base de datos
TRANSCRIPT

SANTIS AGUILAR ARTUROGRUPO:551
PROFESOR: LUIS ROBERTO PEREZ MACIAS

Base de datos
Una base de datos es un “almacén” que nos permite guardar grandes cantidades de información de forma organizada para que luego podamos encontrar y utilizar fácilmente. A continuación te presentamos una guía que te explicará el concepto y características de las bases de datos.
El término de bases de datos fue escuchado por primera vez en 1963, en un simposio celebrado en California, USA. Una base de datos se puede definir como un conjunto de información relacionada que se encuentra agrupada ó estructurada.
Desde el punto de vista informático, la base de datos es un sistema formado por un conjunto de datos almacenados en discos que permiten el acceso directo a ellos y un conjunto de programas que manipulen ese conjunto de datos.
Cada base de datos se compone de una o más tablas que guarda un conjunto de datos. Cada tabla tiene una o más columnas y filas. Las columnas guardan una parte de la información sobre cada elemento que queramos guardar en la tabla, cada fila de la tabla conforma un registro.
Definición de base de datos
Se define una base de datos como una serie de datos organizados y relacionados entre sí, los cuales son recolectados y explotados por los sistemas de información de una empresa o negocio en particular.
Características
Entre las principales características de los sistemas de base de datos podemos mencionar:
Independencia lógica y física de los datos. Redundancia mínima. Acceso concurrente por parte de múltiples usuarios. Integridad de los datos. Consultas complejas optimizadas. Seguridad de acceso y auditoría. Respaldo y recuperación. Acceso a través de lenguajes de programación estándar.

Sistema de Gestión de Base de Datos (SGBD)
Los Sistemas de Gestión de Base de Datos (en inglés DataBase Management System) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan. Se compone de un lenguaje de definición de datos, de un lenguaje de manipulación de datos y de un lenguaje de consulta.
Ventajas de las bases de datos Control sobre la redundancia de datos:
Los sistemas de ficheros almacenan varias copias de los mismos datos en ficheros distintos. Esto hace que se desperdicie espacio de almacenamiento, además de provocar la falta de consistencia de datos.
En los sistemas de bases de datos todos estos ficheros están integrados, por lo que no se almacenan varias copias de los mismos datos. Sin embargo, en una base de datos no se puede eliminar la redundancia completamente, ya que en ocasiones es necesaria para modelar las relaciones entre los datos.

Consistencia de datos:
Eliminando o controlando las redundancias de datos se reduce en gran medida el riesgo de que haya inconsistencias. Si un dato está almacenado una sola vez, cualquier actualización se debe realizar sólo una vez, y está disponible para todos los usuarios inmediatamente. Si un dato está duplicado y el sistema conoce esta redundancia, el propio sistema puede encargarse de garantizar que todas las copias se mantienen consistentes.
Compartición de datos:
En los sistemas de ficheros, los ficheros pertenecen a las personas o a los departamentos que los utilizan. Pero en los sistemas de bases de datos, la base de datos pertenece a la empresa y puede ser compartida por todos los usuarios que estén autorizados.
Mantenimiento de estándares:
Gracias a la integración es más fácil respetar los estándares necesarios, tanto los establecidos a nivel de la empresa como los nacionales e internacionales. Estos estándares pueden establecerse sobre el formato de los datos para facilitar su intercambio, pueden ser estándares de documentación, procedimientos de actualización y también reglas de acceso.

Mejora en la integridad de datos:
La integridad de la base de datos se refiere a la validez y la consistencia de los datos almacenados. Normalmente, la integridad se expresa mediante restricciones o reglas que no se pueden violar. Estas restricciones se pueden aplicar tanto a los datos, como a sus relaciones, y es el SGBD quien se debe encargar de mantenerlas.
Mejora en la seguridad:
La seguridad de la base de datos es la protección de la base de datos frente a usuarios no autorizados. Sin unas buenas medidas de seguridad, la integración de datos en los sistemas de bases de datos hace que éstos sean más vulnerables que en los sistemas de ficheros.
Mejora en la accesibilidad a los datos:
Muchos SGBD proporcionan lenguajes de consultas o generadores de informes que permiten al usuario hacer cualquier tipo de consulta sobre los datos, sin que sea necesario que un programador escriba una aplicación que realice tal tarea.
Mejora en la productividad:
El SGBD proporciona muchas de las funciones estándar que el programador necesita escribir en un sistema de ficheros. A nivel básico, el SGBD proporciona todas las rutinas de manejo de ficheros típicas de los programas de aplicación.
El hecho de disponer de estas funciones permite al programador centrarse mejor en la función específica requerida por los usuarios, sin tener que preocuparse de los detalles de implementación de bajo nivel.
Mejora en el mantenimiento:
En los sistemas de ficheros, las descripciones de los datos se encuentran inmersas en los programas de aplicación que los manejan.
Esto hace que los programas sean dependientes de los datos, de modo que un cambio en su estructura, o un cambio en el modo en que se almacena en disco, requiere cambios importantes en los programas cuyos datos se ven afectados.
Sin embargo, los SGBD separan las descripciones de los datos de las aplicaciones. Esto es lo que se conoce como independencia de datos, gracias a la cual se simplifica el mantenimiento de las aplicaciones que acceden a la base de datos.
Aumento de la concurrencia:
En algunos sistemas de ficheros, si hay varios usuarios que pueden acceder simultáneamente a un mismo fichero, es posible que el acceso interfiera entre ellos de modo que se pierda información o se pierda la integridad. La mayoría de los SGBD gestionan el acceso concurrente a la base de datos y garantizan que no ocurran problemas de este tipo.
Mejora en los servicios de copias de seguridad:
Muchos sistemas de ficheros dejan que sea el usuario quien proporcione las medidas necesarias para proteger los datos ante fallos en el sistema o en las aplicaciones. Los usuarios tienen que hacer copias de seguridad cada día, y si se produce algún fallo, utilizar estas copias para restaurarlos.
En este caso, todo el trabajo realizado sobre los datos desde que se hizo la última copia de seguridad se pierde y se tiene que volver a realizar. Sin embargo, los SGBD actuales funcionan de modo que se minimiza la cantidad de trabajo perdido cuando se produce un fallo.
Desventajas de las bases de datos Complejidad:
Los SGBD son conjuntos de programas que pueden llegar a ser complejos con una gran funcionalidad. Es preciso comprender muy bien esta funcionalidad para poder realizar un buen uso de ellos.
Coste del equipamiento adicional:
Tanto el SGBD, como la propia base de datos, pueden hacer que sea necesario adquirir más espacio de almacenamiento. Además, para alcanzar las prestaciones deseadas, es posible que sea necesario adquirir una máquina más grande o una máquina que se dedique solamente al SGBD. Todo esto hará que la implantación de un sistema de bases de datos sea más cara.
Vulnerable a los fallos:
El hecho de que todo esté centralizado en el SGBD hace que el sistema sea más vulnerable ante los fallos que puedan producirse. Es por ello que deben tenerse copias de seguridad (Backup).
Tipos de Campos
Cada Sistema de Base de Datos posee tipos de campos que pueden ser similares o diferentes. Entre los más comunes podemos nombrar:
Numérico: entre los diferentes tipos de campos numéricos podemos encontrar enteros “sin decimales” y reales “decimales”.
Booleanos: poseen dos estados: Verdadero “Si” y Falso “No”. Memos: son campos alfanuméricos de longitud ilimitada. Presentan el inconveniente de no poder
ser indexados. Fechas: almacenan fechas facilitando posteriormente su explotación. Almacenar fechas de esta
forma posibilita ordenar los registros por fechas o calcular los días entre una fecha y otra. Alfanuméricos: contienen cifras y letras. Presentan una longitud limitada (255 caracteres). Autoincrementables: son campos numéricos enteros que incrementan en una unidad su valor para
cada registro incorporado. Su utilidad resulta: Servir de identificador ya que resultan exclusivos de un registro.
Tipos de Base de Datos
Entre los diferentes tipos de base de datos, podemos encontrar los siguientes:
MySql: es una base de datos con licencia GPL basada en un servidor. Se caracteriza por su rapidez. No es recomendable usar para grandes volúmenes de datos.
PostgreSql y Oracle: Son sistemas de base de datos poderosos. Administra muy bien grandes cantidades de datos, y suelen ser utilizadas en intranets y sistemas de gran calibre.
Access: Es una base de datos desarrollada por Microsoft. Esta base de datos, debe ser creada bajo el programa access, el cual crea un archivo .mdb con la estructura ya explicada.
Microsoft SQL Server: es una base de datos más potente que access desarrollada por Microsoft. Se utiliza para manejar grandes volúmenes de informaciones.

Modelo entidad-relación
Los diagramas o modelos entidad-relación (denominado por su siglas, ERD “Diagram Entity relationship”) son una herramienta para el modelado de datos de un sistema de información. Estos modelos expresan entidades relevantes para un sistema de información, sus inter-relaciones y propiedades.
Base de datos Cardinalidad de las Relaciones
El diseño de relaciones entre las tablas de una base de datos puede ser la siguiente:
Relaciones de uno a uno: una instancia de la entidad A se relaciona con una y solamente una de la entidad B.
Relaciones de uno a muchos: cada instancia de la entidad A se relaciona con varias instancias de la entidad B.
Relaciones de muchos a muchos: cualquier instancia de la entidad A se relaciona con cualquier instancia de la entidad B.
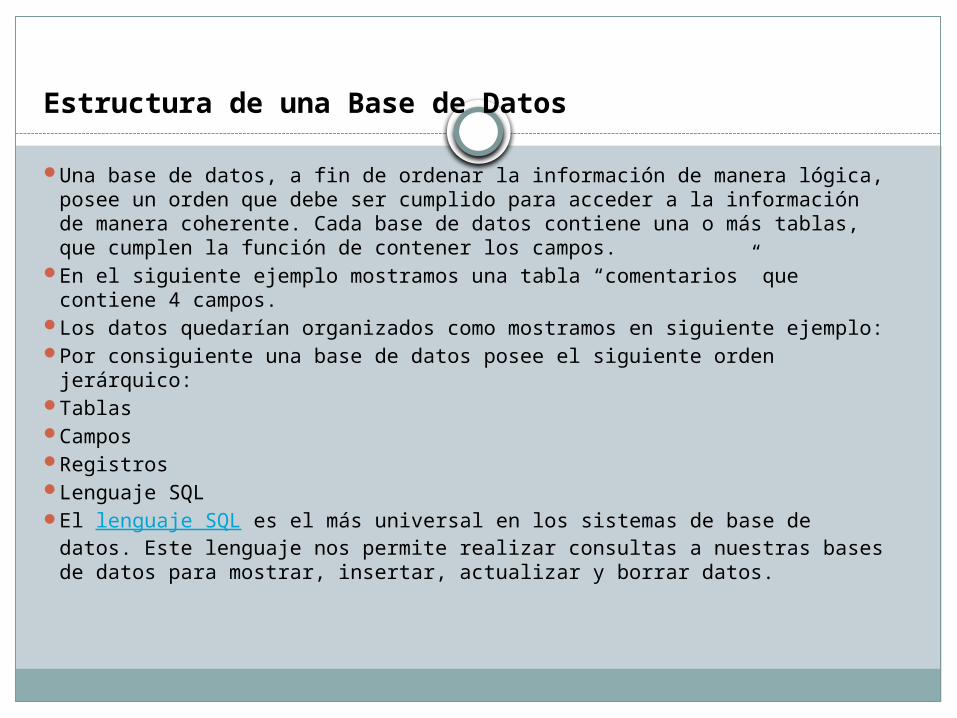
Estructura de una Base de Datos
Una base de datos, a fin de ordenar la información de manera lógica, posee un orden que debe ser cumplido para acceder a la información de manera coherente. Cada base de datos contiene una o más tablas, que cumplen la función de contener los campos.
En el siguiente ejemplo mostramos una tabla “comentarios” que contiene 4 campos.
Los datos quedarían organizados como mostramos en siguiente ejemplo:
Por consiguiente una base de datos posee el siguiente orden jerárquico: Tablas Campos Registros Lenguaje SQL El lenguaje SQL es el más universal en los sistemas de base de datos.
Este lenguaje nos permite realizar consultas a nuestras bases de datos para mostrar, insertar, actualizar y borrar datos.

El enfoque jerárquico Un DBMS jerárquico utiliza jerarquías o árboles para la representación lógica de los datos.
Los archivos son organizados en jerarquías, y normalmente cada uno de ellos se corresponde con una de las entidades de la base de datos. Los árboles jerárquicos se representan de forma invertida, con la raíz hacia arriba y las hojas hacia abajo (Figura 4.7).
Figura 4.7 Estructura de un árbol jerárquico Un DBMS jerárquico recorre los distintos nodos de un árbol en un preorden que requiere
tres pasos: Visitar la raíz. Visitar el hijo más a la izquierda, si lo hubiera, que no haya sido visitado. Si todos los descendientes del segmento considerado se han visitado, volver a su padre e ir
al punto 1. Cada nodo del árbol representa un tipo de registro conceptual, es decir, una entidad. A su
vez, cada registro o segmento está constituido por un número de campos que los describen – las propiedades o atributos de las entidades. Las relaciones entre entidades están representadas por las ramas. En la Figura 4.8. cada departamento es una entidad que mantiene una relación de uno a muchos con los profesores, que a su vez mantienen una relación de uno a muchos con los cursos que imparten.
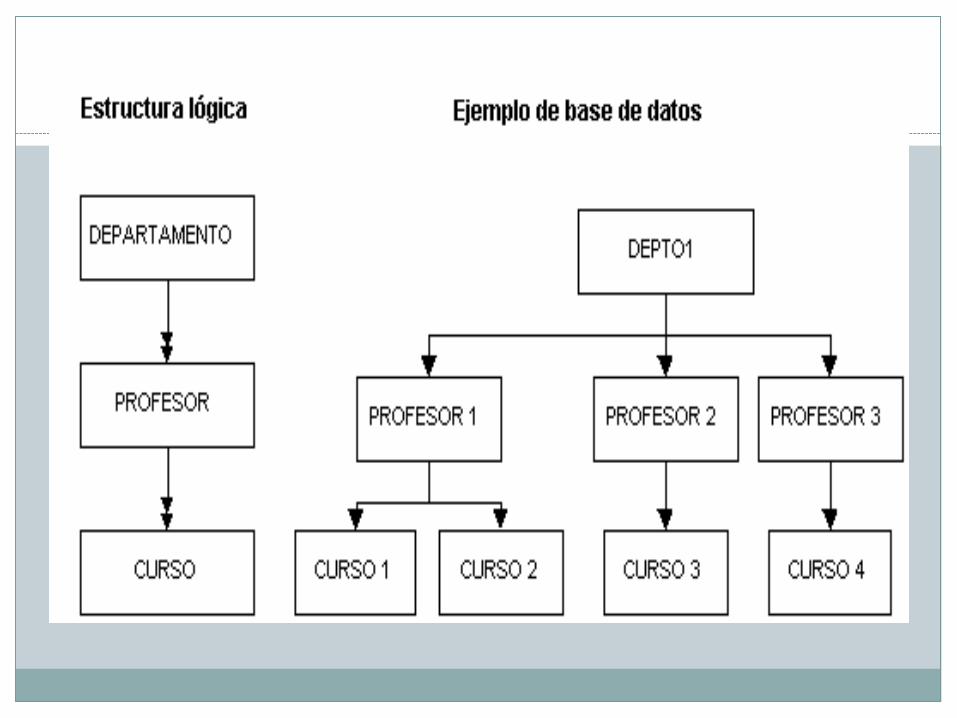

A modo de resumen, enumeramos las siguientes características de las bases de datos jerárquicas:
Los segmentos de un archivo jerárquico están dispuestos en forma de árbol.
Los segmentos están enlazados mediante relaciones uno a muchos. Cada nodo consta de uno o más campos. Cada ocurrencia de un registro padre puede tener distinto número
de ocurrencias de registros hijos. Cuando se elimina un registro padre se deben eliminar todos los
registros hijos (integridad de los datos). Todo registro hijo debe tener un único registro padre excepto la
raíz.
Las reglas de integridad en el modelo jerárquico prácticamente se reducen a la ya mencionada de eliminación en cadena de arriba a abajo. Las relaciones muchos a muchos no pueden ser implementadas de forma directa. Este modelo no es más que una extensión del modelo de ficheros.

El enfoque de red.
Este modelo fue el resultado de estandarización del comité CODASYL. Aunque existen algunos DBMSs de red que no siguen las especificaciones CODASYL, en general, una base de datos CODASYL es sinónimo de base de datos de red. El modelo de red intenta superar las deficiencias del enfoque jerárquico, permitiendo el tipo de relaciones de muchos a muchos.
Una estructura de datos en red, o estructura plex, es muy similar a una estructura jerárquica, de hecho no es más que un superconjunto de ésta. Al igual que en la estructura jerárquica, cada nodo puede tener varios hijos pero, a diferencia de ésta, también puede tener varios padres. La Figura 4.9 muestra una disposición plex. En esta representación, los nodos C y F tienen dos padres, mientras que los nodos D, E, G y H tienen sólo uno.
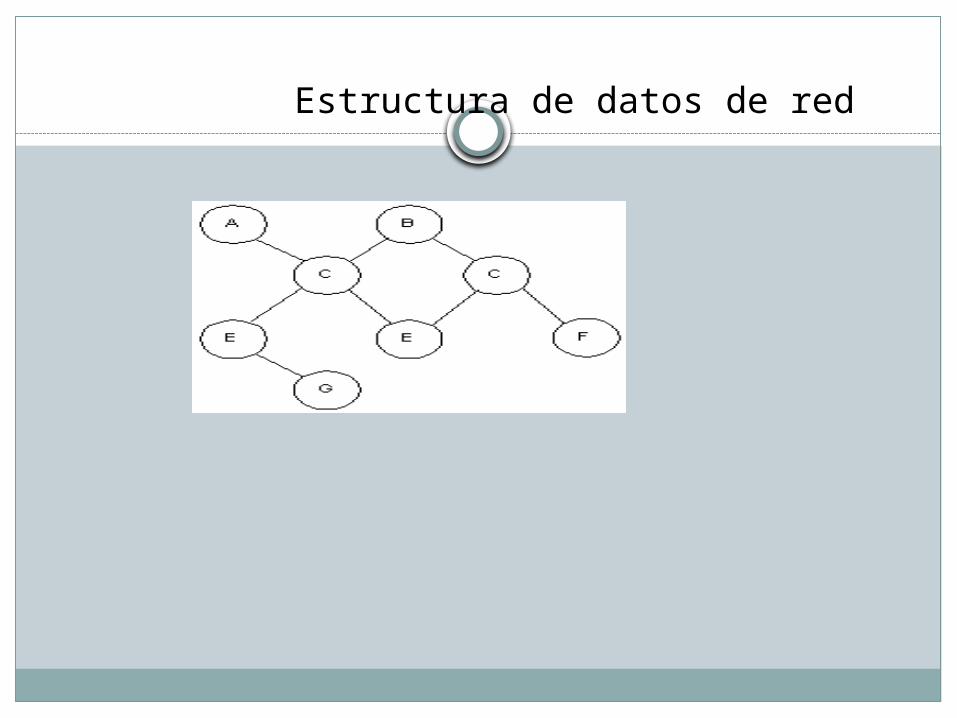
Estructura de datos de red

El concepto básico en el enfoque de red es el conjunto (‘set’), definido por el comité CODASYL. Un conjunto está constituido por dos tipos de registros que mantienen una relación de muchos a muchos. Para conseguir representar este tipo de relación es necesario que los dos tipos de registros estén interconectados por medio de un registro conector llamado conjunto conector. Los conjuntos poseen las siguientes características:
El registro padre se denomina propietario del conjunto, mientras que el registro hijo se denomina miembro.
Un conjunto está formado en un solo registro propietario y uno o más registros miembros. Una ocurrencia de conjuntos es una colección de registros, uno de ellos es el propietario y los
otros los miembros. Todos los registros propietarios de ocurrencias del mismo tipo de conjunto deben ser del
mismo tipo de registro. El tipo de registro propietario de un tipo de conjunto debe ser distinto de los tipos de los
registros miembro. Sólo se permite que un registro miembro aparezca una vez en las ocurrencias de conjuntos
del mismo tipo. Un registro miembro puede asociarse con más de un propietario, es decir, puede pertenecer
al mismo tiempo a dos o más tipos de conjuntos distintos. Esta situación se puede representar por medio de una estructura multianillo.
Se pueden definir niveles múltiples de jerarquías donde un tipo de registro puede ser miembro en un conjunto y al mismo tiempo propietario en otro conjunto diferente.
Como ejemplos de DBMSs comerciales basados en el modelo de red cabe citar el DMS 1100 de UNIVAC; el IDMS, de Cullinane; el TOTAL, de Cincom; el EDMS, de Xerox; el PHOLAS, de Philips; el DBOMP, de IBM, y el IDS, de Honeywell. Tanto el modelo jerárquico de datos como el de red permiten únicamente operaciones y facilidades navegacionales primitivas. Los tipos de relaciones permitidas vienen dadas con el modelo.

INCONSISTENCIA DE LOS DATOSSólo se produce cuando existe redundancia de
datos. La inconsistencia consiste en que no todas las copias redundantes contienen la misma información. Así, si existen diferentes modos de obtener la misma información, y esas formas pueden conducir a datos almacenados en distintos sitios. El problema surge al modificar esa información, si lo sólo cambiamos esos valores en algunos de los lugares en que se guardan, las consultas que hagamos más tarde podrán dar como resultado respuestas inconsistentes (es decir, diferentes). Puede darse el caso de que dos aplicaciones diferentes proporcionen resultados distintos para el mismo dato.
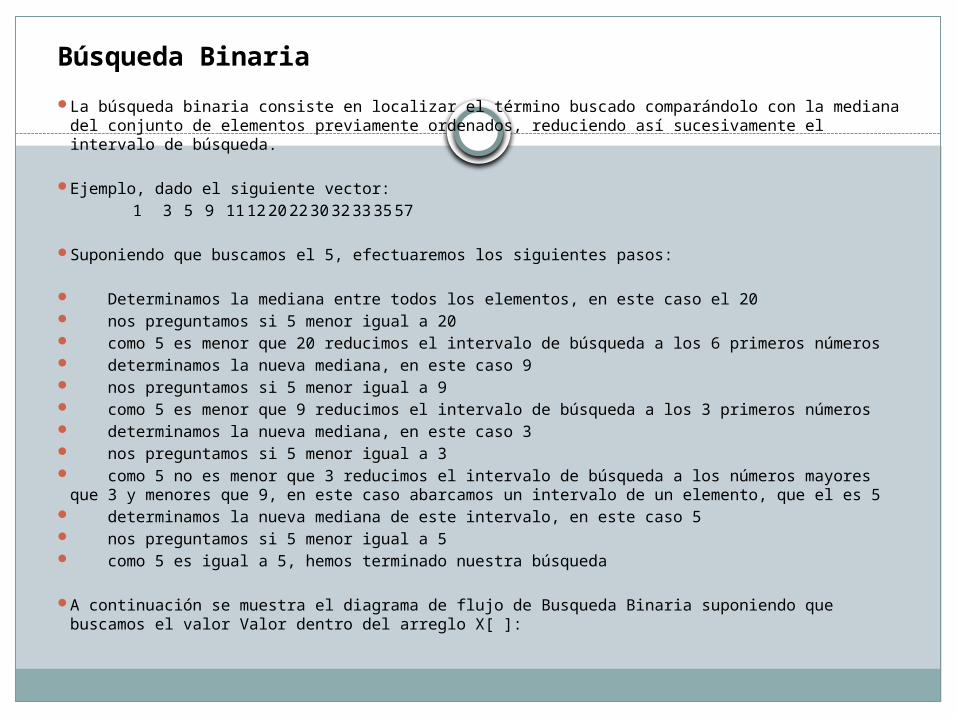
Búsqueda Binaria
La búsqueda binaria consiste en localizar el término buscado comparándolo con la mediana del conjunto de elementos previamente ordenados, reduciendo así sucesivamente el intervalo de búsqueda.
Ejemplo, dado el siguiente vector: 1 3 5 9 11 12 20 22 30 32 33 35 57
Suponiendo que buscamos el 5, efectuaremos los siguientes pasos:
Determinamos la mediana entre todos los elementos, en este caso el 20 nos preguntamos si 5 menor igual a 20 como 5 es menor que 20 reducimos el intervalo de búsqueda a los 6 primeros números determinamos la nueva mediana, en este caso 9 nos preguntamos si 5 menor igual a 9 como 5 es menor que 9 reducimos el intervalo de búsqueda a los 3 primeros números determinamos la nueva mediana, en este caso 3 nos preguntamos si 5 menor igual a 3 como 5 no es menor que 3 reducimos el intervalo de búsqueda a los números mayores que 3 y
menores que 9, en este caso abarcamos un intervalo de un elemento, que el es 5 determinamos la nueva mediana de este intervalo, en este caso 5 nos preguntamos si 5 menor igual a 5 como 5 es igual a 5, hemos terminado nuestra búsqueda
A continuación se muestra el diagrama de flujo de Busqueda Binaria suponiendo que buscamos el valor Valor dentro del arreglo X[ ]:

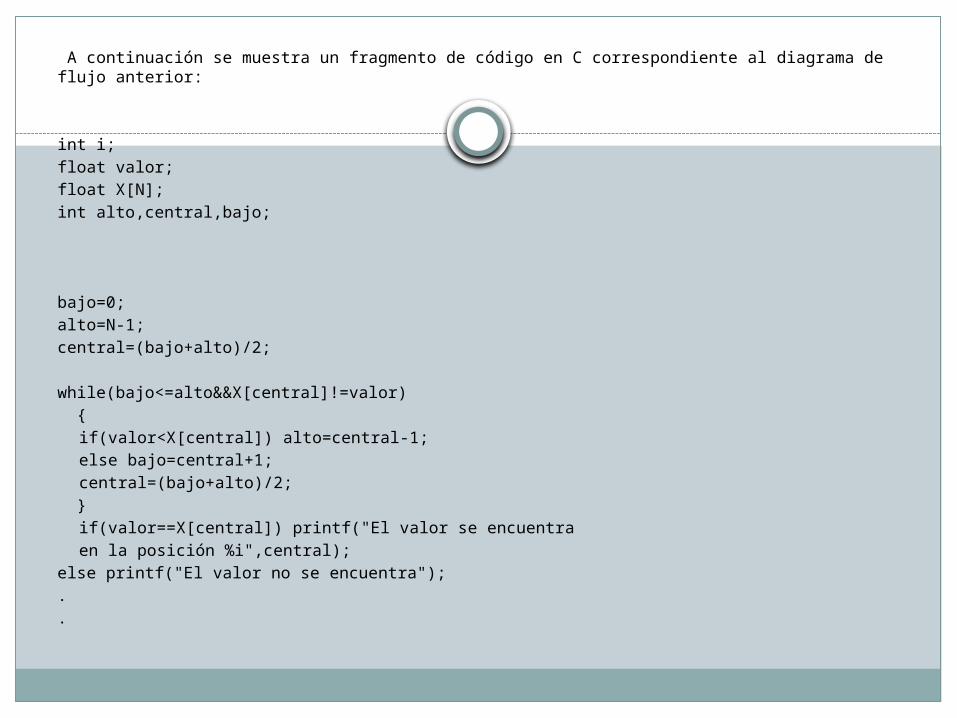
A continuación se muestra un fragmento de código en C correspondiente al diagrama de flujo anterior:
int i;float valor;float X[N];int alto,central,bajo;
bajo=0;alto=N-1;central=(bajo+alto)/2;
while(bajo<=alto&&X[central]!=valor) {
if(valor<X[central]) alto=central-1;else bajo=central+1;central=(bajo+alto)/2;
}if(valor==X[central]) printf("El valor se encuentra
en la posición %i",central);else printf("El valor no se encuentra");..

El Enfoque Relacional
Dentro del denominado enfoque relacional se agrupan una serie de contribuciones teóricas cuyo denominador común es la consideración relacional de la empresa como agente económico, considerando la dimensión relacional de la empresa como estratégica por cuanto que es su capacidad de engarce con otras unidades empresariales u otros sujetos de donde van a derivar gran parte de sus posibles ventajas competitivas. Es decir, los estímulos e insumos que proviene de la esfera exterior incitan e impulsan a la empresa a mejorar su desempeño competitivo arrastrándola hacia determinados cursos de acción, pero para ello la empresa tiene que estar conectada, de ahí la valía de la conexión y de la capacidad de generar tales enlaces.
Una interesante contribución proviene del campo de la geografía económica, a partir de los trabajos de la Escuela Californiana de Geografía Económica (Storper, Sabel, Salais, Scott, Saxenian) Sus posicionamientos podría ser concebidos como una suerte de tertius genus entre la escuela del distrito industrial y la visión del milieu innovador. Va a utilizar como instrumentos analíticos, por una parte la evolución de la trayectoria tecnológica de las organizaciones, y por otra la estructura de coordinación de las acciones individuales y colectivas, mientras que el concepto de economías externas como elemento aglutinador en el espacio viene sustituido por el de economías relacionales, o sea en la capacidad relacional de los actores económicos y empresariales.
Para la escuela californiana la dotación de un territorio determinado consiste en activos físicos y activos relacionales mediante los cuales se construye el sistema productivo en términos organizativos y tecnológicos. Las empresas locales y las relaciones que se producen entre las mismas, no obedecen a simples esquemas imput-output estilo Leontieff, o como entidad vinculada a costes transaccionales estilo Williamson, sino más bien como estructuras donde las interacciones no comerciales desempeñan un papel estratégico para las propias empresas. Para la escuela californiana el principal activo de la proximidad no radica en las economías de aglomeración, la reducción de costos de transacción o las externalidades, sino en el efecto derrame (spillover) tecnológico que se produce entre las empresas y toda la serie de convenciones, reglas y lenguaje común que funcionan como una especie de lingua franca para interpretar, compartir, difundir e innovar el conocimiento tecnológico. Las piedras angulares en el análisis de las aglomeraciones espaciales son la capacidad de aprendizaje y el cambio en las formas y modos de aprendizaje.

Búsqueda indexada
El proceso de búsqueda para conocer el contenido de los archivos y carpetas según su estructura puede acelerarse sensiblemente con la función Buscar de XP. Para ello hacemos clic con el botón derecho del ratón sobre el icono Mi PC y seleccionamos la opción Administrar.
En la ventana emergente, en la parte inferior izquierda encontramos el apartado Servicio de Index Server. Haz clic en «+» para desplegar las opciones bajo este encabezado y después pincha con el botón derecho en Sistema del menú desplegable, selecciona Nuevo, seguido de Directorios.
En Agregar directorio haz clic en el botón Examinar y selecciona la carpeta que deseas agregar al Servidor de Index Server para después Aceptar. Para terminar, presiona Aceptar de nuevo. Repite este proceso las veces que desees agregar al Index Server las carpetas que con más frecuencia consultas.
De esta forma, el sistema operativo tiene un registro de nuestras carpetas más importantes y su posterior búsqueda será infinitamente más rápida y eficiente. Lógicamente, podemos incluir en Index Server todas las carpetas que consideremos oportunas, como si queremos incluir todo el disco duro, aunque esto retardaría notablemente el arranque del sistema.