aprendizaje profundo en dispositivo portable para el reconocimiento de frutas y verduras · 2019....
TRANSCRIPT

APRENDIZAJE PROFUNDO EN DISPOSITIVO PORTABLE PARA EL RECONOCIMIENTO DE FRUTAS Y VERDURAS
RICARDO MUÑOZ BOCANEGRA 213971
UNIVERSIDAD AUTÓNOMA DE OCCIDENTE FACULTAD DE INGENIERÍA
DEPARTAMENTO DE AUTOMÁTICA Y ELECTRÓNICA INGENIERÍA MECATRÓNICA
SANTIAGO DE CALI 2019

APRENDIZAJE PROFUNDO EN DISPOSITIVO PORTABLE PARA EL RECONOCIMIENTO DE FRUTAS Y VERDURAS
RICARDO MUÑOZ BOCANEGRA
PROYECTO DE GRADO para optar al título de INGENIERO MECATRÓNICO
DIRECTOR JESÚS ALFONSO LÓPEZ SOTELO
Doctor en ingeniería
UNIVERSIDAD AUTÓNOMA DE OCCIDENTE FACULTAD DE INGENIERÍA
DEPARTAMENTO DE AUTOMÁTICA Y ELECTRÓNICA INGENIERÍA MECATRÓNICA
SANTIAGO DE CALI 2019

3
Nota de aceptación:
Aprobado por el Comité de Grado en cumplimiento de los requisitos exigidos por la Universidad Autónoma de Occidente para optar al título de Ingeniero Mecatrónico.
Juan Carlos Perafán
_______________________________
Jurado
Víctor Romero Cano
______________________________
Jurado
Santiago de Cali, 23 de mayo de 2019

4
CONTENIDO
pág.
RESUMEN 11
INTRODUCCIÓN 12
1. PLANTEAMIENTO DEL PROBLEMA 14
2. JUSTIFICACIÓN 15
3. ANTECEDENTES 16
4. OBJETIVOS 19
4.1 OBJETIVO GENERAL 19
4.2 OBJETIVOS ESPECÍFICOS 19
5. MARCO TEÓRICO 20
6. METODOLOGÍA 33
6.1 CONSTRUCCIÓN DEL DATASET 33
6.1.1 Recolección de imágenes 33
6.1.2 Procesamiento y aumento de datos 36
6.2 ENTRENAMIENTO DE LA RED 38
6.2.1 Clasificador de juguetes 38
6.2.2 Clasificador de frutas y verduras 40
6.3 MIGRACIÓN A SISTEMA EMBEBIDO 44
6.4 CONSTRUCCIÓN DE LA APLICACIÓN MÓVIL 46
7. RESULTADOS Y DISCUSIÓN 55

5
8. CONCLUSIONES 65
9. RECOMENDACIONES Y TRABAJO FUTURO 67
68 REFERENCIAS
ANEXOS 74

6
LISTA DE FIGURAS
pág.
Figura 1. Captura de LeafSnap. 16
Figura 2. Seeing AI. 17
Figura 3. Perceptrón simple. 20
Figura 4. Red neuronal artificial. 21
Figura 5. Representación de características en red neuronal convolucional. 22
Figura 6. Convolución 2D. 23
Figura 7. Arquitectura típica de red convolucional. 24
Figura 8. Gráfica de entropía cruzada. 28
Figura 9. Validación cruzada. El bloque oscuro es utilizado para validación. 28
Figura 10. Arquitectura de CPU y GPU. 29
Figura 11. Sistemas embebidos. 31
Figura 12. Diagrama de funcionamiento de protocolo TCP/IP. 32
Figura 13. Cámara Intel Realsense SR300. 33
Figura 14. Proceso de corrección de efecto ojo de pez y alineamiento de imágenes. 34
Figura 15. Estructura construida. 35
Figura 16. Escalamiento. 36
Figura 17. Adición de fondo. 37
Figura 18. Variación de brillo. 37
Figura 19. Rotación y padding. 38
Figura 20. Juguetes usados para hacer pruebas. 40
Figura 21. Algunas frutas y verduras usadas. 42

7
Figura 22.Inferencia en computador. 43
Figura 23. Raspberry Pi con módulo de cámara. 44
Figura 24. Kit de desarrollo Jetson TX2. 45
Figura 25. Inferencia en funcionamiento en el kit de desarrollo Jetson TX2. 46
Figura 26. Diagrama de flujo para elaborar aplicación móvil. 47
Figura 27. Funcionamiento de aplicación móvil. 48
Figura 28. Diagrama de flujo de búsqueda en aplicación móvil. 49
Figura 29. Diagrama de caja transparente de la aplicación móvil. 50
Figura 30. Inspección de tabla en USDA food composition database. 51
Figura 31. Resultado de búsqueda de berenjena en Wikipedia. 52
Figura 32. Resultado de búsqueda de berenjena en fruitsandveggiesmatters.org. 54
Figura 33. Métricas de rendimiento durante entrenamiento de modelos. 55
Figura 34. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 160 x 160 de tamaño de imágenes de entrada. 57
Figura 35. Comparación de clases, nabo (izquierda) y raíz de remolacha (derecha). 58
Figura 36. Comparación de clases, calabaza alargada (izquierda) y nabo (derecha). 59
Figura 37. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 224 x 224 de tamaño de imágenes de entrada. 59
Figura 38. Diagrama de cajas para tiempos de evaluación en computador personal hp-14d043la de los modelos de Mobilenet entrenados. 62
Figura 39. Diagrama de cajas para tiempos de evaluación en Raspberry pi 3 b+ de los modelos de Mobilenet entrenados. 62

8
Figura 40. Diagrama de cajas para tiempos de evaluación en Tarjeta Jetson TX2 (CUDA V8) de los modelos de Mobilenet entrenados. 63
Figura 41. Diagrama de cajas para tiempos de evaluación en Motorola Moto G4 play de los modelos Mobilenet entrenados. 63

9
LISTA DE TABLAS
pág.
Tabla 1. Ejemplo de matriz de confusión 25
Tabla 2. Frutas y verduras para entrenamiento y número de imágenes por clase. 41
Tabla 3. Exactitud (rosado) y valor de función de pérdida (azul) al finalizar el entrenamiento de redes Mobilenet con diferentes multiplicadores de anchura y tamaños de imágenes de entrada. 56

10
LISTA DE ANEXOS
pág.
Anexo A. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 160 x 160 de tamaño de imágenes de entrada. 74
Anexo B. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 160 x 160 de tamaño de imágenes de entrada. 74
Anexo C. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 192 x 192 de tamaño de imágenes de entrada. ¡Error! Marcador no definido.
Anexo D. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 192 x 192 de tamaño de imágenes de entrada. 75
Anexo E. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 192 x 192 de tamaño de imágenes de entrada. 76
Anexo F. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 224 x 224 de tamaño de imágenes de entrada. 76
Anexo G. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 224 x 224 de tamaño de imágenes de entrada. 77
Anexo H. Matriz de confusión en valores porcentuales de modelo Mobilenet con 0.25 de multiplicador de anchura y 160 x 160 de tamaño de imágenes de entrada. 78
Anexo I. Matriz de confusión en valores porcentuales de modelo Mobilenet con 0.75 de multiplicador de anchura y 224 x 224 de tamaño de imágenes de entrada. 80
Anexo J. Enlace a repositorio de proyecto. 81

11
RESUMEN
El propósito de este proyecto es entrenar redes neuronales profundas para clasificar alrededor de 20 frutas y vegetales usando imágenes provenientes de las cámaras de un ordenador y algunos dispositivos móviles (teléfonos inteligentes y sistemas embebidos). Se construyó un sistema de adquisición para recolectar imágenes de diferentes tipos de frutas y vegetales, también se utilizaron algunas imágenes de internet para reforzar la eficacia del dataset para re-entrenar redes neuronales convolucionales. En vez de construir una nueva red neuronal desde el principio, se tomó ventaja del transfer learning para reentrenar un modelo de MobileNet para clasificar las imágenes en cuestión entre sus clases correspondientes. También se hizo uso de la herramienta de podado de operaciones innecesarias para inferencia y aproximación de pesos sinápticos para obtener un modelo más liviano capaz de ser puesto en marcha en un teléfono móvil y en un sistema embebido. Adicionalmente, se desarrolló una aplicación móvil para mostrar información importante acerca del alimento reconocido por la red. Por último, se implementó el sistema de inferencia en dos dispositivos embebidos: Raspberry pi 3+ y el kit de desarrollo Jetson TX2 de Nvidia.
This project aims to train deep neural networks to recognize around 20 fruits and vegetables using a camera attached to portable devices (Smartphones and embedded systems). We built an acquisition system to gather pictures of different kinds of fruits and vegetables and collected further images from the Internet to train a Convolutional neural network. Instead of defining a new topology and training it from scratch, we took advantage of transfer learning and fine-tuned MobileNet models to classify our images in their corresponding classes. We also trained a lighter model and embedded it both, on a smartphone and on embedded systems (Raspberry pi 3+ and Jetson TX2 development kit). Last but not least, we developed a smartphone application to provide valuable information regarding the fruits and vegetables
Palabras clave: Convolutional neural networks, transfer learning, image processing, fruits, vegetables, embedded systems.

12
INTRODUCCIÓN
Aunque las redes neuronales no son especialmente nuevas, pues surgieron entre los años 40 y 50, su reciente éxito se debe al planteamiento de algunas técnicas de entrenamiento y disminución del error, también a la aparición de ordenadores con la capacidad de satisfacer la demanda de recursos que exige una red neuronal compleja para ser calibrada dar buenos resultados de acuerdo a la aplicación que se le desea dar.
Los computadores programables se concibieron inicialmente con el propósito de resolver problemas o ecuaciones matemáticas bien estructuradas, en otras palabras, conocimiento formal (Googfellow, 2016, p.2-4). Existen situaciones en las que el humano se desempeña bastante bien, pero se le dificulta especificar una serie de reglas que describan lo que está pasando, por ejemplo, el caso de la visión, le sería complicado a alguien describir a un computador qué características tiene una naranja y que a su vez sean suficientes para que la máquina no las confunda con otros objetos.
Las redes neuronales como rama de la inteligencia artificial, se han destacado por tener la capacidad de aprender de situaciones en las que no se tiene mucho conocimiento formal implicado, recientemente, se han empleado en tareas como reconocimiento de voz u objetos, con resultados bastante buenos, superando en desempeño a casi todas las herramientas que se usaban anteriormente para propósitos similares. Debido a la alta precisión y confiabilidad de las redes neuronales se han podido desarrollar aplicaciones que antes no tenían resultados lo suficientemente buenos como para salir del ámbito meramente académico, como por ejemplo sistemas de conducción autónoma o los asistentes de voz que ahora se alojan en los celulares recientes.
Entre las aplicaciones que se tienen para reconocimiento de objetos usando redes neuronales, están las que se enfocan en brindar al usuario información sobre el entorno más cercano, y así complementar lo que percibe por sus propios medios. Actualmente se encuentran aplicaciones en campos como el deporte y la medicina. En el campo de la salud, por ejemplo, se usa para visualizar los vasos sanguíneos y proyectarlos sobre la piel del paciente con el fin hacerle saber al profesional de la salud de manera más precisa la localización de las vías de transporte sanguíneo para los propósitos que se requiera (Willis, 2018).
Recientemente, se han liberado para el uso público, librerías y herramientas que facilitan el la construcción y entrenamiento de redes neuronales, siendo su fuerte, el hecho de que para el usuario es transparente la derivación que implica la retropropagación y facilitan la implementación de optimizadores, funciones de pérdida, la navegación entre capas de las redes neuronales, entre otros aspectos. Además, dentro de estas herramientas, se tienen apartados en los que

13
se optimiza la inferencia, descartando las operaciones que no son necesarias para este propósito y utilizando estructuras de datos menos demandantes en capacidad de procesamiento y memoria, permitiendo así que una gran variedad de teléfonos móviles y sistemas embebidos puedan ser utilizados para ejecutar tareas de inferencia usando redes neuronales.
Por otro lado, dentro de los lugares de venta de víveres, se pueden encontrar productos alimenticios procesados que en su empaque presentan información relevante acerca del contenido, como puede ser información nutricional, ingredientes, recomendaciones de uso entre otros apartados, situación que no ocurre con los alimentos no procesados como frutas y verduras dado a que en su mayoría carecen de empaques o espacio suficiente en las etiquetas para alojar dicha información. Una situación intuitiva para la falta de información, es agregar empaques a los productos, llevando así a desperdicios innecesarios cuando los productos van a ser consumidos, aportando a la contaminación ambiental.
Haciendo una aproximación al caso de este proyecto, se usaron redes neuronales profundas para implementar en teléfonos móviles y algunos sistemas embebidos (Raspberry pi 3 b+ y kit de desarrollo Jetson TX2), un clasificador de frutas y verduras, para ello se consiguieron algunos especímenes de estos alimentos a los que se les tomaron fotos desde diferentes puntos de vista para construir un dataset con el propósito de aplicar la técnica de transfer learning a algunas redes pre-entrenadas y usarlas como motor del clasificador, dentro de la aplicación de teléfono celular, se muestra al usuario información relacionada al alimento reconocido, como es una descripción, sus valores nutricionales, recomendaciones para escoger y almacenar, y las bondades más relevantes del alimento. Esta información se recopila de diferentes páginas web mediante el protocolo TCP/IP.

14
1. PLANTEAMIENTO DEL PROBLEMA
Habitualmente, los alimentos procesados llevan en su empaque información que le puede servir a los compradores como referencia para elegir entre uno u otro o la manera de emplearlos para consumirlos solos o emplearlos en la elaboración de algunos platos. Con alimentos como frutas o verduras en supermercados o tiendas, encontrar este tipo de información es poco común, desperdiciando así la posibilidad de que las personas puedan beneficiarse de algunos de estos alimentos de acuerdo a sus necesidades debido al desconocimiento de sus características.
De forma natural, la solución más evidente que se le ha dado a este problema es empacar estos tipos de alimentos en envases generalmente plásticos, dejando impresa una parte de la información mencionada, presentando así una serie de problemas, entre ellos, el uso innecesario de envases para un producto que puede no requerirlo (no exceptuando los empaques con fines de proteger el alimento de daños mecánicos u oxidación), generando posteriormente desechos, además el imprimir toda la información de producto puede tornarse poco atractivo para el comprador, el encontrarse con descripciones tan extensas si bien puede interesarle a algunas personas en ciertos casos, como también puede simplemente ser ignorada.
El reconocimiento de objetos permite a los computadores captar información acerca de aquello con el usuario desea trabajar o realizar algún tipo de tarea, y de esta manera poder hacer procesamiento o acciones con la información recibida, permitiendo que luego se puedan automatizar tareas, mejorando algunos indicadores de producción o consumo y la calidad de vida de las personas involucradas en la actividad que se realiza.
Gracias al crecimiento de la capacidad de procesamiento en sistemas portables como celulares y los basados en tarjetas de bajo costo como los Arduino, las Raspberry Pi, entre otras, ahora se pueden emplear en tareas medianamente demandantes de recursos, como puede llegar a ser el reconocimiento de objetos. El hecho de que se puedan instalar este tipo de aplicaciones en dispositivos móviles abre posibilidades más atractivas y amigables con el usuario.
La pregunta que se plantea para formular el problema en el que se enfocará el proyecto es la siguiente:
¿Cómo implementar un sistema basado en redes neuronales profundas que permita brindar al usuario información relevante acerca de frutas y verduras en dispositivos fáciles de transportar como teléfonos móviles o sistemas embebidos.

15
2. JUSTIFICACIÓN
Este proyecto generará un prototipo de herramienta de reconocimiento de objetos que permita a las personas estar mejor informadas acerca de las cualidades, algunos usos y contenido nutricional de los alimentos que consumen, dejando así la posibilidad para que se dé una mejora a su calidad de vida y de sus hábitos de alimentación.
El uso de dispositivos móviles inteligentes ha crecido rápidamente, y junto al desarrollo y liberación al mercado de componentes más potentes, ha permitido que se ejecuten en ellos aplicaciones que antes solo podían usarse en ordenadores de escritorio, permitiendo así tener a la mano diferentes herramientas de forma fácil y cómoda. Adicionalmente, con la optimización de redes neuronales profundas para reducir el espacio que ocupan en disco y la cantidad de recursos computacionales que consumen, se ha abierto la posibilidad de poder alojarlas y ponerlas a funcionar en plataformas no muy ostentosas en cuanto a capacidad de procesamiento se refiere. Por lo anterior, dentro del proyecto, se hará implementación del sistema de reconocimiento de frutas y verduras en un teléfono móvil y en un sistema embebido específicamente en la tarjeta Jetson TX2 de Nvidia.
Además, este proyecto permitirá que en la Universidad Autónoma de Occidente se continúe con el trabajo que se viene realizando en el manejo de redes neuronales profundas en aplicaciones de reconocimiento de objetos a partir de imágenes, por medio de software libre que no represente mayores gastos en licencias.

16
3. ANTECEDENTES
Debido al alto costo computacional que tiene hacer el entrenamiento de una red neuronal convolucional capaz de desempeñarse bien en reconocimiento de imágenes en objetos, es difícil obtener redes complejas que se desempeñen bien en estas tareas. Afortunadamente, actores como Google o la Universidad de Oxford han publicado la configuración de sus sistemas ya entrenados aportando bastante a la democratización del reconocimiento de objetos por medio de redes neuronales.
Adicionalmente se han puesto a disposición general algunos modelos de redes neuronales profundas, optimizadas para que puedan ser alojadas y ejecutadas en dispositivos que no necesariamente tienen los recursos de cómputo y almacenamiento que puede tener un ordenador de escritorio. Gracias a esto, se han podido desarrollar aplicaciones que pueden alojarse y ejecutarse en teléfonos inteligentes o sistemas embebidos, permitiendo la aparición de aplicaciones que pueden dar beneficios reales en situaciones de constante movimiento, en las que no se tienen las instalaciones adecuadas para poner a funcionar un computador de mesa o en las que resulta poco práctico cargar con uno, algunos ejemplos de estas aplicaciones son:
LeafSnap: Es una app móvil en la que la red neuronal profunda se aloja en el celular y permite a botanistas conocer a qué especie de árbol pertenece una de sus hojas. (Ver figura 1).
Figura 1. Captura de LeafSnap.
La aplicación se utiliza la cámara del dispositivo para captar las imágenes, cabe aclarar que las hojas deben ponerse en un fondo claro y uniforme para tomar la foto. Tomado de “Leafsnap, conoce especies de plantas por

17
Seeing AI: Es una app enfocada a ayudar a personas invidentes, hace uso de la cámara del teléfono para realizar tareas como convertir a documento de texto, las palabras tomadas en una foto, reconocer productos de acuerdo a su código de barras, reproduciendo lo que se identifica como audio, reconocer rostros de personas que se hayan tomado antes con el celular y hacer descripción de imágenes tomadas con la cámara del móvil (ver figura 2).
Figura 2. Seeing AI.
Ala izquierda se tiene el apartado en el que se convierte texto a audio, en el centro, el apartado de asociamiento de códigos de barras con productos y a la derecha el de reconocimiento facial. Tomado de “Microsoft’s new AI app describes the world for the visually impaired”. T. Bishop. GeekWire. Limited Liability Company 2011-2019. Recuperado de https://www.geekwire.com/2017/microsofts-new-ai-app-describes-world-visually-impaired-now-available-iphone/
Aipoly Vision: Similar a LeafSnap, esta es una app que funciona a partir de una red profunda ya entrenada alojada en el celular, consiste en usar la cámara para apuntar a objetos de la vida cotidiana para que la app los reconozca y le indique

18
al usuario a qué objeto se refiere. La app está enfocada en ayudar a personas en condición de discapacidad visual en sus tareas de día a día.
Camera translate: Esta aplicación de Google usa la cámara del dispositivo móvil para captar vídeo en el que se tengan anuncios, señales o indicaciones conteniendo texto para traducirlo al idioma que indica al usuario y mostrar en la pantalla la versión traducida de lo que se recibe en la cámara.
LookTel: Para identificación de moneda, es una aplicación de ayuda para personas en condición de discapacidad visual que hace uso de la cámara del dispositivo móvil para reconocer la denominación de dinero en efectivo y reproducir en forma de audio la información obtenida.
Tap Tap See: Es una aplicación de reconocimiento de objetos diseñada para ayuda de personas con discapacidades visuales en las que el usuario toma fotos de lo que desea saber qué se trata y la aplicación se encarga de reconocer los objetos más importantes de la imagen y reproducir los nombres de lo identificado en forma de audio.
Además, dentro de la rama de las aplicaciones de aprendizaje profundo en sistemas embebidos también se han desarrollado aplicaciones relacionadas con procesamiento de imágenes utilizando redes neuronales convolucionales previamente entrenadas para hacer inferencia sobre imágenes provenientes de una cámara, utilizando la tarjeta Jetson TX2 (Taylor, 2018), también se han utilizado este tipo de sistemas embebidos para hacer segmentación semántica en tiempo real (Paszke, 2016).

19
4. OBJETIVOS
4.1 OBJETIVO GENERAL
Implementar el kit de desarrollo Jetson TX2 de Nvidia y en un celular, un sistema capaz de dar información sobre frutas y verduras al usuario usando redes neuronales.
4.2 OBJETIVOS ESPECÍFICOS
● Construir un dataset de frutas y verduras.● Seleccionar la arquitectura de la red neuronal profunda para la aplicación.
● Entrenar la red neuronal profunda con el dataset construido.
● Implementar la red entrenada en un smart phone.
● Implementar la red entrenada en el kit de desarrollo Jetson TX2 de Nvidia.

5. MARCO TEÓRICO
Las estructuras predecesoras al deep learning fueron inspiradas desde una perspectiva neurocientífica, describiendo estos modelos, comportamientos matemáticos o tareas de clasificación simples. Estos fueron diseñados para recibir a su entrada arreglos de n elementos y asociarlos con una salida y. Los modelos podían adaptar un vector w de pesos sinápticos de tamaño n de manera que el modelo fuese capaz de describir el modelo lineal que se desea que aproxime.
El perceptrón simple (Rosenblatt , 1958) es una de las estructuras básicas más utilizadas como bloque para construir redes neuronales de distintos tipos (ver figura 3).
Figura 3. Perceptrón simple.
El perceptrón simple hace un producto punto entre las entradas x y los pesos w que les corresponden, y posteriormente el resultado y = f(x, w) + b , (siendo b un umbral de activación) es ingresado a una función de activación f(y) que según lo requiera la aplicación de la red que se construye puede variar, las más comunes son escalón, lineal, sigmoidea simple, sigmoidea bipolar, RELU, gaussiana y sinusoidal, generando una salida que se conectará a la entrada de otra de estas estructuras. Tomado de “Modulation Format Recognition Using Artificial Neural Networks for the Next Generation Optical Networks”. L. Guesmi, H. Fathallah y F. Menif. IntechOpen. Derechos de autor. Recuperado de https://www.intechopen.com/books/advanced-applications-for-artificial-neural-networks/modulation-format-recognition-using-artificial-neural-networks-for-the-next-generation-optical-netwo. sus hojas”. A. Baldi. 2013. Decoración y jardines. Licencia Creative Commons. 1995-2018 Recuperado de https://decoracionyjardines.com/leafsnap-conoce-especies-de-plantas-por-sus-hojas/7715.
20

21
Para los investigadores y desarrolladores en el área de las redes neuronales profundas, la neurociencia ha sido una gran fuente de inspiración. El mayor motivo por el cual la neurociencia no tiene influencia muy fuerte o representación fiel en el aprendizaje profundo es porque no se tiene información suficiente para usarla como guía. Para entender los algoritmos usados en el cerebro necesitaríamos la capacidad de monitorear la actividad de una vasta cantidad de neuronas interconectadas, por este motivo, todavía se está lejos de entender algunas de las más simples y bien estudiadas partes del cerebro (Olshausen y Field, 2015).
De la neurociencia fue tomada la idea de que se pueden describir algoritmos o ejecutar tareas valiéndose de más y más unidades de computación, según la aplicación lo requiera, de ahí la idea de red neuronal artificial, estas se componen de capas, que son agrupaciones de neuronas con una función específica (ver figura 4).
Figura 4. Red neuronal artificial. Red neuronal profunda, en la que la capa de entrada (unidades azules) tiene contacto con la información presentada al modelo, que puede ser de sensores o arreglos ordenados de datos, posteriormente, se tienen las capas ocultas (unidades rojas) que tienen contacto ya sea con la capa de entrada o capas ocultas previas, estas pueden estar conectadas de diferentes maneras (por ejemplo totalmente conectada, en forma convolucional, recurrente, entre otros esquemas de conexión) y se encargan de transformar y procesar la información para entregarla a la capa de salida (unidades verdes) en la que se entrega el resultado al usuario y opcionalmente se puede hacer una normalización de la información. Tomado de “Predicting the 28 Days Compressive Strength of Concrete Using Artificial Neural Network”. F. Khademi y F. Sayed. ResearchGate. Copyright 2019. Recuperado de 305432476_Predicting_the_28_Days_Compressive_Strength_of_Concrete_Using_Artificial_Neural_Network.

22
La arquitectura de red neuronal mayormente utilizada para detección de objetos es la de tipo convolucional, extrayendo características de las imágenes que se presentan. Al momento de reconocer objetos, existen algunos aspectos que pueden volver esta tarea complicada, tales como los cambios de iluminación en el entorno del objeto, posición relativa al objeto desde la que la red lo observa, deformación de los objetos (como ocurre con las letras que dependen de la escritura de la persona), obstrucción de la vista del objeto debido a otros elementos del entorno, entre otros.
Una de las grandes fortalezas de las redes convolucionales ante estos problemas es su capacidad para detectar características morfológicas de los objetos para los que se entrena y el incremento de complejidad de las características extraídas a medida que se acerca a la capa de salida de la red.
Figura 5. Representación de características en red neuronal convolucional.
Las capas más cercanas a la entrada se pueden encontrar representaciones de líneas rectas en varios ángulos, posteriormente líneas curvas y más adelante características más complejas relacionadas al objeto para el que se entrenó la red. Así pues, con un correcto entrenamiento, la red extrae copias de características del objeto cuando está rotado, obstruido, con iluminación dispareja, etc., permitiéndole desempeñarse de manera acertada en diferentes situaciones. Tomado de “The 8 Neural Network Architectures Machine Learning Researchers Need to Learn”. L. James. Kdnuggets. Copyright 2019. Recuperado de https://www.kdnuggets.com/2018/02/8-neural-network-architectures-machine-learning-researchers-need-learn.html.
En las capas de convolución se usan grupos de neuronas como kernel alojando cada grupo una característica (codificadas en matrices) que se desea encontrar en la imagen, estos kernels recorren la totalidad de la imagen haciendo producto punto en secciones de esta como se muestra en la figura 6, dando como

23
resultado un valor escalar, este valor es cercano a cero cuando no se encuentra la característica y de un valor nominal grande si lo hace.
Figura 6. Convolución 2D.
Representación visual del cálculo de convolución 2D usada para procesamiento de imágenes. Tomado de “Image Filtering”. Machine Learning guru. Derechos de autor. Recuperado de http://machinelearninguru.com/computer_vision/basics/convolution/image_convolution_1.html.
Habitualmente, las capas de convolución van conectadas posteriormente a capas de rectificación lineal con neuronas de función RELU para mejorar el contraste de las imágenes a ser procesadas de mejor manera por capas convolucionales posteriores , seguido de capas de agrupamiento (pooling) con el fin de reducir el tamaño de las imágenes producidas por las capas convolucionales y por consiguiente la carga computacional del sistema que ejecuta las instrucciones, tal como se representa en la figura 7.

24
Figura 7. Arquitectura típica de red convolucional.
Representación gráfica de la arquitectura típica de redes neuronales convolucionales con sus diferentes tipos de capas y operaciones de rectificación de datos. Tomado de “The best explanation of Convolutional Neural Networks on the Internet!”. H. Pokharna. Medium. Derechos de autor. Recuperado de https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks-on-the-internet-fbb8b1ad5df8.
Después de las capas de convolución y agrupamiento, se tienen capas con neuronas completamente conectadas a las de la capa siguiente esto con el fin de unificar toda la información reunida a partir de la búsqueda de características dentro de la imagen y, por último, a la salida, por lo general se tienen neuronas con función tipo softmax, las cuales permiten entregar probabilidades acerca de a qué tipo de objeto se está enfrentando la red.
De la salida de las redes como clasificadoras respecto a la clase real a la que pertenece la entrada, se pueden calcular, métricas que permiten determinar la efectividad del modelo entrenado para diferenciar entre las clases del dataset con el que fue entrenado. Algunas métricas de rendimiento usadas en algoritmos de clasificación son cross entropy, precisión, área bajo la curva, f1-score, etc.
La matriz de confusión (ver tabla 1) es una de las herramientas de extracción de métricas más intuitivas para medir la efectividad de modelos en los que se tengan dos o más clases para clasificar.

25
Tabla 1.
Ejemplo de matriz de confusión
Valor predicho
Perro Gato Pollo
Valor
real
Perro 5 (62.2%) 1 (11.1%) 3 (25%)
Gato 1 (12.5%) 7 (77.8%) 2 (16.7%)
Pollo 2 (25%) 1 (11.1%) 7 (58.3%)
Total 8 (100%) 9 (100%) 12 (100%)
Nota: La matriz de confusión es llenada en la diagonal principal por los aciertos que se tengan y por fuera se indican los fallos que se hayan dado y con respecto a qué clases se han cometido los errores. Se asigna una fila y una columna para cada clase que esté cobijada por el dataset, teniendo así representados en la matriz todos los pares de clases que se puedan dar, estando en la diagonal principal, el emparejamiento de una clase con ella misma.
En las columnas, se indican a qué clase atribuye la red una entrada, siendo los elementos pertenecientes a la diagonal principal las predicciones correctas, por ejemplo, en la clase perro, se tuvieron ocho entradas, cinco fueron clasificadas correctamente y otras tres fueron clasificaciones erróneas atribuidas a otras clases. En la matriz de confusión también pueden separarse los resultados de clasificación por clase en verdaderos positivos (VP) que son las muestras pertenecientes a la clase, clasificadas en correctamente en la clase, falsos positivos (FP) que son la muestras pertenecientes a la clase, clasificadas como si no lo fueran, los verdaderos negativos (VN) que son muestras no pertenecientes a la clase, clasificadas como no pertenecientes a la clase y falsos

26
negativos (FN) que son muestras pertenecientes a la clase, clasificadas como no pertenecientes a ella.
Siempre se busca la minimización de los falsos positivos y los falsos negativos, pero dependiendo de la aplicación del modelo que se construye, se puede prestar atención especial a la minimización de uno u otro. Un ejemplo en el que se prioriza la minimización de falsos negativos es clasificando personas ebrias al volante para hacer una revisión, se esperaría identificar bien a todas las personas que estén bajo los efectos del alcohol para evitar poner situaciones potencialmente riesgosas en carretera, mientras que no importa mucho si por error se clasifica mal a alguien sobrio, pues en el proceso de revisión se comprobará que efectivamente no ha bebido alcohol recientemente. Un ejemplo en el que se debería priorizar la minimización de los falsos negativos puede ser en la clasificación de fallas en la estructura de edificios pues se dejaría latente la posibilidad de catástrofe en caso de que no sea arreglada, mientras que si erróneamente se clasifica como falla algo que no es, luego en las revisiones técnicas se demostrará que no has riesgos en esa zona.
Algunas métricas de rendimiento que pueden ser extraídas de los componentes de la matriz de confusión son:
Exactitud, es el número de predicciones correctas sobre la totalidad de las predicciones hechas por el modelo, esta métrica es un indicador acertado cuando el set de datos con el que se evalúa la red es balanceado:
𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸 =𝑉𝑉𝑉𝑉 + 𝑉𝑉𝑉𝑉
𝑉𝑉𝑉𝑉 + 𝑉𝑉𝑉𝑉 + 𝑉𝑉𝑉𝑉 + 𝑉𝑉𝐹𝐹
Precisión, es el número de predicciones positivas correctas sobre el número total de predicciones positivas, por ejemplo, en un caso de clasificación entre frutas en buen estado y frutas descompuestas, sería el porcentaje de frutas que en verdad estaban buenas, de todas las frutas que fueron agrupadas como buenas por el algoritmo.
𝑉𝑉𝑃𝑃𝑃𝑃𝐸𝐸𝐸𝐸𝑃𝑃𝐸𝐸ó𝑛𝑛 = 𝑉𝑉𝑉𝑉
𝑉𝑉𝑉𝑉 + 𝑉𝑉𝑉𝑉

27
Sensitividad, es el número de verdaderos positivos sobre los verdaderos positivos más los falsos negativos, en el ejemplo de las frutas sería el porcentaje de frutas clasificadas como buenas de la totalidad de frutas que realmente están en buen estado.
𝑆𝑆𝑃𝑃𝑛𝑛𝑃𝑃𝐸𝐸𝐸𝐸𝐸𝐸𝑆𝑆𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸 = 𝑉𝑉𝑉𝑉
𝑉𝑉𝑉𝑉 + 𝑉𝑉𝐹𝐹
Especificidad, es la cantidad de verdaderos negativos entre la suma de los verdaderos negativos y los falsos positivos, esta métrica es exactamente lo opuesto a la sensibilidad, en el ejemplo de las frutas sería el porcentaje de frutas realmente descompuestas entre todo el grupo de frutas que fue clasificado como si estuvieran descompuestas.
𝐸𝐸𝑃𝑃𝐸𝐸𝑃𝑃𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸𝐸 = 𝑉𝑉𝑉𝑉𝑉𝑉𝑉𝑉 + 𝐹𝐹𝑉𝑉
F1-score, esta métrica lleva busca ser un indicador que comprenda la precisión y la sensitivadad, por lo que en primera instancia se puede pensar en un promedio simple entre ambas, dando paso a algoritmos con calificaciones moderadas que tienen puntajes bastante bajos ya sea en precisión o en sensitividad mientras su contraparte es bastante buena, por lo que se recurre a un promedio armónico entre ambas métricas.
𝑉𝑉1 − 𝑃𝑃𝐸𝐸𝑠𝑠𝑃𝑃𝑃𝑃 = 2 ∗ 𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃ó𝑛𝑛 ∗ 𝑆𝑆𝑃𝑃𝑛𝑛𝑃𝑃𝑃𝑃𝑒𝑒𝑃𝑃𝑒𝑒𝑃𝑃𝑒𝑒𝑒𝑒𝑒𝑒𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃𝑃ó𝑛𝑛 + 𝑆𝑆𝑃𝑃𝑛𝑛𝑃𝑃𝑃𝑃𝑒𝑒𝑃𝑃𝑒𝑒𝑃𝑃𝑒𝑒𝑒𝑒𝑒𝑒
La entropía cruzada o cross entropy (ver figura 8), este indicador mide el rendimiento del algoritmo que se usa cuyas salidas tienen un rango determinado, habitualmente entre 0 y 1 para aplicaciones de clasificación, organizando en este rango el grado de confianza que da el clasificador para la entrada que se le entrega.

28
Figura 8. Gráfica de entropía cruzada.
El resultado de esta función incrementa con la diferencia entre la probabilidad predicha y el valor real de la etiqueta de la entrada, así pues, si se entrega a la entrada un perro, esta clase tiene un valor de 1, entonces el resultado de la función será mayor si el algoritmo predice la clase perro con un puntaje de 0.15 a que si hubiera obtenido 0.9. Un modelo idealmente tendría un valor de entropía cruzada de 0. Tomado de “Loss functions”. B. Fortuner, M. Viana, K. Bahrgav. GitHub. Copyright 2019. Recuperado de https://github.com/bfortuner/ml-cheatsheet/blob/master/docs/loss_functions.rst.
La técnica de validación cruzada se usa para medir el rendimiento de los modelos sobre la totalidad del dataset que se le presenta, para ello, usualmente se divide el dataset en n partes iguales, y se toma una de ellas para realizar el proceso de validación, capturando las métricas que se requieran dependiendo de la aplicación a desarrollar, y las partes restantes son utilizadas para el proceso de entrenamiento. El entrenamiento se debe realizar en el modelo n cantidad de veces, de manera en que todas las secciones del dataset hayan sido usadas para la etapa de validación (ver figura 9).
Figura 9. Validación cruzada. El bloque oscuro es utilizado para validación. Representación gráfica de la distribución del dataset para cada uso de los entrenamientos realizados durante la validación cruzada, dividiendo el dataset en tres secciones.

29
Las redes convolucionales, además de poder ser implementadas en computadores de escritorio, también son susceptibles de ser instaladas en teléfonos móviles debido al gran crecimiento de poder de procesamiento que ha experimentado en los últimos años y en single-board computers, dependiendo del procesador y módulo de manejo de gráficos que posea, siendo la capacidad de la segunda, de gran importancia para el buen desempeño en deep learning.
Las unidades de procesamiento de gráficos (GPU) son de gran importancia al momento poner en marcha a las redes neuronales, dado que estas suelen ser más rápidas que las CPU, esto obedece a que las estructuras que componen a las redes neuronales no cambian mucho entre capa y capa, permitiendo sacar provecho de la gran cantidad de núcleos que se pueden ejecutar dentro de las GPU, que, si bien no son tan potentes como los de las CPU, al ser tan numerosos, lo superan en ancho de banda.
Las redes neuronales pueden describirse en términos de operaciones matriciales, y las GPU al estar optimizadas para tratar con imágenes, las cuales con matrices conteniendo niveles de intensidad, llegan a desempeñarse bastante bien haciéndose cargo de estas estructuras. Al momento de mover paquetes de datos desde la memoria RAM, a la caché, las GPU presentan ventaja, si bien la latencia asociada a cada procesador de GPU es menor, el tiempo que tardan los punteros de cada procesador en encontrar datos es menor debido a que el tamaño de la memoria caché en cada núcleo es más pequeño, adicionalmente la gran cantidad de núcleos, permite distribuir grandes paquetes de datos en las memorias de cada uno, en la figura 10, por ejemplo se presenta una representación simple comparando las arquitecturas de CPU y GPU, siendo la cantidad de núcleos la diferencia más notable entre las estructuras.
Figura 10. Arquitectura de CPU y GPU. Representación simplificada comparando las arquitecturas de CPU y GPU, siendo la cantidad de núcleos la diferencia más notable entre las estructuras. Tomado de “CEO de Nvidia: “GPUs reemplazarán la CPU, la ley de Moore está muerta””. C. Chimp. Masgamers. Copyright 2019. Recuperado de http://www.masgamers.com/nvidia-ley-de-moore-gpu

30
Actualmente, existen una amplia variedad de aplicaciones basadas en redes neuronales profundas para el reconocimiento de imágenes, las cuales recientemente gracias al desarrollo de procesadores y GPUs más potentes y la optimización de los sistemas de reconocimiento de objetos (por ejemplo en Tensor Flow Lite o MobileNet), pueden ser usadas no solo en ordenadores sino en plataformas más fáciles de llevar consigo como son los teléfonos móviles o sistemas embebidos como pueden ser la Raspberry o la Jetson de Nvidia (Tensorflow, 2018). Además, en la misma búsqueda de ofrecer aplicaciones más interactivas a los usuarios, existe la posibilidad de alojar las redes neuronales en la nube, usando solo para el tráfico de entradas y salidas al dispositivo cliente, haciéndose todo el procesamiento en los servidores, como se hace en las aplicaciones demostrativas ofrecidas por Tensorflow.js y ConvNet.js
Los sistemas embebidos son plataformas diseñadas en torno a microprocesadores y con el fin de cumplir una función o rango de funciones, a diferencia de los computadores personales, estos no están diseñados para ser reprogramados por el usuario final de la manera en que se hace con los PCs. En los sistemas embebidos, aunque se pueden hacer cambios en la funcionalidad del aplicativo mediante el cambio de variables o accionamiento de controles, no se puede cambiar la funcionalidad base del dispositivo, que es justamente lo que hace el usuario de PC, que en un momento puede estar haciendo análisis de indicadores de mercado, y en otro puede estar renderizando video simplemente con cambiar de software. Los sistemas embebidos usualmente no cuentan con la misma capacidad de cómputo de los PCs, compensándolo con mayor integración de los circuitos y entre los componentes que lo conforman, y por ende mayor movilidad al ocupar menor espacio y ser más compacto, además algunos sistemas embebidos pueden contar con atributos adicionales según lo requiera la aplicación, como puede ser mayor resistencia a vibraciones, al polvo, o a interferencia electromagnética.

31
Figura 11. Sistemas embebidos.
Algunos de los sistemas embebidos mayormente utilizados para hacer inferencia sobre modelos de redes neuronale profundas, se tienen la Raspberry pi y la Udoo que no cuentan con sistemas para acelerar operaciones matriciales, pero su capacidad de cómputo permite ejecutarlas, también se muestran la Coral Board y la Jetson TX2, la primera cuenta con unidades de procesamiento tensorial y de gráficos y la segunda únicamente con unidad de procesamiento gráfico (además de CPU). Tomado de “The biggest-little revolution: 10 single-board computers for under $100”. EDN network. Copyright 2019. Recuperado de https://www.edn.com/design/diy/4419990/The-biggest-little-revolution--10-single-board-computers-for-under--100.
Las tarjetas Jetson de Nvidia, con un tamaño similar al de las tarjetas madre de tamaño mini ITX, ofrece prestaciones bastante superiores a las tarjetas mencionadas con anterioridad (Larabel, 2017) especialmente en manejo de gráficos gracias a que contiene un apartado de manejo gráfico de 256 núcleos CUDA y mayor velocidad de procesamiento en CPU. Esta tarjeta fue diseñada para aplicaciones que habitualmente necesitan de las prestaciones de computadores de escritorio, tales como son visión artificial, conducción automática o machine learning.
En caso de que se decida recolectar la información de los alimentos reconocidos por el modelo, se deberán emplear peticiones HTTP (protocolo de transferencia de hipertexto) para obtener la información de la web. Este es un método de comunicación entre cliente y servidor que posibilita el intercambio de información entre ambas partes, siguiendo una serie de pasos determinada entre el cliente web y los servidores HTTP. Se soporta sobre los servicios de conexión TCP/IP (IBM, 2015) funcionando de la siguiente manera: se tiene un proceso dentro del servidor escuchando a la espera de la entrada de peticiones entrantes por un puerto TCP (usualmente el 80) provenientes de los clientes Web. Al momento en que la conexión se establece, el protocolo TCP tiene como función el encargarse de que la comunicación sea estable durante la transmisión de datos, y que los

32
paquetes de información solicitados lleguen completos y sin cambios de contenido al cliente.
Figura 12. Diagrama de funcionamiento de protocolo TCP/IP.
HTTP funciona mediante un grupo de operaciones sencillas de solicitud y respuesta. En primer lugar, el cliente establece conexión con un servidor al que le envía un mensaje con los datos de solicitud, en respuesta el servidor envía un mensaje conteniendo el estado de la operación de la que se pide información, y su resultado, en caso de que haya ocurrido algún error durante la transacción, se enviará un código indicativo de lo ocurrido. Tomado de “Protocolo HTTP”. C. Villagómez. CMM. Derechos de autor. Recuperado de https://es.ccm.net/contents/264-el-protocolo-http.
Se llevan a cabo los pasos a continuación cada vez que un cliente realiza una petición al servidor (representado en la figura 12): El usuario, la persona que desea traer información del servidor ingresa una URL, haciendo selección de una parte o la totalidad de un documento HTML o especificando la ubicación de un fichero, archivo u operación dentro del servidor. Posteriormente el cliente web descodifica la URL identificando el protocolo de acceso, la dirección IP del servidor, el posible puerto por el que pueda hacerle la petición al servidor, y el objeto que se está pidiendo. Acto seguido establece una conexión TCP/IP, llamando a un puerto disponible en el servidor, la petición lleva en su interior el comando necesario para realizar la operación (Post, Put, Get, Head, Delete, Trace, Options o Connect), la versión del protocolo HTTP que se va a emplear e información adicional en la que se pueden incluir datos sobre las capacidades del buscador o datos opcionales para el servidor. Posteriormente el servidor envía de regreso una respuesta que incluye un código de estado (en el que también se contemplan los errores en la transacción) y en caso de que la transacción sea exitosa, el tipo de dato MIME (Galvin, Murphy, Crocker y Freed, 1995) (la extensión del dato o archivo) y la información de respuesta. Finalmente se cierra la conexión TCP.

33
6. METODOLOGÍA
6.1 CONSTRUCCIÓN DEL DATASET
Puesto que se ha planeado hacer uso de una red neuronal profunda para reconocer frutas y verduras mediante imágenes, primero se debe hacer una recolección de las mismas para poder llevar a cabo el proceso de entrenamiento y validación de la red. Este objetivo bien puede ser logrado mediante la recolección de imágenes provenientes de internet o darse a la tarea de tomar fotos a diferentes alimentos conseguidos de algún sitio de distribución de abastos.
Se optó por tomar las imágenes de objetos físicos y hacer uso de una cámara dotada con sensor de profundidad para posiblemente hacer uso de este canal y conseguir mayor cantidad de características relacionadas a las formas, relieves o en algunos casos, texturas que puedan tener las frutas y verduras o en generalde los objetos que se quieran capturar. Específicamente, se usó el
Figura 13. Cámara Intel Realsense SR300.
Modelo SR300 de la serie Realsense de Intel, mostrado en la figura 13, debido a su resolución de 1080p en el sensor RGB y 480p en el sensor de profundidad, con una cobertura de profundidad para entre 0.2 m y 1.5 m que es un rango justo para tomar bien los detalles de estos alimentos. Tomado de “Tecnología Intel Realsense”. Intel. Intel. Copyright 2019. Recuperado de https://software.intel.com/es-es/realsense/sr300.
6.1.1 Recolección de imágenes
Al momento de hacer las primeras pruebas con la cámara, se notó que la imagen en RGB no coincide con la del canal de profundidad, siendo que el sensor presenta una distorsión de ojo de pez, haciendo que una vez que esta se ha corregido, también se muestre una imagen con mayor apertura, dando como

34
resultado inconsistencias espaciales entre las imágenes, además, el sensor de profundidad no está en el mismo sitio que el RGB, dando como resultado una imagen corrida con respecto a la de color, esto también tuvo que ser corregido.
Para corregir la distorsión de ojo de pez (ver figura 14), se requieren la matriz de cámara y los coeficientes de distorsión del lente que se obtienen haciendo pruebas con patrones en ajedrezados. Para la misma referencia de cámara, estos vectores habían sido publicados en foros (Lyubova, 2016), por lo que fueron usados para el propósito. Posteriormente, se usaron marcas visuales en la escena para sacar las imágenes y hacer la corrección en el canal de profundidad haciendo coincidir las marcas entre las (para este caso bien podrían ser las esquinas de la caja) entre las imágenes de color y profundidad mediante el redimensionamiento de una de ellas.
Figura 14. Proceso de corrección de efecto ojo de pez y alineamiento de imágenes.
Imágenes RGB (superior izquierda), profundidad sin correcciones (superior derecha), profundidad con corrección de ojo de pez (inferior izquierda), profundidad con corrección de ojo de pez y espacial (inferior derecha).
Una vez que logra que coincidan ambas imágenes, se procede a construir una estructura que permita facilitar la captura de fotos, dado que para construir el dataset se necesitará una cantidad considerable. Para ello, se definió que dicha

35
estructura debe permitir mover el objeto en forma continua de manera que se reduzca la intervención manual para cambiar su posición. Además, debe permitir localizar la cámara de manera que las fotos de los alimentos sean lo más descriptivas posibles.
Figura 15. Estructura construida.
Se construyó una base con motor y se decidió colocar la cámara para que tuviera una vista aproximadamente isométrica del objeto a fotografiar con el fin de que cada imagen aportara características diferentes del objeto. También se colocó la base giratoria un poco más alzada que el fondo de color blanco para facilitar la diferenciación con el objeto usando el canal de profundidad.
Cabe recalcar la importancia de evitar posicionar la cámara donde tenga vistas laterales o superior del objeto ya que al momento de hacer aumento de datos rotando las imágenes, se van a conseguir imágenes repetidas, reduciendo la eficacia del dataset para entrenar un modelo. También se tomaron las fotos con el objeto lo más centrado posible, para que en el momento de hacer transformaciones a la imagen ya sea de escalamiento o de traslación, se perdiera la menor parte posible de la imagen correspondiente al objeto.
Por último, teniendo en cuenta que se tienen cuatro canales de información para ser almacenados (RGBD), se decidió usar el formato PNG debido a que primero, permite guardar cuatro canales, tres para color y uno para transparencia, que en este caso fue usado para alojar el de profundidad, y segundo, porque es una estructura de dato que permite guardar las matrices de los canales ocupando
Cámara
Motor

36
menos espacio que guardándolos como matrices puras, sin perder la capacidad de poder visualizar las imágenes con facilidad.
6.1.2 Procesamiento y aumento de datos
Se decidió trabajar con imágenes de tres canales para debido a la carencia de sensor de profundidad de la mayoría de teléfonos móviles y para poder hacer transfer learning a redes ya entrenadas especializadas en reconocimiento de objetos mediante imágenes, las cuales aceptan como entrada tres canales. Ahora, usando la librería OpenCV, se aplicaron cuatro transformaciones a las imágenes tomadas:
Escalamiento: para hacer más robusto el modelo ante la diferencia de cercanía a la que diferentes usuarios puedan mostrarle los alimentos a la cámara para que el sistema los reconozca.
Figura 16. Escalamiento.
Se escalaron las imágenes tomadas con un factor de entre 0.9 y 1.1 para factores mayores a 1 se descartaron los píxeles más exteriores de la imágen para perder la menor parte posible de lo que corresponde al alimento. Tomado de “). Image Scaling”. Mysid. Wikipedia. Creative commons 2007. Recuperado de https://en.wikipedia.org/wiki/Image_scaling#/media/File:2xsai_example.png.
Adición de fondo: para darle un contexto a las imágenes, ya que el fondo que se utilizó al momento de tomar las fotos era de un color plano, para esto se usó el canal de profundidad para diferenciar el fondo del objeto.

37
Figura 17. Adición de fondo.
Se cambió el fondo de color blanco de las imágenes tomadas por uno acorde a los posibles contextos en los que se puedan recolectar con el motivo de incrementar un poco la efectividad del modelo para clasificación.
Variación de brillo (figura 18): para hacer el modelo más robusto ante las diferencias de condiciones de luminosidad, ya que no se puede asegurar que sean siempre iguales a las que se tenían cuando se tomaron las imágenes que constituyen el dataset.
Figura 18. Variación de brillo.
La intensidad de los píxeles se varió multiplicándolos por factores entre 0.9 y 1.1, luego aproximando a enteros y saturando los resultados cuando dan por fuera del rango de 0 a 255. Tomado de “Changing the contrast and brightness of an image!”. Visem. Opencv. Derechos del autor. Recuperado de https://docs.opencv.org/3.4/d3/dc1/tutorial_basic_linear_transform.html.
Rotación y padding (figura 19): para obtener más imágenes de cada foto que se tomó de los alimentos, la rotación deja en la imagen algunos campos vacíos que fueron llenados con los valores de los pixeles del exterior de la imagen.

38
Figura 19. Rotación y padding.
Se rotaron las imágenes obteniendo 7 imágenes por cada una original. Debido a que el proceso de rotación deja campos en negro, se hizo padding con los píxeles exteriores para rellenar estos campos.
Con algunas clases de alimentos que presentaban una variación de forma alta entre muestras, especialmente las raíces como papa dulce o la yuca, se mezclaron las imágenes tomadas del producto físico con algunas bajadas de internet.
6.2 ENTRENAMIENTO DE LA RED
6.2.1 Clasificador de juguetes
Antes de ir a un mercado a conseguir alimentos que puedan expirar, se decidió probar entrenando una red usando juguetes (ver figura 20), con el motivo de aprender sobre qué aspectos dan mejores resultados o son importantes tener en cuenta al momento de construir un dataset robusto para hacer clasificación de objetos. Con base en el tutorial Tensorflow for poets (Daoust, 2018), inicialmente, se deben instalar las librerías requeridas para hacer funcionar el sistema de inteligencia artificial en conjunto con la cámara SR300, para ello se instaló Tensorflow la versión GPU en un servidor con tarjetas gráficas al que se tuvo acceso para hacer entrenamiento de modelos y la versión CPU con soporte para instrucciones AVX (Lomont, 2011)en el portátil hp-14043la en el que se haría inferencia de los modelos ya que este no cuenta con tarjeta de video dedicada pero su procesador acepta este tipo de instrucciones que ayudan con el manejo de datos vectoriales más grandes, además se instaló la librería Pyrealsense2 para el manejo de los datos de la cámara con su canal de profundidad y Opencv para hacer transformaciones y pre procesamiento de las imágenes tomadas,

39
todo instalado en Python 3.6 que es la distribución más reciente para Windows para la que se tiene soporte en la librería de las cámaras Intel realsense.
Una vez instaladas las librerías necesarias, se modificó el código de reentrenamiento que proveían para poder realizar cross validation y también para extraer métricas de rendimiento durante la etapa de validación como son matriz de confusión y f1-score. Además, se modificó el código para hacer inferencia sobre imágenes, para trabajar con las imágenes en directo desde la cámara y no sobre imágenes guardadas en directorios específicos, como es entregado desde el tutorial.
En esta etapa fue cuando se encontró la ventaja de la vista isométrica sobre las laterales del objeto dado que inicialmente se tenía la cámara posicionada justamente encima de ellos, generando imágenes repetidas al momento de hacer data augmentation sobre las fotos tomadas. Se usó para este clasificador una red Inception V3, que daba buenos resultados diferenciando las clases, pero al momento de hacer evaluación de las imágenes en directo de la cámara, se obtuvieron tiempos de evaluación altos dando una sensación poco fluida, por lo que se procedió a usar la red Mobilenet que es más liviana y permite hacer cambios de forma rápida en la anchura de la red y el tamaño de las imágenes de entrada en aras de conseguir una combinación que dé una buena relación entre aciertos en inferencia y tiempo de evaluación.
Cabe resaltar que en todos los procesos de entrenamiento, no se usó el canal de profundidad, dado que se usaron algunas de las redes pre entrenadas más comunes para el procesamiento de imágenes, que aceptan a la entrada imágenes en tres canales, por lo que el uso del cuarto canal implicaría modificar la estructura de la red y perder el entrenamiento con el que ya cuentan estas redes, o la adicción de otra red encargada únicamente del canal de profundidad y la unión con la red pre entrenada en las últimas capas, volviendo la red más pesada e inviable de embarcar en dispositivos de no tan altas prestaciones, que además no cuentan con sensor de profundidad.

40
Figura 20. Juguetes usados para hacer pruebas.
Para tener noción de qué aspectos se deben tener en cuenta, tomaron imágenes de tres juguetes de plástico y se entrenó un clasificador.
Teniendo buenos resultados con estos objetos (f1-score de al menos 90%), se decidió pasar a la etapa de los alimentos, y abordar en ella el problema de los largos tiempos de evaluación.
6.2.2 Clasificador de frutas y verduras
Se consiguieron 21 tipos de frutas y verduras, procurando en su selección que no fuesen muy comunes para que la información relacionada que se entrega al usuario sea relevante, no algo que toda persona da por sentado, se apuntó a evitar escenarios en los que el conocimiento que se muestra es casi cultura general, como por ejemplo que las naranjas o los cítricos en general son ricos en vitamina C.

41
Tabla 2.
Frutas y verduras para entrenamiento y número de imágenes por clase.
1 Berenjena 600 8 Calabacín 800 15 Calabaza común 600
2 Raíz de remolacha 800 9 Calabaza larga 600 16 Rábano negro 600
3 Brócoli 600 10 Endivia 800 17 Nabo 800
4 Zanahoria 800 11 Hinojo 600 18 Tomate de racimo 600
5 Raíz de apio 800 12 Yuca 600 19 Tomate dentado 600
6 Coles de Bruselas 900 13 Chirivía 600 20 Topinambur 600
7 Coliflor 600 14 Pimentón 800 21 Camote 900
Nota: Se Capturaron entre 600 y 900 imágenes por clase, tomando más en las que se tenían mayor cantidad de especímenes disponibles, se ajustó la velocidad del motor y el tiempo de captura entre cada imagen para tomar 200 imágenes por cada giro que se le da al alimento, luego de cada revolución, se posicionó el objeto de forma diferente para proveer en el entrenamiento una visión lo más completa posible de los objetos.

42
Figura 21. Algunas frutas y verduras usadas.
Se muestran algunos de los alimentos usados para la construcción del dataset.
Posteriormente, se ejecutaron transformaciones a las imágenes como escalamiento, variación de brillo, adición de fondo, y rotación, para este último, con el fin de no alargar mucho el tiempo de entrenamiento, se aplicó un multiplicador de ocho a cada quinta imagen. Al igual que con el clasificador de juguetes, se usaron imágenes en RGB, el único uso que se le dio al canal de profundidad fue para hacer segmentación del objeto y posteriormente ponerlo en escenarios en los que más probablemente se puedan encontrar estos alimentos, específicamente se usaron como fondo, imágenes de mesas y platos, se descartó usar como fondo fotos de las secciones de frutas y verduras de supermercados porque en ellas aparecían a la vez distintos tipos de frutas y verduras, llevando a pérdida en la precisión de los modelos para diferenciar entre clases. En la figura 22 se muestra el proceso de inferencia en marcha, apuntando la cámara a imágenes mostradas en pantalla.

43
Figura 22.Inferencia en computador.
Mobilenet con 0.75 de multiplicador de anchura y tamaño de imagen de entrada de 224 x 224 píxeles en funcionamiento usando la cámara Intel Realsense SR300. En la parte derecha de la imagen se encuentra la ventana en la que se muestran los puntajes que obtienen las clases para las imágenes con las que se alimenta la red.
Para entrenar los modelos, se usó un servidor teniendo acceso a una GPU 1080 Ti de Nvidia, por lo que, para sacar su mayor provecho, se instaló la distribución de GPU de Tensorlow. Para acceder a la ventana de comandos del servidor, se estableció una conexión SSH mediante la aplicación Putty.
Se entrenaron varios modelos de Mobilenet en esta etapa, reservando un 20% del dataset para propósitos de testeo y el 80% restante para el entrenamiento de los modelos, además se usó la técnica de cross validation para que la totalidad del dataset tomado sea sometido a testeo por el modelo. Se tomó ventaja de la posibilidad de descargar ya entrenadas varias versiones de Mobilenet que difieren ya sea en el multiplicador de anchura del modelo (0.25, 0.5 y 0.75 fueron usados) que hace referencia a la cantidad de filtros dentro de la red comparado con su homólogo en completa capacidad y el tamaño de las imágenes que acepta a su entrada (160x160, 192x192 y 224x224 pixeles fueron usados).

44
6.3 MIGRACIÓN A SISTEMA EMBEBIDO
Como sistema embebido, se utilizó una Raspberry pi 3 b+ (figura 23), se instalaron las librerías PiCamera, junto a OpenCV y Tensorflow 1.9, que es la primera versión que soporta compatibilidad con Raspbian sin tener que construir el wheel específicamente para el dispositivo con programas como Bazel, para posteriormente modificar el código de inferencia usado en el computador para ser corrido con los recursos de la Raspberry.
Figura 23. Raspberry Pi con módulo de cámara.
En este caso como la cámara SR300 de Intel requiere un puerto USB 3.0 para funcionar, con el que esta tarjeta no cuenta, se decidió usar el módulo de cámara V2 de Raspberry.
Al momento de utilizar la misma red Inception V3 entrenada para frutas y verduras, se consiguieron tiempos de evaluación muy largos, por lo que se decidió utilizar una red más liviana. Para el propósito se reentrenó una MobileNet V2, se entrenaron varias cambiando entre una y otra su anchura y la resolución de las imágenes de entrada, para conseguir en la etapa de prueba, una buena relación de acierto reconociendo los objetos y de rapidez para hacer inferencia. También se dejaron habilitados los cuatro núcleos para ser utilizados para inferencia durante el reconocimiento de las frutas y verduras.
Además, se usó el kit de desarrollo Jetson TX2 y la cámara ya incluida dentro del mismo (ver figura 24). Esta tarjeta tiene un procesador de arquitectura aarch64 que no es compatible con muchas de las librerías que se encuentran comúnmente en internet para los sistemas operativos de Windows o Linux, por

45
lo que Nvidia provee un paquete de librerías llamado JetPack (Nvidia, 2018), conteniendo el CUDA toolkit y cuDNN que ayudan a tener un mejor rendimiento al momento de usar los recursos gráficos de esta tarjeta para aplicaciones de aprendizaje profundo.
Figura 24. Kit de desarrollo Jetson TX2.
Esta tarjeta cuenta con unidad de procesamiento gráfico que puede ser utilizada para acelerar la ejecución de operaciones matriciales que son necesarias para hacer inferencia con redes neuronales en general.
Para instalar Jetpack se necesita ratón y teclado USB y un computador con Ubuntu instalado (16.04 para las versiones superiores a 3.2 de Jetpack y 14.04 para las anteriores), con capacidad de conexión a dos redes, una para conectarse a la red local computador - kit de desarrollo Jetson y otro para conectarse a internet y descargar archivos necesarios durante el proceso de instalación. Se optó por instalar la versión 3.1 de Jetpack debido a que dentro de las versiones posteriores (3.2 y 3.3) al momento de la realización de este trabajo se presentaban problemas para instalar los controladores encargados de manejo de los procesadores CUDA necesarios para acelerar procesos de aprendizaje profundo y la versión para tarjeta gráfica de Tensorflow.
Una vez instalado Jetpack en la tarjeta, esta queda con Ubuntu 16.04 x64 instalado, de ahí se procede a instalar mediante pip3 las librerías de Tensorflow y Opencv dentro de Python para poder poner en funcionamiento el sistema de inferencia para reconocer frutas y verduras. Dado que no funcionan las librerías hechas para procesadores AMD64, fue necesario buscar las que se ajusten al
Cámara
46
procesador de la tarjeta o construirlas mediante la herramienta Bazel (Jingwen, 2018). Existen desarrolladores que se han tomado el trabajo de construir algunas de las librerías (JetsonHacks, 2018) para liberarlas a la comunidad y ser aprovechadas por quien lo requiera.
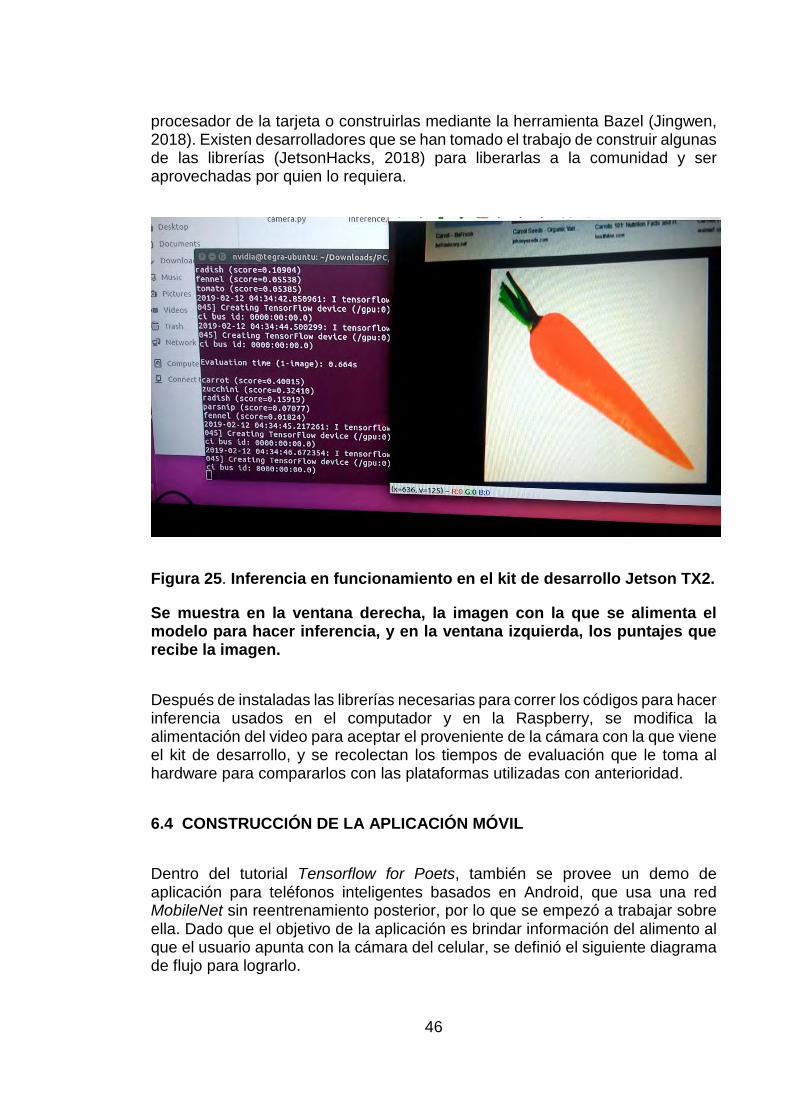
Figura 25. Inferencia en funcionamiento en el kit de desarrollo Jetson TX2.
Se muestra en la ventana derecha, la imagen con la que se alimenta el modelo para hacer inferencia, y en la ventana izquierda, los puntajes que recibe la imagen.
Después de instaladas las librerías necesarias para correr los códigos para hacer inferencia usados en el computador y en la Raspberry, se modifica la alimentación del video para aceptar el proveniente de la cámara con la que viene el kit de desarrollo, y se recolectan los tiempos de evaluación que le toma al hardware para compararlos con las plataformas utilizadas con anterioridad.
6.4 CONSTRUCCIÓN DE LA APLICACIÓN MÓVIL
Dentro del tutorial Tensorflow for Poets, también se provee un demo de aplicación para teléfonos inteligentes basados en Android, que usa una red MobileNet sin reentrenamiento posterior, por lo que se empezó a trabajar sobre ella. Dado que el objetivo de la aplicación es brindar información del alimento al que el usuario apunta con la cámara del celular, se definió el siguiente diagrama de flujo para lograrlo.

47
Figura 26. Diagrama de flujo para elaborar aplicación móvil.
En primer lugar se debe reducir el peso de la red neuronal para disminuir la carga computacional al móvil, posteriormente se creó una nueva instancia en la que se pueda imprimir la información que se mostrará al usuario y por último se recolecta de internet la información relacionada a los alimentos que se reconozcan.
En primera instancia, se debió disminuir el peso de la red, en aras de que el teléfono sea capaz de realizar inferencia sobre ella, por lo que se realizaron dos transformaciones a la red, optimización para inferencia, que consiste en eliminar las operaciones que se usan solo en el entrenamiento como son el guardado de control, la remoción de regiones en el grafo que no son utilizadas en la inferencia de los objetos para los que se reentrena la red y de operaciones de debugging como los checkNumerics , luego se usó quantize_graph para reducir el peso del modelo cuantizado los valores de las conexiones sinápticas a números de 8 bits tomando los valores máximos y mínimos de los pesos para representarlos a un rango de enteros de 0 a 255 el tiempo que le toma al teléfono realizar inferencia sobre cada imagen. Se comenzó utilizando una red Inception V3, pero en teléfonos de especificaciones no muy altas, se tenían tiempos de inferencia muy largos o simplemente la aplicación dejaba de funcionar, por lo que se decidió volver a la red MobileNet, para la red que se va a poner a funcionar en el teléfono, es importante especificar los tensores de entrada y salida y el tamaño de las imágenes de entrada para las que fue entrenada.
Una vez montada la red en el teléfono móvil, se deja en la pantalla un botón que permite al usuario indicarle al teléfono que busque información acerca de lo que se tiene en frente de la cámara. Se separa el nombre del objeto que obtiene mayor puntaje en la inferencia, para pasarla a otro proceso encargado de recolectar y mostrar información relacionada sobre una ventana emergente. Cuando se llama el proceso de búsqueda, se detiene el de inferencia para evitar ocupar innecesariamente los recursos del dispositivo.
Disminuir el tamaño de la red
Crear ventana de información
Recolectar y mostrar información

48
Figura 27. Funcionamiento de aplicación móvil.
Ventana en que se muestra clase con mayor puntaje en la inferencia (izquierda). Ventana en la que se muestra información relacionada al alimento reconocido (derecha).
La búsqueda de información se decidió hacer sobre bases de datos alojadas en internet debido a que tienen información actualizada y sustentada en fuentes confiables, además tienen a disponibilidad ya contenidos los datos de una gran variedad de objetos permitiendo escalar la aplicación a una mayor variedad de frutas y verduras sin necesidad de consumir mucho tiempo para ello. Sobre los alimentos que puede reconocer la aplicación se muestra en la ventana emergente una imagen del alimento buscado, una descripción general proveniente de Wikipedia, los contenidos nutricionales por cada cien gramos provenientes del departamento de agricultura estadounidense y recomendaciones sobre selección y almacenamiento del alimento de la organización Fruits and Veggies Matters.

49
Figura 28. Diagrama de flujo de búsqueda en aplicación móvil.
El uso que el usuario le debe dar a la aplicación comienza abriéndola y apuntando la cámara del teléfono hacia el alimento del que se desea información, como se muestra en la sección izquierda de la figura 27 cuando se empiecen a mostrar texto en la franja superior azul, se presiona el botón de búsqueda (search) lo cual abre una ventana emergente en la que se mostrará error si no se cuenta con conexión a internet o en caso de estar conectado el dispositivo, se mostrará información relacionada al alimento reconocido por la red (sección derecha, figura 27). Pulsando el botón atrás nativo de la interfaz de android, se retorna a la etapa de posicionar el alimento en frente de la cámara. En las figuras 28 y 29, se ilustra una representación detallada del funcionamiento de la aplicación.

50
Figura 29. Diagrama de caja transparente de la aplicación móvil.
La información es obtenida mediante peticiones HTTP get a las bases de datos, para ello, se convierte el resultado de la petición en un documento tipo HTTP y mediante las etiquetas de indexación que contiene, se separa únicamente la información que se eligió de cada base de datos para ser mostrada en la pantalla. En esta tarea, se utilizaron las librerías Picasso 2.7 (para el manejo de imágenes HTML), Jsoup 1.10 y Volley 1.1 en Android Studio para hacer manejo de los documentos HTML. Para explorar sobre las etiquetas de indexación, se inspecciona la página web sobre la cual se quiere traer la información, lo que muestra en pantalla la organización HTML que esta tiene, de ahí se extraen las marcas de texto (id) que etiquetan a los elementos que la conforman.
Hacer inferencia
Imagen
Hacer petición a servidores
Acción de búsqueda
Nombre de Celular
Servidores
Verificar peticiones
Retornar información solicitada
Organizar información
Información del alimento
Nombre del alimento
Peticiones Documentos HTML con imágenes e información del alimento
Mostrar información

51
Figura 30. Inspección de tabla en USDA food composition database.
Se utilizó la indexación por etiquetas del fotmato HTML para extraer únicamente la información que se quiere mostrar al usuario en la ventana emergente. Tomado de “Food Composition Databases”. United States Department of agriculture. Derechos del autor. Recuperado de https://ndb.nal.usda.gov/ndb/search/list.
En el caso de los valores nutricionales que se muestran en la pantalla, fueron obtenidos de la base de datos de la composición alimenticia del USDA, en este caso la tabla tiene un identificador “nutdata”, que es de tipo tabla, de ahí se extraen todos los elementos de las columnas nutrient, unit y value per 100 g, para luego ser mostrados en el teléfono móvil.
Para llevar al teléfono una imagen genérica del alimento reconocido, se usó la primera imagen que se muestra en pantalla dentro de los resultados de Wikipedia cuando se hace una petición de búsqueda sobre un objeto, en este caso se usa una URL de base, y seguido, se pone el nombre del alimento reconocido por el clasificador, tomando como ejemplo el una berenjena (eggplant en inglés), la URL sería: “https://en.wikipedia.org/wiki/Eggplant”, retornando un resultado como el de la figura 31, del que se mostrará en la pantalla del teléfono celular.
La imagen indicada que habitualmente corresponde a una ilustración en la que la mayoría de las personas que conozcan el alimento, coincidirían que así se podría encontrar en un supermercado tienda, esto es mostrado para que el

52
usuario sepa que la información que se le está mostrando en pantalla, corresponde al alimento que realmente está ante sus ojos, de esta manera, en caso de que el modelo haya cometido algún error en la clasificación, el usuario pueda saberlo y retornar a la pantalla de inferencia para hacer una nueva evaluación del objeto mostrado a la cámara.
Figura 31. Resultado de búsqueda de berenjena en Wikipedia.
De los resultados de Wikipedia, se extrajo la descripción general de los alimentos usando la API de JSON que provee la página, facilitando su extracción, la imagen fue extraída usando etiquetas HTML y la librería llamada Picasso en Android Studio. Tomado de “Eggplant”. Wikipedia. Creative commons 2019. Recuperado de https://en.wikipedia.org/wiki/Eggplant.
Posterior a la imagen genérica, se muestra una descripción general del alimento reconocido, esta también se extrae de Wikipedia, y es la información que usualmente se muestra sin necesidad de salir del buscador cuando se le hace una petición sobre algún término. Para esta descripción, se usó la API en formato JSON de Wikipedia, debido a que esta devuelve únicamente la descripción general, junto a algunas etiquetas de identificación de la página, que no se muestran al usuario, evitando la separación de la información de todo el documento HTML que retorna la búsqueda de la URL. Se usa una dirección base, seguido del objeto conocido, para el ejemplo de la berenjena, la dirección sería:
Imagen mostrada.
Descripción mostrada.

53
“https://en.wikipedia.org/w/api.php?format=json&action=query&prop=extracts&exintro=&explaintext=&titles=Eggplant”.
Seguido de la descripción general, se muestran los contenidos nutricionales por cada 100 gramos del alimento reconocido, esta información se extrae de la base de datos de la composición de alimentos del departamento de agricultura estadounidense. En este caso, en la URL no se encuentran los alimentos poniendo en ellos su nombre sino un número de identificación, para el caso de la berenjena es 11209, siendo la dirección: “https://ndb.nal.usda.gov/ndb/foods/show/11209” por lo que se construyó un método en el que se obtiene este número a partir del nombre del alimento reconocido. Dentro del documento HTML que retorna la búsqueda, se tiene la tabla de valores nutricionales, como se muestra en la figura 30, de la que se extraen los nombres de los componentes del alimento (vitaminas, minerales, grasas, calorías, etc.) las unidades de medida y sus valores en la columna de 100 gramos.
Finalmente, se muestra en pantalla, información sobre cómo escoger el alimento reconocido, recomendaciones sobre cómo almacenarlo y sus bondades más significativas (rico en vitamina C, rico en fibra, bajo en azúcar, buena fuente grasas poliinsaturadas, etc.), para ello, se extrae el contenido de la página web de la organización fruits and veggies more matters (figura 32), usando al igual que en la recolección de la imagen y la descripción general, una dirección base, seguido del nombre del alimento. Del documento HTML que retorna la búsqueda, se separa la información. Continuando con el ejemplo de la berenjena, la URL, sería: “https://www.fruitsandveggiesmorematters.org/eggplant”. En esta página, también se entregan descripción general de los alimentos, y tabla de valor nutricional, pero se decidió utilizar las otras fuentes debido a que la descripción de algunos alimentos no existía o era ambigua, y los contenidos nutricionales de la USDA son más completos que los entregados por la organización.

54
Figura 32. Resultado de búsqueda de berenjena en fruitsandveggiesmatters.org.
La información adicional del alimento, se extrajo también usando las etiquetas HTML. Tomado de “Eggplant. Nutrition. Selection. Storage”. Fruits and Veggies More Matters. Copyright 2019. Recuperado de https://www.fruitsandveggiesmorematters.org/eggplant.
Dentro del apartado de accesibilidad de la mayoría de distribuciones de Android, se tiene la posibilidad de activar la función de Talkback que permite al usuario escuchar el contenido de los textos que aparecen en la pantalla del teléfono, siendo esta una posible ayuda para las personas en condición de capacidad reducida en la visión para adquirir información de los alimentos que toma mientras hace sus compras, dándoles así un mayor grado de independencia.
Información mostrada

55
7. RESULTADOS Y DISCUSIÓN
Durante el proceso de entrenamiento, Tensorflow guarda el sumario dentro de una carpeta en el que se almacenan cada cierta cantidad de pasos (100 para los entrenamientos realizados), la exactitud de la red respecto a la porción del dataset reservado para el entrenamiento, la exactitud con respecto a la parte del dataset reservada para validación y el valor de la función de pérdida (cross entropy en este caso) para ese mismo momento. Se realizó validación cruzada dividiendo el dataset en cinco partes iguales, una para testeo y cuatro para entrenamiento, con el propósito de tener unos indicadores de rendimiento que sean válidos para la totalidad del dataset.
Figura 33. Métricas de rendimiento durante entrenamiento de modelos.

56
Gráficos de exactitud (superior) y pérdida (inferior) de modelo de MobileNet con 0.75 de multiplicador de anchura y tamaño de imágenes de entrada de 224x224.
Estos datos, luego pueden ser visualizados indicando el directorio o carpeta en la que se encuentran los eventos a la aplicación de Tensorboard en la que se pueden ver los gráficos de la evolución de algunos estadísticos relacionados a los pesos sinápticos y umbrales de la red durante su entrenamiento. En la figura 33 se muestra en la parte superior la exactitud que idealmente sería 1, correspondiente al cien por ciento de acierto y en la parte inferior, la pérdida, que idealmente debería ser cero, dado que aumenta en función de los fracasos que se hayan tenido al momento de clasificar una imagen. A continuación, se presenta en la Tabla 3 la exactitud y el valor de la función de pérdida que las redes obtuvieron al momento de detener su entrenamiento.
Tabla 3. Exactitud (rosado) y valor de función de pérdida (azul) al finalizar el entrenamiento de redes Mobilenet con diferentes multiplicadores de anchura y tamaños de imágenes de entrada.
Multiplicador de anchura
0.25 0.5 0.75
Tamaño de imagen de entrada
160x160 0.9737 0.1237 0.9853 0.08015 0.9853 0.5966
192x192 0.9792 0.1241 0.9847 0.08580 0.9865 0.06847
224x224 0.9798 0.1146 0.9841 0.08289 0.9884 0.06345
Nota: Aunque se tenga una diferencia ligera entre los valores de exactitud entre los modelos entrenados, se tiene una tendencia a incrementar la exactitud a

57
medida que lo hace el tamaño de la imagen de entrada de la red y el multiplicador de anchura. Dado que estos son datos recogidos durante el proceso de validación, todavía no son suficientes como para hacer una elección concienzuda de cuál es el modelo que mejor se adapta a las necesidades de cuadros por segundo junto a clasificaciones acertadas.
Posteriormente, se capturaron las matrices de confusión elaboradas con las parte tomadas del dataset para testeo de cada una de las cinco evaluaciones hechas durante la validación cruzada, en primera instancia debido la gran cantidad de imágenes usadas en este proceso se tenían número nominalmente grandes fuera de la diagonal principal de la matriz, pero pequeños en comparación a los contenidos en las casillas de aciertos, haciendo algo más difícil y demorada la comprensión de los valores dentro de la matriz de confusión, por lo que se decidió hacer una normalización de las columnas para organizar los datos en un rango porcentual. Para hacer análisis rápidos de las matrices de confusión, se decidió hacer un mapeo de los valores a colores debido a que las filas de la matriz son largas, impidiendo que puedan organizarse las filas de manera en que les corresponda un renglón.
Figura 34. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 160 x 160 de tamaño de imágenes de entrada.
Los pares de clases con los que se confunde más el modelo son nabo-remolacha y nabo-calabaza larga.
En los anexos H e I (Correspondientes a los valores porcentuales de las matrices de confusión del modelo más rápido y más eficaz respectivamente) y en la figura

58
34, y en las matrices de confusión mapeadas a color correspondientes a los otros modelos también adjuntas en el apartado de anexos, se pueden identificar los objetos que más errores de clasificación tienen asociados, y con qué clases son confundidas. Tomando como referencia la numeración que se le otorga a clases mostrada en la Tabla 2, se puede ver por ejemplo que la remolacha (clase número dos) es confundida con los nabos (clase número 17), lo cual tiene sentido en cierta medida pues ambas son raíces redondas con hojas de forma similar y en ocasiones el nabo puede adoptar tonalidades moradas similares a las de la remolacha como se muestra en la figura 35.
Figura 35. Comparación de clases, nabo (izquierda) y raíz de remolacha (derecha).
Accediendo a los componentes numéricos alojados en la matriz de confusión se encuentra que los errores de clasificación entre ambas clases se presentaron en un 2.7% de las veces en las que ingresó una imagen correspondiente a un nabo y la red lo reconoció erróneamente etiquetando la imagen de entrada en el grupo de las remolachas.
Otra pareja de alimentos en las que se presenta confusión por parte del modelo entrenado es entre la calabaza alargada (clase número nueve) y el nabo (clase número 17), esto puede darse debido a que la cáscara de este tipo de calabaza es bastante pálida similar a como ocurre con la parte inferior del nabo que muestra tonalidades muy claras, esto sumado a que dependiendo del punto de vista que se tenga, la calabaza puede verse de forma redonda como es el caso de los nabos.

Figura 36. Comparación de clases, calabaza alargada (izquierda) y nabo (derecha).
En este caso, en el 2.9% de las veces que se alimentó a la red con imágenes de calabaza alargada, estas fueron clasificadas erróneamente en el grupo de los nabos.
En comparación al modelo más efectivo en la clasificación de los objetos que fue el Mobilenet con multiplicador de anchura de 0.75 y tamaño de imágenes de entrada de 224 x 224 píxeles, se tienen las mayores dificultades clasificando los pares de clases mencionados, pero con mejoría en la cantidad de errores cometidos por el modelo al diferenciar entre una u otra, la clasificación errónea de nabos como raíces de remolacha disminuye de 2.7 % a 2.6%, y la de calabazas largas como nabos, disminuye de 2.9% a 2.7%, esta diferencia puede parecer ínfima en valores nominales, pero relativamente la primera pareja problemática tiene una mejoría del 3.7% y en la segunda, de un 6.9%.
Figura 37. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 224 x 224 de tamaño de imágenes de entrada.
En la representación gráfica de la matriz de confusión, del modelo más pesado, también se puede notar una ligera diferencia en el tono de color de las casillas correspondientes a las parejas de alimentos que fueron más confundidas por la red.
59

60
Cabe tener en cuenta que la etapa de testeo se realizó con porciones del dataset elaborado durante este proyecto, en el que para algunas clases se tomaron fotos de únicamente un espécimen del alimento que conforma la clase, siendo esto suficiente en algunos casos, o representando un factor moderadamente influyente para que el modelo pueda confundirse con alimentos que tienen alta variabilidad de forma o de color, como puede ser el caso de las raíces. Otro factor que puede tener peso en confundir al modelo cuando está en funcionamiento, es la diferencia de las características ópticas que se tiene entre las cámaras de los diferentes dispositivos usados para embarcarnos.
Posteriormente, se extrajeron las métricas de rendimiento de precisión y senitividad, en este caso se decidió no priorizar la minimización de falsos positivos ni de falsos negativos, por lo que se tomó el f1-score de promedio armónico simple mostrado en el en el marco teórico como medida para evaluar qué tan bien se desempeña un modelo frente a los otros debido a que esta métrica se ve influenciada en igual medida de la precisión y la sensitividad, a continuación en la tabla 4 se muestran los valores obtenidos por cada uno de los modelos entrenados después de ser puestos a prueba con las diferentes porciones de dataset que fueron reservadas para este propósito durante la validación cruzada para conseguir las etiquetas predichas por los modelos y compararlas con las etiquetas reales de las imágenes con las que estos se alimentan para ser clasificadas.
Tabla 4. F1-score (en porcentaje) obtenido por las redes Mobilenet entrenadas para clasificación de frutas y verduras.
Multiplicador de anchura
0.25 0.5 0.75
Tamaño de imágenes de entrada
160x160 90.3184 94.2134 95.66
192x192 91.1504 95.1642 95.7014

61
224x224 93.2743 95.1835 96.0442
Nota: Al igual que en la tabla 3 con la exactitud, se presenta una tendencia a mejora en efectividad de clasificación de los alimentos a medida aumenta la resolución de las imágenes de entrada y el multiplicador de anchura, siendo más influyente el segundo parámetro, pero al momento montarlos en los diferentes dispositivos de prueba como el computador personal, el teléfono móvil y los sistemas embebidos (Raspberry y Jetson), a los modelos les toma diferentes tiempos hacer la inferencia para las imágenes provenientes de las cámaras usadas como medio de recolección de datos. Se midieron los tiempos de evaluación de los modelos siendo corridos en diferentes dispositivos en aras de elegir los que muestran mejor desempeño para clasificar junto a una tasa de cuadros por segundo que permita utilizar el sistema de clasificación de manera fluida.
A continuación, se presentan los diagramas de cajas en los que se muestran los tiempos de evaluación de los modelos entrenados de MobileNet en el computador portátil hp-14d043la (Hewlett Packard, 2014), el kit de desarrollo Jetson TX2 (Nvidia, 2017), una raspberry 3 b+ (Raspberry pi, 2012) y un Motorola Moto g4 play (GSMarena, 2016) usando 0.25, 0.5 y 0.75 como multiplicadores de anchura y resolución de las imágenes de entrada, fueron usados 160 x 160 (rojo), 192 x 192 (azul) y 224 x 224 (verde). Dentro de cada grupo de color, los tiempos de evaluación de los modelos se organizan de izquierda a derecha comenzando por los modelos de menor multiplicador de anchura.
Tabla 4. (continuación)

62
Figura 38. Diagrama de cajas para tiempos de evaluación en computador personal hp-14d043la de los modelos de Mobilenet entrenados.
En el computador utilizado, se tuvieron unos tiempos de evaluación de alrededor de 0.12 segundos para el modelo más liviano y 0.3 segundos para el más pesado.
Figura 39. Diagrama de cajas para tiempos de evaluación en Raspberry pi 3 b+ de los modelos de Mobilenet entrenados.
En el computador utilizado, se tuvieron unos tiempos de evaluación de alrededor de 0.9 segundos para el modelo más liviano y 2.2 segundos para el más pesado.

63
Figura 40. Diagrama de cajas para tiempos de evaluación en Tarjeta Jetson TX2 (CUDA V8) de los modelos de Mobilenet entrenados.
En el computador utilizado, se tuvieron unos tiempos de evaluación de alrededor de 0.6 segundos para el modelo más liviano y 0.86 segundos para el más pesado.
Figura 41. Diagrama de cajas para tiempos de evaluación en Motorola Moto G4 play de los modelos Mobilenet entrenados.
En el computador utilizado, se tuvieron unos tiempos de evaluación de alrededor de 0.1 segundos para el modelo más liviano y 0.36 segundos para el más pesado. La similitud de tiempos de evaluación entre el computador

64
y el teléfono móvil, se debe a que las librerías que se carga en el móvil están optimizadas para hacer únicamente inferencia.
A diferencia del f1-score, el tiempo de evaluación es una métrica que varía bastante entre modelos entrenados, influyendo ligeramente en su incremento la resolución de las imágenes de entrada y fuertemente el multiplicador de anchura de las redes. En el caso del computador y el kit de desarrollo Jetson, la diferencia en tiempo de evaluación entre lo multiplicadores de 0.25 a 0.5 y de 0.5 a 0.75 es similar, pero en el caso de la Raspberry pi, esta diferencia crece alrededor de un 50%.
Para lograr que se tenga una sensación fluida de video y que no perciban trabas en la experiencia, el ojo humano requiere de una tasa de actualización de las imágenes de al menos 24 (Brunner, 2018) cuadros por segundo, cifra que claramente no será alcanzada en ninguna de las plataformas, por lo que se optará convenientemente por usar el modelo que presente mayor precisión en clasificar los alimentos para los que se entrenó y no hacer inferencia en la totalidad de cuadros capturados por la cámara, sino poniendo entre cuadro y cuadro que entra a la red, otra cierta cantidad con la que no se hace más que mostrarlos en pantalla en aras de darle fluidez.

65
8. CONCLUSIONES
La utilización de sistemas embebidos y dispositivos móviles en aplicaciones relacionadas con aprendizaje profundo, permite que la realización de algunas tareas sea viable, en el caso de la herramienta desarrollada durante este proyecto, disponer de un ordenador personal para dar información en los sitios de venta de frutas y verduras, como los lectores de precios en supermercados, presentaría subutilización de los recursos de este dispositivo. En el caso de la aplicación móvil, el hecho de que el usuario puede llevar el sistema de inferencia consigo al momento de hacer las compras, es lo que le da valor a la herramienta.
Por otro lado, esta aplicación tiene utilidad para hacer mejor informadas a las personas sobre los componentes que llevan los productos alimenticios, contribuyendo a desacelerar el crecimiento del porcentaje de población en estado de obesidad, siendo esta una enfermedad creciente en países de nuestra región latinoamericana (Banco Mundial, 2013), (Organización de naciones Unidas, 2018) que contribuye a la aparición de enfermedades cardiacas, deterioro en articulaciones y desordenes hormonales de quienes la padecen, reduciendo la calidad de vida de los portadores e implicando gastos adicionales del Estado en el sector de salud, que pueden ser invertidos en otros rubros que puedan generar mayor crecimiento económico de los países.
En la construcción de arreglos de imágenes para entrenar redes con propósitos de clasificación, se debe tener alta variabilidad entre los elementos que lo constituyen, de manera que, en su conjunto, puedan dar una descripción lo más completa posible de la clase que se desea diferenciar. En el caso de los alimentos para clasificar dentro de este proyecto, se encontró que en aras de aumentar la eficacia de los modelos a entrenar con las imágenes tomadas, es importante obtenerlas desde ángulos de manera que no se repitan las fotos cuando se haga aumento de datos, también tener en cuenta el entorno y las características (iluminación, distancia entre el objeto y la cámara) de las imágenes que el modelo va a obtener una vez que está en funcionamiento, que para este proyecto son las formas más usuales en que las personas muestran los alimentos a la cámara, ayuda a aumentar la efectividad para la clasificación de los objetos.
Adicionalmente, las herramientas de aprendizaje automático pueden ser implementadas en diversos tipos de plataformas además de los computadores de escritorio, abriendo las puertas a aplicaciones que tienen mayor sentido cuando pueden ser llevadas consigo, como ocurre en el caso de la propuesta de este proyecto: el reconocer los alimentos y obtener información de ellos tiene mayor valor o utilidad para el usuario, si se hace en el sitio de las compras que una vez se han llevado al hogar, o al sitio en donde se vaya a disponer de ellos.

66
Por último, la utilización de sistemas que permitan evitar la utilización de empaques o etiquetas innecesarias en los productos representa una necesidad en pro de reducir el ritmo con el que se contaminan y deterioran entornos que sirven de hábitat para especies importantes dentro de las interacciones o ciclos permiten a la humanidad disfrutar de seguridad alimentaria, agua y aire limpios. La pertinencia de estos sistemas, se hace especialmente importante en países y regiones en vía de desarrollo debido a que estos no cuentan con sistemas de reciclaje capaces (EFE, 2018) de hacerse cargo de la mayoría de los desechos de sus poblaciones y la no utilización o reducción del tamaño de empaques y etiquetas puede representar disminución de los precios que pagan por los productos los compradores finales. La aplicación producida por este proyecto es un prototipo que demuestra que estos sistemas son viables de implementarse.
Posterior a las revisiones realizadas por los jurados evaluadores en la sustentación de este trabajo de grado, se anotaron las siguientes recomendaciones y posibles cambios:
En aplicaciones de clasificación en las que se tienen clases con tan alta información respecto características como es el caso de las frutas y verduras, los canales RGB de color son suficientes para diferenciar entre las clases, haciendo innecesaria la captura del canal de profundidad.
Para efectos de portabilidad, en lugar de hacer la implementación en los sistemas Raspberry pi y el kit de desarrollo Jetson TX2, se pudo haber hecho la comparación e implementación en teléfonos móviles de diferente gamas y marcas puesto que estos ofrecen una mayor facilidad para ser movidos a los sitios de venta de alimentos no procesados, generando así un mayor valor para el usuario. Sin embargo, los single board computer pueden disponerse de manera fija en los sitios de venta de la misma forma en que se sitúan los escáneres de códigos de barras en los supermercados para brindar información relacionada al producto.
Por último, se resaltó la pertinencia de haber hecho la implementación en la Raspberry y el kit de desarrollo para compartir con la comunidad universitaria Autónoma el conocimiento adquirido acerca del manejo de estas plataformas en torno a aplicaciones relacionadas a la inferencia usando redes neuronales profundas.

67
9. RECOMENDACIONES Y TRABAJO FUTURO
Los tiempos de evaluación que toman a los modelos dentro de las plataformas utilizadas, pueden ser acortados utilizando la versión lite de Tensorflow en lugar de emplear modelos con extensión de bytes puros, la versión lite está optimizada para ejecutar operaciones de inferencia en teléfonos inteligentes o en plataformas de recursos limitados, la razón de no haberse utilizado en este proyecto fue que solo estaba disponible en las versiones nightly de Tensorflow, siendo indicado en la página de descarga de la librería que esta podría presentar problemas de estabilidad.
Por otro lado, se proponen mejoras en el set de datos para el entrenamiento de la red, como son la adición de una mayor cantidad de clases y así abarcar una parte considerable de las frutas y verduras que se puedan encontrar en sitios de venta de estos alimentos, por el momento se tienen 21 clases en el set de datos. También se pueden hacer tomas a una mayor cantidad de especímenes por clase para permitirles a los modelos aprender una visión más completa de los alimentos para los que se entrena. Además, se pueden agregar a las imágenes algunas características que acerquen más su contenido al que se pueda encontrar cuando los modelos estén en funcionamiento, como pueden ser dedos del posible usuario manipulando los alimentos o cobijar la posibilidad de que se apunte la cámara al alimento junto a otros del mismo tipo alrededor. Cabe resaltar que este tipo de sistema puede ser empleado para otras aplicaciones, por ejemplo, la detección de enfermedades en las hojas o tallos de cultivos específicos, para luego dar información y posibles tratamientos para ellas. También para dar información cualitativa sobre sobre los valores nutricionales de alimentos ya procesados como ya se hace o se planea hacer en algunos países de la región (Salud Pública de México, 2018),(Ministerio de Salud de Ecuador, 2013), (Instituto Nacional de Salud Pública de México, 2016).
Por último, se puede sacar provecho del canal de profundidad que con el que cuentan las imágenes del set de datos en aras de tener la posibilidad de extraer mayor cantidad de características como formas, relieves o texturas, para ello, se pueden usar redes que ya hayan sido entrenadas para el manejo de tres canales de color y otro para distancia, o hacer el experimento de utilizar una red entrenada únicamente para imágenes a color, y entrenar una red que maneje la profundidad y posteriormente unirla a la primera.

68
REFERENCIAS
Paszke A. (2016). ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. Noviembre 23 de 2018, de Cornell University recuperado de:: https://arxiv.org/pdf/1606.02147.pdf.
Agricultura sensitiva. (2002). Empaque para vegetales y frutas frescas. Agricultura sensitiva, recuperado de: http://www.angelfire.com/ia2/ingenieriaagricola/empaques.htm.
Atwell C. (2013). The biggest-little revolution: 10 single-board computers for
under $100. EDN network recuperado de: https://www.edn.com/design/diy/4419990/The-biggest-little-revolution--10-single-board-computers-for-under--100.
Banco Mundial. (2013). Obesidad en América Latina: un problema creciente.
Banco Mundial.org, recuperado de: http://www.bancomundial.org/es/news/feature/2013/03/27/crece-obesidad-america-latina.
BRUNNER D. (2018). Frame Rate: A Beginner’s Guide. TechSmith recuperado de: https://www.techsmith.com/blog/frame-rate-beginners-guide/.
Chimp C. (2017). CEO de Nvidia: “GPUs reemplazarán la CPU, la ley de Moore está muerta”. 27. Masgamers.com recuperado de: http://www.masgamers.com/nvidia-ley-de-moore-gpu.
Daoust M. (2018). Tensorflow for poets 2. Tensorflow recuperado de: https://codelabs.developers.google.com/codelabs/tensorflow-for-poets-2/#0.
Diamond systems corp (2008). COM-based SBCs. The superior architecture for small form factor embedded systems. Diamond systems corporation, recuperado de: http://whitepaper.opsy.st/WhitePaper.diamondsys-combased-sbcs-wpfinal-.pdf.

69
EFE. (2018). Colombia recicla el 17% de los 12 millones de toneladas de residuos. Portafolio, 1.
Eggplant. (2018), Wikipedia recuperado de: https://en.wikipedia.org/wiki/Eggplant.
Escontrela A. (2018). Convolutional Neural Networks from the ground up. Towards Data Science, recuperado de: https://towardsdatascience.com/convolutional-neural-networks-from-the-ground-up-c67bb41454e1.
Fruits and vegies more matters. Fruit and vegetable nutrition database. for better health foundation recuperado de: https://www.fruitsandveggiesmorematters.org/fruit-nutrition-database.
Fortuner B., Viana M. y Bahrgav K. (2018). Loss functions. GitHub, recuperado de: recuperado de: https://github.com/bfortuner/ml-cheatsheet/blob/master/docs/loss_functions.rst.
Galvin J, Murphy S, Crocker S. Freed N. (1995). Security Multiparts for MIME: Multipart/Signed and Multipart/Encrypted. Innosoft International, Inc recuperado de: https://tools.ietf.org/html/rfc1847.
Godoy D. (2018). Understanding binary cross-entropy / log loss: a visual explanation. Towards datascience, recuperado de: https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a.
Goodfellow I., Bengio Y. y Courville A. (2016). Introduction. En Deep learning (1-26).: MIT press.
Google. (2018). TensorFlow.js. Google, recuperado de: https://js.tensorflow.org/.
GSMarena. (2016). Motorola G4 play, features. GSMarena, recuperado de: https://www.gsmarena.com/motorola_moto_g4_play-8104.php
Guesmi L., Fathallah H. y Menif M. (2018). Modulation Format Recognition Using Artificial Neural Networks for the Next Generation Optical Networks. , recuperado de: 10.5772/intechopen.70954.

70
Guillermo J. (2014). Las redes neuronales: qué son y por qué están volviendo. Xataca, recuperado de: https://www.xataka.com/robotica-e-ia/las-redes-neuronales-que-son-y-por-que-estan-volviendo.
Heath S. (2003). Embedded systems design. EDN series for design engineers (2 ed.). Newnes. p. 2. ISBN 978-0-7506-5546-0.
Hewlett Packard. Notebook HP 14-d043la: Especificaciones del producto. Hewlett Packard, recuperado de: https://support.hp.com/co-es/document/c04091202.
IBM. Protocolos TCP/IP. IBM, recuperado de: https://www.ibm.com/support/knowledgecenter/es/ssw_aix_72/com.ibm.aix.networkcomm/tcpip_protocols.htm.
Introducing JSON. (2015). JSON, recuperado de: https://www.json.org/.
Intel. (2017). Tecnología Intel Realsense. Intel, recuperado de: https://software.intel.com/es-es/realsense/sr300.
James L. (2018). The 8 Neural Network Architectures Machine Learning Researchers Need to Learn. KDnuggets, recuperado de: https://www.kdnuggets.com/2018/02/8-neural-network-architectures-machine-learning-researchers-need-learn.html.
JetsonHacks. (2018). JetsonHacks, developing for NVIDIA Jetson. JetsonHacks.com, recuperado de: https://www.jetsonhacks.com/category/deep-learning/.
Jingwen. (2018). Getting Started with Bazel. GitHub Sitio, recuperado de: https://github.com/bazelbuild/bazel/blob/master/site/docs/getting-started.md.
Khademi F. y SAYED M. (2016). Predicting the 28 Days Compressive Strength of Concrete Using Artificial Neural Network. i-manager's Journal on Civil Engineering. 6. 10.26634/jce.6.2.5936.
Larabel M. (2017). Benchmarks of Many ARM Boards from The Raspberry Pi To NVIDIA Jetson TX2. Phoronix, recuperado de: https://openbenchmarking.org/embed.php?i=1703199-RI-ARMYARM4104&sha=56920d0&p=2.

71
Lavigne D. (1976). Counting Harp Seals with ultra-violet photography. Polar Record, 18(114), 269-277. doi:10.1017/S0032247400000310.
Lomont C. (2011). Introduction toIntel®Advanced Vector Extensions. Intel, recuperado de: https://software.intel.com/sites/default/files/m/d/4/1/d/8/Intro_to_Intel_AVX.pdf.
López R. (2014). ¿Qué es y cómo funciona “Deep Learning”? , recuperado de: https://rubenlopezg.wordpress.com/2014/05/07/que-es-y-como-funciona-deep-learning/.
Lyubova N. (2016). SR300 support in ROS + Distorted Pointcloud. GitHub recuperado de: https://github.com/IntelRealSense/librealsense/issues/61#issuecomment-194747954.
Machine Learning guru. (2017). Image Filtering. Machne Learning guru recuperado de: http://machinelearninguru.com/computer_vision/basics/convolution/image_convolution_1.html.
Mcculloch W y Pitts W. A logical calculus of the ideas immanent in nervousactivity. En: Bulletin of mathematical biophysics. No 5. (1943).
Mysid. (2007). Image Scaling. Wikipedia recuperado de: https://en.wikipedia.org/wiki/Image_scaling#/media/File:2xsai_example.png.
Nvidia. (2018). JetPack 3.2.1 Release Notes. Nvidia recuperado de: https://developer.nvidia.com/embedded/jetpack-3_2_1.
Nvidia. (2017). Nvidia Jetson systems: Module technical specifications. Nvidia corporation recuperado de: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/.
Olshausen B. y Field D. How close are we understanding V1? En Neural Computation . 8 (2015).

72
Organización de Naciones Unidas. (2018). Más hambrientos y más obesos en América Latina en medio de la desigualdad. Organización de Naciones Unidas recuperado de: https://news.un.org/es/story/2018/11/1445101.
Palacios F. (2003). Herramientas en GNU/Linux para estudiantes universitarios: Capítulos 2 y 3. ibiblio.org recuperado de: https://www.ibiblio.org/pub/linux/docs/LuCaS/Presentaciones/200304curso-glisa/redes_neuronales/curso-glisa-redes_neuronales-html/x69.html.
Perez C. (2015). Why are GPUs well-suited to deep learning? Quora recuperado de: https://www.quora.com/Why-are-GPUs-well-suited-to-deep-learning.
Pokharna H. (2016). The best explanation of Convolutional Neural Networks on the Internet! Medium recuperado de: https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks-on-the-internet-fbb8b1ad5df8.
Raspberry pi. (2012). Raspberry pi 3 model b plus: Specifications. Raspberry pi foundation recuperado de: https://www.raspberrypi.org/products/raspberry-pi-3-model-b-plus/
Redacción tecnológica. (2018). Seeing AI, la aplicación que le describe el mundo a quienes no ven. El espectador recuperado de: https://www.elespectador.com/tecnologia/seeing-ai-la-aplicacion-que-le-describe-el-mundo-quienes-no-ven-articulo-73914.
Instituto Nacional de Salud Pública de México. (2016). Review of current labelling regulations and practices for food and beverage targeting children and adolescents in Latin America countries (Mexico, Chile, Costa Rica and Argentina) and recommendations for facilitating consumer information. UNICEF recuperado de:https://www.unicef.org/ecuador/english/20161122_UNICEF_LACRO_Labeling_Report_LR(3).pdf.
Sehgal A y Kehtarnavaz N. (2019). Guidelines and Benchmarks for Deployment of Deep Learning Models on Smartphones as Real-Time Apps. Arxiv recuperado de: https://arxiv.org/ftp/arxiv/papers/1901/1901.02144.pdf
Sistema de etiquetado frontal de alimentos y bebidas para México: una estrategiapara la toma de decisiones saludables. (2018). Salud Pública de México recuperado de: http://saludpublica.mx/index.php/spm/article/view/9615/11536.

73
Sistema de etiquetado de alimetos procesados. Ministerio de salud públida de Ecuador recuperado de: http://instituciones.msp.gob.ec/images/Documentos/infografia2.pdf.
Stanford University. (2015). ConvNetJS deep Learning in your browser. Stanford University recuperado de: https://cs.stanford.edu/people/karpathy/convnetjs/.
Sunasra M. (2017). Performance Metrics for Classification problems in Machine Learning. Medium recuperado de: https://medium.com/thalus-ai/performance-metrics-for-classification-problems-in-machine-learning-part-i-b085d432082b.
Tensorflow. (2018). Introduction to TensorFlow Mobile. Google recuperado de: https://www.tensorflow.org/mobile/mobile_intro.
United States Department of agriculture. USDA Food Composition Databases. USDA recuperado de: https://ndb.nal.usda.gov/ndb/search/list.
Willis, K. (2018). Augmented reality system lets doctors see under patients' skin without the scalpel: New technology lets clinicians see patients' internal anatomy displayed right on the body. ScienceDaily, recuperado de: www.sciencedaily.com/releases/2018/01/180124172408.htm.
Villagómez C. Protocolo HTTP (2014). CMM recuperado de: https://es.ccm.net/contents/264-el-protocolo-http.
Visem. Changing the contrast and brightness of an image!, de Opencv recuperado de: https://docs.opencv.org/3.4/d3/dc1/tutorial_basic_linear_transform.html.
Wikipedia. API sandbox. Wikipedia recuperado de: https://en.wikipedia.org/wiki/Special:ApiSandbox.

74
ANEXOS
Anexo A. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 160 x 160 de tamaño de imágenes de entrada.
Anexo B. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 160 x 160 de tamaño de imágenes de entrada.

75
Anexo C. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 192 x 192 de tamaño de imágenes de entrada.
Anexo C. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 192 x 192 de tamaño de imágenes de entrada.
76
Anexo D. Matriz de confusión mapeada a colores del modelo MobileNet con 0.75 de anchura y 192 x 192 de tamaño de imágenes de entrada.
Anexo E. Matriz de confusión mapeada a colores del modelo MobileNet con 0.25 de anchura y 224 x 224 de tamaño de imágenes de entrada.

77
Anexo F. Matriz de confusión mapeada a colores del modelo MobileNet con 0.5 de anchura y 224 x 224 de tamaño de imágenes de entrada.

78
Anexo G. Matriz de confusión en valores porcentuales de modelo Mobilenet con 0.25 de multiplicador de anchura y 160 x 160 de tamaño de imágenes de entrada.
100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |94.2|0.2 |0.0 |0.0 |0.0 |0.0 |0.0 |0.9 |0.0 |0.0 |0.0 |1.3 |0.0 |0.0 |0.0 |2.7 |0.0 |0.0 |0.7 |0.5
0.0 |0.0 |99.3|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |99.5|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |99.7|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |99.6|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.2 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |98.0|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.5|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.2 |96.7|0.0 |0.2 |0.0 |0.5 |0.0 |0.0 |0.0 |3.0 |0.0 |0.2 |0.2 |0.5
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.1|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.5 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.0 |93.6|0.0 |0.0 |0.0 |1.2 |0.2 |0.0 |0.5 |0.7
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.3 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |2.9 |0.2 |0.2 |0.2 |0.0 |0.4 |0.0 |1.3 |0.0 |0.0 |0.0 |1.1 |0.0 |0.0 |0.0 |92.5|0.0 |0.0 |2.1 |0.4
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.0|0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.6|0.0 |0.0

79
0.0 |0.4 |0.0 |0.0 |0.0 |0.2 |0.9 |0.0 |0.0 |0.0 |0.4 |0.0 |0.2 |0.0 |0.0 |0.0 |1.7 |0.0 |0.0 |95.1|0.4
0.0 |2.1 |0.0 |0.2 |0.0 |0.2 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |1.8 |0.0 |0.0 |0.0 |0.2 |0.0 |0.0 |0.5 |97.9

80
Anexo H. Matriz de confusión en valores porcentuales de modelo Mobilenet con 0.75 de multiplicador de anchura y 224 x 224 de tamaño de imágenes de entrada. 100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |95.0|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.9 |0.2 |0.0 |0.0 |1.4 |0.0 |0.0 |0.2 |0.4
0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |99.6|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.7|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |97.9|0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.0 |1.8 |0.0 |0.0 |0.2 |0.2
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.8|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.7|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.2 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.0 |97.0|0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.0 |1.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.3 |0.0 |0.0 |0.0 |0.0 |0.0 |99.7|0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.7|0.0 |0.0 |0.0 |0.0 |0.0
0.0 |2.7 |0.0 |0.0 |0.0 |0.2 |0.0 |0.0 |1.3 |0.0 |0.0 |0.2 |0.2 |0.0 |0.0 |0.0 |96.2|0.0 |0.2 |0.4 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |100 |0.0 |0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |99.6|0.0 |0.0
0.0 |0.0 |0.0 |0.0 |0.0 |0.2 |0.0 |0.0 |0.0 |0.2 |0.0 |0.0 |0.2 |0.0 |0.0 |0.0 |0.4 |0.0 |0.0 |98.9|0.6

81
0.0 |2.1 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.0 |0.5 |0.0 |0.0 |0.2 |0.2 |0.0 |0.0 |0.2 |98.3
Anexo I. Enlace a repositorio de proyecto.
https://github.com/Sharmineroz/Fruits_roots_veggies