apuntes paralelas 2
DESCRIPTION
bUapaaPUNTESTRANSCRIPT

Parte II: Memoria Distribuida
Material tomado desde la tesis de doctorado de Carolina Bonacic

Capıtulo 1
Indices Invertidos y Busqueda
1.1. Motivacion
A principios de los anos noventa se propuso el modelo BSP de computacion paralela
como una metodologıa de paralelizacion de problemas clasicos en computacion cientıfica
de alto rendimiento. Entre las principales ventajas declaradas para BSP estaban la sim-
plicidad y la portabilidad del software, y la existencia de un modelo de costo que permitıa
hacer el diseno e ingenierıa de algoritmos paralelos de manera sencilla y precisa. Durante
esa decada, otros investigadores fueron mostrando que BSP tambien era capaz de abor-
dar eficientemente la paralelizacion de otras aplicaciones de Ciencia de la Computacion,
y problemas fundamentales en algoritmos y estructuras de datos discretas. El objetivo
fue proponer soluciones escalables a sistemas de gran tamano, y por lo tanto la atencion
estuvo centrada en sistemas de memoria distribuida.
La contribucion del modelo BSP al estado del arte de la epoca no fue proponer una
forma de computacion paralela completamente nueva. En realidad, ese tipo de paralelismo
ya existıa informalmente en numerosas soluciones a problemas variados. La contribucion de
BSP fue su formalizacion en un modelo de computacion paralela completo, sobre el cual el
disenador de algoritmos y software puede desarrollar soluciones sin necesidad de recurrir
a otros metodos de paralelizacion o explotar caracterısticas del hardware tales como la
topologıa de interconexion de procesadores. Posteriormente, el modelo parecio desaparecer.
Sin embargo, las ideas detras de BSP — procesamiento sincronico por lotes — han
prevalecido puesto que actualmente se les ve claramente presentes en sistemas de amplia
difusion para procesamiento paralelo en grandes clusters de memoria distribuida. Ellos
2

son Map-Reduce y Hadoop los cuales, aunque son formas restringidas de BSP, mantienen
la caracterıstica principal de BSP, es decir, su simplicidad, donde un aspecto clave en la
concrecion de esa simplicidad es que el modelo no aleja radicalmente al disenador de lo
que es una solucion secuencial intuitiva al mismo problema.
Lo anterior a nivel macroscopico, es decir, sistemas de memoria distribuida, lo que para
la aplicacion de interes en este trabajo toma la forma de clusters de nodos procesadores
que se comunican entre sı mediante una red de interconexion. A nivel microscopico, la
tendencia actual indica que dichos nodos estan formados por un grupo de procesadores
multi-core que comparten la misma memoria principal. Dichos procesadores permiten la
ejecucion eficiente de muchos threads en el nodo, donde modelos de programacion tales
como OpenMP estan especialmente disenados para explotar esta caracterıstica. OpenMP
ha alcanzado gran difusion en los ultimos anos en aplicaciones de computo cientıfico.
Curiosamente, una de las formas que promueve OpenMP para organizar la compu-
tacion realizada por los threads tambien tiene mucha similitud con BSP. Tal es ası que se
propuso recientemente una extension de BSP para procesadores multi-core (Multi-BSP).
La extension desde el modelo para memoria distribuida es casi directa puesto que los pro-
cesadores multi-core estan construidos en base a una jerarquıa de memorias. Esto se puede
ver como una distancia entre los nucleos y la memoria principal, lo cual se puede modelar
en BSP como una latencia de comunicacion entre ambas unidades.
La paradoja es que mientras para personas no expertas en computacion paralela parece
resultar incluso natural organizar sus codigos en el estilo sincronico por lotes promovido
por BSP en los noventas, al menos para la aplicacion que se estudia en este trabajo —
maquinas de busqueda para la Web — los especialistas en computacion paralela tien-
den a organizar sus soluciones como sistemas completamente asincronicos. Lo habitual es
encontrar soluciones que destinan un thread asincronico a resolver secuencialmente una
determinada tarea y donde los mecanismos principales de control de acceso a los recursos
compartidos son de tipo locks. Desde la experiencia adquirida en las implementaciones
desarrolladas en este trabajo, se puede afirmar que dichas soluciones resultan ser bastante
mas intrincadas y difıciles de depurar, que las desarrolladas utilizando el estilo BSP.
La pregunta que responde este trabajo es si el estilo BSP aplicado a nivel microscopico
viene tambien acompanado de un rendimiento eficiente. Para lograr este objetivo fue ne-
cesario disenar, analizar, implementar y evaluar estrategias sincronicas de procesamiento
de transacciones y compararlas con sus contrapartes asincronicas.
3

El requerimiento de eficiencia, tanto en rendimiento como en uso de recursos de hard-
ware es ineludible en las maquinas de busqueda para la Web. Se trata de sistemas com-
puestos por decenas de miles de nodos procesadores, los cuales reciben centenas de miles
de consultas de usuario por segundo. Entonces, es imperativo ser eficientes en aspectos de
operacion tales como consumo de energıa y cantidad de nodos desplegados en produccion.
Respecto de calidad de servicio, la metrica a optimizar es la cantidad consultas resueltas
por unidad de tiempo pero garantizando un tiempo de respuesta individual menor a una
cota superior. Por lo tanto, si se disena una estrategia de procesamiento de consultas que
le permita a cada nodo alcanzar una mayor tasa de solucion de consultas que otra estra-
tegia alternativa, la recompensa puede ser una reduccion del total de nodos desplegados
en produccion.
No obstante, aun cuando el estilo BSP alcance la misma eficiencia que la mejor estra-
tegia asincronica, la recompensa proviene desde la simplificacion del desarrollo de software
requerido para implementar los distintos servicios que componen una maquina de busque-
da. Tıpicamente, estas contienen servicios de front-end (broker), servicios de cache de
resultados, servicios de ındices y servicios de datos para ranking de documentos basado en
aprendizaje automatico. Entre estos, el servicio de ındice es el de mayor costo en tiempo
de ejecucion puesto que dicho costo es proporcional al tamano de la muestra de la Web
almacenada en cada nodo del cluster de procesadores.
Para consultas normales enviadas por los usuarios a la maquina de busqueda, no es
difıcil demostrar que, en el caso promedio, tanto un algoritmo completamente asincronico
como uno sincronico por lotes como BSP puede alcanzar un rendimiento muy similar. Sin
embargo, las maquinas de busqueda han dejado de ser sistemas en que las transacciones
(consultas) son de solo lectura. Estas han comenzado a posibilitar la actualizacion on-
line de sus ındices, lo cual implica desarrollar estrategias que sean eficientes tanto para
el procesamiento concurrente o paralelo de transacciones de lectura como de escritura.
Esto demanda desafıos mas exigentes para estas estrategias, puesto que deben resolver el
problema de los posibles conflictos de lectura y escritura cuando ocurren periodos de alto
trafico de transacciones que contienen terminos o palabras en comun. Este trabajo propone
soluciones eficientes a este problema en el contexto de servicios implementados utilizando
el enfoque BSP de paralelizacion de threads ejecutados en procesadores multi-core.
Como ejemplos de aplicaciones de maquinas de busqueda que requieren de la actuali-
zacion en tiempo real de sus ındices se pueden mencionar las siguientes.
4

En sistemas Q&A como Yahoo! Answers, miles de usuarios por segundo presentan
preguntas sobre temas variados a la base de texto, las cuales son resueltas eficiente-
mente con la ayuda de ındices invertidos. Al mismo tiempo, otros usuarios responden
con textos pequenos a las preguntas de usuarios anteriores, donde dichos textos con-
tienen palabras que coinciden con las de las respectivas preguntas, originando de
esta manera posibles conflictos entre threads lectores y escritores al momento de
actualizar el ındice invertido. Ciertamente, a los usuarios les gustarıa que sus textos
sean parte de las respuestas a las preguntas lo antes posible. Estos sistemas entre-
gan incentivos a los usuarios que proporcionan respuestas pertinentes a preguntas
de otros usuarios, aplicando votaciones sobre la calidad de las respuestas.
En sistemas para compartir fotos como Flickr, los usuarios suben constantemen-
te nuevas fotos que son etiquetadas por ellos con pequenos textos y un conjunto
pre-definido de tags describiendo el contenido. Esto permite que esas fotografıas
aparezcan en los resultados de las busquedas que realizan otros usuarios en el sis-
tema en forma concurrente. Se estima que en Flickr se suben decenas de millones
de fotografıas por dıa. Si alguien sube una fotografıa que es pertinente a un tema
que ha capturado el interes repentino de muchos usuarios, lo deseable es que dicha
imagen sea visible a las busquedas tan pronto como sea posible.
Aunque aun incipiente, un caso muy exigente de procesamiento concurrente o parale-
lo de transacciones de lectura y escrituras surge cuando se desea incluir en el proceso
de ranking de documentos, los efectos de las preferencias de usuarios anteriores por
documentos seleccionados para consultas similares, pero anteriores en la escala de
los ultimos segundos o minutos. En este caso, los clicks realizados por los usuarios
sobre los URLs presentados como respuestas a sus consultas, deben ser enviados
de vuelta a la maquina de busqueda e indexados de manera on-line. El objetivo es
utilizar estos clicks para refinar el ranking de los resultados de consultas posteriores.
Los clicks pueden ser indexados usando un ındice invertido y ahora la concurrencia
aparece entre la actualizaciones sobre el ındice y las operaciones necesarias para eje-
cutar tareas tales como la determinacion de los terminos de consultas similares y los
clicks en los documentos (URLs) relacionados con dichos terminos.
Recientemente, las principales maquinas de busqueda para la Web han comenzado
a incluir en los resultados de consultas a documentos recuperados de sistemas on-
line con cientos de millones de usuarios, muy activos en generacion de nuevos textos
pequenos, es decir, con gran probabilidad de coincidencia de palabras entre ellos,
tales como Twitter. Esto fuerza a las maquinas de busqueda a incluir estos textos
5

en sus ındices invertidos en tiempo real de manera que puedan ser incluidos en el
proceso de ranking de documentos para las consultas que se recepcionan desde sus
usuarios.
Claramente el requerimiento de actualizaciones en tiempo real de los ındices no puede
ser satisfecho por las tecnicas convencionales de realizar la indexacion de manera off-line
y luego reemplazar la copia en produccion del ındice por una nueva. Generalmente la
indexacion off-line se hace utilizando sistemas como Map-Reduce ejecutados en cluster de
computadores y sistemas de archivos distintos al cluster o los clusters en produccion. La
latencia entre ambos sistemas de archivos es grande y el proceso de copiado a todos los
nodos del cluster de produccion puede tomar varios minutos o incluso decenas de minutos.
El enfoque abordado en este trabajo es indexacion on-line, es decir, los nuevos docu-
mentos son enviados directamente a los nodos del cluster ejecutando el servicio de ındice en
produccion, y cada nodo indexa localmente los documentos recibidos al mismo tiempo que
procesa las consultas que recibe desde el servicio de front-end. Por lo tanto, el nodo debe
realizar estas operaciones de manera eficiente para evitar degradar el tiempo de respuesta
a las consultas de usuario o transacciones de lectura.
1.2. Indices Invertidos
Consiste en una estructura de datos formada por dos partes. La tabla del vocabulario
que contiene todas las palabras (terminos) relevantes encontradas en la coleccion de texto.
Por cada palabra o termino existe una lista de punteros a los documentos que contienen
dichas palabras junto con informacion que permita realizar el ranking de las respuestas
a las consultas de los usuarios tal como el numero de veces que aparece la palabra en el
documento. Ver Figura 1.1. Dicho ranking se realiza mediante distintos metodos como el
presentado en la Seccion 1.3.
Para construir un ındice invertido secuencial, es necesario procesar cada documento
para extraer las palabras o terminos de importancia, registrando su posicion y la canti-
dad de veces que este se repite. Una vez que se obtiene el termino, con su informacion
correspondiente, se almacena en el ındice invertido.
El mayor problema que se presenta en la practica, es la memoria RAM. Para solventar
esta limitacion se suele guardar de forma explıcita en disco ındices parciales cuando se
superan ciertos umbrales, liberandose de este modo la memoria previamente utilizada. Al
6

azul perro rojocasa
doc 3 1
doc 2 1 doc 1 2
doc 2 1
doc 3 1 doc 1 1
Figura 1.1: Estructura de un ındice invertido.
final de esta operacion, se realiza un merge de los ındices parciales, el cual no requiere
demasiada memoria por ser un proceso en que se unen las dos listas invertidas para cada
termino y resulta relativamente rapido.
Respecto de la paralelizacion eficiente de ındices invertidos en clusters de procesadores
de memoria distribuida existen varias estrategias. Las mas utilizadas consisten en (1)
dividir la lista de documentos en P procesadores y procesar consultas de acuerdo a esa
distribucion y en (2) distribuir cada termino con su lista completa uniformemente en cada
procesador.
1.2.1. Distribucion por documentos
Los documentos se distribuyen uniformemente al azar en los nodos. El proceso para
crear un ındice invertido aplicando esta estrategia (figura 1.2), consiste en extraer todos los
terminos de los documentos asociados a cada nodo y con ellos formar una lista invertida por
nodo. Es decir, las listas invertidas se construyen basandose en los documentos que cada
nodo posee. Cuando se resuelve una consulta, esta se debe enviar a cada nodo (broadcast).
1.2.2. Distribucion por terminos
Consiste en distribuir uniformemente entre los nodos, los terminos del vocabulario
junto con sus respectivas listas invertidas. Es decir, la coleccion completa de documentos
es utilizada para construir un unico vocabulario para luego distribuir las listas inverti-
das completas uniformemente al azar entre todos los nodos. En esta estrategia, no es
conveniente ordenar lexicograficamente las palabras de la tabla vocabulario, ya que si se
mantienen desordenadas, se obtiene un mejor balance de carga durante el procesamiento
de las consultas. Ver figura 1.3. En este caso la consulta es separada en los terminos que
la componen, los cuales son enviados a los nodos que los contienen.
7

N o d e 1 N o d e 2Figura 1.2: Estrategia de Distribucion por Documento (node= procesador).
1.2.3. Diferencias entre ambas estrategias
En el ındice particionado por terminos la solucion de una consulta es realizada de
manera secuencial por cada termino de la consulta, a diferencia de la estrategia por docu-
mentos donde el resultado de la consulta es construido en paralelo por todos los nodos. La
estrategia por documentos exhibe un paralelismo de grano mas fino ya que cada consulta
individual se resuelve en paralelo. En la estrategia por terminos solo puede explotarse
paralelismo si se resuelven dos o mas consultas concurrentemente.
Por otra parte, la estrategia de indexacion por documentos permite ir ingresando nue-
vos documentos de manera facil, el documento se envıa a la maquina id doc mod P , y se
modifica la lista local de ese nodo. Sin embargo, para el caso de ranking mediante el meto-
do del vector (descrito mas abajo), se requiere que las listas se mantengan ordenadas por
frecuencia, entonces no es tan sencillo modificar la lista. No obstante, para la estrategia
por terminos, tambien es necesario hacer esa actualizacion cuando se modifican las listas.
La gran desventaja del ındice particionado por terminos esta en la construccion del ındice
debido a la fase de comunicacion global que es necesario realizar para distribuir las listas
invertidas. Inicialmente el ındice puede ser construido en paralelo como si fuese un ındice
particionado por documentos para luego re-distribuir los terminos con sus listas invertidas.
8

N o d e 1N o d e 2
Figura 1.3: Estrategia de Distribucion por Termino (node= procesador).
1.3. Ranking de documentos
El metodo vectorial es bastante utilizado en recuperacion de informacion para hacer
ranking de documentos que satisfacen una consulta. Las consultas y documentos tienen
asignado un peso para cada uno de los terminos (palabras) de la base de texto (docu-
mentos). Estos pesos se usan para calcular el grado de similitud entre cada documento
almacenado en el sistema y las consultas que puedan hacer los usuarios. El grado de simi-
litud calculado, se usa para ordenar de forma decreciente los documentos que el sistema
devuelve al usuario, en forma de clasificacion (ranking).
Se define un vector para representar cada documento y consulta:
El vector dj esta formado por los pesos asociados de cada uno de los terminos en el
documento dj .
El vector q esta compuesto por los pesos de cada uno de los terminos en la consulta
q.
Ası, ambos vectores estaran formados por tantos pesos como terminos se hayan encontrado
en la coleccion, es decir, ambos vectores tendran la misma dimension.
9

El modelo vectorial evalua el grado de similitud entre el documento dj y la consulta
q, utilizando una relacion entre los vectores dj y q. Esta relacion puede ser cuantificada.
Un metodo muy habitual es calcular el coseno del angulo que forman ambos vectores.
Cuanto mas parecidos sean, mas cercano a 0 sera el angulo que formen y en consecuencia,
el coseno de este angulo se aproximara mas a 1. Para angulos de mayor tamano el coseno
tomara valores que iran decreciendo hasta −1, ası que cuanto mas cercano de 1 este el
coseno, mas similitud habra entre ambos vectores, luego mas parecido sera el documento
dj a la consulta q.
La frecuencia interna de un termino en un documento, mide el numero de ocurrencias
del termino sobre el total de terminos del documento y sirve para determinar cuan relevante
es ese termino en ese documento. La frecuencia del termino en el total de documentos,
mide lo habitual que es ese termino en la coleccion, ası, seran poco relevantes aquellos
terminos que aparezcan en la mayorıa de documentos de la coleccion. Invirtiendola, se
consigue que su valor sea directamente proporcional a la relevancia del termino.
Una de las formulas utilizadas para el ranking vectorial es la siguiente:
Sea {t1...tn} el conjunto de terminos y {d1...dn} el conjunto de documentos, un
documento di se modela como un vector:
di → ~di = (w(t1, di), ..., w(tk , di))
donde w(tr, di) es el peso del termino tr en el documento di.
En particular una consulta puede verse como un documento (formada por esas pa-
labras) y por lo tanto como un vector.
La similitud entre la consulta q y el documento d esta dada por:
0 <= sim(d, q) =∑
t(wq,t ∗ wd,t)/Wd <= 1.
Se calcula la similitud entre la consulta q y el documento d como la diferencia coseno,
que geometricamente corresponde al coseno del angulo entre los dos vectores. La
similitud es un valor entre 0 y 1. Notar que los documentos iguales tienen similitud
1 y los ortogonales (si no comparten terminos) tienen similitud 0. Por lo tanto esta
formula permite calcular la relevancia del documento d para la consulta q.
El peso de un termino para un documento es:
10

0 <= wd,t = fd,t/maxk ∗ idft <= 1.
En esta formula se refleja el peso del termino t en el documento d (es decir que tan
importante es este termino para el documento).
fd,t/maxk es la frecuencia normalizada. fd,t es la cantidad de veces que aparece el
termino t en el documento d. Si un termino aparece muchas veces en un documento,
se supone que es importante para ese documento, por lo tanto fd,t crece. maxk es
la frecuencia del termino mas repetido en el documento d o la frecuencia mas alta
de cualquier termino del documento d. En esta formula se divide por maxk para
normalizar el vector y evitar favorecer a los documentos mas largos.
idft = log10(N/nt), donde N es la cantidad de documentos de la coleccion, nt es
el numero de documentos donde aparece t. Esta formula refleja la importancia del
termino t en la coleccion de documentos. Le da mayor peso a los terminos que
aparecen en una cantidad pequena de documentos. Si un termino aparece en muchos
documentos, no es util para distinguir ningun documento de otro (idft decrece). Lo
que se intenta medir es cuanto ayuda ese termino a distinguir ese documento de los
demas. Esta funcion asigna pesos altos a terminos que son encontrados en un numero
pequeno de documentos de la coleccion. Se supone que los terminos raros tienen un
alto valor de discriminacion y la presencia de dicho termino tanto en un documento
como en una consulta, es un buen indicador de que el documento es relevante para
la consulta.
Wd = (∑
(w2
d,t))1/2. Es utilizado como factor de normalizacion. Es el peso del do-
cumento d en la coleccion de documentos. Este valor es precalculado y almacenado
durante la construccion de los ındices para reducir las operaciones realizadas durante
el procesamiento de las consultas.
wq,t = (fq,t/maxk) ∗ idft, donde fq,t es la frecuencia del termino t en la consulta q
y maxk es la frecuencia del termino mas repetido en la consulta q, o dicho de otra
forma, es la frecuencia mas alta de cualquier termino de q. Proporciona el peso del
termino t para la consulta q.
11

Capıtulo 2
Transacciones Concurrentes
En este capıtulo se propone realizar procesamiento sincronico por lotes a nivel de
threads como una alternativa mas eficiente y escalable que el enfoque convencional ba-
sado en threads asincronicos. Sobre esta forma de paralelismo se disenan algoritmos de
procesamiento de consultas (transacciones de lectura) y actualizacion on-line del ındice
invertido (transacciones de escritura) que muestran ser particularmente eficientes frente a
situaciones de trafico alto de transacciones.
Para un cluster con P ×D nodos procesadores, donde cada nodo contiene procesadores
multi-core que permiten ejecutar eficientemente T threads, y donde los nodos se utilizan
para mantener P particiones del ındice invertido, cada particion replicada D veces, se le
llama “nodo de busqueda” a cada nodo en que se despliega un servicio de ındice que opera
en modo exclusivo en el nodo. Se asume que a cada nodo llegan mensajes conteniendo
transacciones de lectura y escritura que deben ser procesadas en tiempo real. Dichos
mensajes son depositados en una unica cola de transacciones, las cuales son retiradas por
los threads para darles servicio. Para el conjunto de P×D nodos de busqueda, se asume que
el valor de P es tal que permite a un solo thread procesar completamente una transaccion
de manera secuencial dentro de una cota superior para el tiempo de respuesta. Se asume
que el nivel de replicacion D es tal que es posible alcanzar el throughput objetivo para la
tasa de llegada de transacciones en regimen permanente.
Lo que propone este capıtulo son soluciones eficientes para enfrentar alzas bruscas en
el trafico de transacciones, especialmente alzas en las transacciones de solo lectura, las
cuales representan las consultas de los usuarios del motor de busqueda.
12

Figura 2.1: Arquitectura de un Nodo de Busqueda.
2.1. Planteamiento del Problema
En la literatura para el diseno de motores de busqueda es posible encontrar numerosas
estrategias de indexacion y caching, las cuales pueden ser combinadas de distintas maneras
para alcanzar un rendimiento eficiente y escalable a sistemas de gran tamano y trafico
de consultas. La combinacion especıfica depende de los requerimientos que dependen de
aspectos tales como el tamano del ındice, el uso de memoria secundaria y/o compresion
del ındice, y uso de distintos tipos de caches. En particular, el diseno de un servicio de
ındice para un motor de busqueda puede tener la forma mostrada en la Figura 2.1. El
cache de listas invertidas esta formado por un gran numero de bloques que se utilizan
para almacenar grupos de ıtemes de las listas invertidas del tipo (doc id, term freq). Cada
lista, por lo general ocupa varios de estos bloques. Un cache secundario almacena los
resultados top-K de las consultas mas frecuentes resueltas por el nodo de busqueda. La
lista invertida completa de cada termino se puede mantener en el disco local al nodo o
en memoria principal en formato comprimido, es decir, se trata de una zona de memoria
relativamente mas lenta que la memoria proporcionada por los caches.
Un camino factible para los threads se ilustra en la Figura 2.2. En este ejemplo, las
consultas llegan a la cola de entrada del nodo de busqueda. Un numero determinado de
threads se encarga de resolver las consultas. Cada vez que un thread obtiene una nueva
consulta desde la cola de entrada, se comprueba si la misma ya esta almacenada en el
cache de top-K (1). Si hay un hit en este cache, el thread responde con los identificadores
de los K documentos almacenados en la entrada correspondiente (2). De lo contrario, el
13

Figura 2.2: Camino seguido por las consultas.
thread verifica si todos los bloques de las listas invertidas de los terminos de la consulta
estan en el cache de listas (3). Si es ası, el thread utiliza esos bloques para resolver la
consulta mediante la aplicacion de un algoritmo de ranking de documentos (3.a). Una
vez que el thread obtiene los identificadores de los documentos top-K para la consulta,
se guarda esta informacion en el cache de top-K aplicando una polıtica de reemplazo de
entradas del cache (4) y se envıa un mensaje con la respuesta a la consulta (5). Si faltan
bloques de listas invertidas en el cache de listas (3.b) el thread deja la consulta en una
cola de requerimientos de memoria secundaria o ındice comprimido (otro thread gestiona
esta transferencia de bloques) y comprueba si en esta segunda cola hay otra consulta
cuya transferencia de bloques al cache de listas ha sido completada para proceder con su
solucion (3.c), (4) y (5).
El enfoque anterior de procesamiento de consultas utilizando varios threads, supone
la existencia de una estrategia capaz de abordar adecuadamente la ejecucion concurrente
de las operaciones de lectura/escritura causadas por los threads en los caches y las colas.
Dado que las entradas de los caches son reemplazadas por nuevos datos constantemente,
es muy posible encontrar lecturas y escrituras concurrentes siendo ejecutadas en la mis-
ma entrada de un cache, y por lo tanto es necesario imponer un protocolo que permita
sincronizar los accesos de los threads a los recursos compartidos para prevenir conflictos
de lectura/escritura. Una solucion intuitiva es aplicar locks a las entradas del cache. Sin
embargo, el problema es mas complicado que eso como se describe a continuacion.
Luego de calcular los identificadores de los documentos top-K para una consulta, es
necesario desalojar una entrada del cache de top-K para almacenar los nuevos identifica-
14

dores top-K. Durante el mismo intervalo de tiempo, otros threads pueden estar leyendo
las entradas del cache para decidir si calcular o no los resultados de sus respectivas con-
sultas. Si el control de concurrencia se realiza a nivel grueso utilizando un lock o unos
pocos locks para proteger todas las entradas del cache, los threads pueden ser serializados
severamente. Por otro lado, mantener un lock por cada entrada del cache incrementa la
concurrencia significativamente. Sin embargo, hacer que cada thread ejecute un lock por
cada entrada que lee mientras recorre el cache secuencialmente, puede tambien producir
un efecto de serializacion de threads y dado que el costo de cada lock no es despreciable,
el tiempo de ejecucion se puede degradar y aumentar con el numero de threads. Este pro-
blema puede aliviarse utilizando estrategias como SDC donde un 80 % de las entradas son
de solo lectura (cache estatico) y un 20 % son de lectura/escritura (cache dinamico).
En el cache de listas invertidas, es necesario seleccionar rapidamente un numero sufi-
cientemente grande de bloques de cache para reemplazarlos por los bloques que contienen
los pares (doc id, term freq) de la nueva lista invertida siendo recuperada desde memoria
secundaria o desde un ındice comprimido. Para este proposito se puede utilizar una cola
de prioridad la cual permite determinar de manera exacta y eficientemente los bloques
de mayor prioridad de desalojo en el cache. Alternativamente, es posible utilizar una lis-
ta enlazada administrada con la heurıstica “mover al frente”, la cual permite obtener de
manera aproximada los bloques con mayor prioridad de ser desalojados del cache. Para la
polıtica LRU, la estrategia de mover al frente deberıa funcionar relativamente bien.
Si los bloques que contienen los ıtemes de las listas invertidas son modificados por
threads escritores, el problema de concurrencia se agrava, con la dificultad adicional que
debe haber consistencia entre los bloques almacenados en las entradas del cache y las
respectivas listas invertidas mantenidas en memoria secundaria o en memoria principal en
formato comprimido. Por ejemplo, si una estrategia de control de concurrencia se basa en
el bloqueo de las listas invertidas asociadas con los terminos de la consulta, entonces, esto
tambien deberıa provocar el bloqueo de todas las entradas del cache que mantienen los
bloques de las respectivas listas invertidas (o alternativamente el ocultamiento de estas
entradas del algoritmo de reemplazo de entradas).
Ademas, mientras un thread lee o actualiza una lista invertida ℓ, el algoritmo de
administracion de cache no debe seleccionar para reemplazo los bloques asignados a ℓ.
Al igual que en el caso anterior, una solucion sencilla es ocultar temporalmente todos los
bloques de ℓ antes que el thread los utilice. Este proceso tambien requiere de una correcta
sincronizacion de los threads y por lo tanto puede degradar el tiempo de ejecucion del
thread que esta operando sobre la lista ℓ.
15

El modificar una lista invertida tambien presenta problemas de coherencia entre la
nueva version y las posibles entradas para el mismo termino que ya estan almacenadas
en el cache de top-K. Si el nuevo ıtem que se inserta en la lista invertida tiene una
frecuencia lo suficientemente alta o mayor a la version anterior, entonces es probable que
el documento asociado pueda tambien estar presente en la respectiva entrada del cache de
top-K. En este caso, es mas practico invalidar todas las entradas del cache relacionadas
con los terminos que aparecen en las respectivas consultas, ya que la unica manera de
estar seguros es volver a calcular el ranking de la consulta. Esto genera requerimientos
adicionales de control de concurrencia en el cache, los cuales imponen una carga adicional
en uso de locks o algun otro mecanismo de sincronizacion de threads.
2.2. Solucion Propuesta
La solucion propuesta esta basada en la observacion de que si las consultas y actuali-
zaciones del ındice fueran procesadas de manera secuencial por un solo thread principal,
no serıa necesario formular una solucion para cada uno de los problemas anteriores. Por
lo tanto, lo que se propone es asignar un thread principal en el nodo de busqueda a seguir
secuencialmente los pasos descritos en la Figura 2.2, el cual recurre al despliegue de tantos
threads auxiliares como nucleos tenga el procesador para paralelizar las operaciones de
mayor costo tales como el ranking de documentos, actualizacion del ındice y la adminis-
tracion de los caches. La granularidad de las demas operaciones en terminos de costo es
muy pequena y las puede ejecutar el mismo thread principal secuencialmente utilizando
uno de los nucleos del nodo sin perdida de eficiencia. Se utiliza paralelismo sincronico para
organizar de manera eficiente las operaciones realizadas por los threads. El numero Nt de
threads disponibles para ser utilizados por el thread principal puede variar dinamicamente
en todo momento con el objetivo de permitir la ejecucion de software de mantencion y
administracion en el nodo de busqueda durante su operacion en produccion.
2.2.1. Query Solver
Las consultas son resueltas en el componente llamado query solver, el cual es el en-
cargado de recorrer las listas invertidas de todos los terminos de la consulta y aplicar el
metodo de ranking de documentos. Los elementos de cada lista invertida se agrupan en
bloques consecuentes con el tamano de las entradas del cache de listas invertidas. Se utili-
zan Nt threads para hacer el ranking de los documentos y cada thread trabaja sobre una
16

Figura 2.3: Organizacion del ındice invertido donde cada lista invertida es almacenada enun numero de bloques y cada bloque se encuentra logicamente dividido en trozos que sonasignados a cada threads. Cada trozo esta compuesto por un numero de ıtemes de la listainvertida, (doc id, freq). En este ejemplo, el primer bloque el termino term 0 es procesadoen paralelo por los threads th0, th1, th2 and th3.
seccion distinta de cada lista invertida, emulando un ındice particionado por documentos.
Por ejemplo, la Figura 2.3 (organizacion de la estructura de datos utilizada) muestra esta
situacion. La figura muestra que para el primer bloque del termino term 0, existen Nt = 4
threads trabajando en paralelo en el mismo bloque.
Dado que el rendimiento de los procesadores multi-core es altamente dependiente de la
localidad de datos, durante el procesamiento de una consulta todos los threads deberıan
maximizar el acceso a memoria local, es decir, accesos a datos almacenados en el cache
privado de los respectivos nucleos, donde los threads estan siendo ejecutados. Con este fin,
cada thread mantiene una estructura de datos llamada fast track destinada a aumentar la
localidad de referencias y por lo tanto las consultas se procesan iterativamente siguiendo
dos pasos principales:
Fetching. El primer paso consiste en leer desde la memoria principal del nodo (cache
de listas) un trozo de lista invertida de tamano K por cada termino presente en la
consulta, y por cada uno de ellos almacenar un trozo distinto de tamano K/Nt en la
memoria fast track de cada uno de los Nt threads que participan en la solucion de la
consulta. En rigor, tan pronto como un segmento de tamano K ha sido almacenado
en las Nt memorias locales, el o los bloques respectivos del cache pueden quedar
disponibles para operaciones de actualizacion dirigidas a esa seccion del ındice o
pueden ser desalojadas del cache.
Ranking. En el segundo paso, los Nt threads ejecutan en paralelo el ranking de
documentos y, si es necesario, se solicitan nuevos trozos de tamano K de las listas
invertidas (fetching) para finalmente producir los K documentos mejor rankeados
17

Figura 2.4: Insercion/Actualizacion de documentos.
para la consulta. El proceso de ranking puede implicar la determinacion de los docu-
mentos que contienen todos los terminos de la consulta, lo que implica realizar una
operacion de interseccion entre las listas invertidas involucradas.
De esta manera el proceso de ranking puede requerir varias iteraciones de la secuencia
(Fetch, Rank) en ser completado. Los documentos son asignados a los threads utilizando
la regla id doc modulo Nt, es decir, particion por documentos, lo cual aumenta la localidad
de operaciones costosas tales como la interseccion de listas invertidas. Para facilitar el uso
de memoria contigua en las transferencias, los bloques que mantienen los pares (doc id,
term freq) de las listas invertidas se pueden mantener explıcitamente particionados en Nt
sub-bloques, donde Nt indica el total de threads a ser utilizados en regimen permanente, o
implıcitamente divididos en Nt particiones almacenando todos los pares (doc id, term freq)
asignados a una particion dada en una region contigua del bloque.
Por otro lado, en la cola de entrada del nodo de busqueda tambien pueden haber
operaciones o transacciones de escritura que representen el caso en que nuevos documentos
son insertados en el ındice (insercion), o que documentos existentes sean reemplazados por
una nueva version (actualizacion). La Figura 2.4 ilustra el caso en que un nuevo documento
es insertado en el ındice, donde se muestra el efecto de la insercion en un conjunto de
terminos y secciones de las respectivas listas invertidas. Una operacion de escritura puede
modificar cualquier bloque de una lista invertida y este puede encontrarse en el cache o
en memoria secundaria o memoria comprimida. Una transaccion de escritura se procesa
distribuyendo uniformemente los terminos en los Nt threads disponibles y cada thread
modifica las respectivas listas en paralelo.
Para consultas de tipo OR (disjunctive queries), las listas invertidas son ordenadas
por frecuencia del termino en los documentos, mientras que para consultas de tipo AND
(conjunctive queries) las listas son ordenadas por identificador de documento. Esto ultimo
requiere de la interseccion de todas las listas invertidas involucradas. En este caso, es util
18

mantener las listas ordenadas por identificador de documento ya que las operaciones de
interseccion pueden tomar tiempo lineal respecto de la longitud de las listas. Para apoyar
la insercion eficiente en listas ordenadas por frecuencia, se mantienen espacios vacıos en
los bloques y se aplica una estrategia similar a la empleada en el B-Tree. Es decir, cuando
un bloque se llena, se crea uno nuevo bloque moviendo al nuevo bloque elementos tomados
desde el bloque afectado y el bloque adyacente a este.
2.2.2. Algoritmo Bulk Processing (BP Local)
La estrategia propuesta utiliza paralelismo BSP para posibilitar el paralelismo a nivel
de threads y donde las barreras de sincronizacion de threads permiten evitar los posibles
conflictos de lectura y escritura entre las transacciones. Basicamente los threads son sin-
cronizados al final de una secuencia de iteraciones realizadas para resolver una consulta
o al final de la insercion o actualizacion de un documento en el ındice invertido. Entre
dos barreras de sincronizacion consecutivas se procesa completamente una transaccion de
lectura o escritura. Los detalles se presentan en la Figura 2.5, la cual presenta un caso
donde el query solver tiene en su cola de entrada un lote de transacciones de lectura y de
escritura, y las procesa todas de una vez antes de entregar los resultados.
En el algoritmo presentado en la Figura 2.5 se utiliza una forma relajada de sincroniza-
cion de barrera que se ha disenado para reducir el costo de la sincronizacion. Tıpicamente,
una barrera de sincronizacion estandar para memoria compartida se implementa utilizan-
do una operacion “conditional wait” para hacer que los threads se bloquen en el punto
de sincronizacion. El ultimo threads despierta a todos los otros para lo cual tambien se
utiliza un contador protegido mediante un lock de acceso exclusivo. Cuando el valor del
contador es igual al total de threads, se indica el fin de la barrera y los Nt − 1 threads
bloqueados se activan. Para un sistema con gran numero de threads, la competencia por
acceder al contador y a la instruccion de espera condicional puede degradar el rendimiento
al transformarse en una fuente de serializacion de threads.
Basados en la idea de sincronizacion relajada (oblivious synchronization) para el mo-
delo BSP sobre memoria distribuida, en la Figura 2.6 se propone una version del mismo
concepto para memoria compartida, la cual usa locks y esperas condicionales. Basicamente
la idea consiste en ampliar a Nt el total de locks y esperas de manera de reducir la compe-
tencia de los threads por acceder a esos recursos compartidos. Las operaciones condWait(a,
b) y condSignal(a) tienen la misma semantica que sus homologos en Posix-threads, es de-
19

F es un trozo de tamano O(K) de memoria local al procesador.D conjunto de documentos rankeados para una consulta.R documentos mejor rankeados para una consulta.Lt es la lista invertida de un termino t.tid es el identificador del thread.pair( d, ft ) es un ıtem de lista invertida, donde ft es la frecuenciadel termino t en el documento d.
BulkProcessing( tid )
for each transaction Tn in input queue doif Tn.type == QUERY then /* read transaction */
empty( D )for each term t in Tn.query do
for each block b in Lt[tid] doF = fetch( Lt[tid][b] )rank( F , D )
endforendforRtid = getLocalTopK( D )
else /* write transaction */
for each term t in Tn.termsForThread[tid] dod = Tn.docIdif Tn.type == UPDATE then
update( Lt[tid], pair(d,ft) )else
insert( Lt[tid], pair(d,ft) )endif
endforendifObliviousBarrier( tid, Tn.id mod Nt )if (Tn.type == QUERY) and (Tn.id mod Nt == tid) then
Rglobal = getGlobalTopK( { R1, R2, ..., RNt} )
ouputQueue[ tid ].store( Rglobal )endif
endfor
EndBulkProcessing
Figura 2.5: Pasos ejecutados por cada thread en paralelo con los otros Nt − 1 threads.
20

ObliviousBarrier( my tid, tid )
set Lock( mutex[tid] )counter[tid]++if my tid == tid then
if counter[tid] < Nt thencondWait( cond[tid], mutex[tid] )
elsecounter[tid]=0
endifelse if counter[tid] == Nt then
counter[tid]=0condSignal( cond[tid] )
endif
unset Lock( mutex[tid] )EndObliviousBarrier
Figura 2.6: Sincronizacion relajada ejecutada por cada thread con identificador my tid.
cir, se bloquea b y se duerme el thread con una variable de condicion a y posteriormente
se despierta a los threads que esperan en la variable a.
Aparte de la mejora en rendimiento proveniente de la reduccion de competencia por
recursos, el costo de los locks y esperas condicionales es amortizado por la vıa del siguiente
concepto que el algoritmo BP explota para lotes de Nt o mas consultas. La ultima parte
del procesamiento de las transacciones de lectura contiene una parte secuencial en que se
determinan los mejores K documentos para la consulta. Una ventaja de la sincronizacion
relajada es que permite que esa fase sea realizada para Nt consultas en paralelo. Lo mismo
es posible con la sincronizacion de barrera estandar, pero la diferencia aquı es que cada
threads puede ingresar a esa fase tan pronto como los otros threads han terminado de
calcular sus mejores documentos locales para la consulta. Este solapamiento tiene el efecto
de amortizar los costos de la sincronizacion.
2.3. Estrategias alternativas
Como alternativas al algoritmo BP de la Figura 2.5 se tienen de la literatura actual una
serie de estrategias de control de concurrencia para transacciones de lectura y escritura.
21
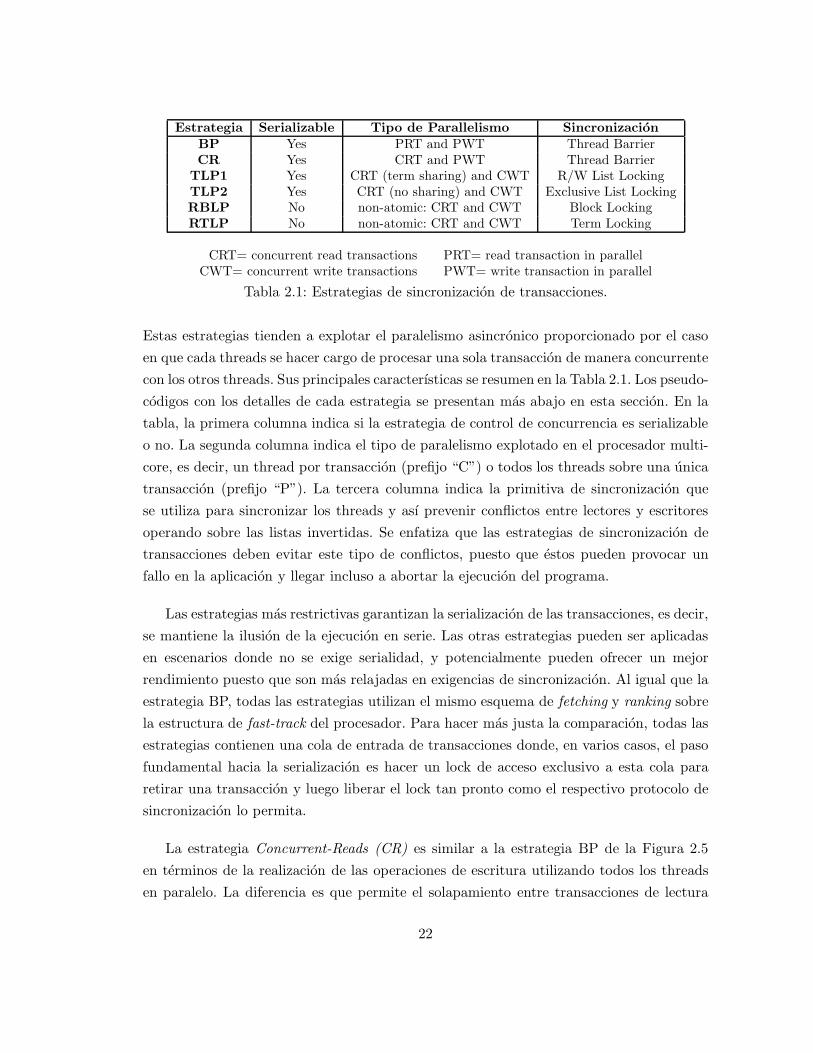
Estrategia Serializable Tipo de Parallelismo SincronizacionBP Yes PRT and PWT Thread BarrierCR Yes CRT and PWT Thread Barrier
TLP1 Yes CRT (term sharing) and CWT R/W List LockingTLP2 Yes CRT (no sharing) and CWT Exclusive List LockingRBLP No non-atomic: CRT and CWT Block LockingRTLP No non-atomic: CRT and CWT Term Locking
CRT= concurrent read transactions PRT= read transaction in parallelCWT= concurrent write transactions PWT= write transaction in parallel
Tabla 2.1: Estrategias de sincronizacion de transacciones.
Estas estrategias tienden a explotar el paralelismo asincronico proporcionado por el caso
en que cada threads se hacer cargo de procesar una sola transaccion de manera concurrente
con los otros threads. Sus principales caracterısticas se resumen en la Tabla 2.1. Los pseudo-
codigos con los detalles de cada estrategia se presentan mas abajo en esta seccion. En la
tabla, la primera columna indica si la estrategia de control de concurrencia es serializable
o no. La segunda columna indica el tipo de paralelismo explotado en el procesador multi-
core, es decir, un thread por transaccion (prefijo “C”) o todos los threads sobre una unica
transaccion (prefijo “P”). La tercera columna indica la primitiva de sincronizacion que
se utiliza para sincronizar los threads y ası prevenir conflictos entre lectores y escritores
operando sobre las listas invertidas. Se enfatiza que las estrategias de sincronizacion de
transacciones deben evitar este tipo de conflictos, puesto que estos pueden provocar un
fallo en la aplicacion y llegar incluso a abortar la ejecucion del programa.
Las estrategias mas restrictivas garantizan la serializacion de las transacciones, es decir,
se mantiene la ilusion de la ejecucion en serie. Las otras estrategias pueden ser aplicadas
en escenarios donde no se exige serialidad, y potencialmente pueden ofrecer un mejor
rendimiento puesto que son mas relajadas en exigencias de sincronizacion. Al igual que la
estrategia BP, todas las estrategias utilizan el mismo esquema de fetching y ranking sobre
la estructura de fast-track del procesador. Para hacer mas justa la comparacion, todas las
estrategias contienen una cola de entrada de transacciones donde, en varios casos, el paso
fundamental hacia la serializacion es hacer un lock de acceso exclusivo a esta cola para
retirar una transaccion y luego liberar el lock tan pronto como el respectivo protocolo de
sincronizacion lo permita.
La estrategia Concurrent-Reads (CR) es similar a la estrategia BP de la Figura 2.5
en terminos de la realizacion de las operaciones de escritura utilizando todos los threads
en paralelo. La diferencia es que permite el solapamiento entre transacciones de lectura
22

a lo largo del tiempo mediante la asignacion de un thread a cada consulta. Cada thread
resuelve de principio a fin la consulta asignada. Antes de procesar una transaccion de
escritura, CR espera a que todas las transacciones concurrentes de lectura en curso hayan
finalizado (mas detalles en la Figura 2.7). De esta manera, la estrategia CR explota el
paralelismo disponible desde todas consultas activas (transacciones de solo lectura) en
un periodo de tiempo. Dado que algunos threads pueden quedar sin trabajo antes del
comienzo de la siguiente transaccion de escritura, se probo una version de CR donde los
threads sin trabajo cooperan con los demas para terminar las transacciones de lectura
en curso. Sin embargo, no se observo mejoras en el rendimiento debido a la computacion
extra que es necesario hacer para la planificacion de threads.
La estrategia Term-Level-Parallelism (TLP) permite el solapamiento entre transaccio-
nes de lectura y escritura. Cada transaccion es ejecutada por un unico thread y se utilizan
locks de exclusion mutua para proteger las listas invertidas involucradas. El lock sobre un
termino en realidad implica un lock sobre la respectiva lista invertida en forma completa.
Para garantizar la serialidad de transacciones, un thread dado no libera el lock sobre la
cola de entrada de transacciones hasta que no ha adquirido los locks de todos los terminos
que debe utilizar. Posteriormente, cada lock es liberado tan pronto como la respectiva lista
invertida ha sido procesada. Se implementaron dos versiones de TLP.
La primera version, llamada TLP1, permite transacciones simultaneas de solo lectura
sobre las mismas listas invertidas. Para esto fue necesario implementar locks de lectura,
es decir, locks que no bloquean a los threads conteniendo transacciones de lectura y que
tienen terminos en comun, mientras que los threads conteniendo transacciones de escritura
son bloqueados si comparten terminos con las transacciones de lectura. Las transacciones
de escritura utilizan locks de acceso exclusivo a las listas invertidas. Los locks son servidos
en modo FIFO lo cual garantiza la serialidad (mas detalles en la Figura 2.8).
La segunda version, llamada TLP2, es mucho mas facil de implementar puesto que
se impide el solapamiento de transacciones de lectura o escritura que tengan terminos en
comun. Esta estrategia es similar al protocolo de 2 fases de bases de datos. Una vez que
el thread adquiere el lock sobre la cola de entrada de transacciones, procede a solicitar
un lock de acceso exclusivo para cada uno de los terminos involucrados en la transaccion.
No existe posibilidad de deadlocks debido a que el lock de acceso exclusivo a la cola de
entrada de transacciones no se libera hasta que el thread ha adquirido todos los locks (mas
detalles en la Figura 2.9).
23

Tambien se estudiaron dos estrategias adicionales que relajan los requisitos de seria-
lidad y atomicidad de las transacciones. Al no adherir a estos dos requisitos, el nivel de
concurrencia de los threads aumenta significativamente. Para motores de busqueda, donde
las consultas de usuarios son respondidas en una fraccion de segundo, ambos requisitos
podrıan ser prescindibles. Para otras aplicaciones tales como sistemas de bolsa electronica
no es tan claro que estos requisitos sean prescindibles. Por otra parte, estas dos estrate-
gias son buenos representantes del mejor rendimiento que podrıa alcanzar una estrategia
optimista que cumpla al menos el requisito de atomicidad por la vıa de abortar y re-
ejecutar una transaccion para la cual se detecta que las versiones de las listas invertidas
involucradas no son las que existıan al momento de iniciar su ejecucion.
La primera estrategia, llamada Relaxed-Block-Level-Parallelism (RBLP), es similar a
TLP pero no obliga a los threads a hacer un lock de la lista invertida completa por
cada termino involucrado tanto para transacciones de lectura como para transacciones de
escritura. Las listas invertidas estan compuestas de un conjunto de bloques. Por lo tanto,
los threads van haciendo locks exclusivos solo de los bloques de las listas invertidas que se
estan procesando en un momento dado del tiempo. Es decir, es minimal, se aplica el lock
solo en la seccion de la lista invertida donde es necesario prevenir que dos o mas threads
lean y escriban los mismos ıtemes (doc id, term freq) de la lista. En la implementacion de
esta estrategia, debido a que los bloques pueden eventualmente llenarse de ıtemes y por
lo tanto dividirse, lo que se hace es aplicar locks exclusivos sobre dos bloques consecutivos
en los casos en que el numero de ıtemes dentro del bloque actual este mas alla de un valor
umbral B − Nt donde B es el tamano del bloque (es decir, existe una probabilidad de
que una transaccion de escritura divida el bloque que se ha llenado siguiendo el algoritmo
descrito al final de la Seccion 2.2.1).
Dado que no existe el requerimiento de serialidad y atomicidad, existen tres optimiza-
ciones adicionales que incrementan el nivel de concurrencia. Primero, los threads liberan el
lock de acceso exclusivo sobre la cola de entrada de transacciones tan pronto como copian
los datos de la transaccion a memoria local. Segundo, los threads liberan los locks sobre los
bloques tan pronto como van siendo copiados al fast-track, y por lo tanto el ranking de los
documentos presentes en el bloque puede involucrar una gran cantidad de computo sin que
este retardo afecte el nivel de concurrencia. En los experimentos realizados se detecto que
el costo del ranking de documentos es la parte dominante en el tiempo de ejecucion. Terce-
ro, durante la solucion de una consulta, el ranking de documentos avanza considerando un
solo bloque por cada termino en oposicion al caso de primero procesar todos los bloques
24

de un termino para pasar al siguiente. Esto reduce el nivel de contencion entre threads
que comparten terminos. Los detalles de RBLP se presentan en la Figura 2.10.
El segundo enfoque, llamado Relaxed-Term-Level-Parallelism (RTLP), es similar a
RBLP pero antes de acceder a un bloque se hace un lock del termino en lugar de lo-
ck de bloques como en RBLP. Esto evita la necesidad de tener que decidir si hacer un
lock de dos bloques consecutivos durante el recorrido de cada lista invertida. Otra ventaja
practica es la significativa reduccion en el tamano del arreglo de locks que es necesario
definir en la implementacion. En rigor, en RTLP se requiere definir una variable de tipo
lock por cada termino del ındice invertido, mientras que en RBLP es mucho mas que esa
cantidad puesto que por cada termino se tienen muchos bloques. En la implementacion de
RBLP y RTLP en realidad se utiliza un arreglo de variables de tipo lock mucho menor y
se utiliza hashing sobre ese arreglo para requerir un lock de termino y de bloque. Natural-
mente, para un mismo tamano de arreglo, la probabilidad de colisiones es mucho menor
en el caso de RTLP que en RBLP. Los detalles de la estrategia RTLP se presentan en la
Figura 2.11.
2.3.1. Detalles de estrategias alternativas
En cada caso, se tiene que
F es un trozo de tamano O(K) de memoria local al procesador.
H es el tamano de la tabla de hashing utilizada para los locks.
Lt lista invertida de un termino.
tid identificador del thread.
pair(d, ft) es un ıtem de lista invertida, donde ft es la frecuencia del termino t en el
documento d.
lockRead(t) permite a todos los lectores entrar en una zona protegida y lockWrite(t)
espera a que todos los que estan en la zona protegida terminen y luego el thread
entra en modo exclusivo.
lock(t) es un lock de acceso exclusivo.
25

global: TnW, q write = false;local: Tn;
while( true )
lock( input queue )if q write == false then
Tn = extractNextTransaction( input queue )endifif q write == false and Tn.type != QUERY then
TnW = Tn;q write = true
endifif q write == true then Tn = TnW;
unlock( input queue )
if Tn.type == QUERY then /*read transaction*/
for each term t in Tn.query dorank( Lt )
endfor
else /*write transaction*/
Barrier()for each term t in Tn.termsForThread[tid] do
d = Tn.docIdif Tn.type == UPDATE then
update( Lt, pair( d, ft ) )else
insert( Lt, pair( d, ft ) )endif
endforif tid == 0 then q write = false
Barrier()endif
endwhile
Figura 2.7: Pseudo-Codigo CR.
26

while ( true )
lock( input queue )Tn = extractNextTransaction( input queue )
if Tn.type == QUERY then /*read transaction*/
for each term t in Tn.query dolockRead( t %H )
endforunlock( input queue )
for each term t in Tn.query dorank( Lt )unlockRead( t %H )
endfor
else /*write transaction*/
for each term t in Tn.terms dolockWrite( t %H )
endforunlock( input queue )
for each term t in Tn.terms dod = Tn.docIdif Tn.type == UPDATE then
update( Lt, pair( d, ft ) )else
insert( Lt, pair( d, ft ) )endifunlockWrite( t %H )
endfor
endifendwhile
Figura 2.8: Pseudo-Codigo TLP1.
27

while ( true )
lock( input queue )Tn = extractNextTransaction( input queue )
if Tn.type == QUERY then /*read transaction*/
for each term t in Tn.query dolock( t %H )
endforunlock( input queue )
for each term t in Tn.query dorank( Lt )unlock( t %H )
endfor
else /*write transaction*/
for each term t in Tn.terms dolock( t %H )
endforunlock( input queue )
for each term t in Tn.terms dod = Tn.docIdif Tn.type == UPDATE then
update( Lt, pair( d, ft ) )else
insert( Lt, pair( d, ft ) )endifunlock( t %H )
endfor
endifendwhile
Figura 2.9: Pseudo-Codigo TLP2.
28

while( true )
lock( input queue )Tn = extractNextTransaction( input queue )
unlock( input queue )
if Tn.type == QUERY then /*read transaction*/
for each term t in Tn.query dofor each block b in Lt do
lock( b%H ); lock( (b + 1)%H )F = fetch(Lt[b])
unlock( (b + 1)%H ); unlock( b%H )rank( F )
endforendfor
else /*write transaction*/
for each term t in Tn.terms dod = Tn.docId
for each block b in Lt dolock ( b%H ); lock ( (b + 1)%H )
if isRightBlock( b, ft ) == true thenif Tn.type == UPDATE then
update( b, pair( d, ft ) )else
insert( b, pair( d, ft ) )endifunlock ( (b + 1)%H ); unlock ( b%H )next term
endif
unlock ( (b + 1)%H ); unlock ( b%H )endfor
endforendif
endwhile
Figura 2.10: Pseudo-Codigo RBLP.
29

while( true )
lock( input queue )Tn = extractNextTransaction( input queue )
unlock( input queue )
if Tn.type == QUERY then /*read transaction*/
for each term t in Tn.query dofor each block b in Lt do
lock( t %H )F = fetch(Lt[b])
unlock( t %H )rank( F )
endforendfor
else /*write transaction*/
for each term t in Tn.terms dod = Tn.docId
lock ( t %H )if Tn.type == UPDATE then
update( Lt, pair( d, ft ) )else
insert( Lt, pair( d, ft ) )endif
unlock ( t %H )
endforendif
endwhile
Figura 2.11: Pseudo-Codigo RTLP.
30

2.3.2. Protocolo optimista de timestamps
Mas adelante se muestra que las estrategias BP y RTLP alcanzan el mejor rendimiento
general para todos los casos considerados. RTLP no procesa las transacciones de manera
atomica. Sin embargo, pese a que la comparacion con BP no es justa por ser RTLP una
estrategia mucho mas relajada respecto de requerimientos de sincronizacion que BP, una
justificacion para estudiar el rendimiento de RTLP es que es una estrategia que represen-
ta lo mejor que puede lograr un protocolo optimista de sincronizacion de transacciones.
Tambien RTLP es el representante de las estrategias asincronicas que alcanza el mejor
rendimiento entre ellas. Para complementar el analisis de las estrategias de sincronizacion,
a continuacion se define (e incluye en los experimentos) una version optimista de RTLP
la cual asegura que las transacciones son atomicas.
A cada transaccion Ti se le asigna un timestamp con valor unico Ts(i) que permita
establecer un orden entre las transacciones. A cada lista invertida Lt de un termino t se
le asocian dos valores:
WTS(Lt) : Maximo de los timestamps de las transacciones que han escrito en Lt,
escritura realizada por la operacion write(Lt).
RTS(Lt) : Maximo de los timestamps de las transacciones que han leıdo Lt, lectura
realizada por la operacion read(Lt).
El protocolo es:
Si Ti intenta ejecutar read(Lt)
◦ Si Ts(i) < WTS(Lt) no se ejecuta la operacion y Ti se aborta.
◦ Si Ts(i) > WTS(Lt) se ejecuta la operacion y RTS(Lt) = max{RTS(Lt), Ts(i)}.
Si Ti intenta un write(Lt)
◦ Si Ts(i) < RTS(Lt) no se ejecuta la operacion y Ti se aborta.
◦ Si Ts(i) < WTS(Lt) no se ejecuta la operacion y Ti continua.
◦ Si no, sı se ejecuta la operacion y WTS(Lt) = Ts(i).
La actualizacion concurrente de los valores de WTS(Lt) y RTS(Lt) se protege con locks
exclusivos. Esta actualizacion tiene una duracion muy corta en tiempo de procesamiento
31

y por lo tanto estos locks de granularidad muy fina no deberıan afectar el rendimiento
significativamente.
Al abortar transaccion se debe hacer el rollback de esta y todas las transacciones que
dependen de ella, es decir, transacciones que hayan leıdo valores escritos por la primera. Es-
to es recursivo y se llama efecto cascada. El efecto cascada se puede evitar obligando a que
las transacciones solo puedan leer valores escritos por transacciones que hayan terminado,
lo cual introduce estados de espera que pueden afectar el rendimiento. El requerimiento de
rollbacks recursivos, necesarios para garantizar la serialidad de las transacciones, se puede
relajar asegurando solo la atomicidad de las transacciones. Para esto solo se re-ejecuta
la transaccion abortada sin afectar a las que dependan de ella. Esta version de RTLP es
denominada RTLP-RB (relaxed term level paralelism with roll-backs).
32

Capıtulo 3
Analisis
El modelo de costo y arquitectura estan construidos sobre el modelo de computacion
Multi-BSP. Este modelo permite abstraer el hardware real, rescatando y parametrizando
las caracterısticas esenciales que originan los costos relevantes de un algoritmo ejecutado
sobre un procesador multi-core.
Respecto del diseno y analisis de algoritmos, la estructura estrictamente sincronica
del modelo Multi-BSP permite hacer matematicamente tratable el analisis comparativo
de algoritmos disenados para resolver un mismo problema. El modelo incluye aspectos
relevantes del rendimiento de algoritmos granularidad gruesa tales como el balance de
carga entre los nucleos y el efecto de la localidad de accesos a los caches mas cercanos a
los nucleos.
3.1. El modelo Multi-BSP
El modelo Multi-BSP es una extension a procesadores multi-core con memoria compar-
tida del modelo BSP de computacion paralela para memoria distribuida. Para facilitar la
explicacion de Multi-BSP conviene recordar el modelo BSP. Un programa BSP esta com-
puesto de una secuencia de supersteps. Durante un superstep los procesadores pueden
realizar computo sobre datos almacenados en memoria local y realizar el envıo de mensa-
jes a otros procesadores. El fin de cada superstep marca el envıo efectivo de los mensajes
acumulados en el procesador y la transmision de mensajes por la red de interconexion de
procesadores finaliza con la sincronizacion en forma de barrera de todos los procesadores.
Esto implica que los mensajes estan disponibles en los procesadores de destino al inicio
33

Figura 3.1: Ejemplo de arquitectura multi-core segun Multi-BSP.
del siguiente superstep. La barrera de sincronizacion asegura que ningun procesador puede
continuar hasta el siguiente superstep sino hasta cuando todos hayan alcanzado la barrera.
En el modelo Multi-BSP el concepto de supersteps y paso de mensajes en memoria
distribuida se ha extendido para considerar el costo de transferencia entre los distintos
niveles de la jerarquıa de memoria presente en los procesadores multi-core. Al igual que en
BSP, el computo de un algoritmo Multi-BSP se divide en una secuencia de supersteps, pero
la ejecucion de un algoritmo Multi-BSP incluye explıcitamente un modelo simplificado para
estimar el costo de las transferencias entre los distintos niveles de memoria. La descripcion
formal y general del modelo Multi-BSP, la cual considera multiples niveles de anidamiento
de caches y componentes, es presentada mas abajo.
La Figura 3.1 muestra un ejemplo de un sistema de memoria compartida equipado
con 4 nucleos con sus correspondientes niveles privados de cache L1, y un nivel de cache
compartido L2. Los caches L2 estan conectados con la memoria principal. En el modelo
Multi-BSP se asume que cada thread se ejecuta en un nucleo distinto y para este ejemplo
concreto se establecen tasas de transferencia entre L1 y L2 (parametro g1), y entre L2
y memoria principal (parametro g2). Los caches L1 y L2 tienen una capacidad m1 y m2
respectivamente y se supone que la memoria principal tiene capacidad suficiente para
almacenar todos los datos del algoritmo en ejecucion.
Para simplificar el modelo y permitir calculos aproximados de forma analıtica, cada
superstep es delimitado por la sincronizacion en forma de barrera de los threads. Las
transferencias de informacion entre L1 y L2, que ocurren a una tasa g1, son efectivas al
inicio del siguiente superstep de nivel 1 y el costo de la sincronizacion de este superstep
esta dado por la latencia ℓ1. Ası mismo, las transferencias entre L2 y la memoria principal
ocurren a una tasa de g2, y son efectivas al inicio del siguiente superstep de nivel 2 a un
costo de sincronizacion dado por la latencia ℓ2. Para realizar computos, cada nucleo C1
34

o C2 debe tener los datos necesarios en su respectivo cache L1. Puesto que estos tienen
capacidad limitada, la ejecucion de un algoritmo Multi-BSP habitualmente requerira de
la transferencia de bloques de memoria entre los caches L1 y L2, y entre los caches L2
y la memoria principal (Ram). En general, las latencias ℓi acumulan tanto el costo de la
sincronizacion de barrera como todos los costos fijos que son necesarios para ejecutar los
pasos del algoritmo Multi-BSP en el superstep.
Como se observa, el modelo simplifica el comportamiento dinamico de la jerarquıa de
memoria y asume la existencia de pasos o etapas en los cuales se realizan transferencias
entre los distintos niveles de la jerarquıa de memoria. Se sabe que en un procesador real las
transferencias entre los distintos niveles se realizan de forma independiente y solapados en
el tiempo y existen tecnicas para explotar el paralelismo a nivel de memoria. No es facil por
tanto delimitar las etapas que se plantean en el modelo o ni siquiera es posible definirlas.
Tambien se sabe que existen mecanismos adicionales como los prefetcher de hardware que
actuan de forma efectiva para ocultar las latencias de acceso y que el rendimiento viene
condicionado adicionalmente por el trafico provocado por los protocolos de coherencia de
cache, que tienen gran relevancia cuando existe comparticion (falsa o verdadera) de datos.
No obstante, dada la naturaleza de la aplicacion estudiada en este trabajo de tesis, en
el analisis de caso promedio se asume que la granularidad del paralelismo que se explota
es lo suficiente grande como para obviar el trafico de coherencia y se supone que todas
las estrategias se benefician por igual de los mecanismos de ocultacion de las latencias de
acceso. Esto ultimo tiene su justificacion en el hecho de que todas las estrategias reali-
zan el mismo tipo de acceso a los datos compartidos, los cuales estan caracterizados por
secuencias largas de accesos a regiones contiguas de memoria.
Con estas simplificaciones, el costo del superstep de nivel 1 esta dado por el nucleo que
ejecuta mas operaciones en el superstep. El costo de transferencia entre L1 y L2 esta dado
por el nucleo que transfirio mas bloques al nivel L1. De la misma manera, el costo en
transferencia del superstep de nivel 2 esta dado por la unidad L2 que transfirio mas
bloques desde la memoria principal. Suponemos que las escrituras a niveles superiores de
la jerarquıa de memoria no suelen ocasionar penalizaciones importantes en el rendimiento
en nuestro contexto, ya que suponemos que no implican invalidaciones debido al protocolo
de coherencia y suponemos que no limitan el ancho de banda con memoria ya que pueden
ocultarse con los correspondientes mecanismos de buffering de escrituras. No obstante, con
la ayuda de simulacion discreta, varios de estos supuestos se relajan mas adelante en este
capıtulo para obtener un modelo de procesador multi-core mas cercano a la realidad.
35

Ambos tipos de supersteps pueden solaparse o pueden actuar en forma consecutiva en
pares, es decir, hypersteps compuestos de un superstep de nivel 1 inmediatamente seguido
de uno de nivel 2. La manera especıfica dependera del modelo de costo que mas se ajuste
a la naturaleza de los algoritmos siendo analizados o simplemente del modelo que haga el
analisis matematicamente tratable.
El modelo descrito en la forma de los dos supersteps globales de nivel 1 y 2 simpli-
fica el analisis caso promedio presentado en la siguiente seccion. Esto contrasta con los
procesadores reales los cuales, si bien tienen relojes que sincronizan globalmente sus ins-
trucciones, presentan una alta asincronıa y solapamiento de actividades entre sus distintas
unidades. Sin embargo, desde la descripcion general de Multi-BSP presentada mas abajo,
se puede concluir que este problema se puede reducir permitiendo que cada componente
pueda operar de manera asincronica respecto de los otros componentes mediante la ejecu-
cion de sus propios supersteps locales. Por ejemplo, en la Figura 3.1 cada par (nucleo-L1,
L2) y (L2, Ram) puede ser considerado como un componente asincronico. Por otra parte,
si se acota la duracion de los supersteps a un valor lo suficientemente pequeno, donde
cada actividad que no alcanzo a ser realizada en el superstep actual es planificada para
el siguiente superstep, entonces el modelo se transforma en una discretizacion del sistema
contınuo donde los componentes del procesador y los threads ejecutados sobre los nucleos
aproximan un comportamiento asincronico.
3.2. Analisis Caso Promedio
Si suponemos un sistema que admite transacciones de solo lectura, entonces no es
necesario utilizar locks o barreras para sincronizar los threads. No obstante, es relevante
mencionar que las barreras de sincronizacion utilizadas en la estrategia BP son imple-
mentadas utilizando locks e instrucciones de espera condicional. El costo de estas ultimas
es similar al costo de los locks. En general, se deberıa esperar que la cantidad de locks
ejecutados por las estrategias asincronicas sea mayor que las estrategias sincronicas. Por
ejemplo, las estrategias RTLP y RBLP descritas en el capıtulo anterior ejecutan una can-
tidad de locks que es proporcional al largo de las listas invertidas por cada transaccion,
mientras que la estrategia BP solamente incurre en un costo similar a 2 p locks por cada
transaccion, donde p es el numero de threads. Mas aun, frente a una situacion de trafico
alto de transacciones, el costo de los 2 p locks por transaccion se puede amortizar proce-
sando lotes de p transacciones en cada superstep. Esto tiene la ventaja de que los calculos
36

de los resultados top-k globales para las transacciones de lectura, pueden ser realizados en
paralelo utilizando un thread distinto despues de la sincronizacion de barrera.
Para analizar el costo de las transacciones de solo lectura y sin locks, se puede pensar en
una estrategia sincronica y otra asincronica que se comparan bajo el contexto de resolver
un flujo grande de consultas que contienen un termino t cada una. El largo de la lista
invertida del termino t es nt y cada estrategia utiliza p threads para determinar los k
documentos mejor rankeados para la consulta. Se asume que el costo de calcular el valor
de relevancia de los documentos presentes en una lista invertida es proporcional al largo
de la lista invertida.
Los parametros Multi-BSP son g1, g2 para la tasa de transferencia de bloques de ca-
che/memoria, y ℓ0, ℓ1 y ℓ2 son las latencias de sincronizacion. Se supone que las estrategias
procesan transacciones utilizando tres supersteps que operan de manera asincronica entre
ellos. Los supersteps de tipo 0 realizan computo sobre datos locales almacenados en el
cache L1 del thread. El costo de este superstep es el costo incurrido por el thread que
realizo la maxima cantidad de trabajo en el superstep.
Los supersteps de tipo 1 se utilizan para las transferencias de bloques de datos entre los
caches L1 y L2, mientras que los supersteps de tipo 2 transfieren bloques de datos entre el
cache L2 y la memoria principal del procesador multi-core. El costo de ambos supersteps
esta dado por el componente que envio y/o recibio mas datos.
Los parametros αt y βt son estimaciones de la tasa promedio de aciertos (hits) que el
termino i tiene en los caches L1 y L2 respectivamente. Se supone que cada estrategia debe
incurrir en una latencia de software constante γ para establecer lo que sea necesario para
administrar el estado de las consultas siendo resueltas. Suponemos que las p nucleos estan
organizadas de manera que se tienen c nucleos por cada cache L2, y cada nucleo tiene su
propio cache L1 local.
Si se utiliza la estrategia BP entonces cada uno de los p threads trabaja en paralelo
resolviendo una sola consulta por vez. Cada thread calcula la relevancia de cada documento
en la lista invertida del termino t y los ordena para determinar los mejores k documentos
locales a un costo O( γ + nt/p + (nt/p) · log(nt/p) + ℓ0 ). No obstante, puesto que interesa
determinar los mejores k resultados locales, no es necesario ordenar puesto que el thread
puede mantener un heap de tamano O(k) donde va manteniendo los documentos mejor
rankeados. Por lo tanto, el costo en computacion puede ser mejorado a O( γ+nt/p+(nt/p)·
log k+ℓ0 ). Para ejecutar esa cantidad de trabajo fue necesario pagar en promedio un costo
O( (1−αt)·(nt/p)·c·g1+ℓ1 ) en transferencias de datos entre los caches L1 y L2. Tambien fue
37

necesario pagar O( (1−αt)·(1−βt)·(c·(nt/p))·(p/c)·g2+ℓ2 ) = O( (1−αt)·(1−βt)·nt·g2+ℓ2 )
para la transferencias entre el cache L2 y la memoria principal.
Luego de que cada thread ha determinado sus mejores k documentos locales, uno
de ellos se hace cargo de ordenar los k · p resultados para determinar los mejores k que
constituyen la respuesta a la consulta. Dado que cada uno de los p conjuntos de tamano
k ya estan ordenados, entonces se puede hacer un merge de los p conjuntos a un costo
O( k · p · log p ). Como las CPUs estan organizadas de manera que se tienen c nucleo por
cada cache L2, entonces el costo total en transferencias de datos hasta el cache L1 del
nucleo encargado de almacenar y ordenar los k · p resultados es O( (c + p) · k · g1 + ℓ1 +
(c · k) · ((p/c) − 1) · g2 + ℓ2 ), lo cual para c constante es O( p · k · (g1 + g2) + ℓ1 + ℓ2 ). Por
otra parte, no es necesario que todos los nucleos envıen k resultados, estos pueden hacer
algunas iteraciones enviando cada vez sus siguientes k/p mejores resultados. El peor caso
es hacer p iteraciones. Con gran probabilidad luego de unas pocas iteraciones se tendran
los k mejores a nivel global. Es decir, el costo de la ordenacion (merge) se puede reducir
a O( k · log p ), lo cual tiene un costo en caches de O( k · (g1 + g2) + ℓ1 + ℓ2 ).
Para poder comparar con la estrategia asincronica es necesario considerar un grupo de
p o mas consultas, puesto que en el caso asincronico se procesan p consultas en paralelo,
donde cada consulta se procesa secuencialmente. Para trafico alto de consultas, se supone
que en un superstep de la estrategia BP se pueden procesar p consultas al mismo tiempo.
Se define para cualquier termino el caso promedio como α = αt, β = βt, n = nt. Entonces
considerando que la determinacion de los k mejores documentos finales para cada consulta
se hace en paralelo debido a la sincronizacion oblivia, el costo total de procesar p consultas
en BP esta dado por
Costo computacion Sync → p · γ + n + n · log k + k · log p + ℓ0 +
Costo caches L1-L2 → (1 − α) · n · g1 + k · p · g1 + ℓ1+
Costo cache L2-Ram → (1 − α) · (1 − β) · n · p · g2 + k · p · g2 + ℓ2 .
Para el caso de la estrategia asincronica se puede seguir un razonamiento similar con
dos importantes diferencias. Primero, la transferencia de una lista de tamano nt se hace
completamente desde el camino que va desde la Ram hasta el nucleo asignado al thread
que va a procesador el termino t. No es necesario copiar p pedazos de tamano nt/p en
los p nucleos como en el caso de BP, pero ahora el tamano del dato a transferir es p
veces mas grande, es decir, ambos costos se compensan. Por ejemplo, para competir con
BP la estrategia asincronica debe copiar p listas de tamano promedio n en los caches L2,
38

colocando c listas en cada cache y por lo tanto desde el punto de vista del componente
Ram la comunicacion es equivalente a realizar una transferencia de costo O(n ·p ·g2 + ℓ2 ).
Segundo, los resultados finales para las p consultas resueltas en forma concurrente deben
quedar en Ram, lo cual implica que este componente recibe p conjuntos de tamano k a un
costo O(k · p · g2 + ℓ2). Luego el costo total de la estrategia asincronica esta dado por
Costo computacion Async → γ + n + n · log k + ℓ0 +
Costo caches L1-L2 → (1 − α) · n · g1 + k · g1 + ℓ1+
Costo cache L2-Ram → (1 − α) · (1 − β) · n · p · g2 + k · p · g2 + ℓ2 .
Los clusters actuales para maquinas de busqueda incluyen memorias principales de
tamanos muy grandes en sus nodos multi-core. Esto implica que las listas invertidas pueden
ser muy grandes haciendo que el costo O(n) de asignar puntajes a los documentos sea
dominante. El valor de k es constante y muy pequeno comparado con el n promedio, y lo
mismo ocurre con p. Es decir, en la practica ambas estrategias deberıan tener un costo
O( n + (1 − α) · n · g1 + (1 − α) · (1 − β) · n · p · g2 ). (3.1)
Solo casos muy especiales con listas invertidas pequenas y metodos de ranking de docu-
mentos que sean muy agresivos respecto de evitar recorrer las listas completas, escapan a
la tendencia del costo de la expresion 3.1. Por otra parte, de acuerdo a la tecnologıa actual
para procesadores multi-core, uno deberıa esperar g2 ≫ g1, y entonces resulta relevante
estudiar el comportamiento de α y β en ambas estrategias.
Para diferenciarlos, ambos parametros se denominan (αS , βS) y (αA, βA) para las
estrategias sincronica y asincronica respectivamente. Para el caso asincronico un thread
puede procesar una consulta conteniendo cualquier termino t. Si el termino es frecuente,
entonces podrıa en momentos distintos ser procesado por threads distintos. Estas copias
multiples de la lista invertida en los caches de dos threads distintos puede hacer que se
reemplacen entradas del cache que contienen listas de terminos que pueden ser utilizadas
por los threads en el futuro cercano. Esto significa que la estrategia asincronica tiende a
hacer un uso menos eficiente del espacio total disponible para cache considerando la suma
del espacio sobre los p nucleos. Una solucion es utilizar una regla tal como id termino
modulo total threads. Pero si hay terminos muy frecuentes existiran problemas de balance
de carga.
Por el contrario, la estrategia sincronica siempre almacena en un y solo un cache los
segmentos de listas invertidas que necesita para resolver las consultas. Esto conduce a un
39

uso optimo del espacio total de caches sin incurrir en problemas de balance de carga. Sin
embargo, en procesadores tales como el Intel utilizado en este trabajo de tesis, el tamano
del cache L1 es bastante mas pequeno que el cache L2. En varios casos las listas invertidas
de un termino son mas grandes que el tamano completo del cache L1. No ocurre lo mismo
respecto del tamano del cache L2. Entonces con gran probabilidad lo que ocurre es lo
siguiente
αS < αA
βS > βA
Lo cual a la vista de lo presentado en la expresion 3.1 resulta favorable para la estrategia
sincronica. En la siguiente seccion se valida esta afirmacion mediante simulaciones. El caso
αS < αA ocurre en situaciones bien fortuitas y la ventaja tiende a desaparecer cuando p
aumenta.
Por ejemplo, dada una secuencia de dos terminos muy frecuentes t1 y t2 donde t1 ocurre
en las consultas qa y qc, y el termino t2 ocurre en la consulta qb. Si estas consultas llegan
al nodo multi-core en el orden qa, qb y qc, y los terminos t1 y t2, por ser muy frecuentes
tienen, por tanto listas invertidas de tamanos n1 y n2 muy grandes respectivamente, tal
que n1/p y n2/p son valores mayores a la capacidad de cualquier cache L1.
Entonces, la estrategia sincronica procesa las tres consultas en el orden qa, qb y qc, lo
cual produce que en el momento de resolver qc ya no exista en ningun cache L1 segmentos
de la lista invertida del termino t1. En cambio, la estrategia asincronica puede acumular
de una sola vez una cantidad de hits equivalentes al tamano completo de un cache L1 si
uno de los threads procesa qa y qc, mientras que un segundo thread procesa qb.
Cuando los caches son lo suficientemente grandes, como en el caso de los caches L2
del procesador Intel, entonces es evidente que la estrategia sincronica no elimina todas las
entradas para el termino t1 y por lo tanto puede acumular hits en los p/c caches L2.
3.2.1. Multi-BSP descrito de manera general
Multi-BSP es una extension del modelo BSP. Presenta multiples niveles con parametros
explıcitos dependiendo del numero de procesadores, tamano de memoria/cache, costos de
comunicacion y sincronizacion. El nivel mas bajo corresponde a la memoria compartida o
PRAM. Ver Figura 3.2.
Un modelo Multi-BSP para profundidad d queda especificado por 4d parametros
numericos (p1, g1, ℓ1, m1), (p2, g2, ℓ2, m2), (p3, g3, ℓ3, m3), ..., (pd, gd, ℓd, md). El
40

Figura 3.2: Modelo Multi-BSP para 8 nucleos.
modelo es un arbol de profundidad d con memorias/caches en los nodos internos and pro-
cesadores en las hojas. En cada nivel los cuatro parametros cuantifican, respectivamente,
el numero de sub-componentes, el ancho de banda, el costo de sincronizacion y el tamano
de la memoria o cache. En el nivel i existe un conjunto de componentes especificados por
los parametros (pi, gi, ℓi, mi), cada uno conteniendo un numero de componentes de nivel
i − 1, donde:
(a) pi es el numero de componentes de nivel i − 1 dentro de un componente de nivel i.
Si i = 1, entonces p1 es el numero de procesadores o CPUs en el componente del
nivel mas bajo. Un paso computacional en el procesador sobre datos en el nivel 1 de
memoria es considerado como la unidad basica de tiempo de ejecucion.
(b) gi el parametro para el ancho de banda de la comunicacion, es el numero de ope-
raciones que el procesador puede ejecutar en un segundo, divido por el numero de
bytes que pueden ser transmitidos en un segundo entre el componente de nivel i y la
memoria del componente de nivel i+1 del cual es parte. Se asume que las memorias
de nivel 1 tienen una velocidad suficiente como para no introducir esperas en los
procesadores, es decir, g0= 1.
(c) Un superstep de nivel i dentro de un componente de nivel i, permite a cada uno de
sus pi componentes de nivel i − 1 ejecutar operaciones independientemente hasta
que cada uno alcanza una barrera de sincronizacion. Cuando los pi componentes
han alcanzado la barrera, cada uno de sus pi componentes de nivel i − 1 puede
intercambiar informacion con la memoria de tamano mi del componente de nivel i.
El siguiente superstep de nivel i puede comenzar luego de finalizar el intercambio
41

de datos. Un costo ℓi es asignado a la barrera de sincronizacion a cada superstep de
nivel i. Se asume L1= 0, puesto que los sub-componentes de un nivel 1 no tienen
memoria y pueden leer y escribir directamente en la memoria de nivel 1.
(d) mi es el numero de bytes de memoria y caches dentro de un componente de nivel i,
que no esta dentro de ningun componente de nivel i − 1.
Los parametros del modelo pueden ser determinados empıricamente mediante la ejecucion
de programas de benchmark en el procesador, o pueden ser estimados desde la especifica-
cion tecnica del procesador. Por ejemplo, para un procesador Niagara T1 que contiene p
nucleos, los parametros pueden ser los siguientes:
Nivel 1: 1 core tiene 1 procesador con 4 threads mas un cache L1:
(p1 = 4, g1 = 1, ℓ1 = 3, m1 = 8KB).
Nivel 2: 1 chip tiene 8 nucleos mas un cache L2:
(p2 = 8, g2 = 3, ℓ2= 23, m2 = 3MB).
Nivel 3: p multi-core chips con memoria externa m3 accesada vıa una red con tasa g2:
(p3 = p, g3 = ∞, ℓ3 = 108, m3 ≤ 128GB).
42

Capıtulo 4
Comparacion de Estrategias
4.1. Evaluacion utilizando un Servicio de Indice
En los experimentos que siguen se considera que siempre el conjunto de listas invertidas
requeridas para procesar una transaccion se encuentra disponible en el cache de listas.
Las evaluaciones realizadas no consideran el costo de administracion del cache. En una
experimentacion separada se evalua el rendimiento de la propuesta de cola de prioridad
para la administracion del cache de listas. La motivacion para separar ambos experimentos
es en primer lugar simplicidad y precision de los resultados, y en segundo lugar es el hecho
de que si la estrategia BP se comporta mejor que las alternativas asincronicas en el caso
de listas siempre residentes en memoria principal, entonces este mismo enfoque debe ser
aplicado a la administracion del cache.
Se asume que la tasa de llegada de transacciones es lo suficientemente alta como para
mantener ocupado a todos los threads. La metrica principal de interes es la tasa de salida
de transacciones, es decir, el throughput. Esto porque todas las estrategias son capaces de
resolver una transaccion en una fraccion de segundo.
Las listas invertidas fueron construidas desde una muestra de la Web de UK proporcio-
nada por Yahoo!. La Figura 4.1 muestra la distribucion del largo de las listas invertidas y la
distribucion de terminos en los documentos. Para las transacciones de lectura se utilizo un
log de consultas real que contiene busquedas de usuarios sobre dicha Web. El texto de los
documentos que participan en las transacciones de escritura fue tomado desde la misma
Web. La generacion del flujo de transacciones (traza) que llegan al nodo de busqueda se
43

0
5000
10000
15000
20000
0 100 200 300 400 500 600 700
Len
gth
of
inver
ted l
ists
per
ter
m
Terms
Web UK
0
1000
2000
3000
4000
5000
6000
0 100 200 300 400 500 600
Num
ber
of
term
s
Document IDs
Web UK
(a) (b)
Figura 4.1: (a) Largo de listas invertidas ordenadas de mayor a menor largo, y largosmostrados cada 50 listas (Web UK). (b) Distribucion de numero de terminos en los docu-mentos.
realiza mezclando de manera aleatoria las consultas de usuarios con documentos existentes
en la base de documentos.
La Figura 4.2 muestra la proporcion de terminos que figuran en el log de consultas y
que estan contenidos en alguno de los documentos de la base de documentos. En el eje
y se refleja la proporcion de terminos del log que estan en los documentos, y el eje x la
cantidad de documentos en unidades de diez mil. La figura indica que existe gran proba-
bilidad de conflictos de escrituras/lecturas con al menos un termino cuando se procesan
inserciones/actualizaciones de documentos en conjunto con las consultas de los usuarios.
Tambien se muestra la distribucion de la cantidad de terminos que tienen las consultas de
los usuarios.
La proporcion de nuevos documentos y consultas se controla por parte del generador
de trazas con el fin de poder disponer de un campo de exploracion lo suficientemente
extenso. Ademas el generador de trazas tambien permite elegir el grado de conflicto entre
consultas consecutivas, es decir la posibilidad de encontrar terminos identicos en busquedas
proximas. Esto se traduce en accesos simultaneos a las lista invertidas correspondientes.
Un grado de conflicto alto se traduce en que la mayorıa de las consultas poseen algun
termino comun con las 40 busquedas mas proximas. De igual modo un grado de conflicto
bajo conlleva la existencia de, como maximo, un 10 % de las busquedas con algun termino
en comun en las 40 consultas mas proximas.
44
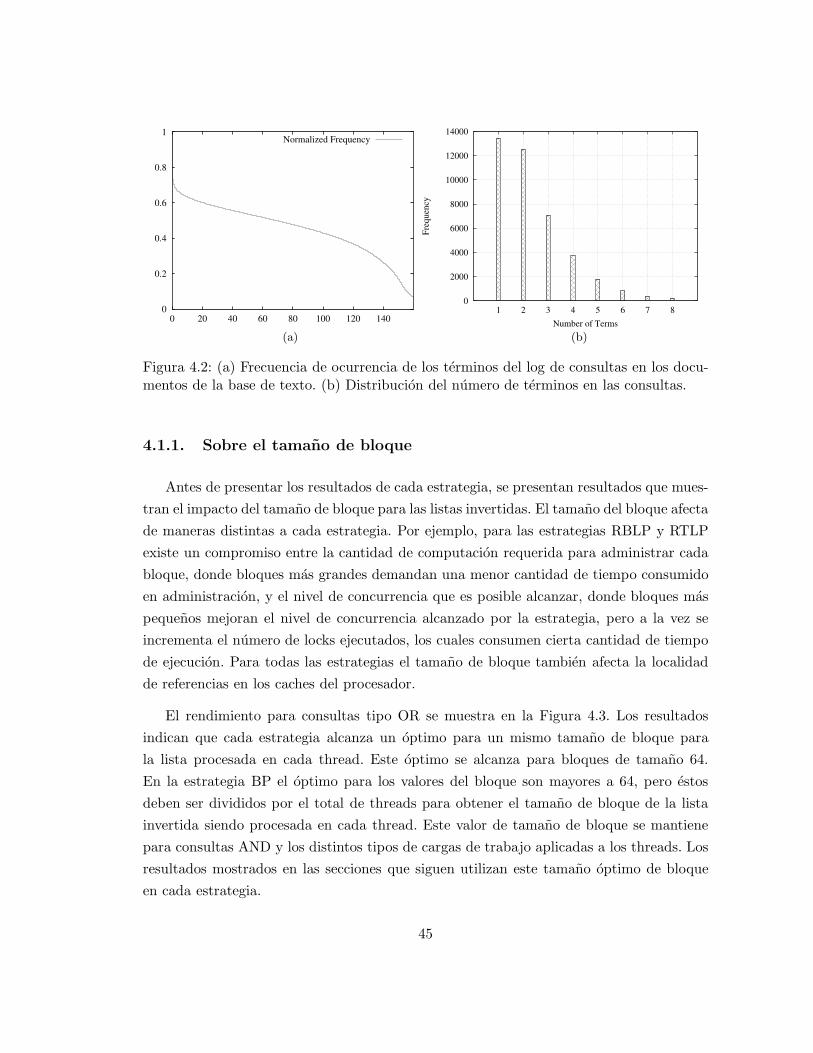
0
0.2
0.4
0.6
0.8
1
140120100806040200
Normalized Frequency
0
2000
4000
6000
8000
10000
12000
14000
1 2 3 4 5 6 7 8
Fre
quen
cy
Number of Terms
(a) (b)
Figura 4.2: (a) Frecuencia de ocurrencia de los terminos del log de consultas en los docu-mentos de la base de texto. (b) Distribucion del numero de terminos en las consultas.
4.1.1. Sobre el tamano de bloque
Antes de presentar los resultados de cada estrategia, se presentan resultados que mues-
tran el impacto del tamano de bloque para las listas invertidas. El tamano del bloque afecta
de maneras distintas a cada estrategia. Por ejemplo, para las estrategias RBLP y RTLP
existe un compromiso entre la cantidad de computacion requerida para administrar cada
bloque, donde bloques mas grandes demandan una menor cantidad de tiempo consumido
en administracion, y el nivel de concurrencia que es posible alcanzar, donde bloques mas
pequenos mejoran el nivel de concurrencia alcanzado por la estrategia, pero a la vez se
incrementa el numero de locks ejecutados, los cuales consumen cierta cantidad de tiempo
de ejecucion. Para todas las estrategias el tamano de bloque tambien afecta la localidad
de referencias en los caches del procesador.
El rendimiento para consultas tipo OR se muestra en la Figura 4.3. Los resultados
indican que cada estrategia alcanza un optimo para un mismo tamano de bloque para
la lista procesada en cada thread. Este optimo se alcanza para bloques de tamano 64.
En la estrategia BP el optimo para los valores del bloque son mayores a 64, pero estos
deben ser divididos por el total de threads para obtener el tamano de bloque de la lista
invertida siendo procesada en cada thread. Este valor de tamano de bloque se mantiene
para consultas AND y los distintos tipos de cargas de trabajo aplicadas a los threads. Los
resultados mostrados en las secciones que siguen utilizan este tamano optimo de bloque
en cada estrategia.
45

50
55
60
65
70
16 32 64 128 256 512 1024 2048
nQ
uer
ies/
sec
nThreds
CRBP
TLP1TLP2RTLPRBLP
110
115
120
125
130
135
140
16 32 64 128 256 512 1024 2048
nQ
uer
ies/
sec
nThreds
CRBP
TLP1TLP2RTLPRBLP
180
200
220
240
260
280
16 32 64 128 256 512 1024 2048
nQ
uer
ies/
sec
nThreds
CRBP
TLP1TLP2RTLPRBLP
250
300
350
400
450
500
550
16 32 64 128 256 512 1024 2048
nQ
uer
ies/
sec
nThreds
CRBP
TLP1TLP2RTLPRBLP
Figura 4.3: Throughput alcanzado por las diferentes estrategias con distinto tamano debloque.
4.1.2. Resultados
La Figura 4.4 muestra el rendimiento alcanzado cuando la carga de trabajo contiene
transacciones de lectura y escritura. Estos son los resultados para consultas de tipo OR
(disjunctive queries). Cada grupo de barras muestra las ejecuciones para 1, 2, 4 y 8 threads.
En cada grafico, la carga de trabajo tiene una proporcion distinta de transacciones de
lectura y escritura, manteniendo constante el numero de total de transacciones procesadas.
Puesto que la insercion o actualizacion de un documento toma un tiempo mucho menor
a la solucion de una consulta, a medida que aumenta el porcentaje de transacciones de
escrituras en la carga de trabajo, se reduce el tiempo total de ejecucion. Es decir, la tasa
de transacciones procesadas por segundo (throughput) aumenta. En promedio, el tiempo
de solucion de una transaccion esta por debajo de los 16 milisegundos.
46

0
100
200
300
400
500
600
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
100
200
300
400
500
600
700
800
900
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0% writers 10 % writers
0
200
400
600
800
1000
1200
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
200
400
600
800
1000
1200
1400
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
20% writers 30 % writers
Figura 4.4: Throughput (transacciones por segundo) alcanzado por las estrategias paradiferentes tasas de escritura y consultas OR, y un total de 40 mil transacciones.
Los resultados de la Figura 4.4 muestran dos aspectos relevantes para la estrategia
BP. Primero, la estrategia BP escala eficientemente con el numero de threads indepen-
dientemente de la proporcion de transacciones de escritura. BP supera a todas las demas
estrategias a medida que aumenta el numero de threads y para mas de dos threads la
aceleracion es super-lineal debido a la gran tasa de hits en el cache L2 que alcanza esta
estrategia. Solo RTLP y RBLP logran un rendimiento competitivo, pero a expensas de
la perdida de atomicidad y serialidad de las transacciones. Segundo, BP logra un ren-
dimiento bastante similar a la estrategia CR para el caso de solo lecturas (0 % writers).
Esto representa a los motores de busqueda convencionales que no actualizan sus ındices
de manera on-line y asignan un thread concurrente a cada consulta activa. Los resultados
47

indican que cualquiera de las estrategias pueden ser usadas en este caso, pero la ventaja
de utilizar BP es que el mismo enfoque de paralelizacion sincronica puede ser aplicado a la
administracion de los caches de top-K y listas, y por lo tanto se logra un mejor rendimiento
ya que en los caches ocurren operaciones de lectura y escritura en una proporcion de 50 %.
Las estrategias CR y TLP1 solamente alcanzan resultados satisfactorios para tasas
bajas de transacciones de escritura. TLP2 no tiene un buen rendimiento debido a que las
transacciones de lectura incluyen terminos que coinciden ocasionalmente. Estas coinciden-
cias causan demoras sustanciales en la ejecucion de los threads que comparten terminos.
Esto debido a que cuando un thread obtiene el lock de la lista compartida, no lo libera
hasta ejecutar la operacion de ranking de documentos sobre la lista completa. Luego los
threads que le suceden deben esperar por la liberacion del lock. Tambien, los terminos que
se repiten en las transacciones tienden a ser terminos populares que, por lo mismo, tienen
listas invertidas muy largas y el tiempo de ejecucion del ranking es proporcional al largo
de las listas. Esto introduce retardos que degradan el rendimiento significativamente.
Una tendencia similar se observa cuando la carga de trabajo incluye consultas AND
(conjunctive queries). Los resultados se muestran en la Figura 4.5. Para este caso el rendi-
miento de BP respecto de las otras estrategias es relativamente mejor que para el caso de
consultas OR. En general, el throughput alcanzado para consultas AND es muy superior
que el alcanzado para las consultas OR puesto que el ranking se hace sobre listas invertidas
mucho mas pequenas, es decir, las listas que resultan de realizar la interseccion entre las
listas de los terminos de cada consulta.
Los graficos de la Figura 4.6 muestran resultados para una carga de trabajo en la que
se aumenta significativamente el nivel de coincidencia entre terminos. Ver figuras 4.6.a y
4.6.b para consultas OR, y figuras 4.6.c y 4.6.d para consultas AND. Para consultas OR
los resultados muestran la misma tendencia a lo observado en los graficos de la Figura 4.4.
Para consultas AND, los resultados muestran que el rendimiento relativo de RBLP y RTLP
con respecto a BP, es relativamente mejor que el alcanzado en los graficos de la Figura 4.5.
En este caso el ranking opera sobre listas mucho mas pequenas y por lo tanto su costo es
mucho menor que en consultas OR, lo cual reduce los tiempos de espera por locks.
Los resultados mostrados a continuacion tienen que ver con tiempos promedio de
transacciones individuales para consultas OR. La Figura 4.7.a muestra el tiempo pro-
medio de respuesta para las transacciones, mientras que la Figura 4.7.b muestra el tiempo
de respuesta maximo observado cada 1000 transacciones procesadas utilizando 8 threads.
La estrategia BP logra el menor tiempo esperado en cada caso, especialmente en el tiempo
48
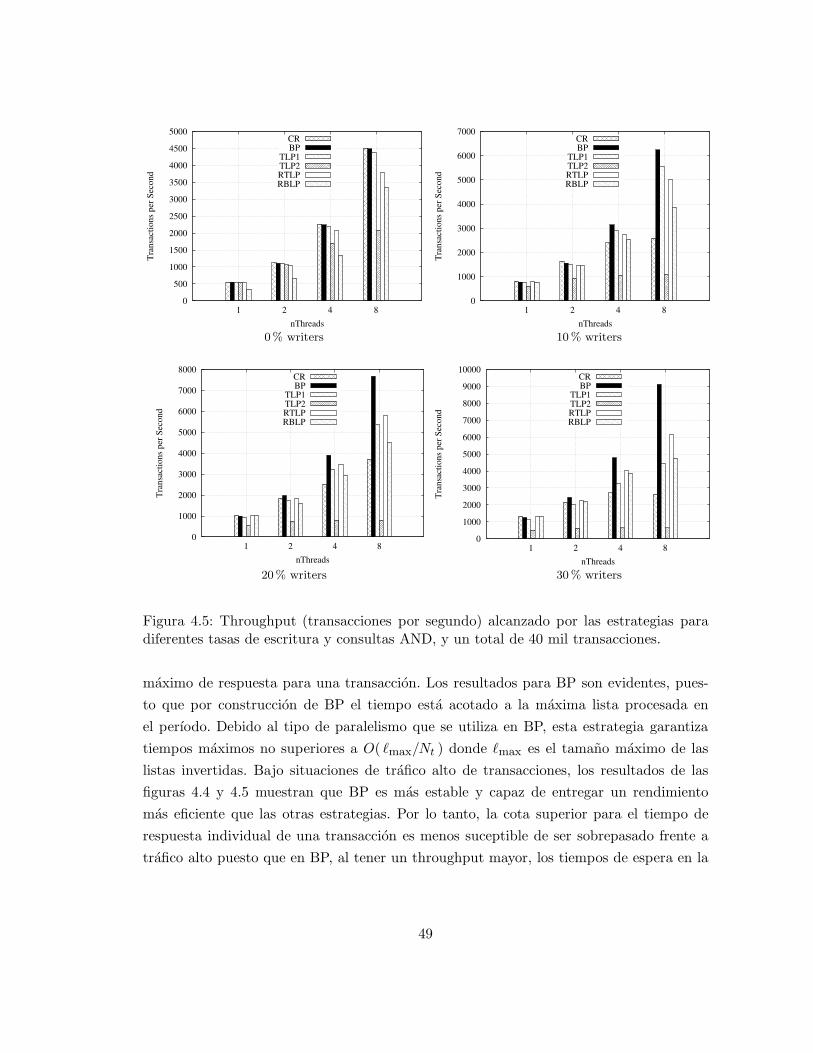
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
1000
2000
3000
4000
5000
6000
7000
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0% writers 10 % writers
0
1000
2000
3000
4000
5000
6000
7000
8000
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
20% writers 30 % writers
Figura 4.5: Throughput (transacciones por segundo) alcanzado por las estrategias paradiferentes tasas de escritura y consultas AND, y un total de 40 mil transacciones.
maximo de respuesta para una transaccion. Los resultados para BP son evidentes, pues-
to que por construccion de BP el tiempo esta acotado a la maxima lista procesada en
el perıodo. Debido al tipo de paralelismo que se utiliza en BP, esta estrategia garantiza
tiempos maximos no superiores a O( ℓmax/Nt ) donde ℓmax es el tamano maximo de las
listas invertidas. Bajo situaciones de trafico alto de transacciones, los resultados de las
figuras 4.4 y 4.5 muestran que BP es mas estable y capaz de entregar un rendimiento
mas eficiente que las otras estrategias. Por lo tanto, la cota superior para el tiempo de
respuesta individual de una transaccion es menos suceptible de ser sobrepasado frente a
trafico alto puesto que en BP, al tener un throughput mayor, los tiempos de espera en la
49

0
100
200
300
400
500
600
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
200
400
600
800
1000
1200
1400
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
(a) 0% writers, OR (b) 30% writers, OR
0
500
1000
1500
2000
2500
3000
3500
4000
4500
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
1000
2000
3000
4000
5000
6000
7000
1 2 4 8
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
(c) 0% writers, AND (d) 30% writers, AND
Figura 4.6: Throughput alcanzado por las estrategias para diferentes tasas de escrituray consultas OR y AND, y un total de 40 mil transacciones. Trazas con alto grado decoincidencia entre terminos de transacciones consecutivas.
cola de entrada de transacciones tienden a ser menores que en las otras estrategias con
throughput inferior.
4.2. Evaluacion utilizando un Servicio de Click-Through
Las maquinas de busqueda para la Web generalmente hacen un seguimiento de los clicks
realizados por los usuarios en las paginas web que contienen los resultados de busquedas.
Esto permite considerar las preferencias de usuarios anteriores en el proceso de ranking
de documentos para una consulta dada. La maquina de busqueda registra todos los clicks
50

0
0.002
0.004
0.006
0.008
0.01
0.012
0.014
0.016
0.018
1 2 4 8 1 2 4 8 1 2 4 8
Aver
age
tim
e per
com
ple
ted o
per
atio
n
Number of threads
0% writers 20% writers 40% writers
CRBP
TLP1TLP2RTLPRBLP
(a) Tiempo medio de respuesta por transaccion.
0
0.05
0.1
0.15
0.2
0.25
1 2 3 4 1 2 3 4
Max
imu
m t
ime
per
co
mp
lete
d o
per
atio
n
Batches of query/index operations
0% writers 40% writers
CRBP
TLP1TLP2RTLPRBLP
(b) Maximo tiempo de respuesta por transaccionpara lotes de 1,000 transacciones y 8 threads.
Figura 4.7: Tiempo en segundos para transacciones de lectura/escritura.
de los usuarios sobre los URLs presentados en las respuestas a sus consultas. Por cada
consulta resuelta y respondida por la maquina de busqueda, en algun momento retornan
a la maquina de busqueda los URLs visitados por el respectivo usuario.
Actualmente las optimizaciones al proceso de ranking de documentos que consideran
las preferencias de usuarios anteriores, provienen de calculos realizados de manera off-line
sobre grandes conjuntos de consultas y sus respectivos user clicks. Esto significa que los
efectos de clicks anteriores a ser incluidos en el proceso de ranking de documentos, solo
se ven reflejados a intervalos de horas o incluso dıas. Una solucion es permitir la inclusion
de user-clicks de manera on-line y mantener un servicio que permita, por cada consulta
51

que llega a la maquina de busqueda principal, recepcionar una copia de cada consulta y
realizar en tiempo real el calculo de un puntaje para los documentos mas visitados por
usuarios que realizaron consultas similares en el pasado muy reciente.
Basicamente el problema consiste en tener un ranking eficiente de las URLs clickeadas
por usuarios anteriores que solicitaron informacion similar a la maquina de busqueda. Para
ello, los clicks deben ser indexados de manera concurrente con el ranking, y los conflictos
de concurrencia surgen por las continuas actualizaciones del ındice y las operaciones ne-
cesarias determinar las consultas similares y realizar el ranking de URLs. Las consultas
son “similares” si se encuentran correlacionadas de alguna manera, para este calculo se
consideran los URL seleccionados y los respectivos terminos de las consultas. El calculo
de las probabilidades consulta-consulta, consulta-URL y URL-URL puede ser exigente en
tiempo ejecucion y espacio de memoria.
El servicio de click-through fue implementado utilizando un ındice invertido que con-
tiene una tabla con los terminos que aparecen en las consultas, y por cada termino los
URLs seleccionados por los usuarios junto con informacion de la cantidad de clicks hechos
sobre el URL. Por otra parte, como se muestra en la Figura 4.8, se utiliza un ındice adicio-
nal de modo que a partir de un conjunto de URLs se pueda llegar a nuevos terminos. Una
operacion basica es comenzar con los terminos de la consulta recibida por el servicio para
llegar hasta el conjunto de URLs relacionados con esos terminos, y a partir de esos URLs
llegar a mas terminos y URLs. Luego de reunir una cantidad lo suficientemente grande
URLs se aplica una rutina de ranking de URLs para responder con los top-K a la maquina
de busqueda.
4.2.1. Diseno de los experimentos
Los resultados mostrados a continuacion estan representados en terminos de la ace-
leracion, la cual se define como la razon A/B, donde A es el menor tiempo de ejecucion
obtenido por cualquiera de las estrategias utilizando un thread, y B es el tiempo de eje-
cucion obtenido por la estrategia utilizando dos o mas threads. Los experimentos fueron
realizados evaluando dos escenarios para las transacciones que arriban a la cola de entrada
del nodo multi-core:
Workload A – Trafico de transacciones alto pero concurrencia limitada –. Es el
escenario mas adverso que se ha evaluado puesto que existe una alta probabilidad de
que las consultas posteriores (en la secuencia de llegada de transacciones al nodo) a
52

Figura 4.8: Estructuras de datos y secuencia de operaciones. La secuencia (1), (2) y (3)indica que a partir de un termino dado (1) es posible llegar a un nuevo termino (2), quea su vez conduce a un nuevo conjunto de URLs (3), los cuales se incluiran en el procesode ranking. Para cada ıtem (URL, freq) del ındice invertido, esta secuencia se repite paracada elemento de la lista del segundo ındice.
una consulta dada sean muy similares, conteniendo muchos terminos en comun. Por
ejemplo, esto emula una situacion en que repentinamente un cierto evento o tema
capta la atencion de muchos usuarios de la maquina de busqueda. En este caso, las
operaciones de ranking de URLs y actualizacion de los ındices tienden a coincidir
muy frecuentemente sobre el mismo subconjunto de terminos.
Workload B – Alto trafico, alta concurrencia –. Este caso es lo opuesto en el sentido
que la probabilidad de terminos en comun entre transacciones es menor, es la normal
observada en el log de consultas AOL que se utilizo en la experimentacion, y por lo
tanto la competencia por las mismas secciones de los ındices es mucho menor que
en Workload A. Dado que existe una menor correlacion entre consultas posteriores,
existe un nivel de concurrencia mayor.
53

Las transacciones de actualizacion de los ındices contienen documentos escogidos al azar
desde los resultados top-K de cada consulta del log de AOL. Las respuestas a las consultas
fueron calculados utilizando ranking vectorial sobre las listas invertidas construidas desde
la muestra de la Web de UK. Para estas transacciones de escritura, lo que recibe el nodo
multi-core desde el exterior son los terminos de la consulta y los URLs que selecciono el
usuario que originalmente envıo la consulta a la maquina de busqueda. Si los URLs son
nuevos, es decir, no existen en el ındice entonces se trata de una operacion de insercion
en las listas invertidas respectivas. Si son URLs que ya existen en el ındice, entonces es
una operacion de actualizacion que modifica la frecuencia de clicks sobre el URL para los
terminos de la consulta. La cantidad de URLs, y los URLs especıficos, son valores definidos
aleatoriamente con distribucion uniforme. Evidentemente esto no representa exactamente
las preferencias de los usuarios frente a la pagina de resultados, pero para el proposito de
la experimentacion que concierne a este trabajo dicho supuesto es suficiente para evaluar
el rendimiento de las estrategias de control de concurrencia. Los experimentos consideran
casos en que el respectivo usuario selecciona uno o varios URLs.
Las transacciones de lectura son consultas del log de AOL y para simular el grado de
colisiones de terminos en las transacciones, se asume que una consulta resuelta por el nodo
multi-core en el instante t1, retorna al nodo como una transaccion de escritura (compuesta
de la misma consulta y los URLs seleccionados por el usuario) en el instante t2 > t1 luego
de haber procesado una cierta cantidad de otras transacciones.
4.2.2. Resultados
La Figura 4.9 muestra la escalabilidad de las diferentes estrategias utilizando el caso
workload B con seleccion de un URL para las transacciones de escritura y cinco URLs.
Los resultados muestran que BP es la estrategia que escala mejor que las otras estrategias
para ambos casos.
Algo similar se observa en la Figura 4.10, la cual muestra resultados para las dos cargas
de trabajo ejecutadas utilizando 8 threads y variando la cantidad de URLs que contienen
las transacciones de escritura. Ambas cargas de trabajo tienen la caracterıstica de que el
peso del proceso de ranking de URLs es mucho menor que en el caso de estudio anterior
sobre el servicio de ındice. Esto porque las listas invertidas que se forman con los URLs
tienen tamano mucho menores a las utilizadas por el servicio de ındice.
54

0
50
100
150
200
250
300
1 2 4 8
Thro
ughput
nThreads
1 click
CRBP
TLP1TLP2RTLPRBLP
0
100
200
300
400
500
600
700
1 2 4 8
Thro
ughput
nThreads
5 clicks
CRBP
TLP1TLP2RTLPRBLP
Figura 4.9: Escalabilidad de las diferentes estrategias para Workload B y suponiendo quelos usuarios hacen un click (grafico izquierdo) en un enlace en cada busqueda o hacen clicksen 5 enlaces (grafico derecho), los cuales se transforman en 5 transacciones de escritura.
Los resultados de la Figura 4.10 muestran que el rendimiento de las estrategias, con
excepcion de TLP2, son relativamente independientes del nivel de la carga de trabajo. La
explicacion es que si bien workload A posee mayor nivel de conflicto, en todo momento
existen tantas transacciones como threads en ejecucion y por lo tanto la probabilidad de
coincidencia de terminos esta acotada.
Finalmente, en la Figura 4.11 se muestran los tiempos promedio de ejecucion individual
por consultas e insercion/actualizacion. Distinto al caso de la Figura 4.7, para calcular los
tiempos de respuesta de transacciones individuales se ha medido directamente el intervalo
de tiempo que transcurre entre el inicio y el final del procesamiento de la transaccion.
El grafico de la Figura 4.11.a muestra que el tiempo promedio de las transacciones que
tienden a ser similares entre sı. Para 5 clicks los tiempos son menores, lo cual indica que las
operaciones de insercion/actualizacion son mas rapidas que las consultas sobre los ındices.
A excepcion de la estrategia BP, todas las estrategias asignan un threads para procesar de
forma secuencial la consulta y/o insercion/actualizacion. Sin embargo, BP tiene la carga de
la barrera de sincronizacion de threads con el fin de comenzar con la siguiente operacion,
y los resultados muestran que este costo es significativo. Por otra parte, los puntos de
la Figura 4.11.b muestran claramente que todas las estrategias tienden a consumir una
cantidad significativa de tiempo para algunas operaciones, lo cual indica que de vez en
cuando, se produce un retraso debido a la contencion de locks de los threads activos.
La estrategia BP no sufre este problema, sencillamente, procesa las operaciones de una
a la vez y, si bien usa locks para implementar la barrera de sincronizacion oblivious, los
55

0
200
400
600
800
1000
1200
1 2 3 5 10
Thro
ughput
Clicks
CRBP
TLP1TLP2RTLPRBLP
0
200
400
600
800
1000
1200
1 2 3 5 10
Thro
ughput
Clicks
CRBP
TLP1TLP2RTLPRBLP
Figura 4.10: Escalabilidad de las diferentes estrategias para Workload A (grafico izquierdo)y Workload B (grafico derecho) para 8 threads y varios clicks indicados en el eje x.
threads no deben competir entre sı para adquirir locks al final de cada operacion. Esto
explica mejor el rendimiento de BP con respecto a la metrica de resultados en este caso,
es decir, rendimiento de las operaciones consultas/insercion/actualizacion.
4.2.2.1. Experimentos con mas threads
Para complementar los resultados mostrados en la Figura 4.4 obtenidos con el proce-
sador Intel Xeon Quad-Core, en la Figura 4.12 se muestran resultados para un procesador
de tecnologıa reciente, Intel i7, el cual contiene tres niveles de cache y cuyo rendimiento
es superior. Este procesador permite el uso de hasta 24 threads de manera eficiente. Los
resultados muestran que las diferencias relativas en rendimiento de las distintas estrategias
son similares a lo presentado en la Figura 4.4. Para transacciones de solo lectura todas las
estrategias alcanzan un rendimiento muy similar.
4.2.3. Resultados considerando roll-backs
En la Figura 4.13 se muestran resultados para el throughput alcanzado por la estrategia
optimista utilizando un simulador por eventos discretos del procesador Intel, consideran-
do hasta 128 threads con cada thread siendo asignado a un nucleo distinto. En el rango
entre 1 y 8 threads, los resultados muestran una tendencia en rendimiento bastante si-
milar a lo observado para las implementaciones reales de las estrategias. Para mas de 8
56
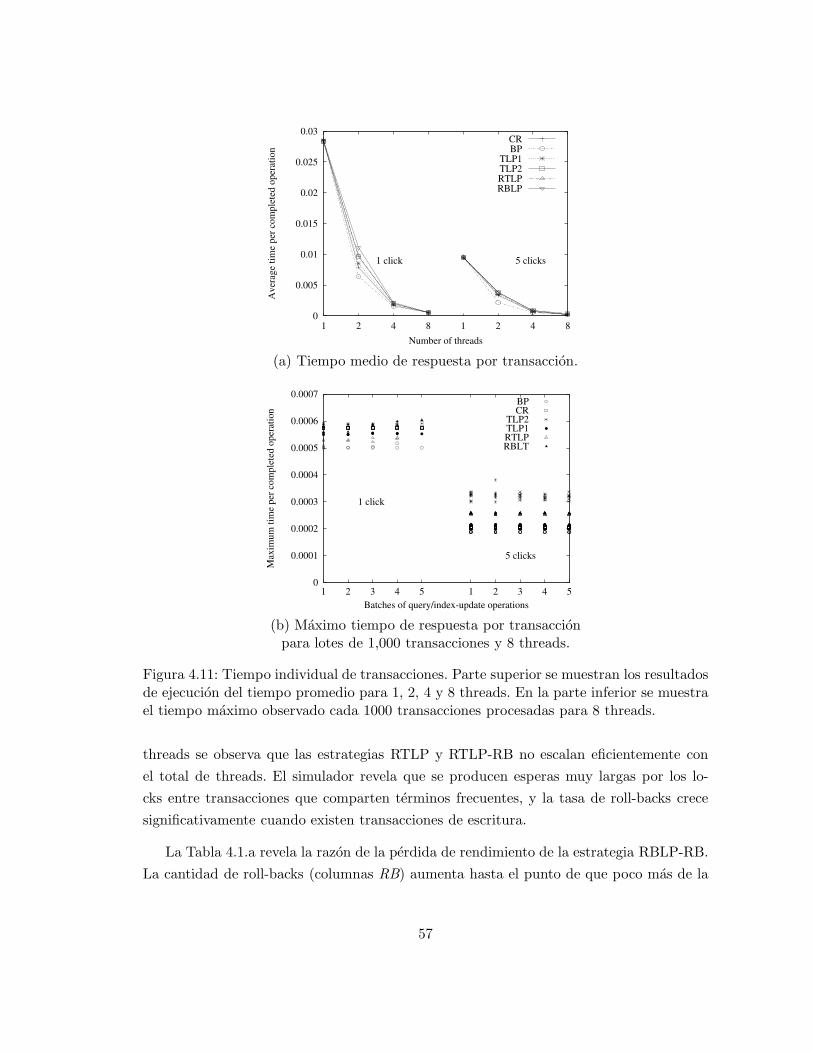
0
0.005
0.01
0.015
0.02
0.025
0.03
1 2 4 8 1 2 4 8
Av
erag
e ti
me
per
co
mp
lete
d o
per
atio
n
Number of threads
1 click 5 clicks
CRBP
TLP1TLP2RTLPRBLP
(a) Tiempo medio de respuesta por transaccion.
0
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
1 2 3 4 5 1 2 3 4 5
Max
imu
m t
ime
per
co
mp
lete
d o
per
atio
n
Batches of query/index-update operations
1 click
5 clicks
BPCR
TLP2TLP1RTLPRBLT
(b) Maximo tiempo de respuesta por transaccionpara lotes de 1,000 transacciones y 8 threads.
Figura 4.11: Tiempo individual de transacciones. Parte superior se muestran los resultadosde ejecucion del tiempo promedio para 1, 2, 4 y 8 threads. En la parte inferior se muestrael tiempo maximo observado cada 1000 transacciones procesadas para 8 threads.
threads se observa que las estrategias RTLP y RTLP-RB no escalan eficientemente con
el total de threads. El simulador revela que se producen esperas muy largas por los lo-
cks entre transacciones que comparten terminos frecuentes, y la tasa de roll-backs crece
significativamente cuando existen transacciones de escritura.
La Tabla 4.1.a revela la razon de la perdida de rendimiento de la estrategia RBLP-RB.
La cantidad de roll-backs (columnas RB) aumenta hasta el punto de que poco mas de la
57

0
500
1000
1500
2000
4 6 8 12 16 24
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
0
500
1000
1500
2000
2500
3000
4 6 8 12 16 24
Tra
nsa
ctio
ns
per
Sec
ond
nThreads
CRBP
TLP1TLP2RTLPRBLP
10% writers 40 % writers
Figura 4.12: Throughput alcanzado por las estrategias para diferentes tasas de escrituray consultas OR, y un total de 40 mil transacciones en un procesador Intel i7.
20% 40%NT RB LB RB LB2 0.04 1 0.06 0.954 0.10 0.95 0.13 0.988 0.18 0.95 0.21 0.8916 0.26 0.92 0.31 0.8732 0.33 0.82 0.42 0.7864 0.41 0.70 0.51 0.69128 0.46 0.56 0.57 0.41
0% 40%NT Pw LB Pw LB2 0 1 0 14 0.01 0.99 0.01 18 0.02 0.99 0.03 116 0.04 0.97 0.09 132 0.06 0.94 0.14 0.9964 0.10 0.88 0.17 0.97128 0.21 0.84 0.37 0.90
(a) 20 % and 40% writers (RTLP-RB) (b) 0% and 40% writers (RTLP)
Tabla 4.1: Razones de la perdida de rendimiento de las estrategias RTLP-RB y RTLP.
mitad de las transacciones deben ser re-ejecutadas. La tabla tambien muestra el efecto que
dichos roll-backs tienen en el balance de carga (columnas LB) de las computaciones ejecu-
tadas por los nucleos. El balance de carga se mide considerando la cantidad computacion
realizada por los threads en los nucleos. Para esto se calcula el promedio de computacion
observado en los threads dividido por el maximo observado en cualquiera de los threads.
Los valores de la Tabla 4.1.a muestran el balance de carga promedio para intervalos gran-
des de tiempo de simulacion. Los resultados muestran que el balance de carga se degrada
significativamente a causa de los roll-backs, donde el balance optimo se alcanza en 1 y el
desbalance extremo para valores cercanos a 0.
58

0
100
200
300
400
500
600
1 2 4 8
Thro
ughput
nThreads
BPRTLP
RTLP-RB
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
16 32 64 128
Thro
ughput
nThreads
BPRTLP
RTLP-RB
0% writers, 1 to 8 threads 0% writers, 16 to 128 threads
0
200
400
600
800
1000
1200
1400
1600
1800
2000
1 2 4 8
Thro
ughput
nThreads
BPRTLP
RTLP-RB
0
5000
10000
15000
20000
25000
30000
35000
16 32 64 128
Thro
ughput
nThreads
BPRTLP
RTLP-RB
40% writers, 1 to 8 threads 40% writers, 16 to 128 threads
Figura 4.13: Throughputs que el modelo de simulacion predice para las estrategias BP,RTLP y RTLP con Rollbacks (RTLP-RB), en el procesador Intel.
La Tabla 4.1.b muestra resultados que explican la perdida de rendimiento de la es-
trategia RTLP cuando aumenta considerablemente el total de threads que participan en
la solucion de las transacciones. Existe una probabilidad no despreciable de que para
cualquier transaccion un thread dado tenga que esperar por un lock. Esta probabilidad
aumenta con el numero de threads (columnas Pw ). Esto hace que se pierda gradualmente
el balance de carga (columnas LB).
4.2.4. Mas resultados utilizando un simulador por eventos discretos
La Figura 4.14 muestra las variaciones en el tiempo de respuesta de transacciones in-
dividuales al final de periodos dados por el procesamiento de un lote de transacciones. Los
59

0
0.1
0.2
0.3
0.4
0.5
1 2 3 4 5 1 2 3 4 5
Tim
e per
tra
nsa
ctio
n
Batches of query/index-update operations
BP RTLP
0
0.1
0.2
0.3
0.4
0.5
1 2 3 4 5 1 2 3 4 5
Tim
e per
tra
nsa
ctio
n
Batches of query/index-update operations
BP RTLP
0 % writers 40% writers
Figura 4.14: Tiempos de respuesta de transacciones recolectados a intervalos regulares deltiempo de simulacion para 8 threads.
resultados muestran que BP mantiene tiempos bajos de respuesta y que RTLP ocasional-
mente supera el tiempo de procesamiento secuencial de la transaccion debido a esperas
por la asignacion de locks.
La Tabla 4.2 verifica las conclusiones del analisis del caso promedio (Seccion 3.2). La
tasa de hits L1 de la estrategia RTLP es mucho mejor que los hits L1 alcanzados por
la estrategia BP. No obstante, la tasa de hits en los caches L2 que alcanza BP es muy
superior a la tasa de hits que alcanza la estrategia RTLP, y al menos en el procesador
Intel las transferencias de datos desde memoria principal al cache L2 toman mas tiempo
en concretarse que las transferencias entre L1 y L2. Tambien debido a que los segmentos
de listas invertidas en la estrategia RTLP tienden a estar replicados en varios caches L2, el
total de invalidaciones de entradas de cache tiende a ser mayor en RTLP que en BP para
un numero grande de threads. En las simulaciones con 40 % de escrituras se observo la
secuencia (NT, VRTLP /VBP )= (16, 1.14), (32, 1.26), (64, 1.34) y (128, 1.40), donde VRTLP
y VBP indican el total de entradas de invalidadas en los cache L1 y L2 para las estrategias
RTLP y BP respectivamente.
El efecto del mejor uso de la localidad en la arquitectura del procesador simulado que
realiza la estrategia BP se puede observar en la Figura 4.15. En este caso se simula una
situacion de granularidad muy fina reduciendo el costo del proceso de ranking de docu-
mentos a un valor 100 veces menor. Los resultados muestran que en este caso la estrategia
RTLP no escala eficientemente mas alla de 8 threads. En todos los casos la estrategia BP
60
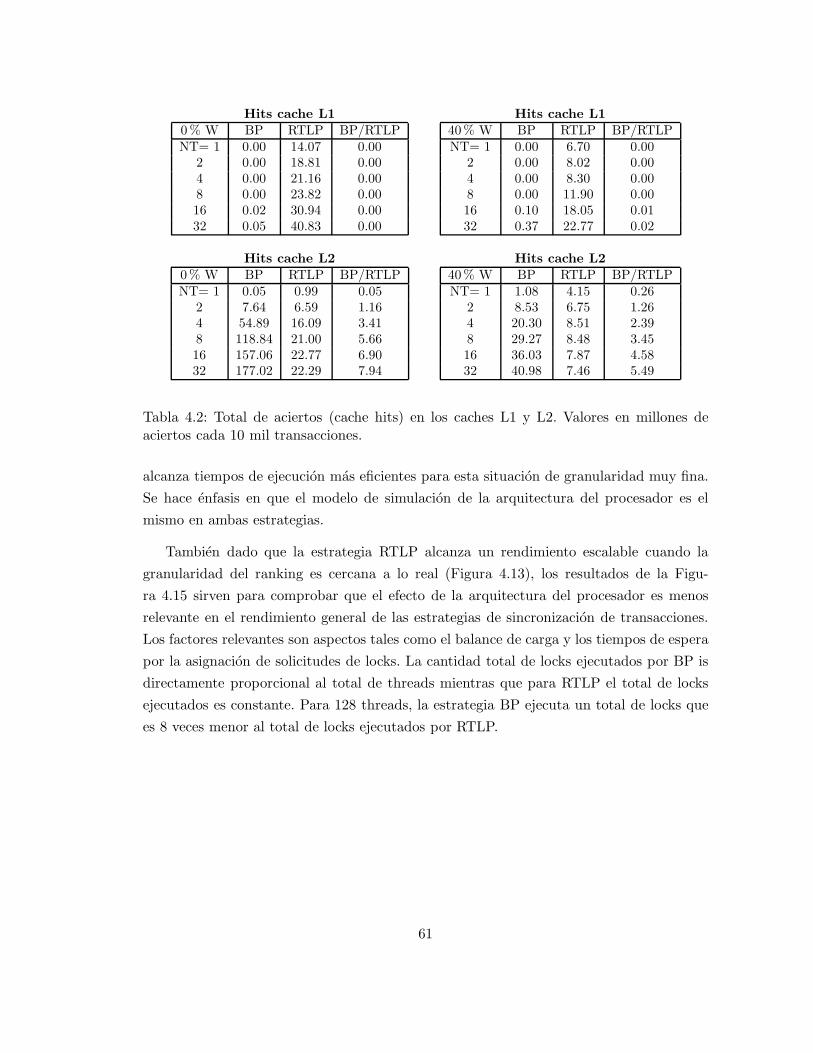
Hits cache L10 % W BP RTLP BP/RTLPNT= 1 0.00 14.07 0.00
2 0.00 18.81 0.004 0.00 21.16 0.008 0.00 23.82 0.0016 0.02 30.94 0.0032 0.05 40.83 0.00
Hits cache L140% W BP RTLP BP/RTLPNT= 1 0.00 6.70 0.00
2 0.00 8.02 0.004 0.00 8.30 0.008 0.00 11.90 0.0016 0.10 18.05 0.0132 0.37 22.77 0.02
Hits cache L20% W BP RTLP BP/RTLPNT= 1 0.05 0.99 0.05
2 7.64 6.59 1.164 54.89 16.09 3.418 118.84 21.00 5.6616 157.06 22.77 6.9032 177.02 22.29 7.94
Hits cache L240% W BP RTLP BP/RTLPNT= 1 1.08 4.15 0.26
2 8.53 6.75 1.264 20.30 8.51 2.398 29.27 8.48 3.4516 36.03 7.87 4.5832 40.98 7.46 5.49
Tabla 4.2: Total de aciertos (cache hits) en los caches L1 y L2. Valores en millones deaciertos cada 10 mil transacciones.
alcanza tiempos de ejecucion mas eficientes para esta situacion de granularidad muy fina.
Se hace enfasis en que el modelo de simulacion de la arquitectura del procesador es el
mismo en ambas estrategias.
Tambien dado que la estrategia RTLP alcanza un rendimiento escalable cuando la
granularidad del ranking es cercana a lo real (Figura 4.13), los resultados de la Figu-
ra 4.15 sirven para comprobar que el efecto de la arquitectura del procesador es menos
relevante en el rendimiento general de las estrategias de sincronizacion de transacciones.
Los factores relevantes son aspectos tales como el balance de carga y los tiempos de espera
por la asignacion de solicitudes de locks. La cantidad total de locks ejecutados por BP is
directamente proporcional al total de threads mientras que para RTLP el total de locks
ejecutados es constante. Para 128 threads, la estrategia BP ejecuta un total de locks que
es 8 veces menor al total de locks ejecutados por RTLP.
61

0
0.2
0.4
0.6
0.8
1
2 4 8 16 32 64 128
No
rmal
ized
ru
nn
ing
tim
e
Number of threads
BP 40% WRTLP 40% W
BP 20% WRTLP 20% W
BP 100% RRTLP 100% R
Figura 4.15: Tiempos totales de ejecucion normalizados a 1 para un caso en que se simulagranularidad fina haciendo que el costo del ranking de documentos sea 100 veces menor.
62