anexo1. normalización de histograma. - servidor de la...
TRANSCRIPT

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
70
8.‐ Anexos.
Anexo1. Normalización de histograma.
El proceso de normalización de histograma modifica el valor de los píxeles de una imagen para conseguir que el histograma de la misma tenga una forma lo más parecida posible a un patrón. Es por tanto un proceso basado en histograma. El histograma de una imagen es una función de probabilidad que determina la probabilidad de que un píxel tenga un valor dado.
Sea
donde Pr es la función de probabilidad original , y
donde Pt es la función de densidad de probabilidad deseada.
Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
71
a y b son iguales, pues no son más que el número total de píxeles si consideramos que Pr y Pt son los histogramas original y deseado para una misma imagen. De la expresión de a deducimos:
y como
resulta:
En el caso discreto:
y
La transformación de un histograma original en otro deseado será el determinar qué valor de t corresponde a cada valor de r.
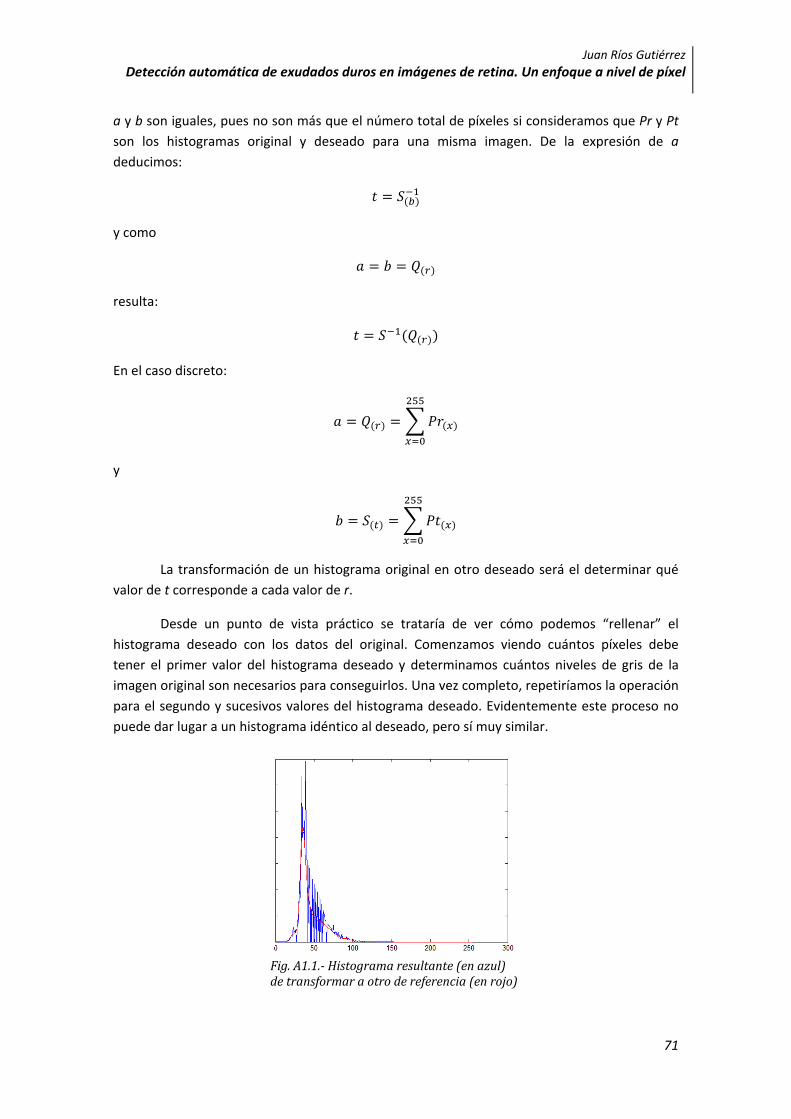
Desde un punto de vista práctico se trataría de ver cómo podemos “rellenar” el histograma deseado con los datos del original. Comenzamos viendo cuántos píxeles debe tener el primer valor del histograma deseado y determinamos cuántos niveles de gris de la imagen original son necesarios para conseguirlos. Una vez completo, repetiríamos la operación para el segundo y sucesivos valores del histograma deseado. Evidentemente este proceso no puede dar lugar a un histograma idéntico al deseado, pero sí muy similar.
Fig. A1.1. Histograma resultante (en azul) de transformar a otro de referencia (en rojo)

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
72
La figura A1.2 muestra el resultado de normalizar los histogramas de una imagen a los de otra empleada como patrón. La figura A1.3 la transformación sufrida por los histogramas de cada capa de la imagen.
a) Imagen original b) Imagen de referencia c) Imagen normalizada Fig. A1.2. Normalización de una imagen a un patrón
a) Histogramas capa R antes de normalizar
b) Histogramas capa G antes de normalizar
c) Histogramas capa B antes de normalizar
d) Histogramas capa R después de normalizar
e) Histogramas capa G después de normalizar
f) Histogramas capa B después de normalizar
Fig. A1.3. Histogramas de la imagen a transformar frente a la de referencia antes y después del proceso de normalización. En rojo los histogramas de la imagen de referencia, en azul los de la imagen a transformar
0 50 100 150 200 250 3000
1
2
3
4
5
6
7x 104
0 50 100 150 200 250 3000
1
2
3
4
5
6
7
8
9
10x 104
0 50 100 150 200 250 3000
2
4
6
8
10
12
14x 104
0 50 100 150 200 250 3000
1
2
3
4
5
6
7x 104
0 50 100 150 200 250 3000
1
2
3
4
5
6
7
8
9
10x 104
0 50 100 150 200 250 3000
2
4
6
8
10
12
14
16x 104
Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
73
Anexo 2. Contrastado.
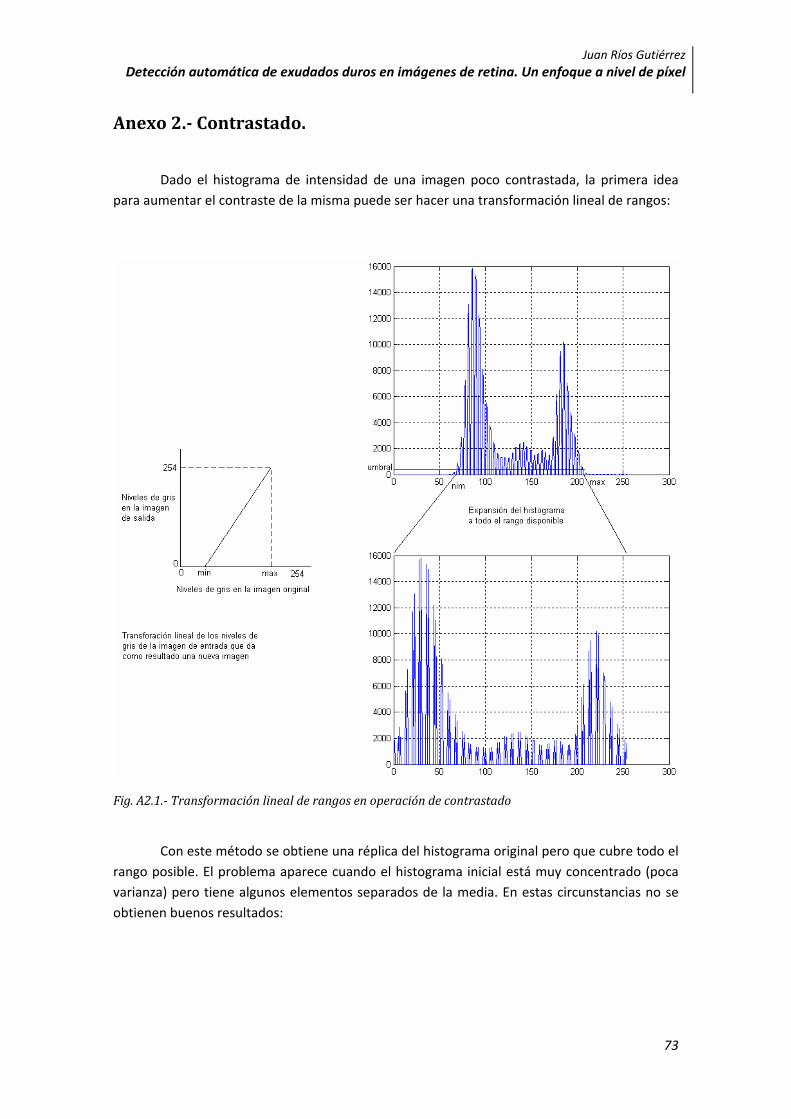
Dado el histograma de intensidad de una imagen poco contrastada, la primera idea para aumentar el contraste de la misma puede ser hacer una transformación lineal de rangos:
Fig. A2.1. Transformación lineal de rangos en operación de contrastado
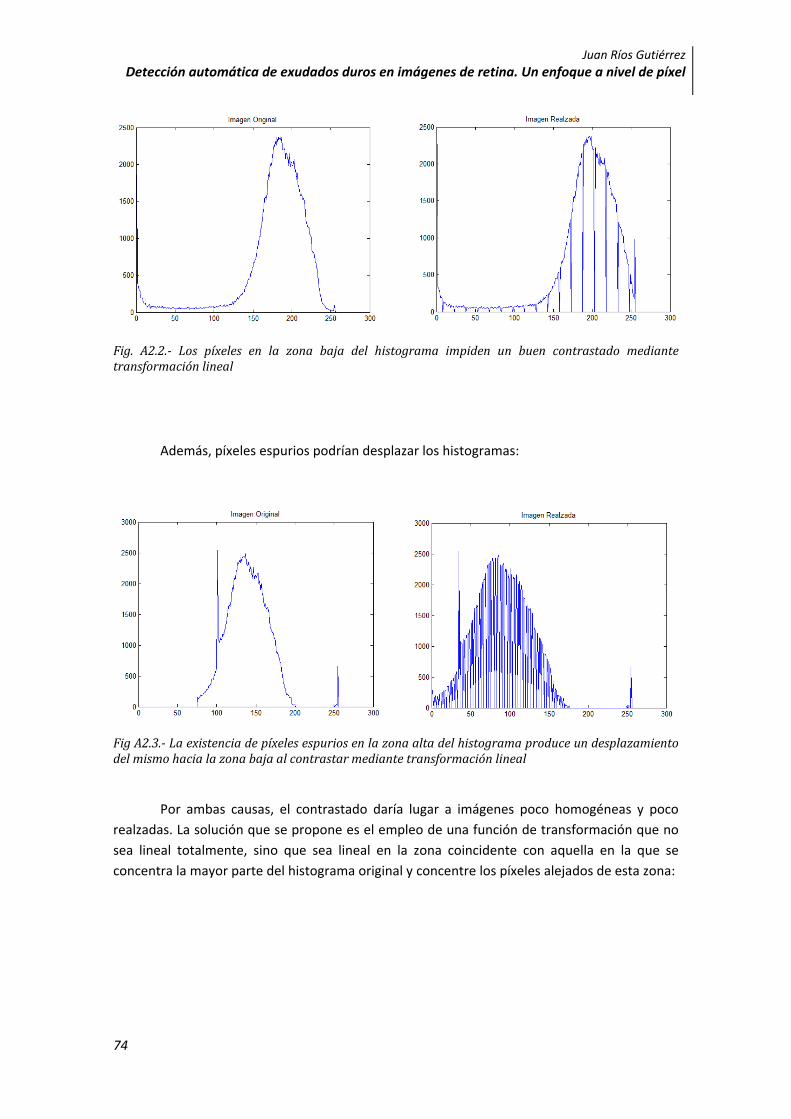
Con este método se obtiene una réplica del histograma original pero que cubre todo el rango posible. El problema aparece cuando el histograma inicial está muy concentrado (poca varianza) pero tiene algunos elementos separados de la media. En estas circunstancias no se obtienen buenos resultados:
Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
74
Fig. A2.2. Los píxeles en la zona baja del histograma impiden un buen contrastado mediante transformación lineal
Además, píxeles espurios podrían desplazar los histogramas:
Fig A2.3. La existencia de píxeles espurios en la zona alta del histograma produce un desplazamiento del mismo hacia la zona baja al contrastar mediante transformación lineal
Por ambas causas, el contrastado daría lugar a imágenes poco homogéneas y poco realzadas. La solución que se propone es el empleo de una función de transformación que no sea lineal totalmente, sino que sea lineal en la zona coincidente con aquella en la que se concentra la mayor parte del histograma original y concentre los píxeles alejados de esta zona:

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
75
Fig. A2.4. Función de transformación no lineal y resultado de su aplicación en un histograma que presenta píxeles espurios
Con esto logramos que:
‐ El histograma resultante esté centrado ‐ La zona importante del histograma original se estira ocupando la mayor parte del
nuevo histograma ‐ Los píxeles que están disgregados fuera de la zona importante del histograma original
se concentran en los extremos del nuevo histograma
Queda claro que la pendiente de la zona central de la función de transformación deberá ser mayor cuanto menor sea la dispersión de los datos del histograma original, y que la posición de esta función de transformación dependerá de la posición del histograma original. Para la definición de la función de transformación se tienen en cuenta la media de los niveles de gris originales y la desviación estándar como media de dispersión.
La Función de transformación es:
1
Para definir una curva centrada en la media, μw y cuya forma dependa de la desviación estándar σw y:
255
0 50 100 150 200 250 3000
50
100
150
200
250

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
76
Para que el histograma resultante varíe entre 0 y 255
Siendo:
‐ min: Valor de gris mínimo en la imagen a contrastar ‐ max: Valor de gris máximo en la imagen a contrastar ‐ P: Valor de gris que queremos transformar ‐ Pn: Valor de gris transformado ‐ μw: Media de los valores de gris de la ventana a contrastar:
1,
,
‐ σw: Desviación estándar de la ventana a contrastar:
1,
,
El proceso de contrastado en imágenes de fondo de ojo aumenta bastante el contraste de lesiones como los exudados, pero también puede contrastar otros píxeles claros debidos a ruido que posteriormente podrán ser falsos positivos. Para reducir el riesgo de que esto ocurra se emplea previamente un filtro de mediana. Se emplea este filtro ya que no desdibuja los bordes, característica importante de los exudados. Para determinar el tamaño de la ventana de filtrado se probó con ventanas de 3x3 y 5x5, comprobándose cómo esta última hace perder bastantes detalles y nitidez en los bordes, por lo que se opta por la primera.

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
77
Anexo 3. Igualación de fondo.
En numerosas imágenes de fondo de ojo se observan variaciones de iluminación que conllevan variaciones de intensidad de los píxeles del fondo en diversas zonas de la imagen. Este hecho, de forma general, dificulta la caracterización de los píxeles del fondo. En el caso de la detección de exudados, es fácil encontrar imágenes en las que en algunas zonas, con fondo más claro que el resto de la imagen, se generen falsos positivos. Los procesos de igualación de fondo tienen como objetivo transformar una imagen en la que el fondo presenta variaciones de intensidad en otra con el fondo lo más homogéneo posible. Hay dos enfoques típicos para realizar la corrección de fondo, el primero de ellos se basa en la sustracción de una imagen de fondo a la imagen original mientras que el segundo método se basa en la división de la imagen original por la de fondo. Ambos enfoques obtienen resultados similares, no demostrando ninguno de ellos una clara ventaja sobre el otro. El algoritmo empleado [15], que pertenece al enfoque sustractivo, se describe en los siguientes párrafos.
El primer paso de este proceso consiste en la obtención de una imagen de fondo. Para ello, a la imagen original se le aplican tres filtros: un primer filtro de media de 3x3 para la reducción del ruido sal y pimienta, un segundo filtro gaussiano, de dimensión 9x9, con media μ=0 y varianza σ2= 1.82:
98.1,0, 22 GGm =
σμ
para suavizar aun más el posible ruido contenido en la imagen y un filtro final de media de tamaño 69x69. Al aplicar este filtro en las cercanías del borde de la imagen el resultado se ve muy influenciado por la zona negra exterior. Para resolver esto los píxeles oscuros del exterior se sustituyen por el valor de la media del resto de píxeles interiores de la ventana. La imagen obtenida es una imagen estimación de fondo, IB.
Por otro lado, se obtiene otra imagen, Iγ, obtenida de la original a la que se somete a un proceso para la eliminación de los reflejos brillantes encontrados frecuentemente en el interior de los vasos sanguíneos. Se consigue aplicando un filtro morfológico (opening16) usando un disco de 3 píxeles de diámetro, definido en una rejilla cuadrada con conectividad a 8, como elemento estructural. El tamaño del disco se definió para reducir el riesgo de fusión de vasos cercanos.
Con estas dos imágenes, IB e Iγ obtenemos una imagen diferencia:
),(),(),( yxByxyx IYD −= γ
Y finalmente la imagen con el fondo corregido se obtiene mediante transformación lineal de los valores de D a un rango de enteros entre 0 y 255.
16 Este filtro consiste en la sustitución del valor de un pixel por el mínimo valor encontrado en una máscara

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
78
En la figura A3.1 se muestra el resultado de aplicar el algoritmo de igualación de fondo sobre la capa I de una imagen que presentaba variaciones de iluminación en el fondo.
a) Imagen original b) Imagen con el fondo corregido Fig. A3.1 Aplicación del algoritmo de igualación de fondo a una imagen con variaciones de iluminación

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
79
Anexo 4. Métodos de clasificación empleados.
Una de las operaciones clave en el enfoque propuesto es la clasificación de los píxeles de la imagen en dos clases: exudado y no exudado en base a una serie de características mediante las que se describen los píxeles. Existen muchos algoritmos de clasificación que pueden emplearse para este fin, muchos de ellos han sido empleados por otros autores para resolver este problema (ver apartado 2, estado del arte). En este anexo se hará una descripción somera de los algoritmos que se han ensayado en este trabajo. Estos algoritmos son:
‐ Red neuronal. Perceptrón multicapa ‐ Máquina de soporte vectorial ‐ Clasificador bayesiano ingenuo (Naïve Bayes) ‐ Red bayesiana ‐ Knn ‐ Árbol ‐ Clasificador por regresión logística
Red neuronal. Perceptrón multicapa.
Las redes neuronales artificiales (RNA o en inglés, ANN) son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de interconexión de neuronas en una red que colabora para producir un estímulo de salida.
La unidad básica de la que se compone la red es la neurona. Cada una de ellas recibe una serie de entradas a través de interconexiones y emite una salida. Esta salida viene dada por tres funciones:
‐ Función de propagación o de excitación, que por lo general consiste en un sumatorio de cada entrada multiplicada por el peso de su conexión.
‐ Función de activación, que modifica la anterior. Puede no existir, siendo es este caso la salida la misma función de propagación.
‐ Función de transferencia, que se aplica al valor devuelto por la función de activación. Se emplea para acotar la salida de la neurona y vendrá dada por la interpretación que queramos darle a dichas salidas. Entre las más empleadas está la función sigmoidea (para obtener valores en el intervalo [0,1]) y la tangente hiperbólica (para obtener valores en el intervalo [‐1,1]).
Fig. A4.1 Red neuronal multicapa

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
80
En base a datos conocidos (datos de entrada cuyos valores de salida de la red están determinados), se determinan los distintos pesos de las funciones de propagación de las distintas neuromas, en lo que se conoce como proceso de aprendizaje.
Las neuronas de una red neuronal artificial se encuentran estructuradas en capas: una capa de entrada, compuesta por las neuronas que reciben la información del exterior, una o más capas internas, en el caso de las redes multicapa y una capa de salida. El caso más simple de red neuronal es el perceptrón, que responde al concepto de neurona y sólo posee las capas de entrada y salida. El perceptrón simple puede emplearse como neurona para la formación de redes más complejas.
El perceptrón multicapa es una red artificial formada por múltiples capas, lo que le permite resolver problemas que no son linealmente separables (principal limitación del perceptrón simple). El perceptrón multicapa puede ser totalmente o localmente conectado. En el primer caso cada salida de una neurona de la capa “i” es entrada para todas las neuronas de la capa “i+1”, mientras que en segundo la salida de una neurona de la capa “i” es entrada sólo para una serie de neuronas o región de la capa “i+1”.
Máquina de soporte vectorial.
Las máquinas de soporte vectorial o máquinas de vector soporte (support vector machine, SVM) son un conjunto de algoritmos de aprendizaje supervisado desarrollados por Vladimir Vapnik.
Las SVM mapean los puntos de entrada a un espacio de características de una dimensión mayor, para luego encontrar el hiperplano que los separe y maximice el margen entre las clases. Pertenecen a la familia de clasificadores lineales puesto que inducen separadores lineales o hiperplanos en espacios de características de muy alta dimensionalidad (introducidos por funciones nucleo o kernel).
La formulación matemática de las máquinas de vectores soporte varía dependiendo de la naturaleza de los datos, es decir, existe una formulación para los casos lineales y otra para los datos no lineales.
Las SVM han sido desarrolladas como una técnica robusta para clasificación y regresión aplicada a grandes conjuntos de datos complejos con ruido, es decir, con variables inherentes al modelo que para otras técnicas aumentan la posibilidad de error en los resultados pues resultan difíciles de cuantificar y observar.
En el caso de problemas linealmente separables las SVM conforman hiperplanos que separan los datos de entrada en dos subgrupos que poseen una etiqueta propia. En medio de todos los posibles planos de separación de las dos clases existe sólo un hiperplano de separación óptimo, de forma que la distancia entre el hiperplano óptimo y el valor de entrada más cercano sea máxima (maximización del margen) con la intención de forzar la

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
81
generalización de la máquina que se esté construyendo. Aquellos puntos o ejemplo sobre los cuales se apoya el margen máximo son los denominados vectores de soporte.
Para el caso no lineal existen dos casos que vale la pena mencionar:
‐ Los datos pueden ser separados con margen máximo pero en un espacio de características de mayor dimensionalidad al que los datos son inducidos mediante el uso de una función kernel.
‐ Cuando no es posible encontrar la transformación de datos que permita la separación con margen máximo se emplea el denominado Soft Margin o margen blando. En este caso se cambia un poco la perspectiva y se busca el mejor hiperplano clasificador relajando las restricciones presentadas en el caso lineal, introduciendo para ello variables de holguras no negativas.
Clasificador bayesiano ingenuo (Naïve Beyes).
Es un método de clasificación supervisada basado en paradigmas probabilistas (teoría de Bayes).
Dada una muestra x representada por n valores, el clasificador bayesiano se basa en encontrar la hipótesis más probable que describa a esa muestra. Si la descripción de esa muestra viene dada por los valores <a1, a2, …, an>, la hipótesis más probable será aquella que cumpla:
)|,...,(maxarg 1 jnjMAP vaavPvv ∈=
Es decir, la probabilidad de que conocidos los valores que describen la muestra ésta pertenezca a la clase vj (donde vj es el valor de la función de clasificación f(x) en el conjunto finito V). Por el teorema de Bayes:
)()|,...,(maxarg),...,(
)()|,...,(maxarg 1
1
1jjnj
n
jjnjMAP vpvaavPv
aaPvpvaaP
vvv ∈=∈=
Fig. A4.2 MVS linealmente separable
Fig. A4.3 MVS con margen blando

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
82
Podemos estimar P(vj) contando las veces que aparece la muestra vj en el conjunto de entrenamiento y dividiéndolo por el número total de muestras que forman este conjunto. Para estimar P(a1, …, an | vj), es decir, las veces en que para cada categoría aparecen los valores de la muestra x, habría que recorrer todo el conjunto de entrenamiento para cada combinación posible de valores. Este cálculo resulta impracticable para un número suficientemente grande de muestras, por lo que se hace necesario simplificar la expresión. El clasificador Naïve Bayes recurre a la hipótesis de interdependencia condicional con el objeto de poder factorizar la probabilidad. Esta hipótesis dice lo siguiente:
Los valores aj que describen un atributo de una muestra cualquiera x son independientes entre sí conocido el valor de la categoría a la que pertenecen. Así, la probabilidad de observar la conjunción de atributos aj dada una categoría a la que pertenece es justamente el producto de las probabilidades de cada valor por separado:
∏= i jijn vaPvaaP )|()|,...,( 1
Red bayesiana.
Una red bayesiana es un grafo dirigido en el que cada nodo representa una variable y cada arco una dependencia probabilística, en la cual se especifica la probabilidad condicional de cada variable dados sus padres. La variable a la que apunta el arco es dependiente (causa‐efecto) de la que está en el origen de éste. La topología o estructura de la red nos da información sobre las dependencias probabilísticas entre las variables pero también sobre las interdependencias condicionales de una variable (o conjunto de variables) dada otra u otras variables. Dichas interdependencias simplifican la representación del conocimiento (menos parámetros) y el razonamiento (propagación de las probabilidades).
El obtener una red bayesiana a partir de datos es un proceso de aprendizaje que se divide en dos etapas: el aprendizaje estructural y el aprendizaje paramétrico. La primera de ellas consiste en obtener la estructura de la red, es decir, las relaciones de dependencia e interdependencia entre las variables involucradas. La segunda etapa tiene como finalidad obtener las probabilidades a priori y condicionales requeridas a partir de una estructura dada.
Knn.
La idea básica en la que se fundamenta el paradigma clasificatorio conocido como Knn (K‐Nearest Neighbour) es que un nuevo caso se va a clasificar en la clase más frecuente a la que pertenecen sus K vecinos más cercanos. El paradigma se fundamenta por tanto en una idea muy simple e intuitiva, lo que unido a su fácil implementación hace que sea un algoritmo de clasificación muy extendido.
Para clasificar una nueva muestra, se calculan las distancias de todos los casos ya clasificados con ella, y se seleccionan los K casos más cercanos a la misma. A la nueva muestra

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
83
se le asignará la clase más frecuente entre esas K muestras más cercanas. La figura A4.4 muestra de manera gráfica un ejemplo de clasificación en dos clases, representando sus miembros por “+” y “ο”. Se tienen ya clasificados 24 casos, y se ha empleado un valor K=3. De los tres casos ya clasificados más cercanos al nuevo elemento que se pretende clasificar (representado por un punto), dos de ellos pertenecen a la clase “ο”, por tanto el clasificador KNN 3 (también 3‐NN) predice esta clase para el nuevo caso. Hay que destacar que el caso más cercano a la nueva muestra pertenece a la clase “+”, por lo que un clasificador KNN 1 hubiese asignado la clase “+” a la nueva muestra.
Es interesante señalar que este paradigma de clasificación es un tanto atípico si lo comparamos con la mayor parte de los paradigmas de clasificación, ya que mientras que en el resto la clasificación de nuevos casos se lleva a cabo a partir de dos tareas, como son la inducción del modelo clasificatorio y la posterior deducción (o aplicación) sobre el nuevo caso, en el paradigma KNN al no existir modelo explícito las dos tareas anteriores se encuentran colapsadas en que se acostumbra a denominar transinducción.
En caso de que se produzca un empate entre dos o más clases, conviene tener una regla heurística para su ruptura. Ejemplos de regla heurística pueden ser: seleccionar la clase que contenga al vecino más próximo, seleccionar la clase con distancia media menor, etc.
Otra cuestión importante es la determinación del valor K. Se constata empíricamente que el porcentaje de casos bien clasificados es no monótono con respecto a K, siendo una buena elección valores de K comprendidos entre 3 y 7.
Árbol.
El paradigma de clasificación conocido como árbol de clasificación (también árbol de decisión) se basa en un particionado recursivo del dominio de definición de las variables predictoras. De este modo se puede representar el conocimiento sobre el problema por medio de una estructura de árbol.
La base del los árboles de clasificación es el algoritmo conocido como TDIDT (Top Down Induction of Decision Tress). La idea subyacente al algoritmo TDIDT es que mientras que todos los patrones que se correspondan con una determinada rama del árbol de clasificación no pertenezcan a una misma clase, se debe seleccionar la que de entre las no seleccionadas en esa rama sea la más informativa o idónea con respecto a un criterio previamente establecido. La elección de esta variable servirá para expandir el árbol en tantas ramas como valores pueda tomar dicha variable.
Fig. A4.4 Clasificación con KNN 3

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
84
La figura A4.5 muestra un conjunto de patrones caracterizados por dos variables predictoras, x1 y x2, y una variable clase C con dos valores posibles denotados como 1 y 2. Una posible representación del conocimiento subyacente al dominio del ejemplo se muestra en la figura A4.6.
Tal como puede verse, las variables predictoras se van a representar en el árbol de clasificación insertadas en un círculo, mientras que las hojas del árbol se representan por medio de un rectángulo en el cual se inserta el valor de la variable clase que el árbol de clasificación asigna a aquellos casos que bajan por las correspondientes ramas.
El árbol mostrado tiene para todas sus ramas una profundidad de 2, siendo este concepto de profundidad el que proporciona una idea de la complejidad del árbol de clasificación.
Clasificador por regresión logística.
El problema de clasificación en dos grupos puede abordarse introduciendo una variable ficticia binaria, y, para representar la pertenencia de un elemento a uno de los grupos. En este contexto, el problema de discriminación es equivalente a la previsión del valor de la variable y. Si el valor previsto está más próximo a 0 que a 1 clasificaremos el elemento en el primer grupo, clasificándolo en el segundo grupo en otro caso.
Una opción es la de construir un modelo que permita prever el valor de la variable ficticia binaria de un elemento en función de ciertas características medibles, x. Supongamos que se cuenta con una muestra de n elementos del tipo (yi,xi), donde yi es igual a 0 cuando el elemento pertenece al primer grupo y 1 cuando pertenece al segundo, siendo xi un vector de variables explicativas. El primer enfoque es formular el siguiente modelo de regresión:
uxy ++= '10 ββ
y estimar los parámetros por el método de los mínimos cuadrados. Este es el método conocido como función lineal discriminante de Fisher. Este método es óptimo para clasificar si la distribución conjunta de las variables explicativas es normal multivariante, con la misma matriz
Fig. A4.5 Representación en el plano de diferentes patrones correspondientes a dos clases
Fig. A4.6 Árbol de clasificación correspondiente al ejemplo de la figura A4.5

Juan Ríos Gutiérrez Detección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
85
de covarianzas, sin embargo puede funcionar mal en otros contextos. Tomando esperanzas en la expresión anterior para x=xi resulta:
ii xxyE '10]|[ ββ +=
Si llamamos pi a la probabilidad de que y tome el valor 1 cuando x=xi
)|1( ii xyPp ==
y la esperanza de y es:
iiii pxyPxyPxyE ==+== 0*)|0(1*)|1(]|[
Resulta que:
ii xp '10 ββ +=
que es una expresión equivalente del modelo. En consecuencia, la predicción iy estima la
probabilidad de que un individuo con características definidas por x=xi pertenezca al grupo correspondiente a y=1.
El problema principal de esta formulación es que pi debe estar entre 0 y 1, y no hay garantías de que la predicción verifique esta restricción. Esto no es un problema en sí para la clasificación pero sí si lo que se pretende es interpretar el resultado de la regla de clasificación como una probabilidad de pertenencia a cada clase. A pesar de estas limitaciones, este modelo conduce a una buena clasificación, ya que según la interpretación de Fisher maximiza la separación entre grupos sea cual sea la distribución de los datos. Sin embargo, cuando éstos no son normales o no tienen la misma matriz de covarianzas, la clasificación mediante una ecuación de relación lineal no es necesariamente óptima y el modelo logístico puede conducir a mejores resultados.
El modelo logístico (Logit) persigue que el modelo proporcione directamente la probabilidad de pertenencia a un grupo, transformando la variable respuesta de algún modo que garantice que la respuesta prevista esté entre 0 y 1. Si tomamos,
)( '10 ii xFp ββ +=
Garantizaremos que pi esté entre 0 y 1 si exigimos que F tenga esa propiedad.
La clase de funciones no decrecientes, acotadas entre 0 y 1 es la clase de las funciones de distribución, por lo que el problema se resuelve tomando como F cualquier función de distribución. Habitualmente se toma como F la función de distribución logística, dada por:
)( '101
1ixi
ep
ββ +−+=
Esta función tiene la ventaja de ser continua. Además, como,

Juan Ríos GutiérrezDetección automática de exudados duros en imágenes de retina. Un enfoque a nivel de píxel
86
)(
)(
'10
'10
11
i
i
x
x
ie
epββ
ββ
+−
+−
+=−
Resulta que
ix
x
x
x
i
ii x
ee
ee
ppg
i
i
i
i '10)(
)(
)(
)(
'10
'10
'10
'10 1log
1
11
log1
log ββββ
ββ
ββ
ββ+=
−=
+
+=−
=+−
+−
+−
+−
de modo que al hacer la transformación se tiene un modelo lineal que se denomina Logit.
La variable g representa en una escala logarítmica la diferencia entre las probabilidades de pertenecer a ambos grupos, y al ser una función lineal de las variables explicativas, facilita la estimación e interpretación del modelo.
Una ventaja adicional del modelo Logit es que si las variables son normales verifican el modelo Logit, siendo también cierto para una amplia gama de situaciones distintas a la normal.