiento de la aplicación completa. Los requerimientos básicos de la plataforma son Servlet API 2.4, JSP API 2.0 y Java EE 5 [Struts 2008].
El framework Struts 2 está basado en el patrón de diseño Modelo-Vista-Controlador, separando sus componentes en tres niveles. El controlador es el encargado de redirigir o asignar una aplicación a cada petición; además debe poseer un mapa de correspondencias entre peticiones y respuestas que se les asignan. El modelo sería la lógica de negocio. Una vez realizadas las operaciones necesarias, el flujo vuelve al controlador y éste devuelve los resultados a una vista asignada [Roughley 2006] (ver Figura 31).
Figura 31. Arquitectura de Struts 2.

Capítulo 4 Implementación
54
4.2.1. Secuencia de una petición en Struts 2 Para comprender mejor cómo interactúan cada uno de los elementos de Struts 2, en la Figura 32 se muestra una ejecución de una petición de usuario [Roughley 2007]. En este diagrama de secuencia los actores representan al usuario que inicia la petición, los componentes, algunas clases y los elementos más importantes.
Figura 32. Secuencia de una petición en Struts 2.
Fuente: Tomado de [Roughley 2007].
4.2.1.1. El inicio de la petición El ciclo de petición-respuesta inicia y termina en el navegador Web del usuario. Una URL que representa una acción puede ser ingresada directamente en la barra de direcciones del navegador Web, o puede ser generada por el framework cuando el usuario hace clic en un hipervínculo o un botón para enviar de un
formulario. La URL tendrá un valor como: http://localhost:8080/app/index.action.
Los archivos de configuración determinan que URLs serán manejadas por el
framework Struts 2. Usualmente, todas las peticiones para una aplicación Web son enviadas al filtro de servlet de Struts 2 y éste toma la decisión.
sd Ejemplo de una petición
Usuario JSPActionFiltro Struts 2 Invocación de
Action
Interceptores Result
/start.action
invoke()
invoke()
execute()
execute()

Capítulo 4 Implementación
55
4.2.1.2. El filtro de servlet de Struts 2 Cuando las peticiones son recibidas por el contenedor del servlet, éstas son enviadas hacia el servlet o un filtro que manejará la petición. En Struts 2, se usa
un filtro y una clase para manejar las peticiones (FilterDispatcher).
El filtro y la clase FilterDispatcher son el corazón del framework de Struts 2.
Juntos proveen el acceso a la infraestructura que será necesaria para procesar la petición. En el arranque, son cargadas las implementaciones de elementos
configurables en el framework, incluyendo ConfigurationManager, ActionMapper y
ObjectFactory. Con respecto al procesamiento de la petición, el filtro Struts 2
desarrolla lo siguiente:
Poner a disposición contenido estático: pueden ser puestos a disposición desde Struts 2 o el archivo JAR de la aplicación Web conteniendo javascript y archivos de usuario configurables, permitiendo que todos los elementos de una aplicación Web sean empaquetados juntos.
Determina la configuración de las acciones: El filtro usa
implementaciones de ConfigurationManager y de ActionMapper para
determinar cual acción se mapea a la URL desde una petición entrante; por
defecto,las acciones se determinan por la extensión .action.
Crea el contexto de la acción: Debido a que las acciones son genéricas y no específicas a HTTP, la información contenida en la petición Web necesita ser convertida a un formato independiente del protocolo para que las acciones lo usen; esto incluye extraer datos desde los objetos
HttpServletRequest y HttpSession.
Crea el proxy de la acción: La clase ActionProxy contiene toda la
configuración e información de contexto para procesar la petición y contendrá los resultados de ejecución después que la petición ha sido procesada.
Ejecuta una limpieza: Para asegurarse que no ocurran pérdidas de memoria, el filtro automáticamente ejecuta una limpieza del objeto
ActionContext.
Cuando la instancia de la clase ActionProxy se crea y configura, el método
execute( ) de la clase de acción se invoca. Esto indica que la preparación de la
acción está completa y el procesamiento real de la acción está por iniciar.

Capítulo 4 Implementación
56
4.2.1.3. La invocación de la acción
El objeto ActionInvocation maneja el ambiente de ejecución y contiene el estado
conversacional de la acción que está siendo procesada. Esta clase es el núcleo de
la clase ActionProxy.
El ambiente de ejecución está hecho de tres diferentes componentes:
acciones, interceptores y resultados.
4.2.1.4. La acción
Una de las primeras tareas que desarrolla el ActionInvocation es consultar la
configuración que está siendo utilizada y crear una instancia de la clase de acción para cada petición que está siendo recibida.
4.2.1.5. Interceptores Los interceptores proveen una forma simple de añadir procesamiento lógico alrededor del método que está siendo llamado en la acción. Estos permiten características de funcionamiento cruzado para ser aplicadas a las acciones en una forma conveniente y consistente, evitando la necesidad de añadir código para cada acción que con el tiempo, crearía sobrecarga adicional de mantenimiento.
Cada acción manejará tantos interceptores como sean invocados, después de que son aplicados a la petición, se llaman al método de la acción que procesan la
lógica de la petición. Por convención, este método es execute( ).
Despues que la lógica de la acción se ejecuta, el flujo se retorna a través de los interceptores configurados en orden inverso.
4.2.1.6. Los resultados Posterior al procesamiento de la acción, es momento de mostrar el resultado de la
petición. El método execute( ) de la clase acción retorna un String como resultado, el
cual es mapeado vía la configuración de Struts a una implementación de la
interface Result, o la acción puede retornar directamente una instancia del objeto
Result.
La interface Result es muy similar a la clase de acción; contiene un método
único que genera una respuesta al usuario. El paso final es retornar la respuesta (si es generada) de regreso al usuario con lo cual, se completa el ciclo de procesamiento de una petición.

Capítulo 4 Implementación
57
4.3. Características generales de la implementación El desarrollo de la herramienta analizador de estructuras de navegación aplicando minería de uso Web y minería de estructura Web se ha hecho bajo las siguientes características:
Java 5 Enterprise Edition (JEE 5).
Framework Struts 2 (2.0.11).
Manejador de base de datos MySQL 5.0.
Contenedor Web Apache Tomcat 6.0.
Navegador Web Mozilla Firefox 2.
Ambiente de Desarrollo NetBeans 6.0.
Sistema Operativo Linux Distribución Suse 10.2.
4.3.1. El paquete analizadorWebSite Las clases que conforman la aplicación Web están englobadas en un paquete
denominado analizadorWebSite (ver Figura 33), el cual a su vez está compuesto
de 5 paquetes, los cuales se describen a continuación.
Figura 33. Paquete analizadorWebSite.

Capítulo 4 Implementación
58
analizadorWebSite.actions: Clases de acción de acuerdo al modelo vista
controlador.
analizadorWebSite.preprocesamiento: Clases para preprocesar los archivos
log y sesionizar antes de obtener patrones de navegación mediante minería de uso Web.
analizadorWebSite.mineriaUso: Clases que implementan el algoritmo a-priori
de extracción de reglas de asociación.
analizadorWebSite.mineriaEstructura: Clases para el proceso de extraer la
estructura del sitio Web y el proceso de minería de estructura Web.
analizadorWebSite.extraccionResultados: Clases que recuperan los patrones
de navegación y el reporte del análisis de la estructura Web.
analizadorWebSite.util: Clases de utilerías para la ejecución del analizador
de sitios Web.
Además del paquete analizadorWebSite, para la presentación gráfica de
resultados se apoya en la herramienta TouchGraph [Touchgraph 2008], la cual se explicará en la sección 4.6.
4.3.2. La base de datos La aplicación utiliza una base de datos para almacenamiento de los procesos intermedios y resultados finales. Las tablas que la conforman y una breve descripción se muestra en la Tabla 11 y el diagrama relacional en la Figura 34.
Tabla 11. Tablas que conforman la base de datos.
Tabla Descripción
logs Almacena cada petición del archivo log que ha sido preprocesada correctamente.
catalogo Esta tabla es llenada en la etapa de sesionización, y guarda cada página diferente que es encontrada en la tabla logs.
sesiones Esta tabla es producto de la etapa de sesionización, recopila un índice de las sesiones encontradas.
regla Guarda un registro por cada regla de asociación encontrada mediante minería de uso Web.
antecedentes Almacena el conjunto de nodos antecedentes para cada regla de asociación.
consecuentes Almacena el conjunto de nodos consecuentes para cada regla de asociación.
sitios Almacena un registro por cada sitio Web del cual se analiza su estructura.
nodos Almacena un registro por cada página Web que es encontrada durante la fase de recolección de la estructura Web.
entradas Almacena para cada nodo los hipervínculos de los nodos que van dirigido hacia él.
salidas Almacena para cada nodo, los nodos hacia los que se dirigen los hipervínculos.
caminosinalcanzables Almacena para cada nodo los caminos inalcanzables que han sido

Capítulo 4 Implementación
59
encontrados.
Figura 34. Diagrama relacional de la base de datos.
4.3.3. Las clases de acción Cuando el cliente hace una petición a un nombre de acción, el framework utiliza el
archivo struts.xml para mapear la acción a ejecutar para procesar la petición. Todas
class BD
antecedentes
«column»
FK idregla: INTEGER
idpagw: INTEGER
«FK»
+ FK_antecedentes_reglas(INTEGER)
catalogo
«column»
*PK idpagw: INTEGER
descripcion: VARCHAR(200)
«PK»
+ PK_catalogo(INTEGER)
«unique»
+ UQ_catalogo_descripcion(VARCHAR)
sesiones
«column»
*PK idsesion: INTEGER
clave: INTEGER
«PK»
+ PK_sesiones(INTEGER)
consecuentes
«column»
*FK idregla: INTEGER
idnodo: INTEGER
idnodos: INTEGER
«FK»
+ FK_consecuentes_reglas(INTEGER)
logs
«column»
*PK clave: INTEGER
hostr: VARCHAR(15)
usuario: VARCHAR(30)
fecha: INTEGER
request: VARCHAR(200)
status: VARCHAR(15)
bytes: VARCHAR(11)
referencia: VARCHAR(120)
navegador: VARCHAR(160)
cookie: VARCHAR(30)
miliseg: VARCHAR(7)
metodo: VARCHAR(10)
htmlv: VARCHAR(70)
FK idsesion: INTEGER
FK idpagw: INTEGER
FK idref: INTEGER
«FK»
+ FK_logs_catalogo(INTEGER)
+ FK_logs_catalogo2(INTEGER)
+ FK_logs_sesiones(INTEGER)
«PK»
+ PK_clave(INTEGER)
«index»
+ request(VARCHAR)
nodos
«column»
FK idsitio: INTEGER
*PK idnodo: INTEGER
descripcion: VARCHAR(100)
gradoglobalessalida: INTEGER
gradolocalesentrada: INTEGER
gradolocalessalida: INTEGER
«FK»
+ FK_nodos_sitios(INTEGER)
«PK»
+ PK_nodos(INTEGER)
caminosinalcanzables
«column»
FK idsitio: INTEGER
FK idnodo: INTEGER
descripcion: VARCHAR(200)
«FK»
+ FK_caminosinalcanzables_nodos(INTEGER)
+ FK_caminosinalcanzables_sitios(INTEGER)
reglas
«column»
*PK idregla: INTEGER
confianza: DECIMAL(10,9)
soporte: DECIMAL(10,9)
confmin: DECIMAL(3)
sopmin: DECIMAL(3)
«PK»
+ PK_reglas(INTEGER)
salidas
«column»
FK idsitio: INTEGER
FK idnodo: INTEGER
idnodos: INTEGER
«FK»
+ FK_salidas_nodos(INTEGER)
+ FK_salidas_sitios(INTEGER)
sitios
«column»
*PK idsitio: INTEGER
descripcion: VARCHAR(90)
fecha: VARCHAR(21)
«PK»
+ PK_sitios(INTEGER)
entradas
«column»
*FK idsitio: INTEGER
FK idnodo: INTEGER
idnodos: INTEGER
«FK»
+ FK_entradas_nodos(INTEGER)
+ FK_entradas_sitios(INTEGER)
+FK_logs_catalogo2
0..*
(idref = idpagw)«FK»
+PK_catalogo
1
+FK_salidas_nodos
0..*
(idnodo = idnodo)
«FK»
+PK_nodos
1
+FK_caminosinalcanzables_nodos 0..*
(idnodo = idnodo)
«FK»
+PK_nodos
1
+FK_logs_catalogo0..*
(idpagw = idpagw)«FK»
+PK_catalogo
1
+FK_consecuentes_reglas
0..*
(idregla = idregla)
«FK»
+PK_reglas
1
+FK_nodos_sitios 0..*
(idsitio = idsitio)
«FK»
+PK_sitios 1
+FK_salidas_sitios
0..*
(idsitio = idsitio)
«FK»
+PK_sitios
1
+FK_logs_sesiones 0..*
(idsesion = idsesion)
«FK»
+PK_sesiones 1
+FK_caminosinalcanzables_sitios
0..*
(idsitio = idsitio)
«FK»
+PK_sitios
1
+FK_antecedentes_reglas 0..*
(idregla = idregla)
«FK»
+PK_reglas 1
+FK_entradas_sitios 0..*
(idsitio = idsitio)
«FK»
+PK_sitios
1
+FK_entradas_nodos0..*
(idnodo = idnodo)
«FK»
+PK_nodos
1

Capítulo 4 Implementación
60
las clases de acción pueden implementar la interface Action, la cual incluye el
método execute( ). Sin embargo, es posible crear POJOs14 que incluyan el método
execute( ) sin implementar ésta interface.
Las clases de acción están agrupadas en el paquete analizadorWebSite.actions (Figura 35), una clase para cada paso que se sigue dentro de la ejecución de la aplicación, como se verá más adelante en los diagramas de secuencia.
Figura 35. Diagrama de clases del paquete analizadorWebSite.actions.
4.3.4. El paquete analizadorWebSite.util
El paquete analizadorWebSite.util (ver Figura 36) incluye clases de apoyo para la
aplicación: ConexionBD implementa un objeto de conexión a la base de datos
MySQL. ReadPropertiesFile recoge los parámetros de configuración de la aplicación
almacenados en un archivo de texto llamado analizadorWebSite.properties; la clase
FastVector implementa un vector, reemplazando a la clase java.util.Vector, con la
ventaja de ser más rápido al no utilizar métodos sincronizados (los métodos
sincronizados tienden a ser más lentos). Las instancias de tipo FastVector se
14
POJO: del inglés Plain Old Java Object. Es un acrónimo para referirse a clases simples y que no dependen de ningún framework especial.
class actions
ActionSupport
InfoSitioAction
- fi leCaption: String
- upload: File
- uploadContentType: String
- uploadFileName: String
- urlSitio: String
+ execute() : String
+ getFileCaption() : String
+ getUpload() : File
+ getUploadContentType() : String
+ getUploadFileName() : String
+ getUrlSitio() : String
+ setFileCaption(String) : void
+ setUpload(File) : void
+ setUploadContentType(String) : void
+ setUploadFileName(String) : void
+ setUrlSitio(String) : void
ActionSupport
InicioAction
+ execute() : String
ActionSupport
MineriaEstructuraAction
- calendario: Calendar
+ execute() : String
ActionSupport
MineriaUsoAction
- calendario: Calendar
- confianza: String
- soporte: String
+ execute() : String
+ getConfianza() : String
+ getSoporte() : String
+ setConfianza(String) : void
+ setSoporte(String) : void
ActionSupport
PreprocesamientoAction
- calendario: Calendar
- extensionesEliminar: List
- extensionesPermitidas: List
+ execute() : String
+ getExtensionesEliminar() : List
+ getExtensionesPermitidas() : List
+ setExtensionesEliminar(List) : void
+ setExtensionesPermitidas(List) : void
ActionSupport
SesionizacionAction
- algoritmoSesionizacion: List
- campo: String
+ execute() : String
+ getAlgoritmoSesionizacion() : List
+ getCampo() : String
+ setAlgoritmoSesionizacion(List) : void
+ setCampo(String) : void

Capítulo 4 Implementación
61
utilizan para almacenar las peticiones que contienen los archivos de bitácora y agilizar el tiempo de procesamiento.
Figura 36. Diagrama de clases del paquete analizadorWebSite.util.
Antes de comenzar con la implementación del módulo de minería de uso Web, es necesario verificar la conexión con la base de datos en MySQL.
class util
ConexionBD
- _host: String
- baseD: String
- conn: Connection
- pwd: String
- url: String
- usr: String
+ cierraConexiones() : void
+ conectaBaseDatos() : Connection
+ ConexionBD(String, String, String, String)
+ ConexionBD(String, String, String, String, int)
+ eliminaSesiones() : void
+ inicializaBD() : void
+ inicializaLogs() : void
+ inicializaMineria() : void
+ inicializaSesiones() : void
+ inicializaSitios() : void
+ inicializaTransacciones() : void
+ pruebaConexion() : boolean
«interface»
Copyable
+ copy() : Object
Serializable
FastVector
- m_CapacityIncrement: int = 1
- m_CapacityMultiplier: int = 2
- m_Objects: Object ([])
- m_Size: int = 0
+ addElement(Object) : void
+ appendElements(FastVector) : void
+ capacity() : int
+ contains(Object) : boolean
+ containsAll(FastVector) : boolean
+ copy() : Object
+ copyElements() : Object
+ elementAt(int) : Object
+ elements() : Enumeration
+ elements(int) : Enumeration
+ FastVector()
+ FastVector(int)
+ firstElement() : Object
+ indexOf(Object) : int
+ insertElementAt(Object, int) : void
+ lastElement() : Object
+ removeAllElements() : void
+ removeElement(Object) : boolean
+ removeElementAt(int) : void
+ setCapacity(int) : void
+ setElementAt(Object, int) : void
+ size() : int
+ swap(int, int) : void
+ toArray() : Object[]
+ trimToSize() : void
Enumeration
FastVector::FastVectorEnumeration
- m_Counter: int
- m_SpecialElement: int
- m_Vector: FastVector
+ FastVectorEnumeration(FastVector)
+ FastVectorEnumeration(FastVector, int)
+ hasMoreElements() : boolean
+ nextElement() : Object
ReadPropertiesFile
- host: String
- nombreBD: String
- password: String
- pathArchivosLog: String
- pathArchivosXml: String
- usuario: String
+ getClassName() : String
+ getHost() : String
+ getLocalDirName() : String
+ getNombreBD() : String
+ getPassword() : String
+ getPathArchivosLog() : String
+ getPathArchivosXml() : String
+ getUsuario() : String
+ getValuesFromBundle() : void
+ ReadPropertiesFile()
-m_Vector

Capítulo 4 Implementación
62
4.4. Implementación del módulo de minería de uso Web A continuación se explica la implementación del módulo de minería de uso Web. Se hizo reutilización de la implementación realizada por [Hernández 2005] en los
paquetes mineriaUso y preprocesamiento.
4.4.1. Validación de conexión a la base de datos El proceso de validación se muestra en la Figura 37, inicia al momento que el usuario solicita la URL de la aplicación Web, por ejemplo
http://localhost:8080/analizadorWebSite/.
La página de inicio de la aplicación es index.jsp, la cual redirecciona la
ejecución a la clase de acción InicioAction. En el método execute( ) de esta clase se
invoca a la clase ReadPropertiesFile. Los parámetros de conexión a la base de datos
tales como el nombre, nombre de usuario, contraseña entre otros, son leídos
desde el archivo AnalizadorWebSite.properties que se incluye dentro de la
aplicación Web. Después de ser recuperados estos parámetros, se prueba la
conexión al servidor MySQL mediante la clase ConexionBD, si ésta no es exitosa,
el sistema no puede continuar y muestra la página de error error.jsp (ver Anexo B),
por el contrario, aparece en pantalla infoSitio.jsp (ver Anexo B) para solicitar la
información del sitio Web a analizar.
Figura 37. Diagrama de secuencia del inicio de la aplicación.
sd Inicio de la aplicación
Usuario
infoSitio.jspConexionBDInicioActionindex.jspNavegador Web ReadPropertiesFile
Introduce URL
Peticion HTTP GET
Ejecuta InicioAction
<constructor>
getValuesFromBundle
Parámetros de
conexión de BD
<constructor>
pruebaConexion
redirecciona

Capítulo 4 Implementación
63
4.4.2. Solicitud de la información del sitio Web a analizar El sistema comienza con la solicitud de la información del sitio Web que será analizado. La Figura 38 muestra esta secuencia. Como primer paso los archivos de bitácoras son enviados al servidor y se almacenan en una ubicación que puede
ser modificada de acuerdo al archivo analizadorWebSite.properties y al igual que la
URL del sitio, las instancias de estos objetos son adjuntados en la sesión de usuario.
Figura 38. Diagrama de secuencia para introducir la información del sitio Web a analizar.
4.4.3. Preprocesamiento de archivos Log
Un archivo de bitácora está representado por un objeto de la clase ArchivoLog,
desde la cual es posible obtener metadatos de éste. La clase ArchivoLog se
encuentra asociada con la clase AnalizadorArchivo, con la cual se realizan
funciones básicas de identificación del formato del archivo log, y la limpieza de las peticiones de documentos Web con extensiones a ser eliminados. Cada tipo de
formato es procesado por separado, para lo cual se tiene la clase ProcesaLinea,
desde la cual se extiende a las clases ProcesaLineaCLF, ProcesaLineaCLFE,
ProcesaLineaCLFTime, ProcesaLineaECLF, ProcesaLineaPLF. Asimismo se eliminan las
sd Introducir información del sitio Web a analizar
Usuario
InfoSitioActionInfoSitio.jsp preprocesamiento.jsp
Proporciona
archivo log
Proporciona URL
Enviar
Guardar archivo log
Guardar URL
redirecciona

Capítulo 4 Implementación
64
peticiones hechas por robot, usando la clase ControlRobot. Cuando una petición ya
ha sido preprocesada se almacena en la tabla “logs”. La Figura 39 muestra el diagrama que incluye estas clases.
Figura 39. Diagrama de clases de analizadorWebSite.preprocesamiento para la limpieza de los
archivos log.
Al término de la etapa de preprocesamiento, las peticiones filtradas resultantes
son almacenadas en la base de datos, mientras que el flujo de la aplicación se
dirige a la página sesionizacion.jsp (ver Anexo B). La Figura 40 muestra el
diagrama de secuencias de la fase de preprocesamiento.
class preprocesamiento
AnalizadorArchiv o
- archivo: File
~ cnBD: ConexionBD
~ conn: Connection
~ stmt: Statement
+ AnalizadorArchivo(File, ConexionBD)
+ AnalizadorArchivo(File)
+ getNumeroLineas() : int
+ getTipoFormato() : String
- isCLF(String) : boolean
- isCLFTime(String) : boolean
- isECLF(String) : boolean
- isECLFC(String) : boolean
- isPLF(String) : boolean
+ limpiaLog(int, String) : boolean
- meteUpdate(Vector) : void
Archiv oLog
- archivo: File
- conexion: ConexionBD
- fecha: String
- formato: String
- l ineas: String
- nombre: String
- proyecto: String
- tamanio: String
- tipoFormato: int
- analizaFormato() : String
+ ArchivoLog()
+ ArchivoLog(File)
+ dameFecha() : String
+ dameFormato() : String
+ dameLineas() : String
+ dameNombre() : String
+ dameTamanio() : String
+ eliminarExtensiones(Vector) : boolean
+ eliminarExtensiones(List) : boolean
+ setConexion(ConexionBD) : void
+ setProyecto(String) : void
+ tomaArchivo(File) : void
ControlRobot
+ ControlRobot()
+ esRobot(String) : boolean
ProcesaLinea
# anio: String = new String("")
# authuser: String = new String("")
# bytes: String = new String("")
# cookie: String = new String("")
# date: String = new String("")
# dia: String = new String("")
# esLimpiaL: boolean = true
# hora: String = new String("")
# limpieza: String
# linea: String
# mes: String = new String("")
# mesesAnio: String ([]) = {"Jan", "Feb", ...
# metodo: String = new String("")
# milis: String = new String("")
# min: String = new String("")
# recurso: String = new String("")
# referrer: String = new String("")
# remotehost: String = new String("")
# request: String = new String("")
# rfc: String = new String("")
# seg: String = new String("")
# status: String = new String("")
# user_agent: String = new String("")
# versionhtml: String = new String("")
# zone: String = new String("")
+ esLimpia() : boolean
+ getAnio() : String
+ getAuthuser() : String
+ getBytes() : String
+ getCookie() : String
+ getDate() : String
+ getDia() : String
+ getHora() : String
+ getIp() : String
+ getMes() : String
+ getMetodo() : String
+ getMilis() : String
+ getMin() : String
+ getRecurso() : String
+ getReferrer() : String
+ getRequest() : String
+ getRfc() : String
+ getSeg() : String
+ getStatus() : String
+ getUser_agent() : String
+ getVersionhtml() : String
- l impiaDinamicas(String) : String
+ ProcesaLinea(String, String)
# separaFecha() : void
+ setLimpieza(String) : void
+ setLinea(String) : void
ProcesaLineaCLF
~ i: int = 0
+ ProcesaLineaCLF(String, String)
+ separarLinea() : boolean
ProcesaLineaCLFE
~ i: int = 0
+ ProcesaLineaCLFE(String, String)
+ separarLinea() : boolean
ProcesaLineaCLFTime
~ i: int = 0
+ ProcesaLineaCLFTime(String, String)
+ separarLinea() : boolean
ProcesaLineaECLFC
~ i: int = 0
+ ProcesaLineaECLFC(String, String)
+ separarLinea() : boolean
ProcesaLineaPLF
~ i: int = 0
+ ProcesaLineaPLF(String, String)
+ separarLinea() : boolean

Capítulo 4 Implementación
65
Figura 40. Diagrama de secuencia para realizar preprocesamiento del archivo de bitácora.
4.4.4. Sesionización de archivos Log Una vez que han sido almacenadas las peticiones en la base de datos, el usuario dispone de 3 opciones para la identificación de sesiones de usuario, método heurístico, por duración en tiempo, o por número de peticiones. La fase de
sesionización está compuesta por las clases SesionizadorHeurístico,
SesionizadorMinutos y SesionizadorPeticiones, cada una para cada opción,
respectivamente.
SesionizadorPeticiones toma como valor de entrada el número máximo de
peticiones para delimitar una sesión de usuario. Por otra parte SesionizadorMinutos delimita una sesión de usuario por el valor que es introducido por el usuario.
Mientras que SesionizadorHeurístico aplica un algoritmo heurístico para definir las
sesiones de usuario sin incluir ningún parámetro proporcionado por el usuario y
utiliza la clase Utilerías para separar los elementos que conforman a las URLs.
Las clases anteriores interactúan con la clase Registro que representa a una
petición almacenada en la tabla “logs”. Por otra parte CreaItems es una clase que
sd Preprocesamiento
Usuario
ProcesaLineaControlRobotAnalizadorArchivopreprocesamiento.jsp ArchivoLogLocalPreprocesamientoAction sesionizacion.jsp
Selección
documentos
Web a
eliminar
Enviar<constructor>(ArchivoLog)
eliminarExtensiones(extensionesEliminar)
<constructor>(archivoLog)
limpiaLog
<constructor>
esRobot
<constructor>(linea,recursosEliminar)
separarLinea
esLimpia
almacenaLinea
redirecciona

Capítulo 4 Implementación
66
realiza un llenado de las tablas “catalogo” y “sesiones”, y sus correspondientes referencias para la tabla “logs”.
Figura 41. Diagrama de clases de analizadorWebSite.preprocesamiento para sesionizar archivos Log.
Las figuras 42, 43 y 44 muestran los diagramas de secuencias para cada una
de las opciones de sesionización de los archivos log. En cada uno de ellos el
usuario interactúa con la interfaz sesionización.jsp seleccionando un algoritmo de
sesionización y proporcionando un valor máximo. Al pulsar enviar, el flujo del
sistema crea una instancia de SesionizacionAction, desde la cual se crea
SesionizadorMinutos, SesionizadorPeticiones o SesionizadorHeurístico según sea la
opción seleccionada por el usuario; una vez finalizado el proceso de sesionización
es instanciada la clase CrearItems, desde la cual se crean catalogos de páginas y
de sesiones. Al terminar este proceso, el flujo de la aplicación se dirige a
mineriaUso.jsp (ver Anexo B).
class preprocesamiento
CreaItems
- actualizaciones: Vector
- calendario: Calendar
- cnn: Connection = null
- contador: int = 0
- tamanio: int = 0
+ CreaItems(ConexionBD)
+ crearItems() : void
- l lena_Clientes() : void
- l lena_Items(String, String) : void
- l lena_Transacciones() : void
- meteUpdate() : void
- obtiene_IdCliente(String) : String
Registro
~ clave: int = 0
~ fecha: int = 0
~ idsesion: int = 0
~ ip: String = new String("")
~ referencia: int
~ request: int
+ getClave() : int
+ getFecha() : int
+ getIdSesion() : int
+ getIP() : String
+ getReferencia() : int
+ getRequest() : int
+ Registro()
+ setDatos(int, int, int, int, int, String) : void
+ setIDSesion(int) : void
+ setRequest(int) : void
SesionizadorHeuristico
- actualizaciones: Vector
- calendario: Calendar
- cnn: Connection
- conn: Connection
- contador: int
- dominioLocal: String
- idsesion: int
- actualiza_Recursos(String, String) : void
- actualiza_Referencias(String, String) : void
+ agregaPerdidos() : void
- agregaRegistros(String, int) : void
- agrupaPerdidos(String) : boolean
+ detectaSesion(Registro) : void
- existeEnCatalogo(String) : boolean
+ getSesiones() : void
- l lena_Transacciones() : void
- l lenaCatalogo() : void
- meteReferencias() : void
- meteSesiones() : void
- meteUpdate() : void
+ SesionizadorHeuristico(String, ConexionBD)
+ sesionizaLog() : void
SesionizadorMinutos
- actualizaciones: Vector
- calendario: Calendar
- claves: Vector
- conn: Connection
- contador1: int
- contador2: int
- idsesion: int
- minutos: int = 0
- segundos: int = 0
- agrupaSesiones() : boolean
- meteUpdate() : void
- obtieneRegistros(String) : boolean
+ SesionizadorMinutos(int, ConexionBD)
+ sesionizaLog() : void
SesionizadorPeticiones
- calendario: Calendar
- conn: Connection
- idsesion: int
- peticiones: int = 0
- agrupaSesiones() : boolean
- meteRegistros(String) : boolean
+ SesionizadorPeticiones(int, ConexionBD)
+ sesionizaLog() : void
Utilerias
+ getDominio() : String
- iniciaValores() : String
+ obtieneRecurso(String, String) : String
+ separaDominio(String) : String
+ Utilerias()
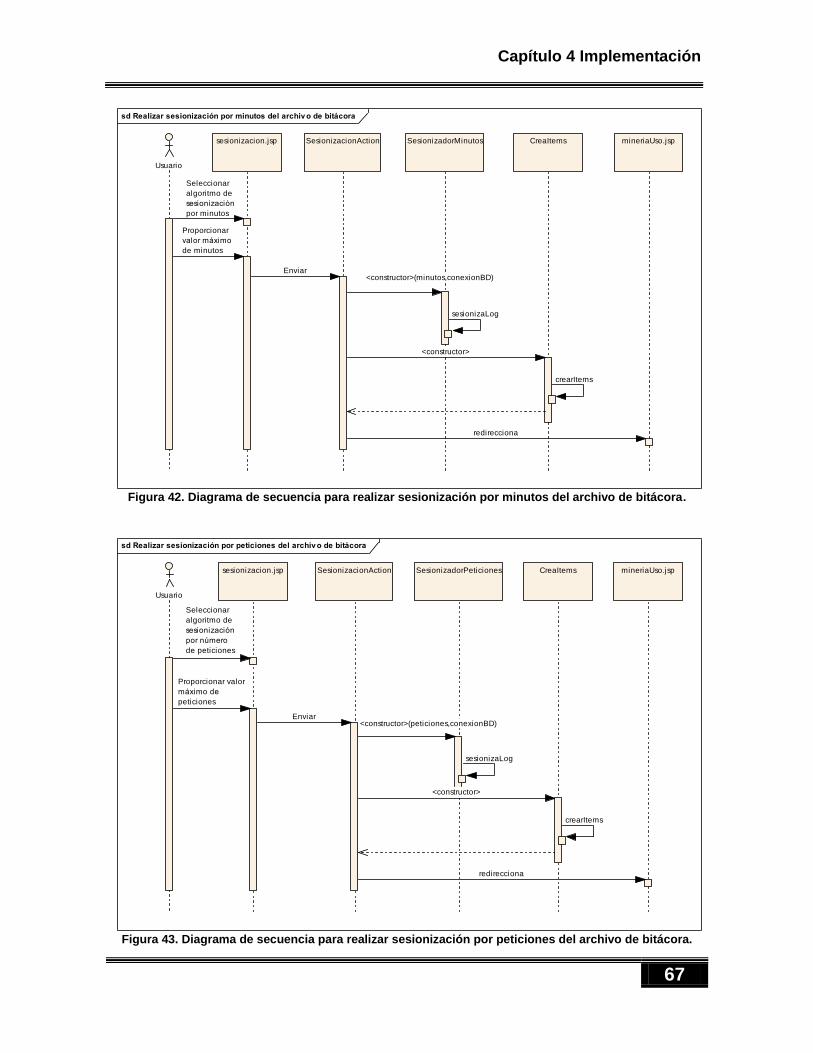
Capítulo 4 Implementación
67
Figura 42. Diagrama de secuencia para realizar sesionización por minutos del archivo de bitácora.
Figura 43. Diagrama de secuencia para realizar sesionización por peticiones del archivo de bitácora.
sd Realizar sesionización por minutos del archiv o de bitácora
Usuario
mineriaUso.jspSesionizadorMinutossesionizacion.jsp SesionizacionAction CreaItems
Seleccionar
algoritmo de
sesionización
por minutos
Proporcionar
valor máximo
de minutos
Enviar<constructor>(minutos,conexionBD)
sesionizaLog
<constructor>
crearItems
redirecciona
sd Realizar sesionización por peticiones del archiv o de bitácora
Usuario
mineriaUso.jspCreaItemsSesionizadorPeticionessesionizacion.jsp SesionizacionAction
Seleccionar
algoritmo de
sesionización
por número
de peticiones
Proporcionar valor
máximo de
peticiones
Enviar<constructor>(peticiones,conexionBD)
sesionizaLog
<constructor>
crearItems
redirecciona

Capítulo 4 Implementación
68
Figura 44. Diagrama de secuencia para realizar sesionización por heurística del archivo de bitácora.
4.4.5. Procesamiento de minería de uso Web Las clases que conforman este módulo están dentro del paquete
analizadorWebSite.mineriaUso (ver Figura 45). La clase AlgoritmoReglasApp
inicializa el algoritmo de extracción de reglas de asociación A-priori, para ello es
necesario crear una tabla de transacciones, utilizando la clase TablaR, compuesta
de instancias de la clase Transaccion. La clase Conjunto y ConjuntoPotencia se
utilizan para el proceso de generación de conjuntos de ítems. Con el fin de lograr una mayor eficiencia, el número de elementos de cada conjunto de ítems generado se incrementa en cada iteración tomando en cuenta solamente aquellos ítems que tengan un soporte mayor o igual al soporte mínimo. Las reglas de
asociación encontradas son instancias de la clase ReglaAsociación.
sd Realizar sesionización por heuristica del archiv o de bitácora
Usuario
mineriaUso.jspSesionizacionActionsesionizacion.jsp SesionizadorHeuristico CreaItems
Seleccionar
algoritmo de
sesionización
heurístico
Enviar
<constructor>(urlSitio,conexionBD)
sesionizaLog
<constructor>
crearItems
redirecciona

Capítulo 4 Implementación
69
Figura 45. Diagramas de clases de analizadorWebSite.mineriaUso.
En la Figura 46 se muestra el diagrama de secuencia en el proceso de minería
de uso. Inicia con la interfaz de usuario mineriaUso.jsp (ver Anexo B) desde el cual
éste proporciona los valores mínimos de soporte y confianza. Al pulsar el botón de
enviar, se crea una instancia de la clase de acción MineriaUsoAction y se llama al
método execute( ). Como primer paso para poder extraer las reglas de asocicación,
es necesario crear la matriz de transacciones, posteriormente AlgoritmoReglasApp y
AlgoritmoReglasAsociacion trabajan en conjunto para realizar el procesamiento de
minería de uso Web y almacenar estas reglas en la base de datos. Al finalizar se
redirige el sistema a mineriaEstructura.jsp (ver Anexo B).
class mineriaUso
AlgoritmoReglasApp
- conexionbd: ConexionBD
- confianza: int
- connection: Connection
- soporte: int
- tablar: TablaR
- vector2: FastVector
+ AlgoritmoReglasApp(int, int, TablaR, ConexionBD)
+ generaReglas() : void
- getMaxIdRegla() : int
+ meteReglasBD() : void
- meteUpdate(FastVector) : void
AlgoritmoReglasAsociacion
~ C: FastVector
~ calendario: Calendar
~ CCan: FastVector
~ CTemp: FastVector = new FastVector()
~ CTempAux: FastVector = new FastVector()
~ idRegla: int
~ L: int = 1
- RAs: FastVector = new FastVector()
+ AlgoritmoReglasAsociacion(TablaR, int, int, FastVector)
- conjuntos_Candidatos(int) : FastVector
- conjuntos_Frecuentes(TablaR, FastVector, int) : FastVector
- ConjuntosFrecuentes1(TablaR, int, FastVector) : FastVector
+ getReglas() : FastVector
- getReglasAsociacion(FastVector) : FastVector
- reglas_Confianza(TablaR, FastVector, int) : FastVector
Conjunto
- contPotencia: int
- elementos: FastVector
+ addElement(String) : boolean
+ addElements(FastVector) : boolean
+ Conjunto()
+ Conjunto(FastVector)
+ Conjunto(String)
+ getElementos() : FastVector
+ getPotencia() : FastVector
+ multiplicacion(FastVector, FastVector, int) : FastVector
+ multiplicacion2(FastVector, FastVector) : FastVector
+ removeElement(String) : boolean
+ removeElementAt(int) : boolean
ConjuntoPotencia
~ elementos: FastVector
~ elementosAux: FastVector
+ ConjuntoPotencia(FastVector)
+ getInterseccion(FastVector) : FastVector
ReglaAsociacion
- antecedente: FastVector
- conf_min: int
- confianza: float
- consecuente: FastVector
- idRegla: int
- sop_min: int
- soporte: float
- soporte_ant: float
- soporte_con: float
+ getAntecedente() : FastVector
+ getConfianza() : float
+ getConfMin() : int
+ getConsecuente() : FastVector
+ getIdRegla() : int
+ getSopMin() : int
+ getSoporte() : float
+ ReglaAsociacion()
+ setAntecedente(FastVector) : void
+ setConfianza(float) : void
+ setConfMin(int) : void
+ setConsecuente(FastVector) : void
+ setIdRegla(int) : void
+ setSopMin(int) : void
+ setSoporte(float) : void
TablaR
~ conexionbd: ConexionBD
~ noTransacciones: int
~ transacciones: FastVector
+ crearTransacciones() : void
+ deleteTransacciones(int) : void
+ getConteoPatron(FastVector) : int
+ getFrecuenciaItem(String) : int
+ getFrecuenciaPatron(FastVector) : float
+ getFrecuenciaRegla(FastVector) : int
+ getNumeroTransacciones() : int
+ getTransacciones() : FastVector
- l lenarTransaccion(Transaccion, Connection) : void
+ TablaR(ConexionBD)
+ TablaR()
Transaccion
- idtransaccion: String = new String("")
- items: FastVector = new FastVector()
+ addItem(String) : void
+ contieneItem(String) : boolean
+ contienePatron(FastVector) : boolean
+ esDeTamanio(int) : boolean
+ getIdItems() : FastVector
+ getIdTransaccion() : String
+ setIdTransaccion(String) : void
+ Transaccion()
+ Transaccion(String)
-tablar

Capítulo 4 Implementación
70
Figura 46. Diagrama de secuencia para realizar procesamiento de minería de uso Web.
4.5. Implementación del módulo de minería de estructura Web
4.5.1. Recolección de la estructura del sitio Web El módulo de minería de estructura Web está compuesto por el paquete
analizadorWebSite.mineriaEstructura (ver Figura 47). Las clases que lo componen
son Spider implementando la interface ISpiderReportable, éstas junto con SpiderAp
recolectan la estructura partiendo de un sitio Web partiendo desde una URL de
entrada (por ejemplo http://www.dominio.com.mx).
sd Realizar procesamiento de minería de uso Web
Usuario
AlgoritmoReglasAsociacion mineriaEstructura.jspAlgoritmoReglasAppmineriaUso.jsp MineriaUsoAction TablaR
Proporcionar
valor mínimo de
soporte
Proporcionar
valor mínimo
de confianza
Enviar
<constructor>(ConexionBD)
crearTransacciones
<constructor>(soporte,confianza,tablaR)
generaReglas
<constructor>(soporte,confianza,tablaR)
getReglas :reglasAsociacion
meteReglasBD
redirecciona

Capítulo 4 Implementación
71
Figura 47. Diagrama de clases de minería de estructura Web.
El proceso de recolección de la estructura siguiendo el algoritmo de búsqueda
primero por anchura, establece una conexión HTTP con la URL inicial y analiza el
flujo devuelto apoyándose en la clase HTMLParse. El proceso consiste en buscar
etiquetas “href” dentro del contenido de la página Web devuelta. Se verifica que cada hipervínculo encontrado pertenezca al dominio del sitio Web que está siendo analizado, además que no sea una URL que ha sido visitada anteriormente. El proceso es iterativo hasta que no existan URLs por visitar. El conjunto de nodos resultantes es almacenado en las tablas nodos, sitios, salidas y entradas. La Figura 48 muestra el diagrama de secuencia de esta etapa.
4.5.2. Procesamiento de minería de estructura Web De acuerdo a la metodología propuesta, del proceso de minería de estructura Web se obtendrá un reporte de la estructura del sitio Web, donde se incluyen el grado o frecuencia de los hipervínculos que son globales (los hipervínculos que se dirigen a sitios Web diferentes), el grado de hipervínculos de entrada y de salida de cada documento Web y los camino inalcanzables, información descrita en el capítulo 3 de análisis y diseño.
class mineriaEstructura
CreateXml
- conexion: ConexionBD
- fi leName: String
- idSitio: int
+ CreateXml(ConexionBD, String, int)
+ getClassName() : String
+ getLocalDirName() : String
+ write() : void
HTMLEditorKit
HTMLParse
+ getParser() : HTMLEditorKit.Parser
Nodo
# caminosInalcanzables: Vector
# descripcionP: String
# entradas: Vector
# gradoGlobales: int
# idNodo: int
# salidas: Vector
+ addCaminoInalcanzable(String) : void
+ addEntrada(int) : void
+ addGradoGlobales() : void
+ addSalida(int) : void
+ getCaminosInalcanzables() : Vector
+ getDescripcion() : String
+ getEntradas() : Vector
+ getGradoGlobales() : int
+ getIdNodo() : int
+ getSalidas() : Vector
+ Nodo()
+ Nodo(String, int)
+ setDescripcion(String) : void
+ setIdNodo(int) : void
Spider
# badLinksCount: int = 0
# base: URL
~ conexion: ConexionBD
# goodLinksCount: int = 0
# spiderAp: SpiderAp
~ urls: Hashtable
~ urlSitio: String
+ addBadLinksCount() : void
+ addGoodLinksCount() : void
+ almacenaEstructura() : void
+ checkDomain(URL, URL) : boolean
+ checkLink(URL) : boolean
+ imprimeNodos() : void
- meteUpdate(Vector) : void
+ run() : void
+ Spider(ConexionBD, String)
+ spiderFoundEMail(String) : void
+ spiderFoundURL(URL, URL) : boolean
+ spiderURLError(URL) : void
SpiderAp
- calendario: Calendar
# cancel: boolean = false
- ContURLProceso: int = 0
- ContURLs: int = 0
# report: ISpiderReportable
- urlEncontrada: String
- urlProcesando: String
# urlsVisitadas: Hashtable = new Hashtable()
# workloadError: Collection = new ArrayList(3)
# workloadProcessed: Collection = new ArrayList(3)
# workloadWaiting: Collection = new ArrayList(3)
+ addURL(URL) : void
# agregaEnlaces() : void
+ begin() : Hashtable
+ cancel() : void
+ clear() : void
+ getWorkloadError() : Collection
+ getWorkloadProcessed() : Collection
+ getWorkloadWaiting() : Collection
+ log(String) : void
+ processURL(URL) : void
+ SpiderAp(ISpiderReportable)
«interface»
ISpiderReportable
+ addBadLinksCount() : void
+ addGoodLinksCount() : void
+ checkDomain(URL, URL) : boolean
+ checkLink(URL) : boolean
+ spiderFoundEMail(String) : void
+ spiderFoundURL(URL, URL) : boolean
+ spiderURLError(URL) : void
#report
#spiderAp

Capítulo 4 Implementación
72
Figura 48. Diagrama de secuencia para realizar minería de estructura Web.
El grado de hipervínculos locales de entrada y salida, y el grado de
hipervínculos globales de salida, son datos afines a cualquier nodo o página dentro del sitio Web, por lo cual esta información obtenida (resultado del proceso de minería Web) se encuentra añadida como campos en la tabla nodos.
La extracción de caminos inalcanzables es almacenada en la tabla que lleva el mismo nombre, conteniendo al identificador del sitio, identificador del nodo y la URL que no ha sido posible acceder.
Como antecedente de la presentación gráfica de resultados, es necesaria la creación de un archivo XML que contenga la estructura que ha sido recolectada del sitio Web. El DTD (del inglés Document Type Definition, definición de tipo de documento) que describe la estructura y la sintaxis del documento XML es propuesto por la herramienta TouchGraph [Touchgraph 2008], en donde se incluyen a los nodos representando a las páginas Web y las aristas a los hipervínculos, incluyendo sus características.
sd mineriaEstructura
Usuario
Archivo XMLSpidermineriaEstructura.jsp MineriaEstructuraAction SpiderAp CreateXML
Inicia procesamiento
EnviarExtrae URL del
sitio de la
sesión de
usuario
<constructor>(ConexionBD,
urlSitio)
run
<constructor>(this)
clear
addURL(urlSitio)
begin Mientras no
se terminen
las URLs a
visitar
Nodos
almacenaEstructura
<constructor>(ConexionBD, xmlName)
write

Capítulo 4 Implementación
73
La aplicación genera el archivo XML automáticamente utilizando la clase
CreateXML, extrayendo la información almacenada en la base de datos. Para la
creación de la estructura, contenido y anidamiento de las etiquetas, se apoya de la API NanoXML (NanoXML 2008).
4.6. Implementación del módulo procesamiento del grafo y extracción de resultados.
La finalidad de esta sección es presentar un reporte con las recomendaciones en base a los resultados del análisis del sitio Web realizado (ver Anexo 1). Estas recomendaciones están basadas sobre los patrones de navegación encontrados en la minería de uso Web, conjuntamente con el reporte de la estructura de navegación, resultado de la minería de estructura Web.
Las clases que componen esta sección (ver Figura 49), son
ExtraePatronesMineriaUso, la cual mediante el método getReglas() obtiene un vector
de instancias de la clase ReglaAsociacion.
Figura 49. Diagrama de clases del paquete analizadorWebSite.extraccionResultados.
Por otra parte, el reporte de la estructura Web se obtiene con la clase
ExtraeReporteMineriaEstructura, desde la cual se implementan métodos para extraer
ésta información de la base de datos mediante sentencias SQL, a los nodos con un mayor y menor grado global de hipervínculos de salida. Del mismo modo es
class extraccionResultados
ReglaAsociacion
- antecedente: String
- confianza: float
- confMin: int
- consecuente: String
- idRegla: int
- sopMin: int
- soporte: float
+ getAntecedente() : String
+ getConfianza() : float
+ getConfMin() : int
+ getConsecuente() : String
+ getIdRegla() : int
+ getSopMin() : int
+ getSoporte() : float
+ ReglaAsociacion()
+ setAntecedente(String) : void
+ setConfianza(float) : void
+ setConfMin(int) : void
+ setConsecuente(String) : void
+ setIdRegla(int) : void
+ setSopMin(int) : void
+ setSoporte(float) : void
ExtraeReporteMineriaEstructura
- conexion: ConexionBD
- idSitio: int
+ ExtraeReporteMineriaEstructura(ConexionBD, int)
+ getCaminosInalcanzables() : Vector
+ getInformacionEstructuralNodos() : Vector
ExtraePatronesMineriaUso
~ conexion: ConexionBD
+ ExtraePatronesMineriaUso(ConexionBD)
+ getReglas() : Vector
CaminoInalcanzable
- nodoOrigen: String
- urlInalcanzable: String
+ CaminoInalcanzable(String, String)
+ getNodoOrigen() : String
+ getUrlInalcanzable() : String
+ setNodoOrigen(String) : void
+ setUrlInalcanzable(String) : void
InformacionEstructuralNodo
- descripcion: String
- gradoGlobalesSalida: int
- gradoLocalesEntrada: int
- gradoLocalesSalida: int
- idNodo: int
- idSitio: int
+ getDescripcion() : String
+ getGradoGlobalesSalida() : int
+ getGradoLocalesEntrada() : int
+ getGradoLocalesSalida() : int
+ getIdNodo() : int
+ getIdSitio() : int
+ InformacionEstructuralNodo()
+ setDescripcion(String) : void
+ setGradoGlobalesSalida(int) : void
+ setGradoLocalesEntrada(int) : void
+ setGradoLocalesSalida(int) : void
+ setIdNodo(int) : void
+ setIdSitio(int) : void

Capítulo 4 Implementación
74
posible extraer a los nodos con un mayor o menor grado de hipervínculos locales, tanto de entrada como salida.
4.6.1. Visualización gráfica utilizando TouchGraph Después de haber analizado un sitio Web los patrones de navegación y la estructura del sitio Web deben mostrarse al usuario, apoyándose en la herramienta para visualización de grafos TouchGraph.
TouchGraph pone a disposición tres distintos proyectos de código abierto y para su descarga [Touchgraph 2008], utilizando componentes antiguos a diferencia de la versión comercial. De los tres proyectos, fue utilizado LinkBrowser por su mayor similitud con las necesidades del analizador de sitios Web.
Figura 50. El paquete com.touchgraph.

Capítulo 4 Implementación
75
Touchgraph está integrado en el paquete com.touchgraph (ver Figura 50). El
núcleo lo compone el paquete graphlayout para la integración de los paneles y
dibujo de los nodos y aristas; para ello se apoya de los paquetes graphelements
que define a cada elemento del grafo, e interaction, en donde se definen las clases
que dan la característica de movilidad del grafo e interactividad con el usuario. La
herramienta LinkBrowser está desarrollada dentro del paquete linkbrowser, el cual
básicamente emplea los elementos que le provee graphlayout extendiendo algunas
clases que le son necesarias. LinkBrowser se ejecuta como una aplicación Java, por lo tanto, para poder
integrarse en una aplicación Web es necesario que sea un applet, con lo cual puede ser ejecutada en el contexto de un navegador Web. La clase con la cual se
crea el applet es LinkBrowserApplet.
En la Figura 51 se presenta una etiqueta jsp:plugin mediante la cual se puede
añadir el applet a una página jsp. El nombre del archivo XML que representa la estructura extraída del sitio Web es enviado como parámetro. Es importante que tanto los archivos JAR que componen al applet y los archivos XML con la estructura de los sitios Web estén dentro de la carpeta raíz de la aplicación Web para que puedan ser visibles y accedidos.
Dentro de este capítulo se incluyó una descripción general de la implementación de la herramienta realizada, mediante los diagramas de clases y diagramas de secuencias; el código fuente completo se proporciona en el CD adjunto.
<jsp:plugin type="applet" code="com.touchgraph.linkbrowser.LinkBrowserApplet.class" codebase="/analizadorWebSite" archive="TGLinkBrowser.jar, nanoxml-2.1.1.jar, BrowserLauncher.jar" jreversion="1.3" align="center" height="520" width="100%" nspluginurl="http://java.sun.com/products/plugin/1.3.0_01/plug-install.html" iepluginurl="http://java.sun.com/products/plugin/1.3.0_01/jinstall-130_01-win32.cab#Version=1,3,0,1"> <jsp:params> <jsp:param name="initialXmlFile" value="<%=(String) session.getAttribute("xmlFileName")%>"/> <jsp:param name="initialNode" value ="1"/> </jsp:params> <jsp:fallback> <p> No se ha podido inicial el applet </p> </jsp:fallback> </jsp:plugin>
Figura 51. Etiqueta para integrar el applet a la página Web.

76
CAPÍTULO 5 PRUEBAS

Capítulo 5 Pruebas
77
5.1. Introducción El plan de pruebas se realiza siguiendo el estándar 829 de la IEEE [IEEE 1998] para pruebas de software, que permitirá verificar la funcionalidad del analizador de estructuras de navegación aplicando minería de uso Web y minería de estructura Web.
5.2. Hipótesis La hipótesis que se persigue demostrar es que, al crear una herramienta que analice las estructuras de navegación utilizando técnicas de minería de datos sobre un sitio Web, permitirá al administrador del sitio un mejor conocimiento de cómo es utilizado y con estos resultados realizar modificaciones a la estructura del mismo, para mejorar la navegación de los usuarios en el sitio en específico.
5.3. Descripción del plan
5.3.1. Características a ser probadas El presente plan de pruebas contiene la descripción de los casos de prueba definidos con el fin de validar y verificar que el software desarrollado cumple con los requisitos establecidos en el análisis y diseño.
5.3.2. Enfoque Las mediciones de funcionalidad de la aplicación se llevaron a cabo con información de sitios Web que actualmente se encuentren en funcionamiento.
5.3.3. Criterio pasa / no pasa de casos de prueba En la descripción de los casos de prueba, se detallan los resultados esperados para cada uno de los casos. Se considera que una prueba pasó con éxito cuando los resultados esperados coincidieron con los descritos en el caso de prueba.
En caso de que no haya coincidencia en cada prueba, se analizan las causas y se hacen las modificaciones necesarias hasta que se cumplan los resultados esperados.
5.3.4. Criterios de suspensión y requerimientos de reanudación En ningún caso se suspende definitivamente las pruebas. Cada vez que se presente que el caso no pasa una prueba, inmediatamente se procede a evaluar y

Capítulo 5 Pruebas
78
corregir el error. Se permanece realizando la prueba de este caso hasta que ya no presente errores.
5.3.5. Tareas de pruebas Las tareas desarrolladas para preparar y aplicar las pruebas fueron:
Tabla 12. Tareas de pruebas.
Tarea Tarea
precedente Habilidades especiales Responsabilidades
1. Preparación del plan de pruebas
Terminación del análisis y diseño de
la aplicación
Conocimientos sobre minería Web y del IEEE Std. 829
Autor de esta tesis
2. Preparación del diseño del plan de pruebas
Tarea 1 Conocimientos de los elementos y funciones de la aplicación y del IEE Std. 829
Autor de esta tesis
3. Preparación de los casos de prueba
Tarea 2 Conocimiento de aplicaciones de minería Web
Autor de esta tesis
4. Aplicación de pruebas
Tarea 3 Conocimiento del entorno y preparación del sistema
desarrollado para su ejecución
Autor de esta tesis
5. Resolver los incidentes de pruebas
Tarea 4 Conocimiento del lenguaje de programación JEE 5.
Autor de esta tesis
6. Evaluación de resultados
Tarea 4, tarea 5 Conocimiento de las preguntas de investigación, la
hipótesis de prueba y los objetivos de esta tesis
Autor de esta tesis
5.3.6. Liberación de pruebas El cumplimiento de cada caso de prueba con la entrada especificada y la salida esperada es suficiente para la comprobación del objetivo alcanzado y por lo tanto de la aceptación de las pruebas.
5.3.7. Requisitos ambientales Las características de hardware y software sobre las que se desarrollan las pruebas fueron las siguientes:

Capítulo 5 Pruebas
79
Tabla 13. Requisitos de hardware.
Hardware
PC (Equipo servidor) Procesador Intel Pentium 4, 3Ghz. o superior. 1 GB de memoria RAM o superior. 200GB Sistema operativo Windows XP
PC (Equipo cliente) Procesador opcional 1Ghz o superior 512MB de memoria RAM o superior
Sistema operativo opcional
Tabla 14. Requisitos de software.
Software
Herramientas de lado servidor Java EE 5 Java NetBeans como entorno de programación Apache Tomcat 6 como contenedor Web MySQL 5 como Sistema Manejador de Bases de Datos (SMBD)
Herramientas de lado cliente Navegador de internet (por ejemplo: Microsoft Internet Explorer 6, Firefox Mozilla 2, Apple Safari, Opera, Konkeror, etc.) Java Runtime Environment (JRE 5)
5.3.8. Responsabilidades Todas las responsabilidades de las pruebas recaen en el autor de esta tesis.
5.3.9. Riesgos Todas las fallas que se pudieran presentar en el transcurso del desarrollo de las pruebas deberán ir resolviéndose de manera iterativa por el responsable de esta tesis, hasta que la falla no se produzca más.
5.4. Casos de pruebas
5.4.1. Características a probar La siguiente lista define las características que fueron probadas:
Procesamiento de minería de uso Web: Se introducen los archivos de bitácoras y se verifica que el módulo produzca las reglas de asociación.
Procesamiento de minería de estructura Web: Se introduce la URL del sitio Web para recuperar la estructura del sitio, almacenarla en una base de datos y generar un reporte de la estructura del sitio.

Capítulo 5 Pruebas
80
Procesamiento del grafo y visualización de resultados: Este módulo debe generar un grafo y extraer y visualizar los resultados de minería de uso Web y minería de estructura Web, para hacer las recomendaciones.
5.4.2. Pruebas de procesamiento de minería de uso Web PRUEBA-01 Pruebas de procesamiento de minería de uso Web. PRUEBA-01-01 Cargar la información del sitio Web. PRUEBA-01-02 Realizar preprocesamiento. PRUEBA-01-03 Realizar sesionización. PRUEBA-01-04 Ejecutar proceso de minería de uso Web.
5.4.3. Pruebas de procesamiento de minería de estructura Web PRUEBA-02 Pruebas de procesamiento de minería de estructura Web. PRUEBA-02-02 Recolectar la estructura del sitio Web. PRUEBA-02-03 Ejecutar proceso de minería de estructura Web.
5.4.4. Pruebas de procesamiento del grafo y visualización de resultados PRUEBA-03 Pruebas de procesamiento del grafo y visualización de resultados.
PRUEBA-03-01 Procesamiento del grafo y visualización de resultados.
5.5. Procedimiento de pruebas Esta sección contiene la descripción de los procedimientos de pruebas correspondientes a los distintos casos de prueba que conforman este plan. Éstos se encuentran organizados en grupos cuyo objetivo es validar y verificar una determinada funcionalidad de las rutinas de transformación. Cada caso de prueba está dirigido a la validación y verificación de una funcionalidad muy concreta.
Para cada uno de los grupos de pruebas se describe el propósito del grupo de pruebas, el entorno necesario de cada prueba y los distintos conjuntos de pruebas que lo conforman. A su vez, para cada caso de prueba se describe el propósito del caso, el entorno necesario para la ejecución de cada caso, el procedimiento de la prueba y los resultados esperados.
Los casos de prueba dentro de un grupo de pruebas deberán ejecutarse en el orden de su descripción.

Capítulo 5 Pruebas
81
5.5.1. Prueba PRUEBA-01-Pruebas de procesamiento de minería de uso Web
5.5.1.1. Propósito Verificar que el módulo realizado cumpla con los requerimientos establecidos de minería de uso Web.
5.5.1.2. Entorno de prueba La ejecución de los casos de prueba contenidos en este grupo se efectuó en un entorno con los siguientes elementos:
Equipo servidor.
Equipo cliente.
5.5.1.3. Prueba PRUEBA-01-01 – Cargar la información del sitio Web
Propósito Comprobar que el módulo creado para agregar los archivos de bitácora y la dirección URL funcione correctamente.
Entorno de prueba
Éste es el primer proceso del análisis del sitio Web.
Proceso 1. Seleccionar la ubicación de los archivos de bitácora. Escribir la
dirección URL del sitio Web y pulsar agregar. Resultado esperado
Se verifica que el sistema cargue correctamente los archivos de bitácora y reconocer si éste es de alguno de los formatos soportados. Asimismo el sistema debe validar la dirección URL del sitio Web y almacenarla para su uso posterior.
5.5.1.4. Prueba PRUEBA-01-02 – Realizar preprocesamiento Propósito
Comprobar que el módulo creado para hacer preprocesamiento de los datos de la bitácora funcione correctamente.

Capítulo 5 Pruebas
82
Entorno de prueba La prueba tiene como prerrequisito haber cargado los archivos de bitácora.
Proceso 1. Seleccionar las extensiones de los documentos Web irrelevantes
que se desea eliminar de las peticiones de la bitácora.
Resultado esperado El sistema debe realizar el preprocesado del archivo de bitácora correctamente, y almacenarlos en la base de datos.
5.5.1.5. Prueba PRUEBA-01-03 – Realizar sesionización
Propósito Comprobar que el módulo creado para identificar las sesiones del archivo de bitácora funciona correctamente. Esta prueba se compone de una prueba para cada opción de sesionización.
Entorno de prueba La prueba tiene como prerrequisito haber cargado el archivo de bitácora.
Proceso
1. Seleccionar alguno de los métodos de sesionización implementados: a) Minutos, b) Peticiones, c) Heurística.
a. Minutos: Se debe introducir un valor numérico que indique el umbral máximo de minutos para que una sesión de usuario sea considerada como válida.
b. Peticiones: Se debe introducir un valor numérico que indique el umbral máximo de peticiones para que una sesión de usuario sea considerada como válida.
c. Heurística: No es necesario introducir parámetros.
Resultado esperado El sistema debe sesionizar y almacenar las sesiones de usuario en la base de datos. Asimismo deben llenarse las tablas de catalogo de clientes y páginas.
5.5.1.6. Prueba PRUEBA-01-04 - Ejecutar proceso de minería de uso Web
Propósito Comprobar que el módulo implementado extraiga las reglas de asociación mediante minería de uso Web.

Capítulo 5 Pruebas
83
Entorno de prueba Esta prueba tiene como prerrequisito haber cargado el archivo de bitácora, estar preprocesado y haber identificado las sesiones de usuario.
Proceso
1. Proporcionar los valores mínimos de soporte y confianza para iniciar el proceso de minería de datos.
Resultado esperado
El módulo debe identificar correctamente las reglas de asociación que cumplan con los valores de soporte y confianza mínimos proporcionados, y almacenarlos en la base de datos.
5.5.2. Prueba PRUEBA-02-Pruebas de procesamiento de minería de estructura Web
5.5.2.1. Propósito
Verificar que el módulo realizado cumpla con los requerimientos establecidos de minería de estructura Web.
5.5.2.2. Entorno de prueba La ejecución de los casos de prueba contenidos en este grupo se efectuó en un entorno con los siguientes elementos:
Equipo servidor.
Equipo cliente.
5.5.2.3. Prueba PRUEBA-02-01 – Recolectar la estructura del sitio Web Propósito
Comprobar que el módulo de recolección de la estructura del sitio Web funcione correctamente.
Entorno de prueba La prueba debe llevarse a cabo en un entorno con los equipos descritos anteriormente, con conexión a internet.
Proceso
1. La URL del usuario ya fue almacenada anteriormente, el usuario sólo debe iniciar el proceso.

Capítulo 5 Pruebas
84
Resultado esperado La estructura del sitio debe ser almacenarse en la BD del sistema.
5.5.2.4. Prueba PRUEBA-02-02 – Ejecutar proceso de minería de estructura Web
Propósito
Comprobar que el módulo del proceso de minería de estructura Web presente un reporte de la estructura del sitio.
Entorno de prueba Esta prueba tiene como prerrequisito tener almacenada la estructura del sitio Web en la base de datos.
Proceso
1. Esta prueba no se inicia por una acción del usuario. Comienza automáticamente al terminar de almacenar la estructura del sitio Web.
Resultado esperado
Reporte del análisis del sitio Web con información que ha sido detallada en la etapa de diseño.
5.5.3. Prueba PRUEBA-04-Pruebas de procesamiento y visualización del grafo de resultados
5.5.3.1. Propósito Verificar que el módulo realizado cumpla con los requerimientos establecidos procesamiento y visualización del grafo de resultados.
5.5.3.2. Entorno de prueba La ejecución de los casos de prueba contenidos en este grupo se efectuó en un entorno con los siguientes elementos:
Equipo servidor.
Equipo cliente. La prueba podrá realizarse únicamente teniendo los resultados de las pruebas 101,102 y 103.

Capítulo 5 Pruebas
85
5.5.3.3. Prueba PRUEBA-04-01 Prueba de procesamiento y visualización del grafo de resultados
Propósito Esta prueba tiene como propósito transformar la información de la estructura del sitio Web en un grafo anexando la información obtenida del analizador de estructuras de navegación.
Entorno de prueba
La prueba debe contar como prerrequisito haber realizado el módulo de minería de uso Web y el módulo de minería de estructura Web.
Proceso
1. La prueba se llevará a cabo automáticamente después de haber concluido el procesamiento de minería de uso y minería de estructura Web.
Resultado esperado El grafo visualizado en pantalla con la información del análisis de estructuras de navegación.
5.4. Resultados de pruebas
Tabla 15. Caso de prueba PRUEBA-01-01.
Caso de prueba: PRUEBA-01-01. Cargar la información del sitio Web Resultado: OK Se seleccionó cargar los archivos del mes de febrero y la URL
http://www.cenidet.edu.mx.
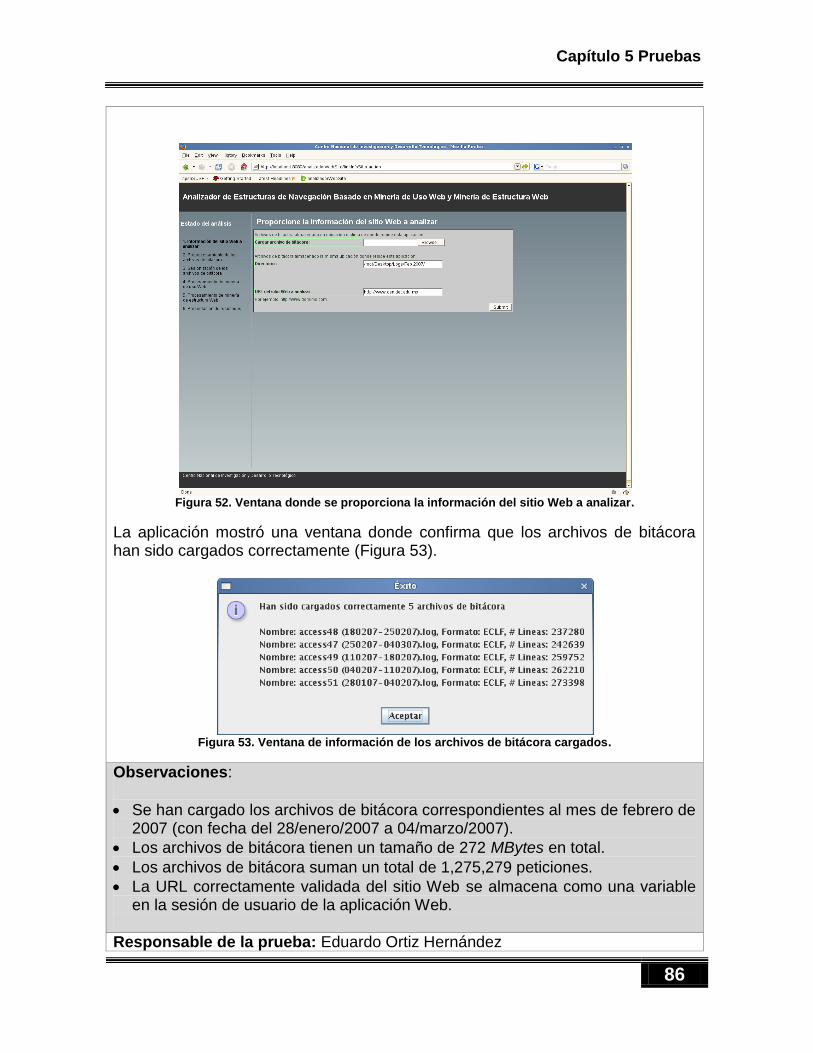
Capítulo 5 Pruebas
86
Figura 52. Ventana donde se proporciona la información del sitio Web a analizar.
La aplicación mostró una ventana donde confirma que los archivos de bitácora han sido cargados correctamente (Figura 53).
Figura 53. Ventana de información de los archivos de bitácora cargados.
Observaciones:
Se han cargado los archivos de bitácora correspondientes al mes de febrero de 2007 (con fecha del 28/enero/2007 a 04/marzo/2007).
Los archivos de bitácora tienen un tamaño de 272 MBytes en total.
Los archivos de bitácora suman un total de 1,275,279 peticiones.
La URL correctamente validada del sitio Web se almacena como una variable en la sesión de usuario de la aplicación Web.
Responsable de la prueba: Eduardo Ortiz Hernández

Capítulo 5 Pruebas
87
Tabla 16. Caso de prueba PRUEBA-01-02.
Caso de prueba: PRUEBA-01-02. Realizar preprocesamiento Resultado: OK La interfaz de usuario de preprocesamiento se muestra al usuario. Ella contiene dos listas: Extensiones de archivos permitidos y extensiones de archivos a eliminar. Mediante botones de acción incluidos, el usuario puede mover un elemento de una lista a la otra. Al finalizar, pulsa el botón Enviar.
Figura 54. Ventana de selección de los tipos de documentos Web a filtrar.
Al finalizar la fase de preprocesamiento, las peticiones filtradas son almacenadas en la tabla “logs”.

Capítulo 5 Pruebas
88
Figura 55. Peticiones almacenadas en la BD
Observaciones:
Los 5 archivos logs de entrada contienen 1,275,279 líneas en total.
Se han filtrado las peticiones con extensiones: „gif‟, „jpg‟, „ico‟, „png‟, „bmp‟, „dib‟, „jpeg‟, ‟jpe‟, „jfif‟, „tif‟, ‟tiff‟, „mp3‟, „css,‟, „cab‟, „swf‟.
Se han obtenido 206,718 peticiones preprocesadas (16.2 % de la entrada original).
El proceso duró 2:45 segundos.
La Figura 55 muestra un ejemplo con las primeras 10 peticiones almacenadas en la base de datos.
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 17. Caso de prueba PRUEBA-01-02 (sesionización por número de peticiones).
Caso de prueba: PRUEBA-01-02. Realizar sesionización (por número de peticiones) Resultado: OK
La interfaz se muestra al usuario para que seleccione un algoritmo de sesionización (en este caso la selección fue por número máximo de peticiones).
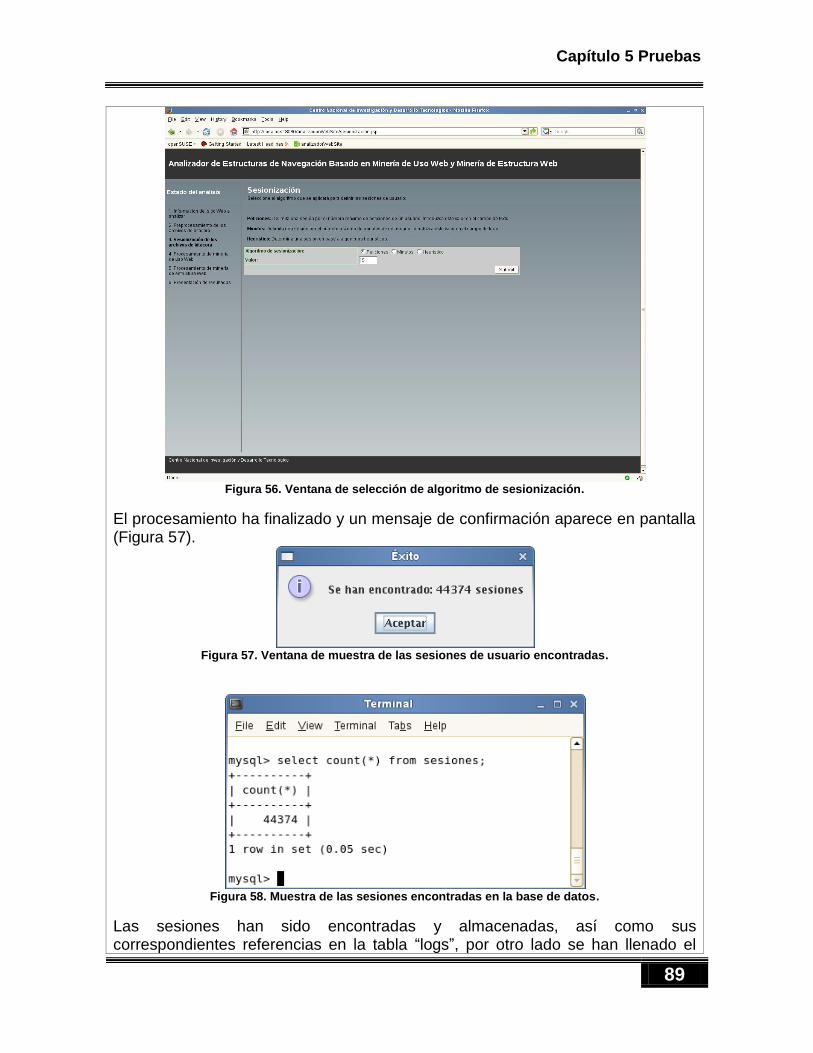
Capítulo 5 Pruebas
89
Figura 56. Ventana de selección de algoritmo de sesionización.
El procesamiento ha finalizado y un mensaje de confirmación aparece en pantalla (Figura 57).
Figura 57. Ventana de muestra de las sesiones de usuario encontradas.
Figura 58. Muestra de las sesiones encontradas en la base de datos.
Las sesiones han sido encontradas y almacenadas, así como sus correspondientes referencias en la tabla “logs”, por otro lado se han llenado el
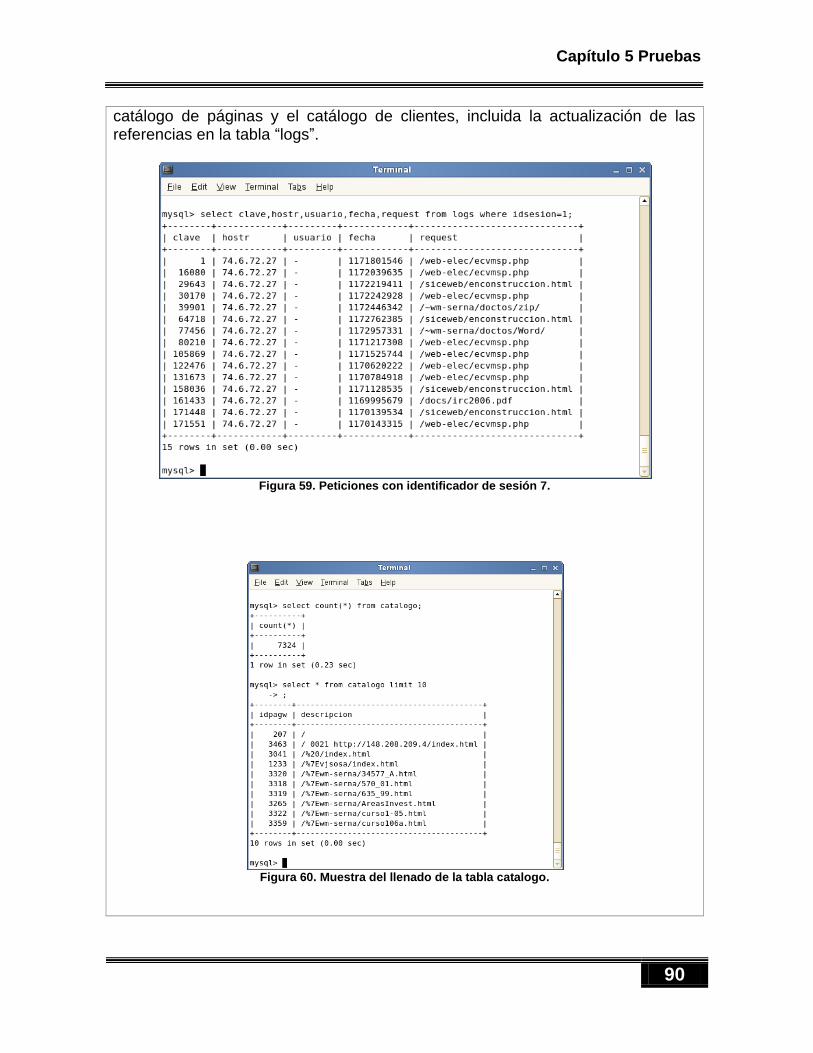
Capítulo 5 Pruebas
90
catálogo de páginas y el catálogo de clientes, incluida la actualización de las referencias en la tabla “logs”.
Figura 59. Peticiones con identificador de sesión 7.
Figura 60. Muestra del llenado de la tabla catalogo.

Capítulo 5 Pruebas
91
Figura 61. Muestra del llenado de la tabla cliente.
Observaciones:
El algoritmo de sesionización fue definido por un número máximo de 15 peticiones.
El número de sesiones encontradas fue de 44,374.
El tiempo de procesamiento fue de 5:51 segundos.
La tabla “catalogo” (Figura 66) fue llenada satisfactoriamente, encontrándose un total de 7,324 distintos documentos.
La tabla “clientes” (Figura 67) fue llenada satisfactoriamente, encontrándose un total de 37,763 clientes (direcciones IP distintas).
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 18. Caso de prueba PRUEBA-01-02 (sesionización por minutos).
Caso de prueba: PRUEBA-01-02. Realizar sesionización (por minutos) Resultado: OK
La interfaz se muestra al usuario para que seleccione un algoritmo de sesionización (en este caso la selección fue por tiempo máximo).

Capítulo 5 Pruebas
92
Figura 62. Ventana de selección de algoritmo de sesionización.
El procesamiento ha finalizado y un mensaje de confirmación aparece en pantalla.
Figura 63. Ventana de muestra de las sesiones de usuario encontradas.
Figura 64. Muestra de las sesiones encontradas en la base de datos.
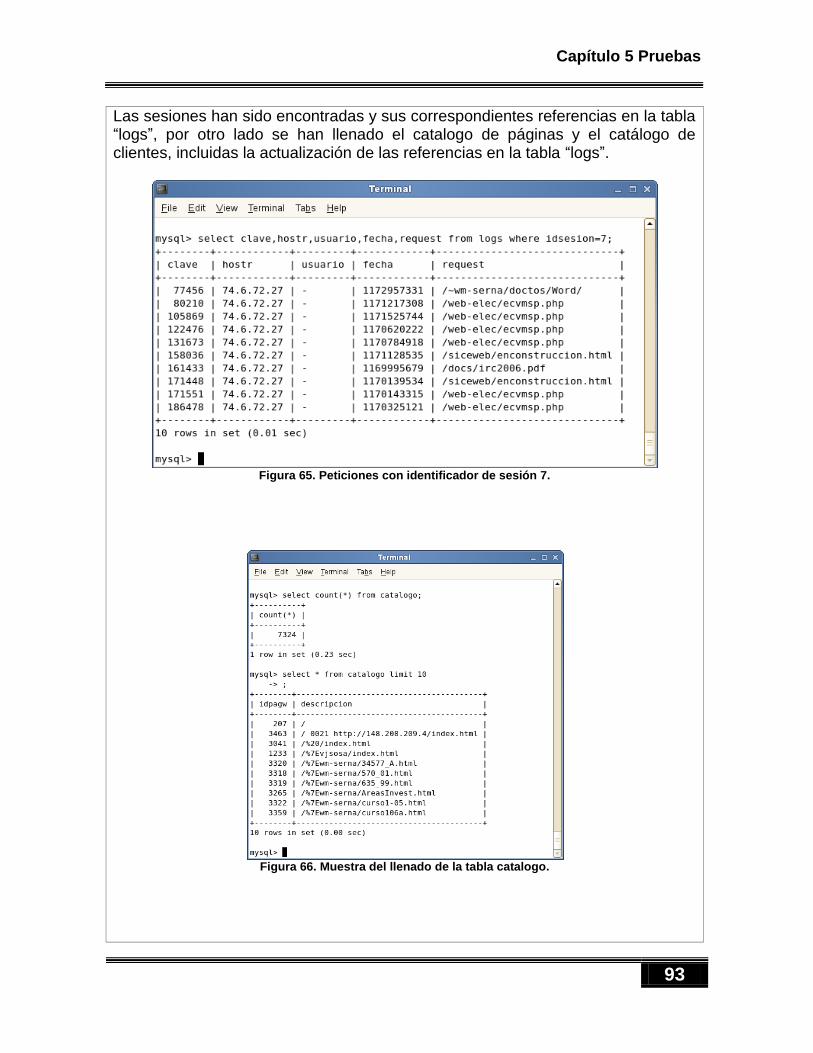
Capítulo 5 Pruebas
93
Las sesiones han sido encontradas y sus correspondientes referencias en la tabla “logs”, por otro lado se han llenado el catalogo de páginas y el catálogo de clientes, incluidas la actualización de las referencias en la tabla “logs”.
Figura 65. Peticiones con identificador de sesión 7.
Figura 66. Muestra del llenado de la tabla catalogo.

Capítulo 5 Pruebas
94
Figura 67. Muestra del llenado de la tabla cliente.
Observaciones:
El algoritmo de sesionización fue definido por un número máximo de 10 minutos.
El número de sesiones encontradas fue de 57,145.
El tiempo de procesamiento fue de 4:48 segundos.
La tabla “catalogo” (Figura 66) fue llenada satisfactoriamente, encontrándose un total de 7,324 distintos documentos.
La tabla de “clientes” (Figura 67) fue llenada satisfactoriamente, encontrándose un total de 37,763 clientes (direcciones IP distintas).
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 19. Caso de prueba PRUEBA-01-02 (sesionización por heurística).
Caso de prueba: PRUEBA-01-02. Realizar sesionización (por heurística) Resultado: OK
La interfaz se muestra al usuario para que seleccione un algoritmo de sesionización (en este caso la selección fue por algoritmo heurístico).
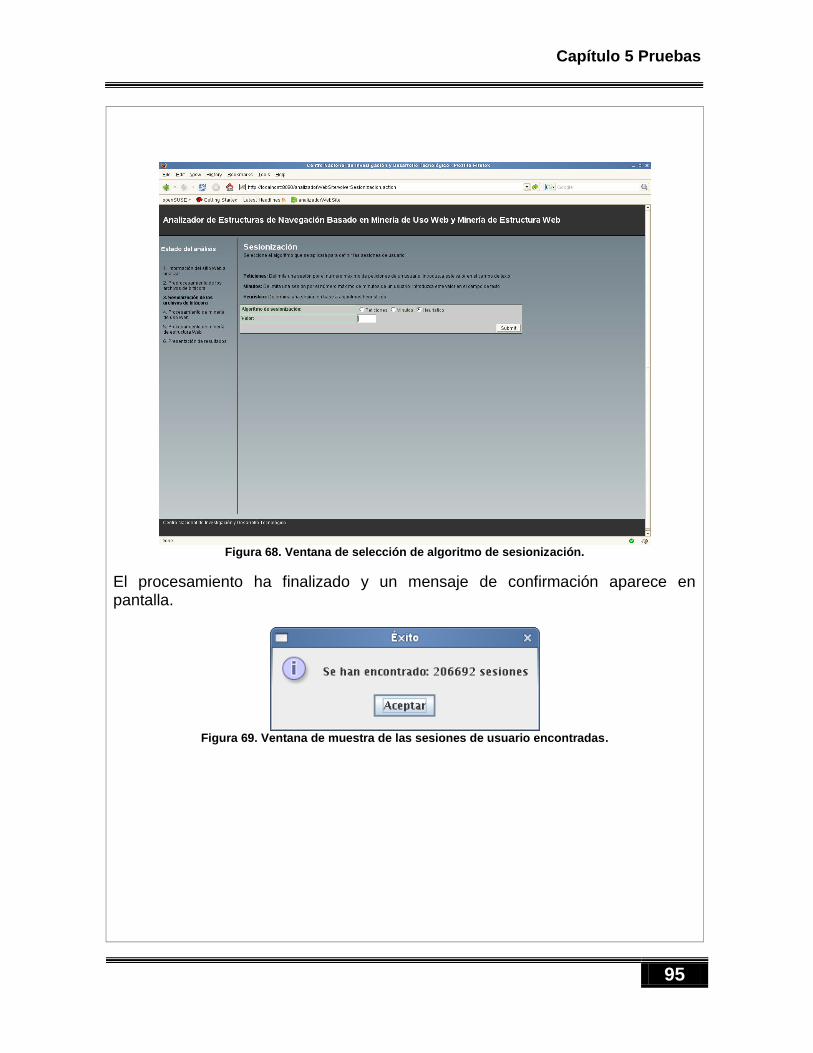
Capítulo 5 Pruebas
95
Figura 68. Ventana de selección de algoritmo de sesionización.
El procesamiento ha finalizado y un mensaje de confirmación aparece en pantalla.
Figura 69. Ventana de muestra de las sesiones de usuario encontradas.
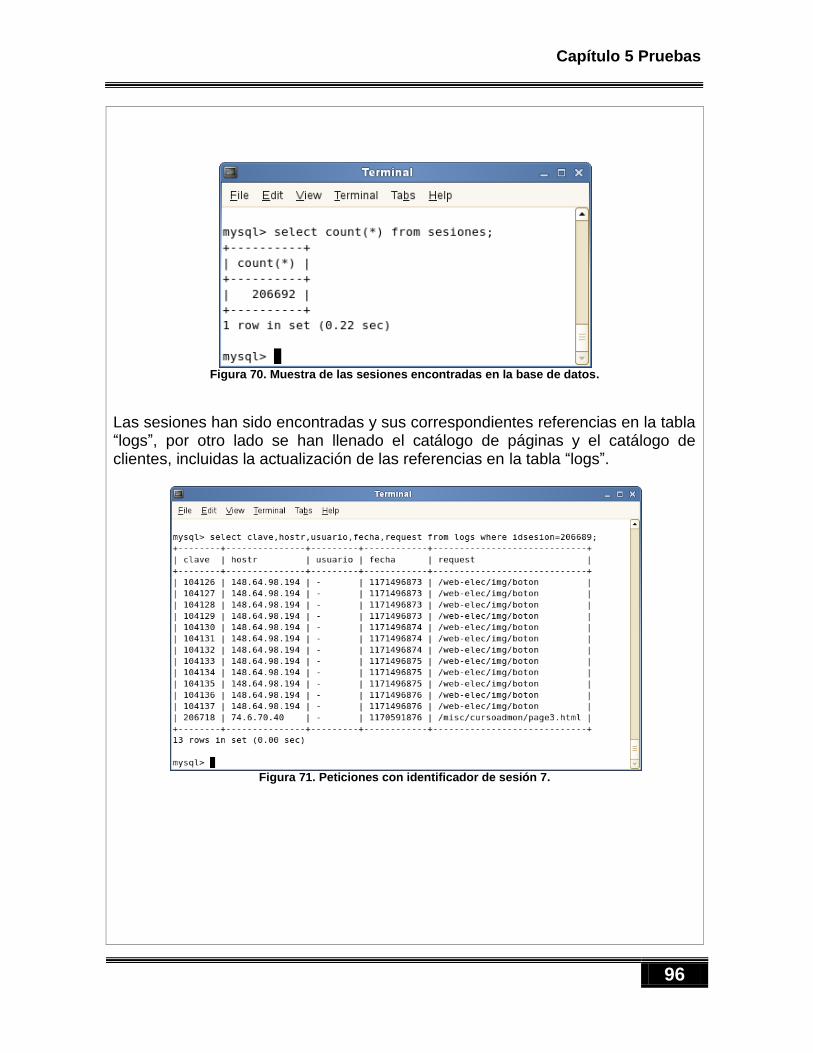
Capítulo 5 Pruebas
96
Figura 70. Muestra de las sesiones encontradas en la base de datos.
Las sesiones han sido encontradas y sus correspondientes referencias en la tabla “logs”, por otro lado se han llenado el catálogo de páginas y el catálogo de clientes, incluidas la actualización de las referencias en la tabla “logs”.
Figura 71. Peticiones con identificador de sesión 7.

Capítulo 5 Pruebas
97
Figura 72. Muestra del llenado de la tabla catalogo.
Figura 73. Muestra del llenado de la tabla cliente.
Observaciones:
El algoritmo de sesionización fue por método heurístico.
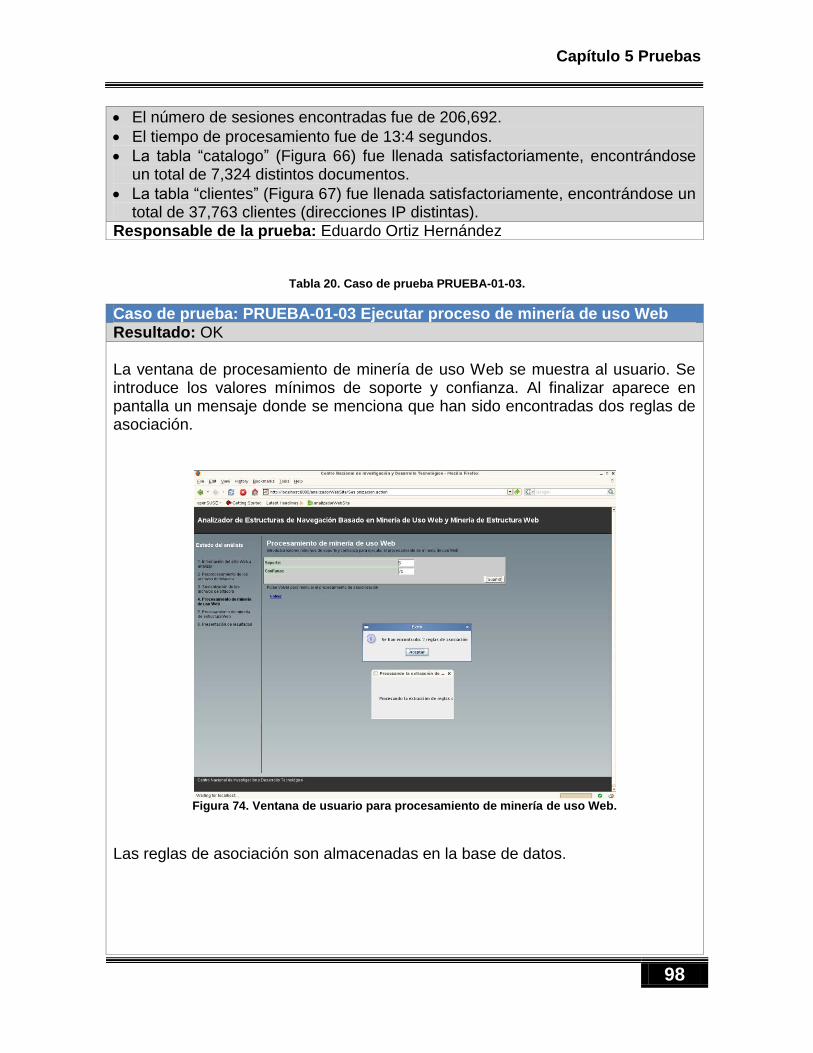
Capítulo 5 Pruebas
98
El número de sesiones encontradas fue de 206,692.
El tiempo de procesamiento fue de 13:4 segundos.
La tabla “catalogo” (Figura 66) fue llenada satisfactoriamente, encontrándose un total de 7,324 distintos documentos.
La tabla “clientes” (Figura 67) fue llenada satisfactoriamente, encontrándose un total de 37,763 clientes (direcciones IP distintas).
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 20. Caso de prueba PRUEBA-01-03.
Caso de prueba: PRUEBA-01-03 Ejecutar proceso de minería de uso Web Resultado: OK La ventana de procesamiento de minería de uso Web se muestra al usuario. Se introduce los valores mínimos de soporte y confianza. Al finalizar aparece en pantalla un mensaje donde se menciona que han sido encontradas dos reglas de asociación.
Figura 74. Ventana de usuario para procesamiento de minería de uso Web.
Las reglas de asociación son almacenadas en la base de datos.

Capítulo 5 Pruebas
99
Figura 75. Reglas de asociación almacenadas en la tabla reglas.
Figura 76. Elementos antecedentes de las reglas.
Figura 77. Elementos consecuentes de las reglas.
Observaciones:
Las sesiones utilizadas como entradas para este caso de prueba fueron las resultantes del algoritmo de sesionización por un máximo de 10 minutos.
Los parámetros introducidos para extraer las reglas son: 5% de soporte 70% de confianza
Fueron encontradas 2 reglas de asociación.
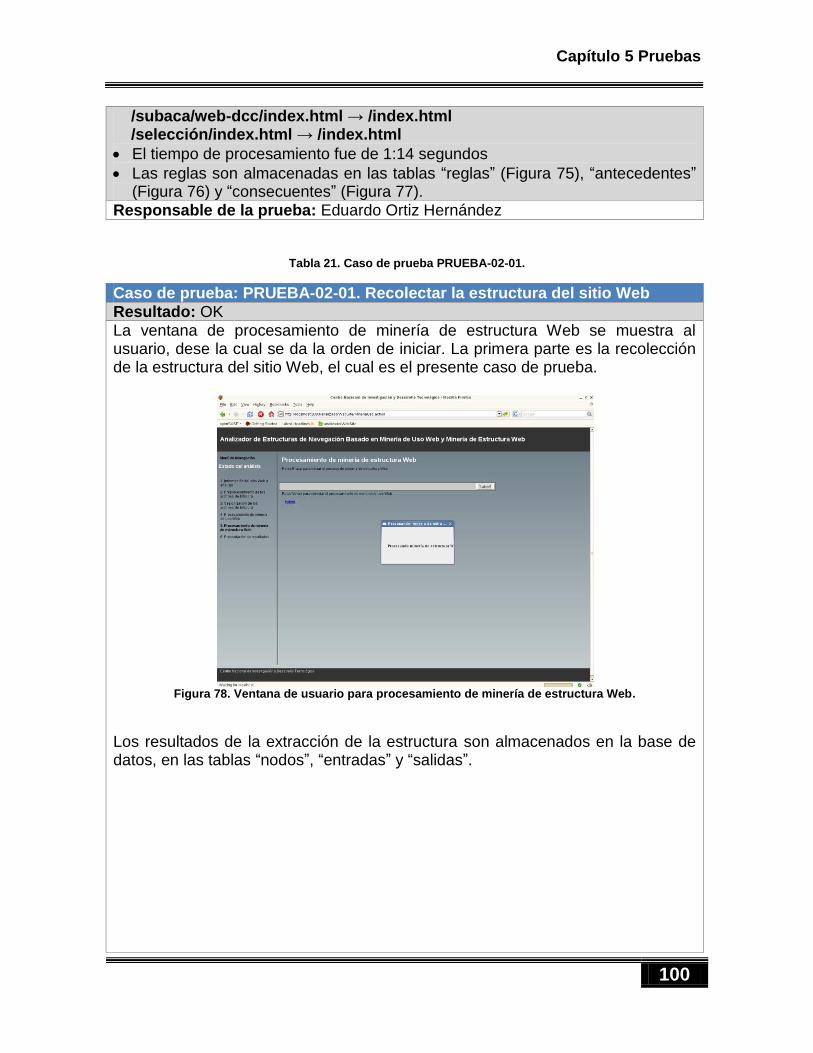
Capítulo 5 Pruebas
100
/subaca/web-dcc/index.html → /index.html /selección/index.html → /index.html
El tiempo de procesamiento fue de 1:14 segundos
Las reglas son almacenadas en las tablas “reglas” (Figura 75), “antecedentes” (Figura 76) y “consecuentes” (Figura 77).
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 21. Caso de prueba PRUEBA-02-01.
Caso de prueba: PRUEBA-02-01. Recolectar la estructura del sitio Web
Resultado: OK La ventana de procesamiento de minería de estructura Web se muestra al usuario, dese la cual se da la orden de iniciar. La primera parte es la recolección de la estructura del sitio Web, el cual es el presente caso de prueba.
Figura 78. Ventana de usuario para procesamiento de minería de estructura Web.
Los resultados de la extracción de la estructura son almacenados en la base de datos, en las tablas “nodos”, “entradas” y “salidas”.

Capítulo 5 Pruebas
101
Figura 79. Muestra del llenado de la tabla nodos.
En la tabla nodos se almacena un catálogo de cada nodo que ha sido encontrado en el sitio Web con un identificador.
Figura 80. Muestra del llenado del la tabla entradas.
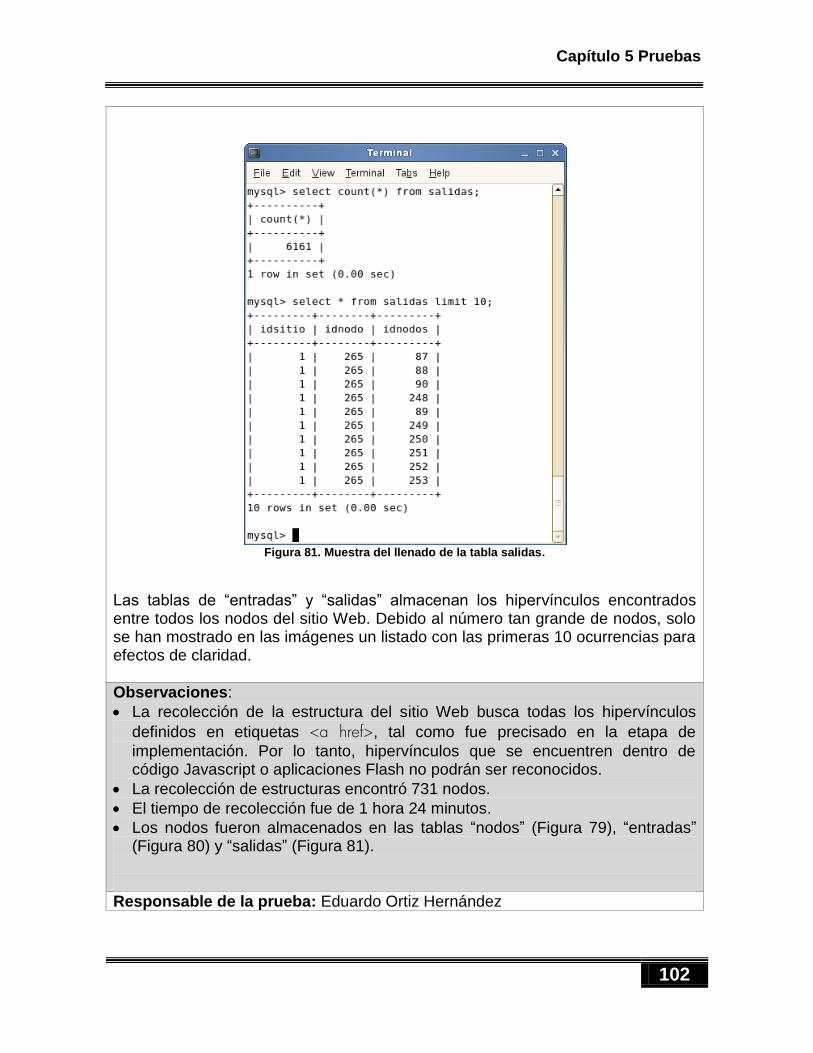
Capítulo 5 Pruebas
102
Figura 81. Muestra del llenado de la tabla salidas.
Las tablas de “entradas” y “salidas” almacenan los hipervínculos encontrados entre todos los nodos del sitio Web. Debido al número tan grande de nodos, solo se han mostrado en las imágenes un listado con las primeras 10 ocurrencias para efectos de claridad. Observaciones:
La recolección de la estructura del sitio Web busca todas los hipervínculos
definidos en etiquetas <a href>, tal como fue precisado en la etapa de
implementación. Por lo tanto, hipervínculos que se encuentren dentro de código Javascript o aplicaciones Flash no podrán ser reconocidos.
La recolección de estructuras encontró 731 nodos.
El tiempo de recolección fue de 1 hora 24 minutos.
Los nodos fueron almacenados en las tablas “nodos” (Figura 79), “entradas” (Figura 80) y “salidas” (Figura 81).
Responsable de la prueba: Eduardo Ortiz Hernández

Capítulo 5 Pruebas
103
Tabla 22. Caso de prueba PRUEBA-02-02.
Caso de prueba: PRUEBA-02-02. Ejecutar proceso de minería de estructura Web Resultado: OK Este caso de prueba comienza al finalizar la recolección de la estructura del sitio Web. Los campos “gradoglobalessalida”, “gradolocalesentrada” y “gradolocalessalida” de la tabla “nodos” son actualizados.
Figura 82. Ventana de llenado de los campos gradoglobalessalida, gradolocalesentrada,
gradolocalessalida de la tabla nodos.
Mientras que la tabla “caminosinalcanzables” también es llenada con las ocurrencias encontradas, y se puede ver detalladamente en la Tabla 23.
Figura 83. Muestra del llenado de la tabla “caminosinalcanzables”.
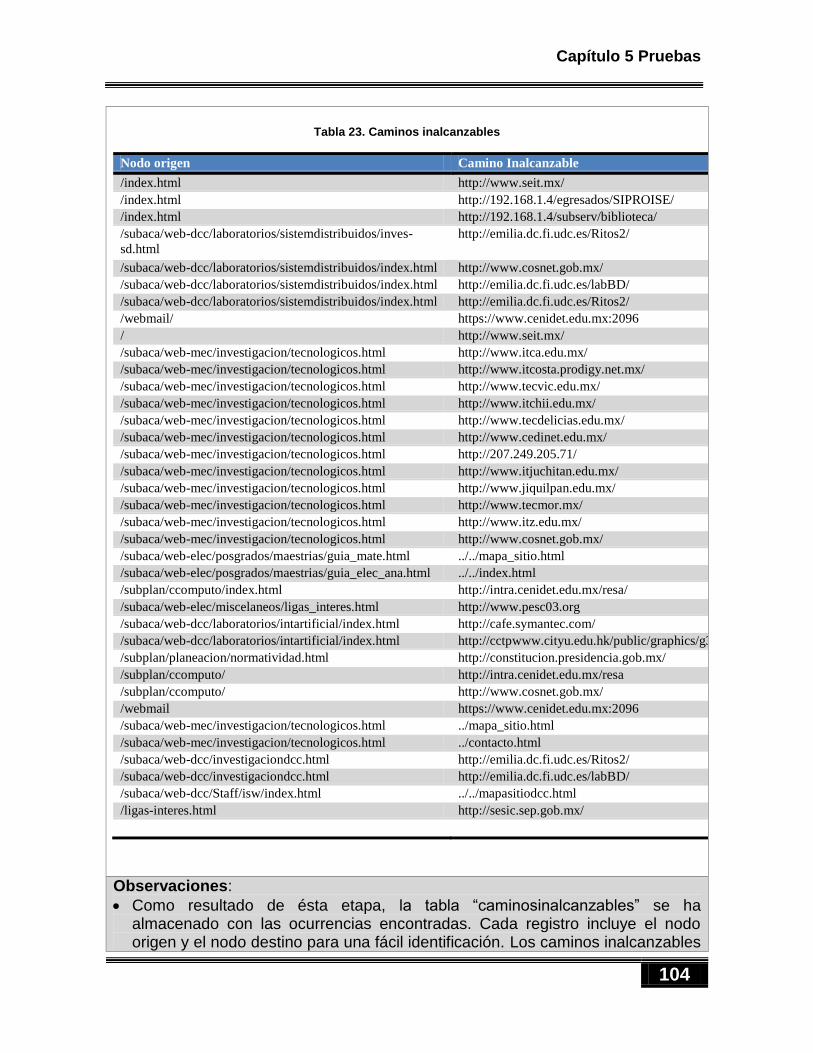
Capítulo 5 Pruebas
104
Tabla 23. Caminos inalcanzables
Nodo origen Camino Inalcanzable
/index.html http://www.seit.mx/
/index.html http://192.168.1.4/egresados/SIPROISE/
/index.html http://192.168.1.4/subserv/biblioteca/
/subaca/web-dcc/laboratorios/sistemdistribuidos/inves-
sd.html
http://emilia.dc.fi.udc.es/Ritos2/
/subaca/web-dcc/laboratorios/sistemdistribuidos/index.html http://www.cosnet.gob.mx/
/subaca/web-dcc/laboratorios/sistemdistribuidos/index.html http://emilia.dc.fi.udc.es/labBD/
/subaca/web-dcc/laboratorios/sistemdistribuidos/index.html http://emilia.dc.fi.udc.es/Ritos2/
/webmail/ https://www.cenidet.edu.mx:2096
/ http://www.seit.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.itca.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.itcosta.prodigy.net.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.tecvic.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.itchii.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.tecdelicias.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.cedinet.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://207.249.205.71/
/subaca/web-mec/investigacion/tecnologicos.html http://www.itjuchitan.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.jiquilpan.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.tecmor.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.itz.edu.mx/
/subaca/web-mec/investigacion/tecnologicos.html http://www.cosnet.gob.mx/
/subaca/web-elec/posgrados/maestrias/guia_mate.html ../../mapa_sitio.html
/subaca/web-elec/posgrados/maestrias/guia_elec_ana.html ../../index.html
/subplan/ccomputo/index.html http://intra.cenidet.edu.mx/resa/
/subaca/web-elec/miscelaneos/ligas_interes.html http://www.pesc03.org
/subaca/web-dcc/laboratorios/intartificial/index.html http://cafe.symantec.com/
/subaca/web-dcc/laboratorios/intartificial/index.html http://cctpwww.cityu.edu.hk/public/graphics/g3_camera.html
/subplan/planeacion/normatividad.html http://constitucion.presidencia.gob.mx/
/subplan/ccomputo/ http://intra.cenidet.edu.mx/resa
/subplan/ccomputo/ http://www.cosnet.gob.mx/
/webmail https://www.cenidet.edu.mx:2096
/subaca/web-mec/investigacion/tecnologicos.html ../mapa_sitio.html
/subaca/web-mec/investigacion/tecnologicos.html ../contacto.html
/subaca/web-dcc/investigaciondcc.html http://emilia.dc.fi.udc.es/Ritos2/
/subaca/web-dcc/investigaciondcc.html http://emilia.dc.fi.udc.es/labBD/
/subaca/web-dcc/Staff/isw/index.html ../../mapasitiodcc.html
/ligas-interes.html http://sesic.sep.gob.mx/
Observaciones:
Como resultado de ésta etapa, la tabla “caminosinalcanzables” se ha almacenado con las ocurrencias encontradas. Cada registro incluye el nodo origen y el nodo destino para una fácil identificación. Los caminos inalcanzables
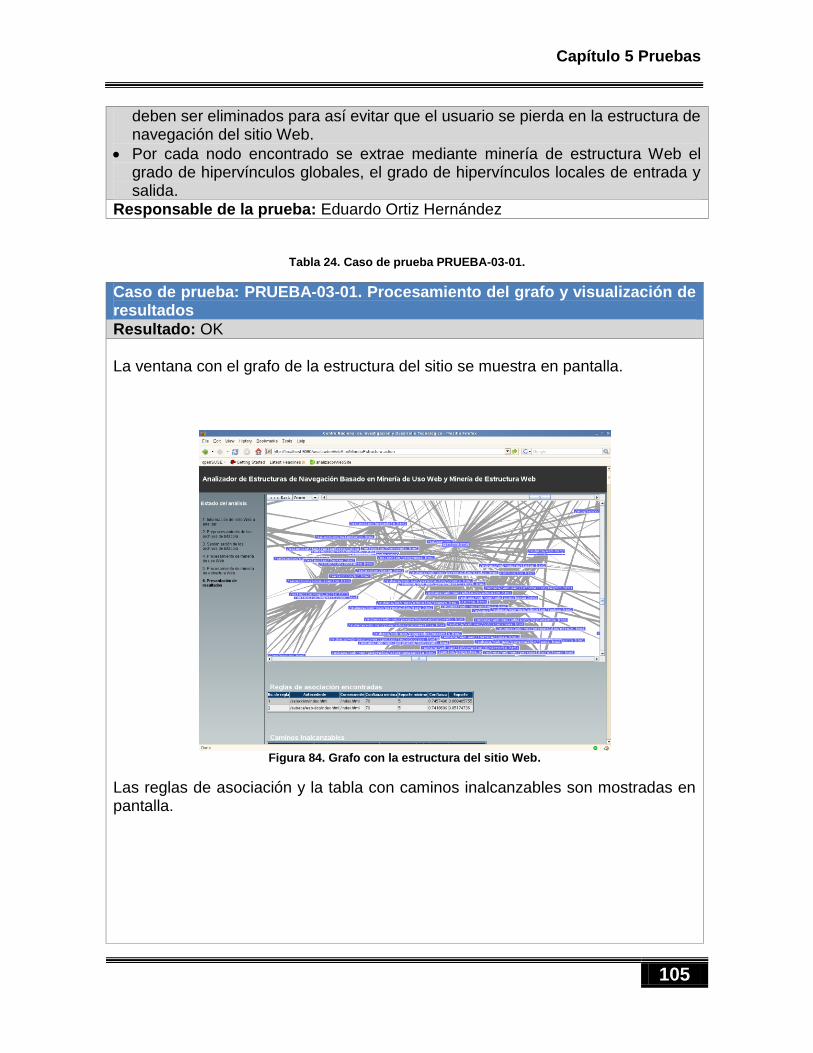
Capítulo 5 Pruebas
105
deben ser eliminados para así evitar que el usuario se pierda en la estructura de navegación del sitio Web.
Por cada nodo encontrado se extrae mediante minería de estructura Web el grado de hipervínculos globales, el grado de hipervínculos locales de entrada y salida.
Responsable de la prueba: Eduardo Ortiz Hernández
Tabla 24. Caso de prueba PRUEBA-03-01.
Caso de prueba: PRUEBA-03-01. Procesamiento del grafo y visualización de resultados
Resultado: OK La ventana con el grafo de la estructura del sitio se muestra en pantalla.
Figura 84. Grafo con la estructura del sitio Web.
Las reglas de asociación y la tabla con caminos inalcanzables son mostradas en pantalla.

Capítulo 5 Pruebas
106
Figura 85. Tablas con las reglas de asociación encontradas y los caminos inalcanzables.
La tabla con un reporte estructural del sitio se muestra en pantalla. Contiene los siguientes campos:
Página
Grado global de salida
Grado local de entrada
Grado local de salida.
Figura 86. Tabla con el reporte estructural del sitio.

Capítulo 5 Pruebas
107
La tabla se puede ordenar de forma ascendente o descendente por cualquiera de estos campos con hacer clic en el nombre de éste, lo que permite facilitar la lectura de resultados. Observaciones:
El grafo de la estructura del sitio Web visualiza los 731 nodos, por lo cual resulta un grafo bastante extenso.
Para la codificación de la información mostrada en la tabla “Reporte estructural del sitio” incorporó una biblioteca denominada DisplayTag, con la cual se incluye la característica que la tabla pueda ordenarse de mayor a menor o viceversa, permitiendo que el usuario de la aplicación tenga una mejor visualización, solo haciendo clic sobre el título de la columna deseada.
Responsable de la prueba: Eduardo Ortiz Hernández
5.3. Análisis de resultados Este apartado muestra el análisis de los resultados obtenidos de acuerdo al plan de pruebas. Éstas fueron realizadas al sitio de CENIDET (http://www.cenidet.edu.mx) y utilizando archivos log correspondientes al mes de febrero de 2007.
Como primera parte del análisis está la etapa de preprocesamiento. De ella se obtienen las peticiones filtradas de los archivos log, eliminando aquellas extensiones seleccionadas por el usuario. Las 206,718 peticiones que se obtienen como resultado final representan a aquellas que son páginas Web y por lo tanto es información útil en los procesamientos posteriores.
Posteriormente continúa la etapa de sesionización. De acuerdo a lo definido
en el capítulo de análisis y diseño, puede ser efectuada en base a 3 algoritmos (por número máximo de peticiones, por número máximo de minutos y por método heurístico).
Las pruebas fueron realizadas para cada uno de éstas opciones de
sesionización (en la Tabla 25 se detalla cada una), con el valor proporcionado por el usuario y el número de sesiones encontradas. Como puede verse, el algoritmo heurístico generó el mayor número de sesiones (206,692) sin embargo, al comparar con el número total de peticiones (206,718) se puede observar una relación muy cercana al uno a uno; con ello se concluye que la mayoría de las sesiones son de una sola petición, y estas no son útiles para el procesamiento de minería. Por otro lado, los otros algoritmos de sesionización generaron un menor número de sesiones, pero con una media más alta de peticiones por sesión, 4.65

Capítulo 5 Pruebas
108
para el algoritmo de número máximo de peticiones por sesión y 3.61 para el algoritmo de número máximo de minutos. En ésta prueba éstos resultados son de mayor utilidad para el procesamiento de minería de uso Web.
Tabla 25. Pruebas de sesionización.
Método de sesionización Valor proporcionado por el usuario
Número de sesiones encontradas
Número máximo de peticiones
15 44,374
Número máximo de minutos 10 57,145 Heurístico - 206,692
Ahora continúa la fase de procesamiento de minería de uso Web. Para ello el algoritmo A-priori para la extracción de reglas de asociación requiere de un conjunto de elementos que hayan sido sesionizados y valores mínimos de soporte y confianza. Las sesiones utilizadas son las generadas por el algoritmo de número máximo de peticiones y los valores de soporte y confianza fueron los siguientes: Soporte mínimo: 5% Confianza mínima: 70%
Estos valores se han ajustado de acuerdo a los valores típicos recomendados en la aplicación de éste algoritmo de extracción de reglas de asociación, producto de los trabajos de investigación que se han hecho en este rubro y se encuentran detallados en el capítulo 3 de análisis y diseño.
Las reglas generadas fueron las siguientes: /subaca/web-dcc/index.html → /index.html (Departamento de Ciencias de la Computación → homepage) /selección/index.html → /index.html (Proceso de selección → homepage)
Como puede verse, una de las reglas encontradas tiene relación con el proceso de selección de aspirantes, esto es porque en el periodo de enero a mayo de cada año se realiza la selección de los aspirantes a los programas de maestría en CENIDET.
Como parte de los resultados obtenidos por la parte de minería de estructura Web. En la primera fase, la de recolección de las páginas del sitio se obtuvo una estructura de 731 nodos. Estos incluyen únicamente a páginas Web y eliminan a cualquier otro contenido como imágenes, archivos de audio, entre otros, de manera similar a la fase de preprocesamiento en minería de uso Web.

Capítulo 5 Pruebas
109
Continuando la recolección de la estructura del sitio, se realiza el procesamiento de minería de estructura Web. De éste se obtiene cuatro puntos que han sido especificados en la etapa de análisis y diseño, y se detalla en la Tabla 26.
Tabla 26. Información generada del procesamiento de minería de estructura Web.
Información estructural Descripción
Grado de hipervínculos globales de salida para cada nodo
Visibilidad de la página con páginas de otros sitios Web.
Grado de hipervínculos locales de entrada y salida para cada nodo
Mide la conectividad entre las páginas que conforman el sitio Web. Una página con mayor grado de hipervínculos de entrada y salida es una página con más visibilidad al usuario. Una página con menor grado de hipervínculos de entrada y salida es una página con menos visibilidad al usuario.
Página con camino inalcanzable Es una página Web que no puede ser accedida. Los caminos inalcanzables deben ser detectados y mostrados al usuario para que sean removidos.
De acuerdo al punto de hipervínculos globales de salida, se encontró un
34.19% de nodos con grado cero. Mientras que los caminos inalcanzables encontrados (37) representan un 5.06% de la totalidad de nodos. Las recomendaciones con respecto a la estructura Web están orientadas a eliminar estos caminos inalcanzables, y mejorar la conectividad de los nodos que componen el sitio Web equilibrando los valores de grado de hipervínculos locales de entrada y salida.

110
CAPÍTULO 6 CONCLUSIONES

Capítulo 6 Conclusiones
111
6.1. Conclusiones Durante el desarrollo de este trabajo de investigación, el tópico principal fue el estudio de las estructuras de navegación, las cuales definen la organización de las páginas de un sitio Web, en base a los hipervínculos que contienen cada una de ellas. La estructura de navegación permite que un usuario que accede al sitio pueda trasladarse entre las páginas. El enfoque que se le da a este trabajo está apoyado en técnicas de minería de datos.
Mediante la minería de datos es posible extraer información que reside de manera implícita en los datos. Estas técnicas han sido trasladadas a la Web dando origen a lo que se denomina minería Web. De acuerdo a la clasificación de minería Web, se aplicó la minería de uso y la minería de estructura Web: la minería de uso proporciona el conocimiento de los patrones de navegación de los usuarios y la minería de estructura permite extraer un reporte de la organización estructural del sitio Web. Es importante notar que durante la investigación de éstas áreas del conocimiento se notó un mayor avance del estado del arte en el área de minería de uso Web con respecto a la minería de estructura Web; sin embargo, el fundamento del reporte estructural que se determinó obtener es sugerido y explicado en trabajos como el de [Madria 1999].
Con la información de la investigación realizada, se procedió a la creación
de una aplicación que utilizará los conocimientos obtenidos en éstas áreas de investigación. Una de las características del desarrollo de software realizado es el hecho que es una aplicación Web, utilizando Java Enteprise Edition (JEE) y el framework de desarrollo Struts 2. Al desarrollar aplicaciones utilizando este modelo, se tiene un aislamiento de las funciones, el control y la vista. Para ello fue necesario su estudio para determinar la forma en que se acoplan los componentes de la aplicación. Al haber diseñado por separado estos componentes se observa una mayor claridad, tan necesaria en las aplicaciones Web y que se carece aplicando otros lenguajes de programación para desarrollo de páginas dinámicas; lo cual también genera como consecuencia una mayor facilidad en las etapas de mantenimiento.
En resumen, las técnicas de minería Web aplicadas permiten combinar sus
resultados para un mejor estudio de la estructura de navegación del sitio Web al mostrar un panorama del estado actual. Utilizando los patrones de navegación extraídos se obtienen recomendaciones (en la estructura del sitio) que beneficiarían a los usuarios del sitio Web en sus nuevas visitas. De manera similar, utilizando la información obtenida mediante minería de estructura Web, es posible mejorar la estructura de navegación al conocer información como la conectividad que tienen las páginas que conforman el sitio, tanto internamente como a páginas de otros sitios Web, así como los caminos inalcanzables. Esta información en su conjunto se pone a disposición del administrador del sitio Web para reorganizar la estructura de navegación, si ésta fuera necesaria, y con ello se cumple el objetivo de ésta tesis al mejorar la navegación de los usuarios.

Capítulo 6 Conclusiones
112
6.2. Aportaciones Análisis, diseño e implementación de una aplicación Web para analizar la estructura de navegación de un sitio Web:
Una herramienta que permite al administrador una vista de la situación actual del sitio Web que controla, en la cual se obtienen patrones de navegación que representan el uso del sitio Web, y un reporte de la estructura del sitio Web, incluyendo caminos inalcanzables, grado de hipervínculos globales de salida y grado de hipervínculos locales de entrada y salida.
La implementación de la aplicación Web bajo el patrón de diseño Modelo-Vista-Controlador, mediante el framework Struts 2.
La integración de la visualización apoyada por el proyecto TouchGraph [Touchgraph 2008] en la aplicación Web.
6.3. Trabajos futuros Este trabajo ha tomado como base a la estructura de navegación de un sitio Web para hacer un análisis en base a algoritmos y técnicas sobre el uso del sitio y la estructura que lo conforma. La aplicación se utiliza sobre un sitio Web en funcionamiento, es por ello que se recomienda que los trabajos futuros aborden los siguientes aspectos para mejorar la herramienta:
Implementación de un módulo que haga uso de los patrones interesantes generados por minería de uso Web para ser mostrados dinámicamente en una sección de sugerencias para cada página del sitio Web. Esto se debe realizar con la finalidad que los patrones sean más visibles y el usuario pueda seleccionarlos fácilmente.
Implementación de un módulo de manera similar al punto anterior, en donde las páginas con patrones interesantes podrían subir dentro de la estructura del sitio Web, simulando el comportamiento de una burbuja.
Implementación de un módulo donde se utilicen los valores de grado de hipervínculos locales de entrada y salida para mejorar la conectividad dentro de las páginas del sitio Web al establecer un mayor equilibrio entre estos valores.
Por otra parte, los trabajos que se recomiendan realizar están orientados hacia el contenido de las páginas del sitio Web, como complemento de la estructura de navegación:

Capítulo 6 Conclusiones
113
Integrar en la herramienta la minería de contenido Web, para conocer la relación entre los contenidos de las páginas, y para dar un sentido semántico a las recomendaciones estructurales.
Otro enfoque es el de utilizar las relaciones de los patrones de navegación encontrados y definir qué tipo de relación semántica existe de acuerdo con el trabajo de [Baños 2008].

114
ANEXOS

Anexos
115
ANEXO A FORMATOS DE ARCHIVOS DE BITÁCORA Formatos de los archivos de bitácora para el servidor Web
Common Log Format (CLF) El formato de un archivo CLF está compuesto de los siguientes campos separados por espacios en blanco. Remotehost: Nombre del host remoto o dirección IP. Rfc931: Nombre o login del usuario remoto. Si no se dispone de un nombre o login, se registra un guión. Authuser: Nombre del usuario autentificado. Este valor está disponible cuando se usan passwords para proteger recursos Web. Date: Fecha y hora de la petición Request: Representa la línea de petición exactamente como llego desde el cliente. Ejemplo: nombre del archivo, método utilizado y versión de HTTP. Status: Representa el código de respuesta retornado al cliente. Indica si el archivo solicitado fue o no devuelto con éxito. Bytes: Número de bytes transmitidos.
La siguiente imagen muestra un ejemplo de una petición almacenada en formato CLF. Remotehost rfc931 authuser [date] “request” status bytes
216.293.51.104
- - [01/Jan/2007:13:07:21 -0600]
"GET /index.html HTTP/1.1"
200 1321
Extended Common Log Format (ECLF)
Un archivo ECLF es una variante del formato CLF donde simplemente se agregan dos campos al final de la línea de petición; estos campos son: referrer y user agent.
Referrer: Representa la URL desde la cual el usuario realizo la petición, si no se puede terminar la referencia, se coloca un guión. User_agent: Representa el software que el cliente utiliza para visitar el sitio Web. Si no se puede determinar el tipo de software utilizado, se coloca un guión.

Anexos
116
La siguiente imagen muestra un ejemplo de una petición almacenada en formato ECLF.
remotehost rfc931 authuser [date] “request” status
Bytes “referer” “user agent”
216.293.51.104 - - [01/Jan/2007:13:07:21 -0600]
"GET /index.html HTTP/1.1"
200 1321 “http://www.google.com/
"Mozilla/2.0GoldB1 (Win95; I)"
Performance Log Format (PLF) EL PLF es una variante del ECLF, la única diferencia es que agrega un campo extra llamado Msec que representa el tiempo en milisegundos que le tomo al servidor Web responder a la petición del cliente. Este nuevo campo se inserta después del campo de bytes. La siguiente imagen muestra un ejemplo de una petición almacenada en formato PLF. Remotehost rfc931 authu
ser [date] “request” status Bytes Msec “referer” “user
agent”
216.293.51.104 - - [01/Jan/2007:13:07:21 -0600]
"GET /index.html HTTP/1.1"
200 1321 200 “http://www.google.com/
"Mozilla/2.0GoldB1 (Win95; I)"

Anexos
117
ANEXO B PANTALLAS DE LA APLICACIÓN
Figura 87. Pantalla de error de conexión a la base de datos (error.jsp).
Figura 88. Pantalla de inicio de análisis de un sitio Web (inicio.jsp).

Anexos
118
Figura 89. Pantalla de introducción de la información del sitio Web a analizar (infoSitio.jsp).
Figura 90. Pantalla de selección de las extensiones a eliminar (preprocesamiento.jsp).

Anexos
119
Figura 91. Pantalla de selección de algoritmo de sesionización (sesionizacion.jsp).
Figura 92. Pantalla de minería de uso Web (mineriaUso.jsp).

Anexos
120
Figura 93. Pantalla de minería de estructura Web (mineriaEstructura.jsp).

121
Referencias [Agrawal 1993] Agrawal R., Imielinski T., Swami A., "Mining association rules between sets
of items in large databases". Proc, ACM SIGMOD, Conf. on Management of Data, pag. 207-216, Washington, D.C., Mayo 1993.
[Agrawal 1994] Agrawal R., Srikant R., "Fast Algorithms for Mining Association Rules", Proc. 1994 Int. Conf. Very Large Database (VLDB‟94), pag. 487-499, Santiago, Chile, 1994.
[ASF Licences 2007] The Apache Software Foundation – Licenses, en línea, “http://apache.org/licenses”, consultado en septiembre de 2007.
[Baños 2008] Baños Nolasco Matilde, “Metodología para Definir una Arquitectura de Sitios Web Basada en Diseños de Ontologías”, Tesis de Maestría en Ciencias en Ciencias Computacionales, Centro Nacional de Investigación y Desarrollo Tecnológico CENIDET, Cuernavaca, Morelos, septiembre 2008.
[Brin 1998] Brin S., Page L., “The Anatomy of Large-Scale Hypertextual Web Search Engine”. In Seventh International World Wide Web Conference, Brisbane, Australia, 1998.
[Chakrabarti 1998] Chakrabarti S., Dom B., Indyk P., “Enhanced Hypertext Categorization Using Hyperlinks”. En L. M. Haas y A. Tiwary, editores, SIGMOD 1998, Proceedings ACM SIGMOD International Conference on Management of Data, June 2-4, 1998, Seattle, Washington, USA, pages 307-318. ACM Press, 1998.
[Chakrabarti 1999] Chakrabarti S., Dom B., Gibson D., Kleinberg J., Kumar S., Raghavan P., Rajagopalan S., Tomkins A., “Mining the Link Structure of the World Wide Web”, IEEE Computer, 32(8), pp. 60-67, 1999.
[Chi 1998] Chi E. H., “Visualizing the Evolution of Web Ecologies”, Proc. Conf. Human Factors in Computing Systems, ACM Press, New York, pp. 400-407, 644-645, 1998.
[Chi 2002] Chi E. H., “Improving Web usability through visualization”, IEEE Internet Computing, 6(2), pp. 64–71, marzo/abril 2002.
[Cooley 1997] Cooley Robert, Mobasher Bamshad, Srivastava Jaideep, “Web Mining: Information and Pattern Discovery on the World Wide Web”, ICTAI 1997, pp. 558-567, 1997.
[Cooley 1999b] Cooley Robert, Mobasher Bamshad, Srivastava Jaideep, “Data Preparation for Mining World Wide Web Browsing Patterns”, Knowledge and Information Systems, 1(1): pp.5-32, 1999.
[Cooley 2000] Cooley Robert, Srivastava Jaideep, Deshpande Mukund, Tan Pang-Ning, “Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data”. SIGKDD Explorations 1(2), pp. 12-23, 2000.
[Faloutsos 1999] Faloutsos M., Faloutsos P., Faloutsos C., “On Power-law Relationships of the Internet Topology”, SIGCOMM 1999, pp. 251-262, 1999.
[Fu 1999] Fu Yongjian, Sandhu Kanwalpreet, Shih Ming-Yi, “Clustering of Web Users Based on Access Patterns”, Computer Science Department. University of Missouri-Rolla, USA, 1999.
[Garofalakis 1999] Garofalakis J., Kappos, P., Mourloukos D., “Web Site Optimization Using Page Popularity”, IEEE Internet Computing, 3(4): 22-29, 1999.
[Hassan 2004] Hassan Montero Yusef, Martín Fernández Francisco J., “Estructuración de la información: Aproximación descendente”, No Solo Usabilidad journal, no. 3. 30 de enero de 2004, ISSN 1886 – 8592, 2004.
[Herder 2005] Herder Helco, Weinreich Harald, “Interactive Web Usage Mining with the Navigation Visualizer”, Proc. CHI 2005, 2005.
[Herder 2006] Herder Helco, “Forward, Back and Home Again - Analyzing User Behaviour on the Web”, Ph. D. Thesis, University of Twente, Holanda, 2006.

122
[Hernández 2005] Hernández Méndez Gabriel, “Generador de Patrones de Navegación de Usuario Aplicando Web Log Mining en Cliente/Servidor”, Tesis de Maestría en Ciencias en Ciencias Computacionales, Centro Nacional de Investigación y Desarrollo Tecnológico CENIDET, Cuernavaca, Morelos, noviembre 2005.
[Kautz 2000] Kautz H., Selman B., Shah M., “The Hidden Web”. AI Magazine, 18(2), pp. 27-36, 2000.
[Kim 2003] Kim Eugene Eric, “An Introduction to Open Source Communities”, Ble Oxen Associates-00007, abril 2003.
[Kleinberg 1998] Kleinberg J. M., “Authoritative Sources in a Hyperlinked Environment”. In Proceedings of ACM-SIAM Symposium on Discrete Algorithms, 1998, pp. 668-677, 1998.
[Kosala 2000] Kosala Raymond, Blockleel Hendrick, “Web Mining Research: A Survey”. SIGKDD Explorations 2(1), pp. 1-15, 2000.
[Kumar 1999] Kumar S. R., Raghavan P., Rajagopalan S., Tomkins A., “Trawling the Web for Emerging Cyber-Communities”. In Proceedings of the Eighth World Wide Web Conference (WWW8), 1999.
[Lee 2004a] Wookey Lee, Geller J. “Semantic Hierarchical Abstraction of Web Site Structures for Web Searchers”, Journal of Research and Practice in Information Technology, 36(1), pp.71-82, 2004.
[Lee 2006] Lee Wokeey. “Hierarchical Web Structuring from the Web as a Graph Approach with Repetitive Cycle Proof”. APWeb Workshops 2006, pp. 1004-1011, 2006.
[Madria 1999] Madria Sanjay, Rhowmich Sourav S., Ng W. K., Lim E.P., “Research issues in Web data mining”. In Proceedings of Data Warehousing and Knowledge Discovery, First International Conference, DaWaK'99, pp. 303-312, 1999.
[Manning 1998] Manning H., McCarthy J.C., Souza R.K., “Why Most Web Sites Fail”, white paper, Forrester Research, Cambridge, Mass, septiembre 1998.
[NanoXML 2008] API NanoXML – a small XML parser for Java, en línea, “http://nanoxml.cyberelf.be/”, consultado en abril de 2008.
[Niu 2002] Niu Yonghe, Zheng Tong, Goebel Randy, “Webframe: In Pursuit of Computationally and Cognitively Efficient Web Mining”. In Proceedings of the 6
th Pacific-Asia Conference, PAKDD, pp. 264-275, Mayo de 2002.
[Nielsen 2002] Nielsen Jakob, Molich Rolf, “E-Commerce User Experience”, Nielsen Norman Group, 2002.
[Oosthizen 2006] Oosthuizen C., Wesson J., Cilliers C., "Visual Web Mining of Organizational Web Sites", iv, Tenth International Conference on Information Visualisation (IV'06), pp. 395-40, 2006.
[Roughley 2006] Roughley Ian, “Starting Struts 2”, 1ra. ed., editorial C4Media, USA, (2006). [Roughley 2007] Roughley Ian, “Practical Apache Struts2 Web 2.0 Projects”, 1ra. ed.,
editorial Apress, USA, (2007). [Scone 2007] Scone Framework, en línea, http://www.scone.de/, consultado en abril de
2008. [Sommerville 2004] Sommerville Ian, “Software Engineering (7th Edition)”, Addison Wesley
Editorial, Mayo de 2004. [Souza 2000] Souza R., et al., “The Best Of Retail Site Design”, white paper, Forrester
Research, Cambridge, Mass., octubre 2000. [Standard 1998] Software Engineering Technical Committee of the IEEE Computer Society.
IEEE Standard for Software Test Documentation. Disponible en http://ieeexplore.ieee.org/iel4/5976/16010/00741968.pdf, 1998.
[Struts 2008] Apache Software Foundation Struts 2, en línea, “http://struts.apache.org/2.x/index.html”, consultado en abril de 2008.
[Touchgraph 2008] SourceForge.net – Touchgraph, en línea, “http://sourceforge.net/projects/touchgraph”, consultado en abril de 2008.

123
[Youssefi 2003] Youssefi A., Duke D., Zaki M., Glinert E., “Toward visual Web mining”. In Proceeding of Visual Data Mining at IEEE Intl Conference on Data Mining (ICDM), Florida, 2003.
[Zaine 2004] Zaïane R. Osmar, Chen Jiyang, Sun Lisheng, Goebel Randy, “ Visualizing and Discovering Web Navigational Patterns”, Seventh ACM SIGMOD International Workshop on the Web and Databases (WebDB 2004), pp 13-18, Paris, France, Junio 2004.
[Zaine 2007] Zaïane R. Osmar, Chen Jiyang, Zheng Tong, Thorne William, Goebel Randy, “Visual Data Mining of Web Navigational Data“, 11th International Conference Information Visualization (IV'07), ETH Zurich, Switzerland, pp 649-656, 3-6 Julio 2007.
[Zaki 2001] Zaki Mohammed J., “SPADE: An Efficient Algorithm for Mining Frequent Sequences”, en Machine Learning Journal, special issue on Unsupervised Learning (Doug Fisher, ed.), pp 31-60, Vol. 42 Nos. 1/2, enero/febrero 2001.