capÍtulo 7 codificacion de canal (parte ii...
TRANSCRIPT

CAPÍTULO 7
CODIFICACION DE CANAL (PARTE II ) Este capitulo trata con codigos convolucionales. El capitulo 6 presento los fundamentos de bloques de códigos lineales, los cuales son descriptos por dos enteros, n y k y una matriz generadora o polinomial. El entero k es el número de bits de datos que forman una entrada a un bloque codificador. El entero n es el número total de bits de la codeword de salida del codificador. Una característica de los códigos de bloques lineales es que cada codeword n-tuple esta solamente determinada por el mensaje de entrada k-tuple. La relación k/n es llamada razon del código (una medida de la cantidad de redundancia agregada). Un código convolucional esta descripto por tres enteros n, k y K , donde la relación k/n tiene el mismo significado ( información por bit codificado) que para los códigos de bloque, aunque n no define un bloque o longitud de la codeword como en el bloque de códigos. El entero K es un parámetro conocido como la limitación de longitud, la cual representa el número de k-tuple estados en el registro de desplazamiento del codificador. Una característica importante de los códigos convolucionales, diferente de los códigos de bloques, es que el codificador tiene memoria – El n-tuple emitido por el procedimiento de la codificación convolucional no es solamente una función de una k-tuple entrada, es también función de las previas K-1 k-tuples entradas-.En la practica, n y k son enteros pequeños y K es variable para controlar la capacidad y complejidad del código. 7.1 Codificación Convolucional En la figura 1.2 presentamos un típico diagrama de bloques de un sistema de comunicación digital. Una versión de este diagrama funcional, focalizada prinzipalmente sobre la codificación / decodificación convolucional y parte de modulación / demodulación del enlace de comunicación, es mostrada en la figura 7.1. La fuente del mensaje de entrada esta denotada por la secuencia m=m1,m2,...........,mi, donde mi representa un dígito binario (bit) e i es un índice de tiempo. Para ser preciso, uno debe denotar los elementos de m con un índice para la clase de asociación ( por ejemplo, para códigos binarios, 1 o 0 ) y un índice para el tiempo (o la ubicación dentro de la secuencia ). Aunque en este capitulo, por comodidad, el índice es solamente usado para indicar el tiempo. Asumiremos que cada mi tiene la misma probabilidad de ser uno o cero y es independiente de dígito a digito. Siendo independiente, la secuencia de bits carece de cualquier redundancia; esto es; el conocimiento del bit mi no da información del bit mj ( i distinto de j) .El codificador transforma cada secuencia m en una única secuencia de codeword U=G(m). Si bien la secuencia m solamente define la secuencia U, una característica de los códigos convolucionales es que un k-tuple dado dentro de m no define solamente su n-tuple asociado dentro de U, ya que la codificación de cada K-tuple no es solo una función de cada k-tuple, sino que es también función de los K-1 k-tuples de entrada que lo preceden. La secuencia U puede ser particionada en una secuencia de ramas de palabras : U1 , U2 , ..... Ui. Cada rama de palabras Ui esta compuesta de símbolos de código binarios, a veces llamados símbolos del canal, bits del canal o bits de código, los bits de los símbolos del código del mensaje de entrada no son independientes. En un aplicación típica de comunicación, la secuencia de codeword U modula una forma de onda s(t). Durante la transmisión, la forma de onda s(t) es contaminada con ruido, resultando una forma de onda recibida s^(t) y una secuencia demodulada Z=Z1 , Z2 ,......,Zi como indica la figura 7.1. La tarea del decodificador es hacer una estimación m^ = m^1 , m^2 ,......,m^i, de la secuencia del mensaje original, usando la secuencia recibida Z junto con un conocimiento previo del procedimiento de codificación. Un codificador convolucional general, mostrado en la figura 7.2 esta mecanizado con registro de kK- estado de corrimiento y n sumadores, este registro de corrimiento de estado y n sumadores de modulo-2, donde K es la limitación de la longitud.
1

La limitación de longitud (constrint length) representa el número de k-bits de corrimiento sobre los cuales un simple bit de información puede influenciar la salida del codificador. En cada unidad de tiempo, k bits son desplazados dentro de los primeros k-estados del registro; todos los bits en el registro son desplazados k-estados a la derecha y las salidas de los n sumadores son muestreadas secuencialmente para producir los símbolos binarios del código o bits del código. Estos bits de código son luego usados por el modulador para especificar las formas de ondas a ser transmitidas sobre el canal. Dado que hay n bits de código para cada grupo de entrada de k bits de mensajes, la relación de código es k/n bit de mensaje por bit de código, donde k< n. Consideraremos solamente los codificadores convolucionales binarios mayormente usados para los cuales k=1 – Esto es, aquellos codificadores en los cuales los bits del mensaje son desplazados dentro del codificador de a un bit por vez, aunque la generalización a alfabetos de orden mas alto es existente [1 ,2]. Para un codificador con k=1 a la i-esima unidad de tiempo, el bit del mensaje mi es desplazado dentro del primer estado del registro de corrimiento; todos los bits previos en el registro de corrimiento son desplazados un estado a la derecha, y como en el caso mas general, las salidas de los n sumadores son secuencialmente muestreadas y transmitidas. Dado que hay n bits de código por cada bit de mensaje, la relación del código es 1/n. Los n símbolos de código ocurriendo en el tiempo ti incluyen la i-esima rama de palabra , Ui=u1i,u2i, .....,uni ,donde uji (j=1,2,...,n) es el j-esimo símbolo de código perteneciente a la i-esima rama de palabra. Note que para la relación del codificador 1/n el kK-estado del registro de corrimiento puede ser referido simplemente como un K-estado registro , y el limite de longitud K, que fue expresada en unidades de k-tuples estados, puede ser referida como una limitación de longitud (constrint length) en unidades de bits. 7.2 REPRESENTACION DEL CODIFICADOR CONVOLUCIONAL Para describir un código convolucional, uno necesita caracterizar la función de codificación G(m), o sea que dada una secuencia de entrada m, uno puede computar la secuencia de salida U. Ciertos métodos son usados para representar un codificador convolucional, los mas populares son la conexión pictorial, vectores de conexión o polinomiales, el diagrama de estado, el diagrama de árbol y el diagrama trellis. Ellos son descriptos luego, uno por uno.
7.2.1 REPRESENTACIÓN DE CONEXIÓN Usaremos el codificador convolucional, mostrado en la figura 7.3, como un modelo para discutir los codificadores convolucionales. La figura ilustra un codificador convolucional (2,1) con limite de longitud K=3. Hay n=2 sumadores de modulo-2; entonces la relación de código k/n es ½.Cada vez que entra un bit, es desplazado al estado mas a la izquierda y los bits en el registro son desplazados una posición a la derecha. Después el swicht de salida muestrea la salida de cada sumador de modulo-2 (ejemplo: primero el sumador superior, luego el inferior), así formando la pareja de símbolos del código caracterizando la rama de palabra asociada con el bit ingresado. El muestreo es repetido para cada bit ingresado. La elección de las conexiones entre los sumadores y los estados de los registros dados eleva las características del código. Las conexiones no son escogidas o cambiadas arbitrariamente. El problema de escoger conexiones para producir buenas propiedades de distancia es complicado y en general no ha sido resuelto; aunque buenos códigos han sido
2

encontrados mediante la búsqueda computarizada para todas las limitaciones de longitudes menores que aproximadamente 20 [3-5]. A diferencia de un código de bloque que tiene una longitud de palabra n fija, un código convolucional no tiene un tamaño de bloque particular. Aunque, los códigos convolucionales aveces son forzados a un estructura de bloque mediante la truncación periódica. Esto requiere un número de bits ceros añadidos al final de la secuencia de datos de entrada, con el propósito de limpiar o nivelar los bits de datos del registro de corrimiento del codificador. Dado que los ceros sumados no transportan información, la relación de código efectiva cae por debajo de k/n. Para mantener la relación de código cerrada a k/n, el truncado periódico es generalmente hecho tan grande como en la practica. Una manera de representar el codificador es especificar un set de n vectores de conexión, uno por cada sumador de modulo-2. Cada vector tiene dimensión K y describe la conexión del registro de corrimiento del codificador al sumador de modulo-2. Un uno en la i-esima posición del vector indica que el correspondiente estado en el registro de corrimientos esta conectado al sumador de modulo 2,
y un cero en una posición dada indica que no existe una conexión entre el estado y el sumador de modulo-2. Para el ejemplo del codificador en la figura 6.3, podemos escribir el vector de conexión g1 para la conexión superior y g2 para la conexión inferior, de la siguiente manera:
g1 = 1 1 1 g2 = 1 0 1
Ahora consideremos que un vector mensaje m = 1 0 1 es convolucionalmente codificado con el codificador mostrado en la figura 7.3. Los tres bits de mensaje son entrados de a uno en los tiempos t1, t2 y t3 como muestra la figura 7.4. Subsecuentemente, (K-1)= 2 ceros son entrados en los tiempos t4 y t5 para nivelar el registro y en consecuencia asegurar que el final de la cola de los mensajes es desplazada para llenar la longitud del registro. La secuencia vista a la salida es 1 1 1 0 0 0 1 0 1 1, donde el símbolo de la izquierda representa la primera transmisión. La secuencia entera de salida, incluyendo los símbolos del código como resultado de la nivelación , son necesarias para decodificar el mensaje. Para limpiar el mensaje, el codificador requiere un cero menos que el número de estados en el registro, o K-1 bits limpiadores. Otra entrada cero es mostrada en el tiempo t6 para que el lector pueda verificar que la nivelación es completada en el tiempo t5. En consecuencia un nuevo mensaje puede ser entrado en el tiempo t6.
7.2.1.1 RESPUESTA AL IMPULSO DEL CODIFICADOR Podemos aproximar el codificador en términos de su respuesta al impulso. Considere el contenido del registro en la figura 7.3 como un uno moviéndose a través del mismo:
Contenido del registro
Rama de palabra
U1 U2
1 0 0 1 1 0 1 0 1 0 0 0 1 1 1
Secuencia de entrada : 1 0 0
3

Secuencia de salida: 11 10 11 La secuencia de salida para un uno en la entrada es llamada “respuesta al impulso del codificador”. Luego para la secuencia de entrada m = 1 0 1, la salida debe ser encontrada mediante la superposición o la adición lineal de los impulsos de entrada desplazados en el tiempo, como a continuación:
Entrada m Salida 1 11 10 11 0 00 00 00 1 11 10 11 Suma de modulo-2
11 10 00 10 11
Observe que es la misma salida obtenida en la figura 7.4, así demostrando que los códigos convolucionales son lineales, como los códigos de bloques lineales del capitulo 6.
Esto es la propiedad de generar la salida mediante la adición lineal de impulsos desplazados en el tiempo o la convolución de la secuencia de entrada con la respuesta al impulso del codificador, que derivamos del codificador convolucional. A veces, esta caracterización del codificador es presentada en términos de una matriz generadora de orden infinito [6].
4

Note que la relación de código efectiva del ejemplo anterior con una secuencia de entrada de tres bits y una secuencia de salida de 10 bits es k/n = 3/10. Casi un bit menos que la relación ½ que debería haberse esperado ya que cada dato de entrada produce una pareja de bits en el canal de salida. La razón de esta disparidad es que el bit de dato final necesita ser desplazado a través del codificador. Todos los bits del canal de salida son necesarios en el proceso de decodificación. Si el mensaje ha sido grande, digamos 300 bits, la secuencia codeword de salida contendrá 604 bits, resultando una relación de código de 300/604, la cual es mucho mas próxima a ½.
7.2.1.2 REPRESENTACION POLINOMIAL A veces, las conexiones del codificador están caracterizadas por generadores polinomiales, similar al usado en el capitulo 6 para describir la implementación del registro de desplazamiento de realimentación de códigos cíclicos. Podemos representar un codificador convolucional con un set de n generadores polinomiales, uno para c/u de los n sumadores de modulo-2. Cada polinomial es de grado K-1 o menor y describe la conexión del registro de desplazamiento del codificador al sumador de modulo-2, del mismo modo que lo hace un vector de conexión. El coeficiente de cada termino en el polinomial de grado K-1 es 1 o 0, dependiendo si existe o no una conexión entre el registro de desplazamiento y el sumador de modulo-2 en cuestión. Para el codificador del ejemplo en la figura 7.3, podemos escribir el generador polinomial g1(X) por la conexión superior y g2(X) por la conexión inferior, como sigue:
g1(X) = 1+X+X2
g2(x) = 1+X2
donde el termino de mas bajo orden en el polinomial corresponde al estado de entrada del registro. La secuencia de salida es encontrada así:
U(X) = m(X)g1(X) entrelazada con m(X)g2(X) Primero expresamos el vector mensaje m = 1 0 1 como un polinomial – que es m(X) = 1+X2. Asumiremos nuevamente el uso de ceros siguiendo los bits del mensaje, para nivelar el registro. Luego la salida polinomial U(X), o la secuencia de salida U, de la figura 7.3 el codificador puede ser encontrado par el mensaje de entrada m, de la siguiente manera:
m(X)g1(X) = (1+X2)(1+X+X2) = 1+X+X3+X4
m(X)g2(X) =(1+X2)(1+X2) = 1+X4
m(X)g1(X) = 1 +X+0X2+X3+X4
m(X)g2(X) = 1+0X+0X2+0X3+X4
U(X) = (1,1)+(1,0)X+(0,0)X2+(1,0)X3+(1,1)X4
U = 1 1 1 0 0 0 1 0 1 1 En este ejemplo comenzamos con otro punto de vista-normalmente, el codificador convolucional puede ser tratado como un set de registros de desplazamiento de códigos cíclicos-. Nosotros representamos el codificador como generadores polinomiales como los usados para describir códigos cíclicos. Aunque arribamos a la misma secuencia de salida de la figura 7.4 y la misma secuencia de salida del tratamiento de la respuesta al impulso de la sección precedente.
7.2.2 REPRESENTACIÓN DE ESTADO Y DIAGRAMA DE ESTADO Un codificador convolucional pertenece a una clase de aparatos conocidos como “maquinas de estado finito”, el cual es el nombre general dado a las maquinas que tienen una memoria de señales pasadas. El adjetivo finito se refiere al hecho de que hay solamente un número finito de estados únicos que la maquina puede encontrar. ¿Que es lo pretendido para el estado de una maquina de estado finito?. En el sentido mas general, el estado consiste de la cantidad mas chica de información que, junto con una entrada corriente a la maquina, puede predecir la salida de la maquina. El estado provee alguna información de los eventos de señalización pasados y el restringido set de posibles salidas en el futuro. Un estado futuro esta restringido por el estado pasado. Para un codificador convolucional con una relación 1/n el estado esta representado por los
5

contenidos de los K-1 estados mas a la derecha (figura 7.3). El conocimiento del estado junto con el conocimiento de la siguiente entrada es necesario y suficiente para determinar la siguiente salida. Sea el estado del codificador en el tiempo ti definido como Xi = mi-1,mi-2,..........,mi-k+1. La i-esima rama de codeword Ui esta completamente determinada por el estado Xi y el presente bit de entrada mi; En consecuencia el estado Xi representa la historia pasada del codificador para determinar la salida del codificador. El estado del codificador es Markov, en el sentido que la probabilidad P(Xi+1|Xi,Xi-1,.....X0) del estado Xi+1, dados todos los estados previos, depende solo del estado mas reciente Xi, o sea, la probabilidad es igual a P(Xi+1|Xi). Una manera de representar simples codificadores es con el diagrama de estado, un diagrama de estado para el codificador de la figura 7.3 es mostrado en la figura 7.5. Los estados mostrados en las cajas del diagrama, representan los posibles contenidos de los K-1 estados del registro mas a la derecha y los caminos entre los estados representan las ramas de palabras de salida resultantes de los estados de transición. Los estados de los registros son designados a = 00 , b = 10 , c = 01 y d = 11, el diagrama mostrado en la figura 7.5 ilustra todas las transiciones de estado que son posibles para el codificador en la figura 7.3. Solo hay dos transiciones emanando de cada estado, correspondientes a los dos posibles bits de entrada. Siguiendo cada camino entre los estados es escrita la palabra de rama de salida asociada con el estado de transición. Para dibujar los caminos, usamos la convención que una línea sólida denota un camino asociado con un bit de entrada cero, y una línea de puntos denota un camino asociado con un bit de entrada uno. Note que no es posible en una simple transición moverse desde un estado dado a un estado arbitrario. Como consecuencia de desplazar un bit por vez, hay solo dos posibles estados de transición que el registro puede hacer en cada tiempo de bit. Por ejemplo, si el estado presente del codificador es 00, las únicas posibilidades para el estado siguiente son 00 o 10.
Ejemplo 7.1 Codificador Convolucional
El codificador mostrado en la Figura 7.3, muestra los cambios de estados y las salidas resultantes de la secuencia U de la codeword para la secuencia de mensaje m=11011, seguido de k-1=2 ceros para vaciar el registro. Asumiendo que los contenidos iniciales del registro son todas ceros. Solución
6

Ejemplo 7.2 Codificador Convolucional En el Ejemplo 7.1 los contenidos iniciales del registro son todos ceros. Esto es equivalente a la condición que la secuencia de entrada es precedida por dos bits ceros (la codificación es una función del bit presente y el bit anterior K-1). Repita el Ejemplo 7.1 con la suposición de que la secuencia de entrada dada, esta precedida por dos bits, y verifique que la nueva secuencia de codeword U para una secuencia de entrada m = 1 1 0 1 1 es diferente que las codeword encontradas en el Ejemplo 7.1. Solución: La entrada "x" significa “no se conoce”
Bit de Entrada mi
Contenido de Los registros
Estado de Tiempo ti
Estado de tiempo ti+1
Word en la rama al tiempo ti u1 u2
- 11x 1x 11 - 1 111 11 11 1 0 1 111 11 11 1 0 0 011 11 01 0 1 1 101 01 10 0 0 1 110 10 11 0 1 0 011 11 01 0 1 0 001
01 00 1 1
Estado ti Estado ti+1 La secuencia de salida: U = 10 10 01 00 01 01 11 Comparando este resultado con el Ejemplo 7.1, podemos ver que cada palabra de la rama de la secuencia de salida U no sólo es una función del bit de entrada, sino también es una función de los K-1 bits anteriores.
7.2.3 EL DIAGRAMA DE ÁRBOL Aunque el diagrama de estado caracteriza completamente al codificador, uno no lo puede usar fácilmente para rastrear las transmisiones del codificador como una función del tiempo, porque el diagrama no representa la historia del tiempo. El diagrama de árbol agrega la dimensión del tiempo al diagrama de estado. El diagrama de árbol para el codificador convolucional mostrado en figura 7.3 se ilustra en Figura 7.6. En cada momento los sucesivos bit de entrada al procedimiento de codificación puede describirse cruzando el diagrama desde izquierda a derecha, cada rama del árbol describe una palabra en la rama de salida, la regla de la bifurcación para encontrar una sucesión de codewor es como sigue: Si el bit de entrada es un cero, la palabra asociada a la rama se encuentra moviéndose a la próxima rama de mas a la derecha, en dirección ascendente. Si la entrada es uno, la palabra asociada a la rama se encuentra moviéndose a la próxima rama de mas a la derecha, en la dirección descendente. Asumiendo que el contenido inicial del codificador son todos ceros, el diagrama muestra que si el primer bit de entrada es cero, la palabra de salida es 00 y si el primer bit de entrada es un uno, la palabra de salida es un 11, de igual forma si el primer bit de entrada es un uno y el segundo bit de entrada es un cero, la palabra de salida es un 10. O, si el primer bit de entrada es un uno y el segundo bit de entrada es un uno, la palabra de salida es 01. Siguiendo este procedimiento nosotros vemos que la secuencia de entrada 11011 rastreando el diagrama de árbol de la figura 7.6. corresponde a la codeword de salida de la sucesión 1 1 0 1 0 1 0 0 0 1. Al aumentar la dimensión del tiempo en el diagrama de árbol (comparado con el diagrama de estado) permite describir dinámicamente al codificador como una función de una secuencia de entrada particular. Sin embargo, ¿Usted tendería algún problema si intenta usar un diagrama de árbol para describir una secuencia de cualquier longitud?. Al aumentar el número de ramas, la cual es una función de , dónde L es el número de palabras en la ramas de la secuencia, con lo cual se quedaría rápidamente sin papel y sin paciencia.
L2
7
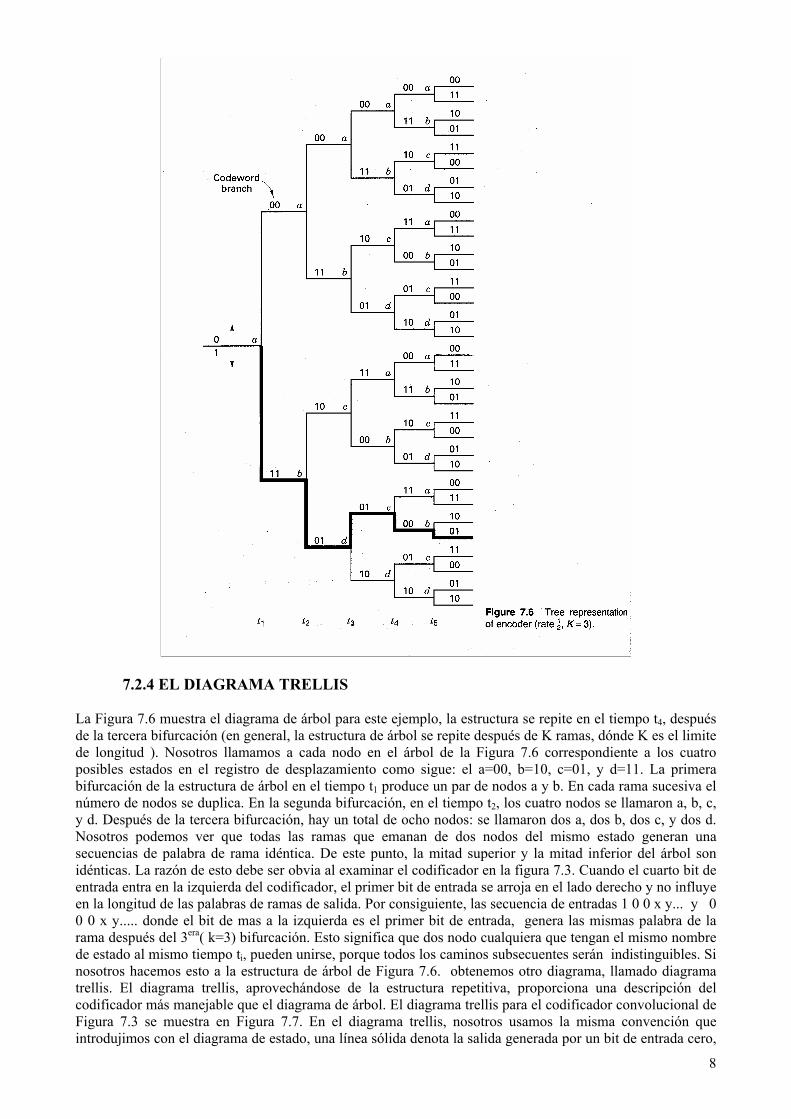
7.2.4 EL DIAGRAMA TRELLIS La Figura 7.6 muestra el diagrama de árbol para este ejemplo, la estructura se repite en el tiempo t4, después de la tercera bifurcación (en general, la estructura de árbol se repite después de K ramas, dónde K es el limite de longitud ). Nosotros llamamos a cada nodo en el árbol de la Figura 7.6 correspondiente a los cuatro posibles estados en el registro de desplazamiento como sigue: el a=00, b=10, c=01, y d=11. La primera bifurcación de la estructura de árbol en el tiempo t1 produce un par de nodos a y b. En cada rama sucesiva el número de nodos se duplica. En la segunda bifurcación, en el tiempo t2, los cuatro nodos se llamaron a, b, c, y d. Después de la tercera bifurcación, hay un total de ocho nodos: se llamaron dos a, dos b, dos c, y dos d. Nosotros podemos ver que todas las ramas que emanan de dos nodos del mismo estado generan una secuencias de palabra de rama idéntica. De este punto, la mitad superior y la mitad inferior del árbol son idénticas. La razón de esto debe ser obvia al examinar el codificador en la figura 7.3. Cuando el cuarto bit de entrada entra en la izquierda del codificador, el primer bit de entrada se arroja en el lado derecho y no influye en la longitud de las palabras de ramas de salida. Por consiguiente, las secuencia de entradas 1 0 0 x y... y 0 0 0 x y..... donde el bit de mas a la izquierda es el primer bit de entrada, genera las mismas palabra de la rama después del 3era( k=3) bifurcación. Esto significa que dos nodo cualquiera que tengan el mismo nombre de estado al mismo tiempo ti, pueden unirse, porque todos los caminos subsecuentes serán indistinguibles. Si nosotros hacemos esto a la estructura de árbol de Figura 7.6. obtenemos otro diagrama, llamado diagrama trellis. El diagrama trellis, aprovechándose de la estructura repetitiva, proporciona una descripción del codificador más manejable que el diagrama de árbol. El diagrama trellis para el codificador convolucional de Figura 7.3 se muestra en Figura 7.7. En el diagrama trellis, nosotros usamos la misma convención que introdujimos con el diagrama de estado, una línea sólida denota la salida generada por un bit de entrada cero,
8
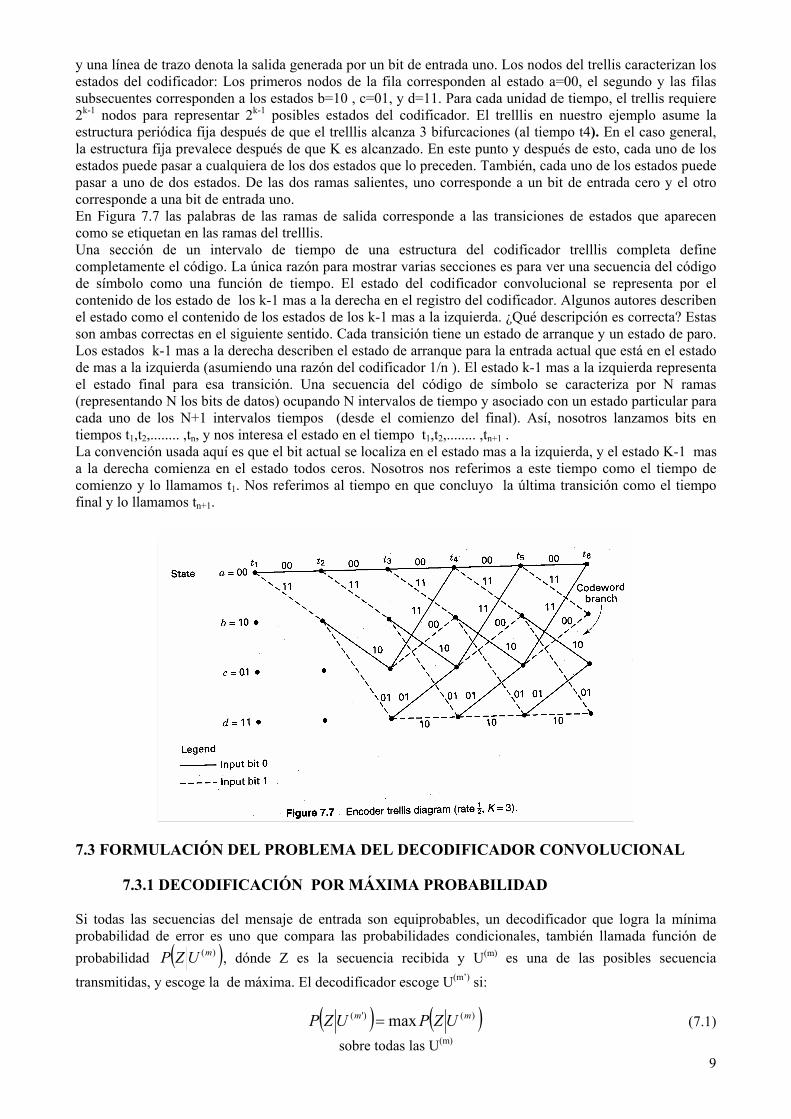
y una línea de trazo denota la salida generada por un bit de entrada uno. Los nodos del trellis caracterizan los estados del codificador: Los primeros nodos de la fila corresponden al estado a=00, el segundo y las filas subsecuentes corresponden a los estados b=10 , c=01, y d=11. Para cada unidad de tiempo, el trellis requiere 2k-1 nodos para representar 2k-1 posibles estados del codificador. El trelllis en nuestro ejemplo asume la estructura periódica fija después de que el trelllis alcanza 3 bifurcaciones (al tiempo t4). En el caso general, la estructura fija prevalece después de que K es alcanzado. En este punto y después de esto, cada uno de los estados puede pasar a cualquiera de los dos estados que lo preceden. También, cada uno de los estados puede pasar a uno de dos estados. De las dos ramas salientes, uno corresponde a un bit de entrada cero y el otro corresponde a una bit de entrada uno. En Figura 7.7 las palabras de las ramas de salida corresponde a las transiciones de estados que aparecen como se etiquetan en las ramas del trelllis. Una sección de un intervalo de tiempo de una estructura del codificador trelllis completa define completamente el código. La única razón para mostrar varias secciones es para ver una secuencia del código de símbolo como una función de tiempo. El estado del codificador convolucional se representa por el contenido de los estado de los k-1 mas a la derecha en el registro del codificador. Algunos autores describen el estado como el contenido de los estados de los k-1 mas a la izquierda. ¿Qué descripción es correcta? Estas son ambas correctas en el siguiente sentido. Cada transición tiene un estado de arranque y un estado de paro. Los estados k-1 mas a la derecha describen el estado de arranque para la entrada actual que está en el estado de mas a la izquierda (asumiendo una razón del codificador 1/n ). El estado k-1 mas a la izquierda representa el estado final para esa transición. Una secuencia del código de símbolo se caracteriza por N ramas (representando N los bits de datos) ocupando N intervalos de tiempo y asociado con un estado particular para cada uno de los N+1 intervalos tiempos (desde el comienzo del final). Así, nosotros lanzamos bits en tiempos t1,t2,........ ,tn, y nos interesa el estado en el tiempo t1,t2,........ ,tn+1 . La convención usada aquí es que el bit actual se localiza en el estado mas a la izquierda, y el estado K-1 mas a la derecha comienza en el estado todos ceros. Nosotros nos referimos a este tiempo como el tiempo de comienzo y lo llamamos t1. Nos referimos al tiempo en que concluyo la última transición como el tiempo final y lo llamamos tn+1.
7.3 FORMULACIÓN DEL PROBLEMA DEL DECODIFICADOR CONVOLUCIONAL
7.3.1 DECODIFICACIÓN POR MÁXIMA PROBABILIDAD Si todas las secuencias del mensaje de entrada son equiprobables, un decodificador que logra la mínima probabilidad de error es uno que compara las probabilidades condicionales, también llamada función de probabilidad ( ))(mUZP , dónde Z es la secuencia recibida y U(m) es una de las posibles secuencia
transmitidas, y escoge la de máxima. El decodificador escoge U(m’) si:
( ) ( ))()'( max mm UZPUZP = (7.1)
sobre todas las U(m) 9

El concepto de máxima probabilidad, como se definió en la Ecuación (7.1), es un desarrollo fundamental de teoría de decisión (vea el apéndice B): es la formalización de un "sentido-común" del modo de tomar las decisiones cuando hay conocimiento estadístico de las posibilidades. En el tratamiento de demodulación binaria, en los Capítulos 3 y 4, había sólo dos señales equiprobables, esto es, se podría haber transmitido s1(t) o s2(t). Por consiguiente, tomar la decisión binaria de máxima probabilidad, dada una señal recibida, sólo quisiéramos decidir que la s1(t) se transmitió si:
( ) ( )21 szpszp > sino, se decide que la s2(t) fue transmitida. El parámetro z representa el z(T), el valor de la predetección recibida al final de cada tiempo de duración del símbolo t=T. Sin embargo, al aplicar la máxima probabilidad al problema de decodificador convolucional, observamos que el código convolucional tiene memoria (la secuencia del receptor representa la superposición de los bits actuales y de los bits posteriores). Así, aplicar la máxima probabilidad a la decodificación del codificador convolucional es actuar, en el contexto de escoger la secuencia más probable, como la mostrada en la Ecuación (7.1), hay muchas posibles secuencias de codeword que se podrían haberse transmitido. Para ser especifico, para un código binario, una secuencia de L palabras de rama es un miembro de un set de 2L posible secuencias. Por consiguiente, en el contexto de máxima probabilidad, nosotros podemos decir que el decodificador escoge un U(m´) particular como la secuencia transmitida si la probabilidad ( )( )'mUZP es mayor que las probabilidades de todas las otras
posibles secuencias transmitidas. Tal decodificador óptimo que minimiza la probabilidad del error (para el caso dónde todas las transmisiones de las secuencias son igualmente probable), es conocido como un decodificador de máxima probabilidad. Las funciones de probabilidad se dan o se calcula de acuerdo a las especificaciones del canal. Nosotros asumiremos que el ruido es ruido blanco aditivo Gaussiano con media cero y el canal es sin memoria, donde la media del ruido afecta a cada símbolo del código independientemente de todos los otros símbolos. Para un código convolucional de razón 1/n, nosotros podemos expresar la probabilidad como.
( )( ) ( )( ) ( )(∏ ∏∏∞
=
∞
= =
==1 1 1i i
n
j
mjiji
mii
m uzPUZPUZP ) (7.2)
donde Zi es la i-esima rama de la secuencia recibida Z. Ui
(m) es el i-esima rama de una secuencia de codeword particular U(m), el zji es el j-esimo código de símbolo de Zi, y el uji
(m) es el j-esimo código de símbolo de Ui
(m), y cada rama comprende n códigos de símbolos. El problema del decodificador consiste en la elección de un camino a través del trelllis de figura 7.7 (cada posible camino define una secuencia de codeword) tal que
( )( ) maximizado este 1 1
∞
=
∞
=i j
mjiji uzP∏∏ (7.3)
Generalmente, es computacionalmente más conveniente usar el logaritmo de la función de probabilidad, subsecuentemente, esto permite la suma, en lugar de la multiplicación, de términos. Nosotros podemos usar esta transformación porque el logaritmo es un función monótonicamente creciente y por lo tanto no alterará el resultado final en nuestra selección de la codeword. Nosotros podemos definir la función de logaritmo de la probabilidad como:
( ) ( )( ) ( )( ) ( )(∑ ∑∑∞
=
∞
= =
===1 1 1
logloglogi i
n
j
mjiji
mii
mU uzPUZPUZPmγ ) (7.4)
10
El problema del decodificador consiste ahora en la elección de un camino a través del árbol de Figura 7.6 o del trellis de Figura 7.7, tal que γU
(m) sea máxima. Para la decodificación de códigos convolucional, la estructura del árbol o el trellis puede usarse. En la representación del árbol de código, el hecho de que se unen los caminos se ignora. Subsecuentemente para un código binario, el número de posibles secuencias compuesta de L palabras de rama es 2L, la máxima probabilidad de decodificación de la secuencia recibida, mientras usando un diagrama de árbol, se requiere la "fuerza bruta" o la comparación exhaustiva de 2L métrica del logaritmo de probabilidad acumulada, representando todas las posibles secuencias de codeword

diferentes que podrían transmitirse. No es práctico considerar la máxima probabilidad de detección con una estructura de árbol. Se muestra en una sección más adelante que con el uso de la representación del código trellis, es posible configurar un decodificador que puede desechar los caminos que posiblemente no podrían ser candidatos para la secuencia de máxima probabilidad. El camino del decodificador es escogido de algún juego reducido de caminos supervivientes. Tal decodificador es aun optimo en el sentido que el camino decodificado es igual que el camino decodificado que obtuvo por "fuerza bruta" en el decodificador de máxima probabilidad, pero el rechazo temprano de caminos improbables reduce la complejidad de decodificación. Para una guía didáctica excelente en la estructura de códigos convolucional, decodificación de máxima probabilidad, y performance del código, vea la Referencia [8]. Hay varios algoritmos que producen soluciones aproximadas al problema de descodificación de máxima probabilidad, incluyendo secuencial [9, 10] y umbral [11]. Cada uno de estos algoritmos satisface ciertas aplicaciones especiales, pero todos estos son suboptimas. En contraste, el algoritmo de decodificación Viterbi realiza la decodificación de máxima probabilidad y es por consiguiente óptimo. Esto no implica que el algoritmo de Viterbi es mejor, para cada aplicación, hay algunas limitaciones impuestas por la complejidad del hardware. El algoritmo de Viterbi se considera en las Secciones 7.3.3 y 7.3.4.
7.3.2 MODELOS DE CANALES: DECISIONES DE HARD VERSUS SOFT Antes de especificar un algoritmo que determinará la máxima probabilidad de decisión, permítanos describir el canal. La secuencia de codeword U(m), compuesto de palabras de rama, con cada palabra de rama comprendida de n códigos de símbolos, donde puede considerarse que son un chorro interminable, opuesto al código de bloque, en donde la fuente de datos y sus codewors son particionadas dentro de un bloque tamaño de preciso. La secuencia de codeword mostrada en Figura 7.1 sale del codificador convolucional y entra al modulador dónde los códigos de símbolos se transforman en señales de forma de onda. La modulación puede ser banda base (por ejemplo, la onda pulso) o banda pasante (ej., PSK o FSK), en general, l símbolos en un tiempo, dónde l es un entero, se mapean en la forma de onda si(t), dónde i = 1, 2.... . . , M = 2l. Cuando l=1, el modulador mapea cada código de símbolo en un forma de onda binaria. Se asume que el canal contamina la forma de onda que se transmite con ruido Gaussiano. Cuando la señal contaminada se recibe, esta es procesa primero por el demodulador y luego por el decodificador. Considere que la señal binaria transmitida en un intervalo de símbolo (0, T) es representada por s1(t) para un uno binario y s2(t) para un cero binario. La señal recibida es r(t)=si(t)+n(t), dónde n(t) es un ruido Gaussiano con media cero. En el Capítulo 3 nosotros describimos la detección de r(t) en términos de dos pasos básicos. En el primer paso, la forma de onda recibida se reduce a un solo número, z(T)=ai+n0, dónde ai es la componente de la señal z(T) y n0 es el componente del ruido. La componente del ruido, n0, es una variable aleatoria Gaussiana con media cero, y por lo tanto z(T) es una variable aleatoria Gaussiana con una media a1 o a2 dependiendo si se envío un uno o un cero binario. El segundo paso del proceso de detección es tomar una decisión acerca de que señal fue transmitida, en base a comparar a z(T) con un umbral. Las probabilidades condicionales de z(T), ( )1szp y ( 2szp ) se muestra en Figura 7.8, llamadas probabilidad de s1 y probabilidad de s2. El demodulador mostrado en la Figura 7.1, convierte el set de variables aleatorias {z(T)} ordenadas en el tiempo dentro de una secuencia de código Z, y esta es pasada al decodificador. La salida del demodulador puede configurarse de muchas maneras. Esto puede llevarse a cabo para tomar una decisión firme o hard acerca de si la z(T) representa un cero o un uno. En este caso, la salida del demodulador es cuantizada en dos niveles, cero y uno, y esta alimenta a la entrada del decodificador (esto es exactamente la misma decisión de umbral que se hacia en el Capítulos 3 y 4)
11

Dado que el decodificador opera con las decisiones-hard hecha por el demodulador, la decodificación es llamada decodificación por decisión-hard. El demodulador también pueden ser configurado para alimentar el decodificador con un valor de cuantización de z(T) mayor que dos niveles. Tal aplicación suministra al decodificador con más información que la proporcionada en el caso de la decisión-hard. Cuando el nivel de cuantización a la salida del demodulador es mayor que dos, la decodificación es llamada decodificación por decisión-soft. Los ocho niveles (3-bits) de cuantización se ilustra en la abscisa de Figura 7.8. Cuando el demodulador envía una decisión binaria hard al decodificador, este le envía un solo símbolo binario. Cuando el demodulador envía una decisión binaria soft, cuantizada con ocho niveles, este le envía al decodificador una palabra de 3-bit descripta en un intervalo a lo largo de z(T ). En efecto, enviando tal palabra de 3-bit en lugar de un solo símbolo binario esto es equivalente a enviar una medida de seguridad al decodificador junto con la decisión del código-símbolo. Refiriéndose a la Figurar 7.8, si el demodulador envía un 1 1 1 al decodificador, esto es equivalente a declarar que este código de símbolo corresponde a un uno con gran seguridad, mientras que enviando un 1 0 0 es equivalente a declara que este código de símbolo corresponde a un uno con muy poca seguridad. Debe estar claro que finalmente, cada decisión de mensaje fuera del decodificador debe ser una decisión hard; por otra parte, uno podría ver en la salida de la computadora donde leeria: "pienso que esto es un 1", "pienso que esto es un 0", y así sucesivamente. La idea de que demodulador no toma decisiones hard y de que envía más datos (decisiones soft) al decodificador puede pensarse como un paso intermedio para proporcionar al decodificador con más información, que el decodificador luego la usa para recuperar la secuencia del mensaje (con una mejor performance del error que la que se pudo en el caso de la decodificación por decisión de hard). En Figura 7.8, la métrica de los ocho niveles en la decisión soft se muestra a menudo como -7, -5, -3, -1, 1, 3, 5, 7. Tal designación se presta a una interpretación simple de la decisión soft: El signo de la métrica representa una decisión (por ejemplo, escoja el s1 si positivo, escoja el s2 si negativo), y la magnitud del métrico representa el nivel de confianza de esa decisión. La única ventaja para el métrico mostrado en Figura 7.8 es que evita el uso de números negativos. Para un canal Gaussian, los resultados de cuantizar con ocho niveles es en un mejoramiento de la porformans de aproximadamente 2 dB en el requerimiento de la relación de señal-ruido comparada con la cuantización con dos niveles. Esto significa que la decodificación por decisión-soft con ocho niveles puede proporcionar la misma probabilidad de error de bit como en la decodificación por decisión hard, pero requiere 2dB menos de la relación para una misma performance. El cuantizador con nivel infinito resulta en un mejoramiento de la performance de 2.2 dB sobre una cuantización con dos niveles; por lo tanto, el cuantizador con ocho niveles tiene una pérdida de aproximadamente 0.2 dB comparado con cuantizador infinitesimal. Por esta razón, cuantizar con más de ocho niveles pueden producir un pequeño mejoramiento en la performance [12]. ¿Qué precio se paga por mejorar la performance en la decodificación por decisión-soft?. En el caso de la decodificación por decisión-hard, un solo bit se usa para describir cada símbolo del código, mientras que para la decodificación por decisión-soft con un cuantizador de ocho niveles, 3 bit son usados para describir cada símbolo del código; por lo tanto, es tres veces mayor la cantidad de datos que debe manejar durante el proceso de decodificación. Es por esto que el precio que se paga en la decodificación por decisión-soft es en un aumento en el tamaño de memoria requerida en el decodificador (y posiblemente una multa de velocidad).
0/ NEb
Los algoritmos de decodificación en bloque y los algoritmos de decodificación convolucional han sido inventados para operar con decisión hard o soft. Sin embargo, el decodificador por decisión-soft generalmente no es usado con los códigos de bloque porque es considerablemente más difícil implementarlo que en la decodificación por decisión-hard . El uso que más prevalece en la decodificación por decisión-soft
12

es con el algoritmo de decodificación convolutional de Viterbi, desde entonces con la decodificación Viterbi, las decisiones soft representan sólo un aumento trivial en el cómputo.
7.3.2.1 CANAL SIMÉTRICO BINARIO Un canal simétrico binario (BSC) es un canal discreto sin memoria (vea Sección 6.3.1) que tiene entrada binaria y salida alfabetica y probabilidades de transición simétricas. Estas pueden ser descriptas por las probabilidades condicionales:
pPP === )0/1()1/0( (7.5)
pPP −=== 1)0/0()1/1( como se ilustra en la Figura 7.9. La probabilidad que un símbolo de salida difiera del símbolo de la entrada es , y la probabilidad que el símbolo de salida sea idéntico al símbolo de la entrada es . El BSC es un ejemplo de un canal con decisión-hard, que significa que, aun cuando muchas señales de valor continuo son recibidas por el demodulador, un BSC permite sólo decisiones firmes o hard tal que cada símbolo de salida del demodulador, z
p )1( p−
ji, como se muestra en la Figura 7.1, consiste en uno de dos valores binarios. El índice de zji pertenece al j-esimo símbolo de código de la i-esima palabra de la rama, Zi .El demodulador alimenta entonces con la secuencia Z= {Zi} al decodificador. Asignando U(m) a una codeword transmitida sobre un BSC con la probabilidad de error de símbolo , y asignando a Z la secuencia recibida en el decodificador. Como se dijo previamente, un decodificador de máxima probabilidad escoge el codeword U
p
(m’) que maximice la probabilidad o su logaritmo. Para un BSC, esto es equivalente a escoger el codeword U
)/( )(mUZP(m’) que este mas cerca en distancia Hamming a Z
[8]. Así la distancia de Hamming es una métrica apropiada para describir la distancia o la proximidad apropiada entre U(m) y Z. De todas las posibles secuencias U(m) transmitidas, el decodificador escoge la secuencia U(m’) con la cual la distancia a Z es mínima.
Suponga que U(m) y Z son todas secuencias de longitud de bit y que ellas difieren en las posiciones [es decir, las distancias Hamming entre U
L md(m) y Z es ]. Entonces, ya que el canal se asume con baja
memoria, la probabilidad de que Umd
(m) se transforme en la Z recibida a distancia , donde esto puede escribirse como:
md
(7.6) mm dLdm ppUZP −−= )1()/( )(
y la función del logaritmo de la probabilidad es:
)1log(1log)/( )( pLp
pdUZP mm −+
−−=log (7.7)
Si nosotros calculamos esta cantidad para cada posible secuencia transmitida, el último término en la ecuación será constante en cada caso. Asumiendo que , nosotros podemos expresar la Ecuación (7.7) como:
5.0<p
(7.8) BAdUZP mm −−=)/(log )(
13

donde A y B son constantes positivas. Por consiguiente, escogiendo la codeword U(m’), tal que la distancia Hamming a la secuencia recibida Z sea mínima, esto corresponde a maximizar la probabilidad o el logaritmo de la probabilidad. Por lo tanto, sobre un BSC, el logaritmo de la probabilidad es convenientemente remplazada por la distancia de Hamming, y un decodificador de máxima probabilidad escogerá, en el diagrama de árbol o diagrama de trellis, el camino cuya secuencia correspondiente U
md
(m’) que está a la mínima distancia de Hamming de la secuencia recibida Z.
7.3.2.2 CANAL GAUSSIANO Para un canal Gaussiano, cada símbolo de salida de demodulador zji, como se muestra en Figura 7.1, es un valor del alfabeto continuo. El símbolo zji , no pueden clasificarse como una decisión de detección correcta o incorrecta. El envió de tales decisiones soft al decodificador pueden ser vistas como el envió de una familia de probabilidades condicionales de los diferentes símbolos(vea Sección 6.3.1). Puede mostrarse [8] que maximizando es equivalente a maximizar el producto interno entre la secuencia codeword U)/( )(mUZp (m) (consistiendo en símbolos binarios representados como valores bipolares) y la secuencia Z recibida de estimación analógica. De este modo, el decodificador escoge la codeword U(m’) si este maximiza:
(7.9) ∑ ∑∞
= =1 1)(
i
n
jm
jijiuz Esto es equivalente a escoger la codeword U(m’) que este mas cerca, en distancia Euclidean, a Z. Aunque los canales de decisión hard y soft requieren de métrica diferente, el concepto de escoger la codeword U(m’) que este mas cerca de la secuencia recibida, Z, es el mismo en ambos casos. Para llevar a cabo la maximización de la Ecuación (7.9) exactamente, el decodificador tendría que ser capaz de manejar operaciones aritméticas de estimación analógica. Esto es impráctico porque el decodificador generalmente se implementa digitalmente. Por eso es necesario cuantizar los símbolos recibido zji. Dada la Ecuación (7.9) recuerda el tratamiento de demodulación en los Capítulos 3 y 4? La ecuación (7.9) es la versión discreta de correlacionar una señal de entrada recibida, r , con una señal de referencia, , como esta expresado en la Ecuación (4.15). El canal Gaussiano cuantizado, típicamente llamado un canal de decisión-soft, es el modelo de canal asumido por la decodificación por decisión-soft descripta anterior.
)(t )(tsi
7.3.3 EL ALGORITMO DE DECODIFICACIÓN CONVOLUTIONAL VITERBI
El algoritmo de decodificación Viterbi fue descubierto y analizado por Viterbi [13] en 1967. El algoritmo de Viterbi esencialmente realiza la decodificación por máxima probabilidad; sin embargo, reduce la carga computacional aprovechándose de la estructura especial en el código trellis. La ventaja de la decodificación Viterbi, comparada con la decodificación de fuerza bruta, es que la complejidad de un decodificador Viterbi no es una función del número de símbolos en la secuencia del codeword. El algoritmo involucra el calculo de una medida de similitud, o distancia, entre el signo recibido, en el tiempo t , y todos los caminos de trellis evaluados en el intervalo de tiempo t . El algoritmo Viterbi quita de la consideración aquéllos caminos trellis que posiblemente no podrían ser candidatos para la opción de máxima probabilidad. Cuando dos caminos entran en el mismo estado, el que teniene la mejor métrica es escogido; este camino se llama el camino superviviente. Esta selección de camino supervivientes es realizada para todos los estados. El decodificador continúa este camino obteniendo ventajas dentro del trellis, tomando las decisiones en base a la eliminación de los caminos menos probables. El rechazo de los caminos improbables reduce la complejidad de la decodificación. En 1969, Omura [14] demostró que el algoritmo Viterbi es, de hecho, la máxima probabilidad. Note que el objetivo de seleccionar el camino óptimo puede expresarse, equivalentemente, como escoger la codeword con la métrica de máxima probabilidad, o como escoger la codeword con la métrica distancia mínima.
i
i
7.3.4 Un Ejemplo de la decodificación convolucional Viterbi
14
Por simplicidad, un BSC es supuesto; así la distancia de Hamming es una medida de distancia apropiada. El codificador para este ejemplo se muestra en Figura 7.3, y el diagrama de trllis del codificador se muestra en Figura 7.7. Una trellis similar puede usarse para representar el decodificador, como se muestra en la Figura 7.10. Nosotros empezamos el análisis en el instante de tiempo t1 con el estado 00 (vaciando el codificador entre mensajes dándole a conocer al decodificador el conocimiento de un nuevo estado). Por lo tanto en este

ejemplo, hay sólo dos posibles transiciones para partir de este estado, no todas las ramas se necesitan mostrar inicialmente. La estructura completa de trellis se desarrolla después del tiempo t3. La idea básica detrás del procedimiento de decodificación puede entenderse mejor examinando la Figura 7.7 del codificador trellis con la Figura 7.10 del decodificador trellis. Para el decodificador trellis es conveniente en cada intervalo de tiempo, etiquetar cada rama con la distancia de Hamming entre los símbolos del código recibido y la palabra de rama correspondiente a la misma rama del codificador trellis. El ejemplo en la Figura 7.10 muestras una secuencia del mensaje m, la secuencia U correspondiente a la codeword, y una secuencia recibida Z contaminada de ruido Z = 11 0l 0l 10 01. . . . Las palabras de rama vistas en las ramas del codificador trellis caracteriza al codificador de la Figura 7.3, y es conocida a priori tanto por el codificador y el decodificador. Estas palabras de ramas del codificador son los símbolos del código que se esperaría que venga de la salida del codificador como resultado de cada una de las transiciones de estados. Las etiquetas en las ramas del decodificador trellis son acumulado por el decodificador al toke. Es decir, cuando los símbolos del código se reciben, cada rama del decodificador trellis se etiqueta con una métrica de similitud (distancia Hamming) entre los símbolos del código recibido y cada una de las palabras de la rama para ese intervalo de tiempo.
De la secuencia recibida Z, mostrado en Figura 7.10, nosotros vemos que los símbolos del código recibido en el (siguiente) tiempo t1 son 11. El orden para etiquetar las ramas del decodificador en el (partiendo) tiempo t1 con la distancia apropiada de Hamming, nosotros lo vimos en la Figura 7.7 del codificador de trellis. Aquí nosotros vemos que un estado 00 de transición produce una palabra de rama de salida de 00. Pero nosotros recibimos 11. Por lo tanto, en el decodificador trellis nosotros etiquetamos el estado de transición con una distancia de Hamming entre ellos, de 2. Mirando el codificador de trellis de nuevo, nosotros vemos que una estado de transición produce una palabra de rama de salida de 11 que corresponden exactamente con los símbolos del código que nosotros recibimos en el tiempo t
00→
1000 →
0000 →
1. Por lo tanto, en el decodificador trellis, nosotros etiquetamos el estado de transición con una distancia de Hamming de 0. En resumen, la métrica de entrada de una rama del decodificador trellis representa la diferencia (la distancia) entre lo que se recibió y lo que se "debió de haber recibido” estando la palabra de la rama asociada con la rama que a sido transmitida. En efecto, éstas métricas describen una medida de la correlación entre una palabra de la rama recibida y cada una de las candidatas. Nosotros continuamos el etiquetado de las ramas en el decodificador de trellis de esta manera con los símbolos que son recibidos en cada tiempo t
1000 →
i. El algoritmo de decodificación usa la métrica de distancia Hamming para encontrar la rama mas probable (la distancia mínima) por medio de trellis. La base de la decodificación Viterbi es la observación siguiente: Si cualquiera de los dos caminos en la trellis une a un solo estado, siempre puede eliminarse uno de ellos en la búsqueda por el camino óptima. Por ejemplo, En la Figure 7.11 se muestran dos caminos que unen al tiempo t5 para el estado 00. Permítanos definer la métrica del camino de Hamming acumulativo de un camino dada al tiempo ti como la suma de las distancias de la rama que Hamming a lo largo de esa trayectoria hasta el tiempo ti.
15

En Figura 7.11 la trayectoria superior tiene una métrica de 4; la inferior tiene una métrica de 1.La trayectoria superior no puede ser una porción del camino óptima porque el camino inferior que entra en el mismo estado tiene una métrica más baja. Esta observación es sostenida debido a la naturaleza de Markov del estado del codificador: El estado presente resume la historia del codificador en el sentido de que los estados anteriores no pueden afectar estados futuros o las futuras ramas de salidas. A cada tiempo ti hay estados en el trellis, dónde es la restricción de la longitud, y a cada estado se puede entrar por medio de dos caminos. El decodificador Viterbi consiste de calcular la métrica de los dos caminos de entran para cada estado y eliminando uno de ellas. Este cómputo se hace para cada uno de los
estados o nodos al tiempo t
12 −K K
12 −K
00 →
aΓ
i ; entonces el decodificador se mueve al tiempo ti+1 y repite el proceso. En un momento dado, la métrica del camino decisivo para cada estado se designa como el estado métrico para ese estado en ese momento. Los primeros pasos en nuestro ejemplo de decodificación son como sigue (vea Figura 7.12). Asuma que la secuencia de datos de entrada m, codeword U, y la secuencia recibida Z son como se muestra en la Figura 7.10. Asuma que el decodificador sabe el estado inicial correcto del trellis. (Esta asunción no es necesaria en la práctica, pero simplifica la explicación.) En el tiempo t1 los símbolos del código recibidos son 11. Del estado 00 las únicas posibles transiciones son el estado 00 o el estado 10, como se muestra en la Figura 7.12a. El estado de transición tiene la métrica rama de 2; el estado
de transición tiene la métrica rama 0. Al tiempo t0000 →
10
bΓ
2 hay dos posibles ramas que dejan cada estado, como se muestra en la Figura 7.12b. La métrica acumulativa de estas ramas se etiquetan métricas de estado
, , , y , correspondiendo al estado terminado. Al tiempo tcΓ dΓ 3 en la Figura 7.12c hay dos ramas que divergen de cada estado de nuevo. Como resultado, hay dos caminos que entran a cada estado al tiempo t4. Uno de los caminos que entra en cada estado puede eliminarse, a saber, es aquella que tiene camino acumulativa mas grande. Si la métrica de los dos caminos de entrada son de igual valor, una trayectoria es escogida para la eliminación usando una regla arbitraria. El camino superviviente en cada estado se muestra en Figura 7.12d. En este punto del proceso de decodificación, hay sólo una trayectoria superviviente, terminado el paso común, en el intervalo de tiempo t1 a t2. Por lo tanto, el decodificador puede decidir ahora que el estado de transición que ocurrió entre el intervalo de tiempo t1 a t2 era . Ya que esta transición se produce por un bit de entrada en uno, las salidas del decodificador esta en uno como el primer bit decodificado.
1000 →
16

Aquí nosotros podemos ver cómo la decodificación de la rama superviviente es facilitada habiendo dibujado las ramas trellis con las líneas continuas para los ceros de entrada y con las líneas de trazo para los unos de entrada. Note que el primer bit no se decodifico hasta que el camino del cómputo métrico había procedido a una profundidad muy mayor dentro de la trellis. Para una aplicación típica del decodificador, esto representa un retraso de decodificación que puede ser tanto como cinco veces la longitud en bits retenidos. En cada paso subsiguiente en el proceso de decodificación, habrá siempre dos trayectorias posibles que entran en cada estado; una de las dos será eliminado comparando la métrica de el camino. En la Figure 7.12e se muestra el próximo paso en el proceso de decodificación. De nuevo, en el tiempo t5 hay dos caminos que entran en cada estado, y puede eliminarse uno de cada par. En la Figure 7.12f se muestran los caminos sobrevivientes al tiempo t5. Note que en nuestro ejemplo nosotros no podemos hacer todavía una decisión del segundos bit de datos porque hay todavía dos caminos que salen del nodo de estado 10 al tiempo t2 . Al tiempo t6 en la Figura 7.12g nosotros vemos de nuevo el dibujo en donde se unen los dos caminos, y en la Figura 7.12h nosotros vemos a los sobrevivientes al tiempo t6.
También, en la Figura 7.12h las salidas del decodificador esta en uno como el segundo bit decodificado, correspondiéndose al camino superviviente entre el intervalo de tiempo t2 y t3. El decodificador continúa de
17

este modo más profundamente en el trellis y toma las decisiones en los momentos de los bits de datos de entrada que hacen eliminar todos las caminos excepto uno. Recortando el trellis (como la unión de caminos) garantiza que nunca abra mas caminos que estados existentes. Para este ejemplo, verificar que después de cada eliminación en las Figuras 7.12b, d, f, y h, hay sólo 4 caminos. Compare esto intentando a fuerza bruta la estimación de la secuencia por máxima probabilidad sin usar el algoritmo Viterbi. En este caso, el número de caminos posibles (representando las posibles secuencias) es una función exponencial de la longitud de la secuencia. Para una secuencia de codeword binaria que tiene una longitud de palabras de rama, con lo cual hay posibles secuencias. L L2
7.3.5 APLICACIÓN DEL DECODIFICADOR En el contexto del diagrama de trellis de la Figura 7.10, pueden agruparse transiciones durante cualquier intervalo de tiempo en celdas disjuntas, para cada celda se grafican cuatro posibles transiciones dónde
se llama la memoria del codificador. Para el ejemplo K = 3, v = 2 y = 2 celdas. Estas celdas se muestran en Figura 7.13, dónde a, b, c, y d se refiere a los estados en el tiempo t
12 −V
1−= Kv 12 −V
i , y a', b', c', y d' se refiere a los estados en el tiempo ti+1 Mostrado en cada transición la métrica de la rama dónde el subíndice indica que la métrica corresponde a la transición del estado al estado . Estas celdas y las unidades de la lógica asociadas que ponen al día el estado de las métrica { }, dónde designa un estado particular, represente los bloques básicos del decodificador.
xyδxΓ
y
x x
7.3.5.1 COMPUTO DE LA SUMA-COMPARACIÓN-SELECCIÓN
Continuando con el ejemplo de 2 celdas para K=3, la Figura 7.14 ilustra la unidad lógica que corresponde a la celda 1. La lógica ejecuta el especial propósito del computo llamado Suma-Comparación-Selección (ACS). La métrica de estado Γa’ es calculada sumando la métrica del estado previos al estado a, Γa, a la métrica de rama δaa’ y la métrica del estado anterior al estado c, Γc , a la métrica de rama δca’. Esto da como resultado dos posibles caminos métricos como candidatas para la nueva métrica de estado Γa’. Las dos candidatas son comparadas en la unidad lógica de la figura 7.14. El más probable (de menor distancia) de ambos caminos métricos es almacenado como la nueva métrica de estado Γa’ para el estado a. Es también almacenada la nueva historia de camino ma’ para el estado a, donde ma’ es el mensaje con la historia del camino que corresponde al estado aumentado por los datos del camino ganador.
18
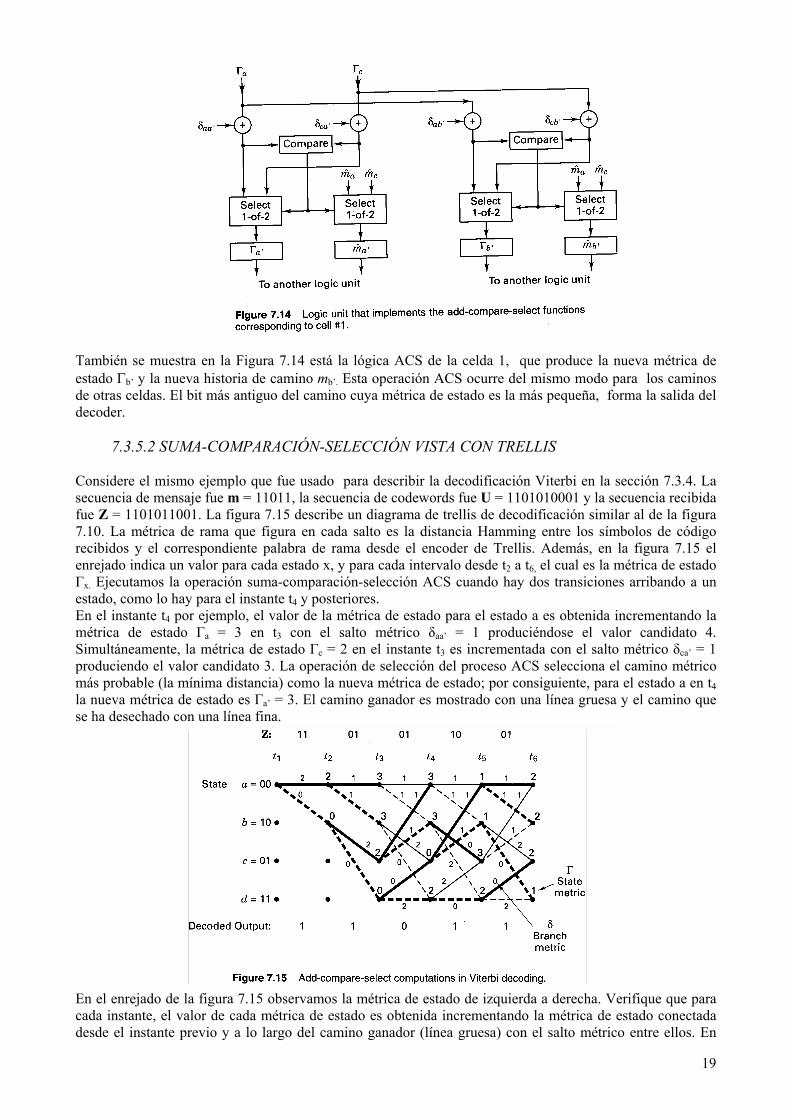
También se muestra en la Figura 7.14 está la lógica ACS de la celda 1, que produce la nueva métrica de estado Γb’ y la nueva historia de camino mb’. Esta operación ACS ocurre del mismo modo para los caminos de otras celdas. El bit más antiguo del camino cuya métrica de estado es la más pequeña, forma la salida del decoder.
7.3.5.2 SUMA-COMPARACIÓN-SELECCIÓN VISTA CON TRELLIS
Considere el mismo ejemplo que fue usado para describir la decodificación Viterbi en la sección 7.3.4. La secuencia de mensaje fue m = 11011, la secuencia de codewords fue U = 1101010001 y la secuencia recibida fue Z = 1101011001. La figura 7.15 describe un diagrama de trellis de decodificación similar al de la figura 7.10. La métrica de rama que figura en cada salto es la distancia Hamming entre los símbolos de código recibidos y el correspondiente palabra de rama desde el encoder de Trellis. Además, en la figura 7.15 el enrejado indica un valor para cada estado x, y para cada intervalo desde t2 a t6, el cual es la métrica de estado Γx. Ejecutamos la operación suma-comparación-selección ACS cuando hay dos transiciones arribando a un estado, como lo hay para el instante t4 y posteriores. En el instante t4 por ejemplo, el valor de la métrica de estado para el estado a es obtenida incrementando la métrica de estado Γa = 3 en t3 con el salto métrico δaa’ = 1 produciéndose el valor candidato 4. Simultáneamente, la métrica de estado Γc = 2 en el instante t3 es incrementada con el salto métrico δca’ = 1 produciendo el valor candidato 3. La operación de selección del proceso ACS selecciona el camino métrico más probable (la mínima distancia) como la nueva métrica de estado; por consiguiente, para el estado a en t4 la nueva métrica de estado es Γa’ = 3. El camino ganador es mostrado con una línea gruesa y el camino que se ha desechado con una línea fina.
En el enrejado de la figura 7.15 observamos la métrica de estado de izquierda a derecha. Verifique que para cada instante, el valor de cada métrica de estado es obtenida incrementando la métrica de estado conectada desde el instante previo y a lo largo del camino ganador (línea gruesa) con el salto métrico entre ellos. En
19

cierto punto del enrejado (luego de un intervalo de 4 o 5 veces la longitud de restricción) los bits más antiguos pueden ser decodificados. Como ejemplo, observando el instante t6 en la figura 7.15 vemos que la métrica de estado de menor distancia tiene un valor igual a 1. Desde este estado d, el camino ganador puede ser trazado de regreso al instante t1, y se puede verificar que el mensaje decodificado es igual al original, por la convención de que las líneas a rayas y continuas representan unos y ceros respectivamente.
7.3.6 MEMORIA Y SINCRONIZACIÓN DEL CAMINO Los requisitos de almacenamiento del decodificador Viterbi crecen exponencialmente con la longitud de restricción K. Para un código con una tasa de 1/n, el decoder retiene un set de 2k-1 caminos luego de cada paso de decodificación. Con alta probabilidad, estos caminos no serán mutuamente distintos a los anteriores del paso de decodificación presente [12]. Todos los 2k-1 caminos tienden a tener una vía común que, eventualmente, salta a diferentes estados. Esto es, sí el decoder almacena suficiente historia de los 2k-1 caminos, los bits más antiguos de todos los caminos serán los mismos. Una simple implementación de un decoder contiene entonces, una cantidad fija de la historia del camino y posee como salida el bit más antiguo de un camino arbitrario cada vez que este pasa a un nivel más profundo (deeper) en el enrejado. La cantidad de camino almacenado requerido es [12]
u = h2k-1 (7.10) donde h es el largo en bits de información de la historia de camino para cada estado. Una mejora que minimiza el valor de h usa el bit más antiguo del camino más probable como salida del decoder, en lugar del bit más antiguo de un camino arbitrario. Ha sido demostrado [12] que si h vale 4 o 5 veces la longitud de restriccion de código es suficiente para obtener una performance del decoder casi óptima. El almacenamiento requerido u es la limitación básica en la implementación del decoder Viterbi. Los decoders comerciales están limitados a una longitud de restricción (constraint lenght) cercana a K = 10. Los esfuerzos por incrementar la ganancia de codificación mediante el incremento de la longitud de restricción choca con el incremento exponencial en los requerimientos (y complejidad) de memoria que se siguen de la ecuación (7.10). Sincronización de la palabra de rama es el proceso de determinación del comienzo de una palabra de rama en la secuencia recibida. Dicha sincronización puede tomar lugar sin que nueva información sea añadida a la cadena de símbolos transmitidos, ya que los datos recibidos parecen tener una excesiva tasa de error cuando no estan sincronizados. Por esta razón, un modo simple de lograr la sincronización es monitorear alguna indicación simultánea de esta gran tasa de error, esto es, la tasa a la cual las métricas de estado son incrementadas o a la cual los caminos sobrevivientes se unen en el enrejado. Los parámetros monitoreados son comparados al umbral, y la sincronización es entonces ajustada de acuerdo a esto. 7.4 PROPIEDADES DE LOS CÓDIGOS CONVOLUCIONALES
7.4.1 Propiedades de Distancia de los Códigos Convolucionales
20
Considere las propiedades de distancia de los códigos convolucionales en el contexto del encoder simple de la figura 7.3 y su diagrama de Trellis de la figura 7.7. Queremos evaluar la distancia entre todos los posibles pares de secuencias de codewords. Como en el caso de los bloques de código (ver sección 6.5.2), estamos interesados en la mínima distancia entre todos los pares de secuencias de codewords en el código, ya que la mínima distancia está relacionada con la capacidad de corrección de error del código. Dado que un código convolucional es un grupo o código lineal [6], no se pierde la generalidad en simplemente encontrar la mínima distancia entre cada una de las secuencias de codewords y la secuencia de todos-ceros. En otras palabras, para un código lineal, cualquier mensaje de testeo es tan “bueno” como cualquier otro mensaje de testeo. Entonces, ¿por qué no elegir uno que sea fácil de mantener la secuencia de todos-ceros? Asumiendo que la secuencia de todos-ceros de entrada fue transmitida, los caminos de interés son aquellos que comienzan y terminan en el estado 00 y no vuelven a este estado hasta el final del camino. Ocurrirá un error siempre que la distancia de cualquier otro camino que se una con el estado 00 al instante ti sea menor que la distancia al camino de todos-ceros al instante up ti , causando que el camino de todos-ceros sea descartado en el proceso de decodificación. En otras palabras, dada la transmisión de todos ceros, ocurre un error siempre que el camino de todos ceros no sobreviva. De este modo un error de interés es asociado con el camino sobreviviente que diverge y luego se re-une al camino de todos-ceros. Surge una pregunta: ¿ por qué es necesario para el camino re-unirse ? ¿ No es la divergencia suficiente para detectar un error ? Sí, por supuesto, pero un error caracterizado por sólo una divergencia indica que el decoder, desde este punto en adelante, tendrá como salida “basura” por el resto de la duración del mensaje. Queremos cuantificar la
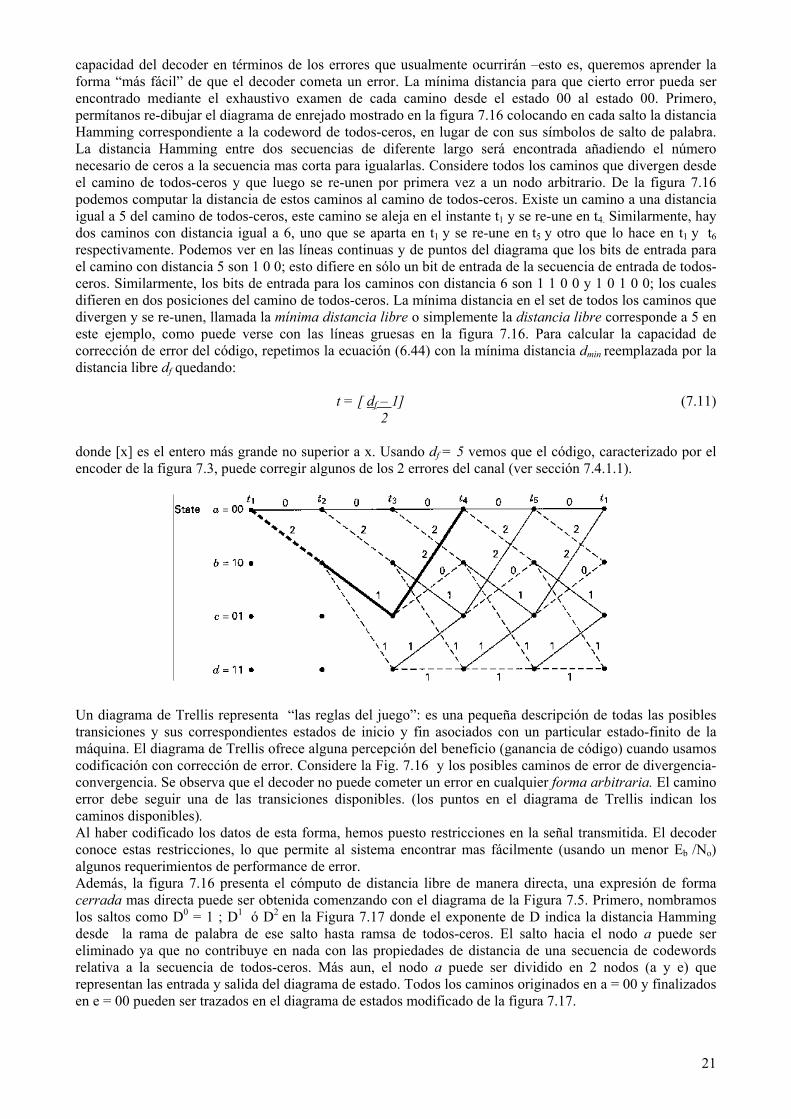
capacidad del decoder en términos de los errores que usualmente ocurrirán –esto es, queremos aprender la forma “más fácil” de que el decoder cometa un error. La mínima distancia para que cierto error pueda ser encontrado mediante el exhaustivo examen de cada camino desde el estado 00 al estado 00. Primero, permítanos re-dibujar el diagrama de enrejado mostrado en la figura 7.16 colocando en cada salto la distancia Hamming correspondiente a la codeword de todos-ceros, en lugar de con sus símbolos de salto de palabra. La distancia Hamming entre dos secuencias de diferente largo será encontrada añadiendo el número necesario de ceros a la secuencia mas corta para igualarlas. Considere todos los caminos que divergen desde el camino de todos-ceros y que luego se re-unen por primera vez a un nodo arbitrario. De la figura 7.16 podemos computar la distancia de estos caminos al camino de todos-ceros. Existe un camino a una distancia igual a 5 del camino de todos-ceros, este camino se aleja en el instante t1 y se re-une en t4. Similarmente, hay dos caminos con distancia igual a 6, uno que se aparta en t1 y se re-une en t5 y otro que lo hace en t1 y t6 respectivamente. Podemos ver en las líneas continuas y de puntos del diagrama que los bits de entrada para el camino con distancia 5 son 1 0 0; esto difiere en sólo un bit de entrada de la secuencia de entrada de todos-ceros. Similarmente, los bits de entrada para los caminos con distancia 6 son 1 1 0 0 y 1 0 1 0 0; los cuales difieren en dos posiciones del camino de todos-ceros. La mínima distancia en el set de todos los caminos que divergen y se re-unen, llamada la mínima distancia libre o simplemente la distancia libre corresponde a 5 en este ejemplo, como puede verse con las líneas gruesas en la figura 7.16. Para calcular la capacidad de corrección de error del código, repetimos la ecuación (6.44) con la mínima distancia dmin reemplazada por la distancia libre df quedando:
t = [ df – 1] (7.11) 2 donde [x] es el entero más grande no superior a x. Usando df = 5 vemos que el código, caracterizado por el encoder de la figura 7.3, puede corregir algunos de los 2 errores del canal (ver sección 7.4.1.1).
Un diagrama de Trellis representa “las reglas del juego”: es una pequeña descripción de todas las posibles transiciones y sus correspondientes estados de inicio y fin asociados con un particular estado-finito de la máquina. El diagrama de Trellis ofrece alguna percepción del beneficio (ganancia de código) cuando usamos codificación con corrección de error. Considere la Fig. 7.16 y los posibles caminos de error de divergencia-convergencia. Se observa que el decoder no puede cometer un error en cualquier forma arbitraria. El camino error debe seguir una de las transiciones disponibles. (los puntos en el diagrama de Trellis indican los caminos disponibles). Al haber codificado los datos de esta forma, hemos puesto restricciones en la señal transmitida. El decoder conoce estas restricciones, lo que permite al sistema encontrar mas fácilmente (usando un menor Eb /No) algunos requerimientos de performance de error. Además, la figura 7.16 presenta el cómputo de distancia libre de manera directa, una expresión de forma cerrada mas directa puede ser obtenida comenzando con el diagrama de la Figura 7.5. Primero, nombramos los saltos como D0 = 1 ; D1 ó D2 en la Figura 7.17 donde el exponente de D indica la distancia Hamming desde la rama de palabra de ese salto hasta ramsa de todos-ceros. El salto hacia el nodo a puede ser eliminado ya que no contribuye en nada con las propiedades de distancia de una secuencia de codewords relativa a la secuencia de todos-ceros. Más aun, el nodo a puede ser dividido en 2 nodos (a y e) que representan las entrada y salida del diagrama de estado. Todos los caminos originados en a = 00 y finalizados en e = 00 pueden ser trazados en el diagrama de estados modificado de la figura 7.17.
21

Podemos calcular la función de transferencia de los camino a b c e (comenzando y terminando en el estado 00) en términos del indeterminado D, como D2 D D2 = D5 . El exponente representa el número acumulativo de unos en el camino y por tanto la distancia Hamming al camino de todos ceros. Similarmente los caminos a b d c e y a b c b c e tienen ambos la función de transferencia D 6 y una distancia Hamming de 6 al caminos de todos ceros. Las ecuaciones de estado quedan como :
Xb = D²Xa + Xc Xc = DXb + DXd (7.12)
Xd = DXb + DXd Xe = D²Xc
Donde Xa, ……, Xe son variables falsas para los caminos parciales a los nodos intermedios. La función de transferencia, T (D)=Xe/Xa llamada a veces función generadora de código puede ser expresada como:
T (D) = D5__ = D5 + 2 D6 + 4 D7 + . . . + 2 l Dl + 5 (7.13) 1-2D La función de transferencia para este código indica que hay sólo un camino de distancia 5 al camino de todos ceros, dos de distancia 6, cuatro de distancia 7 y en general, que hay 2 l caminos de distancia l +5 , donde l = 0, 1, 2, . . . La distancia libre df del código es el peso Hamming del término de menor orden de la función expandida T(D). En este ejemplo df = 5. En la evaluacion de las propiedades de distancia, T(D) no puede usarse para grandes restricciones dado que la complejidad de T(D) crece exponencialmente con la longitud de restricción (k). La función de transferencia puede usarse para brindar información más detallada que sólo las distancias de los distintos caminos. Nos permite introducir un factor L en cada salto del diagrama de estados, de modo que el exponente de L sirve como un indicador del número de saltos en cualquier camino que vaya de a = 00 a e = 00. Además, podemos introducir el factor N en todas las transiciones de los saltos causados por la entrada de un uno. Esto es, cuando una rama es atravesada, el exponente de N se incrementa en uno, sólo si la transición del salto es debido a un uno en la entrada. Para el código convolucional caracterizado en ejemplo de la figura 7.3, los factores adicionales L y N son mostrados en el diagrama modificado de estados de la Fig. 7.18 y las ecuaciones (7.12) quedan como:
Xb = D²LNXa + LNXc Xc = DLXb + DLXd (7.14)
Xd = DLNXb + DLNXd Xe = D²LXc
La función de Transferencia del nuevo diagrama de estado es :
( ) ( )( ) ( )
............11
11,,
135
35724635
35
+++
++++=
+−=
+++ lll NLDNLLDNLLDNLD
NLDLNLDNLDT
(7.15)
Esto es, podemos verificar algunas de las propiedades mostradas en la figura 7.16. Hay un camino de distancia 5 y tamaño 3, que difiere en un bit de entrada del camino de todos ceros. Hay dos caminos de
22

distancia 6, uno de longitud 4 y otro de longitud 6, pero ambos difieren en 2 bits del camino de todos los ceros. Asimismo de los caminos de distancia 7 uno es de longitud 5, dos de longitud 6 y uno de longitud 7; los cuatro corresponden a secuencias de entrada con 3 bits diferentes al camino de todos ceros. Así, si el camino de todos ceros es el correcto y el ruido nos hace elegir uno de los caminos incorrectos de distancia 7, habrá 3 bits erróneos.
7.4.1.1 CAPACIDAD DE CORRECCIÓN DE ERROR DE LOS CÓDIGOS CONVOLUCIONALES.
En el estudio de los bloques de código en el Capítulo 6, vimos que la capacidad de corrección de error, t, representaba el número de errores de símbolo de código, que podrían con máxima probabilidad de decodificación, ser corregidos en cada longitud del bloque de código. Como siempre, cuando decodificamos códigos convolucionales, la capacidad de corrección de error no puede obtenerse brevemente. Mirando la ecuación (7.11) podemos decir que el código puede, con máxima probabilidad de decodificación, corregir t errores con unas pequeña longitud de restricción, donde “pequeña” significa 3 ó 5. La longitud exacta depende de cómo están distribuidos los errores. Para un código y patrón de error particular, la longitud puede ser limitada usando los métodos de la función de transferencia. Dichos límites son descriptos más adelante.
7.4.2 CÓDIGOS CONVOLUCIONALES, SISTEMÁTICOS Y NO SISTEMÁTICOS Un código convolucional sistemático es uno en el cual la entrada k - tuple aparece como parte de la palabra salto de salida de n - tuple asociado con aquel k - tuple . La figura 7.19 muestra un encoder sistemático binario con tasa= ½ y k=3. Para bloques de código lineales, cualquier código no-sistemático puede ser transformado en un código sistemático con las mismas propiedades de distancia. Este no es el caso para códigos convolucionales, la razón es que éstos dependen significativamente de la distancia libre ; Hacer el código convolucional sistemático, en general, reduce la máxima distancia libre posible para una longitud de restricción y tasa dada.
La tabla 7.1 muestra la máxima distancia libre para una tasa = ½ de un código sistemático y no sistemático con k =2 a k= 8. Para grandes longitudes de restricción los resultados están a menudo ampliamente separados [17] .
23

Constrataint length
Frre distance systematic
Free Distance Nonsystematic
2 3 3 3 4 5 4 4 6 5 5 7 6 6 8 7 6 10 8 7 10
7.4.3 PROPAGACIÓN DEL ERROR CATASTRÓFICO EN CÓDIGOS CONVOLUCIONALES.
Un error catastrófico es definido como un evento la cual un numero finito de errores de símbolos causa un numero infinito de errores de bits en los datos decodificados. Massey y Saim [18] han llegado a la conclusión que una condición necesaria y suficiente para los códigos convolucionales se demuestra en la propagación del error catastróficos. Para una velocidad de códigos
n1 con registros diseñados por generadores
polinomiales, como lo describimos en la Sección 7.2.1, la condición para la propagación de errores catastróficos es que los generadores tenga un factor polinomial común ( de grado por lo menos uno). Por ejemplo, la figura 7.20a ilustra una velocidad de
21 , K = 3 un codificador con un g1(x) polinomial superior y
un g2(x) polinomial inferior, como los siguientes:
22
1
1)(
1)(
Xxg
Xxg
+=
+= (7.16)
Los generadores g1(x) y g2(x) tienen en común el factor polinomial 1+X, como:
( )( )XXX ++=+ 111 2
Por lo tanto, en el codificador de la figura 7.20a podemos manifestar error catastrófico de propagación.
Figura 7.20 Codificador mostrando la propagación del error catastrófico.
(a) Codificador. (b) Diagrama de estado. En términos de diagramas de estado para cualquier velocidad de código, el error catastrófico puede ocurrir si y solo si, cuando el camino de lazo cerrado tiene peso cero (distancia cero desde todos los caminos de ceros). En la ilustración, consideramos el ejemplo de la figura 7.20. El diagrama de estado de la figura 7.20b esta dibujado con el estado del nodo a = 00 dividido en dos nodos, como antes. Asumiendo que el camino de todos los ceros es el camino correcto, camino incorrecto es a b d d ... d c e tiene exactamente 6 unos, no importa cuantas veses tiene que girar alrededor del mismo lazo d. Así que para una BSC, por ejemplo, tres errores en el canal pueden causar la elección de un camino incorrecto. Un numero arbitrariamente largo (2 o más números de veces el lazo cerrado es atravesado) puede ser hecho en cada camino. Observamos que para una velocidad de código 1/n, si cada sumador en el codificador tiene un numero igual de conexiones, el lazo cerrado correspondiente a los datos con todos 1 debería tener peso cero, y consecuentemente, el código debería ser catastrófico. La única ventaja de un código sistemático, descripto anteriormente, es que este nunca puede ser catastrófico, donde cada lazo cerrado debe contener por lo menos un rama generada por una entrada de bit no-cero, y por
24

lo tanto cada lazo cerrado debe tener un símbolo no-cero. Sin embargo, podemos ver [19] que únicamente una pequeña fracción de códigos no sistemáticos son catastroficos.
7.4.4 LIMITES DE PERFORMANCE PARA CÓDIGOS CONVOLUCIONALES. La probabilidad de error de bit, PB , para una código convolucional binario usando descodificación con hard-decisión podemos verla en [8], siendo los limites superiores como los siguientes:
( ))1(2,1
,ppDNB dN
NDdTP−==
≤ (7.17)
donde p es la probabilidad de error de símbolo en el canal. Para el ejemplo de la figura 7.3, T(D,N) es obtenido por T(D,L,N) con L = 1, en la ecuación (7.15).
( )DNNDNDT
21,
5
−= (7.18)
( )( )2
5
1 21,
DD
dNNDdT
N−
== (7.19)
combinando las ecuaciones 7.17 y 7.19, podemos escribir.
( )[ ]{ }( )[ ]{ }2
21
52
1
141
12
pp
ppPB
−−
−≤ (7.20)
para una modulación BPSK coherente sobre un canal con ruido blanco gaussiano aditivo (AWGN), estos podemos ver en [8] que la probabilidad de error de bit esta limitada por:
( )( )0/exp,1
00
,exp2 NEDNc
fc
fB cdNNDdT
NE
dNE
dQP −==
≤ (7.21)
donde:
00 // NrENE bc =
=0/ NEb relación de energía de bit de información sobre la densidad espectral de potencia del ruido.
=0/ NEc relación de energía de símbolo en el canal sobre densidad espectral de potencia del ruido. nkr /= velocidad del código.
Y Q(x) esta definido en las ecuaciones (3.43) y (3.44) y tabulada en la tabla B.1. Por lo tanto, para la velocidad de código 2
1 con distancia libre df = 5, en conjunción con la BPSK coherente y la descodificación con decisión dura, podemos escribir:
( )( )[ ]20
0
00 2/exp212/5exp
25
exp5
NENE
NE
NE
QPb
bbbB
−−−
≤ (7.22)
( )( )2
0
0
2/exp21
/5
NE
NEQ
b
b
−−≤
7.4.5 GANANCIA DE CODIFICACIÓN
La ganancia de codificación, como es presentada en la ecuación (6.19), es definida como la reducción, usualmente expresada en decibeles, en el requerido Eb/N0 a realizar una probabilidad de error especifica de un sistema codificado sobre un sistema no codificado con la misma modulación y características del canal. En la tabla 7.2 vemos la ganancia de códigos los limites superiores, comparado con uno sin codificación coherente BPSK, para varias distancia libres máximas para códigos convolucionales con limitación de longitud variable de 3 a 9 sobre un canal gaussiano con decodificación con hard-decisión. La tabla ilustra
25
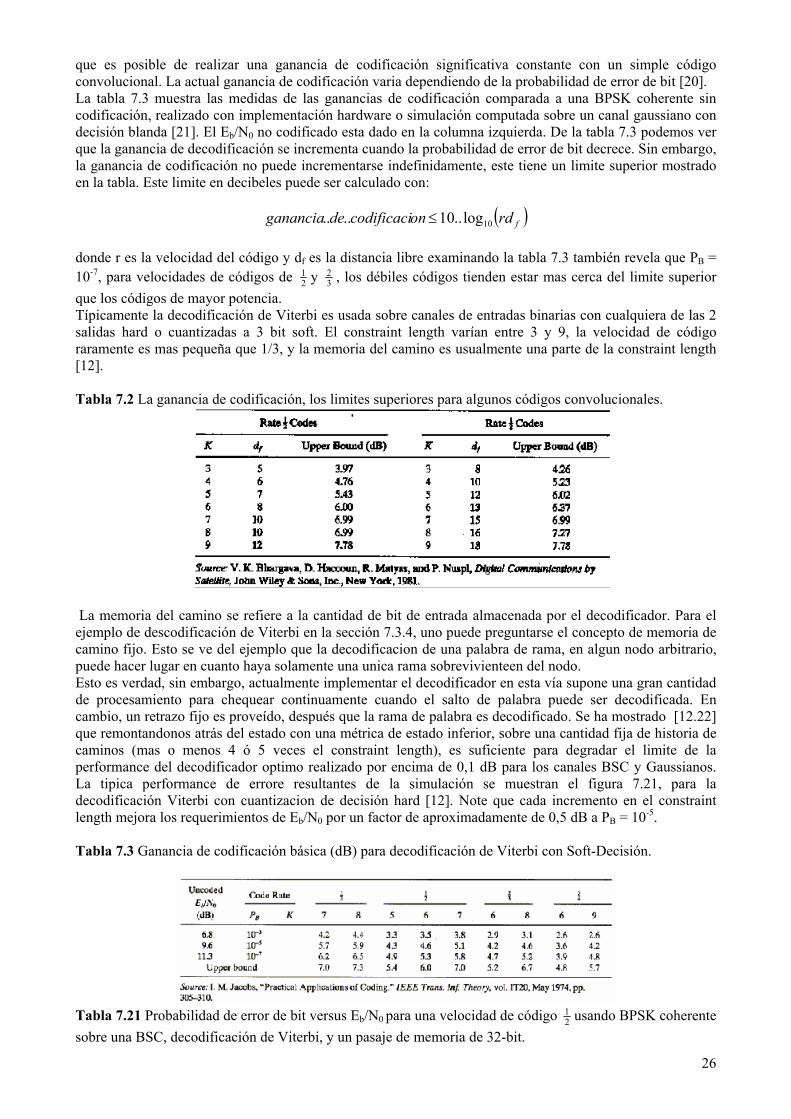
que es posible de realizar una ganancia de codificación significativa constante con un simple código convolucional. La actual ganancia de codificación varia dependiendo de la probabilidad de error de bit [20]. La tabla 7.3 muestra las medidas de las ganancias de codificación comparada a una BPSK coherente sin codificación, realizado con implementación hardware o simulación computada sobre un canal gaussiano con decisión blanda [21]. El Eb/N0 no codificado esta dado en la columna izquierda. De la tabla 7.3 podemos ver que la ganancia de decodificación se incrementa cuando la probabilidad de error de bit decrece. Sin embargo, la ganancia de codificación no puede incrementarse indefinidamente, este tiene un limite superior mostrado en la tabla. Este limite en decibeles puede ser calculado con:
( )frdoncodificacideganancia 10log..10.... ≤ donde r es la velocidad del código y df es la distancia libre examinando la tabla 7.3 también revela que PB = 10-7, para velocidades de códigos de 2
1 y 32 , los débiles códigos tienden estar mas cerca del limite superior
que los códigos de mayor potencia. Típicamente la decodificación de Viterbi es usada sobre canales de entradas binarias con cualquiera de las 2 salidas hard o cuantizadas a 3 bit soft. El constraint length varían entre 3 y 9, la velocidad de código raramente es mas pequeña que 1/3, y la memoria del camino es usualmente una parte de la constraint length [12]. Tabla 7.2 La ganancia de codificación, los limites superiores para algunos códigos convolucionales.
La memoria del camino se refiere a la cantidad de bit de entrada almacenada por el decodificador. Para el ejemplo de descodificación de Viterbi en la sección 7.3.4, uno puede preguntarse el concepto de memoria de camino fijo. Esto se ve del ejemplo que la decodificacion de una palabra de rama, en algun nodo arbitrario, puede hacer lugar en cuanto haya solamente una unica rama sobrevivienteen del nodo. Esto es verdad, sin embargo, actualmente implementar el decodificador en esta vía supone una gran cantidad de procesamiento para chequear continuamente cuando el salto de palabra puede ser decodificada. En cambio, un retrazo fijo es proveído, después que la rama de palabra es decodificado. Se ha mostrado [12.22] que remontandonos atrás del estado con una métrica de estado inferior, sobre una cantidad fija de historia de caminos (mas o menos 4 ó 5 veces el constraint length), es suficiente para degradar el limite de la performance del decodificador optimo realizado por encima de 0,1 dB para los canales BSC y Gaussianos. La tipica performance de errore resultantes de la simulación se muestran el figura 7.21, para la decodificación Viterbi con cuantizacion de decisión hard [12]. Note que cada incremento en el constraint length mejora los requerimientos de Eb/N0 por un factor de aproximadamente de 0,5 dB a PB = 10-5. Tabla 7.3 Ganancia de codificación básica (dB) para decodificación de Viterbi con Soft-Decisión.
Tabla 7.21 Probabilidad de error de bit versus Eb/N0 para una velocidad de código 2
1 usando BPSK coherente sobre una BSC, decodificación de Viterbi, y un pasaje de memoria de 32-bit.
26

7.4.6 CÓDIGOS CONVOLUCIONALES MAS CONOCIDOS Los vectores conectores o generadores polinomial de códigos convolucionales son usualmente seleccionados en base a las propiedades de los códigos a distancia libre. El primer criterio es seleccionar un código que no tenga error catastrófico de propagación y que tenga un máximo de distancia libre para dar la velocidad y la limitación de longitud. Entonces el números de caminos con distancia libre df, ó el numero de errores de bit de datos en el camino representado, debe ser minimizado. El procesamiento de selección puede ser perfeccionado mas adelante considerando el numero de caminos o bit de error en df+1, en df+2, así sucesivamente, hasta únicamente un código o clase de código restantes. Una lista de códigos mas conocidos de velocidad ½, K = 3 a 9, y velocidad 1/3, K = 3 a 8, esta basado en el criterio de compilación de Odenwalder [3,23] y esta dado en la tabla 7.4. Los vectores conectores en esta tabla representa la presencia o ausencia (1 ó 0) de un lugar de conexión correspondiente a la etapa del codificador convolucional, el termino mas a la izquierda corresponde a la etapa mas a la izquierda del registro del codificador. Esto es interesante notar, que las conexiones pueden ser invertidas (el extremo izquierdo y el extremo derecho pueden ser intercambiadas en la descripción de arriba). Bajo la condición de la descodificación de Viterbi la inversión de las conexiones da un aumento de códigos con idénticas propiedades de distancia, por lo tanto es idéntica a la realización que vemos en la Tabla 7.4 Tabla 7.4 Limitación de longitud optima corta para códigos convolucionales.
27

7.4.7 RAZON DE CÓDIGOS CONVOLUCIONALES - TRACE-OFF
7.4.7.1 Performance con señalización PSK coherente La capacidad de corregir errores de un esquema de códigos se incrementa cuando el numero de símbolos n por bit de información k se incrementa, o la velocidad k/n decrece. Sin embargo, el ancho de banda y la complejidad del decodificador se incrementan con n. La ventaja de una velocidad baja de códigos cuando usamos códigos convolucionales con PSK coherente, es que requerimos que Eb/No sea bajo (para un largo rango de velocidad de códigos), permitiendo la transmisión a altas velocidades de datos para una dada cantidad de potencia, o permite reducir la potencia para una razón de datos dada de datos. El estudio de la simulación, mostrado en [16,22], tiene que para una limitación de longitud fija, un decrecimiento en la velocidad de código de 2
1 a 31 resulta una reducción de requerimiento Eb/No de mas o menos 0,4 dB. Sin
embargo, el incremento correspondiente a la complejidad del decodificador es del 17%. Para valores chicos de razón de códigos, la mejora en la performance relativa en incrementar la complejidad del decodificador disminuye rápidamente [22]. Eventualmente, un punto es alcanzado donde sigue decreciendo la velocidad del código y es caracterizada por la reducción en la ganancia de codificación. (Ver sección 9.7.7.2).
7.4.7.2 PERFORMANCE CON SEÑALIZACIÓN ORTOGONAL NO COHERENTE
En contraste a PSK, esta es optima para velocidades de códigos de mas o menos 2
1 . El error aparece para velocidades de códigos 3
1 , 32 y 4
3 ; típicamente se degradan por mas o menos 0,25, 0,5 y 0,3 dB, respectivamente, relativo a la velocidad de realización 2
1 [16].
7.4.8 Decodificación Viterbi con Soft-decisión Para un sistema con códigos convolucionales binarios con velocidad 2
1 , el demodulador entrega 2 códigos símbolos al tiempo del decodificador. Para una descodificación con Hard-decisión (2 niveles), cada par de código recibido puede ser representado en un plano, como una de las esquinas de un cuadrado, como lo muestra la figura 7.22a. Las esquinas son nombradas con números binarios (0,0), (0,1), (1,0) y (1,1), representando 4 posibles valores con Hard-decisión que tiene 2 códigos símbolos. Para 8 niveles con descodificación con soft-decisión, cada par de códigos símbolos pueden ser representados similarmente en un plano espaciado, de igual manera, 8 niveles por 8 niveles, como un punto de un conjunto de 64 puntos mostrados en la figura 7.22b.
Figura 7.22 (a) Plano de Hard-decisión (b) Plano de soft-decisión con 8-niveles por 8-niveles (c) Ejemplo de símbolos de códigos soft (d) sección de codificador enrejada (e) sección de decodificación enrejada.
28

El caso de soft-decisión, el demodulador no entrega decisiones hard, este entrega señales ruidosas cuantizadas. (Soft-decisión). La primera diferencia entre la descodificación de Viterbi con soft o hard-decisión, es que el algoritmo de soft-decisión no puede usar una distancia métrica de Hamming porque limita la resolución. Una distancia métrica con necesidad de resolución es una distancia euclidiana, y facilita el uso, pues podemos transformar números binarios 1 y 0 a números octales 7 y 0, respectivamente. Esto puede ser visto en la figura 7.22c, donde las esquinas del cuadrado han sido nombradas acordemente; esto permite usar un par de enteros, en un rango de 0 a 7, para describir cualquier punto en el conjunto de 64 puntos. También vemos en la figura 7.22c el punto 5,4, representando un ejemplo de un par de códigos símbolos ruidosos que podrían ser el resultado de un demodulador. Imagine que el cuadrado en la figura 7.22c tiene coordenadas x y y. Entonces, ¿cuál es la
distancia euclidiana entre el punto ruidoso 5,4 y el punto sin ruido 0,0? Este es ( ) ( )22 0405 −+− = 41 . Similarmente, si nos preguntamos ¿cuál es la distancia euclidiana entre el punto ruidoso 5,4 y el punto sin
ruido 7,7? Esta es ( ) ( )22 7475 −+− = 13 . La descodificación de Viterbi con soft-decisión, para la mayoría de las partes, procede de la misma manera que la hard-decisión. La única diferencia es que la distancia Hamming no se usa. Consideramos como la descodificación con soft-decisión es realizada con el uso de la distancia euclidiana. La figura 7.22d muestra la primera sección de una codificación treellis, originariamente presentada en la figura 7.7, con ramas de palabras transformadas de binario a octal. Suponer que un par de códigos símbolos con soft-decisión con valores 5,4 arriva a un decodificador durante el primer intervalo de transición. La figura 7.22e muestra la primera sección de una codificación treellis. La métrica 41 , representa la distancia euclidiana entre el arribado 5,4 y la rama de palabra (0,0), es situado en una línea sólida. Similarmente, la métrica 13 , representa la distancia euclidiana entre el arribado 5,4 y el código símbolo 7,7 , es situado en una linea de trazos. El resto de la tarea, reduciendo el enrejado en búsqueda de una rama común, procede que la misma forma que la hard-decisión. Note que en una descodificación convolucional real, la distancia euclidiana no es usada actualmente para una métrica con soft-decisión; en cambio, se usa una métrica monotonica que tiene propiedades similares y es más fácil de implementar. Un ejemplo de una métrica semejante es la distancia métrica al cuadrado, en este caso la operación raíz cuadrada mostrada arriba es eliminada. Además, si los códigos símbolos binarios son representados con valores bipolares, entonces el producto interno métrico en la ecuación (7.9) puede ser usado. Con una métrica semejante, deberíamos buscar la máxima correlación antes que la mínima distancia. 7.5 OTROS ALGORITMOS DE DECODIFICACIÓN CONVOLUCIONAL
7.5.1 Decodificación secuencial Un decodificador secuencial de palabras por generación de hipótesis a través de una secuencia de codeword transmitidas. Esta computa una métrica entre estas hipótesis y la señal recibida. Esta va adelante tanta longitud como dice la métrica, indicando que estas secciones son probables, si no lo son estas van atrás cambiando las hipótesis, hasta que , por medio de un sistema de prueba y error se las encuentre. Este construye probabilidades de hipótesis. Los decodificadores secuenciales pueden ser implementados para trabajar con decisiones hard o soft, aunque estas últimas son usualmente evitadas porque incrementan la cantidad de almacenamiento requerido y la complejidad del cómputo. Considere el decodificador usado en la figura 7.23, con una secuencia m = 1 1 0 1 1 que es codificada dentro de una codeword con secuencia u = 1 1 0 1 0 1 0 0 0 1 como se vio en el ej 7.1. Asuma que la secuencia recibida z es, en realidad una representación de u. El decodificador tiene disponible una réplica del decodificador árbol, y puede usar la secuencia recibida z para penetrar al árbol. El decodificador comienza en t1 (nodo del árbol) y genera además caminos de salida a ese nodo.
29

El decodificador sigue ese camino el cual acepta recibir n símbolos codificados. En el siguiente nivel del árbol, el decodificador genera nuevamente mas caminos de salida al nodo, y sigue el camino accediendo con el segundo grupo de n símbolos codificados. Procediendo de esta manera, el decodificador penetra fácilmente en el arbol. Supongamos ahora, que la secuencia recibida z es una versión degradada de u. El decodificador comienza en t1 del árbol, y genera caminos conduciendo a ese nodo. Si los n símbolos recibidos codificados coincide con uno de los caminos generados, el decodificador sigue ese camino. Si este no coincide, el decodificador sigue el camino mas probable, pero manteniendo un camino acumulativo sobre el número de incoincidencias entre los números recibidos y la palabra de rama, sobre el camino que está siguiendo. Si dos ramas aparecen igualmente probables, el receptor usa un rulo arbitrario, tal como el camino siguiente de entrada 0. A cada nuevo nivel en el árbol, el decodificador le genera nuevas ramas y los compara con el siguiente set de n símbolos recibidos codificados. La búsqueda continua hasta penetrar el árbol a través del camino mas probable y manteniendo el número de incoincidencias acumulativas. Si el contador de incoincidencias supera un cierto número (el cual se incrementa cuando penetramos el árbol), el decodificador decide que está sobre un camino incorrecto, sale del camino y trata con otro. El decodificador se queda con la trayectoria de los caminos descartados, para evitar que se recorra nuevamente un camino erróneo. Ejemplo: Asumamos que el decodificador en la figura 7.3 se usa para codificar el mensaje con secuencia m, dentro de la codeword u. Supongamos que el cuarto y séptimo bit de la secuencia transmitida u se reciben con error, tal como Tiempo t1 t2 t3 t4 t5 Secuencia del mensaje 1 1 0 1 1 Secuencia Transmitida 11 01 01 00 01 Secuencia Recibida 11 00 01 10 01 Siguiendo la figura 7.23 , asuma que cuando el contador de incoincidencias es de tres, el decodificador vuelve y trata con un camino alternativo. En la figura los números a lo largo de la trayectoria del camino representan el contador de incoincidencias.
1) En el tiempo t1 recibimos símbolos 11 y los comparamos con las palabras de rama partiendo del primer nodo.
2) La única rama mas probable es la 11 (correspondiendo a un bit de entrada o ramificación descendente),entonces el decodificador decide que el bit de entrada uno es la correcta decodificación, y va al siguiente nivel.
3) En el tiempo t2, el decodificador recibe símbolos 00 y los compara con las palabras de rama disponibles 10 y 01 en este segundo nivel.
4) No hay mejores caminos, además el decodificador toma arbitrariamente la entrada de bit cero ( o rama de palabra 10) y cuenta las incoincidencias, quedando registrado en 1.
5) En el tiempo t3, el decodificador recibe símbolos 01 y los compara con las palabras de rama disponibles 11 y 00 en este tercer nivel.
6) Nuevamente no hay mejor camino, entonces el decodificador toma arbitrariamente la entrada cero ( o rama de palabra 11), e incrementa el contador de incoincidencia a 2.
7) En el tiempo t4, el decodificador recibe símbolos 10 y los compara con las palabras de ramas disponibles 00 y 11 en este cuarto nivel.
30

8) Otra vez no hay mejores caminos y el decodificador vuelve a tomar el bit cero (o palabra de rama 00) e incrementa el contador de incoincidencias a 3.
9) Dado que el decodificador produce un cambio de criterio cuando el contador de discontinuidades llega a 3, este retrocede y trata un camino alternativo.El contador de incoincidencia vuelve a 2.
10) El camino alternativo es la entrada de bit 1 (o palabra de rama 11), en el cuarto nivel. 11) Se vuelve el contador a 3, el decodificador sale de este camino y el contador se resetea nuevamente a 2. Todas las alternativas han sido ahora en el nivel de t4,entonces el decodificador regresa al nodo t3, y resetea el contador a 1.
12) En el nodo t3, el decodificador compara los símbolos recibidos al tiempo t3, particularmente 01,con el camino 00 no probado. 13) En el nodo t4,el decodificador sigue la palabra de rama 10 que los comparo con los símbolos codificados 10,el contador se queda sin alteración en 2. 14) En el nodo t5,no hay mejores caminos,entonces el decodificador sigue la rama superior como es el rulo, y el contador se incrementa a 3. 15) En este conteo, el decodificador vuelve atrás, resetea a 2 el contador y trata un nodo alternativo en t5. dado que la palabra de rama alternativa es 00, hay una incoincidencia con los símbolos codificados recibidos 01 en t5, y el contador es nuevamente incrementado a 3. 16) El decodificador sale de este camino y el contador es reseteado a 2. Todas estas alternativas no han atravesado el nivel 5, entonces el decodificador retorna al nivel t4 y resetea a el contador a 1. 17) El decodificador trata un camino alternativo en t4, el cual levanta la métrica a 3 dado a que hay incoincidencias en dos posiciones en la palabra de rama. Ahora el decodificador debe regresar todos los niveles hasta t2, debido a que todos los otros caminos ya han sido probados. El contador es ahora decrementado a cero. 18) En t2 el decodificador sigue ahora la palabra de rama 01, y como hay una incoincidencia el contador se incrementa a 1. El decodificador sigue actuando de esta manera hasta que produce la secuencia del mensaje correctamente. La decodificación secuencial puede ser vista como una técnica de prueba y error para buscar el camino correcto en la codificación árbol. Esta acción de búsqueda en forma secuencial actúa de un camino a la vez. Si se hace una decisión incorrecta, las extensiones de los caminos estarán equivocadas. El decodificador puede conocer este error por monitoreo de la métrica del camino. El algoritmo es similar a un viaje de un automóvil siguiendo un mapa, siempre y cuando el viajante reconozca que las marcas terrenas coincide con el mapa sigue. Cuando nota que hay un lugar extraño el conductor asume que esta en un camino incorrecto y vuelve al punto donde el había conocido el lugar (esta métrica tiene un rango aceptable) y luego trata con otro camino.
31

7.5.2 COMPARACIONES Y LIMITACIONES DE LA DECODIFICACIÓN DE VITERBI Y LA SECUENCIAL
1)El mayor inconveniente del algoritmo de Viterbi es que si baja la probabilidad de error exponencialmente con restricción en la longitud, el número de estado de códigos y consecuentemente la complejidad del decodificador, crece exponencialmente con restricción en longitud. 2)Por otro lado, la complejidad computacional del algoritmo de Viterbi es independiente de las características del canal (comparado con la decodificación por decisión hard, la decodificación por decisión soft requiere solo de un incremento normal en el número de cómputos). 3)El mayor inconveniente de la decodificación secuencial es que el número de métricas de estado es una variable aleatoria. 4)Para la decodificación secuencial el número esperado de malas hipótesis y las búsquedas retrasadas son funciones de la SNR del canal. 5)Con una baja SRN más hipótesis deben ser tratadas que con una SNR alta, las secuencias recibidas deben ser almacenadas mientras el decodificador esta trabajando para conseguir una hipótesis probable.
32

En la figura 7.24, vemos algunos gráficos típicos de PB versus Eb/No para las dos soluciones mas conocidas para el problema de la decodificación convoluvional. La decodificación de Viterbi y la secuencial comparándose usando BPSK coherente, por un canal AWGN. La curva compara la decodificación Viterbi ( rates ½ y 1/3 decisión hard k=7) con otra Viterbi ( rates ½ y 1/3 decisión soft k=7) Y con la decodificación secuencial (rates ½ y 1/3 decisión hard k=41)
7.5.3 CODIFICACIÓN CON RETROALIMENTACIÓN Un decodificador con retroalimentación realiza una decisión de hard sobre el bit de datos en el estado j, basado sobre métricas computadas desde estados j, j+1,......., j+m, donde m es un entero positivo seleccionado. Si llamamos L a lo que miramos hacia delante (look-ahead), definida por L = m + 1, el numero de símbolos codificados recibidos expresados en términos de la correspondiente entrada de bits decodificada que se usa para decodificar un bit de información. La decisión de que el bit de dato de cada rama sea 0 ó 1 depende de la distancia mínima de Hamming del camino que atraviesa a la ventana en donde se mira hacia delante (look-ahead window), del estado j al estado j+m. Consideremos ahora el uso de un decodificador retroalimentado, con un código convolucional con índice de ½ , como se muestra en la figura 7.3. La figura 7.24 muestra el diagrama de árbol y la operación del decodificador retroalimentado con un L = 3. Esto es, en decodificación del bit de la rama j, el decodificador considera el camino a las ramas j, j+1 y j+2. Este comienza con la primer rama, el decodificador codifica 2L u ocho métricas de caminos acumulativos de Hamming, y decide que el bit para la primer rama es 0 si la distancia mínima al camino está contenida en la parte que está en la parte mas arriba del árbol, y decide 1 si esta en la parte que está mas abajo. Asuma que la secuencia recibida es Z = 1 1 0 0 0 1 0 0 0 1 Ahora examinemos ocho caminos desde t1 a t3 (A en la fig. 7.24), y computa las métricas comparando otros ocho caminos con los primeros seis símbolos codificados recibidos (tres divisiones de tiempo, dos símbolos por rama). La lista de métricas de caminos acumulativos de Hamming (comenzando desde el principio del camino) es la siguiente: Mitad de métricas más altas 3,3,6,4 Mitad de métricas más bajas 2,2,1,3 Podemos ver que las métricas mínimas están en la parte inferior del árbol. Por consiguiente el primer bit decodificado es uno (caracterizado por un movimiento mas abajo en el árbol. El siguiente paso es extender la parte inferior del árbol, y computamos nuevamente ocho métricas, esto es de t2 hasta t4. Considerando la primera codificación de los dos símbolos codificados, nos deslizamos encima de los dos símbolos codificados a la derecha, y otra vez Computamos las métricas de los caminos para seis símbolos codificados.
33

Esto es lo que se indica con B en la figura 7.24. Nuevamente la lista de métricas desde el principio del camino hasta el final, podemos encontrar que hay Mitad de métricas más altas 2,4,3,3 Mitad de métricas más bajas 3,1,4,4 Para la secuencia recibida se asume que la métrica mínima se encuentra en la mitad inferior del bloque B. Por consiguiente, el segundo bit decodificado es uno. El mismo procedimiento continúa hasta que se decodifica el mensaje completo. Un importante parámetro de diseño de los codificadores convolucionales con retroalimentación es L, la longitud de lo que se mira hacia delante. Incrementando L aumenta la ganancia de decodificación, pero aumentamos la capacidad de implementarlo.
34