cenidet rosa … · 4.2.1 arquitectura cliente/servidor ... 4.6 la base de datos de distribución...
TRANSCRIPT

S.E.P S.E.I.T. D.G.I.T.
CENTRO NACIONAL DE INVESTIGACIÓN Y DESARROLLO TECNOL~GICO
cenidet
UN MODELO MATEMÁTICO GENERADOR DE ESQUEMAS DE UBICACIÓN Y REPLICACIÓN PARA BASES DE DATOS
DISTRIBUIDAS
E I
T E S I S PARA OBTENER EL GRADO DE M A E S T R O E N C I E N C I A S EN CIENCIAS COMPUTACIONALES P R E S E N T A : ROSA LINA MONDRAG~N IBARRA
CUERNAVACA MORELOS JULIO DE 2001

Centro Nacional de Investigación y Desarrollo Tecnológico FORMA C3
REVISION DE TESIS
Cuernavaca, Morelos a 5 de junio de 2001
Dr. Raúl Pinto Elias Presidente de la 'Academia de Ciencias Computacionales Presente
Nos es grato comunicarle, que conforme a los lineamientos para la obtención del grado de Maestro en Ciencias de este Centro, y después de haber sometido a revisión académica la tesis denominada: "Un Modelo Matemático Generador de Esquemas de Ubicación y Replicación para Bases de Datos Distribuidas", realizada por la C. ROSA LlNA MONDRAGÓN IBARRA, y habiendo cumplido con todas las correcciones que le fueron indicadas, acordamos no tener objeción para que se le conceda la autorización de impresión de la tesis.
Sin otro particular, quedamos de usted.
Atentamente
La comisión de revisión de tesis
a. Cd,lC&. M.C Mario Guillén Rodríguez Co-Director de tesis Director de tesis
INTERIOR INTERNADO PALMIRA S/N. CUERNAVACA. MOR. MeXICO APARTADO POSTAL 5-164 CP 62050. CUERNAVACA. TELS. (73)12 2314.12 7613 , I 8 7741. FAX (73) 12 2434 EMAIL [email protected] cenidet

'.
Centro Nacional d e Investigación y Desarrollo Tecnológico FORMA C4
AUTORIZACION DE IMPRESIÓN DE TESIS
Cuernavaca, Morelos a 15 de Junio de 2001
C. Rosa Lina Mondragón lbarra Candidato al grado de Maestro en Ciencias en Ciencias Computacionales Presente
Después de haber atendido las indicaciones sugeridas por la Comisión Revisora de la Academia de Ciencias Computacionaies en relación a su trabajo de tesis: Un Modelo Matemático Generador de Esquemas de Ubicación y Replicación para Bases de Datos Distribuidas, me es grato comunicarle, que conforme a los lineamientos establecidos para la obtención del grado de Maestro en Ciencias en este Centro, se le concede la autorización para que proceda con la impresión de su tesis.
INTERIOR INTERNADO PALMIRA SIN. CUERNAVACA. MOR. MÉXICO APARTADO POSTAL 5-164 CP 62050. CUERNAVACA TELS. (73)12 2314.12 7613 . I 8 7741 F A X (731 ! ? 2434 EMAIL ortizacenidet.edu.mx
crclninlclt

Dedicación
Con todo cariño y admiración a mi madre LASTENIA BARRA BARRERA
por su comprensión, confianza, apoyo y por enseñarme con su ejemplo el deseo
de constante superación.
A mi padre
por cuidarme, protegerme y estar siempre conmigo.
Q ROSALIO MONDRAG~N ALVAREZ

Agradecimientos
Al Centro Nacional de investigación y Desarrollo Tecnológico por brindarme la oportunidad de realizar mis estudios de postgrado.
A mi asesor de tesis Dr. Joaquín Pérez Ortega por dirigir el desarrollo de este proyecto y por compartir conmigo sus horas de trabajo, sus experiencias y conocimientos. Gracias por ayudarme y proporcionarme esas palabras de ánimo en los momentos complicados.
A mis revisores de tesis Dr. Rodolfo A. Pazos Rangel, M.C. José Antonio Zárate Marceleño, M.C. Mario Guillén Rodriguez y Dr. José Torres Jiménez por sus valiosos comentarios que ayudaron a enriquecer el presente trabajo de investigación.
A Joaquín Armenta Trujillo por compartir conmigo todos esos momentos de diferentes matices, por su comprensión, tiempo y ayuda invaluable.
A cada uno de los maestros del Cenidet por sus conocimientos transmitidos.
A Cosnet por el apoyo económico brindado para realizar mis estudios.
... 111

Tabla de Contenido
Página .. Capítulo 1 Introduccion ............................................................................................ 1
.. 1.1 Introduccion ............................................................................................. 2
1.2 Motivaciones ............................................................................................ 3 . . . . . 1.3 Descnpcion del problema ........................................................................ 5
1.4 Objetivo de la tesis ................................................................................... 8
1.5 Alcances ................................................................................................... 8 . . . 1.6 Organizacion de la tesis ........................................................................... 9
Capítulo 2 Estado del arte ......................................................................................... 1 1
2.1 Problema de ubicación de archivos ........................................................ 12
2.2 Fragmentación y ubicación de datos ...................................................... 13
2.3 Replicacion de datos ............................................................................... 17 . . .
Capítulo 3 Metodología Tradicional de Diseño de Base de Datos Distribuid as ..... 23
3.1 Metodología tradicional de Diseño de BDDs ........................................ 24
3.1.1.1 Análisis de requerimientos de distribución ............................................ 24
. . 3.1 . 1 Análisis de Requenmientos ..........................................................
3.1.2 Diseño conceptual global ...... 3.1.3 Diseño lógico global .............
......................... 26 ............................... 26
3.1.4 Diseño de la distribución .......................... .......................................... 26
3.1.5 Diseño físico ............................................................. ....................... 26
3.2 Diseño de la distribución ............. ......................... ....................... 27 .. 3.2.1 Fragmentacion ........................................................................................ 27
3.2.2 Problema de ubicación y replicación de datos ....................................... 28
iv

Capítulo 4 Replicación en SQL Server ...................................................................... 29
.. 4.1 Intmduccion ............................................................................................ 30
4.2 SQL Server .............................................................................................. 30
4.2.1 Arquitectura Cliente/Servidor .................................................................. 31
4.2.2 Sistema administrador de bases de datos relaciona1 ................................ 31
4.2.3 Transact-SQL ........................................................................................... 31
4.3 Replicacion .............................................................................................. 32
4.4 Componentes de la replicacion ................................................................ 32
. . . . . .
. . 4.5 Suscnpciones ........................................................................................... 33
. . .. 4.5.1 Suscnpciones de extraccion ..................................................................... 34
4.5.2 Suscnpciones de insercion ....................................................................... 34 . . .. . . . . 4.5.3 Suscnpciones anonimas ........................................................................... 35
4.6 La base de datos de distribución .............................................................. 35
4.7 Agentes de replicacion ............................................................................. 35
4.7.1 Agente de instantáneas ............... i ............................................................ 35
. . .
4.7.2 Agente de lector de registro ..................................................................... 36
4.7.3 Agente de distnbucion ............................................................................. 36
4.8 Planificación de la replicación en SQL Server ........................................ 36
. . . .
4.8.1 TemporizaciÓn y latencia de los datos replicados ................................... 36
4.8.2 Autonomía del sitio ................................................................................. 37
4.8.3 Métodos de distribución de datos ............................................................ 38
4.9 Tipo de replication seleccionado ............................................................ 39
. .
. . . . . . 4.9.1 Duplication transactional ................................................................
4.9.1.1 El agente de instantáneas ......................................................................... 40
4.9.1.2 El agente de lector de registro .................................................... 4.9.1.3 El agente de distnbucion ............................................................ . . . .
4.9.1.4 Limpieza .................................................................................................. 41
4.9.1.5 Suscriptores de actualización inmediata .................................................. 41 .
V

Capítulo 5 Modelo matemático propuesto ................................................................ 43
.. 5.1 Introduction ........................................................................................... 44
5.2 Funcion objetivo ................................................ ; .................................... 44
5.2.1 Costos de transmisión de datos para aplicaciones de consulta ............... 44
5.2.1.1 Frecuencia de acceso en aplicaciones de lecturahj ................................ 45
. . ..
5.2.1.2 Atributos por consulta q km ...................................................................... 45
5.2.1.3 Número de paquetes de comunicación lkm ............................................. 45
5.2.1.4 Costo de transmisión entre el sitio i y el sitioj C, ................................. 46
5.2.2 Costos de transmisión de datos para aplicaciones de escritura ............... 46
5.2.2.1 Costo de actualizacion cu ....................................................................... 47 . . .
5.2.2.2 Frecuencia de acceso en aplicaciones de escrituraf’u ........................... 47
5.2.2.3 Tamaño en bytes de la i n t n ~ ~ n de SQL 1; ......................................... 48
5.2,2.4 Costo de comunicación entre el sitio de la copia primanap y el sitio i CPi ............................................................................................... 48
5.2.3 Costos de transmisión para copiar datos de un nodo a otro .................... 48
5.2.3.1 Parámetro d, ............................................................................................ 49
5.3 Restricciones intrínsecas del problema ................................................... 49
5.4 Solucion del modelo ................................................................................ 50 .. 5.4.1 Método de ramificar y acotar .................................................................. 50
.. 5.5 Complejidad del modelo ......................................................................... 53
5.5.1 Ubicacion no replicada ............................................................................ 53
5.5.2 Ubicación replicada ........ ................................................................... 54
. . .
Capítulo 6 Casos de prueba ...................................................................................... 56
6.1 Casos de pruebas en el modelo .............................................................. 57 6.1.1 Prueba 1 : Aplicaciones de lectura ......................................................... 57
6.1.2 Prueba 2: Aplicaciones de escritura ....................................................... 61
6.1.3 Prueba 3: Aplicaciones de lectura y escntura ........................................ 63 vi

6.1.4 Prueba 4: Cambio en frecuencias de aplicaciones ................................. 66
6.1.5 Prueba 5: Capacidad de almacenamiento restringida. ........................... 71
Capítulo 7 Comentarios fmales y trabajos futuros .................................................. 77
7.1 Comentarios finales ............................................................................... 78
7.2 Sugerencias de trabajos futuros ............................................................. 79
vii

Lista de Figuras
Figura Título Página
1.1
1.2
1.3
3.1
4.1
4.2
4.3
5.1
5.2
6.1
6.2
6.3
6.4
6.5
6.6
6.7
Ubicación inicial de las tablas y estadísticas de explotación en el tiempo to ........ 6
Cambios en las estadísticas de explotación en el tiempo t , .................................. 7
Nuevo esquema tomando en cuenta las frecuencias de acceso en el tiempo t2.8
Metodología tradicional del diseño de BDDs ..................................................... 25
Comunicación entre un cliente y un servidor con SQL Server ........................... 30
Componentes de la replicacion ........................................................................... 33
Suscripciones de inserción y de extracción ........................................................ 34
Ubicación no replicada de fragmentos ............................................................... 54
Ubicación replicada de fragmentos ..................................................................... 55
Esquema de ubicación y replicación para aplicaciones de sólo lectura .............. 60 .
. . .
Esquema de ubicación y replicación para aplicaciones de sólo escrituras .......... 63
Esquema de ubicación y replicación para aplicaciones de lectura y escritura .... 65
mismo número de frecuencias ............................................................................. 68
de frecuencias diferentes ...................................................................................... 71
Esquema de ubicación y replicación para aplicaciones de lectura con
Esquema de ubicación y replicación para aplicaciones de lectura con número
Esquema de ubicación y replicación con espacio de almacenamiento suficiente para ubicar los atributos ...................................................................... 73
Esquema de ubicación y replicación con espacio de almacenamiento . . restringido en Sz .................................................................................................. 76
... VI11

Lista de Tablas
Tabla Título Página
1.1
2.1
2.2
6.1
6.2
6.3
6.4
6.5
6.6
6.7
6.8
6.9 6.10 Capacidad de almacenamiento en disco para cada sitio ....................................... 74
Tablas que intervienen por consultas .................................................................... 6
Caractensticas principales de los modelos de ubicación de archivos .................. 21
Caractensticas principales de los modelos de ubicación de fragmentos ............. 22
Capacidad de almacenamiento en disco para cada sitio ...................................... 57
Tamaño en bytes de cada atributo ....................................................................... 58
Atributos m usados por consulta k ....................................................................... 58
Frecuencias de emisión de la consulta k desde cada sitioj .................................. 58
Costo de transmision entre sitios ......................................................................... 59 Frecuencias de emisión de la consulta k desde cada sitioj .................................. 66
Atributos m usados por consulta k ....................................................................... 67
Frecuencias de emisión de la consulta k desde cada sitioj .................................. 69
. . Selectividad de las consultas ................................................................................ 59 . . . . .
ix

cenidet Capitulo 1
Capítulo
Introducción
En este capitulo se describe el problema de tesis, las.motivaciones, los objetivos y los alcances de la presente investigación.

1.1 Introducción
En general las grandes organizaciones requieren tanto de s o h a r e como de
hardware para realizar sus actividades, sin embargo, como consecuencia del crecimiento en
la tecnología de comunicaciones, de Sistemas Administradores de Bases de Datos
Distribuidas (SABDD) y el decremento en los costos de las computadoras, dichas
organizaciones han optado por utilizar redes de comunicación para computadoras
incluyendo internet, logrando así que sea más factible la implementación de Sistemas de
Bases de Datos Distribuidas (SBDD).
Aún cuando los SBDD proporcionan una mejor disponibilidad de los datos, una
mejor seguridad, confiabilidad, reducción en los costos de comunicación y mejoramiento
en el desempeño, son considerablemente complicados y sofisticados, por lo que su diseño
lógico presenta una variedad de problemas como son: integridad, control de recuperación,
ubicación y replicación de datos.
El diseño lógico en un sistema distribuido es un factor importante y complicado que
determina la ubicación de los datos en el sistema, si se toma en cuenta que la naturaleza de
los sistemas distribuidos es dinámica, con cambios en la topología de la red, frecuencias
de accesos, costos y recursos, el problema se vuelve aún más complejo.
Hoy en día, los administradores de los sistemas son los encargados de realizar la
ubicación, replicación y monitoreo de la información en los nodos de la red, dicha
actividad es efectuada de manera estática, se determina en el momento del diseño de la
base de datos distribuida y permanece sin cambios (diseño estático) hasta que el
administrador considera un nuevo diseño. En la mayona de los SBDD, el diseño estático
afecta de manera importante el desempeño total del sistema, esto se debe principalmente a
que el tiempo y los costos requeridos para el procesamiento de las consultas y
actualizaciones, dependen en gran parte del lugar donde residen los datos y de las
frecuencias de accesos.

cenidet Capítulo I
Es predecible fácilmente, que un sistema distribuido con un diseño de distribución
estático, pueda irse degradando severamente en su desempeño por su incapacidad de
respuesta a los cambios en la explotación de los datos.
El objetivo de este trabajo es desarrollar un módulo de software factible de ser
incorporado a un SABDD, dicho módulo permitirá evitar la degradación de los sistemas
ante cambios en los patrones de explotación de los datos mediante la utilización de datos
estadísticos de explotación del sistema y un modelo matemático para la fragmentación,
ubicación y replicación.
La principal aportación de este trabajo consiste en obtener un nuevo método de
solución al problema de la degradación de los sistemas al cambiar a nuevos esquemas de
ubicación y replicación que se adapten a los patrones de explotación de acceso a los datos.
1.2 Motivaciones
El presente trabajo de investigación se enfoca principalmente al proceso de diseño
de distribución de bases de datos distribuidas, el cual consiste de fragmentación, ubicación
y replicación de datos. La investigación fue motivada por las siguientes observaciones:
1. La principal motivación de las grandes organizaciones para utilizar un sistema de
base de datos distribuida es que se adapta de manera natural a su estructura
administrativa. Por ejemplo: la organización puede estar dividida en plantas y éstas
pueden estar en sitios geográficamente distantes, cada planta tendría su propia información almacenada en computadoras y estarían conectadas por medio de una
red. Así pues, un sistema distribuido permitirá que la estructura de la base de datos
refleje la estructura de la organización [Dat,1995]. Sin embargo para obtener
beneficios tales como: control local, disminución de tiempos de respuesta y costos
reducidos de comunicación, se requiere obtener una ubicación y replicación óptima
de datos [Kul,l989].
3

cenidet Capítulo 1
2. El problema más difícil para el desarrollo de bases de datos distribuidas es la falta de metodologías y herramientas de apoyo al diseño [Osz,I991; Gar, 1992; Ku1,1991;
Cer,1987].
3. Tradicionalmente se ha considerado que el diseño de distribución (DD) consta de dos
fases cenadas. En contraste con esta creencia generalizada, resulta más sencillo
resolver el diseño de distribución de manera simultánea [Per,1997]. Con el desarrollo
del modelo FURD (Fragmentación, Ubicación y Reubicación de Datos) se iniciaron
los trabajos en esta dirección, en esta tesis se continúa en la misma dirección.
4. En el área de DD, se han realizado numerosas investigaciones, sin embargo, no
existe un puente entre los modelos teóricos y los manejadores comerciales, en este
sentido el presente trabajo tiene como finalidad el adaptar un modelo teórico de DD
para poder ser aplicable en el diseño de Bases de Datos Distribuidas (BDD) que
trabajen sobre manejadores comerciales.
5. En la actualidad, se considera el DD de manera estática, esto es, se establece con el
diseño inicial de la base de datos distribuida, el cual permanece fijo hasta que el
administrador del sistema interviene para realizar cambios [Wol, 19921. Un sistema
distribuido con un diseño de distribución estático puede irse degradando severamente
en su desempeño por su incapacidad de respuesta a los cambios en la explotación de
los datos [Wol,l992], en contraste con lo anterior, en este trabajo se pretende evitar
la degradación de los sistemas mediante esquemas de replicación adaptativos.
6. La replicación es clave para incrementar el desempeño, la disponibilidad y la
tolerancia a fallas [Cou,l994]. Además, la replicación es una herramienta que se ha
incorporado en las últimas versiones de los SABDD.

cenidet Capítulo I
1.3 Descripción del Problema
De manera simplificada se puede enunciar el problema de la siguiente manera:
El problema consiste en la ubicación y replicación de fragmentos, de tal manera que
el costo total en que incurra la transmisión por aplicación procesada por un SABDD sea
minimizado.
A continuación se presenta de manera matemática el problema:
Dado un conjunto de tablas T={tl, 12. ..., t n } , una red de comunicación para
computadoras que consiste de un conjunto de sitios S={si, s2, .... s,} en donde se ejecutan
una sene de aplicaciones Q=(q,,- q2. ..., qn), un esquema inicial de ubicación y replicación
de datos, y las frecuencias de acceso de cada consulta desde cada nodo. Obtener un
nuevo esquema optimizado de ubicación y replicación que permita realizar un
procesamiento más eficiente de las aplicaciones de lectura y escritura,
adaptándose a nuevos patrones de explotación de la base de datos, minimizando
los costos de transmisión.
Para complementar la definición se presenta un ejemplo sencillo que
ilustra el problema.
En la Figura 1. I , se muestra un primer esquema de ubicación de una base
de datos distribuida, en las tablas se muestran tanto datos estadísticos como las
consultas que se llevan a cabo en cada sitio y las frecuencias de acceso.
La Tabla 1 . 1 , nos muestra las entidades de datos involucradas para una
consulta dada, se indica con un 1 si la entidad de datos está involucrada en dicha
consulta, en caso contrario se indica con un O.
5

Capitulo 1 cenidet
as
Inicialmente, desde el sitio SI se ejecutan las consultas q1, q2 y q3, y se
encuentran ubicadas las tablas ti, t 2 y t 3 . De igual manera en s2 se ejecutan las
consultas q i y q4, y se encuentra ubica la tabla t 4 . En el sitio s3 se ejecuta la
consulta 45 y se encuentra ubicada la tabla t 5 .
Esta distribución es adecuada y minimiza costos de transmisión, sin
tiempo los requerimientos de información para los embargo, a través del
usuarios pueden cambiar.
Figura 1.1 Ubicación inicial de las tablas y estadísticas de explotación en el tiempo 7 0 .
6
Capitulo 1 cenidet
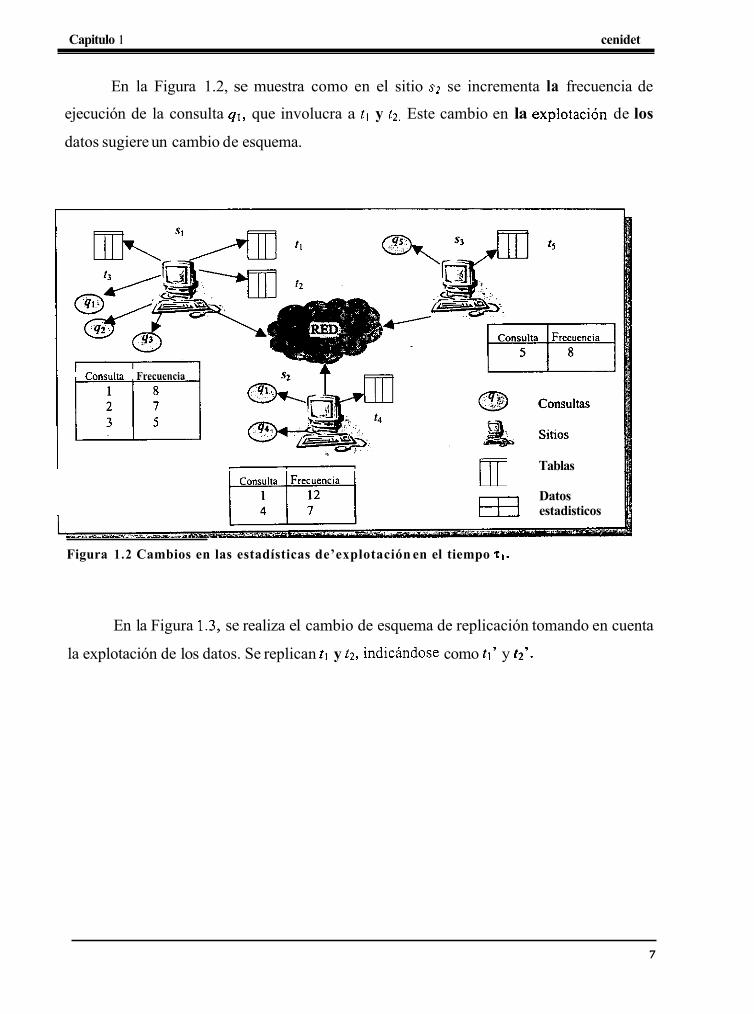
En la Figura 1.2, se muestra como en el sitio s2 se incrementa la frecuencia de
ejecución de la consulta 41, que involucra a tl y t2 . Este cambio en la explotacih de los
datos sugiere un cambio de esquema.
Consulta Frecuencia
conaul~l Frecuencia (*I Tablas
Datos m estadisticos
Figura 1.2 Cambios en las estadísticas de’explotación en el tiempo T,.
En la Figura 1.3, se realiza el cambio de esquema de replicación tomando en cuenta
la explotación de los datos. Se replican ti y t2, indicándose como ti’ y 12’.
7

Capítulo 1 cenidet
Datos a estadísticos
Figura 1.3 Nuevo esquema tomando en cuenta las frecuencias de acceso en el tiempo r l .
1.4 Objetivo de la Tesis
Objetivo General
Desarrollar un módulo computacional que permita evitar la degradación de una
aplicación distribuida que funcione sobre la plataforma de SQL Server para Internet,
mediante la generación de nuevos esquemas de ubicación y replicación que se adapten a
los cambios en los patrones de explotación de los datos.
1.5 Alcances
J El módulo desarrollado incorpora un modelo de optimización matemático para
la ubicación y replicación, llamado FURD Extendido. Como método de
solución se emplea el de “ramificar y acotar”.
8

J El modelo solamente incluye el tipo de replicación transaccional, usado en el
SMBDR SQL Server 7.0.
J Las pruebas funcionales se realizaron tanto en red local como en internet
J Las pruebas en red local, se realizaron en la red local del Centro Nacional de
investigación y Desarrollo Tecnológico (CENIDET), cuyas características son:
tipo Ethernet, velocidad 10 mbps, topología estrella.
J Las pruebas en internet, se realizaron utilizando dos computadoras, una de ellas
ubicada en CENIDET y la segunda en el instituto de Investigaciones Eléctricas
(iiE), ambas con direcciones E' fijas.
No es propósito de esta tesis:
X Probar el modelo utilizando un manejador diferente a SQL Server 7.0.
X Utilizar diferentes métodos de solución para el módelo.
X Utilizar diferentes tipos de replicación proporcionados por el manejador SQL
Server 7.0.
1.6 Organización de la Tesis
La organización de la tesis es de la siguiente manera:
Capítulo 2 Ubica esta tesis en el contexto de otras investigaciones relacionadas. Se
revisan trabajos enfocados a resolver el problema de la fragmentación,
ubicación y replicación.
9

Capítulo 1 cenidet
Capítulo3 Se describe la metodología de diseño tradicional para bases de datos
distribuidas. Esta metodología ha sido desarrollada como una extensión al
diseño de bases de datos centralizadas.
Capítulo4 Se presenta un panorama general de la replicación en SQL Server, se
describen los tipos de replicación que se manejan, cada uno de los elementos
que intervienen, y cómo se relacionan.
Capítulo 5 Describe un modelo matemático que unifica la fragmentación, ubicación y
replicación de fragmentos.
Capítulo 6 Muestra ejemplos que prueban la funcionalidad del modelo implementado
en el presente trabajo de investigación.
Capítulo 7 Muestra las conclusiones a las que se llegaron durante esta investigación y
se sugieren trabajos que pueden dar continuidad a esta investigación.
10

cenidet Capitulo 2
Capítulo
Estado del Arte
En este capíhdo se abordarán los aspectos referentes al estado del arte. Se
presenta una breve descripción de los trabajos referentes al diseño de la distribución y
replicación.
0 1 - 0 5 5 7

2 Estado del Arte
El problema de ubicación y replicación ha sido ampliamente estudiado por diversos investigadores que han propuesto diferentes metodologías para el diseño de
bases de datos distribuidas, iniciando con el problema de ubicación de archivos FAP
(por sus siglas en inglés, File Assignment Problem) a finales de los setentas y principios
de los ochentas. La investigación sobre el FAP es descrita en la sección 2.1.
Recientemente la fragmentación y ubicación de datos en bases de datos distribuidas ha
recibido una atención considerable como se muestra en la sección 2.2. La replicación de
datos provee algunos de los principales beneficios de los sistemas distribuidas. El
problema de la replicación es revisado en la sección 2.3.
2.1 Problema de Ubicación de Archivos
Los primeros modelos de distribución consideraron el archivo como la unidad de
ubicación. Chu fué el primero en articular el FAP [Chu,1969]. Formuló el problema como un modelo de programación entera para un número fijo de copias de cada archivo,
con el objetivo de minimizar costos, tomando en cuenta tiempos de respuesta y
capacidad de almacenamiento. El modelo fue extendido por Casey relajando las
restricciones relacionadas al número de copias y marcando la diferencia entre consultas
y actualizaciones [Cas,l972]. Eswaran mostró que la formulación de Casey era un problema NP-Completo y sugirió una solución heurística al problema [Esw,l974].
Muchos investigadores han modificado el FAP, variando las suposiciones y
niveles de generalización. Ramamoorthy mostró que los costos de comunicación para
operaciones de reunión pueden reducirse replicando los archivos, su modelo supone que
la consulta es procesada en el sitio donde se requiere el resultado sin transmisiones entre
los sitios donde se ubican los archivos [Ram,l979].
Mahmoud incorporó la capacidad del canal en el FAP [Mah,1976]. Morgan
incorporó la ubicación de los programas con los archivos [Mor,l977].
12

Irani combinó la ubicación de archivos, la topología de la red, y la capacidad de los canales en un solo problema [Ira,1979]. Chen generalizó el problema considerando
el costo total de un sistema de base de datos distribuida incluyendo el costo de las
computadoras, bases de datos, programas, enlaces de comunicación y costos de
operación [Che,l980]. Dowdy provee un excelente estudio de investigación sobre el
FAP [Dow,1982]. Jain desarrolló una metodología multi-criterio para la toma de
decisiones combinando la selección del procesador, ubicación de archivos y diseño de la
red [Jai,1986]. Jain consideró -las diferencias en el costo del procesamiento de una
transacción en diferentes computadoras, usando un modelo de programación para la
selección del procesador y la ubicación de archivos [Jai,l987].
2.2 Fragmentación y Ubicación de Datos
Los términos fragmentación, descomposición y particionamiento, se han
utilizado como sinónimos por los diferentes investigadores en el area. La investigación
original de particionamiento fue desarrollada en el contexto de bases de datos centralizadas cuando los beneficios de particionar archivos de datos se daba entre
memoria primaria y memoria secundaria [Eis,1976; Mar,1977]. Hoffer y Babad desarrollaron modelos para particionamiento vertical appando atributos con la
finalidad de minimizar espacio de almacenamiento y costo tanto de lecturas como de
escrituras [Hof,1976; Bab,1977]. Kulkami menciona que la complejidad de los modelos
mencionados es intratable para problemas prácticos [Ku1,1989].
En el área de bases de datos distribuidas los investigadores han tratado el
problema de fragmentación y ubicación de datos en un ambiente distribuido. Un
excelente estudio sobre estrategias de ubicación en bases de datos distribuidas aparece en [Hev,1988].
Chang y Cheng desarrollaron una metodología para descomposición estructural
(particionamiento de bases de datos).
13

cenidet Capitulo 2
El proceso de descomposición estructural de bases de datos requiere relaciones en tercera forma normal, vistas de usuarios específicas, atributos en las vistas y atributos
llave. El proceso inicia con las vistas de usuario desde una base de datos integrada,
después se mapean las vistas con el esquema general. Una vez que el proceso se ha
terminado, la fragmentación de datos ocurre basándose en los traslapes de campos,
cada traslape define un nuevo fragmento [Cha, 19801.
Chang y Liu describen un método para ubicar fragmentos de datos dentro de una
base de datos dishibuida usando el trabajo de Chang y Cheng. Su función objetivo consiste en minimizar costos de transmisión y concurrencia. El costo de concurrencia se
obtiene mediante una función lineal de un número de mensajes necesarios para una
actualización y es válido sólo para topología estrella [Cha,1982].
Cen desarrolló un algoritmo para ubicar un conjunto de fragmentos horizontales
en una red de computadoras. Su solución involucró identificación de transacciones
importantes, estadísticas, fragmentos horizontales candidatos, relaciones de datos
(tamaños y cardinalidades) y una estrategia de cada transacción (número de tuplas de
cada relación accedida). Diseñó un modelo de programación lineal entero que minimiza
el costo global del procesamiento de una transacción para obtener una ubicación no
replicada. La replicación de fragmentos se introduce a través del uso de heuristicas
“codiciosas”, se inicia con una base de datos no replicada y progresivamente se ubica una copia de cada fragmento en cada sitio y se observa el efecto en el costo global para
todas las transacciones [Cer,1983].
Navathe desarrolló algontmos para ubicar fragmentos verticales de relaciones
basadas en aiributos, los cuales son accedidos por transacciones comunes.
Se realiza la fragmentación vertical en tres contextos diferentes: bases de datos
centralizadas con una sola jerarquía de memoria, bases de datos centralizadas con
diferentes jerarquías de memoria y bases de datos distribuidas. AI referirse al contexto de bases de datos distribuidas, la fragmentación vertical se realiza basándose en la
optimización de costos.
14

Como dato de entrada utiliza una matriz de uso de atributos (MUA) que identifica los atributos usados por cada consulta. Con esta matiz y la frecuencia global
de ejecución de cada consulta, construye la matriz de afinidad entre atributos (MAA),
que es una matriz cuadrada, cuyos elementos representan la medición de una cohesión
imaginaria entre cada par de atibutos. Esta medida de la cohesión está en proporción
directa de la frecuencia con que ambos atributos son accedidos por las consultas, y no
tiene ninguna relación con el sitio desde donde la transacción se emite. Esta última
matriz de MAA sirve como entrada al Algoritmo de Energía de Cohesión (AEC), que
permuta filas y columnas de una matiz cuadrada, formando bloques de elementos sobre
la diagonal principal. Estos bloques tienen la característica de estar formados por
elementos de valor similar, debido a que la función objetivo usada por el AEC tiende a
agrupar los valores grandes de la matiz, también se agmpan los valores pequeños. De esta manera, se forma una nueva matriz a la que le llaman matriz agrupada de afinidad
de atributos (MAAA). La matiz MAAA es la entrada de un algoritmo recursivo, que
evalúa la ubicación de cada partición vertical binaria posible en todos los sitios de la red
(mZ casos para m sitios), Puede obtenerse una fragmentación n-aria, repitiendo el
proceso recursivamente en cada partición obtenida hasta que no se produzcan mejoras
con una nueva partición [Nav,1984].
Hale usó información semántica para formación de fragmentos. Las vistas
individuales del usuario se representan usando el modelo entidad-relación (E-C-R). La principal contribución de esta investigación es la representación semántica de la
información de las vistas individuales de los usuarios y su relación con el esquema
global, usando un esquema semántica equivalente [Ha1,1986].
Ceri reconoce que la fragmentación de datos (DF), ubicación de datos (DA),
transformación de consultas (QT) (desde relaciones globales para fragmentos), optimización de consultas (QO) y la evaluación (E) de una alternativa dada son
problemas de optimización relacionados. Presenta un esquema de entidad relación del
diseño de un diccionario de datos, el cual almacena toda la información requerida
durante el proceso de diseño. Esta información es la entrada y salida para cada uno de los sub-problemas mencionados

La interacción entre estos sub-problemas es modelada con la siguiente, DF + DA+ QT + QO 3 E, donde la salida de DF es la entrada para DA y así sucesivamente. Presentan dos herramientas, una rápida y una más lenta. Las dos
herramientas consideran Únicamente pariicionamiento vertical. La herramienta rápida es
recomendada para problemas grandes, y se salta los pasos QT y QO, procede de DF + DA+ E. La herramienta lenta realiza la secuencia completa. La principal contribución
de esta investigación es la representación de la información de entrada-salida de las
diferentes etapas del problema en una forma semántica en el diseño de diccionarios de
datos [Cer,1986].
Ceri, Pemici y Wiederhold investigaron tratamientos metodológicos para el
diseño de bases de datos distribuidas. Especificamente, las metodologías ascendente y
descendente. Los autores presentan DATAID-D, una metodología descendente para el
diseño de distribución, teniendo formas sistemáticas de representar y usar datos
estadísticos acerca del uso de una base de datos, con ayuda de un caso de estudio
[Cer,1987]. Para el enfoque ascendente, se usa una metodología heurística similar a la
presentada en [Cer,1983].
Ramirez realiza una extensión al modelo matemático FURD [Per,1997], dicha
extensión consiste en el modelado matemático de los costos por acceder a dos o más
fragmentos para satisfacer una consulta y los costos derivados de almacenar fragmentos en los nodos de una red. Para dar solución al modelo FURD extendido, se exploraron
dos métodos, un exácto y un heurístico.
Como método exacto se usó el método de ramificar y acotar y como heunstico
una variante de Recocido Simulado, llamado Aceptación por Umbral [Ram,l999].
Cruz profundiza en la caracterización de los métodos de solución empleados en el
diseño de la distribución de la base de datos, el propósito principal de esta investigación
es contestar la pregunta ¿para qué tamaño del problema conviene utilizar un método de
solución exacto y para cuál un heurístico? considerando que el problema pertenece a la
clase de problemas NP-completos.

cenidet Capitulo 2
En particular, en este trabajo se estudia el problema de la fragmentación vertical y
ubicación de datos empleando el modelo FURD. Como método de solución exacto
utiliza ramificar y acotar y como método heuristic0 aceptación por umbral [Cm,1999].
2.3 Replicación de Datos
La replicación selecciona copias de fragmentos de datos en más de un sitio en
una base de datos distribuida. L a replicación puede proveer ventajas y desventajas.
Como ventajas se incluye confiabilidad, disponibiliad y posibilidad de procesamiento
en paralelo. Como desventajas se incluyen control de concurrencia, integridad y
recuperación. Estos beneficios y costos son dificiles de evaluar.
Yoshida evalúa esquemas donde se consideran múltiples copias de datos,
principalmente se enfocan en el tiempo de respuesta y costos de comunicación, para ello
hacen uso de simulaciones, comparan dos sistemas el WOUND-WAIT y el DIE-WAIT.
Los esquemas son derivados de un análisis de las relaciones entre las vistas de usuarios
determinadas por las aplicaciones y la ubicación de datos óptima. En una simulación en
que se comparan ambos sistemas, se consideran parámetros como: las vistas de los
usuarios en cada sitio, ubicación de los datos, el radio de actualización, el tiempo de
transmisión comparando el tiempo de procesamiento, y el tamaño de la porción de datos
considerados.
La ubicación de datos Óptima en las que se prefiere el tiempo de respuesta al
considerar múltiples copias que son visibles entre los sitios, nos proporcionará las bases
para realizar las vistas del usuario, de tal forma que coincidan éstas con las copias de los
datos. El tiempo entre llegadas no afecta el costo de comunicación, pero si tiene efecto en el tiempo de respuesta [Yos,1985].
Apears presenta un modelo que hace posible comparar costos por no especificar
las ubicaciones para los planificadores producidos por algoritmos de procesamiento de
consultas arbitrarias.
17

El modelo se aplica en algoritmos heunsticos y “ramificación y acotamiento” para minimizar varias funciones de costos. El autor hace uso de grafos para realizar
suposiciones heuristicas y dar fundamento a sus razonamientos.
Para minimizar el costo de transmisión total, propone un método que determina
los fragmentos a ser ubicados, partiendo de las relaciones en el esquema conceptual, las
actualizaciones y consultas ejecutadas por los usuarios. La ubicación de fragmentos
depende del planificador de procesamiento para satisfacer las peticiones de los usuarios,
basándose en esto, el planificador puede satisfacer las peticiones de diferentes formas,
debido a que los fragmentos se colocan donde la operación así lo requiera. Se utilizan
planificadores estáticos y dinámicos para la ubicación de los datos [Ape,1988].
Stefano consideró una base de datos distribuida con replicación parcial de objetos de datos localizados en una red de anillo de n sitios sujeta a fallas en el canal y
la ubicación en los sitios es seleccionada aleatoriamente. Suponen que cada sitio en la
red puede mantener cualquier número de copias de varios objetos, pero cada sitio debe
mantener cuando más una copia de un objeto en particular. Manejan probabilidades de
lectura y escritura exitosa a los objetos. Las ubicaciones las consideran de dos tipos:
ubicación dependiente, en la que los objetos se ubican en base a UM estrategia en
particular; y ubicación independiente, en donde la ubicación se realiza sin conocer la
ubicación de otros objetos [Ste,1994].
March realizó la ubicación de datos y operaciones en un sistema de
computadoras distribuido. El método que se propone consta de tres pasos: En el primer
paso se analiza el conjunto de consultas para definir el conjunto de fragmentos del
archivo a ubicar. En el segundo paso cada consulta se descompone en un conjunto de consultas simples, cada una de las cuales hace referencia a los fragmentos del archivo, esto puede requerir de operaciones de reunión o unión adicionales si los datos
solicitados han sido fragmentados. En el tercer paso los fragmentos resultantes y las
consultas son usados como entrada para un modelo de optimización resuelto mediante
algoritmos genéticos.

cenidet Capitulo 2
La función objetivo minimiza los costos de operación del sistema incluyendo
comunicación, entrada-salida al disco, procesamiento de CPU y almacenamiento.
Considera las operaciones de lectura y escritura entre los distintos sitios, el mecanismo
de control de concurrencia, así como las resiricciones de capacidad en los nodos y en los
enlaces de la red.
Determina dónde se ubicarán los datos, el grado de replicación y cuál de las
copias de los datos será usada por la consulta y en qué sitio se efectuarán las
operaciones tales como select, project, union yjoin [Mar, 19951.
Tamhankar propone una metodología integrada para fragmentación, ubicación y
replicación de datos en múltiples sitios, de forma tal, que los objetivos de diseño en
términos de tiempo de respuesta, disponibilidad para transacciones y restricciones en
almacenamiento sean adecuadamente direccionados.
La metodologia propuesta se presenta en dos distribuciones que se detallan a
continuación:
Distribución Primaria: El enfoque se desvía hacia los objetivos de diseño de toda la
aplicación.
Paso I: Se reúne la información clave (sitios de actualización, costo de la
actualización, sitios de consulta, y costo de la consulta) para tomar las
decisiones de distribución. Esta información se usa como base para la
realización del análisis detallado de cómo los datos serán fragmentados,
replicados y ubicados. E1 resultado de este paso es una matnz de distribución la cual especifica la distribución de los datos.
Distribución Secundaria: El enfoque se desvía hacia casos individuales de la aplicación.
Paso II: Se relaciona con las transacciones que requieren de una respuesta rápida.
19

Capitulo 2 cenidet
fusu 111: Se'concentra en transacciones que requieren una alta disponibilidad de
los datos.
Puso IY: Dirige los requerimientos relacionados con el espacio de almacenamiento
en sitios específicos.
Dentro de cada paso se realizan varias iteraciones para alcanzar los resultados
deseados. La metodología propuesta es demostrada usando un caso de estudio con dos
aplicaciones diferentes. Se reporta como resultado un mejoramiento de un 35-40 % en el
costo total de tiempo de respuesta [Tam,l998].
Reyes extiende el modelo matemático FURD [Per,1997] con la finalidad de
incorporar costos derivados de tener réplicas de fragmentos e incluir consultas de
lectura y escritura. El modelo toma en cuenta las siguientes consideraciones: Las
unidades de almacenamiento de datos se restringen únicamente a fragmentos verticales,
las capacidades de CPU y las operaciones U 0 de los nodos se consideran ilimitadas, no
así la capacidad de almacenamiento en disco para cada sitio, los costos de
almacenamiento y CPU se asumirán iguales para todos los nodos, se asume que la red
esta completamente conectada, el costo de procesamiento local y el costo de acceso a
disco son ignorados [Rey,2001].
En la Tabla 2.1 se muestran las características principales de los modelos
presentados en la sección 2.1
Así mismo en la Tabla 2.2 se muestran las caractensticas principales de los
modelos presentados en las secciones 2.2 y 2.3. En la penúltima columna (Perez,2000)
se muestran las caractensticas del modelo desarrollado en el presente trabajo de
investigación, el cual contrasta con los trabajos anteriores en el sentido de que es el
único que modela el funcionamiento de un SABDD.
20

Minimizar J 4
tiempo de J 4
Probabilidad J de lectura y
. . .. . .L^ ., * . . . . escntura
.j 4 . : : . . . -. . ,.< ~
' s . ,' . , . . . . . . . i . . ... i .... . . . .Program= ' . .
~~
Capacidaddel J 4 J J
canal
Towlogia de J
21

Capitulo 2 cenidet
. ,. . 'rabia 2.2 Caraciensticas principales de los modelos de ubicación de fragmentos. Modelos Chang' . Ceri Navathe ' I , . Yoshiba 'Ceri ' Apears . Stefaao Mb&b, '"'.Tamhaoluir. Perez . .Reyes
1998 . 2000 ' . 2091 'f.i 4'
, !<* . '.I985 ':. 1986. 1988'',:. 1994 1995 . . . . . . . . . . . . . . ./ . . . . . . . ..
. . . . . . . . . . . . . . . . . . . . . , .>', ,
I '*'!,' .I , ' ..'!'.; . . . . " . . ' ,;,' ..o:., :, . ,, . , :, , .
, ' . ,,, c. :.* ' , I . . . .
,. . . - . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .
, 1 .~ . . - . ' ., . . " .I:/ (,.
. . _ .. . . . . . . . . . . . . . . . . . 3 . ,' ', . J ' . .Parcial. 8 ' 4. , ' . '
I 1 . . . . . . . . . . . . . . . . . . . Método de Función Programación Algoritmo de Solución. Lineal Lineal Entera Energía de
Cohesión
Programación Ramificar Algoritmos Heurística y Acolar Genéticos
Ramificar Ramificar y Acotar, y Acotar Recocido Simulado
Lectura y J J Escritura
J J J
... .*,,J(< . . . . . . .. .. J 4 ' . , J . . . ,
. . .
~~
., , ,. . . ... . - _ . J . .
. . . . . . . . . . . . . . . . . . . . . ' i; > /
Capacidadde <' I . . _ . Almacenamicnlo , .
Minimizar Costos J costos Costos de Costos de Clobales para Comunicación- ' Comunicación
Transac.
Costos de Costos de Costos de Costo total de Comunic. Operaciones Transm. Transm.
22

Capitulo 3 r-irlnt
Capítulo
Metodología Tradicional de Diseño de BDDs
En este capítulo se describe la metodología tradicional para bases de datos
distribuidas. Esta metodología ha sido desarrollada como una extensión al diseño de
bases de datos centralizadas.

Capitulo 3 cenidet
3.1 Metodología Tradicional de Diseño de BDDs
El diseño de la distribución es aún un problema presente en SABDD
comerciales. Su objetivo es determinar las unidades de datos adecuadas para almacenar,
ya sean fragmentos o relaciones completas, así como su ubicación a través de los nodos
de una red. Dado que los accesos a los datos en una BDD, representan costos de
transmisión dependientes de la ubicación física de los mismos, el diseño de la
distribución es un factor relevante en el desempeño de los sistemas distribuidos, ya que
influye directamente en la eficiencia del procesamiento de las consultas. El diseño de la
distribución es solamente una parte del diseño total de una BDD, es en esta fase en
donde se realiza la principal aportación del presente trabajo de investigación.
El proceso de diseño de una base de datos centralizada incluye análisis de
requerimientos, diseño conceptual, diseño lógico y diseño fisico. Este proceso es la
plataforma para la realización del diseiio de una base de datos distribuida mediante la
adición de dos fases: análisis de requerimientos distribuidos y diseño de la distribución.
A continuación se describen cada UM de las fases de la metodología tradicional de
diseño incluyendo el diseño de la dishibución. En la Figura 3.1 se presenta de manera
esquemática el proceso de diseño.
3.1.1 Análisis de Requerimientos
En esta fase se lleva a cabo la recolección de los requerimientos del usuario, es
decir, se obtiene la información referente a las expectativas del usuario. En esta fase se
analizan los objetivos estratégicos de la organización y se determinan los
requerimientos de información que los satisfagan.
3.1.1. I Análisis de Requerimientos de Disíribución
En esta fase se obtiene la frecuencia con la que las aplicaciones se ejecutan
desde cada uno de los sitios, y se recolectan los criterios para la determinación de la
fragmentación sobre la base de datos.
24

cenidet Capitulo 3
+ Usuarios + ANÁLISIS DE REQUERIMIENTOS
1 DISEÑO CONCEPTUAL GLOBAL
1 J
v L-7 DISENO LÓGICO GLOBAL ANÁLISIS DE REQUERIMIENTOS
DE DISTRIBUCI~N
FRAGMENTACI~N VERTICAL
FRAGMENTACI~N HORIZONTAL
FRAGMENTACI~N UBICACI~N Y MIXTA
DISENO DE DISEÑO LÓGICO LA D I S T R I B U C I ~ N
E
u ct E
.=. Q
-0 - .. s
BASESDEDATOSOPERA
Figura 3.1 Metodología tradicional de diseño de BDDs.
25

Capítulo 3 cenidet
3.1.2 Diseño Conceptual Global
El objetivo de esta fase es trasladar los requerimientos del usuario a un modelo
formal, independiente del SABD empleado. En esta fase se integran los requerimientos
de transacciones globales que describen operaciones que el sistema ejecuta sobre los
datos, asi como información estadística sobre estas operaciones. La salida de esta fase
es el esquema conceptual global y el esquema de transacciones globales.
3.1.3 Diseño Lógico Global
En esta fase se lleva a cabo el mapeo del esquema conceptual global hacia el
SABD empleado. Se realiza la normalización del modelo de datos, se definen todas las
restricciones de integridad, se optimiza el esquema de datos para soportar las
transacciones más importantes y críticas, y se especifican las consultas que soporta el
SABD. Su salida es el esquema de datos lógico y el acceso lógico a tablas.
3.1.4 Diseño de la Distribución
En esta fase se determinan las unidades de información en que se dividirá la base
de datos (fragmentos), asi como la ubicación de cada una de ellas a través de los sitios.
Esta fase se ha desarrollado normalmente en dos pasos senados: la fragmentación y la
ubicación de fragmentos
3.1.5 Diseño Físico
En esta fase se establece el mapeo de los esquemas locales al almacenamiento
fisico disponible en el sitio, tomando en cuenta las características y capacidades del
SABD empleado. Se definen las estructuras fisicas para la implementación de la base de
datos y su salida es el lenguaje de definición de datos.
26

capítulo 3
3.2 El Diseño de la Distribución
En esta sección se hablará más a detalle de los aspectos referentes a las etapas,
que de manera separada, dan lugar al diseño de la distribución, es decir, determinación
de fragmentos y determinación de su ubicación y replicación.
3.2.1 Fragmentación
La fragmentación de los datos se ha sugerido en la literatura como una forma de
mejorar el desempeño de los sistemas administradores de bases de datos. Se argumenta
que una relación completa no es una unidad de distribución de datos adecuada
considerando que (1) generalmente las aplicaciones están definidas sobre sólo una parte
de la relación y (2) cuando una misma relación es accedida desde diferentes sitios
pueden suceder dos cosas. Por una lado, todos los sitios que realicen el acceso, excepto
el que almacena la relación, generarán un gran volumen de transferencia de datos (la
relación completa). Por otro lado, se puede replicar la relación completa dando lugar a
un gran volumen de datos adicionales (que no son requeridos por la aplicación). Cou la
finalidad de obtener las unidades de datos adecuadas para su distribución, las relaciones
se pueden dividir de manera horizontal o de manera vertical.
3 En el caso de la fragmentación horizontal la relación R se divide en varios
subconjuntos rl, rz, ___, r., donde cada subconjunto tiene el esquema de relación
original, es decir, cada fragmento tiene los mismos atributos que la relación
original R. Los fragmentos se determinan en base a un predicado que distingue a
las tuplas del fragmento, asignándoles el máximo potencial de localidad con
respecto a las aplicaciones.
P En la fragmentación vertical, también llamada partición de atributos, la
relación R es divida en vanos subconjuntos rl, rz, ..., r,, donde cada fragmento
es resultado de una proyección sobre la relación original. En este caso, cada
fragmento debe incluir la llave primaria de la relación original. El objetivo de
este tipo de fragmentación es agxupar aquellos atributos que son utilizados
juntos con frecuencia.
27

Capitulo 3
D Existe un tercer tipo de fragmentación, la fragmentación mixta. En este caso se
realizan n hgmentos, donde cada uno se obtiene alternando la fragmentación
horizontal y vertical sobre la relación original o sobre un ñagmento previo.
3.2.2 Problema de Ubicación y Replieaeión de Datos
La segunda etapa en el diseño de la dishibución es la ubicación y replicación de
los datos. Esta etapa implica el siguiente problema: si se tiene un conjunto de
fragmentos F = Ifi,fi, ...,J,}, y una red de comunicaciones con un conjunto de sitios S=
{s,, s2, ___, sn) y un conjunto de aplicaciones Q = {qi, qz, ..., 4,,}, el problema consiste
en encontrar la ubicación y replicación Óptima de F en S de manera que el
procesamiento de las consultas Q sea el mas eficiente.
La ubicación y replicación de datos es un problema complejo y su solución no es
trivial debido al número de parámetros que intervienen en el modelado y a la
complejidad de la solución. El espacio de soluciones es muy amplio aun para problemas
de tamaño pequeño. En el capítulo 5 se presenta un modelo matemático que ayuda a
solucionar el problema de ubicación y replicación.
28

Capítulo
Replicación en SQL Server
En este capítulo se presenta un panorama general de la replicación en SQL Server, se
describen los tipos de replicación que se manejan, cada uno de los elementos que intervienen, y como se relacionan.

4.1 introducción
Con la creciente dependencia con respecto a los datos en el mundo de la
empresa, ha comenzado a tomar importancia que los datos estén en el sitio correcto en
el momento correcto. En el pasado, los datos de la empresa se creaban y distribuían por
medio del papel y libros, haciendo que la distribución fuera costosa y llevara tiempo.
Con la llegada de las computadoras, la distribución de los datos empezó a ser más
sencilla. Los primeros sistemas informáticos que se implementaron arnpiiamente fueron
sistemas centralizados. Con ellos, la distribución de datos no era necesaria. Toda la
información que se creaba en la computadora estaba disponible para el resto de la
organización. Cuando los sistemas cliente/servidor empezaron a predominar, no era
extraño que las empresas almacenaran datos en vanas computadoras, ubicadas en
diferentes zonas geográficas. Debido a esto, las computadoras tenían que determinar
cómo los usuarios que necesitaran los datos podían acceder a ellos fácilmente y a
tiempo [Bjeletich, 19991.
4.2 SQL Server
SQL Server es un Sistema Administrador de Bases de Datos Relaciona1
(SABDR), con arquitectura cliente/servidor, que usa Transact-SQL para enviar
peticiones entre la máquina denominada cliente y la máquina denominada servidor (Fig.
4.1).
A P L I C A C I ~ N SQL SERVER
Resultados
Transact SQL GpJ3 SABDR
CLIENTE SERVIDOR,
Figura 4.1 Comunicación entre un cliente y un servidor con SQL Server.
30

Capitulo 4 cenidet
4.2.1 Arquitectura ClientdServidor
SQL Server usa arquitectura clientelstmidor para dividir la carga de trabajo en
tareas que se ejecuten en la máquina servidor de las tareas que se ejecutan en las
computadoras clientes.
> El cliente tiene la responsabilidad de realizar operaciones lógicas y presentar los
datos a los usuarios. El cliente puede estar en una o más computadoras, pero
cabe mencionar que también puede ser instalado en la computadora servidor.
> El servidor de SQL administra bases de datos y asigna los recursos tales como:
memoria y operaciones de disco entre múltiples solicitudes.
4.2.2 Sistema Administrador de Bases de Datos Relaciona1
El (SABDR) es responsable de las siguientes actividades:
3 Mantener la relación entre los datos de una base de datos.
> Asegurar que los datos sean almacenados correctamente (que las reglas de
integridad de las tablas no se violen).
F Recuperación de los datos a un estado consistente en caso de que ocurra una
falla en el sistema.
4.2.3 Transact-SQL
El Instituto Nacional Americano de Estándares (por sus siglas en inglés, ANSI)
y la Organización Internacional de Estándares (por sus siglas en inglés ISO) han
desarrollado estándares para SQL. Transact-SQL soporta el estándar publicado en 1992,
llamado ANSI SQL-92.
SQL Server utiliza Transact-SQL como lenguaje de programación y como
medio para realizar consultas. Transact-SQL es una versión del Lenguaje Estructurado
de Consultas (por sus siglas en ingles SQL).
31

cenidet Capitulo 4
SQL es un conjunto de comandos por medio de los cuales se especifica la
información que se quiere obtener o modificar en la base de datos.
4.3 Replicación
La replicación es el proceso de copiar datos de una base de datos a otra y
mantener un enlace entre ambas de tal forma que los cambios efectuados en cualquiera
de las bases de datos se vean reflejados en todas las bases de datos designadas a tener
UM copia.
Utilizar replicación proporciona las siguientes ventajas:
1. Disminuye el tráfico en la red y carga innecesaria en el servidor, debido a que
los datos se encuentran en diferentes sitios.
Los datos pueden viajar de un único servidor
proporciona una alta disponibilidad y descentralización de los datos.
2. a varios servidores, lo que
4.4 Componentes de la Replicación
Existen 3 diferentes componentes en la replicación, estos componentes son el
servidor de publicación, el servidor de distribución, y el servidor de suscripción (Figura
4.2).
El servidor de publicación contiene la o las bases de datos que se van a publicar.
para Permite que los datos de las bases de datos publicadas estén disponibles
suscripción, y envía actualizaciones al servidor de distribución.
El servidor de distribución contiene la base de datos de distribución (a la cual
también se le denomina base de datos de almacenamiento y reenvío), y almacena los
cambios que fueron enviados desde la base de datos de publicación a los servidores de
suscripción. Cabe mencionar que la maquina que contiene el software para el servidor
de distribución puede también contener el software para el servidor de publicación. Un
servidor de distribución puede dar soporte a varios servidores de publicación.
32

cenidet Capítulo 4
El servidor de suscripción contiene una copia de la base de datos que está
siendo distribuida. Cualquier cambio hecho en la base de datos distribuida se envía y se
aplica a la copia. Los suscriptares al igual que los publicadores pueden realizar
actualizaciones sobre los datos, sin embargo, un suscriptor que actualiza no es lo mismo
que un publicador.
Es importante mencionar dos conceptos que se utilizan durante la suscripción:
artículo y publicación.
Un articulo es simplemente UM sola tabla o un subconjunto de filas o columnas
de una tabla, que está disponible para su publicación. Un artículo siempre es parte de
una publicación. Una publicación es un grupo de uno o más artículos, y es la unidad
básica de la replicación.
O Mantiene las bases de datos fuente.
O Permite a los datos estar disponibles para replicación.
*:e Recibe los datos modificados. I
I .:. Almacena las I I coDias de los datos. I I I
e:. Recibe y almacena los cambios.
;'= ~...~ O Envia los cambios . " al suscriptor.
Figura 4.2 Componentes de la replicación
4.5 Suscripciones
Antes de que un servidor de suscripción pueda recibir datos procedentes de un
servidor de publicación, debe suscribirse a artículos o publicaciones. Las suscripciones
pueden ser de extracción o de inserción (Figura 4.3).
33

4.5.1 Suscripciones de Extracción
El servidor de suscripción configura y administra las suscripciones de
extracción. En este caso, el servidor de suscripción extrae la publicación del servidor de
publicación. La ventaja más importante es que las suscripciones de extracción permiten
a los administradores del sistema, en los servidores de suscripción, elegir las
publicaciones que quieren recibir. En las suscnpciones de extracción, publicar y
suscribir son acciones separadas no necesariamente realizadas por el mismo usuario.
Normalmente, este tipo de suscripción es el mejor cuando la publicación no requiere
una alta seguridad.
4.5.2 Suscripciones de Inserción
El servidor de publicación crea y gestiona las suscripciones de inserción. En la
práctica, el servidor de publicación inserta la publicación en el servidor de suscripción.
La ventaja de utilizar este tipo de suscnpciones es que toda la administración se realiza
en una ubicación central. La publicación y la suscripción pueden realizarse al mismo
tiempo y se pueden configurar muchos suscnptores a la vez.
Publicación
- Suscripción inserción , A Suscriptor I
Suscripción Entraccion -19cTI
Publicación B
}H Suscriptor 2
Figura 4.3 Suscripciones de inserción y de extracción.
34

Capítulo 4 cenidet
4.5.3 Suscripciones Anónimas
Una suscripción anónima es un tipo especial de suscripción de extracción que,
normalmente, se usa cuando se están publicando bases de datos en Internet.
Generalmente la información acerca de los suscnptores, incluyendo los datos de
rendimiento, se almacena en el servidor de distribución. En el caso de que se tenga una
gran cantidad de suscriptores o que no se desee disponer de información detallada de
ellos, se pueden permitir las suscnpciones anónimas a una publicación. Las
suscripciones anónimas siempre son creadas por el suscnptor. Éste es responsable de
asegurar que la suscripción esté sincronizada.
4.6 La Base de Datos de Distribución
La base de datos de distribución es un tipo especial de base de datos, instalada
en el servidor de distribución. Esta base de datos se conoce como la base de datos de
almacenamiento y reenvío, que contiene todas las transacciones que esperan a ser
distribuidas a cualquier suscnptor. Esta base de datos recibe las transacciones enviadas
desde cualquier base de datos publicada y las almacena hasta que se envían a los
suscriptores.
4.7 Agentes de Replicación
SQL Server contiene agentes de replicación, que son responsables de las
diferentes acciones que se llevan acabo durante el proceso de replicación.
4.7.1 Agente de Instantáneas
El agente de instantáneas es responsable de preparar el esquema y los archivos
de datos iniciales de los procedimientos almacenados y tablas publicadas, almacenar la
instantánea en el servidor de distribución y registrar información sobre el estado de
sincronización en la base de datos de distribución. Cada publicación tendrá su propio
agente de instantáneas, que se ejecuta en el servidor de distribución.
35

Capitulo 4 cenidet
4.7.2 Agente de Lector de Registro
El agente de lector de registro es responsable de trasladar las transacciones
marcadas para duplicación desde el registro de transacciones de la base de datos
publicada a la base de datos de distribución. Cada base de datos publicada utilizando la
duplicación transaccional dispone de su propio agente de lector de registro, que se ejecuta en el servidor de distribución.
4.Z3 Agente de Distribución
El agente de distribución traslada los trabajos de instantáneas y transacciones
almacenadas en la base de datos de distribución a los suscriptores. Cuando se crea una
nueva suscripción de inserción, las publicaciones transaccionales y de instantánea
definidas para sincronización inmediata tendrán su propio agente de distribución, que se ejecutará en el servidor de distribución. Aquellas publicaciones para las que la
sincronización inmediata no se habilite, compartirán un agente de distribución, que se ejecutará en el servidor de distribución. Las suscnpciones de extracción para
publicaciones transaccionales o por instantánea tienen un agente de distribución que se
ejecuta en el suscriptor.
4.8 Planificación de la Replicación en SQL Server
El proceso de compartir y trasladar datos se denomina a menudo distribución de
datos. Cuando se elige un método para distribuir datos, se deben tener en cuenta vanos
factores. Estos factores son: temponzación y latencia de la replicación; la independencia
o autonomía de las ubicaciones individuales, y la capacidad de particionar los datos para
evitar conflictos.
4.8.1 Temporización y Latencia de los Datos Replicados
Hay disponibles dos modelos en el proceso de distribución de datos: el modelo
denominado coherencia transaccional inmediata, el cual requiere que los datos deben
36

Capítulo 4 cenidn
estar sincronizados en todo momento, y el modelo denominado coherencia transaccional
latente, en el cual la sincronización de los datos no es estricta.
SQL Server implementa la distribución de datos según el método de coherencia
transaccional inmediata a través de un protocolo de compromiso en dos fases. Este
protocolo, denominado a veces 2PC, asegura que las transacciones sean comprometidas
o anuladas en todos los servidores. De esta forma, se asegura que todos los datos en
todos los servidores estén sincronizados en todo momento. Uno de los principales
inconvenientes de la coherencia transaccional inmediata es que requiere una red de área
local (por sus siglas en inglés LAN) de alta velocidad para funcionar. Este tipo de
solución no es factible para entomos grandes con muchos servidores, ya que se pueden
producir intenupciones de red ocasionales.
La coherencia transaccional latente se implementa en SQL Server a través de la
replicación. La replicación permite que los datos se actualicen en todos los servidores,
pero el proceso no se realiza de forma simultánea. El resultado son datos “en tiempo
casi real”. Esto se conoce como coherencia transaccional latente, ya que existe un
retardo entre los datos actualizados en el servidor principal y los datos replicados. En
este escenario, s,i se pudieran detener las modificaciones de datos en todos los
servidores, todos los servidores acabarían teniendo los mismos datos. A diferencia del
modelo de coherencia en dos fases, la duplicación funciona tanto en redes de área local
como de área extendida, con enlaces lentos o rápidos.
4.8.2 Autonomía del Sitio
Cuando se planifica una aplicación distribuida, se debe tener en cuenta el efecto
que tendrá en un sitio una operación realizada en otro. Esto se conoce como autonomía
del sitio. Un sitio con una autonomía completa puede continuar funcionando sin
conectarse a ningún otro sitio. Las aplicaciones que utilizan el protocolo de compromiso
en dos fases, confian en que todos los demás sitios podrán aceptar de forma inmediata
cualquier cambio que se les envíe. En el caso de que un sitio no esté disponible,
entonces ninguna transacción podrá comprometerse en ningún servidor.
37

4.8.3 Métodos de Disíribución de Datos
Después de determinar la latencia transaccional y la autonomía del sitio, es
importante seleccionar el método de distribución de los datos que mejor se ajuste a las
necesidades de la empresa. Cada mktodo de distribución de datos proporciona una
cantidad diferente de autonomía del sitio y latencia.
Transacciones distribuidas. Las transacciones distribuidas aseguran que todos los
sitios tienen exactamente los mismos datos en todo momento.
Duplicación transaccional con suscriptores de actualización. Los usuarios
pueden modificar los datos en la ubicación local y dichos cambios se aplican a la base
de origen al mismo tiempo. Eventualmente, los cambios se duplican a otros sitios. Este
tipo de distribución de datos combina la duplicación y las transacciones distribuidas.
Duplicación iransaccional. Con la duplicación transaccional los cambios se
hacen sólo en la ubicación de origen y se envían a los suscnptores. Puesto que los cambios sólo se efectúan en un sitio, no se producen conflictos.
Duplicación de instantáneas con suscriptores de actualización. Este método es
muy similar a la duplicación transaccional con suscriptores de actualización, ya que los
usuarios pueden modificar los datos en la ubicación local y dichos cambios se aplican a
la base de datos de origen al mismo tiempo. Después la publicación completa que se ha
modificado se duplica a todos los suscriptores. Este tipo de duplicación proporciona una
mayor autonomía que la duplicación transaccional.
Duplicación de instantáneas. Una copia completa de la duplicación se envía a
todos los suscriptores, lo que incluye tanto los datos modificados como los no
modificados.
Duplicación de mezcla. Todos los sitios hacen cambios en los .datos locales de
forma independiente y luego actualizan el publicador.
38

4.9 Tipo de Replicación Seleccionado
Para el desarrollo del presente trabajo de investigación se utilizó el tipo de
replicación transaccional con suscriptores actualizables. A continuación dicho tipo se
describe ampliamente.
4.9.1 Duplicación Transaccional.
Es el proceso de capturar las transacciones del registro de transacciones de la
base de datos publicada y aplicarlas a las bases de datos de suscripción. Con la
duplicación transaccional de SQL Server se puede publicar parte de una tabla, la tabla
completa o uno o más procedimientos almacenados, como si fueran un artículo. Todos
los cambios se almacenan en la base de datos de distribución, y luego se envían y
aplican a las bases de datos suscritas, en el mismo orden en que originalmente se hicieron. En la duplicación transaccional, los cambios se realizan en el publicador. Estos
cambios se propagan a los demás sitios casi en tiempo real. Dado que, normalmente, los
cambios sólo se hacen en el servidor de publicación, no se producen conflictos.
Usualmente, los suscriptores de inserción tardan en recibir las actualizaciones desde el
publicador un minuto o menos, dependiendo de la velocidad y disponibilidad de la red.
Los suscnptores también pueden establecer suscnptores de extracción. Esto es Útil para
usuarios desconocidos, que no siempre se conectan a la red.
El agente de instantáneas, el agente de lector del registro y el agente de
distribución realizan la duplicación transaccional. El agente de instantáneas crea los
archivos que contienen el esquema de la publicación y los propios datos. Los archivos
se almacenan en la carpeta de instantáneas del servidor de distribución y luego los
trabajos de distribución se registran en la base de datos de distribución. El agente de
lector de registro supervisa el registro de transacciones en la base de datos de
distribución. El agente de distribución pasa a los suscriptores la instantánea inicial y las
transacciones almacenadas en la base de datos de distribución.
39

Capitulo 4 cenidet
4.9.1.1 El Agente de Instantáneas
El agente de instantáneas es el proceso que asegura que ambas bases de datos
partan del mismo punto inicial. Este proceso se conoce como sincronización. El proceso
de sincronización se realiza cada vez que hay un nuevo suscnptor en una publicación.
La sincronización sólo ocurre una vez para cada nuevo suscriptor y asegura que
el esquema y los datos de la base de datos sean réplicas exactas en ambos servidores.
Después de la sincronización inicial, todas las actualizaciones se hacen mediante
duplicación.
, En el momento en el que un nuevo servidor se suscribe a una publicación, se
realiza la sincronización. Después de que el proceso de sincronización se ha iniciado y
los archivos de datos se han creado, cualquier inserción, aciualización y borrado se almacena en la base de datos de distribución. Estos cambios no se duplicarán en la base
de datos de suscripción mientras no se complete el proceso de sincronización.
Cuando se inicia el proceso de sincronización, sólo se ven afectados los nuevos
suscnptores. Cualquier suscnptor que ya haya sido sincronizado y que haya recibido
modificaciones no se verá afectado. El conjunto de sincronizaciOn se aplica a todos los
servidores que estén esperando la sincronización inicial. Después de que el esquema y
los datos se han creado de nuevo, todas las transacciones que se han almacenado en el
servidor de distribución se envían al suscriptor.
4.9.1.2 El Agente de Lector de Registro.
Después de que la sincronización inicial ha tenido lugar, el agente de lector de
registro pasa las transacciones del servidor de publicación al servidor de distribución.
Todas las acciones que modifiquen datos en una base de datos, se almacenan en el
registro de transacciones de dicha base de datos. Este registro no sólo se usa en el
proceso automático de recuperación, sino también en el proceso de duplicación.
40

Se crea un artículo para publicación y se activa la suscripción, todos los
elementos de dicho artículo se marcan en el registro de transacciones. Para cada
publicación de una base de datos, un agente de lector de registro lee el registro de
transacciones.
Cuando este agente encuentra un cambio en el registro, lo lee y lo convierte en
instrucciones de SQL que se corresponden con la acción que se tomó en el artículo. A
continuación, las instrucciones de SQL se almacenan en una tabla en el servidor de
distribución. Éste leerá los cambios y los ejecutará en el servidor de suscripción.
4.9.1.3 El Agente de Distribución
Una vez que se han pasado las transacciones a la base de datos de distribución,
el agente de distribución inserta los cambios en los suscriptores o los extrae del
distribuidor, dependiendo de cómo se hayan configurado los servidores. Todas las
acciones que modifican los datos en el servidor de publicación, se aplican a los
servidores de suscripción en el mismo orden en que se realizaron.
4.9.1.4 Limpieza
Al momento de que se instala la duplicación en un servidor SQL Server, se
añaden tres tareas para mantener el proceso de duplicación en ejecución durante largos
periodos de tiempo: la limpieza del agente, la limpieza de transacciones y la limpieza
del historial. Estas tareas conservan la información de las transacciones durante un
periodo de tiempo, denominado periodo de conservación, luego, las transacciones se
borran de la base de datos de distribución.
4.9.1.5 Suscriptores de Actualización Inmediata.
Se pueden configurar las publicaciones para admitir suscnpciones de
actualización inmediata, en las que el suscriptor puede modificar los datos duplicados.
41

Este proceso utiliza el compromiso en dos fases para enviar transacciones ai
publicador, de modo que se pueda escribir una aplicación como si estuviera
actualizando un único sitio. En esta configuración, sólo el publicador y el suscnptor que
requiera modificar los datos necesitan estar disponibles. Después de realizado el cambio
en el suscnptor y enviado al publicador, se puede enviar a los restantes suscriptares de
la publicación. Los suscnptores que realizan actualizaciones no tienen autonomía
completa, ya que el publicador debe estar disponible en el momento de la modificación
de los datos.
42

Capítulo 4 cenidet
.Capítulo
Modelo Matemático Propuesto
En este capítulo se presenta un modelo que unifica la fragmentación,
ubicación y replicación de datos. Las expresiones matemáticas desarrolladas
modelan el funcionamiento de la replicación de tipo transaccional del Sistema
Aministrador de Bases de Datos Relaciona1 SQL Server.

5.1 Introducción
En este trabajo se desarrolla un modelo que considera a los atributos como
unidades de datos independientes que pueden ubicarse y replicarse en los diferentes
sitios de una red. El problema de diseño de disiribución es formulado como un problema de programación lineal entera. En particular, se modela la fragmentación,
ubicación y replicación del comportamiento de la replicación transaccional de datos en
un ambiente distribuido empleado por el Sistema Administrador de Bases de Datos
Relaciona1 (por sus siglas en inglés, SABDR) SQL Server.
Otra característica del modelo es que permite generar nuevos esquemas de
replicación que se adaptan a los cambios en los patrones de acceso en las aplicaciones
de lectura o escritura. Logrando así, que el esquema de la base de datos se adapte a la
característica dinámica de un sistema distribuido y evitando la degradación de dicho
sistema.
En la siguiente sección se describe el modelo de fragmentación, ubicación y
replicación dinámica de datos, así mismo se explican los términos que lo componen, los
paráinetros que intervienen, y la forma de cómo obtener sus valores.
5.2 Función Objetivo
La expresión (1) representa la función objetivo desarrollada en este trabajo de
investigación, la cual modela los costos de transmisión y de acceso a los datos usando
tres términos, cada uno de los cuales con sus respectivos parámetros se explican en las
siguientes subsecciones.
5.2.1 Costos de Transmisión de Datos para Aplicaciones de Consulta
44

Capitulo 5 cenidet
La expresión (2) modela los costos de transmisión de los datos necesarios para
satisfacer cada una de las aplicaciones de lectura que son efectuadas desde cada uno de
los sitios. Esto es, para cada consulta que se efectúa desde cada nodo se multiplica la
frecuenciaAi con que se realiza la aplicación de lectura k desde el sitio j por el costo de
acceder a cada uno de los aiributos que participan en la aplicación.
S.2.I .I Frecuencia de Acceso en Aplicaciones de Lectura fe
Este parámetro puede ser obtenido a traves del monitoreo de las aplicaciones de
consultas que se realizan en un SABDD. Como lo muestra [Kauffinan,2000], dicho
parámetro puede ser obtenido empleando principios de Bases de Datos Activas.
Para el desarrollo de pruebas de este trabajo de investigación, a este parametro
se le asignaron valores mínimos que nos permitieran validar la funcionalidad del
modelo.
5.2. I .2 Atributos por Consulta qkm
Este parámetro se obtiene a partir del análisis de las aplicaciones de lectura mas
relevantes en el sistema.
5.2.1.3 NUmero de Paquetes de Comunicación lkm
Este parámetro puede ser obtenido a través de la expresión (2.1),
donde:
p , : se refiere al tamaño en bytes del atributo ni
45

sk : selectividad de la aplicación de lectura k (número de tuplas retornadas cuando la
consulta k es ejecutada [Elm,1989])
PA : tamaño del segmento del paquete de comunicación. Este parámetro puede variar
entre las distintos tipos de redes. Cuando es necesario que se fragmenten los
paquetes que se desplazan de una red que admite paquetes de gran tamaño, a otra
cuyo tamaño de los datos tenga un limite inferior. El tamaño de los paquetes se
ajusta al sitio cuyo tamaño sea menor. Cuando tiene lugar una fragmentación de
paquetes, se copia la información sobre el origen y el destino en cada uno de los
nuevos paquetes creados. También se guarda en cada uno de ellos la información
necesaria para que el dispositivo receptor pueda ensamblar los paquetes
fragmentados y formar la secuencia original [Ray,1998]. Durante. la
configuración de conexión, cada sitio anuncia el tamaño de sus paquetes, si un
sitio no tiene activada esta opción por omisión se utilizan 536 bytes. Con fines prácticos y para el desarrollo de este trabajo se les estableció un tamaño de 536
bytes.
5.2.1.4 Costo de Transmisión entre el Sitio i y el Sitio j c;,
Experimentalmente se puede obtener con los siguientes pasos:
1. Para cada sitio medir el tiempo que tarda el manejador en hacer una consulta que
acceda a atributos ubicados en cada uno de los sitios del sistema.
Realizar nuevamente la operación anterior en tiempo diferente.
Obtener un promedio de tiempo de transmisión para cada sitio.
Asignar un costo para cada unidad de tiempo.
2. 3.
4.
5.2.2 Costos de Transmisión de Datos para Aplicaciones de Escritura
46

La expresión (3) modela los costos de transmisión de los datos necesarios para
satisfacer cada una de las aplicaciones de escritura que son efectuadas desde cada uno
de los sitios.
Esto es, para cada aplicación de escritura que se efectúa desde cada nodo se
multiplica la frecuencia y, con que se realiza la consulta k desde el nodoj por el costo
del protocolo de actualización cu, y esto a su vez por el costo de acceder a cada uno de
los sitios que contienen atributos replicados en la aplicación de escritura.
5.2.2.1 Costo de Actualización cu
Debido a que este costo puede variar de un sistema administrador de bases de
datos a otro, este aspecto se incluye como un parámetro cuyo valor debe ser
suministrado por el diseñador de la base de datos.
Experimentalmente se puede obtener con los siguientes pasos:
1. Medir el tiempo que tarda el manejador en ejecutar una aplicación de
actualización desde un sitio hacia la copia primaria.
Medir el tiempo de propagación de las actualizaciones hacia los sitios que
contienen las réplicas.
Repetir los pasos 1 y 2 en diferente tiempo.
Obtener un promedio de tiempo de actualización de datos.
Asignar un costo para una unidad de tiempo.
2.
3.
4.
5 .
S.2.2.2 Frecuencia de Acceso en Aplicaciones de Escritura f ’h ,
Este parámetro es obtenido de la misma forma que como se explica en la
sección 5.2.1.1, la diferencia radica en que en f k, se monitorean las aplicaciones de
escritura.
41

5.2.2.3 Tamaño en Bytes de la Instrucción de SQL I
@,)/PA (3.1) donde:
Pk : tamaño en bytes de la instrucción ken SQL para efectuar una actualización
PA : tamaño del segmento del paquete de comunicación.
5.2.2.4 Costo de Comunicación entre el Sitio de la Copia Primuria p y el Sitio i cpi
Dado que el protocolo de actualización de réplicas utilizado por SQL Server es
el método de copia primaria, se requiere que el diseñador determine un sitio y que será
designado a tener la copia primaria. El sitio p contiene todos los atributos involucrados
en el sistema.
Experimentalmente se puede obtener con los siguientes pasos:
1. Medir el tiempo que tarda el manejador en transmitir datos desde el sitio de la
copia primaria hacia cada uno de los sitios que contienen réplicas de datos.
Realizar nuevamente la operación anterior en tiempo diferente.
Obtener un promedio de tiempo de transmisión para cada sitio.
Asignar un costo para cada unidad de tiempo.
2. 3.
4.
5.2.3 Costos de Transmisión para Copiar Datos de un Nodo a Otro.
La expresión (4) modela los costos de transmisión para copiar los datos del sitio p
designado a ser la copia primaria hacia un nodo designado a tener una copia o réplica de
datos. Es decir, el costo de transmisión del atributo m desde el sitio de la copia primaria
'a otro sitio se multiplica por el número de paquetes de comunicación requeridos para
transmitir el atributo m.
48

5.2.3. I Parametro d,,,
Parámetro que puede ser obtenido a través de la expresión (4.1)
@,,, * CA)/PA
donde:
pm : CA :
PA :
tamaño en bytes del ahibuto m;
cardinalidad de la relación;
tamaño del segmento del paquete de comunicación.
(4.1)
5.3 Restricciones Intrínsecas del Problema
Debido a que se consideran ahibutos replicados, se especifica que todos los
atributos deben estar almacenados al menos en el sitio designado a contener la copia
primaria. Cuando existan copias de ahibutos, se modela la consideración de usar la
copia con menor costo al efectuarse una consulta. Se considera la restricción de
ubicación mientras no se exceda la capacidad del sitio. Estas restricciones se expresan
de la siguiente manera:
1) x _ = I V m
todos los atributos deben estar ubicados en el sitio que será
designado a contener la copia primaria.
donde:
p = sitio donde reside la copia primaria;
cada atributo m debe ser ubicado en un sitio i que ejecute
al menos una consulta k que lo use;
49

Capítulo 5
3) ns xmi - wjm, 2 o J
V m , i
m
Vi
cuando exista un atributo m ubicado en un sitioj, puede ser
accedido desde un sitio i;
donde:
ns= número de sitios del problema a resolver;
modela la condición de acceder desde el sitioj a sólo un
sitio i donde se encuentre ubicado el atributo m;
la suma de los atributos que forman un
fragmento asignados en el sitio i no debe
exceder su capacidad;
donde:
CSi=capacidad del sitio i.
5.4 Solución del Modelo
El modelo presentado es formulado como un problema de programación lineal
entera y puede ser resuelto mediante las técnicas de programación lineal tradicional. Se
escribió un programa en C++ ver 1.0 que a partir de los datos de entrada genera los
coeficientes de la función objetivo y las restricciones del modelo. El número de
variables de decisión y de restricciones de un modelo a resolver, están en relación
directa con el número de atributos que intervienen en la aplicación y el número de sitios
en la red.
La solución es obtenida mediante la utilización de bibliotecas comerciales de
Programación Lineal Entera de la compañía LINDO, las cuales utilizan como método
de solución el algoritmo de “Ramificar y Acotar”.
50

Capítulo 5 cenidet
5.4.1 Método de Ramificar y Acotar
La idea general del método de ramificar y acotar, es realizar una partición
del conjunto de soluciones factibles de un problema dado, en subconjuntos que
no se traslapen. Posteriormente se calculan los limites para el valor de la mejor
solución en cada subconjunto. Después por medio de un análisis se eliminan
ciertos subconjuntos (la solución que no era factible no se incluye en la nueva
región factible). De esta manera se enumeran parcialmente (en oposición a la
enumeración total) todas las soluciones factibles existentes. El proceso de dividir
y eliminar continúa hasta que puede demostrarse que ninguno de los
subconjuntos tiene una solución óptima que sea mejor que una solución entera
calculada con anterioridad.
Las estrategias que se utilizan en el método de ramificar y acotar son
Ramificación y Acotamiento.
La estrategia de Ramificación consiste en dividir la región factible en
segmentos dando como resultado nuevos subproblemas menores. El proceso de
solución al nivel del subproblema será más simple. El propósito de la
ramificación es eliminar parte del espacio continuo que no es factible para el
problema entero. Esto se logra adicionando a cada subproblema restricciones
mutuamente exclusivas que conservan los puntos enteros factibles del problema
original, pero que eliminan la región continua delimitada por ellas.
La estrategia de Acotamiento obtiene límites de las soluciones. Se tiene un
límite superior del óptimo global en el momento en que el algoritmo produzca
una solución entera. Este límite cambia siempre que una mejor solución entera
aparece durante la ejecución del algoritmo. Por otro lado, el costo mínimo de
cada subproblema creado por ramificación establece un limite inferior para el
valor de la mejor solución entera de este subproblema. Una buena estrategia de
acotamiento puede contribuir significativamente a la eficiencia del método, si
selecciona los subproblemas más prometedores y recorta búsquedas que no
lleguen a mejores soluciones.
51

Capitulo 5 cenidet
A continuación se presenta el algoritmo del método de Ramificar y Acotar.
Paso 1. Inicialización
El método inicia considerando que el problema lineal relajado cubre la
región factible completa, a la cual se le llama nodo raíz. Se resuelve el problema
lineal. Si la solución es entera, entonces se ha encontrado la solución óptima y el
proceso termina. Si el problema relajado usado para determinar el límite inferior
. es infactible, entonces el problema original también es infactible y se da por
terminado el proceso. En caso contrario, se continúa con los siguientes pasos.
Paso 2. Ramificación
La región factible se particiona en dos o más regiones, usando alguna
regla de ramificación. Esos subproblemas forman una partición del problema
original y se convierten en hijos del nodo raíz. El algoritmo se aplica
recursivamente a los subproblemas, generando un árbol de subproblemas.
Paso 3. Acotamiento
Se determinan cotas inferiores para los nuevos nodos. Para cada nuevo
nodo, se obtiene en x la mejor solución lineal del subproblema correspondiente,
la cual se convierte en una cota inferior z (x ) que delimita el valor de la mejor
solución entera del nodo. Cada nodo es un problema candidato para ser elegido
en el siguiente paso.
Paso 4. Selección
Se selecciona un nodo candidato desde el cual se ramifica. Cada nuevo
nodo se sondea o se excluye. Para esto, se determina la mejor solución lineal del
nodo, si es entera, entonces se encontró un Óptimo local del problema original,
pero no es necesariamente el Óptimo global. Este límite superior puede ser usado
para podar el resto del árbol. Esto es, si el límite inferior de un nodo excede una
solución entera, la solución Óptima global no se encuentra en el subespacio de la
región factible representada por el nodo. Por lo tanto, el nodo puede ser ignorado.
52

Capitulo 5 cenidet
Paso 5. Terminación
El proceso de búsqueda continúa nuevamente a partir del paso de
ramificación y termina cuando todos los nodos han sido resueltos o podados. La
mejor de todas las soluciones enteras es aquélla con el menor costo. Si existe,
hemos encontrado el óptimo global, si no existe, el problema no tiene solución.
5.5 Complejidad del Modelo
La ubicación y replicación de datos es un problema complejo y su solución no es
trivial debido al número de parámetros que intervienen en el modelado y a la
complejidad de la solución, ya que el espacio de soluciones es muy amplio aún para
problemas de tamaño pequeño.
La formulación del problema ha sido considerado como NPCompleto
[Lin,1995]. Ademas, si se considera que esta ubicación puede ser resuelta considerando
réplicas, esto es, permitiendo que los fragmentos se encuentren replicados en diversos
sitios de la red, el número de alternativas crece considerablemente.
Para mostrar el número de posibles alternativas que debenan evaluarse si se
hiciera una enumeración exhaustiva de todas las posibles ubicaciones de los fragmentos,
se presenta un ejemplo que consta de 5 sitios y 4 fragmentos.
En las siguientes secciones se calcula el número de posibles asignaciones.
5.5.1 Ubicación no Replicada
Si no existen réplicas de los fragmentos en los sitios, el número de ubicaciones
paraffragmentos ens sitios está dado por sf[Dow, 19821.
53

Capítulo 5 cenidet
Los calculos se realizan como se muestra en la Figura 5.1, dando lugar a
5*5*5*5 = 54= 625 alternativas.
4 diferentes ubicaciones del fragmento A en los sitios Fragmento A
4 diferentes ubicaciones del fragmento B en los sitios
Fragmento B
4 diferentes ubicaciones del fragmento C en
Fragmento C los sitios
4 diferentes ubicaciones del fragmento Den los SltlOS
Fragmento D
Figura 5.1 Ubicación no replicada de fragmentos.
5.5.2 Ubicación Replicada
Si existen réplicas de los fragmentos en los sitios, entonces el numero de
alternativas se incrementa notablemente (2’-lf[Per,1999].
Como lo muestra la figura 5.2 para este caso existen (z4 -1 )5 = 759 375
altemativas.
54

Capítulo 5 cenidet
L Fragmento A
Fragmento B
Fragmento C
If__t_Lf Fragmento D
Figura 5.2 Ubicación replicada de fragmentos.
2'- I ubicaciones del fragmento A en los sitios
2 4 - I ubicaciones del fragmento A en los sitios
z 4 - 1 ubicaciones del fragmento A en los sitios
2'- I ubicaciones del fragmento A en Inc sitios
55

Capítulo 6
Capítulo
Casos de Prueba
En este capítulo se presentan diferentes casos de pruebas realizados al modelo.
Dichas pruebas tienen como propósito mostrar la funcionalidad del modelo
implementado en el presente trabajo de investigación.

Capitulo 6 cenidet
6.1 Casos de Pruebas en el Modelo
En las siguientes secciones se describen diferentes casos de prueba realizados al
modelo, el objetivo de cada prueba, los resultados esperados, los datos de entrada, así
como los resultados obtenidos.
Los casos de prueba presentados en este capítulo han sido diseñados de un
tamaño mínimo, con la finalidad de que el lector verifique que el modelo genera
esquemas de ubicación y replicación que se adaptan a los datos estadísticos de entrada.
Sin embargo, el modelo es capaz de funcionar para casos de prueba que involucren 500
restricciones y 1000 variables.
6.1.1 Prueba 1: Aplicaciones de Lectura
Objetivo de la prueba:
Demostrar que el uso de réplicas, cuando se tienen sólo consultas de
lectura, reduce los costos de transmisión debido a que los accesos se realizan
en la copia local.
Datos de entrada:
> 3 sitios Si, S2, S3 .
hLa capacidad de almacenamiento en disco para cada sitio i (CSJ se muestra en la
Tabla 6- 1.
Tabla 6.1 Capacidad de almacenamiento en disco para cada sitio.
~
57

Capítulo 6 cenidet
pm
m1
P 3 aplicaciones kl , k2, k3. k Las aplicaciones kl, k2, k3 son de lectura.
P3 atributos mi, m2, m3.
P El tamaño en bytes de cada atributo m (pm) se muestra en la Tabla 6.2
Tamaño en bytes del atributo
10
4km mi
ki
k2
ki
J
P En la Tabla 6.3 se muestra cómo cada consulta k utiliza diferentes atributos m
( q k m ) .
m2 7 m
J J
J
J
hi si s2
ki 50
k2 50
k3
P En la Tabla 6.4 se muestra cómo cada consulta k se efectúa con diferente
frecuencia desde cada sitioj (f&).
s3
50
P El tamaño en bytes del bloque de comunicación (PA) es de 536.
P L a seiectividad de cada consulta se muestra en la Tabla 6.5.
58

cenidet Capitulo 6
Tabla 6.5 Selectividad de las consultas.
Ci SI Sl o s2 10
s3 20
>El costo de actualización (Cv) es de 5 .
P El sitio designado a contener la copia primaria es el sitio I .
PEl costo de transmisión (Cji) entre sitios se muestra en la Tabla 6.6.
'S2 s3 10 20
O 30
30 O
Tabla 6.6 Costo de transmisión entre sitios.
Resultados esperados:
Debido a que las frecuencias con que se ejecutan las consultas desde cada uno de
los sitios son las mismas, se espera que en Si se ubiquen los atributos nti, rn2, rn3. En S2
el aiributo m2. En S3 el atributo m3.
Formulación del modelo:
SUBJECT TO
2) X1,l +X2,1 +X3,1 = 3
3) 3X1 ,1 -W1, l , 1 -W2 ,1 ,1 -W3 ,1 ,1~= O
4) 3X2,1-W1,2,1-W2,2,1-W3,2,1>= O
5) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O
6 ) 3X3,1-W1,3,1-W2,3,1-W3,3,1>= O 59

Capitulo 6 cenidet
7) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= 0
8) Wl, l , l = 1
9) w1,2,1 +w1,2,2 = 1
11) w2,1,1 = 1
12) w2,2,1 + w2,2,2 = 1
10) W1,3,1 + Wl,3,3 = 1
13) W2,3,1 + W2,3,3 = 1
14) W3,1,1 = 1
15) W3,2,1 + W3,2,2 = 1
16) W3,3,1 + W3,3,3 = 1
17) 50 X1,l + 100 X2,l + 150 X3,l <= 800
18) 1OOX2,2<= 500
19) ljOX3,3<= 500
END
Resultados de la prueba:
En la Figura 6.1 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo y el tiempo de solución del modelo.
Aplicación de lectura Tiempo de Solución del Modelo en seg: 0.060000 u
Funcion Objetivo = 7.462687
Figura 6.1 Esquema de ubicación y replicacióo para aplicaciones dc sólo lectura.
60

Capitulo 6 cenidet
Conclusión:
Debido a que en esta prueba sólo se tienen consultas de lectura los atributos se
replican en los sitios donde se efectúan consultas que los usen. De esta forma se
disminuyen los costos de transmisión entre sitios, debido a que los accesos se realizan
de manera local. Si no existieran réplicas, el valor de la función objetivo se
incrementaria debido a que mz y mj se ubicarian en un solo sitio, y los demás sitios que
efectuaran consultas que involucraran dichos atributos, tendrían que acceder al sitio de
ubicación del atributo.
6.1.2 Prueba 2: Apliraciones de Esrritura
Objetivo de la prueba:
Mostrar que, cuando se tienen únicamente aplicaciones de escritura, no es
conveniente tener réplicas de los atributos.
Datos de entrada:
Los datos de entrada son iguales que para la prueba que se muestra en la sección
6.1 . I , la única diferencia radica en que las consultas para la prueba 2 son de escritura, es
decir:
> Las consultas k,. kz, k3 son de escritura.
Resultados esperados:
Que los datos permanezcan en el sitio destinado a contener la copia primaria.
Formulación del modelo:
MIN 934.7015 X2,2+2804,104X3,3+ 18 W1,2,2+ 55 W1,3,3 + 18 W2,2,1
+ 55 W3,3,1
61

Capítulo 6 cenidet
SUBJECT TO
2) X1,l +x2,1 +x3 ,1 = 3
3) 3x1,1-w1,1,1-w2,1,1-W3,1,1>= 0
4) 3 x2,1 -w1,2,1 -w2,2,1 - W3,2,1 >= 0
5) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O 6) 3X3,1-W1,3,1-W2,3,1-W3,3,1>= O
7) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O 8) W l , l , l = 1
9) w1,2,1 +w1,2,2 = 1
11) w2,1,1 = 1
12) w2,2,1 + w2,2,2 =
10) W1,3,1 + W1,3,3 = 1
13) W2,3,1 + W2,3,3 =
14) W3,1,1 = 1
15) W3,2,1 + W3,2,2 =
16) W3,3,1 + W3,3,3 =
17) 50X1,l + 1OOX2,l + 150X3,l <= 800
18) 1OOX2,2<= 500
19) 150X3,3<= 500
END
Resultados de la prueba:
En la Figura 6.2 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo, y el tiempo de solución del modelo.
Conclusión:
Cuando se tienen aplicaciones únicamente de escritura, no es conveniente replicar los atributos. Lo anterior es porque las réplicas se deben mantener consistentes,
lo que significa que si se realiza una aplicación de escritura sobre un atributo y dicho
atributo tiene réplica, existirá un costo por mandar la aplicación de escritura sobre la
réplica, incrementando así el valor de la función objetivo del modelo.
62

Capítulo 6 cenidet
A Atributo
Aplicación de escritura
Tiempo de Solución del Modelo en seg: 0.020000
Funcion Objetivo = 73.000000
Figura 6.2 Esquema de ubicación y replicación para aplicaciones de sólo escritura
6.1.3 Prueba 3: Aplicaciones de Lectura y Escritura
Objetivo de la prueba:
Demostrar que, cuando se tienen consultas tanto de lectura como de escritura, el
modelo optimiza el costo de transmisión en el sistema.
Datos de entrada:
Los datos de entrada son iguales que para la prueba que se muestra en la sección
6.1.1, la diferencia se establece a continuación:
P Las consultas k , y k2 son de lectura y k3 es de escritura.
63

Capítulo 6 cenidet
Resultados esperados:
Se espera que el atributo m3 no se replique debido a que k3 es una aplicación de
escritura.
Formulación del modelo:
MIN 1.865672 X2,2 + 1404.851 X3,3 + 18 W1,2,2 + 55 W1,3,3 + 18 W2,2,1
+ 55 W3,3,1
SUBJECT TO 2) X1,l +X2,1 +X3,1 = 3
3) 3 X1,l -Wl , l , l - W2,1,1 - W3,1,1 >= O
4) 3 X2,l - W1,2,1 - W2,2,1 - W3,2,1 >= O
5) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O
6) 3 X3,l - W1,3,1 - W2,3,1 - W3,3,1 >= O
7) 3 X5,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O
8) WI,l,l = 1
9) w1,2,1 + w1,2,2= 1
11) w2,1,1 = 1
12) w2,2,1 + w2,2,2 = 1
IO) W1,3,1 + W1,3,3 = 1
13) W2,3,1 + W2,3,3 = 1
14) W3,1,1 = 1
15) W3,2,1 + W3,2,2 = 1 16) W3,3,1 + W3,3,3 = 1
17) 50 X1,l + 100 X2,l + 150 X3,l <= 800
18) IOOX2,2<= 500
19) 150X3,3<= 500
END
64

Capítulo 6 cenidet
Resultados de la prueba:
En la Figura 6.3 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo y el tiempo de solución del modelo.
sitios
/m\ Atributo
Atributo Replicado
Aplicación de Lectura
Aplicación de Escritura
Tiempo de Solución del Modelo en seg: 0.050000
Funcion Objetivo = 56.865673
Figura 6.3 Esquema de ubicación y replicación para apticaciones de lectura y escritura.
Conclusión:
Cuando existen aplicaciones tanto de leciura como de escritura, el modelo
matemático optimiza los costos totales de transmisión de las aplicaciones. Para el caso
específico de la presente pmeba, se tiene que k, (aplicación de lectura) y k3 (aplicación
de escritura) utilizan m3. El modelo no replica m,, porque las frecuencias y los costos de
transmisión son los mismos, además m j se encuentra inicialmente ubicado en el sitio de
la copia primaria
65

Capitulo 6 cenidet
kz
ki
6.1.4 Prueba 4: Cambio en Frecuencias de Aplicaciones
10
10
Objetivo de la prueba:
Demostrar que, al cambiar las frecuencias de ejecución de las
aplicaciones, se genera un nuevo esquema de ubicación y replicacidn que
optimiza los costos de transmisión.
Para demostrar esta prueba se presenta en la subsección 6.1.4.1 un caso de
prueba con un número determinado de frecuencias de ejecución de aplicaciones, y en la
subsección 6.1.4.2 se realizan modificaciones en las frecuencias de ejecución de dicho
caso.
6.1.4.1 Esquema de Ubicación y Replicación para Aplicaciones de Lectura con Mismo
Número de Frecuencias
Datos de entrada:
Los datos de entrada son iguales que para la prueba que se muestra en la sección
6.1.1. Las diferencias se establecen a continuación:
>Las consultas k, .k2 y k3 son de leciura.
>En la Tabla 6.7 se muestra cómo cada consulta k se efectúa con diferente
frecuencia desde cada sitio j fij).
Tabla 6.7 Frecuencias de emisión de la consulta k desde cada sitio j.

Capitulo 6 cenidet
qkm
ki
k2
k3
mi m2 m3
J J J
J J
J
Resultados esperados:
Debido a que las frecuencias con que se ejecutan las consultas desde cada uno de
los sitios son las mismas, se espera que en Si se ubiquen los atributos mi, mz. m3. En S,
los atributos m2. m3. En S3 el atributo m3.
Formulación del modelo:
MiN 0.9328358 X1,2 + 1.865672 X2,2 + 5.597015 X3,3 + W1,1,2 + 3 W1,2,2
+ 11 W1,3,3 +W2,1,1 + 3 W2,2,1 + 11 W3,3,1
SUBJECT TO 2) X1,l +X2,1 +X3,1 = 3
3) 3 X1,l - Wl,l, l - W2,1,1 - W3,1,l >= O
o 5) 3X2,1-W1,2,1-W2,2,1-W3,2,1>= O
6) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O
7) 3 X3,i - W1,3,1 - W2,3,1 - W3,3,1 >= O
8) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O
4) 3 x1,2 - w1,1,2 - w2,1,2 - w3,1,2 >=
9) Wl,I, l +w1,1,2= 1
10) w1,2,1 + w1,2,2 = 1
12) w2,1,1 + w2,1,2 = 1
11) W1,3,1 + W1,3,3 = 1
13) W2,2,1 + W2,2,2 = 1
14) W2,3,1 + W2,3,3 = 1
15) W3,1,1 + W3,1,2 = 1
61

Capítulo 6 cenidet
16) W3,2,1 + W3,2,2 = i
17) W3,3,1 + W3,3,3 = i
18) 50 x1,1 + 100 x2,1,+ 150 x3, l <= 800
19) 50 X1,2 + 100 X2,2 <= 500
20) 150X3,3<= 500
END
Resultados de la prueba: '
En la Figura 6.4 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo, y el tiempo de solución del modelo.
Frecuencia 1 Frecuencia 10.
Sitios
A Atributo
Frecuencia
Tiempo de Solución del Modelo en seg: 0.060000
Funcion Objetivo = 8.395522"
Figura 6.4 Esquema de ubicación y replicación para aplicaciones de lectura con mismo número de frecuencias.
68

Capitulo 6 cenidet
hi Si ki 50
kz
k3
6.1.4.2 Esquema de Ubicación y Replicación para Aplicaciones de Lectura con Número
de Frecuencias Diferentes
sz s3
1
10
Datos de entrada:
Los datos de entrada son iguales que para la prueba que se muestra en
la subsección 6.4.1.1. La diferencia se establece a continuación:
3 En la Tabla 6.9 se muestra cómo cada consulta k se efectúa con diferente
frecuencia desde cada sitioj cf&
Tabla 6.9 Frecuencias de emisión de la consulta k desde cada sitio j.
Resultados esperados:
Debido a que la frecuencia con que se ejecuta k, se incrementó y la frecuencia
con que se ejecuta kz disminuyó, se espera que en SI se ubiquen los ahibutos mi, m2, n13,
y en S3 se ubique el atributo m3.
Formulación del modelo:
MIN 0,9328358 X1,2 + 1.865672 X2,2 + 5.597015 x3,3
+ 9 W1,1,2 + 18 W1,2,2+55 W1,3,3 + 11 W3,3,1
SUBJECT TO
2) X1,l + X2,l + X3,l = 3
3) 3 X1,l - Wl, l , l - W2,1,1 - W3,1,1 >= O
4) 3x1,2-w1,1,2-w2,1,2-w3,1,2>= O
69

Capítulo 6 cenidet
5 ) 3 m , 1 -w1,2,1 - w2,2,1 - W3,2,1 >= 0
6) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2>= 0
7) 3 X3,l - W1,3,1 - W2,3,1 - W3,3,1 >= O
8) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O
9) Wl,l , l +w1,1,2= 1
10) w1,2,1 + w1,2,2 = 1
12) w2,1,1 + w2,1,2 = ' 1 13) W2,2,1 + W2,2,2 = 1
14) W2,3,1 + W2,3,3 = I
15) W3,1,1 + W3A2 = 1
16) W3,2,1 + W3,2,2 = 1
17) W3,3,1 + W3,3,3 = 1
18) 50 X1,1+ 100 X2,l + 150 X3,i <= 800
11) W1,3,1 + W1,3,3 = 1
19) 50 X1,2 + 100 x2,2 <= 500
20) 1SOX3,3<= 500
END
Resultados de la prueba:
En la Figura 6.5 se muestra la ubicación y replicación de los atributos,
el valor de la función objetivo, y el tiempo de solución del modelo.
70

Capítulo 6 cenidet
Frecuencia 50
S2
GI Frecuencia
1
Tiempo de Solución del Modelo en seg: 0.060000
Fuiicion Objetivo = 5.597015
Frecuencia 10
Sitios
A Atributo
Replicado
Aplicación de Lectura
gura 6.5 Esquema de ubicación y replicacih para aplicaciones de lectura con número frecuencias diferentes.
Conclusión :
Al cambiar las frecuencias de ejecución de las aplicaciones, el modelo obtiene
nuevos esquemas de ubicación y replicación que optimizan los costos de transmisión.
6.1.5 Prueba 5: Capacidad de Almacenamiento Restringida
Objetivo de la prueba:
Mostrar que, cuando se restringe la capacidad de almacenamiento en disco en
cada sitio, se repercute en el esquema de ubicación y replicación así como también en el
valor de la función objetivo.
71

Capítulo 6 cenidet
Para demostrar esta prueba se presenta en la subsección 6.1.5.1 un caso de
prueba cuyos sitios tienen capacidad de almacenamiento suficiente para ubicar los
atributos, y en la subsección 6.1.4.2 se presenta el caw en el cual existe un sitio que no
tiene capacidad de almacenamiento suficiente y obliga al modelo a ubicar los atributos
optimizando los costos de transmisión.
6.1.5.1 Esquema de Ubicación y Replicacibn con Espacio de Almacenamiento
Suficiente para Ubicar los Atributos
Datos de entrada:
Los datos de entrada son iguales que para la prueba quc se muestra en la sección
6.1.4.1.
Resultados esperados:
Se espera que en Si se ubiquen los atributos mi, r n z , mi. En Sz los atributos W ,
ni]. En SI el atributo n i l .
Formulación del modelo:
MIN 0.9328358 X1,2 + 1.865672 X2,2 + 5.597015 X3,3 + Wl,1,2 + 3 W1,2,2
+ 11 W1,3,3 +W2,1,1 + 3 W2,2,1 + 11 W3,3,1
SUBJECT TO 2) X1,l +X2,1 +X3,1 = 3
3) 3Xl,l-W1,1,l-W2,1,1-W3,1,1>= O
4) 3X1,2-W1,1,2-W2,1,2-W3,1,2>= O
5) 3 X2,l - W1,2,1 - W2,2,1 - W3,2,1 >= O
6) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O
7) 3 X3,l - W1,3,1 - W2,3,i - W3,3,1 >= O
8) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O
72

Capítulo 6 cenidet
9) Wl,l,l + w1,1,2= 1
10) w1,2,1 + w1,2,2= 1
12) w2,1,1 + w2,1,2 = 1
11) W1,3,1 + W1,3,3 = 1
13) W2,2,1 + W2,2,2 = ' 1 14) W2,3,1 + W2,3,3 = 1
15) W3,1,1 + W3,1,2= 1
16) W3,2,1 + W3,2,2 = 1
17) W3,3,1 + W3,3,3 = 1
18) 50 X1,l + 100 X2,1 + 150 X3,l <= 800
19) 50 X1,2 + 100 X2,2 <= 500
20) 15OX3,3 <= 500
END
Resultados de la prueba: En la Figura 6.6 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo, y el tiempo de solución del modelo.
A A A
SI S,
€3 500 Bytes
a Sitios
A Atributo
Atributo Replicado ,A ,..?Y ,.j>
Tiempo de Solución del Modelo en seg: 0.060000
Funcion Objetivo = 8.395522
Almacenamiento
Figura 6.6 Esquema de ubicación y replicación con espacio de almacenamiento suficiente para ubicar los atributos.
73

Capitulo 6 cenidet
6.1.5.2 Esquema de Ubicación y Replicación con Espacio de Almacenamiento Restringido en SZ
Datos de entrada:
Los datos de entrada son iguales que para la prueba que se muestra en la sección
6.1. I . En esta prueba se restringe la capacidad de almacenamiento en SZ.
F La capacidad de almacenamiento se muestra en la tabla 6.1 O.
Tabla 6.10 Capacidad de almacenamiento en disco para cada sitio.
s3 500
Resultados esperados:
Se espera que en S, no exista ubicación de atributos debido a que no se tiene la
capacidad de almacenamiento necesaria.
Formulación del modelo:
MIN 0.9328358 X1,2 + 1.865672 X2,2 + 5.597015 X3,3 + W1,1,2 + 3 W1,2,2
+ 1 1 W1,3,3 + W2,l , I + 3 W2,2,1 + 1 1 W3,3,1
SUBJECT TO 2) X1,l +X2,1 +X3,1 = 3 3) 3X1,1-W1,1,1-W2,1,1-W3,1,1>= O
4) 3X1,2-W1,1,2-W2,1,2-W3,1,2>= O
5) 3X2,1-W1,2,1-W2,2,1-W3,2,1>= O
6) 3 X2,2 - W1,2,2 - W2,2,2 - W3,2,2 >= O
74

Capítulo 6 cenidet
7) 3x3,~-W1,3,1-W2,3,1-W3,3,1>= O
8 ) 3 X3,3 - W1,3,3 - W2,3,3 - W3,3,3 >= O
9) WI, l , l +w1,1,2= 1
IO) w1,2,1 + w1,2,2 = 1
12) w2,1,1 + w2,1,2 = 1
1 I ) W1,3,1 + W1,3,3 = 1
13) W2,2,1 + W2,2,2 = 1
14) W2,3,1 + W2,3,3 = 1
15) W3,1,1 + W3,1,2 = 1
16) W3,2,1 + W3,2,2 = 1
17) W3,3,1 + W3,3,3 = 1
18) 50 X1,l + 100 X2,1+ I50 X3,l <= 800
19) 50 X1,2 + 100 X2,2 <= 5
20) 150 X3,3 <= 500
END
Resultados de la prueba:
En la Figura 6.7 se muestra la ubicación y replicación de los atributos, el valor
de la función objetivo, y el tiempo de solución del modelo.
Conclusión:
La capacidad de almacenamiento de cada uno de los sitios repercute en los
esquemas de ubicación y replicación generados con el modelo matamático propuesto,
así como también en el valor de la función objetivo. En la prueba mostrada en la
subsección 6.1.5.2, la capacidad de almacenamiento de S2 es muy pequeña (5 bytes) y
no se pueden ubicar los atributos mi y m2. Por lo tanto, la aplicación kz que utiliza los
aiributos mi y mz , tendrá que acceder al sitio donde se encuentren ubicados (Si), lo cual
incrementa el valor de la función objetivo.
75

Capitulo 6 cenidet
Capacidad de Almacenamiento
Tiempo de Solución del Modelo en seg: 0.060000
Funcion Objetivo = 9.597015
Figura 6.7 Esquema de ubicación y replicación con espacio de almacenamiento restringido en s,.
76

Capítulo 7
Capítulo
-~ ~
Comentarios Finales y Trabajos Futuros
En este capítulo se presentan las conclusiones obtenidas con el presente trabajo
de investigación, incluyendo trabajos futuros relacionados.

Capitulo 7 cenidet
7.1 Comentarios Finales
En este trabajo se muestra que es factible evitar la degradación de una aplicación
distribuida que funciona sobre la plataforma de SQL Server, mediante la
implementación del modelo FURD extendido, el cual genera nuevos esquemas de
ubicación y replicación que se adaptan a los cambios en los patrones de explotación de
los datos.
Uno de los aspectos relevantes de esta investigación fue el desarrollo de un
conjunto de expresiones matemáticas que modelan el funcionamiento de la replicación
de tipo transaccional del sistema manejador de bases de datos SQL Server versión 7.0.
De acuerdo a la literatura especializada no aparece reportado trabajo previo alguno que
haya seguido el método de solución de esta investigación.
Otros resultados relevantes fueron los siguientes:
1. El trabajo desarrollado es pionero en modelar la ubicación y replicación de
datos enfocada hacia un manejador de bases de datos comercial.
2. De acuerdo con la literatura especializada, se han propuesto diversos métodos para
el diseño de la distribución, los cuales han dividido e1 problema en fases seriadas.
En contraste con estos métodos, el modelo matemático propuesto muestra, que es
factible integrar ubicación 'y replicación en un solo paso, permitiendo resolver el
problema de una manera más eficiente.
3. Se formuló una función objetivo que permite ubicar y replicar los atributos de las relaciones en los nodos de manera optimizada, minimizando los costos de
transmisión de datos y considerando restricciones de capacidad de los sitios.
4. La formulación del modelo permite su solución utilizando paquetes comerciales de
programación lineal entera. Para este trabajo se utilizó el paquete comercial llamado
LMDO, el cual utiliza como método exacto de solución el de Ramificar y Acotar.
78
It

Capitulo 7 cenidet
5. Se tipifican las consultas como aplicaciones de lechira o escritura, modelando de
esta forma la realidad de manera más fiel.
6 . Tradicionalmente se realizaban copias de fragmentos completos. Con el modelo
propuesto, se obtiene una,granulandad más fina de las réplicas de datos, al permitir
replicar a nivel de atributos.
7. La implementación del modelo matemático sirve de apoyo para diseñadores de
bases de datos, principalmente porque se minimizan los costos de transmisión de
datos y existe una mayor disponibilidad de ia información.
7.2 Sugerencias de Trabajos Futuros
Existen dos líneas para continuar con los trabajos de esta investigación, una está
relacionada con el manejador de bases de datos a utilizar y la otra es extender el
modelo matemático.
Manejador de Bases de Datos:
P Diseñar modelos para ubicación y replicación utilizando tipos de replicación
diferentes al presentado en este trabajo con el manejador Microsoft SQL Server
7.0.
b Diseñar modelos para ubicación y replicación utilizando un manejador de bases
de datos diferente como por ejemplo ORACLE.
b Implementar el modelo como un módulo de un manejador de bases de datos, con
la finalidad de automatizar el diseño de distribución de datos.
Extender el modelo matemático:
P Integrar en el modelo restricciones de capacidad de canales de comunicación.
3 Análisis de sensibilidad de los parámetros involucrados en el presente modelo.
79

Referencias cenidet
REFERENCIAS
[Ape,1988]
[Bab,1977]
[Cas,l972]
[Cer,1983]
[Cer,1987]
[Cha,1980]
[Cha,1982]
[Che,1980]
[Chu,1969]
[Cou,1994]
Apears P.M.G., “Data Allocation in Distributed Database Systems”, ACM Transactions on Database Systems. Vol. 13, No. 3, 1988, pp. 263 - 304.
Babad J., “A Record and File Partitioning Model”, Comunications of The ACM, Vol. 20, No. 1, 1977, pp.22-30.
Casey R.G., “Allocation of Copies of a File in a information Network”, AFIPS, 1972, SJCC. 40, PP.617-625.
Cen S. Navathe S. y Wiederhold G., “Distribution Design of Logical Database Schemes”, IEEE Trans. on Software Engineering, 1983, vol. SE- 9, NO. 4, pp. 487-503.
Cen S. Pemici B. y Wiederhold G., “Distributed Database Design Methodologies”, Proc. IEEE, 1987, vol. 75, No. 5, pp. 533-546.
Chang S.K., y Cheng W.H., “A Methodology for Structured Database Descomposition”, IEEE Transactions on Software Enginiering, 1980, pp. 205-218.
Chang S.K., y Liu, A.C., “File Allocation in a Distributed Database”, Journal of computer and information Sciencie, 1982.
Chen P.P.S., y Akoka J., “Optimal Desing of Ditnbuted Iinformation Systems”, LEEE Transactions on Computers, 1980, pp.1068-1080.
Chu W.W., “Optimal File Allocation in Multiple Computer Systems”, IEEE Transactions on Computers, 1969, pp. 885-889.
Coulons G. Dollimore J. Y Kindberg T., ”Distributed Systems Concepts and Design”, Addison-Wesley Publishing Company, 1994, Cap. 11.
80

Referencias a [Date,1995] Date C.J., “An Introduction to Database Systems”, Addison-Wesley
Publishing Company, Volume I, 6th ed. 1995.
Dowdy L.W. y Foster D.V. “Comparative Models of the File Assignment Problem”, ACM Computing Surveys, vol. 14, no. 2, 1982, pp. 288-313.
[Dow,1982]
[Eis,1976] Eisner M. y Severance D. “Mathematical Techniques for Efficient Record Segmentation in Large Chared Databases”, ACM, 1976.
[Elm,1989] Elmasn y Navaje., “Fundamentals of Database Systems”, Edit. Benjamin and Cummings, 1989. pp. 150.
[Esw,1974] Eswaran K.P., ‘:Placement of Records in a File and File Allocation in a Computer Network”, iFP, North-Holland, 1974.
[Ha1,1986] Hale D. “A Framework for Distributed Database Fragment Allocation Utilizing Semantic Meta-data to Compose Data Fragments”, Ph.D. Dissertation, University of Wisconsin-Milwaukee, 1986.
[Hev,1988] Hevner A. R. y,Rho A,, "Distributed Data Allocations Strategies”, In Advances in Computers, 1988, pp. 121-155.
[Hof,1976] Hoffer J. “An Integer Programming Formulation of Computer Database Desing Problems”, International Journal Of Computer and Information Sciences 11, 1976, pp.29-48.
[Ira,1979] Irani K.B. y Kabbaz N.G., “A Model for a Combined Comunication Network Design and File Allocation for Distributed Databases”, Proc. 1” International Conference On Distributed Computer Systems, 1979.
[Jai,1986] Jain H.K. y Duiia A,, “Distributed Computer System Design: A Multicntena Decision-Making Methodology”, Decision Science, 1986, pp.437-453.
[Jai,1987] Jain H.K. y Kulkami U.R., “Simulation Model o f a Distributed DBMS”, Joint National Meeting of ORSNTIMS, New Orleans, 1987.
81

[Kau,2000]
IKu1,1989]
[Mar,1977]
[Mar,1995j
[Mab,1976j
[Mor,1977]
[Nav,1984]
[Ozs,1999j
[Per,1998]
IRayJ9981
Kauffmann M., “Módulo para la Detección y Registro de Eventos Relevantes para el Diseño Adaptable de Bases de Datos Distribuidas Empleando Reglas ECA”, tesis de maestría, Departamento de Ciencias Computacionales, Centro Nacional de Investigación y Desarrollo Tecnológico, Cuernavaca, Mor., Feb. 2000.
Kulkami U.R., “An integrated Support System for Design of Distributed Data Bases”, tesis Ph D. The University of Wisconsin-Milwaukee, May 1989.
March S. y Severance D., ‘The Determination of Efficient Record Segmentation and Blocking Factors for Shared Data Files”, ACM Transactions on ‘Database Systems, 1977.
March S. y Rho., “Allocating Data and Operations to Nodos in Distributed Database Desing”, Transactions on Knowledge and Data Enginneering, vol. 7, 1995.
Mahmoud S. y Riordon J.S. “Optimal Allocation of Resorces in Distributed Information Networks”, ACM Transactions on Database Systems, 1976, pp. 993-1003.
Morgan H.L. y Levin K.D., “Optimal Program and Data Locations in Computer Networks”, Comunications ACM, 1977, pp.315-321.
Navathe S. Cen S. Wiederhold G. y Dou J., “Vertical Partitioning Algorithms for Database Design”, ACM Transactions On Database Systems, Vol. 9. No. 4. Stanford, 1984, pp. 680-710.
Ozsu M. y Valduries P., “Principles of Distributed Database Systems”, Prentice Hall, N .J., 1999.
Perez J. Romero D. Frausto J. Pazos R. Rodriguez G. y Reyes F., “Dynamic Allocation of Vertical Fragments in Distributed Databases UCing the Threshold Accepting Algorithm”, Proceeding of the loth iASTED International Conference on Parallel and Distributed Computing and System, Las Vegas, 1998, pp 210-213.
Ray J., ‘TCP/IP”, edit. Prentice Hall, 1998, pp 198,

Referencias
[Ram,1979]
[Ram,1999]
[Rey,2001]
[Tam,1998]
[Tan,1997]
Ramamoorthy C.V. y Wah B.W., “The Placement of Relations on a Distributed Relational Database”, Proceedings 1 I’ International Conference on Distributed Computer Systems, 1979.
Ramírez P.S., “Extensión al Modelo FURD para Incorporar los Costos de Almacenamiento y de Acceso a Fragmentos”, tesis de maestría, Dpto. de Ciencias Computacionales, Centro Nacional de investigación y Desarrollo Tecnológico, 1999.
Reyes S. F., “Extensión al Modelo FURD para Incorporar la Replicación de Datos”, tesis de maestría, Dpto. de Ciencias Computacionales, Centro Nacional de Investigación y Desarrollo Tecnológico, Cuernavaca, Mor. Próxima a publicación, 2001.
Tamhankar A.M. y Sudha Ram., “Database Fragmentation and Allocation: an integrated Methodology and Case Study”, 1998.
Tanenbaum AS., “Redes de Computadoras”, Edit. Prentice Hall, 3“ Edición, 1997.
83