aula 04 – redu¸c˜ao do conjunto de...
TRANSCRIPT

Aula 04 – Reducao do Conjunto de
Dados
Clodoaldo A. M. Lima, Sarajane M. Peres
25 de agosto de 2015
Material baseado em:HAN, J. & KAMBER, M. Data Mining: Conceptsand Techiniques. 2nd. 2006
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 1 / 50

Series Temporais
Definicao
Uma serie temporal estocastica corresponde a uma sequencia ordenada
de observacoes medidas ao longo do tempo: x = x1, x2, · · · , xN.
Uma serie temporal corresponde a uma das possıveis trajetorias passıveis
de serem geradas por um processo fısico em observacao, este denominado
processo estocastico, o qual, por sua vez, pode ser encarado como um
conjunto de variaveis aleatorias, uma para cada ındice de tempo t inteiro.
Cada valor observado de uma trajetoria alude a um dos possıveis valores
que poderiam ter sido observados, de acordo com a densidade de
probabilidades da respectiva variavel aleatoria.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 2 / 34

Series Temporais
Pode ser facilmente obtida de aplicacoes cientıficas, financeiras,
temperatura diaria, marketing, etc.
Geralmente esta associada a:
grande volume de dados
alta dimensionalidade e atualizacao constante
pode ser discreta versus continua
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 3 / 34

O que queremos fazer com os dados
oriundos de series temporais
Figura: Exemplo de uma Serie Temporal
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 4 / 34

Series Temporais
Pesquisa relacionada a dados oriundos de series temporais
Encontrar series temporais que apresentam comportamentossimilares
Buscar uma subsequencia nas series temporais
Reducao da dimensionalidade visando tarefa de classificacao,agrupamento, etc.
Segmentacao, a qual pode ser definida como:Dada uma serie temporal T , produzir a melhor representacao usando
somente K segmentos;
Dada uma serie temporal T , produzir a melhor representacao tal que o
erro maximo para qualquer segmento nao exceda a um limiar
especificado pelo usuario;
Dada uma serie temporal T , produzir a melhor representacao tal que o
erro combinado de todos os segmentos e menor que um limiar
especificado pelo usuario.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 5 / 34

Series temporais
Pesquisa em Series Temporais
No contexto de mineracao de dados temporais, o problema fundamental
e como representar os dados oriundos de series temporais
Solucao tradicional
Uma abordagem seria transformar a serie temporal para outro domınio
para reducao da dimensionalidade seguida por um processo de
segmentacao.
Medida de similaridade entre series temporais ou subsequencia de series
temporais e segmentacao sao duas tarefas principais para varias tarefas
de mineracao de dados.
Baseada na representacao de series temporais, diferentes tarefas de
mineracao de dados podem ser realizadas: descoberta de padrao e
clusterizacao, classificacao, descoberta de regras e sumarizacao.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 6 / 34

Representacao e indexacao de Series
Temporais
Reducao da Dimensionalidade
Realizar uma subamostragem
Discretizacao
Amostragem
O metodo mais simples
Neste metodo, uma taxa de N
me usada, onde N e comprimento da serie temporal T e
m e a dimensao apos reducao da dimensionalidade
Entretanto, o metodo de amostragem tem o problema de distorcer a forma da serie
amostrada.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 7 / 34

Representacao e indexacao de series
temporais
Discretizacao
Usar valor medio de cada segmento para representar o conjunto correspondente de
pontos de dados
Seja a serie temporal x = (x1, x2, · · · , xN) e m e a dimensao apos a reducao de
dimensionalidade, a serie temporal discretizada P = (p1, · · · , pm) pode ser obtida por
xk =1
ek − sk+1
ek∑
i=sk
xi
onde sk e ek denota o ponto inicial e fina do k-esimo segmento na serie temporal P.
Isto e, usando a media segmentada para representar a serie temporal
Este metodo e tambem chamada Piecewise Aggregate Approximation (PAA) por
Keogh et al. (2000)
Keogh et al. (2001) propos uma versao extendida chamada Adaptive Piecewise
Constant Approximation (APCA), na qual o comprimento de cada segmento nao e
fixado a priori, mas adaptativo dependendo da serie temporal
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 8 / 34

Representacao e indexacao de series
temporais
Figura: Reducao da Dimensionalidade de um serie temporal por
amostragem
Figura: Reducao da Dimensionalidade de um serie temporal por
discretizacao. As linhas horizontais representam a media de cada
segmentoClodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 9 / 34

Representacao de Series temporais
Figura: Formas de representacao de series temporais
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 10 / 34

Representacao de Series temporais
Limitacao
Uma importante caracteristica de todas as representacoes acima e que
elas produzem valores reais. Isto limita o algoritmo, estrutura de dados e
algumas definicoes.
Por exemplo, em deteccao de anormalidade nao podemos definir
significativamente a probabilidade de observar quaisquer conjunto de
coeficientes de wavelet.
Tais limitacoes tem levado varios pesquisadores a utilizar uma
representacao simbolica para series temporais.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 11 / 34

SAX - Symbolic Aggregate approXimation
SAX reduz uma serie temporal de comprimento arbitrario N para uma
string de comprimento arbitrario m (w < m, tipicamente w << n). O
tamanho do alfabeto e um numero inteiro arbitrario a, onde a > 2.
Passos envolvidos
Primero Passo - transforma os dados na representacao do PAA e
Segundo Passo - codifica a representacao PAA em uma string discreta.
Ha duas vantagens para fazer isto:
Reducao da Dimensionalidade: nos podemos usar o poder de
reducao da dimensionalidade do PAA e reduzir para representacao
simbolica.
Limintante inferior: medida de distancia entre strings simbolicas e
um limitante inferior da distancia verdadeira entre as series
originais.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 12 / 34
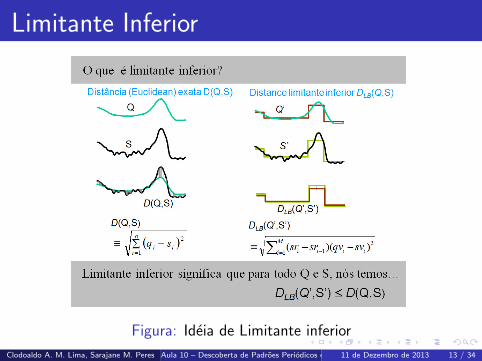
Limitante Inferior
Figura: Ideia de Limitante inferior
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 13 / 34

PAA
Definicao formal
Uma serie temporal T de comprimento N pode ser representada em um
espaco m-dimensional por um vetor C = c1, c2, · · · , cm. O i -esimo
elemento de C e calculado pela seguinte equacao:
ci =w
n
N
mi∑
j= N
m(i−1)+1
cj
Para reduzir a serie temporal de N dimensao para m dimensao, os dados
sao divididos em intervalos de tamanho igual a m. O valor medio dos
dados dentro deste intervalor e calculado e vetor com estes valores
passam a ser a representacao reduzida dos dados
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 14 / 34

PAA
A representacao pode ser vizualida como uma tentativa de aproximar a serie temporal
original com uma combinacao de funcoes como mostrado abaixo
Figura: A representacao PAA
A reducao da dimensionalidade e bastante intuitiva e simples
Tem sido mostrada efetiva quando comparada para transformada de Fourier e
Wavelets.
A serie deve ser normalizada para ter media zero e desvio padrao antes de converter
para o PAA.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 15 / 34

Discretizacao
Apos transformado a serie temporal em uma representacao baseada no
PAA, nos podemos aplicar uma trasnformacao adicional para obter uma
representacao discreta.
E desejavel ter tecnicas de discretizacao que produza simbolos
equiprovaveis
Isto e facilmente obtido uma vez que a serie temporal normalizada possui
uma distribuicao gaussiana.
Dado que a serie temporal normalizada segue uma distribuicao gaussiana,
nos podemos simplesmente determinar os breakpoints que irao produzir
area igual sobre a curva gaussiana.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 16 / 34

Discretizacao
Estes breakpoints podem ser determinados analisando a area sobre a
distribuicao gaussiana.
A tabela abaixo apresenta os breakpoints para os valores de a de 3 ate
10.
Figura: Tabela contendo os breakpoints que dividem a distribuicao
gaussiana em um numero arbitrario de regioes equiprovaveis
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 17 / 34

breakpoints
Uma vez que os breakpoints tem sido obtidos, nos podemos discretizar a
serie temporal da seguinte maneira:
1) Primeiro, obtemos o PAA da serie temporal
2) Todos os coeficientes que estao abaixo do menor breakpoint sao
mapeados para o sımbolo a, todos os coeficientes maiores ou igual ao
primeiro breakpoint e menor que o segundo breakpoint sao mapeados
para o simbolo b e assim sucessivamente.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 18 / 34

breakpoints
Figura: A representacao PAA
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 19 / 34

Palavra
Observe que neste exemplo os 3 sımbolos, a, b e c sao aproximadamente
equiprovaveis como era desejado.
Nos chamamos a concatenacao de simbolos que representa uma
sequencia de uma palavra.
Definicao
Uma subsequencia C de comprimento N pode ser representada como
uma palavra C = c1, · · · , cm como segue.
Seja αi denota o i -esimo elemento do alfabeto, isto e, α1 = a e α2 = b.
Entao o mapeamento de uma aproximacao PAA C para uma palavra C e
obtida como segue
ci = αj , seβj−1 ≤ ci ≤ βj
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 20 / 34

Medida de Distancia
Figura: Medida de Distancia
Figura: Tabela usada
pela funcao MINDIST
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 21 / 34

Descoberta de padrao
Definicao
Considere uma serie temporal T = e0, e1, e2, · · · , en−1 de tamanho n,
onde ei denota o evento gravado no tempo i , T pode ser discretizada em
um conjunto de simbolos tomados de um alfabeto Σ, isto e, |Σ|
representa os simbolos usados no processo de discretizacao. De uma
forma sistematica T pode ser decodificado como uma string de Σ
Por exemplo
A string abbcabcdcbab poderia representar uma serie temporal sobre o
alfabeto Σ = a, b, c , d
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 22 / 34

Algumas Definicoes
Periodicidade Perfeita
Considere uma serie temporal T , um padrao X e dito satisfazer
periodicidade perfeita em T com periodo p se partindo da primeira
ocorrencia de X ate o final de T toda proxima ocorrencia de X existe a p
ocorrencia atual de X . E possıvel que algumas das ocorrencias esperadas
de X possam falhar e esta conduz a uma periodicidade imperfeita.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 23 / 34

Algumas Definicoes
Confianca
A confianca de um padrao perıodico X ocorrendo na serie temporal T e
a razao de sua periodicidade atual para sua periodicidade perfeita
esperada. Formalmente, a confianca de uma padrao X com periodicidade
p partindo da posicao stPos e definida como:
conf (p, stPos,X ) =Periodicidade − atual(p, stPos,X )
Periodicidade − Perfeita(p, stPos,X )
onde Periodicidade-Perfeita (p, stPos,X ) = ⌊T⌋−stPos+1p
e
Periodicidade-Atual e calculada como a soma das ocorrencias de X em T
Por exemplo, em T = abbcaabcdbaccdbabbca, o padrao ab e periodico
com stPos = 0, p = 5 e conf (5, 0, ab) = 34 . Note que a confianca e 1
quando periodicidade perfeita e encontrada.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 24 / 34

Algumas Definicoes
Periodicidade Simbolica
Uma serie temporal e dita ter periodicidade simbolica para um dado
simbolo s com periodo p e partindo da posicao stPos se a periodicidade
de s em T e perfeita ou imperfeita com alta confiancao, isto e, s ocorre
em T na maioria das posicoes especificadas por stPos + i ∗ p, onde p e o
periodo e i um numero interio que assume valores consecutivos partindo
de 0.
Por exemplo, em T = bacdbabcdbaccdabc , o simbolo a e periodico
com stPos = 1 e p = 4, isto e, a ocorre em T na posicao 1, 5, 9 e 13.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 25 / 34

Algumas Definicoes
Periodicidade de Sequencia
Uma serie temporal T e dita ter periodicidade de sequencia para um
padrao X partindo de stPos, se |X | ≥ 1 e a periodicidade de X em T e
ou perfeita ou imperfeita com alta confianca, isto e, X ocorre em T na
maioria das posicoes especificadas stPos + i ∗ p, onde p e o periodo e
i ≥ 0 assume valores consecutivos partindo de 0.
Por exemplo, em T = abbcaabcdbabcdbabbca, o simbolo ab e
parcialmente periodico de stPos = 0 e periodo de valor 5.
Note que periodicidade simbolica e um caso especial da periodicidade de
sequencia, onde |X | = 1.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 26 / 34

Algumas Definicoes
Periodicidade de segmento
Uma serie temporal T de comprimento n e dita ter periodicidade de
segmento para uma padrao X com periodo p e partindo da posicao
stdPos se p = |X | e a periodicidade de X em T e perfeira ou imperfeita
com alta confianca, isto e, X ocorre em T na maioria das posicoes
especificadas por stPos + i ∗ p, onde o inteiro i assume valores
consecutivos partindo de 0.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 27 / 34

Definicao
Periodicidade em Subsecao de uma Serie Temporal
Uma serie temporal T possui periodicidade simbolica, sequencia ou
segmento com periodo p entre posicoes stPos e endPos (onde
0 ≥ stPos < endPos ≥ |T |), se o periodo investigado satisfaz as
definicoes acima, considerando somente subsecao [stPos, endPos] de T .
Por exemplo, em T = abdabbcaabbcdabccdabbbca, o padrao ab e
periodico com p = 5 na subsecao [3, 19] de T
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 28 / 34

Deteccao de Periodicidade
Foi proposto por Faraz et al. (2011) e envolve duas fases.
Na primeira fase e contruida a Suffix Tree para a serie temporal
Na segunda fase, e calculado a periodicidade de varios padroes
encontrados na serie temporal.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 29 / 34

Primeira Fase
Representacao baseada na Suffix-Tree
Suffix tree e uma famosa estrutura de dados que tem sido mostrada ser
muito util no processamento de string.
Uma Suffix tree para uma string representa todos os seus sufixos. p
Para cada sufixo da string ha um caminho distinto da raiz para a
correspondente folha na Suffix Tree.
Consegue capturar eficientemente e destacar as repeticoes de substring
dentro uma string.
Figura abaixo mostra uma Suffix Tree gerada para a string abcabbabb$
onde $ denota um marcador final para a string.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 30 / 34

Suffix Tree gerada para a string
abcabbabb$
Figura: Suffix Tree
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 31 / 34

Geracao da Suffix Tree
Cada ramo e rotulado pela string que ele representa
Cada ramo intermediario le uma string (da raiz ate o ramo), a qual e
repetida pelo menos duas vezes na string original.
Cada no intermediario armazena um numero que e o comprimento da
substring lida quando atravessando da raiz ate o no intermediario
Cada no folha armazena um numero que e a posicao de partida da string
correspondente ao sufixo produzido quando a arvore e atravessada da
raiz ate a folha.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 32 / 34

Detectando a periodicidade
Apos a construcao da arvore, esta e atravessada na ordem bottom-up para constucaodo vetor de ocorrencia para cada ramo conectando um no interno a seus pais.
O algoritmo comeca com os nos tendo somente um no como filho, cada um destes nospassa o valor de seus filhos para o ramo que conecta a seus paisOs valores sao usados pelo ramo anterior para criar seus vetores de ocorrenciaO vetor de ocorrencia do ramo e contem os indices das posicoes na quais a substringda raiz para o ramo e existe na string original.
Segundo, nos consideramos cada ramo v tendo uma mistura de nos folhas e nao folhascomo filhos.O vetor de ocorrencia do ramo v conectando a seus pais e construido por combinandoo vetor de ocorrencia dos ramos que conecta v para seus nos nao folhas e os valoresvindos de seus nos filhos folhas
Finalmente, ate nos encontrarmos todos filhos direto da raiz, nos recursivamenteconsideramos cada no u tendo somente filhos nao folhas. O vetor de ocorrencia doramo conectando u a seus nos pais e construindo combinando os vetores de ocorrenciados ramos conectando u a seus nos filhos.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 33 / 34

Suffix Tree
Aplicando o procedimento de travessia bottom-up sobre a arvore suffix
tree produz o seguinte vetor de ocorrencia mostrado abaixo
Figura: Suffix Tree com travessia bottom-up
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 34 / 34

Deteccao Periodicidade
Para cada ramo intermediario, com base no vetor de ocorrencia, e calculado a
diferenca entre quaisquer dois elementos sucessivos no vetor de ocorrencia, gerando
um outro vetor chamado vetor de diferenca.
Cada valor no vetor de diferenca e um periodo candidato, partindo do valor
correspondente no vetor de ocorrencia
Cada periodo pode ser representado por uma 5-tupla (X , p, stPos, endPos, conf ),
denotando o padrao, valor do periodo, posicao de partida, posicao de termino e
confianca.
Para cada periodo candidato (p = diffvec[j]), o algoritmo scaneia o vetor de ocorrencia
partindo de seu valor correspondente (stPos = occurvec[j]), e incrementa a contagem
de frequencia do periodo (freq(p)) se e somentese o valor do vetor de ocorrencia e
periodico com relacao a stPos e p.
Em seguida, a confianca e calculada, se esta e maior que um certo limiar, este e
considerado um padrao periodico.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 10 – Descoberta de Padroes Periodicos em Series Temporais11 de Dezembro de 2013 35 / 34

Analise em Componentes Independentes -
ICA
Historico
Tecnica ICA surge na decada de 1980 na modelagem de redes
neurais
Em meados de 1990, novos alogritmos introduzidos por varios
grupos de pesquisas (Bell and Sejnowski, 1995; Lee et al., 1999;
Hyvarinen and Oja, 1997; Hvarinen, 199a)
Decada de 1990: uso em problemas reais como processameno de
sinais biomedicos e separacao de sinais de audio em
telecomunicacoes
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 2 / 50

Analise em Componentes Independentes -
ICA
x1(t) = a11s1(t) + a12s2(t)
x2(t) = a11s1(t) + a12s2(t)
Objetivo
Estimar si (t) e tambem aij
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 3 / 50

Analise em Componentes Independentes -
ICA
Motivacao
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 4 / 50

Analise em Componentes Independentes -
ICA
Definicao
Observacao de n combinacao lineares de x1, x2, · · · , xn de n componentes
s
xj = aj1s1 + aj2s2 + · · ·+ ajnsn, ∀j
x = As
Computar a inversa de A e obter as componentes independntes
s = Wx
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 5 / 50

ICA versus PCA - Similaridades
Executam uma transformacao linear
Matriz de fatoracao
PCA: Matriz de Fatoracao de baixo rank paracompressao
ICA: Matriz de Fatoracao rank completo para remover asdependencias entre as colunas
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 6 / 50

ICA versus PCA - Diferenca
PCA versus compressao
M ≤ d
ICA nao faz compressao
Mesmo numero de caracterısticas (M = d)
PCA remove apenas correlacoes, nao dependencia de altas ordens
ICA remove correlacoes, e dependencia de altas ordens
PCA: alguns componentes sao mais importantes que outras
(baseado em auto-valores)
ICA: componentes sao igualmente importante.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 7 / 50

PCA versus iCA
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 8 / 50

ICA para filtragem de Imagem
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 9 / 50

Analise em Componentes Independentes -
ICA
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 10 / 50

Analise em Componentes Independentes -
ICA
Processo whithening (branqueamento)
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 11 / 50

Whithening
Objetivo
Tornar as variaveis aleatorias descorrelacionadas e com variancia 1
z = Vx
V = ED− 12ET
E - e a matriz ortogonal dos autovetores da matriz de covariancia E [xxT ]
D - e a matriz diagonal dos autovalores da matriz de covariancia E [xxT ]
z sera o resultado de vetores medidos x1 e x2 apos whithening
Busca de fontes s1 e s2 atraves das variaveis z1 e z2
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 12 / 50

Whithening
Prova:
E [xxT ] = EDET
E [zzT ] = E [Vx(Vx)T ] = E [VxxTV ] = VE [xxT ]V T
E [zzT ] = (ED− 12ET )(EDET )ED− 1
2ET
E [zzT ] = ED− 12ETEDETED− 1
2ET
E [zzT ] = ED− 12DD− 1
2ET
E [zzT ] = ED12D− 1
2ET = EET = I
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 13 / 50

Whithening - Matlab
Funcoes usadas no Matlab para descobrir V
XX = cov(X );
[E ,D] = eig(XX );
V = E ∗ (D(−1/2)) ∗ E ′;
Assim foi possıvel obter a matriz para descorrelacionar os dados da
matriz de sinais medidos x1 e x2A busca passou a ser feita entao na matriz Z e nao na matriz X
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 14 / 50

Solucionando ICA s = Wx
Dado um x
encontrar z (a estimacao de s)
encontrar w (a estimacao de A−1)
Remova a media, E [x ] = 0
Whithening, E [xxT ] = I
Encontre um W ortogonal otimizando uma funcao objetiva
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 15 / 50

Algoritimos
Ha mais de 100 algoritimos diferentes de ICA
Estimacao da Informacao Mutua
Kernel - ICA (Back and Jordan, 2002)
Estimacao da Entropia, negentropy
Infomax - ICA (Bell and Sejnowski, 1995)Radical (Learned-Miller and Fisher, 2003)FasICA (Hyvarinen, 199)Girolami and Fyfe, 1997
Estimacao ML
KDICA (Chen, 2006)EM - ICA (Welling)Mackay 1996; Pearlmutter and Parra 1996; Cardoso 1997
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 16 / 50

Ha mais de 100 algoritimos diferentes de
ICA
Metodos baseado em cumulantes, momentos de altas ordens
Jade (Cardoso, 1993)
Metodos baseados em correlacao nao-linear
(Jutten and Herault, 1991)
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 17 / 50

Variavel Aleatoria - Adendo
Definicao
Dado um experimento aleatorio, descrito pelo espaco de probabilidade
(Ω,A,P), uma funcao numerica X : Ω → R sera dita uma variavel
aleatoria.
Exemplo
X = numero lancado e uma variavel aleatoria. Mais precisamente
X : Ω = 1, 2, · · · , 6 → R tal que X (ω) = ω e uma funcao numerica do
experimento, e logo e uma variavel aleatoria.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 18 / 50

Entropia, Entropia Conjunta e Entropia
Condicional
Entropia
Shanon mostrou que processos aleatorios tais como a fala ou a musica
tem uma complexidade abaixo da qual o sinal nao pode ser comprimido.
A esta complexidade ele chamou de entropia.
Definicao
Suponhamos que X e uma variavel aleatoria discreta com alfabeto χ e
distribuicao de probalidade p(x) = Pr(X = x), x ∈ χ
A entropia H(X ) de uma variavel aleatoria X e definida por
H(X ) ≡ −∑
x∈χ
p(x) log p(x)
onde o logaritmo e na base 2.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 19 / 50

Exemplo
Pretende-se calcular a entropia de uma v.a. X em que todos os sımbolos do alfabeto
χ = A,B,C ,D sao todos equiprovaveis. Aplicando a definicao de entropia, obtem-se
H(X ) = −4
(
1
4log
1
4
)
= 2bits
que coincide exatamente com o numero de bits necessario para codificar cada sımbolo.
Seria conicidencia?
Reescrevendo
H(x) = −E [log p(X )]
Como − log p(x) representa, no caso de sımbolos equiprovaveis, o numero de bits
necessario para representa cada sımbolo, entao H(X ) e o valor esperado de uma
contante; o numero de bits por sımbolo.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 20 / 50

Entropia conjunta
Definicao
A entropia conjunta H(X ,Y ) das variaveis aleatorias X e Y com
distribuicao de probabilidade conjunta p(x , y) e definida como
H(X ,Y ) ≡ −∑
x∈X
∑
y∈Y
p(x , y) log p(x , y)
ou equivalentemente
H(x ,Y ) ≡ −E [log p(X ,Y )]
a entropia conjunta de n variaveis aleatorias e definida de forma analoga
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 21 / 50

Entropia
Definicao
Se (X ,Y ) ∼ p(x , y), entao a entropia condicional H(Y |X ) e definida como
H(Y |X ) ≡ −∑
x∈X
p(x)H(Y |X = x)
H(Y |X ) = −∑
x∈X
p(x)∑
y∈Y
p(y |x) log p(y |x)
H(Y |X ) = −∑
x∈X
∑
y∈Y
p(x)p(y |x) log p(y |x)
H(Y |X ) = −∑
x∈X
∑
y∈Y
p(x , y) log p(y |x)
H(Y |X ) = −Ep(y,x) log p(Y |X )
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 22 / 50

Regra da cadeia
A entropia verifica a seguinte propriedade
H(X ,Y ) = H(Y |X ) + H(X )
Esta regra deriva da regra da cadeia nas probabilidades, em que sabemos
que
p(x , y) = p(y |x)p(x)
Aplicando o logaritmo a esta equacao e depois o valor esperado relativo a
p(x , y), obtem-se o resultado enunciado no enunciado do teorema.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 23 / 50

Entropia Relativa
Conceito
A entropia relativa D(p‖q) mede a ineficiencia de assumir que uma distribuicao e qquando a distribuicao e p. Por exemplo, se soubermos a distribuicao verdadeira deuma variavel aleatoria, podemos construir um codigo com comprimento medio H(p).No entanto, se usarmos um codigo obtido para uma distribuicao q, haveria umadesadequacao do codigo a variavel aleatoria e seriam necessarios H(p) + D(p‖q) bitsem media para descrever a variavel aleatoria
Definicao
A entropia relativa ou divergencia de Kullback-Leibler entre duas distribuicoes p e q edefinida por
D(p‖q) ≡∑
x∈X
p(x) logp(x)
q(x)
D(p‖q) = Ep(x)
[
logp(X )
q(X )
]
Usa-se a convencao de que 0 log 0q= 0 e p log p
0=∞
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 24 / 50

Informacao Mutua e Informacao Mutua
Condicional
Definicao Informal
E uma medida da quantidade de informacao que uma variavel aleatoria contem acercada outra.
Definicao
Considere duas variaveis aleatorias X e Y com distribuicao conjunta p(x , y) edistribuicoes marginais p(x) e p(y). A informacao mutua I(X;Y) e a entropia relativaentre a distribuicao conjunta e o produto das marginais
I (X ;Y ) ≡∑
x∈X
∑
y∈Y
p(x , y) logp(x , y)
p(x)p(y)
I (X ;Y ) = D(p(x , y)‖p(x)p(y))
I (X ; y) = Ep(x,y)
[
logp(X ,Y )
p(X )p(Y )
]
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 25 / 50

Propriedades da Informacao Mutua
I (X ; y) = I (Y ;X )
I (X ;X ) = H(X )
I (X ;Y ) = H(X )− H(X |Y )
I (X ;Y ) = H(Y )− H(Y |X )
I (X ;Y ) = H(X ) + H(Y )− H(X ,Y )
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 26 / 50

Exercıcio
Considere duas variaveis aleatorias independentes X e Y com distribuicoes
de probabilidade p(x) e p(y). Qual a informacao mutua I (X ;Y )?
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 27 / 50

Teorema do Limite Central
Na figura abaixo pode ser visto um desenho esquematico do teorema do
limite central.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 28 / 50

Teorema do Limite Central
Exemplo
A distribuicao de probabilidade da variavel resultante do lancamento de
um dado segue a distribuicao uniforme, ou seja, qualquer valor
(1,2,3,4,5,6) tem a mesma probabilidade (1/6) de ocorrer.
No entanto, se ao inves de lancar um dado, sejam lancados dois dados e
calculada a media, a media dos dois dados seguira uma distribuicao
aproximadamente Normal.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 29 / 50

Teorema do Limite Central
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 30 / 50

Teorema do Limite Central
Tabela de frequencia da media dos dois dados
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 31 / 50

Teorema do Limite Central
Histograma da media dos dois dados
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 32 / 50

Teorema do Limite Central
Conforme pode ser visto no histograma anterior, o histograma da media
dos dois dados resulta aproximadamente Normal. Alem disso, observa-se
que a aproximacao da distribuicao Normal melhora na medida que se
fizesse a media do lancamento de mais dados.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 33 / 50

Negentropia
Definicao
E uma medida baseada na entropia diferencial, conhecida como medida
de nao gaussianeidade.
A Negentropia para uma variavel aleatoria X e definida como
(Camon,1994)
J(x) = H(xg )− H(x)
onde H(X ) e a entropia de x e H(xg ) e entropia de uma v.a gaussiana
com mesma media e matriz de covariancia da v.a x .
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 34 / 50

Negentropia
Formas para estimar a Negentropia de um sinal sem calcular a entropia dos dados diretamente
O metodo classico para estimacao da Negentropia e representado
pela seguinte equacao:
J(x) ≈1
12E [y3]2 +
1
48K (y)2
onde y tem media zero e variancia unitaria e K e uma medida de
kurtose (mede o grau de achatamento de uma curva).
Outra abordagem seria substituir o momento polinomial por uma
funcao G , propondo, desta forma, uma aproximacao baseada na
experanca E (Hyvarinen;Karhunen; Oja, 2001)
J(x) =
N∑
i=1
ki [E (Gi (x))− E (Gi (xg ))]2
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 35 / 50

Negentropia
Geralmente, a funcao G , e escolhida, de forma que ela nao cresca muito
rapidamente. A seguir, obteremos varios exemplos de funcao G.
G1(y) =1
a1log(cosh(a1)y)
G2(y) = exp(−y2
2)
G3(y) =y4
4
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 36 / 50

Informacao Mutua e Negentropia
Encontrar a direcao em que a informacao mutua e minimia e equivalente
encontrar a direcao em que a negentropia e maxima.
maximizarI (y1, y2, · · · , yn) ⇔ minimizaJ(yi )
Medida de nao-gaussianeidade
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 37 / 50

Abordagens
ICA baseado em cumulantes de segunda e quarta ordem - No ICA ascomponentes de z devem ser estatiscamente independente, isto e equivalente adizer que todos cumulantes cruzados de ordem superior sejam zeros. Como(1994) sugeriu que restringissemos ate os cumulantes de ordem 4 e suficientepara muitas aplicacoes praticas.
k1(zi ) = E [zi ] = 0, k2(zi , zj) = E [zi , zj ], k3(zi , zj , zk) = E(zi , zj , zk)]
k4(zi , zj , zk , zr ) = E [zi , zj , zk , zr ]− E [zizj ]E [yk , zr ]− ...
E [zizk ]E [zjzr ]− E [zizr ]E [zjzk ]
ICA baseado na Informacao Mutua - Estima w , minimizando a informacaomutua entre as variaveis aleatorias transformadas.
ICA baseado na Negentropia - Estima w , maximizando a Negentropia.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 38 / 50

Processo de busca da matriz W
Busca da matriz w de vetores ortogonais onde:
s = wz
Funcao custo
J(w) ∝[
E [G (wT z)]− E [G (v)]]2
Busca do vetor w que maximiza a negentropia J(w) da matriz z na
projecao dada por w .
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 39 / 50

Otimizacao pelo metodo do gradiente
Derivar a funcao custo em relacao a projecao w a ser procurada:
∂J(wn)
∂wn
∝∂(E [G (wT
n z)]− E [G (v)])2]
∂wn
Que pode ser aproximada por
∂J(wn)
∂w= E [G (wT
n z)− E [G (v)]].zg(wTn z)
onde g e a derivada G
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 40 / 50

Ortogonalizacao
E feita apos a busca de cada uma das projecoes w ate que se encontre
todas as projecoes correspondentes a todas as componentes
independentes
wn ↔ wn −
N−1∑
j=1
(wTn wj)wj
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 41 / 50

Algoritmo para ICA
1. Centralize os dados para que tenha media zero;
2. Faca o ”whithening”para obter a matriz z
3. Escolha o numero de componentes independentes (nd) a serem estimadas
4. Escolha um valor inicial para wn para γ
5. Atualize ∆zg(wTn z)
6. Normalize w ← w
‖w‖
7. Atualize ∆ ∝ (G(wTn z)− E(G(v)])− γ
8. Se nao convergir, volte ao passo 4
9 Proceda a ortogonalizacao de wn, conforme expressao
wn ← −N−1∑
i=1
(wTn wj)wj
10. Normalize w ← w
‖w‖
11. Se wn nao convergir, voltar ao passo 5
12 Incremente n = n + 1. Se n < nd , volte ao passo 4
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 42 / 50

Consideracoes
1 ICA busca uma representacao em que as componentes
transformadas possuam a mınima dependencia em termos
estocasticos, utilizando como criterio de busca a medida da nao-
gaussianeidade das componentes.
2 O Algoritmo elaborado (no Matlab) precisou de ajustes quanto as
condicoes iniciais do metodo de otimizacao utilizado.
3 O processo de ortogonalizacao e muito dependente da estimativa
da primeira projecao, pois erro nela se propaga as outras que sao
ortogonais a ela.
4 E uma ferramenta que vai alem da analise em componentes
principais, para a estimativa dos sinais.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 43 / 50

Analise de Discriminante Linear
Seja x1, x2, · · · , xN ∈ Rd , um conjunto de N amostras pertencendo a dois conjuntos de
classes diferentes, A e B. Para cada classe, nos podemos definir a media amostral
xA =1
NA
∑
x∈A
x , xB =1
NB
∑
x∈B
x
onde NA, NB representam a quantidade de instancias em A e B, respectivamente. Paracada classe nos podemos definir uma matriz semidefinida positiva dada por:
SA =∑
x∈A
(x − xA)(x − xA)T, SB =
∑
x∈B
(x − xB)(x − xB)T
Cada uma destas matrizes expressa a variabilidade amostral em cada classe.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 44 / 50

Analise de Discriminante Linear
Idealmente, nos gostariamos de encontrar um hiperplano, definido pelo
vetor φ, tal que, se projetarmos os dados amostrais sobre este, sua
variancia deveria ser minıma. Isto pode ser expressado como:
minφ
(φTSAφ+ φTSBφ) = minφ
(φT (SA + SB)φ) = minφ
φTSφ
onde S = SA + SB por definicao. Por outro lado, a matriz entre as duas
classes e dada por:
SAB = (xA − xB)(xA − xB)T
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 45 / 50

Analise de Discriminante Linear
Logo desejamos encontrar um hiperplano a fim de maximizar a distancia entre as
media das duas classes e ao mesmo tempo minimizar a variancia em cada classe.
Matematicamente,isto pode ser descrito pelo criterio de maximizacao de Fisher
maxφJ (φ) = max
φ
φTSABφ
φTSφ
Este problema de otimizacao pode ter muitas solucoes com o mesmo valor da funcao
objetiva. Isto e, para uma solucao φ∗ todos os vetores cφ∗ da exatamente o mesmo
valor. Se, sem perda de generalidade, nos substituimos o denominador por uma
restricao de igualdade a fim de escolher somente uma direcao. Entao o problema
torna-se
maxφ
φTSABφ
s.t.φTSφ = 1
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 46 / 50

Analise de Discriminante Linear
O lagrangeano associado com este problema e:
L(φ, λ) = φTSABφ− λ(φTSφ− 1)
onde λ e o multiplicador de lagrande que esta assoaciado com a restricao
do problema. Desde que SAB e semidefinida positiva o problema e
convexo e o minımo global sera um ponto tal que:
∂L(φ, λ)
∂φ= 0 ↔ SABφ− λSφ = 0
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 47 / 50

Analise de Discriminante Linear
O φ otimo pode ser obtido como autovetor correspondente para o maior
auto valor do seguinte sistema generalizado
SABφ = λSφ → S−1SABφ = λφ
LDA para varias classes e uma extensao natural do caso anterior. Dado n
classes, nos necessitamos definir a matriz de dispersao: a matriz
intra-classe torna-se
S = S1 + S2 + · · ·+ Sn
enquanto a matriz inter-classe e dada por
S1,··· ,n =
n∑
i=1
pi (xi − x)(xi − x)T
onde pi e o numero de exemplos da i -esima classe, xi e media para cada
classe, e xi e o vetor medio calculado por:
1nClodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 48 / 50

Analise de Discriminante Linear
A transformacao linear φ que nos desejamos encontrar pode ser obtido
por solucionando o seguinte problema de auto-valor generalizado
S1,2,··· ,n = λSφ
LDA pode ser usado a fim de identificar quais as caracteristicas mais
significantes juntas com o nivel de significancia expressado pelo
correspondente coeficiente de projecao do hiperplano.
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 49 / 50

Analise de Discriminante Linear
Tambem LDA pode ser usado para classificar examples desconhecidos.
Desde que a transformacao φ seja dada, a classificacao pode ser realizada
no espaco transformacao baseado na medida de distancia d . A classe do
novo ponto z e determinado por
class(z) = arg minn
d(zφ, xnφ)
onde x e o centroid da n-esima classe. Isto significa que nos projetamos
o centroid de todas as classes e os pontos desconhecidos sobre o espaco
definido por φ e atribuimos o ponto para a classe mais proxima com
relacao a d .
Clodoaldo A. M. Lima, Sarajane M. Peres Aula 04 – Reducao do Conjunto de Dados 25 de agosto de 2015 50 / 50