1. ¿qué es sgbd? - srgiobats.files.wordpress.com · 1. ¿qué es sgbd? los sistemas de gestión...
TRANSCRIPT

1. ¿Qué es SGBD?
Los Sistemas de gestión de base de datos son un tipo de software muy específico, dedicado a
servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan. Se
compone de un lenguaje de definición de datos, de un lenguaje de manipulación de datos y de
un lenguaje de consulta.
2. Tipos de SGBD
6.1 SGBD de red.
Los SGBD relacionales se basan en el modelo de datos de red. Los datos en el
modelo de red se representan mediante colecciones de registros y las relaciones entre los
datos se representan mediante enlaces, que se pueden ver como punteros. Los registros en
la base de datos se organizan como colecciones de grafos dirigidos. En la figura se presenta
un ejemplo de base de datos en red.
6.2 SGBD jerárquicos.
Los SGBD relacionales se basan en el modelo de datos jerárquico. El modelo
jerárquico es similar al modelo de redes, en el sentido en que los datos y las relaciones entre
los datos se representan mediante registros y enlaces, respectivamente. Éste se diferencia
del modelo de redes en que los registros se organizan como colecciones de árboles en lugar
de grafos dirigidos. En la siguiente figura se presenta un ejemplo de base de datos
jerárquica.
6.3. Modelo de datos relacionales.
Basados en el modelo relacional, los datos se describen como relaciones que se
suelen representar como tablas bidimensionales consistentes en filas y columnas. Cada
fila (tupla, en terminología relacional) representa una ocurrencia. Las columnas (atributos)
representan propiedades de las filas. Cada tupla se identifica por un clave primario o
identificador.
Esta organización de la información, permite recuperar de forma flexible los datos
de una o varias tablas, así como combinar registros de diferentes tablas para formar otras

nuevas. No todas las definiciones posibles de tablas son válidas según el modelo
relacional. En él, deben emplearse diseños normalizados que garantizan que no se
producirán anomalías en la actualización de la BD.
De todas formas otras consideraciones, principalmente de rendimiento, llevan en
ocasiones a que los diseños que se implantan no estén totalmente normalizados. Hallar el
punto de equilibrio entre normalización y rendimiento es, con frecuencia, un punto clave
para obtener un buen diseño de la BD cuando se utilizan SGBD relacionales.
Los SGBD relacionales se han impuesto hasta llegar a dominar casi totalmente el
mercado actual. Ello, se ha debido principalmente a su flexibilidad y sencillez de manejo.
Igualmente conviene destacar la amplia implantación del lenguaje SQL, que se ha
convertido en un estándar para el manejo de datos en el modelo relacional, lo que ha
supuesto una ventaja adicional para su desarrollo.
6.4 Modelo orientados a objetos.
Una de las novedades más prometedoras y más desarrolladas comercialmente de
los nuevos SGBD, son los basados en un nuevo modelo de datos conocido como modelo
orientado a objetos. La orientación a objetos es un paradigma que no se aplica sólo al
desarrollo de SGBD sino, en general, al desarrollo de sistemas de información.
El modelo orientado a objetos está basado en una colección de objetos. Un objeto
contiene valores almacenados en variables de ejemplares dentro de ese objeto. Un objeto
también contiene fragmentos de código que operan en el objeto. Estos fragmentos de
código se llaman métodos.
Los objetos que contienen los mismos tipos de valores y los mismos métodos se
agrupan juntos en clases. Una clase se puede ver como una definición de tipo para los
objetos. Esta combinación de datos y métodos constituyendo una definición de tipo es
similar a un tipo abstracto de datos en un lenguaje de programación.
La única manera de que un objeto pueda acceder a los datos de otro objeto es
mediante la invocación de un método de ese otro objeto. Esta acción se llama paso de

mensaje al otro objeto. Así, la interfaz de llamada de los métodos de un objeto define la
parte visible externamente del objeto. La parte interna del objeto no es visible
externamente. El resultado es obtener dos niveles de abstracción de datos.
3. Menciona 4 SGBD
Adaptive Server
Las funciones clave de ASE incluyen encriptación patentada, tecnología de particiones, tecnología de consultas con
patente pendiente para transacciones "más inteligentes" y disponibilidad continua en entornos agrupados en clusters.
La tecnología de bases de datos en memoria en ASE 15.5 permite la virtualización de datos y el escalamiento crítico
para organizaciones con grandes volúmenes de datos y de usuarios concurrentes, ya sea que se implementen en
entornos de centros de datos privados o públicos en la nube.
Brinda un
rendimiento
extremo
Permite a los entornos de TI exigentes alcanzar millones de transacciones por minuto con bases
de datos de varios terabytes, al mismo tiempo que mantiene índices de crecimiento rápido en el
volumen de datos y de transacciones
Reduce el riesgo Ayuda a las organizaciones a evitar interrupciones desastrosas y costosas, tales como una falla
en el sistema, desastres no previstos o datos robados
Protege contra amenazas comunes a los sistemas de TI, incluidas la seguridad de datos, la
estabilidad del sistema y la recuperación en caso de desastre
Permite a las TI ofrecer asistencia técnica eficaz y mitigar el riesgo
Aumenta la
eficiencia
Permite a TI brindar niveles de servicio más altos, incluso con presupuestos reducidos
Utiliza y reduce el hardware subutilizado con eficiencia, y ofrece alto rendimiento con costos
menores
Facilita los requisitos de tareas de DBA
PostgreSQL
Características
Algunas de sus principales características son, entre otras:
Alta concurrencia
Mediante un sistema denominado MVCC (Acceso concurrente multiversión, por sus siglas
en inglés) PostgreSQL permite que mientras un proceso escribe en una tabla, otros accedan

a la misma tabla sin necesidad de bloqueos. Cada usuario obtiene una visión consistente de
lo último a lo que se le hizo commit. Esta estrategia es superior al uso de bloqueos por tabla
o por filas común en otras bases, eliminando la necesidad del uso de bloqueos explícitos.
Amplia variedad de tipos nativos
PostgreSQL provee nativamente soporte para:
Números de precisión arbitraria. Texto de largo ilimitado. Figuras geométricas (con una variedad de funciones asociadas). Direcciones IP (IPv4 e IPv6). Bloques de direcciones estilo CIDR. Direcciones MAC. Arrays.
Adicionalmente los usuarios pueden crear sus propios tipos de datos, los que pueden ser por
completo indexables gracias a la infraestructura GiST de PostgreSQL. Algunos ejemplos
son los tipos de datos GIS creados por el proyecto PostGIS.
Otras características
Claves ajenas también denominadas Llaves ajenas o Claves Foráneas (foreign keys). Disparadores (triggers): Un disparador o trigger se define como una acción específica que
se realiza de acuerdo a un evento, cuando éste ocurra dentro de la base de datos. En PostgreSQL esto significa la ejecución de un procedimiento almacenado basado en una determinada acción sobre una tabla específica. Ahora todos los disparadores se definen por seis características:
o El nombre del disparador o trigger o El momento en que el disparador debe arrancar o El evento del disparador deberá activarse sobre... o La tabla donde el disparador se activará o La frecuencia de la ejecución o La función que podría ser llamada
Entonces combinando estas seis características, PostgreSQL le permitirá crear una amplia
funcionalidad a través de su sistema de activación de disparadores (triggers).
Vistas. Integridad transaccional. Herencia de tablas. Tipos de datos y operaciones geométricas. Soporte para transacciones distribuidas. Permite a PostgreSQL integrase en un sistema
distribuido formado por varios recursos gestionado por un servidor de aplicaciones donde el éxito ("commit") de la transacción global es el resultado del éxito de las transacciones locales

Funciones
Bloques de código que se ejecutan en el servidor. Pueden ser escritos en varios lenguajes,
con la potencia que cada uno de ellos da, desde las operaciones básicas de programación,
tales como bifurcaciones y bucles, hasta las complejidades de la programación orientada a
objetos o la programación funcional.
Los disparadores (triggers en inglés) son funciones enlazadas a operaciones sobre los datos.
Algunos de los lenguajes que se pueden usar son los siguientes:
Un lenguaje propio llamado PL/PgSQL (similar al PL/SQL de oracle). C. C++. Java PL/Java web. PL/Perl. plPHP. PL/Python. PL/Ruby. PL/sh. PL/Tcl. PL/Scheme. Lenguaje para aplicaciones estadísticas R por medio de PL/R.
PostgreSQL soporta funciones que retornan "filas", donde la salida puede tratarse como un
conjunto de valores que pueden ser tratados igual a una fila retornada por una consulta.
Las funciones pueden ser definidas para ejecutarse con los derechos del usuario ejecutor o
con los derechos de un usuario previamente definido. El concepto de funciones, en otros
DBMS, son muchas veces referidas como "procedimientos almacenados".
SQL Server
Soporte de transacciones.
Escalabilidad, estabilidad y seguridad.
Soporta procedimientos almacenados.
Incluye también un potente entorno gráfico de administración, que permite el uso de
comandos DDL y DML gráficamente.
Permite trabajar en modo cliente-servidor, donde la información y datos se alojan en
el servidor y los terminales o clientes de la red sólo acceden a la información.
Además permite administrar información de otros servidores de datos.
Este sistema incluye una versión reducida, llamada MSDE con el mismo motor de base de
datos pero orientado a proyectos más pequeños, que en sus versiónes 2005 y 2008 pasa a
ser el SQL Express Edition, que se distribuye en forma gratuita.

Es común desarrollar completos proyectos complementando Microsoft SQL Server y
Microsoft Access a través de los llamados ADP (Access Data Project). De esta forma se
completa la base de datos (Microsoft SQL Server), con el entorno de desarrollo (VBA
Access), a través de la implementación de aplicaciones de dos capas mediante el uso de
formularios Windows.
En el manejo de SQL mediante líneas de comando se utiliza el SQLCMD
Para el desarrollo de aplicaciones más complejas (tres o más capas), Microsoft SQL Server
incluye interfaces de acceso para varias plataformas de desarrollo, entre ellas .NET, pero el
servidor sólo está disponible para Sistemas Operativos Windows.
DB2
Permite el manejo de objetos grandes (hasta 2 GB), la definición de datos y funciones por parte
del usuario, el chequeo de integridad referencial, SQL recursivo, soporte multimedia: texto,
imágenes, video, audio; queries paralelos, commit de dos fases, backup/recuperación on−line y
offline.
Además cuenta con un monitor gráfico de performance el cual posibilita observar el tiempo de
ejecución de una sentencia SQL y corregir detalles para aumentar el rendimiento.
Mediante los extensores se realiza el manejo de los datos no tradicionales, por ejemplo si tengo
un donde tengo almacenados los currículos de varias personas, mediante este puedo realizar
búsquedas documentos con los datos que me interesen sin tener que ver los CV uno por uno.
Esta capacidad se utiliza en sistemas de búsqueda de personas por huellas digitales, en
sistemas información geográfica, etc.
Internet es siempre la gran estrella, con DB2 es posible acceder a los datos usando JDBC (tan
potente como escribir directamente C contra la base de datos), Java y SQL (tanto el SQL
estático, como complementa el SQL dinámico).
Plataformas host:
OS/390(MVS), VM & VSE, OS/400
Plataformas de servidor:
OS/2 Warp Server, Sinix, SCO Openserver, Windows NT, Aix, HP Ux, Solaris.
Plataformas Cliente:
OS/2, DOS, Sinix, SCO OpenServer, Windows 3.1/95/NT, Macintosh System 7, Aix, HP Ux,
Solaris.
4. Lenguaje incorporado en SGBD
Es el lenguaje de definición de datos (LDD).
5. Pantallas de SGBD investigados
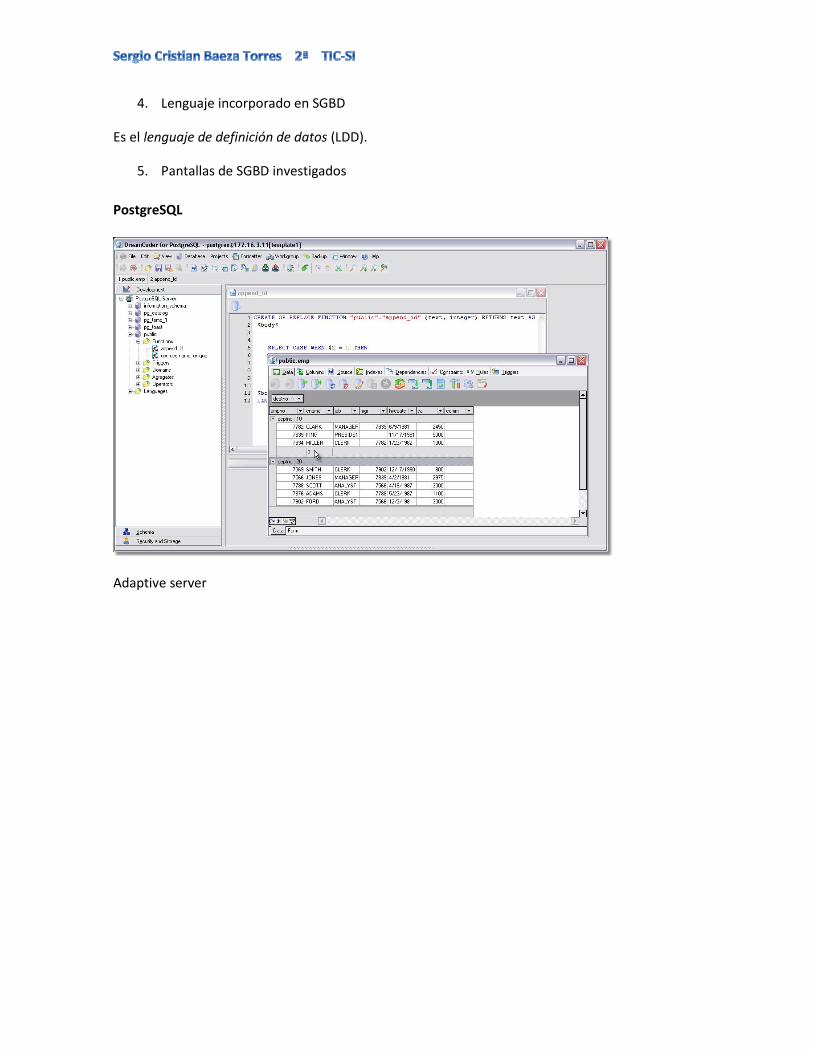
PostgreSQL
Adaptive server
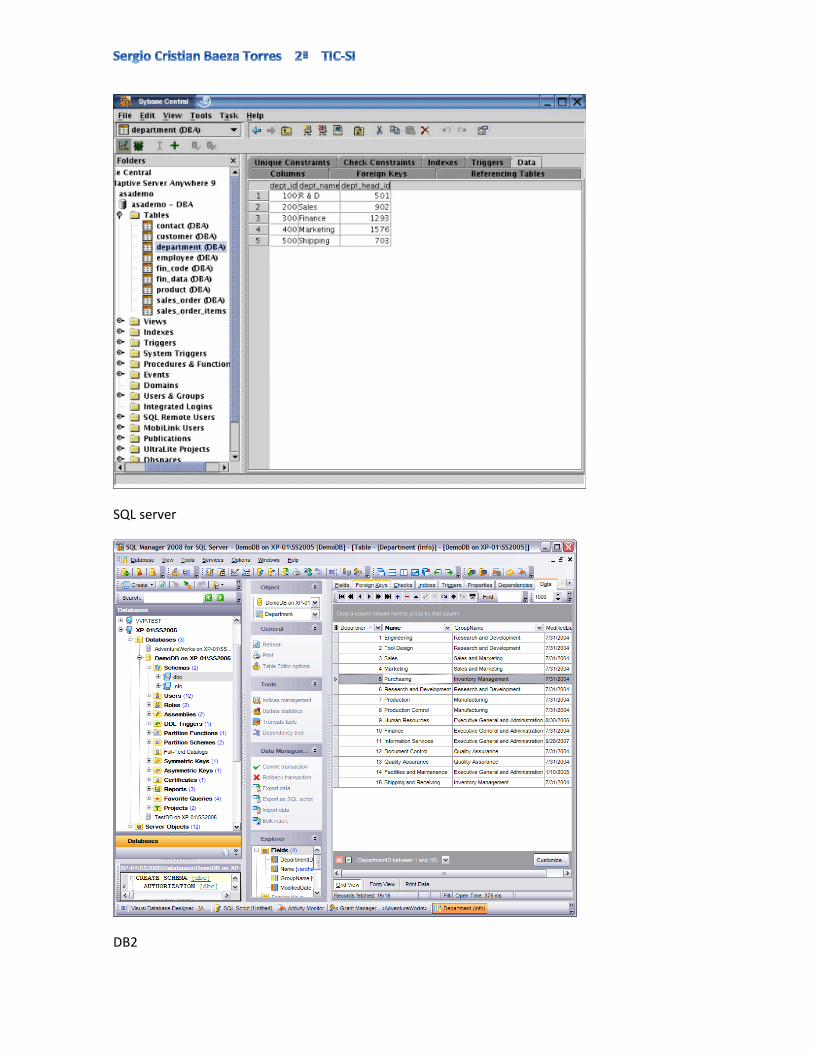
SQL server
DB2
