bases de datos distribuidas
DESCRIPTION
Bases de datos distribuidas. Ing. Fabián Ruano. Base de Datos Distribuida. Definición Diferencias con BD Centralizadas. Ventajas. Almacenamiento cercano Procesamiento paralelo Expansión rápida Tolerancia a fallos Autonomía de nodos. Desventajas. Control y manejo de datos Seguridad - PowerPoint PPT PresentationTRANSCRIPT

Bases de datos distribuidas
Ing. Fabián Ruano
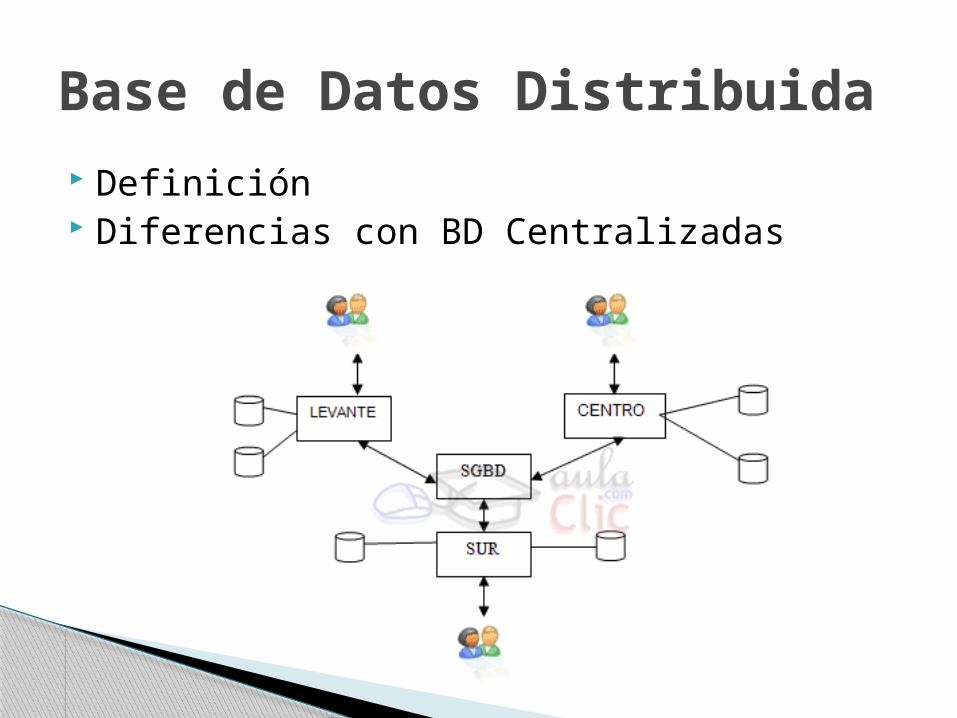
Definición Diferencias con BD Centralizadas
Base de Datos Distribuida

Almacenamiento cercano Procesamiento paralelo Expansión rápida Tolerancia a fallos Autonomía de nodos
Ventajas

Control y manejo de datos Seguridad Complejidad en mantener integridad Control de concurrencia mas complejo
Desventajas

Diseño de la base de datos distribuida: distribución de información entre nodos
Procesamiento de consultas: costo de procesamiento y transmisión de datos
Control de concurrencia: coordinación de acceso a la base de datos
Confiabilidad: manejo de transacciones
Aspectos importantes SGBD distribuidos

• Independencia de datos: aplicaciones inmunes a cambios en definición y organización de datos y viceversa• Lógica: inmunidad a cambios en estructura lógica
de la base de datos• Física: ocultamiento de detalles sobre estructuras
de almacenamiento a las aplicaciones de usuario• Transparencia de replicación: replicas
controladas por el sistema, no por el usuario.
Arquitectura BDD – Niveles de transparencia en SBDD (1/2)

Transparencia a nivel de red◦ Localización de datos: comando usado es
independiente de la ubicación de los datos y lugar donde la operación se realice
◦ Esquema de nombramiento: proporcionando nombre único a cada objeto de sistema distribuido.
Transparencia de fragmentación: sistema maneja conversión de consultas definidas sobre relaciones globales a consultas definidas sobre fragmentos
Arquitectura BDD – Niveles de transparencia en SBDD (2/2)

Mayoría basadas en sistema ANSI-SPARC con tres niveles: interno, conceptual y externo.◦ Externa: vista por usuario◦ Conceptual: vista lógica global◦ Interno: nivel de descripción mas bajo de los
datos en una base de datos
Arquitectura BDD

Dimensiones• Distribución• Heterogeneidad• Autonomía• Diseño: decisión sobre cuestiones de diseño• Comunicación: decisión sobre cuestiones de
comunicación• Ejecución: decisión sobre cuestiones de ejecución
de operaciones de manera local
Alternativas implementacion SMDB

Algoritmos de control de concurrencia:• Candado de dos fases• Ordenamiento por estampas de tiempo• Ordenamiento por estampas de tiempo
múltiple• Control de concurrencia optimista
Tarea

Diseño base de datos distribuidas

Nivel de distribución◦ Ninguno◦ Solo datos (sist. Homogéneo)◦ Datos mas programas (sist. Heteregéneo)
Comportamiento de patrones de acceso◦ Estático◦ Dinámico
Nivel de conocimiento sobre comportamiento de patrones◦ Sin información / parcial◦ Información total
Dimensiones
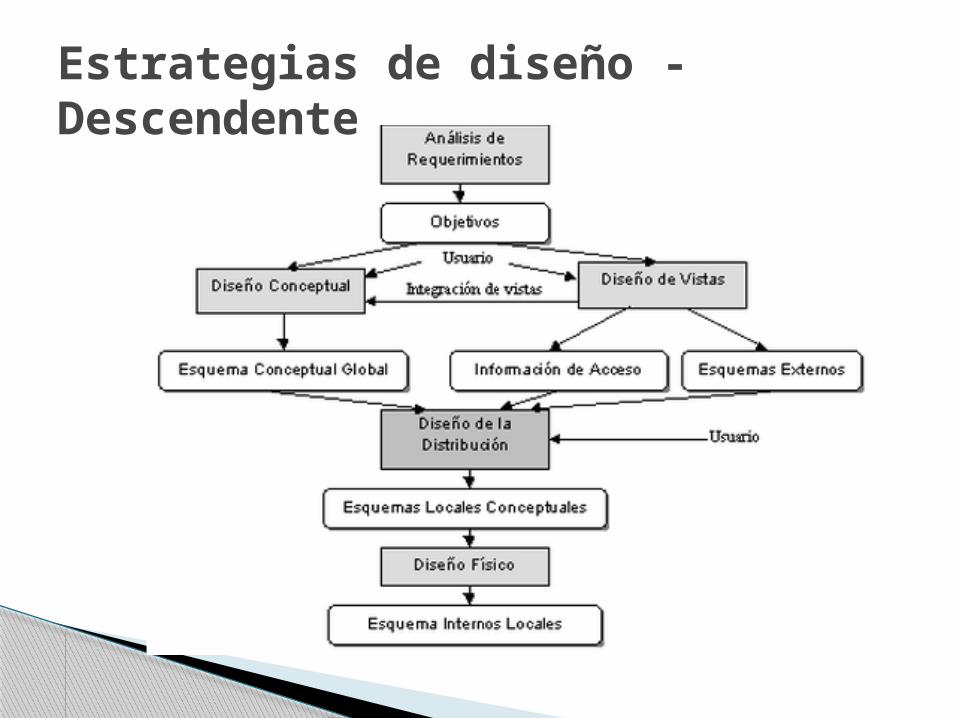
Estrategias de diseño - Descendente

Análisis de requerimientos que define el ambiente del sistema. Determina necesidades de los datos y del proceso.DBMS debe ser definido por: desempeño, confiabilidad, disponibilidad, economía y flexibilidad.
Diseño visual: definir las GUI Diseño conceptual: examina la empresa
para generar diagrama E-R
Estrategias de diseño – Descendente (1-3)

Como resultado de los diseños conceptual y visual debe darse un esquema conceptual global y recopilación de los patrones de acceso.
Diseño de distribución: diseñar esquema conceptual local para cada sitio del SD. Fragmentación y asignación.
Estrategias de diseño - Descendente (2-3)

Diseño físico: mapear esquemas conceptuales locales con los dispositivos de almacenamiento físicos disponibles en cada sitio.
Estrategias de diseño - Descendente (3-3)

Conveniente cuando BD ya existen y tareas de proceso involucran integración.
Punto de inicio son esquemas conceptuales individuales, se integran para obtener esquema conceptual global y posiblemente generar GUI.
Estrategias de diseño - Ascendente

Encontrar unidad de relación apropiada. Diferentes aplicaciones ingresan a diferentes sub-conjuntos de datos.
Replicaciones mas convenientes, solamente de sub-relaciones.
Ejecuciones concurrentes de procesos sobre sub-conjuntos aislados.
¿Por qué fragmentar?

Unión de fragmentos para consultas◦ Costoso en proceso ◦ Costoso en transferencia de datos
Control de semántica de datos y revisión de integridad
Problemas de la fragmentación

Fragmentación vertical
Fragmentación horizontal
Fragmentación híbrida
¿Cómo fragmentar?

Afecta desempeño de la ejecución de los Query.
Dependerá de las necesidades de nuestra aplicación.
Grado de fragmentación

Condición de completitud. La descomposición de una relación R en los fragmentos R1, R2, ..., Rn es completa si y solamente si cada elemento de datos en R se encuentra en algún de los Ri.
Condición de Reconstrucción. Si la relación R se descompone en los fragmentos R1, R2, ..., Rn, entonces debe existir algún operador relacional Ñ , tal que,R = Ñ 1£ i£ n Ri
Condición de Fragmentos Disjuntos. Si la relación R se descompone en los fragmentos R1, R2, ..., Rn, y el dato di está en Rj, entonces, no debe estar en ningún otro fragmento Rk (k¹ j).
Correctitud fragmentación

Forma para asignación de fragmentos de las relaciones en cada uno de los sitios teniendo ya bien realizada nuestra fragmentación.◦ Costos mínimos: costos de actualización entre
sitios y costos de comunicación de datos◦ Desempeño: minimizar el tiempo de respuesta y
maximizar la salida de información a cada sitio.
Alternativas de asignación

Mejora Querys de sólo lectura Confiabilidad Empeora Query de actualización Estrategias:
◦ No soportar replicación. Cada fragmento reside en un solo sitio.
◦ Soportar replicación completa. Cada fragmento en cada uno de los sitios.
◦ Soportar replicación parcial. Cada fragmento en algunos de los sitios.
Replicación
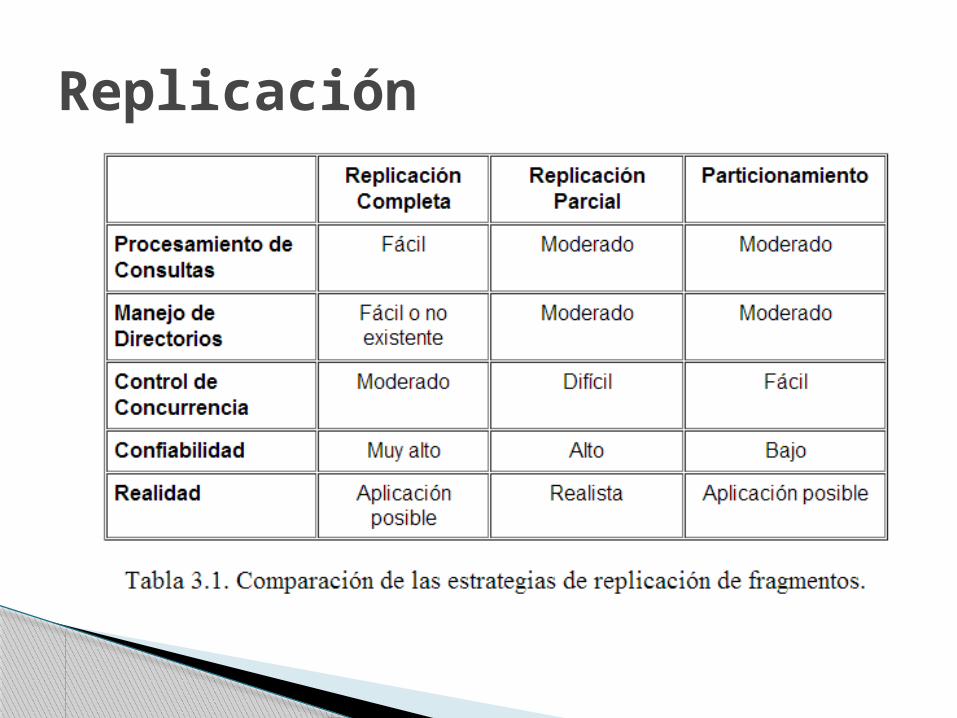
Replicación

En diseño de distribución influyen factorescomo: Información sobre el significado de los
datos Información sobre las aplicaciones que los
usan Información acerca de la red de
comunicaciones Información acerca de los sistemas de
cómputo
Requerimientos de información

Cada subconjunto puede contener datos que tienen propiedades comunes y se puede definir expresando cada fragmento como una operación de selección sobre la relación global
Considere la relación global: SUPPLIER( SNUM, NAME, CITY )entonces, la fragmentación horizontal puede ser definida como:
SUPPLIER1 = SLcity == "SF"SUPPLIERSUPPLIER1 = SLcity == "LA"SUPPLIER
Esta fragmentación satisface la condición de completes si "SF" y "LA" son solamente los únicos valores posibles del atributo CITY.
La condición de reconstrucción se logra con:SUPPLIER = SUPPLIER1 union SUPPLIER2
La condición de disjuntos se cumple claramente en este ejemplo.
Fragm. Horizontal Primaria

La fragmentación derivada horizontal se define partiendo de una fragmentación horizontal.En esta operación se requiere de Semi-junta (Semi-Join) el cual nos sirve para derivar las tuplas o registros de dos relaciones.Las siguientes relaciones definen una fragmentación horizontal derivada de la relación SUPPLY.
SUPPLY1 = SUPPLYSJsnum == snumSUPPLIER1
SUPPLY2 = SUPPLYSJsnum == snumSUPPLIER2
Fragm. Horizontal Derivada

Enfoques◦ Agrupamiento (Clustering): Inicia asignando cada
atributo a un fragmento, y en cada paso, algunos de los fragmentos satisfaciendo algún criterio se unen para formar un solo fragmento.
◦ Division: Inicia con una sola relación realizar un particionamiento basado en el comportamiento de acceso de las consultas sobre los atributos.
Fragmentacion Vertical

Formula general: min( Costo Total )Dadas:- Restricciones tiempo de rta- Restricciones capacidad de almacenamiento- Restricciones en tiempo de procesamientoCosto total = procesamiento de consultas +
almacenamientoProcesamiento de consultas = sumatoria del costo
de procesamiento de todas las consultasAlmacenamiento = sumatoria de costos de
almacenar todos los fragmentos en los correspondientes nodos
Modelo de asignación

Costo de almacenamiento por nodo = costo almacenamiento unitario en el nodo * tamaño del fragmento
Costo del procesamiento por consulta = costo de procesamiento + costo de transmision
Costo de procesamiento = costo de acceso + costo de mantenimiento de integridad + costo debido a control de concurrencia
Modelo de asignación

Costo de acceso = sumatoria(numero total de actualizaciones y lecturas realizadas por consulta en el fragmento i * costo unitario de procesamiento local en el fragmento i)i = cada fragmento involucrado en la consulta
Costos de mantenimiento de integridad y costo de control de concurrencia se calculan similar al costo del control de acceso.
Modelo de asignación

Costo de transmisión - Procesamiento de actualizaciones = costo
de envió de mensajes de actualización a los N nodos involucrados + costo de envió de mensaje de confirmación
- Procesamiento de consultas = costo de transmitir consulta a N nodos involucrados + costo de transmisión de respuestas de los N nodos a las N consultas
Modelo de asignación

Tiempo de respuestaPara cada Qi el tiempo de respuesta <= máximo tiempo de respuesta esperado.
• AlmacenamientoCosto de almacenamiento en Nodoi <= capacidad de almacenamiento de dicho nodo
• Tiempo procesamientoCarga de procesamiento Nodoi <= capacidad de procesamiento de dicho nodo
Restricciones a asignación

http://tododistribuido.files.wordpress.com/2008/10/disdabe_design.pdf
http://cursos.aiu.edu/Base%20de%20Datos%20Distribuidas/pdf/Tema%202.pdf
http://geocities.ws/immonroy7/Cap_3.html http://lihectortorres.files.wordpress.com/201
0/09/base_de_datos_distribuidas.pdf
Referencias