análisis estadístico básico v2 - ferran torresferran.torres.name/edu/iusc/download/analisis...
TRANSCRIPT

Análisis estadístico básico: t-test, anova, pruebas no paramétricas,
regresión...
José Ríos
José Ríos © IUSC - 2009 2
¿Es cierto el bostezo inducido?
José Ríos © IUSC - 2009 3
Hoy toca estadística
José Ríos © IUSC - 2009 4
Por que claroPor que claro…… conociendo toda la informaciconociendo toda la informacióón n somos capaces de saber como se llega a los somos capaces de saber como se llega a los
resultadosresultados
José Ríos © IUSC - 2009 5
Pero antes hablemos de variables…
Presencia Ocurrencia
Tiempo No lo consideran Obligan a determinarlo
Enfermedad
-Prevalencia
Exposición
-Estado opinión Encuestas
No interesa la evolución temporal
-Incidencia Densidad de
(población) incidencia
-Recurrencia
(individuo)
Estudio transversal longitudinal
José Ríos © IUSC - 2009 6
… y de la importancia metodológica del tamaño de la muestra

José Ríos © IUSC - 2009 7
Resumen de datos
Tres tipos básicos Posición: también llamadas medidas de tendencia central.
Dispersión: conocidas también como medidas de escala
Forma: sirven para el estudio de la asimetría y apuntamiento comparado con la curva gaussiana
José Ríos © IUSC - 2009 8
Resumen de datosMedidas de Posición
Media aritmética
En el caso de datos agrupados en intervalos, la media se calculará con el valor medio de intervalo
Únicamente tiene sentido para variables cuantitativas
n
ii
nx
X1
José Ríos © IUSC - 2009 9
Resumen de datosMedidas de Posición
Mediana
Deja a ambos ‘lados’ la misma población.
El valor de la mediana no tiene por que existir en la muestra
Para su cálculo sólo se requiere que las clases sean ordenables, podemos, por tanto, calcularla tanto para variables cuantitativas como cualitativas ordinales
1,3,3,4,6,13,14,14,18 61,3,3,4,6,13,14,14,17,18 6 y 13
Mediana=(6+13)/2=9.5
José Ríos © IUSC - 2009 10
Resumen de datosMedidas de Posición
Moda Es el valor más frecuente en nuestros datos
En el caso de variables que tomen muchos valores, el cálculo de la moda es preferible con los datos agrupados, obtendremos el intervalo modal
Su cálculo tiene sentido para cualquier tipo de variable. Sólo usa el valor de las frecuencias
José Ríos © IUSC - 2009 11
Resumen de datosMedidas de Posición
Cuantiles. Son de orden (). Dejan el 100% de la
población por debajo.
Los percentiles dividen la población en porcentajes, los terciles, cuartiles y quintiles fracciones.
El segundo cuartil coincide con la Mediana
José Ríos © IUSC - 2009 12
Resumen de datosMedidas de Posición
Propiedades. La Media es sensible a los valores extremos, la Mediana
no lo es.
Especial atención en estudios de análisis de supervivencia
Media 1
Mediana 1
Nuevo valor en la muestra
Media 2
Mediana 2

José Ríos © IUSC - 2009 13
¿Pero entonces?
ModaMediana
Media
José Ríos © IUSC - 2009 14
Resumen de datosMedidas de Posición
Atención, siempre es mejor ‘visualizar’ los datos antes de trabajar con ellos.
Es posible que ni la Media ni la Mediana representen bien el comportamiento ‘central’ de la variable
En este caso, Media y Mediana tienen el mismo valor, ¿algún comentario?
José Ríos © IUSC - 2009 15
Resumen de datosMedidas Escala (dispersión)
Dos Grandes Familias
Recorridos
Varianzas
José Ríos © IUSC - 2009 16
Resumen de datosMedidas Escala (dispersión)
Rangos y amplitudes: valores pequeños en recorridos o rangos dan idea de poco dispersión, valores grandes indican mucha dispersión o presencia de valores extremos.
El Rango (Mín – Máx) se ve extremadamente afectado por valores extremos, no es, por tanto, una buena medida.
El recorrido intercualtílico (1er Cuartil – 3er Cuartil) también indica dispersión.
Ambos valores combinados pueden dar buena idea de cómo son los datos
José Ríos © IUSC - 2009 17
Resumen de datosMedidas Escala (dispersión)
Veamos un ejemplo de cálculo
José Ríos © IUSC - 2009 18
Resumen de datosMedidas Escala (dispersión)
¿Qué ocurre si sumamos todas las distancias?
Las distancias negativas son compensadas con las positivas. La suma es siempre cero
Def.: la media es el centro de gravedad de la distribución muestral

José Ríos © IUSC - 2009 19
Resumen de datosMedidas Escala (dispersión)
La varianza es la media de la suma de las desviaciones respecto a la media elevadas al cuadrado.
La Desviación estandares la raíz del anterior
El Coeficiente de variación usa las medidas de posición y escala
n
i in x1
21
12
n
i in xDE1
21
1
100*xCV
José Ríos © IUSC - 2009 20
Resumen de datosMedidas Escala (dispersión)
Pregunta: ¿Por qué si tenemos la varianza acabamos utilizando la
DE? ¿Complicamos los estadísticos inútilmente los cálculos?
El problema de la varianza es que no se mide en las mismas unidades que los datos de la muestra, es por eso que se define la DE
José Ríos © IUSC - 2009 21
Resumen de datosMedidas Escala (dispersión)
Bien.... Pero ¿qué medida es la buena?
Por si sola ninguna. Siempre es preferible ver todas ellas, visualizar los datos siempre ayuda mucho a detectar posibles problemas en los datos
Nos podemos ayudar de Histogramas y Diagramas de cajas (Box-Plot)
José Ríos © IUSC - 2009 22
Resumen de datosMedidas Escala (dispersión)
El diagrama de caja (Box-Plot), interpretación: Nos presenta el Rango y el recorrido
intercuartílico (ojo con el programa utilizado)
Valores fuera de límites son representados con círculos se consideran ‘normales’
Valores presentados como asterísticos se podrían estudiar como atípicos OJO CON DESCARTAR ‘ALEGREMENTE’ VALORES
ATÍPICOS
José Ríos © IUSC - 2009 23
Resumen de datosMedidas Escala (dispersión)
El diagrama de caja (Box-Plot)
142N =
TALLA
190
180
170
160
150
140
130
1
141142
Máximo
Mínimo
Mediana50% de la muestra
Aquí se espera encontrar la mayoría de la muestra
José Ríos © IUSC - 2009 24
Resumen de datosMedidas de forma
Medida de asimetría
Medida de apuntamiento o kurtosis
s
)xx(
)2n)(1n(n
asimetría.Coef3
i
)3n)(2n()1n(3
s
)xx(
)3n)(2n)(1n()1n(n
Kurtosis24
i
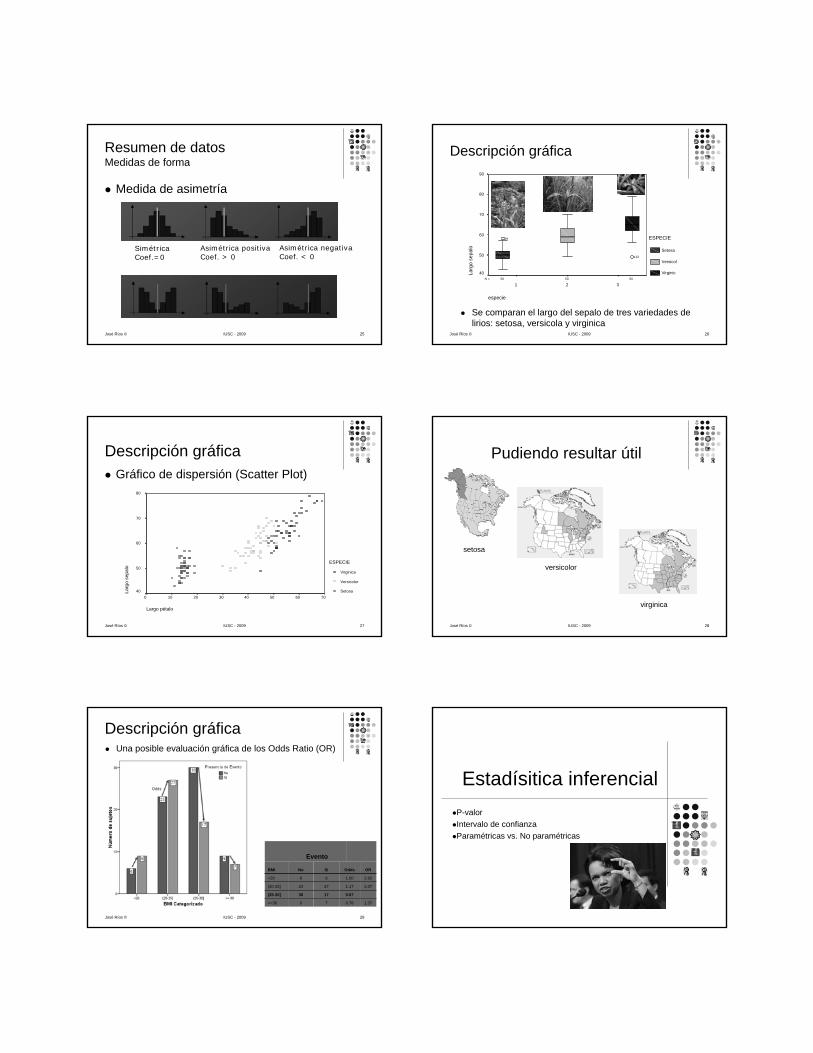
José Ríos © IUSC - 2009 25
Resumen de datosMedidas de forma
Medida de asimetría
SimétricaCoef.=0
Asimétrica positivaCoef. > 0
Asimétrica negativaCoef. < 0
José Ríos © IUSC - 2009 26
Descripción gráfica
Se comparan el largo del sepalo de tres variedades de lirios: setosa, versicola y virginica
505050N =
especie
321
La
rgo
se
pa
lo
90
80
70
60
50
40
ESPECIE
Setosa
Versicol
Virginic
113
19
José Ríos © IUSC - 2009 27
Descripción gráfica Gráfico de dispersión (Scatter Plot)
Largo pétalo
706050403020100
La
rgo
se
pa
lo
80
70
60
50
40
ESPECIE
Virginica
Versicolor
Setosa
José Ríos © IUSC - 2009 28
Pudiendo resultar útil
setosa
versicolor
virginica
José Ríos © IUSC - 2009 29
Descripción gráfica Una posible evaluación gráfica de los Odds Ratio (OR)
Evento
BMI No Sí Odds OR
<20 6 9 1.50 2.65
(20-25] 23 27 1.17 2.07
(25-30] 30 17 0.57
>=30 9 7 0.78 1.37
Estadísitica inferencial
P-valor
Intervalo de confianza
Paramétricas vs. No paramétricas

José Ríos © IUSC - 2009 31
Génesis de las ideas
Karl Raimund Popper (1902-1994)
•1934: La lógica de la investigación científica. ¿Cómo fundamentar el conocimiento científico, por definición universal y necesario, en la experiencia empírica, por definición particular?•Hasta entonces
•Descartes confía en las leyes eternas de la razón•Hume en las leyes que se extraen de la experiencia
•En contra del positivismo: ¿Cómo realizar una ley universal a partir de un número particular de experimentos?•A favor del falibilismo (o falsación): el conocimiento científico no puede avanzar confirmando nuevas leyes, sino descartando leyes que contradicen la experiencia.
POR TANTO: La labor del científico consiste en criticar leyes para ir reduciendo el número de teorías compatibles con observaciones experimentales.CONSECUENCIA:Una proposición científica lo será si es posible crear un experimento que la pudiese contradecir.
José Ríos © IUSC - 2009 32
Pruebas de hipótesis
Unilateral (una cola)Unilateral (una cola)
HHoo: : EE -- CC 00HH11: : EE -- CC > 0> 0
Bilateral (dos colas)Bilateral (dos colas)
HHoo: : EE -- CC = 0= 0HH11: : EE -- CC > 0 > 0 óó EE -- CC < 0< 0
José Ríos © IUSC - 2009 33
¿p? Probabilidad de observar, por azar, una diferencia
como la de la muestra o mayor, cuando H0 es cierta
Es una medida de la evidencia en contra de la H0 Es el azar una explicación posible de las diferencias
observadas? Supongamos que así es (H0). ¿Con qué probabilidad observaríamos unas
diferencias de esa magnitud, o incluso mayor? P-valor
Si P-valor pequeño, rechazamos H0.
¿Difícil?... No, es como un juicio!
José Ríos © IUSC - 2009 34
¿p?
Se acepta un valor máximo de 5% (0,05). Si p0,05 diferencias estadísticamente significativas.
Si p>0,05 diferencias estadísticamente NO significativas.
NO implica importancia clínica.
NO implica magnitud de efecto!! Influenciada por el tamaño de la muestra. Si n p
José Ríos © IUSC - 2009 35
Pero el mío es mejor.
Para un mismo resultado cuantitativo el ‘investigador avispado’puede hacer SU interpretación cualitativa simplemente inundando el artículo de valores de p
Mayor tamaño de muestra
Menor valor de p (habitualmente)
Mayor relevancia clínica
Misma magnitud de efecto
Misma relevancia clínica Menor valor de p (habitualmente)
Mayor relevancia clínica
¿?
Mayor relevancia clínica
¿?
Mayor tamaño de muestra
Menor valor de p (habitualmente)
Mayor relevancia clínica
¿?
José Ríos © IUSC - 2009 36
Y Arguiñano nos dice:

José Ríos © IUSC - 2009 37
Y Arguiñano nos dice:
José Ríos © IUSC - 2009 38
Y Arguiñano nos dice:
José Ríos © IUSC - 2009 39
Intervalos de confianza
Si repetimos el intervalo de confianza a lo largo del tiempo sobre la misma población, los intervalos de confianza al 95% calculados para cada muestra deberían incluir el verdadero valor de la población en el 95% de las veces.
Una persona ‘normal’ es aquella que no ha sido lo suficientemente investigada.
José Ríos © IUSC - 2009 40
Amplitud del IC
También depende de la información que la muestra proporciona sobre el verdadero valor poblacional
Mayor tamaño de muestra -> mayor precisión -> IC más estrecho
Mayor dispersión de la medida ->IC más amplio
José Ríos © IUSC - 2009 41
Por ejemplo…
Fuente: Viñes, R. Larumbe, M.T. Artázcoz, I. Gaminde, D. Guerrero, J.V. Ferrer Estudio epidemiológico de la enfermedad de Parkinson en Navarra. Revista ANALES del Sistema Sanitario de Navarra, Vol. 22, Suplemento 3, 1999
OR entre casos y controles de consumo de tabaco y EP. Intervalos de confianza del 90%.
José Ríos © IUSC - 2009 42
Estimación Pero hemos de tener en cuenta que todo intervalo de
confianza conlleva dos noticias, la buena y la mala
La buena: hemos usado una técnica que en % alto de casos acierta.
La mala: no sabemos si ha acertado en nuestro caso.

José Ríos © IUSC - 2009 43
Pruebas paramétricas y no-paramétricas
Una prueba paramétrica requiere la estimación de uno o más parámetros (estadísticos) de la población Ej.: Una estimación de la diferencia entre la media antes y
después de una intervención
Las pruebas no-paramétricas no involucran ningún tipo de estimación de parámetros Ej.: Facilitarnos la una estimación de la P[X>Y],
probabilidad de que, selecionando un paciente después del tratamiento, su valor sea mayor que antes del tratamiento
José Ríos © IUSC - 2009 44
Ventajas de las pruebas no-paramétricas
No se asume nada sobre la distribución de nuestros datos.
Se pueden usar en multitud de tipos de variables
Inconvenientes Las pruebas no-paramétricas acostumbran a tener un poder estadístico
menor que su equivalente paramétrico.
A propósito de los datos Utiliza rangos (ordenaciones), no da resultados en las unidades de las
variables originales. El efecto de los valores extremos se diluye (buena noticia o mala)
Se deberían utilizar cuando los requerimientos para las pruebas paramétricas no se cumplan.
Pruebas paramétricas y no-paramétricas
Estadísitica inferencial
Regresión y Supervivencia
José Ríos © IUSC - 2009 46
Regresión lineal
Describe como un variable respuesta ‘y’ cambia en función de otra (típicamente ‘diseñada’) factor ‘x’ de forma estrictamente lineal
Formalmente se asume que: X no es una variable aleatoria (no tiene por qué cumplirse
siempre) Para cada valor xi de X existe una v.a. Y|xi cuya media me
predice el modelo lineal Todas las variables Y|xi son Normales, independientes y
de igual varianza
José Ríos © IUSC - 2009 47
Ejemplos macabros
Los llamaré macabros ya que son ilustrativos de que el abuso debido a su simplicidad de ejecución e interpretación puede tener resultados nefastos
José Ríos © IUSC - 2009 48
Ejemplos macabros

José Ríos © IUSC - 2009 49
Ejemplos macabrosY mucho cuidado con la ‘correlación’
La proporción de variabilidad explicada por la regresión es el r2 * 100
José Ríos © IUSC - 2009 50
Ejemplos macabros
Por que los abusos no son nada buenos
José Ríos © IUSC - 2009 51
J Allergy Clin Immunol 2006;117:989-94.)
José Ríos © IUSC - 2009 52
Ejemplo sencillo
¿El hábito tabáquico es un buen predictorlineal para los niveles de tiocianato?
José Ríos © IUSC - 2009 53
Rec.: Y = a + b*X
Correlations
1.000 -.540
-.540 1.000
. .000
.000 .
320 320
320 320
thiocyanato serico
fuma_cig
thiocyanato serico
fuma_cig
thiocyanato serico
fuma_cig
Pearson Correlation
Sig. (1-tailed)
N
thiocyanatoserico fuma_cig
José Ríos © IUSC - 2009 54
ANOVAb
294721.1 1 294721.071 130.587 .000a
717690.6 318 2256.889
1012412 319
Regression
Residual
Total
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), fuma_ciga.
Dependent Variable: thiocyanato sericob.
Coefficientsa
202.840 11.467 17.688 .000 180.278 225.401
-70.456 6.165 -.540 -11.427 .000 -82.586 -58.325
(Constant)
fuma_cig
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: thiocyanato sericoa.
Por tanto, la función que me indicaría la predicción lineal sería: Y = 202.84 – 70.46*X

José Ríos © IUSC - 2009 55
¿A que parecía una buena opción?
José Ríos © IUSC - 2009 56
Otro más para acabar
¿La TAS es un buen predictor lineal para la TAD?
Correlations
1.000 .628
.628 1.000
. .000
.000 .
1245 1245
1245 1245
PADmedia
PASmed
PADmedia
PASmed
PADmedia
PASmed
Pearson Correlation
Sig. (1-tailed)
N
PADmedia PASmed
José Ríos © IUSC - 2009 57
Otro ejemplo
ANOVAb
7458229 1 7458228.588 807.549 .000a
11479900 1243 9235.640
18938129 1244
Regression
Residual
Total
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), PASmeda.
Dependent Variable: PADmediab.
Coefficientsa
386.210 18.509 20.866 .000 349.898 422.522
.347 .012 .628 28.417 .000 .323 .370
(Constant)
PASmed
Model1
B Std. Error
UnstandardizedCoefficients
Beta
StandardizedCoefficients
t Sig. Lower Bound Upper Bound
95% Confidence Interval for B
Dependent Variable: PADmediaa.
Por cada mmHg que aumenta la PAS, la PAD experimenta un aumento, en promedio, de 0.347 mmHg
José Ríos © IUSC - 2009 58
¿Qué conclusión real se puede obtener?
José Ríos © IUSC - 2009 59
Análisis de la supervivencia:Motivos para su uso
En ocasiones importa tanto el tiempo hasta que se produce el evento que su consecución. Por ejemplo (por no ser más morboso): Evaluar el tiempo que se
tarda en la mejoría o curación Estudiar n individuos
Ti será el tiempo que tarda el i-ésimo paciente en curarse
El problema viene cuando no se conoce Ti censura
Por tanto pueden existir variables que explican este tiempo.
Muy útil cuando el seguimiento es incompleto o muy variable
José Ríos © IUSC - 2009 60
Cuando usar estas técnicas
Deseamos un modelo para explicar tiempo hasta un evento ‘Evento’ es dicotómico (regresión lineal no sirve)
Nos interesa el tiempo hasta evento (regresión logística no sirve)
Deseamos comparar supervivencia entre grupos
Podremos evaluar la relación entre covariables y el tiempo de supervivencia

José Ríos © IUSC - 2009 61
No es efectivo ni ético esperar a que se presenten todos los eventos para finalizar el estudio.
Los individuos entran en el estudio a tiempos diferentes.
Cuando usar estas técnicas (II)
José Ríos © IUSC - 2009 62
¿Por qué no otras?
Técnica Variables predictoras
Variable respuesta
¿Existen censuras?
Regresión linear
Categóricas o continuas
Normalmente distribuidas
No
Regresión Logística
Categóricas o continuas
Binaria (menos en regresión
logística politomómica)
No
Análisis de supervivencia
Tiempo y categóricas o
continuas
Binaria Sí
José Ríos © IUSC - 2009 63
¿Qué estimamos?
Técnica Modelo Matemático Evaluamos
Regresión linear
Y=B1X + Bo (linear)
Evaluación de pendiente (cambio
lineal) Regresión Logística
Ln(P/1-P)=B1X+Bo (sigmoidal prob.)
Odds ratios
Análisis de supervivencia
h(t) = ho(t)exp(B1X+Bo) Hazard rates
José Ríos © IUSC - 2009 64
Posibles ejemplos de diseño (o no)
Evaluar la mortalidad en el post-operatorio Reclutamos durante 5 años a 350 pacientes y los
seguimos durante un tiempo de seis meses Se seleccionan a 100 pacientes y se aleatorizan a
dos brazos de tratamiento. La aparición del evento se evalúa en consecutivas visitas programadas durante tres años
Miramos la aparición espontánea de un evento en el trascurso de un estudio de cohortes
José Ríos © IUSC - 2009 65
Yo os doy una de las soluciones
Mortalidad postoperatoria Al no haber un seguimiento prolongado no tiene sentido
hablar de censuras y se dispone de toda la información de los sujetos.
Surgical PriorityDischarge Status
EmergencyNon-EmergencyTotal
Dead Alive Total24 9 33
289 100 389313 109 422
Chi-Square = 0.04Degrees of Freedom = (2-1)(2-1) = 1p = 0.084
José Ríos © IUSC - 2009 66
¿Y las censuras? Existen de varios tipos, pero aquí hablaremos sólo de las
que se producen de forma aleatoria por la derecha http://www.ms.uky.edu/~mai/java/stat/KapMei.html

José Ríos © IUSC - 2009 67
¿Por qué censuras?
Se produce por la imposibilidad práctica de tener información precisa del momento del evento en la totalidad de los sujetos. El día de cierre no se ha presentado el evento
Hemos perdido el seguimiento del sujeto
Motivos Acontecimiento adverso
Cierre del estudio/seguimiento
Pérdida de seguimiento
Evento por causa diferentes a la del estudioJosé Ríos © IUSC - 2009 68
Pero existe una clasificación
Tipo I. Todos los individuos se siguen hasta una fecha fin de estudio
Por la derecha: Pacientes vivos al finalizar el estudio
Pacientes perdidos o abandonos
En intervalo: Las visitas de control son espaciadas
Por la izquierda: Se desconoce la fecha de inicio
Tipo II. Los individuos se siguen hasta que han ocurrido r eventos
José Ríos © IUSC - 2009 69
¿Falta de seguimiento?
José Ríos © IUSC - 2009 70
¿Qué pasó con el último paciente?
José Ríos © IUSC - 2009 71
Por ejemplo…
José Ríos © IUSC - 2009 72
¿Y si el evento es repetido?
Los modelos generales de Cox se realizan contra un evento único El seguimiento del paciente se trunca en el primer
evento
Es suficiente para evaluar eventos ‘no repetibles’como la mortalidad
¿Es este tipo de análisis suficiente en todos los casos?

José Ríos © IUSC - 2009 73
En EC quizás no mucho
El modelo general de Cox lo que pretende es ver como una característica inicial modifica la presencia de un evento En EC, el tratamiento aleatorizado.
Hay variables que se modifican a lo largo del seguimiento que pueden propiciar el evento
Cox con covariables tiempo-dependiente
José Ríos © IUSC - 2009 74
Esquemáticamente
Modelo AG
Modelo PWP
O mezclas…
Evento Evento Evento
Evento Evento Evento Evento
Nota: El grosor de la flecha indica el ‘riesgo’ potencial de presentar el evento
Evento Evento Evento Evento
José Ríos © IUSC - 2009 75
Pero hay muchos métodos para analizar este tipo de datos
José Ríos © IUSC - 2009 76
José Ríos © IUSC - 2009 77
“Los métodos estadísticos no son un sustituto del sentido común y la objetividad. Nunca deberían estar dirigidos a confundir al lector, sino que deben ser una contribución importante a la claridad de los argumentos científicos”
SJ Pocock. Br J Psychiat 1980; 137:188-190
José Ríos © IUSC - 2009 78